Обсуждение: Add support for specifying tables in pg_createsubscriber.
Hi hackers, Currently, pg_createsubscriber supports converting streaming replication to logical replication for selected databases or all databases. However, there is no provision to replicate only a few selected tables. For such cases, users are forced to manually set up logical replication using individual SQL commands (CREATE PUBLICATION, CREATE SUBSCRIPTION, etc.), which can be time-consuming and error-prone. Extending pg_createsubscriber to support table-level replication would significantly improve the time taken to perform the setup. The attached patch introduces a new '--table' option that can be specified after each '--database' argument. It allows users to selectively replicate specific tables within a database instead of defaulting to all tables. The syntax is like that used in 'vacuumdb' and supports multiple '--table' arguments per database, including optional column lists and row filters. Example usage: ./pg_createsubscriber \ --database db1 \ --table 'public.t1' \ --table 'public.t2(a,b) WHERE a > 100' \ --database db2 \ --table 'public.t3' I conducted tests comparing the patched pg_createsubscriber with standard logical replication under various scenarios to assess performance and flexibility. All test results represent the average of five runs. Scenario pg_createsubscriber Logical Replication Improvement Two databases (postgres and db1 each having 100 tables), replicate all 100 in postgres, 50 tables in db1 (100MB/table) total 15GB data 2m4.823s 7m23.294s 71.85% One DB, 100 tables, replicate 50 tables (200 MB/table) total 10GB data 2m47.703s 4m58.003s 43.73% One DB, 200 tables, replicate 100 tables (100 MB/table) total 10GB data 3m6.476s 4m35.130s 32.22% One DB, 100 tables, replicate 50 tables (100MB/table) total 5GB data 1m54.384s 2m23.719s 20.42% These results demonstrate that pg_createsubscriber consistently outperforms standard logical replication by 20.42% for 5GB data to 71.85% for 15GB data, the time taken reduces as the data increases. The attached test scripts were used for all experiments. Scenario 1 (Logical replication setup involving 50 tables across 2 databases, each containing 100 tables with 100 MB of data per table): pg_createsubscriber_setup_multi_db.sh was used for setup, followed by pg_createsubscriber_test_multi_db.sh to measure performance. For logical replication, the setup was done using logical_replication_setup_multi_db.sh, with performance measured via logical_replication_test_multi_db.sh. Scenario 2 and 3: The pg_createsubscriber_setup_single_db.sh (uncomment appropriate scenario mentioned in comments) script was used, with configuration changes specific to Scenario 2 and Scenario 3. In both cases, pg_createsubscriber_test_single_db.sh (uncomment appropriate scenario mentioned in comments) was used for measuring performance. Logical replication followed the same pattern, using logical_replication_setup_single_db.sh (uncomment appropriate scenario mentioned in comments) and logical_replication_test_single_db.sh (uncomment appropriate scenario mentioned in comments) for measurement. Scenario 4 (Logical replication setup on 50 tables from a database containing 100 tables, each with 100 MB of data): pg_createsubscriber_setup_single_db.sh (without modifications) was used for setup, and pg_createsubscriber_test_single_db.sh (without modifications) was used for performance measurement. Logical replication used logical_replication_setup_single_db.sh (without modifications) for setup and logical_replication_test_single_db.sh (without modifications) for measurement. Thoughts? Thanks and regards, Shubham Khanna.
Вложения
Dear Shubham, > The attached patch introduces a new '--table' option that can be > specified after each '--database' argument. Do we have another example which we consider the ordering of options? I'm unsure for it. Does getopt_long() always return parsed options with the specified order? > The syntax is like that used in 'vacuumdb' > and supports multiple '--table' arguments per database, including > optional column lists and row filters. Vacuumdb nor pg_restore do not accept multiple --database, right? I'm afraid that current API has too complex. Per document: ``` + <term><option>-f <replaceable class="parameter">table</replaceable></option></term> + <term><option>--table=<replaceable class="parameter">table</replaceable></option></term> ``` I feel using "-f" is not suitable. Let's remove the shorten option now. Best regards, Hayato Kuroda FUJITSU LIMITED
On Monday, July 21, 2025 1:31 PM Shubham Khanna <khannashubham1197@gmail.com> wrote: > > Hi hackers, > > Currently, pg_createsubscriber supports converting streaming > replication to logical replication for selected databases or all > databases. However, there is no provision to replicate only a few > selected tables. For such cases, users are forced to manually set up > logical replication using individual SQL commands (CREATE PUBLICATION, > CREATE SUBSCRIPTION, etc.), which can be time-consuming and > error-prone. Extending pg_createsubscriber to support table-level > replication would significantly improve the time taken to perform the > setup. > The attached patch introduces a new '--table' option that can be > specified after each '--database' argument. It allows users to > selectively replicate specific tables within a database instead of > defaulting to all tables. The syntax is like that used in 'vacuumdb' > and supports multiple '--table' arguments per database, including > optional column lists and row filters. > Example usage: > ./pg_createsubscriber \ --database db1 \ --table 'public.t1' \ --table > 'public.t2(a,b) WHERE a > 100' \ --database db2 \ --table 'public.t3' > > I conducted tests comparing the patched pg_createsubscriber with > standard logical replication under various scenarios to assess > performance and flexibility. All test results represent the average of > five runs. > > Thoughts? Aside from the interface discussion, I think this is an interesting feature in general. I got some feedback from PGConf.dev this year that many people favor using pg_createsubscriber to accelerate the initial table synchronization phase. However, some users prefer subscribing to a subset of tables from the publisher, whereas pg_createsubscriber currently subscribes all tables by default. This necessitates additional adjustments to publications and subscriptions afterward. So, this feature could streamline the process, reducing the steps users need to take. Best Regards, Hou zj
On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > Dear Shubham, > > > The attached patch introduces a new '--table' option that can be > > specified after each '--database' argument. > > Do we have another example which we consider the ordering of options? I'm > unsure > for it. Does getopt_long() always return parsed options with the specified > order? > > > The syntax is like that used in 'vacuumdb' > > and supports multiple '--table' arguments per database, including > > optional column lists and row filters. > > Vacuumdb nor pg_restore do not accept multiple --database, right? > I'm afraid that current API has too complex. We have another example to consider: pg_amcheck, which allows users to specify multiple databases. Following this precedent, it may be beneficial to adopt a similar style in pg_createsubscriber. E.g., Users could specify tables using database-qualified names, such as: ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' This approach enables the tool to internally categorize specified tables by database and create publications accordingly. Best Regards, Hou zj
On 2025-08-01 Fr 4:03 AM, Zhijie Hou (Fujitsu) wrote:
On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote:Dear Shubham,The attached patch introduces a new '--table' option that can be specified after each '--database' argument.Do we have another example which we consider the ordering of options? I'm unsure for it. Does getopt_long() always return parsed options with the specified order?The syntax is like that used in 'vacuumdb' and supports multiple '--table' arguments per database, including optional column lists and row filters.Vacuumdb nor pg_restore do not accept multiple --database, right? I'm afraid that current API has too complex.We have another example to consider: pg_amcheck, which allows users to specify multiple databases.
I don't think that's quite the point, as I understand it. pg_amcheck might allow you to have multiple --database arguments, but I don't think it depends on the order of arguments. You didn't answer his question about what getopt_long() does. I don't recall if it is free to mangle the argument order.
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
On Friday, August 1, 2025 8:56 PM Andrew Dunstan <andrew@dunslane.net> wrote: > On 2025-08-01 Fr 4:03 AM, Zhijie Hou (Fujitsu) wrote: > > On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) > > mailto:kuroda.hayato@fujitsu.com wrote: > > > Dear Shubham, > > > > > > The attached patch introduces a new '--table' option that can be specified > > > after each '--database' argument. > > > > > > Do we have another example which we consider the ordering of options? I'm > > > unsure for it. Does getopt_long() always return parsed options with the > > > specified order? > > > > > > The syntax is like that used in 'vacuumdb' and supports multiple '--table' > > > arguments per database, including optional column lists and row filters. > > > > > > Vacuumdb nor pg_restore do not accept multiple --database, right? I'm afraid > > > that current API has too complex. > > > > We have another example to consider: pg_amcheck, which allows users to specify > > multiple databases. > > I don't think that's quite the point, as I understand it. pg_amcheck might > allow you to have multiple --database arguments, but I don't think it depends > on the order of arguments. You didn't answer his question about what > getopt_long() does. I don't recall if it is free to mangle the argument order. I think you might misunderstand my proposal. I am suggesting an alternative interface style that employs database-qualified table names, which doesn't depend on the order of options. This style is already used by pg_amcheck when dealing with multiple database specifications. I referenced pg_amcheck as an example. Please see below: -- Following this precedent, it may be beneficial to adopt a similar style in pg_createsubscriber. E.g., Users could specify tables using database-qualified names, such as: ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' This approach enables the tool to internally categorize specified tables by database and create publications accordingly. -- Best Regards, Hou zj
On 2025-08-01 Fr 11:03 AM, Zhijie Hou (Fujitsu) wrote:
On Friday, August 1, 2025 8:56 PM Andrew Dunstan <andrew@dunslane.net> wrote:On 2025-08-01 Fr 4:03 AM, Zhijie Hou (Fujitsu) wrote:On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) mailto:kuroda.hayato@fujitsu.com wrote:Dear Shubham, The attached patch introduces a new '--table' option that can be specified after each '--database' argument. Do we have another example which we consider the ordering of options? I'm unsure for it. Does getopt_long() always return parsed options with the specified order? The syntax is like that used in 'vacuumdb' and supports multiple '--table' arguments per database, including optional column lists and row filters. Vacuumdb nor pg_restore do not accept multiple --database, right? I'm afraid that current API has too complex.We have another example to consider: pg_amcheck, which allows users to specify multiple databases.I don't think that's quite the point, as I understand it. pg_amcheck might allow you to have multiple --database arguments, but I don't think it depends on the order of arguments. You didn't answer his question about what getopt_long() does. I don't recall if it is free to mangle the argument order.I think you might misunderstand my proposal. I am suggesting an alternative interface style that employs database-qualified table names, which doesn't depend on the order of options. This style is already used by pg_amcheck when dealing with multiple database specifications. I referenced pg_amcheck as an example.
I simple took your own description:
The attached patch introduces a new '--table' option that can be specified after each '--database' argument.
Maybe I need some remedial English, but to me that "after" says that argument order is significant.
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
On Saturday, August 2, 2025 12:59 AM Andrew Dunstan <andrew@dunslane.net> wrote: > On 2025-08-01 Fr 11:03 AM, Zhijie Hou (Fujitsu) wrote: > > On Friday, August 1, 2025 8:56 PM Andrew Dunstan mailto:andrew@dunslane.net > wrote: > > > > > We have another example to consider: pg_amcheck, which allows users to > > > > specify multiple databases. > > > > > > I don't think that's quite the point, as I understand it. pg_amcheck might > > > allow you to have multiple --database arguments, but I don't think it depends > > > on the order of arguments. You didn't answer his question about what > > > getopt_long() does. I don't recall if it is free to mangle the argument order. > > > > I think you might misunderstand my proposal. I am suggesting an alternative > > interface style that employs database-qualified table names, which doesn't > > depend on the order of options. This style is already used by pg_amcheck when > > dealing with multiple database specifications. I referenced pg_amcheck as an > > example. > > I simple took your own description: The attached patch introduces a new > '--table' option that can be specified after each '--database' argument. Maybe I > need some remedial English, but to me that "after" says that argument order is > significant. Allow me to clarify the situation. The description you referenced is the original interface proposed by the author in the initial email. However, it was found to be unstable due to its reliance on the argument order. In response to the discussion, instead of supporting the original interface, I suggested an alternative interface to consider, which is the one that does not depend on argument order, as I mentioned in my previous email. Best Regards, Hou zj
On 2025-08-01 Fr 8:24 PM, Zhijie Hou (Fujitsu) wrote: > On Saturday, August 2, 2025 12:59 AM Andrew Dunstan <andrew@dunslane.net> wrote: >> On 2025-08-01 Fr 11:03 AM, Zhijie Hou (Fujitsu) wrote: >>> On Friday, August 1, 2025 8:56 PM Andrew Dunstan mailto:andrew@dunslane.net >> wrote: >> >>>>> We have another example to consider: pg_amcheck, which allows users to >>>>> specify multiple databases. >>>> I don't think that's quite the point, as I understand it. pg_amcheck might >>>> allow you to have multiple --database arguments, but I don't think it depends >>>> on the order of arguments. You didn't answer his question about what >>>> getopt_long() does. I don't recall if it is free to mangle the argument order. >>> I think you might misunderstand my proposal. I am suggesting an alternative >>> interface style that employs database-qualified table names, which doesn't >>> depend on the order of options. This style is already used by pg_amcheck when >>> dealing with multiple database specifications. I referenced pg_amcheck as an >>> example. >> I simple took your own description: The attached patch introduces a new >> '--table' option that can be specified after each '--database' argument. Maybe I >> need some remedial English, but to me that "after" says that argument order is >> significant. > Allow me to clarify the situation. The description you referenced is the > original interface proposed by the author in the initial email. However, it was > found to be unstable due to its reliance on the argument order. In response to > the discussion, instead of supporting the original interface, I suggested an > alternative interface to consider, which is the one that does not depend on > argument order, as I mentioned in my previous email. > Apologies, then, I misread the thread. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Fri, 1 Aug 2025 at 13:33, Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > > > Dear Shubham, > > > > > The attached patch introduces a new '--table' option that can be > > > specified after each '--database' argument. > > > > Do we have another example which we consider the ordering of options? I'm > > unsure > > for it. Does getopt_long() always return parsed options with the specified > > order? > > > > > The syntax is like that used in 'vacuumdb' > > > and supports multiple '--table' arguments per database, including > > > optional column lists and row filters. > > > > Vacuumdb nor pg_restore do not accept multiple --database, right? > > I'm afraid that current API has too complex. > > We have another example to consider: pg_amcheck, which allows users to specify > multiple databases. Following this precedent, it may be beneficial to adopt a > similar style in pg_createsubscriber. E.g., Users could specify tables using > database-qualified names, such as: > > ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table > 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' pg_amcheck allows specifying tables as a pattern, the below note is from [1]: Patterns may be unqualified, e.g. myrel*, or they may be schema-qualified, e.g. myschema*.myrel* or database-qualified and schema-qualified, e.g. mydb*.myschema*.myrel*. A database-qualified pattern will add matching databases to the list of databases to be checked. In pg_createsubscriber will it be using the exact spec of pg_amcheck or will the user have to give fully qualified names? [1] - https://www.postgresql.org/docs/devel/app-pgamcheck.html Regards, Vignesh
On Wednesday, August 6, 2025 7:23 PM vignesh C <vignesh21@gmail.com> wrote: > On Fri, 1 Aug 2025 at 13:33, Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> > wrote: > > > > On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) > <kuroda.hayato@fujitsu.com> wrote: > > > > > > Dear Shubham, > > > > > > > The attached patch introduces a new '--table' option that can be > > > > specified after each '--database' argument. > > > > > > Do we have another example which we consider the ordering of > > > options? I'm unsure for it. Does getopt_long() always return parsed > > > options with the specified order? > > > > > > > The syntax is like that used in 'vacuumdb' > > > > and supports multiple '--table' arguments per database, including > > > > optional column lists and row filters. > > > > > > Vacuumdb nor pg_restore do not accept multiple --database, right? > > > I'm afraid that current API has too complex. > > > > We have another example to consider: pg_amcheck, which allows users to > > specify multiple databases. Following this precedent, it may be > > beneficial to adopt a similar style in pg_createsubscriber. E.g., > > Users could specify tables using database-qualified names, such as: > > > > ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table > > 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' > > pg_amcheck allows specifying tables as a pattern, the below note is from [1]: > Patterns may be unqualified, e.g. myrel*, or they may be schema-qualified, e.g. > myschema*.myrel* or database-qualified and schema-qualified, e.g. > mydb*.myschema*.myrel*. A database-qualified pattern will add matching > databases to the list of databases to be checked. > > In pg_createsubscriber will it be using the exact spec of pg_amcheck or will the > user have to give fully qualified names? Both options are acceptable to me. Fully qualified names might be more familiar to users of publication DDLs, given that regex is not supported for these statements. So, I personally think that if we want to start with something simple, using fully qualified names is sensible, with the possibility to extend this functionality later if needed. Best Regards, Hou zj
On Fri, 8 Aug 2025 at 13:47, Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, August 6, 2025 7:23 PM vignesh C <vignesh21@gmail.com> wrote: > > On Fri, 1 Aug 2025 at 13:33, Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> > > wrote: > > > > > > On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) > > <kuroda.hayato@fujitsu.com> wrote: > > > > > > > > Dear Shubham, > > > > > > > > > The attached patch introduces a new '--table' option that can be > > > > > specified after each '--database' argument. > > > > > > > > Do we have another example which we consider the ordering of > > > > options? I'm unsure for it. Does getopt_long() always return parsed > > > > options with the specified order? > > > > > > > > > The syntax is like that used in 'vacuumdb' > > > > > and supports multiple '--table' arguments per database, including > > > > > optional column lists and row filters. > > > > > > > > Vacuumdb nor pg_restore do not accept multiple --database, right? > > > > I'm afraid that current API has too complex. > > > > > > We have another example to consider: pg_amcheck, which allows users to > > > specify multiple databases. Following this precedent, it may be > > > beneficial to adopt a similar style in pg_createsubscriber. E.g., > > > Users could specify tables using database-qualified names, such as: > > > > > > ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table > > > 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' > > > > pg_amcheck allows specifying tables as a pattern, the below note is from [1]: > > Patterns may be unqualified, e.g. myrel*, or they may be schema-qualified, e.g. > > myschema*.myrel* or database-qualified and schema-qualified, e.g. > > mydb*.myschema*.myrel*. A database-qualified pattern will add matching > > databases to the list of databases to be checked. > > > > In pg_createsubscriber will it be using the exact spec of pg_amcheck or will the > > user have to give fully qualified names? > > Both options are acceptable to me. Fully qualified names might be more familiar > to users of publication DDLs, given that regex is not supported for these > statements. So, I personally think that if we want to start with something > simple, using fully qualified names is sensible, with the possibility to extend > this functionality later if needed. +1 for implementing this way. Regards, Vignesh
On Fri, Aug 8, 2025 at 1:47 PM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, August 6, 2025 7:23 PM vignesh C <vignesh21@gmail.com> wrote: > > On Fri, 1 Aug 2025 at 13:33, Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> > > wrote: > > > > > > On Monday, July 28, 2025 1:07 PM Hayato Kuroda (Fujitsu) > > <kuroda.hayato@fujitsu.com> wrote: > > > > > > > > Dear Shubham, > > > > > > > > > The attached patch introduces a new '--table' option that can be > > > > > specified after each '--database' argument. > > > > > > > > Do we have another example which we consider the ordering of > > > > options? I'm unsure for it. Does getopt_long() always return parsed > > > > options with the specified order? > > > > > > > > > The syntax is like that used in 'vacuumdb' > > > > > and supports multiple '--table' arguments per database, including > > > > > optional column lists and row filters. > > > > > > > > Vacuumdb nor pg_restore do not accept multiple --database, right? > > > > I'm afraid that current API has too complex. > > > > > > We have another example to consider: pg_amcheck, which allows users to > > > specify multiple databases. Following this precedent, it may be > > > beneficial to adopt a similar style in pg_createsubscriber. E.g., > > > Users could specify tables using database-qualified names, such as: > > > > > > ./pg_createsubscriber --database db1 --table 'db1.public.t1' --table > > > 'db1.public.t2(a,b) WHERE a > 100' --database db2 --table 'db2.public.t3' > > > > pg_amcheck allows specifying tables as a pattern, the below note is from [1]: > > Patterns may be unqualified, e.g. myrel*, or they may be schema-qualified, e.g. > > myschema*.myrel* or database-qualified and schema-qualified, e.g. > > mydb*.myschema*.myrel*. A database-qualified pattern will add matching > > databases to the list of databases to be checked. > > > > In pg_createsubscriber will it be using the exact spec of pg_amcheck or will the > > user have to give fully qualified names? > > Both options are acceptable to me. Fully qualified names might be more familiar > to users of publication DDLs, given that regex is not supported for these > statements. So, I personally think that if we want to start with something > simple, using fully qualified names is sensible, with the possibility to extend > this functionality later if needed. > Thanks for the suggestion. I have implemented your approach and incorporated the required changes into the attached patch. Thanks and regards, Shubham Khanna.
Вложения
Hi Shubham,
Some review comments for patch v2-0001
======
1. General - compile errors!
Patch applies OK, but I cannot build pg_createsubscriber. e.g.
pg_createsubscriber.c: In function ‘main’:
pg_createsubscriber.c:2237:5: error: a label can only be part of a
statement and a declaration is not a statement
TableListPerDB * newdb;
^
pg_createsubscriber.c:2324:5: error: a label can only be part of a
statement and a declaration is not a statement
TableSpec * ts = pg_malloc0(sizeof(TableSpec));
^
pg_createsubscriber.c:2325:5: error: expected expression before ‘PQExpBuffer’
PQExpBuffer dbbuf;
^
pg_createsubscriber.c:2326:5: warning: ISO C90 forbids mixed
declarations and code [-Wdeclaration-after-statement]
PQExpBuffer schemabuf;
^
pg_createsubscriber.c:2335:5: error: ‘dbbuf’ undeclared (first use in
this function)
dbbuf = createPQExpBuffer();
I'm not sure how this can be working for you (???). You cannot declare
variables without introducing a code block in the scope of the switch
case.
======
doc/src/sgml/ref/pg_createsubscriber.sgml
2.
--table is missing from synopsis
~~~
3.
+ <term><option>--table=<replaceable
class="parameter">table</replaceable></option></term>
+ <listitem>
+ <para>
+ Adds a table to be included in the publication for the most recently
+ specified database. Can be repeated multiple times. The syntax
+ supports optional column lists and WHERE clauses.
+ </para>
+ </listitem>
+ </varlistentry>
Lacks detail, so I can't tell how to use this. e.g:
- What does the syntax actually look like?
- code suggests you can specify DB, but this doc says it only applies
to the most recent DB
- how supports column lists and WHERE clause (needs examples)
- needs rules FOR ALL TABLES, etc.
- allowed in combination with --all?
- etc.
======
src/bin/pg_basebackup/pg_createsubscriber.c
4.
+typedef struct TableListPerDB
+{
+ char *dbname;
+ TableSpec *tables;
+ struct TableListPerDB *next;
+} TableListPerDB;
I didn't understand the need for this "per-DB" structure.
Later, you declare "TableSpec *tables;" within the "LogicalRepInfo"
structure (which is per-DB) so you already have the "per-DB" table
list right there. Even if you need to maintain some global static
list, then I imagine you could just put a 'dbname' member in
TableSpec. You don't need a whole new structure to do it.
~~~
create_publication:
5.
+ if (dbinfo->tables == NULL)
+ appendPQExpBuffer(str, "CREATE PUBLICATION %s FOR ALL TABLES", ipubname_esc);
+ else
+ {
+ bool first = true;
+
+ appendPQExpBuffer(str, "CREATE PUBLICATION %s FOR TABLE ", ipubname_esc);
+ for (TableSpec * tbl = dbinfo->tables; tbl != NULL; tbl = tbl->next)
What if '*' is specified for the table name? Should that cause a
"CREATE PUBLICATION ... FOR TABLES IN SCHEMA ..." instead of making a
publication with 100s or more tables in a FOR TABLES?
~~~
6.
+ for (int i = 0; i < PQntuples(tres); i++)
+ {
+ char *escaped_schema = PQescapeIdentifier(conn, PQgetvalue(tres, i, 0),
+ strlen(PQgetvalue(tres, i, 0)));
+ char *escaped_table = PQescapeIdentifier(conn, PQgetvalue(tres, i, 1),
+ strlen(PQgetvalue(tres, i, 1)));
+
+ appendPQExpBuffer(str, "%s%s.%s", first ? "" : ", ",
+ escaped_schema, escaped_table);
+
+ PQfreemem(escaped_schema);
+ PQfreemem(escaped_table);
+ first = false;
+ }
6a.
How about some other simple variables to avoid all the repeated PQgetvalue?
e.g.
char *sch = PQgetvalue(tres, i, 0);
char *tbl = PQgetvalue(tres, i, 1);
char *escaped_schema = PQescapeIdentifier(conn, sch, strlen(sch));
char *escaped_table = PQescapeIdentifier(conn, tbl, strlen(tbl));
~
6b.
Variable 'first' is redundant. Same as checking 'i == 0'.
~~~
7.
+ if (dry_run)
+ {
+ res = PQexec(conn, "BEGIN");
+ if (PQresultStatus(res) != PGRES_COMMAND_OK)
+ {
Would it be better to use if/else instead of:
if (dry_run)
if (!dry_run)
~~~
main:
8.
+ TableListPerDB * newdb;
if (!simple_string_list_member(&opt.database_names, optarg))
{
simple_string_list_append(&opt.database_names, optarg);
8a.
Compile error. Need {} scope to declare that variable!
~
8b.
This seems a strange muddle of 'd' which represents DATABASE and
TableListPerDB, which is a list of tables (not a database). I have
doubts that most of this linked list code is even necessary for the
'd' case.
~~~
9.
+ case 6:
+ TableSpec * ts = pg_malloc0(sizeof(TableSpec));
+ PQExpBuffer dbbuf;
Compile error. Need {} scope to declare that variable!
~~~
10.
+ if (dotcnt == 2)
+ {
+ ts->pattern_db_regex = NULL;
+ ts->pattern_schema_regex = pg_strdup(schemabuf->data);
+ ts->pattern_table_regex = pg_strdup(namebuf->data);
+ }
+ else if (dotcnt == 1)
+ {
+ ts->pattern_db_regex = NULL;
+ ts->pattern_schema_regex = pg_strdup(dbbuf->data);
+ ts->pattern_table_regex = pg_strdup(schemabuf->data);
+ }
+ else
+ pg_fatal("invalid --table specification: %s", optarg);
10a.
This code seems quite odd to me:
- The DB becomes the schema?
- The schema becomes the table?
Rather than fudging all the names of the --table parts, if you don't
know what they represent up-fron,t probably it is better to call them
just part1,part2,part3.
~~~
10b.
Why is pattern_db_regex always NULL? If it is always NULL why have it at all?
======
.../t/040_pg_createsubscriber.pl
11.
+# Test: Table-level publication creation
+$node_p->safe_psql($db3, "CREATE TABLE public.t1 (id int, val text)");
+$node_p->safe_psql($db3, "CREATE TABLE public.t2 (id int, val text)");
+$node_p->safe_psql($db4,
+ "CREATE TABLE public.t3 (id int, val text, extra int)");
+
IIUC, the schema name is part of the table syntax. So, you should
include test cases for different schemas.
~~~
12.
+# Run pg_createsubscriber with table-level options
+command_ok(
+ [
+ 'pg_createsubscriber',
+ '--verbose',
+ '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
+ '--pgdata' => $node_s2->data_dir,
+ '--publisher-server' => $node_p->connstr($db3),
+ '--socketdir' => $node_s2->host,
+ '--subscriber-port' => $node_s2->port,
+ '--database' => $db3,
+ '--table' => "$db3.public.t1",
+ '--table' => "$db3.public.t2",
+ '--database' => $db4,
+ '--table' => "$db4.public.t3",
+ ],
+ 'pg_createsubscriber runs with table-level publication (existing nodes)');
12a.
This is not really testing the same as what the commit message
describes. e.g. what about a test case where --table does not mention
the db explicitly, so relies on the most recent.
~
12b.
What should happen if the explicitly named DB in --table is not the
same as the most recent --database, even though it is otherwise
correct?
e.g.
'--database' => $db3,
'--table' => "$db3.public.t1",
'--database' => $db4,
'--table' => "$db3.public.t2",
'--table' => "$db4.public.t3",
I quickly tried it and AFAICT this was silently accepted and then the
test failed because it gave unexpected results. It doesn't seem good
behaviour.
~
12c.
(related to 12b/12c).
I became suspicious that the DB name part of the --table option is
completely bogus. And it is. The test still passes OK even after I
write junk in the --table database part, like below.
command_ok(
[
'pg_createsubscriber',
'--verbose',
'--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
'--pgdata' => $node_s2->data_dir,
'--publisher-server' => $node_p->connstr($db3),
'--socketdir' => $node_s2->host,
'--subscriber-port' => $node_s2->port,
'--database' => $db3,
'--table' => "$db3.public.t1",
'--table' => "REALLY???.public.t2",
'--database' => $db4,
'--table' => "$db4.public.t3",
],
'pg_createsubscriber runs with table-level publication (existing nodes)');
~~~
13.
+# Get the publication name created by pg_createsubscriber for db3
+my $pubname1 = $node_p->safe_psql(
+ $db3, qq(
+ SELECT pubname FROM pg_publication
+ WHERE pubname LIKE 'pg_createsubscriber_%'
+ ORDER BY pubname LIMIT 1
+));
+
Why don't you just name the publication explicitly in the command?
Then you don't need any of this code to discover the publication name
here.
~~~
14.
+# Check publication tables for db3
+my $actual1 = $node_p->safe_psql(
+ $db3, qq(
+ SELECT pubname || '|public|' || tablename
+ FROM pg_publication_tables
+ WHERE pubname = '$pubname1'
+ ORDER BY tablename
+));
+is($actual1, "$pubname1|public|t1\n$pubname1|public|t2",
+ 'single publication for both tables created successfully on database db3'
+);
What is the point of hardwiring the 'public' in the concatenated
string, and then verifying that it is still there in the result? Why
not hardwire 'banana' instead of 'public' -- it passes the test just
the same.
~~~
15.
+# Get the publication name created by pg_createsubscriber for db4
+my $pubname2 = $node_p->safe_psql(
+ $db4, qq(
+ SELECT pubname FROM pg_publication
+ WHERE pubname LIKE 'pg_createsubscriber_%'
+ ORDER BY pubname LIMIT 1
+));
+
(same as #13 before)
Why don't you simply name the publication explicitly in the command?
Then you don't need any of this code to discover the publication name
here.
~~~
16.
+# Check publication tables for db4
+my $actual2 = $node_p->safe_psql(
+ $db4, qq(
+ SELECT pubname || '|public|' || tablename
+ FROM pg_publication_tables
+ WHERE pubname = '$pubname2'
+ ORDER BY tablename
+));
+is($actual2, "$pubname2|public|t3",
+ 'single publication for t3 created successfully on database db4');
+
(same as #14 before)
What is the point of the hardwired 'public'?
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi Shubham,
The patch claims (e.g. in the PG docs and in the commit message) that
"Column lists" and "WHERE clause" are possible, but I don't see how
they can work. AFAICT the patch assumes everything to the right of the
rightmost dot (.) must be the relation name.
~~~
WHERE Clause
------------
e.g.
If I say something like this:
'--table' => "$db3.public.t1 WHERE (id != 1234)",
Gives error like:
2025-08-18 09:41:50.295 AEST client backend[17727]
040_pg_createsubscriber.pl LOG: execute <unnamed>: SELECT n.nspname,
c.relname FROM pg_class c JOIN pg_namespace n ON n.oid =
c.relnamespace WHERE n.nspname ~ $1 AND c.relname ~ $2 AND c.relkind
IN ('r','p') ORDER BY 1, 2
2025-08-18 09:41:50.295 AEST client backend[17727]
040_pg_createsubscriber.pl DETAIL: Parameters: $1 = '^(public)$', $2
= '^(t1 where (id != 1234))$'
~~~
Column Lists
------------
Same. These don't work either...
e.g.
--table' => "$db3.public.t1(id,val)",
Gives error like:
2025-08-18 09:53:20.338 AEST client backend[19785]
040_pg_createsubscriber.pl LOG: execute <unnamed>: SELECT n.nspname,
c.relname FROM pg_class c JOIN pg_namespace n ON n.oid =
c.relnamespace WHERE n.nspname ~ $1 AND c.relname ~ $2 AND c.relkind
IN ('r','p') ORDER BY 1, 2
2025-08-18 09:53:20.338 AEST client backend[19785]
040_pg_createsubscriber.pl DETAIL: Parameters: $1 = '^(public)$', $2
= '^(t1(id,val))$'
======
Kind Regards
Peter Smith.
Fujitsu Australia
On Fri, Aug 15, 2025 at 12:46 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Some review comments for patch v2-0001
>
> ======
> 1. General - compile errors!
>
> Patch applies OK, but I cannot build pg_createsubscriber. e.g.
>
> pg_createsubscriber.c: In function ‘main’:
> pg_createsubscriber.c:2237:5: error: a label can only be part of a
> statement and a declaration is not a statement
> TableListPerDB * newdb;
> ^
> pg_createsubscriber.c:2324:5: error: a label can only be part of a
> statement and a declaration is not a statement
> TableSpec * ts = pg_malloc0(sizeof(TableSpec));
> ^
> pg_createsubscriber.c:2325:5: error: expected expression before ‘PQExpBuffer’
> PQExpBuffer dbbuf;
> ^
> pg_createsubscriber.c:2326:5: warning: ISO C90 forbids mixed
> declarations and code [-Wdeclaration-after-statement]
> PQExpBuffer schemabuf;
> ^
> pg_createsubscriber.c:2335:5: error: ‘dbbuf’ undeclared (first use in
> this function)
> dbbuf = createPQExpBuffer();
>
> I'm not sure how this can be working for you (???). You cannot declare
> variables without introducing a code block in the scope of the switch
> case.
>
Fixed.
> ======
> doc/src/sgml/ref/pg_createsubscriber.sgml
>
> 2.
> --table is missing from synopsis
>
> ~~~
Fixed.
>
> 3.
> + <term><option>--table=<replaceable
> class="parameter">table</replaceable></option></term>
> + <listitem>
> + <para>
> + Adds a table to be included in the publication for the most recently
> + specified database. Can be repeated multiple times. The syntax
> + supports optional column lists and WHERE clauses.
> + </para>
> + </listitem>
> + </varlistentry>
>
> Lacks detail, so I can't tell how to use this. e.g:
> - What does the syntax actually look like?
> - code suggests you can specify DB, but this doc says it only applies
> to the most recent DB
> - how supports column lists and WHERE clause (needs examples)
> - needs rules FOR ALL TABLES, etc.
> - allowed in combination with --all?
> - etc.
>
Fixed.
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> 4.
> +typedef struct TableListPerDB
> +{
> + char *dbname;
> + TableSpec *tables;
> + struct TableListPerDB *next;
> +} TableListPerDB;
>
> I didn't understand the need for this "per-DB" structure.
>
> Later, you declare "TableSpec *tables;" within the "LogicalRepInfo"
> structure (which is per-DB) so you already have the "per-DB" table
> list right there. Even if you need to maintain some global static
> list, then I imagine you could just put a 'dbname' member in
> TableSpec. You don't need a whole new structure to do it.
>
> ~~~
>
Removed the structure TableListPerDB as suggested.
> create_publication:
>
> 5.
> + if (dbinfo->tables == NULL)
> + appendPQExpBuffer(str, "CREATE PUBLICATION %s FOR ALL TABLES", ipubname_esc);
> + else
> + {
> + bool first = true;
> +
> + appendPQExpBuffer(str, "CREATE PUBLICATION %s FOR TABLE ", ipubname_esc);
> + for (TableSpec * tbl = dbinfo->tables; tbl != NULL; tbl = tbl->next)
>
> What if '*' is specified for the table name? Should that cause a
> "CREATE PUBLICATION ... FOR TABLES IN SCHEMA ..." instead of making a
> publication with 100s or more tables in a FOR TABLES?
>
> ~~~
When the user specifies '*' for the table name in pg_createsubscriber,
it makes sense to generate a SQL publication command using FOR TABLES
IN SCHEMA instead of enumerating all tables explicitly. This approach
is more efficient and scalable, especially when dealing with schemas
containing hundreds or more tables, and it ensures future tables added
to the schema are automatically included without needing to recreate
the publication.
Currently, the provided patches do not implement this behavior and
always enumerate tables in the FOR TABLE clause regardless of
wildcards. I acknowledge this and plan to address the handling of the
'*' wildcard and generate FOR TABLES IN SCHEMA publications in a
future update.
>
> 6.
> + for (int i = 0; i < PQntuples(tres); i++)
> + {
> + char *escaped_schema = PQescapeIdentifier(conn, PQgetvalue(tres, i, 0),
> + strlen(PQgetvalue(tres, i, 0)));
> + char *escaped_table = PQescapeIdentifier(conn, PQgetvalue(tres, i, 1),
> + strlen(PQgetvalue(tres, i, 1)));
> +
> + appendPQExpBuffer(str, "%s%s.%s", first ? "" : ", ",
> + escaped_schema, escaped_table);
> +
> + PQfreemem(escaped_schema);
> + PQfreemem(escaped_table);
> + first = false;
> + }
>
> 6a.
> How about some other simple variables to avoid all the repeated PQgetvalue?
>
> e.g.
> char *sch = PQgetvalue(tres, i, 0);
> char *tbl = PQgetvalue(tres, i, 1);
> char *escaped_schema = PQescapeIdentifier(conn, sch, strlen(sch));
> char *escaped_table = PQescapeIdentifier(conn, tbl, strlen(tbl));
>
> ~
>
Fixed.
> 6b.
> Variable 'first' is redundant. Same as checking 'i == 0'.
>
> ~~~
>
Fixed.
> 7.
> + if (dry_run)
> + {
> + res = PQexec(conn, "BEGIN");
> + if (PQresultStatus(res) != PGRES_COMMAND_OK)
> + {
>
> Would it be better to use if/else instead of:
>
> if (dry_run)
> if (!dry_run)
>
> ~~~
>
Fixed.
> main:
>
> 8.
> + TableListPerDB * newdb;
> if (!simple_string_list_member(&opt.database_names, optarg))
> {
> simple_string_list_append(&opt.database_names, optarg);
>
>
> 8a.
> Compile error. Need {} scope to declare that variable!
>
> ~
>
Fixed.
> 8b.
> This seems a strange muddle of 'd' which represents DATABASE and
> TableListPerDB, which is a list of tables (not a database). I have
> doubts that most of this linked list code is even necessary for the
> 'd' case.
>
> ~~~
Fixed.
>
> 9.
> + case 6:
> + TableSpec * ts = pg_malloc0(sizeof(TableSpec));
> + PQExpBuffer dbbuf;
>
> Compile error. Need {} scope to declare that variable!
>
> ~~~
>
Fixed.
> 10.
> + if (dotcnt == 2)
> + {
> + ts->pattern_db_regex = NULL;
> + ts->pattern_schema_regex = pg_strdup(schemabuf->data);
> + ts->pattern_table_regex = pg_strdup(namebuf->data);
> + }
> + else if (dotcnt == 1)
> + {
> + ts->pattern_db_regex = NULL;
> + ts->pattern_schema_regex = pg_strdup(dbbuf->data);
> + ts->pattern_table_regex = pg_strdup(schemabuf->data);
> + }
> + else
> + pg_fatal("invalid --table specification: %s", optarg);
>
> 10a.
> This code seems quite odd to me:
> - The DB becomes the schema?
> - The schema becomes the table?
>
> Rather than fudging all the names of the --table parts, if you don't
> know what they represent up-fron,t probably it is better to call them
> just part1,part2,part3.
>
> ~~~
Fixed.
>
> 10b.
> Why is pattern_db_regex always NULL? If it is always NULL why have it at all?
>
Removed.
>
> ======
> .../t/040_pg_createsubscriber.pl
>
> 11.
> +# Test: Table-level publication creation
> +$node_p->safe_psql($db3, "CREATE TABLE public.t1 (id int, val text)");
> +$node_p->safe_psql($db3, "CREATE TABLE public.t2 (id int, val text)");
> +$node_p->safe_psql($db4,
> + "CREATE TABLE public.t3 (id int, val text, extra int)");
> +
>
> IIUC, the schema name is part of the table syntax. So, you should
> include test cases for different schemas.
>
> ~~~
Fixed.
>
> 12.
> +# Run pg_createsubscriber with table-level options
> +command_ok(
> + [
> + 'pg_createsubscriber',
> + '--verbose',
> + '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
> + '--pgdata' => $node_s2->data_dir,
> + '--publisher-server' => $node_p->connstr($db3),
> + '--socketdir' => $node_s2->host,
> + '--subscriber-port' => $node_s2->port,
> + '--database' => $db3,
> + '--table' => "$db3.public.t1",
> + '--table' => "$db3.public.t2",
> + '--database' => $db4,
> + '--table' => "$db4.public.t3",
> + ],
> + 'pg_createsubscriber runs with table-level publication (existing nodes)');
>
>
> 12a.
> This is not really testing the same as what the commit message
> describes. e.g. what about a test case where --table does not mention
> the db explicitly, so relies on the most recent.
>
> ~
>
> 12b.
> What should happen if the explicitly named DB in --table is not the
> same as the most recent --database, even though it is otherwise
> correct?
>
> e.g.
> '--database' => $db3,
> '--table' => "$db3.public.t1",
> '--database' => $db4,
> '--table' => "$db3.public.t2",
> '--table' => "$db4.public.t3",
> I quickly tried it and AFAICT this was silently accepted and then the
> test failed because it gave unexpected results. It doesn't seem good
> behaviour.
>
> ~
>
> 12c.
>
> (related to 12b/12c).
>
> I became suspicious that the DB name part of the --table option is
> completely bogus. And it is. The test still passes OK even after I
> write junk in the --table database part, like below.
>
> command_ok(
> [
> 'pg_createsubscriber',
> '--verbose',
> '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
> '--pgdata' => $node_s2->data_dir,
> '--publisher-server' => $node_p->connstr($db3),
> '--socketdir' => $node_s2->host,
> '--subscriber-port' => $node_s2->port,
> '--database' => $db3,
> '--table' => "$db3.public.t1",
> '--table' => "REALLY???.public.t2",
> '--database' => $db4,
> '--table' => "$db4.public.t3",
> ],
> 'pg_createsubscriber runs with table-level publication (existing nodes)');
> ~~~
>
v3-0002 patch handles the comment 12.
> 13.
> +# Get the publication name created by pg_createsubscriber for db3
> +my $pubname1 = $node_p->safe_psql(
> + $db3, qq(
> + SELECT pubname FROM pg_publication
> + WHERE pubname LIKE 'pg_createsubscriber_%'
> + ORDER BY pubname LIMIT 1
> +));
> +
>
> Why don't you just name the publication explicitly in the command?
> Then you don't need any of this code to discover the publication name
> here.
>
> ~~~
Fixed.
>
> 14.
> +# Check publication tables for db3
> +my $actual1 = $node_p->safe_psql(
> + $db3, qq(
> + SELECT pubname || '|public|' || tablename
> + FROM pg_publication_tables
> + WHERE pubname = '$pubname1'
> + ORDER BY tablename
> +));
> +is($actual1, "$pubname1|public|t1\n$pubname1|public|t2",
> + 'single publication for both tables created successfully on database db3'
> +);
>
> What is the point of hardwiring the 'public' in the concatenated
> string, and then verifying that it is still there in the result? Why
> not hardwire 'banana' instead of 'public' -- it passes the test just
> the same.
>
> ~~~
>
Fixed.
> 15.
> +# Get the publication name created by pg_createsubscriber for db4
> +my $pubname2 = $node_p->safe_psql(
> + $db4, qq(
> + SELECT pubname FROM pg_publication
> + WHERE pubname LIKE 'pg_createsubscriber_%'
> + ORDER BY pubname LIMIT 1
> +));
> +
>
> (same as #13 before)
>
> Why don't you simply name the publication explicitly in the command?
> Then you don't need any of this code to discover the publication name
> here.
>
> ~~~
>
Fixed.
> 16.
> +# Check publication tables for db4
> +my $actual2 = $node_p->safe_psql(
> + $db4, qq(
> + SELECT pubname || '|public|' || tablename
> + FROM pg_publication_tables
> + WHERE pubname = '$pubname2'
> + ORDER BY tablename
> +));
> +is($actual2, "$pubname2|public|t3",
> + 'single publication for t3 created successfully on database db4');
> +
>
> (same as #14 before)
>
> What is the point of the hardwired 'public'?
>
Fixed.
The attached patches contain the suggested changes. They also address
the comments given by Peter at [1].
[1] - https://www.postgresql.org/message-id/CAHut%2BPuG8Vd%3DMNbQyN-3D1nsfEatmcd5bG6%2BL-GnOyoR9tC_6w%40mail.gmail.com
Thanks and regards,
Shubham Khanna.
Вложения
On Thu, Aug 21, 2025, at 6:08 AM, Shubham Khanna wrote:
> Attachments:
> * v3-0001-Support-tables-via-pg_createsubscriber.patch
> * v3-0002-Support-WHERE-clause-and-COLUMN-list-in-table-arg.patch
+ <term><option>--table=<replaceable class="parameter">table</replaceable></option></term>
+ <listitem>
+ <para>
+ Adds one or more specific tables to the publication for the most recently
+ specified <option>--database</option>. This option can be given multiple
+ times to include additional tables.
+ </para>
I think it is a really bad idea to rely on the order of options to infer which
tables are from which database. The current design about publication and
subscription names imply order but it doesn't mean subscription name must be
the next option after the publication name.
Your explanation from the initial email:
> The attached patch introduces a new '--table' option that can be
> specified after each '--database' argument. It allows users to
> selectively replicate specific tables within a database instead of
> defaulting to all tables. The syntax is like that used in 'vacuumdb'
> and supports multiple '--table' arguments per database, including
> optional column lists and row filters.
vacuumdb doesn't accept multiple --table options if you specify multiple
databases.
$ vacuumdb -a -t public.pgbench_branches -t public.pgbench_tellers -d db1 -d db2
vacuumdb: error: cannot vacuum all databases and a specific one at the same time
However, it accepts multiple --table options if you specify --all options.
(Although, I think it needs better error handling.)
$ vacuumdb -a -t public.pgbench_branches
vacuumdb: vacuuming database "contrib_regression"
vacuumdb: error: query failed: ERROR: relation "public.pgbench_branches" does not exist
LINE 2: VALUES ('public.pgbench_branches'::pg_catalog.regclass, NU...
^
vacuumdb: detail: Query was: WITH listed_objects (object_oid, column_list) AS (
VALUES ('public.pgbench_branches'::pg_catalog.regclass, NULL::pg_catalog.text)
)
Let's recap the initial goal: pg_createsubscriber creates a new logical replica
from a physical standby server. Your proposal is extending the tool to create a
partial logical replica but doesn't mention what you would do with the other
part; that is garbage after the conversion. I'm not convinced that the current
proposal is solid as-is.
+ <para>
+ The argument must be a fully qualified table name in one of the
+ following forms:
+ <itemizedlist><listitem><para><literal>schema.table</literal></para></listitem>
+ <listitem><para><literal>db.schema.table</literal></para></listitem></itemizedlist>
+ If the database name is provided, it must match the most recent
+ <option>--database</option> argument.
+ </para>
Why do you want to include the database if you already specified it?
+ <para>
+ A table specification may also include an optional column list and/or
+ row filter:
+ <itemizedlist>
+ <listitem>
+ <para>
+ <literal>schema.table(col1, col2, ...)</literal> — publishes
+ only the specified columns.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ <literal>schema.table WHERE (predicate)</literal> — publishes
+ only rows that satisfy the given condition.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ Both forms can be combined, e.g.
+ <literal>schema.table(col1, col2) WHERE (id > 100)</literal>.
+ </para>
+ </listitem>
+ </itemizedlist>
+ </para>
This is a bad idea for some cases. Let's say your setup involves a filter that
uses only 10% of the rows from a certain table. It is better to do a manual
setup. Besides that, expressions in options can open a can of worms. In the
column list case, there might be corner cases like if you have a constraint in
a certain column and that column was not included in the column list, the setup
will fail; there isn't a cheap way to detect such cases.
It seems this proposal doesn't serve a general purpose. It is copying a *whole*
cluster to use only a subset of tables. Your task with pg_createsubscriber is
more expensive than doing a manual logical replication setup. If you have 500
tables and want to replicate only 400 tables, it doesn't seem productive to
specify 400 -t options. There are some cases like a small set of big tables
that this feature makes sense. However, I'm wondering if a post script should
be used to adjust your setup. There might be cases that involves only dozens of
tables but my experience says it is rare. My expectation is that this feature
is useful for avoiding some specific tables. Hence, the copy of the whole
cluster is worthwhile.
--
Euler Taveira
EDB https://www.enterprisedb.com/
Hi Shubham.
Some review comments for patch v3-0001.
======
Commit message
1.
Allows optional column lists and row filters.
~
Is this right? Aren't the column lists and row filters now separated
in patch 0002?
======
doc/src/sgml/ref/pg_createsubscriber.sgml
2. synopsis
pg_createsubscriber [option...] { -d | --database }dbname { -D |
--pgdata }datadir { -P | --publisher-server }connstr { --table
}table-name
2a.
The --table should follow the --database instead of being last.
~
2b.
The brackets {--table} don't seem useful
~
2c.
Since there can be multiple tables per database, I feel an ellipsis
(...) is needed too
~
3.
+ <varlistentry>
+ <term><option>--table=<replaceable
class="parameter">table</replaceable></option></term>
+ <listitem>
This belongs more naturally immediately following --database.
~~~
4.
+ <para>
+ The argument must be a fully qualified table name in one of the
+ following forms:
+ <itemizedlist><listitem><para><literal>schema.table</literal></para></listitem>
+ <listitem><para><literal>db.schema.table</literal></para></listitem></itemizedlist>
+ If the database name is provided, it must match the most recent
+ <option>--database</option> argument.
+ </para>
4a.
It would be nicer if the SGML were less compacted.
e.g.
<itemizedlist>
<listitem><para><literal>schema.table</literal></para></listitem>
<listitem><para><literal>db.schema.table</literal></para></listitem>
</itemizedlist>
~
4b.
Why do we insist that the user must explicitly give a schema name?
Can't a missing schema just imply "public" so user doesn't have to
type so much?
~
4c.
FUNDAMENTAL SPEC QUESTION....
I am confused why this patch allows specifying the 'db' name part of
--table when you also insist it must be identical to the most recent
--database name. With this rule, it seems unnecessary and merely means
more validation code is required.
I can understand having the 'db' name part might be useful if you
would also permit the --table to be specified anywhere on the command,
but insisting it must match the most recent --database name seems to
cancel out any reason for allowing it in the first place.
~~~
5.
+ <para>
+ A table specification may also include an optional column list and/or
+ row filter:
+ <itemizedlist>
+ <listitem>
+ <para>
+ <literal>schema.table(col1, col2, ...)</literal> — publishes
+ only the specified columns.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ <literal>schema.table WHERE (predicate)</literal> — publishes
+ only rows that satisfy the given condition.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ Both forms can be combined, e.g.
+ <literal>schema.table(col1, col2) WHERE (id > 100)</literal>.
+ </para>
+ </listitem>
+ </itemizedlist>
+ </para>
+
AFAIK, support for this was separated into patch 0002. So these docs
should be in patch 0002, not here.
======
src/bin/pg_basebackup/pg_createsubscriber.c
6.
+typedef struct TableSpec
+{
+ char *spec;
+ char *dbname;
+ char *pattern_regex;
+ char *pattern_part1_regex;
+ char *pattern_part2_regex;
+ char *pattern_part3_regex;
+ struct TableSpec *next;
+} TableSpec;
+
6a.
Add a typedefs.list entry for this new typedef, and run pg_indent.
~
6b.
pattern_regex is unused?
~
6c.
pattern_part1_regex seems assigned, but it is otherwise unused (??). Needed?
~
6d.
I had previously given a review comment suggesting names like
part1/2/3 because previously, you were using members with different
meanings depending on the tablespec. But, now it seems all the dot
parse logic is re-written, so AFAICT you are always using part1 means
dbregex; part2 means schemaregex; part3 means tableregex ... So, the
"part" names are strange in the current impl - if you really do know
what they represent, then call them by their proper names.
~~~
7.
+static TableSpec * table_list_head = NULL;
+static TableSpec * table_list_tail = NULL;
+static char *current_dbname = NULL;
7a.
Why isn't 'current_dbname' just a local variable of main()?
~
7b.
I doubt the 'tail' var is needed. See a later review comment for details.
~~~
8.
-
/*
* Cleanup objects that were created by pg_createsubscriber if there is an
* error.
Whitespace change unrelated to this patch?
~~~
usage:
9.
printf(_(" --subscription=NAME subscription name\n"));
+ printf(_(" --table table to subscribe to;
can be specified multiple times\n"));
printf(_(" -V, --version output version
information, then exit\n"));
Or, should this say "table to publish". Maybe it amounts to the same
thing, but this patch modifies CREATE PUBLICATION, not CREATE
SUBSCRIPTION.
~~~
store_pub_sub_info:
10.
+ for (i = 0; i < num_dbs; i++)
+ {
+ TableSpec *prev = NULL;
+ TableSpec *cur = table_list_head;
+ TableSpec *filtered_head = NULL;
+ TableSpec *filtered_tail = NULL;
+
+ while (cur != NULL)
+ {
+ TableSpec *next = cur->next;
+
+ if (strcmp(cur->dbname, dbinfo[i].dbname) == 0)
+ {
+ if (prev)
+ prev->next = next;
+ else
+ table_list_head = next;
+
+ cur->next = NULL;
+ if (!filtered_head)
+ filtered_head = filtered_tail = cur;
+ else
+ {
+ filtered_tail->next = cur;
+ filtered_tail = cur;
+ }
+ }
+ else
+ prev = cur;
+ cur = next;
+ }
+ dbinfo[i].tables = filtered_head;
+ }
+
10a.
Is there a bug? I have not debugged this, but when you are assigning
filtered_tail = cur, who is ensuring that "filtered" list is
NULL-terminated? e.g. I suspect the cur->next might still point to
something inappropriate.
~
10b.
I doubt all that 'filered_head/tail' logic is needed at all. Can't you
just assign directly to the head of dbinfo[i].tables list as you
encounter appropriate tables for that db? The order may become
reversed, but does that matter?
e.g. something like this
cur->next = dbinfo[i].tables ? dbinfo[i].tables.next : NULL;
dbinfo[i].tables = cur;
~~~
create_publication:
11.
PGresult *res;
char *ipubname_esc;
char *spubname_esc;
+ bool first_table = true;
This 'first_table' variable is redundant. Just check i == 0 in the loop.
~~~
12.
+ appendPQExpBuffer(str, "%s%s.%s",
+ first_table ? "" : ", ",
+ escaped_schema, escaped_table);
SUGGESTION
if (i > 0)
appendPQExpBuffer(str, ", ");
appendPQExpBuffer(str, "%s.%s", escaped_schema, escaped_table);
~~~
13.
- if (!simple_string_list_member(&opt.database_names, optarg))
{
- simple_string_list_append(&opt.database_names, optarg);
- num_dbs++;
+ if (current_dbname)
+ pg_free(current_dbname);
+ current_dbname = pg_strdup(optarg);
+
+ if (!simple_string_list_member(&opt.database_names, optarg))
+ {
+ simple_string_list_append(&opt.database_names, optarg);
+ num_dbs++;
+ }
+ else
+ pg_fatal("database \"%s\" specified more than once for
-d/--database", optarg);
+ break;
}
- else
- pg_fatal("database \"%s\" specified more than once for
-d/--database", optarg);
- break;
13a.
The scope {} is not needed. You removed the previously declared variable.
~
13b.
The pfree might be overkill. I think a few little database name
strdups leaks are hardly going to be a problem. It's up to you.
~~~
14.
+ char *copy_arg;
+ char *first_dot;
+ char *second_dot;
+ char *dbname_arg = NULL;
+ char *schema_table_part;
+ TableSpec *ts;
Does /dbname_arg/dbname_part/make more sense here?
~~~
15.
+ if (first_dot != NULL)
+ second_dot = strchr(first_dot + 1, '.');
+ else
+ second_dot = NULL;
+
+
The 'else' is not needed if you had assigned NULL at the declaration.
~~~
16.
The logic seems quite brittle. e.g. Maybe you should only parse
looking for dots to the end of the copy_arg or the first space.
Otherwise, other "dots" in the table spec will mess up your logic.
e.g.
"db.sch.tbl" -> 2 dots
"sch.tbl WHERE (x > 1.0)" -> also 2 dots
Similarly, what you called 'schema_table_part' cannot be allowed to
extend beyond any space; otherwise, it can easily return an unexpected
dotcnt.
"db.sch.tbl WHERE (x > 1.0)" -> 3 dots
~~~
17.
+ patternToSQLRegex(encoding, dbbuf, schemabuf, namebuf,
+ schema_table_part, false, false, &dotcnt);
+
+ if (dbname_arg != NULL)
+ dotcnt++;
+
+ if (dotcnt == 2)
+ {
+ ts->pattern_part1_regex = pg_strdup(dbbuf->data);
+ ts->pattern_part2_regex = pg_strdup(schemabuf->data);
+ ts->pattern_part3_regex = namebuf->len > 0 ? pg_strdup(namebuf->data) : NULL;
+ }
+ else if (dotcnt == 1)
+ {
+ ts->pattern_part1_regex = NULL;
+ ts->pattern_part2_regex = pg_strdup(dbbuf->data);
+ ts->pattern_part3_regex = NULL;
+ }
+ else
+ pg_fatal("invalid table specification \"%s\"", optarg);
Something seems very strange here...
I haven't debugged this, but I imagine if "--table sch.tab" then
dotcnt will be 1.
But then
+ ts->pattern_part1_regex = NULL;
+ ts->pattern_part2_regex = pg_strdup(dbbuf->data);
+ ts->pattern_part3_regex = NULL;
The schema regex is assigned the dbbuf->data (???) I don't trust this
logic. I saw that there are no test cases where dbpart is omitted, so
maybe this is a lurking bug?
~~~
18.
+
+ if (!table_list_head)
+ table_list_head = table_list_tail = ts;
+ else
+ table_list_tail->next = ts;
+
+ table_list_tail = ts;
+
All this 'tail' stuff looks potentially unnecessary. e.g. I think you
could simplify all this just by adding to the front of the list.
SUGGESTION
ts->next = table_list_head;
table_list_head = ts;
======
.../t/040_pg_createsubscriber.pl
19.
+# Declare database names
+my $db3 = 'db3';
+my $db4 = 'db4';
+
What do these variables achieve? e.g. Why not just use hardcoded
strings 'db1' and 'db2'.
~~~
20.
+# Test: Table-level publication creation
+$node_p->safe_psql($db3, "CREATE TABLE public.t1 (id int, val text)");
+$node_p->safe_psql($db3, "CREATE TABLE public.t2 (id int, val text)");
+$node_p->safe_psql($db3, "CREATE TABLE myschema.t4 (id int, val text)");
You could combine all these.
~~~
21.
+$node_p->safe_psql($db4,
+ "CREATE TABLE public.t3 (id int, val text, extra int)");
+$node_p->safe_psql($db4,
+ "CREATE TABLE otherschema.t5 (id serial primary key, info text)");
You could combine these.
~~~
22.
+# Create explicit publications
+my $pubname1 = 'pub1';
+my $pubname2 = 'pub2';
+
What does creating these variables achieve? e.g. Why not just use
hardcoded strings 'pub1' and 'pub2'.
~~~
23.
+# Run pg_createsubscriber with table-level options
+command_ok(
+ [
+ 'pg_createsubscriber',
+ '--verbose',
+ '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
+ '--pgdata' => $node_s2->data_dir,
+ '--publisher-server' => $node_p->connstr($db3),
+ '--socketdir' => $node_s2->host,
+ '--subscriber-port' => $node_s2->port,
+ '--publication' => $pubname1,
+ '--publication' => $pubname2,
+ '--database' => $db3,
+ '--table' => "$db3.public.t1",
+ '--table' => "$db3.public.t2",
+ '--table' => "$db3.myschema.t4",
+ '--database' => $db4,
+ '--table' => "$db4.public.t3",
+ '--table' => "$db4.otherschema.t5",
+ ],
+ 'pg_createsubscriber runs with table-level publication (existing nodes)');
+
There is no test for a --table spec where the dbpart is omitted.
~~~
24.
+# Check publication tables for db3 with public schema first
What is the significance "with public schema first" in this comment?
~~
25.
+# Check publication tables for db4, with public schema first
+my $actual2 = $node_p->safe_psql(
+ $db4, qq(
+ SELECT pubname || '|' || schemaname || '|' || tablename
+ FROM pg_publication_tables
+ WHERE pubname = '$pubname2'
+ ORDER BY schemaname, tablename
+ )
+);
+is( $actual2,
+ "$pubname2|otherschema|t5\n$pubname2|public|t3",
+ 'publication includes tables in public and otherschema schemas on db4');
+
Ditto. What is the significance "with public schema first" in this comment?
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi Shubham,
Some brief review comments about patch v3-0002.
======
Commit message
1.
This patch support the specification of both a WHERE clause (row filter) and a
column list in the table specification via pg_createsubscriber, and modify the
utility's name (for example, to a more descriptive or aligned name).
For eg:-
CREATE PUBLICATION pub FOR TABLE schema.table (col1, col2) WHERE
(predicate);
1a.
/support/supports/
~
1b.
"and modify the utility's name (for example, to a more descriptive or
aligned name)."
/modify/modifies/ but more importantly, what does this sentence mean?
======
GENERAL
2.
Should be some docs moved to this patch
~~~
3.
Missing test cases
======
src/bin/pg_basebackup/pg_createsubscriber.c
typedef struct TableSpec:
4.
char *dbname;
+ char *att_names;
+ char *row_filter;
char *pattern_regex;
4a.
FUNDAMENTAL DESIGN QUESTION
Why do we even want to distinguish these? IIUC, all you need to know
is "char *extra;" which can represent *anything* else the user may
tack onto the end of the table name. You don't even need to parse
it... e.g. You could let the "CREATE PUBLICATION" check the syntax.
~
4b.
Current patch is not even assigning these members (??)
~~~
5.
+char *
+pg_strcasestr(const char *haystack, const char *needle)
+{
+ if (!*needle)
+ return (char *) haystack;
+ for (; *haystack; haystack++)
+ {
+ const char *h = haystack;
+ const char *n = needle;
+
+ while (*h && *n && pg_tolower((unsigned char) *h) ==
pg_tolower((unsigned char) *n))
+ ++h, ++n;
+ if (!*n)
+ return (char *) haystack;
+ }
+ return NULL;
+}
+
Not needed.
~~~
create_publication:
6.
+ if (tbl->att_names && strlen(tbl->att_names) > 0)
+ appendPQExpBuffer(str, " ( %s )", tbl->att_names);
+
+ if (tbl->row_filter && strlen(tbl->row_filter) > 0)
+ appendPQExpBuffer(str, " WHERE %s", tbl->row_filter);
Overkill? I imagine this could all be replaced with something simple
without trying to distinguish between them.
if (tbl->extra)
appendPQExpBuffer(str, " %s", tbl->extra);
~~~
main:
7.
+ where_start = pg_strcasestr(copy_arg, " where ");
+ if (where_start != NULL)
+ {
+ *where_start = '\0';
+ where_start += 7;
+ }
+
+ paren_start = strchr(copy_arg, '(');
+ if (paren_start != NULL)
+ {
+ char *paren_end = strrchr(paren_start, ')');
+
+ if (!paren_end)
+ pg_fatal("unmatched '(' in --table argument \"%s\"", optarg);
+
+ *paren_start = '\0';
+ *paren_end = '\0';
+
+ paren_start++;
+ }
+
Overkill? IIUC, all you need to know is whether there's something
beyond the table name. Just looking for a space ' ' or a parenthesis
'(' delimiter could be enough, right?
e.g. Something like:
char *extra = strpbk(copy_arg, ' (');
if (extra)
ts->extra = extra + 1;
======
Kind Regards,
Peter Smith.
Fujitsu Australia
On Friday, August 22, 2025 11:19 AM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Aug 21, 2025, at 6:08 AM, Shubham Khanna wrote: > > Attachments: > > * v3-0001-Support-tables-via-pg_createsubscriber.patch > > * v3-0002-Support-WHERE-clause-and-COLUMN-list-in-table-arg.patch > > + <term><option>--table=<replaceable > class="parameter">table</replaceable></option></term> > + <listitem> > + <para> > + Adds one or more specific tables to the publication for the most > recently > + specified <option>--database</option>. This option can be given > multiple > + times to include additional tables. > + </para> > > I think it is a really bad idea to rely on the order of options to infer which tables > are from which database. The current design about publication and > subscription names imply order but it doesn't mean subscription name must > be the next option after the publication name. The documentation appears incorrect and needs revision. The latest version no longer depends on the option order; instead, it requires users to provide database-qualified table names, such as -t "db1.sch1.tb1". This adjustment allows the command to internally categorize tables by their target database. > > Let's recap the initial goal: pg_createsubscriber creates a new logical replica > from a physical standby server. Your proposal is extending the tool to create a > partial logical replica but doesn't mention what you would do with the other > part; that is garbage after the conversion. I'm not convinced that the current > proposal is solid as-is. I think we can explore extending the existing --clean option in a separate patch to support table cleanup. This option is implemented in a way that allows adding further cleanup objects later, so it should be easy to extend it for table. Prior to this extension, it should be noted in the documentation that users are required to clean up the tables themselves. > > + <para> > + The argument must be a fully qualified table name in one of the > + following forms: > + > <itemizedlist><listitem><para><literal>schema.table</literal></para></li > stitem> > + > <listitem><para><literal>db.schema.table</literal></para></listitem></it > emizedlist> > + If the database name is provided, it must match the most recent > + <option>--database</option> argument. > + </para> > > Why do you want to include the database if you already specified it? As mentioned earlier, this document needs to be corrected. > > + <para> > + A table specification may also include an optional column list and/or > + row filter: > + <itemizedlist> > + <listitem> > + <para> > + <literal>schema.table(col1, col2, ...)</literal> — publishes > + only the specified columns. > + </para> > + </listitem> > + <listitem> > + <para> > + <literal>schema.table WHERE (predicate)</literal> — > publishes > + only rows that satisfy the given condition. > + </para> > + </listitem> > + <listitem> > + <para> > + Both forms can be combined, e.g. > + <literal>schema.table(col1, col2) WHERE (id > 100)</literal>. > + </para> > + </listitem> > + </itemizedlist> > + </para> > > This is a bad idea for some cases. Let's say your setup involves a filter that uses > only 10% of the rows from a certain table. It is better to do a manual setup. > Besides that, expressions in options can open a can of worms. In the column > list case, there might be corner cases like if you have a constraint in a certain > column and that column was not included in the column list, the setup will fail; > there isn't a cheap way to detect such cases. I agree that supporting row filter and column list is not straightforward, and we can consider it separately and do not implement that in the first version. > > It seems this proposal doesn't serve a general purpose. It is copying a *whole* > cluster to use only a subset of tables. Your task with pg_createsubscriber is > more expensive than doing a manual logical replication setup. If you have 500 > tables and want to replicate only 400 tables, it doesn't seem productive to > specify 400 -t options. Specifying multiple -t options should not be problematic, as users has already done similar things for "FOR TABLE" publication DDLs. I think it's not hard for user to convert FOR TABLE list to -t option list. > There are some cases like a small set of big tables that > this feature makes sense. However, I'm wondering if a post script should be > used to adjust your setup. I think it's not very convenient for users to perform this conversion manually. I've learned in PGConf.dev this year that some users avoid using pg_createsubscriber because they are unsure of the standard steps required to convert it into subset table replication. Automating this process would be beneficial, enabling more users to use pg_createsubscriber and take advantage of the rapid initial table synchronization. > There might be cases that involves only dozens of > tables but my experience says it is rare. My expectation is that this feature is > useful for avoiding some specific tables. Hence, the copy of the whole cluster is > worthwhile. We could consider adding an --exclude-table option later if needed. However, as mentioned earlier, I think specifying multiple -t options can address this use case as well. Best Regards, Hou zj
On Fri, Aug 22, 2025, at 6:57 AM, Zhijie Hou (Fujitsu) wrote: > The documentation appears incorrect and needs revision. The latest version no > longer depends on the option order; instead, it requires users to provide > database-qualified table names, such as -t "db1.sch1.tb1". This adjustment > allows the command to internally categorize tables by their target database. > I don't like this design. There is no tool that uses 3 elements. It is also confusing and redundant to have the database in the --database option and also in the --table option. I'm wondering if we allow using a specified publication is a better UI. If you specify --publication and it exists on primary, use it. The current behavior is a failure if the publication exists. It changes the current behavior but I don't expect someone relying on this failure to abort the execution. Moreover, the error message was added to allow only FOR ALL TABLES; the proposal is to relax this restriction. > I think we can explore extending the existing --clean option in a separate patch > to support table cleanup. This option is implemented in a way that allows adding > further cleanup objects later, so it should be easy to extend it for table. > Prior to this extension, it should be noted in the documentation that users are > required to clean up the tables themselves. > I would say that these cleanup feature (starting with the cleanup databases) is equally important as the feature that selects specific objects. > I agree that supporting row filter and column list is not straightforward, and > we can consider it separately and do not implement that in the first version. > The proposal above would allow it with no additional lines of code. >> >> It seems this proposal doesn't serve a general purpose. It is copying a *whole* >> cluster to use only a subset of tables. Your task with pg_createsubscriber is >> more expensive than doing a manual logical replication setup. If you have 500 >> tables and want to replicate only 400 tables, it doesn't seem productive to >> specify 400 -t options. > > Specifying multiple -t options should not be problematic, as users has already > done similar things for "FOR TABLE" publication DDLs. I think it's not hard > for user to convert FOR TABLE list to -t option list. > Of course it is. Shell limits the number of arguments. >> There are some cases like a small set of big tables that >> this feature makes sense. However, I'm wondering if a post script should be >> used to adjust your setup. > > I think it's not very convenient for users to perform this conversion manually. > I've learned in PGConf.dev this year that some users avoid using > pg_createsubscriber because they are unsure of the standard steps required to > convert it into subset table replication. Automating this process would be > beneficial, enabling more users to use pg_createsubscriber and take advantage of > the rapid initial table synchronization. > You missed my point. I'm not talking about manually converting a physical replica into a logical replica. I'm talking about the plain logical replication setup (CREATE PUBLICATION, CREATE SUBSCRIPTION). IME this tool is beneficial for large clusters that we want to replicate (almost) all tables. -- Euler Taveira EDB https://www.enterprisedb.com/
IIUC, the only purpose of the proposed '--table' spec is to allow some users the ability to tweak the default "CREATE PUBLICATION p FOR ALL TABLES;" that the 'pg_createsubscriber' tool would otherwise construct. But --table is introducing problems too: e.g. - tricky option ordering rules (e.g. most recent --database if dbname not specified?) - too many --table may be needed; redundant repeating of databases and schemas also seems very verbose. - limitations for syntax (e.g. what about FOR TABLES IN SCHEMA?) - limitations for future syntax (e.g. what about SEQUENCES?; what about EXCEPT?) Can these problems disappear just by slightly changing the meaning of the existing '--publication' option to allow specifying more than just the publication name: e.g. --publication = 'pub1' ==> "CREATE PUBLICATION pub1 FOR ALL TABLES;" --publication = 'pub1 FOR TABLE t1,t2(c1,c2),t3' ==> "CREATE PUBLICATION pub1 FOR TABLE t1,t2(c1,c2),t3;" --publication = 'pub1 FOR TABLES IN SCHEMA s1' ==> "CREATE PUBLICATION pub1 FOR TABLES IN SCHEMA s1;" --publication = 'pub1 FOR ALL TABLES WITH (publish_via_partition_root)' ==> "CREATE PUBLICATION pub1 FOR ALL TABLES WITH (publish_via_partition_root);" Here: - no new ordering rules; --publication/--database rules are already well-defined; nothing to do. - no new options; minimal document changes - no limitations on existing CREATE PUBLICATION syntax; minimal new code changes - future proof for new CREATE PUBLICATION syntax; zero code changes - expanding the '--publication' meaning could also be compatible with Euler's idea [1] to reuse existing publications ~~~ This idea could be error-prone, but it's only for a small subset of users who need more flexibility than the default pg_createsubscriber provides. And while it might be typo-prone, so is --table (e.g., --table 'db.typo.doesnotexist' is currently allowed). Did you consider this approach already? The thread seems to have started with --table as the assumed solution without mentioning if other options were discussed. Thoughts? ====== [1] https://www.postgresql.org/message-id/30cc34eb-07a0-4b55-b4fe-6c526886b2c4%40app.fastmail.com Kind Regards, Peter Smith. Fujitsu Australia.
On Friday, August 22, 2025 11:26 PM Euler Taveira <euler@eulerto.com> wrote: > > On Fri, Aug 22, 2025, at 6:57 AM, Zhijie Hou (Fujitsu) wrote: > > The documentation appears incorrect and needs revision. The latest > > version no longer depends on the option order; instead, it requires > > users to provide database-qualified table names, such as -t > > "db1.sch1.tb1". This adjustment allows the command to internally categorize > tables by their target database. > > > > I don't like this design. There is no tool that uses 3 elements. It is also confusing > and redundant to have the database in the --database option and also in the > --table option. > > I'm wondering if we allow using a specified publication is a better UI. If you > specify --publication and it exists on primary, use it. The current behavior is a > failure if the publication exists. It changes the current behavior but I don't > expect someone relying on this failure to abort the execution. Moreover, the > error message was added to allow only FOR ALL TABLES; the proposal is to > relax this restriction. I think allowing the use of an existing publication is a good idea. If we do not want to modify the behavior of the current --publication option, introducing a new option like --existing-publication might be prudent. With this change, it's also necessary to implement checks to ensure column lists or row filters are not used, as previously discussed. What do you think ? > > > I think we can explore extending the existing --clean option in a > > separate patch to support table cleanup. This option is implemented in > > a way that allows adding further cleanup objects later, so it should be easy to > extend it for table. > > Prior to this extension, it should be noted in the documentation that > > users are required to clean up the tables themselves. > > > > I would say that these cleanup feature (starting with the cleanup databases) is > equally important as the feature that selects specific objects. > > > I agree that supporting row filter and column list is not > > straightforward, and we can consider it separately and do not implement that > in the first version. > > > > The proposal above would allow it with no additional lines of code. > > >> > >> It seems this proposal doesn't serve a general purpose. It is copying > >> a *whole* cluster to use only a subset of tables. Your task with > >> pg_createsubscriber is more expensive than doing a manual logical > >> replication setup. If you have 500 tables and want to replicate only > >> 400 tables, it doesn't seem productive to specify 400 -t options. > > > > Specifying multiple -t options should not be problematic, as users has > > already done similar things for "FOR TABLE" publication DDLs. I think > > it's not hard for user to convert FOR TABLE list to -t option list. > > > > Of course it is. Shell limits the number of arguments. I initially thought that other commands had a similar limit, so did not worry about that, but given that publication features may necessitate specifying a larger number of tables, I agree that this limitation arises from using multiple -t options. > >> There are some cases like a small set of big tables that this feature > >> makes sense. However, I'm wondering if a post script should be used > >> to adjust your setup. > > > > I think it's not very convenient for users to perform this conversion manually. > > I've learned in PGConf.dev this year that some users avoid using > > pg_createsubscriber because they are unsure of the standard steps > > required to convert it into subset table replication. Automating this > > process would be beneficial, enabling more users to use > > pg_createsubscriber and take advantage of the rapid initial table > synchronization. > > > > You missed my point. I'm not talking about manually converting a physical > replica into a logical replica. I'm talking about the plain logical replication setup > (CREATE PUBLICATION, CREATE SUBSCRIPTION). IME this tool is beneficial > for large clusters that we want to replicate (almost) all tables. I understand, but the initial synchronization in plain logical replication can be slow in many cases, which has been a major complaint I received recently. Using pg_createsubscriber can significantly improve performance in those cases, even when subset of tables is published, particularly if the tables are large or if the number of tables are huge. Of course, there are cases where plain logical replication outperforms pg_createsubscriber. However, we could also provide documentation with guidelines to assist users in choosing when to use this new option in pg_createsubscriber. Best Regards, Hou zj
On Monday, August 25, 2025 8:08 AM Peter Smith <smithpb2250@gmail.com> wrote: > > IIUC, the only purpose of the proposed '--table' spec is to allow some users the > ability to tweak the default "CREATE PUBLICATION p FOR ALL TABLES;" that > the 'pg_createsubscriber' tool would otherwise construct. > > But --table is introducing problems too: e.g. > - tricky option ordering rules (e.g. most recent --database if dbname not > specified?) > - too many --table may be needed; redundant repeating of databases and > schemas also seems very verbose. > - limitations for syntax (e.g. what about FOR TABLES IN SCHEMA?) > - limitations for future syntax (e.g. what about SEQUENCES?; what about > EXCEPT?) > > Can these problems disappear just by slightly changing the meaning of the > existing '--publication' option to allow specifying more than just the > publication name: e.g. > --publication = 'pub1' ==> "CREATE PUBLICATION pub1 FOR ALL TABLES;" > --publication = 'pub1 FOR TABLE t1,t2(c1,c2),t3' ==> "CREATE > PUBLICATION pub1 FOR TABLE t1,t2(c1,c2),t3;" > --publication = 'pub1 FOR TABLES IN SCHEMA s1' ==> "CREATE > PUBLICATION > pub1 FOR TABLES IN SCHEMA s1;" > --publication = 'pub1 FOR ALL TABLES WITH (publish_via_partition_root)' > ==> "CREATE PUBLICATION pub1 FOR ALL TABLES WITH > (publish_via_partition_root);" I think embedding commands directly in the option value poses SQL injection risks, so is not very safe. We could directly allow users to use an existing publication (as mentioned by Euler[1]). [1] https://www.postgresql.org/message-id/30cc34eb-07a0-4b55-b4fe-6c526886b2c4%40app.fastmail.com Best Regards, Hou zj
On Mon, Aug 25, 2025 at 12:53 PM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Monday, August 25, 2025 8:08 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > IIUC, the only purpose of the proposed '--table' spec is to allow some users the > > ability to tweak the default "CREATE PUBLICATION p FOR ALL TABLES;" that > > the 'pg_createsubscriber' tool would otherwise construct. > > > > But --table is introducing problems too: e.g. > > - tricky option ordering rules (e.g. most recent --database if dbname not > > specified?) > > - too many --table may be needed; redundant repeating of databases and > > schemas also seems very verbose. > > - limitations for syntax (e.g. what about FOR TABLES IN SCHEMA?) > > - limitations for future syntax (e.g. what about SEQUENCES?; what about > > EXCEPT?) > > > > Can these problems disappear just by slightly changing the meaning of the > > existing '--publication' option to allow specifying more than just the > > publication name: e.g. > > --publication = 'pub1' ==> "CREATE PUBLICATION pub1 FOR ALL TABLES;" > > --publication = 'pub1 FOR TABLE t1,t2(c1,c2),t3' ==> "CREATE > > PUBLICATION pub1 FOR TABLE t1,t2(c1,c2),t3;" > > --publication = 'pub1 FOR TABLES IN SCHEMA s1' ==> "CREATE > > PUBLICATION > > pub1 FOR TABLES IN SCHEMA s1;" > > --publication = 'pub1 FOR ALL TABLES WITH (publish_via_partition_root)' > > ==> "CREATE PUBLICATION pub1 FOR ALL TABLES WITH > > (publish_via_partition_root);" > > I think embedding commands directly in the option value poses SQL injection > risks, so is not very safe. We could directly allow users to use an existing > publication (as mentioned by Euler[1]). > > [1] https://www.postgresql.org/message-id/30cc34eb-07a0-4b55-b4fe-6c526886b2c4%40app.fastmail.com > I have incorporated the latest approach suggested by Hou-san at [1] and added a new --existing-publication option. This enhancement allows users to specify existing publications instead of always creating new ones. The attached patch includes the corresponding changes. [1] - https://www.postgresql.org/message-id/TY4PR01MB169075A23F8D5EED4154A4AF3943EA%40TY4PR01MB16907.jpnprd01.prod.outlook.com Thanks and regards, Shubham Khanna.
Вложения
Hi Shubham,
My first impression of patch v4-0001 was that the new design is adding
unnecessary complexity by introducing a new --existing-publication
option, instead of just allowing reinterpretation of the --publication
by allowing it to name/reuse an existing publication.
e.g.
Q. What if there are multiple databases, but there's a publication on
only one of them? How can the user specify this, given that the rules
say there must be the same number of --existing-publication as
--database? The rules also say --existing-publication and
--publication cannot coexist. So what is this user supposed to do in
this scenario?
Q. What if there are multiple databases with publications, but the
user wants to use the existing publication for only one of those and
FOR ALL TABLES for the other one? The rules say there must be the same
number of --existing-publication as --database, so how can the user
achieve what they want?
~~
AFAICT, these problems don't happen if you allow a reinterpretation of
--publication switch like Euler had suggested [1]. The dry-run logs
should make it clear whether an existing publication will be reused or
not, so I'm not sure even that the validation code (checking if the
publication exists) is needed.
Finally, I think the implementation might be simpler too -- e.g. fewer
rules/docs needed, no option conflict code needed.
Anyway, maybe you disagree. But, even if you still decide an
--existing-publication option is needed, IMO the rules should be
relaxed to permit this to co-exist with the --publication option, so
that the scenarios described above can have solutions.
~
Below are some more review comments for patch v4-0001, but since I had
doubts about the basic design, I did not review it in much detail.
======
Commit message
1.
The number of existing publication names must match the number of database
names, following the same pattern as other pg_createsubscriber options.
~
This assumes that if one database has existing publications, then they
all will. That does not seem like a valid assumption.
~~~
2.
This design aligns with the principle of other PostgreSQL tools that
allow both creation of new objects and reuse of existing ones.
~
What tools? Can you provide examples? I'd like to check the design
alignment for myself.
======
doc/src/sgml/ref/pg_createsubscriber.sgml
3.
+ <para>
+ This option cannot be used together with <option>--publication</option>.
+ Use either <option>--publication</option> to create new publications
+ or <option>--existing-publication</option> to use existing ones, but
+ not both.
+ </para>
Why not? How else can a user say to use an existing publication for
one database when another database does not have any publications?
~~~
4.
+ <para>
+ The number of existing publication names specified must equal the number
+ of database names when multiple databases are being configured. Each
+ existing publication will be used for its corresponding database in
+ the order specified.
+ </para>
Ditto above. What about when the second database does not even have an
existing publication?
======
src/bin/pg_basebackup/pg_createsubscriber.c
5.
-
/*
* Cleanup objects that were created by pg_createsubscriber if there is an
Does this whitespace change belong be in this patch?
~~~
6a.
- if (dbinfo->made_publication)
+ if (dbinfo->made_publication && !dbinfo->is_existing_publication)
6b.
- if (dbinfo->made_publication)
+ if (dbinfo->made_publication && !dbinfo->is_existing_publication)
~
Why do you need to check both flags in these places? IIUC, it's the
publication can be "made" or "existing"; it cannot be both. Why not
just check "made"?
~~~
7.
+ if (PQresultStatus(res) == PGRES_TUPLES_OK && PQntuples(res) == 1)
+ exists = true;
+ else if (PQresultStatus(res) != PGRES_TUPLES_OK)
+ pg_fatal("could not check for publication \"%s\" in database \"%s\": %s",
+ pubname, dbname, PQerrorMessage(conn));
This logic should not need to check PQresultStatus(res) multiple times.
======
.../t/040_pg_createsubscriber.pl
8.
+# Run pg_createsubscriber with invalid --existing-publication option
+# (conflict with --publication)
+command_fails_like(
Why not allow these to coexist?
======
[1] Euler - https://www.postgresql.org/message-id/30cc34eb-07a0-4b55-b4fe-6c526886b2c4%40app.fastmail.com
Kind Regards,
Peter Smith
Fujitsu Australia
On Wednesday, September 3, 2025 9:58 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Shubham, > > My first impression of patch v4-0001 was that the new design is adding > unnecessary complexity by introducing a new --existing-publication > option, instead of just allowing reinterpretation of the --publication > by allowing it to name/reuse an existing publication. > > e.g. > > Q. What if there are multiple databases, but there's a publication on > only one of them? How can the user specify this, given that the rules > say there must be the same number of --existing-publication as > --database? The rules also say --existing-publication and > --publication cannot coexist. So what is this user supposed to do in > this scenario? > > Q. What if there are multiple databases with publications, but the > user wants to use the existing publication for only one of those and > FOR ALL TABLES for the other one? The rules say there must be the same > number of --existing-publication as --database, so how can the user > achieve what they want? > > ~~ > > AFAICT, these problems don't happen if you allow a reinterpretation of > --publication switch like Euler had suggested [1]. The dry-run logs > should make it clear whether an existing publication will be reused or > not, so I'm not sure even that the validation code (checking if the > publication exists) is needed. > > Finally, I think the implementation might be simpler too -- e.g. fewer > rules/docs needed, no option conflict code needed. I'm hesitant to directly change the behavior of --publication, as it seems unexpected for the command in the new version to silently use an existing publication when it previously reported an ERROR. Although the number of users relying on the ERROR may be small, the change still appears risky to me. I think it's reasonable to introduce an option that allows users to preserve the original behavior. If --existing-publication appears too complex, we might consider adding a more straightforward option, such as --if-not-exists or --use-existing-pub (name subject to further discussion). When this option is specified, the command will not report an ERROR if a publication with the specified --publication name already exists; instead, it will use the existing publication to set up the publisher. If the option is not specified, the original behavior will be maintained. Best Regards, Hou zj
On Wed, Sep 10, 2025 at 8:05 AM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, September 3, 2025 9:58 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Hi Shubham, > > > > My first impression of patch v4-0001 was that the new design is adding > > unnecessary complexity by introducing a new --existing-publication > > option, instead of just allowing reinterpretation of the --publication > > by allowing it to name/reuse an existing publication. > > > > e.g. > > > > Q. What if there are multiple databases, but there's a publication on > > only one of them? How can the user specify this, given that the rules > > say there must be the same number of --existing-publication as > > --database? The rules also say --existing-publication and > > --publication cannot coexist. So what is this user supposed to do in > > this scenario? > > > > Q. What if there are multiple databases with publications, but the > > user wants to use the existing publication for only one of those and > > FOR ALL TABLES for the other one? The rules say there must be the same > > number of --existing-publication as --database, so how can the user > > achieve what they want? > > > > ~~ > > > > AFAICT, these problems don't happen if you allow a reinterpretation of > > --publication switch like Euler had suggested [1]. The dry-run logs > > should make it clear whether an existing publication will be reused or > > not, so I'm not sure even that the validation code (checking if the > > publication exists) is needed. > > > > Finally, I think the implementation might be simpler too -- e.g. fewer > > rules/docs needed, no option conflict code needed. > > I'm hesitant to directly change the behavior of --publication, as it seems > unexpected for the command in the new version to silently use an existing > publication when it previously reported an ERROR. Although the number of users > relying on the ERROR may be small, the change still appears risky to me. > > I think it's reasonable to introduce an option that allows users to preserve the > original behavior. If --existing-publication appears too complex, we might > consider adding a more straightforward option, such as --if-not-exists or > --use-existing-pub (name subject to further discussion). When this option is > specified, the command will not report an ERROR if a publication with the > specified --publication name already exists; instead, it will use the existing > publication to set up the publisher. If the option is not specified, the original > behavior will be maintained. > As suggested I introduced a new option --if-not-exists. When this option is specified, if the given --publication already exists, it will be reused instead of raising an ERROR. If the option is not specified, the current behavior is preserved, ensuring backward compatibility. The attached patch contains the suggested changes. Thanks and regards, Shubham Khanna.
Вложения
Hi Shubham,
My first impression of this latest patch is that the new option name
is not particularly intuitive.
Below are some more review comments for patch v5-0001; any changes to
the name will propagate all through this with different member names
and usage, etc, so I did not repeat that same comment over and over.
======
Commit message
1.
Add a new '--if-not-exists' option to pg_createsubscriber, allowing users to
reuse existing publications if they are already present, or create them if they
do not exist.
~
IMO, this option name ("if-not-exists") gives the user no clues as to
its purpose.
I suppose you wanted the user to associate this option with a CREATE
PUBLICATION, so that they can deduce that it acts internally like a
"CREATE PUBLICATION pub ... IF NOT EXISTS" (if there was such a
thing), I don't see how a user is able to find any meaning at all from
this vague name. The only way they can know what this means is to read
all the documentation.
e.g.
- if WHAT doesn't exist?
- if <??> not exists, then do WHAT?
Alternatives like "--reuse-pub-if-exists" or "--reuse-existing-pubs"
might be easier to understand.
~~~
2.
Key features:
1. New '--if-not-exists' flag changes the behavior of '--publication'.
2. If the publication exists, it is reused.
3. If it does not exist, it is created automatically.
4. Supports per-database specification, consistent with other options.
5. Avoids the complexity of option conflicts and count-matching rules.
6. Provides semantics consistent with SQL’s IF NOT EXISTS syntax.
~
Some of those "features" seem wrong, and some seem inappropriate for
the commit message:
e.g. TBH, I doubt that "4. Supports per-database specification" can
work as claimed here. Supposing I have multiple databases, then I
cannot see how I can say "if-not-exists" for some databases but not
for others.
e.g. The "5. Avoids the complexity..." seems like a reason why an
alternative design was rejected; Why does this comment belong here?
e.g. The "6. Provides semantics..." seems like your internal
implementation justification, whereas IMO this patch should be more
focused on making any new command-line option more
intuitive/meaningful from the point of view of the user.
======
doc/src/sgml/ref/pg_createsubscriber.sgml
3.
+ <para>
+ This option provides flexibility for mixed scenarios where some
+ publications may already exist while others need to be created.
+ It eliminates the need to know in advance which publications exist on
+ the publisher.
+ </para>
Hmm. Is that statement ("It eliminates the need to know...") correct?
I feel it should say the total opposite of this.
For example, IMO now the user needs to be extra careful because if
they say --publication=pub1 --if-not-exists then they have to be 100%
sure if 'pub1' exists or does not exist, otherwise they might
accidentally be making pub1 FOR ALL TABLES when really they expected
they were reusing some existing publication 'pub1', or vice versa.
In fact, I think the docs should go further and *recommend* that the
user never uses this new option without firstly doing a --dry-run to
verify they are actually getting the publications that they assume
they are getting.
~~~
4.
+ <para>
+ This option follows the same semantics as SQL
+ <literal>IF NOT EXISTS</literal> clauses, providing consistent behavior
+ with other PostgreSQL tools.
+ </para>
Why even say this in the docs? What other "tools" are you referring to?
======
src/bin/pg_basebackup/pg_createsubscriber.c
5.
bool made_publication; /* publication was created */
+ bool publication_existed; /* publication existed before we
+ * started */
};
This new member feels redundant to me.
AFAIK, the publication will either exist already, OR it will be
created/made by pg_createsubscriber. You don't need 2 booleans to
represent that.
At most, maybe all you want is another local variable in the function
setup_publisher().
~~~
cleanup_objects_atexit:
(same comments as posted in my v4 review)
6a.
- if (dbinfo->made_publication)
+ if (dbinfo->made_publication && !dbinfo->publication_existed)
Same as above review comment #5. It's either made or it's not made,
right? Why the extra boolean?
~
6b.
- if (dbinfo->made_publication)
+ if (dbinfo->made_publication && !dbinfo->publication_existed)
Ditto.
~~~
check_publication_exists:
7.
+/*
+ * Add function to check if publication exists.
+ */
Function comment should not say "Add function".
~
8.
+ PGresult *res;
+ bool exists = false;
+ char *query;
Redundant assignment?
~~~
setup_publisher:
9.
+ /*
+ * Check if publication already exists when --if-not-exists is
+ * specified
+ */
+ if (opt->if_not_exists)
+ {
+ dbinfo[i].publication_existed = check_publication_exists(conn,
dbinfo[i].pubname, dbinfo[i].dbname);
+ if (dbinfo[i].publication_existed)
+ {
+ pg_log_info("using existing publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ }
+ }
+
/*
* Create publication on publisher. This step should be executed
* *before* promoting the subscriber to avoid any transactions between
* consistent LSN and the new publication rows (such transactions
* wouldn't see the new publication rows resulting in an error).
*/
- create_publication(conn, &dbinfo[i]);
+ if (opt->if_not_exists && dbinfo[i].publication_existed)
+ dbinfo[i].made_publication = false;
+ else
+ {
+ create_publication(conn, &dbinfo[i]);
+ if (opt->if_not_exists)
+ {
+ pg_log_info("created publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ }
+ }
This all seems way more complicated than it needs to be. e.g. I doubt
that you need to be checking opt->if_not_exists 3 times.
Simpler logic might be more like below:
bool make_pub = true;
if (opt->if_not_exists && check_publication_exists(...))
{
pg_log_info("using existing...");
make_pub = false;
}
...
if (make_pub)
{
create_publication(conn, &dbinfo[i]);
pg_log_info("created publication...");
}
dbinfo[i].made_publication = make_pub;
======
.../t/040_pg_createsubscriber.pl
10.
+# Initialize node_s2 as a fresh standby of node_p for table-level
+# publication test.
I don't know that you should still be calling this a "table-level"
test. Maybe it's more like an "existing publication" test now?
~~~
11.
+is( $result, qq({test_pub_existing}
+{test_pub_new}),
+ "subscriptions use the correct publications with --if-not-exists in
$db1 and $db2"
+);
Something seems broken. I deliberately caused an error to occur to see
what would happen, and the substitutions of $db1 and $db2 went crazy.
# Failed test 'subscriptions use the correct publications with
--if-not-exists in regression\"\
¬ !"\#$%&'()*+,-\\"\\\
and regression./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ'
# at t/040_pg_createsubscriber.pl line 614.
======
Kind Regards,
Peter Smith
Fujitsu Australia
On Thu, Sep 11, 2025 at 8:02 AM Peter Smith <smithpb2250@gmail.com> wrote:
Hi Peter,
Thank you for the review. I have addressed your comments in the latest patch.
> My first impression of this latest patch is that the new option name
> is not particularly intuitive.
>
> Below are some more review comments for patch v5-0001; any changes to
> the name will propagate all through this with different member names
> and usage, etc, so I did not repeat that same comment over and over.
>
> ======
> Commit message
>
> 1.
> Add a new '--if-not-exists' option to pg_createsubscriber, allowing users to
> reuse existing publications if they are already present, or create them if they
> do not exist.
>
> ~
>
> IMO, this option name ("if-not-exists") gives the user no clues as to
> its purpose.
>
> I suppose you wanted the user to associate this option with a CREATE
> PUBLICATION, so that they can deduce that it acts internally like a
> "CREATE PUBLICATION pub ... IF NOT EXISTS" (if there was such a
> thing), I don't see how a user is able to find any meaning at all from
> this vague name. The only way they can know what this means is to read
> all the documentation.
>
> e.g.
> - if WHAT doesn't exist?
> - if <??> not exists, then do WHAT?
>
> Alternatives like "--reuse-pub-if-exists" or "--reuse-existing-pubs"
> might be easier to understand.
>
I agree that --if-not-exists may not be very intuitive, as it doesn’t
clearly convey the intended behavior without reading the
documentation.
For this version, I have renamed the option to
"--reuse-existing-publications", which I believe makes the purpose
clearer: if the specified publication already exists, it will be
reused; otherwise, a new one will be created. This avoids ambiguity
while still keeping the semantics aligned with the original intent.
> ~~~
>
> 2.
> Key features:
> 1. New '--if-not-exists' flag changes the behavior of '--publication'.
> 2. If the publication exists, it is reused.
> 3. If it does not exist, it is created automatically.
> 4. Supports per-database specification, consistent with other options.
> 5. Avoids the complexity of option conflicts and count-matching rules.
> 6. Provides semantics consistent with SQL’s IF NOT EXISTS syntax.
>
> ~
>
> Some of those "features" seem wrong, and some seem inappropriate for
> the commit message:
>
> e.g. TBH, I doubt that "4. Supports per-database specification" can
> work as claimed here. Supposing I have multiple databases, then I
> cannot see how I can say "if-not-exists" for some databases but not
> for others.
>
> e.g. The "5. Avoids the complexity..." seems like a reason why an
> alternative design was rejected; Why does this comment belong here?
>
> e.g. The "6. Provides semantics..." seems like your internal
> implementation justification, whereas IMO this patch should be more
> focused on making any new command-line option more
> intuitive/meaningful from the point of view of the user.
>
Updated the commit message.
> ======
> doc/src/sgml/ref/pg_createsubscriber.sgml
>
> 3.
> + <para>
> + This option provides flexibility for mixed scenarios where some
> + publications may already exist while others need to be created.
> + It eliminates the need to know in advance which publications exist on
> + the publisher.
> + </para>
>
> Hmm. Is that statement ("It eliminates the need to know...") correct?
> I feel it should say the total opposite of this.
>
> For example, IMO now the user needs to be extra careful because if
> they say --publication=pub1 --if-not-exists then they have to be 100%
> sure if 'pub1' exists or does not exist, otherwise they might
> accidentally be making pub1 FOR ALL TABLES when really they expected
> they were reusing some existing publication 'pub1', or vice versa.
>
> In fact, I think the docs should go further and *recommend* that the
> user never uses this new option without firstly doing a --dry-run to
> verify they are actually getting the publications that they assume
> they are getting.
>
Fixed.
> ~~~
>
> 4.
> + <para>
> + This option follows the same semantics as SQL
> + <literal>IF NOT EXISTS</literal> clauses, providing consistent behavior
> + with other PostgreSQL tools.
> + </para>
>
> Why even say this in the docs? What other "tools" are you referring to?
>
Fixed.
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> 5.
> bool made_publication; /* publication was created */
> + bool publication_existed; /* publication existed before we
> + * started */
> };
>
> This new member feels redundant to me.
>
> AFAIK, the publication will either exist already, OR it will be
> created/made by pg_createsubscriber. You don't need 2 booleans to
> represent that.
> At most, maybe all you want is another local variable in the function
> setup_publisher().
>
Fixed.
> ~~~
>
> cleanup_objects_atexit:
>
> (same comments as posted in my v4 review)
>
Fixed.
> 6a.
> - if (dbinfo->made_publication)
> + if (dbinfo->made_publication && !dbinfo->publication_existed)
>
> Same as above review comment #5. It's either made or it's not made,
> right? Why the extra boolean?
>
> ~
>
> 6b.
> - if (dbinfo->made_publication)
> + if (dbinfo->made_publication && !dbinfo->publication_existed)
>
> Ditto.
>
Fixed.
> ~~~
>
> check_publication_exists:
>
> 7.
> +/*
> + * Add function to check if publication exists.
> + */
>
> Function comment should not say "Add function".
>
Fixed.
> ~
>
> 8.
> + PGresult *res;
> + bool exists = false;
> + char *query;
>
> Redundant assignment?
>
Fixed.
> ~~~
>
> setup_publisher:
>
> 9.
> + /*
> + * Check if publication already exists when --if-not-exists is
> + * specified
> + */
> + if (opt->if_not_exists)
> + {
> + dbinfo[i].publication_existed = check_publication_exists(conn,
> dbinfo[i].pubname, dbinfo[i].dbname);
> + if (dbinfo[i].publication_existed)
> + {
> + pg_log_info("using existing publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + }
> + }
> +
> /*
> * Create publication on publisher. This step should be executed
> * *before* promoting the subscriber to avoid any transactions between
> * consistent LSN and the new publication rows (such transactions
> * wouldn't see the new publication rows resulting in an error).
> */
> - create_publication(conn, &dbinfo[i]);
> + if (opt->if_not_exists && dbinfo[i].publication_existed)
> + dbinfo[i].made_publication = false;
> + else
> + {
> + create_publication(conn, &dbinfo[i]);
> + if (opt->if_not_exists)
> + {
> + pg_log_info("created publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + }
> + }
>
> This all seems way more complicated than it needs to be. e.g. I doubt
> that you need to be checking opt->if_not_exists 3 times.
>
> Simpler logic might be more like below:
>
> bool make_pub = true;
>
> if (opt->if_not_exists && check_publication_exists(...))
> {
> pg_log_info("using existing...");
> make_pub = false;
> }
>
> ...
>
> if (make_pub)
> {
> create_publication(conn, &dbinfo[i]);
> pg_log_info("created publication...");
> }
>
> dbinfo[i].made_publication = make_pub;
>
Fixed.
> ======
> .../t/040_pg_createsubscriber.pl
>
> 10.
> +# Initialize node_s2 as a fresh standby of node_p for table-level
> +# publication test.
>
> I don't know that you should still be calling this a "table-level"
> test. Maybe it's more like an "existing publication" test now?
>
Fixed.
> ~~~
>
> 11.
> +is( $result, qq({test_pub_existing}
> +{test_pub_new}),
> + "subscriptions use the correct publications with --if-not-exists in
> $db1 and $db2"
> +);
>
> Something seems broken. I deliberately caused an error to occur to see
> what would happen, and the substitutions of $db1 and $db2 went crazy.
>
> # Failed test 'subscriptions use the correct publications with
> --if-not-exists in regression\"\
>
>
> ¬ !"\#$%&'()*+,-\\"\\\
> and regression./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ'
> # at t/040_pg_createsubscriber.pl line 614.
>
Fixed.
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna,
Вложения
On Tue, Sep 9, 2025, at 11:34 PM, Zhijie Hou (Fujitsu) wrote: > On Wednesday, September 3, 2025 9:58 AM Peter Smith > <smithpb2250@gmail.com> wrote: >> >> AFAICT, these problems don't happen if you allow a reinterpretation of >> --publication switch like Euler had suggested [1]. The dry-run logs >> should make it clear whether an existing publication will be reused or >> not, so I'm not sure even that the validation code (checking if the >> publication exists) is needed. >> >> Finally, I think the implementation might be simpler too -- e.g. fewer >> rules/docs needed, no option conflict code needed. > > I'm hesitant to directly change the behavior of --publication, as it seems > unexpected for the command in the new version to silently use an existing > publication when it previously reported an ERROR. Although the number of users > relying on the ERROR may be small, the change still appears risky to me. > I don't buy this argument. Every feature that is not supported emits an error. You can interpret it as (a) we don't support using existing publications until v18 but we will start support it from now on or (b) it is a hard error that we shouldn't allow, hence, stop now. I would say this case is (a) rather than (b). The proposed extra option would do pg_createsubscriber behaves in a different way if it is specified or not. That's not a good UI. It will cause confusion. If you are not reading the manual, it isn't intuitive that you need to specify an extra option until executing it. If you have a good hint message, the second try can succeed. -- Euler Taveira EDB https://www.enterprisedb.com/
On Thu, Sep 11, 2025 at 6:34 PM Euler Taveira <euler@eulerto.com> wrote: > > On Tue, Sep 9, 2025, at 11:34 PM, Zhijie Hou (Fujitsu) wrote: > > On Wednesday, September 3, 2025 9:58 AM Peter Smith > > <smithpb2250@gmail.com> wrote: > >> > >> AFAICT, these problems don't happen if you allow a reinterpretation of > >> --publication switch like Euler had suggested [1]. The dry-run logs > >> should make it clear whether an existing publication will be reused or > >> not, so I'm not sure even that the validation code (checking if the > >> publication exists) is needed. > >> > >> Finally, I think the implementation might be simpler too -- e.g. fewer > >> rules/docs needed, no option conflict code needed. > > > > I'm hesitant to directly change the behavior of --publication, as it seems > > unexpected for the command in the new version to silently use an existing > > publication when it previously reported an ERROR. Although the number of users > > relying on the ERROR may be small, the change still appears risky to me. > > > > I don't buy this argument. Every feature that is not supported emits an error. > You can interpret it as (a) we don't support using existing publications until > v18 but we will start support it from now on or (b) it is a hard error that we > shouldn't allow, hence, stop now. I would say this case is (a) rather than (b). > Yeah, I am also not sure that it is worth adding a new option to save backward compatibility for this option. It seems intuitive to use existing publications when they exist, though we should clearly document it. -- With Regards, Amit Kapila.
On Fri, Sep 12, 2025, at 2:05 AM, Amit Kapila wrote: > Yeah, I am also not sure that it is worth adding a new option to save > backward compatibility for this option. It seems intuitive to use > existing publications when they exist, though we should clearly > document it. > That's why we have a "Migration to Version XY" in the release notes. ;) -- Euler Taveira EDB https://www.enterprisedb.com/
Hi Shubham,
IIUC the v6 will be rewritten to remove the new option, in favour of
just redefining the --publication option behaviour.
So, much of the current v6 will become obsolete. The below comment is
just for one piece of code that I thought will survive the rewrite.
======
src/bin/pg_basebackup/pg_createsubscriber.c
setup_publisher:
1.
+ /*
+ * Check if publication already exists when
+ * --reuse-existing-publications is specified
+ */
+ if (opt->reuse_existing_pubs && check_publication_exists(conn,
dbinfo[i].pubname, dbinfo[i].dbname))
+ {
+ pg_log_info("using existing publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ make_pub = false;
+ }
+
/*
* Create publication on publisher. This step should be executed
* *before* promoting the subscriber to avoid any transactions between
* consistent LSN and the new publication rows (such transactions
* wouldn't see the new publication rows resulting in an error).
*/
- create_publication(conn, &dbinfo[i]);
+ if (make_pub)
+ {
+ create_publication(conn, &dbinfo[i]);
+ dbinfo[i].made_publication = true;
+ if (opt->reuse_existing_pubs)
+ pg_log_info("created publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ }
+ else
+ dbinfo[i].made_publication = false;
I think there are still too many if/else here. This logic can be
simplified like below:
if (check_publication_exists(...))
{
pg_log_info("using existing publication...");
dbinfo[i].made_publication = false;
}
else
{
create_publication(conn, &dbinfo[i]);
pg_log_info("created publication ...");
dbinfo[i].made_publication = true;
}
======
Kind Regards,
Peter Smith
Fujitsu Australia
On Mon, Sep 15, 2025 at 6:01 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> IIUC the v6 will be rewritten to remove the new option, in favour of
> just redefining the --publication option behaviour.
>
> So, much of the current v6 will become obsolete. The below comment is
> just for one piece of code that I thought will survive the rewrite.
>
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> setup_publisher:
>
> 1.
> + /*
> + * Check if publication already exists when
> + * --reuse-existing-publications is specified
> + */
> + if (opt->reuse_existing_pubs && check_publication_exists(conn,
> dbinfo[i].pubname, dbinfo[i].dbname))
> + {
> + pg_log_info("using existing publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + make_pub = false;
> + }
> +
> /*
> * Create publication on publisher. This step should be executed
> * *before* promoting the subscriber to avoid any transactions between
> * consistent LSN and the new publication rows (such transactions
> * wouldn't see the new publication rows resulting in an error).
> */
> - create_publication(conn, &dbinfo[i]);
> + if (make_pub)
> + {
> + create_publication(conn, &dbinfo[i]);
> + dbinfo[i].made_publication = true;
> + if (opt->reuse_existing_pubs)
> + pg_log_info("created publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + }
> + else
> + dbinfo[i].made_publication = false;
>
> I think there are still too many if/else here. This logic can be
> simplified like below:
>
> if (check_publication_exists(...))
> {
> pg_log_info("using existing publication...");
> dbinfo[i].made_publication = false;
> }
> else
> {
> create_publication(conn, &dbinfo[i]);
> pg_log_info("created publication ...");
> dbinfo[i].made_publication = true;
> }
>
I have now removed the extra option and reworked the patch so that the
behavior is handled directly through the --publication option. This
way, the command will either reuse an existing publication (if it
already exists) or create a new one, making it simpler and more
intuitive for users.
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham,
Here are some v7 review comments.
======
Commit message
1.
This change eliminates the need to know in advance which publications exist
on the publisher, making the tool more user-friendly. Users can specify
publication names and the tool will handle both existing and new publications
appropriately.
~
I disagree with the "eliminates the need to know" part. This change
doesn't remove that responsibility from the user. They still need to
be aware of what the existing publications are so they don't end up
reusing a publication they did not intend to reuse.
~~~
2. <general>
It would be better if the commit message wording was consistent with
the wording in the docs.
======
doc/src/sgml/ref/pg_createsubscriber.sgml
3.
+ <para>
+ When reusing existing publications, you should understand their current
+ configuration. Existing publications are used exactly as configured,
+ which may replicate different tables than expected.
+ New publications created with <literal>FOR ALL TABLES</literal> will
+ replicate all tables in the database, which may be more than intended.
+ </para>
Is that paragraph needed? What does it say that was not already said
by the previous paragraph?
~~~
4.
+ <para>
+ Use <option>--dry-run</option> to see which publications will be reused
+ and which will be created before running the actual command.
+ When publications are reused, they will not be dropped during cleanup
+ operations, ensuring they remain available for other uses.
+ Only publications created by
+ <application>pg_createsubscriber</application> will be cleaned up.
+ </para>
There also needs to be more clarity about the location of the
publications that are getting "cleaned up". AFAIK the function
check_and_drop_publications() only cleans up for the target server,
but that does not seem at all obvious here.
======
src/bin/pg_basebackup/pg_createsubscriber.c
setup_publisher:
5.
- if (num_pubs == 0 || num_subs == 0 || num_replslots == 0)
+ if (dbinfo[i].pubname == NULL || dbinfo[i].subname == NULL ||
dbinfo[i].replslotname == NULL)
genname = generate_object_name(conn);
- if (num_pubs == 0)
+ if (dbinfo[i].pubname == NULL)
dbinfo[i].pubname = pg_strdup(genname);
- if (num_subs == 0)
+ if (dbinfo[i].subname == NULL)
dbinfo[i].subname = pg_strdup(genname);
- if (num_replslots == 0)
+ if (dbinfo[i].replslotname == NULL)
dbinfo[i].replslotname = pg_strdup(dbinfo[i].subname);
~
Are these changes related to the --publication change, or are these
some other issue?
~~~
6.
* consistent LSN and the new publication rows (such transactions
* wouldn't see the new publication rows resulting in an error).
*/
- create_publication(conn, &dbinfo[i]);
+ if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
The comment preceding this if/else is only talking about "Create the
publications..", but it should be more like "Reuse existing or create
new publications...". Alternatively, move the comments within the if
and else.
~~~
check_and_drop_publications:
7.
if (!drop_all_pubs || dry_run)
- drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
- &dbinfo->made_publication);
+ {
+ if (dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ }
I find this function logic confusing. In particular, why is the
"made_publication" flag only checked for dry_run?
This function comment says it will "drop all pre-existing
publications." but doesn't that contradict your commit message and
docs that said statements like "When publications are reused, they are
never dropped during cleanup operations"?
======
.../t/040_pg_createsubscriber.pl
8.
IMO one of the most important things for the user is that they must be
able to know exactly which publications will be reused, and which
publications will be created as FOR ALL TABLES. So, there should be a
test to verify that the --dry_run option emits all the necessary
logging so the user can tell that.
======
Kind Regards,
Peter Smith
Fujitsu Australia
On Tue, Sep 16, 2025 at 7:20 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v7 review comments.
>
> ======
> Commit message
>
> 1.
> This change eliminates the need to know in advance which publications exist
> on the publisher, making the tool more user-friendly. Users can specify
> publication names and the tool will handle both existing and new publications
> appropriately.
>
> ~
>
> I disagree with the "eliminates the need to know" part. This change
> doesn't remove that responsibility from the user. They still need to
> be aware of what the existing publications are so they don't end up
> reusing a publication they did not intend to reuse.
>
> ~~~
>
> 2. <general>
> It would be better if the commit message wording was consistent with
> the wording in the docs.
>
Updated the commit message as suggested.
> ======
> doc/src/sgml/ref/pg_createsubscriber.sgml
>
> 3.
> + <para>
> + When reusing existing publications, you should understand their current
> + configuration. Existing publications are used exactly as configured,
> + which may replicate different tables than expected.
> + New publications created with <literal>FOR ALL TABLES</literal> will
> + replicate all tables in the database, which may be more than intended.
> + </para>
>
> Is that paragraph needed? What does it say that was not already said
> by the previous paragraph?
>
Removed.
> ~~~
>
> 4.
> + <para>
> + Use <option>--dry-run</option> to see which publications will be reused
> + and which will be created before running the actual command.
> + When publications are reused, they will not be dropped during cleanup
> + operations, ensuring they remain available for other uses.
> + Only publications created by
> + <application>pg_createsubscriber</application> will be cleaned up.
> + </para>
>
> There also needs to be more clarity about the location of the
> publications that are getting "cleaned up". AFAIK the function
> check_and_drop_publications() only cleans up for the target server,
> but that does not seem at all obvious here.
>
Fixed.
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> setup_publisher:
>
> 5.
> - if (num_pubs == 0 || num_subs == 0 || num_replslots == 0)
> + if (dbinfo[i].pubname == NULL || dbinfo[i].subname == NULL ||
> dbinfo[i].replslotname == NULL)
> genname = generate_object_name(conn);
> - if (num_pubs == 0)
> + if (dbinfo[i].pubname == NULL)
> dbinfo[i].pubname = pg_strdup(genname);
> - if (num_subs == 0)
> + if (dbinfo[i].subname == NULL)
> dbinfo[i].subname = pg_strdup(genname);
> - if (num_replslots == 0)
> + if (dbinfo[i].replslotname == NULL)
> dbinfo[i].replslotname = pg_strdup(dbinfo[i].subname);
> ~
>
> Are these changes related to the --publication change, or are these
> some other issue?
>
No, these changes are not related to the --publication modification.
They were unrelated adjustments, and I have now reverted them back to
match the behavior in HEAD.
> ~~~
>
> 6.
> * consistent LSN and the new publication rows (such transactions
> * wouldn't see the new publication rows resulting in an error).
> */
> - create_publication(conn, &dbinfo[i]);
> + if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
>
> The comment preceding this if/else is only talking about "Create the
> publications..", but it should be more like "Reuse existing or create
> new publications...". Alternatively, move the comments within the if
> and else.
>
Fixed.
> ~~~
>
> check_and_drop_publications:
>
> 7.
> if (!drop_all_pubs || dry_run)
> - drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> - &dbinfo->made_publication);
> + {
> + if (dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + }
>
> I find this function logic confusing. In particular, why is the
> "made_publication" flag only checked for dry_run?
>
> This function comment says it will "drop all pre-existing
> publications." but doesn't that contradict your commit message and
> docs that said statements like "When publications are reused, they are
> never dropped during cleanup operations"?
>
Fixed.
> ======
> .../t/040_pg_createsubscriber.pl
>
> 8.
> IMO one of the most important things for the user is that they must be
> able to know exactly which publications will be reused, and which
> publications will be created as FOR ALL TABLES. So, there should be a
> test to verify that the --dry_run option emits all the necessary
> logging so the user can tell that.
>
Fixed.
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham, Here are some v8 review comments. ====== Commit message 1. Previously, pg_createsubscriber would fail if any specified publication already existed. Now, existing publications are reused as-is with their current configuration, and non-existing publications are createdcautomatically with FOR ALL TABLES. ~ typo: "createdcautomatically" ====== doc/src/sgml/ref/pg_createsubscriber.sgml 2. + <para> + Use <option>--dry-run</option> to see which publications will be reused + and which will be created before running the actual command. + When publications are reused, they will not be dropped during cleanup + operations, ensuring they remain available for other uses. + Only publications created by + <application>pg_createsubscriber</application> on the target server will + be cleaned up if the operation fails. Publications on the publisher + server are never modified or dropped by cleanup operations. + </para> I still find all this confusing, for the following reasons: * The "dry-run" advice is OK, but the "cleanup of existing pubs" seems like a totally different topic which has nothing much to do with the --publication option. I'm wondering if you need to talk about cleaning existing pubs, maybe that info belongs in the "Notes" part of this documentation. * I don't understand how does saying "existing pubs will not be dropped" reconcile with the --clean=publication option which says it will drop all publications? They seem contradictory. ====== src/bin/pg_basebackup/pg_createsubscriber.c check_and_drop_publications: 3. /* - * In dry-run mode, we don't create publications, but we still try to drop - * those to provide necessary information to the user. + * Only drop publications that were created by pg_createsubscriber during + * this operation. Pre-existing publications are preserved. */ - if (!drop_all_pubs || dry_run) + if (dbinfo->made_publication) drop_publication(conn, dbinfo->pubname, dbinfo->dbname, &dbinfo->made_publication); 3a. Sorry, but I still have the same question that I had in my previous v7 review. This function logic will already remove all pre-existing publications when the 'drop_all_pubs' variable is true. It seems contrary to the commit message that says "When publications are reused, they are never dropped during cleanup operations, ensuring pre-existing publications remain available for other uses." ~ 3b. Kind of similar to the previous review -- If the 'drop_all_pubs' variable is true, then AFAICT this code attempts to drop again one of the publications that was already dropped in the earlier part of this function? ~ 3c. If this drop logic is broken wrt the intended cleanup rules then it also means more/better --clean option tests are needed, otherwise how was this passing the tests? ====== Kind Regards, Peter Smith Fujitsu Australia
On Tue, Sep 16, 2025 at 2:17 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Shubham, > > Here are some v8 review comments. > > ====== > Commit message > > 1. > Previously, pg_createsubscriber would fail if any specified publication already > existed. Now, existing publications are reused as-is with their current > configuration, and non-existing publications are createdcautomatically with > FOR ALL TABLES. > > ~ > > typo: "createdcautomatically" > Fixed. > ====== > doc/src/sgml/ref/pg_createsubscriber.sgml > > 2. > + <para> > + Use <option>--dry-run</option> to see which publications will be reused > + and which will be created before running the actual command. > + When publications are reused, they will not be dropped during cleanup > + operations, ensuring they remain available for other uses. > + Only publications created by > + <application>pg_createsubscriber</application> on the target server will > + be cleaned up if the operation fails. Publications on the publisher > + server are never modified or dropped by cleanup operations. > + </para> > > I still find all this confusing, for the following reasons: > > * The "dry-run" advice is OK, but the "cleanup of existing pubs" seems > like a totally different topic which has nothing much to do with the > --publication option. I'm wondering if you need to talk about cleaning > existing pubs, maybe that info belongs in the "Notes" part of this > documentation. > > * I don't understand how does saying "existing pubs will not be > dropped" reconcile with the --clean=publication option which says it > will drop all publications? They seem contradictory. > I have now moved the paragraph about publications being preserved or dropped under the description of the --clean option instead, where it fits more naturally. This way, the --publication section focuses only on creation/reuse semantics, while the --clean section clearly documents the cleanup behavior. > ====== > src/bin/pg_basebackup/pg_createsubscriber.c > > check_and_drop_publications: > > 3. > /* > - * In dry-run mode, we don't create publications, but we still try to drop > - * those to provide necessary information to the user. > + * Only drop publications that were created by pg_createsubscriber during > + * this operation. Pre-existing publications are preserved. > */ > - if (!drop_all_pubs || dry_run) > + if (dbinfo->made_publication) > drop_publication(conn, dbinfo->pubname, dbinfo->dbname, > &dbinfo->made_publication); > > 3a. > Sorry, but I still have the same question that I had in my previous v7 > review. This function logic will already remove all pre-existing > publications when the 'drop_all_pubs' variable is true. It seems > contrary to the commit message that says "When publications are > reused, they are never dropped during cleanup operations, ensuring > pre-existing publications remain available for other uses." > Fixed. The logic has been updated so that pre-existing publications are not dropped, consistent with the commit message. > ~ > > 3b. > Kind of similar to the previous review -- If the 'drop_all_pubs' > variable is true, then AFAICT this code attempts to drop again one of > the publications that was already dropped in the earlier part of this > function? > Fixed. The redundant drop call has been removed. > ~ > > 3c. > If this drop logic is broken wrt the intended cleanup rules then it > also means more/better --clean option tests are needed, otherwise how > was this passing the tests? > I have added a dedicated test case for the --clean option to cover these scenarios and verify correct cleanup behavior. The attached patch contains the suggested changes. Thanks and regards, Shubham Khanna.
Вложения
Hi Shubham,
Here are some v9 review comments.
======
doc/src/sgml/ref/pg_createsubscriber.sgml
--clean:
1.
+ <para>
+ When publications are reused, they will not be dropped during cleanup
+ operations, ensuring they remain available for other uses.
+ Only publications created by
+ <application>pg_createsubscriber</application> on the target server
+ will be cleaned up if the operation fails. Publications on the
+ publisher server are never modified or dropped by cleanup operations.
+ </para>
1a.
OK, I understand now that you want the --clean switch to behave the
same as before and remove all publications, except now it will *not*
drop any publications that are being reused.
I can imagine how that might be convenient to keep those publications
around if the subscriber ends up being promoted to a primary node.
OTOH, it seems a bit peculiar that the behaviour of the --clean option
is now depending on the other --publication option.
I wonder what others think about this feature/quirk? e.g. maybe you
need to introduce a --clean=unused_publications?
~
1b.
Anyway, even if this behaviour is what you wanted, that text
describing --clean needs rewording.
Before this paragraph, the docs still say --clean=publications:
"...causes all other publications replicated from the source server to
be dropped as well."
Which is then immediately contradicted when you wrote:
"When publications are reused, they will not be dropped"
~~~
--publication:
2.
+ <para>
+ Use <option>--dry-run</option> to see which publications will be reused
+ and which will be created before running the actual command.
+ </para>
It seemed a bit strange to say "the actual command" because IMO it's
always an actual command regardless of the options.
SUGGEST:
Use --dry-run to safely preview which publications will be reused and
which will be created.
======
src/bin/pg_basebackup/pg_createsubscriber.c
check_and_drop_publications:
3.
The function comment has not been updated with the new rules. It still
says, "Additionally, if requested, drop all pre-existing
publications."
~~~
4.
/* Drop each publication */
for (int i = 0; i < PQntuples(res); i++)
- drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
- &dbinfo->made_publication);
-
+ {
+ if (dbinfo->made_publication)
+ drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
+ &dbinfo->made_publication);
+ }
PQclear(res);
}
/*
- * In dry-run mode, we don't create publications, but we still try to drop
- * those to provide necessary information to the user.
+ * Only drop publications that were created by pg_createsubscriber during
+ * this operation. Pre-existing publications are preserved.
*/
if (!drop_all_pubs || dry_run)
- drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
- &dbinfo->made_publication);
+ {
+ if (dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ else
+ pg_log_info("preserving existing publication \"%s\" in database \"%s\"",
+ dbinfo->pubname, dbinfo->dbname);
+ }
4a.
I always find it difficult to follow the logic of this function.
AFAICT the "dry_mode" logic is already handled within the
drop_publication(), so check_and_drop_publications() can be simplified
by refactoring it:
CURRENT
if (drop_all_pubs)
{
...
}
if (!drop_all_pub || dry_mode)
{
...
}
SUGGEST
if (drop_all_pubs)
{
...
}
else
{
...
}
~
4b.
Why is "preserving existing publication" logged in a --dry-run only?
Shouldn't you see the same logs regardless of --dry-run? That's kind
of the whole point of a dry run, right?
======
.../t/040_pg_createsubscriber.pl
5.
+my $node_s3 = PostgreSQL::Test::Cluster->new('node_s3');
+$node_s3->init_from_backup($node_p, 'backup_tablepub', has_streaming => 1);
+
Should this be done later, where it is needed, combined with the
node_s3->start/stop?
~~~
6.
+# Run pg_createsubscriber on node S3 without --dry-run and --clean option
+# to verify that the existing publications are preserved.
+command_ok(
+ [
+ 'pg_createsubscriber',
+ '--verbose', '--verbose',
+ '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
+ '--pgdata' => $node_s3->data_dir,
+ '--publisher-server' => $node_p->connstr($db1),
+ '--socketdir' => $node_s3->host,
+ '--subscriber-port' => $node_s3->port,
+ '--database' => $db1,
+ '--database' => $db2,
+ '--publication' => 'test_pub_existing',
+ '--publication' => 'test_pub_new',
+ '--clean' => 'publications',
+ ],
+ 'run pg_createsubscriber on node S3');
6a.
That comment wording "without --dry-run and --clean option" is
confusing because it sounds like "without --dry-run" and "without
--clean"
~
6b.
There are other untested combinations like --dry-run with --clean,
which would give more confidence about the logic of function
check_and_drop_publications().
Perhaps this test could have been written using --dry-run, and you
could be checking the logs for the expected "drop" or "preserving"
messages.
~~~
7.
+# Confirm publication created by pg_createsubscriber is removed
+is( $node_s3->safe_psql(
+ $db1,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new';"
+ ),
+ '0',
+ 'publication created by pg_createsubscriber have been removed');
+
Hmm. Here you are testing the new publication was deleted, so nowhere
is testing what the earlier comment said it was doing "...verify that
the existing publications are preserved.".
======
Kind Regards,
Peter Smith
Fujitsu Australia
On Thu, Sep 18, 2025 at 5:23 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v9 review comments.
>
> ======
> doc/src/sgml/ref/pg_createsubscriber.sgml
>
> --clean:
>
> 1.
> + <para>
> + When publications are reused, they will not be dropped during cleanup
> + operations, ensuring they remain available for other uses.
> + Only publications created by
> + <application>pg_createsubscriber</application> on the target server
> + will be cleaned up if the operation fails. Publications on the
> + publisher server are never modified or dropped by cleanup operations.
> + </para>
>
> 1a.
> OK, I understand now that you want the --clean switch to behave the
> same as before and remove all publications, except now it will *not*
> drop any publications that are being reused.
>
> I can imagine how that might be convenient to keep those publications
> around if the subscriber ends up being promoted to a primary node.
> OTOH, it seems a bit peculiar that the behaviour of the --clean option
> is now depending on the other --publication option.
>
> I wonder what others think about this feature/quirk? e.g. maybe you
> need to introduce a --clean=unused_publications?
>
> ~
>
> 1b.
> Anyway, even if this behaviour is what you wanted, that text
> describing --clean needs rewording.
>
> Before this paragraph, the docs still say --clean=publications:
> "...causes all other publications replicated from the source server to
> be dropped as well."
>
> Which is then immediately contradicted when you wrote:
> "When publications are reused, they will not be dropped"
>
Removed this contradictory paragraph.
> ~~~
>
> --publication:
>
> 2.
> + <para>
> + Use <option>--dry-run</option> to see which publications will be reused
> + and which will be created before running the actual command.
> + </para>
>
> It seemed a bit strange to say "the actual command" because IMO it's
> always an actual command regardless of the options.
>
> SUGGEST:
> Use --dry-run to safely preview which publications will be reused and
> which will be created.
>
>
Fixed.
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> check_and_drop_publications:
>
> 3.
> The function comment has not been updated with the new rules. It still
> says, "Additionally, if requested, drop all pre-existing
> publications."
>
Fixed.
> ~~~
>
> 4.
> /* Drop each publication */
> for (int i = 0; i < PQntuples(res); i++)
> - drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
> - &dbinfo->made_publication);
> -
> + {
> + if (dbinfo->made_publication)
> + drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
> + &dbinfo->made_publication);
> + }
> PQclear(res);
> }
>
> /*
> - * In dry-run mode, we don't create publications, but we still try to drop
> - * those to provide necessary information to the user.
> + * Only drop publications that were created by pg_createsubscriber during
> + * this operation. Pre-existing publications are preserved.
> */
> if (!drop_all_pubs || dry_run)
> - drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> - &dbinfo->made_publication);
> + {
> + if (dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + else
> + pg_log_info("preserving existing publication \"%s\" in database \"%s\"",
> + dbinfo->pubname, dbinfo->dbname);
> + }
>
> 4a.
> I always find it difficult to follow the logic of this function.
> AFAICT the "dry_mode" logic is already handled within the
> drop_publication(), so check_and_drop_publications() can be simplified
> by refactoring it:
>
> CURRENT
> if (drop_all_pubs)
> {
> ...
> }
> if (!drop_all_pub || dry_mode)
> {
> ...
> }
>
> SUGGEST
> if (drop_all_pubs)
> {
> ...
> }
> else
> {
> ...
> }
>
> ~
>
Fixed.
> 4b.
> Why is "preserving existing publication" logged in a --dry-run only?
> Shouldn't you see the same logs regardless of --dry-run? That's kind
> of the whole point of a dry run, right?
>
Fixed.
> ======
> .../t/040_pg_createsubscriber.pl
>
> 5.
> +my $node_s3 = PostgreSQL::Test::Cluster->new('node_s3');
> +$node_s3->init_from_backup($node_p, 'backup_tablepub', has_streaming => 1);
> +
>
> Should this be done later, where it is needed, combined with the
> node_s3->start/stop?
>
Fixed.
> ~~~
>
> 6.
> +# Run pg_createsubscriber on node S3 without --dry-run and --clean option
> +# to verify that the existing publications are preserved.
> +command_ok(
> + [
> + 'pg_createsubscriber',
> + '--verbose', '--verbose',
> + '--recovery-timeout' => $PostgreSQL::Test::Utils::timeout_default,
> + '--pgdata' => $node_s3->data_dir,
> + '--publisher-server' => $node_p->connstr($db1),
> + '--socketdir' => $node_s3->host,
> + '--subscriber-port' => $node_s3->port,
> + '--database' => $db1,
> + '--database' => $db2,
> + '--publication' => 'test_pub_existing',
> + '--publication' => 'test_pub_new',
> + '--clean' => 'publications',
> + ],
> + 'run pg_createsubscriber on node S3');
>
>
> 6a.
> That comment wording "without --dry-run and --clean option" is
> confusing because it sounds like "without --dry-run" and "without
> --clean"
>
Fixed.
> ~
>
> 6b.
> There are other untested combinations like --dry-run with --clean,
> which would give more confidence about the logic of function
> check_and_drop_publications().
>
> Perhaps this test could have been written using --dry-run, and you
> could be checking the logs for the expected "drop" or "preserving"
> messages.
>
Added a test case with --dry-run and --clean=publications option.
> ~~~
>
> 7.
> +# Confirm publication created by pg_createsubscriber is removed
> +is( $node_s3->safe_psql(
> + $db1,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new';"
> + ),
> + '0',
> + 'publication created by pg_createsubscriber have been removed');
> +
>
> Hmm. Here you are testing the new publication was deleted, so nowhere
> is testing what the earlier comment said it was doing "...verify that
> the existing publications are preserved.".
>
Fixed.
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham,
Here are some v10 review comments.
======
1. GENERAL
A couple of my review comments below (#4, #7) are about the tense of
the info messages; My comments are trying to introduce some
consistency in the patch but unfortunately I see there are already
lots of existing messages where the tense is a muddle of past/present
(e.g. "creating"/"could not create" instead of "created"/"could not
create" or "creating"/"cannot create". Perhaps it's better to just
ignore my pg_log_info comments and do whatever seems right for this
patch, but also make another thread to fix the tense for all the
messages in one go.
======
Commit Message
2.
When publications are reused, they are never dropped during cleanup operations,
ensuring pre-existing publications remain available for other uses.
Only publications created by pg_createsubscriber are cleaned up.
~
AFAICT, the implemented behaviour has flip-flopped again regarding
--clean; I think now --clean=publications is unchanged from master
(e.g. --clean=publication will drop all publications).
That's OK, but you need to ensure the commit message is saying the
same thing. e.g. currently it says "cleanup operations" never drop
reused publications, but what about "--clean=publications" -- that's a
cleanup operation, isn't it?
======
src/bin/pg_basebackup/pg_createsubscriber.c
check_publication_exists:
3.
+/*
+ * Check if a publication with the given name exists in the specified database.
+ * Returns true if it exists, false otherwise.
+ */
It seems a verbose way of saying:
Return whether a specified publication exists in the specified database.
~~~
check_and_drop_publications:
4.
+ if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
+ {
+ /* Reuse existing publication on publisher. */
+ pg_log_info("using existing publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ dbinfo[i].made_publication = false;
+ }
+ else
+ {
+ /*
+ * Create publication on publisher. This step should be executed
+ * *before* promoting the subscriber to avoid any transactions
+ * between consistent LSN and the new publication rows (such
+ * transactions wouldn't see the new publication rows resulting in
+ * an error).
+ */
+ create_publication(conn, &dbinfo[i]);
+ pg_log_info("created publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ dbinfo[i].made_publication = true;
+ }
The tense of these messages seems inconsistent, and is also different
from another nearby message: "create replication slot..."
So, should these pg_log_info change to match? For example:
"using existing publication" --> "use existing..."
"created publication" --> "create publication..."
~~~
check_and_drop_publications:
5.
* Since the publications were created before the consistent LSN, they
* remain on the subscriber even after the physical replica is
* promoted. Remove these publications from the subscriber because
- * they have no use. Additionally, if requested, drop all pre-existing
- * publications.
+ * they have no use. If --clean=publications is specified, drop all existing
+ * publications in the database. Otherwise, only drop publications that were
+ * created by pg_createsubscriber during this operation, preserving any
+ * pre-existing publications.
*/
This function comment seems overkill now that this function has
evolved. e.g. That whole first part (before "If --clean...") seems
like it would be better just as a comment within the function body
'else' block rather than needing to say anything in the function
comment.
~~~
6.
for (int i = 0; i < PQntuples(res); i++)
drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
&dbinfo->made_publication);
-
PQclear(res);
This whitespace change is not needed for the patch.
~~~
7.
+ else
+ {
+ /*
+ * Only drop publications that were created by pg_createsubscriber
+ * during this operation. Pre-existing publications are preserved.
+ */
+ if (dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ else
+ pg_log_info("preserving existing publication \"%s\" in database \"%s\"",
+ dbinfo->pubname, dbinfo->dbname);
+ }
For consistency with earlier review comment, maybe the message should
be reworded:
"preserving existing publication" --> "preserve existing publication"
======
.../t/040_pg_createsubscriber.pl
8.
+# Run pg_createsubscriber on node S2 without --dry-run
+command_ok(
and later...
+# Run pg_createsubscriber on node S2 without --dry-run
+command_ok(
~
These are not very informative comments. It should say more about the
purpose -- e.g. you are specifying --publication to reuse one
publication and create another ... to demonstrate that yada yada...
~~~
9.
+# Verify the existing publication is still there and unchanged
+my $existing_pub_count = $node_p->safe_psql($db1,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing'"
+);
+is($existing_pub_count, '1',
+ 'existing publication remains unchanged after dry-run');
+
+# Verify no actual publications were created during dry-run
+my $pub_count_after_dry_run = $node_p->safe_psql($db2,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new'");
+is($pub_count_after_dry_run, '0',
+ 'dry-run did not actually create publications');
+
Instead of 2 SQLs to check whether something exists and something else
does not exist, can't you just have 1 SELECT to fetch all publication
names, then you can deduce the same thing from the result.
~~~
10.
+# Run pg_createsubscriber on node S3 with --dry-run
+($stdout, $stderr) = run_command(
Again, it's not a very informative comment. It should say more about
the purpose -- e.g. you are specifying --publication and
--clean=publications at the same time ... to demonstrate yada yada...
~~~
11.
+# Verify nothing was actually changed
+my $existing_pub_still_exists = $node_p->safe_psql($db1,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing'"
+);
+is($existing_pub_still_exists, '1',
+ 'existing publication still exists after dry-run with --clean');
+
+my $new_pub_still_exists = $node_p->safe_psql($db2,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new'");
+is($new_pub_still_exists, '1',
+ 'pg_createsubscriber publication still exists after dry-run with --clean'
+);
+
Isn't this another example of something that is easily verified with a
single SQL instead of checking both publications separately?
~~~
12.
# Run pg_createsubscriber on node S3 with --clean option to verify that the
# existing publications are preserved.
command_ok(
Is that comment correct? I don't think so because --clean=publications
is supposed to drop all publications, right?
~~~
13.
+# Confirm ALL publications were removed (both existing and new)
+is( $node_s3->safe_psql(
+ $db1,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing';"
+ ),
+ '0',
+ 'pre-existing publication was removed by --clean=publications');
+
+is( $node_s3->safe_psql(
+ $db2,
+ "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new';"
+ ),
+ '0',
+ 'publication created by pg_createsubscriber was removed by
--clean=publications'
+);
+
Are 2x SELECT needed here? Can't you just have a single select to
discover that there are zero publications?
======
Kind Regards,
Peter Smith
Fujitsu Australia
On Tue, Sep 23, 2025 at 1:22 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v10 review comments.
>
> ======
> 1. GENERAL
>
> A couple of my review comments below (#4, #7) are about the tense of
> the info messages; My comments are trying to introduce some
> consistency in the patch but unfortunately I see there are already
> lots of existing messages where the tense is a muddle of past/present
> (e.g. "creating"/"could not create" instead of "created"/"could not
> create" or "creating"/"cannot create". Perhaps it's better to just
> ignore my pg_log_info comments and do whatever seems right for this
> patch, but also make another thread to fix the tense for all the
> messages in one go.
>
As of now, I’ve addressed your comments related to the pg_log_info
messages. If you still feel there are more cases that should be
corrected, please let me know and I can start a separate thread to
handle tense consistency across all such messages.
> ======
> Commit Message
>
> 2.
> When publications are reused, they are never dropped during cleanup operations,
> ensuring pre-existing publications remain available for other uses.
> Only publications created by pg_createsubscriber are cleaned up.
>
> ~
>
> AFAICT, the implemented behaviour has flip-flopped again regarding
> --clean; I think now --clean=publications is unchanged from master
> (e.g. --clean=publication will drop all publications).
>
> That's OK, but you need to ensure the commit message is saying the
> same thing. e.g. currently it says "cleanup operations" never drop
> reused publications, but what about "--clean=publications" -- that's a
> cleanup operation, isn't it?
>
Fixed.
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> check_publication_exists:
>
> 3.
> +/*
> + * Check if a publication with the given name exists in the specified database.
> + * Returns true if it exists, false otherwise.
> + */
>
> It seems a verbose way of saying:
> Return whether a specified publication exists in the specified database.
>
Fixed.
> ~~~
>
> check_and_drop_publications:
>
> 4.
> + if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
> + {
> + /* Reuse existing publication on publisher. */
> + pg_log_info("using existing publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + dbinfo[i].made_publication = false;
> + }
> + else
> + {
> + /*
> + * Create publication on publisher. This step should be executed
> + * *before* promoting the subscriber to avoid any transactions
> + * between consistent LSN and the new publication rows (such
> + * transactions wouldn't see the new publication rows resulting in
> + * an error).
> + */
> + create_publication(conn, &dbinfo[i]);
> + pg_log_info("created publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + dbinfo[i].made_publication = true;
> + }
>
> The tense of these messages seems inconsistent, and is also different
> from another nearby message: "create replication slot..."
>
> So, should these pg_log_info change to match? For example:
> "using existing publication" --> "use existing..."
> "created publication" --> "create publication..."
>
Fixed.
> ~~~
>
> check_and_drop_publications:
>
> 5.
> * Since the publications were created before the consistent LSN, they
> * remain on the subscriber even after the physical replica is
> * promoted. Remove these publications from the subscriber because
> - * they have no use. Additionally, if requested, drop all pre-existing
> - * publications.
> + * they have no use. If --clean=publications is specified, drop all existing
> + * publications in the database. Otherwise, only drop publications that were
> + * created by pg_createsubscriber during this operation, preserving any
> + * pre-existing publications.
> */
>
>
> This function comment seems overkill now that this function has
> evolved. e.g. That whole first part (before "If --clean...") seems
> like it would be better just as a comment within the function body
> 'else' block rather than needing to say anything in the function
> comment.
>
Fixed.
> ~~~
>
> 6.
> for (int i = 0; i < PQntuples(res); i++)
> drop_publication(conn, PQgetvalue(res, i, 0), dbinfo->dbname,
> &dbinfo->made_publication);
> -
> PQclear(res);
> This whitespace change is not needed for the patch.
>
Fixed.
> ~~~
>
> 7.
> + else
> + {
> + /*
> + * Only drop publications that were created by pg_createsubscriber
> + * during this operation. Pre-existing publications are preserved.
> + */
> + if (dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + else
> + pg_log_info("preserving existing publication \"%s\" in database \"%s\"",
> + dbinfo->pubname, dbinfo->dbname);
> + }
>
> For consistency with earlier review comment, maybe the message should
> be reworded:
> "preserving existing publication" --> "preserve existing publication"
Fixed.
> ======
> .../t/040_pg_createsubscriber.pl
>
> 8.
> +# Run pg_createsubscriber on node S2 without --dry-run
> +command_ok(
>
> and later...
>
> +# Run pg_createsubscriber on node S2 without --dry-run
> +command_ok(
>
> ~
>
> These are not very informative comments. It should say more about the
> purpose -- e.g. you are specifying --publication to reuse one
> publication and create another ... to demonstrate that yada yada...
>
Fixed.
> ~~~
>
> 9.
> +# Verify the existing publication is still there and unchanged
> +my $existing_pub_count = $node_p->safe_psql($db1,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing'"
> +);
> +is($existing_pub_count, '1',
> + 'existing publication remains unchanged after dry-run');
> +
> +# Verify no actual publications were created during dry-run
> +my $pub_count_after_dry_run = $node_p->safe_psql($db2,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new'");
> +is($pub_count_after_dry_run, '0',
> + 'dry-run did not actually create publications');
> +
>
> Instead of 2 SQLs to check whether something exists and something else
> does not exist, can't you just have 1 SELECT to fetch all publication
> names, then you can deduce the same thing from the result.
>
In the attached patch, I have removed that test case. It’s not really
valid to combine multiple switches in this way, since using
--publication together with --clean=publications is effectively the
same as running pg_createsubscriber twice (once with each switch).
That makes the extra combination test redundant, so I have dropped it.
> ~~~
>
> 10.
> +# Run pg_createsubscriber on node S3 with --dry-run
> +($stdout, $stderr) = run_command(
>
> Again, it's not a very informative comment. It should say more about
> the purpose -- e.g. you are specifying --publication and
> --clean=publications at the same time ... to demonstrate yada yada...
>
Fixed.
> ~~~
>
> 11.
> +# Verify nothing was actually changed
> +my $existing_pub_still_exists = $node_p->safe_psql($db1,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing'"
> +);
> +is($existing_pub_still_exists, '1',
> + 'existing publication still exists after dry-run with --clean');
> +
> +my $new_pub_still_exists = $node_p->safe_psql($db2,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new'");
> +is($new_pub_still_exists, '1',
> + 'pg_createsubscriber publication still exists after dry-run with --clean'
> +);
> +
>
> Isn't this another example of something that is easily verified with a
> single SQL instead of checking both publications separately?
>
Fixed.
> ~~~
>
> 12.
> # Run pg_createsubscriber on node S3 with --clean option to verify that the
> # existing publications are preserved.
> command_ok(
>
> Is that comment correct? I don't think so because --clean=publications
> is supposed to drop all publications, right?
>
Fixed.
> ~~~
>
> 13.
> +# Confirm ALL publications were removed (both existing and new)
> +is( $node_s3->safe_psql(
> + $db1,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_existing';"
> + ),
> + '0',
> + 'pre-existing publication was removed by --clean=publications');
> +
> +is( $node_s3->safe_psql(
> + $db2,
> + "SELECT COUNT(*) FROM pg_publication WHERE pubname = 'test_pub_new';"
> + ),
> + '0',
> + 'publication created by pg_createsubscriber was removed by
> --clean=publications'
> +);
> +
>
> Are 2x SELECT needed here? Can't you just have a single select to
> discover that there are zero publications?
>
Fixed.
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham. On Wed, Sep 24, 2025 at 4:37 PM Shubham Khanna <khannashubham1197@gmail.com> wrote: > ... > > In the attached patch, I have removed that test case. It’s not really > valid to combine multiple switches in this way, since using > --publication together with --clean=publications is effectively the > same as running pg_createsubscriber twice (once with each switch). > That makes the extra combination test redundant, so I have dropped it. I disagree with the "it's not really valid to combine..." part. IMO, it should be perfectly valid to mix multiple switches if the tool accepts them; otherwise, the tool ought to give an error for any invalid combinations. OTOH, I agree that there is no point in burdening this patch with redundant test cases. ////////// Here are some v11 review comments. ====== src/sgml/ref/pg_createsubscriber.sgml 1. + <para> + If a publication with the specified name already exists on the publisher, + it will be reused as-is with its current configuration, including its + table list, row filters, column filters, and all other settings. + If a publication does not exist, it will be created automatically with + <literal>FOR ALL TABLES</literal>. + </para> Below is a minor rewording suggestion for the first sentence by AI, which I felt was a small improvement. SUGGESTION: If a publication with the specified name already exists on the publisher, it will be reused with its current configuration, including its table list, row filters, and column filters. ====== .../t/040_pg_createsubscriber.pl 2. +# Confirm ALL publications were removed by --clean=publications +my $remaining_pubs_db1 = $node_s3->safe_psql($db1, + "SELECT pubname FROM pg_publication ORDER BY pubname"); +is($remaining_pubs_db1, '', + 'all publications were removed from db1 by --clean=publications'); + +my $remaining_pubs_db2 = $node_s3->safe_psql($db2, + "SELECT pubname FROM pg_publication ORDER BY pubname"); +is($remaining_pubs_db2, '', + 'all publications were removed from db2 by --clean=publications'); + Since you are expecting no results, the "ORDER BY pubname" clauses are redundant here. In hindsight, since you expect zero results, just "SELECT COUNT(*) FROM pg_publications;" would also be ok. ====== Kind Regards, Peter Smith Fujitsu Australia
On Sep 24, 2025, at 14:37, Shubham Khanna <khannashubham1197@gmail.com> wrote:
The attached patch contains the suggested changes.
Thanks and regards,
Shubham Khanna.
<v11-0001-Support-existing-publications-in-pg_createsubscr.patch>
1.
```
+ if (dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ else
+ pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
+ dbinfo->pubname, dbinfo->dbname);
+ }
```
Should we preserve “|| dry_run”? Because based on the old comment, in dry-run mode, even if we don’t create publications, we still want to inform the user.
2.
```
+ create_publication(conn, &dbinfo[i]);
+ pg_log_info("create publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ dbinfo[i].made_publication = true;
```
dbinfo[i].made_publication = true; seems a redundant as create_publication() has done the assignment.
3.
```
@@ -1729,11 +1769,9 @@ drop_publication(PGconn *conn, const char *pubname, const char *dbname,
/*
* Retrieve and drop the publications.
*
- * Since the publications were created before the consistent LSN, they
- * remain on the subscriber even after the physical replica is
- * promoted. Remove these publications from the subscriber because
- * they have no use. Additionally, if requested, drop all pre-existing
- * publications.
+ * If --clean=publications is specified, drop all existing
+ * publications in the database. Otherwise, only drop publications that were
+ * created by pg_createsubscriber.
*/
static void
check_and_drop_publications(PGconn *conn, struct LogicalRepInfo *dbinfo)
```
The old comment clearly stated that deleting publication on target server, the updated comment loses that important information.
--
Chao Li (Evan)
HighGo Software Co., Ltd.
https://www.highgo.com/
HighGo Software Co., Ltd.
https://www.highgo.com/
On Thu, Sep 25, 2025 at 9:02 AM Chao Li <li.evan.chao@gmail.com> wrote:
>
>
>
> On Sep 24, 2025, at 14:37, Shubham Khanna <khannashubham1197@gmail.com> wrote:
>
>
>
> The attached patch contains the suggested changes.
>
> Thanks and regards,
> Shubham Khanna.
> <v11-0001-Support-existing-publications-in-pg_createsubscr.patch>
>
>
> 1.
> ```
> + if (dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + else
> + pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
> + dbinfo->pubname, dbinfo->dbname);
> + }
> ```
>
> Should we preserve “|| dry_run”? Because based on the old comment, in dry-run mode, even if we don’t create
publications,we still want to inform the user.
>
We don’t need to add an explicit "|| dry_run" here, since the
made_publication flag already accounts for that case. In dry-run mode,
no publications are actually created, so made_publication is never
set. This ensures we still hit the “preserve existing publication …”
branch and inform the user accordingly.
> 2.
> ```
> + create_publication(conn, &dbinfo[i]);
> + pg_log_info("create publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + dbinfo[i].made_publication = true;
> ```
>
> dbinfo[i].made_publication = true; seems a redundant as create_publication() has done the assignment.
>
I have removed the redundant dbinfo[i].made_publication = true;, since
create_publication() already sets that flag.
> 3.
> ```
> @@ -1729,11 +1769,9 @@ drop_publication(PGconn *conn, const char *pubname, const char *dbname,
> /*
> * Retrieve and drop the publications.
> *
> - * Since the publications were created before the consistent LSN, they
> - * remain on the subscriber even after the physical replica is
> - * promoted. Remove these publications from the subscriber because
> - * they have no use. Additionally, if requested, drop all pre-existing
> - * publications.
> + * If --clean=publications is specified, drop all existing
> + * publications in the database. Otherwise, only drop publications that were
> + * created by pg_createsubscriber.
> */
> static void
> check_and_drop_publications(PGconn *conn, struct LogicalRepInfo *dbinfo)
> ```
>
> The old comment clearly stated that deleting publication on target server, the updated comment loses that important
information.
>
I have adjusted the comments so that the function header now contains
the general description, while the else block comment explains the
subscriber (target server) context that was missing earlier. This way,
the header stays concise, and the important detail about where the
publications are being dropped is still preserved in the right place.
The attached patch contains the suggested changes. It also contains
the fix for Peter's comments at [1].
[1] - https://www.postgresql.org/message-id/CAHut%2BPsCQxWoPh-UXBUWu%3D6Pc6GuEQ4wnHZtDOwUnZN%3DkrMxvQ%40mail.gmail.com
Thanks and regards,
Shubham Khanna.
Вложения
On Sep 25, 2025, at 15:07, Shubham Khanna <khannashubham1197@gmail.com> wrote:
1.
```
+ if (dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ else
+ pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
+ dbinfo->pubname, dbinfo->dbname);
+ }
```
Should we preserve “|| dry_run”? Because based on the old comment, in dry-run mode, even if we don’t create publications, we still want to inform the user.
We don’t need to add an explicit "|| dry_run" here, since the
made_publication flag already accounts for that case. In dry-run mode,
no publications are actually created, so made_publication is never
set. This ensures we still hit the “preserve existing publication …”
branch and inform the user accordingly.
I doubt that. Looking the code in create_publication():
if (!dry_run)
{
res = PQexec(conn, str->data);
if (PQresultStatus(res) != PGRES_COMMAND_OK)
{
pg_log_error("could not create publication \"%s\" in database \"%s\": %s",
dbinfo->pubname, dbinfo->dbname, PQresultErrorMessage(res));
disconnect_database(conn, true);
}
PQclear(res);
}
/* For cleanup purposes */
dbinfo->made_publication = true;
made_publication will always be set regardless of dry_run.
--
Chao Li (Evan)
HighGo Software Co., Ltd.
https://www.highgo.com/
HighGo Software Co., Ltd.
https://www.highgo.com/
On Thu, Sep 25, 2025 at 1:15 PM Chao Li <li.evan.chao@gmail.com> wrote:
>
>
> On Sep 25, 2025, at 15:07, Shubham Khanna <khannashubham1197@gmail.com> wrote:
>
>
>
> 1.
> ```
> + if (dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + else
> + pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
> + dbinfo->pubname, dbinfo->dbname);
> + }
> ```
>
> Should we preserve “|| dry_run”? Because based on the old comment, in dry-run mode, even if we don’t create
publications,we still want to inform the user.
>
>
> We don’t need to add an explicit "|| dry_run" here, since the
> made_publication flag already accounts for that case. In dry-run mode,
> no publications are actually created, so made_publication is never
> set. This ensures we still hit the “preserve existing publication …”
> branch and inform the user accordingly.
>
>
> I doubt that. Looking the code in create_publication():
> if (!dry_run)
> {
> res = PQexec(conn, str->data);
> if (PQresultStatus(res) != PGRES_COMMAND_OK)
> {
> pg_log_error("could not create publication \"%s\" in database \"%s\": %s",
> dbinfo->pubname, dbinfo->dbname, PQresultErrorMessage(res));
> disconnect_database(conn, true);
> }
> PQclear(res);
> }
>
> /* For cleanup purposes */
> dbinfo->made_publication = true;
>
> made_publication will always be set regardless of dry_run.
>
You’re right — I made a mistake in my earlier explanation.
made_publication is always set in create_publication(), regardless of
dry-run. I have double-checked the dry-run output across the cases,
and from what I can see the messages are being logged correctly.
If you think there’s a specific combination where the dry-run logging
isn’t behaving as expected, could you point me to it? From my testing
it looks fine, but I want to be sure I’m not missing a corner case.
Thanks and regards,
Shubham Khanna.
On Sep 25, 2025, at 16:18, Shubham Khanna <khannashubham1197@gmail.com> wrote:
made_publication will always be set regardless of dry_run.
You’re right — I made a mistake in my earlier explanation.
made_publication is always set in create_publication(), regardless of
dry-run. I have double-checked the dry-run output across the cases,
and from what I can see the messages are being logged correctly.
If you think there’s a specific combination where the dry-run logging
isn’t behaving as expected, could you point me to it? From my testing
it looks fine, but I want to be sure I’m not missing a corner case.
I think, here you code has a logic difference from the old code:
* With the old code, even if drop_all_pubs, as long as dry_run, it will still run drop_publication().
* With your code, if drop_all_pubs, then never run drop_publication(), because you moved the logic into “else”.
To be honest, I am not 100% sure which is correct, I am just pointing out the difference.
--
Chao Li (Evan)
HighGo Software Co., Ltd.
https://www.highgo.com/
HighGo Software Co., Ltd.
https://www.highgo.com/
On Thu, Sep 25, 2025 at 6:36 PM Chao Li <li.evan.chao@gmail.com> wrote: > > > > On Sep 25, 2025, at 16:18, Shubham Khanna <khannashubham1197@gmail.com> wrote: > > > > made_publication will always be set regardless of dry_run. > > > You’re right — I made a mistake in my earlier explanation. > made_publication is always set in create_publication(), regardless of > dry-run. I have double-checked the dry-run output across the cases, > and from what I can see the messages are being logged correctly. > > If you think there’s a specific combination where the dry-run logging > isn’t behaving as expected, could you point me to it? From my testing > it looks fine, but I want to be sure I’m not missing a corner case. > > > I think, here you code has a logic difference from the old code: > > * With the old code, even if drop_all_pubs, as long as dry_run, it will still run drop_publication(). > * With your code, if drop_all_pubs, then never run drop_publication(), because you moved the logic into “else”. > > To be honest, I am not 100% sure which is correct, I am just pointing out the difference. > Hi Shubham. Chao is correct - that logic has changed slightly now. That stems from my suggestion a couple of versions back to rewrite this as an if/else. At that time, I thought there was a risk of a double-drop/double-logging happening for the scenario of 'drop_all_pubs' in a 'dry_run'. In hindsight, it looks like that was not possible because the 'drop_all_pubs' code can only drop publications that it *finds*, but for 'dry_run', it's not going to find the newly "made" publications because although create_publication() was called, they were not actually created. I did not recognise that was the intended meaning of the original code comment. ~~ Even if the patch reverts to the original condition, there still seem to be some quirks to be worked out: * The original explanatory comment could have been better: BEFORE In dry-run mode, we don't create publications, but we still try to drop those to provide necessary information to the user. AFTER In dry-run mode, create_publication() and drop_publication() do not actually create or drop anything -- they only do logging. So, we still need to call drop_publication() to log information to the user. * I'm not sure if that "preserve existing" logging should be there or not? What exactly is it for? If you reinstate the original "(!drop_all_pubs || dry_run)" condition, then it seems possible to log "preserve existing" also for 'drop_all_pubs', but that is contrary to the docs. Is this just a leftover from a few versions back, when 'drop_all_pubs' would not drop everything? * It is a bit concerning that although this function appears slightly broken (e.g. causing wrong logging), the tests cannot detect it. ~~ The bottom line is, I think you'll need to make a matrix of every possible combination of made=Y/N; drop_all_pub=Y/N; dry_run=Y/N; etc and then decide exactly what logging you want for each. I don't know if it is possible to automate such testing -- it might be overkill -- but at least the expected logging can be posted in this thread, so the code can be reviewed properly. ====== Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Sep 26, 2025 at 6:06 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Sep 25, 2025 at 6:36 PM Chao Li <li.evan.chao@gmail.com> wrote: > > > > > > > > On Sep 25, 2025, at 16:18, Shubham Khanna <khannashubham1197@gmail.com> wrote: > > > > > > > > made_publication will always be set regardless of dry_run. > > > > > > You’re right — I made a mistake in my earlier explanation. > > made_publication is always set in create_publication(), regardless of > > dry-run. I have double-checked the dry-run output across the cases, > > and from what I can see the messages are being logged correctly. > > > > If you think there’s a specific combination where the dry-run logging > > isn’t behaving as expected, could you point me to it? From my testing > > it looks fine, but I want to be sure I’m not missing a corner case. > > > > > > I think, here you code has a logic difference from the old code: > > > > * With the old code, even if drop_all_pubs, as long as dry_run, it will still run drop_publication(). > > * With your code, if drop_all_pubs, then never run drop_publication(), because you moved the logic into “else”. > > > > To be honest, I am not 100% sure which is correct, I am just pointing out the difference. > > > > Hi Shubham. > > Chao is correct - that logic has changed slightly now. That stems from > my suggestion a couple of versions back to rewrite this as an if/else. > At that time, I thought there was a risk of a > double-drop/double-logging happening for the scenario of > 'drop_all_pubs' in a 'dry_run'. In hindsight, it looks like that was > not possible because the 'drop_all_pubs' code can only drop > publications that it *finds*, but for 'dry_run', it's not going to > find the newly "made" publications because although > create_publication() was called, they were not actually created. I did > not recognise that was the intended meaning of the original code > comment. > > ~~ > > Even if the patch reverts to the original condition, there still seem > to be some quirks to be worked out: > > * The original explanatory comment could have been better: > BEFORE > In dry-run mode, we don't create publications, but we still try to > drop those to provide necessary information to the user. > AFTER > In dry-run mode, create_publication() and drop_publication() do not > actually create or drop anything -- they only do logging. So, we still > need to call drop_publication() to log information to the user. > > * I'm not sure if that "preserve existing" logging should be there or > not? What exactly is it for? If you reinstate the original > "(!drop_all_pubs || dry_run)" condition, then it seems possible to log > "preserve existing" also for 'drop_all_pubs', but that is contrary to > the docs. Is this just a leftover from a few versions back, when > 'drop_all_pubs' would not drop everything? > > * It is a bit concerning that although this function appears slightly > broken (e.g. causing wrong logging), the tests cannot detect it. > > ~~ > > The bottom line is, I think you'll need to make a matrix of every > possible combination of made=Y/N; drop_all_pub=Y/N; dry_run=Y/N; etc > and then decide exactly what logging you want for each. I don't know > if it is possible to automate such testing -- it might be overkill -- > but at least the expected logging can be posted in this thread, so the > code can be reviewed properly. > Hi Peter, Chao, Thanks for the detailed observations. I went back and prepared a logging matrix for the different combinations of made_publication, drop_all_pubs, and dry_run. This highlights where the behavior diverges from the old code. Summary of findings: - When --clean=publications is used together with --dry-run, the code correctly logs "dropping all existing publications", but it fails to log the individual drop_publication() messages (e.g., "dropping publication pubX"). - This affects both user-created (--publication=...) and auto-created publications. - Most other cases (new pub only, existing pub only, auto pub only) behave as expected. - New bug discovered: In the existing pub + clean case, the logs show both "dropping publication pub1" and "preserve existing publication pub1". This is contradictory and comes from the original code path falling through to the “preserve” branch even when drop_all_pubs=true. The restructuring into if/else caused the missing individual drop_publication() logs in dry-run mode when drop_all_pubs=true. The original condition also had a flaw: in the existing pub + clean case, it could log both drop and preserve for the same publication. I have updated the conditions so that: - drop_publication() is always invoked in dry-run for correct logging. - The “preserve existing” log is suppressed when drop_all_pubs=true, eliminating the contradictory messages. The attached patch contains the changes, and the attached image shows the complete logging matrix for reference. Thanks and regards, Shubham Khanna.
Вложения
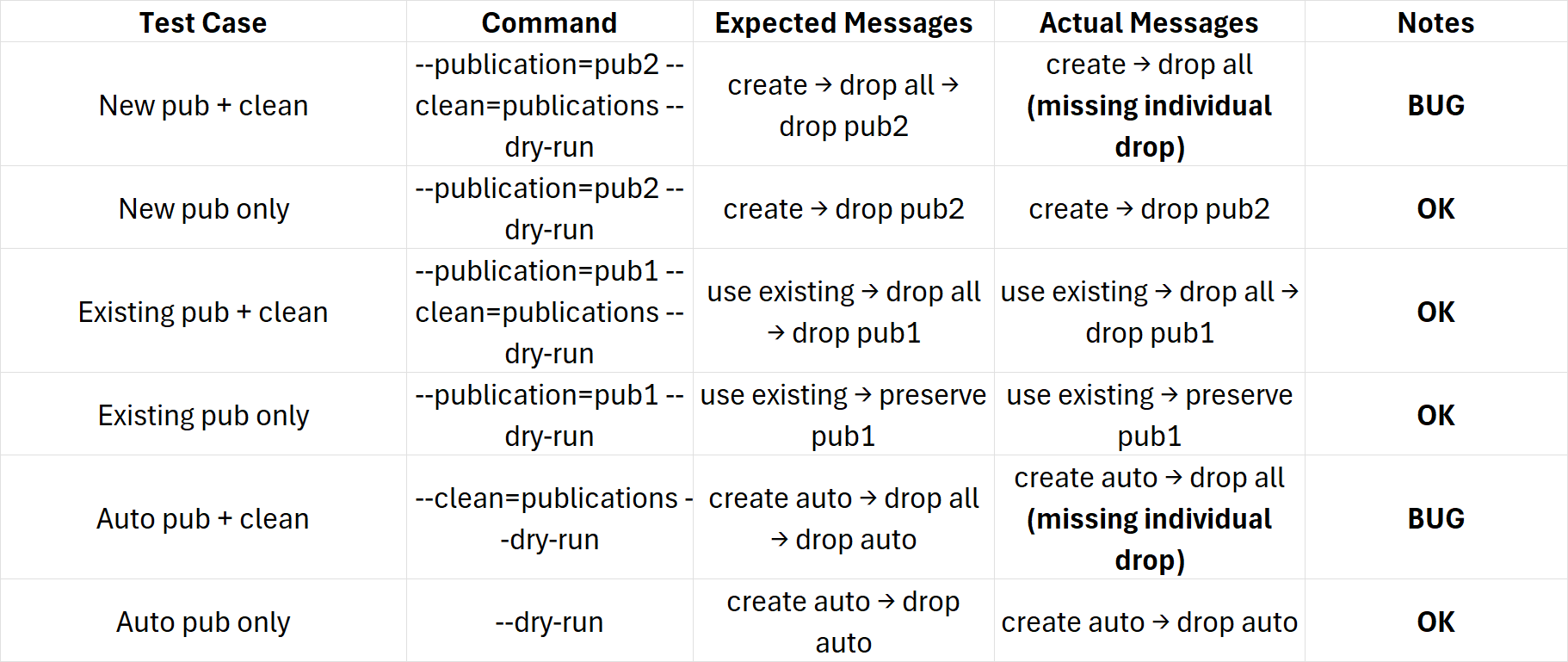{kind=link}
Hi Shubham,
Here are some v13 review comments.
======
src/bin/pg_basebackup/pg_createsubscriber.c
1.
- /*
- * In dry-run mode, we don't create publications, but we still try to drop
- * those to provide necessary information to the user.
- */
if (!drop_all_pubs || dry_run)
- drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
- &dbinfo->made_publication);
+ {
+ /*
+ * Since the publications were created before the consistent LSN, they
+ * remain on the subscriber even after the physical replica is
+ * promoted. Only drop publications that were created by
+ * pg_createsubscriber during this operation. Pre-existing
+ * publications are preserved.
+ */
+ if (!drop_all_pubs && dbinfo->made_publication)
+ drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
+ &dbinfo->made_publication);
+ else if (!drop_all_pubs)
+ pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
+ dbinfo->pubname, dbinfo->dbname);
+ }
1a.
Sorry, that code looks wrong to me. Notice, the result of that patch
fragment is essentially:
if (!drop_all_pubs || dry_run)
{
if (!drop_all_pubs && dbinfo->made_publication)
drop_publication(...);
else if (!drop_all_pubs)
pg_log_info("preserve existing...";
}
You've coded *every* condition say !drop_all_pubs, which is basically
saying when drop_all_pubs == true then dry_run does nothing at all
(??). Surely, that's not the intention.
Let's see a specific test case: --publication=mynew
--clean=publications --dry-run
According to your matrix, AFAICT, you expect this to log:
- "create publication mynew"
- "dropping all existing"
- "dropping other existing..." (loop)
- "drop publication mynew"
But, I don't see how that "drop publication mynew" is possible with
this code. Can you provide some test/script output as proof that it
actually works like you say it does?
~~~
1b.
The original code at least had a comment saying what it was trying to do:
- /*
- * In dry-run mode, we don't create publications, but we still try to drop
- * those to provide necessary information to the user.
- */
Why was that comment removed? In my v12 review, I suggested some
possible better wording [1] for that. Please imagine someone reading
this code without handy access to that "expected logging" matrix, and
write explanatory comments accordingly.
======
[1] https://www.postgresql.org/message-id/CAHut%2BPtk%3Ds9VweQWXatEZ7i9GiFxZn_3A5wMSE_gDO9h7jEcRA%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Wed, Oct 1, 2025 at 6:00 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v13 review comments.
>
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> 1.
> - /*
> - * In dry-run mode, we don't create publications, but we still try to drop
> - * those to provide necessary information to the user.
> - */
> if (!drop_all_pubs || dry_run)
> - drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> - &dbinfo->made_publication);
> + {
> + /*
> + * Since the publications were created before the consistent LSN, they
> + * remain on the subscriber even after the physical replica is
> + * promoted. Only drop publications that were created by
> + * pg_createsubscriber during this operation. Pre-existing
> + * publications are preserved.
> + */
> + if (!drop_all_pubs && dbinfo->made_publication)
> + drop_publication(conn, dbinfo->pubname, dbinfo->dbname,
> + &dbinfo->made_publication);
> + else if (!drop_all_pubs)
> + pg_log_info("preserve existing publication \"%s\" in database \"%s\"",
> + dbinfo->pubname, dbinfo->dbname);
> + }
>
> 1a.
> Sorry, that code looks wrong to me. Notice, the result of that patch
> fragment is essentially:
>
> if (!drop_all_pubs || dry_run)
> {
> if (!drop_all_pubs && dbinfo->made_publication)
> drop_publication(...);
> else if (!drop_all_pubs)
> pg_log_info("preserve existing...";
> }
>
> You've coded *every* condition say !drop_all_pubs, which is basically
> saying when drop_all_pubs == true then dry_run does nothing at all
> (??). Surely, that's not the intention.
>
> Let's see a specific test case: --publication=mynew
> --clean=publications --dry-run
>
> According to your matrix, AFAICT, you expect this to log:
> - "create publication mynew"
> - "dropping all existing"
> - "dropping other existing..." (loop)
> - "drop publication mynew"
>
> But, I don't see how that "drop publication mynew" is possible with
> this code. Can you provide some test/script output as proof that it
> actually works like you say it does?
>
> ~~~
>
> 1b.
> The original code at least had a comment saying what it was trying to do:
>
> - /*
> - * In dry-run mode, we don't create publications, but we still try to drop
> - * those to provide necessary information to the user.
> - */
>
> Why was that comment removed? In my v12 review, I suggested some
> possible better wording [1] for that. Please imagine someone reading
> this code without handy access to that "expected logging" matrix, and
> write explanatory comments accordingly.
>
> ======
> [1] https://www.postgresql.org/message-id/CAHut%2BPtk%3Ds9VweQWXatEZ7i9GiFxZn_3A5wMSE_gDO9h7jEcRA%40mail.gmail.com
>
Hi Peter,
Thanks for the detailed review. You are right — with the earlier code,
the “drop publication mynew” case was indeed not possible. I’ve
reworked the logic so that the behavior now matches the expected
matrix in all scenarios.
I’ve also prepared a script and captured the output to demonstrate
this, which I’ve attached for reference.
Additionally, I have updated the comments per your suggestion to
better explain the intended behavior, especially around the dry-run
handling, so that it’s clearer to a future reader without needing to
refer back to the logging matrix.
The attached patch includes these changes.
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham, Here are some v14 review comments. ====== src/bin/pg_basebackup/pg_createsubscriber.c check_and_drop_publications: 1. + * Publications copied during physical replication remain on the subscriber + * after promotion. If --clean=publications is specified, drop all existing + * publications in the subscriber database. Otherwise, only drop publications + * that were created by pg_createsubscriber during this operation. + * + * In dry-run mode, create_publication() and drop_publication() only log actions + * without modifying the database. Importantly, since no publication is actually + * created in dry-run, the query for existing publications won't include the + * "would-be" made publication. Thus, we must call drop_publication() for it + * regardless of drop_all_pubs to ensure the user sees the intended log message. */ I think the "In dry-mode ..." paragraph is a good comment, but it doesn't need to be at the function level. IMO, this can all be cut/paste to later (see the next review comment). ~~~ 2. /* - * In dry-run mode, we don't create publications, but we still try to drop - * those to provide necessary information to the user. + * Handle the publication created (or would-be created) by + * pg_createsubscriber. In dry-run mode, enter this block regardless of + * drop_all_pubs to log the drop action for the made publication (which + * isn't actually present). */ The wording in the function header seemed better. IMO, this entire comment can be replaced like: /* * Handle publications created by pg_createsubscriber. * * <here cut/paste all the "In dry-mode..." wording from the function header comment> */ ~~~ I provided a top-up diff patch to illustrate my point. //////////////////// I also had a look at the 'results' logging from your script. ~~~ For test case 1. (new pub pub2 + clean): I hoped to see some evidence that --clean is dropping all other existing pubs; e.g. pub1,pub2,pub3, whatever... ~~~ For test case 3. (Existing pub pub1 + clean): I hoped to see some evidence that --clean is dropping existing pubs; e.g. pub1,pub2,pub3, whatever... ~~~ For test case 5. (Auto pub + clean): I hoped to see some evidence that --clean is dropping existing pubs; e.g. pub1,pub2,pub3, whatever... ====== Kind Regards, Peter Smith. Fujitsu Australia.
Вложения
Hi Shubham,
Another review comment about patch v14...
While reviewing pg_createsubscriber logs, I was surprised to see some
almost duplicate consecutive logs for the pub/slot creation. e.g.
----------
pg_createsubscriber: creating publication "pub2" in database "db2"
pg_createsubscriber: create publication "pub2" in database "db2"
----------
I found the code is doing:
- pg_log_info("creating publication...") unconditionally inside
create_publication
- pg_log_info("create publication...") immediately after call to
create_publication
(patch fragment)
+ create_publication(conn, &dbinfo[i]);
+ pg_log_info("create publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
I think the logging *after* the call is redundant and should be removed.
======
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Oct 8, 2025 at 11:10 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v14 review comments.
>
> ======
> src/bin/pg_basebackup/pg_createsubscriber.c
>
> check_and_drop_publications:
>
> 1.
> + * Publications copied during physical replication remain on the subscriber
> + * after promotion. If --clean=publications is specified, drop all existing
> + * publications in the subscriber database. Otherwise, only drop publications
> + * that were created by pg_createsubscriber during this operation.
> + *
> + * In dry-run mode, create_publication() and drop_publication() only
> log actions
> + * without modifying the database. Importantly, since no publication
> is actually
> + * created in dry-run, the query for existing publications won't include the
> + * "would-be" made publication. Thus, we must call drop_publication() for it
> + * regardless of drop_all_pubs to ensure the user sees the intended
> log message.
> */
>
> I think the "In dry-mode ..." paragraph is a good comment, but it
> doesn't need to be at the function level. IMO, this can all be
> cut/paste to later (see the next review comment).
>
Updated as suggested — the detailed explanation about dry-run handling
has been moved to the appropriate block-level comment.
> ~~~
>
> 2.
> /*
> - * In dry-run mode, we don't create publications, but we still try to drop
> - * those to provide necessary information to the user.
> + * Handle the publication created (or would-be created) by
> + * pg_createsubscriber. In dry-run mode, enter this block regardless of
> + * drop_all_pubs to log the drop action for the made publication (which
> + * isn't actually present).
> */
>
> The wording in the function header seemed better. IMO, this entire
> comment can be replaced like:
>
> /*
> * Handle publications created by pg_createsubscriber.
> *
> * <here cut/paste all the "In dry-mode..." wording from the function
> header comment>
> */
> ~~~
>
> I provided a top-up diff patch to illustrate my point.
>
> ////////////////////
>
Fixed. The comments have been restructured to improve clarity and
placement per your suggestion.
> I also had a look at the 'results' logging from your script.
>
> ~~~
>
> For test case 1. (new pub pub2 + clean):
>
> I hoped to see some evidence that --clean is dropping all other
> existing pubs; e.g. pub1,pub2,pub3, whatever...
>
> ~~~
>
> For test case 3. (Existing pub pub1 + clean):
>
> I hoped to see some evidence that --clean is dropping existing pubs;
> e.g. pub1,pub2,pub3, whatever...
>
> ~~~
>
> For test case 5. (Auto pub + clean):
>
> I hoped to see some evidence that --clean is dropping existing pubs;
> e.g. pub1,pub2,pub3, whatever...
>
For these cases, I manually created multiple publications in the
postgres, db1, and db2 databases to make the --clean behavior clearly
visible in the logs.
I’ve attached the updated test script, captured logs, and the expected
log matrix for all cases to demonstrate the behavior.
Additionally, following your note in [1], I have removed the redundant
pg_log_info("create publication..."); statement since the same message
was already being logged inside create_publication().
The attached patch incorporates the revised comments and test-related updates.
[1] - https://www.postgresql.org/message-id/CAHut%2BPsYKXKmMSim5FcFo177gosY7a5xgMH_p4AY1_25HMVL7Q%40mail.gmail.com
Thanks and regards,
Shubham Khanna.
Вложения
Hi Shubham,
Here are some v15 review comments.
======
IIUC the test cases #3 and #4 are supposed to reuse an existing publication.
There is logging in the code:
+ /* Reuse existing publication on publisher. */
+ pg_log_info("use existing publication \"%s\" in database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
But I do not see those logs appearing anywhere in the test results.
I think this is caused by a simple mismatch in your test script
between the pub names in the db versus the pub names you are using in
those test commands.
======
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Sun, Oct 12, 2025 at 4:25 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham,
>
> Here are some v15 review comments.
>
> ======
> IIUC the test cases #3 and #4 are supposed to reuse an existing publication.
>
> There is logging in the code:
> + /* Reuse existing publication on publisher. */
> + pg_log_info("use existing publication \"%s\" in database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
>
> But I do not see those logs appearing anywhere in the test results.
>
> I think this is caused by a simple mismatch in your test script
> between the pub names in the db versus the pub names you are using in
> those test commands.
>
Hi Peter,
You are correct — the issue was due to a mismatch between the
publication names used in the databases and those referenced in the
test commands for cases #3 and #4. I’ve corrected the test script, and
the expected “use existing publication ...” logs now appear as
intended.
I’ve attached the updated test script, captured logs, and the expected
log matrix for reference. The patch I used for these runs is also
available at [1].
[1] - https://www.postgresql.org/message-id/CAHv8RjJPCRwGs0tbLCi36W6rKdUWQmLCtp6G%3D3YVQVCkO_B8QA%40mail.gmail.com
Thanks and regards,
Shubham Khanna.
Вложения
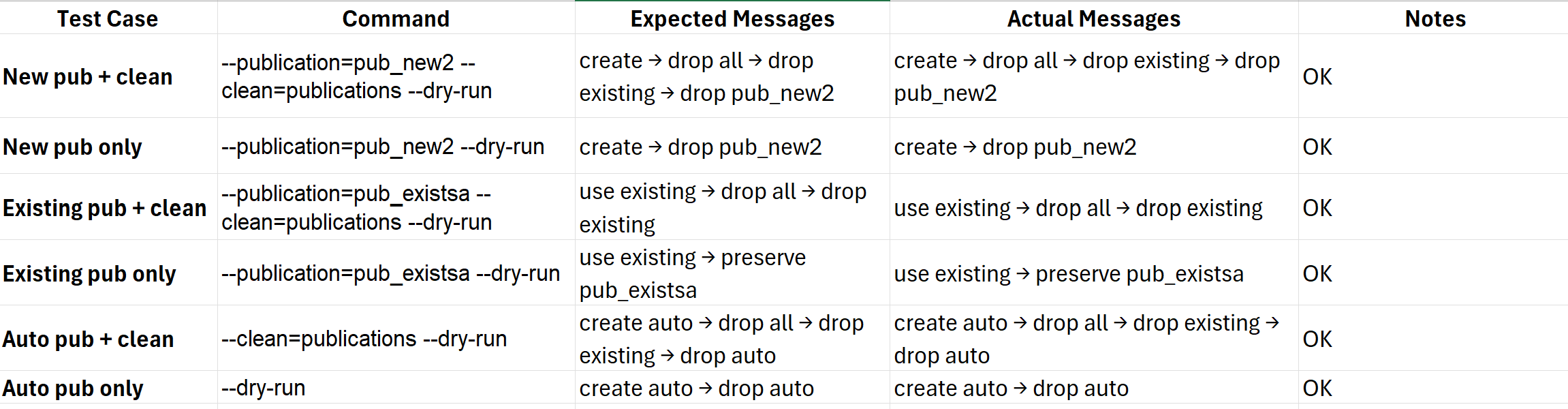{kind=link}
Hi Shubham. The log output looks OK now. So, I don't have any more review comments for this thread. Meanwhile, please watch my other pending patches [1][2] re pg_createsubscriber logging. If those get pushed first, then your patch will probably need rebasing. ====== [1] dropall - https://www.postgresql.org/message-id/flat/CAHut%2BPtm%2BWJwbbYXhC0s6FP_98KzZCR%3D5CPu8F8N5uV8P7BpqA%40mail.gmail.com [2] dryrun - https://www.postgresql.org/message-id/CAHut%2BPsvQJQnQO0KT0S2oegenkvJ8FUuY-QS5syyqmT24R2xFQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia.
On Mon, Oct 13, 2025 at 11:15 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Shubham. > > The log output looks OK now. So, I don't have any more review comments > for this thread. > > Meanwhile, please watch my other pending patches [1][2] re > pg_createsubscriber logging. If those get pushed first, then your > patch will probably need rebasing. > > ====== > [1] dropall - https://www.postgresql.org/message-id/flat/CAHut%2BPtm%2BWJwbbYXhC0s6FP_98KzZCR%3D5CPu8F8N5uV8P7BpqA%40mail.gmail.com > [2] dryrun - https://www.postgresql.org/message-id/CAHut%2BPsvQJQnQO0KT0S2oegenkvJ8FUuY-QS5syyqmT24R2xFQ%40mail.gmail.com > Attached is the rebased version of the patch. Thanks and regards, Shubham Khanna.
Вложения
On Mon, Oct 13, 2025 at 11:15 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Shubham. > > The log output looks OK now. So, I don't have any more review comments > for this thread. > > Meanwhile, please watch my other pending patches [1][2] re > pg_createsubscriber logging. If those get pushed first, then your > patch will probably need rebasing. > > ====== > [1] dropall - https://www.postgresql.org/message-id/flat/CAHut%2BPtm%2BWJwbbYXhC0s6FP_98KzZCR%3D5CPu8F8N5uV8P7BpqA%40mail.gmail.com > [2] dryrun - https://www.postgresql.org/message-id/CAHut%2BPsvQJQnQO0KT0S2oegenkvJ8FUuY-QS5syyqmT24R2xFQ%40mail.gmail.com > Hi Peter, I noticed that your logging patch from [1] has now been committed. Accordingly, I have rebased my patch at [2] to align with the updated dry-run and drop-all logging behavior. Please find the rebased version attached. [1] - https://www.postgresql.org/message-id/CAHut+PsvQJQnQO0KT0S2oegenkvJ8FUuY-QS5syyqmT24R2xFQ@mail.gmail.com [2] - https://www.postgresql.org/message-id/CAHv8Rj%2BSTAopLQVRp9K%2BWvse5P0qb9w99nPBQxzK5hXzPVi0aw%40mail.gmail.com Thanks and regards, Shubham Khanna.
Вложения
Hi Shubham.
A comment about the v17-0001.
======
1.
+ if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
+ {
+ /* Reuse existing publication on publisher. */
+ pg_log_info("dry-run: would use existing publication \"%s\" in
database \"%s\"",
+ dbinfo[i].pubname, dbinfo[i].dbname);
+ dbinfo[i].made_publication = false;
+ }
Is that correct? Won't this code now unconditionally log with the
"dry-run:" prefix, even when the tool is *not* doing a dry-run?
I thought code would be something like:
SUGGESTION #1 (if/else)
/* Reuse existing publication on publisher. */
if (dry_run)
pg_log_info("dry-run: would use existing publication ...);
else
pg_log_info("use existing publication ...);
~~~
OTOH, (since here is just an info message with no destructive
operation) perhaps it would be harmless also to keep the original log
message for both dry-run and normal mode.
SUGGESTION #2 (do nothing)
pg_log_info("use existing publication ...);
======
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Nov 3, 2025 at 12:55 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Shubham.
>
> A comment about the v17-0001.
>
> ======
> 1.
> + if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
> + {
> + /* Reuse existing publication on publisher. */
> + pg_log_info("dry-run: would use existing publication \"%s\" in
> database \"%s\"",
> + dbinfo[i].pubname, dbinfo[i].dbname);
> + dbinfo[i].made_publication = false;
> + }
>
> Is that correct? Won't this code now unconditionally log with the
> "dry-run:" prefix, even when the tool is *not* doing a dry-run?
>
> I thought code would be something like:
>
> SUGGESTION #1 (if/else)
> /* Reuse existing publication on publisher. */
> if (dry_run)
> pg_log_info("dry-run: would use existing publication ...);
> else
> pg_log_info("use existing publication ...);
>
> ~~~
>
> OTOH, (since here is just an info message with no destructive
> operation) perhaps it would be harmless also to keep the original log
> message for both dry-run and normal mode.
>
> SUGGESTION #2 (do nothing)
> pg_log_info("use existing publication ...);
>
> ======
Hi Peter,
Thank you for your review and suggestions.
I agree with your reasoning regarding the logging behavior. I will
proceed with Suggestion #2 and retain the existing `pg_log_info("use
existing publication ...");` message for both dry-run and normal
modes. This message is purely informational and does not perform any
destructive action, making it suitable for both scenarios.
The attached patch includes these changes.
Thanks and regards,
Shubham Khanna.
Вложения
On Wed, Nov 5, 2025 at 3:42 PM Shubham Khanna
<khannashubham1197@gmail.com> wrote:
>
> On Mon, Nov 3, 2025 at 12:55 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Hi Shubham.
> >
> > A comment about the v17-0001.
> >
> > ======
> > 1.
> > + if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
> > + {
> > + /* Reuse existing publication on publisher. */
> > + pg_log_info("dry-run: would use existing publication \"%s\" in
> > database \"%s\"",
> > + dbinfo[i].pubname, dbinfo[i].dbname);
> > + dbinfo[i].made_publication = false;
> > + }
> >
> > Is that correct? Won't this code now unconditionally log with the
> > "dry-run:" prefix, even when the tool is *not* doing a dry-run?
> >
> > I thought code would be something like:
> >
> > SUGGESTION #1 (if/else)
> > /* Reuse existing publication on publisher. */
> > if (dry_run)
> > pg_log_info("dry-run: would use existing publication ...);
> > else
> > pg_log_info("use existing publication ...);
> >
> > ~~~
> >
> > OTOH, (since here is just an info message with no destructive
> > operation) perhaps it would be harmless also to keep the original log
> > message for both dry-run and normal mode.
> >
> > SUGGESTION #2 (do nothing)
> > pg_log_info("use existing publication ...);
> >
> > ======
>
> Hi Peter,
>
> Thank you for your review and suggestions.
> I agree with your reasoning regarding the logging behavior. I will
> proceed with Suggestion #2 and retain the existing `pg_log_info("use
> existing publication ...");` message for both dry-run and normal
> modes. This message is purely informational and does not perform any
> destructive action, making it suitable for both scenarios.
> The attached patch includes these changes.
>
OK, but you did not do quite what you said you did.
Notice that v18 has modified the message to "would use existing
publication...", instead of just leaving it how it was in v16 ("use
existing publication...").
======
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 6, 2025 at 7:18 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Wed, Nov 5, 2025 at 3:42 PM Shubham Khanna
> <khannashubham1197@gmail.com> wrote:
> >
> > On Mon, Nov 3, 2025 at 12:55 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > Hi Shubham.
> > >
> > > A comment about the v17-0001.
> > >
> > > ======
> > > 1.
> > > + if (check_publication_exists(conn, dbinfo[i].pubname, dbinfo[i].dbname))
> > > + {
> > > + /* Reuse existing publication on publisher. */
> > > + pg_log_info("dry-run: would use existing publication \"%s\" in
> > > database \"%s\"",
> > > + dbinfo[i].pubname, dbinfo[i].dbname);
> > > + dbinfo[i].made_publication = false;
> > > + }
> > >
> > > Is that correct? Won't this code now unconditionally log with the
> > > "dry-run:" prefix, even when the tool is *not* doing a dry-run?
> > >
> > > I thought code would be something like:
> > >
> > > SUGGESTION #1 (if/else)
> > > /* Reuse existing publication on publisher. */
> > > if (dry_run)
> > > pg_log_info("dry-run: would use existing publication ...);
> > > else
> > > pg_log_info("use existing publication ...);
> > >
> > > ~~~
> > >
> > > OTOH, (since here is just an info message with no destructive
> > > operation) perhaps it would be harmless also to keep the original log
> > > message for both dry-run and normal mode.
> > >
> > > SUGGESTION #2 (do nothing)
> > > pg_log_info("use existing publication ...);
> > >
> > > ======
> >
> > Hi Peter,
> >
> > Thank you for your review and suggestions.
> > I agree with your reasoning regarding the logging behavior. I will
> > proceed with Suggestion #2 and retain the existing `pg_log_info("use
> > existing publication ...");` message for both dry-run and normal
> > modes. This message is purely informational and does not perform any
> > destructive action, making it suitable for both scenarios.
> > The attached patch includes these changes.
> >
>
> OK, but you did not do quite what you said you did.
>
> Notice that v18 has modified the message to "would use existing
> publication...", instead of just leaving it how it was in v16 ("use
> existing publication...").
>
> ======
Fixed.
The attached patch includes these changes.
Thanks and regards,
Shubham Khanna.