Обсуждение: GB18030-2022 Support in PostgreSQL
Hi hackers,
I noticed that PostgreSQL currently supports GB18030 encoding based on the older GB18030-2000 standard (as seen in commits like extend GB18030 conversion). However, China has since updated its mandatory character set standard to GB18030-2022, which includes additional characters and stricter compliance requirements.GB18030-2022 is now the official standard in China, and ensuring PostgreSQL’s full compliance would be beneficial for users in Chinese-speaking regions.
I would like to ask:
Are there any plans to upgrade PostgreSQL’s GB18030 support to the 2022 version?Would the community be open to contributions in this area?
Best regards,
JiaoShuntian
HighGo Inc.
> I would like to ask:
>
> Are there any plans to upgrade PostgreSQL’s GB18030 support to the 2022 version?Would the community be open to contributions in this area?
Hi hackers,
I noticed that PostgreSQL currently supports GB18030 encoding based on the older GB18030-2000 standard (as seen in commits like extend GB18030 conversion). However, China has since updated its mandatory character set standard to GB18030-2022, which includes additional characters and stricter compliance requirements.GB18030-2022 is now the official standard in China, and ensuring PostgreSQL’s full compliance would be beneficial for users in Chinese-speaking regions.
I would like to ask:
Are there any plans to upgrade PostgreSQL’s GB18030 support to the 2022 version?Would the community be open to contributions in this area?
Best regards,
JiaoShuntian
HighGo Inc.
On Mon, Aug 4, 2025 at 3:08 PM JiaoShuntian <jiaoshuntian@highgo.com> wrote: > I noticed that PostgreSQL currently supports GB18030 encoding based on the older GB18030-2000 standard (as seen in commitslike extend GB18030 conversion). However, China has since updated its mandatory character set standard to GB18030-2022,which includes additional characters and stricter compliance requirements.GB18030-2022 is now the official standardin China, and ensuring PostgreSQL’s full compliance would be beneficial for users in Chinese-speaking regions. This is a non-backwards-compatible change: https://www.unicode.org/L2/L2022/22274-disruptive-changes.pdf https://www.unicode.org/L2/L2023/23003r-gb18030-recommendations.pdf There is a risk of breaking applications, although only a few dozen mappings changed. If it were added as a separate encoding, users could opt in. -- John Naylor Amazon Web Services
On 2025-08-04 Mo 6:35 AM, John Naylor wrote: > On Mon, Aug 4, 2025 at 3:08 PM JiaoShuntian <jiaoshuntian@highgo.com> wrote: >> I noticed that PostgreSQL currently supports GB18030 encoding based on the older GB18030-2000 standard (as seen in commitslike extend GB18030 conversion). However, China has since updated its mandatory character set standard to GB18030-2022,which includes additional characters and stricter compliance requirements.GB18030-2022 is now the official standardin China, and ensuring PostgreSQL’s full compliance would be beneficial for users in Chinese-speaking regions. > This is a non-backwards-compatible change: > > https://www.unicode.org/L2/L2022/22274-disruptive-changes.pdf > https://www.unicode.org/L2/L2023/23003r-gb18030-recommendations.pdf > > There is a risk of breaking applications, although only a few dozen > mappings changed. If it were added as a separate encoding, users could > opt in. > That makes sense ... naming the new encoding so as to avoid confusion might be a challenge. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Andrew Dunstan <andrew@dunslane.net> writes:
> On 2025-08-04 Mo 6:35 AM, John Naylor wrote:
>> There is a risk of breaking applications, although only a few dozen
>> mappings changed. If it were added as a separate encoding, users could
>> opt in.
> That makes sense ... naming the new encoding so as to avoid confusion
> might be a challenge.
We have precedent for that in SHIFT_JIS_2004. Presumably if we
make this a new encoding, it'd be GB18030_2022.
However, adding a new encoding ID is not without breakage risks
of its own, stemming from some code knowing the new ID and others
not. I recall that we had some actual problems of that ilk when
we added SHIFT_JIS_2004, and some of them were pretty subtle.
See e.g. this comment from src/bin/initdb/Makefile:
# Note: it's important that we link to encnames.o from libpgcommon, not
# from libpq, else we have risks of version skew if we run with a libpq
# shared library from a different PG version. Define
# USE_PRIVATE_ENCODING_FUNCS to ensure that that happens.
That was long enough ago that I have little faith either that that
fix still does what it intended to (the code has been rejiggered
significantly since the issue was last battle-tested), or that
there are not similar hazards elsewhere.
So on the whole I'd lean a bit towards just redefining GB18030 as
meaning the new standard. The fact that we don't support it as a
server-side encoding perhaps makes that idea more tenable than it
would be if the encoding governed the interpretation of our own
stored data.
regards, tom lane
On Mon, Aug 04, 2025 at 04:08:24PM +0800, JiaoShuntian wrote: > Hi hackers, > > I noticed that PostgreSQL currently supports GB18030 encoding based on the older GB18030-2000 standard (as seen in commitslike extend GB18030 conversion). However, China has since updated its mandatory character set standard to GB18030-2022,which includes additional characters and stricter compliance requirements.GB18030-2022 is now the official standardin China, and ensuring PostgreSQL’s full compliance would be beneficial for users in Chinese-speaking regions. > > I would like to ask: > > Are there any plans to upgrade PostgreSQL’s GB18030 support to the 2022 version?Would the community be open to contributionsin this area? > > Best regards, > > JiaoShuntian > HighGo Inc. Hi, I believe that it is in ICU already. You should be able to use that as your locale provider. Regards, Ken
2025年8月4日 21:51,Tom Lane <tgl@sss.pgh.pa.us> wrote:
So on the whole I'd lean a bit towards just redefining GB18030 as
meaning the new standard. The fact that we don't support it as a
server-side encoding perhaps makes that idea more tenable than it
would be if the encoding governed the interpretation of our own
stored data.
regards, tom lane
https://www.highgo.com/
On Tue, Aug 5, 2025 at 1:22 PM Chao Li <li.evan.chao@gmail.com> wrote: > > 2025年8月4日 21:51,Tom Lane <tgl@sss.pgh.pa.us> wrote: > > So on the whole I'd lean a bit towards just redefining GB18030 as > meaning the new standard. The fact that we don't support it as a > server-side encoding perhaps makes that idea more tenable than it > would be if the encoding governed the interpretation of our own > stored data. > I agree with Tom that we may just redefine GB18030 to comply with the 2022 standard. > > As John Naylor pointed, 2022 is not backward compatible, that is true. However, I went through all the incompatible changes,those are all characters rarely used. If that's the case than redefining is probably okay. > One use case I am thinking is that, say a database uses default encoding (UTF-8) and ICU locale provider. As ICU startedto support GB180303-2022 since version 73.1. ICU locales can only be used with sever-side encodings. > At the time when the new version is released, if some third party migration tools are known working fine, the release notemay recommend the tools. I highly doubt such a large hammer will be necessary. Whatever advice we give for discovery and conversion of affected text is our responsibility and can be in the form of example queries. -- John Naylor Amazon Web Services
On 05.08.25 08:22, Chao Li wrote: > I agree with Tom that we may just redefine GB18030 to comply with the > 2022 standard. > > As John Naylor pointed, 2022 is not backward compatible, that is true. > However, I went through all the incompatible changes, those are all > characters rarely used. So I would guess most of the existing databases > won’t be impacted and the rest with encoding GB18030 need to do data > migration before upgrading to a PG version that switches to > GB18030-2022. I think PG may delegate data migration tasks to third > party PG service vendors. They may develop simple or complex migration > tools to help different use cases. Note that you can also create custom conversions using CREATE CONVERSION, so that would be something for those who would need the old behavior.
https://www.highgo.com/
On Tue, Aug 5, 2025 at 1:22 PM Chao Li <li.evan.chao@gmail.com> wrote:
>
> 2025年8月4日 21:51,Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> So on the whole I'd lean a bit towards just redefining GB18030 as
> meaning the new standard. The fact that we don't support it as a
> server-side encoding perhaps makes that idea more tenable than it
> would be if the encoding governed the interpretation of our own
> stored data.
> I agree with Tom that we may just redefine GB18030 to comply with the 2022 standard.
>
> As John Naylor pointed, 2022 is not backward compatible, that is true. However, I went through all the incompatible changes, those are all characters rarely used.
If that's the case than redefining is probably okay.
> One use case I am thinking is that, say a database uses default encoding (UTF-8) and ICU locale provider. As ICU started to support GB180303-2022 since version 73.1.
ICU locales can only be used with sever-side encodings.
> At the time when the new version is released, if some third party migration tools are known working fine, the release note may recommend the tools.
I highly doubt such a large hammer will be necessary. Whatever advice
we give for discovery and conversion of affected text is our
responsibility and can be in the form of example queries.
--
John Naylor
Amazon Web Services
Вложения
I have created a patch https://commitfest.postgresql.org/patch/5954/. CommitFests requested a rebase, so I rebased the code and created the v2 patch.
BTW, I have tested all 66 new characters, 9 not-required characters and 18 changed characters in a way as:
evantest=# SELECT encode(convert_from(decode('82359632', 'hex'), 'GB18030')::bytea, 'hex');
encode
--------
e9bfab
(1 row)
All encoded correctly.
Chao Li (Evan)
https://www.highgo.com/
I did more researches about the changes in 2022 over 2000, here is a summary:* 66 new characters have been added in 2022. All these are 4 bytes characters. As the map files store only 2 bytes GB code mappings, 4 bytes GB code mapping are calculated, thus these chars can be properly encoded/decoded without this patch, I tested that.* 9 characters are no longer required by 2022, but application may decide to retain them or not. As the ucm file (https://github.com/unicode-org/icu/blob/main/icu4c/source/data/mappings/gb18030-2022.ucm) retains them, we also retain them.* Unicode mappings for 18 characters have changed. Only these changes will cause backward compatibility issues. However, half of them are rarely used punctuation marks and rests are glyphs that I cannot recognize as a native Chinese speaker. So these changes should not significantly impact most existing databases.I added a test case with a mapping changed char, and the test passes:% make check...# All 229 tests passed.For more details on the standard change, see https://ken-lunde.medium.com/the-gb-18030-2022-standard-3d0ebaeb4132I am attaching the patch file.Chao Li (Evan)---------------------Highgo Software Co., Ltd.
https://www.highgo.com/
Вложения
On Mon, Aug 11, 2025 at 9:01 AM Chao Li <li.evan.chao@gmail.com> wrote: > > I have created a patch https://commitfest.postgresql.org/patch/5954/. CommitFests requested a rebase, so I rebased thecode and created the v2 patch. > > BTW, I have tested all 66 new characters, 9 not-required characters and 18 changed characters in a way as: "9 characters are no longer required by the new standard, but are retained in this patch for compatibility" How is that done? > I added a test case with a mapping changed char, and the test passes: > > % make check > ... > # All 229 tests passed. > > For more details on the standard change, see https://ken-lunde.medium.com/the-gb-18030-2022-standard-3d0ebaeb4132 > > I am attaching the patch file. Going from the old .xml file to the .ucm file makes it difficult to see the relevant changes. Also, there are nearly 1000 non-user-visible changes like this in the output file that are not explained: - /*** Three byte table, leaf: efa8xx - offset 0x07aba ***/ + /*** Three byte table, leaf: efa8xx - offset 0x07b3a ***/ The 2000 version is available in the .ucm format, so maybe converting to that first would be a good preparatory patch: https://github.com/unicode-org/icu-data/blob/main/charset/data/ucm/gb-18030-2000.ucm Looking at the history, it looks like that file has seen small revisions, so it may take some research to get the exact equivalent to the XML file we use. That will also tell us if anything will change for us besides the actual 2022 revision. -- John Naylor Amazon Web Services
"9 characters are no longer required by the new standard, but are
retained in this patch for compatibility"
How is that done?
--------------------
HighGo Software Co., Ltd.
https://www.highgo.com/
On Aug 11, 2025, at 13:50, John Naylor <johncnaylorls@gmail.com> wrote:On Mon, Aug 11, 2025 at 9:01 AM Chao Li <li.evan.chao@gmail.com> wrote:
I have created a patch https://commitfest.postgresql.org/patch/5954/. CommitFests requested a rebase, so I rebased the code and created the v2 patch.
BTW, I have tested all 66 new characters, 9 not-required characters and 18 changed characters in a way as:
"9 characters are no longer required by the new standard, but are
retained in this patch for compatibility"
How is that done?I added a test case with a mapping changed char, and the test passes:
% make check
...
# All 229 tests passed.
For more details on the standard change, see https://ken-lunde.medium.com/the-gb-18030-2022-standard-3d0ebaeb4132
I am attaching the patch file.
Going from the old .xml file to the .ucm file makes it difficult to
see the relevant changes. Also, there are nearly 1000 non-user-visible
changes like this in the output file that are not explained:
- /*** Three byte table, leaf: efa8xx - offset 0x07aba ***/
+ /*** Three byte table, leaf: efa8xx - offset 0x07b3a ***/
The 2000 version is available in the .ucm format, so maybe converting
to that first would be a good preparatory patch:
https://github.com/unicode-org/icu-data/blob/main/charset/data/ucm/gb-18030-2000.ucm
Looking at the history, it looks like that file has seen small
revisions, so it may take some research to get the exact equivalent to
the XML file we use. That will also tell us if anything will change
for us besides the actual 2022 revision.
--
John Naylor
Amazon Web Services
On Mon, Aug 11, 2025 at 3:22 PM Chao Li <li.evan.chao@gmail.com> wrote: Hi, For future reference, please don't quote my entire message below yours -- it clutters the archives and also removes context. > Yes, I did a diff between 2000.ucm and 2022.ucm when I worked on the patch. The diff between 2000.ucm and 2022.ucm arequite small: That would match my expectation. In case it wasn't clear before, my preference is to split this patch into two patches: First convert to .ucm, then update to 2022 revision. Then the small diff will be obvious to everyone who looks at the second commit. > For your question: > > "9 characters are no longer required by the new standard, but are > retained in this patch for compatibility" > > How is that done? > > > The 9 mappings are not changed between 2000.ucm and 2022.ucm. For example, GB18030 code 0xFD9C is one of the 9 not-requiredcode, but the mapping: > > <UF92C> \xFD\x9C |0 > > Still appears in 2022.ucm, so that this character is retained. Thanks for clarifying -- by saying "retained in the patch", the commit message implied to me that the patch added something not in the upstream file. -- John Naylor Amazon Web Services
> That would match my expectation. In case it wasn't clear before, my > preference is to split this patch into two patches: First convert to > .ucm, then update to 2022 revision. Then the small diff will be > obvious to everyone who looks at the second commit. Sure I can split the patch into two. The patch only changes the .xml file to .ucm file and updating the perl script. As aresult, map files should not be changed. Then the second patch will update the ucm file, so that the second patch should be small, contains only ucm changes and mapfile changes. One thing to confirm with you. To archive that, we will rename the ucm file as gb18030.ucm without suffix of “-2000” and“-2022”, otherwise git won’t be able to show the diff. Is that what you meant? > > Thanks for clarifying -- by saying "retained in the patch", the commit > message implied to me that the patch added something not in the > upstream file. > I will update the commit message in the new patch. Chao Li (Evan) -------------------- HighGo Software Co., Ltd. https://www.highgo.com/
On Mon, Aug 11, 2025 at 4:25 PM Chao Li <li.evan.chao@gmail.com> wrote: > > Sure I can split the patch into two. The patch only changes the .xml file to .ucm file and updating the perl script. Asa result, map files should not be changed. > > Then the second patch will update the ucm file, so that the second patch should be small, contains only ucm changes andmap file changes. > > One thing to confirm with you. To archive that, we will rename the ucm file as gb18030.ucm without suffix of “-2000” and“-2022”, otherwise git won’t be able to show the diff. Is that what you meant? Usually git is pretty smart about renames combined with small changes, so I would try keeping the original names and see what it does. -- John Naylor Amazon Web Services
On Tue, Aug 12, 2025 at 9:09 AM Chao Li <li.evan.chao@gmail.com> wrote: [bringing this back to the original thread] > So, I compared 2000 ucm with 2005 ucm also compared 2005 ucm with 2022 ucm. Then I found that some changed in 2005 is revertedin 2022, that why diff between 2000 and 2022 is small. For example, the following mappings Yes, this was mentioned in the "disruptive changes" document linked in my first email in this thread: "The 2005 edition included 6 characters with double mappings. The 2022 edition removes the double mappings. The 2005 edition included 9 characters from the CJK Compatibility Ideographs block. In Unicode/10646, these all have canonical decomposition mappings to characters in the URO. In the 2022 edition, these nine compatibility characters are removed." > So, for how to create patch 2, I think we have 3 options: > > 1. As planned, update to the latest version of 2000 ucm, then skip 2005 and directly upgrade to 2022 in patch 3. This way,we just honor 2000 ucm regardless that the change is actually introduced by 2005. > > 2. Skip the latest version of 2000 ucm and upgrade to 2005 ucm. This way will clearly show the upgrade path 2000->2005->2022.Downside is that 2005 introduced some changes that are reverted in 2022, which will cause some unnecessarychanges in map files. > > 3. Skip patch 2, directly go to patch 3. So that, patch 3 will include changes introduced by both 2005 and 2022. This waymakes minimum changes to map files. #3 is what I had in mind to begin with unless we found some reason not to. Minimizing churn is a lucky side effect that reinforces that choice. Before getting to that, I thought I'd bring this up to the community: +# Copyright (C) 2000-2009, International Business Machines Corporation and others. +# All Rights Reserved. The previous XML file didn't contain a copyright notice -- does anyone want to make a case for not checking unicode-org's source file into our tree because of this? The 2022 update changes it to # Copyright (C) 2016 and later: Unicode, Inc. and others. # License & terms of use: http://www.unicode.org/copyright.html # Copyright (C) 2000-2012, International Business Machines Corporation and others. # All Rights Reserved. ...and the above links to https://www.unicode.org/license.txt -- John Naylor Amazon Web Services
3. Skip patch 2, directly go to patch 3. So that, patch 3 will include changes introduced by both 2005 and 2022. This way makes minimum changes to map files.
#3 is what I had in mind to begin with unless we found some reason not
to. Minimizing churn is a lucky side effect that reinforces that
choice.
Before getting to that, I thought I'd bring this up to the community:
The previous XML file didn't contain a copyright notice -- does anyone
want to make a case for not checking unicode-org's source file into
our tree because of this? The 2022 update changes it to
--------------------
HighGo Software Co., Ltd.
https://www.highgo.com/
On 12.08.25 06:57, John Naylor wrote: > Before getting to that, I thought I'd bring this up to the community: > > +# Copyright (C) 2000-2009, International Business Machines > Corporation and others. > +# All Rights Reserved. > > The previous XML file didn't contain a copyright notice -- does anyone > want to make a case for not checking unicode-org's source file into > our tree because of this? The 2022 update changes it to > > # Copyright (C) 2016 and later: Unicode, Inc. and others. > # License & terms of use:http://www.unicode.org/copyright.html > # Copyright (C) 2000-2012, International Business Machines Corporation > and others. > # All Rights Reserved. > > ...and the above links tohttps://www.unicode.org/license.txt Could we download this file on demand, like we do for the other input files for the conversion mappings?
On Wed, Aug 13, 2025 at 2:41 AM Peter Eisentraut <peter@eisentraut.org> wrote: > Could we download this file on demand, like we do for the other input > files for the conversion mappings? That sounds like the way to go. While poking around, I found that UCS_to_EUC_CN.pl also uses gb-18030-2000.xml for its input, so now it seems wrong to delete the XML file as a side effect of changing the source for GB18030. Maybe EUC_CN could use a downloaded-on-demand .ucm source as well (whether 2000 or 2022) but we can consider that later. For now let's leave the XML file alone. -- John Naylor Amazon Web Services
On Aug 13, 2025, at 15:17, John Naylor <johncnaylorls@gmail.com> wrote:On Wed, Aug 13, 2025 at 2:41 AM Peter Eisentraut <peter@eisentraut.org> wrote:Could we download this file on demand, like we do for the other input
files for the conversion mappings?
That sounds like the way to go.
While poking around, I found that UCS_to_EUC_CN.pl also uses
gb-18030-2000.xml for its input, so now it seems wrong to delete the
XML file as a side effect of changing the source for GB18030. Maybe
EUC_CN could use a downloaded-on-demand .ucm source as well (whether
2000 or 2022) but we can consider that later. For now let's leave the
XML file alone.
--------------------
HighGo Software Co., Ltd.
https://www.highgo.com/
Sounds good. Let me recreate the patch.
Best regards,
Вложения
On Wed, Aug 13, 2025 at 3:08 PM Chao Li <li.evan.chao@gmail.com> wrote:
> Attached is the new patch. It downloads the UCM file in make:
> After regenerating the map files, there is no change found in the map files.
I can confirm, thanks.
We split a patch into multiple patches, it's customary include all of
them, since that process may result in unwelcome artifacts to sort
out. (When the first step has architectural questions or change in
behavior, we may treat it as independent, possibly with a separate
thread, but that's not the case here.) I do have some comments
already, though:
-my $in_file = "gb-18030-2000.xml";
-
+my $in_file = "gb-18030-2000.ucm";
-while (<$in>)
-{
+while (<$in>) {
-# The lines we care about in the source file look like
+# The lines we care about in the source file look like:
These are spurious changes, which we try to avoid.
- next if (!m/<a u="([0-9A-F]+)" b="([0-9A-F ]+)"/);
+ if (/^<U([0-9A-Fa-f]+)>\s+((?:\\x[0-9A-Fa-f]{2})+)\s*\|(\d+)/) {
This change in style caused extra whitespace-only churn. That obscures
what the actual changes are.
+ # Match lines like: <UXXXX> \xYY[\xYY...] |n, and use only (|0) mappings
This is missing an explanation of why we skip non-zero mappings.
Code-wise, this only matters for the output in the follow-on patch for
2022, but one of these patches needs to include a brief explanation. I
did not like the detailed description that was present in one of the
earlier 2022 patches that told how many characters were flagged a
certain way -- that's irrelevant detail and will likely get out of
date in some future version anyway.
+# and n is a flag indicating the type of mapping having
+# a single value of 0.
This seems weird when combined with the logic to filter out non-zero
mappings. We need to think about when and where to show relevant
information.
+ next if ($flag ne '0'); # non-0 flags
This comment is just repeating what the code is doing, and it's very
obvious what it's doing.
BTW, it sounds like your proposed Makefile changes are needed for the
follow-on patch with .map changes to work at all, is that right?
https://www.postgresql.org/message-id/1CA8625F-AA41-4ED2-B60F-E28AC71F37DC@highgo.com
--
John Naylor
Amazon Web Services
We split a patch into multiple patches, it's customary include all of them, since that process may result in unwelcome artifacts to sort out. (When the first step has architectural questions or change in behavior, we may treat it as independent, possibly with a separate thread, but that's not the case here.)
Thanks for the explanation. I thought to make the second patch only after the first patch is pushed. I am new to PostgreSQL contribution, your guidance is very helpful for my future work.
Now I attach the both patch files.
For the second patch, I have tested it manually again. And "make check" test passed.
-# The lines we care about in the source file look like +# The lines we care about in the source file look like: These are spurious changes, which we try to avoid.
Updated.
- next if (!m/<a u="([0-9A-F]+)" b="([0-9A-F ]+)"/);
+ if (/^<U([0-9A-Fa-f]+)>\s+((?:\\x[0-9A-Fa-f]{2})+)\s*\|(\d+)/) {
This change in style caused extra whitespace-only churn. That obscures
what the actual changes are.Updated.
+ # Match lines like: <UXXXX> \xYY[\xYY...] |n, and use only (|0) mappings This is missing an explanation of why we skip non-zero mappings. Code-wise, this only matters for the output in the follow-on patch for 2022, but one of these patches needs to include a brief explanation. I did not like the detailed description that was present in one of the earlier 2022 patches that told how many characters were flagged a certain way -- that's irrelevant detail and will likely get out of date in some future version anyway.
Okay, I kept a neat version of comment now.
+# and n is a flag indicating the type of mapping having +# a single value of 0. This seems weird when combined with the logic to filter out non-zero mappings. We need to think about when and where to show relevant information.
Updated the comment.
+ next if ($flag ne '0'); # non-0 flags This comment is just repeating what the code is doing, and it's very obvious what it's doing.
Removed the useless comment.
BTW, it sounds like your proposed Makefile changes are needed for the follow-on patch with .map changes to work at all, is that right? https://www.postgresql.org/message-id/1CA8625F-AA41-4ED2-B60F-E28AC71F37DC@highgo.com
I think that patch could be separate, because the makefile changes are generic to all map files. The current GB18030 patch doesn't depend on that makefile patch at all. The makefile patch just makes build a little bit easier upon map file changes.
Best regards,
--
Chao Li (Evan)
--------------------
HighGo Software Co., Ltd.
https://www.highgo.com/
Вложения
On Mon, Aug 18, 2025 at 1:36 PM Chao Li <li.evan.chao@gmail.com> wrote: > I think that patch could be separate, because the makefile changes are generic to all map files. The current GB18030 patchdoesn't depend on that makefile patch at all. The makefile patch just makes build a little bit easier upon map filechanges. I verified that both autoconf and meson builds pick up the change with these two patches, and the new test passes. I'm still not sure what circumstances you found where a change doesn't get picked up, but we can come back to that later if need be. BTW, the Commitfest shows these patches as "needs rebase". The reason for that is the naming. Commands like `git am` apply a series in order, and expects to find something like v3-0001-* v3-0002-* Your last attachment was v1-0001-* v2-0001-* ...and confusingly v2 needed to be applied first. To create a series from a branch, use `git format-patch master -v <version number>` and it will output an ordered series with one patch per commit. -- John Naylor Amazon Web Services
I verified that both autoconf and meson builds pick up the change with these two patches, and the new test passes. I'm still not sure what circumstances you found where a change doesn't get picked up, but we can come back to that later if need be.
Let's talk about the makefile change separately.
...and confusingly v2 needed to be applied first. To create a series from a branch, use `git format-patch master -v <version number>` and it will output an ordered series with one patch per commit.
This is my first spitted patch. I was confused about the "0001" part in patch file names. Now I understood. I just recreated the both patch files as v3:
chaol@ChaodeMacBook-Air postgresql % git format-patch -v3 master v3-0001-GB18030-Switch-to-using-gb-18030-2000.ucm.patch v3-0002-Upgrade-GB18030-encoding-support-from-2000-to-202.patch
Regard regards,
-- Chao Li (Evan) HighGo Software Co., Ltd. https://www.highgo.com/
Вложения
On Aug 18, 2025, at 16:50, Chao Li <li.evan.chao@gmail.com> wrote:<v3-0001-GB18030-Switch-to-using-gb-18030-2000.ucm.patch><v3-0002-Upgrade-GB18030-encoding-support-from-2000-to-202.patch>
HighGo Software Co., Ltd.
https://www.highgo.com/
On Mon, Aug 18, 2025 at 3:50 PM Chao Li <li.evan.chao@gmail.com> wrote: > This is my first spitted patch. I was confused about the "0001" part in patch file names. Now I understood. I just recreatedthe both patch files as v3: I've attached v4, in which I made some cosmetic changes to the perl script, mostly to make it resemble master more closely. These changes are separated out into a separate patch for visibility, but will be squashed in the final commit. Two things are worth calling out: - The URL at the top currently points to a directory in Github, but v3 changed it to point to the actual file. A directory can be navigated for inspection, so I used: 2000: https://github.com/unicode-org/icu-data/tree/main/charset/data/ucm 2022: https://github.com/unicode-org/icu/blob/main/icu4c/source/data/mappings/ - I also made the regex a multiline regex for readability, even though the previous one was not. For 2022 version, I think it would be good to once run a test to verify that no mappings changed that we didn't expect. Perhaps the tests here can be used: https://www.postgresql.org/message-id/b9e3167f-f84b-7aa4-5738-be578a4db924%40iki.fi The upstream correction to the 2000 version is not present in our mappings, so we should mention that, unless it was reverted in or before 2022. In the documentation (charset.sgml), do we want to mention the version e.g. the following? <entry><literal>GB18030</literal></entry> -<entry>National Standard</entry> +<entry>National Standard, version 2022</entry> I've whacked around the commit messages, so those should be reviewed for accuracy. Your draft commit message had "9 characters are no longer required by the new standard, but are retained in this patch for compatibility" ...but those nine were introduced in the 2005 version, right? In which case it doesn't affect us. Please confirm. "Author: Zheng Tao <taoz@highgo.com>" -- I haven't seen any messages from this address in this thread, so could you confirm this was intentional? -- John Naylor Amazon Web Services
Вложения
- The URL at the top currently points to a directory in Github, but v3
changed it to point to the actual file. A directory can be navigated
for inspection, so I used:
2000:
https://github.com/unicode-org/icu-data/tree/main/charset/data/ucm
2022:
https://github.com/unicode-org/icu/blob/main/icu4c/source/data/mappings/
- I also made the regex a multiline regex for readability, even though
the previous one was not.
For 2022 version, I think it would be good to once run a test to
verify that no mappings changed that we didn't expect. Perhaps the
tests here can be used:
https://www.postgresql.org/message-id/b9e3167f-f84b-7aa4-5738-be578a4db924%40iki.fi
The upstream correction to the 2000 version is not present in our
mappings, so we should mention that, unless it was reverted in or
before 2022.
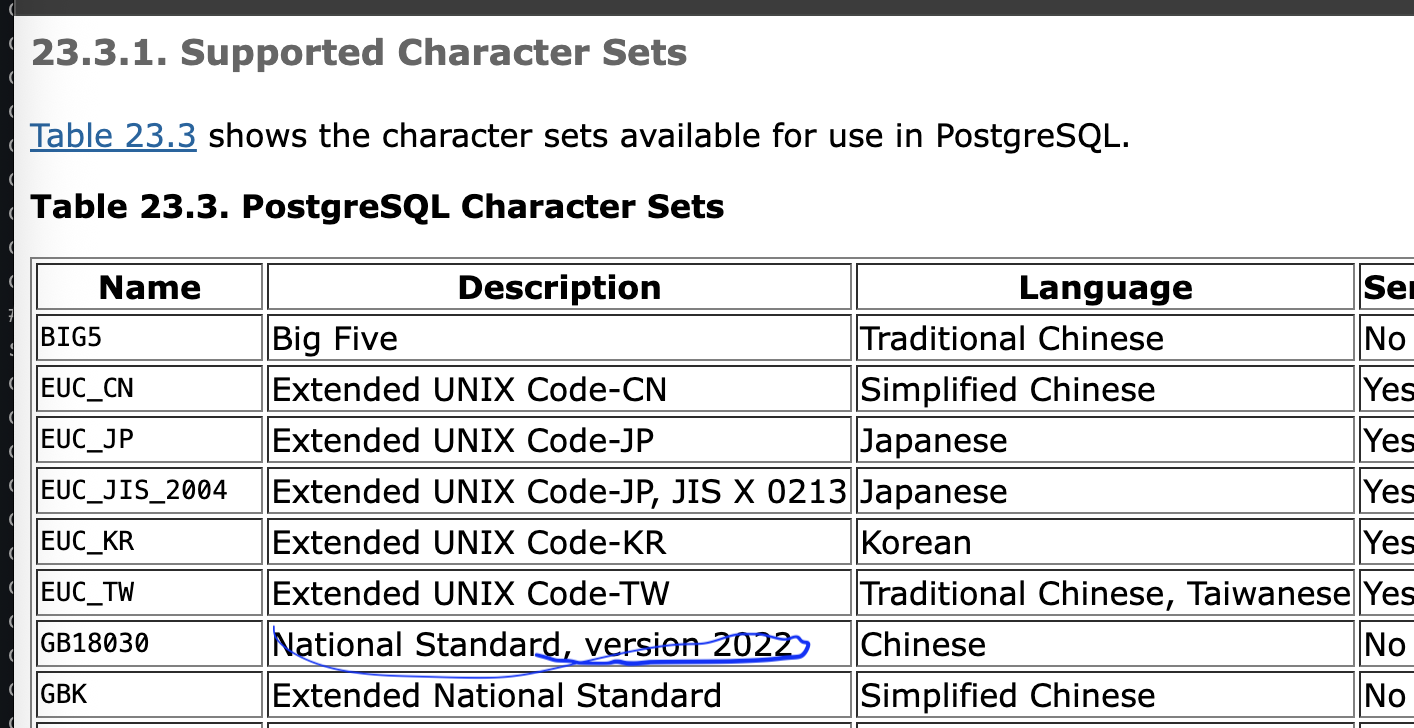
In the documentation (charset.sgml), do we want to mention the version
e.g. the following?
<entry><literal>GB18030</literal></entry>
-<entry>National Standard</entry>
+<entry>National Standard, version 2022</entry>
I've whacked around the commit messages, so those should be reviewed
for accuracy.
Your draft commit message had "9 characters are no longer required by
the new standard, but are retained in this patch for compatibility"
...but those nine were introduced in the 2005 version, right? In which
case it doesn't affect us. Please confirm.
encode
--------
efa5b9
(1 row)
"Author: Zheng Tao <taoz@highgo.com>" -- I haven't seen any messages
from this address in this thread, so could you confirm this was
intentional?
https://www.highgo.com/
Вложения
On Wed, Sep 10, 2025 at 6:54 PM Chao Li <li.evan.chao@gmail.com> wrote:
> I downloaded the tests from the referenced mail, but I cannot make the tests to run. After extracting the 2 patch files, it added src/test/encodings, but "make check" seems to not run them. I tried to copy .out and .sql files to src/test/regress, but the tests still not running. Did I miss anything?
Sorry, I'm not quite sure either how to get it to run like a normal test. I got it to show the result by doing
psql -f src/test/encodings/sql/init.sql
psql -f src/test/encodings/sql/gb18030.sql > patch.out
diff -u src/test/encodings/expected/gb18030.out patch.out > v5-test.diff
I've attached what I got with the v5 patches, renamed to avoid being picked up by CI.
>> The upstream correction to the 2000 version is not present in our
>> mappings, so we should mention that, unless it was reverted in or
>> before 2022.
>
>
> I think the upstream correction to the 2000 version is just a few not round-trip chars that are ignored by us. So I feel we don't need to mention them.
This is the commit, and both of these are in the 2022 file as a round trip mapping. I don't see any mappings with non-zero flag in the 2000 file (in any upstream commit).
https://github.com/unicode-org/icu-data/commit/91850aec0209fee0f91248731c9dd4b2b768d2b5
We should mention this correction for completeness. It seems to just move 'ḿ' out of the private use area. To be sure, likely almost no one will notice.
>> Your draft commit message had "9 characters are no longer required by
>> the new standard, but are retained in this patch for compatibility"
>> ...but those nine were introduced in the 2005 version, right? In which
>> case it doesn't affect us. Please confirm.
>
>
> I don't find any hint about if the 9 characters were introduced in the 2005 version.
Okay, I must have been confused by language "was included" in one of the linked references, which doesn't necessarily mean they were introduced there.
The 66 new mappings required are not in the 2022 UCM file and we already cover them algorithmically in utf8_and_gb18030.c, so they already work without this patch (see below, the glyphs render on my OS but maybe not everyone can see them). The commit message needs to focus on what actually changed for users (I'll work on that). Related information should be an afterthought.
# SELECT convert_from(decode('82358F33', 'hex'), 'GB18030');
convert_from
--------------
龦
(1 row)
# SELECT convert_from(decode('82359636', 'hex'), 'GB18030');
convert_from
--------------
鿯
(1 row)
While looking at utf8_and_gb18030.c, I see it refers to the XML file as the source of the algorithmic ranges. We'll want to keep some reference to the ranges independent of the XML file. I found
https://htmlpreview.github.io/?https://github.com/unicode-org/icu-data/blob/main/charset/source/gb18030/gb18030.html
...which gives general info and mentions that U+10000 starts at GB+90308130, and also links to
https://github.com/unicode-org/icu-data/blob/main/charset/source/gb18030/ranges.txt
...which has the same ranges we have below U+10000. Links can always disappear, but if the algorithmic ranges ever need to change (unlikely), we'll have new information about that.
--
John Naylor
Amazon Web Services
Вложения
On Sep 11, 2025, at 15:39, John Naylor <johncnaylorls@gmail.com> wrote:
On Wed, Sep 10, 2025 at 6:54 PM Chao Li <li.evan.chao@gmail.com> wrote:
> I downloaded the tests from the referenced mail, but I cannot make the tests to run. After extracting the 2 patch files, it added src/test/encodings, but "make check" seems to not run them. I tried to copy .out and .sql files to src/test/regress, but the tests still not running. Did I miss anything?
Sorry, I'm not quite sure either how to get it to run like a normal test. I got it to show the result by doing
psql -f src/test/encodings/sql/init.sql
psql -f src/test/encodings/sql/gb18030.sql > patch.out
diff -u src/test/encodings/expected/gb18030.out patch.out > v5-test.diff
I've attached what I got with the v5 patches, renamed to avoid being picked up by CI.
>> The upstream correction to the 2000 version is not present in our
>> mappings, so we should mention that, unless it was reverted in or
>> before 2022.
>
>
> I think the upstream correction to the 2000 version is just a few not round-trip chars that are ignored by us. So I feel we don't need to mention them.
This is the commit, and both of these are in the 2022 file as a round trip mapping. I don't see any mappings with non-zero flag in the 2000 file (in any upstream commit).
https://github.com/unicode-org/icu-data/commit/91850aec0209fee0f91248731c9dd4b2b768d2b5
We should mention this correction for completeness. It seems to just move 'ḿ' out of the private use area. To be sure, likely almost no one will notice.
>> Your draft commit message had "9 characters are no longer required by
>> the new standard, but are retained in this patch for compatibility"
>> ...but those nine were introduced in the 2005 version, right? In which
>> case it doesn't affect us. Please confirm.
>
>
> I don't find any hint about if the 9 characters were introduced in the 2005 version.
Okay, I must have been confused by language "was included" in one of the linked references, which doesn't necessarily mean they were introduced there.
The 66 new mappings required are not in the 2022 UCM file and we already cover them algorithmically in utf8_and_gb18030.c, so they already work without this patch (see below, the glyphs render on my OS but maybe not everyone can see them). The commit message needs to focus on what actually changed for users (I'll work on that). Related information should be an afterthought.
# SELECT convert_from(decode('82358F33', 'hex'), 'GB18030');
convert_from
--------------
龦
(1 row)
# SELECT convert_from(decode('82359636', 'hex'), 'GB18030');
convert_from
--------------
鿯
(1 row)
While looking at utf8_and_gb18030.c, I see it refers to the XML file as the source of the algorithmic ranges. We'll want to keep some reference to the ranges independent of the XML file. I found
https://htmlpreview.github.io/?https://github.com/unicode-org/icu-data/blob/main/charset/source/gb18030/gb18030.html
...which gives general info and mentions that U+10000 starts at GB+90308130, and also links to
https://github.com/unicode-org/icu-data/blob/main/charset/source/gb18030/ranges.txt
...which has the same ranges we have below U+10000. Links can always disappear, but if the algorithmic ranges ever need to change (unlikely), we'll have new information about that.
HighGo Software Co., Ltd.
https://www.highgo.com/
Вложения
I will post v6 soon with updated commit message.
Вложения
I am attaching the v6 patch set:* Updated 0003's commit comment.* In 0003, updated a function comment in utf8_and_gb18030.c to address John's comment about reference to the xml file.Best regards,Chao Li (Evan)---------------------HighGo Software Co., Ltd.
Вложения
On Thu, Sep 11, 2025 at 4:09 PM Chao Li <li.evan.chao@gmail.com> wrote: > Then I switched to the patch branch, it got 21 different lines. After I updated the 18 known changes in the out file, thenit got only 3 different lines: > > ``` > - \x8135f437 | \xe1b8bf > + \x8135f437 | \xee9f87 > > - \xa3a0 | \xee97a5 > + \xa3a0 | character with byte sequence 0xa3 0xa0 in encoding "GB18030" has no equivalent in encoding “UTF8" > > - \xa8bc | \xee9f87 > + \xa8bc | \xe1b8bf > ``` > > Where, \x8135f437 and \xa8bc reflect to the change pointed by above link: > > \xA8BC used to map to unicode UE7C7, now \x8135f437 changed to map to UE7C7, and \xA8BC changed to map to U1E3F in version2005. Maybe we can phrase it like this: ``` There have been two corrections to the 2000 version that were carried forward to later versions. The following mappings were previously swapped: U+E7C7 (Private Use Area) now maps to \x8135f437 U+1E3F (Latin Small Letter M with Acute) now maps to \xA8BC ``` > For \xa3a0, in 2022.ucm, it is a not a roundtrip mapping: > > ``` > <U3000> \xA3\xA0 |3 > <UE5E5> \xA3\xA0 |4 > ``` > > So we ignored it. Then everything is clear. Yes, I see this in the file, but it's not described in any of the documents about the 2022 version, although they mention other cases regarding the Private Use Area. I'm not sure we need to worry too much, but we need to describe the behavior changes, maybe like this: ``` Previously, U+E5E5 (Private Use Area) was mapped to \xA3A0. This code point now maps to \x65356535. Attempting to convert \xA3A0 will now raise an error. ``` I'm open to suggestions. -- John Naylor Amazon Web Services
On Fri, Sep 12, 2025 at 8:57 AM Chao Li <li.evan.chao@gmail.com> wrote: > * In 0003, updated a function comment in utf8_and_gb18030.c to address John's comment about reference to the xml file. Thanks, but the entire point of that comment change was to remove the reference to the XML file, yet it didn't actually do that. Also, the words in my email were to explain to you what should go there and why. That doesn't mean those words belong in the comment. The comment change seems like it belongs in the preparatory commit anyway, so I put the links there and pushed 0001 (along with the squashed 0002). -- John Naylor Amazon Web Services
On Sep 16, 2025, at 17:36, John Naylor <johncnaylorls@gmail.com> wrote:
The comment change seems like it belongs in the preparatory commit
anyway, so I put the links there and pushed 0001 (along with the
squashed 0002).
Вложения
On Wed, Sep 17, 2025 at 9:08 AM Chao Li <li.evan.chao@gmail.com> wrote: > I see you have updated the function comment in utf8_and_gb18030.c, so I removed it from the v8 patch. > > Attached is the v8 patch: I've reworked the commit message I started in v5 to incorporate later discussions. (I was not a fan of including a complete table there, nor of using UTF-8 encoding instead of code points as a reference.) The only change I made for v9 is to reword the regression test addition from "upgrades" to "change". I'm planning to commit next week unless there are objections. (If anyone otherwise busy with the PG18 release wants a chance to weigh in, let me know and I'll hold off). It'll be a good idea to communicate how to detect (unlikely but not impossible) incompatibilities for existing systems, but I don't think committing needs to wait for that piece. -- John Naylor Amazon Web Services
Вложения
On Sep 18, 2025, at 15:59, John Naylor <johncnaylorls@gmail.com> wrote:
It'll be a good idea to communicate how to detect (unlikely but not
impossible) incompatibilities for existing systems, but I don't think
committing needs to wait for that piece.
--
John Naylor
Amazon Web Services
<v9-0001-Update-GB18030-encoding-from-version-2000-to-2022.patch>
HighGo Software Co., Ltd.
https://www.highgo.com/
On Thu, Sep 18, 2025 at 3:16 PM Chao Li <li.evan.chao@gmail.com> wrote: > > When you say “communicate how to detect incompatibility for existing systems”, what would be the communication channel?I am actually very new to the PG development community, your guidance will be greatly appreciated. My first thought was to include a sample query in the release notes that filters on text with the affected code points, but I'd be happy to hear other ideas. We start working on release notes around April/May. -- John Naylor Amazon Web Services
On Sep 18, 2025, at 16:53, John Naylor <johncnaylorls@gmail.com> wrote:On Thu, Sep 18, 2025 at 3:16 PM Chao Li <li.evan.chao@gmail.com> wrote:
When you say “communicate how to detect incompatibility for existing systems”, what would be the communication channel? I am actually very new to the PG development community, your guidance will be greatly appreciated.
My first thought was to include a sample query in the release notes
that filters on text with the affected code points, but I'd be happy
to hear other ideas. We start working on release notes around
April/May.
HighGo Software Co., Ltd.
https://www.highgo.com/
On Thu, Sep 18, 2025 at 2:59 PM John Naylor <johncnaylorls@gmail.com> wrote: > The only change I made for v9 is to reword the regression test > addition from "upgrades" to "change". I'm planning to commit next week > unless there are objections. (If anyone otherwise busy with the PG18 > release wants a chance to weigh in, let me know and I'll hold off). Pushed. On Thu, Sep 18, 2025 at 4:45 PM Chao Li <li.evan.chao@gmail.com> wrote: > So, no immediate action to take, right? I may work out such a query before starting of release note work. Sounds good. Were you also interested in seeing if EUC_CN can use the same UCM file? That would allow us to get rid of the XML file. -- John Naylor Amazon Web Services
On Sep 24, 2025, at 14:42, John Naylor <johncnaylorls@gmail.com> wrote:
Sounds good. Were you also interested in seeing if EUC_CN can use the
same UCM file? That would allow us to get rid of the XML file.
HighGo Software Co., Ltd.
https://www.highgo.com/
On Sep 24, 2025, at 15:04, Chao Li <li.evan.chao@gmail.com> wrote:On Sep 24, 2025, at 14:42, John Naylor <johncnaylorls@gmail.com> wrote:
Sounds good. Were you also interested in seeing if EUC_CN can use the
same UCM file? That would allow us to get rid of the XML file.Sure, let me take a look.
Вложения
On Sep 24, 2025, at 15:04, Chao Li <li.evan.chao@gmail.com> wrote:On Sep 24, 2025, at 14:42, John Naylor <johncnaylorls@gmail.com> wrote:
Sounds good. Were you also interested in seeing if EUC_CN can use the
same UCM file? That would allow us to get rid of the XML file.Sure, let me take a look.I found that both EUC_CN and UHC use the same XML file, so I updated both.I didn’t delete gb-18030-2000.xml in this patch, because it would make the patch file very large, you can just add the deletion to the commit when you push it.Basically, the changes are all borrowed from the previous commit. With this patch, regenerating the maps file lead to no map file change, which is expected:```% make utf8_to_uhc.map utf8_to_euc_cn.map'/usr/bin/perl' -I . UCS_to_UHC.pl- Writing UTF8=>UHC conversion table: utf8_to_uhc.map- Writing UHC=>UTF8 conversion table: uhc_to_utf8.map'/usr/bin/perl' -I . UCS_to_EUC_CN.pl- Writing UTF8=>EUC_CN conversion table: utf8_to_euc_cn.map- Writing EUC_CN=>UTF8 conversion table: euc_cn_to_utf8.map% git diff # no map file change%```I am not sure if you should also upgrade the UCM file to 2022 version, but if we need, let’s do it with a separate commit.
Вложения
On Wed, Sep 24, 2025 at 4:18 PM Chao Li <li.evan.chao@gmail.com> wrote: > I am not sure if you should also upgrade the UCM file to 2022 version, but if we need, let’s do it with a separate commit. If they can all use the same file, we should just do that for the sake of simplicity, in which case a separate commit is just extra noise. -- John Naylor Amazon Web Services
On Wed, Sep 24, 2025 at 4:18 PM Chao Li <li.evan.chao@gmail.com> wrote:
> I am not sure if you should also upgrade the UCM file to 2022 version, but if we need, let’s do it with a separate commit.
If they can all use the same file, we should just do that for the sake
of simplicity, in which case a separate commit is just extra noise.
wget -O windows-949-2000.ucm --no-use-server-timestamps https://raw.githubusercontent.com/unicode-org/icu/refs/heads/main/icu4c/source/data/mappings/windows-949-2000.ucm
--2025-09-29 16:00:40-- https://raw.githubusercontent.com/unicode-org/icu/refs/heads/main/icu4c/source/data/mappings/windows-949-2000.ucm
HTTP request sent, awaiting response... 200 OK
Length: 356253 (348K) [text/plain]
Saving to: ‘windows-949-2000.ucm’
windows-949-2000.ucm 100%[=========================================================================================================>] 347.90K 222KB/s in 1.6s
2025-09-29 16:00:43 (222 KB/s) - ‘windows-949-2000.ucm’ saved [356253/356253]
'/usr/bin/perl' -I . UCS_to_UHC.pl
- Writing UTF8=>UHC conversion table: utf8_to_uhc.map
- Writing UHC=>UTF8 conversion table: uhc_to_utf8.map
wget -O gb18030-2022.ucm --no-use-server-timestamps https://raw.githubusercontent.com/unicode-org/icu/refs/heads/main/icu4c/source/data/mappings/gb18030-2022.ucm
--2025-09-29 16:00:43-- https://raw.githubusercontent.com/unicode-org/icu/refs/heads/main/icu4c/source/data/mappings/gb18030-2022.ucm
HTTP request sent, awaiting response... 200 OK
Length: 675312 (659K) [text/plain]
Saving to: ‘gb18030-2022.ucm’
gb18030-2022.ucm 100%[=========================================================================================================>] 659.48K 1.33MB/s in 0.5s
2025-09-29 16:00:44 (1.33 MB/s) - ‘gb18030-2022.ucm’ saved [675312/675312]
'/usr/bin/perl' -I . UCS_to_EUC_CN.pl
- Writing UTF8=>EUC_CN conversion table: utf8_to_euc_cn.map
- Writing EUC_CN=>UTF8 conversion table: euc_cn_to_utf8.map
% git diff
Вложения
On Wed, Sep 24, 2025 at 4:18 PM Chao Li <li.evan.chao@gmail.com> wrote: > > I found that both EUC_CN and UHC use the same XML file, so I updated both. When you say "same file", that implies to me the file we have checked in our repo. They have different names and the UHC file is downloaded on demand, so it doesn't seem like we need to change UHC at all to delete gb-18030-2000.xml. Is that right? -- John Naylor Amazon Web Services
On Sep 29, 2025, at 17:32, John Naylor <johncnaylorls@gmail.com> wrote:On Wed, Sep 24, 2025 at 4:18 PM Chao Li <li.evan.chao@gmail.com> wrote:
I found that both EUC_CN and UHC use the same XML file, so I updated both.
When you say "same file", that implies to me the file we have checked
in our repo. They have different names and the UHC file is downloaded
on demand, so it doesn't seem like we need to change UHC at all to
delete gb-18030-2000.xml. Is that right?
--
John Naylor
Amazon Web Services
HighGo Software Co., Ltd.
https://www.highgo.com/
On Mon, Sep 29, 2025 at 5:36 PM Chao Li <li.evan.chao@gmail.com> wrote: > “same file" was a mistake. windows-949-2000.ucm is a different file from gb-18030-2000(2022).ucm. > > In theory, we don’t need to change UHC if our goal is to delete gb-18030-2000.xml. That was my goal, yes. Let's stay focused on that and not change unrelated things. -- John Naylor Amazon Web Services
On Mon, Sep 29, 2025 at 5:36 PM Chao Li <li.evan.chao@gmail.com> wrote:
> “same file" was a mistake. windows-949-2000.ucm is a different file from gb-18030-2000(2022).ucm.
>
> In theory, we don’t need to change UHC if our goal is to delete gb-18030-2000.xml.
That was my goal, yes. Let's stay focused on that and not change
unrelated things.
Вложения
On Tue, Sep 30, 2025 at 1:31 PM Chao Li <li.evan.chao@gmail.com> wrote: > Sure, no problem. Please see the attached v4, I reverted UHC change from v3. Again, please "git rm" the xml file when youpush the commit. Thanks, pushed after correcting the file name in the perl script comment. I've marked the CF entry committed. -- John Naylor Amazon Web Services