Обсуждение: index prefetching
Hi,
At pgcon unconference I presented a PoC patch adding prefetching for
indexes, along with some benchmark results demonstrating the (pretty
significant) benefits etc. The feedback was quite positive, so let me
share the current patch more widely.
Motivation
----------
Imagine we have a huge table (much larger than RAM), with an index, and
that we're doing a regular index scan (e.g. using a btree index). We
first walk the index to the leaf page, read the item pointers from the
leaf page and then start issuing fetches from the heap.
The index access is usually pretty cheap, because non-leaf pages are
very likely cached, so we may do perhaps I/O for the leaf. But the
fetches from heap are likely very expensive - unless the page is
clustered, we'll do a random I/O for each item pointer. Easily ~200 or
more I/O requests per leaf page. The problem is index scans do these
requests synchronously at the moment - we get the next TID, fetch the
heap page, process the tuple, continue to the next TID etc.
That is slow and can't really leverage the bandwidth of modern storage,
which require longer queues. This patch aims to improve this by async
prefetching.
We already do prefetching for bitmap index scans, where the bitmap heap
scan prefetches future pages based on effective_io_concurrency. I'm not
sure why exactly was prefetching implemented only for bitmap scans, but
I suspect the reasoning was that it only helps when there's many
matching tuples, and that's what bitmap index scans are for. So it was
not worth the implementation effort.
But there's three shortcomings in logic:
1) It's not clear the thresholds for prefetching being beneficial and
switching to bitmap index scans are the same value. And as I'll
demonstrate later, the prefetching threshold is indeed much lower
(perhaps a couple dozen matching tuples) on large tables.
2) Our estimates / planning are not perfect, so we may easily pick an
index scan instead of a bitmap scan. It'd be nice to limit the damage a
bit by still prefetching.
3) There are queries that can't do a bitmap scan (at all, or because
it's hopelessly inefficient). Consider queries that require ordering, or
queries by distance with GiST/SP-GiST index.
Implementation
--------------
When I started looking at this, I only really thought about btree. If
you look at BTScanPosData, which is what the index scans use to
represent the current leaf page, you'll notice it has "items", which is
the array of item pointers (TIDs) that we'll fetch from the heap. Which
is exactly the thing we need.
The easiest thing would be to just do prefetching from the btree code.
But then I realized there's no particular reason why other index types
(except for GIN, which only allows bitmap scans) couldn't do prefetching
too. We could have a copy in each AM, of course, but that seems sloppy
and also violation of layering. After all, bitmap heap scans do prefetch
from the executor, so AM seems way too low level.
So I ended up moving most of the prefetching logic up into indexam.c,
see the index_prefetch() function. It can't be entirely separate,
because each AM represents the current state in a different way (e.g.
SpGistScanOpaque and BTScanOpaque are very different).
So what I did is introducing a IndexPrefetch struct, which is part of
IndexScanDesc, maintaining all the info about prefetching for that
particular scan - current/maximum distance, progress, etc.
It also contains two AM-specific callbacks (get_range and get_block)
which say valid range of indexes (into the internal array), and block
number for a given index.
This mostly does the trick, although index_prefetch() is still called
from the amgettuple() functions. That seems wrong, we should call it
from indexam.c right aftter calling amgettuple.
Problems / Open questions
-------------------------
There's a couple issues I ran into, I'll try to list them in the order
of importance (most serious ones first).
1) pairing-heap in GiST / SP-GiST
For most AMs, the index state is pretty trivial - matching items from a
single leaf page. Prefetching that is pretty trivial, even if the
current API is a bit cumbersome.
Distance queries on GiST and SP-GiST are a problem, though, because
those do not just read the pointers into a simple array, as the distance
ordering requires passing stuff through a pairing-heap :-(
I don't know how to best deal with that, especially not in the simple
API. I don't think we can "scan forward" stuff from the pairing heap, so
the only idea I have is actually having two pairing-heaps. Or maybe
using the pairing heap for prefetching, but stashing the prefetched
pointers into an array and then returning stuff from it.
In the patch I simply prefetch items before we add them to the pairing
heap, which is good enough for demonstrating the benefits.
2) prefetching from executor
Another question is whether the prefetching shouldn't actually happen
even higher - in the executor. That's what Andres suggested during the
unconference, and it kinda makes sense. That's where we do prefetching
for bitmap heap scans, so why should this happen lower, right?
I'm also not entirely sure the way this interfaces with the AM (through
the get_range / get_block callbaces) is very elegant. It did the trick,
but it seems a bit cumbersome. I wonder if someone has a better/nicer
idea how to do this ...
3) prefetch distance
I think we can do various smart things about the prefetch distance.
The current code does about the same thing bitmap scans do - it starts
with distance 0 (no prefetching), and then simply ramps the distance up
until the maximum value from get_tablespace_io_concurrency(). Which is
either effective_io_concurrency, or per-tablespace value.
I think we could be a bit smarter, and also consider e.g. the estimated
number of matching rows (but we shouldn't be too strict, because it's
just an estimate). We could also track some statistics for each scan and
use that during a rescans (think index scan in a nested loop).
But the patch doesn't do any of that now.
4) per-leaf prefetching
The code is restricted only prefetches items from one leaf page. If the
index scan needs to scan multiple (many) leaf pages, we have to process
the first leaf page first before reading / prefetching the next one.
I think this is acceptable limitation, certainly for v0. Prefetching
across multiple leaf pages seems way more complex (particularly for the
cases using pairing heap), so let's leave this for the future.
5) index-only scans
I'm not sure what to do about index-only scans. On the one hand, the
point of IOS is not to read stuff from the heap at all, so why prefetch
it. OTOH if there are many allvisible=false pages, we still have to
access that. And if that happens, this leads to the bizarre situation
that IOS is slower than regular index scan. But to address this, we'd
have to consider the visibility during prefetching.
Benchmarks
----------
1) OLTP
For OLTP, this tested different queries with various index types, on
data sets constructed to have certain number of matching rows, forcing
different types of query plans (bitmap, index, seqscan).
The data sets have ~34GB, which is much more than available RAM (8GB).
For example for BTREE, we have a query like this:
SELECT * FROM btree_test WHERE a = $v
with data matching 1, 10, 100, ..., 100000 rows for each $v. The results
look like this:
rows bitmapscan master patched seqscan
1 19.8 20.4 18.8 31875.5
10 24.4 23.8 23.2 30642.4
100 27.7 40.0 26.3 31871.3
1000 45.8 178.0 45.4 30754.1
10000 171.8 1514.9 174.5 30743.3
100000 1799.0 15993.3 1777.4 30937.3
This says that the query takes ~31s with a seqscan, 1.8s with a bitmap
scan and 16s index scan (on master). With the prefetching patch, it
takes about ~1.8s, i.e. about the same as the bitmap scan.
I don't know where exactly would the plan switch from index scan to
bitmap scan, but the table has ~100M rows, so all of this is tiny. I'd
bet most of the cases would do plain index scan.
For a query with ordering:
SELECT * FROM btree_test WHERE a >= $v ORDER BY a LIMIT $n
the results look a bit different:
rows bitmapscan master patched seqscan
1 52703.9 19.5 19.5 31145.6
10 51208.1 22.7 24.7 30983.5
100 49038.6 39.0 26.3 32085.3
1000 53760.4 193.9 48.4 31479.4
10000 56898.4 1600.7 187.5 32064.5
100000 50975.2 15978.7 1848.9 31587.1
This is a good illustration of a query where bitmapscan is terrible
(much worse than seqscan, in fact), and the patch is a massive
improvement over master (about an order of magnitude).
Of course, if you only scan a couple rows, the benefits are much more
modest (say 40% for 100 rows, which is still significant).
The results for other index types (HASH, GiST, SP-GiST) follow roughly
the same pattern. See the attached PDF for more charts, and [1] for
complete results.
Benchmark / TPC-H
-----------------
I ran the 22 queries on 100GB data set, with parallel query either
disabled or enabled. And I measured timing (and speedup) for each query.
The speedup results look like this (see the attached PDF for details):
query serial parallel
1 101% 99%
2 119% 100%
3 100% 99%
4 101% 100%
5 101% 100%
6 12% 99%
7 100% 100%
8 52% 67%
10 102% 101%
11 100% 72%
12 101% 100%
13 100% 101%
14 13% 100%
15 101% 100%
16 99% 99%
17 95% 101%
18 101% 106%
19 30% 40%
20 99% 100%
21 101% 100%
22 101% 107%
The percentage is (timing patched / master, so <100% means faster, >100%
means slower).
The different queries are affected depending on the query plan - many
queries are close to 100%, which means "no difference". For the serial
case, there are about 4 queries that improved a lot (6, 8, 14, 19),
while for the parallel case the benefits are somewhat less significant.
My explanation is that either (a) parallel case used a different plan
with fewer index scans or (b) the parallel query does more concurrent
I/O simply by using parallel workers. Or maybe both.
There are a couple regressions too, I believe those are due to doing too
much prefetching in some cases, and some of the heuristics mentioned
earlier should eliminate most of this, I think.
regards
[1] https://github.com/tvondra/index-prefetch-tests
[2] https://github.com/tvondra/postgres/tree/dev/index-prefetch
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Thu, Jun 8, 2023 at 8:40 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > We already do prefetching for bitmap index scans, where the bitmap heap > scan prefetches future pages based on effective_io_concurrency. I'm not > sure why exactly was prefetching implemented only for bitmap scans, but > I suspect the reasoning was that it only helps when there's many > matching tuples, and that's what bitmap index scans are for. So it was > not worth the implementation effort. I have an educated guess as to why prefetching was limited to bitmap index scans this whole time: it might have been due to issues with ScalarArrayOpExpr quals. Commit 9e8da0f757 taught nbtree to deal with ScalarArrayOpExpr quals "natively". This meant that "indexedcol op ANY(ARRAY[...])" conditions were supported by both index scans and index-only scans -- not just bitmap scans, which could handle ScalarArrayOpExpr quals even without nbtree directly understanding them. The commit was in late 2011, shortly after the introduction of index-only scans -- which seems to have been the real motivation. And so it seems to me that support for ScalarArrayOpExpr was built with bitmap scans and index-only scans in mind. Plain index scan ScalarArrayOpExpr quals do work, but support for them seems kinda perfunctory to me (maybe you can think of a specific counter-example where plain index scans really benefit from ScalarArrayOpExpr, but that doesn't seem particularly relevant to the original motivation). ScalarArrayOpExpr for plain index scans don't really make that much sense right now because there is no heap prefetching in the index scan case, which is almost certainly going to be the major bottleneck there. At the same time, adding useful prefetching for ScalarArrayOpExpr execution more or less requires that you first improve how nbtree executes ScalarArrayOpExpr quals in general. Bear in mind that ScalarArrayOpExpr execution (whether for bitmap index scans or index scans) is related to skip scan/MDAM techniques -- so there are tricky dependencies that need to be considered together. Right now, nbtree ScalarArrayOpExpr execution must call _bt_first() to descend the B-Tree for each array constant -- even though in principle we could avoid all that work in cases that happen to have locality. In other words we'll often descend the tree multiple times and land on exactly the same leaf page again and again, without ever noticing that we could have gotten away with only descending the tree once (it'd also be possible to start the next "descent" one level up, not at the root, intelligently reusing some of the work from an initial descent -- but you don't need anything so fancy to greatly improve matters here). This lack of smarts around how many times we call _bt_first() to descend the index is merely a silly annoyance when it happens in btgetbitmap(). We do at least sort and deduplicate the array up-front (inside _bt_sort_array_elements()), so there will be significant locality of access each time we needlessly descend the tree. Importantly, there is no prefetching "pipeline" to mess up in the bitmap index scan case -- since that all happens later on. Not so for the superficially similar (though actually rather different) plain index scan case -- at least not once you add prefetching. If you're uselessly processing the same leaf page multiple times, then there is no way that heap prefetching can notice that it should be batching things up. The context that would allow prefetching to work well isn't really available right now. So the plain index scan case is kinda at a gratuitous disadvantage (with prefetching) relative to the bitmap index scan case. Queries with (say) quals with many constants appearing in an "IN()" are both common and particularly likely to benefit from prefetching. I'm not suggesting that you need to address this to get to a committable patch. But you should definitely think about it now. I'm strongly considering working on this problem for 17 anyway, so we may end up collaborating on these aspects of prefetching. Smarter ScalarArrayOpExpr execution for index scans is likely to be quite compelling if it enables heap prefetching. > But there's three shortcomings in logic: > > 1) It's not clear the thresholds for prefetching being beneficial and > switching to bitmap index scans are the same value. And as I'll > demonstrate later, the prefetching threshold is indeed much lower > (perhaps a couple dozen matching tuples) on large tables. As I mentioned during the pgCon unconference session, I really like your framing of the problem; it makes a lot of sense to directly compare an index scan's execution against a very similar bitmap index scan execution -- there is an imaginary continuum between index scan and bitmap index scan. If the details of when and how we scan the index are rather similar in each case, then there is really no reason why the performance shouldn't be fairly similar. I suspect that it will be useful to ask the same question for various specific cases, that you might not have thought about just yet. Things like ScalarArrayOpExpr queries, where bitmap index scans might look like they have a natural advantage due to an inherent need for random heap access in the plain index scan case. It's important to carefully distinguish between cases where plain index scans really are at an inherent disadvantage relative to bitmap index scans (because there really is no getting around the need to access the same heap page many times with an index scan) versus cases that merely *appear* that way. Implementation restrictions that only really affect the plain index scan case (e.g., the lack of a reasonably sized prefetch buffer, or the ScalarArrayOpExpr thing) should be accounted for when assessing the viability of index scan + prefetch over bitmap index scan + prefetch. This is very subtle, but important. That's what I was mostly trying to get at when I talked about testing strategy at the unconference session (this may have been unclear at the time). It could be done in a way that helps you to think about the problem from first principles. It could be really useful as a way of avoiding confusing cases where plain index scan + prefetch does badly due to implementation restrictions, versus cases where it's *inherently* the wrong strategy. And a testing strategy that starts with very basic ideas about what I/O is truly necessary might help you to notice and fix regressions. The difference will never be perfectly crisp, of course (isn't bitmap index scan basically just index scan with a really huge prefetch buffer anyway?), but it still seems like a useful direction to go in. > Implementation > -------------- > > When I started looking at this, I only really thought about btree. If > you look at BTScanPosData, which is what the index scans use to > represent the current leaf page, you'll notice it has "items", which is > the array of item pointers (TIDs) that we'll fetch from the heap. Which > is exactly the thing we need. > So I ended up moving most of the prefetching logic up into indexam.c, > see the index_prefetch() function. It can't be entirely separate, > because each AM represents the current state in a different way (e.g. > SpGistScanOpaque and BTScanOpaque are very different). Maybe you were right to do that, but I'm not entirely sure. Bear in mind that the ScalarArrayOpExpr case already looks like a single index scan whose qual involves an array to the executor, even though nbtree more or less implements it as multiple index scans with plain constant quals (one per unique-ified array element). Index scans whose results can be "OR'd together". Is that a modularity violation? And if so, why? As I've pointed out earlier in this email, we don't do very much with that context right now -- but clearly we should. In other words, maybe you're right to suspect that doing this in AMs like nbtree is a modularity violation. OTOH, maybe it'll turn out that that's exactly the right place to do it, because that's the only way to make the full context available in one place. I myself struggled with this when I reviewed the skip scan patch. I was sure that Tom wouldn't like the way that the skip-scan patch doubles-down on adding more intelligence/planning around how to execute queries with skippable leading columns. But, it turned out that he saw the merit in it, and basically accepted that general approach. Maybe this will turn out to be a little like that situation, where (counter to intuition) what you really need to do is add a new "layering violation". Sometimes that's the only thing that'll allow the information to flow to the right place. It's tricky. > 4) per-leaf prefetching > > The code is restricted only prefetches items from one leaf page. If the > index scan needs to scan multiple (many) leaf pages, we have to process > the first leaf page first before reading / prefetching the next one. > > I think this is acceptable limitation, certainly for v0. Prefetching > across multiple leaf pages seems way more complex (particularly for the > cases using pairing heap), so let's leave this for the future. I tend to agree that this sort of thing doesn't need to happen in the first committed version. But FWIW nbtree could be taught to scan multiple index pages and act as if it had just processed them as one single index page -- up to a point. This is at least possible with plain index scans that use MVCC snapshots (though not index-only scans), since we already drop the pin on the leaf page there anyway. AFAICT stops us from teaching nbtree to "lie" to the executor and tell it that we processed 1 leaf page, even though it was actually 5 leaf pages (maybe there would also have to be restrictions for the markpos stuff). > the results look a bit different: > > rows bitmapscan master patched seqscan > 1 52703.9 19.5 19.5 31145.6 > 10 51208.1 22.7 24.7 30983.5 > 100 49038.6 39.0 26.3 32085.3 > 1000 53760.4 193.9 48.4 31479.4 > 10000 56898.4 1600.7 187.5 32064.5 > 100000 50975.2 15978.7 1848.9 31587.1 > > This is a good illustration of a query where bitmapscan is terrible > (much worse than seqscan, in fact), and the patch is a massive > improvement over master (about an order of magnitude). > > Of course, if you only scan a couple rows, the benefits are much more > modest (say 40% for 100 rows, which is still significant). Nice! And, it'll be nice to be able to use the kill_prior_tuple optimization in many more cases (possible by teaching the optimizer to favor index scans over bitmap index scans more often). -- Peter Geoghegan
On 6/8/23 20:56, Peter Geoghegan wrote:
> On Thu, Jun 8, 2023 at 8:40 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> We already do prefetching for bitmap index scans, where the bitmap heap
>> scan prefetches future pages based on effective_io_concurrency. I'm not
>> sure why exactly was prefetching implemented only for bitmap scans, but
>> I suspect the reasoning was that it only helps when there's many
>> matching tuples, and that's what bitmap index scans are for. So it was
>> not worth the implementation effort.
>
> I have an educated guess as to why prefetching was limited to bitmap
> index scans this whole time: it might have been due to issues with
> ScalarArrayOpExpr quals.
>
> Commit 9e8da0f757 taught nbtree to deal with ScalarArrayOpExpr quals
> "natively". This meant that "indexedcol op ANY(ARRAY[...])" conditions
> were supported by both index scans and index-only scans -- not just
> bitmap scans, which could handle ScalarArrayOpExpr quals even without
> nbtree directly understanding them. The commit was in late 2011,
> shortly after the introduction of index-only scans -- which seems to
> have been the real motivation. And so it seems to me that support for
> ScalarArrayOpExpr was built with bitmap scans and index-only scans in
> mind. Plain index scan ScalarArrayOpExpr quals do work, but support
> for them seems kinda perfunctory to me (maybe you can think of a
> specific counter-example where plain index scans really benefit from
> ScalarArrayOpExpr, but that doesn't seem particularly relevant to the
> original motivation).
>
I don't think SAOP is the reason. I did a bit of digging in the list
archives, and found thread [1], which says:
Regardless of what mechanism is used and who is responsible for
doing it someone is going to have to figure out which blocks are
specifically interesting to prefetch. Bitmap index scans happen
to be the easiest since we've already built up a list of blocks
we plan to read. Somehow that information has to be pushed to the
storage manager to be acted upon.
Normal index scans are an even more interesting case but I'm not
sure how hard it would be to get that information. It may only be
convenient to get the blocks from the last leaf page we looked at,
for example.
So this suggests we simply started prefetching for the case where the
information was readily available, and it'd be harder to do for index
scans so that's it.
There's a couple more ~2008 threads mentioning prefetching, bitmap scans
and even regular index scans (like [2]). None of them even mentions SAOP
stuff at all.
[1]
https://www.postgresql.org/message-id/871wa17vxb.fsf%40oxford.xeocode.com
[2]
https://www.postgresql.org/message-id/87wsnnz046.fsf%40oxford.xeocode.com
> ScalarArrayOpExpr for plain index scans don't really make that much
> sense right now because there is no heap prefetching in the index scan
> case, which is almost certainly going to be the major bottleneck
> there. At the same time, adding useful prefetching for
> ScalarArrayOpExpr execution more or less requires that you first
> improve how nbtree executes ScalarArrayOpExpr quals in general. Bear
> in mind that ScalarArrayOpExpr execution (whether for bitmap index
> scans or index scans) is related to skip scan/MDAM techniques -- so
> there are tricky dependencies that need to be considered together.
>
> Right now, nbtree ScalarArrayOpExpr execution must call _bt_first() to
> descend the B-Tree for each array constant -- even though in principle
> we could avoid all that work in cases that happen to have locality. In
> other words we'll often descend the tree multiple times and land on
> exactly the same leaf page again and again, without ever noticing that
> we could have gotten away with only descending the tree once (it'd
> also be possible to start the next "descent" one level up, not at the
> root, intelligently reusing some of the work from an initial descent
> -- but you don't need anything so fancy to greatly improve matters
> here).
>
> This lack of smarts around how many times we call _bt_first() to
> descend the index is merely a silly annoyance when it happens in
> btgetbitmap(). We do at least sort and deduplicate the array up-front
> (inside _bt_sort_array_elements()), so there will be significant
> locality of access each time we needlessly descend the tree.
> Importantly, there is no prefetching "pipeline" to mess up in the
> bitmap index scan case -- since that all happens later on. Not so for
> the superficially similar (though actually rather different) plain
> index scan case -- at least not once you add prefetching. If you're
> uselessly processing the same leaf page multiple times, then there is
> no way that heap prefetching can notice that it should be batching
> things up. The context that would allow prefetching to work well isn't
> really available right now. So the plain index scan case is kinda at a
> gratuitous disadvantage (with prefetching) relative to the bitmap
> index scan case.
>
> Queries with (say) quals with many constants appearing in an "IN()"
> are both common and particularly likely to benefit from prefetching.
> I'm not suggesting that you need to address this to get to a
> committable patch. But you should definitely think about it now. I'm
> strongly considering working on this problem for 17 anyway, so we may
> end up collaborating on these aspects of prefetching. Smarter
> ScalarArrayOpExpr execution for index scans is likely to be quite
> compelling if it enables heap prefetching.
>
Even if SAOP (probably) wasn't the reason, I think you're right it may
be an issue for prefetching, causing regressions. It didn't occur to me
before, because I'm not that familiar with the btree code and/or how it
deals with SAOP (and didn't really intend to study it too deeply).
So if you're planning to work on this for PG17, collaborating on it
would be great.
For now I plan to just ignore SAOP, or maybe just disabling prefetching
for SAOP index scans if it proves to be prone to regressions. That's not
great, but at least it won't make matters worse.
>> But there's three shortcomings in logic:
>>
>> 1) It's not clear the thresholds for prefetching being beneficial and
>> switching to bitmap index scans are the same value. And as I'll
>> demonstrate later, the prefetching threshold is indeed much lower
>> (perhaps a couple dozen matching tuples) on large tables.
>
> As I mentioned during the pgCon unconference session, I really like
> your framing of the problem; it makes a lot of sense to directly
> compare an index scan's execution against a very similar bitmap index
> scan execution -- there is an imaginary continuum between index scan
> and bitmap index scan. If the details of when and how we scan the
> index are rather similar in each case, then there is really no reason
> why the performance shouldn't be fairly similar. I suspect that it
> will be useful to ask the same question for various specific cases,
> that you might not have thought about just yet. Things like
> ScalarArrayOpExpr queries, where bitmap index scans might look like
> they have a natural advantage due to an inherent need for random heap
> access in the plain index scan case.
>
Yeah, although all the tests were done with a random table generated
like this:
insert into btree_test select $d * random(), md5(i::text)
from generate_series(1, $ROWS) s(i)
So it's damn random anyway. Although maybe it's random even for the
bitmap case, so maybe if the SAOP had some sort of locality, that'd be
an advantage for the bitmap scan. But how would such table look like?
I guess something like this might be a "nice" bad case:
insert into btree_test mod(i,100000), md5(i::text)
from generate_series(1, $ROWS) s(i)
select * from btree_test where a in (999, 1000, 1001, 1002)
The values are likely colocated on the same heap page, the bitmap scan
is going to do a single prefetch. With index scan we'll prefetch them
repeatedly. I'll give it a try.
> It's important to carefully distinguish between cases where plain
> index scans really are at an inherent disadvantage relative to bitmap
> index scans (because there really is no getting around the need to
> access the same heap page many times with an index scan) versus cases
> that merely *appear* that way. Implementation restrictions that only
> really affect the plain index scan case (e.g., the lack of a
> reasonably sized prefetch buffer, or the ScalarArrayOpExpr thing)
> should be accounted for when assessing the viability of index scan +
> prefetch over bitmap index scan + prefetch. This is very subtle, but
> important.
>
I do agree, but what do you mean by "assessing"? Wasn't the agreement at
the unconference session was we'd not tweak costing? So ultimately, this
does not really affect which scan type we pick. We'll keep doing the
same planning decisions as today, no?
If we pick index scan and enable prefetching, causing a regression (e.g.
for the SAOP with locality), that'd be bad. But how is that related to
viability of index scans over bitmap index scans?
> That's what I was mostly trying to get at when I talked about testing
> strategy at the unconference session (this may have been unclear at
> the time). It could be done in a way that helps you to think about the
> problem from first principles. It could be really useful as a way of
> avoiding confusing cases where plain index scan + prefetch does badly
> due to implementation restrictions, versus cases where it's
> *inherently* the wrong strategy. And a testing strategy that starts
> with very basic ideas about what I/O is truly necessary might help you
> to notice and fix regressions. The difference will never be perfectly
> crisp, of course (isn't bitmap index scan basically just index scan
> with a really huge prefetch buffer anyway?), but it still seems like a
> useful direction to go in.
>
I'm all for building a more comprehensive set of test cases - the stuff
presented at pgcon was good for demonstration, but it certainly is not
enough for testing. The SAOP queries are a great addition, I also plan
to run those queries on different (less random) data sets, etc. We'll
probably discover more interesting cases as the patch improves.
>> Implementation
>> --------------
>>
>> When I started looking at this, I only really thought about btree. If
>> you look at BTScanPosData, which is what the index scans use to
>> represent the current leaf page, you'll notice it has "items", which is
>> the array of item pointers (TIDs) that we'll fetch from the heap. Which
>> is exactly the thing we need.
>
>> So I ended up moving most of the prefetching logic up into indexam.c,
>> see the index_prefetch() function. It can't be entirely separate,
>> because each AM represents the current state in a different way (e.g.
>> SpGistScanOpaque and BTScanOpaque are very different).
>
> Maybe you were right to do that, but I'm not entirely sure.
>
> Bear in mind that the ScalarArrayOpExpr case already looks like a
> single index scan whose qual involves an array to the executor, even
> though nbtree more or less implements it as multiple index scans with
> plain constant quals (one per unique-ified array element). Index scans
> whose results can be "OR'd together". Is that a modularity violation?
> And if so, why? As I've pointed out earlier in this email, we don't do
> very much with that context right now -- but clearly we should.
>
> In other words, maybe you're right to suspect that doing this in AMs
> like nbtree is a modularity violation. OTOH, maybe it'll turn out that
> that's exactly the right place to do it, because that's the only way
> to make the full context available in one place. I myself struggled
> with this when I reviewed the skip scan patch. I was sure that Tom
> wouldn't like the way that the skip-scan patch doubles-down on adding
> more intelligence/planning around how to execute queries with
> skippable leading columns. But, it turned out that he saw the merit in
> it, and basically accepted that general approach. Maybe this will turn
> out to be a little like that situation, where (counter to intuition)
> what you really need to do is add a new "layering violation".
> Sometimes that's the only thing that'll allow the information to flow
> to the right place. It's tricky.
>
There are two aspects why I think AM is not the right place:
- accessing table from index code seems backwards
- we already do prefetching from the executor (nodeBitmapHeapscan.c)
It feels kinda wrong in hindsight.
>> 4) per-leaf prefetching
>>
>> The code is restricted only prefetches items from one leaf page. If the
>> index scan needs to scan multiple (many) leaf pages, we have to process
>> the first leaf page first before reading / prefetching the next one.
>>
>> I think this is acceptable limitation, certainly for v0. Prefetching
>> across multiple leaf pages seems way more complex (particularly for the
>> cases using pairing heap), so let's leave this for the future.
>
> I tend to agree that this sort of thing doesn't need to happen in the
> first committed version. But FWIW nbtree could be taught to scan
> multiple index pages and act as if it had just processed them as one
> single index page -- up to a point. This is at least possible with
> plain index scans that use MVCC snapshots (though not index-only
> scans), since we already drop the pin on the leaf page there anyway.
> AFAICT stops us from teaching nbtree to "lie" to the executor and tell
> it that we processed 1 leaf page, even though it was actually 5 leaf pages
> (maybe there would also have to be restrictions for the markpos stuff).
>
Yeah, I'm not saying it's impossible, and imagined we might teach nbtree
to do that. But it seems like work for future someone.
>> the results look a bit different:
>>
>> rows bitmapscan master patched seqscan
>> 1 52703.9 19.5 19.5 31145.6
>> 10 51208.1 22.7 24.7 30983.5
>> 100 49038.6 39.0 26.3 32085.3
>> 1000 53760.4 193.9 48.4 31479.4
>> 10000 56898.4 1600.7 187.5 32064.5
>> 100000 50975.2 15978.7 1848.9 31587.1
>>
>> This is a good illustration of a query where bitmapscan is terrible
>> (much worse than seqscan, in fact), and the patch is a massive
>> improvement over master (about an order of magnitude).
>>
>> Of course, if you only scan a couple rows, the benefits are much more
>> modest (say 40% for 100 rows, which is still significant).
>
> Nice! And, it'll be nice to be able to use the kill_prior_tuple
> optimization in many more cases (possible by teaching the optimizer to
> favor index scans over bitmap index scans more often).
>
Right, I forgot to mention that benefit. Although, that'd only happen if
we actually choose index scans in more places, which I guess would
require tweaking the costing model ...
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Jun 8, 2023 at 3:17 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Normal index scans are an even more interesting case but I'm not > sure how hard it would be to get that information. It may only be > convenient to get the blocks from the last leaf page we looked at, > for example. > > So this suggests we simply started prefetching for the case where the > information was readily available, and it'd be harder to do for index > scans so that's it. What the exact historical timeline is may not be that important. My emphasis on ScalarArrayOpExpr is partly due to it being a particularly compelling case for both parallel index scan and prefetching, in general. There are many queries that have huge in() lists that naturally benefit a great deal from prefetching. Plus they're common. > Even if SAOP (probably) wasn't the reason, I think you're right it may > be an issue for prefetching, causing regressions. It didn't occur to me > before, because I'm not that familiar with the btree code and/or how it > deals with SAOP (and didn't really intend to study it too deeply). I'm pretty sure that you understand this already, but just in case: ScalarArrayOpExpr doesn't even "get the blocks from the last leaf page" in many important cases. Not really -- not in the sense that you'd hope and expect. We're senselessly processing the same index leaf page multiple times and treating it as a different, independent leaf page. That makes heap prefetching of the kind you're working on utterly hopeless, since it effectively throws away lots of useful context. Obviously that's the fault of nbtree ScalarArrayOpExpr handling, not the fault of your patch. > So if you're planning to work on this for PG17, collaborating on it > would be great. > > For now I plan to just ignore SAOP, or maybe just disabling prefetching > for SAOP index scans if it proves to be prone to regressions. That's not > great, but at least it won't make matters worse. Makes sense, but I hope that it won't come to that. IMV it's actually quite reasonable that you didn't expect to have to think about ScalarArrayOpExpr at all -- it would make a lot of sense if that was already true. But the fact is that it works in a way that's pretty silly and naive right now, which will impact prefetching. I wasn't really thinking about regressions, though. I was actually more concerned about missing opportunities to get the most out of prefetching. ScalarArrayOpExpr really matters here. > I guess something like this might be a "nice" bad case: > > insert into btree_test mod(i,100000), md5(i::text) > from generate_series(1, $ROWS) s(i) > > select * from btree_test where a in (999, 1000, 1001, 1002) > > The values are likely colocated on the same heap page, the bitmap scan > is going to do a single prefetch. With index scan we'll prefetch them > repeatedly. I'll give it a try. This is the sort of thing that I was thinking of. What are the conditions under which bitmap index scan starts to make sense? Why is the break-even point whatever it is in each case, roughly? And, is it actually because of laws-of-physics level trade-off? Might it not be due to implementation-level issues that are much less fundamental? In other words, might it actually be that we're just doing something stoopid in the case of plain index scans? Something that is just papered-over by bitmap index scans right now? I see that your patch has logic that avoids repeated prefetching of the same block -- plus you have comments that wonder about going further by adding a "small lru array" in your new index_prefetch() function. I asked you about this during the unconference presentation. But I think that my understanding of the situation was slightly different to yours. That's relevant here. I wonder if you should go further than this, by actually sorting the items that you need to fetch as part of processing a given leaf page (I said this at the unconference, you may recall). Why should we *ever* pin/access the same heap page more than once per leaf page processed per index scan? Nothing stops us from returning the tuples to the executor in the original logical/index-wise order, despite having actually accessed each leaf page's pointed-to heap pages slightly out of order (with the aim of avoiding extra pin/unpin traffic that isn't truly necessary). We can sort the heap TIDs in scratch memory, then do our actual prefetching + heap access, and then restore the original order before returning anything. This is conceptually a "mini bitmap index scan", though one that takes place "inside" a plain index scan, as it processes one particular leaf page. That's the kind of design that "plain index scan vs bitmap index scan as a continuum" leads me to (a little like the continuum between nested loop joins, block nested loop joins, and merge joins). I bet it would be practical to do things this way, and help a lot with some kinds of queries. It might even be simpler than avoiding excessive prefetching using an LRU cache thing. I'm talking about problems that exist today, without your patch. I'll show a concrete example of the kind of index/index scan that might be affected. Attached is an extract of the server log when the regression tests ran against a server patched to show custom instrumentation. The log output shows exactly what's going on with one particular nbtree opportunistic deletion (my point has nothing to do with deletion, but it happens to be convenient to make my point in this fashion). This specific example involves deletion of tuples from the system catalog index "pg_type_typname_nsp_index". There is nothing very atypical about it; it just shows a certain kind of heap fragmentation that's probably very common. Imagine a plain index scan involving a query along the lines of "select * from pg_type where typname like 'part%' ", or similar. This query runs an instant before the example LD_DEAD-bit-driven opportunistic deletion (a "simple deletion" in nbtree parlance) took place. You'll be able to piece together from the log output that there would only be about 4 heap blocks involved with such a query. Ideally, our hypothetical index scan would pin each buffer/heap page exactly once, for a total of 4 PinBuffer()/UnpinBuffer() calls. After all, we're talking about a fairly selective query here, that only needs to scan precisely one leaf page (I verified this part too) -- so why wouldn't we expect "index scan parity"? While there is significant clustering on this example leaf page/key space, heap TID is not *perfectly* correlated with the logical/keyspace order of the index -- which can have outsized consequences. Notice that some heap blocks are non-contiguous relative to logical/keyspace/index scan/index page offset number order. We'll end up pinning each of the 4 or so heap pages more than once (sometimes several times each), when in principle we could have pinned each heap page exactly once. In other words, there is way too much of a difference between the case where the tuples we scan are *almost* perfectly clustered (which is what you see in my example) and the case where they're exactly perfectly clustered. In other other words, there is way too much of a difference between plain index scan, and bitmap index scan. (What I'm saying here is only true because this is a composite index and our query uses "like", returning rows matches a prefix -- if our index was on the column "typname" alone and we used a simple equality condition in our query then the Postgres 12 nbtree work would be enough to avoid the extra PinBuffer()/UnpinBuffer() calls. I suspect that there are still relatively many important cases where we perform extra PinBuffer()/UnpinBuffer() calls during plain index scans that only touch one leaf page anyway.) Obviously we should expect bitmap index scans to have a natural advantage over plain index scans whenever there is little or no correlation -- that's clear. But that's not what we see here -- we're way too sensitive to minor imperfections in clustering that are naturally present on some kinds of leaf pages. The potential difference in pin/unpin traffic (relative to the bitmap index scan case) seems pathological to me. Ideally, we wouldn't have these kinds of differences at all. It's going to disrupt usage_count on the buffers. > > It's important to carefully distinguish between cases where plain > > index scans really are at an inherent disadvantage relative to bitmap > > index scans (because there really is no getting around the need to > > access the same heap page many times with an index scan) versus cases > > that merely *appear* that way. Implementation restrictions that only > > really affect the plain index scan case (e.g., the lack of a > > reasonably sized prefetch buffer, or the ScalarArrayOpExpr thing) > > should be accounted for when assessing the viability of index scan + > > prefetch over bitmap index scan + prefetch. This is very subtle, but > > important. > > > > I do agree, but what do you mean by "assessing"? I mean performance validation. There ought to be a theoretical model that describes the relationship between index scan and bitmap index scan, that has actual predictive power in the real world, across a variety of different cases. Something that isn't sensitive to the current phase of the moon (e.g., heap fragmentation along the lines of my pg_type_typname_nsp_index log output). I particularly want to avoid nasty discontinuities that really make no sense. > Wasn't the agreement at > the unconference session was we'd not tweak costing? So ultimately, this > does not really affect which scan type we pick. We'll keep doing the > same planning decisions as today, no? I'm not really talking about tweaking the costing. What I'm saying is that we really should expect index scans to behave similarly to bitmap index scans at runtime, for queries that really don't have much to gain from using a bitmap heap scan (queries that may or may not also benefit from prefetching). There are several reasons why this makes sense to me. One reason is that it makes tweaking the actual costing easier later on. Also, your point about plan robustness was a good one. If we make the wrong choice about index scan vs bitmap index scan, and the consequences aren't so bad, that's a very useful enhancement in itself. The most important reason of all may just be to build confidence in the design. I'm interested in understanding when and how prefetching stops helping. > I'm all for building a more comprehensive set of test cases - the stuff > presented at pgcon was good for demonstration, but it certainly is not > enough for testing. The SAOP queries are a great addition, I also plan > to run those queries on different (less random) data sets, etc. We'll > probably discover more interesting cases as the patch improves. Definitely. > There are two aspects why I think AM is not the right place: > > - accessing table from index code seems backwards > > - we already do prefetching from the executor (nodeBitmapHeapscan.c) > > It feels kinda wrong in hindsight. I'm willing to accept that we should do it the way you've done it in the patch provisionally. It's complicated enough that it feels like I should reserve the right to change my mind. > >> I think this is acceptable limitation, certainly for v0. Prefetching > >> across multiple leaf pages seems way more complex (particularly for the > >> cases using pairing heap), so let's leave this for the future. > Yeah, I'm not saying it's impossible, and imagined we might teach nbtree > to do that. But it seems like work for future someone. Right. You probably noticed that this is another case where we'd be making index scans behave more like bitmap index scans (perhaps even including the downsides for kill_prior_tuple that accompany not processing each leaf page inline). There is probably a point where that ceases to be sensible, but I don't know what that point is. They're way more similar than we seem to imagine. -- Peter Geoghegan
Вложения
Hi, On 2023-06-08 17:40:12 +0200, Tomas Vondra wrote: > At pgcon unconference I presented a PoC patch adding prefetching for > indexes, along with some benchmark results demonstrating the (pretty > significant) benefits etc. The feedback was quite positive, so let me > share the current patch more widely. I'm really excited about this work. > 1) pairing-heap in GiST / SP-GiST > > For most AMs, the index state is pretty trivial - matching items from a > single leaf page. Prefetching that is pretty trivial, even if the > current API is a bit cumbersome. > > Distance queries on GiST and SP-GiST are a problem, though, because > those do not just read the pointers into a simple array, as the distance > ordering requires passing stuff through a pairing-heap :-( > > I don't know how to best deal with that, especially not in the simple > API. I don't think we can "scan forward" stuff from the pairing heap, so > the only idea I have is actually having two pairing-heaps. Or maybe > using the pairing heap for prefetching, but stashing the prefetched > pointers into an array and then returning stuff from it. > > In the patch I simply prefetch items before we add them to the pairing > heap, which is good enough for demonstrating the benefits. I think it'd be perfectly fair to just not tackle distance queries for now. > 2) prefetching from executor > > Another question is whether the prefetching shouldn't actually happen > even higher - in the executor. That's what Andres suggested during the > unconference, and it kinda makes sense. That's where we do prefetching > for bitmap heap scans, so why should this happen lower, right? Yea. I think it also provides potential for further optimizations in the future to do it at that layer. One thing I have been wondering around this is whether we should not have split the code for IOS and plain indexscans... > 4) per-leaf prefetching > > The code is restricted only prefetches items from one leaf page. If the > index scan needs to scan multiple (many) leaf pages, we have to process > the first leaf page first before reading / prefetching the next one. > > I think this is acceptable limitation, certainly for v0. Prefetching > across multiple leaf pages seems way more complex (particularly for the > cases using pairing heap), so let's leave this for the future. Hm. I think that really depends on the shape of the API we end up with. If we move the responsibility more twoards to the executor, I think it very well could end up being just as simple to prefetch across index pages. > 5) index-only scans > > I'm not sure what to do about index-only scans. On the one hand, the > point of IOS is not to read stuff from the heap at all, so why prefetch > it. OTOH if there are many allvisible=false pages, we still have to > access that. And if that happens, this leads to the bizarre situation > that IOS is slower than regular index scan. But to address this, we'd > have to consider the visibility during prefetching. That should be easy to do, right? > Benchmark / TPC-H > ----------------- > > I ran the 22 queries on 100GB data set, with parallel query either > disabled or enabled. And I measured timing (and speedup) for each query. > The speedup results look like this (see the attached PDF for details): > > query serial parallel > 1 101% 99% > 2 119% 100% > 3 100% 99% > 4 101% 100% > 5 101% 100% > 6 12% 99% > 7 100% 100% > 8 52% 67% > 10 102% 101% > 11 100% 72% > 12 101% 100% > 13 100% 101% > 14 13% 100% > 15 101% 100% > 16 99% 99% > 17 95% 101% > 18 101% 106% > 19 30% 40% > 20 99% 100% > 21 101% 100% > 22 101% 107% > > The percentage is (timing patched / master, so <100% means faster, >100% > means slower). > > The different queries are affected depending on the query plan - many > queries are close to 100%, which means "no difference". For the serial > case, there are about 4 queries that improved a lot (6, 8, 14, 19), > while for the parallel case the benefits are somewhat less significant. > > My explanation is that either (a) parallel case used a different plan > with fewer index scans or (b) the parallel query does more concurrent > I/O simply by using parallel workers. Or maybe both. > > There are a couple regressions too, I believe those are due to doing too > much prefetching in some cases, and some of the heuristics mentioned > earlier should eliminate most of this, I think. I'm a bit confused by some of these numbers. How can OS-level prefetching lead to massive prefetching in the alread cached case, e.g. in tpch q06 and q08? Unless I missed what "xeon / cached (speedup)" indicates? I think it'd be good to run a performance comparison of the unpatched vs patched cases, with prefetching disabled for both. It's possible that something in the patch caused unintended changes (say spilling during a hashagg, due to larger struct sizes). Greetings, Andres Freund
On Thu, Jun 8, 2023 at 4:38 PM Peter Geoghegan <pg@bowt.ie> wrote:
> This is conceptually a "mini bitmap index scan", though one that takes
> place "inside" a plain index scan, as it processes one particular leaf
> page. That's the kind of design that "plain index scan vs bitmap index
> scan as a continuum" leads me to (a little like the continuum between
> nested loop joins, block nested loop joins, and merge joins). I bet it
> would be practical to do things this way, and help a lot with some
> kinds of queries. It might even be simpler than avoiding excessive
> prefetching using an LRU cache thing.
I'll now give a simpler (though less realistic) example of a case
where "mini bitmap index scan" would be expected to help index scans
in general, and prefetching during index scans in particular.
Something very simple:
create table bitmap_parity_test(randkey int4, filler text);
create index on bitmap_parity_test (randkey);
insert into bitmap_parity_test select (random()*1000),
repeat('filler',10) from generate_series(1,250) i;
This gives me a table with 4 pages, and an index with 2 pages.
The following query selects about half of the rows from the table:
select * from bitmap_parity_test where randkey < 500;
If I force the query to use a bitmap index scan, I see that the total
number of buffers hit is exactly as expected (according to
EXPLAIN(ANALYZE,BUFFERS), that is): there are 5 buffers/pages hit. We
need to access every single heap page once, and we need to access the
only leaf page in the index once.
I'm sure that you know where I'm going with this already. I'll force
the same query to use a plain index scan, and get a very different
result. Now EXPLAIN(ANALYZE,BUFFERS) shows that there are a total of
89 buffers hit -- 88 of which must just be the same 5 heap pages,
again and again. That's just silly. It's probably not all that much
slower, but it's not helping things. And it's likely that this effect
interferes with the prefetching in your patch.
Obviously you can come up with a variant of this test case where
bitmap index scan does way fewer buffer accesses in a way that really
makes sense -- that's not in question. This is a fairly selective
index scan, since it only touches one index page -- and yet we still
see this difference.
(Anybody pedantic enough to want to dispute whether or not this index
scan counts as "selective" should run "insert into bitmap_parity_test
select i, repeat('actshually',10) from generate_series(2000,1e5) i"
before running the "randkey < 500" query, which will make the index
much larger without changing any of the details of how the query pins
pages -- non-pedants should just skip that step.)
--
Peter Geoghegan
On 6/9/23 02:06, Andres Freund wrote: > Hi, > > On 2023-06-08 17:40:12 +0200, Tomas Vondra wrote: >> At pgcon unconference I presented a PoC patch adding prefetching for >> indexes, along with some benchmark results demonstrating the (pretty >> significant) benefits etc. The feedback was quite positive, so let me >> share the current patch more widely. > > I'm really excited about this work. > > >> 1) pairing-heap in GiST / SP-GiST >> >> For most AMs, the index state is pretty trivial - matching items from a >> single leaf page. Prefetching that is pretty trivial, even if the >> current API is a bit cumbersome. >> >> Distance queries on GiST and SP-GiST are a problem, though, because >> those do not just read the pointers into a simple array, as the distance >> ordering requires passing stuff through a pairing-heap :-( >> >> I don't know how to best deal with that, especially not in the simple >> API. I don't think we can "scan forward" stuff from the pairing heap, so >> the only idea I have is actually having two pairing-heaps. Or maybe >> using the pairing heap for prefetching, but stashing the prefetched >> pointers into an array and then returning stuff from it. >> >> In the patch I simply prefetch items before we add them to the pairing >> heap, which is good enough for demonstrating the benefits. > > I think it'd be perfectly fair to just not tackle distance queries for now. > My concern is that if we cut this from v0 entirely, we'll end up with an API that'll not be suitable for adding distance queries later. > >> 2) prefetching from executor >> >> Another question is whether the prefetching shouldn't actually happen >> even higher - in the executor. That's what Andres suggested during the >> unconference, and it kinda makes sense. That's where we do prefetching >> for bitmap heap scans, so why should this happen lower, right? > > Yea. I think it also provides potential for further optimizations in the > future to do it at that layer. > > One thing I have been wondering around this is whether we should not have > split the code for IOS and plain indexscans... > Which code? We already have nodeIndexscan.c and nodeIndexonlyscan.c? Or did you mean something else? > >> 4) per-leaf prefetching >> >> The code is restricted only prefetches items from one leaf page. If the >> index scan needs to scan multiple (many) leaf pages, we have to process >> the first leaf page first before reading / prefetching the next one. >> >> I think this is acceptable limitation, certainly for v0. Prefetching >> across multiple leaf pages seems way more complex (particularly for the >> cases using pairing heap), so let's leave this for the future. > > Hm. I think that really depends on the shape of the API we end up with. If we > move the responsibility more twoards to the executor, I think it very well > could end up being just as simple to prefetch across index pages. > Maybe. I'm open to that idea if you have idea how to shape the API to make this possible (although perhaps not in v0). > >> 5) index-only scans >> >> I'm not sure what to do about index-only scans. On the one hand, the >> point of IOS is not to read stuff from the heap at all, so why prefetch >> it. OTOH if there are many allvisible=false pages, we still have to >> access that. And if that happens, this leads to the bizarre situation >> that IOS is slower than regular index scan. But to address this, we'd >> have to consider the visibility during prefetching. > > That should be easy to do, right? > It doesn't seem particularly complicated (famous last words), and we need to do the VM checks anyway so it seems like it wouldn't add a lot of overhead either > > >> Benchmark / TPC-H >> ----------------- >> >> I ran the 22 queries on 100GB data set, with parallel query either >> disabled or enabled. And I measured timing (and speedup) for each query. >> The speedup results look like this (see the attached PDF for details): >> >> query serial parallel >> 1 101% 99% >> 2 119% 100% >> 3 100% 99% >> 4 101% 100% >> 5 101% 100% >> 6 12% 99% >> 7 100% 100% >> 8 52% 67% >> 10 102% 101% >> 11 100% 72% >> 12 101% 100% >> 13 100% 101% >> 14 13% 100% >> 15 101% 100% >> 16 99% 99% >> 17 95% 101% >> 18 101% 106% >> 19 30% 40% >> 20 99% 100% >> 21 101% 100% >> 22 101% 107% >> >> The percentage is (timing patched / master, so <100% means faster, >100% >> means slower). >> >> The different queries are affected depending on the query plan - many >> queries are close to 100%, which means "no difference". For the serial >> case, there are about 4 queries that improved a lot (6, 8, 14, 19), >> while for the parallel case the benefits are somewhat less significant. >> >> My explanation is that either (a) parallel case used a different plan >> with fewer index scans or (b) the parallel query does more concurrent >> I/O simply by using parallel workers. Or maybe both. >> >> There are a couple regressions too, I believe those are due to doing too >> much prefetching in some cases, and some of the heuristics mentioned >> earlier should eliminate most of this, I think. > > I'm a bit confused by some of these numbers. How can OS-level prefetching lead > to massive prefetching in the alread cached case, e.g. in tpch q06 and q08? > Unless I missed what "xeon / cached (speedup)" indicates? > I forgot to explain what "cached" means in the TPC-H case. It means second execution of the query, so you can imagine it like this: for q in `seq 1 22`; do 1. drop caches and restart postgres 2. run query $q -> uncached 3. run query $q -> cached done So the second execution has a chance of having data in memory - but maybe not all, because this is a 100GB data set (so ~200GB after loading), but the machine only has 64GB of RAM. I think a likely explanation is some of the data wasn't actually in memory, so prefetching still did something. > I think it'd be good to run a performance comparison of the unpatched vs > patched cases, with prefetching disabled for both. It's possible that > something in the patch caused unintended changes (say spilling during a > hashagg, due to larger struct sizes). > That's certainly a good idea. I'll do that in the next round of tests. I also plan to do a test on data set that fits into RAM, to test "properly cached" case. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 6/9/23 01:38, Peter Geoghegan wrote:
> On Thu, Jun 8, 2023 at 3:17 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> Normal index scans are an even more interesting case but I'm not
>> sure how hard it would be to get that information. It may only be
>> convenient to get the blocks from the last leaf page we looked at,
>> for example.
>>
>> So this suggests we simply started prefetching for the case where the
>> information was readily available, and it'd be harder to do for index
>> scans so that's it.
>
> What the exact historical timeline is may not be that important. My
> emphasis on ScalarArrayOpExpr is partly due to it being a particularly
> compelling case for both parallel index scan and prefetching, in
> general. There are many queries that have huge in() lists that
> naturally benefit a great deal from prefetching. Plus they're common.
>
Did you mean parallel index scan or bitmap index scan?
But yeah, I get the point that SAOP queries are an interesting example
of queries to explore. I'll add some to the next round of tests.
>> Even if SAOP (probably) wasn't the reason, I think you're right it may
>> be an issue for prefetching, causing regressions. It didn't occur to me
>> before, because I'm not that familiar with the btree code and/or how it
>> deals with SAOP (and didn't really intend to study it too deeply).
>
> I'm pretty sure that you understand this already, but just in case:
> ScalarArrayOpExpr doesn't even "get the blocks from the last leaf
> page" in many important cases. Not really -- not in the sense that
> you'd hope and expect. We're senselessly processing the same index
> leaf page multiple times and treating it as a different, independent
> leaf page. That makes heap prefetching of the kind you're working on
> utterly hopeless, since it effectively throws away lots of useful
> context. Obviously that's the fault of nbtree ScalarArrayOpExpr
> handling, not the fault of your patch.
>
I think I understand, although maybe my mental model is wrong. I agree
it seems inefficient, but I'm not sure why would it make prefetching
hopeless. Sure, it puts index scans at a disadvantage (compared to
bitmap scans), but it we pick index scan it should still be an
improvement, right?
I guess I need to do some testing on a range of data sets / queries, and
see how it works in practice.
>> So if you're planning to work on this for PG17, collaborating on it
>> would be great.
>>
>> For now I plan to just ignore SAOP, or maybe just disabling prefetching
>> for SAOP index scans if it proves to be prone to regressions. That's not
>> great, but at least it won't make matters worse.
>
> Makes sense, but I hope that it won't come to that.
>
> IMV it's actually quite reasonable that you didn't expect to have to
> think about ScalarArrayOpExpr at all -- it would make a lot of sense
> if that was already true. But the fact is that it works in a way
> that's pretty silly and naive right now, which will impact
> prefetching. I wasn't really thinking about regressions, though. I was
> actually more concerned about missing opportunities to get the most
> out of prefetching. ScalarArrayOpExpr really matters here.
>
OK
>> I guess something like this might be a "nice" bad case:
>>
>> insert into btree_test mod(i,100000), md5(i::text)
>> from generate_series(1, $ROWS) s(i)
>>
>> select * from btree_test where a in (999, 1000, 1001, 1002)
>>
>> The values are likely colocated on the same heap page, the bitmap scan
>> is going to do a single prefetch. With index scan we'll prefetch them
>> repeatedly. I'll give it a try.
>
> This is the sort of thing that I was thinking of. What are the
> conditions under which bitmap index scan starts to make sense? Why is
> the break-even point whatever it is in each case, roughly? And, is it
> actually because of laws-of-physics level trade-off? Might it not be
> due to implementation-level issues that are much less fundamental? In
> other words, might it actually be that we're just doing something
> stoopid in the case of plain index scans? Something that is just
> papered-over by bitmap index scans right now?
>
Yeah, that's partially why I do this kind of testing on a wide range of
synthetic data sets - to find cases that behave in unexpected way (say,
seem like they should improve but don't).
> I see that your patch has logic that avoids repeated prefetching of
> the same block -- plus you have comments that wonder about going
> further by adding a "small lru array" in your new index_prefetch()
> function. I asked you about this during the unconference presentation.
> But I think that my understanding of the situation was slightly
> different to yours. That's relevant here.
>
> I wonder if you should go further than this, by actually sorting the
> items that you need to fetch as part of processing a given leaf page
> (I said this at the unconference, you may recall). Why should we
> *ever* pin/access the same heap page more than once per leaf page
> processed per index scan? Nothing stops us from returning the tuples
> to the executor in the original logical/index-wise order, despite
> having actually accessed each leaf page's pointed-to heap pages
> slightly out of order (with the aim of avoiding extra pin/unpin
> traffic that isn't truly necessary). We can sort the heap TIDs in
> scratch memory, then do our actual prefetching + heap access, and then
> restore the original order before returning anything.
>
I think that's possible, and I thought about that a bit (not just for
btree, but especially for the distance queries on GiST). But I don't
have a good idea if this would be 1% or 50% improvement, and I was
concerned it might easily lead to regressions if we don't actually need
all the tuples.
I mean, imagine we have TIDs
[T1, T2, T3, T4, T5, T6]
Maybe T1, T5, T6 are from the same page, so per your proposal we might
reorder and prefetch them in this order:
[T1, T5, T6, T2, T3, T4]
But maybe we only need [T1, T2] because of a LIMIT, and the extra work
we did on processing T5, T6 is wasted.
> This is conceptually a "mini bitmap index scan", though one that takes
> place "inside" a plain index scan, as it processes one particular leaf
> page. That's the kind of design that "plain index scan vs bitmap index
> scan as a continuum" leads me to (a little like the continuum between
> nested loop joins, block nested loop joins, and merge joins). I bet it
> would be practical to do things this way, and help a lot with some
> kinds of queries. It might even be simpler than avoiding excessive
> prefetching using an LRU cache thing.
>
> I'm talking about problems that exist today, without your patch.
>
> I'll show a concrete example of the kind of index/index scan that
> might be affected.
>
> Attached is an extract of the server log when the regression tests ran
> against a server patched to show custom instrumentation. The log
> output shows exactly what's going on with one particular nbtree
> opportunistic deletion (my point has nothing to do with deletion, but
> it happens to be convenient to make my point in this fashion). This
> specific example involves deletion of tuples from the system catalog
> index "pg_type_typname_nsp_index". There is nothing very atypical
> about it; it just shows a certain kind of heap fragmentation that's
> probably very common.
>
> Imagine a plain index scan involving a query along the lines of
> "select * from pg_type where typname like 'part%' ", or similar. This
> query runs an instant before the example LD_DEAD-bit-driven
> opportunistic deletion (a "simple deletion" in nbtree parlance) took
> place. You'll be able to piece together from the log output that there
> would only be about 4 heap blocks involved with such a query. Ideally,
> our hypothetical index scan would pin each buffer/heap page exactly
> once, for a total of 4 PinBuffer()/UnpinBuffer() calls. After all,
> we're talking about a fairly selective query here, that only needs to
> scan precisely one leaf page (I verified this part too) -- so why
> wouldn't we expect "index scan parity"?
>
> While there is significant clustering on this example leaf page/key
> space, heap TID is not *perfectly* correlated with the
> logical/keyspace order of the index -- which can have outsized
> consequences. Notice that some heap blocks are non-contiguous
> relative to logical/keyspace/index scan/index page offset number order.
>
> We'll end up pinning each of the 4 or so heap pages more than once
> (sometimes several times each), when in principle we could have pinned
> each heap page exactly once. In other words, there is way too much of
> a difference between the case where the tuples we scan are *almost*
> perfectly clustered (which is what you see in my example) and the case
> where they're exactly perfectly clustered. In other other words, there
> is way too much of a difference between plain index scan, and bitmap
> index scan.
>
> (What I'm saying here is only true because this is a composite index
> and our query uses "like", returning rows matches a prefix -- if our
> index was on the column "typname" alone and we used a simple equality
> condition in our query then the Postgres 12 nbtree work would be
> enough to avoid the extra PinBuffer()/UnpinBuffer() calls. I suspect
> that there are still relatively many important cases where we perform
> extra PinBuffer()/UnpinBuffer() calls during plain index scans that
> only touch one leaf page anyway.)
>
> Obviously we should expect bitmap index scans to have a natural
> advantage over plain index scans whenever there is little or no
> correlation -- that's clear. But that's not what we see here -- we're
> way too sensitive to minor imperfections in clustering that are
> naturally present on some kinds of leaf pages. The potential
> difference in pin/unpin traffic (relative to the bitmap index scan
> case) seems pathological to me. Ideally, we wouldn't have these kinds
> of differences at all. It's going to disrupt usage_count on the
> buffers.
>
I'm not sure I understand all the nuance here, but the thing I take away
is to add tests with different levels of correlation, and probably also
some multi-column indexes.
>>> It's important to carefully distinguish between cases where plain
>>> index scans really are at an inherent disadvantage relative to bitmap
>>> index scans (because there really is no getting around the need to
>>> access the same heap page many times with an index scan) versus cases
>>> that merely *appear* that way. Implementation restrictions that only
>>> really affect the plain index scan case (e.g., the lack of a
>>> reasonably sized prefetch buffer, or the ScalarArrayOpExpr thing)
>>> should be accounted for when assessing the viability of index scan +
>>> prefetch over bitmap index scan + prefetch. This is very subtle, but
>>> important.
>>>
>>
>> I do agree, but what do you mean by "assessing"?
>
> I mean performance validation. There ought to be a theoretical model
> that describes the relationship between index scan and bitmap index
> scan, that has actual predictive power in the real world, across a
> variety of different cases. Something that isn't sensitive to the
> current phase of the moon (e.g., heap fragmentation along the lines of
> my pg_type_typname_nsp_index log output). I particularly want to avoid
> nasty discontinuities that really make no sense.
>
>> Wasn't the agreement at
>> the unconference session was we'd not tweak costing? So ultimately, this
>> does not really affect which scan type we pick. We'll keep doing the
>> same planning decisions as today, no?
>
> I'm not really talking about tweaking the costing. What I'm saying is
> that we really should expect index scans to behave similarly to bitmap
> index scans at runtime, for queries that really don't have much to
> gain from using a bitmap heap scan (queries that may or may not also
> benefit from prefetching). There are several reasons why this makes
> sense to me.
>
> One reason is that it makes tweaking the actual costing easier later
> on. Also, your point about plan robustness was a good one. If we make
> the wrong choice about index scan vs bitmap index scan, and the
> consequences aren't so bad, that's a very useful enhancement in
> itself.
>
> The most important reason of all may just be to build confidence in
> the design. I'm interested in understanding when and how prefetching
> stops helping.
>
Agreed.
>> I'm all for building a more comprehensive set of test cases - the stuff
>> presented at pgcon was good for demonstration, but it certainly is not
>> enough for testing. The SAOP queries are a great addition, I also plan
>> to run those queries on different (less random) data sets, etc. We'll
>> probably discover more interesting cases as the patch improves.
>
> Definitely.
>
>> There are two aspects why I think AM is not the right place:
>>
>> - accessing table from index code seems backwards
>>
>> - we already do prefetching from the executor (nodeBitmapHeapscan.c)
>>
>> It feels kinda wrong in hindsight.
>
> I'm willing to accept that we should do it the way you've done it in
> the patch provisionally. It's complicated enough that it feels like I
> should reserve the right to change my mind.
>
>>>> I think this is acceptable limitation, certainly for v0. Prefetching
>>>> across multiple leaf pages seems way more complex (particularly for the
>>>> cases using pairing heap), so let's leave this for the future.
>
>> Yeah, I'm not saying it's impossible, and imagined we might teach nbtree
>> to do that. But it seems like work for future someone.
>
> Right. You probably noticed that this is another case where we'd be
> making index scans behave more like bitmap index scans (perhaps even
> including the downsides for kill_prior_tuple that accompany not
> processing each leaf page inline). There is probably a point where
> that ceases to be sensible, but I don't know what that point is.
> They're way more similar than we seem to imagine.
>
OK. Thanks for all the comments.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, Jun 9, 2023 at 3:45 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > What the exact historical timeline is may not be that important. My > > emphasis on ScalarArrayOpExpr is partly due to it being a particularly > > compelling case for both parallel index scan and prefetching, in > > general. There are many queries that have huge in() lists that > > naturally benefit a great deal from prefetching. Plus they're common. > > > > Did you mean parallel index scan or bitmap index scan? I meant parallel index scan (also parallel bitmap index scan). Note that nbtree parallel index scans have special ScalarArrayOpExpr handling code. ScalarArrayOpExpr is kind of special -- it is simultaneously one big index scan (to the executor), and lots of small index scans (to nbtree). Unlike the queries that you've looked at so far, which really only have one plausible behavior at execution time, there are many ways that ScalarArrayOpExpr index scans can be executed at runtime -- some much faster than others. The nbtree implementation can in principle reorder how it processes ranges from the key space (i.e. each range of array elements) with significant flexibility. > I think I understand, although maybe my mental model is wrong. I agree > it seems inefficient, but I'm not sure why would it make prefetching > hopeless. Sure, it puts index scans at a disadvantage (compared to > bitmap scans), but it we pick index scan it should still be an > improvement, right? Hopeless might have been too strong of a word. More like it'd fall far short of what is possible to do with a ScalarArrayOpExpr with a given high end server. The quality of the implementation (including prefetching) could make a huge difference to how well we make use of the available hardware resources. A really high quality implementation of ScalarArrayOpExpr + prefetching can keep the system busy with useful work, which is less true with other types of queries, which have inherently less predictable I/O (and often have less I/O overall). What could be more amenable to predicting I/O patterns than a query with a large IN() list, with many constants that can be processed in whatever order makes sense at runtime? What I'd like to do with ScalarArrayOpExpr is to teach nbtree to coalesce together those "small index scans" into "medium index scans" dynamically, where that makes sense. That's the main part that's missing right now. Dynamic behavior matters a lot with ScalarArrayOpExpr stuff -- that's where the challenge lies, but also where the opportunities are. Prefetching builds on all that. > I guess I need to do some testing on a range of data sets / queries, and > see how it works in practice. If I can figure out a way of getting ScalarArrayOpExpr to visit each leaf page exactly once, that might be enough to make things work really well most of the time. Maybe it won't even be necessary to coordinate very much, in the end. Unsure. I've already done a lot of work that tries to minimize the chances of regular (non-ScalarArrayOpExpr) queries accessing more than a single leaf page, which will help your strategy of just prefetching items from a single leaf page at a time -- that will get you pretty far already. Consider the example of the tenk2_hundred index from the bt_page_items documentation. You'll notice that the high key for the page shown in the docs (and every other page in the same index) nicely makes the leaf page boundaries "aligned" with natural keyspace boundaries, due to suffix truncation. That helps index scans to access no more than a single leaf page when accessing any one distinct "hundred" value. We are careful to do the right thing with the "boundary cases" when we descend the tree, too. This _bt_search behavior builds on the way that suffix truncation influences the on-disk structure of indexes. Queries such as "select * from tenk2 where hundred = ?" will each return 100 rows spread across almost as many heap pages. That's a fairly large number of rows/heap pages, but we still only need to access one leaf page for every possible constant value (every "hundred" value that might be specified as the ? in my point query example). It doesn't matter if it's the leftmost or rightmost item on a leaf page -- we always descend to exactly the correct leaf page directly, and we always terminate the scan without having to move to the right sibling page (we check the high key before going to the right page in some cases, per the optimization added by commit 29b64d1d). The same kind of behavior is also seen with the TPC-C line items primary key index, which is a composite index. We want to access the items from a whole order in one go, from one leaf page -- and we reliably do the right thing there too (though with some caveats about CREATE INDEX). We should never have to access more than one leaf page to read a single order's line items. This matters because it's quite natural to want to access whole orders with that particular table/workload (it's also unnatural to only access one single item from any given order). Obviously there are many queries that need to access two or more leaf pages, because that's just what needs to happen. My point is that we *should* only do that when it's truly necessary on modern Postgres versions, since the boundaries between pages are "aligned" with the "natural boundaries" from the keyspace/application. Maybe your testing should verify that this effect is actually present, though. It would be a shame if we sometimes messed up prefetching that could have worked well due to some issue with how page splits divide up items. CREATE INDEX is much less smart about suffix truncation -- it isn't capable of the same kind of tricks as nbtsplitloc.c, even though it could be taught to do roughly the same thing. Hopefully this won't be an issue for your work. The tenk2 case still works as expected with CREATE INDEX/REINDEX, due to help from deduplication. Indexes like the TPC-C line items PK will leave the index with some "orders" (or whatever the natural grouping of things is) that span more than a single leaf page, which is undesirable, and might hinder your prefetching work. I wouldn't mind fixing that if it turned out to hurt your leaf-page-at-a-time prefetching patch. Something to consider. We can fit at most 17 TPC-C orders on each order line PK leaf page. Could be as few as 15. If we do the wrong thing with prefetching for 2 out of every 15 orders then that's a real problem, but is still subtle enough to easily miss with conventional benchmarking. I've had a lot of success with paying close attention to all the little boundary cases, which is why I'm kind of zealous about it now. > > I wonder if you should go further than this, by actually sorting the > > items that you need to fetch as part of processing a given leaf page > > (I said this at the unconference, you may recall). Why should we > > *ever* pin/access the same heap page more than once per leaf page > > processed per index scan? Nothing stops us from returning the tuples > > to the executor in the original logical/index-wise order, despite > > having actually accessed each leaf page's pointed-to heap pages > > slightly out of order (with the aim of avoiding extra pin/unpin > > traffic that isn't truly necessary). We can sort the heap TIDs in > > scratch memory, then do our actual prefetching + heap access, and then > > restore the original order before returning anything. > > > > I think that's possible, and I thought about that a bit (not just for > btree, but especially for the distance queries on GiST). But I don't > have a good idea if this would be 1% or 50% improvement, and I was > concerned it might easily lead to regressions if we don't actually need > all the tuples. I get that it could be invasive. I have the sense that just pinning the same heap page more than once in very close succession is just the wrong thing to do, with or without prefetching. > I mean, imagine we have TIDs > > [T1, T2, T3, T4, T5, T6] > > Maybe T1, T5, T6 are from the same page, so per your proposal we might > reorder and prefetch them in this order: > > [T1, T5, T6, T2, T3, T4] > > But maybe we only need [T1, T2] because of a LIMIT, and the extra work > we did on processing T5, T6 is wasted. Yeah, that's possible. But isn't that par for the course? Any optimization that involves speculation (including all prefetching) comes with similar risks. They can be managed. I don't think that we'd literally order by TID...we wouldn't change the order that each heap page was *initially* pinned. We'd just reorder the tuples minimally using an approach that is sufficient to avoid repeated pinning of heap pages during processing of any one leaf page's heap TIDs. ISTM that the risk of wasting work is limited to wasting cycles on processing extra tuples from a heap page that we definitely had to process at least one tuple from already. That doesn't seem particularly risky, as speculative optimizations go. The downside is bounded and well understood, while the upside could be significant. I really don't have that much confidence in any of this just yet. I'm not trying to make this project more difficult. I just can't help but notice that the order that index scans end up pinning heap pages already has significant problems, and is sensitive to things like small amounts of heap fragmentation -- maybe that's not a great basis for prefetching. I *really* hate any kind of sharp discontinuity, where a minor change in an input (e.g., from minor amounts of heap fragmentation) has outsized impact on an output (e.g., buffers pinned). Interactions like that tend to be really pernicious -- they lead to bad performance that goes unnoticed and unfixed because the problem effectively camouflages itself. It may even be easier to make the conservative (perhaps paranoid) assumption that weird nasty interactions will cause harm somewhere down the line...why take a chance? I might end up prototyping this myself. I may have to put my money where my mouth is. :-) -- Peter Geoghegan
We already do prefetching for bitmap index scans, where the bitmap heap
scan prefetches future pages based on effective_io_concurrency. I'm not
sure why exactly was prefetching implemented only for bitmap scans
| \set range 67 * (:multiplier + 1) |
| \set limit 100000 * :scale |
| \set limit :limit - :range |
| \set aid random(1, :limit) |
Hi, On 2023-06-09 12:18:11 +0200, Tomas Vondra wrote: > > > >> 2) prefetching from executor > >> > >> Another question is whether the prefetching shouldn't actually happen > >> even higher - in the executor. That's what Andres suggested during the > >> unconference, and it kinda makes sense. That's where we do prefetching > >> for bitmap heap scans, so why should this happen lower, right? > > > > Yea. I think it also provides potential for further optimizations in the > > future to do it at that layer. > > > > One thing I have been wondering around this is whether we should not have > > split the code for IOS and plain indexscans... > > > > Which code? We already have nodeIndexscan.c and nodeIndexonlyscan.c? Or > did you mean something else? Yes, I meant that. > >> 4) per-leaf prefetching > >> > >> The code is restricted only prefetches items from one leaf page. If the > >> index scan needs to scan multiple (many) leaf pages, we have to process > >> the first leaf page first before reading / prefetching the next one. > >> > >> I think this is acceptable limitation, certainly for v0. Prefetching > >> across multiple leaf pages seems way more complex (particularly for the > >> cases using pairing heap), so let's leave this for the future. > > > > Hm. I think that really depends on the shape of the API we end up with. If we > > move the responsibility more twoards to the executor, I think it very well > > could end up being just as simple to prefetch across index pages. > > > > Maybe. I'm open to that idea if you have idea how to shape the API to > make this possible (although perhaps not in v0). I'll try to have a look. > > I'm a bit confused by some of these numbers. How can OS-level prefetching lead > > to massive prefetching in the alread cached case, e.g. in tpch q06 and q08? > > Unless I missed what "xeon / cached (speedup)" indicates? > > > > I forgot to explain what "cached" means in the TPC-H case. It means > second execution of the query, so you can imagine it like this: > > for q in `seq 1 22`; do > > 1. drop caches and restart postgres Are you doing it in that order? If so, the pagecache can end up being seeded by postgres writing out dirty buffers. > 2. run query $q -> uncached > > 3. run query $q -> cached > > done > > So the second execution has a chance of having data in memory - but > maybe not all, because this is a 100GB data set (so ~200GB after > loading), but the machine only has 64GB of RAM. > > I think a likely explanation is some of the data wasn't actually in > memory, so prefetching still did something. Ah, ok. > > I think it'd be good to run a performance comparison of the unpatched vs > > patched cases, with prefetching disabled for both. It's possible that > > something in the patch caused unintended changes (say spilling during a > > hashagg, due to larger struct sizes). > > > > That's certainly a good idea. I'll do that in the next round of tests. I > also plan to do a test on data set that fits into RAM, to test "properly > cached" case. Cool. It'd be good to measure both the case of all data already being in s_b (to see the overhead of the buffer mapping lookups) and the case where the data is in the kernel pagecache (to see the overhead of pointless posix_fadvise calls). Greetings, Andres Freund
On 6/10/23 22:34, Andres Freund wrote: > Hi, > > On 2023-06-09 12:18:11 +0200, Tomas Vondra wrote: >>> >>>> 2) prefetching from executor >>>> >>>> Another question is whether the prefetching shouldn't actually happen >>>> even higher - in the executor. That's what Andres suggested during the >>>> unconference, and it kinda makes sense. That's where we do prefetching >>>> for bitmap heap scans, so why should this happen lower, right? >>> >>> Yea. I think it also provides potential for further optimizations in the >>> future to do it at that layer. >>> >>> One thing I have been wondering around this is whether we should not have >>> split the code for IOS and plain indexscans... >>> >> >> Which code? We already have nodeIndexscan.c and nodeIndexonlyscan.c? Or >> did you mean something else? > > Yes, I meant that. > Ah, you meant that maybe we shouldn't have done that. Sorry, I misunderstood. >>>> 4) per-leaf prefetching >>>> >>>> The code is restricted only prefetches items from one leaf page. If the >>>> index scan needs to scan multiple (many) leaf pages, we have to process >>>> the first leaf page first before reading / prefetching the next one. >>>> >>>> I think this is acceptable limitation, certainly for v0. Prefetching >>>> across multiple leaf pages seems way more complex (particularly for the >>>> cases using pairing heap), so let's leave this for the future. >>> >>> Hm. I think that really depends on the shape of the API we end up with. If we >>> move the responsibility more twoards to the executor, I think it very well >>> could end up being just as simple to prefetch across index pages. >>> >> >> Maybe. I'm open to that idea if you have idea how to shape the API to >> make this possible (although perhaps not in v0). > > I'll try to have a look. > > >>> I'm a bit confused by some of these numbers. How can OS-level prefetching lead >>> to massive prefetching in the alread cached case, e.g. in tpch q06 and q08? >>> Unless I missed what "xeon / cached (speedup)" indicates? >>> >> >> I forgot to explain what "cached" means in the TPC-H case. It means >> second execution of the query, so you can imagine it like this: >> >> for q in `seq 1 22`; do >> >> 1. drop caches and restart postgres > > Are you doing it in that order? If so, the pagecache can end up being seeded > by postgres writing out dirty buffers. > Actually no, I do it the other way around - first restart, then drop. It shouldn't matter much, though, because after building the data set (and vacuum + checkpoint), the data is not modified - all the queries run on the same data set. So there shouldn't be any dirty buffers. > >> 2. run query $q -> uncached >> >> 3. run query $q -> cached >> >> done >> >> So the second execution has a chance of having data in memory - but >> maybe not all, because this is a 100GB data set (so ~200GB after >> loading), but the machine only has 64GB of RAM. >> >> I think a likely explanation is some of the data wasn't actually in >> memory, so prefetching still did something. > > Ah, ok. > > >>> I think it'd be good to run a performance comparison of the unpatched vs >>> patched cases, with prefetching disabled for both. It's possible that >>> something in the patch caused unintended changes (say spilling during a >>> hashagg, due to larger struct sizes). >>> >> >> That's certainly a good idea. I'll do that in the next round of tests. I >> also plan to do a test on data set that fits into RAM, to test "properly >> cached" case. > > Cool. It'd be good to measure both the case of all data already being in s_b > (to see the overhead of the buffer mapping lookups) and the case where the > data is in the kernel pagecache (to see the overhead of pointless > posix_fadvise calls). > OK, I'll make sure the next round of tests includes a sufficiently small data set too. I should have some numbers sometime early next week. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 2023-06-08 at 17:40 +0200, Tomas Vondra wrote: > Hi, > > At pgcon unconference I presented a PoC patch adding prefetching for > indexes, along with some benchmark results demonstrating the (pretty > significant) benefits etc. The feedback was quite positive, so let me > share the current patch more widely. > I added entry to https://wiki.postgresql.org/wiki/PgCon_2023_Developer_Unconference based on notes I took during that session. Hope it helps. -- Tomasz Rybak, Debian Developer <serpent@debian.org> GPG: A565 CE64 F866 A258 4DDC F9C7 ECB7 3E37 E887 AA8C
On Thu, Jun 8, 2023 at 9:10 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > We already do prefetching for bitmap index scans, where the bitmap heap > scan prefetches future pages based on effective_io_concurrency. I'm not > sure why exactly was prefetching implemented only for bitmap scans, but > I suspect the reasoning was that it only helps when there's many > matching tuples, and that's what bitmap index scans are for. So it was > not worth the implementation effort. One of the reasons IMHO is that in the bitmap scan before starting the heap fetch TIDs are already sorted in heap block order. So it is quite obvious that once we prefetch a heap block most of the subsequent TIDs will fall on that block i.e. each prefetch will satisfy many immediate requests. OTOH, in the index scan the I/O request is very random so we might have to prefetch many blocks even for satisfying the request for TIDs falling on one index page. I agree with prefetching with an index scan will definitely help in reducing the random I/O, but this is my guess that thinking of prefetching with a Bitmap scan appears more natural and that would have been one of the reasons for implementing this only for a bitmap scan. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi, I have results from the new extended round of prefetch tests. I've pushed everything to https://github.com/tvondra/index-prefetch-tests-2 There are scripts I used to run this (run-*.sh), raw results and various kinds of processed summaries (pdf, ods, ...) that I'll mention later. As before, this tests a number of query types: - point queries with btree and hash (equality) - ORDER BY queries with btree (inequality + order by) - SAOP queries with btree (column IN (values)) It's probably futile to go through details of all the tests - it's easier to go through the (hopefully fairly readable) shell scripts. But in principle, runs some simple queries while varying both the data set and workload: - data set may be random, sequential or cyclic (with different length) - the number of matches per value differs (i.e. equality condition may match 1, 10, 100, ..., 100k rows) - forces a particular scan type (indexscan, bitmapscan, seqscan) - each query is executed twice - first run (right after restarting DB and dropping caches) is uncached, second run should have data cached - the query is executed 5x with different parameters (so 10x in total) This is tested with three basic data sizes - fits into shared buffers, fits into RAM and exceeds RAM. The sizes are roughly 350MB, 3.5GB and 20GB (i5) / 40GB (xeon). Note: xeon has 64GB RAM, so technically the largest scale fits into RAM. But should not matter, thanks to drop-caches and restart. I also attempted to pin the backend to a particular core, in effort to eliminate scheduling-related noise. It's mostly what taskset does, but I did that from extension (https://github.com/tvondra/taskset) which allows me to do that as part of the SQL script. For the results, I'll talk about the v1 patch (as submitted here) fist. I'll use the PDF results in the "pdf" directory which generally show a pivot table by different test parameters, comparing the results by different parameters (prefetching on/off, master/patched). Feel free to do your own analysis from the raw CSV data, ofc. For example, this: https://github.com/tvondra/index-prefetch-tests-2/blob/master/pdf/patch-v1-point-queries-builds.pdf shows how the prefetching affects timing for point queries with different numbers of matches (1 to 100k). The numbers are timings for master and patched build. The last group is (patched/master), so the lower the number the better - 50% means patch makes the query 2x faster. There's also a heatmap, with green=good, red=bad, which makes it easier to cases that got slower/faster. The really interesting stuff starts on page 7 (in this PDF), because the first couple pages are "cached" (so it's more about measuring overhead when prefetching has no benefit). Right on page 7 you can see a couple cases with a mix of slower/faster cases, roughtly in the +/- 30% range. However, this is unrelated from the patch because those are results for bitmapheapscan. For indexscans (page 8), the results are invariably improved - the more matches the better (up to ~10x faster for 100k matches). Those were results for the "cyclic" data set. For random data set (pages 9-11) the results are pretty similar, but for "sequential" data (11-13) the prefetching is actually harmful - there are red clusters, with up to 500% slowdowns. I'm not going to explain the summary for SAOP queries (https://github.com/tvondra/index-prefetch-tests-2/blob/master/pdf/patch-v1-saop-queries-builds.pdf), the story is roughly the same, except that there are more tested query combinations (because we also vary the pattern in the IN() list - number of values etc.). So, the conclusion from this is - generally very good results for random and cyclic data sets, but pretty bad results for sequential. But even for the random/cyclic cases there are combinations (especially with many matches) where prefetching doesn't help or even hurts. The only way to deal with this is (I think) a cheap way to identify and skip inefficient prefetches, essentially by doing two things: a) remembering more recently prefetched blocks (say, 1000+) and not prefetching them over and over b) ability to identify sequential pattern, when readahead seems to do pretty good job already (although I heard some disagreement) I've been thinking about how to do this - doing (a) seem pretty hard, because on the one hand we want to remember a fair number of blocks and we want the check "did we prefetch X" to be very cheap. So a hash table seems nice. OTOH we want to expire "old" blocks and only keep the most recent ones, and hash table doesn't really support that. Perhaps there is a great data structure for this, not sure. But after thinking about this I realized we don't need a perfect accuracy - it's fine to have false positives/negatives - it's fine to forget we already prefetched block X and prefetch it again, or prefetch it again. It's not a matter of correctness, just a matter of efficiency - after all, we can't know if it's still in memory, we only know if we prefetched it fairly recently. This led me to a "hash table of LRU caches" thing. Imagine a tiny LRU cache that's small enough to be searched linearly (say, 8 blocks). And we have many of them (e.g. 128), so that in total we can remember 1024 block numbers. Now, every block number is mapped to a single LRU by hashing, as if we had a hash table index = hash(blockno) % 128 and we only use tha one LRU to track this block. It's tiny so we can search it linearly. To expire prefetched blocks, there's a counter incremented every time we prefetch a block, and we store it in the LRU with the block number. When checking the LRU we ignore old entries (with counter more than 1000 values back), and we also evict/replace the oldest entry if needed. This seems to work pretty well for the first requirement, but it doesn't allow identifying the sequential pattern cheaply. To do that, I added a tiny queue with a couple entries that can checked it the last couple entries are sequential. And this is what the attached 0002+0003 patches do. There are PDF with results for this build prefixed with "patch-v3" and the results are pretty good - the regressions are largely gone. It's even cleared in the PDFs comparing the impact of the two patches: https://github.com/tvondra/index-prefetch-tests-2/blob/master/pdf/comparison-point.pdf https://github.com/tvondra/index-prefetch-tests-2/blob/master/pdf/comparison-saop.pdf Which simply shows the "speedup heatmap" for the two patches, and the "v3" heatmap has much less red regression clusters. Note: The comparison-point.pdf summary has another group of columns illustrating if this scan type would be actually used, with "green" meaning "yes". This provides additional context, because e.g. for the "noisy bitmapscans" it's all white, i.e. without setting the GUcs the optimizer would pick something else (hence it's a non-issue). Let me know if the results are not clear enough (I tried to cover the important stuff, but I'm sure there's a lot of details I didn't cover), or if you think some other summary would be better. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
Hi, attached is a v4 of the patch, with a fairly major shift in the approach. Until now the patch very much relied on the AM to provide information which blocks to prefetch next (based on the current leaf index page). This seemed like a natural approach when I started working on the PoC, but over time I ran into various drawbacks: * a lot of the logic is at the AM level * can't prefetch across the index page boundary (have to wait until the next index leaf page is read by the indexscan) * doesn't work for distance searches (gist/spgist), After thinking about this, I decided to ditch this whole idea of exchanging prefetch information through an API, and make the prefetching almost entirely in the indexam code. The new patch maintains a queue of TIDs (read from index_getnext_tid), with up to effective_io_concurrency entries - calling getnext_slot() adds a TID at the queue tail, issues a prefetch for the block, and then returns TID from the queue head. Maintaining the queue is up to index_getnext_slot() - it can't be done in index_getnext_tid(), because then it'd affect IOS (and prefetching heap would mostly defeat the whole point of IOS). And we can't do that above index_getnext_slot() because that already fetched the heap page. I still think prefetching for IOS is doable (and desirable), in mostly the same way - except that we'd need to maintain the queue from some other place, as IOS doesn't do index_getnext_slot(). FWIW there's also the "index-only filters without IOS" patch [1] which switches even regular index scans to index_getnext_tid(), so maybe relying on index_getnext_slot() is a lost cause anyway. Anyway, this has the nice consequence that it makes AM code entirely oblivious of prefetching - there's no need to API, we just get TIDs as before, and the prefetching magic happens after that. Thus it also works for searches ordered by distance (gist/spgist). The patch got much smaller (about 40kB, down from 80kB), which is nice. I ran the benchmarks [2] with this v4 patch, and the results for the "point" queries are almost exactly the same as for v3. The SAOP part is still running - I'll add those results in a day or two, but I expect similar outcome as for point queries. regards [1] https://commitfest.postgresql.org/43/4352/ [2] https://github.com/tvondra/index-prefetch-tests-2/ -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
Here's a v5 of the patch, rebased to current master and fixing a couple compiler warnings reported by cfbot (%lu vs. UINT64_FORMAT in some debug messages). No other changes compared to v4. cfbot also reported a failure on windows in pg_dump [1], but it seem pretty strange: [11:42:48.708] ------------------------------------- 8< ------------------------------------- [11:42:48.708] stderr: [11:42:48.708] # Failed test 'connecting to an invalid database: matches' The patch does nothing related to pg_dump, and the test works perfectly fine for me (I don't have windows machine, but 32-bit and 64-bit linux works fine for me). regards [1] https://cirrus-ci.com/task/6398095366291456 -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
Hi, Attached is a v6 of the patch, which rebases v5 (just some minor bitrot), and also does a couple changes which I kept in separate patches to make it obvious what changed. 0001-v5-20231016.patch ---------------------- Rebase to current master. 0002-comments-and-minor-cleanup-20231012.patch ---------------------------------------------- Various comment improvements (remove obsolete ones clarify a bunch of other comments, etc.). I tried to explain the reasoning why some places disable prefetching (e.g. in catalogs, replication, ...), explain how the caching / LRU works etc. 0003-remove-prefetch_reset-20231016.patch ----------------------------------------- I decided to remove the separate prefetch_reset parameter, so that all the index_beginscan() methods only take a parameter specifying the maximum prefetch target. The reset was added early when the prefetch happened much lower in the AM code, at the index page level, and the reset was when moving to the next index page. But now after the prefetch moved to the executor, this doesn't make much sense - the resets happen on rescans, and it seems right to just reset to 0 (just like for bitmap heap scans). 0004-PoC-prefetch-for-IOS-20231016.patch ---------------------------------------- This is a PoC adding the prefetch to index-only scans too. At first that may seem rather strange, considering eliminating the heap fetches is the whole point of IOS. But if the pages are not marked as all-visible (say, the most recent part of the table), we may still have to fetch them. In which case it'd be easy to see cases that IOS is slower than a regular index scan (with prefetching). The code is quite rough. It adds a separate index_getnext_tid_prefetch() function, adding prefetching on top of index_getnext_tid(). I'm not sure it's the right pattern, but it's pretty much what index_getnext_slot() does too, except that it also does the fetch + store to the slot. Note: There's a second patch adding index-only filters, which requires the regular index scans from index_getnext_slot() to _tid() too. The prefetching then happens only after checking the visibility map (if requested). This part definitely needs improvements - for example there's no attempt to reuse the VM buffer, which I guess might be expensive. index-prefetch.pdf ------------------ Attached is also a PDF with results of the same benchmark I did before, comparing master vs. patched with various data patterns and scan types. It's not 100% comparable to earlier results as I only ran it on a laptop, and it's a bit noisier too. The overall behavior and conclusions are however the same. I was specifically interested in the IOS behavior, so I added two more cases to test - indexonlyscan and indexonlyscan-clean. The first is the worst-case scenario, with no pages marked as all-visible in VM (the test simply deletes the VM), while indexonlyscan-clean is the good-case (no heap fetches needed). The results mostly match the expected behavior, particularly for the uncached runs (when the data is expected to not be in memory): * indexonlyscan (i.e. bad case) - About the same results as "indexscans", with the same speedups etc. Which is a good thing (i.e. IOS is not unexpectedly slower than regular indexscans). * indexonlyscan-clean (i.e. good case) - Seems to have mostly the same performance as without the prefetching, except for the low-cardinality runs with many rows per key. I haven't checked what's causing this, but I'd bet it's the extra buffer lookups/management I mentioned. I noticed there's another prefetching-related patch [1] from Thomas Munro. I haven't looked at it yet, so hard to say how much it interferes with this patch. But the idea looks interesting. [1] https://www.postgresql.org/message-id/flat/CA+hUKGJkOiOCa+mag4BF+zHo7qo=o9CFheB8=g6uT5TUm2gkvA@mail.gmail.com regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
Hi, Here's a new WIP version of the patch set adding prefetching to indexes, exploring a couple alternative approaches. After the patch 2023/10/16 version, I happened to have an off-list discussion with Andres, and he suggested to try a couple things, and there's a couple more things I tried on my own too. Attached is the patch series starting with the 2023/10/16 patch, and then trying different things in separate patches (discussed later). As usual, there's also a bunch of benchmark results - due to size I'm unable to attach all of them here (the PDFs are pretty large), but you can find them at (with all the scripts etc.): https://github.com/tvondra/index-prefetch-tests/tree/master/2023-11-23 I'll attach only a couple small PNG with highlighted speedup/regression patterns, but it's unreadable and more of a pointer to the PDF. A quick overview of the patches ------------------------------- v20231124-0001-prefetch-2023-10-16.patch - same as the October 16 patch, with only minor comment tweaks v20231124-0002-rely-on-PrefetchBuffer-instead-of-custom-c.patch - removes custom cache of recently prefetched blocks, replaces it simply by calling PrefetchBuffer (which check shared buffers) v20231124-0003-check-page-cache-using-preadv2.patch - adds a check using preadv2(RWF_NOWAIT) to check if the whole page is in page cache v20231124-0004-reintroduce-the-LRU-cache-of-recent-blocks.patch - adds back a small LRU cache to identify sequential patterns (based on benchmarks of 0002/0003 patches) v20231124-0005-hold-the-vm-buffer-for-IOS-prefetching.patch v20231124-0006-poc-reuse-vm-information.patch - optimizes the visibilitymap handling when prefetching for IOS (to deal with overhead in the all-visible cases) by v20231124-0007-20231016-reworked.patch - returns back to the 20231016 patch, but this time with the VM optimizations in patches 0005/0006 (in retrospect I might have simply moved 0005+0006 right after 0001, but the patch evolved differently - shouldn't matter here) Now, let's talk about the patches one by one ... PrefetchBuffer + preadv2 (0002+0003) ------------------------------------ After I posted the patch in October, I happened to have an off-list discussion with Andres, and he suggested to try ditching the local cache of recently prefetched blocks, and instead: 1) call PrefetchBuffer (which checks if the page is in shared buffers, and skips the prefetch if it's already there) 2) if the page is not in shared buffers, use preadv2(RWF_NOWAIT) to check if it's in the kernel page cache Doing (1) is trivial - PrefetchBuffer() already does the shared buffer check, so 0002 simply removes the custom cache code. Doing (2) needs a bit more code to actually call preadv2() - 0003 adds FileCached() to fd.c, smgrcached() to smgr.c, and then calls it from PrefetchBuffer() right before smgrprefetch(). There's a couple loose ends (e.g. configure should check if preadv2 is supported), but in principle I think this is generally correct. Unfortunately, these changes led to a bunch of clear regressions :-( Take a look at the attached point-4-regressions-small.png, which is page 5 from the full results PDF [1][2]. As before, I plotted this as a huge pivot table with various parameters (test, dataset, prefetch, ...) on the left, and (build, nmatches) on the top. So each column shows timings for a particular patch and query returning nmatches rows. After the pivot table (on the right) is a heatmap, comparing timings for each build to master (the first couple of columns). As usual, the numbers are "timing compared to master" so e.g. 50% means the query completed in 1/2 the time compared to master. Color coding is simple too, green means "good" (speedup), red means "bad" (regression). The higher the saturation, the bigger the difference. I find this visualization handy as it quickly highlights differences between the various patches. Just look for changes in red/green areas. In the points-5-regressions-small.png image, you can see three areas of clear regressions, either compared to the master or the 20231016 patch. All of this is for "uncached" runs, i.e. after instance got restarted and the page cache was dropped too. The first regression is for bitmapscan. The first two builds show no difference compared to master - which makes sense, because the 20231016 patch does not touch any code used by bitmapscan, and the 0003 patch simply uses PrefetchBuffer as is. But then 0004 adds preadv2 to it, and the performance immediately sinks, with timings being ~5-6x higher for queries matching 1k-100k rows. The patches 0005/0006 can't possibly improve this, because visibilitymap are entirely unrelated to bitmapscans, and so is the small LRU to detect sequential patterns. The indexscan regression #1 shows a similar pattern, but in the opposite direction - indesxcan cases massively improved with the 20231016 patch (and even after just using PrefetchBuffer) revert back to master with 0003 (adding preadv2). Ditching the preadv2 restores the gains (the last build results are nicely green again). The indexscan regression #2 is interesting too, and it illustrates the importance of detecting sequential access patterns. It shows that as soon as we call PrefetBuffer() directly, the timings increase to maybe 2-5x compared to master. That's pretty terrible. Once the small LRU cache used to detect sequential patterns is added back, the performance recovers and regression disappears. Clearly, this detection matters. Unfortunately, the LRU can't do anything for the two other regresisons, because those are on random/cyclic patterns, so the LRU won't work (certainly not for the random case). preadv2 issues? --------------- I'm not entirely sure if I'm using preadv2 somehow wrong, but it doesn't seem to perform terribly well in this use case. I decided to do some microbenchmarks, measuring how long it takes to do preadv2 when the pages are [not] in cache etc. The C files are at [3]. preadv2-test simply reads file twice, first with NOWAIT and then without it. With clean page cache, the results look like this: file: ./tmp.img size: 1073741824 (131072) block 8192 check 8192 preadv2 NOWAIT time 78472 us calls 131072 hits 0 misses 131072 preadv2 WAIT time 9849082 us calls 131072 hits 131072 misses 0 and then, if you run it again with the file still being in page cache: file: ./tmp.img size: 1073741824 (131072) block 8192 check 8192 preadv2 NOWAIT time 258880 us calls 131072 hits 131072 misses 0 preadv2 WAIT time 213196 us calls 131072 hits 131072 misses 0 This is pretty terrible, IMO. It says that if the page is not in cache, the preadv2 calls take ~80ms. Which is very cheap, compared to the total read time (so if we can speed that up by prefetching, it's worth it). But if the file is already in cache, it takes ~260ms, and actually exceeds the time needed to just do preadv2() without the NOWAIT flag. AFAICS the problem is preadv2() doesn't just check if the data is available, it also copies the data and all that. But even if we only ask for the first byte, it's still way more expensive than with empty cache: file: ./tmp.img size: 1073741824 (131072) block 8192 check 1 preadv2 NOWAIT time 119751 us calls 131072 hits 131072 misses 0 preadv2 WAIT time 208136 us calls 131072 hits 131072 misses 0 There's also a fadvise-test microbenchmark that just does fadvise all the time, and even that is way cheaper than using preadv2(NOWAIT) in both cases: no cache: file: ./tmp.img size: 1073741824 (131072) block 8192 fadvise time 631686 us calls 131072 hits 0 misses 0 preadv2 time 207483 us calls 131072 hits 131072 misses 0 cache: file: ./tmp.img size: 1073741824 (131072) block 8192 fadvise time 79874 us calls 131072 hits 0 misses 0 preadv2 time 239141 us calls 131072 hits 131072 misses 0 So that's 300ms vs. 500ms in the caches case (the difference in the no-cache case is even more significant). It's entirely possible I'm doing something wrong, or maybe I just think about this the wrong way, but I can't quite imagine this being useful for this working - at least not for reasonably good local storage. Maybe it could help for slow/remote storage, or something? For now, I think the right approach is to go back to the cache of recently prefetched blocks. I liked on the preadv2 approach is that it knows exactly what is currently in page cache, while the local cache is just an approximation cache of recently prefetched blocks. And it also knows about stuff prefetched by other backends, while the local cache is private to the particular backend (or even to the particular scan node). But the local cache seems to perform much better, so there's that. LRU cache of recent blocks (0004) --------------------------------- The importance of this optimization is clearly visible in the regression image mentioned earlier - the "indexscan regression #2" shows that the sequential pattern regresses with 0002+0003 patches, but once the small LRU cache is introduced back and uses to skip prefetching for sequential patterns, the regression disappears. Ofc, this is part of the origina 20231016 patch, so going back to that version naturally includes this. visibility map optimizations (0005/0006) ---------------------------------------- Earlier benchmark results showed a bit annoying regression for index-only scans that don't need prefetching (i.e. with all pages all-visible). There was quite a bit of inefficiency because both the prefetcher and IOS code accessed the visibilitymap independently, and the prefetcher did that in a rather inefficient way. These patches make the prefetcher more efficient by reusing buffer, and also share the visibility info between prefetcher and the IOS code. I'm sure this needs more work / cleanup, but the regresion is mostly gone, as illustrated by the attached point-0-ios-improvement-small.png. layering questions ------------------ Aside from the preadv2() question, the main open question remains to be the "layering", i.e. which code should be responsible for prefetching. At the moment all the magic happens in indexam.c, in index_getnext_* functions, so that all callers benefit from prefetching. But as mentioned earlier in this thread, indexam.c seems to be the wrong layer, and I think I agree. The problem is - the prefetching needs to happen in index_getnext_* so that all index_getnext_* callers benefit from it. We could do that in the executor for index_getnext_tid(), but that's a bit weird - it'd work for index-only scans, but the primary target is regular index scans, which calls index_getnext_slot(). However, it seems it'd be good if the prefetcher and the executor code could exchange/share information more easily. Take for example the visibilitymap stuff in IOS in patches 0005/0006). I made it work, but it sure looks inconvenient, partially due to the split between executor and indexam code. The only idea I have is to have the prefetcher code somewhere in the executor, but then pass it to index_getnext_* functions, either as a new parameter (with NULL => no prefetching), or maybe as a field of scandesc (but that seems wrong, to point from the desc to something that's essentially a part of the executor state). There's also the thing that the prefetcher is part of IndexScanDesc, but it really should be in the IndexScanState. That's weird, but mostly down to my general laziness. regards [1] https://github.com/tvondra/index-prefetch-tests/blob/master/2023-11-23/pdf/point.pdf [2] https://github.com/tvondra/index-prefetch-tests/blob/master/2023-11-23/png/point-4.png [3] https://github.com/tvondra/index-prefetch-tests/tree/master/2023-11-23/preadv-tests -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
{kind=link}
Вложения
- v20231124-0006-poc-reuse-vm-information.patch
- v20231124-0001-prefetch-2023-10-16.patch
- v20231124-0002-rely-on-PrefetchBuffer-instead-of-custom-c.patch
- v20231124-0003-check-page-cache-using-preadv2.patch
- v20231124-0004-reintroduce-the-LRU-cache-of-recent-blocks.patch
- v20231124-0005-hold-the-vm-buffer-for-IOS-prefetching.patch
- v20231124-0007-20231016-reworked.patch
- point-0-ios-improvement-small.png
- point-4-regressions-small.png
{kind=link}
{kind=link}
Hi, Here's a simplified version of the patch series, with two important changes from the last version shared on 2023/11/24. Firstly, it abandons the idea to use preadv2() to check page cache. This initially seemed like a great way to check if prefetching is needed, but in practice it seems so expensive it's not really beneficial (especially in the "cached" case, which is where it matters most). Note: There's one more reason to not want rely on preadv2() that I forgot to mention - it's a Linux-specific thing. I wouldn't mind using it to improve already acceptable behavior, but it doesn't seem like a great idea if performance without would be poor. Secondly, this reworks multiple aspects of the "layering". Until now, the prefetching info was stored in IndexScanDesc and initialized in indexam.c in the various "beginscan" functions. That was obviously wrong - IndexScanDesc is just a description of what the scan should do, not a place where execution state (which the prefetch queue is) should be stored. IndexScanState (and IndexOnlyScanState) is a more appropriate place, so I moved it there. This also means the various "beginscan" functions don't need any changes (i.e. not even get prefetch_max), which is nice. Because the prefetch state is created/initialized elsewhere. But there's a layering problem that I don't know how to solve - I don't see how we could make indexam.c entirely oblivious to the prefetching, and move it entirely to the executor. Because how else would you know what to prefetch? With index_getnext_tid() I can imagine fetching XIDs ahead, stashing them into a queue, and prefetching based on that. That's kinda what the patch does, except that it does it from inside index_getnext_tid(). But that does not work for index_getnext_slot(), because that already reads the heap tuples. We could say prefetching only works for index_getnext_tid(), but that seems a bit weird because that's what regular index scans do. (There's a patch to evaluate filters on index, which switches index scans to index_getnext_tid(), so that'd make prefetching work too, but I'd ignore that here. There are other index_getnext_slot() callers, and I don't think we should accept does not work for those places seems wrong (e.g. execIndexing/execReplication would benefit from prefetching, I think). The patch just adds a "prefetcher" argument to index_getnext_*(), and the prefetching still happens there. I guess we could move most of the prefether typedefs/code somewhere, but I don't quite see how it could be done in executor entirely. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
On Sat, Dec 9, 2023 at 1:08 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > But there's a layering problem that I don't know how to solve - I don't > see how we could make indexam.c entirely oblivious to the prefetching, > and move it entirely to the executor. Because how else would you know > what to prefetch? Yeah, that seems impossible. Some thoughts: * I think perhaps the subject line of this thread is misleading. It doesn't seem like there is any index prefetching going on here at all, and there couldn't be, unless you extended the index AM API with new methods. What you're actually doing is prefetching heap pages that will be needed by a scan of the index. I think this confusing naming has propagated itself into some parts of the patch, e.g. index_prefetch() reads *from the heap* which is not at all clear from the comment saying "Prefetch the TID, unless it's sequential or recently prefetched." You're not prefetching the TID: you're prefetching the heap tuple to which the TID points. That's not an academic distinction IMHO -- the TID would be stored in the index, so if we were prefetching the TID, we'd have to be reading index pages, not heap pages. * Regarding layering, my first thought was that the changes to index_getnext_tid() and index_getnext_slot() are sensible: read ahead by some number of TIDs, keep the TIDs you've fetched in an array someplace, use that to drive prefetching of blocks on disk, and return the previously-read TIDs from the queue without letting the caller know that the queue exists. I think that's the obvious design for a feature of this type, to the point where I don't really see that there's a viable alternative design. Driving something down into the individual index AMs would make sense if you wanted to prefetch *from the indexes*, but it's unnecessary otherwise, and best avoided. * But that said, the skip_all_visible flag passed down to index_prefetch() looks like a VERY strong sign that the layering here is not what it should be. Right now, when some code calls index_getnext_tid(), that function does not need to know or care whether the caller is going to fetch the heap tuple or not. But with this patch, the code does need to care. So knowledge of the executor concept of an index-only scan trickles down into indexam.c, which now has to be able to make decisions that are consistent with the ones that the executor will make. That doesn't seem good at all. * I think it might make sense to have two different prefetching schemes. Ideally they could share some structure. If a caller is using index_getnext_slot(), then it's easy for prefetching to be fully transparent. The caller can just ask for TIDs and the prefetching distance and TID queue can be fully under the control of something that is hidden from the caller. But when using index_getnext_tid(), the caller needs to have an opportunity to evaluate each TID and decide whether we even want the heap tuple. If yes, then we feed that TID to the prefetcher; if no, we don't. That way, we're not replicating executor logic in lower-level code. However, that also means that the IOS logic needs to be aware that this TID queue exists and interact with whatever controls the prefetch distance. Perhaps after calling index_getnext_tid() you call index_prefetcher_put_tid(prefetcher, tid, bool fetch_heap_tuple) and then you call index_prefetcher_get_tid() to drain the queue. Perhaps also the prefetcher has a "fill" callback that gets invoked when the TID queue isn't as full as the prefetcher wants it to be. Then index_getnext_slot() can just install a trivial fill callback that says index_prefetecher_put_tid(prefetcher, index_getnext_tid(...), true), but IOS can use a more sophisticated callback that checks the VM to determine what to pass for the third argument. * I realize that I'm being a little inconsistent in what I just said, because in the first bullet point I said that this wasn't really index prefetching, and now I'm proposing function names that still start with index_prefetch. It's not entirely clear to me what the best thing to do about the terminology is here -- could it be a heap prefetcher, or a TID prefetcher, or an index scan prefetcher? I don't really know, but whatever we can do to make the naming more clear seems like a really good idea. Maybe there should be a clearer separation between the queue of TIDs that we're going to return from the index and the queue of blocks that we want to prefetch to get the corresponding heap tuples -- making that separation crisper might ease some of the naming issues. * Not that I want to be critical because I think this is a great start on an important project, but it does look like there's an awful lot of stuff here that still needs to be sorted out before it would be reasonable to think of committing this, both in terms of design decisions and just general polish. There's a lot of stuff marked with XXX and I think that's great because most of those seem to be good questions but that does leave the, err, small problem of figuring out the answers. index_prefetch_is_sequential() makes me really nervous because it seems to depend an awful lot on whether the OS is doing prefetching, and how the OS is doing prefetching, and I think those might not be consistent across all systems and kernel versions. Similarly with index_prefetch(). There's a lot of "magical" assumptions here. Even index_prefetch_add_cache() has this problem -- the function assumes that it's OK if we sometimes fail to detect a duplicate prefetch request, which makes sense, but under what circumstances is it necessary to detect duplicates and in what cases is it optional? The function comments are silent about that, which makes it hard to assess whether the algorithm is good enough. * In terms of polish, one thing I noticed is that index_getnext_slot() calls index_prefetch_tids() even when scan->xs_heap_continue is set, which seems like it must be a waste, since we can't really need to kick off more prefetch requests halfway through a HOT chain referenced by a single index tuple, can we? Also, blks_prefetch_rounds doesn't seem to be used anywhere, and neither that nor blks_prefetches are documented. In fact there's no new documentation at all, which seems probably not right. That's partly because there are no new GUCs, which I feel like typically for a feature like this would be the place where the feature behavior would be mentioned in the documentation. I don't think it's a good idea to tie the behavior of this feature to effective_io_concurrency partly because it's usually a bad idea to make one setting control multiple different things, but perhaps even more because effective_io_concurrency doesn't actually work in a useful way AFAICT and people typically have to set it to some very artificially large value compared to how much real I/O parallelism they have. So probably there should be new GUCs with hopefully-better semantics, but at least the documentation for any existing ones would need updating, I would think. -- Robert Haas EDB: http://www.enterprisedb.com
On 12/18/23 22:00, Robert Haas wrote: > On Sat, Dec 9, 2023 at 1:08 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> But there's a layering problem that I don't know how to solve - I don't >> see how we could make indexam.c entirely oblivious to the prefetching, >> and move it entirely to the executor. Because how else would you know >> what to prefetch? > > Yeah, that seems impossible. > > Some thoughts: > > * I think perhaps the subject line of this thread is misleading. It > doesn't seem like there is any index prefetching going on here at all, > and there couldn't be, unless you extended the index AM API with new > methods. What you're actually doing is prefetching heap pages that > will be needed by a scan of the index. I think this confusing naming > has propagated itself into some parts of the patch, e.g. > index_prefetch() reads *from the heap* which is not at all clear from > the comment saying "Prefetch the TID, unless it's sequential or > recently prefetched." You're not prefetching the TID: you're > prefetching the heap tuple to which the TID points. That's not an > academic distinction IMHO -- the TID would be stored in the index, so > if we were prefetching the TID, we'd have to be reading index pages, > not heap pages. Yes, that's a fair complaint. I think the naming is mostly obsolete - the prefetching initially happened way way lower - in the index AMs. It was prefetching the heap pages, ofc, but it kinda seemed reasonable to call it "index prefetching". And even now it's called from indexam.c where most functions start with "index_". But I'll think about some better / cleared name. > > * Regarding layering, my first thought was that the changes to > index_getnext_tid() and index_getnext_slot() are sensible: read ahead > by some number of TIDs, keep the TIDs you've fetched in an array > someplace, use that to drive prefetching of blocks on disk, and return > the previously-read TIDs from the queue without letting the caller > know that the queue exists. I think that's the obvious design for a > feature of this type, to the point where I don't really see that > there's a viable alternative design. I agree. > Driving something down into the individual index AMs would make sense > if you wanted to prefetch *from the indexes*, but it's unnecessary > otherwise, and best avoided. > Right. In fact, the patch moved exactly in the opposite direction - it was originally done at the AM level, and moved up. First to indexam.c, then even more to the executor. > * But that said, the skip_all_visible flag passed down to > index_prefetch() looks like a VERY strong sign that the layering here > is not what it should be. Right now, when some code calls > index_getnext_tid(), that function does not need to know or care > whether the caller is going to fetch the heap tuple or not. But with > this patch, the code does need to care. So knowledge of the executor > concept of an index-only scan trickles down into indexam.c, which now > has to be able to make decisions that are consistent with the ones > that the executor will make. That doesn't seem good at all. > I agree the all_visible flag is a sign the abstraction is not quite right. I did that mostly to quickly verify whether the duplicate VM checks are causing for the perf regression (and they are). Whatever the right abstraction is, it probably needs to do these VM checks only once. > * I think it might make sense to have two different prefetching > schemes. Ideally they could share some structure. If a caller is using > index_getnext_slot(), then it's easy for prefetching to be fully > transparent. The caller can just ask for TIDs and the prefetching > distance and TID queue can be fully under the control of something > that is hidden from the caller. But when using index_getnext_tid(), > the caller needs to have an opportunity to evaluate each TID and > decide whether we even want the heap tuple. If yes, then we feed that > TID to the prefetcher; if no, we don't. That way, we're not > replicating executor logic in lower-level code. However, that also > means that the IOS logic needs to be aware that this TID queue exists > and interact with whatever controls the prefetch distance. Perhaps > after calling index_getnext_tid() you call > index_prefetcher_put_tid(prefetcher, tid, bool fetch_heap_tuple) and > then you call index_prefetcher_get_tid() to drain the queue. Perhaps > also the prefetcher has a "fill" callback that gets invoked when the > TID queue isn't as full as the prefetcher wants it to be. Then > index_getnext_slot() can just install a trivial fill callback that > says index_prefetecher_put_tid(prefetcher, index_getnext_tid(...), > true), but IOS can use a more sophisticated callback that checks the > VM to determine what to pass for the third argument. > Yeah, after you pointed out the "leaky" abstraction, I also started to think about customizing the behavior using a callback. Not sure what exactly you mean by "fully transparent" but as I explained above I think we need to allow passing some information between the prefetcher and the executor - for example results of the visibility map checks in IOS. I have imagined something like this: nodeIndexscan / index_getnext_slot() -> no callback, all TIDs are prefetched nodeIndexonlyscan / index_getnext_tid() -> callback checks VM for the TID, prefetches if not all-visible -> the VM check result is stored in the queue with the VM (but in an extensible way, so that other callback can store other stuff) -> index_getnext_tid() also returns this extra information So not that different from the WIP patch, but in a "generic" and extensible way. Instead of hard-coding the all-visible flag, there'd be a something custom information. A bit like qsort_r() has a void* arg to pass custom context. Or if envisioned something different, could you elaborate a bit? > * I realize that I'm being a little inconsistent in what I just said, > because in the first bullet point I said that this wasn't really index > prefetching, and now I'm proposing function names that still start > with index_prefetch. It's not entirely clear to me what the best thing > to do about the terminology is here -- could it be a heap prefetcher, > or a TID prefetcher, or an index scan prefetcher? I don't really know, > but whatever we can do to make the naming more clear seems like a > really good idea. Maybe there should be a clearer separation between > the queue of TIDs that we're going to return from the index and the > queue of blocks that we want to prefetch to get the corresponding heap > tuples -- making that separation crisper might ease some of the naming > issues. > I think if the code stays in indexam.c, it's sensible to keep the index_ prefix, but then also have a more appropriate rest of the name. For example it might be index_prefetch_heap_pages() or something like that. > * Not that I want to be critical because I think this is a great start > on an important project, but it does look like there's an awful lot of > stuff here that still needs to be sorted out before it would be > reasonable to think of committing this, both in terms of design > decisions and just general polish. There's a lot of stuff marked with > XXX and I think that's great because most of those seem to be good > questions but that does leave the, err, small problem of figuring out > the answers. Absolutely. I certainly don't claim this is close to commit ... > index_prefetch_is_sequential() makes me really nervous > because it seems to depend an awful lot on whether the OS is doing > prefetching, and how the OS is doing prefetching, and I think those > might not be consistent across all systems and kernel versions. If the OS does not have read-ahead, or it's not configured properly, then the patch does not perform worse than what we have now. I'm far more concerned about the opposite issue, i.e. causing regressions with OS-level read-ahead. And the check handles that well, I think. > Similarly with index_prefetch(). There's a lot of "magical" > assumptions here. Even index_prefetch_add_cache() has this problem -- > the function assumes that it's OK if we sometimes fail to detect a > duplicate prefetch request, which makes sense, but under what > circumstances is it necessary to detect duplicates and in what cases > is it optional? The function comments are silent about that, which > makes it hard to assess whether the algorithm is good enough. > I don't quite understand what problem with duplicates you envision here. Strictly speaking, we don't need to detect/prevent duplicates - it's just that if you do posix_fadvise() for a block that's already in memory, it's overhead / wasted time. The whole point is to not do that very often. In this sense it's entirely optional, but desirable. I'm in no way claiming the comments are perfect, ofc. > * In terms of polish, one thing I noticed is that index_getnext_slot() > calls index_prefetch_tids() even when scan->xs_heap_continue is set, > which seems like it must be a waste, since we can't really need to > kick off more prefetch requests halfway through a HOT chain referenced > by a single index tuple, can we? Yeah, I think that's true. > Also, blks_prefetch_rounds doesn't > seem to be used anywhere, and neither that nor blks_prefetches are > documented. In fact there's no new documentation at all, which seems > probably not right. That's partly because there are no new GUCs, which > I feel like typically for a feature like this would be the place where > the feature behavior would be mentioned in the documentation. That's mostly because the explain fields were added to help during development. I'm not sure we actually want to make them part of EXPLAIN. > I don't > think it's a good idea to tie the behavior of this feature to > effective_io_concurrency partly because it's usually a bad idea to > make one setting control multiple different things, but perhaps even > more because effective_io_concurrency doesn't actually work in a > useful way AFAICT and people typically have to set it to some very > artificially large value compared to how much real I/O parallelism > they have. So probably there should be new GUCs with hopefully-better > semantics, but at least the documentation for any existing ones would > need updating, I would think. > I really don't want to have multiple knobs. At this point we have three GUCs, each tuning prefetching for a fairly large part of the system: effective_io_concurrency = regular queries maintenance_io_concurrency = utility commands recovery_prefetch = recovery / PITR This seems sensible, but I really don't want many more GUCs tuning prefetching for different executor nodes or something like that. If we have issues with how effective_io_concurrency works (and I'm not sure that's actually true), then perhaps we should fix that rather than inventing new GUCs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 19, 2023 at 8:41 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Whatever the right abstraction is, it probably needs to do these VM > checks only once. Makes sense. > Yeah, after you pointed out the "leaky" abstraction, I also started to > think about customizing the behavior using a callback. Not sure what > exactly you mean by "fully transparent" but as I explained above I think > we need to allow passing some information between the prefetcher and the > executor - for example results of the visibility map checks in IOS. Agreed. > I have imagined something like this: > > nodeIndexscan / index_getnext_slot() > -> no callback, all TIDs are prefetched > > nodeIndexonlyscan / index_getnext_tid() > -> callback checks VM for the TID, prefetches if not all-visible > -> the VM check result is stored in the queue with the VM (but in an > extensible way, so that other callback can store other stuff) > -> index_getnext_tid() also returns this extra information > > So not that different from the WIP patch, but in a "generic" and > extensible way. Instead of hard-coding the all-visible flag, there'd be > a something custom information. A bit like qsort_r() has a void* arg to > pass custom context. > > Or if envisioned something different, could you elaborate a bit? I can't totally follow the sketch you give above, but I think we're thinking along similar lines, at least. > I think if the code stays in indexam.c, it's sensible to keep the index_ > prefix, but then also have a more appropriate rest of the name. For > example it might be index_prefetch_heap_pages() or something like that. Yeah, that's not a bad idea. > > index_prefetch_is_sequential() makes me really nervous > > because it seems to depend an awful lot on whether the OS is doing > > prefetching, and how the OS is doing prefetching, and I think those > > might not be consistent across all systems and kernel versions. > > If the OS does not have read-ahead, or it's not configured properly, > then the patch does not perform worse than what we have now. I'm far > more concerned about the opposite issue, i.e. causing regressions with > OS-level read-ahead. And the check handles that well, I think. I'm just not sure how much I believe that it's going to work well everywhere. I mean, I have no evidence that it doesn't, it just kind of looks like guesswork to me. For instance, the behavior of the algorithm depends heavily on PREFETCH_QUEUE_HISTORY and PREFETCH_SEQ_PATTERN_BLOCKS, but those are just magic numbers. Who is to say that on some system or workload you didn't test the required values aren't entirely different, or that the whole algorithm doesn't need rethinking? Maybe we can't really answer that question perfectly, but the patch doesn't really explain the reasoning behind this choice of algorithm. > > Similarly with index_prefetch(). There's a lot of "magical" > > assumptions here. Even index_prefetch_add_cache() has this problem -- > > the function assumes that it's OK if we sometimes fail to detect a > > duplicate prefetch request, which makes sense, but under what > > circumstances is it necessary to detect duplicates and in what cases > > is it optional? The function comments are silent about that, which > > makes it hard to assess whether the algorithm is good enough. > > I don't quite understand what problem with duplicates you envision here. > Strictly speaking, we don't need to detect/prevent duplicates - it's > just that if you do posix_fadvise() for a block that's already in > memory, it's overhead / wasted time. The whole point is to not do that > very often. In this sense it's entirely optional, but desirable. Right ... but the patch sets up some data structure that will eliminate duplicates in some circumstances and fail to eliminate them in others. So it's making a judgement that the things it catches are the cases that are important enough that we need to catch them, and the things that it doesn't catch are cases that aren't particularly important to catch. Here again, PREFETCH_LRU_SIZE and PREFETCH_LRU_COUNT seem like they will have a big impact, but why these values? The comments suggest that it's because we want to cover ~8MB of data, but it's not clear why that should be the right amount of data to cover. My naive thought is that we'd want to avoid prefetching a block during the time between we had prefetched it and when we later read it, but then the value that is here magically 8MB should really be replaced by the operative prefetch distance. > I really don't want to have multiple knobs. At this point we have three > GUCs, each tuning prefetching for a fairly large part of the system: > > effective_io_concurrency = regular queries > maintenance_io_concurrency = utility commands > recovery_prefetch = recovery / PITR > > This seems sensible, but I really don't want many more GUCs tuning > prefetching for different executor nodes or something like that. > > If we have issues with how effective_io_concurrency works (and I'm not > sure that's actually true), then perhaps we should fix that rather than > inventing new GUCs. Well, that would very possibly be a good idea, but I still think using the same GUC for two different purposes is likely to cause trouble. I think what effective_io_concurrency currently controls is basically the heap prefetch distance for bitmap scans, and what you want to control here is the heap prefetch distance for index scans. If those are necessarily related in some understandable way (e.g. always the same, one twice the other, one the square of the other) then it's fine to use the same parameter for both, but it's not clear to me that this is the case. I fear someone will find that if they crank up effective_io_concurrency high enough to get the amount of prefetching they want for bitmap scans, it will be too much for index scans, or the other way around. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Dec 20, 2023 at 7:11 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
I was going through to understand the idea, couple of observations
--
+ for (int i = 0; i < PREFETCH_LRU_SIZE; i++)
+ {
+ entry = &prefetch->prefetchCache[lru * PREFETCH_LRU_SIZE + i];
+
+ /* Is this the oldest prefetch request in this LRU? */
+ if (entry->request < oldestRequest)
+ {
+ oldestRequest = entry->request;
+ oldestIndex = i;
+ }
+
+ /*
+ * If the entry is unused (identified by request being set to 0),
+ * we're done. Notice the field is uint64, so empty entry is
+ * guaranteed to be the oldest one.
+ */
+ if (entry->request == 0)
+ continue;
If the 'entry->request == 0' then we should break instead of continue, right?
---
/*
* Used to detect sequential patterns (and disable prefetching).
*/
#define PREFETCH_QUEUE_HISTORY 8
#define PREFETCH_SEQ_PATTERN_BLOCKS 4
If for sequential patterns we search only 4 blocks then why we are
maintaining history for 8 blocks
---
+ *
+ * XXX Perhaps this should be tied to effective_io_concurrency somehow?
+ *
+ * XXX Could it be harmful that we read the queue backwards? Maybe memory
+ * prefetching works better for the forward direction?
+ */
+ for (int i = 1; i < PREFETCH_SEQ_PATTERN_BLOCKS; i++)
Correct, I think if we fetch this forward it will have an advantage
with memory prefetching.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On 12/20/23 20:09, Robert Haas wrote: > On Tue, Dec 19, 2023 at 8:41 PM Tomas Vondra > ... >> I have imagined something like this: >> >> nodeIndexscan / index_getnext_slot() >> -> no callback, all TIDs are prefetched >> >> nodeIndexonlyscan / index_getnext_tid() >> -> callback checks VM for the TID, prefetches if not all-visible >> -> the VM check result is stored in the queue with the VM (but in an >> extensible way, so that other callback can store other stuff) >> -> index_getnext_tid() also returns this extra information >> >> So not that different from the WIP patch, but in a "generic" and >> extensible way. Instead of hard-coding the all-visible flag, there'd be >> a something custom information. A bit like qsort_r() has a void* arg to >> pass custom context. >> >> Or if envisioned something different, could you elaborate a bit? > > I can't totally follow the sketch you give above, but I think we're > thinking along similar lines, at least. > Yeah, it's hard to discuss vague descriptions of code that does not exist yet. I'll try to do the actual patch, then we can discuss. >>> index_prefetch_is_sequential() makes me really nervous >>> because it seems to depend an awful lot on whether the OS is doing >>> prefetching, and how the OS is doing prefetching, and I think those >>> might not be consistent across all systems and kernel versions. >> >> If the OS does not have read-ahead, or it's not configured properly, >> then the patch does not perform worse than what we have now. I'm far >> more concerned about the opposite issue, i.e. causing regressions with >> OS-level read-ahead. And the check handles that well, I think. > > I'm just not sure how much I believe that it's going to work well > everywhere. I mean, I have no evidence that it doesn't, it just kind > of looks like guesswork to me. For instance, the behavior of the > algorithm depends heavily on PREFETCH_QUEUE_HISTORY and > PREFETCH_SEQ_PATTERN_BLOCKS, but those are just magic numbers. Who is > to say that on some system or workload you didn't test the required > values aren't entirely different, or that the whole algorithm doesn't > need rethinking? Maybe we can't really answer that question perfectly, > but the patch doesn't really explain the reasoning behind this choice > of algorithm. > You're right a lot of this is a guesswork. I don't think we can do much better, because it depends on stuff that's out of our control - each OS may do things differently, or perhaps it's just configured differently. But I don't think this is really a serious issue - all the read-ahead implementations need to work about the same, because they are meant to work in a transparent way. So it's about deciding at which point we think this is a sequential pattern. Yes, the OS may use a slightly different threshold, but the exact value does not really matter - in the worst case we prefetch a couple more/fewer blocks. The OS read-ahead can't really prefetch anything except sequential cases, so the whole question is "When does the access pattern get sequential enough?". I don't think there's a perfect answer, and I don't think we need a perfect one - we just need to be reasonably close. Also, while I don't want to lazily dismiss valid cases that might be affected by this, I think that sequential access for index paths is not that common (with the exception of clustered indexes). FWIW bitmap index scans have exactly the same "problem" except that no one cares about it because that's how it worked from the start, so it's not considered a regression. >>> Similarly with index_prefetch(). There's a lot of "magical" >>> assumptions here. Even index_prefetch_add_cache() has this problem -- >>> the function assumes that it's OK if we sometimes fail to detect a >>> duplicate prefetch request, which makes sense, but under what >>> circumstances is it necessary to detect duplicates and in what cases >>> is it optional? The function comments are silent about that, which >>> makes it hard to assess whether the algorithm is good enough. >> >> I don't quite understand what problem with duplicates you envision here. >> Strictly speaking, we don't need to detect/prevent duplicates - it's >> just that if you do posix_fadvise() for a block that's already in >> memory, it's overhead / wasted time. The whole point is to not do that >> very often. In this sense it's entirely optional, but desirable. > > Right ... but the patch sets up some data structure that will > eliminate duplicates in some circumstances and fail to eliminate them > in others. So it's making a judgement that the things it catches are > the cases that are important enough that we need to catch them, and > the things that it doesn't catch are cases that aren't particularly > important to catch. Here again, PREFETCH_LRU_SIZE and > PREFETCH_LRU_COUNT seem like they will have a big impact, but why > these values? The comments suggest that it's because we want to cover > ~8MB of data, but it's not clear why that should be the right amount > of data to cover. My naive thought is that we'd want to avoid > prefetching a block during the time between we had prefetched it and > when we later read it, but then the value that is here magically 8MB > should really be replaced by the operative prefetch distance. > True. Ideally we'd not issue prefetch request for data that's already in memory - either in shared buffers or page cache (or whatever). And we already do that for shared buffers, but not for page cache. The preadv2 experiment was an attempt to do that, but it's too expensive to help. So we have to approximate, and the only way I can think of is checking if we recently prefetched that block. Which is the whole point of this simple cache - remembering which blocks we prefetched, so that we don't prefetch them over and over again. I don't understand what you mean by "cases that are important enough". In a way, all the blocks are equally important, with exactly the same impact of making the wrong decision. You're certainly right the 8MB is a pretty arbitrary value, though. It seemed reasonable, so I used that, but I might just as well use 32MB or some other sensible value. Ultimately, any hard-coded value is going to be wrong, but the negative consequences are a bit asymmetrical. If the cache is too small, we may end up doing prefetches for data that's already in cache. If it's too large, we may not prefetch data that's not in memory at that point. Obviously, the latter case has much more severe impact, but it depends on the exact workload / access pattern etc. The only "perfect" solution would be to actually check the page cache, but well - that seems to be fairly expensive. What I was envisioning was something self-tuning, based on the I/O we may do later. If the prefetcher decides to prefetch something, but finds it's already in cache, we'd increase the distance, to remember more blocks. Likewise, if a block is not prefetched but then requires I/O later, decrease the distance. That'd make it adaptive, but I don't think we actually have the info about I/O. A bigger "flaw" is that these caches are per-backend, so there's no way to check if a block was recently prefetched by some other backend. I actually wonder if maybe this cache should be in shared memory, but I haven't tried. Alternatively, I was thinking about moving the prefetches into a separate worker process (or multiple workers), so we'd just queue the request and all the overhead would be done by the worker. The main problem is the overhead of calling posix_fadvise() for blocks that are already in memory, and this would just move it to a separate backend. I wonder if that might even make the custom cache unnecessary / optional. AFAICS this seems similar to some of the AIO patch, I wonder what that plans to do. I need to check. >> I really don't want to have multiple knobs. At this point we have three >> GUCs, each tuning prefetching for a fairly large part of the system: >> >> effective_io_concurrency = regular queries >> maintenance_io_concurrency = utility commands >> recovery_prefetch = recovery / PITR >> >> This seems sensible, but I really don't want many more GUCs tuning >> prefetching for different executor nodes or something like that. >> >> If we have issues with how effective_io_concurrency works (and I'm not >> sure that's actually true), then perhaps we should fix that rather than >> inventing new GUCs. > > Well, that would very possibly be a good idea, but I still think using > the same GUC for two different purposes is likely to cause trouble. I > think what effective_io_concurrency currently controls is basically > the heap prefetch distance for bitmap scans, and what you want to > control here is the heap prefetch distance for index scans. If those > are necessarily related in some understandable way (e.g. always the > same, one twice the other, one the square of the other) then it's fine > to use the same parameter for both, but it's not clear to me that this > is the case. I fear someone will find that if they crank up > effective_io_concurrency high enough to get the amount of prefetching > they want for bitmap scans, it will be too much for index scans, or > the other way around. > I understand, but I think we should really try to keep the number of knobs as low as possible, unless we actually have very good arguments for having separate GUCs. And I don't think we have that. This is very much about how many concurrent requests the storage can handle (or rather requires to benefit from the capabilities), and that's pretty orthogonal to which operation is generating the requests. I think this is pretty similar to what we do with work_mem - there's one value for all possible parts of the query plan, no matter if it's sort, group by, or something else. We do have separate limits for maintenance commands, because that's a different matter, and we have the same for the two I/O GUCs. If we come to the realization that really need two GUCs, fine with me. But at this point I don't see a reason to do that. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/21/23 07:49, Dilip Kumar wrote:
> On Wed, Dec 20, 2023 at 7:11 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>>
> I was going through to understand the idea, couple of observations
>
> --
> + for (int i = 0; i < PREFETCH_LRU_SIZE; i++)
> + {
> + entry = &prefetch->prefetchCache[lru * PREFETCH_LRU_SIZE + i];
> +
> + /* Is this the oldest prefetch request in this LRU? */
> + if (entry->request < oldestRequest)
> + {
> + oldestRequest = entry->request;
> + oldestIndex = i;
> + }
> +
> + /*
> + * If the entry is unused (identified by request being set to 0),
> + * we're done. Notice the field is uint64, so empty entry is
> + * guaranteed to be the oldest one.
> + */
> + if (entry->request == 0)
> + continue;
>
> If the 'entry->request == 0' then we should break instead of continue, right?
>
Yes, I think that's true. The small LRU caches are accessed/filled
linearly, so once we find an empty entry, all following entries are
going to be empty too.
I thought this shouldn't make any difference, because the LRUs are very
small (only 8 entries, and I don't think we should make them larger).
And it's going to go away once the cache gets full. But now that I think
about it, maybe this could matter for small queries that only ever hit a
couple rows. Hmmm, I'll have to check.
Thanks for noticing this!
> ---
> /*
> * Used to detect sequential patterns (and disable prefetching).
> */
> #define PREFETCH_QUEUE_HISTORY 8
> #define PREFETCH_SEQ_PATTERN_BLOCKS 4
>
> If for sequential patterns we search only 4 blocks then why we are
> maintaining history for 8 blocks
>
> ---
Right, I think there's no reason to keep these two separate constants. I
believe this is a remnant from an earlier patch version which tried to
do something smarter, but I ended up abandoning that.
>
> + *
> + * XXX Perhaps this should be tied to effective_io_concurrency somehow?
> + *
> + * XXX Could it be harmful that we read the queue backwards? Maybe memory
> + * prefetching works better for the forward direction?
> + */
> + for (int i = 1; i < PREFETCH_SEQ_PATTERN_BLOCKS; i++)
>
> Correct, I think if we fetch this forward it will have an advantage
> with memory prefetching.
>
OK, although we only really have a couple uint32 values, so it should be
the same cacheline I guess.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi, On 2023-12-09 19:08:20 +0100, Tomas Vondra wrote: > But there's a layering problem that I don't know how to solve - I don't > see how we could make indexam.c entirely oblivious to the prefetching, > and move it entirely to the executor. Because how else would you know > what to prefetch? > With index_getnext_tid() I can imagine fetching XIDs ahead, stashing > them into a queue, and prefetching based on that. That's kinda what the > patch does, except that it does it from inside index_getnext_tid(). But > that does not work for index_getnext_slot(), because that already reads > the heap tuples. > We could say prefetching only works for index_getnext_tid(), but that > seems a bit weird because that's what regular index scans do. (There's a > patch to evaluate filters on index, which switches index scans to > index_getnext_tid(), so that'd make prefetching work too, but I'd ignore > that here. I think we should just switch plain index scans to index_getnext_tid(). It's one of the primary places triggering index scans, so a few additional lines don't seem problematic. I continue to think that we should not have split plain and index only scans into separate files... > There are other index_getnext_slot() callers, and I don't > think we should accept does not work for those places seems wrong (e.g. > execIndexing/execReplication would benefit from prefetching, I think). I don't think it'd be a problem to have to opt into supporting prefetching. There's plenty places where it doesn't really seem likely to be useful, e.g. doing prefetching during syscache lookups is very likely just a waste of time. I don't think e.g. execReplication is likely to benefit from prefetching - you're just fetching a single row after all. You'd need a lot of dead rows to make it beneficial. I think it's similar in execIndexing.c. I suspect we should work on providing executor nodes with some estimates about the number of rows that are likely to be consumed. If an index scan is under a LIMIT 1, we shoulnd't prefetch. Similar for sequential scan with the infrastructure in https://postgr.es/m/CA%2BhUKGJkOiOCa%2Bmag4BF%2BzHo7qo%3Do9CFheB8%3Dg6uT5TUm2gkvA%40mail.gmail.com Greetings, Andres Freund
Hi, On 2023-12-21 13:30:42 +0100, Tomas Vondra wrote: > You're right a lot of this is a guesswork. I don't think we can do much > better, because it depends on stuff that's out of our control - each OS > may do things differently, or perhaps it's just configured differently. > > But I don't think this is really a serious issue - all the read-ahead > implementations need to work about the same, because they are meant to > work in a transparent way. > > So it's about deciding at which point we think this is a sequential > pattern. Yes, the OS may use a slightly different threshold, but the > exact value does not really matter - in the worst case we prefetch a > couple more/fewer blocks. > > The OS read-ahead can't really prefetch anything except sequential > cases, so the whole question is "When does the access pattern get > sequential enough?". I don't think there's a perfect answer, and I don't > think we need a perfect one - we just need to be reasonably close. For the streaming read interface (initially backed by fadvise, to then be replaced by AIO) we found that it's clearly necessary to avoid fadvises in cases of actual sequential IO - the overhead otherwise leads to easily reproducible regressions. So I don't think we have much choice. > Also, while I don't want to lazily dismiss valid cases that might be > affected by this, I think that sequential access for index paths is not > that common (with the exception of clustered indexes). I think sequential access is common in other cases as well. There's lots of indexes where heap tids are almost perfectly correlated with index entries, consider insert only insert-only tables and serial PKs or inserted_at timestamp columns. Even leaving those aside, for indexes with many entries for the same key, we sort by tid these days, which will also result in "runs" of sequential access. > Obviously, the latter case has much more severe impact, but it depends > on the exact workload / access pattern etc. The only "perfect" solution > would be to actually check the page cache, but well - that seems to be > fairly expensive. > What I was envisioning was something self-tuning, based on the I/O we > may do later. If the prefetcher decides to prefetch something, but finds > it's already in cache, we'd increase the distance, to remember more > blocks. Likewise, if a block is not prefetched but then requires I/O > later, decrease the distance. That'd make it adaptive, but I don't think > we actually have the info about I/O. How would the prefetcher know that hte data wasn't in cache? > Alternatively, I was thinking about moving the prefetches into a > separate worker process (or multiple workers), so we'd just queue the > request and all the overhead would be done by the worker. The main > problem is the overhead of calling posix_fadvise() for blocks that are > already in memory, and this would just move it to a separate backend. I > wonder if that might even make the custom cache unnecessary / optional. The AIO patchset provides this. > AFAICS this seems similar to some of the AIO patch, I wonder what that > plans to do. I need to check. Yes, most of this exists there. The difference that with the AIO you don't need to prefetch, as you can just initiate the IO for real, and wait for it to complete. Greetings, Andres Freund
On 12/21/23 14:43, Andres Freund wrote: > Hi, > > On 2023-12-21 13:30:42 +0100, Tomas Vondra wrote: >> You're right a lot of this is a guesswork. I don't think we can do much >> better, because it depends on stuff that's out of our control - each OS >> may do things differently, or perhaps it's just configured differently. >> >> But I don't think this is really a serious issue - all the read-ahead >> implementations need to work about the same, because they are meant to >> work in a transparent way. >> >> So it's about deciding at which point we think this is a sequential >> pattern. Yes, the OS may use a slightly different threshold, but the >> exact value does not really matter - in the worst case we prefetch a >> couple more/fewer blocks. >> >> The OS read-ahead can't really prefetch anything except sequential >> cases, so the whole question is "When does the access pattern get >> sequential enough?". I don't think there's a perfect answer, and I don't >> think we need a perfect one - we just need to be reasonably close. > > For the streaming read interface (initially backed by fadvise, to then be > replaced by AIO) we found that it's clearly necessary to avoid fadvises in > cases of actual sequential IO - the overhead otherwise leads to easily > reproducible regressions. So I don't think we have much choice. > Yeah, the regression are pretty easy to demonstrate. In fact, I didn't have such detection in the first patch, but after the first round of benchmarks it became obvious it's needed. > >> Also, while I don't want to lazily dismiss valid cases that might be >> affected by this, I think that sequential access for index paths is not >> that common (with the exception of clustered indexes). > > I think sequential access is common in other cases as well. There's lots of > indexes where heap tids are almost perfectly correlated with index entries, > consider insert only insert-only tables and serial PKs or inserted_at > timestamp columns. Even leaving those aside, for indexes with many entries > for the same key, we sort by tid these days, which will also result in > "runs" of sequential access. > True. I should have thought about those cases. > >> Obviously, the latter case has much more severe impact, but it depends >> on the exact workload / access pattern etc. The only "perfect" solution >> would be to actually check the page cache, but well - that seems to be >> fairly expensive. > >> What I was envisioning was something self-tuning, based on the I/O we >> may do later. If the prefetcher decides to prefetch something, but finds >> it's already in cache, we'd increase the distance, to remember more >> blocks. Likewise, if a block is not prefetched but then requires I/O >> later, decrease the distance. That'd make it adaptive, but I don't think >> we actually have the info about I/O. > > How would the prefetcher know that hte data wasn't in cache? > I don't think there's a good way to do that, unfortunately, or at least I'm not aware of it. That's what I meant by "we don't have the info" at the end. Which is why I haven't tried implementing it. The only "solution" I could come up with was some sort of "timing" for the I/O requests and deducing what was cached. Not great, of course. > >> Alternatively, I was thinking about moving the prefetches into a >> separate worker process (or multiple workers), so we'd just queue the >> request and all the overhead would be done by the worker. The main >> problem is the overhead of calling posix_fadvise() for blocks that are >> already in memory, and this would just move it to a separate backend. I >> wonder if that might even make the custom cache unnecessary / optional. > > The AIO patchset provides this. > OK, I guess it's time for me to take a look at the patch again. > >> AFAICS this seems similar to some of the AIO patch, I wonder what that >> plans to do. I need to check. > > Yes, most of this exists there. The difference that with the AIO you don't > need to prefetch, as you can just initiate the IO for real, and wait for it to > complete. > Right, although the line where things stop being "prefetch" and becomes "async" seems a bit unclear to me / perhaps more a point of view. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/21/23 14:27, Andres Freund wrote: > Hi, > > On 2023-12-09 19:08:20 +0100, Tomas Vondra wrote: >> But there's a layering problem that I don't know how to solve - I don't >> see how we could make indexam.c entirely oblivious to the prefetching, >> and move it entirely to the executor. Because how else would you know >> what to prefetch? > >> With index_getnext_tid() I can imagine fetching XIDs ahead, stashing >> them into a queue, and prefetching based on that. That's kinda what the >> patch does, except that it does it from inside index_getnext_tid(). But >> that does not work for index_getnext_slot(), because that already reads >> the heap tuples. > >> We could say prefetching only works for index_getnext_tid(), but that >> seems a bit weird because that's what regular index scans do. (There's a >> patch to evaluate filters on index, which switches index scans to >> index_getnext_tid(), so that'd make prefetching work too, but I'd ignore >> that here. > > I think we should just switch plain index scans to index_getnext_tid(). It's > one of the primary places triggering index scans, so a few additional lines > don't seem problematic. > > I continue to think that we should not have split plain and index only scans > into separate files... > I do agree with that opinion. Not just because of this prefetching thread, but also because of the discussions about index-only filters in a nearby thread. > >> There are other index_getnext_slot() callers, and I don't >> think we should accept does not work for those places seems wrong (e.g. >> execIndexing/execReplication would benefit from prefetching, I think). > > I don't think it'd be a problem to have to opt into supporting > prefetching. There's plenty places where it doesn't really seem likely to be > useful, e.g. doing prefetching during syscache lookups is very likely just a > waste of time. > > I don't think e.g. execReplication is likely to benefit from prefetching - > you're just fetching a single row after all. You'd need a lot of dead rows to > make it beneficial. I think it's similar in execIndexing.c. > Yeah, systable scans are unlikely to benefit from prefetching of this type. I'm not sure about execIndexing/execReplication, it wasn't clear to me but maybe you're right. > > I suspect we should work on providing executor nodes with some estimates about > the number of rows that are likely to be consumed. If an index scan is under a > LIMIT 1, we shoulnd't prefetch. Similar for sequential scan with the > infrastructure in > https://postgr.es/m/CA%2BhUKGJkOiOCa%2Bmag4BF%2BzHo7qo%3Do9CFheB8%3Dg6uT5TUm2gkvA%40mail.gmail.com > Isn't this mostly addressed by the incremental ramp-up at the beginning? Even with target set to 1000, we only start prefetching 1, 2, 3, ... blocks ahead, it's not like we'll prefetch 1000 blocks right away. I did initially plan to also consider the number of rows we're expected to need, but I think it's actually harder than it might seem. With LIMIT for example we often don't know how selective the qual is, it's not like we can just stop prefetching after the reading the first N tids. With other nodes it's good to remember those are just estimates - it'd be silly to be bitten both by a wrong estimate and also prefetching doing the wrong thing based on an estimate. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2023-12-21 16:20:45 +0100, Tomas Vondra wrote: > On 12/21/23 14:43, Andres Freund wrote: > >> AFAICS this seems similar to some of the AIO patch, I wonder what that > >> plans to do. I need to check. > > > > Yes, most of this exists there. The difference that with the AIO you don't > > need to prefetch, as you can just initiate the IO for real, and wait for it to > > complete. > > > > Right, although the line where things stop being "prefetch" and becomes > "async" seems a bit unclear to me / perhaps more a point of view. Agreed. What I meant with not needing prefetching was that you'd not use fadvise(), because it's better to instead just asynchronously read data into shared buffers. That way you don't have the doubling of syscalls and you don't need to care less about the buffering rate in the kernel. Greetings, Andres Freund
On Thu, Dec 21, 2023 at 10:33 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > I continue to think that we should not have split plain and index only scans > > into separate files... > > I do agree with that opinion. Not just because of this prefetching > thread, but also because of the discussions about index-only filters in > a nearby thread. For the record, in the original patch I submitted for this feature, it wasn't in separate files. If memory serves, Tom changed it. So don't blame me. :-) -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2023-12-21 11:00:34 -0500, Robert Haas wrote: > On Thu, Dec 21, 2023 at 10:33 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > I continue to think that we should not have split plain and index only scans > > > into separate files... > > > > I do agree with that opinion. Not just because of this prefetching > > thread, but also because of the discussions about index-only filters in > > a nearby thread. > > For the record, in the original patch I submitted for this feature, it > wasn't in separate files. If memory serves, Tom changed it. > > So don't blame me. :-) But I'd like you to feel guilty (no, not really) and fix it (yes, really) :) Greetings, Andres Freund
On Thu, Dec 21, 2023 at 11:08 AM Andres Freund <andres@anarazel.de> wrote: > But I'd like you to feel guilty (no, not really) and fix it (yes, really) :) Sadly, you're more likely to get the first one than you are to get the second one. I can't really see going back to revisit that decision as a basis for somebody else's new work -- it'd be better if the person doing the new work figured out what makes sense here. -- Robert Haas EDB: http://www.enterprisedb.com
On 12/21/23 18:14, Robert Haas wrote: > On Thu, Dec 21, 2023 at 11:08 AM Andres Freund <andres@anarazel.de> wrote: >> But I'd like you to feel guilty (no, not really) and fix it (yes, really) :) > > Sadly, you're more likely to get the first one than you are to get the > second one. I can't really see going back to revisit that decision as > a basis for somebody else's new work -- it'd be better if the person > doing the new work figured out what makes sense here. > I think it's a great example of "hindsight is 20/20". There were perfectly valid reasons to have two separate nodes, and it's not like these reasons somehow disappeared. It still is a perfectly reasonable decision. It's just that allowing index-only filters for regular index scans seems to eliminate pretty much all executor differences between the two nodes. But that's hard to predict - I certainly would not have even think about that back when index-only scans were added. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, Here's a somewhat reworked version of the patch. My initial goal was to see if it could adopt the StreamingRead API proposed in [1], but that turned out to be less straight-forward than I hoped, for two reasons: (1) The StreamingRead API seems to be designed for pages, but the index code naturally works with TIDs/tuples. Yes, the callbacks can associate the blocks with custom data (in this case that'd be the TID), but it seemed a bit strange ... (2) The place adding requests to the StreamingRead queue is pretty far from the place actually reading the pages - for prefetching, the requests would be generated in nodeIndexscan, but the page reading happens somewhere deep in index_fetch_heap/heapam_index_fetch_tuple. Sure, the TIDs would come from a callback, so it's a bit as if the requests were generated in heapam_index_fetch_tuple - but it has no idea StreamingRead exists, so where would it get it. We might teach it about it, but what if there are multiple places calling index_fetch_heap()? Not all of which may be using StreamingRead (only indexscans would do that). Or if there are multiple index scans, there's need to be a separate StreamingRead queues, right? In any case, I felt a bit out of my depth here, and I chose not to do all this work without discussing the direction here. (Also, see the point about cursors and xs_heap_continue a bit later in this post.) I did however like the general StreamingRead API - how it splits the work between the API and the callback. The patch used to do everything, which meant it hardcoded a lot of the IOS-specific logic etc. I did plan to have some sort of "callback" for reading from the queue, but that didn't quite solve this issue - a lot of the stuff remained hard-coded. But the StreamingRead API made me realize that having a callback for the first phase (that adds requests to the queue) would fix that. So I did that - there's now one simple callback in for index scans, and a bit more complex callback for index-only scans. Thanks to this the hard-coded stuff mostly disappears, which is good. Perhaps a bigger change is that I decided to move this into a separate API on top of indexam.c. The original idea was to integrate this into index_getnext_tid/index_getnext_slot, so that all callers benefit from the prefetching automatically. Which would be nice, but it also meant it's need to happen in the indexam.c code, which seemed dirty. This patch introduces an API similar to StreamingRead. It calls the indexam.c stuff, but does all the prefetching on top of it, not in it. If a place calling index_getnext_tid() wants to allow prefetching, it needs to switch to IndexPrefetchNext(). (There's no function that would replace index_getnext_slot, at the moment. Maybe there should be.) Note 1: The IndexPrefetch name is a bit misleading, because it's used even with prefetching disabled - all index reads from the index scan happen through it. Maybe it should be called IndexReader or something like that. Note 2: I left the code in indexam.c for now, but in principle it could (should) be moved to a different place. I think this layering makes sense, and it's probably much closer to what Andres meant when he said the prefetching should happen in the executor. Even if the patch ends up using StreamingRead in the future, I guess we'll want something like IndexPrefetch - it might use the StreamingRead internally, but it would still need to do some custom stuff to detect I/O patterns or something that does not quite fit into the StreamingRead. Now, let's talk about two (mostly unrelated) problems I ran into. Firstly, I realized there's a bit of a problem with cursors. The prefetching works like this: 1) reading TIDs from the index 2) stashing them into a queue in IndexPrefetch 3) doing prefetches for the new TIDs added to the queue 4) returning the TIDs to the caller, one by one And all of this works ... unless the direction of the scan changes. Which for cursors can happen if someone does FETCH BACKWARD or stuff like that. I'm not sure how difficult it'd be to make this work. I suppose we could simply discard the prefetched entries and do the right number of steps back for the index scan. But I haven't tried, and maybe it's more complex than I'm imagining. Also, if the cursor changes the direction a lot, it'd make the prefetching harmful. The patch simply disables prefetching for such queries, using the same logic that we do for parallelism. This may be over-zealous. FWIW this is one of the things that probably should remain outside of StreamingRead API - it seems pretty index-specific, and I'm not sure we'd even want to support these "backward" movements in the API. The other issue I'm aware of is handling xs_heap_continue. I believe it works fine for "false" but I need to take a look at non-MVCC snapshots (i.e. when xs_heap_continue=true). I haven't done any benchmarks with this reworked API - there's a couple more allocations etc. but it did not change in a fundamental way. I don't expect any major difference. regards [1] https://www.postgresql.org/message-id/CA%2BhUKGJkOiOCa%2Bmag4BF%2BzHo7qo%3Do9CFheB8%3Dg6uT5TUm2gkvA%40mail.gmail.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
On Thu, Jan 4, 2024 at 9:55 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Here's a somewhat reworked version of the patch. My initial goal was to > see if it could adopt the StreamingRead API proposed in [1], but that > turned out to be less straight-forward than I hoped, for two reasons: I guess we need Thomas or Andres or maybe Melanie to comment on this. > Perhaps a bigger change is that I decided to move this into a separate > API on top of indexam.c. The original idea was to integrate this into > index_getnext_tid/index_getnext_slot, so that all callers benefit from > the prefetching automatically. Which would be nice, but it also meant > it's need to happen in the indexam.c code, which seemed dirty. This patch is hard to review right now because there's a bunch of comment updating that doesn't seem to have been done for the new design. For instance: + * XXX This does not support prefetching of heap pages. When such prefetching is + * desirable, use index_getnext_tid(). But not any more. + * XXX The prefetching may interfere with the patch allowing us to evaluate + * conditions on the index tuple, in which case we may not need the heap + * tuple. Maybe if there's such filter, we should prefetch only pages that + * are not all-visible (and the same idea would also work for IOS), but + * it also makes the indexing a bit "aware" of the visibility stuff (which + * seems a somewhat wrong). Also, maybe we should consider the filter selectivity I'm not sure whether all the problems in this area are solved, but I think you've solved enough of them that this at least needs rewording, if not removing. + * XXX Comment/check seems obsolete. This occurs in two places. I'm not sure if it's accurate or not. + * XXX Could this be an issue for the prefetching? What if we prefetch something + * but the direction changes before we get to the read? If that could happen, + * maybe we should discard the prefetched data and go back? But can we even + * do that, if we already fetched some TIDs from the index? I don't think + * indexorderdir can't change, but es_direction maybe can? But your email claims that "The patch simply disables prefetching for such queries, using the same logic that we do for parallelism." FWIW, I think that's a fine way to handle that case. + * XXX Maybe we should enable prefetching, but prefetch only pages that + * are not all-visible (but checking that from the index code seems like + * a violation of layering etc). Isn't this fixed now? Note this comment occurs twice. + * XXX We need to disable this in some cases (e.g. when using index-only + * scans, we don't want to prefetch pages). Or maybe we should prefetch + * only pages that are not all-visible, that'd be even better. Here again. And now for some comments on other parts of the patch, mostly other XXX comments: + * XXX This does not support prefetching of heap pages. When such prefetching is + * desirable, use index_getnext_tid(). There's probably no reason to write XXX here. The comment is fine. + * XXX Notice we haven't added the block to the block queue yet, and there + * is a preceding block (i.e. blockIndex-1 is valid). Same here, possibly? If this XXX indicates a defect in the code, I don't know what the defect is, so I guess it needs to be more clear. If it is just explaining the code, then there's no reason for the comment to say XXX. + * XXX Could it be harmful that we read the queue backwards? Maybe memory + * prefetching works better for the forward direction? It does. But I don't know whether that matters here or not. + * XXX We do add the cache size to the request in order not to + * have issues with uint64 underflows. I don't know what this means. + * XXX not sure this correctly handles xs_heap_continue - see index_getnext_slot, + * maybe nodeIndexscan needs to do something more to handle this? Although, that + * should be in the indexscan next_cb callback, probably. + * + * XXX If xs_heap_continue=true, we need to return the last TID. You've got a bunch of comments about xs_heap_continue here -- and I don't fully understand what the issues are here with respect to this particular patch, but I think that the general purpose of xs_heap_continue is to handle the case where we need to return more than one tuple from the same HOT chain. With an MVCC snapshot that doesn't happen, but with say SnapshotAny or SnapshotDirty, it could. As far as possible, the prefetcher shouldn't be involved at all when xs_heap_continue is set, I believe, because in that case we're just returning a bunch of tuples from the same page, and the extra fetches from that heap page shouldn't trigger or require any further prefetching. + * XXX Should this also look at plan.plan_rows and maybe cap the target + * to that? Pointless to prefetch more than we expect to use. Or maybe + * just reset to that value during prefetching, after reading the next + * index page (or rather after rescan)? It seems questionable to use plan_rows here because (1) I don't think we have existing cases where we use the estimated row count in the executor for anything, we just carry it through so EXPLAIN can print it and (2) row count estimates can be really far off, especially if we're on the inner side of a nested loop, we might like to figure that out eventually instead of just DTWT forever. But on the other hand this does feel like an important case where we have a clue that prefetching might need to be done less aggressively or not at all, and it doesn't seem right to ignore that signal either. I wonder if we want this shaped in some other way, like a Boolean that says are-we-under-a-potentially-row-limiting-construct e.g. limit or inner side of a semi-join or anti-join. + * We reach here if the index only scan is not parallel, or if we're + * serially executing an index only scan that was planned to be + * parallel. Well, this seems sad. + * XXX This might lead to IOS being slower than plain index scan, if the + * table has a lot of pages that need recheck. How? + /* + * XXX Only allow index prefetching when parallelModeOK=true. This is a bit + * of a misuse of the flag, but we need to disable prefetching for cursors + * (which might change direction), and parallelModeOK does that. But maybe + * we might (or should) have a separate flag. + */ I think the correct flag to be using here is execute_once, which captures whether the executor could potentially be invoked a second time for the same portal. Changes in the fetch direction are possible if and only if !execute_once. > Note 1: The IndexPrefetch name is a bit misleading, because it's used > even with prefetching disabled - all index reads from the index scan > happen through it. Maybe it should be called IndexReader or something > like that. My biggest gripe here is the capitalization. This version adds, inter alia, IndexPrefetchAlloc, PREFETCH_QUEUE_INDEX, and index_heap_prefetch_target, which seems like one or two too many conventions. But maybe the PREFETCH_* macros don't even belong in a public header. I do like the index_heap_prefetch_* naming. Possibly that's too verbose to use for everything, but calling this index-heap-prefetch rather than index-prefetch seems clearer. -- Robert Haas EDB: http://www.enterprisedb.com
Hi,
Here's an improved version of this patch, finishing a lot of the stuff
that I alluded to earlier - moving the code from indexam.c, renaming a
bunch of stuff, etc. I've also squashed it into a single patch, to make
it easier to review.
I'll briefly go through the main changes in the patch, and then will
respond in-line to Robert's points.
1) I moved the code from indexam.c to (new) execPrefetch.c. All the
prototypes / typedefs now live in executor.h, with only minimal changes
in execnodes.h (adding it to scan descriptors).
I believe this finally moves the code to the right place - it feels much
nicer and cleaner than in indexam.c. And it allowed me to hide a bunch
of internal structs and improve the general API, I think.
I'm sure there's stuff that could be named differently, but the layering
feels about right, I think.
2) A bunch of stuff got renamed to start with IndexPrefetch... to make
the naming consistent / clearer. I'm not entirely sure IndexPrefetch is
the right name, though - it's still a bit misleading, as it might seem
it's about prefetching index stuff, but really it's about heap pages
from indexes. Maybe IndexScanPrefetch() or something like that?
3) If there's a way to make this work with the streaming I/O API, I'm
not aware of it. But the overall design seems somewhat similar (based on
"next" callback etc.) so hopefully that'd make it easier to adopt it.
4) I initially relied on parallelModeOK to disable prefetching, which
kinda worked, but not really. Robert suggested to use the execute_once
flag directly, and I think that's much better - not only is it cleaner,
it also seems more appropriate (the parallel flag considers other stuff
that is not quite relevant to prefetching).
Thinking about this, I think it should be possible to make prefetching
work even for plans with execute_once=false. In particular, when the
plan changes direction it should be possible to simply "walk back" the
prefetch queue, to get to the "correct" place in in the scan. But I'm
not sure it's worth it, because plans that change direction often can't
really benefit from prefetches anyway - they'll often visit stuff they
accessed shortly before anyway. For plans that don't change direction
but may pause, we don't know if the plan pauses long enough for the
prefetched pages to get evicted or something. So I think it's OK that
execute_once=false means no prefetching.
5) I haven't done anything about the xs_heap_continue=true case yet.
6) I went through all the comments and reworked them considerably. The
main comment at execPrefetch.c start, with some overall design etc. And
then there are comments for each function, explaining that bit in more
detail. Or at least that's the goal - there's still work to do.
There's two trivial FIXMEs, but you can ignore those - it's not that
there's a bug, but that I'd like to rework something and just don't know
how yet.
There's also a couple of XXX comments. Some are a bit wild ideas for the
future, others are somewhat "open questions" to be discussed during a
review.
Anyway, there should be no outright obsolete comments - if there's
something I missed, let me know.
Now to Robert's message ...
On 1/9/24 21:31, Robert Haas wrote:
> On Thu, Jan 4, 2024 at 9:55 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> Here's a somewhat reworked version of the patch. My initial goal was to
>> see if it could adopt the StreamingRead API proposed in [1], but that
>> turned out to be less straight-forward than I hoped, for two reasons:
>
> I guess we need Thomas or Andres or maybe Melanie to comment on this.
>
Yeah. Or maybe Thomas if he has thoughts on how to combine this with the
streaming I/O stuff.
>> Perhaps a bigger change is that I decided to move this into a separate
>> API on top of indexam.c. The original idea was to integrate this into
>> index_getnext_tid/index_getnext_slot, so that all callers benefit from
>> the prefetching automatically. Which would be nice, but it also meant
>> it's need to happen in the indexam.c code, which seemed dirty.
>
> This patch is hard to review right now because there's a bunch of
> comment updating that doesn't seem to have been done for the new
> design. For instance:
>
> + * XXX This does not support prefetching of heap pages. When such
> prefetching is
> + * desirable, use index_getnext_tid().
>
> But not any more.
>
True. And this is now even more obsolete, as the prefetching was moved
from indexam.c layer to the executor.
> + * XXX The prefetching may interfere with the patch allowing us to evaluate
> + * conditions on the index tuple, in which case we may not need the heap
> + * tuple. Maybe if there's such filter, we should prefetch only pages that
> + * are not all-visible (and the same idea would also work for IOS), but
> + * it also makes the indexing a bit "aware" of the visibility stuff (which
> + * seems a somewhat wrong). Also, maybe we should consider the filter
> selectivity
>
> I'm not sure whether all the problems in this area are solved, but I
> think you've solved enough of them that this at least needs rewording,
> if not removing.
>
> + * XXX Comment/check seems obsolete.
>
> This occurs in two places. I'm not sure if it's accurate or not.
>
> + * XXX Could this be an issue for the prefetching? What if we
> prefetch something
> + * but the direction changes before we get to the read? If that
> could happen,
> + * maybe we should discard the prefetched data and go back? But can we even
> + * do that, if we already fetched some TIDs from the index? I don't think
> + * indexorderdir can't change, but es_direction maybe can?
>
> But your email claims that "The patch simply disables prefetching for
> such queries, using the same logic that we do for parallelism." FWIW,
> I think that's a fine way to handle that case.
>
True. I left behind this comment partly intentionally, to point out why
we disable the prefetching in these cases, but you're right the comment
now explains something that can't happen.
> + * XXX Maybe we should enable prefetching, but prefetch only pages that
> + * are not all-visible (but checking that from the index code seems like
> + * a violation of layering etc).
>
> Isn't this fixed now? Note this comment occurs twice.
>
> + * XXX We need to disable this in some cases (e.g. when using index-only
> + * scans, we don't want to prefetch pages). Or maybe we should prefetch
> + * only pages that are not all-visible, that'd be even better.
>
> Here again.
>
Sorry, you're right those comments (and a couple more nearby) were
stale. Removed / clarified.
> And now for some comments on other parts of the patch, mostly other
> XXX comments:
>
> + * XXX This does not support prefetching of heap pages. When such
> prefetching is
> + * desirable, use index_getnext_tid().
>
> There's probably no reason to write XXX here. The comment is fine.
>
> + * XXX Notice we haven't added the block to the block queue yet, and there
> + * is a preceding block (i.e. blockIndex-1 is valid).
>
> Same here, possibly? If this XXX indicates a defect in the code, I
> don't know what the defect is, so I guess it needs to be more clear.
> If it is just explaining the code, then there's no reason for the
> comment to say XXX.
>
Yeah, removed the XXX / reworded a bit.
> + * XXX Could it be harmful that we read the queue backwards? Maybe memory
> + * prefetching works better for the forward direction?
>
> It does. But I don't know whether that matters here or not.
>
> + * XXX We do add the cache size to the request in order not to
> + * have issues with uint64 underflows.
>
> I don't know what this means.
>
There's a check that does this:
(x + PREFETCH_CACHE_SIZE) >= y
it might also be done as "mathematically equivalent"
x >= (y - PREFETCH_CACHE_SIZE)
but if the "y" is an uint64, and the value is smaller than the constant,
this would underflow. It'd eventually disappear, once the "y" gets large
enough, ofc.
> + * XXX not sure this correctly handles xs_heap_continue - see
> index_getnext_slot,
> + * maybe nodeIndexscan needs to do something more to handle this?
> Although, that
> + * should be in the indexscan next_cb callback, probably.
> + *
> + * XXX If xs_heap_continue=true, we need to return the last TID.
>
> You've got a bunch of comments about xs_heap_continue here -- and I
> don't fully understand what the issues are here with respect to this
> particular patch, but I think that the general purpose of
> xs_heap_continue is to handle the case where we need to return more
> than one tuple from the same HOT chain. With an MVCC snapshot that
> doesn't happen, but with say SnapshotAny or SnapshotDirty, it could.
> As far as possible, the prefetcher shouldn't be involved at all when
> xs_heap_continue is set, I believe, because in that case we're just
> returning a bunch of tuples from the same page, and the extra fetches
> from that heap page shouldn't trigger or require any further
> prefetching.
>
Yes, that's correct. The current code simply ignores that flag and just
proceeds to the next TID. Which is correct for xs_heap_continue=false,
and thus all MVCC snapshots work fine. But for the Any/Dirty case it
needs to work a bit differently.
> + * XXX Should this also look at plan.plan_rows and maybe cap the target
> + * to that? Pointless to prefetch more than we expect to use. Or maybe
> + * just reset to that value during prefetching, after reading the next
> + * index page (or rather after rescan)?
>
> It seems questionable to use plan_rows here because (1) I don't think
> we have existing cases where we use the estimated row count in the
> executor for anything, we just carry it through so EXPLAIN can print
> it and (2) row count estimates can be really far off, especially if
> we're on the inner side of a nested loop, we might like to figure that
> out eventually instead of just DTWT forever. But on the other hand
> this does feel like an important case where we have a clue that
> prefetching might need to be done less aggressively or not at all, and
> it doesn't seem right to ignore that signal either. I wonder if we
> want this shaped in some other way, like a Boolean that says
> are-we-under-a-potentially-row-limiting-construct e.g. limit or inner
> side of a semi-join or anti-join.
>
The current code actually does look at plan_rows when calculating the
prefetch target:
prefetch_max = IndexPrefetchComputeTarget(node->ss.ss_currentRelation,
node->ss.ps.plan->plan_rows,
estate->es_use_prefetching);
but I agree maybe it should not, for the reasons you explain. I'm not
attached to this part.
> + * We reach here if the index only scan is not parallel, or if we're
> + * serially executing an index only scan that was planned to be
> + * parallel.
>
> Well, this seems sad.
>
Stale comment, I believe. However, I didn't see much benefits with
parallel index scan during testing. Having I/O from multiple workers
generally had the same effect, I think.
> + * XXX This might lead to IOS being slower than plain index scan, if the
> + * table has a lot of pages that need recheck.
>
> How?
>
The comment is not particularly clear what "this" means, but I believe
this was about index-only scan with many not-all-visible pages. If it
didn't do prefetching, a regular index scan with prefetching may be way
faster. But the code actually allows doing prefetching even for IOS, by
checking the vm in the "next" callback.
> + /*
> + * XXX Only allow index prefetching when parallelModeOK=true. This is a bit
> + * of a misuse of the flag, but we need to disable prefetching for cursors
> + * (which might change direction), and parallelModeOK does that. But maybe
> + * we might (or should) have a separate flag.
> + */
>
> I think the correct flag to be using here is execute_once, which
> captures whether the executor could potentially be invoked a second
> time for the same portal. Changes in the fetch direction are possible
> if and only if !execute_once.
>
Right. The new patch version does that.
>> Note 1: The IndexPrefetch name is a bit misleading, because it's used
>> even with prefetching disabled - all index reads from the index scan
>> happen through it. Maybe it should be called IndexReader or something
>> like that.
>
> My biggest gripe here is the capitalization. This version adds, inter
> alia, IndexPrefetchAlloc, PREFETCH_QUEUE_INDEX, and
> index_heap_prefetch_target, which seems like one or two too many
> conventions. But maybe the PREFETCH_* macros don't even belong in a
> public header.
>
> I do like the index_heap_prefetch_* naming. Possibly that's too
> verbose to use for everything, but calling this index-heap-prefetch
> rather than index-prefetch seems clearer.
>
Yeah. I renamed all the structs and functions to IndexPrefetchSomething,
to keep it consistent. And then the constants are all capital, ofc.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
Not a full response, but just to address a few points: On Fri, Jan 12, 2024 at 11:42 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Thinking about this, I think it should be possible to make prefetching > work even for plans with execute_once=false. In particular, when the > plan changes direction it should be possible to simply "walk back" the > prefetch queue, to get to the "correct" place in in the scan. But I'm > not sure it's worth it, because plans that change direction often can't > really benefit from prefetches anyway - they'll often visit stuff they > accessed shortly before anyway. For plans that don't change direction > but may pause, we don't know if the plan pauses long enough for the > prefetched pages to get evicted or something. So I think it's OK that > execute_once=false means no prefetching. +1. > > + * XXX We do add the cache size to the request in order not to > > + * have issues with uint64 underflows. > > > > I don't know what this means. > > > > There's a check that does this: > > (x + PREFETCH_CACHE_SIZE) >= y > > it might also be done as "mathematically equivalent" > > x >= (y - PREFETCH_CACHE_SIZE) > > but if the "y" is an uint64, and the value is smaller than the constant, > this would underflow. It'd eventually disappear, once the "y" gets large > enough, ofc. The problem is, I think, that there's no particular reason that someone reading the existing code should imagine that it might have been done in that "mathematically equivalent" fashion. I imagined that you were trying to make a point about adding the cache size to the request vs. adding nothing, whereas in reality you were trying to make a point about adding from one side vs. subtracting from the other. > > + * We reach here if the index only scan is not parallel, or if we're > > + * serially executing an index only scan that was planned to be > > + * parallel. > > > > Well, this seems sad. > > Stale comment, I believe. However, I didn't see much benefits with > parallel index scan during testing. Having I/O from multiple workers > generally had the same effect, I think. Fair point, likely worth mentioning explicitly in the comment. > Yeah. I renamed all the structs and functions to IndexPrefetchSomething, > to keep it consistent. And then the constants are all capital, ofc. It'd still be nice to get table or heap in there, IMHO, but maybe we can't, and consistency is certainly a good thing regardless of the details, so thanks for that. -- Robert Haas EDB: http://www.enterprisedb.com
Hi,
Hi, Here's an improved version of this patch, finishing a lot of the stuff that I alluded to earlier - moving the code from indexam.c, renaming a bunch of stuff, etc. I've also squashed it into a single patch, to make it easier to review.
I am thinking about testing you patch with Neon (cloud Postgres). As far as Neon seaprates compute and storage, prefetch is much more critical for Neon
architecture than for vanilla Postgres.
I have few complaints:
1. It disables prefetch for sequential access pattern (i.e. INDEX MERGE), motivating it that in this case OS read-ahead will be more efficient than prefetch. It may be true for normal storage devices, bit not for Neon storage and may be also for Postgres on top of DFS (i.e. Amazon RDS). I wonder if we can delegate decision whether to perform prefetch in this case or not to some other level. I do not know precisely where is should be handled. The best candidate IMHO is storager manager. But it most likely requires extension of SMGR API. Not sure if you want to do it... Straightforward solution is to move this logic to some callback, which can be overwritten by user.
2. It disables prefetch for direct_io. It seems to be even more obvious than 1), because prefetching using `posix_fadvise` definitely not possible in case of using direct_io. But in theory if SMGR provides some alternative prefetch implementation (as in case of Neon), this also may be not true. Still unclear why we can want to use direct_io in Neon... But still I prefer to mo.ve this decision outside executor.
3. It doesn't perform prefetch of leave pages for IOS, only referenced heap pages which are not marked as all-visible. It seems to me that if optimized has chosen IOS (and not bitmap heap scan for example), then there should be large enough fraction for all-visible pages. Also index prefetch is most efficient for OLAp queries and them are used to be performance for historical data which is all-visible. But IOS can be really handled separately in some other PR. Frankly speaking combining prefetch of leave B-Tree pages and referenced heap pages seems to be very challenged task.
4. I think that performing prefetch at executor level is really great idea and so prefetch can be used by all indexes, including custom indexes. But prefetch will be efficient only if index can provide fast access to next TID (located at the same page). I am not sure that it is true for all builtin indexes (GIN, GIST, BRIN,...) and especially for custom AM. I wonder if we should extend AM API to make index make a decision weather to perform prefetch of TIDs or not.
5. Minor notice: there are few places where index_getnext_slot is called with last NULL parameter (disabled prefetch) with the following comment
"XXX Would be nice to also benefit from prefetching here." But all this places corresponds to "point loopkup", i.e. unique constraint check, find replication tuple by index... Prefetch seems to be unlikely useful here, unlkess there is index bloating and and we have to skip a lot of tuples before locating right one. But should we try to optimize case of bloated indexes?
On 1/16/24 09:13, Konstantin Knizhnik wrote: > Hi, > > On 12/01/2024 6:42 pm, Tomas Vondra wrote: >> Hi, >> >> Here's an improved version of this patch, finishing a lot of the stuff >> that I alluded to earlier - moving the code from indexam.c, renaming a >> bunch of stuff, etc. I've also squashed it into a single patch, to make >> it easier to review. > > I am thinking about testing you patch with Neon (cloud Postgres). As far > as Neon seaprates compute and storage, prefetch is much more critical > for Neon > architecture than for vanilla Postgres. > > I have few complaints: > > 1. It disables prefetch for sequential access pattern (i.e. INDEX > MERGE), motivating it that in this case OS read-ahead will be more > efficient than prefetch. It may be true for normal storage devices, bit > not for Neon storage and may be also for Postgres on top of DFS (i.e. > Amazon RDS). I wonder if we can delegate decision whether to perform > prefetch in this case or not to some other level. I do not know > precisely where is should be handled. The best candidate IMHO is > storager manager. But it most likely requires extension of SMGR API. Not > sure if you want to do it... Straightforward solution is to move this > logic to some callback, which can be overwritten by user. > Interesting point. You're right these decisions (whether to prefetch particular patterns) are closely tied to the capabilities of the storage system. So it might make sense to maybe define it at that level. Not sure what exactly RDS does with the storage - my understanding is that it's mostly regular Postgres code, but managed by Amazon. So how would that modify the prefetching logic? However, I'm not against making this modular / wrapping this in some sort of callbacks, for example. > 2. It disables prefetch for direct_io. It seems to be even more obvious > than 1), because prefetching using `posix_fadvise` definitely not > possible in case of using direct_io. But in theory if SMGR provides some > alternative prefetch implementation (as in case of Neon), this also may > be not true. Still unclear why we can want to use direct_io in Neon... > But still I prefer to mo.ve this decision outside executor. > True. I think this would / should be customizable by the callback. > 3. It doesn't perform prefetch of leave pages for IOS, only referenced > heap pages which are not marked as all-visible. It seems to me that if > optimized has chosen IOS (and not bitmap heap scan for example), then > there should be large enough fraction for all-visible pages. Also index > prefetch is most efficient for OLAp queries and them are used to be > performance for historical data which is all-visible. But IOS can be > really handled separately in some other PR. Frankly speaking combining > prefetch of leave B-Tree pages and referenced heap pages seems to be > very challenged task. > I see prefetching of leaf pages as interesting / worthwhile improvement, but out of scope for this patch. I don't think it can be done at the executor level - the prefetch requests need to be submitted from the index AM code (by calling PrefetchBuffer, etc.) > 4. I think that performing prefetch at executor level is really great > idea and so prefetch can be used by all indexes, including custom > indexes. But prefetch will be efficient only if index can provide fast > access to next TID (located at the same page). I am not sure that it is > true for all builtin indexes (GIN, GIST, BRIN,...) and especially for > custom AM. I wonder if we should extend AM API to make index make a > decision weather to perform prefetch of TIDs or not. I'm not against having a flag to enable/disable prefetching, but the question is whether doing prefetching for such indexes can be harmful. I'm not sure about that. > > 5. Minor notice: there are few places where index_getnext_slot is called > with last NULL parameter (disabled prefetch) with the following comment > "XXX Would be nice to also benefit from prefetching here." But all this > places corresponds to "point loopkup", i.e. unique constraint check, > find replication tuple by index... Prefetch seems to be unlikely useful > here, unlkess there is index bloating and and we have to skip a lot of > tuples before locating right one. But should we try to optimize case of > bloated indexes? > Are you sure you're looking at the last patch version? Because the current patch does not have any new parameters in index_getnext_* and the comments were removed too (I suppose you're talking about execIndexing, execReplication and those places). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 16, 2024 at 11:25 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 3. It doesn't perform prefetch of leave pages for IOS, only referenced > > heap pages which are not marked as all-visible. It seems to me that if > > optimized has chosen IOS (and not bitmap heap scan for example), then > > there should be large enough fraction for all-visible pages. Also index > > prefetch is most efficient for OLAp queries and them are used to be > > performance for historical data which is all-visible. But IOS can be > > really handled separately in some other PR. Frankly speaking combining > > prefetch of leave B-Tree pages and referenced heap pages seems to be > > very challenged task. > > I see prefetching of leaf pages as interesting / worthwhile improvement, > but out of scope for this patch. I don't think it can be done at the > executor level - the prefetch requests need to be submitted from the > index AM code (by calling PrefetchBuffer, etc.) +1. This is a good feature, and so is that, but they're not the same feature, despite the naming problems. -- Robert Haas EDB: http://www.enterprisedb.com
On 1/16/24 09:13, Konstantin Knizhnik wrote:Hi, On 12/01/2024 6:42 pm, Tomas Vondra wrote:Hi, Here's an improved version of this patch, finishing a lot of the stuff that I alluded to earlier - moving the code from indexam.c, renaming a bunch of stuff, etc. I've also squashed it into a single patch, to make it easier to review.I am thinking about testing you patch with Neon (cloud Postgres). As far as Neon seaprates compute and storage, prefetch is much more critical for Neon architecture than for vanilla Postgres. I have few complaints: 1. It disables prefetch for sequential access pattern (i.e. INDEX MERGE), motivating it that in this case OS read-ahead will be more efficient than prefetch. It may be true for normal storage devices, bit not for Neon storage and may be also for Postgres on top of DFS (i.e. Amazon RDS). I wonder if we can delegate decision whether to perform prefetch in this case or not to some other level. I do not know precisely where is should be handled. The best candidate IMHO is storager manager. But it most likely requires extension of SMGR API. Not sure if you want to do it... Straightforward solution is to move this logic to some callback, which can be overwritten by user.Interesting point. You're right these decisions (whether to prefetch particular patterns) are closely tied to the capabilities of the storage system. So it might make sense to maybe define it at that level. Not sure what exactly RDS does with the storage - my understanding is that it's mostly regular Postgres code, but managed by Amazon. So how would that modify the prefetching logic?
Amazon RDS is just vanilla Postgres with file system mounted on EBS (Amazon distributed file system).
EBS provides good throughput but larger latencies comparing with local SSDs.
I am not sure if read-ahead works for EBS.
4. I think that performing prefetch at executor level is really greatidea and so prefetch can be used by all indexes, including custom indexes. But prefetch will be efficient only if index can provide fast access to next TID (located at the same page). I am not sure that it is true for all builtin indexes (GIN, GIST, BRIN,...) and especially for custom AM. I wonder if we should extend AM API to make index make a decision weather to perform prefetch of TIDs or not.I'm not against having a flag to enable/disable prefetching, but the question is whether doing prefetching for such indexes can be harmful. I'm not sure about that.
I tend to agree with you - it is hard to imagine index implementation which doesn't win from prefetching heap pages.
May be only the filtering case you have mentioned. But it seems to me that current B-Tree index scan (not IOS) implementation in Postgres
doesn't try to use index tuple to check extra condition - it will fetch heap tuple in any case.
5. Minor notice: there are few places where index_getnext_slot is called with last NULL parameter (disabled prefetch) with the following comment "XXX Would be nice to also benefit from prefetching here." But all this places corresponds to "point loopkup", i.e. unique constraint check, find replication tuple by index... Prefetch seems to be unlikely useful here, unlkess there is index bloating and and we have to skip a lot of tuples before locating right one. But should we try to optimize case of bloated indexes?Are you sure you're looking at the last patch version? Because the current patch does not have any new parameters in index_getnext_* and the comments were removed too (I suppose you're talking about execIndexing, execReplication and those places).
Sorry, I looked at v20240103-0001-prefetch-2023-12-09.patch , I didn't noticed v20240112-0001-Prefetch-heap-pages-during-index-scans.patch
regards
On 1/16/24 2:10 PM, Konstantin Knizhnik wrote: > Amazon RDS is just vanilla Postgres with file system mounted on EBS > (Amazon distributed file system). > EBS provides good throughput but larger latencies comparing with local SSDs. > I am not sure if read-ahead works for EBS. Actually, EBS only provides a block device - it's definitely not a filesystem itself (*EFS* is a filesystem - but it's also significantly different than EBS). So as long as readahead is happening somewheer above the block device I would expect it to JustWork on EBS. Of course, Aurora Postgres (like Neon) is completely different. If you look at page 53 of [1] you'll note that there's two different terms used: prefetch and batch. I'm not sure how much practical difference there is, but batched IO (one IO request to Aurora Storage for many blocks) predates index prefetch; VACUUM in APG has used batched IO for a very long time (it also *only* reads blocks that aren't marked all visble/frozen; none of the "only skip if skipping at least 32 blocks" logic is used). 1: https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Deep_dive_on_Amazon_Aurora_with_PostgreSQL_compatibility_DAT328-R1.pdf -- Jim Nasby, Data Architect, Austin TX
On 16/01/2024 11:58 pm, Jim Nasby wrote: > On 1/16/24 2:10 PM, Konstantin Knizhnik wrote: >> Amazon RDS is just vanilla Postgres with file system mounted on EBS >> (Amazon distributed file system). >> EBS provides good throughput but larger latencies comparing with >> local SSDs. >> I am not sure if read-ahead works for EBS. > > Actually, EBS only provides a block device - it's definitely not a > filesystem itself (*EFS* is a filesystem - but it's also significantly > different than EBS). So as long as readahead is happening somewheer > above the block device I would expect it to JustWork on EBS. Thank you for clarification. Yes, EBS is just block device and read-ahead can be used fir it as for any other local device. There is actually recommendation to increase read-ahead for EBS device to reach better performance on some workloads: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSPerformance.html So looks like for sequential access pattern manual prefetching at EBS is not needed. But at Neon situation is quite different. May be Aurora Postgres is using some other mechanism for speed-up vacuum and seqscan, but Neon is using Postgres prefetch mechanism for it.
On 16/01/2024 11:58 pm, Jim Nasby wrote: > On 1/16/24 2:10 PM, Konstantin Knizhnik wrote: >> Amazon RDS is just vanilla Postgres with file system mounted on EBS >> (Amazon distributed file system). >> EBS provides good throughput but larger latencies comparing with >> local SSDs. >> I am not sure if read-ahead works for EBS. > > Actually, EBS only provides a block device - it's definitely not a > filesystem itself (*EFS* is a filesystem - but it's also significantly > different than EBS). So as long as readahead is happening somewheer > above the block device I would expect it to JustWork on EBS. Thank you for clarification. Yes, EBS is just block device and read-ahead can be used fir it as for any other local device. There is actually recommendation to increase read-ahead for EBS device to reach better performance on some workloads: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSPerformance.html So looks like for sequential access pattern manual prefetching at EBS is not needed. But at Neon situation is quite different. May be Aurora Postgres is using some other mechanism for speed-up vacuum and seqscan, but Neon is using Postgres prefetch mechanism for it.
I have integrated your prefetch patch in Neon and it actually works! Moreover, I combined it with prefetch of leaf pages for IOS and it also seems to work. Just small notice: you are reporting `blks_prefetch_rounds` in explain, but it is not incremented anywhere. Moreover, I do not precisely understand what it mean and wonder if such information is useful for analyzing query executing plan. Also your patch always report number of prefetched blocks (and rounds) if them are not zero. I think that adding new information to explain it may cause some problems because there are a lot of different tools which parse explain report to visualize it, make some recommendations top improve performance, ... Certainly good practice for such tools is to ignore all unknown tags. But I am not sure that everybody follow this practice. It seems to be more safe and at the same time convenient for users to add extra tag to explain to enable/disable prefetch info (as it was done in Neon). Here we come back to my custom explain patch;) Actually using it is not necessary. You can manually add "prefetch" option to Postgres core (as it is currently done in Neon). Best regards, Konstantin
On 1/16/24 21:10, Konstantin Knizhnik wrote: > > ... > >> 4. I think that performing prefetch at executor level is really great >>> idea and so prefetch can be used by all indexes, including custom >>> indexes. But prefetch will be efficient only if index can provide fast >>> access to next TID (located at the same page). I am not sure that it is >>> true for all builtin indexes (GIN, GIST, BRIN,...) and especially for >>> custom AM. I wonder if we should extend AM API to make index make a >>> decision weather to perform prefetch of TIDs or not. >> I'm not against having a flag to enable/disable prefetching, but the >> question is whether doing prefetching for such indexes can be harmful. >> I'm not sure about that. > > I tend to agree with you - it is hard to imagine index implementation > which doesn't win from prefetching heap pages. > May be only the filtering case you have mentioned. But it seems to me > that current B-Tree index scan (not IOS) implementation in Postgres > doesn't try to use index tuple to check extra condition - it will fetch > heap tuple in any case. > That's true, but that's why I started working on this: https://commitfest.postgresql.org/46/4352/ I need to think about how to combine that with the prefetching. The good thing is that both changes require fetching TIDs, not slots. I think the condition can be simply added to the prefetch callback. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/17/24 09:45, Konstantin Knizhnik wrote: > I have integrated your prefetch patch in Neon and it actually works! > Moreover, I combined it with prefetch of leaf pages for IOS and it also > seems to work. > Cool! And do you think this is the right design/way to do this? > Just small notice: you are reporting `blks_prefetch_rounds` in explain, > but it is not incremented anywhere. > Moreover, I do not precisely understand what it mean and wonder if such > information is useful for analyzing query executing plan. > Also your patch always report number of prefetched blocks (and rounds) > if them are not zero. > Right, this needs fixing. > I think that adding new information to explain it may cause some > problems because there are a lot of different tools which parse explain > report to visualize it, > make some recommendations top improve performance, ... Certainly good > practice for such tools is to ignore all unknown tags. But I am not sure > that everybody follow this practice. > It seems to be more safe and at the same time convenient for users to > add extra tag to explain to enable/disable prefetch info (as it was done > in Neon). > I think we want to add this info to explain, but maybe it should be behind a new flag and disabled by default. > Here we come back to my custom explain patch;) Actually using it is not > necessary. You can manually add "prefetch" option to Postgres core (as > it is currently done in Neon). > Yeah, I think that's the right solution. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 18/01/2024 6:00 pm, Tomas Vondra wrote: > On 1/17/24 09:45, Konstantin Knizhnik wrote: >> I have integrated your prefetch patch in Neon and it actually works! >> Moreover, I combined it with prefetch of leaf pages for IOS and it also >> seems to work. >> > Cool! And do you think this is the right design/way to do this? I like the idea of prefetching TIDs in executor. But looking though your patch I have some questions: 1. Why it is necessary to allocate and store all_visible flag in data buffer. Why caller of IndexPrefetchNext can not look at prefetch field? + /* store the all_visible flag in the private part of the entry */ + entry->data = palloc(sizeof(bool)); + *(bool *) entry->data = all_visible; 2. Names of the functions `IndexPrefetchNext` and `IndexOnlyPrefetchNext` are IMHO confusing because they look similar and one can assume that for one is used for normal index scan and last one - for index only scan. But actually `IndexOnlyPrefetchNext` is callback and `IndexPrefetchNext` is used in both nodeIndexscan.c and nodeIndexonlyscan.c
On 1/19/24 09:34, Konstantin Knizhnik wrote: > > On 18/01/2024 6:00 pm, Tomas Vondra wrote: >> On 1/17/24 09:45, Konstantin Knizhnik wrote: >>> I have integrated your prefetch patch in Neon and it actually works! >>> Moreover, I combined it with prefetch of leaf pages for IOS and it also >>> seems to work. >>> >> Cool! And do you think this is the right design/way to do this? > > I like the idea of prefetching TIDs in executor. > > But looking though your patch I have some questions: > > > 1. Why it is necessary to allocate and store all_visible flag in data > buffer. Why caller of IndexPrefetchNext can not look at prefetch field? > > + /* store the all_visible flag in the private part of the entry */ > + entry->data = palloc(sizeof(bool)); > + *(bool *) entry->data = all_visible; > What you mean by "prefetch field"? The reason why it's done like this is to only do the VM check once - without keeping the value, we'd have to do it in the "next" callback, to determine if we need to prefetch the heap tuple, and then later in the index-only scan itself. That's a significant overhead, especially in the case when everything is visible. > 2. Names of the functions `IndexPrefetchNext` and > `IndexOnlyPrefetchNext` are IMHO confusing because they look similar and > one can assume that for one is used for normal index scan and last one - > for index only scan. But actually `IndexOnlyPrefetchNext` is callback > and `IndexPrefetchNext` is used in both nodeIndexscan.c and > nodeIndexonlyscan.c > Yeah, that's a good point. The naming probably needs rethinking. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/16/24 21:10, Konstantin Knizhnik wrote:...4. I think that performing prefetch at executor level is really greatidea and so prefetch can be used by all indexes, including custom indexes. But prefetch will be efficient only if index can provide fast access to next TID (located at the same page). I am not sure that it is true for all builtin indexes (GIN, GIST, BRIN,...) and especially for custom AM. I wonder if we should extend AM API to make index make a decision weather to perform prefetch of TIDs or not.I'm not against having a flag to enable/disable prefetching, but the question is whether doing prefetching for such indexes can be harmful. I'm not sure about that.I tend to agree with you - it is hard to imagine index implementation which doesn't win from prefetching heap pages. May be only the filtering case you have mentioned. But it seems to me that current B-Tree index scan (not IOS) implementation in Postgres doesn't try to use index tuple to check extra condition - it will fetch heap tuple in any case.That's true, but that's why I started working on this: https://commitfest.postgresql.org/46/4352/ I need to think about how to combine that with the prefetching. The good thing is that both changes require fetching TIDs, not slots. I think the condition can be simply added to the prefetch callback. regards
Looks like I was not true, even if it is not index-only scan but index condition involves only index attributes, then heap is not accessed until we find tuple satisfying search condition.
Inclusive index case described above (https://commitfest.postgresql.org/46/4352/) is interesting but IMHO exotic case. If keys are actually used in search, then why not to create normal compound index instead?
On Fri, Jan 12, 2024 at 11:42 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 1/9/24 21:31, Robert Haas wrote: > > On Thu, Jan 4, 2024 at 9:55 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> Here's a somewhat reworked version of the patch. My initial goal was to > >> see if it could adopt the StreamingRead API proposed in [1], but that > >> turned out to be less straight-forward than I hoped, for two reasons: > > > > I guess we need Thomas or Andres or maybe Melanie to comment on this. > > > > Yeah. Or maybe Thomas if he has thoughts on how to combine this with the > streaming I/O stuff. I've been studying your patch with the intent of finding a way to change it and or the streaming read API to work together. I've attached a very rough sketch of how I think it could work. We fill a queue with blocks from TIDs that we fetched from the index. The queue is saved in a scan descriptor that is made available to the streaming read callback. Once the queue is full, we invoke the table AM specific index_fetch_tuple() function which calls pg_streaming_read_buffer_get_next(). When the streaming read API invokes the callback we registered, it simply dequeues a block number for prefetching. The only change to the streaming read API is that now, even if the callback returns InvalidBlockNumber, we may not be finished, so make it resumable. Structurally, this changes the timing of when the heap blocks are prefetched. Your code would get a tid from the index and then prefetch the heap block -- doing this until it filled a queue that had the actual tids saved in it. With my approach and the streaming read API, you fetch tids from the index until you've filled up a queue of block numbers. Then the streaming read API will prefetch those heap blocks. I didn't actually implement the block queue -- I just saved a single block number and pretended it was a block queue. I was imagining we replace this with something like your IndexPrefetch->blockItems -- which has light deduplication. We'd probably have to flesh it out more than that. There are also table AM layering violations in my sketch which would have to be worked out (not to mention some resource leakage I didn't bother investigating [which causes it to fail tests]). 0001 is all of Thomas' streaming read API code that isn't yet in master and 0002 is my rough sketch of index prefetching using the streaming read API There are also numerous optimizations that your index prefetching patch set does that would need to be added in some way. I haven't thought much about it yet. I wanted to see what you thought of this approach first. Basically, is it workable? - Melanie
Вложения
On 1/19/24 16:19, Konstantin Knizhnik wrote: > > On 18/01/2024 5:57 pm, Tomas Vondra wrote: >> On 1/16/24 21:10, Konstantin Knizhnik wrote: >>> ... >>> >>>> 4. I think that performing prefetch at executor level is really great >>>>> idea and so prefetch can be used by all indexes, including custom >>>>> indexes. But prefetch will be efficient only if index can provide fast >>>>> access to next TID (located at the same page). I am not sure that >>>>> it is >>>>> true for all builtin indexes (GIN, GIST, BRIN,...) and especially for >>>>> custom AM. I wonder if we should extend AM API to make index make a >>>>> decision weather to perform prefetch of TIDs or not. >>>> I'm not against having a flag to enable/disable prefetching, but the >>>> question is whether doing prefetching for such indexes can be harmful. >>>> I'm not sure about that. >>> I tend to agree with you - it is hard to imagine index implementation >>> which doesn't win from prefetching heap pages. >>> May be only the filtering case you have mentioned. But it seems to me >>> that current B-Tree index scan (not IOS) implementation in Postgres >>> doesn't try to use index tuple to check extra condition - it will fetch >>> heap tuple in any case. >>> >> That's true, but that's why I started working on this: >> >> https://commitfest.postgresql.org/46/4352/ >> >> I need to think about how to combine that with the prefetching. The good >> thing is that both changes require fetching TIDs, not slots. I think the >> condition can be simply added to the prefetch callback. >> >> >> regards >> > Looks like I was not true, even if it is not index-only scan but index > condition involves only index attributes, then heap is not accessed > until we find tuple satisfying search condition. > Inclusive index case described above > (https://commitfest.postgresql.org/46/4352/) is interesting but IMHO > exotic case. If keys are actually used in search, then why not to create > normal compound index instead? > Not sure I follow ... Firstly, I'm not convinced the example addressed by that other patch is that exotic. IMHO it's quite possible it's actually quite common, but the users do no realize the possible gains. Also, there are reasons to not want very wide indexes - it has overhead associated with maintenance, disk space, etc. I think it's perfectly rational to design indexes in a way eliminates most heap fetches necessary to evaluate conditions, but does not guarantee IOS (so the last heap fetch is still needed). What do you mean by "create normal compound index"? The patch addresses a limitation that not every condition can be translated into a proper scan key. Even if we improve this, there will always be such conditions. The the IOS can evaluate them on index tuple, the regular index scan can't do that (currently). Can you share an example demonstrating the alternative approach? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Looks like I was not true, even if it is not index-only scan but indexcondition involves only index attributes, then heap is not accessed until we find tuple satisfying search condition. Inclusive index case described above (https://commitfest.postgresql.org/46/4352/) is interesting but IMHO exotic case. If keys are actually used in search, then why not to create normal compound index instead?Not sure I follow ... Firstly, I'm not convinced the example addressed by that other patch is that exotic. IMHO it's quite possible it's actually quite common, but the users do no realize the possible gains. Also, there are reasons to not want very wide indexes - it has overhead associated with maintenance, disk space, etc. I think it's perfectly rational to design indexes in a way eliminates most heap fetches necessary to evaluate conditions, but does not guarantee IOS (so the last heap fetch is still needed).
We are comparing compound index (a,b) and covering (inclusive) index (a) include (b)
This indexes have exactly the same width and size and almost the same maintenance overhead.
First index has more expensive comparison function (involving two columns) but I do not think that it can significantly affect
performance and maintenance cost. Also if selectivity of "a" is good enough, then there is no need to compare "b"
Why we can prefer covering index to compound index? I see only two good reasons:
1. Extra columns type do not have comparison function need for AM.
2. The extra columns are never used in query predicate.
If you are going to use this columns in query predicates I do not see much sense in creating inclusive index rather than compound index.
Do you?
What do you mean by "create normal compound index"? The patch addresses a limitation that not every condition can be translated into a proper scan key. Even if we improve this, there will always be such conditions. The the IOS can evaluate them on index tuple, the regular index scan can't do that (currently). Can you share an example demonstrating the alternative approach?
May be I missed something.
This is the example from https://www.postgresql.org/message-id/flat/N1xaIrU29uk5YxLyW55MGk5fz9s6V2FNtj54JRaVlFbPixD5z8sJ07Ite5CvbWwik8ZvDG07oSTN-usENLVMq2UAcizVTEd5b-o16ZGDIIU=@yamlcoder.me :
```
And here is the plan with index on (a,b).
Limit (cost=0.42..4447.90 rows=1 width=12) (actual time=6.883..6.884 rows=0 loops=1) Output: a, b, d Buffers: shared hit=613 -> Index Scan using t_a_b_idx on public.t (cost=0.42..4447.90 rows=1 width=12) (actual time=6.880..6.881 rows=0 loops=1) Output: a, b, d Index Cond: ((t.a > 1000000) AND (t.b = 4)) Buffers: shared hit=613 Planning: Buffers: shared hit=41 Planning Time: 0.314 ms Execution Time: 6.910 ms ```
Isn't it an optimal plan for this query?
And cite from self reproducible example https://dbfiddle.uk/iehtq44L :
```
create unique index t_a_include_b on t(a) include (b);
-- I'd expecd index above to behave the same as index below for this query
--create unique index on t(a,b);
```
I agree that it is natural to expect the same result for both indexes. So this PR definitely makes sense.
My point is only that compound index (a,b) in this case is more natural and preferable.
On 19/01/2024 2:35 pm, Tomas Vondra wrote:
>
> On 1/19/24 09:34, Konstantin Knizhnik wrote:
>> On 18/01/2024 6:00 pm, Tomas Vondra wrote:
>>> On 1/17/24 09:45, Konstantin Knizhnik wrote:
>>>> I have integrated your prefetch patch in Neon and it actually works!
>>>> Moreover, I combined it with prefetch of leaf pages for IOS and it also
>>>> seems to work.
>>>>
>>> Cool! And do you think this is the right design/way to do this?
>> I like the idea of prefetching TIDs in executor.
>>
>> But looking though your patch I have some questions:
>>
>>
>> 1. Why it is necessary to allocate and store all_visible flag in data
>> buffer. Why caller of IndexPrefetchNext can not look at prefetch field?
>>
>> + /* store the all_visible flag in the private part of the entry */
>> + entry->data = palloc(sizeof(bool));
>> + *(bool *) entry->data = all_visible;
>>
> What you mean by "prefetch field"?
I mean "prefetch" field of IndexPrefetchEntry:
+
+typedef struct IndexPrefetchEntry
+{
+ ItemPointerData tid;
+
+ /* should we prefetch heap page for this TID? */
+ bool prefetch;
+
You store the same flag twice:
+ /* prefetch only if not all visible */
+ entry->prefetch = !all_visible;
+
+ /* store the all_visible flag in the private part of the entry */
+ entry->data = palloc(sizeof(bool));
+ *(bool *) entry->data = all_visible;
My question was: why do we need to allocate something in entry->data and
store all_visible in it, while we already stored !all-visible in
entry->prefetch.
On 1/21/24 20:50, Konstantin Knizhnik wrote: > > On 20/01/2024 12:14 am, Tomas Vondra wrote: >> Looks like I was not true, even if it is not index-only scan but index >>> condition involves only index attributes, then heap is not accessed >>> until we find tuple satisfying search condition. >>> Inclusive index case described above >>> (https://commitfest.postgresql.org/46/4352/) is interesting but IMHO >>> exotic case. If keys are actually used in search, then why not to create >>> normal compound index instead? >>> >> Not sure I follow ... >> >> Firstly, I'm not convinced the example addressed by that other patch is >> that exotic. IMHO it's quite possible it's actually quite common, but >> the users do no realize the possible gains. >> >> Also, there are reasons to not want very wide indexes - it has overhead >> associated with maintenance, disk space, etc. I think it's perfectly >> rational to design indexes in a way eliminates most heap fetches >> necessary to evaluate conditions, but does not guarantee IOS (so the >> last heap fetch is still needed). > > We are comparing compound index (a,b) and covering (inclusive) index (a) > include (b) > This indexes have exactly the same width and size and almost the same > maintenance overhead. > > First index has more expensive comparison function (involving two > columns) but I do not think that it can significantly affect > performance and maintenance cost. Also if selectivity of "a" is good > enough, then there is no need to compare "b" > > Why we can prefer covering index to compound index? I see only two good > reasons: > 1. Extra columns type do not have comparison function need for AM. > 2. The extra columns are never used in query predicate. > Or maybe you don't want to include the columns in a UNIQUE constraint? > If you are going to use this columns in query predicates I do not see > much sense in creating inclusive index rather than compound index. > Do you? > But this is also about conditions that can't be translated into index scan keys. Consider this: create table t (a int, b int, c int); insert into t select 1000 * random(), 1000 * random(), 1000 * random() from generate_series(1,1000000) s(i); create index on t (a,b); vacuum analyze t; explain (analyze, buffers) select * from t where a = 10 and mod(b,10) = 1111111; QUERY PLAN ----------------------------------------------------------------------------------------------------------------- Index Scan using t_a_b_idx on t (cost=0.42..3670.74 rows=5 width=12) (actual time=4.562..4.564 rows=0 loops=1) Index Cond: (a = 10) Filter: (mod(b, 10) = 1111111) Rows Removed by Filter: 974 Buffers: shared hit=980 Prefetches: blocks=901 Planning Time: 0.304 ms Execution Time: 5.146 ms (8 rows) Notice that this still fetched ~1000 buffers in order to evaluate the filter on "b", because it's complex and can't be transformed into a nice scan key. Or this: explain (analyze, buffers) select a from t where a = 10 and (b+1) < 100 and c < 0; QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using t_a_b_idx on t (cost=0.42..3673.22 rows=1 width=4) (actual time=4.446..4.448 rows=0 loops=1) Index Cond: (a = 10) Filter: ((c < 0) AND ((b + 1) < 100)) Rows Removed by Filter: 974 Buffers: shared hit=980 Prefetches: blocks=901 Planning Time: 0.313 ms Execution Time: 4.878 ms (8 rows) where it's "broken" by the extra unindexed column. FWIW there are the primary cases I had in mind for this patch. > >> What do you mean by "create normal compound index"? The patch addresses >> a limitation that not every condition can be translated into a proper >> scan key. Even if we improve this, there will always be such conditions. >> The the IOS can evaluate them on index tuple, the regular index scan >> can't do that (currently). >> >> Can you share an example demonstrating the alternative approach? > > May be I missed something. > > This is the example from > https://www.postgresql.org/message-id/flat/N1xaIrU29uk5YxLyW55MGk5fz9s6V2FNtj54JRaVlFbPixD5z8sJ07Ite5CvbWwik8ZvDG07oSTN-usENLVMq2UAcizVTEd5b-o16ZGDIIU=@yamlcoder.me : > > ``` > > And here is the plan with index on (a,b). > > Limit (cost=0.42..4447.90 rows=1 width=12) (actual time=6.883..6.884 > rows=0 loops=1) Output: a, b, d Buffers: shared hit=613 -> > Index Scan using t_a_b_idx on public.t (cost=0.42..4447.90 rows=1 > width=12) (actual time=6.880..6.881 rows=0 loops=1) Output: a, > b, d Index Cond: ((t.a > 1000000) AND (t.b = 4)) > Buffers: shared hit=613 Planning: Buffers: shared hit=41 Planning > Time: 0.314 ms Execution Time: 6.910 ms ``` > > > Isn't it an optimal plan for this query? > > And cite from self reproducible example https://dbfiddle.uk/iehtq44L : > ``` > create unique index t_a_include_b on t(a) include (b); > -- I'd expecd index above to behave the same as index below for this query > --create unique index on t(a,b); > ``` > > I agree that it is natural to expect the same result for both indexes. > So this PR definitely makes sense. > My point is only that compound index (a,b) in this case is more natural > and preferable. > Yes, perhaps. But you may also see it from the other direction - if you already have an index with included columns (for whatever reason), it would be nice to leverage that if possible. And as I mentioned above, it's not always the case that move a column from "included" to a proper key, or stuff like that. Anyway, it seems entirely unrelated to this prefetching thread. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/21/24 20:56, Konstantin Knizhnik wrote:
>
> On 19/01/2024 2:35 pm, Tomas Vondra wrote:
>>
>> On 1/19/24 09:34, Konstantin Knizhnik wrote:
>>> On 18/01/2024 6:00 pm, Tomas Vondra wrote:
>>>> On 1/17/24 09:45, Konstantin Knizhnik wrote:
>>>>> I have integrated your prefetch patch in Neon and it actually works!
>>>>> Moreover, I combined it with prefetch of leaf pages for IOS and it
>>>>> also
>>>>> seems to work.
>>>>>
>>>> Cool! And do you think this is the right design/way to do this?
>>> I like the idea of prefetching TIDs in executor.
>>>
>>> But looking though your patch I have some questions:
>>>
>>>
>>> 1. Why it is necessary to allocate and store all_visible flag in data
>>> buffer. Why caller of IndexPrefetchNext can not look at prefetch field?
>>>
>>> + /* store the all_visible flag in the private part of the
>>> entry */
>>> + entry->data = palloc(sizeof(bool));
>>> + *(bool *) entry->data = all_visible;
>>>
>> What you mean by "prefetch field"?
>
>
> I mean "prefetch" field of IndexPrefetchEntry:
>
> +
> +typedef struct IndexPrefetchEntry
> +{
> + ItemPointerData tid;
> +
> + /* should we prefetch heap page for this TID? */
> + bool prefetch;
> +
>
> You store the same flag twice:
>
> + /* prefetch only if not all visible */
> + entry->prefetch = !all_visible;
> +
> + /* store the all_visible flag in the private part of the entry */
> + entry->data = palloc(sizeof(bool));
> + *(bool *) entry->data = all_visible;
>
> My question was: why do we need to allocate something in entry->data and
> store all_visible in it, while we already stored !all-visible in
> entry->prefetch.
>
Ah, right. Well, you're right in this case we perhaps could set just one
of those flags, but the "purpose" of the two places is quite different.
The "prefetch" flag is fully controlled by the prefetcher, and it's up
to it to change it (e.g. I can easily imagine some new logic touching
setting it to "false" for some reason).
The "data" flag is fully controlled by the custom callbacks, so whatever
the callback stores, will be there.
I don't think it's worth simplifying this. In particular, I don't think
the callback can assume it can rely on the "prefetch" flag.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
2024-01 Commitfest. Hi, This patch has a CF status of "Needs Review" [1], but it seems like there were CFbot test failures last time it was run [2]. Please have a look and post an updated version if necessary. ====== [1] https://commitfest.postgresql.org/46/4351/ [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest/46/4351 Kind Regards, Peter Smith.
h, right. Well, you're right in this case we perhaps could set just oneof those flags, but the "purpose" of the two places is quite different. The "prefetch" flag is fully controlled by the prefetcher, and it's up to it to change it (e.g. I can easily imagine some new logic touching setting it to "false" for some reason). The "data" flag is fully controlled by the custom callbacks, so whatever the callback stores, will be there. I don't think it's worth simplifying this. In particular, I don't think the callback can assume it can rely on the "prefetch" flag.
Why not to add "all_visible" flag to IndexPrefetchEntry ? If will not cause any extra space overhead (because of alignment), but allows to avoid dynamic memory allocation (not sure if it is critical, but nice to avoid if possible).
Why we can prefer covering index to compound index? I see only two good reasons: 1. Extra columns type do not have comparison function need for AM. 2. The extra columns are never used in query predicate.Or maybe you don't want to include the columns in a UNIQUE constraint?
Do you mean that compound index (a,b) can not be used to enforce uniqueness of "a"?
If so, I agree.
If you are going to use this columns in query predicates I do not see much sense in creating inclusive index rather than compound index. Do you?But this is also about conditions that can't be translated into index scan keys. Consider this: create table t (a int, b int, c int); insert into t select 1000 * random(), 1000 * random(), 1000 * random() from generate_series(1,1000000) s(i); create index on t (a,b); vacuum analyze t; explain (analyze, buffers) select * from t where a = 10 and mod(b,10) = 1111111; QUERY PLAN ----------------------------------------------------------------------------------------------------------------- Index Scan using t_a_b_idx on t (cost=0.42..3670.74 rows=5 width=12) (actual time=4.562..4.564 rows=0 loops=1) Index Cond: (a = 10) Filter: (mod(b, 10) = 1111111) Rows Removed by Filter: 974 Buffers: shared hit=980 Prefetches: blocks=901 Planning Time: 0.304 ms Execution Time: 5.146 ms (8 rows) Notice that this still fetched ~1000 buffers in order to evaluate the filter on "b", because it's complex and can't be transformed into a nice scan key.
O yes.
Looks like I didn't understand the logic when predicate is included in index condition and when not.
It seems to be natural that only such predicate which specifies some range can be included in index condition.
But it is not the case:
postgres=# explain select * from t where a = 10 and b in (10,20,30); QUERY PLAN
--------------------------------------------------------------------- Index Scan using t_a_b_idx on t (cost=0.42..25.33 rows=3 width=12) Index Cond: ((a = 10) AND (b = ANY ('{10,20,30}'::integer[])))
(2 rows)
So I though ANY predicate using index keys is included in index condition.
But it is not true (as your example shows).
But IMHO mod(b,10)=111111 or (b+1) < 100 are both quite rare predicates this is why I named this use cases "exotic".
In any case, if we have some columns in index tuple it is desired to use them for filtering before extracting heap tuple.
But I afraid it will be not so easy to implement...
On 1/19/24 22:43, Melanie Plageman wrote: > On Fri, Jan 12, 2024 at 11:42 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 1/9/24 21:31, Robert Haas wrote: >>> On Thu, Jan 4, 2024 at 9:55 AM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> Here's a somewhat reworked version of the patch. My initial goal was to >>>> see if it could adopt the StreamingRead API proposed in [1], but that >>>> turned out to be less straight-forward than I hoped, for two reasons: >>> >>> I guess we need Thomas or Andres or maybe Melanie to comment on this. >>> >> >> Yeah. Or maybe Thomas if he has thoughts on how to combine this with the >> streaming I/O stuff. > > I've been studying your patch with the intent of finding a way to > change it and or the streaming read API to work together. I've > attached a very rough sketch of how I think it could work. > Thanks. > We fill a queue with blocks from TIDs that we fetched from the index. > The queue is saved in a scan descriptor that is made available to the > streaming read callback. Once the queue is full, we invoke the table > AM specific index_fetch_tuple() function which calls > pg_streaming_read_buffer_get_next(). When the streaming read API > invokes the callback we registered, it simply dequeues a block number > for prefetching. So in a way there are two queues in IndexFetchTableData. One (blk_queue) is being filled from IndexNext, and then the queue in StreamingRead. > The only change to the streaming read API is that now, even if the > callback returns InvalidBlockNumber, we may not be finished, so make > it resumable. > Hmm, not sure when can the callback return InvalidBlockNumber before reaching the end. Perhaps for the first index_fetch_heap call? Any reason not to fill the blk_queue before calling index_fetch_heap? > Structurally, this changes the timing of when the heap blocks are > prefetched. Your code would get a tid from the index and then prefetch > the heap block -- doing this until it filled a queue that had the > actual tids saved in it. With my approach and the streaming read API, > you fetch tids from the index until you've filled up a queue of block > numbers. Then the streaming read API will prefetch those heap blocks. > And is that a good/desirable change? I'm not saying it's not, but maybe we should not be filling either queue in one go - we don't want to overload the prefetching. > I didn't actually implement the block queue -- I just saved a single > block number and pretended it was a block queue. I was imagining we > replace this with something like your IndexPrefetch->blockItems -- > which has light deduplication. We'd probably have to flesh it out more > than that. > I don't understand how this passes the TID to the index_fetch_heap. Isn't it working only by accident, due to blk_queue only having a single entry? Shouldn't the first queue (blk_queue) store TIDs instead? > There are also table AM layering violations in my sketch which would > have to be worked out (not to mention some resource leakage I didn't > bother investigating [which causes it to fail tests]). > > 0001 is all of Thomas' streaming read API code that isn't yet in > master and 0002 is my rough sketch of index prefetching using the > streaming read API > > There are also numerous optimizations that your index prefetching > patch set does that would need to be added in some way. I haven't > thought much about it yet. I wanted to see what you thought of this > approach first. Basically, is it workable? > It seems workable, yes. I'm not sure it's much simpler than my patch (considering a lot of the code is in the optimizations, which are missing from this patch). I think the question is where should the optimizations happen. I suppose some of them might/should happen in the StreamingRead API itself - like the detection of sequential patterns, recently prefetched blocks, ... But I'm not sure what to do about optimizations that are more specific to the access path. Consider for example the index-only scans. We don't want to prefetch all the pages, we need to inspect the VM and prefetch just the not-all-visible ones. And then pass the info to the index scan, so that it does not need to check the VM again. It's not clear to me how to do this with this approach. The main -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 23, 2024 at 12:43 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 1/19/24 22:43, Melanie Plageman wrote: > > > We fill a queue with blocks from TIDs that we fetched from the index. > > The queue is saved in a scan descriptor that is made available to the > > streaming read callback. Once the queue is full, we invoke the table > > AM specific index_fetch_tuple() function which calls > > pg_streaming_read_buffer_get_next(). When the streaming read API > > invokes the callback we registered, it simply dequeues a block number > > for prefetching. > > So in a way there are two queues in IndexFetchTableData. One (blk_queue) > is being filled from IndexNext, and then the queue in StreamingRead. I've changed the name from blk_queue to tid_queue to fix the issue you mention in your later remarks. I suppose there are two queues. The tid_queue is just to pass the block requests to the streaming read API. The prefetch distance will be the smaller of the two sizes. > > The only change to the streaming read API is that now, even if the > > callback returns InvalidBlockNumber, we may not be finished, so make > > it resumable. > > Hmm, not sure when can the callback return InvalidBlockNumber before > reaching the end. Perhaps for the first index_fetch_heap call? Any > reason not to fill the blk_queue before calling index_fetch_heap? The callback will return InvalidBlockNumber whenever the queue is empty. Let's say your queue size is 5 and your effective prefetch distance is 10 (some combination of the PgStreamingReadRange sizes and PgStreamingRead->max_ios). The first time you call index_fetch_heap(), the callback returns InvalidBlockNumber. Then the tid_queue is filled with 5 tids. Then index_fetch_heap() is called. pg_streaming_read_look_ahead() will prefetch all 5 of these TID's blocks, emptying the queue. Once all 5 have been dequeued, the callback will return InvalidBlockNumber. pg_streaming_read_buffer_get_next() will return one of the 5 blocks in a buffer and save the associated TID in the per_buffer_data. Before index_fetch_heap() is called again, we will see that the queue is not full and fill it up again with 5 TIDs. So, the callback will return InvalidBlockNumber 3 times in this scenario. > > Structurally, this changes the timing of when the heap blocks are > > prefetched. Your code would get a tid from the index and then prefetch > > the heap block -- doing this until it filled a queue that had the > > actual tids saved in it. With my approach and the streaming read API, > > you fetch tids from the index until you've filled up a queue of block > > numbers. Then the streaming read API will prefetch those heap blocks. > > And is that a good/desirable change? I'm not saying it's not, but maybe > we should not be filling either queue in one go - we don't want to > overload the prefetching. We can focus on the prefetch distance algorithm maintained in the streaming read API and then make sure that the tid_queue is larger than the desired prefetch distance maintained by the streaming read API. > > I didn't actually implement the block queue -- I just saved a single > > block number and pretended it was a block queue. I was imagining we > > replace this with something like your IndexPrefetch->blockItems -- > > which has light deduplication. We'd probably have to flesh it out more > > than that. > > I don't understand how this passes the TID to the index_fetch_heap. > Isn't it working only by accident, due to blk_queue only having a single > entry? Shouldn't the first queue (blk_queue) store TIDs instead? Oh dear! Fixed in the attached v2. I've replaced the single BlockNumber with a single ItemPointerData. I will work on implementing an actual queue next week. > > There are also table AM layering violations in my sketch which would > > have to be worked out (not to mention some resource leakage I didn't > > bother investigating [which causes it to fail tests]). > > > > 0001 is all of Thomas' streaming read API code that isn't yet in > > master and 0002 is my rough sketch of index prefetching using the > > streaming read API > > > > There are also numerous optimizations that your index prefetching > > patch set does that would need to be added in some way. I haven't > > thought much about it yet. I wanted to see what you thought of this > > approach first. Basically, is it workable? > > It seems workable, yes. I'm not sure it's much simpler than my patch > (considering a lot of the code is in the optimizations, which are > missing from this patch). > > I think the question is where should the optimizations happen. I suppose > some of them might/should happen in the StreamingRead API itself - like > the detection of sequential patterns, recently prefetched blocks, ... So, the streaming read API does detection of sequential patterns and not prefetching things that are in shared buffers. It doesn't handle avoiding prefetching recently prefetched blocks yet AFAIK. But I daresay this would be relevant for other streaming read users and could certainly be implemented there. > But I'm not sure what to do about optimizations that are more specific > to the access path. Consider for example the index-only scans. We don't > want to prefetch all the pages, we need to inspect the VM and prefetch > just the not-all-visible ones. And then pass the info to the index scan, > so that it does not need to check the VM again. It's not clear to me how > to do this with this approach. Yea, this is an issue I'll need to think about. To really spell out the problem: the callback dequeues a TID from the tid_queue and looks up its block in the VM. It's all visible. So, it shouldn't return that block to the streaming read API to fetch from the heap because it doesn't need to be read. But, where does the callback put the TID so that the caller can get it? I'm going to think more about this. As for passing around the all visible status so as to not reread the VM block -- that feels solvable but I haven't looked into it. - Melanie
Вложения
On 1/24/24 01:51, Melanie Plageman wrote: > On Tue, Jan 23, 2024 at 12:43 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 1/19/24 22:43, Melanie Plageman wrote: >> >>> We fill a queue with blocks from TIDs that we fetched from the index. >>> The queue is saved in a scan descriptor that is made available to the >>> streaming read callback. Once the queue is full, we invoke the table >>> AM specific index_fetch_tuple() function which calls >>> pg_streaming_read_buffer_get_next(). When the streaming read API >>> invokes the callback we registered, it simply dequeues a block number >>> for prefetching. >> >> So in a way there are two queues in IndexFetchTableData. One (blk_queue) >> is being filled from IndexNext, and then the queue in StreamingRead. > > I've changed the name from blk_queue to tid_queue to fix the issue you > mention in your later remarks. > I suppose there are two queues. The tid_queue is just to pass the > block requests to the streaming read API. The prefetch distance will > be the smaller of the two sizes. > FWIW I think the two queues are a nice / elegant approach. In hindsight my problems with trying to utilize the StreamingRead were due to trying to use the block-oriented API directly from places that work with TIDs, and this just makes that go away. I wonder what the overhead of shuffling stuff between queues will be, but hopefully not too high (that's my assumption). >>> The only change to the streaming read API is that now, even if the >>> callback returns InvalidBlockNumber, we may not be finished, so make >>> it resumable. >> >> Hmm, not sure when can the callback return InvalidBlockNumber before >> reaching the end. Perhaps for the first index_fetch_heap call? Any >> reason not to fill the blk_queue before calling index_fetch_heap? > > The callback will return InvalidBlockNumber whenever the queue is > empty. Let's say your queue size is 5 and your effective prefetch > distance is 10 (some combination of the PgStreamingReadRange sizes and > PgStreamingRead->max_ios). The first time you call index_fetch_heap(), > the callback returns InvalidBlockNumber. Then the tid_queue is filled > with 5 tids. Then index_fetch_heap() is called. > pg_streaming_read_look_ahead() will prefetch all 5 of these TID's > blocks, emptying the queue. Once all 5 have been dequeued, the > callback will return InvalidBlockNumber. > pg_streaming_read_buffer_get_next() will return one of the 5 blocks in > a buffer and save the associated TID in the per_buffer_data. Before > index_fetch_heap() is called again, we will see that the queue is not > full and fill it up again with 5 TIDs. So, the callback will return > InvalidBlockNumber 3 times in this scenario. > Thanks for the explanation. Yes, I didn't realize that the queues may be of different length, at which point it makes sense to return invalid block to signal the TID queue is empty. >>> Structurally, this changes the timing of when the heap blocks are >>> prefetched. Your code would get a tid from the index and then prefetch >>> the heap block -- doing this until it filled a queue that had the >>> actual tids saved in it. With my approach and the streaming read API, >>> you fetch tids from the index until you've filled up a queue of block >>> numbers. Then the streaming read API will prefetch those heap blocks. >> >> And is that a good/desirable change? I'm not saying it's not, but maybe >> we should not be filling either queue in one go - we don't want to >> overload the prefetching. > > We can focus on the prefetch distance algorithm maintained in the > streaming read API and then make sure that the tid_queue is larger > than the desired prefetch distance maintained by the streaming read > API. > Agreed. I think I wasn't quite right when concerned about "overloading" the prefetch, because that depends entirely on the StreamingRead API queue. A lage TID queue can't cause overload of anything. What could happen is a TID queue being too small, so the prefetch can't hit the target distance. But that can happen already, e.g. indexes that are correlated and/or index-only scans with all-visible pages. >>> There are also table AM layering violations in my sketch which would >>> have to be worked out (not to mention some resource leakage I didn't >>> bother investigating [which causes it to fail tests]). >>> >>> 0001 is all of Thomas' streaming read API code that isn't yet in >>> master and 0002 is my rough sketch of index prefetching using the >>> streaming read API >>> >>> There are also numerous optimizations that your index prefetching >>> patch set does that would need to be added in some way. I haven't >>> thought much about it yet. I wanted to see what you thought of this >>> approach first. Basically, is it workable? >> >> It seems workable, yes. I'm not sure it's much simpler than my patch >> (considering a lot of the code is in the optimizations, which are >> missing from this patch). >> >> I think the question is where should the optimizations happen. I suppose >> some of them might/should happen in the StreamingRead API itself - like >> the detection of sequential patterns, recently prefetched blocks, ... > > So, the streaming read API does detection of sequential patterns and > not prefetching things that are in shared buffers. It doesn't handle > avoiding prefetching recently prefetched blocks yet AFAIK. But I > daresay this would be relevant for other streaming read users and > could certainly be implemented there. > Yes, the "recently prefetched stuff" cache seems like a fairly natural complement to the pattern detection and shared-buffers check. FWIW I wonder if we should make some of this customizable, so that systems with customized storage (e.g. neon or with direct I/O) can e.g. disable some of these checks. Or replace them with their version. >> But I'm not sure what to do about optimizations that are more specific >> to the access path. Consider for example the index-only scans. We don't >> want to prefetch all the pages, we need to inspect the VM and prefetch >> just the not-all-visible ones. And then pass the info to the index scan, >> so that it does not need to check the VM again. It's not clear to me how >> to do this with this approach. > > Yea, this is an issue I'll need to think about. To really spell out > the problem: the callback dequeues a TID from the tid_queue and looks > up its block in the VM. It's all visible. So, it shouldn't return that > block to the streaming read API to fetch from the heap because it > doesn't need to be read. But, where does the callback put the TID so > that the caller can get it? I'm going to think more about this. > Yes, that's the problem for index-only scans. I'd generalize it so that it's about the callback being able to (a) decide if it needs to read the heap page, and (b) store some custom info for the TID. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/22/24 08:21, Konstantin Knizhnik wrote:
>
> On 22/01/2024 1:39 am, Tomas Vondra wrote:
>>> Why we can prefer covering index to compound index? I see only two good
>>> reasons:
>>> 1. Extra columns type do not have comparison function need for AM.
>>> 2. The extra columns are never used in query predicate.
>>>
>> Or maybe you don't want to include the columns in a UNIQUE constraint?
>>
> Do you mean that compound index (a,b) can not be used to enforce
> uniqueness of "a"?
> If so, I agree.
>
Yes.
>>> If you are going to use this columns in query predicates I do not see
>>> much sense in creating inclusive index rather than compound index.
>>> Do you?
>>>
>> But this is also about conditions that can't be translated into index
>> scan keys. Consider this:
>>
>> create table t (a int, b int, c int);
>> insert into t select 1000 * random(), 1000 * random(), 1000 * random()
>> from generate_series(1,1000000) s(i);
>> create index on t (a,b);
>> vacuum analyze t;
>>
>> explain (analyze, buffers) select * from t where a = 10 and mod(b,10) =
>> 1111111;
>> QUERY PLAN
>>
>> -----------------------------------------------------------------------------------------------------------------
>> Index Scan using t_a_b_idx on t (cost=0.42..3670.74 rows=5 width=12)
>> (actual time=4.562..4.564 rows=0 loops=1)
>> Index Cond: (a = 10)
>> Filter: (mod(b, 10) = 1111111)
>> Rows Removed by Filter: 974
>> Buffers: shared hit=980
>> Prefetches: blocks=901
>> Planning Time: 0.304 ms
>> Execution Time: 5.146 ms
>> (8 rows)
>>
>> Notice that this still fetched ~1000 buffers in order to evaluate the
>> filter on "b", because it's complex and can't be transformed into a nice
>> scan key.
>
> O yes.
> Looks like I didn't understand the logic when predicate is included in
> index condition and when not.
> It seems to be natural that only such predicate which specifies some
> range can be included in index condition.
> But it is not the case:
>
> postgres=# explain select * from t where a = 10 and b in (10,20,30);
> QUERY PLAN
> ---------------------------------------------------------------------
> Index Scan using t_a_b_idx on t (cost=0.42..25.33 rows=3 width=12)
> Index Cond: ((a = 10) AND (b = ANY ('{10,20,30}'::integer[])))
> (2 rows)
>
> So I though ANY predicate using index keys is included in index condition.
> But it is not true (as your example shows).
>
> But IMHO mod(b,10)=111111 or (b+1) < 100 are both quite rare predicates
> this is why I named this use cases "exotic".
Not sure I agree with describing this as "exotic".
The same thing applies to an arbitrary function call. And those are
pretty common in conditions - date_part/date_trunc. Arithmetic
expressions are not that uncommon either. Also, users sometimes have
conditions comparing multiple keys (a<b) etc.
But even if it was "uncommon", the whole point of this patch is to
eliminate these corner cases where a user does something minor (like
adding an output column), and the executor disables an optimization
unnecessarily, causing unexpected regressions.
>
> In any case, if we have some columns in index tuple it is desired to use
> them for filtering before extracting heap tuple.
> But I afraid it will be not so easy to implement...
>
I'm not sure what you mean. The patch does that, more or less. There's
issues that need to be solved (e.g. to decide when not to do this), and
how to integrate that into the scan interface (where the quals are
evaluated at the end).
What do you mean when you say "will not be easy to implement"? What
problems do you foresee?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 1/22/24 07:35, Konstantin Knizhnik wrote: > > On 22/01/2024 1:47 am, Tomas Vondra wrote: >> h, right. Well, you're right in this case we perhaps could set just one >> of those flags, but the "purpose" of the two places is quite different. >> >> The "prefetch" flag is fully controlled by the prefetcher, and it's up >> to it to change it (e.g. I can easily imagine some new logic touching >> setting it to "false" for some reason). >> >> The "data" flag is fully controlled by the custom callbacks, so whatever >> the callback stores, will be there. >> >> I don't think it's worth simplifying this. In particular, I don't think >> the callback can assume it can rely on the "prefetch" flag. >> > Why not to add "all_visible" flag to IndexPrefetchEntry ? If will not > cause any extra space overhead (because of alignment), but allows to > avoid dynamic memory allocation (not sure if it is critical, but nice to > avoid if possible). > Because it's specific to index-only scans, while IndexPrefetchEntry is a generic thing, for all places. However: (1) Melanie actually presented a very different way to implement this, relying on the StreamingRead API. So chances are this struct won't actually be used. (2) After going through Melanie's patch, I realized this is actually broken. The IOS case needs to keep more stuff, not just the all-visible flag, but also the index tuple. Otherwise it'll just operate on the last tuple read from the index, which happens to be in xs_ituple. Attached is a patch with a trivial fix. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
On Wed, Jan 24, 2024 at 4:19 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 1/24/24 01:51, Melanie Plageman wrote: > > >>> There are also table AM layering violations in my sketch which would > >>> have to be worked out (not to mention some resource leakage I didn't > >>> bother investigating [which causes it to fail tests]). > >>> > >>> 0001 is all of Thomas' streaming read API code that isn't yet in > >>> master and 0002 is my rough sketch of index prefetching using the > >>> streaming read API > >>> > >>> There are also numerous optimizations that your index prefetching > >>> patch set does that would need to be added in some way. I haven't > >>> thought much about it yet. I wanted to see what you thought of this > >>> approach first. Basically, is it workable? > >> > >> It seems workable, yes. I'm not sure it's much simpler than my patch > >> (considering a lot of the code is in the optimizations, which are > >> missing from this patch). > >> > >> I think the question is where should the optimizations happen. I suppose > >> some of them might/should happen in the StreamingRead API itself - like > >> the detection of sequential patterns, recently prefetched blocks, ... > > > > So, the streaming read API does detection of sequential patterns and > > not prefetching things that are in shared buffers. It doesn't handle > > avoiding prefetching recently prefetched blocks yet AFAIK. But I > > daresay this would be relevant for other streaming read users and > > could certainly be implemented there. > > > > Yes, the "recently prefetched stuff" cache seems like a fairly natural > complement to the pattern detection and shared-buffers check. > > FWIW I wonder if we should make some of this customizable, so that > systems with customized storage (e.g. neon or with direct I/O) can e.g. > disable some of these checks. Or replace them with their version. That's a promising idea. > >> But I'm not sure what to do about optimizations that are more specific > >> to the access path. Consider for example the index-only scans. We don't > >> want to prefetch all the pages, we need to inspect the VM and prefetch > >> just the not-all-visible ones. And then pass the info to the index scan, > >> so that it does not need to check the VM again. It's not clear to me how > >> to do this with this approach. > > > > Yea, this is an issue I'll need to think about. To really spell out > > the problem: the callback dequeues a TID from the tid_queue and looks > > up its block in the VM. It's all visible. So, it shouldn't return that > > block to the streaming read API to fetch from the heap because it > > doesn't need to be read. But, where does the callback put the TID so > > that the caller can get it? I'm going to think more about this. > > > > Yes, that's the problem for index-only scans. I'd generalize it so that > it's about the callback being able to (a) decide if it needs to read the > heap page, and (b) store some custom info for the TID. Actually, I think this is no big deal. See attached. I just don't enqueue tids whose blocks are all visible. I had to switch the order from fetch heap then fill queue to fill queue then fetch heap. While doing this I noticed some wrong results in the regression tests (like in the alter table test), so I suspect I have some kind of control flow issue. Perhaps I should fix the resource leak so I can actually see the failing tests :) As for your a) and b) above. Regarding a): We discussed allowing speculative prefetching and separating the logic for prefetching from actually reading blocks (so you can prefetch blocks you ultimately don't read). We decided this may not belong in a streaming read API. What do you think? Regarding b): We can store per buffer data for anything that actually goes down through the streaming read API, but, in the index only case, we don't want the streaming read API to know about blocks that it doesn't actually need to read. - Melanie
Вложения
On Wed, Jan 24, 2024 at 11:43 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> On 1/22/24 07:35, Konstantin Knizhnik wrote:
> >
> > On 22/01/2024 1:47 am, Tomas Vondra wrote:
> >> h, right. Well, you're right in this case we perhaps could set just one
> >> of those flags, but the "purpose" of the two places is quite different.
> >>
> >> The "prefetch" flag is fully controlled by the prefetcher, and it's up
> >> to it to change it (e.g. I can easily imagine some new logic touching
> >> setting it to "false" for some reason).
> >>
> >> The "data" flag is fully controlled by the custom callbacks, so whatever
> >> the callback stores, will be there.
> >>
> >> I don't think it's worth simplifying this. In particular, I don't think
> >> the callback can assume it can rely on the "prefetch" flag.
> >>
> > Why not to add "all_visible" flag to IndexPrefetchEntry ? If will not
> > cause any extra space overhead (because of alignment), but allows to
> > avoid dynamic memory allocation (not sure if it is critical, but nice to
> > avoid if possible).
> >
>
While reading through the first patch I got some questions, I haven't
read it complete yet but this is what I got so far.
1.
+static bool
+IndexPrefetchBlockIsSequential(IndexPrefetch *prefetch, BlockNumber block)
+{
+ int idx;
...
+ if (prefetch->blockItems[idx] != (block - i))
+ return false;
+
+ /* Don't prefetch if the block happens to be the same. */
+ if (prefetch->blockItems[idx] == block)
+ return false;
+ }
+
+ /* not sequential, not recently prefetched */
+ return true;
+}
The above function name is BlockIsSequential but at the end, it
returns true if it is not sequential, seem like a problem?
Also other 2 checks right above the end of the function are returning
false if the block is the same or the pattern is sequential I think
those are wrong too.
2.
I have noticed that the prefetch history is maintained at the backend
level, but what if multiple backends are trying to fetch the same heap
blocks maybe scanning the same index, so should that be in some shared
structure? I haven't thought much deeper about this from the
implementation POV, but should we think about it, or it doesn't
matter?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On 1/25/24 11:45, Dilip Kumar wrote:
> On Wed, Jan 24, 2024 at 11:43 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>
>> On 1/22/24 07:35, Konstantin Knizhnik wrote:
>>>
>>> On 22/01/2024 1:47 am, Tomas Vondra wrote:
>>>> h, right. Well, you're right in this case we perhaps could set just one
>>>> of those flags, but the "purpose" of the two places is quite different.
>>>>
>>>> The "prefetch" flag is fully controlled by the prefetcher, and it's up
>>>> to it to change it (e.g. I can easily imagine some new logic touching
>>>> setting it to "false" for some reason).
>>>>
>>>> The "data" flag is fully controlled by the custom callbacks, so whatever
>>>> the callback stores, will be there.
>>>>
>>>> I don't think it's worth simplifying this. In particular, I don't think
>>>> the callback can assume it can rely on the "prefetch" flag.
>>>>
>>> Why not to add "all_visible" flag to IndexPrefetchEntry ? If will not
>>> cause any extra space overhead (because of alignment), but allows to
>>> avoid dynamic memory allocation (not sure if it is critical, but nice to
>>> avoid if possible).
>>>
>>
> While reading through the first patch I got some questions, I haven't
> read it complete yet but this is what I got so far.
>
> 1.
> +static bool
> +IndexPrefetchBlockIsSequential(IndexPrefetch *prefetch, BlockNumber block)
> +{
> + int idx;
> ...
> + if (prefetch->blockItems[idx] != (block - i))
> + return false;
> +
> + /* Don't prefetch if the block happens to be the same. */
> + if (prefetch->blockItems[idx] == block)
> + return false;
> + }
> +
> + /* not sequential, not recently prefetched */
> + return true;
> +}
>
> The above function name is BlockIsSequential but at the end, it
> returns true if it is not sequential, seem like a problem?
Actually, I think it's the comment that's wrong - the last return is
reached only for a sequential pattern (and when the block was not
accessed recently).
> Also other 2 checks right above the end of the function are returning
> false if the block is the same or the pattern is sequential I think
> those are wrong too.
>
Hmmm. You're right this is partially wrong. There are two checks:
/*
* For a sequential pattern, blocks "k" step ago needs to have block
* number by "k" smaller compared to the current block.
*/
if (prefetch->blockItems[idx] != (block - i))
return false;
/* Don't prefetch if the block happens to be the same. */
if (prefetch->blockItems[idx] == block)
return false;
The first condition is correct - we want to return "false" when the
pattern is not sequential.
But the second condition is wrong - we want to skip prefetching when the
block was already prefetched recently, so this should return true (which
is a bit misleading, as it seems to imply the pattern is sequential,
when it's not).
However, this is harmless, because we then identify this block as
recently prefetched in the "full" cache check, so we won't prefetch it
anyway. So it's harmless, although a bit more expensive.
There's another inefficiency - we stop looking for the same block once
we find the first block breaking the non-sequential pattern. Imagine a
sequence of blocks 1, 2, 3, 1, 2, 3, ... in which case we never notice
the block was recently prefetched, because we always find the break of
the sequential pattern. But again, it's harmless, thanks to the full
cache of recently prefetched blocks.
> 2.
> I have noticed that the prefetch history is maintained at the backend
> level, but what if multiple backends are trying to fetch the same heap
> blocks maybe scanning the same index, so should that be in some shared
> structure? I haven't thought much deeper about this from the
> implementation POV, but should we think about it, or it doesn't
> matter?
Yes, the cache is at the backend level - it's a known limitation, but I
see it more as a conscious tradeoff.
Firstly, while the LRU cache is at backend level, PrefetchBuffer also
checks shared buffers for each prefetch request. So with sufficiently
large shared buffers we're likely to find it there (and for direct I/O
there won't be any other place to check).
Secondly, the only other place to check is page cache, but there's no
good (sufficiently cheap) way to check that. See the preadv2/nowait
experiment earlier in this thread.
I suppose we could implement a similar LRU cache for shared memory (and
I don't think it'd be very complicated), but I did not plan to do that
in this patch unless absolutely necessary.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jan 24, 2024 at 3:20 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Wed, Jan 24, 2024 at 4:19 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > On 1/24/24 01:51, Melanie Plageman wrote: > > >> But I'm not sure what to do about optimizations that are more specific > > >> to the access path. Consider for example the index-only scans. We don't > > >> want to prefetch all the pages, we need to inspect the VM and prefetch > > >> just the not-all-visible ones. And then pass the info to the index scan, > > >> so that it does not need to check the VM again. It's not clear to me how > > >> to do this with this approach. > > > > > > Yea, this is an issue I'll need to think about. To really spell out > > > the problem: the callback dequeues a TID from the tid_queue and looks > > > up its block in the VM. It's all visible. So, it shouldn't return that > > > block to the streaming read API to fetch from the heap because it > > > doesn't need to be read. But, where does the callback put the TID so > > > that the caller can get it? I'm going to think more about this. > > > > > > > Yes, that's the problem for index-only scans. I'd generalize it so that > > it's about the callback being able to (a) decide if it needs to read the > > heap page, and (b) store some custom info for the TID. > > Actually, I think this is no big deal. See attached. I just don't > enqueue tids whose blocks are all visible. I had to switch the order > from fetch heap then fill queue to fill queue then fetch heap. > > While doing this I noticed some wrong results in the regression tests > (like in the alter table test), so I suspect I have some kind of > control flow issue. Perhaps I should fix the resource leak so I can > actually see the failing tests :) Attached is a patch which implements a real queue and fixes some of the issues with the previous version. It doesn't pass tests yet and has issues. Some are bugs in my implementation I need to fix. Some are issues we would need to solve in the streaming read API. Some are issues with index prefetching generally. Note that these two patches have to be applied before 21d9c3ee4e because Thomas hasn't released a rebased version of the streaming read API patches yet. Issues --- - kill prior tuple This optimization doesn't work with index prefetching with the current design. Kill prior tuple relies on alternating between fetching a single index tuple and visiting the heap. After visiting the heap we can potentially kill the immediately preceding index tuple. Once we fetch multiple index tuples, enqueue their TIDs, and later visit the heap, the next index page we visit may not contain all of the index tuples deemed killable by our visit to the heap. In our case, we could try and fix this by prefetching only heap blocks referred to by index tuples on the same index page. Or we could try and keep a pool of index pages pinned and go back and kill index tuples on those pages. Having disabled kill_prior_tuple is why the mvcc test fails. Perhaps there is an easier way to fix this, as I don't think the mvcc test failed on Tomas' version. - switching scan directions If the index scan switches directions on a given invocation of IndexNext(), heap blocks may have already been prefetched and read for blocks containing tuples beyond the point at which we want to switch directions. We could fix this by having some kind of streaming read "reset" callback to drop all of the buffers which have been prefetched which are now no longer needed. We'd have to go backwards from the last TID which was yielded to the caller and figure out which buffers in the pgsr buffer ranges are associated with all of the TIDs which were prefetched after that TID. The TIDs are in the per_buffer_data associated with each buffer in pgsr. The issue would be searching through those efficiently. The other issue is that the streaming read API does not currently support backwards scans. So, if we switch to a backwards scan from a forwards scan, we would need to fallback to the non streaming read method. We could do this by just setting the TID queue size to 1 (which is what I have currently implemented). Or we could add backwards scan support to the streaming read API. - mark and restore Similar to the issue with switching the scan direction, mark and restore requires us to reset the TID queue and streaming read queue. For now, I've hacked in something to the PlannerInfo and Plan to set the TID queue size to 1 for plans containing a merge join (yikes). - multiple executions For reasons I don't entirely understand yet, multiple executions (not rescan -- see ExecutorRun(...execute_once)) do not work. As in Tomas' patch, I have disabled prefetching (and made the TID queue size 1) when execute_once is false. - Index Only Scans need to return IndexTuples Because index only scans return either the IndexTuple pointed to by IndexScanDesc->xs_itup or the HeapTuple pointed to by IndexScanDesc->xs_hitup -- both of which are populated by the index AM, we have to save copies of those IndexTupleData and HeapTupleDatas for every TID whose block we prefetch. This might be okay, but it is a bit sad to have to make copies of those tuples. In this patch, I still haven't figured out the memory management part. I copy over the tuples when enqueuing a TID queue item and then copy them back again when the streaming read API returns the per_buffer_data to us. Something is still not quite right here. I suspect this is part of the reason why some of the other tests are failing. Other issues/gaps in my implementation: Determining where to allocate the memory for the streaming read object and the TID queue is an outstanding TODO. To implement a fallback method for cases in which streaming read doesn't work, I set the queue size to 1. This is obviously not good. Right now, I allocate the TID queue and streaming read objects in IndexNext() and IndexOnlyNext(). This doesn't seem ideal. Doing it in index_beginscan() (and index_beginscan_parallel()) is tricky though because we don't know the scan direction at that point (and the scan direction can change). There are also callers of index_beginscan() who do not call Index[Only]Next() (like systable_getnext() which calls index_getnext_slot() directly). Also, my implementation does not yet have the optimization Tomas does to skip prefetching recently prefetched blocks. As he has said, it probably makes sense to add something to do this in a lower layer -- such as in the streaming read API or even in bufmgr.c (maybe in PrefetchSharedBuffer()). - Melanie
Вложения
On 2/7/24 22:48, Melanie Plageman wrote: > ... > > Attached is a patch which implements a real queue and fixes some of > the issues with the previous version. It doesn't pass tests yet and > has issues. Some are bugs in my implementation I need to fix. Some are > issues we would need to solve in the streaming read API. Some are > issues with index prefetching generally. > > Note that these two patches have to be applied before 21d9c3ee4e > because Thomas hasn't released a rebased version of the streaming read > API patches yet. > Thanks for working on this, and for investigating the various issues. > Issues > --- > - kill prior tuple > > This optimization doesn't work with index prefetching with the current > design. Kill prior tuple relies on alternating between fetching a > single index tuple and visiting the heap. After visiting the heap we > can potentially kill the immediately preceding index tuple. Once we > fetch multiple index tuples, enqueue their TIDs, and later visit the > heap, the next index page we visit may not contain all of the index > tuples deemed killable by our visit to the heap. > I admit I haven't thought about kill_prior_tuple until you pointed out. Yeah, prefetching separates (de-synchronizes) the two scans (index and heap) in a way that prevents this optimization. Or at least makes it much more complex :-( > In our case, we could try and fix this by prefetching only heap blocks > referred to by index tuples on the same index page. Or we could try > and keep a pool of index pages pinned and go back and kill index > tuples on those pages. > I think restricting the prefetching to a single index page would not be a huge issue performance-wise - that's what the initial patch version (implemented at the index AM level) did, pretty much. The prefetch queue would get drained as we approach the end of the index page, but luckily index pages tend to have a lot of entries. But it'd put an upper bound on the prefetch distance (much lower than the e_i_c maximum 1000, but I'd say common values are 10-100 anyway). But how would we know we're on the same index page? That knowledge is not available outside the index AM - the executor or indexam.c does not know this, right? Presumably we could expose this, somehow, but it seems like a violation of the abstraction ... The same thing affects keeping multiple index pages pinned, for TIDs that are yet to be used by the index scan. We'd need to know when to release a pinned page, once we're done with processing all items. FWIW I haven't tried to implementing any of this, so maybe I'm missing something and it can be made to work in a nice way. > Having disabled kill_prior_tuple is why the mvcc test fails. Perhaps > there is an easier way to fix this, as I don't think the mvcc test > failed on Tomas' version. > I kinda doubt it worked correctly, considering I simply ignored the optimization. It's far more likely it just worked by luck. > - switching scan directions > > If the index scan switches directions on a given invocation of > IndexNext(), heap blocks may have already been prefetched and read for > blocks containing tuples beyond the point at which we want to switch > directions. > > We could fix this by having some kind of streaming read "reset" > callback to drop all of the buffers which have been prefetched which > are now no longer needed. We'd have to go backwards from the last TID > which was yielded to the caller and figure out which buffers in the > pgsr buffer ranges are associated with all of the TIDs which were > prefetched after that TID. The TIDs are in the per_buffer_data > associated with each buffer in pgsr. The issue would be searching > through those efficiently. > Yeah, that's roughly what I envisioned in one of my previous messages about this issue - walking back the TIDs read from the index and added to the prefetch queue. > The other issue is that the streaming read API does not currently > support backwards scans. So, if we switch to a backwards scan from a > forwards scan, we would need to fallback to the non streaming read > method. We could do this by just setting the TID queue size to 1 > (which is what I have currently implemented). Or we could add > backwards scan support to the streaming read API. > What do you mean by "support for backwards scans" in the streaming read API? I imagined it naively as 1) drop all requests in the streaming read API queue 2) walk back all "future" requests in the TID queue 3) start prefetching as if from scratch Maybe there's a way to optimize this and reuse some of the work more efficiently, but my assumption is that the scan direction does not change very often, and that we process many items in between. > - mark and restore > > Similar to the issue with switching the scan direction, mark and > restore requires us to reset the TID queue and streaming read queue. > For now, I've hacked in something to the PlannerInfo and Plan to set > the TID queue size to 1 for plans containing a merge join (yikes). > Haven't thought about this very much, will take a closer look. > - multiple executions > > For reasons I don't entirely understand yet, multiple executions (not > rescan -- see ExecutorRun(...execute_once)) do not work. As in Tomas' > patch, I have disabled prefetching (and made the TID queue size 1) > when execute_once is false. > Don't work in what sense? What is (not) happening? > - Index Only Scans need to return IndexTuples > > Because index only scans return either the IndexTuple pointed to by > IndexScanDesc->xs_itup or the HeapTuple pointed to by > IndexScanDesc->xs_hitup -- both of which are populated by the index > AM, we have to save copies of those IndexTupleData and HeapTupleDatas > for every TID whose block we prefetch. > > This might be okay, but it is a bit sad to have to make copies of those tuples. > > In this patch, I still haven't figured out the memory management part. > I copy over the tuples when enqueuing a TID queue item and then copy > them back again when the streaming read API returns the > per_buffer_data to us. Something is still not quite right here. I > suspect this is part of the reason why some of the other tests are > failing. > It's not clear to me what you need to copy the tuples back - shouldn't it be enough to copy the tuple just once? FWIW if we decide to pin multiple index pages (to make kill_prior_tuple work), that would also mean we don't need to copy any tuples, right? We could point into the buffers for all of them, right? > Other issues/gaps in my implementation: > > Determining where to allocate the memory for the streaming read object > and the TID queue is an outstanding TODO. To implement a fallback > method for cases in which streaming read doesn't work, I set the queue > size to 1. This is obviously not good. > I think IndexFetchTableData seems like a not entirely terrible place for allocating the pgsr, but I wonder what Andres thinks about this. IIRC he advocated for doing the prefetching in executor, and I'm not sure heapam_handled.c + relscan.h is what he imagined ... Also, when you say "obviously not good" - why? Are you concerned about the extra overhead of shuffling stuff between queues, or something else? > Right now, I allocate the TID queue and streaming read objects in > IndexNext() and IndexOnlyNext(). This doesn't seem ideal. Doing it in > index_beginscan() (and index_beginscan_parallel()) is tricky though > because we don't know the scan direction at that point (and the scan > direction can change). There are also callers of index_beginscan() who > do not call Index[Only]Next() (like systable_getnext() which calls > index_getnext_slot() directly). > Yeah, not sure this is the right layering ... the initial patch did everything in individual index AMs, then it moved to indexam.c, then to executor. And this seems to move it to lower layers again ... > Also, my implementation does not yet have the optimization Tomas does > to skip prefetching recently prefetched blocks. As he has said, it > probably makes sense to add something to do this in a lower layer -- > such as in the streaming read API or even in bufmgr.c (maybe in > PrefetchSharedBuffer()). > I agree this should happen in lower layers. I'd probably do this in the streaming read API, because that would define "scope" of the cache (pages prefetched for that read). Doing it in PrefetchSharedBuffer seems like it would do a single cache (for that particular backend). But that's just an initial thought ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 13, 2024 at 2:01 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 2/7/24 22:48, Melanie Plageman wrote: > I admit I haven't thought about kill_prior_tuple until you pointed out. > Yeah, prefetching separates (de-synchronizes) the two scans (index and > heap) in a way that prevents this optimization. Or at least makes it > much more complex :-( Another thing that argues against doing this is that we might not need to visit any more B-Tree leaf pages when there is a LIMIT n involved. We could end up scanning a whole extra leaf page (including all of its tuples) for want of the ability to "push down" a LIMIT to the index AM (that's not what happens right now, but it isn't really needed at all right now). This property of index scans is fundamental to how index scans work. Pinning an index page as an interlock against concurrently TID recycling by VACUUM is directly described by the index API docs [1], even (the docs actually use terms like "buffer pin" rather than something more abstract sounding). I don't think that anything affecting that behavior should be considered an implementation detail of the nbtree index AM as such (nor any particular index AM). I think that it makes sense to put the index AM in control here -- that almost follows from what I said about the index AM API. The index AM already needs to be in control, in about the same way, to deal with kill_prior_tuple (plus it helps with the LIMIT issue I described). There doesn't necessarily need to be much code duplication to make that work. Offhand I suspect it would be kind of similar to how deletion of LP_DEAD-marked index tuples by non-nbtree index AMs gets by with generic logic implemented by index_compute_xid_horizon_for_tuples -- that's all that we need to determine a snapshotConflictHorizon value for recovery conflict purposes. Note that index_compute_xid_horizon_for_tuples() reads *index* pages, despite not being aware of the caller's index AM and index tuple format. (The only reason why nbtree needs a custom solution is because it has posting list tuples to worry about, unlike GiST and unlike Hash, which consistently use unadorned generic IndexTuple structs with heap TID represented in the standard/generic way only. While these concepts probably all originated in nbtree, they're still not nbtree implementation details.) > > Having disabled kill_prior_tuple is why the mvcc test fails. Perhaps > > there is an easier way to fix this, as I don't think the mvcc test > > failed on Tomas' version. > > > > I kinda doubt it worked correctly, considering I simply ignored the > optimization. It's far more likely it just worked by luck. The test that did fail will have only revealed that the kill_prior_tuple wasn't operating as expected -- which isn't the same thing as giving wrong answers. Note that there are various ways that concurrent TID recycling might prevent _bt_killitems() from setting LP_DEAD bits. It's totally unsurprising that breaking kill_prior_tuple in some way could be missed. Andres wrote the MVCC test in question precisely because certain aspects of kill_prior_tuple were broken for months without anybody noticing. [1] https://www.postgresql.org/docs/devel/index-locking.html -- Peter Geoghegan
On Thu, Feb 8, 2024 at 3:18 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > - kill prior tuple > > This optimization doesn't work with index prefetching with the current > design. Kill prior tuple relies on alternating between fetching a > single index tuple and visiting the heap. After visiting the heap we > can potentially kill the immediately preceding index tuple. Once we > fetch multiple index tuples, enqueue their TIDs, and later visit the > heap, the next index page we visit may not contain all of the index > tuples deemed killable by our visit to the heap. Is this maybe just a bookkeeping problem? A Boolean that says "you can kill the prior tuple" is well-suited if and only if the prior tuple is well-defined. But perhaps it could be replaced with something more sophisticated that tells you which tuples are eligible to be killed. -- Robert Haas EDB: http://www.enterprisedb.com
On 2/13/24 20:54, Peter Geoghegan wrote: > On Tue, Feb 13, 2024 at 2:01 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 2/7/24 22:48, Melanie Plageman wrote: >> I admit I haven't thought about kill_prior_tuple until you pointed out. >> Yeah, prefetching separates (de-synchronizes) the two scans (index and >> heap) in a way that prevents this optimization. Or at least makes it >> much more complex :-( > > Another thing that argues against doing this is that we might not need > to visit any more B-Tree leaf pages when there is a LIMIT n involved. > We could end up scanning a whole extra leaf page (including all of its > tuples) for want of the ability to "push down" a LIMIT to the index AM > (that's not what happens right now, but it isn't really needed at all > right now). > I'm not quite sure I understand what is "this" that you argue against. Are you saying we should not separate the two scans? If yes, is there a better way to do this? The LIMIT problem is not very clear to me either. Yes, if we get close to the end of the leaf page, we may need to visit the next leaf page. But that's kinda the whole point of prefetching - reading stuff ahead, and reading too far ahead is an inherent risk. Isn't that a problem we have even without LIMIT? The prefetch distance ramp up is meant to limit the impact. > This property of index scans is fundamental to how index scans work. > Pinning an index page as an interlock against concurrently TID > recycling by VACUUM is directly described by the index API docs [1], > even (the docs actually use terms like "buffer pin" rather than > something more abstract sounding). I don't think that anything > affecting that behavior should be considered an implementation detail > of the nbtree index AM as such (nor any particular index AM). > Good point. > I think that it makes sense to put the index AM in control here -- > that almost follows from what I said about the index AM API. The index > AM already needs to be in control, in about the same way, to deal with > kill_prior_tuple (plus it helps with the LIMIT issue I described). > In control how? What would be the control flow - what part would be managed by the index AM? I initially did the prefetching entirely in each index AM, but it was suggested doing this in the executor would be better. So I gradually moved it to executor. But the idea to combine this with the streaming read API seems as a move from executor back to the lower levels ... and now you're suggesting to make the index AM responsible for this again. I'm not saying any of those layering options is wrong, but it's not clear to me which is the right one. > There doesn't necessarily need to be much code duplication to make > that work. Offhand I suspect it would be kind of similar to how > deletion of LP_DEAD-marked index tuples by non-nbtree index AMs gets > by with generic logic implemented by > index_compute_xid_horizon_for_tuples -- that's all that we need to > determine a snapshotConflictHorizon value for recovery conflict > purposes. Note that index_compute_xid_horizon_for_tuples() reads > *index* pages, despite not being aware of the caller's index AM and > index tuple format. > > (The only reason why nbtree needs a custom solution is because it has > posting list tuples to worry about, unlike GiST and unlike Hash, which > consistently use unadorned generic IndexTuple structs with heap TID > represented in the standard/generic way only. While these concepts > probably all originated in nbtree, they're still not nbtree > implementation details.) > I haven't looked at the details, but I agree the LP_DEAD deletion seems like a sensible inspiration. >>> Having disabled kill_prior_tuple is why the mvcc test fails. Perhaps >>> there is an easier way to fix this, as I don't think the mvcc test >>> failed on Tomas' version. >>> >> >> I kinda doubt it worked correctly, considering I simply ignored the >> optimization. It's far more likely it just worked by luck. > > The test that did fail will have only revealed that the > kill_prior_tuple wasn't operating as expected -- which isn't the same > thing as giving wrong answers. > Possible. But AFAIK it did fail for Melanie, and I don't have a very good explanation for the difference in behavior. > Note that there are various ways that concurrent TID recycling might > prevent _bt_killitems() from setting LP_DEAD bits. It's totally > unsurprising that breaking kill_prior_tuple in some way could be > missed. Andres wrote the MVCC test in question precisely because > certain aspects of kill_prior_tuple were broken for months without > anybody noticing. > > [1] https://www.postgresql.org/docs/devel/index-locking.html Yeah. There's clearly plenty of space for subtle issues. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/14/24 08:10, Robert Haas wrote: > On Thu, Feb 8, 2024 at 3:18 AM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> - kill prior tuple >> >> This optimization doesn't work with index prefetching with the current >> design. Kill prior tuple relies on alternating between fetching a >> single index tuple and visiting the heap. After visiting the heap we >> can potentially kill the immediately preceding index tuple. Once we >> fetch multiple index tuples, enqueue their TIDs, and later visit the >> heap, the next index page we visit may not contain all of the index >> tuples deemed killable by our visit to the heap. > > Is this maybe just a bookkeeping problem? A Boolean that says "you can > kill the prior tuple" is well-suited if and only if the prior tuple is > well-defined. But perhaps it could be replaced with something more > sophisticated that tells you which tuples are eligible to be killed. > I don't think it's just a bookkeeping problem. In a way, nbtree already does keep an array of tuples to kill (see btgettuple), but it's always for the current index page. So it's not that we immediately go and kill the prior tuple - nbtree already stashes it in an array, and kills all those tuples when moving to the next index page. The way I understand the problem is that with prefetching we're bound to determine the kill_prior_tuple flag with a delay, in which case we might have already moved to the next index page ... So to make this work, we'd need to: 1) keep index pages pinned for all "in flight" TIDs (read from the index, not yet consumed by the index scan) 2) keep a separate array of "to be killed" index tuples for each page 3) have a more sophisticated way to decide when to kill tuples and unpin the index page (instead of just doing it when moving to the next index page) Maybe that's what you meant by "more sophisticated bookkeeping", ofc. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 13, 2024 at 2:01 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/7/24 22:48, Melanie Plageman wrote: > > ... Issues > > --- > > - kill prior tuple > > > > This optimization doesn't work with index prefetching with the current > > design. Kill prior tuple relies on alternating between fetching a > > single index tuple and visiting the heap. After visiting the heap we > > can potentially kill the immediately preceding index tuple. Once we > > fetch multiple index tuples, enqueue their TIDs, and later visit the > > heap, the next index page we visit may not contain all of the index > > tuples deemed killable by our visit to the heap. > > > > I admit I haven't thought about kill_prior_tuple until you pointed out. > Yeah, prefetching separates (de-synchronizes) the two scans (index and > heap) in a way that prevents this optimization. Or at least makes it > much more complex :-( > > > In our case, we could try and fix this by prefetching only heap blocks > > referred to by index tuples on the same index page. Or we could try > > and keep a pool of index pages pinned and go back and kill index > > tuples on those pages. > > > > I think restricting the prefetching to a single index page would not be > a huge issue performance-wise - that's what the initial patch version > (implemented at the index AM level) did, pretty much. The prefetch queue > would get drained as we approach the end of the index page, but luckily > index pages tend to have a lot of entries. But it'd put an upper bound > on the prefetch distance (much lower than the e_i_c maximum 1000, but > I'd say common values are 10-100 anyway). > > But how would we know we're on the same index page? That knowledge is > not available outside the index AM - the executor or indexam.c does not > know this, right? Presumably we could expose this, somehow, but it seems > like a violation of the abstraction ... The easiest way to do this would be to have the index AM amgettuple() functions set a new member in the IndexScanDescData which is either the index page identifier or a boolean that indicates we have moved on to the next page. Then, when filling the queue, we would stop doing so when the page switches. Now, this wouldn't really work for the first index tuple on each new page, so, perhaps we would need the index AMs to implement some kind of "peek" functionality. Or, we could provide the index AM with a max queue size and allow it to fill up the queue with the TIDs it wants (which it could keep to the same index page). And, for the index-only scan case, could have some kind of flag which indicates if the caller is putting TIDs+HeapTuples or TIDS+IndexTuples on the queue, which might reduce the amount of space we need. I'm not sure who manages the memory here. I wasn't quite sure how we could use index_compute_xid_horizon_for_tuples() for inspiration -- per Peter's suggestion. But, I'd like to understand. > > - switching scan directions > > > > If the index scan switches directions on a given invocation of > > IndexNext(), heap blocks may have already been prefetched and read for > > blocks containing tuples beyond the point at which we want to switch > > directions. > > > > We could fix this by having some kind of streaming read "reset" > > callback to drop all of the buffers which have been prefetched which > > are now no longer needed. We'd have to go backwards from the last TID > > which was yielded to the caller and figure out which buffers in the > > pgsr buffer ranges are associated with all of the TIDs which were > > prefetched after that TID. The TIDs are in the per_buffer_data > > associated with each buffer in pgsr. The issue would be searching > > through those efficiently. > > > > Yeah, that's roughly what I envisioned in one of my previous messages > about this issue - walking back the TIDs read from the index and added > to the prefetch queue. > > > The other issue is that the streaming read API does not currently > > support backwards scans. So, if we switch to a backwards scan from a > > forwards scan, we would need to fallback to the non streaming read > > method. We could do this by just setting the TID queue size to 1 > > (which is what I have currently implemented). Or we could add > > backwards scan support to the streaming read API. > > > > What do you mean by "support for backwards scans" in the streaming read > API? I imagined it naively as > > 1) drop all requests in the streaming read API queue > > 2) walk back all "future" requests in the TID queue > > 3) start prefetching as if from scratch > > Maybe there's a way to optimize this and reuse some of the work more > efficiently, but my assumption is that the scan direction does not > change very often, and that we process many items in between. Yes, the steps you mention for resetting the queues make sense. What I meant by "backwards scan is not supported by the streaming read API" is that Thomas/Andres had mentioned that the streaming read API does not support backwards scans right now. Though, since the callback just returns a block number, I don't know how it would break. When switching between a forwards and backwards scan, does it go backwards from the current position or start at the end (or beginning) of the relation? If it is the former, then the blocks would most likely be in shared buffers -- which the streaming read API handles. It is not obvious to me from looking at the code what the gap is, so perhaps Thomas could weigh in. As for handling this in index prefetching, if you think a TID queue size of 1 is a sufficient fallback method, then resetting the pgsr queue and resizing the TID queue to 1 would work with no issues. If the fallback method requires the streaming read code path not be used at all, then that is more work. > > - multiple executions > > > > For reasons I don't entirely understand yet, multiple executions (not > > rescan -- see ExecutorRun(...execute_once)) do not work. As in Tomas' > > patch, I have disabled prefetching (and made the TID queue size 1) > > when execute_once is false. > > > > Don't work in what sense? What is (not) happening? I got wrong results for this. I'll have to do more investigation, but I assumed that not resetting the TID queue and pgsr queue was also the source of this issue. What I imagined we would do is figure out if there is a viable solution for the larger design issues and then investigate what seemed like smaller issues. But, perhaps I should dig into this first to ensure there isn't a larger issue. > > - Index Only Scans need to return IndexTuples > > > > Because index only scans return either the IndexTuple pointed to by > > IndexScanDesc->xs_itup or the HeapTuple pointed to by > > IndexScanDesc->xs_hitup -- both of which are populated by the index > > AM, we have to save copies of those IndexTupleData and HeapTupleDatas > > for every TID whose block we prefetch. > > > > This might be okay, but it is a bit sad to have to make copies of those tuples. > > > > In this patch, I still haven't figured out the memory management part. > > I copy over the tuples when enqueuing a TID queue item and then copy > > them back again when the streaming read API returns the > > per_buffer_data to us. Something is still not quite right here. I > > suspect this is part of the reason why some of the other tests are > > failing. > > > > It's not clear to me what you need to copy the tuples back - shouldn't > it be enough to copy the tuple just once? When enqueueing it, IndexTuple has to be copied from the scan descriptor to somewhere in memory with a TIDQueueItem pointing to it. Once we do this, the IndexTuple memory should stick around until we free it, so yes, I'm not sure why I was seeing the IndexTuple no longer be valid when I tried to put it in a slot. I'll have to do more investigation. > FWIW if we decide to pin multiple index pages (to make kill_prior_tuple > work), that would also mean we don't need to copy any tuples, right? We > could point into the buffers for all of them, right? Yes, this would be a nice benefit. > > Other issues/gaps in my implementation: > > > > Determining where to allocate the memory for the streaming read object > > and the TID queue is an outstanding TODO. To implement a fallback > > method for cases in which streaming read doesn't work, I set the queue > > size to 1. This is obviously not good. > > > > I think IndexFetchTableData seems like a not entirely terrible place for > allocating the pgsr, but I wonder what Andres thinks about this. IIRC he > advocated for doing the prefetching in executor, and I'm not sure > heapam_handled.c + relscan.h is what he imagined ... > > Also, when you say "obviously not good" - why? Are you concerned about > the extra overhead of shuffling stuff between queues, or something else? Well, I didn't resize the queue, I just limited how much of it we can use to a single member (thus wasting the other memory). But resizing a queue isn't free either. Also, I wondered if a queue size of 1 for index AMs using the fallback method is too confusing (like it is a fake queue?). But, I'd really, really rather not maintain both a queue and non-queue control flow for Index[Only]Next(). The maintenance overhead seems like it would outweigh the potential downsides. > > Right now, I allocate the TID queue and streaming read objects in > > IndexNext() and IndexOnlyNext(). This doesn't seem ideal. Doing it in > > index_beginscan() (and index_beginscan_parallel()) is tricky though > > because we don't know the scan direction at that point (and the scan > > direction can change). There are also callers of index_beginscan() who > > do not call Index[Only]Next() (like systable_getnext() which calls > > index_getnext_slot() directly). > > > > Yeah, not sure this is the right layering ... the initial patch did > everything in individual index AMs, then it moved to indexam.c, then to > executor. And this seems to move it to lower layers again ... If we do something like make the index AM responsible for the TID queue (as mentioned above as a potential solution to the kill prior tuple issue), then we might be able to allocate the TID queue in the index AMs? As for the streaming read object, if we were able to solve the issue where callers of index_beginscan() don't call Index[Only]Next() (and thus shouldn't allocate a streaming read object), then it seems easy enough to move the streaming read object allocation into the table AM-specific begin scan method. > > Also, my implementation does not yet have the optimization Tomas does > > to skip prefetching recently prefetched blocks. As he has said, it > > probably makes sense to add something to do this in a lower layer -- > > such as in the streaming read API or even in bufmgr.c (maybe in > > PrefetchSharedBuffer()). > > > > I agree this should happen in lower layers. I'd probably do this in the > streaming read API, because that would define "scope" of the cache > (pages prefetched for that read). Doing it in PrefetchSharedBuffer seems > like it would do a single cache (for that particular backend). Hmm. I wonder if there are any upsides to having the cache be per-backend. Though, that does sound like a whole other project... - Melanie
On Wed, Feb 14, 2024 at 8:34 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> > Another thing that argues against doing this is that we might not need
> > to visit any more B-Tree leaf pages when there is a LIMIT n involved.
> > We could end up scanning a whole extra leaf page (including all of its
> > tuples) for want of the ability to "push down" a LIMIT to the index AM
> > (that's not what happens right now, but it isn't really needed at all
> > right now).
> >
>
> I'm not quite sure I understand what is "this" that you argue against.
> Are you saying we should not separate the two scans? If yes, is there a
> better way to do this?
What I'm concerned about is the difficulty and complexity of any
design that requires revising "63.4. Index Locking Considerations",
since that's pretty subtle stuff. In particular, if prefetching
"de-synchronizes" (to use your term) the index leaf page level scan
and the heap page scan, then we'll probably have to totally revise the
basic API.
Maybe that'll actually turn out to be the right thing to do -- it
could just be the only thing that can unleash the full potential of
prefetching. But I'm not aware of any evidence that points in that
direction. Are you? (I might have just missed it.)
> The LIMIT problem is not very clear to me either. Yes, if we get close
> to the end of the leaf page, we may need to visit the next leaf page.
> But that's kinda the whole point of prefetching - reading stuff ahead,
> and reading too far ahead is an inherent risk. Isn't that a problem we
> have even without LIMIT? The prefetch distance ramp up is meant to limit
> the impact.
Right now, the index AM doesn't know anything about LIMIT at all. That
doesn't matter, since the index AM can only read/scan one full leaf
page before returning control back to the executor proper. The
executor proper can just shut down the whole index scan upon finding
that we've already returned N tuples for a LIMIT N.
We don't do prefetching right now, but we also don't risk reading a
leaf page that'll just never be needed. Those two things are in
tension, but I don't think that that's quite the same thing as the
usual standard prefetching tension/problem. Here there is uncertainty
about whether what we're prefetching will *ever* be required -- not
uncertainty about when exactly it'll be required. (Perhaps this
distinction doesn't mean much to you. I'm just telling you how I think
about it, in case it helps move the discussion forward.)
> > This property of index scans is fundamental to how index scans work.
> > Pinning an index page as an interlock against concurrently TID
> > recycling by VACUUM is directly described by the index API docs [1],
> > even (the docs actually use terms like "buffer pin" rather than
> > something more abstract sounding). I don't think that anything
> > affecting that behavior should be considered an implementation detail
> > of the nbtree index AM as such (nor any particular index AM).
> >
>
> Good point.
The main reason why the index AM docs require this interlock is
because we need such an interlock to make non-MVCC snapshot scans
safe. If you remove the interlock (the buffer pin interlock that
protects against TID recycling by VACUUM), you can still avoid the
same race condition by using an MVCC snapshot. This is why using an
MVCC snapshot is a requirement for bitmap index scans. I believe that
it's also a requirement for index-only scans, but the index AM docs
don't spell that out.
Another factor that complicates things here is mark/restore
processing. The design for that has the idea of processing one page at
a time baked-in. Kinda like with the kill_prior_tuple issue.
It's certainly possible that you could figure out various workarounds
for each of these issues (plus the kill_prior_tuple issue) with a
prefetching design that "de-synchronizes" the index access and the
heap access. But it might well be better to extend the existing design
in a way that just avoids all these problems in the first place. Maybe
"de-synchronization" really can pay for itself (because the benefits
will outweigh these costs), but if you go that way then I'd really
prefer it that way.
> > I think that it makes sense to put the index AM in control here --
> > that almost follows from what I said about the index AM API. The index
> > AM already needs to be in control, in about the same way, to deal with
> > kill_prior_tuple (plus it helps with the LIMIT issue I described).
> >
>
> In control how? What would be the control flow - what part would be
> managed by the index AM?
ISTM that prefetching for an index scan is about the index scan
itself, first and foremost. The heap accesses are usually the dominant
cost, of course, but sometimes the index leaf page accesses really do
make up a significant fraction of the overall cost of the index scan.
Especially with an expensive index qual. So if you just assume that
the TIDs returned by the index scan are the only thing that matters,
you might have a model that's basically correct on average, but is
occasionally very wrong. That's one reason for "putting the index AM
in control".
As I said back in June, we should probably be marrying information
from the index scan with information from the heap. This is something
that is arguably a modularity violation. But it might just be that you
really do need to take information from both places to consistently
make the right trade-off.
Perhaps the best arguments for "putting the index AM in control" only
work when you go to fix the problems that "naive de-synchronization"
creates. Thinking about that side of things some more might make
"putting the index AM in control" seem more natural.
Suppose, for example, you try to make a prefetching design based on
"de-synchronization" work with kill_prior_tuple -- suppose you try to
fix that problem. You're likely going to need to make some kind of
trade-off that gets you most of the advantages that that approach
offers (assuming that there really are significant advantages), while
still retaining most of the advantages that we already get from
kill_prior_tuple (basically we want to LP_DEAD-mark index tuples with
almost or exactly the same consistency as we manage today). Maybe your
approach involves tracking multiple LSNs for each prefetch-pending
leaf page, or perhaps you hold on to a pin on some number of leaf
pages instead (right now nbtree does both [1], which I go into more
below). Either way, you're pushing stuff down into the index AM.
Note that we already hang onto more than one pin at a time in rare
cases involving mark/restore processing. For example, it can happen
for a merge join that happens to involve an unlogged index, if the
markpos and curpos are a certain way relative to the current leaf page
(yeah, really). So putting stuff like that under the control of the
index AM (while also applying basic information that comes from the
heap) in order to fix the kill_prior_tuple issue is arguably something
that has a kind of a precedent for us to follow.
Even if you disagree with me here ("precedent" might be overstating
it), perhaps you still get some general sense of why I have an inkling
that putting prefetching in the index AM is the way to go. It's very
hard to provide one really strong justification for all this, and I'm
certainly not expecting you to just agree with me right away. I'm also
not trying to impose any conditions on committing this patch.
Thinking about this some more, "making kill_prior_tuple work with
de-synchronization" is a bit of a misleading way of putting it. The
way that you'd actually work around this is (at a very high level)
*dynamically* making some kind of *trade-off* between synchronization
and desynchronization. Up until now, we've been talking in terms of a
strict dichotomy between the old index AM API design
(index-page-at-a-time synchronization), and a "de-synchronizing"
prefetching design that
embraces the opposite extreme -- a design where we only think in terms
of heap TIDs, and completely ignore anything that happens in the index
structure (and consequently makes kill_prior_tuple ineffective). That
now seems like a false dichotomy.
> I initially did the prefetching entirely in each index AM, but it was
> suggested doing this in the executor would be better. So I gradually
> moved it to executor. But the idea to combine this with the streaming
> read API seems as a move from executor back to the lower levels ... and
> now you're suggesting to make the index AM responsible for this again.
I did predict that there'd be lots of difficulties around the layering
back in June. :-)
> I'm not saying any of those layering options is wrong, but it's not
> clear to me which is the right one.
I don't claim to know what the right trade-off is myself. The fact
that all of these things are in tension doesn't surprise me. It's just
a hard problem.
> Possible. But AFAIK it did fail for Melanie, and I don't have a very
> good explanation for the difference in behavior.
If you take a look at _bt_killitems(), you'll see that it actually has
two fairly different strategies for avoiding TID recycling race
condition issues, applied in each of two different cases:
1. Cases where we really have held onto a buffer pin, per the index AM
API -- the "inde AM orthodox" approach. (The aforementioned issue
with unlogged indexes exists because with an unlogged index we must
use approach 1, per the nbtree README section [1]).
2. Cases where we drop the pin as an optimization (also per [1]), and
now have to detect the possibility of concurrent modifications by
VACUUM (that could have led to concurrent TID recycling). We
conservatively do nothing (don't mark any index tuples LP_DEAD),
unless the LSN is exactly the same as it was back when the page was
scanned/read by _bt_readpage().
So some accidental detail with LSNs (like using or not using an
unlogged index) could cause bugs in this area to "accidentally fail to
fail". Since the nbtree index AM has its own optimizations here, which
probably has a tendency to mask problems/bugs. (I sometimes use
unlogged indexes for some of my nbtree related test cases, just to
reduce certain kinds of variability, including variability in this
area.)
[1]
https://git.postgresql.org/gitweb/?p=postgresql.git;a=blob;f=src/backend/access/nbtree/README;h=52e646c7f759a5d9cfdc32b86f6aff8460891e12;hb=3e8235ba4f9cc3375b061fb5d3f3575434539b5f#l443
--
Peter Geoghegan
On Wed, Feb 14, 2024 at 11:40 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > I wasn't quite sure how we could use > index_compute_xid_horizon_for_tuples() for inspiration -- per Peter's > suggestion. But, I'd like to understand. The point I was trying to make with that example was: a highly generic mechanism can sometimes work across disparate index AMs (that all at least support plain index scans) when it just so happens that these AMs don't actually differ in a way that could possibly matter to that mechanism. While it's true that (say) nbtree and hash are very different at a high level, it's nevertheless also true that the way things work at the level of individual index pages is much more similar than different. With index deletion, we know that we're differences between each supported index AM either don't matter at all (which is what obviates the need for index_compute_xid_horizon_for_tuples() to be directly aware of which index AM the page it is passed comes from), or matter only in small, incidental ways (e.g., nbtree stores posting lists in its tuples, despite using IndexTuple structs). With prefetching, it seems reasonable to suppose that an index-AM specific approach would end up needing very little truly custom code. This is pretty strongly suggested by the fact that the rules around buffer pins (as an interlock against concurrent TID recycling by VACUUM) are standardized by the index AM API itself. Those rules might be slightly more natural with nbtree, but that's kinda beside the point. While the basic organizing principle for where each index tuple goes can vary enormously, it doesn't necessarily matter at all -- in the end, you're really just reading each index page (that has TIDs to read) exactly once per scan, in some fixed order, with interlaced inline heap accesses (that go fetch heap tuples for each individual TID read from each index page). In general I don't accept that we need to do things outside the index AM, because software architecture encapsulation something something. I suspect that we'll need to share some limited information across different layers of abstraction, because that's just fundamentally what's required by the constraints we're operating under. Can't really prove it, though. -- Peter Geoghegan
On Wed, Feb 14, 2024 at 11:40 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Tue, Feb 13, 2024 at 2:01 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > On 2/7/24 22:48, Melanie Plageman wrote: > > > ... > > > - switching scan directions > > > > > > If the index scan switches directions on a given invocation of > > > IndexNext(), heap blocks may have already been prefetched and read for > > > blocks containing tuples beyond the point at which we want to switch > > > directions. > > > > > > We could fix this by having some kind of streaming read "reset" > > > callback to drop all of the buffers which have been prefetched which > > > are now no longer needed. We'd have to go backwards from the last TID > > > which was yielded to the caller and figure out which buffers in the > > > pgsr buffer ranges are associated with all of the TIDs which were > > > prefetched after that TID. The TIDs are in the per_buffer_data > > > associated with each buffer in pgsr. The issue would be searching > > > through those efficiently. > > > > > > > Yeah, that's roughly what I envisioned in one of my previous messages > > about this issue - walking back the TIDs read from the index and added > > to the prefetch queue. > > > > > The other issue is that the streaming read API does not currently > > > support backwards scans. So, if we switch to a backwards scan from a > > > forwards scan, we would need to fallback to the non streaming read > > > method. We could do this by just setting the TID queue size to 1 > > > (which is what I have currently implemented). Or we could add > > > backwards scan support to the streaming read API. > > > > > > > What do you mean by "support for backwards scans" in the streaming read > > API? I imagined it naively as > > > > 1) drop all requests in the streaming read API queue > > > > 2) walk back all "future" requests in the TID queue > > > > 3) start prefetching as if from scratch > > > > Maybe there's a way to optimize this and reuse some of the work more > > efficiently, but my assumption is that the scan direction does not > > change very often, and that we process many items in between. > > Yes, the steps you mention for resetting the queues make sense. What I > meant by "backwards scan is not supported by the streaming read API" > is that Thomas/Andres had mentioned that the streaming read API does > not support backwards scans right now. Though, since the callback just > returns a block number, I don't know how it would break. > > When switching between a forwards and backwards scan, does it go > backwards from the current position or start at the end (or beginning) > of the relation? Okay, well I answered this question for myself, by, um, trying it :). FETCH backward will go backwards from the current cursor position. So, I don't see exactly why this would be an issue. > If it is the former, then the blocks would most > likely be in shared buffers -- which the streaming read API handles. > It is not obvious to me from looking at the code what the gap is, so > perhaps Thomas could weigh in. I have the same problem with the sequential scan streaming read user, so I am going to try and figure this backwards scan and switching scan direction thing there (where we don't have other issues). - Melanie
On Wed, Feb 14, 2024 at 1:21 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Feb 14, 2024 at 8:34 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > Another thing that argues against doing this is that we might not need > > > to visit any more B-Tree leaf pages when there is a LIMIT n involved. > > > We could end up scanning a whole extra leaf page (including all of its > > > tuples) for want of the ability to "push down" a LIMIT to the index AM > > > (that's not what happens right now, but it isn't really needed at all > > > right now). > > > > > > > I'm not quite sure I understand what is "this" that you argue against. > > Are you saying we should not separate the two scans? If yes, is there a > > better way to do this? > > What I'm concerned about is the difficulty and complexity of any > design that requires revising "63.4. Index Locking Considerations", > since that's pretty subtle stuff. In particular, if prefetching > "de-synchronizes" (to use your term) the index leaf page level scan > and the heap page scan, then we'll probably have to totally revise the > basic API. So, a pin on the index leaf page is sufficient to keep line pointers from being reused? If we stick to prefetching heap blocks referred to by index tuples in a single index leaf page, and we keep that page pinned, will we still have a problem? > > The LIMIT problem is not very clear to me either. Yes, if we get close > > to the end of the leaf page, we may need to visit the next leaf page. > > But that's kinda the whole point of prefetching - reading stuff ahead, > > and reading too far ahead is an inherent risk. Isn't that a problem we > > have even without LIMIT? The prefetch distance ramp up is meant to limit > > the impact. > > Right now, the index AM doesn't know anything about LIMIT at all. That > doesn't matter, since the index AM can only read/scan one full leaf > page before returning control back to the executor proper. The > executor proper can just shut down the whole index scan upon finding > that we've already returned N tuples for a LIMIT N. > > We don't do prefetching right now, but we also don't risk reading a > leaf page that'll just never be needed. Those two things are in > tension, but I don't think that that's quite the same thing as the > usual standard prefetching tension/problem. Here there is uncertainty > about whether what we're prefetching will *ever* be required -- not > uncertainty about when exactly it'll be required. (Perhaps this > distinction doesn't mean much to you. I'm just telling you how I think > about it, in case it helps move the discussion forward.) I don't think that the LIMIT problem is too different for index scans than heap scans. We will need some advice from planner to come down to prevent over-eager prefetching in all cases. > Another factor that complicates things here is mark/restore > processing. The design for that has the idea of processing one page at > a time baked-in. Kinda like with the kill_prior_tuple issue. Yes, I mentioned this in my earlier email. I think we can resolve mark/restore by resetting the prefetch and TID queues and restoring the last used heap TID in the index scan descriptor. > It's certainly possible that you could figure out various workarounds > for each of these issues (plus the kill_prior_tuple issue) with a > prefetching design that "de-synchronizes" the index access and the > heap access. But it might well be better to extend the existing design > in a way that just avoids all these problems in the first place. Maybe > "de-synchronization" really can pay for itself (because the benefits > will outweigh these costs), but if you go that way then I'd really > prefer it that way. Forcing each index access to be synchronous and interleaved with each table access seems like an unprincipled design constraint. While it is true that we rely on that in our current implementation (when using non-MVCC snapshots), it doesn't seem like a principle inherent to accessing indexes and tables. > > > I think that it makes sense to put the index AM in control here -- > > > that almost follows from what I said about the index AM API. The index > > > AM already needs to be in control, in about the same way, to deal with > > > kill_prior_tuple (plus it helps with the LIMIT issue I described). > > > > > > > In control how? What would be the control flow - what part would be > > managed by the index AM? > > ISTM that prefetching for an index scan is about the index scan > itself, first and foremost. The heap accesses are usually the dominant > cost, of course, but sometimes the index leaf page accesses really do > make up a significant fraction of the overall cost of the index scan. > Especially with an expensive index qual. So if you just assume that > the TIDs returned by the index scan are the only thing that matters, > you might have a model that's basically correct on average, but is > occasionally very wrong. That's one reason for "putting the index AM > in control". I don't think the fact that it would also be valuable to do index prefetching is a reason not to do prefetching of heap pages. And, while it is true that were you to add index interior or leaf page prefetching, it would impact the heap prefetching, at the end of the day, the table AM needs some TID or TID-equivalents that whose blocks it can go fetch. The index AM has to produce something that the table AM will consume. So, if we add prefetching of heap pages and get the table AM input right, it shouldn't require a full redesign to add index page prefetching later. You could argue that my suggestion to have the index AM manage and populate a queue of TIDs for use by the table AM puts the index AM in control. I do think having so many members of the IndexScanDescriptor which imply a one-at-a-time (xs_heaptid, xs_itup, etc) synchronous interplay between fetching an index tuple and fetching a heap tuple is confusing and error prone. > As I said back in June, we should probably be marrying information > from the index scan with information from the heap. This is something > that is arguably a modularity violation. But it might just be that you > really do need to take information from both places to consistently > make the right trade-off. Agreed that we are going to need to mix information from both places. > If you take a look at _bt_killitems(), you'll see that it actually has > two fairly different strategies for avoiding TID recycling race > condition issues, applied in each of two different cases: > > 1. Cases where we really have held onto a buffer pin, per the index AM > API -- the "inde AM orthodox" approach. (The aforementioned issue > with unlogged indexes exists because with an unlogged index we must > use approach 1, per the nbtree README section [1]). > > 2. Cases where we drop the pin as an optimization (also per [1]), and > now have to detect the possibility of concurrent modifications by > VACUUM (that could have led to concurrent TID recycling). We > conservatively do nothing (don't mark any index tuples LP_DEAD), > unless the LSN is exactly the same as it was back when the page was > scanned/read by _bt_readpage(). Re 2: so the LSN could have been changed by some other process (i.e. not vacuum), so how often in practice is the LSN actually the same as when the page was scanned/read? Do you think we would catch a meaningful number of kill prior tuple opportunities if we used an LSN tracking method like this? Something that let us drop the pin on the page would obviously be better. - Melanie
On Wed, Feb 14, 2024 at 4:46 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > So, a pin on the index leaf page is sufficient to keep line pointers > from being reused? If we stick to prefetching heap blocks referred to > by index tuples in a single index leaf page, and we keep that page > pinned, will we still have a problem? That's certainly one way of dealing with it. Obviously, there are questions about how you do that in a way that consistently avoids creating new problems. > I don't think that the LIMIT problem is too different for index scans > than heap scans. We will need some advice from planner to come down to > prevent over-eager prefetching in all cases. I think that I'd rather use information at execution time instead, if at all possible (perhaps in addition to a hint given by the planner). But it seems a bit premature to discuss this problem now, except to say that it might indeed be a problem. > > It's certainly possible that you could figure out various workarounds > > for each of these issues (plus the kill_prior_tuple issue) with a > > prefetching design that "de-synchronizes" the index access and the > > heap access. But it might well be better to extend the existing design > > in a way that just avoids all these problems in the first place. Maybe > > "de-synchronization" really can pay for itself (because the benefits > > will outweigh these costs), but if you go that way then I'd really > > prefer it that way. > > Forcing each index access to be synchronous and interleaved with each > table access seems like an unprincipled design constraint. While it is > true that we rely on that in our current implementation (when using > non-MVCC snapshots), it doesn't seem like a principle inherent to > accessing indexes and tables. There is nothing sacred about the way plain index scans work right now -- especially the part about buffer pins as an interlock. If the pin thing really was sacred, then we could never have allowed nbtree to selectively opt-out in cases where it's possible to provide an equivalent correctness guarantee without holding onto buffer pins, which, as I went into, is how it actually works in nbtree's _bt_killitems() today (see commit 2ed5b87f96 for full details). And so in principle I have no problem with the idea of revising the basic definition of plain index scans -- especially if it's to make the definition more abstract, without fundamentally changing it (e.g., to make it no longer reference buffer pins, making life easier for prefetching, while at the same time still implying the same underlying guarantees sufficient to allow nbtree to mostly work the same way as today). All I'm really saying is: 1. The sort of tricks that we can do in nbtree's _bt_killitems() are quite useful, and ought to be preserved in something like their current form, even when prefetching is in use. This seems to push things in the direction of centralizing control of the process in index scan code. For example, it has to understand that _bt_killitems() will be called at some regular cadence that is well defined and sensible from an index point of view. 2. Are you sure that the leaf-page-at-a-time thing is such a huge hindrance to effective prefetching? I suppose that it might be much more important than I imagine it is right now, but it'd be nice to have something a bit more concrete to go on. 3. Even if it is somewhat important, do you really need to get that part working in v1? Tomas' original prototype worked with the leaf-page-at-a-time thing, and that still seemed like a big improvement to me. While being less invasive, in effect. If we can agree that something like that represents a useful step in the right direction (not an evolutionary dead end), then we can make good incremental progress within a single release. > I don't think the fact that it would also be valuable to do index > prefetching is a reason not to do prefetching of heap pages. And, > while it is true that were you to add index interior or leaf page > prefetching, it would impact the heap prefetching, at the end of the > day, the table AM needs some TID or TID-equivalents that whose blocks > it can go fetch. I wasn't really thinking of index page prefetching at all. Just the cost of applying index quals to read leaf pages that might never actually need to be read, due to the presence of a LIMIT. That is kind of a new problem created by eagerly reading (without actually prefetching) leaf pages. > You could argue that my suggestion to have the index AM manage and > populate a queue of TIDs for use by the table AM puts the index AM in > control. I do think having so many members of the IndexScanDescriptor > which imply a one-at-a-time (xs_heaptid, xs_itup, etc) synchronous > interplay between fetching an index tuple and fetching a heap tuple is > confusing and error prone. But that's kinda how amgettuple is supposed to work -- cursors need it to work that way. Having some kind of general notion of scan order is also important to avoid returning duplicate TIDs to the scan. In contrast, GIN heavily relies on the fact that it only supports bitmap scans -- that allows it to not have to reason about returning duplicate TIDs (when dealing with a concurrently merged pending list, and other stuff like that). And so nbtree (and basically every other index AM that supports plain index scans) kinda pretends to process a single tuple at a time, in some fixed order that's convenient for the scan to work with (that's how the executor thinks of things). In reality these index AMs actually process batches consisting of a single leaf page worth of tuples. I don't see how the IndexScanDescData side of things makes life any harder for this patch -- ISTM that you'll always need to pretend to return one tuple at a time from the index scan, regardless of what happens under the hood, with pins and whatnot. The page-at-a-time thing is more or less an implementation detail that's private to index AMs (albeit in a way that follows certain standard conventions across index AMs) -- it's a leaky abstraction only due to the interactions with VACUUM/TID recycle safety. > Re 2: so the LSN could have been changed by some other process (i.e. > not vacuum), so how often in practice is the LSN actually the same as > when the page was scanned/read? It seems very hard to make generalizations about that sort of thing. It doesn't help that we now have batching logic inside _bt_simpledel_pass() that will make up for the problem of not setting as many LP_DEAD bits as we could in many important cases. (I recall that that was one factor that allowed the bug that Andres fixed in commit 90c885cd to go undetected for months. I recall discussing the issue with Andres around that time.) > Do you think we would catch a > meaningful number of kill prior tuple opportunities if we used an LSN > tracking method like this? Something that let us drop the pin on the > page would obviously be better. Quite possibly, yes. But it's hard to say for sure without far more detailed analysis. Plus you have problems with things like unlogged indexes not having an LSN to use as a canary condition, which makes it a bit messy (it's already kind of weird that we treat unlogged indexes differently here IMV). -- Peter Geoghegan
Hi, On 2024-02-14 16:45:57 -0500, Melanie Plageman wrote: > > > The LIMIT problem is not very clear to me either. Yes, if we get close > > > to the end of the leaf page, we may need to visit the next leaf page. > > > But that's kinda the whole point of prefetching - reading stuff ahead, > > > and reading too far ahead is an inherent risk. Isn't that a problem we > > > have even without LIMIT? The prefetch distance ramp up is meant to limit > > > the impact. > > > > Right now, the index AM doesn't know anything about LIMIT at all. That > > doesn't matter, since the index AM can only read/scan one full leaf > > page before returning control back to the executor proper. The > > executor proper can just shut down the whole index scan upon finding > > that we've already returned N tuples for a LIMIT N. > > > > We don't do prefetching right now, but we also don't risk reading a > > leaf page that'll just never be needed. Those two things are in > > tension, but I don't think that that's quite the same thing as the > > usual standard prefetching tension/problem. Here there is uncertainty > > about whether what we're prefetching will *ever* be required -- not > > uncertainty about when exactly it'll be required. (Perhaps this > > distinction doesn't mean much to you. I'm just telling you how I think > > about it, in case it helps move the discussion forward.) > > I don't think that the LIMIT problem is too different for index scans > than heap scans. We will need some advice from planner to come down to > prevent over-eager prefetching in all cases. I'm not sure that that's really true. I think the more common and more problematic case for partially executing a sub-tree of a query are nested loops (worse because that happens many times within a query). Particularly for anti-joins prefetching too aggressively could lead to a significant IO amplification. At the same time it's IMO more important to ramp up prefetching distance fairly aggressively for index scans than it is for sequential scans. For sequential scans it's quite likely that either the whole scan takes quite a while (thus slowly ramping doesn't affect overall time that much) or that the data is cached anyway because the tables are small and frequently used (in which case we don't need to ramp). And even if smaller tables aren't cached, because it's sequential IO, the IOs are cheaper as they're sequential. Contrast that to index scans, where it's much more likely that you have cache misses in queries that do an overall fairly small number of IOs and where that IO is largely random. I think we'll need some awareness at ExecInitNode() time about how the results of the nodes are used. I see a few "classes": 1) All rows are needed, because the node is below an Agg, Hash, Materialize, Sort, .... Can be determined purely by the plan shape. 2) All rows are needed, because the node is completely consumed by the top-level (i.e. no limit, anti-joins or such inbetween) and the top-level wants to run the whole query. Unfortunately I don't think we know this at plan time at the moment (it's just determined by what's passed to ExecutorRun()). 3) Some rows are needed, but it's hard to know the precise number. E.g. because of a LIMIT further up. 4) Only a single row is going to be needed, albeit possibly after filtering on the node level. E.g. the anti-join case. There are different times at which we could determine how each node is consumed: a) Determine node consumption "class" purely within ExecInit*, via different eflags. Today that couldn't deal with 2), but I think it'd not too hard to modify callers that consume query results completely to tell that ExecutorStart(), not just ExecutorRun(). A disadvantage would be that this prevents us from taking IO depth into account during costing. There very well might be plans that are cheaper than others because the plan shape allows more concurrent IO. b) Determine node consumption class at plan time. This also couldn't deal with 2), but fixing that probably would be harder, because we'll often not know at plan time how the query will be executed. And in fact the same plan might be executed multiple ways, in case of prepared statements. The obvious advantage is of course that we can influence the choice of paths. I suspect we'd eventually want a mix of both. Plan time to be able to influence plan shape, ExecInit* to deal with not knowing how the query will be consumed at plan time. Which suggests that we could start with whichever is easier and extend later. Greetings, Andres Freund
Hi, On 2024-02-13 14:54:14 -0500, Peter Geoghegan wrote: > This property of index scans is fundamental to how index scans work. > Pinning an index page as an interlock against concurrently TID > recycling by VACUUM is directly described by the index API docs [1], > even (the docs actually use terms like "buffer pin" rather than > something more abstract sounding). I don't think that anything > affecting that behavior should be considered an implementation detail > of the nbtree index AM as such (nor any particular index AM). Given that the interlock is only needed for non-mvcc scans, that non-mvcc scans are rare due to catalog accesses using snapshots these days and that most non-mvcc scans do single-tuple lookups, it might be viable to be more restrictive about prefetching iff non-mvcc snapshots are in use and to use method of cleanup that allows multiple pages to be cleaned up otherwise. However, I don't think we would necessarily have to relax the IAM pinning rules, just to be able to do prefetching of more than one index leaf page. Restricting prefetching to entries within a single leaf page obviously has the disadvantage of not being able to benefit from concurrent IO whenever crossing a leaf page boundary, but at the same time processing entries from just two leaf pages would often allow for a sufficiently aggressive prefetching. Pinning a small number of leaf pages instead of a single leaf page shouldn't be a problem. One argument for loosening the tight coupling between kill_prior_tuples and index scan progress is that the lack of kill_prior_tuples for bitmap scans is quite problematic. I've seen numerous production issues with bitmap scans caused by subsequent scans processing a growing set of dead tuples, where plain index scans were substantially slower initially but didn't get much slower over time. We might be able to design a system where the bitmap contains a certain number of back-references to the index, allowing later cleanup if there weren't any page splits or such. > I think that it makes sense to put the index AM in control here -- > that almost follows from what I said about the index AM API. The index > AM already needs to be in control, in about the same way, to deal with > kill_prior_tuple (plus it helps with the LIMIT issue I described). Depending on what "control" means I'm doubtful: Imo there are decisions influencing prefetching that an index AM shouldn't need to know about directly, e.g. how the plan shape influences how many tuples are actually going to be consumed. Of course that determination could be made in planner/executor and handed to IAMs, for the IAM to then "control" the prefetching. Another aspect is that *long* term I think we want to be able to execute different parts of the plan tree when one part is blocked for IO. Of course that's not always possible. But particularly with partitioned queries it often is. Depending on the form of "control" that's harder if IAMs are in control, because control flow needs to return to the executor to be able to switch to a different node, so we can't wait for IO inside the AM. There probably are ways IAMs could be in "control" that would be compatible with such constraints however. Greetings, Andres Freund
On Wed, Feb 14, 2024 at 7:28 PM Andres Freund <andres@anarazel.de> wrote: > On 2024-02-13 14:54:14 -0500, Peter Geoghegan wrote: > > This property of index scans is fundamental to how index scans work. > > Pinning an index page as an interlock against concurrently TID > > recycling by VACUUM is directly described by the index API docs [1], > > even (the docs actually use terms like "buffer pin" rather than > > something more abstract sounding). I don't think that anything > > affecting that behavior should be considered an implementation detail > > of the nbtree index AM as such (nor any particular index AM). > > Given that the interlock is only needed for non-mvcc scans, that non-mvcc > scans are rare due to catalog accesses using snapshots these days and that > most non-mvcc scans do single-tuple lookups, it might be viable to be more > restrictive about prefetching iff non-mvcc snapshots are in use and to use > method of cleanup that allows multiple pages to be cleaned up otherwise. I agree, but don't think that it matters all that much. If you have an MVCC snapshot, that doesn't mean that TID recycle safety problems automatically go away. It only means that you have one known and supported alternative approach to dealing with such problems. It's not like you just get that for free, just by using an MVCC snapshot, though -- it has downsides. Downsides such as the current _bt_killitems() behavior with a concurrently-modified leaf page (modified when we didn't hold a leaf page pin). It'll just give up on setting any LP_DEAD bits due to noticing that the leaf page's LSN changed. (Plus there are implementation restrictions that I won't repeat again now.) When I refer to the buffer pin interlock, I'm mostly referring to the general need for something like that in the context of index scans. Principally in order to make kill_prior_tuple continue to work in something more or less like its current form. > However, I don't think we would necessarily have to relax the IAM pinning > rules, just to be able to do prefetching of more than one index leaf > page. To be clear, we already do relax the IAM pinning rules. Or at least nbtree selectively opts out, as I've gone into already. > Restricting prefetching to entries within a single leaf page obviously > has the disadvantage of not being able to benefit from concurrent IO whenever > crossing a leaf page boundary, but at the same time processing entries from > just two leaf pages would often allow for a sufficiently aggressive > prefetching. Pinning a small number of leaf pages instead of a single leaf > page shouldn't be a problem. You're probably right. I just don't see any need to solve that problem in v1. > One argument for loosening the tight coupling between kill_prior_tuples and > index scan progress is that the lack of kill_prior_tuples for bitmap scans is > quite problematic. I've seen numerous production issues with bitmap scans > caused by subsequent scans processing a growing set of dead tuples, where > plain index scans were substantially slower initially but didn't get much > slower over time. I've seen production issues like that too. No doubt it's a problem. > We might be able to design a system where the bitmap > contains a certain number of back-references to the index, allowing later > cleanup if there weren't any page splits or such. That does seem possible, but do you really want a design for index prefetching that relies on that massive enhancement (a total redesign of kill_prior_tuple) happening at some point in the not-too-distant future? Seems risky, from a project management point of view. This back-references idea seems rather complicated, especially if it needs to work with very large bitmap index scans. Since you'll still have the basic problem of TID recycle safety to deal with (even with an MVCC snapshot), you don't just have to revisit the leaf pages. You also have to revisit the corresponding heap pages (generally they'll be a lot more numerous than leaf pages). You'll have traded one problem for another (which is not to say that it's not a good trade-off). Right now the executor uses a amgettuple interface, and knows nothing about index related costs (e.g., pages accessed in any index, index qual costs). While the index AM has some limited understanding of heap access costs. So the index AM kinda knows a small bit about both types of costs (possibly not enough, but something). That informs the language I'm using to describe all this. To do something like your "back-references to the index" thing well, I think that you need more dynamic behavior around when you visit the heap to get heap tuples pointed to by TIDs from index pages (i.e. dynamic behavior that determines how many leaf pages to go before going to the heap to get pointed-to TIDs). That is basically what I meant by "put the index AM in control" -- it doesn't *strictly* require that the index AM actually do that. Just that a single piece of code has to have access to the full context, in order to make the right trade-offs around how both index and heap accesses are scheduled. > > I think that it makes sense to put the index AM in control here -- > > that almost follows from what I said about the index AM API. The index > > AM already needs to be in control, in about the same way, to deal with > > kill_prior_tuple (plus it helps with the LIMIT issue I described). > > Depending on what "control" means I'm doubtful: > > Imo there are decisions influencing prefetching that an index AM shouldn't > need to know about directly, e.g. how the plan shape influences how many > tuples are actually going to be consumed. Of course that determination could > be made in planner/executor and handed to IAMs, for the IAM to then "control" > the prefetching. I agree with all this. -- Peter Geoghegan
On Wed, Feb 14, 2024 at 7:43 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > I don't think it's just a bookkeeping problem. In a way, nbtree already > does keep an array of tuples to kill (see btgettuple), but it's always > for the current index page. So it's not that we immediately go and kill > the prior tuple - nbtree already stashes it in an array, and kills all > those tuples when moving to the next index page. > > The way I understand the problem is that with prefetching we're bound to > determine the kill_prior_tuple flag with a delay, in which case we might > have already moved to the next index page ... Well... I'm not clear on all of the details of how this works, but this sounds broken to me, for the reasons that Peter G. mentions in his comments about desynchronization. If we currently have a rule that you hold a pin on the index page while processing the heap tuples it references, you can't just throw that out the window and expect things to keep working. Saying that kill_prior_tuple doesn't work when you throw that rule out the window is probably understating the extent of the problem very considerably. I would have thought that the way this prefetching would work is that we would bring pages into shared_buffers sooner than we currently do, but not actually pin them until we're ready to use them, so that it's possible they might be evicted again before we get around to them, if we prefetch too far and the system is too busy. Alternately, it also seems OK to read those later pages and pin them right away, as long as (1) we don't also give up pins that we would have held in the absence of prefetching and (2) we have some mechanism for limiting the number of extra pins that we're holding to a reasonable number given the size of shared_buffers. However, it doesn't seem OK at all to give up pins that the current code holds sooner than the current code would do. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2024-02-15 09:59:27 +0530, Robert Haas wrote: > I would have thought that the way this prefetching would work is that > we would bring pages into shared_buffers sooner than we currently do, > but not actually pin them until we're ready to use them, so that it's > possible they might be evicted again before we get around to them, if > we prefetch too far and the system is too busy. The issue here is that we need to read index leaf pages (synchronously for now!) to get the tids to do readahead of table data. What you describe is done for the table data (IMO not a good idea medium term [1]), but the problem at hand is that once we've done readahead for all the tids on one index page, we can't do more readahead without looking at the next index leaf page. Obviously that would lead to a sawtooth like IO pattern, where you'd regularly have to wait for IO for the first tuples referenced by an index leaf page. However, if we want to issue table readahead for tids on the neighboring index leaf page, we'll - as the patch stands - not hold a pin on the "current" index leaf page. Which makes index prefetching as currently implemented incompatible with kill_prior_tuple, as that requires the index leaf page pin being held. > Alternately, it also seems OK to read those later pages and pin them right > away, as long as (1) we don't also give up pins that we would have held in > the absence of prefetching and (2) we have some mechanism for limiting the > number of extra pins that we're holding to a reasonable number given the > size of shared_buffers. FWIW, there's already some logic for (2) in LimitAdditionalPins(). Currently used to limit how many buffers a backend may pin for bulk relation extension. Greetings, Andres Freund [1] The main reasons that I think that just doing readahead without keeping a pin is a bad idea, at least medium term, are: a) To do AIO you need to hold a pin on the page while the IO is in progress, as the target buffer contents will be modified at some moment you don't control, so that buffer should better not be replaced while IO is in progress. So at the very least you need to hold a pin until the IO is over. b) If you do not keep a pin until you actually use the page, you need to either do another buffer lookup (expensive!) or you need to remember the buffer id and revalidate that it's still pointing to the same block (cheaper, but still not cheap). That's not just bad because it's slow in an absolute sense, more importantly it increases the potential performance downside of doing readahead for fully cached workloads, because you don't gain anything, but pay the price of two lookups/revalidation. Note that these reasons really just apply to cases where we read ahead because we are quite certain we'll need exactly those blocks (leaving errors or queries ending early aside), not for "heuristic" prefetching. If we e.g. were to issue prefetch requests for neighboring index pages while descending during an ordered index scan, without checking that we'll need those, it'd make sense to just do a "throway" prefetch request.
On Thu, Feb 15, 2024 at 10:33 AM Andres Freund <andres@anarazel.de> wrote: > The issue here is that we need to read index leaf pages (synchronously for > now!) to get the tids to do readahead of table data. What you describe is done > for the table data (IMO not a good idea medium term [1]), but the problem at > hand is that once we've done readahead for all the tids on one index page, we > can't do more readahead without looking at the next index leaf page. Oh, right. > However, if we want to issue table readahead for tids on the neighboring index > leaf page, we'll - as the patch stands - not hold a pin on the "current" index > leaf page. Which makes index prefetching as currently implemented incompatible > with kill_prior_tuple, as that requires the index leaf page pin being held. But I think it probably also breaks MVCC, as Peter was saying. -- Robert Haas EDB: http://www.enterprisedb.com
On 2/15/24 00:06, Peter Geoghegan wrote: > On Wed, Feb 14, 2024 at 4:46 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: > >> ... > > 2. Are you sure that the leaf-page-at-a-time thing is such a huge > hindrance to effective prefetching? > > I suppose that it might be much more important than I imagine it is > right now, but it'd be nice to have something a bit more concrete to > go on. > This probably depends on which corner cases are considered important. The page-at-a-time approach essentially means index items at the beginning of the page won't get prefetched (or vice versa, prefetch distance drops to 0 when we get to end of index page). That may be acceptable, considering we can usually fit 200+ index items on a single page. Even then it limits what effective_io_concurrency values are sensible, but in my experience quickly diminish past ~32. > 3. Even if it is somewhat important, do you really need to get that > part working in v1? > > Tomas' original prototype worked with the leaf-page-at-a-time thing, > and that still seemed like a big improvement to me. While being less > invasive, in effect. If we can agree that something like that > represents a useful step in the right direction (not an evolutionary > dead end), then we can make good incremental progress within a single > release. > It certainly was a great improvement, no doubt about that. I dislike the restriction, but that's partially for aesthetic reasons - it just seems it'd be nice to not have this. That being said, I'd be OK with having this restriction if it makes v1 feasible. For me, the big question is whether it'd mean we're stuck with this restriction forever, or whether there's a viable way to improve this in v2. And I don't have answer to that :-( I got completely lost in the ongoing discussion about the locking implications (which I happily ignored while working on the PoC patch), layering tensions and questions which part should be "in control". regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 15, 2024 at 9:36 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 2/15/24 00:06, Peter Geoghegan wrote: > > I suppose that it might be much more important than I imagine it is > > right now, but it'd be nice to have something a bit more concrete to > > go on. > > > > This probably depends on which corner cases are considered important. > > The page-at-a-time approach essentially means index items at the > beginning of the page won't get prefetched (or vice versa, prefetch > distance drops to 0 when we get to end of index page). I don't think that's true. At least not for nbtree scans. As I went into last year, you'd get the benefit of the work I've done on "boundary cases" (most recently in commit c9c0589f from just a couple of months back), which helps us get the most out of suffix truncation. This maximizes the chances of only having to scan a single index leaf page in many important cases. So I can see no reason why index items at the beginning of the page are at any particular disadvantage (compared to those from the middle or the end of the page). Where you might have a problem is cases where it's just inherently necessary to visit more than a single leaf page, despite the best efforts of the nbtsplitloc.c logic -- cases where the scan just inherently needs to return tuples that "straddle the boundary between two neighboring pages". That isn't a particularly natural restriction, but it's also not obvious that it's all that much of a disadvantage in practice. > It certainly was a great improvement, no doubt about that. I dislike the > restriction, but that's partially for aesthetic reasons - it just seems > it'd be nice to not have this. > > That being said, I'd be OK with having this restriction if it makes v1 > feasible. For me, the big question is whether it'd mean we're stuck with > this restriction forever, or whether there's a viable way to improve > this in v2. I think that there is no question that this will need to not completely disable kill_prior_tuple -- I'd be surprised if one single person disagreed with me on this point. There is also a more nuanced way of describing this same restriction, but we don't necessarily need to agree on what exactly that is right now. > And I don't have answer to that :-( I got completely lost in the ongoing > discussion about the locking implications (which I happily ignored while > working on the PoC patch), layering tensions and questions which part > should be "in control". Honestly, I always thought that it made sense to do things on the index AM side. When you went the other way I was surprised. Perhaps I should have said more about that, sooner, but I'd already said quite a bit at that point, so... Anyway, I think that it's pretty clear that "naive desynchronization" is just not acceptable, because that'll disable kill_prior_tuple altogether. So you're going to have to do this in a way that more or less preserves something like the current kill_prior_tuple behavior. It's going to have some downsides, but those can be managed. They can be managed from within the index AM itself, a bit like the _bt_killitems() no-pin stuff does things already. Obviously this interpretation suggests that doing things at the index AM level is indeed the right way to go, layering-wise. Does it make sense to you, though? -- Peter Geoghegan
On 2/15/24 17:42, Peter Geoghegan wrote: > On Thu, Feb 15, 2024 at 9:36 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 2/15/24 00:06, Peter Geoghegan wrote: >>> I suppose that it might be much more important than I imagine it is >>> right now, but it'd be nice to have something a bit more concrete to >>> go on. >>> >> >> This probably depends on which corner cases are considered important. >> >> The page-at-a-time approach essentially means index items at the >> beginning of the page won't get prefetched (or vice versa, prefetch >> distance drops to 0 when we get to end of index page). > > I don't think that's true. At least not for nbtree scans. > > As I went into last year, you'd get the benefit of the work I've done > on "boundary cases" (most recently in commit c9c0589f from just a > couple of months back), which helps us get the most out of suffix > truncation. This maximizes the chances of only having to scan a single > index leaf page in many important cases. So I can see no reason why > index items at the beginning of the page are at any particular > disadvantage (compared to those from the middle or the end of the > page). > I may be missing something, but it seems fairly self-evident to me an entry at the beginning of an index page won't get prefetched (assuming the page-at-a-time thing). If I understand your point about boundary cases / suffix truncation, that helps us by (a) picking the split in a way to minimize a single key spanning multiple pages, if possible and (b) increasing the number of entries that fit onto a single index page. That's certainly true / helpful, and it makes the "first entry" issue much less common. But the issue is still there. Of course, this says nothing about the importance of the issue - the impact may easily be so small it's not worth worrying about. > Where you might have a problem is cases where it's just inherently > necessary to visit more than a single leaf page, despite the best > efforts of the nbtsplitloc.c logic -- cases where the scan just > inherently needs to return tuples that "straddle the boundary between > two neighboring pages". That isn't a particularly natural restriction, > but it's also not obvious that it's all that much of a disadvantage in > practice. > One case I've been thinking about is sorting using index, where we often read large part of the index. >> It certainly was a great improvement, no doubt about that. I dislike the >> restriction, but that's partially for aesthetic reasons - it just seems >> it'd be nice to not have this. >> >> That being said, I'd be OK with having this restriction if it makes v1 >> feasible. For me, the big question is whether it'd mean we're stuck with >> this restriction forever, or whether there's a viable way to improve >> this in v2. > > I think that there is no question that this will need to not > completely disable kill_prior_tuple -- I'd be surprised if one single > person disagreed with me on this point. There is also a more nuanced > way of describing this same restriction, but we don't necessarily need > to agree on what exactly that is right now. > Even for the page-at-a-time approach? Or are you talking about the v2? >> And I don't have answer to that :-( I got completely lost in the ongoing >> discussion about the locking implications (which I happily ignored while >> working on the PoC patch), layering tensions and questions which part >> should be "in control". > > Honestly, I always thought that it made sense to do things on the > index AM side. When you went the other way I was surprised. Perhaps I > should have said more about that, sooner, but I'd already said quite a > bit at that point, so... > > Anyway, I think that it's pretty clear that "naive desynchronization" > is just not acceptable, because that'll disable kill_prior_tuple > altogether. So you're going to have to do this in a way that more or > less preserves something like the current kill_prior_tuple behavior. > It's going to have some downsides, but those can be managed. They can > be managed from within the index AM itself, a bit like the > _bt_killitems() no-pin stuff does things already. > > Obviously this interpretation suggests that doing things at the index > AM level is indeed the right way to go, layering-wise. Does it make > sense to you, though? > Yeah. The basic idea was that by moving this above index AM it will work for all indexes automatically - but given the current discussion about kill_prior_tuple, locking etc. I'm not sure that's really feasible. The index AM clearly needs to have more control over this. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 15, 2024 at 12:26 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > I may be missing something, but it seems fairly self-evident to me an > entry at the beginning of an index page won't get prefetched (assuming > the page-at-a-time thing). Sure, if the first item on the page is also the first item that we need the scan to return (having just descended the tree), then it won't get prefetched under a scheme that sticks with the current page-at-a-time behavior (at least in v1). Just like when the first item that we need the scan to return is from the middle of the page, or more towards the end of the page. It is of course also true that we can't prefetch the next page's first item until we actually visit the next page -- clearly that's suboptimal. Just like we can't prefetch any other, later tuples from the next page (until such time as we have determined for sure that there really will be a next page, and have called _bt_readpage for that next page.) This is why I don't think that the tuples with lower page offset numbers are in any way significant here. The significant part is whether or not you'll actually need to visit more than one leaf page in the first place (plus the penalty from not being able to reorder the work across page boundaries in your initial v1 of prefetching). > If I understand your point about boundary cases / suffix truncation, > that helps us by (a) picking the split in a way to minimize a single key > spanning multiple pages, if possible and (b) increasing the number of > entries that fit onto a single index page. More like it makes the boundaries between leaf pages (i.e. high keys) align with the "natural boundaries of the key space". Simple point queries should practically never require more than a single leaf page access as a result. Even somewhat complicated index scans that are reasonably selective (think tens to low hundreds of matches) don't tend to need to read more than a single leaf page match, at least with equality type scan keys for the index qual. > That's certainly true / helpful, and it makes the "first entry" issue > much less common. But the issue is still there. Of course, this says > nothing about the importance of the issue - the impact may easily be so > small it's not worth worrying about. Right. And I want to be clear: I'm really *not* sure how much it matters. I just doubt that it's worth worrying about in v1 -- time grows short. Although I agree that we should commit a v1 that leaves the door open to improving matters in this area in v2. > One case I've been thinking about is sorting using index, where we often > read large part of the index. That definitely seems like a case where reordering work/desynchronization of the heap and index scans might be relatively important. > > I think that there is no question that this will need to not > > completely disable kill_prior_tuple -- I'd be surprised if one single > > person disagreed with me on this point. There is also a more nuanced > > way of describing this same restriction, but we don't necessarily need > > to agree on what exactly that is right now. > > > > Even for the page-at-a-time approach? Or are you talking about the v2? I meant that the current kill_prior_tuple behavior isn't sacred, and can be revised in v2, for the benefit of lifting the restriction on prefetching. But that's going to involve a trade-off of some kind. And not a particularly simple one. > Yeah. The basic idea was that by moving this above index AM it will work > for all indexes automatically - but given the current discussion about > kill_prior_tuple, locking etc. I'm not sure that's really feasible. > > The index AM clearly needs to have more control over this. Cool. I think that that makes the layering question a lot clearer, then. -- Peter Geoghegan
Hi, On 2024-02-15 12:53:10 -0500, Peter Geoghegan wrote: > On Thu, Feb 15, 2024 at 12:26 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > I may be missing something, but it seems fairly self-evident to me an > > entry at the beginning of an index page won't get prefetched (assuming > > the page-at-a-time thing). > > Sure, if the first item on the page is also the first item that we > need the scan to return (having just descended the tree), then it > won't get prefetched under a scheme that sticks with the current > page-at-a-time behavior (at least in v1). Just like when the first > item that we need the scan to return is from the middle of the page, > or more towards the end of the page. > > It is of course also true that we can't prefetch the next page's > first item until we actually visit the next page -- clearly that's > suboptimal. Just like we can't prefetch any other, later tuples from > the next page (until such time as we have determined for sure that > there really will be a next page, and have called _bt_readpage for > that next page.) > > This is why I don't think that the tuples with lower page offset > numbers are in any way significant here. The significant part is > whether or not you'll actually need to visit more than one leaf page > in the first place (plus the penalty from not being able to reorder > the work across page boundaries in your initial v1 of prefetching). To me this your phrasing just seems to reformulate the issue. In practical terms you'll have to wait for the full IO latency when fetching the table tuple corresponding to the first tid on a leaf page. Of course that's also the moment you had to visit another leaf page. Whether the stall is due to visit another leaf page or due to processing the first entry on such a leaf page is a distinction without a difference. > > That's certainly true / helpful, and it makes the "first entry" issue > > much less common. But the issue is still there. Of course, this says > > nothing about the importance of the issue - the impact may easily be so > > small it's not worth worrying about. > > Right. And I want to be clear: I'm really *not* sure how much it > matters. I just doubt that it's worth worrying about in v1 -- time > grows short. Although I agree that we should commit a v1 that leaves > the door open to improving matters in this area in v2. I somewhat doubt that it's realistic to aim for 17 at this point. We seem to still be doing fairly fundamental architectual work. I think it might be the right thing even for 18 to go for the simpler only-a-single-leaf-page approach though. I wonder if there are prerequisites that can be tackled for 17. One idea is to work on infrastructure to provide executor nodes with information about the number of tuples likely to be fetched - I suspect we'll trigger regressions without that in place. One way to *sometimes* process more than a single leaf page, without having to redesign kill_prior_tuple, would be to use the visibilitymap to check if the target pages are all-visible. If all the table pages on a leaf page are all-visible, we know that we don't need to kill index entries, and thus can move on to the next leaf page Greetings, Andres Freund
On Thu, Feb 15, 2024 at 3:13 PM Andres Freund <andres@anarazel.de> wrote: > > This is why I don't think that the tuples with lower page offset > > numbers are in any way significant here. The significant part is > > whether or not you'll actually need to visit more than one leaf page > > in the first place (plus the penalty from not being able to reorder > > the work across page boundaries in your initial v1 of prefetching). > > To me this your phrasing just seems to reformulate the issue. What I said to Tomas seems very obvious to me. I think that there might have been some kind of miscommunication (not a real disagreement). I was just trying to work through that. > In practical terms you'll have to wait for the full IO latency when fetching > the table tuple corresponding to the first tid on a leaf page. Of course > that's also the moment you had to visit another leaf page. Whether the stall > is due to visit another leaf page or due to processing the first entry on such > a leaf page is a distinction without a difference. I don't think anybody said otherwise? > > > That's certainly true / helpful, and it makes the "first entry" issue > > > much less common. But the issue is still there. Of course, this says > > > nothing about the importance of the issue - the impact may easily be so > > > small it's not worth worrying about. > > > > Right. And I want to be clear: I'm really *not* sure how much it > > matters. I just doubt that it's worth worrying about in v1 -- time > > grows short. Although I agree that we should commit a v1 that leaves > > the door open to improving matters in this area in v2. > > I somewhat doubt that it's realistic to aim for 17 at this point. That's a fair point. Tomas? > We seem to > still be doing fairly fundamental architectual work. I think it might be the > right thing even for 18 to go for the simpler only-a-single-leaf-page > approach though. I definitely think it's a good idea to have that as a fall back option. And to not commit ourselves to having something better than that for v1 (though we probably should commit to making that possible in v2). > I wonder if there are prerequisites that can be tackled for 17. One idea is to > work on infrastructure to provide executor nodes with information about the > number of tuples likely to be fetched - I suspect we'll trigger regressions > without that in place. I don't think that there'll be regressions if we just take the simpler only-a-single-leaf-page approach. At least it seems much less likely. > One way to *sometimes* process more than a single leaf page, without having to > redesign kill_prior_tuple, would be to use the visibilitymap to check if the > target pages are all-visible. If all the table pages on a leaf page are > all-visible, we know that we don't need to kill index entries, and thus can > move on to the next leaf page It's possible that we'll need a variety of different strategies. nbtree already has two such strategies in _bt_killitems(), in a way. Though its "Modified while not pinned means hinting is not safe" path (LSN doesn't match canary value path) seems pretty naive. The prefetching stuff might present us with a good opportunity to replace that with something fundamentally better. -- Peter Geoghegan
On Wed, Jan 24, 2024 at 7:13 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
[
>
> (1) Melanie actually presented a very different way to implement this,
> relying on the StreamingRead API. So chances are this struct won't
> actually be used.
Given lots of effort already spent on this and the fact that is thread
is actually two:
a. index/table prefetching since Jun 2023 till ~Jan 2024
b. afterwards index/table prefetching with Streaming API, but there
are some doubts of whether it could happen for v17 [1]
... it would be pitty to not take benefits of such work (even if
Streaming API wouldn't be ready for this; although there's lots of
movement in the area), so I've played a little with with the earlier
implementation from [2] without streaming API as it already received
feedback, it demonstrated big benefits, and earlier it got attention
on pgcon unconference. Perhaps, some of those comment might be passed
later to the "b"-patch (once that's feasible):
1. v20240124-0001-Prefetch-heap-pages-during-index-scans.patch does
not apply cleanly anymore, due show_buffer_usage() being quite
recently refactored in 5de890e3610d5a12cdaea36413d967cf5c544e20 :
patching file src/backend/commands/explain.c
Hunk #1 FAILED at 3568.
Hunk #2 FAILED at 3679.
2 out of 2 hunks FAILED -- saving rejects to file
src/backend/commands/explain.c.rej
2. v2 applies (fixup), but it would nice to see that integrated into
main patch (it adds IndexOnlyPrefetchInfo) into one patch
3. execMain.c :
+ * XXX It might be possible to improve the prefetching code
to handle this
+ * by "walking back" the TID queue, but it's not clear if
it's worth it.
Shouldn't we just remove the XXX? The walking-back seems to be niche
so are fetches using cursors when looking at real world users queries
? (support cases bias here when looking at peopel's pg_stat_activity)
4. Wouldn't it be better to leave PREFETCH_LRU_SIZE at static of 8,
but base PREFETCH_LRU_COUNT on effective_io_concurrency instead?
(allowing it to follow dynamically; the more prefetches the user wants
to perform, the more you spread them across shared LRUs and the more
memory for history is required?)
+ * XXX Maybe we could consider effective_cache_size when sizing the cache?
+ * Not to size the cache for that, ofc, but maybe as a guidance of how many
+ * heap pages it might keep. Maybe just a fraction fraction of the value,
+ * say Max(8MB, effective_cache_size / max_connections) or something.
+ */
+#define PREFETCH_LRU_SIZE 8 /* slots in one LRU */
+#define PREFETCH_LRU_COUNT 128 /* number of LRUs */
+#define PREFETCH_CACHE_SIZE (PREFETCH_LRU_SIZE *
PREFETCH_LRU_COUNT)
BTW:
+ * heap pages it might keep. Maybe just a fraction fraction of the value,
that's a duplicated "fraction" word over there.
5.
+ * XXX Could it be harmful that we read the queue backwards?
Maybe memory
+ * prefetching works better for the forward direction?
I wouldn't care, we are optimizing I/O (and context-switching) which
weighs much more than memory access direction impact and Dilipi
earlier also expressed no concern, so maybe it could be also removed
(one less "XXX" to care about)
6. in IndexPrefetchFillQueue()
+ while (!PREFETCH_QUEUE_FULL(prefetch))
+ {
+ IndexPrefetchEntry *entry
+ = prefetch->next_cb(scan, direction, prefetch->data);
If we are at it... that's a strange split and assignment not indented :^)
7. in IndexPrefetchComputeTarget()
+ * XXX We cap the target to plan_rows, becausse it's pointless to prefetch
+ * more than we expect to use.
That's a nice fact that's already in patch, so XXX isn't needed?
8.
+ * XXX Maybe we should reduce the value with parallel workers?
I was assuming it could be a good idea, but the same doesn't seem
(eic/actual_parallel_works_per_gather) to be performed for bitmap heap
scan prefetches, so no?
9.
+ /*
+ * No prefetching for direct I/O.
+ *
+ * XXX Shouldn't we do prefetching even for direct I/O? We would only
+ * pretend doing it now, ofc, because we'd not do posix_fadvise(), but
+ * once the code starts loading into shared buffers, that'd work.
+ */
+ if ((io_direct_flags & IO_DIRECT_DATA) != 0)
+ return 0;
It's redundant (?) and could be removed as
PrefetchBuffer()->PrefetchSharedBuffer() already has this at line 571:
5 #ifdef USE_PREFETCH
4 │ │ /*
3 │ │ │* Try to initiate an asynchronous read. This
returns false in
2 │ │ │* recovery if the relation file doesn't exist.
1 │ │ │*/
571 │ │ if ((io_direct_flags & IO_DIRECT_DATA) == 0 &&
1 │ │ │ smgrprefetch(smgr_reln, forkNum, blockNum, 1))
2 │ │ {
3 │ │ │ result.initiated_io = true;
4 │ │ }
5 #endif> > > > > > > /* USE_PREFETCH */
11. in IndexPrefetchStats() and ExecReScanIndexScan()
+ * FIXME Should be only in debug builds, or something like that.
+ /* XXX Print some debug stats. Should be removed. */
+ IndexPrefetchStats(indexScanDesc, node->iss_prefetch);
Hmm, but it could be useful in tuning the real world systems, no? E.g.
recovery prefetcher gives some info through pg_stat_recovery_prefetch
view, but e.g. bitmap heap scans do not provide us with anything at
all. I don't have a strong opinion. Exposing such stuff would take
away your main doubt (XXX) from execPrefetch.c
``auto-tuning/self-adjustment". And if we are at it, we could think in
far future about adding new session GUC track_cachestat or EXPLAIN
(cachestat/prefetch, analyze) (this new syscall for Linux >= 6.5)
where we could present both index stats (as what IndexPrefetchStats()
does) *and* cachestat() results there for interested users. Of course
it would have to be generic enough for the bitmap heap scan case too.
Such insight would also allow fine tuning eic, PREFETCH_LRU_COUNT,
PREFETCH_QUEUE_HISTORY. Just an idea.
12.
+ * XXX Maybe we should reduce the target in case this is
a parallel index
+ * scan. We don't want to issue a multiple of
effective_io_concurrency.
in IndexOnlyPrefetchCleanup() and IndexNext()
+ * XXX Maybe we should reduce the value with parallel workers?
It's redundant XXX-comment (there are two for the same), as you it was
already there just before IndexPrefetchComputeTarget()
13. The previous bitmap prefetch code uses #ifdef USE_PREFETCH, maybe
it would make some sense to follow the consistency pattern , to avoid
adding implementation on platforms without prefetching ?
14. The patch is missing documentation, so how about just this?
--- a/doc/src/sgml/config.sgml
+++ b/doc/src/sgml/config.sgml
@@ -2527,7 +2527,8 @@ include_dir 'conf.d'
operations that any individual
<productname>PostgreSQL</productname> session
attempts to initiate in parallel. The allowed range is 1 to 1000,
or zero to disable issuance of asynchronous I/O requests. Currently,
- this setting only affects bitmap heap scans.
+ this setting only enables prefetching for HEAP data blocks
when performing
+ bitmap heap scans and index (only) scans.
</para>
Some further tests, given data:
CREATE TABLE test (id bigint, val bigint, str text);
ALTER TABLE test ALTER COLUMN str SET STORAGE EXTERNAL;
INSERT INTO test SELECT g, g, repeat(chr(65 + (10*random())::int),
3000) FROM generate_series(1, 10000) g;
-- or INSERT INTO test SELECT x.r, x.r, repeat(chr(65 +
(10*random())::int), 3000) from (select 10000 * random() as r from
generate_series(1, 10000)) x;
VACUUM ANALYZE test;
CREATE INDEX on test (id) ;
1. the patch correctly detects sequential access (e.g. we issue up to
6 fadvise() syscalls (8kB each) out and 17 preads() to heap fd for
query like `SELECT sum(val) FROM test WHERE id BETWEEN 10 AND 2000;`
-- offset of fadvise calls and pread match), so that's good.
2. Prefetching for TOASTed heap seems to be not implemented at all,
correct? (Is my assumption that we should go like this:
t_index->t->toast_idx->toast_heap)?, but I'm too newbie to actually
see the code path where it could be added - certainly it's not blocker
-- but maybe in commit message a list of improvements for future could
be listed?):
2024-02-29 11:45:14.259 CET [11098] LOG: index prefetch stats:
requests 1990 prefetches 17 (0.854271) skip cached 0 sequential 1973
2024-02-29 11:45:14.259 CET [11098] STATEMENT: SELECT
md5(string_agg(md5(str),',')) FROM test WHERE id BETWEEN 10 AND 2000;
fadvise64(37, 40960, 8192, POSIX_FADV_WILLNEED) = 0
pread64(50, "\0\0\0\0\350Jv\1\0\0\4\0(\0\0\10\0 \4
\0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2998272) = 8192
pread64(49, "\0\0\0\0@Hw\1\0\0\0\0\324\5\0\t\360\37\4 \0\0\0\0\340\237
\0\320\237 \0"..., 8192, 40960) = 8192
pread64(50, "\0\0\0\0\2200v\1\0\0\4\0(\0\0\10\0 \4
\0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2990080) = 8192
pread64(50, "\0\0\0\08\26v\1\0\0\4\0(\0\0\10\0 \4
\0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2981888) = 8192
pread64(50, "\0\0\0\0\340\373u\1\0\0\4\0(\0\0\10\0 \4
\0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2973696) = 8192
[..no fadvises for fd=50 which was pg_toast_rel..]
3. I'm not sure if I got good-enough results for DESCending index
`create index on test (id DESC);`- with eic=16 it doesnt seem to be
be able prefetch 16 blocks in advance? (e.g. highlight offset 557056
below in some text editor and it's distance is far lower between that
fadvise<->pread):
pread64(45, "\0\0\0\0x\305b\3\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 0) = 8192
fadvise64(45, 417792, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\0\370\330\235\4\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 417792) = 8192
fadvise64(45, 671744, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 237568, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\08`]\5\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 671744) = 8192
fadvise64(45, 491520, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 360448, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\0\200\357\25\4\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 237568) = 8192
fadvise64(45, 557056, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 106496, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\0\240s\325\4\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 491520) = 8192
fadvise64(45, 401408, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 335872, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\0\250\233r\4\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 360448) = 8192
fadvise64(45, 524288, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 352256, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, "\0\0\0\0\240\342\6\5\0\0\4\0\370\1\0\2\0 \4
\0\0\0\0\300\237t\0\200\237t\0"..., 8192, 557056) = 8192
-Jakub Wartak.
[1] - https://www.postgresql.org/message-id/20240215201337.7amzw3hpvng7wphb%40awork3.anarazel.de
[2] - https://www.postgresql.org/message-id/777e981c-bf0c-4eb9-a9e0-42d677e94327%40enterprisedb.com
Hi,
Thanks for looking at the patch!
On 3/1/24 09:20, Jakub Wartak wrote:
> On Wed, Jan 24, 2024 at 7:13 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
> [
>>
>> (1) Melanie actually presented a very different way to implement this,
>> relying on the StreamingRead API. So chances are this struct won't
>> actually be used.
>
> Given lots of effort already spent on this and the fact that is thread
> is actually two:
>
> a. index/table prefetching since Jun 2023 till ~Jan 2024
> b. afterwards index/table prefetching with Streaming API, but there
> are some doubts of whether it could happen for v17 [1]
>
> ... it would be pitty to not take benefits of such work (even if
> Streaming API wouldn't be ready for this; although there's lots of
> movement in the area), so I've played a little with with the earlier
> implementation from [2] without streaming API as it already received
> feedback, it demonstrated big benefits, and earlier it got attention
> on pgcon unconference. Perhaps, some of those comment might be passed
> later to the "b"-patch (once that's feasible):
>
TBH I don't have a clear idea what to do. It'd be cool to have at least
some benefits in v17, but I don't know how to do that in a way that
would be useful in the future.
For example, the v20240124 patch implements this in the executor, but
based on the recent discussions it seems that's not the right layer -
the index AM needs to have some control, and I'm not convinced it's
possible to improve it in that direction (even ignoring the various
issues we identified in the executor-based approach).
I think it might be more practical to do this from the index AM, even if
it has various limitations. Ironically, that's what I proposed at pgcon,
but mostly because it was the quick&dirty way to do this.
> 1. v20240124-0001-Prefetch-heap-pages-during-index-scans.patch does
> not apply cleanly anymore, due show_buffer_usage() being quite
> recently refactored in 5de890e3610d5a12cdaea36413d967cf5c544e20 :
>
> patching file src/backend/commands/explain.c
> Hunk #1 FAILED at 3568.
> Hunk #2 FAILED at 3679.
> 2 out of 2 hunks FAILED -- saving rejects to file
> src/backend/commands/explain.c.rej
>
> 2. v2 applies (fixup), but it would nice to see that integrated into
> main patch (it adds IndexOnlyPrefetchInfo) into one patch
>
Yeah, but I think it was an old patch version, no point in rebasing that
forever. Also, I'm not really convinced the executor-level approach is
the right path forward.
> 3. execMain.c :
>
> + * XXX It might be possible to improve the prefetching code
> to handle this
> + * by "walking back" the TID queue, but it's not clear if
> it's worth it.
>
> Shouldn't we just remove the XXX? The walking-back seems to be niche
> so are fetches using cursors when looking at real world users queries
> ? (support cases bias here when looking at peopel's pg_stat_activity)
>
> 4. Wouldn't it be better to leave PREFETCH_LRU_SIZE at static of 8,
> but base PREFETCH_LRU_COUNT on effective_io_concurrency instead?
> (allowing it to follow dynamically; the more prefetches the user wants
> to perform, the more you spread them across shared LRUs and the more
> memory for history is required?)
>
> + * XXX Maybe we could consider effective_cache_size when sizing the cache?
> + * Not to size the cache for that, ofc, but maybe as a guidance of how many
> + * heap pages it might keep. Maybe just a fraction fraction of the value,
> + * say Max(8MB, effective_cache_size / max_connections) or something.
> + */
> +#define PREFETCH_LRU_SIZE 8 /* slots in one LRU */
> +#define PREFETCH_LRU_COUNT 128 /* number of LRUs */
> +#define PREFETCH_CACHE_SIZE (PREFETCH_LRU_SIZE *
> PREFETCH_LRU_COUNT)
>
I don't see why would this be related to effective_io_concurrency? It's
merely about how many recently accessed pages we expect to find in the
page cache. It's entirely separate from the prefetch distance.
> BTW:
> + * heap pages it might keep. Maybe just a fraction fraction of the value,
> that's a duplicated "fraction" word over there.
>
> 5.
> + * XXX Could it be harmful that we read the queue backwards?
> Maybe memory
> + * prefetching works better for the forward direction?
>
> I wouldn't care, we are optimizing I/O (and context-switching) which
> weighs much more than memory access direction impact and Dilipi
> earlier also expressed no concern, so maybe it could be also removed
> (one less "XXX" to care about)
>
Yeah, I think it's negligible. Probably a microoptimization we can
investigate later, I don't want to complicate the code unnecessarily.
> 6. in IndexPrefetchFillQueue()
>
> + while (!PREFETCH_QUEUE_FULL(prefetch))
> + {
> + IndexPrefetchEntry *entry
> + = prefetch->next_cb(scan, direction, prefetch->data);
>
> If we are at it... that's a strange split and assignment not indented :^)
>
> 7. in IndexPrefetchComputeTarget()
>
> + * XXX We cap the target to plan_rows, becausse it's pointless to prefetch
> + * more than we expect to use.
>
> That's a nice fact that's already in patch, so XXX isn't needed?
>
Right, which is why it's not a TODO/FIXME. But I think it's good to
point this out - I'm not 100% convinced we should be using plan_rows
like this (because what happens if the estimate happens to be wrong?).
> 8.
> + * XXX Maybe we should reduce the value with parallel workers?
>
> I was assuming it could be a good idea, but the same doesn't seem
> (eic/actual_parallel_works_per_gather) to be performed for bitmap heap
> scan prefetches, so no?
>
Yeah, if we don't do that now, I'm not sure this patch should change
that behavior.
> 9.
> + /*
> + * No prefetching for direct I/O.
> + *
> + * XXX Shouldn't we do prefetching even for direct I/O? We would only
> + * pretend doing it now, ofc, because we'd not do posix_fadvise(), but
> + * once the code starts loading into shared buffers, that'd work.
> + */
> + if ((io_direct_flags & IO_DIRECT_DATA) != 0)
> + return 0;
>
> It's redundant (?) and could be removed as
> PrefetchBuffer()->PrefetchSharedBuffer() already has this at line 571:
>
> 5 #ifdef USE_PREFETCH
> 4 │ │ /*
> 3 │ │ │* Try to initiate an asynchronous read. This
> returns false in
> 2 │ │ │* recovery if the relation file doesn't exist.
> 1 │ │ │*/
> 571 │ │ if ((io_direct_flags & IO_DIRECT_DATA) == 0 &&
> 1 │ │ │ smgrprefetch(smgr_reln, forkNum, blockNum, 1))
> 2 │ │ {
> 3 │ │ │ result.initiated_io = true;
> 4 │ │ }
> 5 #endif> > > > > > > /* USE_PREFETCH */
>
Yeah, I think it might be redundant. I think it allowed skipping a bunch
things without prefetching (like initialization of the prefetcher), but
after the reworks that's no longer true.
> 11. in IndexPrefetchStats() and ExecReScanIndexScan()
>
> + * FIXME Should be only in debug builds, or something like that.
>
> + /* XXX Print some debug stats. Should be removed. */
> + IndexPrefetchStats(indexScanDesc, node->iss_prefetch);
>
> Hmm, but it could be useful in tuning the real world systems, no? E.g.
> recovery prefetcher gives some info through pg_stat_recovery_prefetch
> view, but e.g. bitmap heap scans do not provide us with anything at
> all. I don't have a strong opinion. Exposing such stuff would take
> away your main doubt (XXX) from execPrefetch.c
You're right it'd be good to collect/expose such statistics, to help
with monitoring/tuning, etc. But I think there are better / more
convenient ways to do this - exposing that in EXPLAIN, and adding a
counter to pgstat_all_tables / pgstat_all_indexes.
> ``auto-tuning/self-adjustment". And if we are at it, we could think in
> far future about adding new session GUC track_cachestat or EXPLAIN
> (cachestat/prefetch, analyze) (this new syscall for Linux >= 6.5)
> where we could present both index stats (as what IndexPrefetchStats()
> does) *and* cachestat() results there for interested users. Of course
> it would have to be generic enough for the bitmap heap scan case too.
> Such insight would also allow fine tuning eic, PREFETCH_LRU_COUNT,
> PREFETCH_QUEUE_HISTORY. Just an idea.
>
I haven't really thought about this, but I agree some auto-tuning would
be very helpful (assuming it's sufficiently reliable).
> 12.
>
> + * XXX Maybe we should reduce the target in case this is
> a parallel index
> + * scan. We don't want to issue a multiple of
> effective_io_concurrency.
>
> in IndexOnlyPrefetchCleanup() and IndexNext()
>
> + * XXX Maybe we should reduce the value with parallel workers?
>
> It's redundant XXX-comment (there are two for the same), as you it was
> already there just before IndexPrefetchComputeTarget()
>
> 13. The previous bitmap prefetch code uses #ifdef USE_PREFETCH, maybe
> it would make some sense to follow the consistency pattern , to avoid
> adding implementation on platforms without prefetching ?
>
Perhaps, but I'm not sure how to do that with the executor-based
approach, where essentially everything goes through the prefetch queue
(except that the prefetch distance is 0). So the amount of code that
would be disabled by the ifdef would be tiny.
> 14. The patch is missing documentation, so how about just this?
>
> --- a/doc/src/sgml/config.sgml
> +++ b/doc/src/sgml/config.sgml
> @@ -2527,7 +2527,8 @@ include_dir 'conf.d'
> operations that any individual
> <productname>PostgreSQL</productname> session
> attempts to initiate in parallel. The allowed range is 1 to 1000,
> or zero to disable issuance of asynchronous I/O requests. Currently,
> - this setting only affects bitmap heap scans.
> + this setting only enables prefetching for HEAP data blocks
> when performing
> + bitmap heap scans and index (only) scans.
> </para>
>
> Some further tests, given data:
>
> CREATE TABLE test (id bigint, val bigint, str text);
> ALTER TABLE test ALTER COLUMN str SET STORAGE EXTERNAL;
> INSERT INTO test SELECT g, g, repeat(chr(65 + (10*random())::int),
> 3000) FROM generate_series(1, 10000) g;
> -- or INSERT INTO test SELECT x.r, x.r, repeat(chr(65 +
> (10*random())::int), 3000) from (select 10000 * random() as r from
> generate_series(1, 10000)) x;
> VACUUM ANALYZE test;
> CREATE INDEX on test (id) ;
>
It's not clear to me what's the purpose of this test? Can you explain?
> 1. the patch correctly detects sequential access (e.g. we issue up to
> 6 fadvise() syscalls (8kB each) out and 17 preads() to heap fd for
> query like `SELECT sum(val) FROM test WHERE id BETWEEN 10 AND 2000;`
> -- offset of fadvise calls and pread match), so that's good.
>
> 2. Prefetching for TOASTed heap seems to be not implemented at all,
> correct? (Is my assumption that we should go like this:
> t_index->t->toast_idx->toast_heap)?, but I'm too newbie to actually
> see the code path where it could be added - certainly it's not blocker
> -- but maybe in commit message a list of improvements for future could
> be listed?):
>
Yes, that's true. I haven't thought about TOAST very much, but with
prefetching happening in executor, that does not work. There'd need to
be some extra code for TOAST prefetching. I'm not sure how beneficial
that would be, considering most TOAST values tend to be stored on
consecutive heap pages.
> 2024-02-29 11:45:14.259 CET [11098] LOG: index prefetch stats:
> requests 1990 prefetches 17 (0.854271) skip cached 0 sequential 1973
> 2024-02-29 11:45:14.259 CET [11098] STATEMENT: SELECT
> md5(string_agg(md5(str),',')) FROM test WHERE id BETWEEN 10 AND 2000;
>
> fadvise64(37, 40960, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(50, "\0\0\0\0\350Jv\1\0\0\4\0(\0\0\10\0 \4
> \0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2998272) = 8192
> pread64(49, "\0\0\0\0@Hw\1\0\0\0\0\324\5\0\t\360\37\4 \0\0\0\0\340\237
> \0\320\237 \0"..., 8192, 40960) = 8192
> pread64(50, "\0\0\0\0\2200v\1\0\0\4\0(\0\0\10\0 \4
> \0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2990080) = 8192
> pread64(50, "\0\0\0\08\26v\1\0\0\4\0(\0\0\10\0 \4
> \0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2981888) = 8192
> pread64(50, "\0\0\0\0\340\373u\1\0\0\4\0(\0\0\10\0 \4
> \0\0\0\0\20\230\340\17\0\224 \10"..., 8192, 2973696) = 8192
> [..no fadvises for fd=50 which was pg_toast_rel..]
>
> 3. I'm not sure if I got good-enough results for DESCending index
> `create index on test (id DESC);`- with eic=16 it doesnt seem to be
> be able prefetch 16 blocks in advance? (e.g. highlight offset 557056
> below in some text editor and it's distance is far lower between that
> fadvise<->pread):
>
> pread64(45, "\0\0\0\0x\305b\3\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 0) = 8192
> fadvise64(45, 417792, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\0\370\330\235\4\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 417792) = 8192
> fadvise64(45, 671744, 8192, POSIX_FADV_WILLNEED) = 0
> fadvise64(45, 237568, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\08`]\5\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 671744) = 8192
> fadvise64(45, 491520, 8192, POSIX_FADV_WILLNEED) = 0
> fadvise64(45, 360448, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\0\200\357\25\4\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 237568) = 8192
> fadvise64(45, 557056, 8192, POSIX_FADV_WILLNEED) = 0
> fadvise64(45, 106496, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\0\240s\325\4\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 491520) = 8192
> fadvise64(45, 401408, 8192, POSIX_FADV_WILLNEED) = 0
> fadvise64(45, 335872, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\0\250\233r\4\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 360448) = 8192
> fadvise64(45, 524288, 8192, POSIX_FADV_WILLNEED) = 0
> fadvise64(45, 352256, 8192, POSIX_FADV_WILLNEED) = 0
> pread64(45, "\0\0\0\0\240\342\6\5\0\0\4\0\370\1\0\2\0 \4
> \0\0\0\0\300\237t\0\200\237t\0"..., 8192, 557056) = 8192
>
I'm not sure I understand these strace snippets. Can you elaborate a
bit, explain what the strace log says?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2/15/24 21:30, Peter Geoghegan wrote: > On Thu, Feb 15, 2024 at 3:13 PM Andres Freund <andres@anarazel.de> wrote: >>> This is why I don't think that the tuples with lower page offset >>> numbers are in any way significant here. The significant part is >>> whether or not you'll actually need to visit more than one leaf page >>> in the first place (plus the penalty from not being able to reorder >>> the work across page boundaries in your initial v1 of prefetching). >> >> To me this your phrasing just seems to reformulate the issue. > > What I said to Tomas seems very obvious to me. I think that there > might have been some kind of miscommunication (not a real > disagreement). I was just trying to work through that. > >> In practical terms you'll have to wait for the full IO latency when fetching >> the table tuple corresponding to the first tid on a leaf page. Of course >> that's also the moment you had to visit another leaf page. Whether the stall >> is due to visit another leaf page or due to processing the first entry on such >> a leaf page is a distinction without a difference. > > I don't think anybody said otherwise? > >>>> That's certainly true / helpful, and it makes the "first entry" issue >>>> much less common. But the issue is still there. Of course, this says >>>> nothing about the importance of the issue - the impact may easily be so >>>> small it's not worth worrying about. >>> >>> Right. And I want to be clear: I'm really *not* sure how much it >>> matters. I just doubt that it's worth worrying about in v1 -- time >>> grows short. Although I agree that we should commit a v1 that leaves >>> the door open to improving matters in this area in v2. >> >> I somewhat doubt that it's realistic to aim for 17 at this point. > > That's a fair point. Tomas? > I think that's a fair assessment. To me it seems doing the prefetching solely at the executor level is not really workable. And if it can be made to work, there's far too many open questions to do that in the last commitfest. I think the consensus is at least some of the logic/control needs to move back to the index AM. Maybe there's some minimal part that we could do for v17, even if it has various limitations, and then improve that in v18. Say, doing the leaf-page-at-a-time and passing a little bit of information from the index scan to drive this. But I have very hard time figuring out what the MVP version should be, because I have very limited understanding on how much control the index AM ought to have :-( And it'd be a bit silly to do something in v17, only to have to rip it out in v18 because it turned out to not get the split right. >> We seem to >> still be doing fairly fundamental architectual work. I think it might be the >> right thing even for 18 to go for the simpler only-a-single-leaf-page >> approach though. > > I definitely think it's a good idea to have that as a fall back > option. And to not commit ourselves to having something better than > that for v1 (though we probably should commit to making that possible > in v2). > Yeah, I agree with that. >> I wonder if there are prerequisites that can be tackled for 17. One idea is to >> work on infrastructure to provide executor nodes with information about the >> number of tuples likely to be fetched - I suspect we'll trigger regressions >> without that in place. > > I don't think that there'll be regressions if we just take the simpler > only-a-single-leaf-page approach. At least it seems much less likely. > I'm sure we could pass additional information from the index scans to improve that further. But I think the gradual ramp-up would deal with most regressions. At least that's my experience from benchmarking the early version. The hard thing is what to do about cases where neither of this helps. The example I keep thinking about is IOS - if we don't do prefetching, it's not hard to construct cases where regular index scan gets much faster than IOS (with many not-all-visible pages). But we can't just prefetch all pages, because that'd hurt IOS cases with most pages fully visible (when we don't need to actually access the heap). I managed to deal with this in the executor-level version, but I'm not sure how to do this if the control moves closer to the index AM. >> One way to *sometimes* process more than a single leaf page, without having to >> redesign kill_prior_tuple, would be to use the visibilitymap to check if the >> target pages are all-visible. If all the table pages on a leaf page are >> all-visible, we know that we don't need to kill index entries, and thus can >> move on to the next leaf page > > It's possible that we'll need a variety of different strategies. > nbtree already has two such strategies in _bt_killitems(), in a way. > Though its "Modified while not pinned means hinting is not safe" path > (LSN doesn't match canary value path) seems pretty naive. The > prefetching stuff might present us with a good opportunity to replace > that with something fundamentally better. > No opinion. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 1, 2024 at 10:18 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > But I have very hard time figuring out what the MVP version should be, > because I have very limited understanding on how much control the index > AM ought to have :-( And it'd be a bit silly to do something in v17, > only to have to rip it out in v18 because it turned out to not get the > split right. I suspect that you're overestimating the difficulty of getting the layering right (at least relative to the difficulty of everything else). The executor proper doesn't know anything about pins on leaf pages (and in reality nbtree usually doesn't hold any pins these days). All the executor knows is that it had better not be possible for an in-flight index scan to get confused by concurrent TID recycling by VACUUM. When amgettuple/btgettuple is called, nbtree usually just returns TIDs it collected from a just-scanned leaf page. This sort of stuff already lives in the index AM. It seems to me that everything at the API and executor level can continue to work in essentially the same way as it always has, with only minimal revision to the wording around buffer pins (in fact that really should have happened back in 2015, as part of commit 2ed5b87f). The hard part will be figuring out how to make the physical index scan prefetch optimally, in a way that balances various considerations. These include: * Managing heap prefetch distance. * Avoiding making kill_prior_tuple significantly less effective (perhaps the new design could even make it more effective, in some scenarios, by holding onto multiple buffer pins based on a dynamic model). * Figuring out how many leaf pages it makes sense to read ahead of accessing the heap, since there is no fixed relationship between the number of leaf pages we need to scan to collect a given number of distinct heap blocks that we need for prefetching. (This is made more complicated by things like LIMIT, but is actually an independent problem.) So I think that you need to teach index AMs to behave roughly as if multiple leaf pages were read as one single leaf page, at least in terms of things like how the BTScanOpaqueData.currPos state is managed. I imagine that currPos will need to be filled with TIDs from multiple index pages, instead of just one, with entries that are organized in a way that preserves the illusion of one continuous scan from the point of view of the executor proper. By the time we actually start really returning TIDs via btgettuple, it looks like we scanned one giant leaf page instead of several (the exact number of leaf pages scanned will probably have to be indeterminate, because it'll depend on things like heap prefetch distance). The good news (assuming that I'm right here) is that you don't need to have specific answers to most of these questions in order to commit a v1 of index prefeteching. ISTM that all you really need is to have confidence that the general approach that I've outlined is the right approach, long term (certainly not nothing, but I'm at least reasonably confident here). > The hard thing is what to do about cases where neither of this helps. > The example I keep thinking about is IOS - if we don't do prefetching, > it's not hard to construct cases where regular index scan gets much > faster than IOS (with many not-all-visible pages). But we can't just > prefetch all pages, because that'd hurt IOS cases with most pages fully > visible (when we don't need to actually access the heap). > > I managed to deal with this in the executor-level version, but I'm not > sure how to do this if the control moves closer to the index AM. The reality is that nbtree already knows about index-only scans. It has to, because it wouldn't be safe to drop the pin on a leaf page's buffer when the scan is "between pages" in the specific case of index-only scans (so the _bt_killitems code path used when kill_prior_tuple has index tuples to kill knows about index-only scans). I actually added commentary to the nbtree README that goes into TID recycling by VACUUM not too long ago. This includes stuff about how LP_UNUSED items in the heap are considered dead to all index scans (which can actually try to look at a TID that just became LP_UNUSED in the heap!), even though LP_UNUSED items don't prevent VACUUM from setting heap pages all-visible. This seemed like the only way of explaining the _bt_killitems IOS issue, that actually seemed to make sense. What you really want to do here is to balance costs and benefits. That's just what's required. The fact that those costs and benefits span multiple levels of abstractions makes it a bit awkward, but doesn't (and can't) change the basic shape of the problem. -- Peter Geoghegan
On Fri, Mar 1, 2024 at 3:58 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
[..]
> TBH I don't have a clear idea what to do. It'd be cool to have at least
> some benefits in v17, but I don't know how to do that in a way that
> would be useful in the future.
>
> For example, the v20240124 patch implements this in the executor, but
> based on the recent discussions it seems that's not the right layer -
> the index AM needs to have some control, and I'm not convinced it's
> possible to improve it in that direction (even ignoring the various
> issues we identified in the executor-based approach).
>
> I think it might be more practical to do this from the index AM, even if
> it has various limitations. Ironically, that's what I proposed at pgcon,
> but mostly because it was the quick&dirty way to do this.
... that's a pity! :( Well, then let's just finish that subthread, I
gave some explanations, but I'll try to take a look in future
revisions.
> > 4. Wouldn't it be better to leave PREFETCH_LRU_SIZE at static of 8,
> > but base PREFETCH_LRU_COUNT on effective_io_concurrency instead?
> > (allowing it to follow dynamically; the more prefetches the user wants
> > to perform, the more you spread them across shared LRUs and the more
> > memory for history is required?)
> >
> > + * XXX Maybe we could consider effective_cache_size when sizing the cache?
> > + * Not to size the cache for that, ofc, but maybe as a guidance of how many
> > + * heap pages it might keep. Maybe just a fraction fraction of the value,
> > + * say Max(8MB, effective_cache_size / max_connections) or something.
> > + */
> > +#define PREFETCH_LRU_SIZE 8 /* slots in one LRU */
> > +#define PREFETCH_LRU_COUNT 128 /* number of LRUs */
> > +#define PREFETCH_CACHE_SIZE (PREFETCH_LRU_SIZE *
> > PREFETCH_LRU_COUNT)
> >
>
> I don't see why would this be related to effective_io_concurrency? It's
> merely about how many recently accessed pages we expect to find in the
> page cache. It's entirely separate from the prefetch distance.
Well, my thought was the higher eic is - the more I/O parallelism we
are introducing - in such a case, the more requests we need to
remember from the past to avoid prefetching the same (N * eic, where N
would be some multiplier)
> > 7. in IndexPrefetchComputeTarget()
> >
> > + * XXX We cap the target to plan_rows, becausse it's pointless to prefetch
> > + * more than we expect to use.
> >
> > That's a nice fact that's already in patch, so XXX isn't needed?
> >
>
> Right, which is why it's not a TODO/FIXME.
OH! That explains it to me. I've taken all of the XXXs as literally
FIXME that you wanted to go away (things to be removed before the
patch is considered mature).
> But I think it's good to
> point this out - I'm not 100% convinced we should be using plan_rows
> like this (because what happens if the estimate happens to be wrong?).
Well, somewhat similiar problematic pattern was present in different
codepath - get_actual_variable_endpoint() - see [1], 9c6ad5eaa95. So
the final fix was to get away without adding new GUC (which always an
option...), but just introduce a sensible hard-limit (fence) and stick
to the 100 heap visited pages limit. Here we could have similiar
heuristics same from start: if (plan_rows <
we_have_already_visited_pages * avgRowsPerBlock) --> ignore plan_rows
and rampup prefetches back to the full eic value.
> > Some further tests, given data:
> >
> > CREATE TABLE test (id bigint, val bigint, str text);
> > ALTER TABLE test ALTER COLUMN str SET STORAGE EXTERNAL;
> > INSERT INTO test SELECT g, g, repeat(chr(65 + (10*random())::int),
> > 3000) FROM generate_series(1, 10000) g;
> > -- or INSERT INTO test SELECT x.r, x.r, repeat(chr(65 +
> > (10*random())::int), 3000) from (select 10000 * random() as r from
> > generate_series(1, 10000)) x;
> > VACUUM ANALYZE test;
> > CREATE INDEX on test (id) ;
> >
>
> It's not clear to me what's the purpose of this test? Can you explain?
It's just schema&data preparation for the tests below:
> >
> > 2. Prefetching for TOASTed heap seems to be not implemented at all,
> > correct? (Is my assumption that we should go like this:
> > t_index->t->toast_idx->toast_heap)?, but I'm too newbie to actually
> > see the code path where it could be added - certainly it's not blocker
> > -- but maybe in commit message a list of improvements for future could
> > be listed?):
> >
>
> Yes, that's true. I haven't thought about TOAST very much, but with
> prefetching happening in executor, that does not work. There'd need to
> be some extra code for TOAST prefetching. I'm not sure how beneficial
> that would be, considering most TOAST values tend to be stored on
> consecutive heap pages.
Assuming that in the above I've generated data using cyclic / random
version and I run:
SELECT md5(string_agg(md5(str),',')) FROM test WHERE id BETWEEN 10 AND 2000;
(btw: I wanted to use octet_length() at first instead of string_agg()
but that's not enough)
where fd 45,54,55 correspond to :
lrwx------ 1 postgres postgres 64 Mar 5 12:56 /proc/8221/fd/45 ->
/tmp/blah/base/5/16384 // "test"
lrwx------ 1 postgres postgres 64 Mar 5 12:56 /proc/8221/fd/54 ->
/tmp/blah/base/5/16388 // "pg_toast_16384_index"
lrwx------ 1 postgres postgres 64 Mar 5 12:56 /proc/8221/fd/55 ->
/tmp/blah/base/5/16387 // "pg_toast_16384"
I've got for the following data:
- 83 pread64 and 83x fadvise() for random offsets for fd=45 - the main
intent of this patch (main relation heap prefetching), works good
- 54 pread64 calls for fd=54 (no favdises())
- 1789 (!) calls to pread64 for fd=55 for RANDOM offsets (TOAST heap,
no prefetch)
so at least in theory it makes a lot of sense to prefetch TOAST too,
pattern looks like cyclic random:
// pread(fd, "", blocksz, offset)
fadvise64(45, 40960, 8192, POSIX_FADV_WILLNEED) = 0
pread64(55, ""..., 8192, 38002688) = 8192
pread64(55, ""..., 8192, 12034048) = 8192
pread64(55, ""..., 8192, 36560896) = 8192
pread64(55, ""..., 8192, 8871936) = 8192
pread64(55, ""..., 8192, 17965056) = 8192
pread64(55, ""..., 8192, 18710528) = 8192
pread64(55, ""..., 8192, 35635200) = 8192
pread64(55, ""..., 8192, 23379968) = 8192
pread64(55, ""..., 8192, 25141248) = 8192
pread64(55, ""..., 8192, 3457024) = 8192
pread64(55, ""..., 8192, 24633344) = 8192
pread64(55, ""..., 8192, 36462592) = 8192
pread64(55, ""..., 8192, 18120704) = 8192
pread64(55, ""..., 8192, 27066368) = 8192
pread64(45, ""..., 8192, 40960) = 8192
pread64(55, ""..., 8192, 2768896) = 8192
pread64(55, ""..., 8192, 10846208) = 8192
pread64(55, ""..., 8192, 30179328) = 8192
pread64(55, ""..., 8192, 7700480) = 8192
pread64(55, ""..., 8192, 38846464) = 8192
pread64(55, ""..., 8192, 1040384) = 8192
pread64(55, ""..., 8192, 10985472) = 8192
It's probably a separate feature (prefetching blocks from TOAST), but
it could be mentioned that this patch is not doing that (I was
assuming it could).
> > 3. I'm not sure if I got good-enough results for DESCending index
> > `create index on test (id DESC);`- with eic=16 it doesnt seem to be
> > be able prefetch 16 blocks in advance? (e.g. highlight offset 557056
> > below in some text editor and it's distance is far lower between that
> > fadvise<->pread):
> >
[..]
> >
>
> I'm not sure I understand these strace snippets. Can you elaborate a
> bit, explain what the strace log says?
set enable_seqscan to off;
set enable_bitmapscan to off;
drop index test_id_idx;
create index on test (id DESC); -- DESC one
SELECT sum(val) FROM test WHERE id BETWEEN 10 AND 2000;
Ok, so cleaner output of strace -s 0 for PID doing that SELECT with
eic=16, annotated with [*]:
lseek(45, 0, SEEK_END) = 688128
lseek(47, 0, SEEK_END) = 212992
pread64(47, ""..., 8192, 172032) = 8192
pread64(45, ""..., 8192, 90112) = 8192
fadvise64(45, 172032, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 172032) = 8192
fadvise64(45, 319488, 8192, POSIX_FADV_WILLNEED) = 0 [*off 319488 start]
fadvise64(45, 335872, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 319488) = 8192 [*off 319488,
read, distance=1 fadvises]
fadvise64(45, 466944, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 393216, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 335872) = 8192
fadvise64(45, 540672, 8192, POSIX_FADV_WILLNEED) = 0 [*off 540672 start]
fadvise64(45, 262144, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 466944) = 8192
fadvise64(45, 491520, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 393216) = 8192
fadvise64(45, 163840, 8192, POSIX_FADV_WILLNEED) = 0
fadvise64(45, 385024, 8192, POSIX_FADV_WILLNEED) = 0
pread64(45, ""..., 8192, 540672) = 8192 [*off 540672,
read, distance=4 fadvises]
fadvise64(45, 417792, 8192, POSIX_FADV_WILLNEED) = 0
[..]
I was wondering why the distance never got >4 in such case for eic=16,
it should spawn more fadvises calls, shouldn't it? (it was happening
only for DESC, in normal ASC index the prefetching distance easily
achieves ~~ eic values) and I think today i've got the answer -- after
dropping/creating DESC index I did NOT execute ANALYZE so probably the
Min(..., plan_rows) was kicking in and preventing the full
prefetching.
Hitting above, makes me think that the XXX for plan_rows , should
really be real-FIXME.
-J.
[1] - https://www.postgresql.org/message-id/CAKZiRmznOwi0oaV%3D4PHOCM4ygcH4MgSvt8%3D5cu_vNCfc8FSUug%40mail.gmail.com
On Wed, Nov 6, 2024 at 12:25 PM Tomas Vondra <tomas@vondra.me> wrote: > Attached is an updated version of this patch series. The first couple > parts (adding batching + updating built-in index AMs) remain the same, > the new part is 0007 which switches index scans to read stream API. The first thing that I notice about this patch series is that it doesn't fully remove amgettuple as a concept. That seems a bit odd to me. After all, you've invented a single page batching mechanism, which is duplicative of the single page batching mechanism that each affected index AM has to use already, just to be able to allow the amgettuple interface to iterate backwards and forwards with a scrollable cursor (and to make mark/restore work). ISTM that you have one too many batching interfaces here. I can think of nothing that makes the task of completely replacing amgettuple particularly difficult. I don't think that the need to do the _bt_killitems stuff actually makes this task all that much harder. It will need to be generalized, too, by keeping track of multiple BTScanOpaqueData.killedItems[] style states, each of which is associated with its own page-level currPos state. But that's not rocket science. (Also don't think that mark/restore support is all that hard.) The current way in which _bt_kill_batch() is called from _bt_steppage() by the patch seems weird to me. You're copying what you actually know to be the current page's kill items such that _bt_steppage() will magically do what it does already when the amgetttuple/btgettuple interface is in use, just as we're stepping off the page. It seems to be working at the wrong level. Notice that the current way of doing things in your patch means that your new batching interface tacitly knows about the nbtree batching interface, and that it too works along page boundaries -- that's the only reason why it can hook into _bt_steppage like this in the first place. Things are way too tightly coupled, and the old and new way of doing things are hopelessly intertwined. What's being abstracted away here, really? I suspect that _bt_steppage() shouldn't be calling _bt_kill_batch() at all -- nor should it even call _bt_killitems(). Things need to be broken down into smaller units of work that can be reordered, instead. The first half of the current _bt_steppage() function deals with finishing off the current leaf page should be moved to some other function -- let's call it _bt_finishpage. A new callback should be called as part of the new API when the time comes to tell nbtree that we're now done with a given leaf page -- that's what this new _bt_finishpage function is for. All that remains of _bt_steppage() are the parts that deal with figuring out which page should be visited next -- the second half of _bt_steppage stays put. That way stepping to the next page and reading multiple pages can be executed as eagerly as makes sense -- we don't need to "coordinate" the heap accesses in lockstep with the leaf page accesses. Maybe you won't take advantage of this flexibility right away, but ISTM that you need nominal support for this kind of reordering to make the new API really make sense. There are some problems with this scheme, but they seem reasonably tractable to me. We already have strategies for dealing with the risk of concurrent TID recycling when _bt_killitems is called with some maybe-recycled TIDs -- we're already dropping the pin on the leaf page early in many cases. I've pointed this out many times already (again, see _bt_drop_lock_and_maybe_pin). It's true that we're still going to have to hold onto a buffer pin on leaf pages whose TIDs haven't all been read from the table AM side yet, unless we know that it's a case where that's safe for other reasons -- otherwise index-only scans might give wrong answers. But that other problem shouldn't be confused with the _bt_killitems problem, just because of the superficial similarity around holding onto a leaf page pin. To repeat: it is important that you not conflate the problems on the table AM side (TID recycle safety for index scans) with the problems on the index AM side (safely setting LP_DEAD bits in _bt_killitems). They're two separate problems that are currently dealt with as one problem on the nbtree side -- but that isn't fundamental. Teasing them apart seems likely to be helpful here. > I speculated that with the batching concept it might work better, and I > think that turned out to be the case. The batching is still the core > idea, giving the index AM enough control to make kill tuples work (by > not generating batches spanning multiple leaf pages, or doing something > smarter). And the read stream leverages that too - the next_block > callback returns items from the current batch, and the stream is reset > between batches. This is the same prefetch restriction as with the > explicit prefetching (done using posix_fadvise), except that the > prefetching is done by the read stream. ISTM that the central feature of the new API should be the ability to reorder certain kinds of work. There will have to be certain constraints, of course. Sometimes these will principally be problems for the table AM (e.g., we musn't allow concurrent TID recycling unless it's for a plain index scan using an MVCC snapshot), other times they're principally problems for the index AM (e.g., the _bt_killitems safety issues). I get that you're not that excited about multi-page batches; it's not the priority. Fair enough. I just think that the API needs to work in terms of batches that are sized as one or more pages, in order for it to make sense. BTW, the README changes you made are slightly wrong about pins and locks. We don't actually keep around C pointers to IndexTuples for index-only scans that point into shared memory -- that won't work. We simply copy whatever IndexTuples the scan returns into local state, associated with so->currPos. So that isn't a complicating factor, at all. That's all I have right now. Hope it helps. -- Peter Geoghegan
On 11/7/24 01:38, Peter Geoghegan wrote: > On Wed, Nov 6, 2024 at 12:25 PM Tomas Vondra <tomas@vondra.me> wrote: >> Attached is an updated version of this patch series. The first couple >> parts (adding batching + updating built-in index AMs) remain the same, >> the new part is 0007 which switches index scans to read stream API. > > The first thing that I notice about this patch series is that it > doesn't fully remove amgettuple as a concept. That seems a bit odd to > me. After all, you've invented a single page batching mechanism, which > is duplicative of the single page batching mechanism that each > affected index AM has to use already, just to be able to allow the > amgettuple interface to iterate backwards and forwards with a > scrollable cursor (and to make mark/restore work). ISTM that you have > one too many batching interfaces here. > > I can think of nothing that makes the task of completely replacing > amgettuple particularly difficult. I don't think that the need to do > the _bt_killitems stuff actually makes this task all that much harder. > It will need to be generalized, too, by keeping track of multiple > BTScanOpaqueData.killedItems[] style states, each of which is > associated with its own page-level currPos state. But that's not > rocket science. (Also don't think that mark/restore support is all > that hard.) > The primary reason why I kept amgettuple() as is, and added a new AM callback for the "batch" mode is backwards compatibility. I did not want to force all AMs to do this, I think it should be optional. Not only to limit the disruption for out-of-core AMs, but also because I'm not 100% sure every AM will be able to do batching in a reasonable way. I do agree having an AM-level batching, and then another batching in the indexam.c is a bit ... weird. To some extent this is a remainder of an earlier patch version, but it's also based on some suggestions by Andres about batching these calls into AM for efficiency reasons. To be fair, I was jetlagged and I'm not 100% sure this is what he meant, or that it makes a difference in practice. Yes, we could ditch the batching in indexam.c, and just rely on the AM batching, just like now. There are a couple details why the separate batching seemed convenient: 1) We may need to stash some custom data for each TID (e.g. so that IOS does not need to check VM repeatedly). But perhaps that could be delegated to the index AM too ... 2) We need to maintain two "positions" in the index. One for the item the executor is currently processing (and which might end up getting marked as "killed" etc). And another one for "read" position, i.e. items passed to the read stream API / prefetching, etc. 3) It makes it clear when the items are no longer needed, and the AM can do cleanup. process kill tuples, etc. > The current way in which _bt_kill_batch() is called from > _bt_steppage() by the patch seems weird to me. You're copying what you > actually know to be the current page's kill items such that > _bt_steppage() will magically do what it does already when the > amgetttuple/btgettuple interface is in use, just as we're stepping off > the page. It seems to be working at the wrong level. > True, but that's how it was working before, it wasn't my ambition to rework that. > Notice that the current way of doing things in your patch means that > your new batching interface tacitly knows about the nbtree batching > interface, and that it too works along page boundaries -- that's the > only reason why it can hook into _bt_steppage like this in the first > place. Things are way too tightly coupled, and the old and new way of > doing things are hopelessly intertwined. What's being abstracted away > here, really? > I'm not sure sure if by "new batching interface" you mean the indexam.c code, or the code in btgetbatch() etc. I don't think indexam.c knows all that much about the nbtree internal batching. It "just" relies on amgetbatch() producing items the AM can handle later (during killtuples/cleanup etc.). It does not even need to be a single-leaf-page batch, if the AM knows how to track/deal with that internally. It just was easier to do by restricting to a single leaf page for now. But that's internal to AM. Yes, it's true inside the AM it's more intertwined, and some of it sets things up so that the existing code does the right thing ... > I suspect that _bt_steppage() shouldn't be calling _bt_kill_batch() at > all -- nor should it even call _bt_killitems(). Things need to be > broken down into smaller units of work that can be reordered, instead. > > The first half of the current _bt_steppage() function deals with > finishing off the current leaf page should be moved to some other > function -- let's call it _bt_finishpage. A new callback should be > called as part of the new API when the time comes to tell nbtree that > we're now done with a given leaf page -- that's what this new > _bt_finishpage function is for. All that remains of _bt_steppage() are > the parts that deal with figuring out which page should be visited > next -- the second half of _bt_steppage stays put. > > That way stepping to the next page and reading multiple pages can be > executed as eagerly as makes sense -- we don't need to "coordinate" > the heap accesses in lockstep with the leaf page accesses. Maybe you > won't take advantage of this flexibility right away, but ISTM that you > need nominal support for this kind of reordering to make the new API > really make sense. > Yes, splitting _bt_steppage() like this makes sense to me, and I agree being able to proceed to the next page before we're done with the current page seems perfectly reasonable for batches spanning multiple leaf pages. > There are some problems with this scheme, but they seem reasonably > tractable to me. We already have strategies for dealing with the risk > of concurrent TID recycling when _bt_killitems is called with some > maybe-recycled TIDs -- we're already dropping the pin on the leaf page > early in many cases. I've pointed this out many times already (again, > see _bt_drop_lock_and_maybe_pin). > > It's true that we're still going to have to hold onto a buffer pin on > leaf pages whose TIDs haven't all been read from the table AM side > yet, unless we know that it's a case where that's safe for other > reasons -- otherwise index-only scans might give wrong answers. But > that other problem shouldn't be confused with the _bt_killitems > problem, just because of the superficial similarity around holding > onto a leaf page pin. > > To repeat: it is important that you not conflate the problems on the > table AM side (TID recycle safety for index scans) with the problems > on the index AM side (safely setting LP_DEAD bits in _bt_killitems). > They're two separate problems that are currently dealt with as one > problem on the nbtree side -- but that isn't fundamental. Teasing them > apart seems likely to be helpful here. > Hmm. I've intentionally tried to ignore these issues, or rather to limit the scope of the patch so that v1 does not require dealing with it. Hence the restriction to single-leaf batches, for example. But I guess I may have to look at this after all ... not great. >> I speculated that with the batching concept it might work better, and I >> think that turned out to be the case. The batching is still the core >> idea, giving the index AM enough control to make kill tuples work (by >> not generating batches spanning multiple leaf pages, or doing something >> smarter). And the read stream leverages that too - the next_block >> callback returns items from the current batch, and the stream is reset >> between batches. This is the same prefetch restriction as with the >> explicit prefetching (done using posix_fadvise), except that the >> prefetching is done by the read stream. > > ISTM that the central feature of the new API should be the ability to > reorder certain kinds of work. There will have to be certain > constraints, of course. Sometimes these will principally be problems > for the table AM (e.g., we musn't allow concurrent TID recycling > unless it's for a plain index scan using an MVCC snapshot), other > times they're principally problems for the index AM (e.g., the > _bt_killitems safety issues). > Not sure. By "new API" you mean the read stream API, or the index AM API to allow batching? > I get that you're not that excited about multi-page batches; it's not > the priority. Fair enough. I just think that the API needs to work in > terms of batches that are sized as one or more pages, in order for it > to make sense. > True, but isn't that already the case? I mean, what exactly prevents an index AM to "build" a batch for multiple leaf pages? The current patch does not implement that for any of the AMs, true, but isn't that already possible if the AM chooses to? If you were to design the index AM API to support this (instead of adding the amgetbatch callback etc.), how would it look? In one of the previous patch versions I tried to rely on amgettuple(). It got a bunch of TIDs ahead from that, depending on prefetch distance. Then those TIDs were prefetched/passed to the read stream, and stashed in a queue (in IndexScanDesc). And then indexam would get the TIDs from the queue, and pass them to index scans etc. Unfortunately that didn't work because of killtuples etc. because the index AM had no idea about the indexam queue and has it's own concept of "current item", so it was confused about which item to mark as killed. And that old item might even be from an earlier leaf page (not the "current" currPos). I was thinking maybe the AM could keep the leaf pages, and then free them once they're no longer needed. But it wasn't clear to me how to exchange this information between indexam.c and the index AM, because right now the AM only knows about a single (current) position. But imagine we have this: a) A way to switch the scan into "batch" mode, where the AM keeps the leaf page (and a way for the AM to indicate it supports this). b) Some way to track two "positions" in the scan - one for read, one for prefetch. I'm not sure if this would be internal in each index AM, or at the indexam.c level. c) A way to get the index tuple for either of the two positions (and advance the position). It might be a flag for amgettuple(), or maybe even a callaback for the "prefetch" position. d) A way to inform the AM items up to some position are no longer needed, and thus the leaf pages can be cleaned up and freed. AFAICS it could always be "up to the current read position". Does that sound reasonable / better than the current approach, or have I finally reached the "raving lunatic" stage? > BTW, the README changes you made are slightly wrong about pins and > locks. We don't actually keep around C pointers to IndexTuples for > index-only scans that point into shared memory -- that won't work. We > simply copy whatever IndexTuples the scan returns into local state, > associated with so->currPos. So that isn't a complicating factor, at > all. > Ah, OK. Thanks for the correction. > That's all I have right now. Hope it helps. > Yes, very interesting insights. Thanks! regards -- Tomas Vondra
On Thu, Nov 7, 2024 at 10:03 AM Tomas Vondra <tomas@vondra.me> wrote: > The primary reason why I kept amgettuple() as is, and added a new AM > callback for the "batch" mode is backwards compatibility. I did not want > to force all AMs to do this, I think it should be optional. Not only to > limit the disruption for out-of-core AMs, but also because I'm not 100% > sure every AM will be able to do batching in a reasonable way. All index AMs that implement amgettuple are fairly similar to nbtree. They are: * nbtree itself * GiST * Hash * SP-GiST They all have the same general notion of page-at-a-time processing, with buffering of items for the amgettuple callback to return. There are perhaps enough differences to be annoying in SP-GiST, and with GiST's ordered scans (which use a pairing heap rather than true page-at-a-time processing). I guess you're right that you'll need to maintain amgettuple support for the foreseeable future, to support these special cases. I still think that you shouldn't need to use amgettuple in either nbtree or hash, since neither AM does anything non-generic in this area. It should be normal to never need to use amgettuple. > Yes, we could ditch the batching in indexam.c, and just rely on the AM > batching, just like now. To be clear, I had imagined completely extracting the batching from the index AM, since it isn't really at all coupled to individual index AM implementation details anyway. I don't hate the idea of doing more in the index AM, but whether or not it happens there vs. somewhere else isn't my main concern at this point. My main concern right now is that one single place be made to see every relevant piece of information about costs and benefits. Probably something inside indexam.c. > There are a couple details why the separate > batching seemed convenient: > > 1) We may need to stash some custom data for each TID (e.g. so that IOS > does not need to check VM repeatedly). But perhaps that could be > delegated to the index AM too ... > > 2) We need to maintain two "positions" in the index. One for the item > the executor is currently processing (and which might end up getting > marked as "killed" etc). And another one for "read" position, i.e. items > passed to the read stream API / prefetching, etc. That all makes sense. > 3) It makes it clear when the items are no longer needed, and the AM can > do cleanup. process kill tuples, etc. But it doesn't, really. The index AM is still subject to exactly the same constraints in terms of page-at-a-time processing. These existing constraints always came from the table AM side, so it's not as if your patch can remain totally neutral on these questions. Basically, it looks like you've invented a shadow batching interface that is technically not known to the index AM, but nevertheless coordinates with the existing so->currPos batching interface. > I don't think indexam.c knows all that much about the nbtree internal > batching. It "just" relies on amgetbatch() producing items the AM can > handle later (during killtuples/cleanup etc.). It does not even need to > be a single-leaf-page batch, if the AM knows how to track/deal with that > internally. I'm concerned that no single place will know about everything under this scheme. Having one single place that has visibility into all relevant costs, whether they're index AM or table AM related, is what I think you should be aiming for. I think that you should be removing the parts of the nbtree (and other index AM) code that deal with the progress of the scan explicitly. What remains is code that simply reads the next page, and saves its details in the relevant data structures. Or code that "finishes off" a leaf page by dropping its pin, and maybe doing the _bt_killitems stuff. The index AM itself should no longer know about the current next tuple to return, nor about mark/restore. It is no longer directly in control of the scan's progress. It loses all context that survives across API calls. > Yes, splitting _bt_steppage() like this makes sense to me, and I agree > being able to proceed to the next page before we're done with the > current page seems perfectly reasonable for batches spanning multiple > leaf pages. I think that it's entirely possible that it'll just be easier to do things this way from the start. I understand that that may be far from obvious right now, but, again, I just don't see what's so special about the way that each index AM batches results. What about that it is so hard to generalize across index AMs that must support amgettuple right now? (At least in the case of nbtree and hash, which have no special requirements for things like KNN-GiST.) Most individual calls to btgettuple just return the next batched-up so->currPos tuple/TID via another call to _bt_next. Things like the _bt_first-new-primitive-scan case don't really add any complexity -- the core concept of processing a page at a time still applies. It really is just a simple batching scheme, with a couple of extra fiddly details attached to it -- but nothing too hairy. The hardest part will probably be rigorously describing the rules for not breaking index-only scans due to concurrent TID recycling by VACUUM, and the rules for doing _bt_killitems. But that's also not a huge problem, in the grand scheme of things. > Hmm. I've intentionally tried to ignore these issues, or rather to limit > the scope of the patch so that v1 does not require dealing with it. > Hence the restriction to single-leaf batches, for example. > > But I guess I may have to look at this after all ... not great. To be clear, I don't think that you necessarily have to apply these capabilities in v1 of this project. I would be satisfied if the patch could just break things out in the right way, so that some later patch could improve things later on. I only really want to see the capabilities within the index AM decomposed, such that one central place can see a global view of the costs and benefits of the index scan. You should be able to validate the new API by stress-testing the code. You can make the index AM read several leaf pages at a time when a certain debug mode is enabled. Once you prove that the index AM correctly performs the same processing as today correctly, without any needless restrictions on the ordering that these decomposed operators perform (only required restrictions that are well explained and formalized), then things should be on the right path. > > ISTM that the central feature of the new API should be the ability to > > reorder certain kinds of work. There will have to be certain > > constraints, of course. Sometimes these will principally be problems > > for the table AM (e.g., we musn't allow concurrent TID recycling > > unless it's for a plain index scan using an MVCC snapshot), other > > times they're principally problems for the index AM (e.g., the > > _bt_killitems safety issues). > > > > Not sure. By "new API" you mean the read stream API, or the index AM API > to allow batching? Right now those two concepts seem incredibly blurred to me. > > I get that you're not that excited about multi-page batches; it's not > > the priority. Fair enough. I just think that the API needs to work in > > terms of batches that are sized as one or more pages, in order for it > > to make sense. > > > > True, but isn't that already the case? I mean, what exactly prevents an > index AM to "build" a batch for multiple leaf pages? The current patch > does not implement that for any of the AMs, true, but isn't that already > possible if the AM chooses to? That's unclear, but overall I'd say no. The index AM API says that they need to hold on to a buffer pin to avoid confusing scans due to concurrent TID recycling by VACUUM. The index AM API fails to adequately describe what is expected here. And it provides no useful context for larger batching of index pages. nbtree already does its own thing by dropping leaf page pins selectively. Whether or not it's technically possible is a matter of interpretation (I came down on the "no" side, but it's still ambiguous). I would prefer it if the index AM API was much simpler for ordered scans. As I said already, something along the lines of "when you're told to scan the next index page, here's how we'll call you, here's the data structure that you need to fill up". Or "when we tell you that we're done fetching tuples from a recently read index page, here's how we'll call you". These discussions about where the exact boundaries lie don't seem very helpful. The simple fact is that nobody is ever going to invent an index AM side interface that batches up more than a single leaf page. Why would they? It just doesn't make sense to, since the index AM has no idea about certain clearly-relevant context. For example, it has no idea whether or not there's a LIMIT involved. The value that comes from using larger batches on the index AM side comes from making life easier for heap prefetching, which index AMs know nothing about whatsoever. Again, the goal should be to marry information from the index AM and the table AM in one central place. > Unfortunately that didn't work because of killtuples etc. because the > index AM had no idea about the indexam queue and has it's own concept of > "current item", so it was confused about which item to mark as killed. > And that old item might even be from an earlier leaf page (not the > "current" currPos). Currently, during a call to btgettuple, so->currPos.itemIndex is updated within _bt_next. But before _bt_next is called, so->currPos.itemIndex indicates the item returned by the most recent prior call to btgettuple -- which is also the tuple that the scan->kill_prior_tuple reports on. In short, btgettuple does some trivial things to remember which entries from so->currPos ought to be marked dead later on due to the scan->kill_prior_tuple flag having been set for those entries. This can be moved outside of each index AM. The index AM shouldn't need to use a scan->kill_prior_tuple style flag under the new batching API at all, though. It should work at a higher level than that. The index AM should be called through a callback that tells it to drop the pin on a page that the table AM has been reading from, and maybe perform _bt_killitems on these relevant known-dead TIDs first. In short, all of the bookkeeping for so->killedItems[] should be happening at a completely different layer. And the so->killedItems[] structure should be directly associated with a single index page subset of a batch (a subset similar to the current so->currPos batches). The first time the index AM sees anything about dead TIDs, it should see a whole leaf page worth of them. > I was thinking maybe the AM could keep the leaf pages, and then free > them once they're no longer needed. But it wasn't clear to me how to > exchange this information between indexam.c and the index AM, because > right now the AM only knows about a single (current) position. I'm imagining a world in which the index AM doesn't even know about the current position. Basically, it has no real context about the progress of the scan to maintain at all. It merely does what it is told by some higher level, that is sensitive to the requirements of both the index AM and the table AM. > But imagine we have this: > > a) A way to switch the scan into "batch" mode, where the AM keeps the > leaf page (and a way for the AM to indicate it supports this). I don't think that there needs to be a batch mode. There could simply be the total absence of batching, which is one point along a continuum, rather than a discrete mode. > b) Some way to track two "positions" in the scan - one for read, one for > prefetch. I'm not sure if this would be internal in each index AM, or at > the indexam.c level. I think that it would be at the indexam.c level. > c) A way to get the index tuple for either of the two positions (and > advance the position). It might be a flag for amgettuple(), or maybe > even a callaback for the "prefetch" position. Why does the index AM need to know anything about the fact that the next tuple has been requested? Why can't it just be 100% ignorant of all that? (Perhaps barring a few special cases, such as KNN-GiST scans, which continue to use the legacy amgettuple interface.) > d) A way to inform the AM items up to some position are no longer > needed, and thus the leaf pages can be cleaned up and freed. AFAICS it > could always be "up to the current read position". Yeah, I like this idea. But the index AM doesn't need to know about positions and whatnot. It just needs to do what it's told: to drop the pin, and maybe to perform _bt_killitems first. Or maybe just to drop the pin, with instruction to do _bt_killitems coming some time later (the index AM will need to be a bit more careful within its _bt_killitems step when this happens). The index AM doesn't need to drop the current pin for the current position -- not as such. The index AM doesn't directly know about what pins are held, since that'll all be tracked elsewhere. Again, the index AM should need to hold onto zero context, beyond the immediate request to perform one additional unit of work, which will usually/always happen at the index page level (all of which is tracked by data structures that are under the control of the new indexam.c level). I don't think that it'll ultimately be all that hard to schedule when and how index pages are read from outside of the index AM in question. In general all relevant index AMs already work in much the same way here. Maybe we can ultimately invent a way for the index AM to influence that scheduling, but that might never be required. > Does that sound reasonable / better than the current approach, or have I > finally reached the "raving lunatic" stage? The stage after "raving lunatic" is enlightenment. :-) -- Peter Geoghegan
On 11/7/24 18:55, Peter Geoghegan wrote: > On Thu, Nov 7, 2024 at 10:03 AM Tomas Vondra <tomas@vondra.me> wrote: >> The primary reason why I kept amgettuple() as is, and added a new AM >> callback for the "batch" mode is backwards compatibility. I did not want >> to force all AMs to do this, I think it should be optional. Not only to >> limit the disruption for out-of-core AMs, but also because I'm not 100% >> sure every AM will be able to do batching in a reasonable way. > > All index AMs that implement amgettuple are fairly similar to nbtree. They are: > > * nbtree itself > * GiST > * Hash > * SP-GiST > > They all have the same general notion of page-at-a-time processing, > with buffering of items for the amgettuple callback to return. There > are perhaps enough differences to be annoying in SP-GiST, and with > GiST's ordered scans (which use a pairing heap rather than true > page-at-a-time processing). I guess you're right that you'll need to > maintain amgettuple support for the foreseeable future, to support > these special cases. > > I still think that you shouldn't need to use amgettuple in either > nbtree or hash, since neither AM does anything non-generic in this > area. It should be normal to never need to use amgettuple. > Right, I can imagine not using amgettuple() in nbtree/hash. I guess we could even remove it altogether, although I'm not sure that'd work right now (haven't tried). >> Yes, we could ditch the batching in indexam.c, and just rely on the AM >> batching, just like now. > > To be clear, I had imagined completely extracting the batching from > the index AM, since it isn't really at all coupled to individual index > AM implementation details anyway. I don't hate the idea of doing more > in the index AM, but whether or not it happens there vs. somewhere > else isn't my main concern at this point. > > My main concern right now is that one single place be made to see > every relevant piece of information about costs and benefits. Probably > something inside indexam.c. > Not sure I understand, but I think I'm somewhat confused by "index AM" vs. indexam. Are you suggesting the individual index AMs should know as little about the batching as possible, and instead it should be up to indexam.c to orchestrate most of the stuff? If yes, then I agree in principle, and I think indexam.c is the right place to do that (or at least I can't think of a better one). That's what the current patch aimed to do, more or less. I'm not saying it got it perfectly right, and I'm sure there is stuff that can be improved (like reworking _steppage to not deal with killed tuples). But surely the index AMs need to have some knowledge about batching, because how else would it know which leaf pages to still keep, etc? >> There are a couple details why the separate >> batching seemed convenient: >> >> 1) We may need to stash some custom data for each TID (e.g. so that IOS >> does not need to check VM repeatedly). But perhaps that could be >> delegated to the index AM too ... >> >> 2) We need to maintain two "positions" in the index. One for the item >> the executor is currently processing (and which might end up getting >> marked as "killed" etc). And another one for "read" position, i.e. items >> passed to the read stream API / prefetching, etc. > > That all makes sense. > OK >> 3) It makes it clear when the items are no longer needed, and the AM can >> do cleanup. process kill tuples, etc. > > But it doesn't, really. The index AM is still subject to exactly the > same constraints in terms of page-at-a-time processing. These existing > constraints always came from the table AM side, so it's not as if your > patch can remain totally neutral on these questions. > Not sure I understand. Which part of my sentence you disagree with? Or what constraints you mean? The interface does not require page-at-a-time processing - the index AM is perfectly within it's rights to produce a batch spanning 10 leaf pages, as long as it keeps track of them, and perhaps keeps some mapping of items (returned in the batch) to leaf pages. So that when the next batch is requested, it can do the cleanup, and move to the next batch. Yes, the current implementation does not do that, to keep the patches simple. But it should be possible, I believe. > Basically, it looks like you've invented a shadow batching interface > that is technically not known to the index AM, but nevertheless > coordinates with the existing so->currPos batching interface. > Perhaps, but which part of that you consider a problem? Are you saying this shouldn't use the currPos stuff at all, and instead do stuff in some other way? >> I don't think indexam.c knows all that much about the nbtree internal >> batching. It "just" relies on amgetbatch() producing items the AM can >> handle later (during killtuples/cleanup etc.). It does not even need to >> be a single-leaf-page batch, if the AM knows how to track/deal with that >> internally. > > I'm concerned that no single place will know about everything under > this scheme. Having one single place that has visibility into all > relevant costs, whether they're index AM or table AM related, is what > I think you should be aiming for. > > I think that you should be removing the parts of the nbtree (and other > index AM) code that deal with the progress of the scan explicitly. > What remains is code that simply reads the next page, and saves its > details in the relevant data structures. Or code that "finishes off" a > leaf page by dropping its pin, and maybe doing the _bt_killitems > stuff. Does that mean not having a simple amgetbatch() callback, but some finer grained interface? Or maybe one callback that returns the next "AM page" (essentially the currPos), and then another callback to release it? (This is what I mean by "two-callback API" later.) Or what would it look like? > The index AM itself should no longer know about the current next tuple > to return, nor about mark/restore. It is no longer directly in control > of the scan's progress. It loses all context that survives across API > calls. > I'm lost. How could the index AM not know about mark/restore? >> Yes, splitting _bt_steppage() like this makes sense to me, and I agree >> being able to proceed to the next page before we're done with the >> current page seems perfectly reasonable for batches spanning multiple >> leaf pages. > > I think that it's entirely possible that it'll just be easier to do > things this way from the start. I understand that that may be far from > obvious right now, but, again, I just don't see what's so special > about the way that each index AM batches results. What about that it > is so hard to generalize across index AMs that must support amgettuple > right now? (At least in the case of nbtree and hash, which have no > special requirements for things like KNN-GiST.) > I don't think the batching in various AMs is particularly unique, that's true. But my goal was to wrap that in a single amgetbatch callback, because that seemed natural, and that moves some of the responsibilities to the AM. I still don't quite understand what API you imagine, but if we want to make more of this the responsibility of indexam.c, I guess it will require multiple smaller callbacks (I'm not opposed to that, but I also don't know if that's what you imagine). > Most individual calls to btgettuple just return the next batched-up > so->currPos tuple/TID via another call to _bt_next. Things like the > _bt_first-new-primitive-scan case don't really add any complexity -- > the core concept of processing a page at a time still applies. It > really is just a simple batching scheme, with a couple of extra fiddly > details attached to it -- but nothing too hairy. > True, although the details (how the batches are represented etc.) are often quite different, so did you imagine some shared structure to represent that, or wrapping that in a new callback? Or how would indexam.c work with that? > The hardest part will probably be rigorously describing the rules for > not breaking index-only scans due to concurrent TID recycling by > VACUUM, and the rules for doing _bt_killitems. But that's also not a > huge problem, in the grand scheme of things. > It probably is not a huge problem ... for someone who's already familiar with the rules, at least intuitively. But TBH this part really scares me a little bit. >> Hmm. I've intentionally tried to ignore these issues, or rather to limit >> the scope of the patch so that v1 does not require dealing with it. >> Hence the restriction to single-leaf batches, for example. >> >> But I guess I may have to look at this after all ... not great. > > To be clear, I don't think that you necessarily have to apply these > capabilities in v1 of this project. I would be satisfied if the patch > could just break things out in the right way, so that some later patch > could improve things later on. I only really want to see the > capabilities within the index AM decomposed, such that one central > place can see a global view of the costs and benefits of the index > scan. > Yes, I understand that. Getting the overall design right is my main concern, even if some of the advanced stuff is not implemented until later. But with the wrong design, that may turn out to be difficult. That's the feedback I was hoping for when I kept bugging you, and this discussion was already very useful in this regard. Thank you for that. > You should be able to validate the new API by stress-testing the code. > You can make the index AM read several leaf pages at a time when a > certain debug mode is enabled. Once you prove that the index AM > correctly performs the same processing as today correctly, without any > needless restrictions on the ordering that these decomposed operators > perform (only required restrictions that are well explained and > formalized), then things should be on the right path. > Yeah, stress testing is my primary tool ... >>> ISTM that the central feature of the new API should be the ability to >>> reorder certain kinds of work. There will have to be certain >>> constraints, of course. Sometimes these will principally be problems >>> for the table AM (e.g., we musn't allow concurrent TID recycling >>> unless it's for a plain index scan using an MVCC snapshot), other >>> times they're principally problems for the index AM (e.g., the >>> _bt_killitems safety issues). >>> >> >> Not sure. By "new API" you mean the read stream API, or the index AM API >> to allow batching? > > Right now those two concepts seem incredibly blurred to me. > Same here. >>> I get that you're not that excited about multi-page batches; it's not >>> the priority. Fair enough. I just think that the API needs to work in >>> terms of batches that are sized as one or more pages, in order for it >>> to make sense. >>> >> >> True, but isn't that already the case? I mean, what exactly prevents an >> index AM to "build" a batch for multiple leaf pages? The current patch >> does not implement that for any of the AMs, true, but isn't that already >> possible if the AM chooses to? > > That's unclear, but overall I'd say no. > > The index AM API says that they need to hold on to a buffer pin to > avoid confusing scans due to concurrent TID recycling by VACUUM. The > index AM API fails to adequately describe what is expected here. And > it provides no useful context for larger batching of index pages. > nbtree already does its own thing by dropping leaf page pins > selectively. > Not sure I understand. I imagined the index AM would just read a sequence of leaf pages, keeping all the same pins etc. just like it does for the one leaf it reads right now (pins, etc.). I'm probably too dumb for that, but I still don't quite understand how that's different from just reading and processing that sequence of leaf pages by amgettuple without batching. > Whether or not it's technically possible is a matter of interpretation > (I came down on the "no" side, but it's still ambiguous). I would > prefer it if the index AM API was much simpler for ordered scans. As I > said already, something along the lines of "when you're told to scan > the next index page, here's how we'll call you, here's the data > structure that you need to fill up". Or "when we tell you that we're > done fetching tuples from a recently read index page, here's how we'll > call you". > I think this is pretty much "two-callback API" I mentioned earlier. > These discussions about where the exact boundaries lie don't seem very > helpful. The simple fact is that nobody is ever going to invent an > index AM side interface that batches up more than a single leaf page. > Why would they? It just doesn't make sense to, since the index AM has > no idea about certain clearly-relevant context. For example, it has no > idea whether or not there's a LIMIT involved. > > The value that comes from using larger batches on the index AM side > comes from making life easier for heap prefetching, which index AMs > know nothing about whatsoever. Again, the goal should be to marry > information from the index AM and the table AM in one central place. > True, although the necessary context could be passed to the index AM in some way. That's what happens in the current patch, where indexam.c could size the batch just right for a LIMIT clause, before asking the index AM to fill it with items. >> Unfortunately that didn't work because of killtuples etc. because the >> index AM had no idea about the indexam queue and has it's own concept of >> "current item", so it was confused about which item to mark as killed. >> And that old item might even be from an earlier leaf page (not the >> "current" currPos). > > Currently, during a call to btgettuple, so->currPos.itemIndex is > updated within _bt_next. But before _bt_next is called, > so->currPos.itemIndex indicates the item returned by the most recent > prior call to btgettuple -- which is also the tuple that the > scan->kill_prior_tuple reports on. In short, btgettuple does some > trivial things to remember which entries from so->currPos ought to be > marked dead later on due to the scan->kill_prior_tuple flag having > been set for those entries. This can be moved outside of each index > AM. > > The index AM shouldn't need to use a scan->kill_prior_tuple style flag > under the new batching API at all, though. It should work at a higher > level than that. The index AM should be called through a callback that > tells it to drop the pin on a page that the table AM has been reading > from, and maybe perform _bt_killitems on these relevant known-dead > TIDs first. In short, all of the bookkeeping for so->killedItems[] > should be happening at a completely different layer. And the > so->killedItems[] structure should be directly associated with a > single index page subset of a batch (a subset similar to the current > so->currPos batches). > > The first time the index AM sees anything about dead TIDs, it should > see a whole leaf page worth of them. > I need to think about this a bit, but I agree passing this information to an index AM through the kill_prior_tuple seems weird. >> I was thinking maybe the AM could keep the leaf pages, and then free >> them once they're no longer needed. But it wasn't clear to me how to >> exchange this information between indexam.c and the index AM, because >> right now the AM only knows about a single (current) position. > > I'm imagining a world in which the index AM doesn't even know about > the current position. Basically, it has no real context about the > progress of the scan to maintain at all. It merely does what it is > told by some higher level, that is sensitive to the requirements of > both the index AM and the table AM. > Hmmm, OK. If the idea is to just return a leaf page as an array of items (in some fancy way) to indexam.c, then it'd be indexam.c responsible for tracking what the current position (or multiple positions are), I guess. >> But imagine we have this: >> >> a) A way to switch the scan into "batch" mode, where the AM keeps the >> leaf page (and a way for the AM to indicate it supports this). > > I don't think that there needs to be a batch mode. There could simply > be the total absence of batching, which is one point along a > continuum, rather than a discrete mode. > >> b) Some way to track two "positions" in the scan - one for read, one for >> prefetch. I'm not sure if this would be internal in each index AM, or at >> the indexam.c level. > > I think that it would be at the indexam.c level. > Yes, if the index AM returns page as a set of items, then it'd be up to indexam.c to maintain all this information. >> c) A way to get the index tuple for either of the two positions (and >> advance the position). It might be a flag for amgettuple(), or maybe >> even a callaback for the "prefetch" position. > > Why does the index AM need to know anything about the fact that the > next tuple has been requested? Why can't it just be 100% ignorant of > all that? (Perhaps barring a few special cases, such as KNN-GiST > scans, which continue to use the legacy amgettuple interface.) > Well, I was thinking about how it works now, for the "current" position. And I was thinking about how would it need to change to handle the prefetch position too, in the same way ... But if you're suggesting to move this logic and context to the upper layer indexam.c, that changes things ofc. >> d) A way to inform the AM items up to some position are no longer >> needed, and thus the leaf pages can be cleaned up and freed. AFAICS it >> could always be "up to the current read position". > > Yeah, I like this idea. But the index AM doesn't need to know about > positions and whatnot. It just needs to do what it's told: to drop the > pin, and maybe to perform _bt_killitems first. Or maybe just to drop > the pin, with instruction to do _bt_killitems coming some time later > (the index AM will need to be a bit more careful within its > _bt_killitems step when this happens). > Well, if the AM works with "batches of tuples for a leaf page" (through the two callbacks to read / release a page), then positions to exact items are no longer needed. It just needs to know which pages are still needed, etc. Correct? > The index AM doesn't need to drop the current pin for the current > position -- not as such. The index AM doesn't directly know about what > pins are held, since that'll all be tracked elsewhere. Again, the > index AM should need to hold onto zero context, beyond the immediate > request to perform one additional unit of work, which will > usually/always happen at the index page level (all of which is tracked > by data structures that are under the control of the new indexam.c > level). > No idea. > I don't think that it'll ultimately be all that hard to schedule when > and how index pages are read from outside of the index AM in question. > In general all relevant index AMs already work in much the same way > here. Maybe we can ultimately invent a way for the index AM to > influence that scheduling, but that might never be required. > I haven't thought about scheduling at all. Maybe there's something we could improve in the future, but I don't see what would it look like, and it seems unrelated to this patch. >> Does that sound reasonable / better than the current approach, or have I >> finally reached the "raving lunatic" stage? > > The stage after "raving lunatic" is enlightenment. :-) > That's my hope. regards -- Tomas Vondra
On Thu, Nov 7, 2024 at 4:34 PM Tomas Vondra <tomas@vondra.me> wrote: > Not sure I understand, but I think I'm somewhat confused by "index AM" > vs. indexam. Are you suggesting the individual index AMs should know as > little about the batching as possible, and instead it should be up to > indexam.c to orchestrate most of the stuff? Yes, that's what I'm saying. Knowing "as little as possible" turns out to be pretty close to knowing nothing at all. There might be some minor exceptions, such as the way that nbtree needs to remember the scan's array keys. But that already works in a way that's very insensitive to the exact position in the scan. For example, right now if you restore a mark that doesn't just come from the existing so->currPos batch then we cheat and reset the array keys. > If yes, then I agree in principle, and I think indexam.c is the right > place to do that (or at least I can't think of a better one). Good. > That's what the current patch aimed to do, more or less. I'm not saying > it got it perfectly right, and I'm sure there is stuff that can be > improved (like reworking _steppage to not deal with killed tuples). But > surely the index AMs need to have some knowledge about batching, because > how else would it know which leaf pages to still keep, etc? I think that your new thing can directly track which leaf pages have pins. As well as tracking the order that it has to return tuples from among those leaf page batch subsets. Your new thing can think about this in very general terms, that really aren't tied to any index AM specifics. It'll have some general notion of an ordered sequence of pages (in scan/key space order), each of which contains one or more tuples to return. It needs to track which pages have tuples that we've already done all the required visibility checks for, in order to be able to instruct the index AM to drop the pin. Suppose, for example, that we're doing an SAOP index scan, where the leaf pages that our multi-page batch consists of aren't direct siblings. That literally doesn't matter at all. The pages still have to be in the same familiar key space/scan order, regardless. And that factor shouldn't really need to influence how many pins we're willing to hold on to (no more than it would when there are large numbers of index leaf pages with no interesting tuples to return that we must still scan over). > >> 3) It makes it clear when the items are no longer needed, and the AM can > >> do cleanup. process kill tuples, etc. > > > > But it doesn't, really. The index AM is still subject to exactly the > > same constraints in terms of page-at-a-time processing. These existing > > constraints always came from the table AM side, so it's not as if your > > patch can remain totally neutral on these questions. > > > > Not sure I understand. Which part of my sentence you disagree with? Or > what constraints you mean? What I was saying here was something I said more clearly a bit further down: it's technically possible to do multi-page batches within the confines of the current index AM API, but that's not true in any practical sense. And it'll never be true with an API that looks very much like the current amgettuple API. > The interface does not require page-at-a-time processing - the index AM > is perfectly within it's rights to produce a batch spanning 10 leaf > pages, as long as it keeps track of them, and perhaps keeps some mapping > of items (returned in the batch) to leaf pages. So that when the next > batch is requested, it can do the cleanup, and move to the next batch. How does an index AM actually do that in a way that's useful? It only sees a small part of the picture. That's why it's the wrong place for it. > > Basically, it looks like you've invented a shadow batching interface > > that is technically not known to the index AM, but nevertheless > > coordinates with the existing so->currPos batching interface. > > > > Perhaps, but which part of that you consider a problem? Are you saying > this shouldn't use the currPos stuff at all, and instead do stuff in > some other way? I think that you should generalize the currPos stuff, and move it to some other, higher level module. > Does that mean not having a simple amgetbatch() callback, but some finer > grained interface? Or maybe one callback that returns the next "AM page" > (essentially the currPos), and then another callback to release it? > > (This is what I mean by "two-callback API" later.) I'm not sure. Why does the index AM need to care about the batch size at all? It merely needs to read the next leaf page. The high level understanding of batches and the leaf pages that constitute batches lives elsewhere. The nbtree code will know about buffer pins held, in the sense that it'll be the one setting the Buffer variables in the new scan descriptor thing. But it's not going to remember to drop those buffer pins on its own. It'll need to be told. So it's not ever really in control. > > The index AM itself should no longer know about the current next tuple > > to return, nor about mark/restore. It is no longer directly in control > > of the scan's progress. It loses all context that survives across API > > calls. > > > > I'm lost. How could the index AM not know about mark/restore? Restoring a mark already works by restoring an earlier so->currPos batch. Actually, more often it works by storing an offset into the current so->currPos, without actually copying anything into so->markPos, and without restoring so->markPos into so->currPos. In short, there is virtually nothing about how mark/restore works that really needs to live inside nbtree. It's all just restoring an earlier batch and/or offset into a batch. The only minor caveat is the stuff about array keys that I went into already -- that isn't quite a piece of state that lives in so->currPos, but it's a little bit like that. You can probably poke one or two more minor holes in some of this -- it's not 100% trivial. But it's doable. > I don't think the batching in various AMs is particularly unique, that's > true. But my goal was to wrap that in a single amgetbatch callback, > because that seemed natural, and that moves some of the responsibilities > to the AM. Why is it natural? I mean all of the index AMs that support amgettuple copied everything from ntree already. Including all of the kill_prior_tuple stuff. It's already quite generic. > I still don't quite understand what API you imagine, but if > we want to make more of this the responsibility of indexam.c, I guess it > will require multiple smaller callbacks (I'm not opposed to that, but I > also don't know if that's what you imagine). I think that you understood me correctly here. > > Most individual calls to btgettuple just return the next batched-up > > so->currPos tuple/TID via another call to _bt_next. Things like the > > _bt_first-new-primitive-scan case don't really add any complexity -- > > the core concept of processing a page at a time still applies. It > > really is just a simple batching scheme, with a couple of extra fiddly > > details attached to it -- but nothing too hairy. > > > > True, although the details (how the batches are represented etc.) are > often quite different, so did you imagine some shared structure to > represent that, or wrapping that in a new callback? In what sense are they sometimes different? In general batches will consist of one or more groups of tuples, each of which is associated with a particular leaf page (if the scan returns no tuples for a given scanned leaf page then it won't form a part of the final batch). You can do amgettuple style scrolling back and forth with this structure, across page boundaries. Seems pretty general to me. > Yes, I understand that. Getting the overall design right is my main > concern, even if some of the advanced stuff is not implemented until > later. But with the wrong design, that may turn out to be difficult. > > That's the feedback I was hoping for when I kept bugging you, and this > discussion was already very useful in this regard. Thank you for that. I don't want to insist on doing all this. But it just seems really weird to have this shadow batching system for the so->currPos batches. > > The index AM API says that they need to hold on to a buffer pin to > > avoid confusing scans due to concurrent TID recycling by VACUUM. The > > index AM API fails to adequately describe what is expected here. And > > it provides no useful context for larger batching of index pages. > > nbtree already does its own thing by dropping leaf page pins > > selectively. > > > > Not sure I understand. I imagined the index AM would just read a > sequence of leaf pages, keeping all the same pins etc. just like it does > for the one leaf it reads right now (pins, etc.). Right. But it wouldn't necessarily drop the leaf pages right away. It might try to coalesce together multiple heap page accesses, for index tuples that happen to span page boundaries (but are part of the same higher level batch). > I'm probably too dumb for that, but I still don't quite understand how > that's different from just reading and processing that sequence of leaf > pages by amgettuple without batching. It's not so much different, as just more flexible. It's possible that v1 would effectively do exactly the same thing in practice. It'd only be able to do fancier things with holding onto leaf pages in a debug build, that validated the general approach. > True, although the necessary context could be passed to the index AM in > some way. That's what happens in the current patch, where indexam.c > could size the batch just right for a LIMIT clause, before asking the > index AM to fill it with items. What difference does it make where it happens? It might make some difference, but as I keep saying, the important point is that *somebody* has to know all of these things at the same time. > I need to think about this a bit, but I agree passing this information > to an index AM through the kill_prior_tuple seems weird. Right. Because it's a tuple-at-a-time interface, which isn't suitable for the direction you want to take things in. > Hmmm, OK. If the idea is to just return a leaf page as an array of items > (in some fancy way) to indexam.c, then it'd be indexam.c responsible for > tracking what the current position (or multiple positions are), I guess. Right. It would have to have some basic idea of the laws-of-physics underlying the index scan. It would have to sensibly limit the number of index page buffer pins held at any given time. > > Why does the index AM need to know anything about the fact that the > > next tuple has been requested? Why can't it just be 100% ignorant of > > all that? (Perhaps barring a few special cases, such as KNN-GiST > > scans, which continue to use the legacy amgettuple interface.) > > > > Well, I was thinking about how it works now, for the "current" position. > And I was thinking about how would it need to change to handle the > prefetch position too, in the same way ... > > But if you're suggesting to move this logic and context to the upper > layer indexam.c, that changes things ofc. Yes, I am suggesting that. > Well, if the AM works with "batches of tuples for a leaf page" (through > the two callbacks to read / release a page), then positions to exact > items are no longer needed. It just needs to know which pages are still > needed, etc. Correct? Right, correct. > > I don't think that it'll ultimately be all that hard to schedule when > > and how index pages are read from outside of the index AM in question. > > In general all relevant index AMs already work in much the same way > > here. Maybe we can ultimately invent a way for the index AM to > > influence that scheduling, but that might never be required. > > > > I haven't thought about scheduling at all. Maybe there's something we > could improve in the future, but I don't see what would it look like, > and it seems unrelated to this patch. It's only related to this patch in the sense that we have to imagine that it'll be worth having in some form in the future. It might also be a good exercise architecturally. We don't need to do the same thing in several slightly different ways in each index AM. -- Peter Geoghegan
On 11/8/24 02:35, Peter Geoghegan wrote: > On Thu, Nov 7, 2024 at 4:34 PM Tomas Vondra <tomas@vondra.me> wrote: >> Not sure I understand, but I think I'm somewhat confused by "index AM" >> vs. indexam. Are you suggesting the individual index AMs should know as >> little about the batching as possible, and instead it should be up to >> indexam.c to orchestrate most of the stuff? > > Yes, that's what I'm saying. Knowing "as little as possible" turns out > to be pretty close to knowing nothing at all. > > There might be some minor exceptions, such as the way that nbtree > needs to remember the scan's array keys. But that already works in a > way that's very insensitive to the exact position in the scan. For > example, right now if you restore a mark that doesn't just come from > the existing so->currPos batch then we cheat and reset the array keys. > >> If yes, then I agree in principle, and I think indexam.c is the right >> place to do that (or at least I can't think of a better one). > > Good. > >> That's what the current patch aimed to do, more or less. I'm not saying >> it got it perfectly right, and I'm sure there is stuff that can be >> improved (like reworking _steppage to not deal with killed tuples). But >> surely the index AMs need to have some knowledge about batching, because >> how else would it know which leaf pages to still keep, etc? > > I think that your new thing can directly track which leaf pages have > pins. As well as tracking the order that it has to return tuples from > among those leaf page batch subsets. > > Your new thing can think about this in very general terms, that really > aren't tied to any index AM specifics. It'll have some general notion > of an ordered sequence of pages (in scan/key space order), each of > which contains one or more tuples to return. It needs to track which > pages have tuples that we've already done all the required visibility > checks for, in order to be able to instruct the index AM to drop the > pin. > Is it a good idea to make this part (in indexam.c) aware of / responsible for managing stuff like pins? Perhaps it'd work fine for index AMs that always return an array of items for a single leaf-page (like btree or hash). But I'm still thinking about cases like gist with ORDER BY clauses, or maybe something even weirder in custom AMs. It seems to me knowing which pages may be pinned is very AM-specific knowledge, and my intention was to let the AM to manage that. That is, the new indexam code would be responsible for deciding when the "AM batches" are loaded and released, using the two new callbacks. But it'd be the AM responsible for making sure everything is released. > Suppose, for example, that we're doing an SAOP index scan, where the > leaf pages that our multi-page batch consists of aren't direct > siblings. That literally doesn't matter at all. The pages still have > to be in the same familiar key space/scan order, regardless. And that > factor shouldn't really need to influence how many pins we're willing > to hold on to (no more than it would when there are large numbers of > index leaf pages with no interesting tuples to return that we must > still scan over). > I agree that in the simple cases it's not difficult to determine what pins we need for the sequence of tuples/pages. But is it guaranteed to be that easy, and is it easy to communicate this information to the indexam.c layer? I'm not sure about that. In an extreme case it may be that each tuple comes from entirely different leaf page, and stuff like that. And while most out-of-core AMs that I'm aware of are rather close to nbtree/gist/gin, I wonder what weird things can be out there. >>>> 3) It makes it clear when the items are no longer needed, and the AM can >>>> do cleanup. process kill tuples, etc. >>> >>> But it doesn't, really. The index AM is still subject to exactly the >>> same constraints in terms of page-at-a-time processing. These existing >>> constraints always came from the table AM side, so it's not as if your >>> patch can remain totally neutral on these questions. >>> >> >> Not sure I understand. Which part of my sentence you disagree with? Or >> what constraints you mean? > > What I was saying here was something I said more clearly a bit further > down: it's technically possible to do multi-page batches within the > confines of the current index AM API, but that's not true in any > practical sense. And it'll never be true with an API that looks very > much like the current amgettuple API. > OK >> The interface does not require page-at-a-time processing - the index AM >> is perfectly within it's rights to produce a batch spanning 10 leaf >> pages, as long as it keeps track of them, and perhaps keeps some mapping >> of items (returned in the batch) to leaf pages. So that when the next >> batch is requested, it can do the cleanup, and move to the next batch. > > How does an index AM actually do that in a way that's useful? It only > sees a small part of the picture. That's why it's the wrong place for > it. > Sure, maybe it'd need some more information - say, how many items we expect to read, but if indexam knows that bit, surely it can pass it down to the AM. But yeah, I agree doing it in amgettuple() would be inconvenient and maybe even awkward. I can imagine the AM maintaining an array of currPos, but then it'd also need to be made aware of multiple positions, and stuff like that. Which it shouldn't need to know about. >>> Basically, it looks like you've invented a shadow batching interface >>> that is technically not known to the index AM, but nevertheless >>> coordinates with the existing so->currPos batching interface. >>> >> >> Perhaps, but which part of that you consider a problem? Are you saying >> this shouldn't use the currPos stuff at all, and instead do stuff in >> some other way? > > I think that you should generalize the currPos stuff, and move it to > some other, higher level module. > By generalizing you mean defining a common struct serving the same purpose, but for all the index AMs? And the new AM callbacks would produce/consume this new struct, right? >> Does that mean not having a simple amgetbatch() callback, but some finer >> grained interface? Or maybe one callback that returns the next "AM page" >> (essentially the currPos), and then another callback to release it? >> >> (This is what I mean by "two-callback API" later.) > > I'm not sure. Why does the index AM need to care about the batch size > at all? It merely needs to read the next leaf page. The high level > understanding of batches and the leaf pages that constitute batches > lives elsewhere. > I don't think I suggested the index AM would need to know about the batch size. Only indexam.c would be aware of that, and would read enough stuff from the index to satisfy that. > The nbtree code will know about buffer pins held, in the sense that > it'll be the one setting the Buffer variables in the new scan > descriptor thing. But it's not going to remember to drop those buffer > pins on its own. It'll need to be told. So it's not ever really in > control. > Right. So those pins would be released after indexam invokes the second new callback, instructing the index AM to release everything associated with a chunk of items returned sometime earlier. >>> The index AM itself should no longer know about the current next tuple >>> to return, nor about mark/restore. It is no longer directly in control >>> of the scan's progress. It loses all context that survives across API >>> calls. >>> >> >> I'm lost. How could the index AM not know about mark/restore? > > Restoring a mark already works by restoring an earlier so->currPos > batch. Actually, more often it works by storing an offset into the > current so->currPos, without actually copying anything into > so->markPos, and without restoring so->markPos into so->currPos. > > In short, there is virtually nothing about how mark/restore works that > really needs to live inside nbtree. It's all just restoring an earlier > batch and/or offset into a batch. The only minor caveat is the stuff > about array keys that I went into already -- that isn't quite a piece > of state that lives in so->currPos, but it's a little bit like that. > > You can probably poke one or two more minor holes in some of this -- > it's not 100% trivial. But it's doable. > OK. The thing that worries me is whether it's going to be this simple for other AMs. Maybe it is, I don't know. >> I don't think the batching in various AMs is particularly unique, that's >> true. But my goal was to wrap that in a single amgetbatch callback, >> because that seemed natural, and that moves some of the responsibilities >> to the AM. > > Why is it natural? I mean all of the index AMs that support amgettuple > copied everything from ntree already. Including all of the > kill_prior_tuple stuff. It's already quite generic. > I don't recall my reasoning, and I'm not saying it was the right instinct. But if we have one callback to read tuples, it seemed like maybe we should have one callback to read a bunch of tuples in a similar way. >> I still don't quite understand what API you imagine, but if >> we want to make more of this the responsibility of indexam.c, I guess it >> will require multiple smaller callbacks (I'm not opposed to that, but I >> also don't know if that's what you imagine). > > I think that you understood me correctly here. > >>> Most individual calls to btgettuple just return the next batched-up >>> so->currPos tuple/TID via another call to _bt_next. Things like the >>> _bt_first-new-primitive-scan case don't really add any complexity -- >>> the core concept of processing a page at a time still applies. It >>> really is just a simple batching scheme, with a couple of extra fiddly >>> details attached to it -- but nothing too hairy. >>> >> >> True, although the details (how the batches are represented etc.) are >> often quite different, so did you imagine some shared structure to >> represent that, or wrapping that in a new callback? > > In what sense are they sometimes different? > > In general batches will consist of one or more groups of tuples, each > of which is associated with a particular leaf page (if the scan > returns no tuples for a given scanned leaf page then it won't form a > part of the final batch). You can do amgettuple style scrolling back > and forth with this structure, across page boundaries. Seems pretty > general to me. > I meant that each of the AMs uses a separate typedef, with different fields, etc. I'm sure there are similarities (it's always an array of elements, either TIDs, index or heap tuples, or some combination of that). But maybe there is stuff unique to some AMs - chances are that can be either "generalized" or extended using some private member. >> Yes, I understand that. Getting the overall design right is my main >> concern, even if some of the advanced stuff is not implemented until >> later. But with the wrong design, that may turn out to be difficult. >> >> That's the feedback I was hoping for when I kept bugging you, and this >> discussion was already very useful in this regard. Thank you for that. > > I don't want to insist on doing all this. But it just seems really > weird to have this shadow batching system for the so->currPos batches. > >>> The index AM API says that they need to hold on to a buffer pin to >>> avoid confusing scans due to concurrent TID recycling by VACUUM. The >>> index AM API fails to adequately describe what is expected here. And >>> it provides no useful context for larger batching of index pages. >>> nbtree already does its own thing by dropping leaf page pins >>> selectively. >>> >> >> Not sure I understand. I imagined the index AM would just read a >> sequence of leaf pages, keeping all the same pins etc. just like it does >> for the one leaf it reads right now (pins, etc.). > > Right. But it wouldn't necessarily drop the leaf pages right away. It > might try to coalesce together multiple heap page accesses, for index > tuples that happen to span page boundaries (but are part of the same > higher level batch). > No opinion, but it's not clear to me how exactly would this work. I've imagined we'd just acquire (and release) multiple pins as we go. >> I'm probably too dumb for that, but I still don't quite understand how >> that's different from just reading and processing that sequence of leaf >> pages by amgettuple without batching. > > It's not so much different, as just more flexible. It's possible that > v1 would effectively do exactly the same thing in practice. It'd only > be able to do fancier things with holding onto leaf pages in a debug > build, that validated the general approach. > >> True, although the necessary context could be passed to the index AM in >> some way. That's what happens in the current patch, where indexam.c >> could size the batch just right for a LIMIT clause, before asking the >> index AM to fill it with items. > > What difference does it make where it happens? It might make some > difference, but as I keep saying, the important point is that > *somebody* has to know all of these things at the same time. > Agreed. >>> I don't think that it'll ultimately be all that hard to schedule when >>> and how index pages are read from outside of the index AM in question. >>> In general all relevant index AMs already work in much the same way >>> here. Maybe we can ultimately invent a way for the index AM to >>> influence that scheduling, but that might never be required. >>> >> >> I haven't thought about scheduling at all. Maybe there's something we >> could improve in the future, but I don't see what would it look like, >> and it seems unrelated to this patch. > > It's only related to this patch in the sense that we have to imagine > that it'll be worth having in some form in the future. > > It might also be a good exercise architecturally. We don't need to do > the same thing in several slightly different ways in each index AM. > Could you briefly outline how you think this might interact with the scheduling of index page reads? I can imagine telling someone about which future index pages we might need to read (say, the next leaf page), or something like that. But this patch is about prefetching the heap pages it seems like an entirely independent thing. And ISTM there are concurrency challenges with prefetching index pages (at least when leveraging read stream API to do async reads). regards -- Tomas Vondra
On Sun, Nov 10, 2024 at 4:41 PM Tomas Vondra <tomas@vondra.me> wrote: > Is it a good idea to make this part (in indexam.c) aware of / > responsible for managing stuff like pins? My sense is that that's the right long term architectural direction. I can't really prove it. > Perhaps it'd work fine for > index AMs that always return an array of items for a single leaf-page > (like btree or hash). But I'm still thinking about cases like gist with > ORDER BY clauses, or maybe something even weirder in custom AMs. Nothing is perfect. What you really have to worry about not supporting is index AMs that implement amgettuple -- AMs that aren't quite a natural fit for this. At least for in-core index AMs that's really just GiST (iff KNN GiST is in use, which it usually isn't) plus SP-GiST. AFAIK most out-of-core index AMs only support lossy index scans in practice. Just limiting yourself to that makes an awful lot of things easier. For example I think that GIN gets away with a lot by only supporting lossy scans -- there's a comment above ginInsertCleanup() that says "On first glance it looks completely not crash-safe", but stuff like that is automatically okay with lossy scans. So many index AMs automatically don't need to be considered here at all. > It seems to me knowing which pages may be pinned is very AM-specific > knowledge, and my intention was to let the AM to manage that. This is useful information, because it helps me to understand how you're viewing this. I totally disagree with this characterization. This is an important difference in perspective. IMV index AMs hardly care at all about holding onto buffer pins, very much unlike heapam. I think that holding onto pins and whatnot has almost nothing to do with the index AM as such -- it's about protecting against unsafe concurrent TID recycling, which is a table AM/heap issue. You can make a rather weak argument that the index AM needs it for _bt_killitems, but that seems very secondary to me (if you go back long enough there are no _bt_killitems, but the pin thing itself still existed). As I pointed out before, the index AM API docs (at https://www.postgresql.org/docs/devel/index-locking.html) talk about holding onto buffer pins on leaf pages during amgettuple. So the need to mess around with pins just doesn't come from the index AM side, at all. The cleanup lock interlock against TID recycling protects the scan from seeing transient wrong answers -- it doesn't protect the index structure itself. The only thing that's a bit novel about what I'm proposing now is that I'm imagining that it'll be possible to eventually usefully schedule multi-leaf-page batches using code that has no more than a very general notion of how an ordered index scan works. That might turn out to be more complicated than I suppose it will now. If it is then it should still be fixable. > That is, > the new indexam code would be responsible for deciding when the "AM > batches" are loaded and released, using the two new callbacks. But it'd > be the AM responsible for making sure everything is released. What does it really mean for the index AM to be responsible for a thing? I think that the ReleaseBuffer() calls would be happening in index AM code, for sure. But that would probably always be called through your new index scan management code in practice. I don't have any fixed ideas about the resource management aspects of this. That doesn't seem particularly fundamental to the design. > I agree that in the simple cases it's not difficult to determine what > pins we need for the sequence of tuples/pages. But is it guaranteed to > be that easy, and is it easy to communicate this information to the > indexam.c layer? I think that it's fairly generic. The amount of work required to read an index page is (in very round numbers) more or less uniform across index AMs. Maybe you'd need to have some kind of way of measuring how many pages you had to read without returning any tuples, for scheduling purposes -- that cost is a relevant cost, and so would probably have to be tracked. But that still seems fairly general -- any kind of order index scan is liable to sometimes scan multiple pages without having any index tuples to return. > Sure, maybe it'd need some more information - say, how many items we > expect to read, but if indexam knows that bit, surely it can pass it > down to the AM. What are you arguing for here? Practically speaking, I think that the best way to do it is to have one layer that manages all this stuff. It would also be possible to split it up any way you can think of, but why would you want to? I'm not asking you to solve these problems. I'm only suggesting that you move things in a direction that is amenable to adding these things later on. > By generalizing you mean defining a common struct serving the same > purpose, but for all the index AMs? And the new AM callbacks would > produce/consume this new struct, right? Yes. > I don't think I suggested the index AM would need to know about the > batch size. Only indexam.c would be aware of that, and would read enough > stuff from the index to satisfy that. I don't think that you'd ultimately want to make the batch sizes fixed (though they'd probably always consist of tuples taken from 1 or more index pages). Ultimately the size would vary over time, based on competing considerations. > > The nbtree code will know about buffer pins held, in the sense that > > it'll be the one setting the Buffer variables in the new scan > > descriptor thing. But it's not going to remember to drop those buffer > > pins on its own. It'll need to be told. So it's not ever really in > > control. > > > Right. So those pins would be released after indexam invokes the second > new callback, instructing the index AM to release everything associated > with a chunk of items returned sometime earlier. Yes. It might all look very similar to today, at least for your initial commited version. You might also want to combine reading the next page with dropping the pin on the previous page. But also maybe not. > OK. The thing that worries me is whether it's going to be this simple > for other AMs. Maybe it is, I don't know. Really? I mean if we're just talking about the subset of GiST scans that use KNN-GiST as well as SP-GiST scans not using your new facility, that seems quite acceptable to me. > I don't recall my reasoning, and I'm not saying it was the right > instinct. But if we have one callback to read tuples, it seemed like > maybe we should have one callback to read a bunch of tuples in a similar > way. The tuple-level interface will still need to exist, of course. It just won't be directly owned by affected index AMs. > I meant that each of the AMs uses a separate typedef, with different > fields, etc. I'm sure there are similarities (it's always an array of > elements, either TIDs, index or heap tuples, or some combination of > that). But maybe there is stuff unique to some AMs - chances are that > can be either "generalized" or extended using some private member. Right. Maybe it won't even be that hard to do SP-GiST and KNN-GiST index scans with this too. > No opinion, but it's not clear to me how exactly would this work. I've > imagined we'd just acquire (and release) multiple pins as we go. More experimentation is required to get good intuitions about how useful it is to reorder stuff, to make heap prefetching work best. > Could you briefly outline how you think this might interact with the > scheduling of index page reads? I can imagine telling someone about > which future index pages we might need to read (say, the next leaf > page), or something like that. But this patch is about prefetching the > heap pages it seems like an entirely independent thing. I agree that prefetching of index pages themselves would be entirely independent (and probably much less useful). I wasn't talking about that at all, though. I was talking about the potential value in reading multiple leaf pages at a time as an enabler of heap prefetching -- to avoid "pipeline stalls" for heap prefetching, with certain workloads. The simplest example of how these two things (heap prefetching and eager leaf page reading) could be complementary is the idea of coalescing together accesses to the same heap page from TIDs that don't quite appear in order (when read from the index), but are clustered together. Not just clustered together on one leaf page -- clustered together on a few sibling leaf pages. (The exactly degree to which you'd vary how many leaf pages you read at a time might need to be fully dynamic/adaptive.) We've talked about this already. Reading multiple index pages at a time could in general result in pinning/reading the same heap pages far less often. Imagine if our scan will inherently need to read a total of no more than 3 or 4 index leaf pages. Reading all of those leaf pages in one go probably doesn't add any real latency, but literally guarantees that no heap page will need to be accessed twice. So it's almost a hybrid of an index scan and bitmap index scan, offering the best of both worlds. -- Peter Geoghegan
On Sun, Nov 10, 2024 at 5:41 PM Peter Geoghegan <pg@bowt.ie> wrote: > > It seems to me knowing which pages may be pinned is very AM-specific > > knowledge, and my intention was to let the AM to manage that. > > This is useful information, because it helps me to understand how > you're viewing this. > > I totally disagree with this characterization. This is an important > difference in perspective. IMV index AMs hardly care at all about > holding onto buffer pins, very much unlike heapam. > > I think that holding onto pins and whatnot has almost nothing to do > with the index AM as such -- it's about protecting against unsafe > concurrent TID recycling, which is a table AM/heap issue. You can make > a rather weak argument that the index AM needs it for _bt_killitems, > but that seems very secondary to me (if you go back long enough there > are no _bt_killitems, but the pin thing itself still existed). Much of this discussion is going over my head, but I have a comment on this part. I suppose that when any code in the system takes a pin on a buffer page, the initial concern is almost always to keep the page from disappearing out from under it. There might be a few exceptions, but hopefully not many. So I suppose what is happening here is that index AM pins an index page so that it can read that page -- and then it defers releasing the pin because of some interlocking concern. So at any given moment, there's some set of pins (possibly empty) that the index AM is holding for its own purposes, and some other set of pins (also possibly empty) that the index AM no longer requires for its own purposes but which are still required for heap/index interlocking. The second set of pins could possibly be managed in some AM-agnostic way. The AM could communicate that after the heap is done with X set of TIDs, it can unpin Y set of pages. But the first set of pins are of direct and immediate concern to the AM. Or at least, so it seems to me. Am I confused? -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Nov 11, 2024 at 12:23 PM Robert Haas <robertmhaas@gmail.com> wrote: > > I think that holding onto pins and whatnot has almost nothing to do > > with the index AM as such -- it's about protecting against unsafe > > concurrent TID recycling, which is a table AM/heap issue. You can make > > a rather weak argument that the index AM needs it for _bt_killitems, > > but that seems very secondary to me (if you go back long enough there > > are no _bt_killitems, but the pin thing itself still existed). > > Much of this discussion is going over my head, but I have a comment on > this part. I suppose that when any code in the system takes a pin on a > buffer page, the initial concern is almost always to keep the page > from disappearing out from under it. That almost never comes up in index AM code, though -- cases where you simply want to avoid having an index page evicted do exist, but are naturally very rare. I think that nbtree only does this during page deletion by VACUUM, since it works out to be slightly more convenient to hold onto just the pin at one point where we quickly drop and reacquire the lock. Index AMs find very little use for pins that don't naturally coexist with buffer locks. And even the supposed exception that happens for page deletion could easily be replaced by just dropping the pin and the lock (there'd just be no point in it). I almost think of "pin held" and "buffer lock held" as synonymous when working on the nbtree code, even though you have this one obscure page deletion case where that isn't quite true (plus the TID recycle safety business imposed by heapam). As far as protecting the structure of the index itself is concerned, holding on to buffer pins alone does not matter at all. I have a vague recollection of hash doing something novel with cleanup locks, but I also seem to recall that that had problems -- I think that we got rid of it not too long back. In any case my mental model is that cleanup locks are for the benefit of heapam, never for the benefit of index AMs themselves. This is why we require cleanup locks for nbtree VACUUM but not nbtree page deletion, even though both operations perform precisely the same kinds of page-level modifications to the index leaf page. > There might be a few exceptions, > but hopefully not many. So I suppose what is happening here is that > index AM pins an index page so that it can read that page -- and then > it defers releasing the pin because of some interlocking concern. So > at any given moment, there's some set of pins (possibly empty) that > the index AM is holding for its own purposes, and some other set of > pins (also possibly empty) that the index AM no longer requires for > its own purposes but which are still required for heap/index > interlocking. That summary is correct, but FWIW I find the emphasis on index pins slightly odd from an index AM point of view. The nbtree code virtually always calls _bt_getbuf and _bt_relbuf, as opposed to independently acquiring pins and locks -- that's why "lock" and "pin" seem almost synonymous to me in nbtree contexts. Clearly no index AM should hold onto a buffer lock for more than an instant, so my natural instinct is to wonder why you're even talking about buffer pins or buffer locks that the index AM cares about directly. As I said to Tomas, yeah, the index AM kinda sometimes needs to hold onto a leaf page pin to be able to correctly perform _bt_killitems. But this is only because it needs to reason about concurrent TID recycling. So this is also not really any kind of exception. (_bt_killitems is even prepared to reason about cases where no pin was held at all, and has been since commit 2ed5b87f96.) > The second set of pins could possibly be managed in some > AM-agnostic way. The AM could communicate that after the heap is done > with X set of TIDs, it can unpin Y set of pages. But the first set of > pins are of direct and immediate concern to the AM. > > Or at least, so it seems to me. Am I confused? I think that this is exactly what I propose to do, said in a different way. (Again, I wouldn't have expressed it in this way because it seems obvious to me that buffer pins don't have nearly the same significance to an index AM as they do to heapam -- they have no value in protecting the index structure, or helping an index scan to reason about concurrency that isn't due to a heapam issue.) Does that make sense? -- Peter Geoghegan
On Mon, Nov 11, 2024 at 1:03 PM Peter Geoghegan <pg@bowt.ie> wrote: > I almost think of "pin held" and "buffer lock held" as synonymous when > working on the nbtree code, even though you have this one obscure page > deletion case where that isn't quite true (plus the TID recycle safety > business imposed by heapam). As far as protecting the structure of the > index itself is concerned, holding on to buffer pins alone does not > matter at all. That makes sense from the point of view of working with the btree code itself, but from a system-wide perspective, it's weird to pretend like the pins don't exist or don't matter just because a buffer lock is also held. I had actually forgotten that the btree code tends to pin+lock together; now that you mention it, I remember that I knew it at one point, but it fell out of my head a long time ago... > I think that this is exactly what I propose to do, said in a different > way. (Again, I wouldn't have expressed it in this way because it seems > obvious to me that buffer pins don't have nearly the same significance > to an index AM as they do to heapam -- they have no value in > protecting the index structure, or helping an index scan to reason > about concurrency that isn't due to a heapam issue.) > > Does that make sense? Yeah, it just really throws me for a loop that you're using "pin" to mean "pin at a time when we don't also hold a lock." The fundamental purpose of a pin is to prevent a buffer from being evicted while someone is in the middle of looking at it, and nothing that uses buffers can possibly work correctly without that guarantee. Everything you've written in parentheses there is, AFAICT, 100% wrong if you mean "any pin" and 100% correct if you mean "a pin held without a corresponding lock." -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Nov 11, 2024 at 1:33 PM Robert Haas <robertmhaas@gmail.com> wrote: > That makes sense from the point of view of working with the btree code > itself, but from a system-wide perspective, it's weird to pretend like > the pins don't exist or don't matter just because a buffer lock is > also held. I can see how that could cause confusion. If you're working on nbtree all day long, it becomes natural, though. Both points are true, and relevant to the discussion. I prefer to over-communicate when discussing these points -- it's too easy to talk past each other here. I think that the precise reasons why the index AM does things with buffer pins will need to be put on a more rigorous and formalized footing with Tomas' patch. The different requirements/safety considerations will have to be carefully teased apart. > I had actually forgotten that the btree code tends to > pin+lock together; now that you mention it, I remember that I knew it > at one point, but it fell out of my head a long time ago... The same thing appears to mostly be true of hash, which mostly uses _hash_getbuf + _hash_relbuf (hash's idiosyncratic use of cleanup locks notwithstanding). To be fair it does look like GiST's gistdoinsert function holds onto multiple buffer pins at a time, for its own reasons -- index AM reasons. But this looks to be more or less an optimization to deal with navigating the tree with a loose index order, where multiple descents and ascents are absolutely expected. (This makes it a bit like the nbtree "drop lock but not pin" case that I mentioned in my last email.) It's not as if these gistdoinsert buffer pins persist across calls to amgettuple, though, so for the purposes of this discussion about the new batch API to replace amgettuple they are not relevant -- they don't actually undermine my point. (Though to be fair their existence does help to explain why you found my characterization of buffer pins as irrelevant to index AMs confusing.) The real sign that what I said is generally true of index AMs is that you'll see so few calls to LockBufferForCleanup/ConditionalLockBufferForCleanup. Only hash calls ConditionalLockBufferForCleanup at all (which I find a bit weird). Both GiST and SP-GiST call neither functions -- even during VACUUM. So GiST and SP-GiST make clear that index AMs (that support only MVCC snapshot scans) can easily get by without any use of cleanup locks (and with no externally significant use of buffer pins). > > I think that this is exactly what I propose to do, said in a different > > way. (Again, I wouldn't have expressed it in this way because it seems > > obvious to me that buffer pins don't have nearly the same significance > > to an index AM as they do to heapam -- they have no value in > > protecting the index structure, or helping an index scan to reason > > about concurrency that isn't due to a heapam issue.) > > > > Does that make sense? > > Yeah, it just really throws me for a loop that you're using "pin" to > mean "pin at a time when we don't also hold a lock." I'll try to be more careful about that in the future, then. > The fundamental > purpose of a pin is to prevent a buffer from being evicted while > someone is in the middle of looking at it, and nothing that uses > buffers can possibly work correctly without that guarantee. Everything > you've written in parentheses there is, AFAICT, 100% wrong if you mean > "any pin" and 100% correct if you mean "a pin held without a > corresponding lock." I agree. -- Peter Geoghegan
On Mon, Nov 11, 2024 at 2:00 PM Peter Geoghegan <pg@bowt.ie> wrote: > The real sign that what I said is generally true of index AMs is that > you'll see so few calls to > LockBufferForCleanup/ConditionalLockBufferForCleanup. Only hash calls > ConditionalLockBufferForCleanup at all (which I find a bit weird). > Both GiST and SP-GiST call neither functions -- even during VACUUM. So > GiST and SP-GiST make clear that index AMs (that support only MVCC > snapshot scans) can easily get by without any use of cleanup locks > (and with no externally significant use of buffer pins). Actually, I'm pretty sure that it's wrong for GiST VACUUM to not acquire a full cleanup lock (which used to be called a super-exclusive lock in index AM contexts), as I went into some years ago: https://www.postgresql.org/message-id/flat/CAH2-Wz%3DPqOziyRSrnN5jAtfXWXY7-BJcHz9S355LH8Dt%3D5qxWQ%40mail.gmail.com I plan on playing around with injection points soon. I might try my hand at proving that GiST VACUUM needs to do more here to avoid breaking concurrent GiST index-only scans. Issues such as this are why I place so much emphasis on formalizing all the rules around TID recycling and dropping pins with index scans. I think that we're still a bit sloppy about things in this area. -- Peter Geoghegan
Hi, Since the patch has needed a rebase since mid February and is in Waiting on Author since mid March, I think it'd be appropriate to mark this as Returned with Feedback for now? Or at least moved to the next CF? Greetings, Andres Freund
On 4/2/25 18:05, Andres Freund wrote: > Hi, > > Since the patch has needed a rebase since mid February and is in Waiting on > Author since mid March, I think it'd be appropriate to mark this as Returned > with Feedback for now? Or at least moved to the next CF? > Yes, I agree. regards -- Tomas Vondra
Hi, here's an improved (rebased + updated) version of the patch series, with some significant fixes and changes. The patch adds infrastructure and modifies btree indexes to do prefetching - and AFAIK it passes all tests (no results, correct results). There's still a fair amount of work to be done, of course - the btree changes are not very polished, more time needs to be spent on profiling and optimization, etc. And I'm sure that while the patch passes tests, there certainly are bugs. Compared to the last patch version [1] shared on list (in November), there's a number of significant design changes - a lot of this is based on a number of off-list discussions I had with Peter Geoghegan, which was very helpful. Let me try to sum the main conclusions and changes: 1) patch now relies on read_stream The November patch still relied on sync I/O and PrefetchBuffer(). At some point I added a commit switching it to read_stream - which turned out non-trivial, especially for index-only scans. But it works, and for a while I kept it separate - with PrefetchBuffer first, and a switch to read_stream later. But then I realized it does not make much sense to keep the first part - why would we introduce a custom fadvise-based prefetch, only to immediately rip it out and replace it with with read_stream code with a comparable amount of complexity, right? So I squashed these two parts, and the patch now does read_stream (for the table reads) from the beginning. 2) two new index AM callbacks - amgetbatch + amfreebatch The [1] patch introduced a new callback for reading a "batch" (essentially a leaf page) from the index. But there was a limitation of only allowing a single batch at a time, which was causing trouble with prefetch distance and read_stream stalls at the end of the batch, etc. Based on the discussions with Peter I decided to make this a bit more ambitious, moving the whole batch management from the index AM to the indexam.c level. So now there are two callbacks - amgetbatch and amfreebatch, and it's up to indexam.c to manage the batches - decide how many batches to allow, etc. The index AM is responsible merely for loading the next batch, but does not decide when to load or free a batch, how many to keep in memory, etc. There's a section in indexam.c with a more detailed description of the design, I'm not going to explain all the design details here. In a way, this design is a compromise between the initial AM-level approach I presented as a PoC at pgconf.dev 2023, and the executor level approach I shared a couple months back. Each of those "extreme" cases had it's issues with either happening "too deep" or "too high" - being too integrated in the AM, or not having enough info about the AM. I think the indexam.c is a sensible layer for this. I was hoping doing this at the "executor level" would mean no need for AM code changes, but that turned out not possible - the AM clearly needs to know about the batch boundaries, so that it can e.g. do killtuples, etc. That's why we need the two callbacks (not just the "amgetbatch" one). At least this way it's "hidden" by the indexam.c API, like index_getnext_slot(). (You could argue indexam.c is "executor" and maybe it is - I don't know where exactly to draw the line. I don't think it matters, really. The "hidden in indexam API" is the important bit.) 3) btree prefetch The patch implements the new callbacks only for btree indexes, and it's not very pretty / clean - it's mostly a massaged version of the old code backing amgettuple(). This needs cleanup/improvements, and maybe refactoring to allow reusing more of the code, etc.. Or maybe we should even rip out the amgettuple() entirely, and only support one of those for each AM? That's what Peter suggested, but I'm not convinced we should do that. For now it was very useful to be able to flip between the APIs by setting a GUC, and I left prefetching disabled in some places (e.g. when accessing catalogs, ...) that are unlikely to benefit. But more importantly, I'm not 100% we want to require the index AMs to support prefetching for all cases - if we do, a single "can't prefetch" case would mean we can't prefetch anything for that AM. In particular, I'm thinking about GiST / SP-GiST and indexes ordered by distance, which don't return items in leaf pages but sort them through a binary heap. Maybe we can do prefetch for that, but if we can't it would be silly if it meant we can't do prefetch for any other SP-GiST queries. Anyway, the current patch only implements prefetch for btree. I expect it won't be difficult to do this for other index AMs, considering how similar the design usually is to btree. This is one of the next things on my TODO. I want to be able to validate the design works for multiple AMs, not just btree. 4) duplicate blocks While working on the patch, I realized the old index_fetch_heap code skips reads for duplicate blocks - index the TID matches the immediately preceding block, ReleaseAndReadBuffer() skips most of the work. But read_stream() doesn't do that - if the callback returns the same block, it starts a new read for it, pins it, etc. That can be quite expensive, and I've seen a couple cases where the impact was not negligible (correlated index, fits in memory, ...). I've speculated that maybe read_stream_next_buffer() should detect and handle these cases better - not unlike it detects sequential reads. It might even keep a small cache of already requested reads, etc. so that it can handle a wider range of workloads, not just perfect duplicates. But it does not do that, and I'm not sure if/when that will happen. So for now I simply reproduced the "skip duplicate blocks" behavior. It's not as simple with read_stream, because this logic needs to happen in two places - in the callback (when generating reads), and then also when reading the blocks from the stream - if these places get "out of sync" the stream won't return the blocks expected by the reader. But it does work, and it's not that complex. But there's an issue with prefetch distance ... 5) prefetch distance Traditionally, we measure distance in "tuples" - e.g. in bitmap heap scan, we make sure we prefetched pages for X tuples ahead. But that's not what read_stream does for prefetching - it works with pages. That can cause various issues. Consider for example the "skip duplicate blocks" optimization described in (4). And imagine a perfectly correlated index, with ~200 items per leaf page. The heap tuples are likely wider, let's say we have 50 of them per page. That means that for each leaf page, we have only ~4 blocks per leaf page. With effective_io_concurrency=16 the read_stream will try to prefetch 16 heap pages, that's 3200 index entries. Is that what we want? I'm not quite sure, maybe it's OK? It sure is not quite what I expected. But now imagine an index-only scan on nearly all-visible table. If the fraction of index entries that don't pass the visibility check is very low, we can quickly get into a situation when the read_stream has to read a lot of leaf pages to get the next block number. Sure, we'd need to read that block number eventually, but doing it this early means we may need to keep the batch (leaf page) - a lot of them, actually. Essentially, pick a number and I can construct an IOS that needs to keep more batches. I think this is a consequence of read_stream having an internal idea how far ahead to prefetch, based on the number of requests it got so far, measured in heap blocks. It has not idea about the context (how that maps to index entries, batches we need to keep in memory, ...). Ideally, we'd be able to give this feedback to read_stream in some way, say by "pausing" it when we get too far ahead in the index. But we don't have that - the only thing we can do is to return IndalidBlockNumber to the stream, so that it stops. And then we need to "reset" the stream, and let it continue - but only after we consumed all scheduled reads. In principle it's very similar to the "pause/resume" I mentioned, except that it requires completely draining the queue - a pipeline stall. That's not great, but hopefully it's not very common, and more importantly - it only happens when only a tiny fraction of the index items requires a heap block. So that's what the patch does. I think it's acceptable, but some optimizations may be necessary (see next section). 6) performance and optimization It's not difficult to construct cases where the prefetching is a huge improvement - 5-10x speedup for a query is common, depending on the hardware, dataset, etc. But there are also cases where it doesn't (and can't) help very much. For example fully-cached data, or index-only scans of all-visible tables. I've done basic benchmarking based on that (I'll share some results in the coming days), and in various cases I see a consistent regression in the 10-20% range. The queries are very short (~1ms) and there's a fair amount of noise, but it seems fairly consistent. I haven't figured out the root cause(s) yet, but I believe there's a couple contributing factors: (a) read_stream adds a bit of complexity/overhead, but these cases worked great with just the sync API, and can't benefit from that. (b) There's inefficiencies in how I integrated read_stream into the btree AM. For example every batch allocates the same buffer btbeginscan, which turned out to be an issue before [2] - and now we do that for every batch, not just once per scan - that's not great. (c) Possibly the prefetch distance issue from (4) might matter too. regards [1] https://www.postgresql.org/message-id/accd03eb-0379-416d-9936-41a4de3c47ef%40vondra.me [2] https://www.postgresql.org/message-id/510b887e-c0ce-4a0c-a17a-2c6abb8d9a5c@enterprisedb.com regards -- Tomas Vondra
Вложения
On Tue, Apr 22, 2025 at 6:46 AM Tomas Vondra <tomas@vondra.me> wrote: > here's an improved (rebased + updated) version of the patch series, with > some significant fixes and changes. The patch adds infrastructure and > modifies btree indexes to do prefetching - and AFAIK it passes all tests > (no results, correct results). Cool! > Compared to the last patch version [1] shared on list (in November), > there's a number of significant design changes - a lot of this is based > on a number of off-list discussions I had with Peter Geoghegan, which > was very helpful. Thanks for being so receptive to my feedback. I know that I wasn't particularly clear. I mostly only gave you my hand-wavy, caveat-laden ideas about how best to layer things. But you were willing to give them full and fair consideration. > 1) patch now relies on read_stream > So I squashed these two parts, and the patch now does read_stream (for > the table reads) from the beginning. Make sense. > Based on the discussions with Peter I decided to make this a bit more > ambitious, moving the whole batch management from the index AM to the > indexam.c level. So now there are two callbacks - amgetbatch and > amfreebatch, and it's up to indexam.c to manage the batches - decide how > many batches to allow, etc. The index AM is responsible merely for > loading the next batch, but does not decide when to load or free a > batch, how many to keep in memory, etc. > > There's a section in indexam.c with a more detailed description of the > design, I'm not going to explain all the design details here. To me, the really important point about this high-level design is that it provides a great deal of flexibility around reordering work, while still preserving the appearance of an index scan that performs work in the same old fixed order. All relevant kinds of work (whether table AM and index AM related work) are under the direct control of one single module. There's one central place for a mechanism that weighs both costs and benefits, keeping things in balance. (I realize that there's still some sense in which that isn't true, partly due to the read stream interface, but for now the important thing is that we're agreed on this high level direction.) > I think the indexam.c is a sensible layer for this. I was hoping doing > this at the "executor level" would mean no need for AM code changes, but > that turned out not possible - the AM clearly needs to know about the > batch boundaries, so that it can e.g. do killtuples, etc. That's why we > need the two callbacks (not just the "amgetbatch" one). At least this > way it's "hidden" by the indexam.c API, like index_getnext_slot(). Right. But (if I'm not mistaken) the index AM doesn't actually need to know *when* to do killtuples. It still needs to have some handling for this, since we're actually modifying index pages, and we need to have handling for certain special cases (e.g., posting list tuples) on the scan side. But it can be made to work in a way that isn't rigidly tied to the progress of the scan -- it's perfectly fine to do this work somewhat out of order, if that happens to make sense. It doesn't have to happen in perfect lockstep with the scan, right after the items from the relevant leaf page have all been returned. It should also eventually be possible to do things like perform killtuples in a different process (perhaps even thread?) to the one that originally read the corresponding leaf page items. That's the kind of long term goal to keep in mind, I feel. > (You could argue indexam.c is "executor" and maybe it is - I don't know > where exactly to draw the line. I don't think it matters, really. The > "hidden in indexam API" is the important bit.) The term that I've used is "index scan manager", since it subsumes some of the responsibilities related to scheduling work that has traditionally been under the control of index AMs. I'm not attached to that name, but we should agree upon some name for this new concept. It is a new layer, above the index AM but below the executor proper, and so it feels like it needs to be clearly distinguished from the two adjoining layers. > Or maybe we should > even rip out the amgettuple() entirely, and only support one of those > for each AM? That's what Peter suggested, but I'm not convinced we > should do that. Just to be clear, for other people reading along: I never said that we should fully remove amgettuple as an interface. What I said was that I think that we should remove btgettuple(), and any other amgettuple routine within index AMs that switch over to using the new interface. I'm not religious about removing amgettuple() from index AMs that also support the new batch interface. It's probably useful to keep around for now, for debugging purposes. My point was only this: I know of no good reason to keep around btgettuple in the first committed version of the patch. So if you're going to keep it around, you should surely have at least one explicit reason for doing so. I don't remember hearing such a reason? Even if there is such a reason, maybe there doesn't have to be. Maybe this reason can be eliminated by improving the batch design such that we no longer need btgettuple at all (not even for catalogs). Or maybe it won't be so easy -- maybe we'll have to keep around btgettuple after all. Either way, I'd like to know the details. > For now it was very useful to be able to flip between the APIs by > setting a GUC, and I left prefetching disabled in some places (e.g. when > accessing catalogs, ...) that are unlikely to benefit. But more > importantly, I'm not 100% we want to require the index AMs to support > prefetching for all cases - if we do, a single "can't prefetch" case > would mean we can't prefetch anything for that AM. I don't see why prefetching should be mandatory with this new interface. Surely it has to have adaptive "ramp-up" behavior already, even when we're pretty sure that prefetching is a good idea from the start? > In particular, I'm thinking about GiST / SP-GiST and indexes ordered by > distance, which don't return items in leaf pages but sort them through a > binary heap. Maybe we can do prefetch for that, but if we can't it would > be silly if it meant we can't do prefetch for any other SP-GiST queries. Again, I would be absolutely fine with continuing to support the amgettuple interface indefinitely. Again, my only concern is with index AMs that support both the old and new interfaces at the same time. > Anyway, the current patch only implements prefetch for btree. I expect > it won't be difficult to do this for other index AMs, considering how > similar the design usually is to btree. > > This is one of the next things on my TODO. I want to be able to validate > the design works for multiple AMs, not just btree. What's the most logical second index AM to support, after nbtree, then? Probably hash/hashgettuple? > I think this is a consequence of read_stream having an internal idea how > far ahead to prefetch, based on the number of requests it got so far, > measured in heap blocks. It has not idea about the context (how that > maps to index entries, batches we need to keep in memory, ...). I think that that just makes read_stream an awkward fit for index prefetching. You legitimately need to see all of the resources that are in flight. That context will really matter, at least at times. I'm much less sure what to do about it. Maybe using read_stream is still the right medium-term design. Further testing/perf validation is required to be able to say anything sensible about it. > But there are also cases where it doesn't (and can't) help very much. > For example fully-cached data, or index-only scans of all-visible > tables. I've done basic benchmarking based on that (I'll share some > results in the coming days), and in various cases I see a consistent > regression in the 10-20% range. The queries are very short (~1ms) and > there's a fair amount of noise, but it seems fairly consistent. I'd like to know more about these cases. I'll wait for your benchmark results, which presumably have examples of this. -- Peter Geoghegan
On 4/22/25 18:26, Peter Geoghegan wrote: > On Tue, Apr 22, 2025 at 6:46 AM Tomas Vondra <tomas@vondra.me> wrote: >> here's an improved (rebased + updated) version of the patch series, with >> some significant fixes and changes. The patch adds infrastructure and >> modifies btree indexes to do prefetching - and AFAIK it passes all tests >> (no results, correct results). > > Cool! > >> Compared to the last patch version [1] shared on list (in November), >> there's a number of significant design changes - a lot of this is based >> on a number of off-list discussions I had with Peter Geoghegan, which >> was very helpful. > > Thanks for being so receptive to my feedback. I know that I wasn't > particularly clear. I mostly only gave you my hand-wavy, caveat-laden > ideas about how best to layer things. But you were willing to give > them full and fair consideration. > >> 1) patch now relies on read_stream > >> So I squashed these two parts, and the patch now does read_stream (for >> the table reads) from the beginning. > > Make sense. > >> Based on the discussions with Peter I decided to make this a bit more >> ambitious, moving the whole batch management from the index AM to the >> indexam.c level. So now there are two callbacks - amgetbatch and >> amfreebatch, and it's up to indexam.c to manage the batches - decide how >> many batches to allow, etc. The index AM is responsible merely for >> loading the next batch, but does not decide when to load or free a >> batch, how many to keep in memory, etc. >> >> There's a section in indexam.c with a more detailed description of the >> design, I'm not going to explain all the design details here. > > To me, the really important point about this high-level design is that > it provides a great deal of flexibility around reordering work, while > still preserving the appearance of an index scan that performs work in > the same old fixed order. All relevant kinds of work (whether table AM > and index AM related work) are under the direct control of one single > module. There's one central place for a mechanism that weighs both > costs and benefits, keeping things in balance. > > (I realize that there's still some sense in which that isn't true, > partly due to the read stream interface, but for now the important > thing is that we're agreed on this high level direction.) > Yeah, that makes sense, although I've been thinking about this a bit differently. I haven't been trying to establish a new "component" to manage prefetching. For me the question was what's the right layer, so that unnecessary details don't leak into AM and/or executor. The AM could issue fadvise prefetches, or perhaps even feed blocks into a read_stream, but it doesn't seem like the right place to ever do more decisions. OTOH we don't want every place in the executor to reimplement the prefetching, and indexam.c seems like a good place in between. It requires exchanging some additional details with the AM, provided by the new callbacks. It seems the indexam.c achieves both your and mine goals, more or less. >> I think the indexam.c is a sensible layer for this. I was hoping doing >> this at the "executor level" would mean no need for AM code changes, but >> that turned out not possible - the AM clearly needs to know about the >> batch boundaries, so that it can e.g. do killtuples, etc. That's why we >> need the two callbacks (not just the "amgetbatch" one). At least this >> way it's "hidden" by the indexam.c API, like index_getnext_slot(). > > Right. But (if I'm not mistaken) the index AM doesn't actually need to > know *when* to do killtuples. It still needs to have some handling for > this, since we're actually modifying index pages, and we need to have > handling for certain special cases (e.g., posting list tuples) on the > scan side. But it can be made to work in a way that isn't rigidly tied > to the progress of the scan -- it's perfectly fine to do this work > somewhat out of order, if that happens to make sense. It doesn't have > to happen in perfect lockstep with the scan, right after the items > from the relevant leaf page have all been returned. > > It should also eventually be possible to do things like perform > killtuples in a different process (perhaps even thread?) to the one > that originally read the corresponding leaf page items. That's the > kind of long term goal to keep in mind, I feel. > Right. The amfreebatch() does not mean the batch needs to be freed immediately, it's just handed over back to the AM, and it's up to the AM to do the necessary cleanup at some point. It might queue it for later, or perhaps even do that in a separate thread ... >> (You could argue indexam.c is "executor" and maybe it is - I don't know >> where exactly to draw the line. I don't think it matters, really. The >> "hidden in indexam API" is the important bit.) > > The term that I've used is "index scan manager", since it subsumes > some of the responsibilities related to scheduling work that has > traditionally been under the control of index AMs. I'm not attached to > that name, but we should agree upon some name for this new concept. It > is a new layer, above the index AM but below the executor proper, and > so it feels like it needs to be clearly distinguished from the two > adjoining layers. > Yes. I wonder if we should introduce a separate abstraction for this, as a subset of indexam.c. >> Or maybe we should >> even rip out the amgettuple() entirely, and only support one of those >> for each AM? That's what Peter suggested, but I'm not convinced we >> should do that. > > Just to be clear, for other people reading along: I never said that we > should fully remove amgettuple as an interface. What I said was that I > think that we should remove btgettuple(), and any other amgettuple > routine within index AMs that switch over to using the new interface. > > I'm not religious about removing amgettuple() from index AMs that also > support the new batch interface. It's probably useful to keep around > for now, for debugging purposes. My point was only this: I know of no > good reason to keep around btgettuple in the first committed version > of the patch. So if you're going to keep it around, you should surely > have at least one explicit reason for doing so. I don't remember > hearing such a reason? > > Even if there is such a reason, maybe there doesn't have to be. Maybe > this reason can be eliminated by improving the batch design such that > we no longer need btgettuple at all (not even for catalogs). Or maybe > it won't be so easy -- maybe we'll have to keep around btgettuple > after all. Either way, I'd like to know the details. > My argument was (a) ability to disable prefetching, and fall back to the old code if needed, and (b) handling use cases where prefetching does not work / is not implemented, even if only temporarily (e.g. ordered scan in SP-GiST). Maybe (a) is unnecessarily defensive, and (b) may not be needed. Not sure. >> For now it was very useful to be able to flip between the APIs by >> setting a GUC, and I left prefetching disabled in some places (e.g. when >> accessing catalogs, ...) that are unlikely to benefit. But more >> importantly, I'm not 100% we want to require the index AMs to support >> prefetching for all cases - if we do, a single "can't prefetch" case >> would mean we can't prefetch anything for that AM. > > I don't see why prefetching should be mandatory with this new > interface. Surely it has to have adaptive "ramp-up" behavior already, > even when we're pretty sure that prefetching is a good idea from the > start? > Possibly, I may be too defensive. And perhaps in cases where we know the prefetching can't help we could disable that for the read_stream. >> In particular, I'm thinking about GiST / SP-GiST and indexes ordered by >> distance, which don't return items in leaf pages but sort them through a >> binary heap. Maybe we can do prefetch for that, but if we can't it would >> be silly if it meant we can't do prefetch for any other SP-GiST queries. > > Again, I would be absolutely fine with continuing to support the > amgettuple interface indefinitely. Again, my only concern is with > index AMs that support both the old and new interfaces at the same > time. > Understood. >> Anyway, the current patch only implements prefetch for btree. I expect >> it won't be difficult to do this for other index AMs, considering how >> similar the design usually is to btree. >> >> This is one of the next things on my TODO. I want to be able to validate >> the design works for multiple AMs, not just btree. > > What's the most logical second index AM to support, after nbtree, > then? Probably hash/hashgettuple? > I think hash should be fairly easy to support. But I was really thinking about doing SP-GiST, exactly because it's very different in some aspects, and I wanted to validate the design on that (for hash I think it's almost certain it's OK). >> I think this is a consequence of read_stream having an internal idea how >> far ahead to prefetch, based on the number of requests it got so far, >> measured in heap blocks. It has not idea about the context (how that >> maps to index entries, batches we need to keep in memory, ...). > > I think that that just makes read_stream an awkward fit for index > prefetching. You legitimately need to see all of the resources that > are in flight. That context will really matter, at least at times. > > I'm much less sure what to do about it. Maybe using read_stream is > still the right medium-term design. Further testing/perf validation is > required to be able to say anything sensible about it. > Agreed. That's why I've suggested it might help if the read_stream had ability to pause/resume in some way, without having to stall for a while (which the read_stream_reset workaround does). Based on what the read_next callback decides. >> But there are also cases where it doesn't (and can't) help very much. >> For example fully-cached data, or index-only scans of all-visible >> tables. I've done basic benchmarking based on that (I'll share some >> results in the coming days), and in various cases I see a consistent >> regression in the 10-20% range. The queries are very short (~1ms) and >> there's a fair amount of noise, but it seems fairly consistent. > > I'd like to know more about these cases. I'll wait for your benchmark > results, which presumably have examples of this. > I expect to have better data sometime next week. I think the cases affected by this the most are index-only scans on all-visible tables that fit into shared buffers, with correlated/sequential pattern. Or even regular index scans with all data in shred buffers. It also seems quite hardware / CPU dependent - I see much worse impact on an older Xeon than on a new Ryzen. regards -- Tomas Vondra
On Tue, Apr 22, 2025 at 2:34 PM Tomas Vondra <tomas@vondra.me> wrote: > Yeah, that makes sense, although I've been thinking about this a bit > differently. I haven't been trying to establish a new "component" to > manage prefetching. For me the question was what's the right layer, so > that unnecessary details don't leak into AM and/or executor. FWIW that basically seems equivalent to what I said. If there's any difference at all between what each of us has said, then it's only a difference in emphasis. The "index scan manager" doesn't just manage prefetching -- it manages the whole index scan, including details that were previously only supposed to be known inside index AMs. It can do so while weighing all relevant factors -- regardless of whether they're related to the index structure or the heap structure. It would be possible to (say) do everything at the index AM level instead. But then we'd be teaching index AMs about heap/table AM related costs, which would be a bad design, primarily because it would have to duplicate the same logic in every supported index AM. Better to have one dedicated layer that has an abstract-ish understanding of both index AM scan costs, and table AM scan costs. It needs to be abstract, but not too abstract -- costs like "read one index leaf page" generalize well across all index AMs. And costs like "read one table AM page" should also generalize quite well, at least across block-based table AMs. You primarily care about "doing the layering right", while I primarily care about "making sure that one layer can see all relevant costs". ISTM that these are two sides of the same coin. > It requires exchanging some additional details with the AM, provided by > the new callbacks. I think of it as primarily externalizing decisions about index page accesses. The index AM reads the next leaf page to be read because the index scan manager tells it to. The index AM performs killitems exactly as instructed by the index scan manager. And the index AM doesn't really own as much context about the progress of the scan -- that all lives inside the scan manager instead. The scan manager has a fairly fuzzy idea about how the index AM organizes data, but that shouldn't matter. > It seems the indexam.c achieves both your and mine goals, more or less. Agreed. > Yes. I wonder if we should introduce a separate abstraction for this, as > a subset of indexam.c. I like that idea. > My argument was (a) ability to disable prefetching, and fall back to the > old code if needed, and (b) handling use cases where prefetching does > not work / is not implemented, even if only temporarily (e.g. ordered > scan in SP-GiST). Maybe (a) is unnecessarily defensive, and (b) may not > be needed. Not sure. We don't need to make a decision on this for some time, but I still lean towards forcing index AMs to make a choice between this new interface, and the old amgettuple interface. > > I don't see why prefetching should be mandatory with this new > > interface. Surely it has to have adaptive "ramp-up" behavior already, > > even when we're pretty sure that prefetching is a good idea from the > > start? > > > > Possibly, I may be too defensive. And perhaps in cases where we know the > prefetching can't help we could disable that for the read_stream. Shouldn't the index scan manager be figuring all this out for us, automatically? Maybe that works in a very trivial way, at first. The important point is that the design be able to support these requirements in some later iteration of the feature -- though it's unlikely to happen in the first Postgres version that the scan manager thing appears in. > I think hash should be fairly easy to support. But I was really thinking > about doing SP-GiST, exactly because it's very different in some > aspects, and I wanted to validate the design on that (for hash I think > it's almost certain it's OK). WFM. There are still bugs in SP-GiST (and GiST) index-only scans: https://www.postgresql.org/message-id/CAH2-Wz%3DPqOziyRSrnN5jAtfXWXY7-BJcHz9S355LH8Dt%3D5qxWQ@mail.gmail.com It would be nice if the new index scan manager interface could fix that bug, at least in the case of SP-GiST. By generalizing the approach that nbtree takes, where we hang onto a leaf buffer pin. Admittedly this would necessitate changes to SP-GiST VACUUM, which doesn't cleanup lock any pages, but really has to in order to fix the underlying bug. There are draft patches that try to fix the bug, which might be a useful starting point. > I think the cases affected by this the most are index-only scans on > all-visible tables that fit into shared buffers, with > correlated/sequential pattern. Or even regular index scans with all data > in shred buffers. My hope is that the index scan manager can be taught to back off when this is happening, to avoid the regressions. Or that it can avoid them by only gradually ramping up the prefetching. Does that sound plausible to you? -- Peter Geoghegan
Hi, Here's a rebased version of the patch, addressing a couple bugs with scrollable cursors that Peter reported to me off-list. The patch did not handle that quite right, resulting either in incorrect results (when the position happened to be off by one), or crashes (when it got out of sync with the read stream). But then there are some issues with array keys and mark/restore, triggered by Peter's "dynamic SAOP advancement" tests in extra tests (some of the tests use data files too large to post on hackers, it's available in the github branch). The patch used to handle mark/restore entirely in indexam.c, and for simple scans that works. But with array keys the btree code needs to update the moreLeft/moreRight/needPrimScan flags, so that after restoring it knows where to continue. There's two "fix" patches trying to make this work - it does not crash, and almost all the "incorrect" query results are actually stats about buffer hits etc. And that is expected to change with prefetching, not a bug. But then there are a bunch of explains where the number of index scans changed, e.g. like - Index Searches: 5 + Index Searches: 4 And that is almost certainly a bug. I haven't figured this out yet, and I feel a bit lost again :-( It made me think again whether it makes sense to make this fundamental redesign of the index AM interface a prerequisite for prefetching. I don't dispute the advantages of this new design, with indexam.c responsible for more stuff (e.g. when a batch gets freed). It seems more flexible and might make some stuff easier, and if we were designing it now, we'd do it that way ... Even if I eventually to fix this issue, will I ever be sufficiently confident about correctness of the new code, enough to commit that? Perhaps I'm too skeptical, but I'm not really sure about that anymore. After thinking about this for a while, I decided to revisit the approach used in the experimental patch I spoke about at pgconf.dev unconference in 2023, and see if maybe it could be made to work. That patch was pretty dumb - it simply initiated prefetches from the AM, by calling PrefetchBuffer(). And the arguments against that doing this from the AM seems like a layering violation, that every AM would need to do a copy of this, because each AM has a different representation of the internal scan state. But after looking at it with fresh eyes, this seems fixable. It might have been "more true" with the fadvise-based prefetching, but with the ReadStream the amount of new AM code is *much* smaller. It doesn't need to track the distance, or anything like that - that's handled by the ReadStream. It just needs to respond to read_next callback. It also doesn't feel like a layering violation, for the same reason. I gave this a try last week, and I was surprised how easy it was to make this work, and how small and simple the patches are - see the attached simple-prefetch.tgz archive: infrastructure - 22kB btree - 10kB hash - 7kB gist - 10kB spgist - 16kB That's a grand total of ~64kB (there might be some more improvements necessary, esp. in the gist/spgist part). Now compare that with the more complex patch, where we have infrastructure - 100kB nbtree - 100kB And that's just one index type. The other index types would probably need a comparable amount of new code eventually ... Sure, it can probably be made somewhat smaller (e.g. the nbtree code copies a lot of stuff to support both the old and new approach, and that might be reduced if we ditch the old one), and some of the diff are comments. But even considering all that the size/complexity difference will remain significant. The one real limitation of the simpler approach is that prefetching is limited to a single leaf page - we can't prefetch from the next one, until the scan advances to it. But based on experiments comparing this simpler and the "complex" approach, I don't think that really matters that much. I haven't seen any difference for regular queries. The one case where I think it might matter is queries with array keys, where each array key matches a single tuple on a different leaf page. The complex patch might prefetch tuples for later array values, while the simpler patch won't be able to do that. If an array key matches multiple tuples, the simple patch can prefetch those just fine, of course. I don't know which case is more likely. One argument for moving more stuff (including prefetching) to indexam.c was it seems desirable to have one "component" aware of all the relevant information, so that it can adjust prefetching in some way. I believe that's still possible even with the simpler patch - nothing prevents adding a "struct" to the scan descriptor, and using it from the read_next callback or something like that. regards [1] https://github.com/tvondra/postgres/tree/index-prefetch-2025 -- Tomas Vondra
Вложения
Hi, I got pinged about issues (compiler warnings, and some test failures) in the simple patch version shared in May. So here's a rebased and cleaned up version addressing that, and a couple additional issues I ran into. FWIW if you run check-world on this, you may get failures in io_workers TAP test. That's a pre-existing issue [1], the patch just makes it easier to hit as it (probably) added AIO in some part of the test. Otherwise it should pass all tests (and it does for me on CI). The main changes in the patches and remaining questions: (1) fixed compiler warnings These were mostly due to contrib/test AMs with not-updated ambeginscan() implementations. (2) GiST fixes I fixed a bug in how the prefetching handled distances, leading to "tuples returned out of order" errors. It did not copy the Datums when batching the reordered values, not realizing it may be FLOAT8, and on 32-bit systems the Datum is just a pointer. Fixed by datumCopy(). I'm not aware of any actual bug in the GiST code, but I'm sure the memory management there is sketchy and likely leaks memory. Needs some more thought and testing. The SP-GiST may have similar issues. (3) ambeginscan(heap, index, ....) I originally undid the changes to ambeginscan(), i.e. the callback was restored back to what master has. To to create the ReadStream the AM needs the heap, but it could build Relation using index->rd_index->indrelid. That worked, but I did not like it for two reasons. The AM then needs to manage the relation (close it etc.). And there was no way to know when ambeginscan() gets called for a bitmap scan, in which case the read_stream is unnecessary/useless. So it got created, but never used. Not very expensive, but messy. So I ended up restoring the ambeginscan() change, i.e. it now gets the heap relation. I ended up passing it as the first argument, mostly for consistency with index_beginscan(), which also does (heap, index, ...). I renamed the index argument from 'rel' to 'index' in a couple of the indexes, it was confusing to have 'heap' and 'rel'. (4) lastBlock I added the optimization to not queue duplicate block numbers, i.e. if the index returns a sequence of TIDs from the same block, we skip queueing that and simply use the buffer we already have. This is quite a bit more efficient. This is something the read_next callback in each AM needs to do, but it's pretty simple. (5) xs_visible The current patch expects the AM to set the xs_visible even if it's not using ReadStream (which is required to do that in the callback). If the AM does not do that, index-only scans are broken. But it occurs to me we could handle this in index_getnext_tid(). If the AM does not use a ReadStream (xs_rs==NULL), we can check the VM and store the value in xs_visible. It'd need moving the vmBuffer to the scan descriptor (it's now in IndexOnlyScanState), but that seems OK. And the AMs now add the buffer anyway. (6) SGML I added a couple paragraphs to indexam.sgml, documenting the new heap argument, and also requirements from the read_next callback (e.g. the lastBlock and xs_visible setting). (7) remaining annoyances There's a couple things that still annoy me - the "read_next" callbacks are very similar, and duplicate a fair amount of code to stuff they're required to. There's a little bit AM-specific code to get the next item from the ScanOpaque structs, and then code to skip duplicate block numbers and check the visibility map (if needed). I believe both of these things could be refactored into some shared place. The AMs would just call a function from indexam.c (which seems OK from layering POV, and there's plenty of such calls). I believe the same place could also act as the "scan manager" component managing the prefetching (and related stuff?), as suggested by Peter Geoghegan some time ago. I ran out of time to work on this today, but I'll look into this soon. FWIW I'm still planning to work on the "complex" patch version and see if it can be moved forward. I've been having some very helpful chats about this with Peter Geoghegan, and I'm still open to the possibility of making it work. This simpler version is partially a hedge to have at least something in case the complex patch does not make it. regards [1] https://www.postgresql.org/message-id/t5aqjhkj6xdkido535pds7fk5z4finoxra4zypefjqnlieevbg%40357aaf6u525j -- Tomas Vondra
Вложения
On Thu, May 1, 2025 at 7:02 PM Tomas Vondra <tomas@vondra.me> wrote: > There's two "fix" patches trying to make this work - it does not crash, > and almost all the "incorrect" query results are actually stats about > buffer hits etc. And that is expected to change with prefetching, not a > bug. But then there are a bunch of explains where the number of index > scans changed, e.g. like > > - Index Searches: 5 > + Index Searches: 4 > > And that is almost certainly a bug. > > I haven't figured this out yet, and I feel a bit lost again :-( For the benefit of other people reading this thread: I sent Tomas a revised version of this "complex" patch this week, fixing all these bugs. It only took me a few hours, and I regret not doing that work sooner. I also cleaned up nbtree aspects of the "complex" patch considerably. The nbtree footprint was massively reduced: 17 files changed, 422 insertions(+), 685 deletions(-) So there's a net negative nbtree code footprint. We're effectively just moving things out of nbtree that are already completely index-AM-generic. I think that the amount of code that can be removed from nbtree (and other AMs that currently use amgettuple) will be even higher if we go this way. > The one real limitation of the simpler approach is that prefetching is > limited to a single leaf page - we can't prefetch from the next one, > until the scan advances to it. But based on experiments comparing this > simpler and the "complex" approach, I don't think that really matters > that much. I haven't seen any difference for regular queries. Did you model/benchmark it? > The one case where I think it might matter is queries with array keys, > where each array key matches a single tuple on a different leaf page. > The complex patch might prefetch tuples for later array values, while > the simpler patch won't be able to do that. If an array key matches > multiple tuples, the simple patch can prefetch those just fine, of > course. I don't know which case is more likely. We discussed this in Montreal, but I'd like to respond to this point again on list: I don't think that array keys are in any way relevant to the design of this patch. Nothing I've said about this project has anything to do with array keys, except when I was concerned about specific bugs in the patch. (Bugs that I've now fixed in a way that is wholly confined to nbtree.) The overarching goal of my work on nbtree array scans was to make them work just like other scans to the maximum extent possible. Array scans "where each array key matches a single tuple on a different leaf page" are virtually identical to any other scan that'll return only one or two tuples from each neighboring page. You could see a similar pattern with literally any kind of key. Again, what I'm concerned about is coming up with a design that gives scans maximum freedom to reorder work (not necessarily in the first committed version), so that we can keep the read stream busy by giving it sufficiently many heap pages to read: a truly adaptive design, that weighs all relevant costs. Sometimes that'll necessitate eagerly reading leaf pages. There is nothing fundamentally complicated about that idea. Nothing in index AMs cares about how or when heap accesses take place. Again, it just *makes sense* to centralize the code that controls the progress of ordered/amgettuple scans. Every affected index AM is already doing virtually the same thing as each other. They're all following the rules around index locking/pinning for amgettuple [1]. Individual index AMs are *already* required to read leaf pages a certain way, in a certain order *relative to the heap accesses*. All for the benefit of scan correctness (to avoid breaking things in a way that relates to heapam implementation details). Why wouldn't we want to relieve all AMs of that responsibility? Leaving it up to index AMs has resulted in subtle bugs [2][3], and AFAICT has no redeeming quality. If affected index AMs were *forced* to do *exactly* the same thing as each other (not just *oblidged* to do *almost* the same thing), it would make life easier for everybody. [1] https://www.postgresql.org/docs/current/index-locking.html [2] https://commitfest.postgresql.org/patch/5721/ [3] https://commitfest.postgresql.org/patch/5542/ -- Peter Geoghegan
On 7/13/25 01:50, Peter Geoghegan wrote: > On Thu, May 1, 2025 at 7:02 PM Tomas Vondra <tomas@vondra.me> wrote: >> There's two "fix" patches trying to make this work - it does not crash, >> and almost all the "incorrect" query results are actually stats about >> buffer hits etc. And that is expected to change with prefetching, not a >> bug. But then there are a bunch of explains where the number of index >> scans changed, e.g. like >> >> - Index Searches: 5 >> + Index Searches: 4 >> >> And that is almost certainly a bug. >> >> I haven't figured this out yet, and I feel a bit lost again :-( > > For the benefit of other people reading this thread: I sent Tomas a > revised version of this "complex" patch this week, fixing all these > bugs. It only took me a few hours, and I regret not doing that work > sooner. > > I also cleaned up nbtree aspects of the "complex" patch considerably. > The nbtree footprint was massively reduced: > > 17 files changed, 422 insertions(+), 685 deletions(-) > > So there's a net negative nbtree code footprint. We're effectively > just moving things out of nbtree that are already completely > index-AM-generic. I think that the amount of code that can be removed > from nbtree (and other AMs that currently use amgettuple) will be even > higher if we go this way. > Thank you! I'll take a look next week, but these numbers suggest you simplified it a lot.. >> The one real limitation of the simpler approach is that prefetching is >> limited to a single leaf page - we can't prefetch from the next one, >> until the scan advances to it. But based on experiments comparing this >> simpler and the "complex" approach, I don't think that really matters >> that much. I haven't seen any difference for regular queries. > > Did you model/benchmark it? > Yes. I did benchmark the simple and complex versions I had at the time. But you know how it's with benchmarking - I'm sure it's possible to pick queries where it'd make a (significant) difference. For example if you make the index tuples "fat" that would make the prefetching less efficient. Another thing is hardware. I've been testing on local NVMe drives, and those don't seem to need very long queues (it's diminishing returns). Maybe the results would be different on systems with more I/O latency (e.g. because the storage is not local). >> The one case where I think it might matter is queries with array keys, >> where each array key matches a single tuple on a different leaf page. >> The complex patch might prefetch tuples for later array values, while >> the simpler patch won't be able to do that. If an array key matches >> multiple tuples, the simple patch can prefetch those just fine, of >> course. I don't know which case is more likely. > > We discussed this in Montreal, but I'd like to respond to this point > again on list: > > I don't think that array keys are in any way relevant to the design of > this patch. Nothing I've said about this project has anything to do > with array keys, except when I was concerned about specific bugs in > the patch. (Bugs that I've now fixed in a way that is wholly confined > to nbtree.) > > The overarching goal of my work on nbtree array scans was to make them > work just like other scans to the maximum extent possible. Array scans > "where each array key matches a single tuple on a different leaf page" > are virtually identical to any other scan that'll return only one or > two tuples from each neighboring page. You could see a similar pattern > with literally any kind of key. > > Again, what I'm concerned about is coming up with a design that gives > scans maximum freedom to reorder work (not necessarily in the first > committed version), so that we can keep the read stream busy by giving > it sufficiently many heap pages to read: a truly adaptive design, that > weighs all relevant costs. Sometimes that'll necessitate eagerly > reading leaf pages. There is nothing fundamentally complicated about > that idea. Nothing in index AMs cares about how or when heap accesses > take place. > > Again, it just *makes sense* to centralize the code that controls the > progress of ordered/amgettuple scans. Every affected index AM is > already doing virtually the same thing as each other. They're all > following the rules around index locking/pinning for amgettuple [1]. > Individual index AMs are *already* required to read leaf pages a > certain way, in a certain order *relative to the heap accesses*. All > for the benefit of scan correctness (to avoid breaking things in a way > that relates to heapam implementation details). > > Why wouldn't we want to relieve all AMs of that responsibility? > Leaving it up to index AMs has resulted in subtle bugs [2][3], and > AFAICT has no redeeming quality. If affected index AMs were *forced* > to do *exactly* the same thing as each other (not just *oblidged* to > do *almost* the same thing), it would make life easier for everybody. > > [1] https://www.postgresql.org/docs/current/index-locking.html > [2] https://commitfest.postgresql.org/patch/5721/ > [3] https://commitfest.postgresql.org/patch/5542/ Thanks. I don't remember the array key details, I'll need to swap the context back in. But I think the thing I've been concerned about the most is the coordination of advancing to the next leaf page vs. the next array key (and then perhaps having to go back when the scan direction changes). regards -- Tomas Vondra
On Sun, Jul 13, 2025 at 5:57 PM Tomas Vondra <tomas@vondra.me> wrote: > Thank you! I'll take a look next week, but these numbers suggest you > simplified it a lot.. Right. I'm still not done removing code from nbtree here. I still haven't done things like generalize _bt_killitems across all index AMs. That can largely (though not entirely) work the same way across all index AMs. Including the stuff about checking LSN/not dropping pins to avoid blocking VACUUM. It's already totally index-AM-agnostic, even though the avoid-blocking-vacuum thing happens to be nbtree-only right now. > Another thing is hardware. I've been testing on local NVMe drives, and > those don't seem to need very long queues (it's diminishing returns). > Maybe the results would be different on systems with more I/O latency > (e.g. because the storage is not local). That seems likely. Cloud storage with 1ms latency is going to have very different performance characteristics. The benefit of reading multiple leaf pages will also only be seen with certain workloads. Other thing is that leaf pages are typically much denser and more likely to be cached than heap pages. And, the potential to combine heap I/Os for TIDs that appear on adjacent index leaf pages seems like an interesting avenue. > I don't remember the array key details, I'll need to swap the context > back in. But I think the thing I've been concerned about the most is the > coordination of advancing to the next leaf page vs. the next array key > (and then perhaps having to go back when the scan direction changes). But we don't require anything like that. That's just not how it works. The scan can change direction, and the array keys will automatically be maintained correctly; _bt_advance_array_keys will be called as needed, taking care of everything. This all happens in a way that code in nbtree.c and nbtsearch.c knows nothing about (obviously that means that your patch won't need to, either). We do need to be careful about the scan direction changing when the so->needPrimscan flag is set, but that won't affect your patch/indexam.c, either. It also isn't very complicated; we only have to be sure to *unset* the flag when we detect a *change* in direction at the point where we're stepping off a page/pos. We don't need to modify the array keys themselves at this point -- the next call to _bt_advance_array_keys will just take care of that for us automatically (we lean on _bt_advance_array_keys like this in a number of places). The only thing in my revised version of your "complex" patch set does in indexam.c that is in any way related to nbtree arrays is the call to amrestrpos. But you'd never be able to tell -- since the amrestrpos call is nothing new. It just so happens that the only reason we still need the amrestrpos call/the whole entire concept of amrestrpos (having completely moved mark/restore out of nbtree and into indexam.c) is so that the index AM (nbtree) gets a signal that we (indexam.c) are going to restore *some* mark. Because nbtree *will* need to reset its array keys (if any) at that point. But that's it. We don't need to tell the index AM any specific details about the mark, and indexam.c is blissfully unaware of why it is that an index AM might need this. So it's a total non-issue, from a layering cleanliness point of view. There is no mutable state involved at *any* layer. (FWIW, even when we restore a mark like this, nbtree is still mostly leaning on _bt_advance_array_keys to advance the array keys properly later on. If you're interested in why we need the remaining hard reset of the arrays within amrestrpos/btrestrpos, let me know and I'll explain.) -- Peter Geoghegan
On Sat, Jul 12, 2025 at 7:50 PM Peter Geoghegan <pg@bowt.ie> wrote: > Why wouldn't we want to relieve all AMs of that responsibility? > Leaving it up to index AMs has resulted in subtle bugs [2][3], and > AFAICT has no redeeming quality. If affected index AMs were *forced* > to do *exactly* the same thing as each other (not just *oblidged* to > do *almost* the same thing), it would make life easier for everybody. > > [1] https://www.postgresql.org/docs/current/index-locking.html > [2] https://commitfest.postgresql.org/patch/5721/ > [3] https://commitfest.postgresql.org/patch/5542/ The kill_prior_tuple code that GiST uses to set LP_DEAD bits is also buggy, as is the equivalent code used by hash indexes: https://www.postgresql.org/message-id/CAH2-Wz%3D3eeujcHi3P_r%2BL8n-vDjdue9yGa%2Bytb95zh--S9kWfA%40mail.gmail.com This seems like another case where a non-nbtree index AM copied something from nbtree but didn't quite get the details right. Most likely because the underlying principles weren't really understood (even though they are in fact totally independent of index AM/amgettuple implementation details). BTW, neither gistkillitems() nor _hash_kill_items() have any test coverage. -- Peter Geoghegan
On 7/13/25 23:56, Tomas Vondra wrote: > > ... > >>> The one real limitation of the simpler approach is that prefetching is >>> limited to a single leaf page - we can't prefetch from the next one, >>> until the scan advances to it. But based on experiments comparing this >>> simpler and the "complex" approach, I don't think that really matters >>> that much. I haven't seen any difference for regular queries. >> >> Did you model/benchmark it? >> > > Yes. I did benchmark the simple and complex versions I had at the time. > But you know how it's with benchmarking - I'm sure it's possible to pick > queries where it'd make a (significant) difference. > > For example if you make the index tuples "fat" that would make the > prefetching less efficient. > > Another thing is hardware. I've been testing on local NVMe drives, and > those don't seem to need very long queues (it's diminishing returns). > Maybe the results would be different on systems with more I/O latency > (e.g. because the storage is not local). > I decided to do some fresh benchmarks, to confirm my claims about the simple vs. complex patches is still true even for the recent versions. And there's a lot of strange stuff / stuff I don't quite understand. The results are in git (still running, so only some data sets): https://github.com/tvondra/indexscan-prefetch-tests/ there's a run.sh script, it expects three builds - master, prefetch-simple and prefetch-complex (for the two patches). And then it does queries with index scans (and bitmap scans, for comparison), forcing different io_methods, eic, ... Tests are running on the same data directory, in random order. Consider for example this (attached): https://github.com/tvondra/indexscan-prefetch-tests/blob/master/d16-rows-cold-32GB-16-scaled.pdf There's one column for each io_method ("worker" has two different counts), different data sets in rows. There's not much difference between io_methods, so I'll focus on "sync" (it's the simplest one). For "uniform" data set, both prefetch patches do much better than master (for low selectivities it's clearer in the log-scale chart). The "complex" prefetch patch appears to have a bit of an edge for >1% selectivities. I find this a bit surprising, the leaf pages have ~360 index items, so I wouldn't expect such impact due to not being able to prefetch beyond the end of the current leaf page. But could be on storage with higher latencies (this is the cloud SSD on azure). But the thing I don't really understand it the "cyclic" dataset (for example). And the "simple" patch performs really badly here. This data set is designed to not work for prefetching, it's pretty much an adversary case. There's ~100 TIDs from 100 pages for each key value, and once you read the 100 pages you'll hit them many times for following values. Prefetching is pointless, and skipping duplicate blocks can't help, because the blocks are not effective. But how come the "complex" patch does so much better? It can't really benefit from prefetching TID from the next leaf - not this much. Yet it does a bit better than master. I'm looking at this since yesterday, and it makes no sense to me. Per "perf trace" it actually does 2x many fadvise calls compared to the "simple" patch (which is strange on it's own, I think), yet it's apparently so much faster? regards -- Tomas Vondra
Вложения
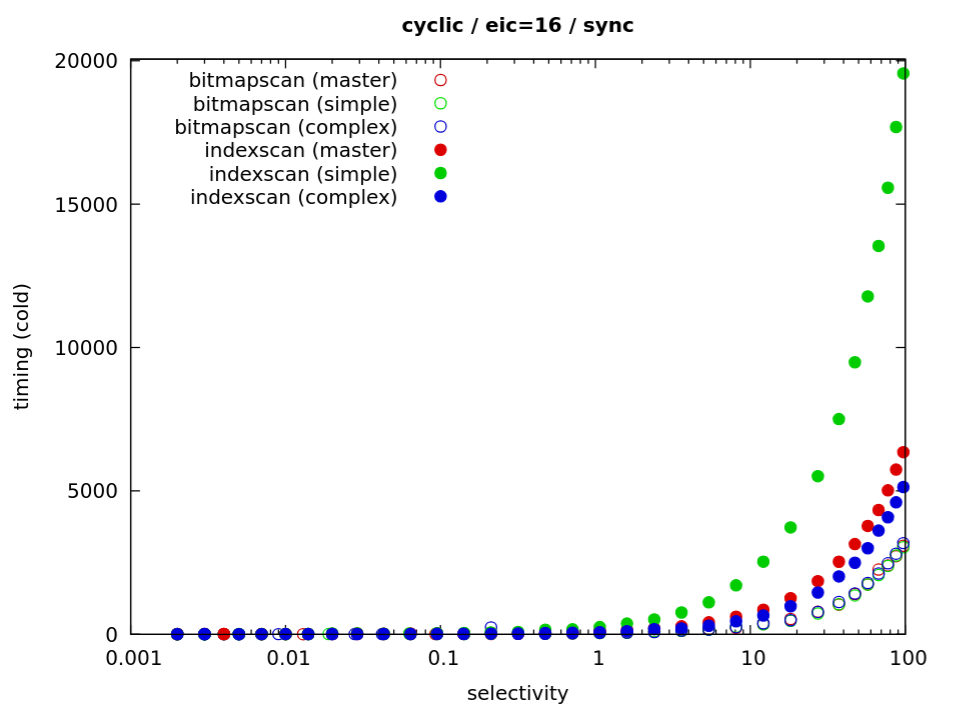{kind=link}
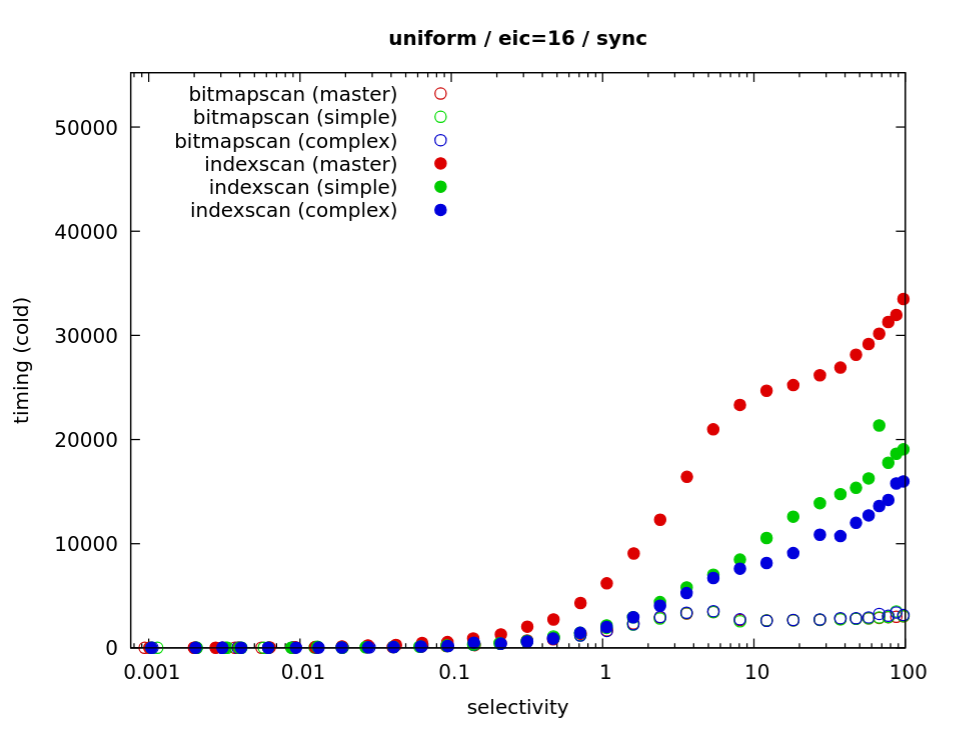{kind=link}
On Wed, Jul 16, 2025 at 4:40 AM Tomas Vondra <tomas@vondra.me> wrote: > But the thing I don't really understand it the "cyclic" dataset (for > example). And the "simple" patch performs really badly here. This data > set is designed to not work for prefetching, it's pretty much an > adversary case. There's ~100 TIDs from 100 pages for each key value, and > once you read the 100 pages you'll hit them many times for following > values. Prefetching is pointless, and skipping duplicate blocks can't > help, because the blocks are not effective. > > But how come the "complex" patch does so much better? It can't really > benefit from prefetching TID from the next leaf - not this much. Yet it > does a bit better than master. I'm looking at this since yesterday, and > it makes no sense to me. Per "perf trace" it actually does 2x many > fadvise calls compared to the "simple" patch (which is strange on it's > own, I think), yet it's apparently so much faster? The "simple" patch has _bt_readpage reset the read stream. That doesn't make any sense to me. Though it does explain why the "complex" patch does so many more fadvise calls. Another issue with the "simple" patch: it adds 2 bool fields to "BTScanPosItem". That increases its size considerably. We're very sensitive to the size of this struct (I think that you know about this already). Bloating it like this will blow up our memory usage, since right now we allocate MaxTIDsPerBTreePage/1358 such structs for so->currPos (and so->markPos). Wasting all that memory on alignment padding is probably going to have consequences beyond memory bloat. -- Peter Geoghegan
On Wed, Jul 16, 2025 at 9:36 AM Peter Geoghegan <pg@bowt.ie> wrote: > Another issue with the "simple" patch: it adds 2 bool fields to > "BTScanPosItem". That increases its size considerably. We're very > sensitive to the size of this struct (I think that you know about this > already). Bloating it like this will blow up our memory usage, since > right now we allocate MaxTIDsPerBTreePage/1358 such structs for > so->currPos (and so->markPos). Wasting all that memory on alignment > padding is probably going to have consequences beyond memory bloat. Actually, there is no alignment padding involved. Even still, increasing that from 10 bytes to 12 bytes will hurt us. Remember the issue with support function #6/skip support putting us over that critical glibc threshold? (I've been meaning to get back to that thread...) -- Peter Geoghegan
On 7/16/25 15:36, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 4:40 AM Tomas Vondra <tomas@vondra.me> wrote: >> But the thing I don't really understand it the "cyclic" dataset (for >> example). And the "simple" patch performs really badly here. This data >> set is designed to not work for prefetching, it's pretty much an >> adversary case. There's ~100 TIDs from 100 pages for each key value, and >> once you read the 100 pages you'll hit them many times for following >> values. Prefetching is pointless, and skipping duplicate blocks can't >> help, because the blocks are not effective. >> >> But how come the "complex" patch does so much better? It can't really >> benefit from prefetching TID from the next leaf - not this much. Yet it >> does a bit better than master. I'm looking at this since yesterday, and >> it makes no sense to me. Per "perf trace" it actually does 2x many >> fadvise calls compared to the "simple" patch (which is strange on it's >> own, I think), yet it's apparently so much faster? > > The "simple" patch has _bt_readpage reset the read stream. That > doesn't make any sense to me. Though it does explain why the "complex" > patch does so many more fadvise calls. > Why it doesn't make sense? The reset_stream_reset() restarts the stream after it got "terminated" on the preceding leaf page (by returning InvalidBlockNumber). It'd be better to "pause" the stream somehow, but there's nothing like that yet. We have to terminate it and start again. But why would it explain the increase in fadvise calls? FWIW the pattern of fadvise call is quite different. For the simple patch we end up doing just this: fadvise block 1 read block 1 fadvise block 2 read block 2 fadvise block 3 read block 3 ... while for the complex patch we do a small batch (~10) of fadvise calls, followed by the fadvise/read calls for the same set of blocks: fadvise block 1 fadvise block 2 ... fadvise block 10 read block 1 fadvise block 2 read block 2 ... fadvise block 10 read block 10 This might explain the advantage of the "complex" patch, because it can actually do some prefetching every now and then (if my calculation is right, about 5% blocks needs prefetching). Te pattern of fadvise+pread for the same block seems a bit silly. And this is not just about "sync" method, the other methods will have a similar issue with no starting the I/O earlier. The fadvise is just easier to trace/inspect. I suspect this might be an unintended consequence of the stream reset. AFAIK it wasn't quite meant to be used this way, so maybe it confuses the built-in heuristics deciding what to prefetch? If that's the case, I'm afraid the "complex" patch will have the issue too, because it will need to "pause" the prefetching in some cases too (e.g. for index-only scans, or when the leaf pages contain very few index tuples). Will be less common, of course. > Another issue with the "simple" patch: it adds 2 bool fields to > "BTScanPosItem". That increases its size considerably. We're very > sensitive to the size of this struct (I think that you know about this > already). Bloating it like this will blow up our memory usage, since > right now we allocate MaxTIDsPerBTreePage/1358 such structs for > so->currPos (and so->markPos). Wasting all that memory on alignment > padding is probably going to have consequences beyond memory bloat. > True, no argument here. regards -- Tomas Vondra
On Wed, Jul 16, 2025 at 9:58 AM Tomas Vondra <tomas@vondra.me> wrote: > > The "simple" patch has _bt_readpage reset the read stream. That > > doesn't make any sense to me. Though it does explain why the "complex" > > patch does so many more fadvise calls. > > > > Why it doesn't make sense? The reset_stream_reset() restarts the stream > after it got "terminated" on the preceding leaf page (by returning > InvalidBlockNumber). Resetting the prefetch distance at the end of _bt_readpage doesn't make any sense to me. Why there? It makes about as much sense as doing so every 7th index tuple. Reaching the end of _bt_readpage isn't meaningful -- since it in no way signifies that the scan has been terminated (it might have been, but you're not checking that at all). > It'd be better to "pause" the stream somehow, but > there's nothing like that yet. We have to terminate it and start again. I don't follow. > Te pattern of fadvise+pread for the same block seems a bit silly. And > this is not just about "sync" method, the other methods will have a > similar issue with no starting the I/O earlier. The fadvise is just > easier to trace/inspect. It's not at all surprising that you're seeing duplicate prefetch requests. I have no reason to believe that it's important to suppress those ourselves, rather than leaving it up to the OS (though I also have no reason to believe that the opposite is true). -- Peter Geoghegan
On 7/16/25 16:07, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 9:58 AM Tomas Vondra <tomas@vondra.me> wrote: >>> The "simple" patch has _bt_readpage reset the read stream. That >>> doesn't make any sense to me. Though it does explain why the "complex" >>> patch does so many more fadvise calls. >>> >> >> Why it doesn't make sense? The reset_stream_reset() restarts the stream >> after it got "terminated" on the preceding leaf page (by returning >> InvalidBlockNumber). > > Resetting the prefetch distance at the end of _bt_readpage doesn't > make any sense to me. Why there? It makes about as much sense as doing > so every 7th index tuple. Reaching the end of _bt_readpage isn't > meaningful -- since it in no way signifies that the scan has been > terminated (it might have been, but you're not checking that at all). > Again, resetting the prefetch distance is merely a side-effect (and I agree it's not desirable). The "reset" merely says the stream is able to produce blocks again - call the "next" callback etc. >> It'd be better to "pause" the stream somehow, but >> there's nothing like that yet. We have to terminate it and start again. > > I don't follow. > The read stream can only return blocks generated by the "next" callback. When we return the block for the last item on a leaf page, we can only return "InvalidBlockNumber" which means "no more blocks in the stream". And once we advance to the next leaf, we say "hey, there's more blocks". Which is what read_stream_reset() does. It's a bit like what rescan does. In an ideal world we'd have a function that'd "pause" the stream, without resetting the distance etc. But we don't have that, and the reset thing was suggested to me as a workaround. >> Te pattern of fadvise+pread for the same block seems a bit silly. And >> this is not just about "sync" method, the other methods will have a >> similar issue with no starting the I/O earlier. The fadvise is just >> easier to trace/inspect. > > It's not at all surprising that you're seeing duplicate prefetch > requests. I have no reason to believe that it's important to suppress > those ourselves, rather than leaving it up to the OS (though I also > have no reason to believe that the opposite is true). > True, but in practice those duplicate calls are fairly expensive. Even just calling fadvise() on data you already have in page cache costs something (not much, but it's clearly visible for cached queries). regards -- Tomas Vondra
Hi, On 2025-07-16 16:20:25 +0200, Tomas Vondra wrote: > On 7/16/25 16:07, Peter Geoghegan wrote: > >> Te pattern of fadvise+pread for the same block seems a bit silly. And > >> this is not just about "sync" method, the other methods will have a > >> similar issue with no starting the I/O earlier. The fadvise is just > >> easier to trace/inspect. > > > > It's not at all surprising that you're seeing duplicate prefetch > > requests. I have no reason to believe that it's important to suppress > > those ourselves, rather than leaving it up to the OS (though I also > > have no reason to believe that the opposite is true). > > > > True, but in practice those duplicate calls are fairly expensive. Even > just calling fadvise() on data you already have in page cache costs > something (not much, but it's clearly visible for cached queries). This imo isn't something worth optimizing for - if you use an io_method that actually can execute IO asynchronously this issue does not exist, as the start of the IO will already have populated the buffer entry (without BM_VALID set, of course). Thus we won't start another IO for that block. Greetings, Andres Freund
On Wed, Jul 16, 2025 at 10:25 AM Andres Freund <andres@anarazel.de> wrote: > This imo isn't something worth optimizing for - if you use an io_method that > actually can execute IO asynchronously this issue does not exist, as the start > of the IO will already have populated the buffer entry (without BM_VALID set, > of course). Thus we won't start another IO for that block. Even if it was worth optimizing for, it'd probably still be too far down the list of problems to be worth discussing right now. -- Peter Geoghegan
On Wed, Jul 16, 2025 at 10:20 AM Tomas Vondra <tomas@vondra.me> wrote: > The read stream can only return blocks generated by the "next" callback. > When we return the block for the last item on a leaf page, we can only > return "InvalidBlockNumber" which means "no more blocks in the stream". > And once we advance to the next leaf, we say "hey, there's more blocks". > Which is what read_stream_reset() does. > > It's a bit like what rescan does. That sounds weird. > In an ideal world we'd have a function that'd "pause" the stream, > without resetting the distance etc. But we don't have that, and the > reset thing was suggested to me as a workaround. Does the "complex" patch require a similar workaround? Why or why not? -- Peter Geoghegan
On 7/16/25 16:29, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 10:20 AM Tomas Vondra <tomas@vondra.me> wrote: >> The read stream can only return blocks generated by the "next" callback. >> When we return the block for the last item on a leaf page, we can only >> return "InvalidBlockNumber" which means "no more blocks in the stream". >> And once we advance to the next leaf, we say "hey, there's more blocks". >> Which is what read_stream_reset() does. >> >> It's a bit like what rescan does. > > That sounds weird. > What sounds weird? That the read_stream works like a stream of blocks, or that it can't do "pause" and we use "reset" as a workaround? >> In an ideal world we'd have a function that'd "pause" the stream, >> without resetting the distance etc. But we don't have that, and the >> reset thing was suggested to me as a workaround. > > Does the "complex" patch require a similar workaround? Why or why not? > I think it'll need to do something like that in some cases, when we need to limit the number of leaf pages kept in memory to something sane. (a) index-only scans, with most of the tuples all-visible (we don't prefetch all-visible pages, so finding the next "prefetchable" block may force reading a lot of leaf pages) (b) scans on correlated indexes - we skip duplicate block numbers, so again, we may need to read a lot of leafs to find enough prefetchable blocks to reach the "distance" (measured in queued blocks) (c) indexes with "fat" index tuples (but it's less of an issue, because with one tuple per leaf we still have a clear idea how many leafs we'll need to read) regards -- Tomas Vondra
On Wed, Jul 16, 2025 at 10:37 AM Tomas Vondra <tomas@vondra.me> wrote: > What sounds weird? That the read_stream works like a stream of blocks, > or that it can't do "pause" and we use "reset" as a workaround? The fact that prefetch distance is in any way affected by a temporary inability to return more blocks. Just starting from scratch seems particularly bad. Doesn't that mean that it's simply impossible for us to remember ramping up the distance on an earlier leaf page? There is nothing about leaf page boundaries that should be meaningful to the read stream/our heap accesses. I get that index characteristics could be the limiting factor, especially in a world where we're not yet eagerly reading leaf pages. But that in no way justifies just forgetting about prefetch distance like this. > >> In an ideal world we'd have a function that'd "pause" the stream, > >> without resetting the distance etc. But we don't have that, and the > >> reset thing was suggested to me as a workaround. > > > > Does the "complex" patch require a similar workaround? Why or why not? > > > > I think it'll need to do something like that in some cases, when we need > to limit the number of leaf pages kept in memory to something sane. That's the only reason? The memory usage for batches? That doesn't seem like a big deal. It's something to keep an eye on, but I see no reason why it'd be particularly difficult. Doesn't this argue for the "complex" patch's approach? -- Peter Geoghegan
On Wed, Jul 16, 2025 at 4:40 AM Tomas Vondra <tomas@vondra.me> wrote: > For "uniform" data set, both prefetch patches do much better than master > (for low selectivities it's clearer in the log-scale chart). The > "complex" prefetch patch appears to have a bit of an edge for >1% > selectivities. I find this a bit surprising, the leaf pages have ~360 > index items, so I wouldn't expect such impact due to not being able to > prefetch beyond the end of the current leaf page. But could be on > storage with higher latencies (this is the cloud SSD on azure). How can you say that the "complex" patch has "a bit of an edge for >1% selectivities"? It looks like a *massive* advantage on all "linear" test results. Those are only about 1/3 of all tests -- but if I'm not mistaken they're the *only* tests where prefetching could be expected to help a lot. The "cyclic" tests are adversarial/designed to make the patch look bad. The "uniform" tests have uniformly random heap accesses (I think), which can only be helped so much by prefetching. For example, with "linear_10 / eic=16 / sync", it looks like "complex" has about half the latency of "simple" in tests where selectivity is 10. The advantage for "complex" is even greater at higher "selectivity" values. All of the other "linear" test results look about the same. Have I missed something? -- Peter Geoghegan
On Wed, Jul 16, 2025 at 11:29 AM Peter Geoghegan <pg@bowt.ie> wrote: > For example, with "linear_10 / eic=16 / sync", it looks like "complex" > has about half the latency of "simple" in tests where selectivity is > 10. The advantage for "complex" is even greater at higher > "selectivity" values. All of the other "linear" test results look > about the same. It's hard to interpret the raw data that you've provided. For example, I cannot figure out where "selectivity" appears in the raw CSV file from your results repro. Can you post a single spreadsheet or CSV file, with descriptive column names, and a row for every test case you ran? And with the rows ordered such that directly comparable results/rows appear close together? Thanks -- Peter Geoghegan
On 7/16/25 16:45, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 10:37 AM Tomas Vondra <tomas@vondra.me> wrote: >> What sounds weird? That the read_stream works like a stream of blocks, >> or that it can't do "pause" and we use "reset" as a workaround? > > The fact that prefetch distance is in any way affected by a temporary > inability to return more blocks. Just starting from scratch seems > particularly bad. > > Doesn't that mean that it's simply impossible for us to remember > ramping up the distance on an earlier leaf page? There is nothing > about leaf page boundaries that should be meaningful to the read > stream/our heap accesses. > > I get that index characteristics could be the limiting factor, > especially in a world where we're not yet eagerly reading leaf pages. > But that in no way justifies just forgetting about prefetch distance > like this. > True. I think it's simply a matter of "no one really needed that yet", so the read stream does not have a way to do that. I suspect Thomas might have a WIP patch for that somewhere ... >>>> In an ideal world we'd have a function that'd "pause" the stream, >>>> without resetting the distance etc. But we don't have that, and the >>>> reset thing was suggested to me as a workaround. >>> >>> Does the "complex" patch require a similar workaround? Why or why not? >>> >> >> I think it'll need to do something like that in some cases, when we need >> to limit the number of leaf pages kept in memory to something sane. > > That's the only reason? The memory usage for batches? > > That doesn't seem like a big deal. It's something to keep an eye on, > but I see no reason why it'd be particularly difficult. > > Doesn't this argue for the "complex" patch's approach? > Memory pressure is the "implementation" reason, because the indexam.c layer has a fixed-length array of batches, so it can't load more than INDEX_SCAN_MAX_BATCHES of them. That could be reworked to allow loading arbitrary number of batches, of course. But I think we don't really want to do that, because what would be the benefit? If you need to load many leaf pages to find the next thing to prefetch, is the prefetching really improving anything? How would we even know there actually is a prefetchable item? We could load the whole index only to find everything is all-visible. And then what if the query has LIMIT 10? So that's the other thing this probably needs to consider - some concept of how much effort to invest into finding the next prefetchable block. regards -- Tomas Vondra
On 7/16/25 17:29, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 4:40 AM Tomas Vondra <tomas@vondra.me> wrote: >> For "uniform" data set, both prefetch patches do much better than master >> (for low selectivities it's clearer in the log-scale chart). The >> "complex" prefetch patch appears to have a bit of an edge for >1% >> selectivities. I find this a bit surprising, the leaf pages have ~360 >> index items, so I wouldn't expect such impact due to not being able to >> prefetch beyond the end of the current leaf page. But could be on >> storage with higher latencies (this is the cloud SSD on azure). > > How can you say that the "complex" patch has "a bit of an edge for >1% > selectivities"? > > It looks like a *massive* advantage on all "linear" test results. > Those are only about 1/3 of all tests -- but if I'm not mistaken > they're the *only* tests where prefetching could be expected to help a > lot. The "cyclic" tests are adversarial/designed to make the patch > look bad. The "uniform" tests have uniformly random heap accesses (I > think), which can only be helped so much by prefetching. > > For example, with "linear_10 / eic=16 / sync", it looks like "complex" > has about half the latency of "simple" in tests where selectivity is > 10. The advantage for "complex" is even greater at higher > "selectivity" values. All of the other "linear" test results look > about the same. > > Have I missed something? > That paragraph starts with "for uniform data set", and the statement about 1% selectivities was only about that particular data set. You're right there's a massive difference on all the "correlated" data sets. I believe (assume) that's caused by the same issue, discussed in this thread (where the simple patch seems to do fewer fadvise calls). I only picked the "cyclic" data set as an example, representing this. FWIW I suspect the difference on "uniform" data set might be caused by this too, because at ~5% selectivity the queries start to hit pages multiple times (there are ~20 rows/page, hence ~5% means ~1 row). But it's much weaker than on the correlated data sets, of course. regards -- Tomas Vondra
On 7/16/25 18:39, Peter Geoghegan wrote:
> On Wed, Jul 16, 2025 at 11:29 AM Peter Geoghegan <pg@bowt.ie> wrote:
>> For example, with "linear_10 / eic=16 / sync", it looks like "complex"
>> has about half the latency of "simple" in tests where selectivity is
>> 10. The advantage for "complex" is even greater at higher
>> "selectivity" values. All of the other "linear" test results look
>> about the same.
>
> It's hard to interpret the raw data that you've provided. For example,
> I cannot figure out where "selectivity" appears in the raw CSV file
> from your results repro.
>
> Can you post a single spreadsheet or CSV file, with descriptive column
> names, and a row for every test case you ran? And with the rows
> ordered such that directly comparable results/rows appear close
> together?
>
That's a good point, sorry about that. I forgot the CSV files don't have
proper headers, I'll fix that and document the structure better.
The process.sh script starts by loading the CSV(s) into sqlite, in order
to do the processing / aggregations. If you copy the first couple lines,
you'll get scans.db, with nice column names and all that..
The selectivity is calculated as
(rows / total_rows)
where rows is the rowcount returned by the query, and total_rows is
reltuples. I also had charts with "page selectivity", but that often got
a bunch of 100% points squashed on the right edge, so I stopped
generating those.
regards
--
Tomas Vondra
On Wed, Jul 16, 2025 at 1:42 PM Tomas Vondra <tomas@vondra.me> wrote:
> On 7/16/25 16:45, Peter Geoghegan wrote:
> > I get that index characteristics could be the limiting factor,
> > especially in a world where we're not yet eagerly reading leaf pages.
> > But that in no way justifies just forgetting about prefetch distance
> > like this.
> >
>
> True. I think it's simply a matter of "no one really needed that yet",
> so the read stream does not have a way to do that. I suspect Thomas
> might have a WIP patch for that somewhere ...
This seems really important.
I don't fully understand why this appears to be less of a problem with
the complex patch. Can you help me to confirm my understanding?
I think that this "complex" patch code is relevant:
static bool
index_batch_getnext(IndexScanDesc scan)
{
...
/*
* If we already used the maximum number of batch slots available, it's
* pointless to try loading another one. This can happen for various
* reasons, e.g. for index-only scans on all-visible table, or skipping
* duplicate blocks on perfectly correlated indexes, etc.
*
* We could enlarge the array to allow more batches, but that's futile, we
* can always construct a case using more memory. Not only it would risk
* OOM, it'd also be inefficient because this happens early in the scan
* (so it'd interfere with LIMIT queries).
*
* XXX For now we just error out, but the correct solution is to pause the
* stream by returning InvalidBlockNumber and then unpause it by doing
* read_stream_reset.
*/
if (INDEX_SCAN_BATCH_FULL(scan))
{
DEBUG_LOG("index_batch_getnext: ran out of space for batches");
scan->xs_batches->reset = true;
}
It looks like we're able to fill up quite a few batches/pages before
having to give anything to the read stream. Is that all this is?
We do still need to reset the read stream with the "complex" patch --
I see that. But it's just much less of a frequent thing, presumably
contributing to the performance advantages that we see for the
"complex" patch over the "simple" patch from your testing. Does that
seem like a fair summary?
BTW, don't think that we actually error-out here? Is that XXX comment
block obsolete?
> So that's the other thing this probably needs to consider - some concept
> of how much effort to invest into finding the next prefetchable block.
I agree, of course. That's the main argument in favor of the "complex"
design. Every possible cost/benefit is relevant (or may be), so one
centralized decision that weighs all those factors seems like the way
to go. We don't need to start with a very sophisticated approach, but
I do think that we need a design that is orientated around this view
of things from the start.
The "simple" patch basically has all the same problems, but doesn't
even try to address them. The INDEX_SCAN_BATCH_FULL thing is probably
still pretty far from optimal, but at least all the pieces are there
in one place. At least we're not leaving it up to chance index AM
implementation details (i.e. leaf page boundaries) that have very
little to do with heapam related costs/what really matters.
--
Peter Geoghegan
Hi, On 2025-07-16 14:18:54 -0400, Peter Geoghegan wrote: > I don't fully understand why this appears to be less of a problem with > the complex patch. Can you help me to confirm my understanding? Could you share the current version of the complex patch (happy with a git tree)? Afaict it hasn't been posted, which makes this pretty hard follow along / provide feedback on, for others. Greetings, Andres Freund
On Wed, Jul 16, 2025 at 2:27 PM Andres Freund <andres@anarazel.de> wrote: > Could you share the current version of the complex patch (happy with a git > tree)? Afaict it hasn't been posted, which makes this pretty hard follow along > / provide feedback on, for others. Sure: https://github.com/petergeoghegan/postgres/tree/index-prefetch-2025-pg-revisions-v0.11 I think that the version that Tomas must have used is a few days old, and might be a tiny bit different. But I don't think that that's likely to matter, especially not if you just want to get the general idea. -- Peter Geoghegan
On 7/16/25 20:18, Peter Geoghegan wrote:
> On Wed, Jul 16, 2025 at 1:42 PM Tomas Vondra <tomas@vondra.me> wrote:
>> On 7/16/25 16:45, Peter Geoghegan wrote:
>>> I get that index characteristics could be the limiting factor,
>>> especially in a world where we're not yet eagerly reading leaf pages.
>>> But that in no way justifies just forgetting about prefetch distance
>>> like this.
>>>
>>
>> True. I think it's simply a matter of "no one really needed that yet",
>> so the read stream does not have a way to do that. I suspect Thomas
>> might have a WIP patch for that somewhere ...
>
> This seems really important.
>
> I don't fully understand why this appears to be less of a problem with
> the complex patch. Can you help me to confirm my understanding?
>
> I think that this "complex" patch code is relevant:
>
> static bool
> index_batch_getnext(IndexScanDesc scan)
> {
> ...
> /*
> * If we already used the maximum number of batch slots available, it's
> * pointless to try loading another one. This can happen for various
> * reasons, e.g. for index-only scans on all-visible table, or skipping
> * duplicate blocks on perfectly correlated indexes, etc.
> *
> * We could enlarge the array to allow more batches, but that's futile, we
> * can always construct a case using more memory. Not only it would risk
> * OOM, it'd also be inefficient because this happens early in the scan
> * (so it'd interfere with LIMIT queries).
> *
> * XXX For now we just error out, but the correct solution is to pause the
> * stream by returning InvalidBlockNumber and then unpause it by doing
> * read_stream_reset.
> */
> if (INDEX_SCAN_BATCH_FULL(scan))
> {
> DEBUG_LOG("index_batch_getnext: ran out of space for batches");
> scan->xs_batches->reset = true;
> }
>
> It looks like we're able to fill up quite a few batches/pages before
> having to give anything to the read stream. Is that all this is?
>
> We do still need to reset the read stream with the "complex" patch --
> I see that. But it's just much less of a frequent thing, presumably
> contributing to the performance advantages that we see for the
> "complex" patch over the "simple" patch from your testing. Does that
> seem like a fair summary?
>
Yes, sounds like a fair summary.
> BTW, don't think that we actually error-out here? Is that XXX comment
> block obsolete?
>
Right, obsolete comment.
>> So that's the other thing this probably needs to consider - some concept
>> of how much effort to invest into finding the next prefetchable block.
>
> I agree, of course. That's the main argument in favor of the "complex"
> design. Every possible cost/benefit is relevant (or may be), so one
> centralized decision that weighs all those factors seems like the way
> to go. We don't need to start with a very sophisticated approach, but
> I do think that we need a design that is orientated around this view
> of things from the start.
>
> The "simple" patch basically has all the same problems, but doesn't
> even try to address them. The INDEX_SCAN_BATCH_FULL thing is probably
> still pretty far from optimal, but at least all the pieces are there
> in one place. At least we're not leaving it up to chance index AM
> implementation details (i.e. leaf page boundaries) that have very
> little to do with heapam related costs/what really matters.
>
Perhaps, although I don't quite see why the simpler patch couldn't
address some of those problems (within the limit of a single leaf page,
of course). I don't think there's anything that's prevent collecting the
"details" somewhere (e.g. in the IndexScanDesc), and querying it from
the callbacks. Or something like that.
I understand you may see the "one leaf page" as a limitation of various
optimizations, and that's perfectly correct, ofc. I also saw it as a
crude limitation of how "bad" the things can go.
regards
--
Tomas Vondra
On Wed, Jul 16, 2025 at 3:00 PM Tomas Vondra <tomas@vondra.me> wrote: > Yes, sounds like a fair summary. Cool. > Perhaps, although I don't quite see why the simpler patch couldn't > address some of those problems (within the limit of a single leaf page, > of course). I don't think there's anything that's prevent collecting the > "details" somewhere (e.g. in the IndexScanDesc), and querying it from > the callbacks. Or something like that. That is technically possible. But ISTM that that's just an inferior version of the "complex" patch, that duplicates lots of things across index AMs. > I understand you may see the "one leaf page" as a limitation of various > optimizations, and that's perfectly correct, ofc. I also saw it as a > crude limitation of how "bad" the things can go. I'm not opposed to some fairly crude mechanism that stops the prefetching from ever being too aggressive based on index characteristics. But the idea of exclusively relying on leaf page boundaries to do that for us doesn't even seem like a good stopgap solution. On average, the cost of accessing leaf pages is relatively insignificant. But occasionally, very occasionally, it's the dominant cost. I don't think that you can get away with making a static assumption about how much leaf page access costs matter -- it doesn't average out like that. I think that you need at least a simple dynamic approach, that mostly doesn't care too much about how many leaf pages we've read, but occasionally makes heap prefetching much less aggressive in response to the number of leaf pages the scan needs to read being much higher than is typical. I get the impression that you're still of the opinion that the "simple" approach might well have the best chance of success. If that's still how you view things, then I genuinely don't understand why you still see things that way. That perspective definitely made sense to me 6 months ago, but no longer. Do you imagine that (say) Thomas will be able to add pause-and-resume to the read stream interface some time soon, at which point the regressions we see with the "simple" patch (but not the "complex" patch) go away? -- Peter Geoghegan
Hi, On 2025-07-16 14:30:05 -0400, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 2:27 PM Andres Freund <andres@anarazel.de> wrote: > > Could you share the current version of the complex patch (happy with a git > > tree)? Afaict it hasn't been posted, which makes this pretty hard follow along > > / provide feedback on, for others. > > Sure: > > https://github.com/petergeoghegan/postgres/tree/index-prefetch-2025-pg-revisions-v0.11 > > I think that the version that Tomas must have used is a few days old, > and might be a tiny bit different. But I don't think that that's > likely to matter, especially not if you just want to get the general > idea. As a first thing I just wanted to get a feel for the improvements we can get. I had a scale 5 tpch already loaded, so I ran a bogus query on that to see. The improvement with either of the patchsets with a quick trial query is rather impressive when using direct IO (presumably also with an empty cache, but DIO is more predictable). As Peter's branch doesn't seem to have an enable_* GUC, I used SET effective_io_concurrency=0 to test the non-prefetching results (and verified with master that the results are similar). Test: Peter's: Without prefetching: SET effective_io_concurrency=0;SELECT pg_buffercache_evict_relation('lineitem');EXPLAIN ANALYZE SELECT * FROM lineitem ORDERBY l_shipdate LIMIT 10000; ┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Limit (cost=0.44..2332.06 rows=10000 width=106) (actual time=0.611..957.874 rows=10000.00 loops=1) │ │ Buffers: shared hit=1213 read=8626 │ │ I/O Timings: shared read=943.344 │ │ -> Index Scan using i_l_shipdate on lineitem (cost=0.44..6994824.33 rows=29999796 width=106) (actual time=0.611..956.593rows=10000.00 loops=1) │ │ Index Searches: 1 │ │ Buffers: shared hit=1213 read=8626 │ │ I/O Timings: shared read=943.344 │ │ Planning Time: 0.083 ms │ │ Execution Time: 958.508 ms │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ (9 rows) With prefetching: SET effective_io_concurrency=64;SELECT pg_buffercache_evict_relation('lineitem');EXPLAIN ANALYZE SELECT * FROM lineitem ORDERBY l_shipdate LIMIT 10000; ┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Limit (cost=0.44..2332.06 rows=10000 width=106) (actual time=0.497..67.737 rows=10000.00 loops=1) │ │ Buffers: shared hit=1227 read=8667 │ │ I/O Timings: shared read=48.473 │ │ -> Index Scan using i_l_shipdate on lineitem (cost=0.44..6994824.33 rows=29999796 width=106) (actual time=0.496..66.471rows=10000.00 loops=1) │ │ Index Searches: 1 │ │ Buffers: shared hit=1227 read=8667 │ │ I/O Timings: shared read=48.473 │ │ Planning Time: 0.090 ms │ │ Execution Time: 68.965 ms │ └────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ (9 rows) Tomas': With prefetching: SET effective_io_concurrency=64;SELECT pg_buffercache_evict_relation('lineitem');EXPLAIN ANALYZE SELECT * FROM lineitem ORDERBY l_shipdate LIMIT 10000; ┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Limit (cost=0.44..2332.06 rows=10000 width=106) (actual time=0.278..70.609 rows=10000.00 loops=1) │ │ Buffers: shared hit=1227 read=8668 │ │ I/O Timings: shared read=52.578 │ │ -> Index Scan using i_l_shipdate on lineitem (cost=0.44..6994824.33 rows=29999796 width=106) (actual time=0.277..69.304rows=10000.00 loops=1) │ │ Index Searches: 1 │ │ Buffers: shared hit=1227 read=8668 │ │ I/O Timings: shared read=52.578 │ │ Planning Time: 0.072 ms │ │ Execution Time: 71.549 ms │ └────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ (9 rows) The wins are similar without DIO and a cold OS cache, but i don't like emptying out the entire OS cache all the time... I call that a hell of an impressive improvement with either patch - it's really really hard to find order of magnitude improvements in anything close to realistic cases. And that's on a local reasonably fast NVMe - with networked storage we'll see much bigger wins. This also doesn't just repro with toy queries, e.g. TPCH Q02 shows a 2X improvement too (with either patch) - the only reason it's not bigger is that all the remaining IO time is on the inner side of a nestloop that isn't currently prefetchable. Peter, it'd be rather useful if your patch also had an enable/disable GUC, otherwise it's more work to study the performance effects. The effective_io_concurrency approach isn't great, because it also affects bitmap scans, seqscans etc. Just playing around, there are many cases where there is effectively no difference between the two approaches, from a runtime perspective. There, unsurprisingly, are some where the complex approach clearly wins, mostly around IN(list-of-constants) so far. Looking at the actual patches now. Greetings, Andres Freund
Hi, On 2025-07-16 15:39:58 -0400, Andres Freund wrote: > Looking at the actual patches now. I just did an initial, not particularly in depth look. A few comments and questions below. For either patch, I think it's high time we split the index/table buffer stats in index scans. It's really annoying to not be able to see if IO time was inside the index itself or in the table. What we're discussing here obviously can never avoid stalls due to fetching index pages, but so far neither patch is able to fully utilize hardware when bound on heap fetches, but that's harder to know without those stats. The BufferMatches() both patches add seems to check more than needed? It's not like the old buffer could have changed what relation it is for while pinned. Seems like it'd be better to just keep track what the prior block was and not go into bufmgr.c at all. WRT the complex patch: Maybe I'm missing something, but the current interface doesn't seem to work for AMs that don't have a 1:1 mapping between the block number portion of the tid and the actual block number? Currently the API wouldn't easily allow the table AM to do batched TID lookups - if you have a query that looks at a lot of table tuples in the same buffer consecutively, we spend a lot of time locking/unlocking said buffer. We also spend a lot of time dispatching from nodeIndexscan.c to tableam in such queries. I'm not suggesting to increase the scope to handle that, but it might be worth keeping in mind. I think the potential gains here are really substantial. Even just not having to lock/unlock the heap block for every tuple in the page would be a huge win, a quick and incorrect hack suggests it's like 25% faster A batched heap_hot_search_buffer() could be a larger improvement, it's often bound by memory latency and per-call overhead. I see some slowdown for well-cached queries with the patch, I've not dug into why. WRT the simple patch: Seems to have the same issue that it assumes TID block numbers correspond to actual disk location? Greetings, Andres Freund
On Wed, Jul 16, 2025 at 3:40 PM Andres Freund <andres@anarazel.de> wrote: > As a first thing I just wanted to get a feel for the improvements we can get. > I had a scale 5 tpch already loaded, so I ran a bogus query on that to see. Cool. > Test: > > Peter's: To be clear, the "complex" patch is still almost all Tomas' work -- at least right now. I'd like to do a lot more work on this project, though. So far, my main contribution has been debugging advice, and removing code/simplifying things on the nbtree side. > I call that a hell of an impressive improvement with either patch - it's > really really hard to find order of magnitude improvements in anything close > to realistic cases. Nice. > Peter, it'd be rather useful if your patch also had an enable/disable GUC, > otherwise it's more work to study the performance effects. The > effective_io_concurrency approach isn't great, because it also affects > bitmap scans, seqscans etc. FWIW I took out the GUC because it works by making indexam.c use the amgettuple interface. The "complex" patch completely gets rid of btgettuple, whereas the simple patch keeps btgettuple in largely its current form. I agree that having such a GUC is important during development, and will try to add it back soon. It'll have to work in some completely different way, but that still shouldn't be difficult. -- Peter Geoghegan
On 7/16/25 19:56, Tomas Vondra wrote: > On 7/16/25 18:39, Peter Geoghegan wrote: >> On Wed, Jul 16, 2025 at 11:29 AM Peter Geoghegan <pg@bowt.ie> wrote: >>> For example, with "linear_10 / eic=16 / sync", it looks like "complex" >>> has about half the latency of "simple" in tests where selectivity is >>> 10. The advantage for "complex" is even greater at higher >>> "selectivity" values. All of the other "linear" test results look >>> about the same. >> >> It's hard to interpret the raw data that you've provided. For example, >> I cannot figure out where "selectivity" appears in the raw CSV file >> from your results repro. >> >> Can you post a single spreadsheet or CSV file, with descriptive column >> names, and a row for every test case you ran? And with the rows >> ordered such that directly comparable results/rows appear close >> together? >> > > That's a good point, sorry about that. I forgot the CSV files don't have > proper headers, I'll fix that and document the structure better. > > The process.sh script starts by loading the CSV(s) into sqlite, in order > to do the processing / aggregations. If you copy the first couple lines, > you'll get scans.db, with nice column names and all that.. > > The selectivity is calculated as > > (rows / total_rows) > > where rows is the rowcount returned by the query, and total_rows is > reltuples. I also had charts with "page selectivity", but that often got > a bunch of 100% points squashed on the right edge, so I stopped > generating those. > I've pushed results from a couple more runs (the cyclic_25 is still running), and I added "export.csv" which has a subset of columns, and calculated row/page selectivities. Does this work for you? regards -- Tomas Vondra
On Wed, Jul 16, 2025 at 4:46 PM Andres Freund <andres@anarazel.de> wrote: > Currently the API wouldn't easily allow the table AM to do batched TID lookups > - if you have a query that looks at a lot of table tuples in the same buffer > consecutively, we spend a lot of time locking/unlocking said buffer. We also > spend a lot of time dispatching from nodeIndexscan.c to tableam in such > queries. > > I'm not suggesting to increase the scope to handle that, but it might be worth > keeping in mind. > > I think the potential gains here are really substantial. I agree. I've actually discussed this possibility with Tomas a few times, though not recently. It's really common for TIDs that appear on a leaf page to be slightly out of order due to minor heap fragmentation. Even minor fragmentation can significantly increase pin/buffer lock traffic right now. I think that it makes a lot of sense for the general design to open up possibilities such as this. > I see some slowdown for well-cached queries with the patch, I've not dug into > why. I saw less than a 5% regression in pgbench SELECT with the "complex" patch with 32 clients. My guess is that it's due to the less efficient memory allocation with batching. Obviously this isn't acceptable, but I'm not particularly concerned about it right now. I was actually pleased to see that there wasn't a much larger regression there. -- Peter Geoghegan
Hi, On 2025-07-16 16:54:06 -0400, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 3:40 PM Andres Freund <andres@anarazel.de> wrote: > > As a first thing I just wanted to get a feel for the improvements we can get. > > I had a scale 5 tpch already loaded, so I ran a bogus query on that to see. > > Cool. > > > Test: > > > > Peter's: > > To be clear, the "complex" patch is still almost all Tomas' work -- at > least right now. I'd like to do a lot more work on this project, > though. Indeed. Sorry - what I intended but failed to write was "the approach that Peter is arguing for"... Greetings, Andres Freund
On Wed, Jul 16, 2025 at 4:46 PM Andres Freund <andres@anarazel.de> wrote: > Maybe I'm missing something, but the current interface doesn't seem to work > for AMs that don't have a 1:1 mapping between the block number portion of the > tid and the actual block number? I'm not completely sure what you mean here. Even within nbtree, posting list tuples work by setting the INDEX_ALT_TID_MASK index tuple header bit. That makes nbtree interpret IndexTupleData.t_tid as metadata (in this case describing a posting list). Obviously, that isn't "a standard IndexTuple", but that won't break either patch/approach. The index AM is obligated to pass back heap TIDs, without any external code needing to understand these sorts of implementation details. The on-disk representation of TIDs remains an implementation detail known only to index AMs. -- Peter Geoghegan
Hi,
On 2025-07-16 17:27:23 -0400, Peter Geoghegan wrote:
> On Wed, Jul 16, 2025 at 4:46 PM Andres Freund <andres@anarazel.de> wrote:
> > Maybe I'm missing something, but the current interface doesn't seem to work
> > for AMs that don't have a 1:1 mapping between the block number portion of the
> > tid and the actual block number?
>
> I'm not completely sure what you mean here.
>
> Even within nbtree, posting list tuples work by setting the
> INDEX_ALT_TID_MASK index tuple header bit. That makes nbtree interpret
> IndexTupleData.t_tid as metadata (in this case describing a posting
> list). Obviously, that isn't "a standard IndexTuple", but that won't
> break either patch/approach.
>
> The index AM is obligated to pass back heap TIDs, without any external
> code needing to understand these sorts of implementation details. The
> on-disk representation of TIDs remains an implementation detail known
> only to index AMs.
I don't mean the index tids, but how the read stream is fed block numbers. In
the "complex" patch that's done by index_scan_stream_read_next(). And the
block number it returns is simply
return ItemPointerGetBlockNumber(tid);
without the table AM having any way of influencing that. Which means that if
your table AM does not use the block number of the tid 1:1 as the real block
number, the fetched block will be completely bogus.
It's similar in the simple patch, bt_stream_read_next() etc also just use
ItemPointerGetBlockNumber().
Greetings,
Andres Freund
On Wed, Jul 16, 2025 at 5:41 PM Andres Freund <andres@anarazel.de> wrote: > I don't mean the index tids, but how the read stream is fed block numbers. In > the "complex" patch that's done by index_scan_stream_read_next(). And the > block number it returns is simply > > return ItemPointerGetBlockNumber(tid); > > without the table AM having any way of influencing that. Which means that if > your table AM does not use the block number of the tid 1:1 as the real block > number, the fetched block will be completely bogus. How is that handled when such a table AM uses the existing amgettuple interface? I think that it shouldn't be hard to implement an opt-out of prefetching for such table AMs, so at least you won't fetch random garbage. Right now, the amgetbatch interface is oriented around returning TIDs. Obviously it works that way because that's what heapam expects, and what amgettuple (which I'd like to replace with amgetbatch) does. -- Peter Geoghegan
Hi, On 2025-07-16 17:47:53 -0400, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 5:41 PM Andres Freund <andres@anarazel.de> wrote: > > I don't mean the index tids, but how the read stream is fed block numbers. In > > the "complex" patch that's done by index_scan_stream_read_next(). And the > > block number it returns is simply > > > > return ItemPointerGetBlockNumber(tid); > > > > without the table AM having any way of influencing that. Which means that if > > your table AM does not use the block number of the tid 1:1 as the real block > > number, the fetched block will be completely bogus. > > How is that handled when such a table AM uses the existing amgettuple > interface? There's no problem today - the indexams never use the tids to look up blocks themselves. They're always passed to the tableam to do so (via table_index_fetch_tuple() etc). I.e. the translation from TIDs to specific blocks & buffers happens entirely inside the tableam, therefore the tableam can choose to not use a 1:1 mapping or even to not use any buffers at all. > I think that it shouldn't be hard to implement an opt-out > of prefetching for such table AMs, so at least you won't fetch random > garbage. I don't think that's the right answer here. ISTM the layering in both patches just isn't quite correct right now. The read stream shouldn't be "filled" with table buffers by index code, it needs to be filled by tableam specific code. > Right now, the amgetbatch interface is oriented around returning TIDs. > Obviously it works that way because that's what heapam expects, and > what amgettuple (which I'd like to replace with amgetbatch) does. ISTM the right answer would be to allow the tableam to get the batches, without indexam feeding the read stream. That, perhaps not so coincidentally, is also what's needed for batching heap page locking and and HOT search. I think this means that it has to be the tableam that creates the read stream and that does the work that's currently done in index_scan_stream_read_next(), i.e. the translation from TID to whatever resources are required by the tableam. Which presumably would include the tableam calling index_batch_getnext(). Greetings, Andres Freund
On Wed, Jul 16, 2025 at 6:18 PM Andres Freund <andres@anarazel.de> wrote: > There's no problem today - the indexams never use the tids to look up blocks > themselves. They're always passed to the tableam to do so (via > table_index_fetch_tuple() etc). I.e. the translation from TIDs to specific > blocks & buffers happens entirely inside the tableam, therefore the tableam > can choose to not use a 1:1 mapping or even to not use any buffers at all. Of course. Somehow, I missed that obvious point. That is the bare minimum for a new interface such as this. > ISTM the right answer would be to allow the tableam to get the batches, > without indexam feeding the read stream. That, perhaps not so coincidentally, > is also what's needed for batching heap page locking and and HOT search. I agree. > I think this means that it has to be the tableam that creates the read stream > and that does the work that's currently done in index_scan_stream_read_next(), > i.e. the translation from TID to whatever resources are required by the > tableam. Which presumably would include the tableam calling > index_batch_getnext(). It probably makes sense to put that off for (let's say) a couple more months. Just so we can get what we have now in better shape. The "complex" patch only very recently started to pass all my tests (my custom nbtree test suite used for my work in 17 and 18). I still need buy-in from Tomas on the "complex" approach. We chatted briefly on IM, and he seems more optimistic about it than I thought (in my on-list remarks from earlier). It is definitely his patch, and I don't want to speak for him. -- Peter Geoghegan
On 7/17/25 00:33, Peter Geoghegan wrote: > On Wed, Jul 16, 2025 at 6:18 PM Andres Freund <andres@anarazel.de> wrote: >> There's no problem today - the indexams never use the tids to look up blocks >> themselves. They're always passed to the tableam to do so (via >> table_index_fetch_tuple() etc). I.e. the translation from TIDs to specific >> blocks & buffers happens entirely inside the tableam, therefore the tableam >> can choose to not use a 1:1 mapping or even to not use any buffers at all. > > Of course. Somehow, I missed that obvious point. That is the bare > minimum for a new interface such as this. > >> ISTM the right answer would be to allow the tableam to get the batches, >> without indexam feeding the read stream. That, perhaps not so coincidentally, >> is also what's needed for batching heap page locking and and HOT search. > > I agree. > >> I think this means that it has to be the tableam that creates the read stream >> and that does the work that's currently done in index_scan_stream_read_next(), >> i.e. the translation from TID to whatever resources are required by the >> tableam. Which presumably would include the tableam calling >> index_batch_getnext(). > > It probably makes sense to put that off for (let's say) a couple more > months. Just so we can get what we have now in better shape. The > "complex" patch only very recently started to pass all my tests (my > custom nbtree test suite used for my work in 17 and 18). > I agree tableam needs to have a say in this, so that it can interpret the TIDs in a way that fits how it actually stores data. But I'm not sure it should be responsible for calling index_batch_getnext(). Isn't the batching mostly an "implementation" detail of the index AM? That's how I was thinking about it, at least. Some of these arguments could be used against the current patch, where the next_block callback is defined by executor nodes. So in a way those are also "aware" of the batching. > I still need buy-in from Tomas on the "complex" approach. We chatted > briefly on IM, and he seems more optimistic about it than I thought > (in my on-list remarks from earlier). It is definitely his patch, > and I don't want to speak for him. I think I feel much better about the "complex" approach, mostly because you got involved and fixed some of the issues I've been struggling with. That is a huge help, thank you for that. The reasons why I started to look at the "simple" patch again [1] were not entirely technical, at least not in the sense "Which of the two designs is better?" It was mostly about my (in)ability to get it into a shape I'd be confident enough to commit. I kept running into weird and subtle issues in parts of the code I knew nothing about. Great way to learn stuff, but also a great way to burnout ... So the way I was thinking about it is more "perfect approach that I'll never be able to commit" vs. "good (and much simpler) approach". It's a bit like in the saying about a tree falling in forest. If a perfect patch never gets committed, does it make a sound? From the technical point of view, the "complex" approach is clearly more flexible. Because how could it not be? It can do everything the simple approach can, but also some additional stuff thanks to having multiple leaf pages at once. The question I'm still trying to figure out is how significant those benefits are, and whether it's worth it the extra complexity. I realize there's a difference between "complexity of a patch" and "complexity of the final code", and it may very well be that the complex approach would result in a much cleaner final code - I don't know. I don't have any clear "vision" of how the index AMs should work. My ambition was (and still is) limited to "add prefetching to index scans", and I don't feel qualified to make judgments about the overall design of index AMs (interfaces, layering). I have opinions, of course, but I also realize my insights are not very deep in this area. Which is why I've been trying to measure the "practical" differences between the two approaches, e.g. trying to compare how it performs on different data sets, etc. There are some pretty massive differences in favor of the "complex" approach, mostly due to the single-leaf-page limitation of the simple patch. I'm still trying to understand if this is "inherent" or if it could be mitigated in read_stream_reset(). (Will share results from a couple experiments in a separate message later.) This is the context of the benchmarks I've been sharing - me trying to understand the practical implications/limits of the simple approach. Not an attempt to somehow prove it's better, or anything like that. I'm not opposed to continuing work on the "complex" approach, but as I said, I'm sure I can't pull that off on my own. With your help, I think the chance of success would be considerably higher. Does this clarify how I think about the complex patch? regards [1] https://www.postgresql.org/message-id/32c15a30-6e25-4f6d-9191-76a19482c556%40vondra.me -- Tomas Vondra
Hi,
I was wondering why the "simple" approach performs so much worse than
the "complex" one on some of the data sets. The theory was that it's due
to using read_stream_reset(), which resets the prefetch distance, and so
we need to "ramp up" from scratch (distance=1) for every batch. Which
for the correlated data sets is very often.
So I decided to do some experiments, to see if this is really the case,
and maybe see if read_stream_reset() could fix this in some way.
First, I added an
elog(LOG, "distance %d", stream->distance);
at the beginning of read_stream_next_block() to see how the distance
changes during the scan. Consider a query returning 2M rows from the
"cyclic" table (the attached .sql creates/pupulates it):
-- selects 20% rows
SELECT * FROM cyclic WHERE a BETWEEN 0 AND 20000;
With the "complex" patch, the CDF of the distance looks like this:
+----------+-----+
| distance | pct |
+----------+-----+
| 0 | 0 |
| 25 | 0 |
| 50 | 0 |
| 75 | 0 |
| 100 | 0 |
| 125 | 0 |
| 150 | 0 |
| 175 | 0 |
| 200 | 0 |
| 225 | 0 |
| 250 | 0 |
| 275 | 99 |
| 300 | 99 |
+----------+-----+
That is, 99% of the distances is in the range [275, 300].
Note: This is much higher than the effective_io_concurrency value (16),
which may be surprising. But the ReadStream uses that to limit the
number of I/O requests, not as a limit of how far to look ahead. A lot
of the blocks are in the cache, so it looks far ahead.
But with the "simple" patch it looks like this:
+----------+-----+
| distance | pct |
+----------+-----+
| 0 | 0 |
| 25 | 99 |
| 50 | 99 |
| 75 | 99 |
| 100 | 99 |
| 125 | 99 |
| 150 | 99 |
| 175 | 99 |
| 200 | 99 |
| 225 | 99 |
| 250 | 99 |
| 275 | 100 |
| 300 | 100 |
+----------+-----+
So 99% of the distances is in [0, 25]. A more detailed view on the first
couple distances:
+----------+-----+
| distance | pct |
+----------+-----+
| 0 | 0 |
| 1 | 99 |
| 2 | 99 |
| 3 | 99 |
| 4 | 99 |
...
So 99% of distances is 1. Well, that's not very far, it effectively
means no prefetching (We still issue the fadvise, though, although a
comment in read_stream.c suggests we won't. Possible bug?).
This means *there's no ramp-up at all*. On the first leaf the distance
grows to ~270, but after the stream gets reset it stays at 1 and never
increases. That's ... not great?
I'm not entirely sure
I decided to hack the ReadStream a bit, so that it restores the last
non-zero distance seen (i.e. right before reaching end of the stream).
And with that I got this:
+----------+-----+
| distance | pct |
+----------+-----+
| 0 | 0 |
| 25 | 38 |
| 50 | 38 |
| 75 | 38 |
| 100 | 39 |
| 125 | 42 |
| 150 | 47 |
| 175 | 47 |
| 200 | 48 |
| 225 | 49 |
| 250 | 50 |
| 275 | 100 |
| 300 | 100 |
+----------+-----+
Not as good as the "complex" patch, but much better than the original.
And the performance got almost the same (for this one query).
Perhaps the ReadStream should do something like this? Of course, the
simple patch resets the stream very often, likely mcuh more often than
anything else in the code. But wouldn't it be beneficial for streams
reset because of a rescan? Possibly needs to be optional.
regards
--
Tomas Vondra
Вложения
On Fri, Jul 18, 2025 at 1:44 PM Tomas Vondra <tomas@vondra.me> wrote: > I agree tableam needs to have a say in this, so that it can interpret > the TIDs in a way that fits how it actually stores data. But I'm not > sure it should be responsible for calling index_batch_getnext(). Isn't > the batching mostly an "implementation" detail of the index AM? That's > how I was thinking about it, at least. I think of it in roughly the opposite way: to me, the table AM should mostly be in control of the whole process. The index AM (or really some generalized layer that is used for every index AM) should have some influence over the scheduling of index scans, but in typical cases where prefetching might be helpful the index AM should have little or no impact on the scheduling. All of this business with holding on to buffer pins is 100% due to heap AM implementation details. Index vacuuming doesn't acquire cleanup locks because the index AM requires it. Cleanup locks are only required because otherwise there are races that affect index scans, where we get confused about which TID relates to which logical row. That's why bitmap index scans don't need to hold onto pins at all. It's true that the current index AM API makes this the direct responsibility of index AMs, by requiring them to hold on to buffer pins across heap accesses. But that's just a historical accident. > The reasons why I started to look at the "simple" patch again [1] were > not entirely technical, at least not in the sense "Which of the two > designs is better?" It was mostly about my (in)ability to get it into a > shape I'd be confident enough to commit. I kept running into weird and > subtle issues in parts of the code I knew nothing about. Great way to > learn stuff, but also a great way to burnout ... I was almost 100% sure that those nbtree implementation details were quite fixable from a very early stage. I didn't really get involved too much at first, because I didn't want to encroach. I probably could have done a lot better with that myself. > So the way I was thinking about it is more "perfect approach that I'll > never be able to commit" vs. "good (and much simpler) approach". It's a > bit like in the saying about a tree falling in forest. If a perfect > patch never gets committed, does it make a sound? Give yourself some credit. The complex patch is roughly 98% your work, and already works quite well. It's far from committable, of course, but it feels like it's already in roughly the right shape. > From the technical point of view, the "complex" approach is clearly more > flexible. Because how could it not be? It can do everything the simple > approach can, but also some additional stuff thanks to having multiple > leaf pages at once. Right. More than anything else, I don't like the "simple" approach because limiting the number of leaf pages that can read to exactly one feels so unnatural to me. It works in terms of the existing behavior with reading one leaf page at a time to do heap prefetching. But that existing behavior is itself a behavior that only exists for the benefit of heapam. It just seems circular to me: "simple" heap prefetching does things in a way that's convenient for index AMs, specifically around the leaf-at-a-time implementation details -- details which only exist for the benefit of heapam. My sense is that just cutting out the index AM entirely is a much more principled approach. It's also because of the ability to reorder work, and to centralize scheduling of index scans, of course -- there are practical benefits, too. But, honestly, my primary concern is this issue with "circularity". The "simple" patch is simpler only as one incremental step. But it doesn't actually leave the codebase as a whole in a simpler state than I believe to be possible with the "complex" patch. It won't really be simpler in the first committed version, and it definitely won't be if we ever want to improve on that. If anybody else has an opinion on this, please speak up. I'm pretty sure that only Tomas and I have commented on this important aspect directly. I don't want to win the argument; I just want the best design. > I don't have any clear "vision" of how the index AMs should work. My > ambition was (and still is) limited to "add prefetching to index scans", > and I don't feel qualified to make judgments about the overall design of > index AMs (interfaces, layering). I have opinions, of course, but I also > realize my insights are not very deep in this area. Thanks for being so open. Your position is completely reasonable. > Which is why I've been trying to measure the "practical" differences > between the two approaches, e.g. trying to compare how it performs on > different data sets, etc. There are some pretty massive differences in > favor of the "complex" approach, mostly due to the single-leaf-page > limitation of the simple patch. I'm still trying to understand if this > is "inherent" or if it could be mitigated in read_stream_reset(). (Will > share results from a couple experiments in a separate message later.) At a minimum, you should definitely teach the "simple" patchset to not reset the prefetch distance when there's no real need for it. That puts the "simple" patch at an artificial and unfair disadvantage. > This is the context of the benchmarks I've been sharing - me trying to > understand the practical implications/limits of the simple approach. Not > an attempt to somehow prove it's better, or anything like that. Makes sense. > I'm not opposed to continuing work on the "complex" approach, but as I > said, I'm sure I can't pull that off on my own. With your help, I think > the chance of success would be considerably higher. I can commit to making this project my #1 focus for Postgres 19 (#1 focus by far), provided the "complex" approach is used - just say the word. I cannot promise that we will be successful. But I can say for sure that I'll have skin in the game. If the project fails, then I'll have failed too. > Does this clarify how I think about the complex patch? Yes, it does. BTW, I don't think that there's all that much left to be said about nbtree in particular here. I don't think that there's very much work left there. -- Peter Geoghegan
Hi,
On 2025-07-18 19:44:51 +0200, Tomas Vondra wrote:
> I agree tableam needs to have a say in this, so that it can interpret
> the TIDs in a way that fits how it actually stores data. But I'm not
> sure it should be responsible for calling index_batch_getnext(). Isn't
> the batching mostly an "implementation" detail of the index AM? That's
> how I was thinking about it, at least.
I don't agree with that. For efficiency reasons alone table AMs should get a
whole batch of TIDs at once. If you have an ordered indexscan that returns
TIDs that are correlated with the table, we waste *tremendous* amount of
cycles right now.
Instead of locking the page, doing a HOT search for every tuple, and then
unlocking the page, we lock and unlock the page for every single TID. The
locking alone is a significant overhead (it's like 25% of the cycles or so),
but what's worse, it reduces what out-of-order execution can do to hide
cache-misses.
Even leaving locking overhead and out-of-order execution aside, there's a good
bit of constant overhead work in heap_hot_search_buffer() that can be avoided
by doing the work all at once.
Just to show how big that effect is, I hacked up a patch that holds the buffer
lock from when the buffer is first pinned in heapam_index_fetch_tuple() until
another buffer is pinned, or until the scan ends. That's totally not a valid
change due to holding the lock for far too long, but it's a decent
approximation of the gain of reducing the locking. This query
SELECT * FROM lineitem ORDER BY l_orderkey OFFSET 10000000 LIMIT 1;
speeds up by 28%. Of course that's an extreme case, but still.
That likely undersells the gain, because the out-of-order benefits aren't
really there due to all the other code that runs inbetween two
heap_hot_search_buffer() calls. It obviously also doesn't show any of the
amortization benefits.
IMO the flow really should be something like this:
IndexScan executor node
-> table "index" scan using the passed in IndexScanDesc
-> read stream doing readahead for all the required heap blocks
-> table AM next page callback
-> index scans returning batches
I think the way that IndexOnlyScan works today (independent of this patch)
really is a layering violation. It "knows" about the way the visibilitymap,
which it really has no business accessing, that's a heap specific thing. It
also knows too much about different formats that can be stored by indexes, but
that's kind of a separate issue.
Greetings,
Andres Freund
On Fri, Jul 18, 2025 at 4:52 PM Andres Freund <andres@anarazel.de> wrote: > I don't agree with that. For efficiency reasons alone table AMs should get a > whole batch of TIDs at once. If you have an ordered indexscan that returns > TIDs that are correlated with the table, we waste *tremendous* amount of > cycles right now. I agree, I think. But the terminology in this area can be confusing, so let's make sure that we all understand each other: I think that the table AM probably needs to have its own definition of a batch (or some other distinct phrase/concept) -- it's not necessarily the same group of TIDs that are associated with a batch on the index AM side. (Within an index AM, there is a 1:1 correspondence between batches and leaf pages, and batches need to hold on to a leaf page buffer pin for a time. None of this should really matter to the table AM.) At a high level, the table AM (and/or its read stream) asks for so many heap blocks/TIDs. Occasionally, index AM implementation details (i.e. the fact that many index leaf pages have to be read to get very few TIDs) will result in that request not being honored. The interface that the table AM uses must therefore occasionally answer "I'm sorry, I can only reasonably give you so many TIDs at this time". When that happens, the table AM has to make do. That can be very temporary, or it can happen again and again, depending on implementation details known only to the index AM side (though typically it'll never happen even once). Does that sound roughly right to you? Obviously these details are still somewhat hand-wavy -- I'm not fully sure of what the interface should look like, by any means. But the important points are: * The table AM drives the whole process. * The table AM knows essentially nothing about leaf pages/index AM batches -- it just has some general idea that sometimes it cannot have its request honored, in which case it must make do. * Some other layer represents the index AM -- though that layer actually lives outside of index AMs (this is the code that the "complex" patch currently puts in indexam.c). This other layer manages resources (primarily leaf page buffer pins) on behalf of each index AM. It also determines whether or not index AM implementation details make it impractical to give the table AM exactly what it asked for (this might actually require a small amount of cooperation from index AM code, based on simple generic measures like leaf pages read). * This other index AM layer does still know that it isn't cool to drop leaf page buffer pins before we're done reading the corresponding heap TIDs, due to heapam implementation details around making concurrent heap TID recycling safe. I'm not really sure how the table AM lets the new index AM layer know "okay, done with all those TIDs now" in a way that is both correct (in terms of avoiding unsafe concurrent TID recycling) and also gives the table AM the freedom to do its own kind of batch access at the level of heap pages. We don't necessarily have to figure all that out in the first committed version, though. -- Peter Geoghegan
Hi, On 2025-07-18 17:44:26 -0400, Peter Geoghegan wrote: > On Fri, Jul 18, 2025 at 4:52 PM Andres Freund <andres@anarazel.de> wrote: > > I don't agree with that. For efficiency reasons alone table AMs should get a > > whole batch of TIDs at once. If you have an ordered indexscan that returns > > TIDs that are correlated with the table, we waste *tremendous* amount of > > cycles right now. > > I agree, I think. But the terminology in this area can be confusing, > so let's make sure that we all understand each other: > > I think that the table AM probably needs to have its own definition of > a batch (or some other distinct phrase/concept) -- it's not > necessarily the same group of TIDs that are associated with a batch on > the index AM side. I assume, for heap, it'll always be a narrower definition than for the indexam, basically dealing with all the TIDs that fit within one page at once? > (Within an index AM, there is a 1:1 correspondence between batches and leaf > pages, and batches need to hold on to a leaf page buffer pin for a > time. None of this should really matter to the table AM.) To some degree the table AM will need to care about the index level batching - we have to be careful about how many pages we keep pinned overall. Which is something that both the table and the index AM have some influence over. > At a high level, the table AM (and/or its read stream) asks for so > many heap blocks/TIDs. Occasionally, index AM implementation details > (i.e. the fact that many index leaf pages have to be read to get very > few TIDs) will result in that request not being honored. The interface > that the table AM uses must therefore occasionally answer "I'm sorry, > I can only reasonably give you so many TIDs at this time". When that > happens, the table AM has to make do. That can be very temporary, or > it can happen again and again, depending on implementation details > known only to the index AM side (though typically it'll never happen > even once). I think that requirement will make things more complicated. Why do we need to have it? > Does that sound roughly right to you? Obviously these details are > still somewhat hand-wavy -- I'm not fully sure of what the interface > should look like, by any means. But the important points are: > > * The table AM drives the whole process. Check. > * The table AM knows essentially nothing about leaf pages/index AM > batches -- it just has some general idea that sometimes it cannot have > its request honored, in which case it must make do. Not entirely convinced by this one. > * Some other layer represents the index AM -- though that layer > actually lives outside of index AMs (this is the code that the > "complex" patch currently puts in indexam.c). This other layer manages > resources (primarily leaf page buffer pins) on behalf of each index > AM. It also determines whether or not index AM implementation details > make it impractical to give the table AM exactly what it asked for > (this might actually require a small amount of cooperation from index > AM code, based on simple generic measures like leaf pages read). I don't really have an opinion about this one. > * This other index AM layer does still know that it isn't cool to drop > leaf page buffer pins before we're done reading the corresponding heap > TIDs, due to heapam implementation details around making concurrent > heap TID recycling safe. I'm not sure why this needs to live in the generic code, rather than the specific index AM? > I'm not really sure how the table AM lets the new index AM layer know "okay, > done with all those TIDs now" in a way that is both correct (in terms of > avoiding unsafe concurrent TID recycling) and also gives the table AM the > freedom to do its own kind of batch access at the level of heap pages. I'd assume that the table AM has to call some indexam function to release index-batches, whenever it doesn't need the reference anymore? And the index-batch release can then unpin? Greetings, Andres Freund
On Fri, Jul 18, 2025 at 10:47 PM Andres Freund <andres@anarazel.de> wrote: > > I think that the table AM probably needs to have its own definition of > > a batch (or some other distinct phrase/concept) -- it's not > > necessarily the same group of TIDs that are associated with a batch on > > the index AM side. > > I assume, for heap, it'll always be a narrower definition than for the > indexam, basically dealing with all the TIDs that fit within one page at once? Yes, I think so. > > (Within an index AM, there is a 1:1 correspondence between batches and leaf > > pages, and batches need to hold on to a leaf page buffer pin for a > > time. None of this should really matter to the table AM.) > > To some degree the table AM will need to care about the index level batching - > we have to be careful about how many pages we keep pinned overall. Which is > something that both the table and the index AM have some influence over. Can't they operate independently? If not (if there must be a per-executor-node hard limit on pins held or whatever), then I still see no need for close coordination. > > At a high level, the table AM (and/or its read stream) asks for so > > many heap blocks/TIDs. Occasionally, index AM implementation details > > (i.e. the fact that many index leaf pages have to be read to get very > > few TIDs) will result in that request not being honored. The interface > > that the table AM uses must therefore occasionally answer "I'm sorry, > > I can only reasonably give you so many TIDs at this time". When that > > happens, the table AM has to make do. That can be very temporary, or > > it can happen again and again, depending on implementation details > > known only to the index AM side (though typically it'll never happen > > even once). > > I think that requirement will make things more complicated. Why do we need to > have it? What if it turns out that there is a large run of contiguous leaf pages that contain no more than 2 or 3 matching index tuples? What if there's no matches across many leaf pages? Surely we have to back off with prefetching when that happens. > > * The table AM knows essentially nothing about leaf pages/index AM > > batches -- it just has some general idea that sometimes it cannot have > > its request honored, in which case it must make do. > > Not entirely convinced by this one. We can probably get away with modelling all costs on the index AM side as the number of pages read. This isn't all that accurate; some pages are more expensive to read than others, it's more expensive to start a new primitive index scan/index search than it is to just step to the next page. But it's probably close enough for our purposes. And, I think that it'll generalize reasonably well across all index AMs. > > * This other index AM layer does still know that it isn't cool to drop > > leaf page buffer pins before we're done reading the corresponding heap > > TIDs, due to heapam implementation details around making concurrent > > heap TID recycling safe. > > I'm not sure why this needs to live in the generic code, rather than the > specific index AM? Currently, the "complex" patch calls into nbtree to release its buffer pin -- it does this by calling btfreebatch(). btfreebatch is not completely trivial (it also calls _bt_killitems as needed). But nbtree doesn't know when or how that'll happen. We're not obligated to do it in precisely the same order as the order the pages were read in, for example. In principle, the new indexam.c layer could do this in almost any order. > > I'm not really sure how the table AM lets the new index AM layer know "okay, > > done with all those TIDs now" in a way that is both correct (in terms of > > avoiding unsafe concurrent TID recycling) and also gives the table AM the > > freedom to do its own kind of batch access at the level of heap pages. > > I'd assume that the table AM has to call some indexam function to release > index-batches, whenever it doesn't need the reference anymore? And the > index-batch release can then unpin? It does. But that can be fairly generic -- btfreebatch will probably end up looking very similar to (say) hashfreebatch and gistfreebatch. Again, the indexam.c layer actually gets to decide when it happens -- that's what I meant about it being under its control (I didn't mean that it literally did everything without involving the index AM). -- Peter Geoghegan
On Sat, Jul 19, 2025 at 6:31 AM Tomas Vondra <tomas@vondra.me> wrote: > Perhaps the ReadStream should do something like this? Of course, the > simple patch resets the stream very often, likely mcuh more often than > anything else in the code. But wouldn't it be beneficial for streams > reset because of a rescan? Possibly needs to be optional. Right, that's also discussed, with a similar patch, here: https://www.postgresql.org/message-id/CA%2BhUKG%2Bx2BcqWzBC77cN0ewhzMF0kYhC6c4G_T2gJLPbqYQ6Ow%40mail.gmail.com Resetting the distance was a short-sighted mistake: I was thinking about rescans, the original use case for the reset operation, and guessing that the data would remain cached. But all the new users of _reset() have a completely different motivation, namely temporary exhaustion in their source data, so that guess was simply wrong. There was also some discussion at the time about whether "reset so I can rescan", and "reset so I can continue after a temporary stop" should be different operations requiring different APIs. It now seems like one operation is sufficient, but it should preserve the distance as you showed and then let the algorithm learn about already-cached data in the rescan case (if it is even true then, which is also debatable since it depends on the size of the scan). So, I think we should just go ahead and commit a patch like that.
On 7/19/25 06:03, Thomas Munro wrote: > On Sat, Jul 19, 2025 at 6:31 AM Tomas Vondra <tomas@vondra.me> wrote: >> Perhaps the ReadStream should do something like this? Of course, the >> simple patch resets the stream very often, likely mcuh more often than >> anything else in the code. But wouldn't it be beneficial for streams >> reset because of a rescan? Possibly needs to be optional. > > Right, that's also discussed, with a similar patch, here: > > https://www.postgresql.org/message-id/CA%2BhUKG%2Bx2BcqWzBC77cN0ewhzMF0kYhC6c4G_T2gJLPbqYQ6Ow%40mail.gmail.com > > Resetting the distance was a short-sighted mistake: I was thinking > about rescans, the original use case for the reset operation, and > guessing that the data would remain cached. But all the new users of > _reset() have a completely different motivation, namely temporary > exhaustion in their source data, so that guess was simply wrong. Thanks for the link. It seems I came up with an almost the same patch, with three minor differences: 1) There's another place that sets "distance = 0" in read_stream_next_buffer, so maybe this should preserve the distance too? 2) I suspect we need to preserve the distance at the beginning of read_stream_reset, like stream->reset_distance = Max(stream->reset_distance, stream->distance); because what if you call _reset before reaching the end of the stream? 3) Shouldn't it reset the reset_distance to 0 after restoring it? > There was also some discussion at the time about whether "reset so I > can rescan", and "reset so I can continue after a temporary stop" > should be different operations requiring different APIs. It now seems > like one operation is sufficient, but it should preserve the distance > as you showed and then let the algorithm learn about already-cached > data in the rescan case (if it is even true then, which is also > debatable since it depends on the size of the scan). So, I think we > should just go ahead and commit a patch like that. Not sure. To me it seems more like two distinct cases, but I'm not sure if it requires two distinct "operations" with distinct API. Perhaps a simple flag for the _reset() would be enough? It'd need to track the distance anyway, just in case. Consider for example a nested loop, which does a rescan every time the outer row changes. Is there a reason to believe the outer rows will need the same number of inner rows? Aren't those "distinct streams"? Maybe I'm thinking about this wrong, of course. The thing that however concerns me is that what I observed was not the distance getting reset to 1, and then ramping up. Which should happen pretty quickly, thanks to the doubling. In my experiments it *never* ramped up again, it stayed at 1. I still don't quite understand why. If this is happening for the nestloop case too, that'd be quite bad. regards -- Tomas Vondra
On Sat, Jul 19, 2025 at 11:23 PM Tomas Vondra <tomas@vondra.me> wrote: > Thanks for the link. It seems I came up with an almost the same patch, > with three minor differences: > > 1) There's another place that sets "distance = 0" in > read_stream_next_buffer, so maybe this should preserve the distance too? > > 2) I suspect we need to preserve the distance at the beginning of > read_stream_reset, like > > stream->reset_distance = Max(stream->reset_distance, > stream->distance); > > because what if you call _reset before reaching the end of the stream? > > 3) Shouldn't it reset the reset_distance to 0 after restoring it? Probably. Hmm... an earlier version of this code didn't use distance == 0 to indicate end-of-stream, but instead had a separate internal end_of_stream flag. If we brought that back and didn't clobber distance, we wouldn't need this save-and-restore dance. It seemed shorter and sweeter without it back then, before _reset() existed in its present form, but I wonder if end_of_stream would be nicer than having to add this kind of stuff, without measurable downsides. > > There was also some discussion at the time about whether "reset so I > > can rescan", and "reset so I can continue after a temporary stop" > > should be different operations requiring different APIs. It now seems > > like one operation is sufficient, but it should preserve the distance > > as you showed and then let the algorithm learn about already-cached > > data in the rescan case (if it is even true then, which is also > > debatable since it depends on the size of the scan). So, I think we > > should just go ahead and commit a patch like that. > > Not sure. To me it seems more like two distinct cases, but I'm not sure > if it requires two distinct "operations" with distinct API. Perhaps a > simple flag for the _reset() would be enough? It'd need to track the > distance anyway, just in case. > > Consider for example a nested loop, which does a rescan every time the > outer row changes. Is there a reason to believe the outer rows will need > the same number of inner rows? Aren't those "distinct streams"? Maybe > I'm thinking about this wrong, of course. Good question. Yeah, your flag idea seems like a good way to avoid baking opinion into this level. I wonder if it should be a bitmask rather than a boolean, in case we think of more things that need to be included or not when resetting. > The thing that however concerns me is that what I observed was not the > distance getting reset to 1, and then ramping up. Which should happen > pretty quickly, thanks to the doubling. In my experiments it *never* > ramped up again, it stayed at 1. I still don't quite understand why. Huh. Will look into that on Monday.
On Sun, Jul 20, 2025 at 1:07 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Sat, Jul 19, 2025 at 11:23 PM Tomas Vondra <tomas@vondra.me> wrote: > > The thing that however concerns me is that what I observed was not the > > distance getting reset to 1, and then ramping up. Which should happen > > pretty quickly, thanks to the doubling. In my experiments it *never* > > ramped up again, it stayed at 1. I still don't quite understand why. > > Huh. Will look into that on Monday. I suspect that it might be working as designed, but suffering from a bit of a weakness in the distance control algorithm, which I described in another thread[1]. In short, the simple minded algorithm that doubles on miss and subtracts one on hit can get stuck alternating between 1 and 2 if you hit certain patterns. Bilal pinged me off-list to say that he'd repro'd something like your test case and that's what seemed to be happening, anyway? I will dig out my experimental patches that tried different adjustments to escape from that state.... [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGLPakwZiFUa5fQXpYDpCXvZXQ%3DP3cWOGACCoobh7U2r3A%40mail.gmail.com
Hi, On Mon, 21 Jul 2025 at 03:59, Thomas Munro <thomas.munro@gmail.com> wrote: > > On Sun, Jul 20, 2025 at 1:07 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Sat, Jul 19, 2025 at 11:23 PM Tomas Vondra <tomas@vondra.me> wrote: > > > The thing that however concerns me is that what I observed was not the > > > distance getting reset to 1, and then ramping up. Which should happen > > > pretty quickly, thanks to the doubling. In my experiments it *never* > > > ramped up again, it stayed at 1. I still don't quite understand why. > > > > Huh. Will look into that on Monday. > > I suspect that it might be working as designed, but suffering from a > bit of a weakness in the distance control algorithm, which I described > in another thread[1]. In short, the simple minded algorithm that > doubles on miss and subtracts one on hit can get stuck alternating > between 1 and 2 if you hit certain patterns. Bilal pinged me off-list > to say that he'd repro'd something like your test case and that's what > seemed to be happening, anyway? I will dig out my experimental > patches that tried different adjustments to escape from that state.... I used Tomas Vondra's test [1]. I tracked how many times StartReadBuffersImpl() functions return true (IO is needed) and false (IO is not needed, cache hit). It returns true ~%6 times on both simple and complex patches (~116000 times true, ~1900000 times false on both patches). A complex patch ramps up to ~250 distance at the start of the stream and %6 is enough to stay at distance. Actually, it is enough to ramp up more but it seems the max distance is about ~270 so it stays there. On the other hand, a simple patch doesn't ramp up at the start of the stream and %6 is not enough to ramp up. It is always like distance is 1 and IO needed, so multiplying the distance by 2 -> distance = 2 but then the next block is cached, so decreasing the distance by 1 and distance is 1 again. [1] https://www.postgresql.org/message-id/aa46af80-5219-47e6-a7d0-7628106965a6%40vondra.me -- Regards, Nazir Bilal Yavuz Microsoft
On Sun, Jul 20, 2025 at 1:07 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Sat, Jul 19, 2025 at 11:23 PM Tomas Vondra <tomas@vondra.me> wrote: > > Thanks for the link. It seems I came up with an almost the same patch, > > with three minor differences: > > > > 1) There's another place that sets "distance = 0" in > > read_stream_next_buffer, so maybe this should preserve the distance too? > > > > 2) I suspect we need to preserve the distance at the beginning of > > read_stream_reset, like > > > > stream->reset_distance = Max(stream->reset_distance, > > stream->distance); > > > > because what if you call _reset before reaching the end of the stream? > > > > 3) Shouldn't it reset the reset_distance to 0 after restoring it? > > Probably. Hmm... an earlier version of this code didn't use distance > == 0 to indicate end-of-stream, but instead had a separate internal > end_of_stream flag. If we brought that back and didn't clobber > distance, we wouldn't need this save-and-restore dance. It seemed > shorter and sweeter without it back then, before _reset() existed in > its present form, but I wonder if end_of_stream would be nicer than > having to add this kind of stuff, without measurable downsides. ... > Good question. Yeah, your flag idea seems like a good way to avoid > baking opinion into this level. I wonder if it should be a bitmask > rather than a boolean, in case we think of more things that need to be > included or not when resetting. Here's a sketch of the above two ideas for discussion (.txt to stay off cfbot's radar for this thread). Better than save/restore? Here also are some alternative experimental patches for preserving accumulated look-ahead distance better in cases like that. Needs more exploration... thoughts/ideas welcome...
Вложения
On 7/21/25 08:53, Nazir Bilal Yavuz wrote: > Hi, > > On Mon, 21 Jul 2025 at 03:59, Thomas Munro <thomas.munro@gmail.com> wrote: >> >> On Sun, Jul 20, 2025 at 1:07 AM Thomas Munro <thomas.munro@gmail.com> wrote: >>> On Sat, Jul 19, 2025 at 11:23 PM Tomas Vondra <tomas@vondra.me> wrote: >>>> The thing that however concerns me is that what I observed was not the >>>> distance getting reset to 1, and then ramping up. Which should happen >>>> pretty quickly, thanks to the doubling. In my experiments it *never* >>>> ramped up again, it stayed at 1. I still don't quite understand why. >>> >>> Huh. Will look into that on Monday. >> >> I suspect that it might be working as designed, but suffering from a >> bit of a weakness in the distance control algorithm, which I described >> in another thread[1]. In short, the simple minded algorithm that >> doubles on miss and subtracts one on hit can get stuck alternating >> between 1 and 2 if you hit certain patterns. Bilal pinged me off-list >> to say that he'd repro'd something like your test case and that's what >> seemed to be happening, anyway? I will dig out my experimental >> patches that tried different adjustments to escape from that state.... > > I used Tomas Vondra's test [1]. I tracked how many times > StartReadBuffersImpl() functions return true (IO is needed) and false > (IO is not needed, cache hit). It returns true ~%6 times on both > simple and complex patches (~116000 times true, ~1900000 times false > on both patches). > > A complex patch ramps up to ~250 distance at the start of the stream > and %6 is enough to stay at distance. Actually, it is enough to ramp > up more but it seems the max distance is about ~270 so it stays there. > On the other hand, a simple patch doesn't ramp up at the start of the > stream and %6 is not enough to ramp up. It is always like distance is > 1 and IO needed, so multiplying the distance by 2 -> distance = 2 but > then the next block is cached, so decreasing the distance by 1 and > distance is 1 again. > > [1] https://www.postgresql.org/message-id/aa46af80-5219-47e6-a7d0-7628106965a6%40vondra.me > Yes, this is the behavior I observed too. I was wondering if the 5% miss ratio hit some special "threshold" in the distance heuristics, and maybe it'd work fine with a couple more misses. But I don't think so, I think pretty workloads with up to 50% misses may hit this problem. We reset the distance to 1, and then with 50% misses we'll do about 1 hit + 1 miss, which doubles the distance to 2 and then reduces the distance to 1, infinitely. Of course, that's only for even distribution hits/misses (and the synthetic workloads are fairly even). Real workloads are likely to have multiple misses in a row, which indeed ramps up the distance quickly. So maybe it's not that bad. Could we track a longer history of hits/misses, and consider that when adjusting the distance? Not just the most recent hit/miss? FWIW I re-ran the index-prefetch-test benchmarks with restoring the distance for the "simple" patch. The results are in the same github repository, in a separate branch: https://github.com/tvondra/indexscan-prefetch-tests/tree/with-distance-restore-after-reset I'm attaching two PDFs with results for eic=16 (linear and log-scale, to compare timings for quick queries). This shows that with restoring distance after reset, the simple patch is pretty much the same as the complex patch. The only data set where that's not the case is the "linear" data set, when everything is perfectly sequential. In this case the simple patch performs like "master" (i.e. no prefetching). I'm not sure why is that. Anyway, it seems to confirm most of the differences between the two patches is due to the "distance collapse". The impact of the resets in the first benchmarks surprised me quite a bit, but if we don't ramp up the distance that makes perfect sense. The issue probably affects other queries that do a lot of resets. Index scan prefetching just makes it very obvious. regards -- Tomas Vondra
Вложения
On 7/21/25 14:39, Thomas Munro wrote: > ... > > Here's a sketch of the above two ideas for discussion (.txt to stay > off cfbot's radar for this thread). Better than save/restore? > > Here also are some alternative experimental patches for preserving > accumulated look-ahead distance better in cases like that. Needs more > exploration... thoughts/ideas welcome... Thanks! I'll rerun the tests with these patches once the current round of tests (with the simple distance restore after a reset) completes. -- Tomas Vondra
On Tue, Jul 22, 2025 at 9:06 AM Tomas Vondra <tomas@vondra.me> wrote: > Real workloads are likely to have multiple misses in a row, which indeed > ramps up the distance quickly. So maybe it's not that bad. Could we > track a longer history of hits/misses, and consider that when adjusting > the distance? Not just the most recent hit/miss? +1 > FWIW I re-ran the index-prefetch-test benchmarks with restoring the > distance for the "simple" patch. The results are in the same github > repository, in a separate branch: > > https://github.com/tvondra/indexscan-prefetch-tests/tree/with-distance-restore-after-reset These results make way more sense. There was absolutely no reason why the "simple" patch should have done so much worse than the "complex" one for most of the tests you've been running. Obviously, whatever advantage that the "complex" patch has is bound to be limited to cases where index characteristics are naturally the limiting factor. For example, with the pgbench_accounts_pkey table there are only ever 6 distinct heap blocks on each leaf page. I bet that your "linear" test more or less looks like that, too. I attach pgbench_accounts_pkey_nhblks.txt, which shows a query that (among other things) ouputs "nhblks" for each leaf page from a given index (while showing the details of each leaf page in index key space order). It also shows results for pgbench_accounts_pkey with pgbench scale 1. This is how I determined that every pgbench_accounts_pkey leaf page points to exactly 6 distinct heap blocks -- "nhblks" is always 6. Note that this is what I see regardless of the pgbench scale, indicating that things always perfectly line up (even more than I would expect for very synthetic data such as this). This query is unwieldy when run against larger indexes, but that shouldn't be necessary. As with pgbench_accounts_pkey, it's typical for synthetically generated data to have a very consistent "nhblks", regardless of the total amount of data. With your "uniform" test cases, I'd expect this query to show "nhtids == nhblks" (or very close to it), which of course makes our ability to eagerly read further leaf pages almost irrelevant. If there are hundreds of distinct heap blocks on each leaf page, but effective_io_concurrency is 16 (or even 64), there's little we can do about it. > I'm attaching two PDFs with results for eic=16 (linear and log-scale, to > compare timings for quick queries). This shows that with restoring > distance after reset, the simple patch is pretty much the same as the > complex patch. > > The only data set where that's not the case is the "linear" data set, > when everything is perfectly sequential. In this case the simple patch > performs like "master" (i.e. no prefetching). I'm not sure why is that. Did you restore the distance for the "complex" patch, too? I think that it might well matter there too. Isn't the obvious explanation that the complex patch benefits from being able to prefetch without being limited by index characteristics/leaf page boundaries, while the simple patch doesn't? > Anyway, it seems to confirm most of the differences between the two > patches is due to the "distance collapse". The impact of the resets in > the first benchmarks surprised me quite a bit, but if we don't ramp up > the distance that makes perfect sense. > > The issue probably affects other queries that do a lot of resets. Index > scan prefetching just makes it very obvious. What is the difference between cases like "linear / eic=16 / sync" and "linear_1 / eic=16 / sync"? One would imagine that these tests are very similar, based on the fact that they have very similar names. But we see very different results for each: with the former ("linear") test results, the "complex" patch is 2x-4x faster than the "simple" patch. But, with the latter test results ("linear_1", and other similar pairs of "linear_N" tests) the advantage for the "complex" patch *completely* evaporates. I find that very suspicious, and wonder if it might be due to a bug/inefficiency that could easily be fixed (possibly an issue on the read stream side, like the one you mentioned to Nazir just now). -- Peter Geoghegan
Вложения
On Tue, Jul 22, 2025 at 1:35 PM Peter Geoghegan <pg@bowt.ie> wrote: > I attach pgbench_accounts_pkey_nhblks.txt, which shows a query that > (among other things) ouputs "nhblks" for each leaf page from a given > index (while showing the details of each leaf page in index key space > order). I just realized that my terminal corrupted the SQL query (but not the results). Attached is a valid and complete version of the same query. -- Peter Geoghegan
Вложения
On Tue, Jul 22, 2025 at 1:35 PM Peter Geoghegan <pg@bowt.ie> wrote:
> What is the difference between cases like "linear / eic=16 / sync" and
> "linear_1 / eic=16 / sync"?
I figured this out for myself.
> One would imagine that these tests are very similar, based on the fact
> that they have very similar names. But we see very different results
> for each: with the former ("linear") test results, the "complex" patch
> is 2x-4x faster than the "simple" patch. But, with the latter test
> results ("linear_1", and other similar pairs of "linear_N" tests) the
> advantage for the "complex" patch *completely* evaporates. I find that
> very suspicious
Turns out that the "linear" test's table is actually very different to
the "linear_1" test's table (same applies to all of the other
"linear_N" test tables). The query that I posted earlier clearly shows
this when run against the test data [1].
The "linear" test's linear_a_idx index consists of leaf pages that
each point to exactly 21 heap blocks. That is a lot more than the
pgbench_accounts_pkey's 6 blocks. But it's still low enough to see a huge
advantage on Tomas' test -- an index scan like that can be 2x - 4x
faster with the "complex" patch, relative to the "simple" patch. I
would expect an even larger advantage with a similar range query that
ran against pgbench_accounts.
OTOH, the "linear_1" tests's linear_1_a_idx index shows leaf pages
that each have about 300 distinct heap blocks. Since the total number
of heap TIDs is always 366, it's absolutely not surprising that we can
derive little value from the "complex" patch's ability to eagerly read
more than one leaf page at a time -- a scan like that simply isn't going to
benefit from eagerly reading pages (or it'll only see a very small benefit).
In summary, the only test that has any significant ability to
differentiate the "complex" patch from the "simple" patch is the
"linear" test, which is 2x - 4x faster. Everything else seems to be
about equal, which is what I'd expect, given the particulars of the
tests. This even includes the confusingly named "linear_1" and other
"linear_N" tests.
[1] https://github.com/tvondra/iomethod-tests/blob/master/create2.sql
--
Peter Geoghegan
On 7/22/25 19:35, Peter Geoghegan wrote: > On Tue, Jul 22, 2025 at 9:06 AM Tomas Vondra <tomas@vondra.me> wrote: >> Real workloads are likely to have multiple misses in a row, which indeed >> ramps up the distance quickly. So maybe it's not that bad. Could we >> track a longer history of hits/misses, and consider that when adjusting >> the distance? Not just the most recent hit/miss? > > +1 > >> FWIW I re-ran the index-prefetch-test benchmarks with restoring the >> distance for the "simple" patch. The results are in the same github >> repository, in a separate branch: >> >> https://github.com/tvondra/indexscan-prefetch-tests/tree/with-distance-restore-after-reset > > These results make way more sense. There was absolutely no reason why > the "simple" patch should have done so much worse than the "complex" > one for most of the tests you've been running. > > Obviously, whatever advantage that the "complex" patch has is bound to > be limited to cases where index characteristics are naturally the > limiting factor. For example, with the pgbench_accounts_pkey table > there are only ever 6 distinct heap blocks on each leaf page. I bet > that your "linear" test more or less looks like that, too. > Yes. It's definitely true we could construct examples where the complex patch beats the simple one for this reason. And I believe some of those examples could be quite realistic, even if not very common (like when very few index tuples fit on a leaf page). However, I'm not sure the pgbench example with only 6 heap blocks per leaf is very significant. Sure, the simple patch can't prefetch TIDs from the following leaf, but AFAICS the complex patch won't do that either. Not because it couldn't, but because with that many hits the distance will drop to ~1 (or close to it). (It'll probably prefetch a couple TIDs from the next leaf at the very end of the page, but I don't think that matters overall.) I'm not sure what prefetch distances will be sensible in queries that do other stuff. The queries in the benchmark do just the index scan, but if the query does something with the tuple (in the nodes on top), that shortens the required prefetch distance. Of course, simple queries will benefit from prefetching far ahead. > I attach pgbench_accounts_pkey_nhblks.txt, which shows a query that > (among other things) ouputs "nhblks" for each leaf page from a given > index (while showing the details of each leaf page in index key space > order). It also shows results for pgbench_accounts_pkey with pgbench > scale 1. This is how I determined that every pgbench_accounts_pkey > leaf page points to exactly 6 distinct heap blocks -- "nhblks" is > always 6. Note that this is what I see regardless of the pgbench > scale, indicating that things always perfectly line up (even more than > I would expect for very synthetic data such as this). > Thanks. I wonder how difficult would it be to add something like this to pgstattuple. I mean, it shouldn't be difficult to look at leaf pages and count distinct blocks, right? Seems quite useful. Explain would also greatly benefit from tracking something like this. The buffer "hits" and "reads" can be very difficult to interpret. > This query is unwieldy when run against larger indexes, but that > shouldn't be necessary. As with pgbench_accounts_pkey, it's typical > for synthetically generated data to have a very consistent "nhblks", > regardless of the total amount of data. > > With your "uniform" test cases, I'd expect this query to show "nhtids > == nhblks" (or very close to it), which of course makes our ability to > eagerly read further leaf pages almost irrelevant. If there are > hundreds of distinct heap blocks on each leaf page, but > effective_io_concurrency is 16 (or even 64), there's little we can do > about it. > Right. >> I'm attaching two PDFs with results for eic=16 (linear and log-scale, to >> compare timings for quick queries). This shows that with restoring >> distance after reset, the simple patch is pretty much the same as the >> complex patch. >> >> The only data set where that's not the case is the "linear" data set, >> when everything is perfectly sequential. In this case the simple patch >> performs like "master" (i.e. no prefetching). I'm not sure why is that. > > Did you restore the distance for the "complex" patch, too? I think > that it might well matter there too. > No, I did not. I did consider it, but it seemed to me it can't really make a difference (for these data sets), because each leaf has ~300 items, and the patch limits the prefetch to 64 leafs. That means it can prefetch ~20k TIDs ahead, and each heap page has ~20 items. So this should be good enough for eic=1000. It should never hit stream reset. It'd be useful to show some prefetch info in explain, I guess. It should not be difficult to track how many times was the stream reset, the average prefetch distance, and perhaps even a histogram of distances. The simple patch tracks the average distance, at least. > Isn't the obvious explanation that the complex patch benefits from > being able to prefetch without being limited by index > characteristics/leaf page boundaries, while the simple patch doesn't? > That's a valid interpretation, yes. Although the benefit comes mostly >> Anyway, it seems to confirm most of the differences between the two >> patches is due to the "distance collapse". The impact of the resets in >> the first benchmarks surprised me quite a bit, but if we don't ramp up >> the distance that makes perfect sense. >> >> The issue probably affects other queries that do a lot of resets. Index >> scan prefetching just makes it very obvious. > > What is the difference between cases like "linear / eic=16 / sync" and > "linear_1 / eic=16 / sync"? > > One would imagine that these tests are very similar, based on the fact > that they have very similar names. But we see very different results > for each: with the former ("linear") test results, the "complex" patch > is 2x-4x faster than the "simple" patch. But, with the latter test > results ("linear_1", and other similar pairs of "linear_N" tests) the > advantage for the "complex" patch *completely* evaporates. I find that > very suspicious, and wonder if it might be due to a bug/inefficiency > that could easily be fixed (possibly an issue on the read stream side, > like the one you mentioned to Nazir just now). > Yes, there's some similarity. Attached is the script I use to create the tables and load the data. The "linear" is a table with a simple sequence of values (0 to 100k). More or less - the value is a floating point, and there are 10M rows. But you get the idea. The "linear_X" variants mean the value has a noise of X% of the range. So with "linear_1" you get the "linear" value, and then random(0,1000), with normal distribution. The "cyclic" data sets are similar, except that the "sequence" also wraps around 100x. There's nothing "special" about the particular values. I simply wanted different "levels" of noise, and 1, 10 and 25 seemed good. I initially had a couple higher values, but that was pretty close to "uniform". regards -- Tomas Vondra
Вложения
Hi, On 2025-07-18 23:25:38 -0400, Peter Geoghegan wrote: > On Fri, Jul 18, 2025 at 10:47 PM Andres Freund <andres@anarazel.de> wrote: > > > (Within an index AM, there is a 1:1 correspondence between batches and leaf > > > pages, and batches need to hold on to a leaf page buffer pin for a > > > time. None of this should really matter to the table AM.) > > > > To some degree the table AM will need to care about the index level batching - > > we have to be careful about how many pages we keep pinned overall. Which is > > something that both the table and the index AM have some influence over. > > Can't they operate independently? I'm somewhat doubtful. Read stream is careful to limit how many things it pins, lest we get errors about having too many buffers pinned. Somehow the number of pins held within the index needs to be limited too, and how much that needs to be limited depends on how many buffers are pinned in the read stream :/ > > > At a high level, the table AM (and/or its read stream) asks for so > > > many heap blocks/TIDs. Occasionally, index AM implementation details > > > (i.e. the fact that many index leaf pages have to be read to get very > > > few TIDs) will result in that request not being honored. The interface > > > that the table AM uses must therefore occasionally answer "I'm sorry, > > > I can only reasonably give you so many TIDs at this time". When that > > > happens, the table AM has to make do. That can be very temporary, or > > > it can happen again and again, depending on implementation details > > > known only to the index AM side (though typically it'll never happen > > > even once). > > > > I think that requirement will make things more complicated. Why do we need to > > have it? > > What if it turns out that there is a large run of contiguous leaf > pages that contain no more than 2 or 3 matching index tuples? I think that's actually likely a case where you want *deeper* prefetching, as it makes it more likely that the table tuples are on different pages, i.e. you need a lot more in-flight IOs to avoid stalling on IO. > What if there's no matches across many leaf pages? We don't need to keep leaf nodes without matches pinned in that case, so I don't think there's really an issue? Greetings, Andres Freund
On Tue, Jul 22, 2025 at 4:50 PM Tomas Vondra <tomas@vondra.me> wrote:
> > Obviously, whatever advantage that the "complex" patch has is bound to
> > be limited to cases where index characteristics are naturally the
> > limiting factor. For example, with the pgbench_accounts_pkey table
> > there are only ever 6 distinct heap blocks on each leaf page. I bet
> > that your "linear" test more or less looks like that, too.
> >
>
> Yes. It's definitely true we could construct examples where the complex
> patch beats the simple one for this reason.
It's literally the only possible valid reason why the complex patch could win!
The sole performance justification for the complex patch is that it
can prevent the heap prefetching from getting bottlenecked on factors
tied to physical index characteristics (when it's possible in
principle to avoid getting bottlenecked in that way). Unsurprisingly,
if you assume that that'll never happen, then yeah, the complex patch
has no performance advantage over the simple one.
I happen to think that that's a very unrealistic assumption. Most
standard benchmarks have indexes that almost all look fairly similar
to pgbench_accounts_pkey, from the point of view of "heap page blocks
per leaf page". There are exceptions, of course (e.g., the TPC-C order
table's primary key suffers from fragmentation).
> And I believe some of those
> examples could be quite realistic, even if not very common (like when
> very few index tuples fit on a leaf page).
I don't think cases like that matter very much at all. The only thing
that *really* matters on the index AM side is the logical/physical
correlation. Which your testing seems largely unconcerned with.
> However, I'm not sure the pgbench example with only 6 heap blocks per
> leaf is very significant. Sure, the simple patch can't prefetch TIDs
> from the following leaf, but AFAICS the complex patch won't do that
> either.
Why not?
> Not because it couldn't, but because with that many hits the
> distance will drop to ~1 (or close to it). (It'll probably prefetch a
> couple TIDs from the next leaf at the very end of the page, but I don't
> think that matters overall.)
Then why do your own test results continue to show such a big
advantage for the complex patch, over the simple patch?
> I'm not sure what prefetch distances will be sensible in queries that do
> other stuff. The queries in the benchmark do just the index scan, but if
> the query does something with the tuple (in the nodes on top), that
> shortens the required prefetch distance. Of course, simple queries will
> benefit from prefetching far ahead.
Doing *no* prefetching will usually be the right thing to do. Does
that make index prefetching pointless in general?
> Thanks. I wonder how difficult would it be to add something like this to
> pgstattuple. I mean, it shouldn't be difficult to look at leaf pages and
> count distinct blocks, right? Seems quite useful.
I agree that that would be quite useful.
> > Did you restore the distance for the "complex" patch, too? I think
> > that it might well matter there too.
> >
>
> No, I did not. I did consider it, but it seemed to me it can't really
> make a difference (for these data sets), because each leaf has ~300
> items, and the patch limits the prefetch to 64 leafs. That means it can
> prefetch ~20k TIDs ahead, and each heap page has ~20 items. So this
> should be good enough for eic=1000. It should never hit stream reset.
It looks like the complex patch can reset the read stream for a couple
of reasons, which I don't fully understand right now.
I'm mostly thinking of this stuff:
/*
* If we advanced to the next batch, release the batch we no
* longer need. The positions is the "read" position, and we can
* compare it to firstBatch.
*/
if (pos->batch != scan->batchState->firstBatch)
{
batch = INDEX_SCAN_BATCH(scan, scan->batchState->firstBatch);
Assert(batch != NULL);
/*
* XXX When advancing readPos, the streamPos may get behind as
* we're only advancing it when actually requesting heap
* blocks. But we may not do that often enough - e.g. IOS may
* not need to access all-visible heap blocks, so the
* read_next callback does not get invoked for a long time.
* It's possible the stream gets so mucu behind the position
* gets invalid, as we already removed the batch. But that
* means we don't need any heap blocks until the current read
* position - if we did, we would not be in this situation (or
* it's a sign of a bug, as those two places are expected to
* be in sync). So if the streamPos still points at the batch
* we're about to free, just reset the position - we'll set it
* to readPos in the read_next callback later.
*
* XXX This can happen after the queue gets full, we "pause"
* the stream, and then reset it to continue. But I think that
* just increases the probability of hitting the issue, it's
* just more chance to to not advance the streamPos, which
* depends on when we try to fetch the first heap block after
* calling read_stream_reset().
*/
if (scan->batchState->streamPos.batch ==
scan->batchState->firstBatch)
index_batch_pos_reset(scan, &scan->batchState->streamPos);
> > Isn't the obvious explanation that the complex patch benefits from
> > being able to prefetch without being limited by index
> > characteristics/leaf page boundaries, while the simple patch doesn't?
> >
>
> That's a valid interpretation, yes. Although the benefit comes mostly
The benefit comes mostly from....?
> Yes, there's some similarity. Attached is the script I use to create the
> tables and load the data.
Another issue with the testing that biases it against the complex
patch: heap fill factor is set to only 25 (but you use the default
index fill-factor).
> The "linear" is a table with a simple sequence of values (0 to 100k).
> More or less - the value is a floating point, and there are 10M rows.
> But you get the idea.
>
> The "linear_X" variants mean the value has a noise of X% of the range.
> So with "linear_1" you get the "linear" value, and then random(0,1000),
> with normal distribution.
I don't get why this is helpful to test, except perhaps as a general smoke test.
If I zoom into any given "linear_1" leaf page, I see TIDs that appear
in an order that isn't technically uniformly random order, but is
fairly close to it. At least in a practical sense. At least for the
purposes of prefetching.
For example:
pg@regression:5432 [104789]=# select
itemoffset,
htid
from
bt_page_items('linear_1_a_idx', 4);
┌────────────┬───────────┐
│ itemoffset │ htid │
├────────────┼───────────┤
│ 1 │ ∅ │
│ 2 │ (10,18) │
│ 3 │ (463,9) │
│ 4 │ (66,8) │
│ 5 │ (79,9) │
│ 6 │ (594,7) │
│ 7 │ (289,13) │
│ 8 │ (568,2) │
│ 9 │ (237,2) │
│ 10 │ (156,10) │
│ 11 │ (432,9) │
│ 12 │ (372,17) │
│ 13 │ (554,6) │
│ 14 │ (1698,11) │
│ 15 │ (389,6) │
*** SNIP ***
│ 288 │ (1264,5) │
│ 289 │ (738,16) │
│ 290 │ (1143,3) │
│ 291 │ (400,1) │
│ 292 │ (1157,10) │
│ 293 │ (266,2) │
│ 294 │ (502,9) │
│ 295 │ (85,15) │
│ 296 │ (282,2) │
│ 297 │ (453,5) │
│ 298 │ (396,6) │
│ 299 │ (267,18) │
│ 300 │ (733,15) │
│ 301 │ (108,8) │
│ 302 │ (356,16) │
│ 303 │ (235,10) │
│ 304 │ (812,18) │
│ 305 │ (675,1) │
│ 306 │ (258,13) │
│ 307 │ (1187,9) │
│ 308 │ (185,2) │
│ 309 │ (179,2) │
│ 310 │ (951,2) │
└────────────┴───────────┘
(310 rows)
There's actually 55,556 heap blocks in total in the underlying table.
So clearly there is some correlation here. Just not enough to ever
matter very much to prefetching. Again, the sole test case that has
that quality to it is the "linear" test case.
--
Peter Geoghegan
Hi, On 2025-07-22 22:50:00 +0200, Tomas Vondra wrote: > Yes. It's definitely true we could construct examples where the complex > patch beats the simple one for this reason. And I believe some of those > examples could be quite realistic, even if not very common (like when > very few index tuples fit on a leaf page). > > However, I'm not sure the pgbench example with only 6 heap blocks per > leaf is very significant. Sure, the simple patch can't prefetch TIDs > from the following leaf, but AFAICS the complex patch won't do that > either. Not because it couldn't, but because with that many hits the > distance will drop to ~1 (or close to it). (It'll probably prefetch a > couple TIDs from the next leaf at the very end of the page, but I don't > think that matters overall.) > > I'm not sure what prefetch distances will be sensible in queries that do > other stuff. The queries in the benchmark do just the index scan, but if > the query does something with the tuple (in the nodes on top), that > shortens the required prefetch distance. Of course, simple queries will > benefit from prefetching far ahead. That may be true with local fast NVMe disks, but won't be true for networked storage like in common clouds. Latencies of 0.3 - 4ms leave a lot of CPU cycles for actual processing of the data. The high latencies for such storage also means that you need fairly deep queues and that missing prefetches can introduce substantial slowdowns. A hypothetical disk that can do 20k iops at 3ms latency needs an average IO depth of 60. If you have a bubble after every few dozen IOs, you're not going to reach that effective IO depth. And even for local NVMes, the IO-depth required to fully utilize the capacity for small random IO can be fairly high. I have a raid-10 of four SSDs that peaks at a depth around ~350. Also, plenty indexes are on multiple columns and/or wider datatypes, making bubbles triggered due to "crossing-the-leaf-page" more common. > Thanks. I wonder how difficult would it be to add something like this to > pgstattuple. I mean, it shouldn't be difficult to look at leaf pages and > count distinct blocks, right? Seems quite useful. +1 > Explain would also greatly benefit from tracking something like this. > The buffer "hits" and "reads" can be very difficult to interpret. Indeed. I actually observed that sometimes the reason that the real iodepth (i.e. measured at the OS level) ends up less high than one would hope is that, while prefetching, we again need a heap buffer that is already being prefetched. Currently the behaviour in that case is to synchronously wait for IO on that buffer to complete. That obviously causes a "pipeline bubble"... Greetings, Andres Freund
On Tue, Jul 22, 2025 at 6:53 PM Andres Freund <andres@anarazel.de> wrote: > That may be true with local fast NVMe disks, but won't be true for networked > storage like in common clouds. Latencies of 0.3 - 4ms leave a lot of CPU > cycles for actual processing of the data. I don't understand why it wouldn't be a problem for NVMe disks, too. Take a range scan on pgbench_accounts_pkey, for example -- something like your ORDER BY ... LIMIT N test case, but with pgbench data instead of TPC-H data. There are 6 heap blocks per leaf page. As I understand it, the simple patch will only be able to see up to 6 heap blocks "into the future", at any given time. Why isn't that quite a significant drawback, regardless of the underlying storage? > Also, plenty indexes are on multiple columns and/or wider datatypes, making > bubbles triggered due to "crossing-the-leaf-page" more common. I actually don't think that that's a significant factor. Even with fairly wide tuples, we'll still tend to be able to fit about 200 on each leaf page. For a variety of reasons that doesn't compare too badly to simple indexes (like pgbench_accounts_pkey), which will store about 370 when the index is in a pristine state. It does matter, but in the grand scheme of things it's unlikely to be decisive. -- Peter Geoghegan
Hi,
On 2025-07-22 19:13:23 -0400, Peter Geoghegan wrote:
> On Tue, Jul 22, 2025 at 6:53 PM Andres Freund <andres@anarazel.de> wrote:
> > That may be true with local fast NVMe disks, but won't be true for networked
> > storage like in common clouds. Latencies of 0.3 - 4ms leave a lot of CPU
> > cycles for actual processing of the data.
>
> I don't understand why it wouldn't be a problem for NVMe disks, too.
> Take a range scan on pgbench_accounts_pkey, for example -- something
> like your ORDER BY ... LIMIT N test case, but with pgbench data
> instead of TPC-H data. There are 6 heap blocks per leaf page. As I
> understand it, the simple patch will only be able to see up to 6 heap
> blocks "into the future", at any given time. Why isn't that quite a
> significant drawback, regardless of the underlying storage?
My response was specific to Tomas' comment that for many queries, which tend
to be more complicated than the toys we are using here, there will be CPU
costs in the query.
E.g. on my local NVMe SSD I get about 55k IOPS with an iodepth of 6 (that's
without stalls between leaf pages, so not really correct, but it's too much
math for me to compute). If you have 6 heap blocks referenced per index
block, with 60 tuples on those heap pages and you can get 55k iops with that,
you can fetch 20 million tuples / second. If per-tuple CPU processing takes
longer 10**9/20_000_000 = 50 nanoseconds, you'll not be bottlenecked on
storage.
E.g. for this silly query:
SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
while also using io_combine_limit=1 (to actually see the achieved IO depth), I
see an achieved IO depth of ~6.3 (complex).
Whereas this even sillier query:
SELECT max(abalance), min(abalance), sum(abalance::numeric), avg(abalance::numeric), avg(aid::numeric),
avg(bid::numeric)FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
only achieves an IO depth of ~4.1 (complex).
cheaper query expensive query
simple readahead 8723.209 ms 10615.232 ms
complex readahead 5069.438 ms 8018.347 ms
Obviously the CPU overhead in this example didn't completely eliminate the IO
bottleneck, but sure reduced the difference.
If your assumption is that real queries are more CPU intensive that the toy
stuff above, e.g. due to joins etc, you can see why the really attained IO
depth is lower.
Btw, something with the batching is off with the complex patch. I was
wondering why I was not seing 100% CPU usage while also not seeing very deep
queues - and I get deeper queues and better times with a lowered
INDEX_SCAN_MAX_BATCHES and worse with a higher one.
Greetings,
Andres Freund
On Tue, Jul 22, 2025 at 5:11 PM Andres Freund <andres@anarazel.de> wrote: > On 2025-07-18 23:25:38 -0400, Peter Geoghegan wrote: > > > To some degree the table AM will need to care about the index level batching - > > > we have to be careful about how many pages we keep pinned overall. Which is > > > something that both the table and the index AM have some influence over. > > > > Can't they operate independently? > > I'm somewhat doubtful. Read stream is careful to limit how many things it > pins, lest we get errors about having too many buffers pinned. Somehow the > number of pins held within the index needs to be limited too, and how much > that needs to be limited depends on how many buffers are pinned in the read > stream :/ That makes sense. Currently, the complex patch holds on to leaf page buffer pins until btfreebatch is called for the relevant batch -- no matter what. This is actually a short term workaround. I removed _bt_drop_lock_and_maybe_pin from nbtree (the thing added by commit 2ed5b87f), without adding back an equivalent function that can work across all index AMs. That shouldn't be hard. Once I do that, then plain index scans with MVCC snapshots should never actually have to hold on to buffer pins. I'm not sure if that makes the underlying resource management problem any easier to address -- but at least we won't *actually* hold on to any extra leaf page buffer pins most of the time (once I make this fix). > > What if there's no matches across many leaf pages? > > We don't need to keep leaf nodes without matches pinned in that case, so I > don't think there's really an issue? That might be true, but if we're reading leaf pages then we're not returning tuples to the scan -- even when, in principle, we could return at least a few more right away. That's the kind of trade-off I'm concerned about here. -- Peter Geoghegan
On 7/22/25 23:35, Peter Geoghegan wrote: > On Tue, Jul 22, 2025 at 4:50 PM Tomas Vondra <tomas@vondra.me> wrote: >>> Obviously, whatever advantage that the "complex" patch has is bound to >>> be limited to cases where index characteristics are naturally the >>> limiting factor. For example, with the pgbench_accounts_pkey table >>> there are only ever 6 distinct heap blocks on each leaf page. I bet >>> that your "linear" test more or less looks like that, too. >>> >> >> Yes. It's definitely true we could construct examples where the complex >> patch beats the simple one for this reason. > > It's literally the only possible valid reason why the complex patch could win! > > The sole performance justification for the complex patch is that it > can prevent the heap prefetching from getting bottlenecked on factors > tied to physical index characteristics (when it's possible in > principle to avoid getting bottlenecked in that way). Unsurprisingly, > if you assume that that'll never happen, then yeah, the complex patch > has no performance advantage over the simple one. > > I happen to think that that's a very unrealistic assumption. Most > standard benchmarks have indexes that almost all look fairly similar > to pgbench_accounts_pkey, from the point of view of "heap page blocks > per leaf page". There are exceptions, of course (e.g., the TPC-C order > table's primary key suffers from fragmentation). > I agree with all of this. >> And I believe some of those >> examples could be quite realistic, even if not very common (like when >> very few index tuples fit on a leaf page). > > I don't think cases like that matter very much at all. The only thing > that *really* matters on the index AM side is the logical/physical > correlation. Which your testing seems largely unconcerned with. > >> However, I'm not sure the pgbench example with only 6 heap blocks per >> leaf is very significant. Sure, the simple patch can't prefetch TIDs >> from the following leaf, but AFAICS the complex patch won't do that >> either. > > Why not? > >> Not because it couldn't, but because with that many hits the >> distance will drop to ~1 (or close to it). (It'll probably prefetch a >> couple TIDs from the next leaf at the very end of the page, but I don't >> think that matters overall.) > > Then why do your own test results continue to show such a big > advantage for the complex patch, over the simple patch? > I assume you mean results for the "linear" data set, because for every other data set the patches perform almost exactly the same (when restoring the distance after stream reset): https://github.com/tvondra/indexscan-prefetch-tests/blob/with-distance-restore-after-reset/d16-rows-cold-32GB-16-unscaled.pdf And it's a very good point. I was puzzled by this too for a while, and it took me a while to understand how/why this happens. It pretty much boils down to the "duplicate block" detection and how it interacts with the stream resets (again!). Both patches detect duplicate blocks the same way - using a lastBlock field, checked in the next_block callback, and skip reading the same block multiple times. Which for the "linear" data set happens a lot, because the index is correlated and so every block repeats ~20x. This seems to trigger entirely different behaviors in the two patches. For the complex patch, this results in very high prefetch distance, about ~270. Which seems like less than one leaf page (which has ~360 items). But if I log the read/stream positions seen in index_batch_getnext_tid, I often see this: LOG: index_batch_getnext_tid match 0 read (9,271) stream (22,264) That is, the stream ~13 batches ahead. AFAICS this happens because the read_next callback (which "produces" block numbers to the stream), skips the duplicate blocks, so that the stream never even knows about them. So the stream thinks the distance is 270, but it's really 20x that (when measured in index items). I realize this is another way to trigger the stream resets with the complex patch, even though that didn't happen here (the limit is 64 leafs, we used 13). So you're right the complex patch prefetches far ahead. I thought the distance will quickly decrease because of the duplicate blocks, but I missed the fact the read stream will not seem them at all. I'm not sure it's desirable to "hide" blocks from the read stream like this - it'll never see the misses. How could it make good decisions, when we skew the data used by the heuristics like this? For the simple patch, the effect seems exactly the opposite. It detects duplicate blocks the same way, but there's a caveat - resetting the stream invalidates the lastBlock field, so it can't detect duplicate blocks from the previous leaf. And so the distance drops. But this should not matter I think (it's just a single miss for the first item), so the rest really has to be about the single-leaf limit. (This is my working theory, I still need to investigate it a bit more.) >> I'm not sure what prefetch distances will be sensible in queries that do >> other stuff. The queries in the benchmark do just the index scan, but if >> the query does something with the tuple (in the nodes on top), that >> shortens the required prefetch distance. Of course, simple queries will >> benefit from prefetching far ahead. > > Doing *no* prefetching will usually be the right thing to do. Does > that make index prefetching pointless in general? > I don't think so. Why would it? There's plenty of queries that can benefit from it a lot, and as long as it doesn't cause harm to other queries it's a win. >> Thanks. I wonder how difficult would it be to add something like this to >> pgstattuple. I mean, it shouldn't be difficult to look at leaf pages and >> count distinct blocks, right? Seems quite useful. > > I agree that that would be quite useful. > Good first patch for someone ;-) >>> Did you restore the distance for the "complex" patch, too? I think >>> that it might well matter there too. >>> >> >> No, I did not. I did consider it, but it seemed to me it can't really >> make a difference (for these data sets), because each leaf has ~300 >> items, and the patch limits the prefetch to 64 leafs. That means it can >> prefetch ~20k TIDs ahead, and each heap page has ~20 items. So this >> should be good enough for eic=1000. It should never hit stream reset. > > It looks like the complex patch can reset the read stream for a couple > of reasons, which I don't fully understand right now. > > I'm mostly thinking of this stuff: > > /* > * If we advanced to the next batch, release the batch we no > * longer need. The positions is the "read" position, and we can > * compare it to firstBatch. > */ > if (pos->batch != scan->batchState->firstBatch) > { > batch = INDEX_SCAN_BATCH(scan, scan->batchState->firstBatch); > Assert(batch != NULL); > > /* > * XXX When advancing readPos, the streamPos may get behind as > * we're only advancing it when actually requesting heap > * blocks. But we may not do that often enough - e.g. IOS may > * not need to access all-visible heap blocks, so the > * read_next callback does not get invoked for a long time. > * It's possible the stream gets so mucu behind the position > * gets invalid, as we already removed the batch. But that > * means we don't need any heap blocks until the current read > * position - if we did, we would not be in this situation (or > * it's a sign of a bug, as those two places are expected to > * be in sync). So if the streamPos still points at the batch > * we're about to free, just reset the position - we'll set it > * to readPos in the read_next callback later. > * > * XXX This can happen after the queue gets full, we "pause" > * the stream, and then reset it to continue. But I think that > * just increases the probability of hitting the issue, it's > * just more chance to to not advance the streamPos, which > * depends on when we try to fetch the first heap block after > * calling read_stream_reset(). > */ > if (scan->batchState->streamPos.batch == > scan->batchState->firstBatch) > index_batch_pos_reset(scan, &scan->batchState->streamPos); > This is not resetting the stream, though. This is resetting the position tracking how far the stream got. This happens because the stream moves forward only in response to reading buffers from it. So without calling read_stream_next_buffer() it won't call the read_next callback generating the blocks. And it's the callback that advances the streamPos field, so it may get stale. This happens e.g. for index only scans, when we read a couple blocks that are not all-visible (so that goes through the stream). And then we get a bunch of all-visible blocks, so we only return the TIDs and index tuples. The stream gets "behind" the readPos, and may even point at a batch that was already freed. >>> Isn't the obvious explanation that the complex patch benefits from >>> being able to prefetch without being limited by index >>> characteristics/leaf page boundaries, while the simple patch doesn't? >>> >> >> That's a valid interpretation, yes. Although the benefit comes mostly > > The benefit comes mostly from....? > Sorry, got distracted and forgot to complete the sentence. I think I wanted to write "mostly from not resetting the distance to 1". Which is true, but the earlier "linear" example also shows there are cases where the page boundaries are significant. >> Yes, there's some similarity. Attached is the script I use to create the >> tables and load the data. > > Another issue with the testing that biases it against the complex > patch: heap fill factor is set to only 25 (but you use the default > index fill-factor). > That's actually intentional. I wanted to model tables with wider tuples, without having to generate all the data etc. Maybe 25% is too much, and real table have more than 20 tuples. It's true 400B is fairly large. I'm not against testing with other parameters, of course. The test was not originally written for comparing different prefetching patches, so it may not be quite fair (and I'm not sure how to define "fair"). >> The "linear" is a table with a simple sequence of values (0 to 100k). >> More or less - the value is a floating point, and there are 10M rows. >> But you get the idea. >> >> The "linear_X" variants mean the value has a noise of X% of the range. >> So with "linear_1" you get the "linear" value, and then random(0,1000), >> with normal distribution. > > I don't get why this is helpful to test, except perhaps as a general smoke test. > > If I zoom into any given "linear_1" leaf page, I see TIDs that appear > in an order that isn't technically uniformly random order, but is > fairly close to it. At least in a practical sense. At least for the > purposes of prefetching. > It's not uniformly random, I wrote it uses normal distribution. The query in the SQL script does this: select x + random_normal(0, 1000) from ... It is a synthetic test data set, of course. It's meant to be simple to generate, reason about, and somewhere in between the "linear" and "uniform" data sets. But it also has realistic motivation - real tables are usually not as clean as "linear", nor as random as the "uniform" data sets (not for all columns, at least). If you're looking at data sets like "orders" or whatever, there's usually a bit of noise even for columns like "date" etc. People modify the orders, or fill-in data from a couple days ago, etc. Perfect correlation for one column implies slightly worse correlation for another column (order date vs. delivery date). > For example: > > pg@regression:5432 [104789]=# select > itemoffset, > htid > from > bt_page_items('linear_1_a_idx', 4); > ┌────────────┬───────────┐ > │ itemoffset │ htid │ > ├────────────┼───────────┤ > │ 1 │ ∅ │ > │ 2 │ (10,18) │ > │ 3 │ (463,9) │ > │ 4 │ (66,8) │ > │ 5 │ (79,9) │ > │ 6 │ (594,7) │ > │ 7 │ (289,13) │ > │ 8 │ (568,2) │ > │ 9 │ (237,2) │ > │ 10 │ (156,10) │ > │ 11 │ (432,9) │ > │ 12 │ (372,17) │ > │ 13 │ (554,6) │ > │ 14 │ (1698,11) │ > │ 15 │ (389,6) │ > *** SNIP *** > │ 288 │ (1264,5) │ > │ 289 │ (738,16) │ > │ 290 │ (1143,3) │ > │ 291 │ (400,1) │ > │ 292 │ (1157,10) │ > │ 293 │ (266,2) │ > │ 294 │ (502,9) │ > │ 295 │ (85,15) │ > │ 296 │ (282,2) │ > │ 297 │ (453,5) │ > │ 298 │ (396,6) │ > │ 299 │ (267,18) │ > │ 300 │ (733,15) │ > │ 301 │ (108,8) │ > │ 302 │ (356,16) │ > │ 303 │ (235,10) │ > │ 304 │ (812,18) │ > │ 305 │ (675,1) │ > │ 306 │ (258,13) │ > │ 307 │ (1187,9) │ > │ 308 │ (185,2) │ > │ 309 │ (179,2) │ > │ 310 │ (951,2) │ > └────────────┴───────────┘ > (310 rows) > > There's actually 55,556 heap blocks in total in the underlying table. > So clearly there is some correlation here. Just not enough to ever > matter very much to prefetching. Again, the sole test case that has > that quality to it is the "linear" test case. > Right. I don't see a problem with this. I'm not saying parameters for this particular data set are "perfect", but the intent is to have a range of data sets from "perfectly clean" to "random" and see how the patch(es) behave on all of them. If you have a suggestion for different data sets, or how to tweak the parameters to make it more realistic, I'm happy to try those. regards -- Tomas Vondra
On Tue, Jul 22, 2025 at 8:08 PM Andres Freund <andres@anarazel.de> wrote: > My response was specific to Tomas' comment that for many queries, which tend > to be more complicated than the toys we are using here, there will be CPU > costs in the query. Got it. That makes sense. > cheaper query expensive query > simple readahead 8723.209 ms 10615.232 ms > complex readahead 5069.438 ms 8018.347 ms > > Obviously the CPU overhead in this example didn't completely eliminate the IO > bottleneck, but sure reduced the difference. That's a reasonable distinction, of course. > If your assumption is that real queries are more CPU intensive that the toy > stuff above, e.g. due to joins etc, you can see why the really attained IO > depth is lower. Right. Perhaps I was just repeating myself. Tomas seemed to be suggesting that cases where we'll actually get a decent and completely worthwhile improvement with the complex patch would be naturally rare, due in part to these effects with CPU overhead. I don't think that that's true at all. > Btw, something with the batching is off with the complex patch. I was > wondering why I was not seing 100% CPU usage while also not seeing very deep > queues - and I get deeper queues and better times with a lowered > INDEX_SCAN_MAX_BATCHES and worse with a higher one. I'm not at all surprised that there'd be bugs like that. I don't know about Tomas, but I've given almost no thought to INDEX_SCAN_MAX_BATCHES specifically just yet. -- Peter Geoghegan
On 7/23/25 02:39, Peter Geoghegan wrote: > On Tue, Jul 22, 2025 at 8:08 PM Andres Freund <andres@anarazel.de> wrote: >> My response was specific to Tomas' comment that for many queries, which tend >> to be more complicated than the toys we are using here, there will be CPU >> costs in the query. > > Got it. That makes sense. > >> cheaper query expensive query >> simple readahead 8723.209 ms 10615.232 ms >> complex readahead 5069.438 ms 8018.347 ms >> >> Obviously the CPU overhead in this example didn't completely eliminate the IO >> bottleneck, but sure reduced the difference. > > That's a reasonable distinction, of course. > >> If your assumption is that real queries are more CPU intensive that the toy >> stuff above, e.g. due to joins etc, you can see why the really attained IO >> depth is lower. > > Right. > > Perhaps I was just repeating myself. Tomas seemed to be suggesting > that cases where we'll actually get a decent and completely worthwhile > improvement with the complex patch would be naturally rare, due in > part to these effects with CPU overhead. I don't think that that's > true at all. > >> Btw, something with the batching is off with the complex patch. I was >> wondering why I was not seing 100% CPU usage while also not seeing very deep >> queues - and I get deeper queues and better times with a lowered >> INDEX_SCAN_MAX_BATCHES and worse with a higher one. > > I'm not at all surprised that there'd be bugs like that. I don't know > about Tomas, but I've given almost no thought to > INDEX_SCAN_MAX_BATCHES specifically just yet. > I think I mostly picked a value high enough to make it unlikely to hit it in realistic cases, while also not using too much memory, and 64 seemed like a good value. But I don't see why would this have any effect on the prefetch distance, queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve that. I'd have expected exactly the opposite behavior. Could be bug, of course. But it'd be helpful to see the dataset/query. regards -- Tomas Vondra
Hi, On 2025-07-23 02:50:04 +0200, Tomas Vondra wrote: > But I don't see why would this have any effect on the prefetch distance, > queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve > that. I'd have expected exactly the opposite behavior. > > Could be bug, of course. But it'd be helpful to see the dataset/query. Pgbench scale 500, with the simpler query from my message. Greetings, Andres Freund
On 7/23/25 02:39, Peter Geoghegan wrote: > On Tue, Jul 22, 2025 at 8:08 PM Andres Freund <andres@anarazel.de> wrote: >> My response was specific to Tomas' comment that for many queries, which tend >> to be more complicated than the toys we are using here, there will be CPU >> costs in the query. > > Got it. That makes sense. > >> cheaper query expensive query >> simple readahead 8723.209 ms 10615.232 ms >> complex readahead 5069.438 ms 8018.347 ms >> >> Obviously the CPU overhead in this example didn't completely eliminate the IO >> bottleneck, but sure reduced the difference. > > That's a reasonable distinction, of course. > >> If your assumption is that real queries are more CPU intensive that the toy >> stuff above, e.g. due to joins etc, you can see why the really attained IO >> depth is lower. > > Right. > > Perhaps I was just repeating myself. Tomas seemed to be suggesting > that cases where we'll actually get a decent and completely worthwhile > improvement with the complex patch would be naturally rare, due in > part to these effects with CPU overhead. I don't think that that's > true at all. It's entirely possible my mental model is too naive, or my intuition about the queries is wrong ... My mental model of how this works is that if I know the amount of time T1 to process a page, and the amount of time T2 to handle an I/O, then I can estimate when I should have submitted a read for a page. For example if T1=1ms and T2=10ms, then I know I should submit an I/O ~10 pages ahead in order to not have to wait. That's the "minimal" queue depth. Of course, on high latency "cloud storage" the queue depth needs to grow, because the time T1 to process a page is likely about the same (if determined by CPU), but the T2 time for I/O is much higher. So we need to issue the I/O much sooner. When I mentioned "complex" queries, I meant queries where processing a page takes much more time. Because it reads the page, and passes it to other operators in the query plan, some of which may do CPU stuff, some will trigger some synchronous I/O, etc. Which means T1 grows, and the "minimal" queue depth decreases. Which part of this is not quite right? -- Tomas Vondra
On 7/23/25 02:59, Andres Freund wrote: > Hi, > > On 2025-07-23 02:50:04 +0200, Tomas Vondra wrote: >> But I don't see why would this have any effect on the prefetch distance, >> queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve >> that. I'd have expected exactly the opposite behavior. >> >> Could be bug, of course. But it'd be helpful to see the dataset/query. > > Pgbench scale 500, with the simpler query from my message. > With direct I/O, I guess? I'll take a look tomorrow. regard -- Tomas Vondra
On Wed, Jul 23, 2025 at 1:55 AM Tomas Vondra <tomas@vondra.me> wrote: > On 7/21/25 14:39, Thomas Munro wrote: > > Here also are some alternative experimental patches for preserving > > accumulated look-ahead distance better in cases like that. Needs more > > exploration... thoughts/ideas welcome... > > Thanks! I'll rerun the tests with these patches once the current round > of tests (with the simple distance restore after a reset) completes. Here's C, a tider expression of the policy from the B patch. Also, I realised that the quickly-drafted A patch didn't actually implement what Andres suggested in the other thread as I had intended, what he actually speculated about is distance * 2 + nblocks. But it doesn't seem to matter much: anything you come up with along those lines seems to suffer from the problem that you can easily produce a test that defeats it by inserting just one more hit in between the misses, where the numbers involved can be quite small. The only policy I've come up with so far that doesn't give up until we definitely can't do better is the one that tracks a hypothetical window of the largest distance we possibly could have, and refuses to shrink the actual window until even the maximum wouldn't be enough, as expressed in the B and C patches. On the flip side, that degree of pessimism has a cost: of course it takes much longer to come back to distance = 1 and perhaps the fast path. Does it matter? I don't know. (It's only a hunch at this point but I think I can see a potentially better way to derive that sustain value from information available with another in-development patch that adds a new io_currency_target value, using IO subsystem feedback to compute the IO concurrency level that avoids I/O stalls but not more instead of going all the way to the GUC limits and making it the user's problem to set them sensibly. I'll have to look into that properly, but I think it might be able to produce an ideal sustain value...)
Вложения
On Tue, Jul 22, 2025 at 8:37 PM Tomas Vondra <tomas@vondra.me> wrote: > > I happen to think that that's a very unrealistic assumption. Most > > standard benchmarks have indexes that almost all look fairly similar > > to pgbench_accounts_pkey, from the point of view of "heap page blocks > > per leaf page". There are exceptions, of course (e.g., the TPC-C order > > table's primary key suffers from fragmentation). > > > > I agree with all of this. Cool. > I assume you mean results for the "linear" data set, because for every > other data set the patches perform almost exactly the same (when > restoring the distance after stream reset): > > https://github.com/tvondra/indexscan-prefetch-tests/blob/with-distance-restore-after-reset/d16-rows-cold-32GB-16-unscaled.pdf Right. > And it's a very good point. I was puzzled by this too for a while, and > it took me a while to understand how/why this happens. It pretty much > boils down to the "duplicate block" detection and how it interacts with > the stream resets (again!). I think that you slightly misunderstand where I'm coming from here: it *doesn't* puzzle me. What puzzled me was that it puzzled you. Andres' test query is very simple, and not entirely sympathetic towards the complex patch (by design). And yet it *also* gets quite a decent improvement from the complex patch. It doesn't speed things up by another order of magnitude or anything, but it's a very decent improvement -- one well worth having. I'm also unsurprised at the fact that all the other tests that you ran were more or less a draw between simple and complex. At least not now that I've drilled down and understood what the indexes from those other test cases actually look like, in practice. > So you're right the complex patch prefetches far ahead. I thought the > distance will quickly decrease because of the duplicate blocks, but I > missed the fact the read stream will not seem them at all. FWIW I wasn't thinking about it at anything like that level of sophistication. Everything I've said about it was based on intuitions about how the prefetching was bound to work, for each different kind of index. I just looked at individual leaf pages (or small groups of them) from each index/test, and considered their TIDs, and imagined how that was likely to affect the scan. It just seems obvious to me that all the tests (except for "linear") couldn't possibly be helped by eagerly reading multiple leaf pages. It seemed equally obvious that it's quite possible to come up with a suite of tests that have several tests that could benefit in the same way (not just 1). Although your "linear_1"/"linear_N" tests aren't actually like that, many cases will be -- and not just those that are perfectly correlated ala pgbench. > I'm not sure it's desirable to "hide" blocks from the read stream like > this - it'll never see the misses. How could it make good decisions, > when we skew the data used by the heuristics like this? I don't think that I fully understand what's desirable here myself. > > Doing *no* prefetching will usually be the right thing to do. Does > > that make index prefetching pointless in general? > > > > I don't think so. Why would it? There's plenty of queries that can > benefit from it a lot, and as long as it doesn't cause harm to other > queries it's a win. I was being sarcastic. That wasn't a useful thing for me to do. Apologies. > This is not resetting the stream, though. This is resetting the position > tracking how far the stream got. My main point is that there's stuff going on here that nobody quite understands just yet. And so it probably makes sense to defensively assume that the prefetch distance resetting stuff might matter with either the complex or simple patch. > Sorry, got distracted and forgot to complete the sentence. I think I > wanted to write "mostly from not resetting the distance to 1". Which is > true, but the earlier "linear" example also shows there are cases where > the page boundaries are significant. Of course that's true. But that was just a temporary defect of the "simple" patch (and perhaps even for the "complex" patch, albeit to a much lesser degree). It isn't really relevant to the important question of whether the simple or complex design should be pursued -- we know that now. As I said, I don't think that the test suite is particularly well suited to evaluating simple vs complex. Because there's only one test ("linear") that has any hope of being better with the complex patch. And because having only 1 such test isn't representative. > That's actually intentional. I wanted to model tables with wider tuples, > without having to generate all the data etc. Maybe 25% is too much, and > real table have more than 20 tuples. It's true 400B is fairly large. My point about fill factor isn't particularly important. > I'm not against testing with other parameters, of course. The test was > not originally written for comparing different prefetching patches, so > it may not be quite fair (and I'm not sure how to define "fair"). I'd like to see more than 1 test where eagerly reading leaf pages has any hope of helping. That's my only important concern. > It's not uniformly random, I wrote it uses normal distribution. The > query in the SQL script does this: > > select x + random_normal(0, 1000) from ... > > It is a synthetic test data set, of course. It's meant to be simple to > generate, reason about, and somewhere in between the "linear" and > "uniform" data sets. I always start by looking at the index leaf pages, and imagining how an index scan can/will deal with that. Just because it's not truly uniformly random doesn't mean that that's apparent when you just look at one leaf page -- heap blocks might very well *appear* to be uniformly random (or close to it) when you drill down like that. Or even when you look at (say) 50 neighboring leaf pages. > But it also has realistic motivation - real tables are usually not as > clean as "linear", nor as random as the "uniform" data sets (not for all > columns, at least). If you're looking at data sets like "orders" or > whatever, there's usually a bit of noise even for columns like "date" > etc. People modify the orders, or fill-in data from a couple days ago, > etc. Perfect correlation for one column implies slightly worse > correlation for another column (order date vs. delivery date). I agree. > Right. I don't see a problem with this. I'm not saying parameters for > this particular data set are "perfect", but the intent is to have a > range of data sets from "perfectly clean" to "random" and see how the > patch(es) behave on all of them. Obviously none of your test cases are invalid -- they're all basically reasonable, when considered in isolation. But the "linear_1" test is *far* closer to the "uniform" test than it is to the "linear" test. At least as far as the simple vs complex question is concerned. > If you have a suggestion for different data sets, or how to tweak the > parameters to make it more realistic, I'm happy to try those. I'll get back to you on this soon. There are plenty of indexes that are not perfectly correlated (like pgbench_accounts_pkey is) that'll nevertheless benefit significantly from the approach taken by the complex patch. I'm sure of this because I've been using the query I posted early for many years now -- I've thought about and directly instrumented the "nhtids:nhblks" of an index of interest many times in the past. Thanks -- Peter Geoghegan
On 7/23/25 03:31, Peter Geoghegan wrote: > On Tue, Jul 22, 2025 at 8:37 PM Tomas Vondra <tomas@vondra.me> wrote: >>> I happen to think that that's a very unrealistic assumption. Most >>> standard benchmarks have indexes that almost all look fairly similar >>> to pgbench_accounts_pkey, from the point of view of "heap page blocks >>> per leaf page". There are exceptions, of course (e.g., the TPC-C order >>> table's primary key suffers from fragmentation). >>> >> >> I agree with all of this. > > Cool. > >> I assume you mean results for the "linear" data set, because for every >> other data set the patches perform almost exactly the same (when >> restoring the distance after stream reset): >> >> https://github.com/tvondra/indexscan-prefetch-tests/blob/with-distance-restore-after-reset/d16-rows-cold-32GB-16-unscaled.pdf > > Right. > >> And it's a very good point. I was puzzled by this too for a while, and >> it took me a while to understand how/why this happens. It pretty much >> boils down to the "duplicate block" detection and how it interacts with >> the stream resets (again!). > > I think that you slightly misunderstand where I'm coming from here: it > *doesn't* puzzle me. What puzzled me was that it puzzled you. > > Andres' test query is very simple, and not entirely sympathetic > towards the complex patch (by design). And yet it *also* gets quite a > decent improvement from the complex patch. It doesn't speed things up > by another order of magnitude or anything, but it's a very decent > improvement -- one well worth having. > > I'm also unsurprised at the fact that all the other tests that you ran > were more or less a draw between simple and complex. At least not now > that I've drilled down and understood what the indexes from those > other test cases actually look like, in practice. > >> So you're right the complex patch prefetches far ahead. I thought the >> distance will quickly decrease because of the duplicate blocks, but I >> missed the fact the read stream will not seem them at all. > > FWIW I wasn't thinking about it at anything like that level of > sophistication. Everything I've said about it was based on intuitions > about how the prefetching was bound to work, for each different kind > of index. I just looked at individual leaf pages (or small groups of > them) from each index/test, and considered their TIDs, and imagined > how that was likely to affect the scan. > > It just seems obvious to me that all the tests (except for "linear") > couldn't possibly be helped by eagerly reading multiple leaf pages. It > seemed equally obvious that it's quite possible to come up with a > suite of tests that have several tests that could benefit in the same > way (not just 1). Although your "linear_1"/"linear_N" tests aren't > actually like that, many cases will be -- and not just those that are > perfectly correlated ala pgbench. > >> I'm not sure it's desirable to "hide" blocks from the read stream like >> this - it'll never see the misses. How could it make good decisions, >> when we skew the data used by the heuristics like this? > > I don't think that I fully understand what's desirable here myself. > >>> Doing *no* prefetching will usually be the right thing to do. Does >>> that make index prefetching pointless in general? >>> >> >> I don't think so. Why would it? There's plenty of queries that can >> benefit from it a lot, and as long as it doesn't cause harm to other >> queries it's a win. > > I was being sarcastic. That wasn't a useful thing for me to do. Apologies. > >> This is not resetting the stream, though. This is resetting the position >> tracking how far the stream got. > > My main point is that there's stuff going on here that nobody quite > understands just yet. And so it probably makes sense to defensively > assume that the prefetch distance resetting stuff might matter with > either the complex or simple patch. > >> Sorry, got distracted and forgot to complete the sentence. I think I >> wanted to write "mostly from not resetting the distance to 1". Which is >> true, but the earlier "linear" example also shows there are cases where >> the page boundaries are significant. > > Of course that's true. But that was just a temporary defect of the > "simple" patch (and perhaps even for the "complex" patch, albeit to a > much lesser degree). It isn't really relevant to the important > question of whether the simple or complex design should be pursued -- > we know that now. > > As I said, I don't think that the test suite is particularly well > suited to evaluating simple vs complex. Because there's only one test > ("linear") that has any hope of being better with the complex patch. > And because having only 1 such test isn't representative. > >> That's actually intentional. I wanted to model tables with wider tuples, >> without having to generate all the data etc. Maybe 25% is too much, and >> real table have more than 20 tuples. It's true 400B is fairly large. > > My point about fill factor isn't particularly important. > Yeah, the randomness of the TIDs matters too much. >> I'm not against testing with other parameters, of course. The test was >> not originally written for comparing different prefetching patches, so >> it may not be quite fair (and I'm not sure how to define "fair"). > > I'd like to see more than 1 test where eagerly reading leaf pages has > any hope of helping. That's my only important concern. > Agreed. >> It's not uniformly random, I wrote it uses normal distribution. The >> query in the SQL script does this: >> >> select x + random_normal(0, 1000) from ... >> >> It is a synthetic test data set, of course. It's meant to be simple to >> generate, reason about, and somewhere in between the "linear" and >> "uniform" data sets. > > I always start by looking at the index leaf pages, and imagining how > an index scan can/will deal with that. > > Just because it's not truly uniformly random doesn't mean that that's > apparent when you just look at one leaf page -- heap blocks might very > well *appear* to be uniformly random (or close to it) when you drill > down like that. Or even when you look at (say) 50 neighboring leaf > pages. > Yeah, the number of heap blocks per leaf page is a useful measure. I should have thought about that. The other thing worth tracking is probably how the number of heap blocks increases with multiple leaf pages, to measure the "hit ratio". I should have thought about this more when creating the data sets ... >> But it also has realistic motivation - real tables are usually not as >> clean as "linear", nor as random as the "uniform" data sets (not for all >> columns, at least). If you're looking at data sets like "orders" or >> whatever, there's usually a bit of noise even for columns like "date" >> etc. People modify the orders, or fill-in data from a couple days ago, >> etc. Perfect correlation for one column implies slightly worse >> correlation for another column (order date vs. delivery date). > > I agree. > >> Right. I don't see a problem with this. I'm not saying parameters for >> this particular data set are "perfect", but the intent is to have a >> range of data sets from "perfectly clean" to "random" and see how the >> patch(es) behave on all of them. > > Obviously none of your test cases are invalid -- they're all basically > reasonable, when considered in isolation. But the "linear_1" test is > *far* closer to the "uniform" test than it is to the "linear" test. At > least as far as the simple vs complex question is concerned. > Perhaps not invalid, but it also does not cover the space of possible data sets the way I intended. It seems all the data sets are much more random than I expected. >> If you have a suggestion for different data sets, or how to tweak the >> parameters to make it more realistic, I'm happy to try those. > > I'll get back to you on this soon. There are plenty of indexes that > are not perfectly correlated (like pgbench_accounts_pkey is) that'll > nevertheless benefit significantly from the approach taken by the > complex patch. I'm sure of this because I've been using the query I > posted early for many years now -- I've thought about and directly > instrumented the "nhtids:nhblks" of an index of interest many times in > the past. > Thanks! regards -- Tomas Vondra
On 7/23/25 02:59, Andres Freund wrote:
> Hi,
>
> On 2025-07-23 02:50:04 +0200, Tomas Vondra wrote:
>> But I don't see why would this have any effect on the prefetch distance,
>> queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve
>> that. I'd have expected exactly the opposite behavior.
>>
>> Could be bug, of course. But it'd be helpful to see the dataset/query.
>
> Pgbench scale 500, with the simpler query from my message.
>
I tried to reproduce this, but I'm not seeing behavior. I'm not sure how
you monitor the queue depth (presumably iostat?), but I added a basic
prefetch info to explain (see the attached WIP patch), reporting the
average prefetch distance, number of stalls (with distance=0) and stream
resets (after filling INDEX_SCAN_MAX_BATCHES).
And I see this (there's a complete explain output attached) for the two
queries from your message [1]. The
simple query:
SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid
LIMIT 10000000);
complex query:
SELECT max(abalance), min(abalance), sum(abalance::numeric),
avg(abalance::numeric), avg(aid::numeric), avg(bid::numeric) FROM
(SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
The stats actually look *exactly* the same, which makes sense because
it's reading the same index.
max_batches distance stalls resets stalls/reset
--------------------------------------------------------------------
64 272 3 3 1
32 59 122939 653 188
16 36 108101 1190 90
8 21 98775 2104 46
4 11 95627 4556 20
I think this behavior mostly matches my expectations, although it's
interesting the stalls jump so much between 64 and 32 batches.
I did test both with buffered I/O (io_method=sync) and direct I/O
(io_method=worker), and the results are exactly the same for me. Not the
timings, of course, but the prefetch stats.
Of course, maybe there's something wrong in how the stats are collected.
I wonder if maybe we should update the distance in get_block() and not
in next_buffer().
Or maybe there's some interference from having to read the leaf pages
sooner. But I don't see why that would affect the queue depth, fewer
reset should keep the queues fuller I think.
I'll think about adding some sort of distance histogram to the stats.
Maybe something like tinyhist [2] would work here.
[1]
https://www.postgresql.org/message-id/h2n7d7zb2lbkdcemopvrgmteo35zzi5ljl2jmk32vz5f4pziql%407ppr6r6yfv4z
[2] https://github.com/tvondra/tinyhist
regards
--
Tomas Vondra
Вложения
Hi,
On 2025-07-23 14:50:15 +0200, Tomas Vondra wrote:
> On 7/23/25 02:59, Andres Freund wrote:
> > Hi,
> >
> > On 2025-07-23 02:50:04 +0200, Tomas Vondra wrote:
> >> But I don't see why would this have any effect on the prefetch distance,
> >> queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve
> >> that. I'd have expected exactly the opposite behavior.
> >>
> >> Could be bug, of course. But it'd be helpful to see the dataset/query.
> >
> > Pgbench scale 500, with the simpler query from my message.
> >
>
> I tried to reproduce this, but I'm not seeing behavior. I'm not sure how
> you monitor the queue depth (presumably iostat?)
Yes, iostat, since I was looking at what the "actually required" lookahead
distance is.
Do you actually get the query to be entirely CPU bound? What amount of IO
waiting do you see EXPLAIN (ANALYZE, TIMING OFF) with track_io_timing=on
report?
Ah - I was using a very high effective_io_concurrency. With a high
effective_io_concurrency value I see a lot of stalls, even at
INDEX_SCAN_MAX_BATCHES = 64. And a lower prefetch distance, which seems
somewhat odd.
FWIW, in my tests I was just evicting lineitem from shared buffers, since I
wanted to test the heap prefetching, without stalls induced by blocking on
index reads. But what I described happens with either.
;SET effective_io_concurrency = 256;SELECT pg_buffercache_evict_relation('pgbench_accounts'); explain (analyze, costs
off,timing off) SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Aggregate (actual rows=1.00 loops=1) │
│ Buffers: shared hit=27369 read=164191 │
│ I/O Timings: shared read=358.795 │
│ -> Limit (actual rows=10000000.00 loops=1) │
│ Buffers: shared hit=27369 read=164191 │
│ I/O Timings: shared read=358.795 │
│ -> Index Scan using pgbench_accounts_pkey on pgbench_accounts (actual rows=10000000.00 loops=1) │
│ Index Searches: 1 │
│ Prefetch Distance: 256.989 │
│ Prefetch Stalls: 3 │
│ Prefetch Resets: 3 │
│ Buffers: shared hit=27369 read=164191 │
│ I/O Timings: shared read=358.795 │
│ Planning Time: 0.086 ms │
│ Execution Time: 4194.845 ms │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────┘
;SET effective_io_concurrency = 512;SELECT pg_buffercache_evict_relation('pgbench_accounts'); explain (analyze, costs
off,timing off) SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Aggregate (actual rows=1.00 loops=1) │
│ Buffers: shared hit=27368 read=164190 │
│ I/O Timings: shared read=832.515 │
│ -> Limit (actual rows=10000000.00 loops=1) │
│ Buffers: shared hit=27368 read=164190 │
│ I/O Timings: shared read=832.515 │
│ -> Index Scan using pgbench_accounts_pkey on pgbench_accounts (actual rows=10000000.00 loops=1) │
│ Index Searches: 1 │
│ Prefetch Distance: 56.778 │
│ Prefetch Stalls: 160569 │
│ Prefetch Resets: 423 │
│ Buffers: shared hit=27368 read=164190 │
│ I/O Timings: shared read=832.515 │
│ Planning Time: 0.084 ms │
│ Execution Time: 4413.058 ms │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Greetings,
Andres Freund
On Tue, Jul 22, 2025 at 9:31 PM Peter Geoghegan <pg@bowt.ie> wrote: > I'll get back to you on this soon. There are plenty of indexes that > are not perfectly correlated (like pgbench_accounts_pkey is) that'll > nevertheless benefit significantly from the approach taken by the > complex patch. I'll give you a few examples that look like this. I'm not necessarily suggesting that you adopt these example indexes into your test suite -- these are just to stimulate discussion. * The TPC-C order line table primary key. This is the single largest index used by TPC-C, by quite some margin. This is the index that my Postgres 12 "split after new tuple" optimization made about 40% smaller with retail inserts -- I've already studied it in detail. It's a composite index on 4 integer columns, where each leaf page contains about 260 index tuples. Note that this is true regardless of whether retail inserts or CREATE INDEX were used (thanks to the "split after new tuple" thing). And yet I see that nhblks is even *lower* than pgbench_accounts: the average per-leaf-page nhblks is about 4 or 5. While the odd leaf page has an nhblks of 7 or 8, some individual leaf pages that are full, but have an nhblks of only 4. I would expect such an index to benefit to the maximum possible extent from the complex patch/eager leaf page reading. This is true in spite of the fact that technically the overall correlation is weak. Here's what a random leaf page looks like, in terms of TIDs: ┌────────────┬───────────┐ │ itemoffset │ htid │ ├────────────┼───────────┤ │ 1 │ ∅ │ │ 2 │ (1510,55) │ │ 3 │ (1510,56) │ │ 4 │ (1510,57) │ │ 5 │ (1510,58) │ │ 6 │ (1510,59) │ │ 7 │ (1510,60) │ │ 8 │ (1510,61) │ │ 9 │ (1510,62) │ │ 10 │ (1510,63) │ │ 11 │ (1510,64) │ │ 12 │ (1510,65) │ │ 13 │ (1510,66) │ │ 14 │ (1510,67) │ │ 15 │ (1510,68) │ │ 16 │ (1510,69) │ │ 17 │ (1510,70) │ │ 18 │ (1510,71) │ │ 19 │ (1510,72) │ │ 20 │ (1510,73) │ │ 21 │ (1510,74) │ │ 22 │ (1510,75) │ │ 23 │ (1510,76) │ │ 24 │ (1510,77) │ │ 25 │ (1510,78) │ │ 26 │ (1510,79) │ │ 27 │ (1510,80) │ │ 28 │ (1510,81) │ │ 29 │ (1517,1) │ │ 30 │ (1517,2) │ │ 31 │ (1517,3) │ │ 32 │ (1517,4) │ │ 33 │ (1517,5) │ │ 34 │ (1517,6) │ │ 35 │ (1517,7) │ │ 36 │ (1517,8) │ │ 37 │ (1517,9) │ │ 38 │ (1517,10) │ │ 39 │ (1517,11) │ │ 40 │ (1517,12) │ │ 41 │ (1517,13) │ │ 42 │ (1517,14) │ │ 43 │ (1517,15) │ │ 44 │ (1517,16) │ │ 45 │ (1517,17) │ │ 46 │ (1517,18) │ │ 47 │ (1517,19) │ │ 48 │ (1517,20) │ │ 49 │ (1517,21) │ │ 50 │ (1517,22) │ │ 51 │ (1517,23) │ │ 52 │ (1517,24) │ │ 53 │ (1517,25) │ │ 54 │ (1517,26) │ │ 55 │ (1517,27) │ │ 56 │ (1517,28) │ │ 57 │ (1517,29) │ │ 58 │ (1517,30) │ │ 59 │ (1517,31) │ │ 60 │ (1517,32) │ │ 61 │ (1517,33) │ │ 62 │ (1517,34) │ │ 63 │ (1517,35) │ │ 64 │ (1517,36) │ │ 65 │ (1517,37) │ │ 66 │ (1517,38) │ │ 67 │ (1517,39) │ │ 68 │ (1517,40) │ │ 69 │ (1517,41) │ │ 70 │ (1517,42) │ │ 71 │ (1517,43) │ │ 72 │ (1517,44) │ │ 73 │ (1517,45) │ │ 74 │ (1517,46) │ │ 75 │ (1517,47) │ │ 76 │ (1517,48) │ │ 77 │ (1517,49) │ │ 78 │ (1517,50) │ │ 79 │ (1517,51) │ │ 80 │ (1517,52) │ │ 81 │ (1517,53) │ │ 82 │ (1517,54) │ │ 83 │ (1517,55) │ │ 84 │ (1517,56) │ │ 85 │ (1517,57) │ │ 86 │ (1517,58) │ │ 87 │ (1517,59) │ │ 88 │ (1517,60) │ │ 89 │ (1517,62) │ │ 90 │ (1523,1) │ │ 91 │ (1523,2) │ │ 92 │ (1523,3) │ │ 93 │ (1523,4) │ │ 94 │ (1523,5) │ │ 95 │ (1523,6) │ │ 96 │ (1523,7) │ │ 97 │ (1523,8) │ │ 98 │ (1523,9) │ │ 99 │ (1523,10) │ │ 100 │ (1523,11) │ │ 101 │ (1523,12) │ │ 102 │ (1523,13) │ │ 103 │ (1523,14) │ │ 104 │ (1523,15) │ │ 105 │ (1523,16) │ │ 106 │ (1523,17) │ │ 107 │ (1523,18) │ │ 108 │ (1523,19) │ │ 109 │ (1523,20) │ │ 110 │ (1523,21) │ │ 111 │ (1523,22) │ │ 112 │ (1523,23) │ │ 113 │ (1523,24) │ │ 114 │ (1523,25) │ │ 115 │ (1523,26) │ │ 116 │ (1523,27) │ │ 117 │ (1523,28) │ │ 118 │ (1523,29) │ │ 119 │ (1523,30) │ │ 120 │ (1523,31) │ │ 121 │ (1523,32) │ │ 122 │ (1523,33) │ │ 123 │ (1523,34) │ │ 124 │ (1523,35) │ │ 125 │ (1523,36) │ │ 126 │ (1523,37) │ │ 127 │ (1523,38) │ │ 128 │ (1523,39) │ │ 129 │ (1523,40) │ │ 130 │ (1523,41) │ │ 131 │ (1523,42) │ │ 132 │ (1523,43) │ │ 133 │ (1523,44) │ │ 134 │ (1523,45) │ │ 135 │ (1523,46) │ │ 136 │ (1523,47) │ │ 137 │ (1523,48) │ │ 138 │ (1523,49) │ │ 139 │ (1523,50) │ │ 140 │ (1523,51) │ │ 141 │ (1523,52) │ │ 142 │ (1523,53) │ │ 143 │ (1523,54) │ │ 144 │ (1523,55) │ │ 145 │ (1523,56) │ │ 146 │ (1523,57) │ │ 147 │ (1523,58) │ │ 148 │ (1523,59) │ │ 149 │ (1523,60) │ │ 150 │ (1523,61) │ │ 151 │ (1523,62) │ │ 152 │ (1523,63) │ │ 153 │ (1523,64) │ │ 154 │ (1523,65) │ │ 155 │ (1523,66) │ │ 156 │ (1523,67) │ │ 157 │ (1523,68) │ │ 158 │ (1523,69) │ │ 159 │ (1523,70) │ │ 160 │ (1523,71) │ │ 161 │ (1523,72) │ │ 162 │ (1523,73) │ │ 163 │ (1523,74) │ │ 164 │ (1523,75) │ │ 165 │ (1523,76) │ │ 166 │ (1523,77) │ │ 167 │ (1523,78) │ │ 168 │ (1523,79) │ │ 169 │ (1523,80) │ │ 170 │ (1523,81) │ │ 171 │ (1531,1) │ │ 172 │ (1531,2) │ │ 173 │ (1531,3) │ │ 174 │ (1531,4) │ │ 175 │ (1531,5) │ │ 176 │ (1531,6) │ │ 177 │ (1531,7) │ │ 178 │ (1531,8) │ │ 179 │ (1531,9) │ │ 180 │ (1531,10) │ │ 181 │ (1531,11) │ │ 182 │ (1531,12) │ │ 183 │ (1531,13) │ │ 184 │ (1531,14) │ │ 185 │ (1531,15) │ │ 186 │ (1531,16) │ │ 187 │ (1531,17) │ │ 188 │ (1531,18) │ │ 189 │ (1531,19) │ │ 190 │ (1531,20) │ │ 191 │ (1531,21) │ │ 192 │ (1531,22) │ │ 193 │ (1531,23) │ │ 194 │ (1531,24) │ │ 195 │ (1531,25) │ │ 196 │ (1531,26) │ │ 197 │ (1531,27) │ │ 198 │ (1531,28) │ │ 199 │ (1531,29) │ │ 200 │ (1531,30) │ │ 201 │ (1531,31) │ │ 202 │ (1531,32) │ │ 203 │ (1531,33) │ │ 204 │ (1531,34) │ │ 205 │ (1531,35) │ │ 206 │ (1531,36) │ │ 207 │ (1531,37) │ │ 208 │ (1531,38) │ │ 209 │ (1531,39) │ │ 210 │ (1531,40) │ │ 211 │ (1531,41) │ │ 212 │ (1531,42) │ │ 213 │ (1531,43) │ │ 214 │ (1531,44) │ │ 215 │ (1531,45) │ │ 216 │ (1531,46) │ │ 217 │ (1531,47) │ │ 218 │ (1531,48) │ │ 219 │ (1531,49) │ │ 220 │ (1531,50) │ │ 221 │ (1531,51) │ │ 222 │ (1531,52) │ │ 223 │ (1531,53) │ │ 224 │ (1531,54) │ │ 225 │ (1531,55) │ │ 226 │ (1531,56) │ │ 227 │ (1531,57) │ │ 228 │ (1531,58) │ │ 229 │ (1531,59) │ │ 230 │ (1531,60) │ │ 231 │ (1531,61) │ │ 232 │ (1531,62) │ │ 233 │ (1531,63) │ │ 234 │ (1531,64) │ │ 235 │ (1531,65) │ │ 236 │ (1531,66) │ │ 237 │ (1531,67) │ │ 238 │ (1531,68) │ │ 239 │ (1531,69) │ │ 240 │ (1531,70) │ │ 241 │ (1531,71) │ │ 242 │ (1531,72) │ │ 243 │ (1531,73) │ │ 244 │ (1531,74) │ │ 245 │ (1531,75) │ │ 246 │ (1531,76) │ │ 247 │ (1531,77) │ │ 248 │ (1531,78) │ │ 249 │ (1531,79) │ │ 250 │ (1531,80) │ │ 251 │ (1531,81) │ │ 252 │ (1539,1) │ │ 253 │ (1539,2) │ │ 254 │ (1539,3) │ │ 255 │ (1539,4) │ │ 256 │ (1539,5) │ │ 257 │ (1539,6) │ │ 258 │ (1539,7) │ │ 259 │ (1539,8) │ │ 260 │ (1539,9) │ │ 261 │ (1539,10) │ └────────────┴───────────┘ (261 rows) Notice that there are contiguous groups of tuples that all point to the same heap block. These groups are really groups of items (on average 10 items) from a given order. Individual warehouses seem to have a tendency to insert multiple orders together, which further lowers nhtids. You can tell that tuples aren't inserted in strict ascending order because there are "heap TID discontinuities". For example, item 165 (which is the last item from a given order) points to (15377,81), while item 166 (which is the first item from the next order made to the same warehouse) points to (15385,1). There is a "heap block gap" between index tuple item 165 and 166 -- these "missing" heap blocks don't appear anywhere on the same leaf page. Note also that many of the other TPC-C indexes have this same quality to them. They also consist of groups of related tuples, that get inserted together in ascending order -- and yet the *overall* pattern for the index is pretty far from inserts happening in ascending key space order. * A low cardinality index. In one way, this works against the complex patch: if there are ~1350 TIDs on every leaf page (thanks to nbtree deduplication), we're presumably less likely to ever need to read very many leaf pages eagerly. But in another way it favors the complex patch: each individual distinct value will have its TIDs stored/read in TID order, which can be enough of a factor to get us a low nhtids value for each leaf page. I see a nhtids of 5 - 7 for leaf pages from the following index: create table low_cardinality(foo int4); CREATE TABLE create index on low_cardinality (foo); CREATE INDEX insert into low_cardinality select hashint4(j) from generate_series(1,10_000) i, generate_series(1,100) j; INSERT 0 1000000 This is actually kinda like the TPC-C index, in a way: "foo" column values all look random. But within a given value, the TIDs are in ascending order, which (at least here) is enough to get us a very low nhtids -- even in spite of each leaf page storing more than 4x as many TIDs than could be stored within each of the TPC-C index's pages. Note that the number of CPU cycles needed within nbtree to read a leaf page from a low cardinality index is probably *lower* than the typical case for a unique index. This is due to a variety of factors -- the main factor is that there aren't very many index tuples to evaluate on the page. So the scan isn't bottlenecked at that (certainly not to an extent that is commensurate with the overall number of TIDs). The terminology in this area is tricky. We say "correlation", when perhaps we should say something like "heap clustering factor" -- a concept that seems hard to define precisely. It doesn't help that the planner models all this using a correlation stat -- that encourages us to reduce everything to a single scalar correlation number, which can be quite misleading. I could give more examples, if you want. But they'd all just be variations of the same thing. -- Peter Geoghegan
On 7/23/25 17:09, Andres Freund wrote:
> Hi,
>
> On 2025-07-23 14:50:15 +0200, Tomas Vondra wrote:
>> On 7/23/25 02:59, Andres Freund wrote:
>>> Hi,
>>>
>>> On 2025-07-23 02:50:04 +0200, Tomas Vondra wrote:
>>>> But I don't see why would this have any effect on the prefetch distance,
>>>> queue depth etc. Or why decreasing INDEX_SCAN_MAX_BATCHES should improve
>>>> that. I'd have expected exactly the opposite behavior.
>>>>
>>>> Could be bug, of course. But it'd be helpful to see the dataset/query.
>>>
>>> Pgbench scale 500, with the simpler query from my message.
>>>
>>
>> I tried to reproduce this, but I'm not seeing behavior. I'm not sure how
>> you monitor the queue depth (presumably iostat?)
>
> Yes, iostat, since I was looking at what the "actually required" lookahead
> distance is.
>
> Do you actually get the query to be entirely CPU bound? What amount of IO
> waiting do you see EXPLAIN (ANALYZE, TIMING OFF) with track_io_timing=on
> report?
>
No, it definitely needs to wait for I/O (FWIW it's on the xeon, with a
single NVMe SSD).
> Ah - I was using a very high effective_io_concurrency. With a high
> effective_io_concurrency value I see a lot of stalls, even at
> INDEX_SCAN_MAX_BATCHES = 64. And a lower prefetch distance, which seems
> somewhat odd.
>
I think that's a bug in the explain patch. The counters were updated at
the beginning of _next_buffer(), but that's wrong - a single call to
_next_buffer() can prefetch multiple blocks. This skewed the stats, as
the prefetches are not counted with "distance=0". With higher eic this
happens sooner, so the average distance seemed to decrease.
The attached patch does the updates in _get_block(), which I think is
better. And "stall" now means (distance == 1), which I think detects
requests without prefetching.
I also added a separate "Count" for the actual number of prefetched
blocks, and "Skipped" for duplicate blocks skipped (which the read
stream never even sees, because it's skipped in the callback).
>
> FWIW, in my tests I was just evicting lineitem from shared buffers, since I
> wanted to test the heap prefetching, without stalls induced by blocking on
> index reads. But what I described happens with either.
>
> ;SET effective_io_concurrency = 256;SELECT pg_buffercache_evict_relation('pgbench_accounts'); explain (analyze, costs
off,timing off) SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
> ┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
> │ QUERY PLAN │
> ├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤
> │ Aggregate (actual rows=1.00 loops=1) │
> │ Buffers: shared hit=27369 read=164191 │
> │ I/O Timings: shared read=358.795 │
> │ -> Limit (actual rows=10000000.00 loops=1) │
> │ Buffers: shared hit=27369 read=164191 │
> │ I/O Timings: shared read=358.795 │
> │ -> Index Scan using pgbench_accounts_pkey on pgbench_accounts (actual rows=10000000.00 loops=1) │
> │ Index Searches: 1 │
> │ Prefetch Distance: 256.989 │
> │ Prefetch Stalls: 3 │
> │ Prefetch Resets: 3 │
> │ Buffers: shared hit=27369 read=164191 │
> │ I/O Timings: shared read=358.795 │
> │ Planning Time: 0.086 ms │
> │ Execution Time: 4194.845 ms │
> └──────────────────────────────────────────────────────────────────────────────────────────────────────────┘
>
> ;SET effective_io_concurrency = 512;SELECT pg_buffercache_evict_relation('pgbench_accounts'); explain (analyze, costs
off,timing off) SELECT max(abalance) FROM (SELECT * FROM pgbench_accounts ORDER BY aid LIMIT 10000000);
> ┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
> │ QUERY PLAN │
> ├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤
> │ Aggregate (actual rows=1.00 loops=1) │
> │ Buffers: shared hit=27368 read=164190 │
> │ I/O Timings: shared read=832.515 │
> │ -> Limit (actual rows=10000000.00 loops=1) │
> │ Buffers: shared hit=27368 read=164190 │
> │ I/O Timings: shared read=832.515 │
> │ -> Index Scan using pgbench_accounts_pkey on pgbench_accounts (actual rows=10000000.00 loops=1) │
> │ Index Searches: 1 │
> │ Prefetch Distance: 56.778 │
> │ Prefetch Stalls: 160569 │
> │ Prefetch Resets: 423 │
> │ Buffers: shared hit=27368 read=164190 │
> │ I/O Timings: shared read=832.515 │
> │ Planning Time: 0.084 ms │
> │ Execution Time: 4413.058 ms │
> └──────────────────────────────────────────────────────────────────────────────────────────────────────────┘
>
> Greetings,
>
The attached v2 explain patch should fix that. I'm also attaching logs
from my explain, for 64 and 16 batches. I think the output makes much
more sense now.
cheers
--
Tomas Vondra
Вложения
On Wed, Jul 23, 2025 at 12:36 PM Peter Geoghegan <pg@bowt.ie> wrote:
> * The TPC-C order line table primary key.
I tested this for myself.
Tomas' index-prefetch-simple-master branch:
set max_parallel_workers_per_gather =0;
SELECT pg_buffercache_evict_relation('order_line');
select pg_prewarm('order_line_pkey');
:ea select sum(ol_amount) from order_line where ol_w_id < 10;
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│
QUERY PLAN
│
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Aggregate (cost=264259.55..264259.56 rows=1 width=32) (actual
time=2015.711..2015.712 rows=1.00 loops=1)
│
│ Output: sum(ol_amount)
│
│ Buffers: shared hit=17815 read=33855
│
│ I/O Timings: shared read=1490.918
│
│ -> Index Scan using order_line_pkey on public.order_line
(cost=0.56..257361.93 rows=2759049 width=4) (actual
time=7.936..1768.236 rows=2700116.00 loops=1) │
│ Output: ol_w_id, ol_d_id, ol_o_id, ol_number, ol_i_id,
ol_delivery_d, ol_amount, ol_supply_w_id, ol_quantity, ol_dist_info
│
│ Index Cond: (order_line.ol_w_id < 10)
│
│ Index Searches: 1
│
│ Index Prefetch: true
│
│ Index Distance: 110.7
│
│ Buffers: shared hit=17815 read=33855
│
│ I/O Timings: shared read=1490.918
│
│ Planning Time: 0.049 ms
│
│ Serialization: time=0.003 ms output=1kB format=text
│
│ Execution Time: 2015.731 ms
│
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(15 rows)
Complex patch (same prewarming/eviction are omitted this time):
:ea select sum(ol_amount) from order_line where ol_w_id < 10;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│
QUERY PLAN
│
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Aggregate (cost=264259.55..264259.56 rows=1 width=32) (actual
time=768.387..768.388 rows=1.00 loops=1)
│
│ Output: sum(ol_amount)
│
│ Buffers: shared hit=17815 read=33855
│
│ I/O Timings: shared read=138.856
│
│ -> Index Scan using order_line_pkey on public.order_line
(cost=0.56..257361.93 rows=2759049 width=4) (actual
time=7.956..493.694 rows=2700116.00 loops=1) │
│ Output: ol_w_id, ol_d_id, ol_o_id, ol_number, ol_i_id,
ol_delivery_d, ol_amount, ol_supply_w_id, ol_quantity, ol_dist_info
│
│ Index Cond: (order_line.ol_w_id < 10)
│
│ Index Searches: 1
│
│ Buffers: shared hit=17815 read=33855
│
│ I/O Timings: shared read=138.856
│
│ Planning Time: 0.043 ms
│
│ Serialization: time=0.003 ms output=1kB format=text
│
│ Execution Time: 768.454 ms
│
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(13 rows)
I'm using direct IO in both cases. This can easily be repeated, and is stable.
To be fair, the planner wants to use a parallel index scan for this.
If I allow the scan to be parallel, 5 parallel workers are used. The
simple patch now takes 295.722 ms, while the complex patch takes
301.875 ms. I imagine that that's because the use of parallelism
eliminates the natural advantage that the complex has with this
workload/index -- the scan as a whole is presumably no longer
bottlenecked on physical index characteristics. The parallel workers
can almost behave as 5 independent scans, all kept sufficiently busy,
even without our having to read ahead to later leaf pages.
It's possible that something weird is going on with the prefetch
distance, in the context of parallel scans specifically -- it's not
like we've really tested parallel scans just yet (with either patch).
Even if there is an addressable problem in either patch here, I'd be
surprised if it was the main factor behind the simple patch doing
relatively well when scanning in parallel like this.
--
Peter Geoghegan
On Wed, Jul 23, 2025 at 9:59 PM Peter Geoghegan <pg@bowt.ie> wrote: > Tomas' index-prefetch-simple-master branch: > │ I/O Timings: shared read=1490.918 > │ Execution Time: 2015.731 ms > Complex patch (same prewarming/eviction are omitted this time): > │ I/O Timings: shared read=138.856 > │ Execution Time: 768.454 ms > I'm using direct IO in both cases. This can easily be repeated, and is stable. Forget to add context about the master branch: Master can do this in 2386.850 ms, with "I/O Timings: shared read=1825.161". That's with buffered I/O (not direct I/O), and with the same pg_prewarm + pg_buffercache_evict_relation function calls as before. I'm running "echo 3 > /proc/sys/vm/drop_caches" to drop the filesystem cache here, too (unlike when testing the patches, where my use of direct i/o makes that step unnecessary). In summary, the simple patch + direct I/O clearly beats the master branch + buffered I/O here -- though not by much. While the complex patch gets a far greater benefit. -- Peter Geoghegan
On 7/23/25 02:37, Tomas Vondra wrote: > ... > >>> Thanks. I wonder how difficult would it be to add something like this to >>> pgstattuple. I mean, it shouldn't be difficult to look at leaf pages and >>> count distinct blocks, right? Seems quite useful. >> >> I agree that that would be quite useful. >> > > Good first patch for someone ;-) > I got a bit bored yesterday, so I gave this a try and whipped up a patch that adds two pgstattuple functins that I think could be useful for analyzing index metrics that matter for prefetching. The patch adds two functions, that are meant to provide data for additional analysis rather than computing something final. Each function splits the index into a sequence of block ranges (of given length), and calculates some metrics on that. pgstatindex_nheap - number of leafs in the range - number of block numbers - number of distinct block numbers - number of runs (of the same block) pgstatindex_runs - number of leafs in the range - run length - number of runs with the length It's trivial to summarize this into a per-index statistic (of course, there may be some inaccuracies when the run spans multiple ranges), but it also seems useful to be able to look at parts of the index. This is meant as a quick experimental patch, to help with generating better datasets for the evaluation. And I think it works for that, and I don't have immediate plans to work on this outside that context. There are a couple things we'd need to address before actually merging this, I think. Two that I can think of right now: First, the "range length" determines memory usage. Right now it's a bit naive, and just extracts all blocks (for the range) into an array. That might be an issue for larger ranges, I'm sure there are strategies to mitigate that - doing some of the processing when reading block numbers, using hyperloglog to estimate distincts, etc. Second, the index is walked sequentially in physical order, from block 0 to the last block. But that's not really what the index prefetch sees. To make it "more accurate" it'd be better to just scan the leaf pages as if during a "full index scan". Also, I haven't updated the docs. That'd also need to be done. regards -- Tomas Vondra
Вложения
On Thu, Jul 24, 2025 at 7:19 AM Tomas Vondra <tomas@vondra.me> wrote: > I got a bit bored yesterday, so I gave this a try and whipped up a patch > that adds two pgstattuple functins that I think could be useful for > analyzing index metrics that matter for prefetching. This seems quite useful. I notice that you're not accounting for posting lists. That'll lead to miscounts of the number of heap blocks in many cases. I think that that's worth fixing, even given that this patch is experimental. > It's trivial to summarize this into a per-index statistic (of course, > there may be some inaccuracies when the run spans multiple ranges), but > it also seems useful to be able to look at parts of the index. FWIW in my experience, the per-leaf-page "nhtids:nhblks" tends to be fairly consistent across all leaf pages from a given index. There are no doubt some exceptions, but they're probably pretty rare. > Second, the index is walked sequentially in physical order, from block 0 > to the last block. But that's not really what the index prefetch sees. > To make it "more accurate" it'd be better to just scan the leaf pages as > if during a "full index scan". Why not just do it that way to begin with? It wouldn't be complicated to make the function follow a chain of right sibling links. I suggest an interface that takes a block number, and an nblocks int8 argument that must be >= 1. The function would start from the block number arg leaf page. If it's not a non-ignorable leaf page, throw an error. Otherwise, count the number of distinct heap blocks on the leaf page, and count the number of heap blocks on each additional leaf page to the right -- until we've counted the heap blocks from nblocks-many leaf pages (or until we reach the rightmost leaf page). I suggest that a P_IGNORE() page shouldn't have its heap blocks counted, and shouldn't count towards our nblocks tally of leaf pages whose heap blocks are to be counted. Upon encountering a P_IGNORE() page, just move to the right without doing anything. Note that the rightmost page cannot be P_IGNORE(). This scheme will always succeed, no matter the nblocks argument, provided the initial leaf page is a valid leaf page (and provided the nblocks arg is >= 1). I get that this is just a prototype that might not go anywhere, but the scheme I've described requires few changes. -- Peter Geoghegan
On 7/24/25 16:40, Peter Geoghegan wrote: > On Thu, Jul 24, 2025 at 7:19 AM Tomas Vondra <tomas@vondra.me> wrote: >> I got a bit bored yesterday, so I gave this a try and whipped up a patch >> that adds two pgstattuple functins that I think could be useful for >> analyzing index metrics that matter for prefetching. > > This seems quite useful. > > I notice that you're not accounting for posting lists. That'll lead to > miscounts of the number of heap blocks in many cases. I think that > that's worth fixing, even given that this patch is experimental. > Yeah, I forgot about that. Should be fixed in the v2. Admittedly I don't know that much about nbtree internals, so this is mostly copy pasting from verify_nbtree. >> It's trivial to summarize this into a per-index statistic (of course, >> there may be some inaccuracies when the run spans multiple ranges), but >> it also seems useful to be able to look at parts of the index. > > FWIW in my experience, the per-leaf-page "nhtids:nhblks" tends to be > fairly consistent across all leaf pages from a given index. There are > no doubt some exceptions, but they're probably pretty rare. > Yeah, probably. And we'll probably test on such uniform data sets, or at least we we'll start with those. But at some point I'd like to test with some of these "weird" indexes too, if only to test how well the prefetch heuristics adjusts the distance. >> Second, the index is walked sequentially in physical order, from block 0 >> to the last block. But that's not really what the index prefetch sees. >> To make it "more accurate" it'd be better to just scan the leaf pages as >> if during a "full index scan". > > Why not just do it that way to begin with? It wouldn't be complicated > to make the function follow a chain of right sibling links. > I have a very good reason why I didn't do it that way. I was lazy. But v2 should be doing that, I think. > I suggest an interface that takes a block number, and an nblocks int8 > argument that must be >= 1. The function would start from the block > number arg leaf page. If it's not a non-ignorable leaf page, throw an > error. Otherwise, count the number of distinct heap blocks on the leaf > page, and count the number of heap blocks on each additional leaf page > to the right -- until we've counted the heap blocks from nblocks-many > leaf pages (or until we reach the rightmost leaf page). > Yeah, this interface seems useful. I suppose it'll be handy when looking at an index scan, to get stats from the currently loaded batches. In principle you get that from v3 by filtering, but it might be slow on large indexes. I'll try doing that in v3. > I suggest that a P_IGNORE() page shouldn't have its heap blocks > counted, and shouldn't count towards our nblocks tally of leaf pages > whose heap blocks are to be counted. Upon encountering a P_IGNORE() > page, just move to the right without doing anything. Note that the > rightmost page cannot be P_IGNORE(). > I think v2 does all of this. > This scheme will always succeed, no matter the nblocks argument, > provided the initial leaf page is a valid leaf page (and provided the > nblocks arg is >= 1). > > I get that this is just a prototype that might not go anywhere, but > the scheme I've described requires few changes. > Yep, thanks. -- Tomas Vondra
Вложения
On Thu, Jul 24, 2025 at 7:52 PM Tomas Vondra <tomas@vondra.me> wrote: > Yeah, I forgot about that. Should be fixed in the v2. Admittedly I don't > know that much about nbtree internals, so this is mostly copy pasting > from verify_nbtree. As long as the scan only moves to the right (never the left), and as long as you don't forget about P_IGNORE() pages, everything should be fairly straightforward. You don't really need to understand things like page deletion, and you'll never need to hold more than a single buffer lock at a time, provided you stick to the happy path. I've taken a quick look at v2, and it looks fine to me. It's acceptable for the purpose that you have in mind, at least. > Yeah, probably. And we'll probably test on such uniform data sets, or at > least we we'll start with those. But at some point I'd like to test with > some of these "weird" indexes too, if only to test how well the prefetch > heuristics adjusts the distance. That makes perfect sense. I was just providing context. > I have a very good reason why I didn't do it that way. I was lazy. But > v2 should be doing that, I think. I respect that. That's why I framed my feedback as "it'll be less effort to just do it than to explain why you haven't done so". :-) > Yeah, this interface seems useful. I suppose it'll be handy when looking > at an index scan, to get stats from the currently loaded batches. In > principle you get that from v3 by filtering, but it might be slow on > large indexes. I'll try doing that in v3. Cool. -- Peter Geoghegan
Hi,
I ran some more tests, comparing the two patches, using data sets
generated in a way to have a more gradual transition between correlated
and random cases.
I'll explain how the new benchmark generates data sets (the goal, and
limitations). Then I'll discuss some of the results. And then there's a
brief conclusion / next steps for the index prefetching ...
data sets
---------
I experimented with several ways to generate such data sets, and what I
ended up doing is this:
INSERT INTO t SELECT i, md5(i::text)
FROM generate_series(1, $rows) s(i)
ORDER BY i + $fuzz * (random() - 0.5)
See the "generate-*.sh" scripts for the exact details.
The basic idea is that we generate a sequence of $rows values, but we
also allow the values to jump a random distance determined by $fuzz.
With fuzz=0 we get perfect correlation, with fuzz=1 the value can move
by one position, with fuzz=1000 it can move by up to 1000 positions, and
so on. For very high fuzz (~rows) this will be close to random.
So this fuzz is the primary knob. Obviously, incrementing fuzz by "1" it
would be way too many tests, with very little change. Instead, I used
the doubling strategy - 0, 1, 2, 4, 8, 16, 32, 64, ... $rows. This way
it takes only about ~25 steps for the $fuzz to exceed $rows=10M.
I also used "fillfactor" as another knob, determining how many items fit
on a heap page. I used 20-40-60-80-100, but this turned out to not have
too many doesn't have much impact. From now I'll use fillfactor=20,
results and charts for other fillfactors are in the github repo [1].
I generated some charts visualizing the data sets - see [2] and [3]
(there's also PDFs, but those are pretty huge). Those charts show
percentiles of blocks vs. values, in either dimension. [2] shows
percentiles of "value" (from the sequence) for 1MB chunks. It seems very
correlated (simple "diagonal" line), because the ranges are so narrow.
But at fuzz ~256k the randomness starts to show.
The [3] shows the other direction, i.e. percentiles of heap blocks for
ranges of values. But the patterns are almost exactly the same, it's
very symmetrical.
Fuzz -1 means "random with uniform distribution". It's clear the "most
random" data set (fuzz ~8M) is still quite different, there's still some
correlation. But the behavior seems fairly close to random.
I don't claim those data sets are perfect, or a great representation of
particular (real-world) data sets. It seems like a much nicer transition
between random and correlated data sets. I have some ideas how to evolve
this, for example to introduce some duplicate (and not unique) values,
and also longer runs.
The other thing that annoys me a bit is the weird behavior close to the
beginning/end of the table, where the percentiles get closer and closer.
I suspect this might affect runs that happen to hit those parts, adding
some "noise" into the results.
results
-------
I'm going to talk about results from the Ryzen machine with NVMe RAID,
with 10M rows (which is about 3.7GB with fillfactor=20) [4]. There are
also results from "ryzen / SATA RAID" and "Xeon / NVMe", and 1M data
sets. But the conclusions are almost exactly the same, as with earlier
benchmarks.
- ryzen-nvme-cold-10000000-20-16-scaled.pdf [5]
This compares master, simple and complex prefetch with different
iomethod values (in columns), and fuzz values (in rows, starting from
fuzz=0).
In most cases the two patches perform fairly close - the green and red
data series mostly overlap. But there are cases where the complex patch
performs much better - especially for low fuzz values. Which is not
surprising, because those cases require higher prefetch distance, and
the complex patch can do that.
It surprised me a bit the complex patch can actually help even cases
where I'd not expect prefetching to help very much - e.g. fuzz=0 is
perfectly correlated, I'd expect read-ahead to work just fine. Yet the
complex patch can help ~2x (at least when scanning larger fraction of
the data).
- ryzen-nvme-cold-10000000-20-16-scaled-relative.pdf
Some of the differences are more visible on this chart, which shows
patches relative to master (so 1.0 means "as fast as master", while 0.5
means 2x faster, etc).
I think there are a couple "fuzz ranges" with distinct behaviors:
* 0-1: simple does mostly on par with "master", complex is actually
quite a bit faster
* 2-4: both mostly on par with master
* 8-256: zone of regressions (compared to master)
* 512-64K: mixed results (good for low selectivity, then regression)
* 128K+: clear benefits
The results from the other systems follow this pattern too, although the
ranges may be shifted a bit.
There are some interesting differences between the io_method values. In
a number of cases the "sync" method performs much worse than "worker"
and "io_uring" - which is not entirely surprising, but it just supports
my argument we should stick with "worker" as default for PG18. But
that's not the topic of this thread.
There are also a couple cases where "simple" performs better than
"complex". But most of the time this is only for the "sync" iomethod,
and when scanning significant fraction of the data (10%+). So that
doesn't seem like a great argument in favor of the simple patch,
considering "sync" is not a proper AIO method, I've been arguing against
using it as a default, and with methods like "worker" the "complex"
patch often performs better ...
conclusion
----------
Let's say the complex patch is the way to go. What are the open problems
/ missing parts we need to address to make it committable?
I can think of these issues. I'm sure the list is incomplete and there
are many "smaller issues" and things I haven't even thought about:
1) Making sure the interface can work for other index AMs (both in core
and out-of-core), including cases like GiST etc.
2) Proper layering between index AM and table AM (like the TID issue
pointed out by Andres some time ago).
3) Allowing more flexible management of prefetch distance (this might
involve something like the "scan manager" idea suggested by Peter),
various improvements to ReadStream heuristics, etc.
4) More testing to minimize the risk of regressions.
5) Figuring out how to make this work for IOS (the simple patch has some
special logic in the callback, which may not be great, not sure what's
the right solution in the complex patch).
6) ????
regards
[1] https://github.com/tvondra/index-prefetch-tests-2
[2]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/visualize/datasets.png
[3]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/visualize/datasets-2.png
[4]
https://github.com/tvondra/index-prefetch-tests-2/tree/master/ryzen-nvme/10
[5]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/ryzen-nvme/10/ryzen-nvme-cold-10000000-20-16-scaled.pdf
[6]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/ryzen-nvme/10/ryzen-nvme-cold-10000000-20-16-scaled-relative.pdf
[7]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/xeon-nvme/10/xeon-nvme-cold-10000000-20-16-scaled-relative.pdf
[8]
https://github.com/tvondra/index-prefetch-tests-2/blob/master/ryzen-sata/10/ryzen-sata-cold-10000000-20-16-scaled-relative.pdf
--
Tomas Vondra
{kind=link}
{kind=link}
Вложения
On Tue, Aug 5, 2025 at 10:52 AM Tomas Vondra <tomas@vondra.me> wrote: > I ran some more tests, comparing the two patches, using data sets > generated in a way to have a more gradual transition between correlated > and random cases. Cool. > So this fuzz is the primary knob. Obviously, incrementing fuzz by "1" it > would be way too many tests, with very little change. Instead, I used > the doubling strategy - 0, 1, 2, 4, 8, 16, 32, 64, ... $rows. This way > it takes only about ~25 steps for the $fuzz to exceed $rows=10M. I think that it probably makes sense to standardize on using fewer distinct "fuzz" settings than this going forward. It's useful to test more things at first, but I expect that the performance impact of changes from a given new patch revision will become important soon. > I don't claim those data sets are perfect, or a great representation of > particular (real-world) data sets. It seems like a much nicer transition > between random and correlated data sets. That makes sense to me. A test suite that is representative of real-world usage patterns isn't so important. But it is important that we have at least one test for each interesting variation of an index scan. What exactly that means is subject to interpretation, and will likely evolve over time. But the general idea is that we should choose tests that experience has shown to be particularly good at highlighting the advantages or disadvantages of one approach over another (e.g., simple vs complex). It's just as important that we cut tests that don't seem to tell us anything we can't get from some other tests. I suspect that many $fuzz values aren't at all interesting. We double to get each increment, but that probably isn't all that informative, outside of the extremes. It'd also be good to just not test "sync" anymore, at some point. And maybe to standardize on testing either "worker" or "io_uring" for most individual tests. There's just too many tests right now. > In most cases the two patches perform fairly close - the green and red > data series mostly overlap. But there are cases where the complex patch > performs much better - especially for low fuzz values. Which is not > surprising, because those cases require higher prefetch distance, and > the complex patch can do that. Right. > It surprised me a bit the complex patch can actually help even cases > where I'd not expect prefetching to help very much - e.g. fuzz=0 is > perfectly correlated, I'd expect read-ahead to work just fine. Yet the > complex patch can help ~2x (at least when scanning larger fraction of > the data). Maybe it has something to do with reading multiple leaf pages together leading to fewer icache misses. Andres recently told me that he isn't expecting to be able to simulate read-ahead with direct I/O. It seems possible that read-ahead eventually won't be used at all, which argues for the complex patch. BTW, I experimented with using READ_STREAM_USE_BATCHING (not READ_STREAM_DEFAULT) in the complex patch. That's probably deadlock-prone, but I suspect that it works well enough to get a good sense of what is possible. What I saw (with that same TPC-C test query) was that "I/O Timings" was about 10x lower, even though the query runtime didn't change at all. This suggests to me that "I/O Timings" is an independently interesting measure: getting it lower might not visibly help when only one query runs, but it'll likely still lead to more efficient use of available I/O bandwidth in the aggregate (when many queries run at the same time). > There are also a couple cases where "simple" performs better than > "complex". But most of the time this is only for the "sync" iomethod, > and when scanning significant fraction of the data (10%+). So that > doesn't seem like a great argument in favor of the simple patch, > considering "sync" is not a proper AIO method, I've been arguing against > using it as a default, and with methods like "worker" the "complex" > patch often performs better ... I suspect that this is just a case of "sync" making aggressive prefetching a bad idea in general. > Let's say the complex patch is the way to go. What are the open problems > / missing parts we need to address to make it committable? I think that what you're interested in here is mostly project risk -- things that come with a notable risk of blocking commit/significantly undermining our general approach. > I can think of these issues. I'm sure the list is incomplete and there > are many "smaller issues" and things I haven't even thought about: I have a list of issues to solve in my personal notes. Most of them aren't particularly important. > 1) Making sure the interface can work for other index AMs (both in core > and out-of-core), including cases like GiST etc. What would put your mind at ease here? Maybe you'd feel better about this if we also implemented prefetching for at least one other index AM. Maybe GiST, since it's likely both the next-hardest and next most important index AM (after nbtree). Right now, I'm not motivated to work on the patch at all, since it's still not clear that any of it has buy-in from you. I'm willing to do more work to try to convince you, but it's not clear what it would take/where your doubts are. I'm starting to be concerned about that just never happening, quite honestly. Getting a feature of this complexity into committable shape requires laser focus. > 2) Proper layering between index AM and table AM (like the TID issue > pointed out by Andres some time ago). > > 3) Allowing more flexible management of prefetch distance (this might > involve something like the "scan manager" idea suggested by Peter), > various improvements to ReadStream heuristics, etc. The definition of "scan manager" is quite fuzzy right now. I think that the "complex" patch already implements a very basic version of that idea. To me, the important point was always that the general design/API of index prefetching be structured in a way that would allow us to accomodate more sophisticated strategies. As I've said many times, somebody needs to see all of the costs and all of the benefits -- that's what's needed to make optimal choices. > 4) More testing to minimize the risk of regressions. > > 5) Figuring out how to make this work for IOS (the simple patch has some > special logic in the callback, which may not be great, not sure what's > the right solution in the complex patch). I agree that all these items are probably the biggest risks to the project. I'm not sure that I can attribute this to the use of the "complex" approach over the "simple" approach. > 6) ???? I guess that this means "unknown unknowns", which are another significant risk. -- Peter Geoghegan
On 8/5/25 19:19, Peter Geoghegan wrote: > On Tue, Aug 5, 2025 at 10:52 AM Tomas Vondra <tomas@vondra.me> wrote: >> I ran some more tests, comparing the two patches, using data sets >> generated in a way to have a more gradual transition between correlated >> and random cases. > > Cool. > >> So this fuzz is the primary knob. Obviously, incrementing fuzz by "1" it >> would be way too many tests, with very little change. Instead, I used >> the doubling strategy - 0, 1, 2, 4, 8, 16, 32, 64, ... $rows. This way >> it takes only about ~25 steps for the $fuzz to exceed $rows=10M. > > I think that it probably makes sense to standardize on using fewer > distinct "fuzz" settings than this going forward. It's useful to test > more things at first, but I expect that the performance impact of > changes from a given new patch revision will become important soon. > Probably. It was hard to predict which values will be interesting, maybe we can pick some subset now. I'll start by just doing larger steps, I think. Maybe increase by 4x rather than 2x, that'll reduce the number of combinations a lot. Also, I plan to stick to fillfactor=20, it doesn't seem to have a lot of impact anyway. >> I don't claim those data sets are perfect, or a great representation of >> particular (real-world) data sets. It seems like a much nicer transition >> between random and correlated data sets. > > That makes sense to me. > > A test suite that is representative of real-world usage patterns isn't > so important. But it is important that we have at least one test for > each interesting variation of an index scan. What exactly that means > is subject to interpretation, and will likely evolve over time. But > the general idea is that we should choose tests that experience has > shown to be particularly good at highlighting the advantages or > disadvantages of one approach over another (e.g., simple vs complex). > True. These tests use very simple queries, with a single range clause. So what other index scan variations would you suggest to test? I can imagine e.g. IN () conditions with variable list length, maybe multi-column indexes, and/or skip scan cases. Any other ideas? FWIW I'm not planning to keep testing simple vs complex patches. We've seen the complex patch can do much better in certain workloads cases, the fact that we can discover more such cases does not change much. I'm much more interested in benchmarking master vs. complex patch. > It's just as important that we cut tests that don't seem to tell us > anything we can't get from some other tests. I suspect that many $fuzz > values aren't at all interesting. We double to get each increment, but > that probably isn't all that informative, outside of the extremes. > > It'd also be good to just not test "sync" anymore, at some point. And > maybe to standardize on testing either "worker" or "io_uring" for most > individual tests. There's just too many tests right now. > Agreed. >> In most cases the two patches perform fairly close - the green and red >> data series mostly overlap. But there are cases where the complex patch >> performs much better - especially for low fuzz values. Which is not >> surprising, because those cases require higher prefetch distance, and >> the complex patch can do that. > > Right. > >> It surprised me a bit the complex patch can actually help even cases >> where I'd not expect prefetching to help very much - e.g. fuzz=0 is >> perfectly correlated, I'd expect read-ahead to work just fine. Yet the >> complex patch can help ~2x (at least when scanning larger fraction of >> the data). > > Maybe it has something to do with reading multiple leaf pages together > leading to fewer icache misses. > Maybe, not sure. > Andres recently told me that he isn't expecting to be able to simulate > read-ahead with direct I/O. It seems possible that read-ahead > eventually won't be used at all, which argues for the complex patch. > True, the complex patch could prefetch the leaf pages. > BTW, I experimented with using READ_STREAM_USE_BATCHING (not > READ_STREAM_DEFAULT) in the complex patch. That's probably > deadlock-prone, but I suspect that it works well enough to get a good > sense of what is possible. What I saw (with that same TPC-C test > query) was that "I/O Timings" was about 10x lower, even though the > query runtime didn't change at all. This suggests to me that "I/O > Timings" is an independently interesting measure: getting it lower > might not visibly help when only one query runs, but it'll likely > still lead to more efficient use of available I/O bandwidth in the > aggregate (when many queries run at the same time). > Interesting. Does that mean we should try enabling batching in some cases? Or just that there's room for improvement? Could we do the next_block callbacks in a way that make deadlocks impossible? I'm not that familiar with the batch mode - how would the deadlock even happen in index scans? I suppose there might be two index scans in opposite directions, requesting the pages in different order. Or even just index scans with different keys, that happen to touch the heap pages in different order. Also, if we "streamify" the access to leaf pages, there could be a deadlock between the two streams. Not sure how to prevent these cases. >> There are also a couple cases where "simple" performs better than >> "complex". But most of the time this is only for the "sync" iomethod, >> and when scanning significant fraction of the data (10%+). So that >> doesn't seem like a great argument in favor of the simple patch, >> considering "sync" is not a proper AIO method, I've been arguing against >> using it as a default, and with methods like "worker" the "complex" >> patch often performs better ... > > I suspect that this is just a case of "sync" making aggressive > prefetching a bad idea in general. > >> Let's say the complex patch is the way to go. What are the open problems >> / missing parts we need to address to make it committable? > > I think that what you're interested in here is mostly project risk -- > things that come with a notable risk of blocking commit/significantly > undermining our general approach. > In a way, yes. I'm interested in anything I have not thought about. >> I can think of these issues. I'm sure the list is incomplete and there >> are many "smaller issues" and things I haven't even thought about: > > I have a list of issues to solve in my personal notes. Most of them > aren't particularly important. > Good to hear. >> 1) Making sure the interface can work for other index AMs (both in core >> and out-of-core), including cases like GiST etc. > > What would put your mind at ease here? Maybe you'd feel better about > this if we also implemented prefetching for at least one other index > AM. Maybe GiST, since it's likely both the next-hardest and next most > important index AM (after nbtree). > > Right now, I'm not motivated to work on the patch at all, since it's > still not clear that any of it has buy-in from you. I'm willing to do > more work to try to convince you, but it's not clear what it would > take/where your doubts are. I'm starting to be concerned about that > just never happening, quite honestly. Getting a feature of this > complexity into committable shape requires laser focus. > I think the only way is to try reworking some of the index AMs to use the new interface. For some AMs (e.g. hash) it's going to be very similar to what you did with btree, because it basically works like a btree. For others (GiST/SP-GiST) it may be more work. Not sure about out-of-core AMs, like pgvector etc. That may be a step too far / too much work. It doesn't need to be committable, just good enough to be reasonably certain it's possible. >> 2) Proper layering between index AM and table AM (like the TID issue >> pointed out by Andres some time ago). >> >> 3) Allowing more flexible management of prefetch distance (this might >> involve something like the "scan manager" idea suggested by Peter), >> various improvements to ReadStream heuristics, etc. > > The definition of "scan manager" is quite fuzzy right now. I think > that the "complex" patch already implements a very basic version of > that idea. > > To me, the important point was always that the general design/API of > index prefetching be structured in a way that would allow us to > accomodate more sophisticated strategies. As I've said many times, > somebody needs to see all of the costs and all of the benefits -- > that's what's needed to make optimal choices. > Understood, and I agree in principle. It's just that given the fuzziness I find it hard how it should look like. >> 4) More testing to minimize the risk of regressions. >> >> 5) Figuring out how to make this work for IOS (the simple patch has some >> special logic in the callback, which may not be great, not sure what's >> the right solution in the complex patch). > > I agree that all these items are probably the biggest risks to the > project. I'm not sure that I can attribute this to the use of the > "complex" approach over the "simple" approach. > True, most of these points applies to both patches - including the IOS handling in callback. And the complex patch could do it the same way, except there would be just one callback, not a callback per index AM. >> 6) ???? > > I guess that this means "unknown unknowns", which are another significant risk. > Yeah, that's what I meant. Sorry, I should have been more explicit. regards -- Tomas Vondra
On Tue, Aug 5, 2025 at 4:56 PM Tomas Vondra <tomas@vondra.me> wrote: > Probably. It was hard to predict which values will be interesting, maybe > we can pick some subset now. I'll start by just doing larger steps, I > think. Maybe increase by 4x rather than 2x, that'll reduce the number of > combinations a lot. Also, I plan to stick to fillfactor=20, it doesn't > seem to have a lot of impact anyway. I don't think that fillfactor matters all that much, either way. A low setting provides a simple way of simulating "wide" heap tuples, but that probably isn't going to make the crucial difference. It's not like the TPC-C index I used in my own recent testing (which showed that the complex patch was almost 3x faster than the simple patch) has all that strong of a pg_stats.correlation. You can probably come up with indexes/test cases where groups of related TIDs that each point to the same heap block appear together, even though in general the index tuple heap TIDs appear completely out of order. It probably isn't even that different to a simple pgbench_accounts_pkey from a prefetching POV, though, in spite of these rather conspicuous differences. In time we might find that just using pgbench_accounts_pkey directly works just as well for our purposes (unsure of that, but seems possible). > So what other index scan variations would you suggest to test? I can > imagine e.g. IN () conditions with variable list length, maybe > multi-column indexes, and/or skip scan cases. Any other ideas? The only thing that's really interesting about IN() conditions is that they provide an easy way to write a query that only returns a subset of all index tuples from every leaf page read. You can get a similar access pattern from other types of quals, but that's not quite as intuitive. I really don't think that IN() conditions are all that special. They're perfectly fine as a way of getting this general access pattern. I like to look for and debug "behavioral inconsistencies". For example, I have an open item in my notes (which I sent to you over IM a short while ago) about a backwards scan that is significantly slower than an "equivalent" forwards scan. This involves pgbench_accounts_pkey. It's quite likely that the underlying problem has nothing much to do with backwards scans. I suspect that the underlying problem is a more general one, that could also be seen with the right forwards scan test case. In general, it might make the most sense to look for pairs of similar-ish queries that are inconsistent in a way that doesn't make sense intuitively, in order to understand and fix the inconsistency. Since chances are that it's actually just some kind of performance bug that accidentally doesn't happen in only one variant of the query. I bet that there's at least a couple of not-that-noticeable performance bugs, for example due to some hard to pin down issue with prefetch distance getting out of hand. Possibly because the read stream doesn't get to see contiguous requests for TIDs that point to the same heap page, but does see it when things are slightly out of order. Two different queries that have approximately the same accesses should have approximately the same performance -- minor variations in leaf page layout or heap page layout or scan direction shouldn't be confounding. > FWIW I'm not planning to keep testing simple vs complex patches. We've > seen the complex patch can do much better in certain workloads cases, > the fact that we can discover more such cases does not change much. > > I'm much more interested in benchmarking master vs. complex patch. Great! > > It'd also be good to just not test "sync" anymore, at some point. And > > maybe to standardize on testing either "worker" or "io_uring" for most > > individual tests. There's just too many tests right now. > > > > Agreed. Might also make sense to standardize on direct I/O when testing the patch (but probably not when testing master). The fact that we can't get any OS readahead is likely to be useful. > > Andres recently told me that he isn't expecting to be able to simulate > > read-ahead with direct I/O. It seems possible that read-ahead > > eventually won't be used at all, which argues for the complex patch. > > > > True, the complex patch could prefetch the leaf pages. What I meant was that the complex patch can make up for the fact that direct I/O presumably won't ever have an equivalent to simple read-ahead. Just by having a very flexible prefetching implementation (and without any special sequential access heuristics ever being required). > > BTW, I experimented with using READ_STREAM_USE_BATCHING (not > > READ_STREAM_DEFAULT) in the complex patch. That's probably > > deadlock-prone, but I suspect that it works well enough to get a good > > sense of what is possible. What I saw (with that same TPC-C test > > query) was that "I/O Timings" was about 10x lower, even though the > > query runtime didn't change at all. This suggests to me that "I/O > > Timings" is an independently interesting measure: getting it lower > > might not visibly help when only one query runs, but it'll likely > > still lead to more efficient use of available I/O bandwidth in the > > aggregate (when many queries run at the same time). > > > > Interesting. Does that mean we should try enabling batching in some > cases? Or just that there's room for improvement? I don't know what it means myself. I never got as far as even starting to understand what it would take to make READ_STREAM_USE_BATCHING work. AFAIK it wouldn't be hard to make that work here at all, in which case we should definitely use it. OTOH, maybe it's really hard. I just don't know right now. > Could we do the next_block callbacks in a way that make deadlocks > impossible? > > I'm not that familiar with the batch mode - how would the deadlock even > happen in index scans? I have no idea. Maybe it's already safe. I didn't notice any problems (but didn't look for them, beyond running my tests plus the regression tests). > I think the only way is to try reworking some of the index AMs to use > the new interface. For some AMs (e.g. hash) it's going to be very > similar to what you did with btree, because it basically works like a > btree. For others (GiST/SP-GiST) it may be more work. The main difficulty with GiST may be that we may be obligated to fix existing (unfixed!) bugs that affect index-only scans. The master branch is subtly broken, but we can't in good conscience ignore those problems while making these kinds of changes. > It doesn't need to be committable, just good enough to be reasonably > certain it's possible. That's what I have in mind, too. If we have support for a second index AM, then we're much less likely to over-optimize for nbtree in a way that doesn't really make sense. > Understood, and I agree in principle. It's just that given the fuzziness > I find it hard how it should look like. I suspect that index AMs are much more similar for the purposes of prefetching than they are in other ways. -- Peter Geoghegan
On Wed, Aug 6, 2025 at 9:35 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Tue, Aug 5, 2025 at 4:56 PM Tomas Vondra <tomas@vondra.me> wrote: > > True, the complex patch could prefetch the leaf pages. There must be a similar opportunity for parallel index scans. It has that "seize the scan" concept where parallel workers do one-at-a-time locked linked list leapfrog. > What I meant was that the complex patch can make up for the fact that > direct I/O presumably won't ever have an equivalent to simple > read-ahead. Just by having a very flexible prefetching implementation > (and without any special sequential access heuristics ever being > required). I'm not so sure, there are certainly opportunities in different layers of the system. I'm going to dust off a couple of experimental patches (stuff I talked to Peter about back in Athens), and try to describe some other vague ideas Andres and I have bounced around over the past few years when chatting about what you lose when you turn on direct I/O. Basically, the stuff that we can't fix with "precise" I/O streaming as I like to call it, where it might still be interesting to think about opportunities to do fuzzier speculative lookahead. I'll start a new thread.
On 8/5/25 23:35, Peter Geoghegan wrote: > On Tue, Aug 5, 2025 at 4:56 PM Tomas Vondra <tomas@vondra.me> wrote: >> Probably. It was hard to predict which values will be interesting, maybe >> we can pick some subset now. I'll start by just doing larger steps, I >> think. Maybe increase by 4x rather than 2x, that'll reduce the number of >> combinations a lot. Also, I plan to stick to fillfactor=20, it doesn't >> seem to have a lot of impact anyway. > > I don't think that fillfactor matters all that much, either way. A low > setting provides a simple way of simulating "wide" heap tuples, but > that probably isn't going to make the crucial difference. > Agreed. > It's not like the TPC-C index I used in my own recent testing (which > showed that the complex patch was almost 3x faster than the simple > patch) has all that strong of a pg_stats.correlation. You can probably > come up with indexes/test cases where groups of related TIDs that each > point to the same heap block appear together, even though in general > the index tuple heap TIDs appear completely out of order. It probably > isn't even that different to a simple pgbench_accounts_pkey from a > prefetching POV, though, in spite of these rather conspicuous > differences. In time we might find that just using > pgbench_accounts_pkey directly works just as well for our purposes > (unsure of that, but seems possible). > That's quite possible. What concerns me about using tables like pgbench accounts table is reproducibility - initially it's correlated, and then it gets "randomized" by the workload. But maybe the exact pattern depends on the workload - how many clients, how long, how it correlates with vacuum, etc. Reproducing the dataset might be quite tricky. That's why I prefer using "reproducible" data sets. I think the data sets with "fuzz" seem like a pretty good model. I plan to experiment with adding some duplicate values / runs, possibly with two "levels" of randomness (global for all runs, and smaller local perturbations). >> So what other index scan variations would you suggest to test? I can >> imagine e.g. IN () conditions with variable list length, maybe >> multi-column indexes, and/or skip scan cases. Any other ideas? > > The only thing that's really interesting about IN() conditions is that > they provide an easy way to write a query that only returns a subset > of all index tuples from every leaf page read. You can get a similar > access pattern from other types of quals, but that's not quite as > intuitive. > > I really don't think that IN() conditions are all that special. > They're perfectly fine as a way of getting this general access > pattern. > OK > I like to look for and debug "behavioral inconsistencies". For > example, I have an open item in my notes (which I sent to you over IM > a short while ago) about a backwards scan that is significantly slower > than an "equivalent" forwards scan. This involves > pgbench_accounts_pkey. It's quite likely that the underlying problem > has nothing much to do with backwards scans. I suspect that the > underlying problem is a more general one, that could also be seen with > the right forwards scan test case. > > In general, it might make the most sense to look for pairs of > similar-ish queries that are inconsistent in a way that doesn't make > sense intuitively, in order to understand and fix the inconsistency. > Since chances are that it's actually just some kind of performance bug > that accidentally doesn't happen in only one variant of the query. > Yeah, cases like that are interesting. I plan to do some randomized testing, exploring "strange" combinations of parameters, looking for weird behaviors like that. The question is what parameters to consider - the data distributions is one such parameter. Different "types" of scans are another. > I bet that there's at least a couple of not-that-noticeable > performance bugs, for example due to some hard to pin down issue with > prefetch distance getting out of hand. Possibly because the read > stream doesn't get to see contiguous requests for TIDs that point to > the same heap page, but does see it when things are slightly out of > order. Two different queries that have approximately the same accesses > should have approximately the same performance -- minor variations in > leaf page layout or heap page layout or scan direction shouldn't be > confounding. > I think in a way cases like that are somewhat inherent, I wouldn't even call that "bug" probably. Any heuristics (driving the distance) will have such issues. Give me a heuristics and I'll construct an adversary case breaking it. I think the question will be how likely (and how serious) such cases are. If it's rare / limited to cases where we're unlikely to pick an index scan etc. then maybe it's OK. >> FWIW I'm not planning to keep testing simple vs complex patches. We've >> seen the complex patch can do much better in certain workloads cases, >> the fact that we can discover more such cases does not change much. >> >> I'm much more interested in benchmarking master vs. complex patch. > > Great! > >>> It'd also be good to just not test "sync" anymore, at some point. And >>> maybe to standardize on testing either "worker" or "io_uring" for most >>> individual tests. There's just too many tests right now. >>> >> >> Agreed. > > Might also make sense to standardize on direct I/O when testing the > patch (but probably not when testing master). The fact that we can't > get any OS readahead is likely to be useful. > I plan to keep testing with buffered I/O (with "io_method=worker"), simply because that's what most systems will keep using for a while. But it's a good idea to test with direct I/O too. >>> Andres recently told me that he isn't expecting to be able to simulate >>> read-ahead with direct I/O. It seems possible that read-ahead >>> eventually won't be used at all, which argues for the complex patch. >>> >> >> True, the complex patch could prefetch the leaf pages. > > What I meant was that the complex patch can make up for the fact that > direct I/O presumably won't ever have an equivalent to simple > read-ahead. Just by having a very flexible prefetching implementation > (and without any special sequential access heuristics ever being > required). > OK >>> BTW, I experimented with using READ_STREAM_USE_BATCHING (not >>> READ_STREAM_DEFAULT) in the complex patch. That's probably >>> deadlock-prone, but I suspect that it works well enough to get a good >>> sense of what is possible. What I saw (with that same TPC-C test >>> query) was that "I/O Timings" was about 10x lower, even though the >>> query runtime didn't change at all. This suggests to me that "I/O >>> Timings" is an independently interesting measure: getting it lower >>> might not visibly help when only one query runs, but it'll likely >>> still lead to more efficient use of available I/O bandwidth in the >>> aggregate (when many queries run at the same time). >>> >> >> Interesting. Does that mean we should try enabling batching in some >> cases? Or just that there's room for improvement? > > I don't know what it means myself. I never got as far as even starting > to understand what it would take to make READ_STREAM_USE_BATCHING > work. > > AFAIK it wouldn't be hard to make that work here at all, in which case > we should definitely use it. OTOH, maybe it's really hard. I just > don't know right now. > Same here. I read the comments about batch mode and deadlocks multiple times, and it's still not clear to me what exactly would be needed to make it safe. >> Could we do the next_block callbacks in a way that make deadlocks >> impossible? >> >> I'm not that familiar with the batch mode - how would the deadlock even >> happen in index scans? > > I have no idea. Maybe it's already safe. I didn't notice any problems > (but didn't look for them, beyond running my tests plus the regression > tests). > OK >> I think the only way is to try reworking some of the index AMs to use >> the new interface. For some AMs (e.g. hash) it's going to be very >> similar to what you did with btree, because it basically works like a >> btree. For others (GiST/SP-GiST) it may be more work. > > The main difficulty with GiST may be that we may be obligated to fix > existing (unfixed!) bugs that affect index-only scans. The master > branch is subtly broken, but we can't in good conscience ignore those > problems while making these kinds of changes. > Right, that's a valid point. The thing that worries me a bit is that the ordered scans (e.g. with reordering by distance) detach the scan from the leaf pages, i.e. the batches are no longer "tied" to a leaf page. Perhaps "worries" is not the right word - I don't think it should be a problem, but it's a difference. >> It doesn't need to be committable, just good enough to be reasonably >> certain it's possible. > > That's what I have in mind, too. If we have support for a second index > AM, then we're much less likely to over-optimize for nbtree in a way > that doesn't really make sense. > Yep. >> Understood, and I agree in principle. It's just that given the fuzziness >> I find it hard how it should look like. > > I suspect that index AMs are much more similar for the purposes of > prefetching than they are in other ways. > Probably. regards -- Tomas Vondra
On Wed, Aug 6, 2025 at 10:12 AM Tomas Vondra <tomas@vondra.me> wrote: > That's quite possible. What concerns me about using tables like pgbench > accounts table is reproducibility - initially it's correlated, and then > it gets "randomized" by the workload. But maybe the exact pattern > depends on the workload - how many clients, how long, how it correlates > with vacuum, etc. Reproducing the dataset might be quite tricky. I meant a pristine/newly created pgbench_accounts_pkey index. > That's why I prefer using "reproducible" data sets. I think the data > sets with "fuzz" seem like a pretty good model. I plan to experiment > with adding some duplicate values / runs, possibly with two "levels" of > randomness (global for all runs, and smaller local perturbations). Agreed that reproducibility is really important. > > I bet that there's at least a couple of not-that-noticeable > > performance bugs, for example due to some hard to pin down issue with > > prefetch distance getting out of hand. Possibly because the read > > stream doesn't get to see contiguous requests for TIDs that point to > > the same heap page, but does see it when things are slightly out of > > order. Two different queries that have approximately the same accesses > > should have approximately the same performance -- minor variations in > > leaf page layout or heap page layout or scan direction shouldn't be > > confounding. > > > > I think in a way cases like that are somewhat inherent, I wouldn't even > call that "bug" probably. Any heuristics (driving the distance) will > have such issues. Give me a heuristics and I'll construct an adversary > case breaking it. > > I think the question will be how likely (and how serious) such cases > are. If it's rare / limited to cases where we're unlikely to pick an > index scan etc. then maybe it's OK. It's something that needs to be considered on a case-by-case basis. But in general when I see an inconsistency like that, I'm suspicious. The difference that I see right now feels quite random and unprincipled. It's not a small difference (375.752 ms vs 465.370 ms for the backwards scan). Maybe if I go down the road of fixing this particular issue, I'll find myself playing performance whack-a-mole, where every change that benefits one query comes at some cost to some other query. But I doubt it. > I plan to keep testing with buffered I/O (with "io_method=worker"), > simply because that's what most systems will keep using for a while. But > it's a good idea to test with direct I/O too. OK. > Same here. I read the comments about batch mode and deadlocks multiple > times, and it's still not clear to me what exactly would be needed to > make it safe. It feels like the comments about READ_STREAM_USE_BATCHING could use some work. > > The main difficulty with GiST may be that we may be obligated to fix > > existing (unfixed!) bugs that affect index-only scans. The master > > branch is subtly broken, but we can't in good conscience ignore those > > problems while making these kinds of changes. > > > > Right, that's a valid point. > > The thing that worries me a bit is that the ordered scans (e.g. with > reordering by distance) detach the scan from the leaf pages, i.e. the > batches are no longer "tied" to a leaf page. > > Perhaps "worries" is not the right word - I don't think it should be a > problem, but it's a difference. Obviously, the problem that GiST ordered scans create for us isn't a new one. The new API isn't that different to the old amgettuple one in all the ways that matter here. amgettuple has exactly the same stipulations about holding on to buffer pins to prevent unsafe concurrent TID recycling -- stipulations that GiST currently just ignores (at least in the case of index-only scans, which cannot rely on a _bt_drop_lock_and_maybe_pin-like mechanism to avoid unsafe concurrent TID recycling hazards). If, in the end, the only solution that really works for GiST is a more aggressive/invasive one than we'd prefer, then making those changes must have been inevitable all along -- even with the old amgettuple interface. That's why I'm not too worried about GiST ordered scans; we're not making that problem any harder to solve. It's even possible that it'll be a bit *easier* to fix the problem with the new batch interface, since it somewhat normalizes the idea of hanging on to buffer pins for longer. -- Peter Geoghegan
On Tue, Aug 5, 2025 at 7:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > There must be a similar opportunity for parallel index scans. It has > that "seize the scan" concept where parallel workers do one-at-a-time > locked linked list leapfrog. True. More generally, flexibility to reorder work would be useful there. The structure of parallel B-tree scans is one where each worker performs its own "independent" index scan. The workers each only return tuples from those leaf pages that they themselves manage to read. That isn't particularly efficient, since we'll usually have to merge the "independent" index scan tuples together once again using a GatherMerge. In principle, we could avoid a GatherMerge by keeping track of the logical order of leaf pages at some higher level, and outputting tuples in that same order -- which isn't a million miles from what the batch interface that Tomas wrote already does. Imagine an enhanced version of that design where the current read_stream callback wholly farms out the work of reading leaf pages to parallel workers. Once we decouple the index page reading from the heap access, we might be able to invent the idea of "task specialization", where some workers more or less exclusively read leaf pages, and other workers more or less exclusively perform related heap accesses. > Basically, the stuff that we can't fix with "precise" I/O > streaming as I like to call it, where it might still be interesting to > think about opportunities to do fuzzier speculative lookahead. I'll > start a new thread. That sounds interesting. I worry that we won't ever be able to get away without some fallback that behaves roughly like OS readahead. -- Peter Geoghegan
On Thu, Aug 7, 2025 at 8:41 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Tue, Aug 5, 2025 at 7:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > There must be a similar opportunity for parallel index scans. It has > > that "seize the scan" concept where parallel workers do one-at-a-time > > locked linked list leapfrog. > > True. More generally, flexibility to reorder work would be useful there. > > The structure of parallel B-tree scans is one where each worker > performs its own "independent" index scan. The workers each only > return tuples from those leaf pages that they themselves manage to > read. That isn't particularly efficient, since we'll usually have to > merge the "independent" index scan tuples together once again using a > GatherMerge. Yeah. This all sails close to the stuff I wrote about in the post-mortem of my failed attempt to teach parallel bitmap heapscan not to throw I/O combining opportunities out the window for v18, after Melanie streamified BHS. Basically you have competing goals: * preserve natural ranges of blocks up to io_combine_limit * make workers run out of work at the same time * avoiding I/O stalls using lookahead and concurrency You can't have all three right now: I/O streams are elastic so allocation decisions made at the producer end don't control work *finishing* time, so we need something new. I wrote about an idea based on work stealing when data runs out. Read streams would work independently, but cooperate at end of stream, avoiding interlocking almost all the time. That was basically a refinement of an earlier "shared" read stream that seems too locky. (Obviously the seize-the-scan block producer is a total lockfest navitaging a link-at-a-time data structure, but let's call that a use-case specific problem.) Other architectures are surely possible too, including admitting that precise streams are not right for that problem, and using something like the PredictBlock() approach mentioned below for prefetching and then sticking to block-at-a-time work distribution. Or we could go the other way and admit that block-at-a-time is also not ideal -- what if some blocks are 10,000 times more expensive to process than others? -- and do work stealing that degrades ultimately to tuple granularity, a logical extreme position. > > Basically, the stuff that we can't fix with "precise" I/O > > streaming as I like to call it, where it might still be interesting to > > think about opportunities to do fuzzier speculative lookahead. I'll > > start a new thread. > > That sounds interesting. I worry that we won't ever be able to get > away without some fallback that behaves roughly like OS readahead. Yeah. I might write about some of these things properly but here is an unfiltered brain dump of assorted theories of varying crackpottedness and some illustrative patches that I'm *not* proposing: * you can make a dumb speculative sequential readahead stream pretty easily, but it's not entirely satisfying: here's one of the toy patches I mentioned in Athens, that shows btree leaf scans (but not parallel ones) doing that, producing nice I/O combining and concurrency that ramps up in the usual way if it happens to be sequential (well I just rebased this and didn't test it, but it should still work); I will describe some other approaches to try to place this in the space of possibilities I'm aware of... * you could make a stream that pulls leaf pages from higher level internal pages on demand (if you want to avoid the flow control problems that come from trying to choose a batch size up front before you know you'll even need it by using a pull approach), or just notice that it looks sequential and install a block range producer, and if that doesn't match the next page pointers by the time you get there then you destroy it and switch strategies, or something * you could just pretend it's always sequential and reset the stream every time you're wrong or some only slightly smarter scheme than that, but it's still hard to know what's going on in cooperating processes... * you could put sequential extent information in meta blocks or somehow scatter hints around... * you could instead give up on explicit streams for fuzzy problems, and teach the buffer pool to do the same tricks as the kernel, with a scheme that lets go of the pins and reacquires them later (hopefully cheaply with ReadRecentBuffer(), by leaving a trail of breadcrumbs in SMgrRelation or shared memory, similar to what I already proposed for btree root pages and another related patch that speeds up seq scans, which I plan to repost soon): SMgrRelation could hold the state necessary for the buffer pool to notice when you keep calling ReadBuffer() for sequential blocks and begin to prefetch them speculatively with growing distance heuristics so it doesn't overdo it, but somehow not hold pins on your behalf (this was one of the driving concerns that made me originally think that I needed an explicit stream as an explicit opt-in and scoping for extra pins, which an AM might not want at certain times, truncation or cleanup or something, who knows) * you could steal Linux's BM_READAHEAD concept, where speculatively loaded pages carry a special marker so they can be recognized by later ReadBuffer() calls to encourage more magic readahead, because it's measurably fruitful; this will be seen also by other backends, eg parallel workers working on the same problem, though there is a bit of an interleaving edge problem (you probably want to know if adjacent pages have the flag in some window, and I have an idea for that that doesn't involve the buffer mapping table); in other words the state tracked in SMgrRelation is only used to ignite readahead, but shared flags in or parallel with the buffer pool apply fuel * from 30,000 feet, the question is what scope you do the detection at; you can find examples of OSes that only look at one fd for sequential detection and only consider strict-next-block (old Unixen, I suspect maybe Windows but IDK), systems that have a tolerance windows (Linux), systems that search a small table of active streams no matter which fds they're coming through (ZFS does this I think, sort of like our own synchronized_scan detector), and systems that use per-page accounting to measure and amplify success, and we have analogies in our architecture as candidate scopes: explicit stream objects, the per-backend SMgrRelation, the proposed system-wide SharedSMgrRelation, the buffer pool itself, and perhaps a per-buffer hint array with relaxed access (this last is something I've experimented with, both as a way to store relaxed navigation information for sequential scans skipping the buffer mapping table and as a place to accumulate prefetch-driving statistics) * so far that's just talking about sequential heuristics, but we have many clues the kernel doesn't, it's just that they're not always reliable enough for a "precise" read streams and we might not want to use the approach to speculation I mentioned above where you have a read stream but as soon as it gives you something you didn't expect you have to give up completely or reset it and start feeding it again; presumably you could code around that with a fuzzy speculation buffer that tolerates a bit of disorder * you could make a better version of PrefetchBuffer() for guided prefetching, let's call it PredictBuffer(), that is initially lazy but if the predictions turn out to be correct it starts looking further ahead in the stream of predictions you made and eventually becomes quite eager, like PrefetchBuffer(), but just lazy enough to perform I/O combining; note that I'm now talking about "pushing" rather than "pulling" predictions, another central question with implications, and one of the nice things about read streams * for a totally different line of attack that goes back to precise pull-based streams, you could imagine a read stream that lets you 'peek' at data coming down the pipe as soon as it is ready (ie it's already in cache, or it isn't but the IO finishes before the stream consumer gets to it), so you can get a head start on a jump requiring I/O in a self-referential data structure like a linked list (with some obvious limitations); here is a toy patch that allows you to install such a callback, which could feed next-block information to the main block number callback, so now we have three times of interest in the I/O stream: block numbers are pulled into the producer end, valid pages are pushed out to you as soon as possible somewhere in the middle or probably often just a step ahead the producer and can feed block numbers back to it, and pages are eventually pulled out of the consumer end for processing; BUT NOTE: this idea is not entirely compatible with the lazy I/O completion draining of io_method=io_uring (or the posix_aio patch I dumped on the list the other day, and the Windows equivalent could plausibly go either way), and works much better with io_method=worker whose completions are advertised eagerly, so this implementation of the idea is a dead end, if even the goal itself is interesting, not sure * the same effect could be achieved with chained streams where the consumer-facing stream is a simple elastic queue of buffers that is fed by the real I/O stream, with the peeking in between; that would suit those I/O methods much better; it might need a new read_stream_next_buffer_conditional() that calls that WaitReadBuffersWouldStall() function, unless the consumer queue is empty and it has to call read_stream_next_buffer() which might block; the point being to periodically pump the peeking mechanism * the peek concept is pretty weak on its own because it's hard to reach a state where you have enough lookahead window that it can follow a navigational jump in time to save you from a stall but ... maybe there are streams that contain a lot of either sequential or well cached blocks with occasional jumps to random I/O; if you could somehow combine the advanced vapourware of several of these magic bullet points, then perhaps you can avoid some stalls Please take all of that with an absolutely massive grain of salt, it's just very raw ideas...
Вложения
Hi, On 2025-08-06 16:12:53 +0200, Tomas Vondra wrote: > That's quite possible. What concerns me about using tables like pgbench > accounts table is reproducibility - initially it's correlated, and then > it gets "randomized" by the workload. But maybe the exact pattern > depends on the workload - how many clients, how long, how it correlates > with vacuum, etc. Reproducing the dataset might be quite tricky. > > That's why I prefer using "reproducible" data sets. I think the data > sets with "fuzz" seem like a pretty good model. I plan to experiment > with adding some duplicate values / runs, possibly with two "levels" of > randomness (global for all runs, and smaller local perturbations). > [...] > Yeah, cases like that are interesting. I plan to do some randomized > testing, exploring "strange" combinations of parameters, looking for > weird behaviors like that. I'm just catching up: Isn't it a bit early to focus this much on testing? ISMT that the patchsets for both approaches currently have some known architectural issues and that addressing them seems likely to change their performance characteristics. Greetings, Andres Freund
On 8/9/25 01:47, Andres Freund wrote: > Hi, > > On 2025-08-06 16:12:53 +0200, Tomas Vondra wrote: >> That's quite possible. What concerns me about using tables like pgbench >> accounts table is reproducibility - initially it's correlated, and then >> it gets "randomized" by the workload. But maybe the exact pattern >> depends on the workload - how many clients, how long, how it correlates >> with vacuum, etc. Reproducing the dataset might be quite tricky. >> >> That's why I prefer using "reproducible" data sets. I think the data >> sets with "fuzz" seem like a pretty good model. I plan to experiment >> with adding some duplicate values / runs, possibly with two "levels" of >> randomness (global for all runs, and smaller local perturbations). >> [...] >> Yeah, cases like that are interesting. I plan to do some randomized >> testing, exploring "strange" combinations of parameters, looking for >> weird behaviors like that. > > I'm just catching up: Isn't it a bit early to focus this much on testing? ISMT > that the patchsets for both approaches currently have some known architectural > issues and that addressing them seems likely to change their performance > characteristics. > Perhaps. For me benchmarks are a way to learn about stuff and better understand the pros/cons of approaches. It's possible some of the changes will impact the characteristics, but I doubt it can change the fundamental differences due to the simple approach being limited to a single leaf page, etc. regards -- Tomas Vondra
On Mon, Aug 11, 2025 at 10:16 AM Tomas Vondra <tomas@vondra.me> wrote: > Perhaps. For me benchmarks are a way to learn about stuff and better > understand the pros/cons of approaches. It's possible some of the > changes will impact the characteristics, but I doubt it can change the > fundamental differences due to the simple approach being limited to a > single leaf page, etc. I think that we're all now agreed that we want to take the complex patch's approach. ISTM that that development makes comparative benchmarking much less interesting, at least for the time being. IMV we should focus on cleaning up the complex patch, and on closing out at least a few open items. The main thing that I'm personally interested in right now, benchmark-wise, is cases where the complex patch doesn't perform as well as expected when we compare (say) backwards scans to forwards scans with the complex patch. In other words, I'm mostly interested in getting an overall sense of the performance profile of the complex patch -- which has nothing to do with how it performs against the master branch. I'd like to find and debug any weird performance bugs/strange discontinuities in performance. I have a feeling that there are at least a couple of those lurking in the complex patch right now. Once we have some confidence that the overall performance profile of the complex patch "makes sense", we can do more invasive refactoring (while systematically avoiding new regressions for the cases that were fixed). In summary, I think that we should focus on fixing smaller open items for now -- with an emphasis on fixing strange inconsistencies in performance for distinct-though-similar queries (pairs of queries that intuitively seem like they should perform very similarly, but somehow have very different performance). I can't really justify that, but my gut feeling is that that's the best place to focus our efforts for the time being. -- Peter Geoghegan
On Thu, Aug 7, 2025 at 1:25 AM Thomas Munro <thomas.munro@gmail.com> wrote: > * you could make a stream that pulls leaf pages from higher level > internal pages on demand (if you want to avoid the flow control > problems that come from trying to choose a batch size up front before > you know you'll even need it by using a pull approach), or just notice > that it looks sequential and install a block range producer, and if > that doesn't match the next page pointers by the time you get there > then you destroy it and switch strategies, or something I was hoping that we wouldn't ever have to teach index scans to prefetch leaf pages like this. It is pretty complicated, primarily because it completely breaks with the idea of the scan having to access pages in some fixed order. (Whereas if we're just prefetching heap pages, then there is a fixed order, which makes maintaining prefetch distance relatively straightforward and index AM neutral.) It's also awkward to make such a scheme work, especially when there's any uncertainty about how many leaf pages will ultimately be read/how much work to do speculatively. There might not be that many relevant leaf pages (level 0 pages) whose block numbers are conveniently available as prefetchable downlinks/block numbers to the right of the downlink we use to descend to the first leaf page to be read (our initial downlink might be positioned towards the end of the relevant internal page at level 1). I guess we could re-read the internal page only when prefetching later leaf pages starts to look like a good idea, but that's another complicated code path to maintain. -- Peter Geoghegan
On 8/11/25 22:14, Peter Geoghegan wrote: > On Mon, Aug 11, 2025 at 10:16 AM Tomas Vondra <tomas@vondra.me> wrote: >> Perhaps. For me benchmarks are a way to learn about stuff and better >> understand the pros/cons of approaches. It's possible some of the >> changes will impact the characteristics, but I doubt it can change the >> fundamental differences due to the simple approach being limited to a >> single leaf page, etc. > > I think that we're all now agreed that we want to take the complex > patch's approach. ISTM that that development makes comparative > benchmarking much less interesting, at least for the time being. IMV > we should focus on cleaning up the complex patch, and on closing out > at least a few open items. > I agree comparing "simple" and "complex" patches is less interesting. I still plan to keep comparing "master" and "complex", mostly to look for unexpected regressions etc. > The main thing that I'm personally interested in right now, > benchmark-wise, is cases where the complex patch doesn't perform as > well as expected when we compare (say) backwards scans to forwards > scans with the complex patch. In other words, I'm mostly interested in > getting an overall sense of the performance profile of the complex > patch -- which has nothing to do with how it performs against the > master branch. I'd like to find and debug any weird performance > bugs/strange discontinuities in performance. I have a feeling that > there are at least a couple of those lurking in the complex patch > right now. Once we have some confidence that the overall performance > profile of the complex patch "makes sense", we can do more invasive > refactoring (while systematically avoiding new regressions for the > cases that were fixed). > I can do some tests with forward vs. backwards scans. Of course, the trouble with finding these weird cases is that they may be fairly rare. So hitting them is a matter or luck or just happening to generate the right data / query. But I'll give it a try and we'll see. > In summary, I think that we should focus on fixing smaller open items > for now -- with an emphasis on fixing strange inconsistencies in > performance for distinct-though-similar queries (pairs of queries that > intuitively seem like they should perform very similarly, but somehow > have very different performance). I can't really justify that, but my > gut feeling is that that's the best place to focus our efforts for the > time being. > OK -- Tomas Vondra
On Mon, Aug 11, 2025 at 5:07 PM Tomas Vondra <tomas@vondra.me> wrote:
> I can do some tests with forward vs. backwards scans. Of course, the
> trouble with finding these weird cases is that they may be fairly rare.
> So hitting them is a matter or luck or just happening to generate the
> right data / query. But I'll give it a try and we'll see.
I was talking more about finding "performance bugs" through a
semi-directed process of trying random things while looking out for
discrepancies. Something like that shouldn't require the usual
"benchmarking rigor", since suspicious inconsistencies should be
fairly obvious once encountered. I expect similar queries to have
similar performance, regardless of superficial differences such as
scan direction, DESC vs ASC column order, etc.
I tested this issue again (using my original pgbench_account query),
having rebased on top of HEAD as of today. I found that the
inconsistency seems to be much smaller now -- so much so that I don't
think that the remaining inconsistency is particularly suspicious.
I also think that performance might have improved across the board. I
see that the same TPC-C query that took 768.454 ms a few weeks back
now takes only 617.408 ms. Also, while I originally saw "I/O Timings:
shared read=138.856" with this query, I now see "I/O Timings: shared
read=46.745". That feels like a performance bug fix to me.
I wonder if today's commit b4212231 from Thomas ("Fix rare bug in
read_stream.c's split IO handling") fixed the issue, without anyone
realizing that the bug in question could manifest like this.
--
Peter Geoghegan
On Tue, Aug 12, 2025 at 11:42 AM Peter Geoghegan <pg@bowt.ie> wrote:
> On Mon, Aug 11, 2025 at 5:07 PM Tomas Vondra <tomas@vondra.me> wrote:
> > I can do some tests with forward vs. backwards scans. Of course, the
> > trouble with finding these weird cases is that they may be fairly rare.
> > So hitting them is a matter or luck or just happening to generate the
> > right data / query. But I'll give it a try and we'll see.
>
> I was talking more about finding "performance bugs" through a
> semi-directed process of trying random things while looking out for
> discrepancies. Something like that shouldn't require the usual
> "benchmarking rigor", since suspicious inconsistencies should be
> fairly obvious once encountered. I expect similar queries to have
> similar performance, regardless of superficial differences such as
> scan direction, DESC vs ASC column order, etc.
I'd be interested to hear more about reverse scans. Bilal was
speculating about backwards I/O combining in read_stream.c a while
back, but we didn't have anything interesting to use it yet. You'll
probably see a flood of uncombined 8KB IOs in the pg_aios view while
travelling up the heap with cache misses today. I suspect Linux does
reverse sequential prefetching with buffered I/O (less sure about
other OSes) which should help but we'd still have more overheads than
we could if we combined them, not to mention direct I/O.
Not tested, but something like this might do it:
/* Can we merge it with the pending read? */
- if (stream->pending_read_nblocks > 0 &&
- stream->pending_read_blocknum +
stream->pending_read_nblocks == blocknum)
+ if (stream->pending_read_nblocks > 0)
{
- stream->pending_read_nblocks++;
- continue;
+ if (stream->pending_read_blocknum +
stream->pending_read_nblocks ==
+ blocknum)
+ {
+ stream->pending_read_nblocks++;
+ continue;
+ }
+ else if (stream->pending_read_blocknum ==
blocknum + 1 &&
+ stream->forwarded_buffers == 0)
+ {
+ stream->pending_read_blocknum--;
+ stream->pending_read_nblocks++;
+ continue;
+ }
}
> I tested this issue again (using my original pgbench_account query),
> having rebased on top of HEAD as of today. I found that the
> inconsistency seems to be much smaller now -- so much so that I don't
> think that the remaining inconsistency is particularly suspicious.
>
> I also think that performance might have improved across the board. I
> see that the same TPC-C query that took 768.454 ms a few weeks back
> now takes only 617.408 ms. Also, while I originally saw "I/O Timings:
> shared read=138.856" with this query, I now see "I/O Timings: shared
> read=46.745". That feels like a performance bug fix to me.
>
> I wonder if today's commit b4212231 from Thomas ("Fix rare bug in
> read_stream.c's split IO handling") fixed the issue, without anyone
> realizing that the bug in question could manifest like this.
I can't explain that. If you can consistently reproduce the change at
the two base commits, maybe bisect? If it's a real phenomenon I'm
definitely curious to know what you're seeing.
Hi,
On Tue, 12 Aug 2025 at 08:07, Thomas Munro <thomas.munro@gmail.com> wrote:
>
> On Tue, Aug 12, 2025 at 11:42 AM Peter Geoghegan <pg@bowt.ie> wrote:
> > On Mon, Aug 11, 2025 at 5:07 PM Tomas Vondra <tomas@vondra.me> wrote:
> > > I can do some tests with forward vs. backwards scans. Of course, the
> > > trouble with finding these weird cases is that they may be fairly rare.
> > > So hitting them is a matter or luck or just happening to generate the
> > > right data / query. But I'll give it a try and we'll see.
> >
> > I was talking more about finding "performance bugs" through a
> > semi-directed process of trying random things while looking out for
> > discrepancies. Something like that shouldn't require the usual
> > "benchmarking rigor", since suspicious inconsistencies should be
> > fairly obvious once encountered. I expect similar queries to have
> > similar performance, regardless of superficial differences such as
> > scan direction, DESC vs ASC column order, etc.
>
> I'd be interested to hear more about reverse scans. Bilal was
> speculating about backwards I/O combining in read_stream.c a while
> back, but we didn't have anything interesting to use it yet. You'll
> probably see a flood of uncombined 8KB IOs in the pg_aios view while
> travelling up the heap with cache misses today. I suspect Linux does
> reverse sequential prefetching with buffered I/O (less sure about
> other OSes) which should help but we'd still have more overheads than
> we could if we combined them, not to mention direct I/O.
If I remember correctly, I didn't continue working on this as I didn't
see performance improvement. Right now, my changes don't apply cleanly
to the current HEAD but I can give it another try if you see value in
this.
> Not tested, but something like this might do it:
>
> /* Can we merge it with the pending read? */
> - if (stream->pending_read_nblocks > 0 &&
> - stream->pending_read_blocknum +
> stream->pending_read_nblocks == blocknum)
> + if (stream->pending_read_nblocks > 0)
> {
> - stream->pending_read_nblocks++;
> - continue;
> + if (stream->pending_read_blocknum +
> stream->pending_read_nblocks ==
> + blocknum)
> + {
> + stream->pending_read_nblocks++;
> + continue;
> + }
> + else if (stream->pending_read_blocknum ==
> blocknum + 1 &&
> + stream->forwarded_buffers == 0)
> + {
> + stream->pending_read_blocknum--;
> + stream->pending_read_nblocks++;
> + continue;
> + }
> }
Unfortunately this doesn't work. We need to handle backwards I/O
combining in the StartReadBuffersImpl() function too as buffer indexes
won't have correct blocknums. Also, I think buffer forwarding of split
backwards I/O should be handled in a couple of places.
--
Regards,
Nazir Bilal Yavuz
Microsoft
On 8/12/25 13:22, Nazir Bilal Yavuz wrote:
> Hi,
>
> On Tue, 12 Aug 2025 at 08:07, Thomas Munro <thomas.munro@gmail.com> wrote:
>>
>> On Tue, Aug 12, 2025 at 11:42 AM Peter Geoghegan <pg@bowt.ie> wrote:
>>> On Mon, Aug 11, 2025 at 5:07 PM Tomas Vondra <tomas@vondra.me> wrote:
>>>> I can do some tests with forward vs. backwards scans. Of course, the
>>>> trouble with finding these weird cases is that they may be fairly rare.
>>>> So hitting them is a matter or luck or just happening to generate the
>>>> right data / query. But I'll give it a try and we'll see.
>>>
>>> I was talking more about finding "performance bugs" through a
>>> semi-directed process of trying random things while looking out for
>>> discrepancies. Something like that shouldn't require the usual
>>> "benchmarking rigor", since suspicious inconsistencies should be
>>> fairly obvious once encountered. I expect similar queries to have
>>> similar performance, regardless of superficial differences such as
>>> scan direction, DESC vs ASC column order, etc.
>>
>> I'd be interested to hear more about reverse scans. Bilal was
>> speculating about backwards I/O combining in read_stream.c a while
>> back, but we didn't have anything interesting to use it yet. You'll
>> probably see a flood of uncombined 8KB IOs in the pg_aios view while
>> travelling up the heap with cache misses today. I suspect Linux does
>> reverse sequential prefetching with buffered I/O (less sure about
>> other OSes) which should help but we'd still have more overheads than
>> we could if we combined them, not to mention direct I/O.
>
> If I remember correctly, I didn't continue working on this as I didn't
> see performance improvement. Right now, my changes don't apply cleanly
> to the current HEAD but I can give it another try if you see value in
> this.
>
>> Not tested, but something like this might do it:
>>
>> /* Can we merge it with the pending read? */
>> - if (stream->pending_read_nblocks > 0 &&
>> - stream->pending_read_blocknum +
>> stream->pending_read_nblocks == blocknum)
>> + if (stream->pending_read_nblocks > 0)
>> {
>> - stream->pending_read_nblocks++;
>> - continue;
>> + if (stream->pending_read_blocknum +
>> stream->pending_read_nblocks ==
>> + blocknum)
>> + {
>> + stream->pending_read_nblocks++;
>> + continue;
>> + }
>> + else if (stream->pending_read_blocknum ==
>> blocknum + 1 &&
>> + stream->forwarded_buffers == 0)
>> + {
>> + stream->pending_read_blocknum--;
>> + stream->pending_read_nblocks++;
>> + continue;
>> + }
>> }
>
> Unfortunately this doesn't work. We need to handle backwards I/O
> combining in the StartReadBuffersImpl() function too as buffer indexes
> won't have correct blocknums. Also, I think buffer forwarding of split
> backwards I/O should be handled in a couple of places.
>
I'm running some tests looking for these weird changes, not just with
the patches, but on master too. And I don't think b4212231 changed the
situation very much.
FWIW this issue is not caused by the index prefetching patches, I can
reproduce it with master (on b227b0bb4e032e19b3679bedac820eba3ac0d1cf
from yesterday). So maybe we should split this into a separate thread.
Consider for example the dataset built by create.sql - it's randomly
generated, but the idea is that it's correlated, but not perfectly. The
table is ~3.7GB, and it's a cold run - caches dropped + restart).
Anyway, a simple range query look like this:
EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a ASC;
QUERY PLAN
------------------------------------------------------------------------
Index Scan using idx on t
(actual time=0.584..433.208 rows=1048576.00 loops=1)
Index Cond: ((a >= 16336) AND (a <= 49103))
Index Searches: 1
Buffers: shared hit=7435 read=50872
I/O Timings: shared read=332.270
Planning:
Buffers: shared hit=78 read=23
I/O Timings: shared read=2.254
Planning Time: 3.364 ms
Execution Time: 463.516 ms
(10 rows)
EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a DESC;
QUERY PLAN
------------------------------------------------------------------------
Index Scan Backward using idx on t
(actual time=0.566..22002.780 rows=1048576.00 loops=1)
Index Cond: ((a >= 16336) AND (a <= 49103))
Index Searches: 1
Buffers: shared hit=36131 read=50872
I/O Timings: shared read=21217.995
Planning:
Buffers: shared hit=82 read=23
I/O Timings: shared read=2.375
Planning Time: 3.478 ms
Execution Time: 22231.755 ms
(10 rows)
That's a pretty massive difference ... this is on my laptop, and the
timing changes quite a bit, but it's always a multiple of the first
query with forward scan.
I did look into pg_aios, but there's only 8kB requests in both cases. I
didn't have time to look closer yet.
regards
--
Tomas Vondra
Вложения
On 8/12/25 18:53, Tomas Vondra wrote: > ... > > EXPLAIN (ANALYZE, COSTS OFF) > SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a ASC; > > QUERY PLAN > ------------------------------------------------------------------------ > Index Scan using idx on t > (actual time=0.584..433.208 rows=1048576.00 loops=1) > Index Cond: ((a >= 16336) AND (a <= 49103)) > Index Searches: 1 > Buffers: shared hit=7435 read=50872 > I/O Timings: shared read=332.270 > Planning: > Buffers: shared hit=78 read=23 > I/O Timings: shared read=2.254 > Planning Time: 3.364 ms > Execution Time: 463.516 ms > (10 rows) > > EXPLAIN (ANALYZE, COSTS OFF) > SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a DESC; > > QUERY PLAN > ------------------------------------------------------------------------ > Index Scan Backward using idx on t > (actual time=0.566..22002.780 rows=1048576.00 loops=1) > Index Cond: ((a >= 16336) AND (a <= 49103)) > Index Searches: 1 > Buffers: shared hit=36131 read=50872 > I/O Timings: shared read=21217.995 > Planning: > Buffers: shared hit=82 read=23 > I/O Timings: shared read=2.375 > Planning Time: 3.478 ms > Execution Time: 22231.755 ms > (10 rows) > > That's a pretty massive difference ... this is on my laptop, and the > timing changes quite a bit, but it's always a multiple of the first > query with forward scan. > > I did look into pg_aios, but there's only 8kB requests in both cases. I > didn't have time to look closer yet. > One more detail I just noticed - the DESC scan apparently needs more buffers (~87k vs. 57k). That probably shouldn't cause such massive regression, though. regards -- Tomas Vondra
On Tue, Aug 12, 2025 at 11:22 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > Unfortunately this doesn't work. We need to handle backwards I/O > combining in the StartReadBuffersImpl() function too as buffer indexes > won't have correct blocknums. Also, I think buffer forwarding of split > backwards I/O should be handled in a couple of places. Perhaps there could be a flag pending_read_backwards that can only become set with pending_read_nblocks goes from 1 to 2, and then a new flag stream->ios[x].backwards (in struct InProgressIO) that is set in read_stream_start_pending_read(). Then immediately after WaitReadBuffers(), we reverse the buffers it returned in place if that flag was set. Oh, I see, you were imagining a flag READ_BUFFERS_REVERSE that tells WaitReadBuffers() to do that internally. Hmm. Either way I don't think you need to consider the forwarded buffers because they will be reversed during a later call that includes them in *nblocks (output value), no?
On Tue, Aug 12, 2025 at 1:51 PM Tomas Vondra <tomas@vondra.me> wrote: > One more detail I just noticed - the DESC scan apparently needs more > buffers (~87k vs. 57k). That probably shouldn't cause such massive > regression, though. I can reproduce this. I wondered if the difference might be attributable to the issue with posting lists and backwards scans (this index has fairly large posting lists), which is addressed by this patch of mine: https://commitfest.postgresql.org/patch/5824/ This makes the difference in buffers read identical between the forwards and backwards scan case. However, it makes exactly no difference to the execution time of the backwards scan case -- it's still way higher. I imagine that this is down to some linux readahead implementation detail. Maybe it is more willing to speculatively read ahead when the scan is mostly in ascending order, compared to when the scan is mostly in descending order. The performance gap that I see is surprisingly large, but I agree that it has nothing to do with this prefetching work/the issue that I saw with backwards scans. I had imagined that we'd be much less sensitive to these kinds of differences once we don't need to depend on heuristic-driven OS readahead. Maybe that was wrong. -- Peter Geoghegan
Hi, On 2025-08-12 18:53:13 +0200, Tomas Vondra wrote: > I'm running some tests looking for these weird changes, not just with > the patches, but on master too. And I don't think b4212231 changed the > situation very much. > > FWIW this issue is not caused by the index prefetching patches, I can > reproduce it with master (on b227b0bb4e032e19b3679bedac820eba3ac0d1cf > from yesterday). So maybe we should split this into a separate thread. > > Consider for example the dataset built by create.sql - it's randomly > generated, but the idea is that it's correlated, but not perfectly. The > table is ~3.7GB, and it's a cold run - caches dropped + restart). > > Anyway, a simple range query look like this: > > EXPLAIN (ANALYZE, COSTS OFF) > SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a ASC; > > QUERY PLAN > ------------------------------------------------------------------------ > Index Scan using idx on t > (actual time=0.584..433.208 rows=1048576.00 loops=1) > Index Cond: ((a >= 16336) AND (a <= 49103)) > Index Searches: 1 > Buffers: shared hit=7435 read=50872 > I/O Timings: shared read=332.270 > Planning: > Buffers: shared hit=78 read=23 > I/O Timings: shared read=2.254 > Planning Time: 3.364 ms > Execution Time: 463.516 ms > (10 rows) > > EXPLAIN (ANALYZE, COSTS OFF) > SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a DESC; > > QUERY PLAN > ------------------------------------------------------------------------ > Index Scan Backward using idx on t > (actual time=0.566..22002.780 rows=1048576.00 loops=1) > Index Cond: ((a >= 16336) AND (a <= 49103)) > Index Searches: 1 > Buffers: shared hit=36131 read=50872 > I/O Timings: shared read=21217.995 > Planning: > Buffers: shared hit=82 read=23 > I/O Timings: shared read=2.375 > Planning Time: 3.478 ms > Execution Time: 22231.755 ms > (10 rows) > > That's a pretty massive difference ... this is on my laptop, and the > timing changes quite a bit, but it's always a multiple of the first > query with forward scan. I suspect what you're mainly seeing here is that the OS can do readahead for us for forward scans, but not for backward scans. Indeed, if I look at iostat, the forward scan shows: Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util nvme6n1 3352.00 400.89 0.00 0.00 0.18 122.47 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.62 47.90 whereas the backward scan shows: Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util nvme6n1 10958.00 85.57 0.00 0.00 0.06 8.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.69 63.80 Note the different read sizes... > I did look into pg_aios, but there's only 8kB requests in both cases. I > didn't have time to look closer yet. That's what we'd expect, right? There's nothing on master that'd perform read combining for index scans... Greetings, Andres Freund
On Tue Aug 12, 2025 at 1:06 AM EDT, Thomas Munro wrote:
> I'd be interested to hear more about reverse scans. Bilal was
> speculating about backwards I/O combining in read_stream.c a while
> back, but we didn't have anything interesting to use it yet. You'll
> probably see a flood of uncombined 8KB IOs in the pg_aios view while
> travelling up the heap with cache misses today. I suspect Linux does
> reverse sequential prefetching with buffered I/O (less sure about
> other OSes) which should help but we'd still have more overheads than
> we could if we combined them, not to mention direct I/O.
Doesn't look like Linux will do this, if what my local testing shows is anything
to go on. I'm a bit surprised by this (I also thought that OS readahead on linux
was quite sophisticated).
There does seem to be something fishy going on with the patch here. I can see
strange inconsistencies in EXPLAIN ANALYZE output when the server is started
with --debug_io_direct=data with the master, compared to what I see with the
patch.
Test case
=========
My test case is a minor refinement of Tomas' backwards scan test case from
earlier today, though with one important difference: I ran
"alter index idx set (deduplicate_items = off); reindex index idx;" to get a
pristine index without any posting lists (since the unrelated issue with posting
list TIDs otherwise risks obscuring something relevant).
master
------
pg@regression:5432 [2390630]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2390630]=# EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a;
┌────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────┤
│ Index Scan using idx on t (actual time=0.117..982.469 rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=10353 read=49933 │
│ I/O Timings: shared read=861.953 │
│ Planning: │
│ Buffers: shared hit=63 read=20 │
│ I/O Timings: shared read=1.898 │
│ Planning Time: 2.131 ms │
│ Execution Time: 1015.679 ms │
└────────────────────────────────────────────────────────────────────────────────┘
(10 rows)
pg@regression:5432 [2390630]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2390630]=# EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a desc;
┌──────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using idx on t (actual time=7.919..6340.579 rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=10350 read=49933 │
│ I/O Timings: shared read=6219.776 │
│ Planning: │
│ Buffers: shared hit=5 │
│ Planning Time: 0.076 ms │
│ Execution Time: 6374.008 ms │
└──────────────────────────────────────────────────────────────────────────────────────────┘
(9 rows)
Notice that readahead seems to be effective with the forwards scan only (even
though I'm using debug_io_direct=data for this). Also notice that each query
shows identical "Buffers:" output -- that detail is exactly as expected.
Prefetch patch
--------------
Same pair of queries/prewarming/eviction steps with my working copy of the
prefetching patch:
pg@regression:5432 [2400564]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2400564]=# EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a;
┌────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────┤
│ Index Scan using idx on t (actual time=0.136..298.301 rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=6619 read=49933 │
│ I/O Timings: shared read=45.313 │
│ Planning: │
│ Buffers: shared hit=63 read=20 │
│ I/O Timings: shared read=2.232 │
│ Planning Time: 2.634 ms │
│ Execution Time: 330.379 ms │
└────────────────────────────────────────────────────────────────────────────────┘
(10 rows)
pg@regression:5432 [2400564]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2400564]=# EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a desc;
┌──────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using idx on t (actual time=7.926..1201.988 rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=10350 read=49933 │
│ I/O Timings: shared read=194.774 │
│ Planning: │
│ Buffers: shared hit=5 │
│ Planning Time: 0.097 ms │
│ Execution Time: 1236.655 ms │
└──────────────────────────────────────────────────────────────────────────────────────────┘
(9 rows)
It looks like the patch does significantly better with the forwards scan,
compared to the backwards scan (though both are improved by a lot). But that's
not the main thing about these results that I find interesting.
The really odd thing is that we get "shared hit=6619 read=49933" for the
forwards scan, and "shared hit=10350 read=49933" for the backwards scan. The
latter matches master (regardless of the scan direction used on master), while
the former just looks wrong. What explains the "missing buffer hits" seen with
the forwards scan?
Discrepancies
-------------
All 4 query executions agree that "rows=1048576.00", so the patch doesn't appear
to simply be broken/giving wrong answers. Might it be that the "Buffers"
instrumentation is broken?
The premise of my original complaint was that big inconsistencies in performance
shouldn't happen between similar forwards and backwards scans (at least not with
direct I/O). I now have serious doubts about that premise, since it looks like
OS readahead remains a big factor with direct I/O. Did I just miss something
obvious?
>> I wonder if today's commit b4212231 from Thomas ("Fix rare bug in
>> read_stream.c's split IO handling") fixed the issue, without anyone
>> realizing that the bug in question could manifest like this.
>
> I can't explain that. If you can consistently reproduce the change at
> the two base commits, maybe bisect?
Commit b4212231 was a wild guess on my part. Probably should have refrained
from that.
--
Peter Geoghegan
On 8/12/25 23:22, Peter Geoghegan wrote:
> ...
>
> It looks like the patch does significantly better with the forwards scan,
> compared to the backwards scan (though both are improved by a lot). But that's
> not the main thing about these results that I find interesting.
>
> The really odd thing is that we get "shared hit=6619 read=49933" for the
> forwards scan, and "shared hit=10350 read=49933" for the backwards scan. The
> latter matches master (regardless of the scan direction used on master), while
> the former just looks wrong. What explains the "missing buffer hits" seen with
> the forwards scan?
>
> Discrepancies
> -------------
>
> All 4 query executions agree that "rows=1048576.00", so the patch doesn't appear
> to simply be broken/giving wrong answers. Might it be that the "Buffers"
> instrumentation is broken?
>
I think a bug in the prefetch patch is more likely. I tried with a patch
that adds various prefetch-related counters to explain, and I see this:
test=# EXPLAIN (ANALYZE, VERBOSE, COSTS OFF) SELECT * FROM t WHERE a
BETWEEN 16336 AND 49103 ORDER BY a;
QUERY PLAN
------------------------------------------------------------------------
Index Scan using idx on public.t (actual time=0.682..527.055
rows=1048576.00 loops=1)
Output: a, b
Index Cond: ((t.a >= 16336) AND (t.a <= 49103))
Index Searches: 1
Prefetch Distance: 271.263
Prefetch Count: 60888
Prefetch Stalls: 1
Prefetch Skips: 991211
Prefetch Resets: 3
Prefetch Histogram: [2,4) => 2, [4,8) => 8, [8,16) => 17, [16,32) =>
24, [32,64) => 34, [64,128) => 52, [128,256) => 82, [256,512) => 60669
Buffers: shared hit=5027 read=50872
I/O Timings: shared read=33.528
Planning:
Buffers: shared hit=78 read=23
I/O Timings: shared read=2.349
Planning Time: 3.686 ms
Execution Time: 559.659 ms
(17 rows)
test=# EXPLAIN (ANALYZE, VERBOSE, COSTS OFF) SELECT * FROM t WHERE a
BETWEEN 16336 AND 49103 ORDER BY a DESC;
QUERY PLAN
------------------------------------------------------------------------
Index Scan Backward using idx on public.t (actual time=1.110..4116.201
rows=1048576.00 loops=1)
Output: a, b
Index Cond: ((t.a >= 16336) AND (t.a <= 49103))
Index Searches: 1
Prefetch Distance: 271.061
Prefetch Count: 118806
Prefetch Stalls: 1
Prefetch Skips: 962515
Prefetch Resets: 3
Prefetch Histogram: [2,4) => 2, [4,8) => 7, [8,16) => 12, [16,32) =>
17, [32,64) => 24, [64,128) => 3, [128,256) => 4, [256,512) => 118737
Buffers: shared hit=30024 read=50872
I/O Timings: shared read=581.353
Planning:
Buffers: shared hit=82 read=23
I/O Timings: shared read=3.168
Planning Time: 4.289 ms
Execution Time: 4185.407 ms
(17 rows)
These two parts are interesting:
Prefetch Count: 60888
Prefetch Skips: 991211
Prefetch Count: 118806
Prefetch Skips: 962515
It looks like the backwards scan skips fewer blocks. This is based on
the lastBlock optimization, i.e. looking for runs of the same block
number. I don't quite see why would it affect just the backwards scan,
though. Seems weird.
> The premise of my original complaint was that big inconsistencies in performance
> shouldn't happen between similar forwards and backwards scans (at least not with
> direct I/O). I now have serious doubts about that premise, since it looks like
> OS readahead remains a big factor with direct I/O. Did I just miss something
> obvious?
>
I don't think you missed anything. It does seem the assumption relies on
the OS handling the underlying I/O patterns equally, and unfortunately
that does not seem to be the case. Maybe we could "invert" the data set,
i.e. make it "descending" instead of "ascending"? That would make the
heap access direction "forward" again ...
regards
--
Tomas Vondra
Hi, On 2025-08-12 17:22:20 -0400, Peter Geoghegan wrote: > Doesn't look like Linux will do this, if what my local testing shows is anything > to go on. Yes, matches my experiments outside of postgres too. > I'm a bit surprised by this (I also thought that OS readahead on linux > was quite sophisticated). It's mildly sophisticated in detecting various *forward scan* patterns. There just isn't anything for backward scans - presumably because there's not actually much that generates backward reads of files... > The premise of my original complaint was that big inconsistencies in performance > shouldn't happen between similar forwards and backwards scans (at least not with > direct I/O). I now have serious doubts about that premise, since it looks like > OS readahead remains a big factor with direct I/O. Did I just miss something > obvious? There is absolutely no OS level readahead with direct IO (there can be *merging* of neighboring IOs though, if they're submitted close enough together). However that doesn't mean that your storage hardware can't have its own set of heuristics for faster access - afaict several NVMes I have access to have shorter IO times for forward scans than for backward scans. Besides actual IO times, there also is the issue that the page level access might be differently efficient, the order in which tuples are accessed also plays a role in how efficient memory level prefetching is. OS level readahead is visible in some form in iostat - you get bigger reads or multiple in-flight IOs. Greetings, Andres Freund
On Tue, Aug 12, 2025 at 5:22 PM Peter Geoghegan <pg@bowt.ie> wrote: > There does seem to be something fishy going on with the patch here. I can see > strange inconsistencies in EXPLAIN ANALYZE output when the server is started > with --debug_io_direct=data with the master, compared to what I see with the > patch. Attached is my working version of the patch, in case that helps anyone with reproducing the problem. Note that the nbtree changes are now included in this one patch/commit. Definitely might make sense to revert to one patch per index AM again later, but for now it's convenient to have one commit that both adds the concept of amgetbatch, and removes nbtree's btgettuple (since it bleeds into things like how indexam.c wants to do mark and restore). There are only fairly minor changes here. Most notably: * Generalizes nbtree's _bt_drop_lock_and_maybe_pin, making it an index-AM-generic thing I call index_batch_unlock. Previous versions of this complex patch avoided the issue by always holding on to a leaf page buffer pin, even when it wasn't truly necessary (i.e. with plain index scans that use an MVCC snapshot). It shouldn't be too hard to teach GiST to use index_batch_unlock to continue dropping buffer pins on leaf pages, as before (with gistgettuple). The hard part will be ordered GiST scans, and perhaps every kind of GiST index-only scan (since in general index-only scans cannot drop pins eagerly within index_batch_unlock, due to race conditions with VACUUM concurrently setting VM bits all-visible). * Replaces BufferMatches() with something a bit less invasive, which works based on block numbers (not buffers). * Various refinements to the way that nbtree deals with setting things up using an existing batch. In particular, the interface of _bt_readnextpage has been revised. It now makes much more sense in a world where nbtree doesn't "own" existing batches -- we no longer directly pass an existing batch to _bt_readnextpage, and it no longer thinks it can clobber what is actually an old batch. -- Peter Geoghegan
Вложения
On 8/12/25 23:52, Tomas Vondra wrote:
>
> On 8/12/25 23:22, Peter Geoghegan wrote:
>> ...
>>
>> It looks like the patch does significantly better with the forwards scan,
>> compared to the backwards scan (though both are improved by a lot). But that's
>> not the main thing about these results that I find interesting.
>>
>> The really odd thing is that we get "shared hit=6619 read=49933" for the
>> forwards scan, and "shared hit=10350 read=49933" for the backwards scan. The
>> latter matches master (regardless of the scan direction used on master), while
>> the former just looks wrong. What explains the "missing buffer hits" seen with
>> the forwards scan?
>>
>> Discrepancies
>> -------------
>>
>> All 4 query executions agree that "rows=1048576.00", so the patch doesn't appear
>> to simply be broken/giving wrong answers. Might it be that the "Buffers"
>> instrumentation is broken?
>>
>
> I think a bug in the prefetch patch is more likely. I tried with a patch
> that adds various prefetch-related counters to explain, and I see this:
>
>
> test=# EXPLAIN (ANALYZE, VERBOSE, COSTS OFF) SELECT * FROM t WHERE a
> BETWEEN 16336 AND 49103 ORDER BY a;
>
> QUERY PLAN
> ------------------------------------------------------------------------
> Index Scan using idx on public.t (actual time=0.682..527.055
> rows=1048576.00 loops=1)
> Output: a, b
> Index Cond: ((t.a >= 16336) AND (t.a <= 49103))
> Index Searches: 1
> Prefetch Distance: 271.263
> Prefetch Count: 60888
> Prefetch Stalls: 1
> Prefetch Skips: 991211
> Prefetch Resets: 3
> Prefetch Histogram: [2,4) => 2, [4,8) => 8, [8,16) => 17, [16,32) =>
> 24, [32,64) => 34, [64,128) => 52, [128,256) => 82, [256,512) => 60669
> Buffers: shared hit=5027 read=50872
> I/O Timings: shared read=33.528
> Planning:
> Buffers: shared hit=78 read=23
> I/O Timings: shared read=2.349
> Planning Time: 3.686 ms
> Execution Time: 559.659 ms
> (17 rows)
>
>
> test=# EXPLAIN (ANALYZE, VERBOSE, COSTS OFF) SELECT * FROM t WHERE a
> BETWEEN 16336 AND 49103 ORDER BY a DESC;
> QUERY PLAN
> ------------------------------------------------------------------------
> Index Scan Backward using idx on public.t (actual time=1.110..4116.201
> rows=1048576.00 loops=1)
> Output: a, b
> Index Cond: ((t.a >= 16336) AND (t.a <= 49103))
> Index Searches: 1
> Prefetch Distance: 271.061
> Prefetch Count: 118806
> Prefetch Stalls: 1
> Prefetch Skips: 962515
> Prefetch Resets: 3
> Prefetch Histogram: [2,4) => 2, [4,8) => 7, [8,16) => 12, [16,32) =>
> 17, [32,64) => 24, [64,128) => 3, [128,256) => 4, [256,512) => 118737
> Buffers: shared hit=30024 read=50872
> I/O Timings: shared read=581.353
> Planning:
> Buffers: shared hit=82 read=23
> I/O Timings: shared read=3.168
> Planning Time: 4.289 ms
> Execution Time: 4185.407 ms
> (17 rows)
>
> These two parts are interesting:
>
> Prefetch Count: 60888
> Prefetch Skips: 991211
>
> Prefetch Count: 118806
> Prefetch Skips: 962515
>
> It looks like the backwards scan skips fewer blocks. This is based on
> the lastBlock optimization, i.e. looking for runs of the same block
> number. I don't quite see why would it affect just the backwards scan,
> though. Seems weird.
>
Actually, this might be a consequence of how backwards scans work (at
least in btree). I logged the block in index_scan_stream_read_next, and
this is what I see in the forward scan (at the beginning):
index_scan_stream_read_next: block 24891
index_scan_stream_read_next: block 24892
index_scan_stream_read_next: block 24893
index_scan_stream_read_next: block 24892
index_scan_stream_read_next: block 24893
index_scan_stream_read_next: block 24894
index_scan_stream_read_next: block 24895
index_scan_stream_read_next: block 24896
index_scan_stream_read_next: block 24895
index_scan_stream_read_next: block 24896
index_scan_stream_read_next: block 24897
index_scan_stream_read_next: block 24898
index_scan_stream_read_next: block 24899
index_scan_stream_read_next: block 24900
index_scan_stream_read_next: block 24901
index_scan_stream_read_next: block 24902
index_scan_stream_read_next: block 24903
index_scan_stream_read_next: block 24904
index_scan_stream_read_next: block 24905
index_scan_stream_read_next: block 24906
index_scan_stream_read_next: block 24907
index_scan_stream_read_next: block 24908
index_scan_stream_read_next: block 24909
index_scan_stream_read_next: block 24910
while in the backwards scan (at the end) I see this
index_scan_stream_read_next: block 24910
index_scan_stream_read_next: block 24911
index_scan_stream_read_next: block 24908
index_scan_stream_read_next: block 24909
index_scan_stream_read_next: block 24906
index_scan_stream_read_next: block 24907
index_scan_stream_read_next: block 24908
index_scan_stream_read_next: block 24905
index_scan_stream_read_next: block 24906
index_scan_stream_read_next: block 24903
index_scan_stream_read_next: block 24904
index_scan_stream_read_next: block 24905
index_scan_stream_read_next: block 24902
index_scan_stream_read_next: block 24903
index_scan_stream_read_next: block 24900
index_scan_stream_read_next: block 24901
index_scan_stream_read_next: block 24902
index_scan_stream_read_next: block 24899
index_scan_stream_read_next: block 24900
index_scan_stream_read_next: block 24897
index_scan_stream_read_next: block 24898
index_scan_stream_read_next: block 24899
index_scan_stream_read_next: block 24895
index_scan_stream_read_next: block 24896
index_scan_stream_read_next: block 24897
index_scan_stream_read_next: block 24894
index_scan_stream_read_next: block 24895
index_scan_stream_read_next: block 24896
index_scan_stream_read_next: block 24892
index_scan_stream_read_next: block 24893
index_scan_stream_read_next: block 24894
index_scan_stream_read_next: block 24891
index_scan_stream_read_next: block 24892
index_scan_stream_read_next: block 24893
These are only the blocks that ended up passes to the read stream, not
the skipped ones. And you can immediately see the backward scan requests
more blocks for (roughly) the same part of the scan - the min/max block
roughly match.
The reason is pretty simple - the table is very correlated, and the
forward scan requests blocks mostly in the right order. Only rarely it
has to jump "back" when progressing to the next value, and so the
lastBlock optimization works nicely.
But with the backwards scan we apparently scan the values backwards, but
then the blocks for each value are accessed in forward direction. So we
do a couple blocks "forward" and then jump to the preceding value - but
that's a couple blocks *back*. And that breaks the lastBlock check.
I believe this applies both to master and the prefetching, except that
master doesn't have read stream - so it only does sync I/O. Could that
hide the extra buffer accesses, somehow?
Anyway, this access pattern in backwards scans seems a bit unfortunate.
regards
--
Tomas Vondra
On Tue, Aug 12, 2025 at 7:10 PM Tomas Vondra <tomas@vondra.me> wrote: > Actually, this might be a consequence of how backwards scans work (at > least in btree). I logged the block in index_scan_stream_read_next, and > this is what I see in the forward scan (at the beginning): Just to be clear: you did disable deduplication and then reindex, right? You're accounting for the known issue with posting list TIDs returning TIDs in the wrong order, relative to the scan direction (when the scan direction is backwards)? It won't be necessary to do this once I commit my patch that fixes the issue directly, on the nbtree side, but for now deduplication messes things up here. And so for now you have to work around it. > But with the backwards scan we apparently scan the values backwards, but > then the blocks for each value are accessed in forward direction. So we > do a couple blocks "forward" and then jump to the preceding value - but > that's a couple blocks *back*. And that breaks the lastBlock check. I don't think that this should be happening. The read stream ought to be seeing blocks in exactly the same order as everything else. > I believe this applies both to master and the prefetching, except that > master doesn't have read stream - so it only does sync I/O. In what sense is it an issue on master? On master, we simply access the TIDs in whatever order amgettuple returns TIDs in. That should always be scan order/index key space order, where heap TID counts as a tie-breaker/affects the key space in the presence of duplicates (at least once that issue with posting lists is fixed, or once deduplication has been disabled in a way that leaves no posting list TIDs around via a reindex). It is certainly not surprising that master does poorly on backwards scans. And it isn't all that surprising that master does worse on backwards scans when direct I/O is in use (per the explanation Andres offered just now). But master should nevertheless always read the TIDs in whatever order it gets them from amgettuple in. It sounds like amgetbatch doesn't really behave analogously to master here, at least with backwards scans. It sounds like you're saying that we *won't* feed TIDs heap block numbers to the read stream in exactly scan order (when we happen to be scanning backwards) -- which seems wrong to me. As you pointed out, a forwards scan of a DESC column index should feed heap blocks to the read stream in a way that is very similar to an equivalent backwards scan of a similar ASC column on the same table. There might be some very minor differences, due to differences in the precise leaf page boundaries among each of the indexes. But that should hardly be noticeable at all. > Could that hide the extra buffer accesses, somehow? I think that you meant to ask about *missing* buffer hits with the patch, for the forwards scan. That doesn't agree with the backwards scan with the patch, nor does it agree with master (with either the forwards or backwards scan). Note that the heap accesses themselves appear to have sane/consistent numbers, since we always see "read=49933" as expected for those, for all 4 query executions that I showed. The "missing buffer hits" issue seems like an issue with the instrumentation itself. Possibly one that is totally unrelated to everything else we're discussing. -- Peter Geoghegan
Hi, On Tue, 12 Aug 2025 at 22:30, Thomas Munro <thomas.munro@gmail.com> wrote: > > On Tue, Aug 12, 2025 at 11:22 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > > Unfortunately this doesn't work. We need to handle backwards I/O > > combining in the StartReadBuffersImpl() function too as buffer indexes > > won't have correct blocknums. Also, I think buffer forwarding of split > > backwards I/O should be handled in a couple of places. > > Perhaps there could be a flag pending_read_backwards that can only > become set with pending_read_nblocks goes from 1 to 2, and then a new > flag stream->ios[x].backwards (in struct InProgressIO) that is set in > read_stream_start_pending_read(). Then immediately after > WaitReadBuffers(), we reverse the buffers it returned in place if that > flag was set. Oh, I see, you were imagining a flag > READ_BUFFERS_REVERSE that tells WaitReadBuffers() to do that > internally. Hmm. Either way I don't think you need to consider the > forwarded buffers because they will be reversed during a later call > that includes them in *nblocks (output value), no? I think the problem is that we are not sure whether we will run WaitReadBuffers() or not. Let's say that we will process blocknums 25, 24, 23, 22, 21 and 20 so we combined these IOs. We set the pending_read_backwards flag and sent this IO operation to the StartReadBuffers(). Let's consider that 22 and 20 are cache hits and the rest are cache misses. In that case, starting processing buffers (inside StartReadBuffers()) from 20 will fail because we will try to return that immediately since this is a first buffer and it is cache hit. I think something like this, we will pass the pending_read_backwards to the StartReadBuffers() and it will start to process blocknums from backwards because of the pending_read_backwards being true. So, buffer[0] -> 25 ... buffer[2] -> 23 and we will stop there because 22 is a cache hit. Now, we will reverse these buffers so that buffer[0] -> 23 ... buffer[2] -> 25, and then send this IO operation to the WaitReadBuffers() and reverse these buffers again after WaitReadBuffers(). The problem with that approach is that we need to forward 22, 21 and 20 and pending_read_blocknum shouldn't change because we are still at 20, processed buffers don't affect pending_read_blocknum. And we need to preserve pending_read_backwards until we process all forwarded buffers, otherwise we may try to combine forward (pending_read_blocknum is 20 and the let's say next blocknum from read_stream_get_block() is 21, we shouldn't do IO combining in that case). -- Regards, Nazir Bilal Yavuz Microsoft
On 8/13/25 01:33, Peter Geoghegan wrote:
> On Tue, Aug 12, 2025 at 7:10 PM Tomas Vondra <tomas@vondra.me> wrote:
>> Actually, this might be a consequence of how backwards scans work (at
>> least in btree). I logged the block in index_scan_stream_read_next, and
>> this is what I see in the forward scan (at the beginning):
>
> Just to be clear: you did disable deduplication and then reindex,
> right? You're accounting for the known issue with posting list TIDs
> returning TIDs in the wrong order, relative to the scan direction
> (when the scan direction is backwards)?
>
> It won't be necessary to do this once I commit my patch that fixes the
> issue directly, on the nbtree side, but for now deduplication messes
> things up here. And so for now you have to work around it.
>
No, I forgot about that (and the the patch only applies to master).
>> But with the backwards scan we apparently scan the values backwards, but
>> then the blocks for each value are accessed in forward direction. So we
>> do a couple blocks "forward" and then jump to the preceding value - but
>> that's a couple blocks *back*. And that breaks the lastBlock check.
>
> I don't think that this should be happening. The read stream ought to
> be seeing blocks in exactly the same order as everything else.
>
>> I believe this applies both to master and the prefetching, except that
>> master doesn't have read stream - so it only does sync I/O.
>
> In what sense is it an issue on master?
>
> On master, we simply access the TIDs in whatever order amgettuple
> returns TIDs in. That should always be scan order/index key space
> order, where heap TID counts as a tie-breaker/affects the key space in
> the presence of duplicates (at least once that issue with posting
> lists is fixed, or once deduplication has been disabled in a way that
> leaves no posting list TIDs around via a reindex).
>
> It is certainly not surprising that master does poorly on backwards
> scans. And it isn't all that surprising that master does worse on
> backwards scans when direct I/O is in use (per the explanation
> Andres offered just now). But master should nevertheless always read
> the TIDs in whatever order it gets them from amgettuple in.
>
> It sounds like amgetbatch doesn't really behave analogously to master
> here, at least with backwards scans. It sounds like you're saying that
> we *won't* feed TIDs heap block numbers to the read stream in exactly
> scan order (when we happen to be scanning backwards) -- which seems
> wrong to me.
>
> As you pointed out, a forwards scan of a DESC column index should feed
> heap blocks to the read stream in a way that is very similar to an
> equivalent backwards scan of a similar ASC column on the same table.
> There might be some very minor differences, due to differences in the
> precise leaf page boundaries among each of the indexes. But that
> should hardly be noticeable at all.
>
I gave this another try, this time with disabled deduplication, and on
master I also applied the patch (but now I realize that's probably
unnecessary, right?).
I did a couple more things for this experiment:
1) created a second table with an "inverse pattern" that's decreasing:
create table t2 (like t) with (fillfactor = 20);
insert into t2 select -a, b from t;
create index idx2 on t2 (a);
alter index idx2 set (deduplicate_items = false);
reindex index idx2;
The idea is that
SELECT * FROM t WHERE (a BETWEEN x AND y) ORDER BY a ASC
is the same "block pattern" as
SELECT * FROM t2 WHERE (a BETWEEN -y AND -x) ORDER BY a DESC
2) added logging to heapam_index_fetch_tuple
elog(LOG, "heapam_index_fetch_tuple block %u",
ItemPointerGetBlockNumber(tid));
3) disabled autovacuum (so that it doesn't trigger any logs)
4) python script that processes the block numbers and counts number of
blocks, runs, forward/backward advances
5) bash script that runs 4 "equivalent" queries on t/t2, with ASC/DESC.
And the results look like this (FWIW this is with io_method=sync):
Q1: SELECT * FROM t WHERE a BETWEEN 16336 AND 49103
Q2: SELECT * FROM t2 WHERE a BETWEEN -49103 AND -16336
master / buffered
query order time blocks runs forward backward
---------------------------------------------------------------
Q1 ASC 575 1048576 57365 53648 3716
Q1 DESC 10245 1048576 57365 3716 53648
Q2 ASC 14819 1048576 86061 53293 32767
Q2 DESC 1063 1048576 86061 32767 53293
prefetch / buffered
query order time blocks runs forward backward
---------------------------------------------------------------
Q1 ASC 701 1048576 57365 53648 3716
Q1 DESC 1805 1048576 57365 3716 53648
Q2 ASC 1221 1048576 86061 53293 32767
Q2 DESC 2101 1048576 86061 32767 53293
master / direct
query order time blocks runs forward backward
---------------------------------------------------------------
Q1 ASC 6101 1048576 57365 53648 3716
Q1 DESC 12041 1048576 57365 3716 53648
Q2 ASC 14837 1048576 86061 53293 32767
Q2 DESC 14690 1048576 86061 32767 53293
prefetch / direct
query order time blocks runs forward backward
---------------------------------------------------------------
Q1 ASC 1504 1048576 57365 53648 3716
Q1 DESC 9034 1048576 57365 3716 53648
Q2 ASC 6988 1048576 86061 53293 32767
Q2 DESC 8959 1048576 86061 32767 53293
The timings are from runs without the extra logging, but there's still
quite a bit of run to run variation. But the differences are somewhat
stable.
Some observations:
* The block stats are perfectly stable (for each query), both for each
build and between builds. And also perfectly symmetrical between the
ASC/DESC version of each query. The ASC does the same number of
"forward" steps like DESC does "backward" steps.
* There's a clear difference between Q1 and Q2, with Q2 having many more
runs (and not as "nice" forward/backward steps). When I created the t2
data set, I expected Q1 ASC to behave the same as Q2 DESC, but it
doesn't seem to work that way. Clearly, the "descending" pattern in t2
breaks the sequence of block numbers into many more runs.
>> Could that hide the extra buffer accesses, somehow?
>
> I think that you meant to ask about *missing* buffer hits with the
> patch, for the forwards scan. That doesn't agree with the backwards
> scan with the patch, nor does it agree with master (with either the
> forwards or backwards scan). Note that the heap accesses themselves
> appear to have sane/consistent numbers, since we always see
> "read=49933" as expected for those, for all 4 query executions that I
> showed.
>
> The "missing buffer hits" issue seems like an issue with the
> instrumentation itself. Possibly one that is totally unrelated to
> everything else we're discussing.
>
Yes, I came to this conclusion too. The fact that the stats presented
above are exactly the same for all the different cases (for each query)
is a sign it's about the tracking.
In fact, I believe this is about io_method. I initially didn't see the
difference you described, and then I realized I set io_method=sync to
make it easier to track the block access. And if I change io_method to
worker, I get different stats, that also change between runs.
With "sync" I always get this (after a restart):
Buffers: shared hit=7435 read=52801
while with "worker" I get this:
Buffers: shared hit=4879 read=52801
Buffers: shared hit=5151 read=52801
Buffers: shared hit=4978 read=52801
So not only it changes run to tun, it also does not add up to 60236.
I vaguely recall I ran into this some time ago during AIO benchmarking,
and IIRC it's due to how StartReadBuffersImpl() may behave differently
depending on I/O started earlier. It only calls PinBufferForBlock() in
some cases, and PinBufferForBlock() is what updates the hits.
In any case, it seems to depend on io_method, and it's confusing.
regards
--
Tomas Vondra
Вложения
Hi,
On 2025-08-13 14:15:37 +0200, Tomas Vondra wrote:
> In fact, I believe this is about io_method. I initially didn't see the
> difference you described, and then I realized I set io_method=sync to
> make it easier to track the block access. And if I change io_method to
> worker, I get different stats, that also change between runs.
>
> With "sync" I always get this (after a restart):
>
> Buffers: shared hit=7435 read=52801
>
> while with "worker" I get this:
>
> Buffers: shared hit=4879 read=52801
> Buffers: shared hit=5151 read=52801
> Buffers: shared hit=4978 read=52801
>
> So not only it changes run to tun, it also does not add up to 60236.
This is reproducible on master? If so, how?
> I vaguely recall I ran into this some time ago during AIO benchmarking,
> and IIRC it's due to how StartReadBuffersImpl() may behave differently
> depending on I/O started earlier. It only calls PinBufferForBlock() in
> some cases, and PinBufferForBlock() is what updates the hits.
Hm, I don't immediately see an issue there. The only case we don't call
PinBufferForBlock() is if we already have pinned the relevant buffer in a
prior call to StartReadBuffersImpl().
If this happens only with the prefetching patch applied, is is possible that
what happens here is that we occasionally re-request buffers that already in
the process of being read in? That would only happen with a read stream and
io_method != sync (since with sync we won't read ahead). If we have to start
reading in a buffer that's already undergoing IO we wait for the IO to
complete and count that access as a hit:
/*
* Check if we can start IO on the first to-be-read buffer.
*
* If an I/O is already in progress in another backend, we want to wait
* for the outcome: either done, or something went wrong and we will
* retry.
*/
if (!ReadBuffersCanStartIO(buffers[nblocks_done], false))
{
...
/*
* Report and track this as a 'hit' for this backend, even though it
* must have started out as a miss in PinBufferForBlock(). The other
* backend will track this as a 'read'.
*/
...
if (persistence == RELPERSISTENCE_TEMP)
pgBufferUsage.local_blks_hit += 1;
else
pgBufferUsage.shared_blks_hit += 1;
...
Greetings,
Andres Freund
On Wed, Aug 13, 2025 at 11:28 AM Andres Freund <andres@anarazel.de> wrote:
> > With "sync" I always get this (after a restart):
> >
> > Buffers: shared hit=7435 read=52801
> >
> > while with "worker" I get this:
> >
> > Buffers: shared hit=4879 read=52801
> > Buffers: shared hit=5151 read=52801
> > Buffers: shared hit=4978 read=52801
> >
> > So not only it changes run to tun, it also does not add up to 60236.
>
> This is reproducible on master? If so, how?
AFAIK it is *not* reproducible on master.
> If this happens only with the prefetching patch applied, is is possible that
> what happens here is that we occasionally re-request buffers that already in
> the process of being read in? That would only happen with a read stream and
> io_method != sync (since with sync we won't read ahead). If we have to start
> reading in a buffer that's already undergoing IO we wait for the IO to
> complete and count that access as a hit:
This theory seems quite plausible to me. Though it is a bit surprising
that I see incorrect buffer hit counts on the "good" forwards scan
case, rather than on the "bad" backwards scan case.
Here's what I mean by things being broken on the read stream side (at
least with certain backwards scan cases):
When I add instrumentation to the read stream side, by adding elog
debug calls that show the blocknum seen by read_stream_get_block, I
see out-of-order and repeated blocknums with the "bad" backwards scan
case ("SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a
desc"):
...
NOTICE: index_scan_stream_read_next: index 1163 TID (25052,21)
WARNING: prior lastBlock is 25053 for batchno 2856, new one: 25052
WARNING: blocknum: 25052, 0x55614810efb0
WARNING: blocknum: 25052, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 1161 TID (25053,3)
WARNING: prior lastBlock is 25052 for batchno 2856, new one: 25053
WARNING: blocknum: 25053, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 1160 TID (25052,19)
WARNING: prior lastBlock is 25053 for batchno 2856, new one: 25052
WARNING: blocknum: 25052, 0x55614810efb0
WARNING: blocknum: 25052, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 1141 TID (25051,21)
WARNING: prior lastBlock is 25052 for batchno 2856, new one: 25051
WARNING: blocknum: 25051, 0x55614810efb0
...
Notice that we see the same blocknum twice in close succession. Also
notice that we're passed 25052 and then subsequently passed 25053,
only to be passed 25053 once more.
OTOH, when I run the equivalent "good" backwards scan ("SELECT * FROM
t WHERE a BETWEEN 16336 AND 49103 ORDER BY a"), the output looks just
about perfect. I have to look around quite a bit longer before I can
find repeated blocknum within successive read_stream_get_block calls:
...
NOTICE: index_scan_stream_read_next: index 303 TID (74783,1)
WARNING: prior lastBlock is 74782 for batchno 2862, new one: 74783
WARNING: blocknum: 74783, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 323 TID (74784,1)
WARNING: prior lastBlock is 74783 for batchno 2862, new one: 74784
WARNING: blocknum: 74784, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 324 TID (74783,21)
WARNING: prior lastBlock is 74784 for batchno 2862, new one: 74783
WARNING: blocknum: 74783, 0x55614810efb0
NOTICE: index_scan_stream_read_next: index 325 TID (74784,2)
WARNING: prior lastBlock is 74783 for batchno 2862, new one: 74784
WARNING: blocknum: 74784, 0x55614810efb0
...
These out-of-order repeat requests are much rarer. And I *never* see
identical requests in *immediate* succession, whereas those are common
with the backwards scan case.
I believe that the out-of-order repeat requests shown here are a
legitimate consequence of the TIDs being slightly out of order in
relatively few places (so the forwards scan case may well already be
behaving exactly as I expect):
pg@regression:5432 [2470184]=# select ctid, a from t where ctid
between '(74783,1)' and '(74784,1)';
┌────────────┬────────┐
│ ctid │ a │
├────────────┼────────┤
│ (74783,1) │ 49,077 │
│ (74783,2) │ 49,077 │
│ (74783,3) │ 49,077 │
│ (74783,4) │ 49,077 │
│ (74783,5) │ 49,077 │
│ (74783,6) │ 49,077 │
│ (74783,7) │ 49,077 │
│ (74783,8) │ 49,077 │
│ (74783,9) │ 49,077 │
│ (74783,10) │ 49,077 │
│ (74783,11) │ 49,077 │
│ (74783,12) │ 49,077 │
│ (74783,13) │ 49,077 │
│ (74783,14) │ 49,077 │
│ (74783,15) │ 49,077 │
│ (74783,16) │ 49,077 │
│ (74783,17) │ 49,077 │
│ (74783,18) │ 49,077 │
│ (74783,19) │ 49,077 │
│ (74783,20) │ 49,077 │
│ (74783,21) │ 49,078 │
│ (74784,1) │ 49,077 │
└────────────┴────────┘
(22 rows)
Bear in mind that EXPLAIN ANALYZE shows *identical* "Buffers:" details
for each query on master. So I believe that I am completely justified
in expecting the calls to read_stream_get_block for the backwards scan
to use identical blocknums to the ones for the equivalent/good
forwards scan (except that they should be in the exact opposite
order). And yet that's not what I see.
Maybe this is something to do with the read position and the stream
position becoming mixed up? I find it odd that the relevant readstream
callback, index_scan_stream_read_next, says "If the stream position
is undefined, just use the read position". That's just a guess,
though. This issue is tricky to debug. I'm not yet used to debugging
problems such as these (though I'll probably become an expert on it in
the months ahead).
--
Peter Geoghegan
On Wed, Aug 13, 2025 at 8:15 AM Tomas Vondra <tomas@vondra.me> wrote: > 1) created a second table with an "inverse pattern" that's decreasing: > > create table t2 (like t) with (fillfactor = 20); > insert into t2 select -a, b from t; > create index idx2 on t2 (a); > alter index idx2 set (deduplicate_items = false); > reindex index idx2; > > The idea is that > > SELECT * FROM t WHERE (a BETWEEN x AND y) ORDER BY a ASC > > is the same "block pattern" as > > SELECT * FROM t2 WHERE (a BETWEEN -y AND -x) ORDER BY a DESC A quick look at "idx2" using pageinspect seems to show heap block numbers that are significantly less in-order than those from the original "idx" index, though. While the original "idx" has block numbers that are *almost* in perfect order (I do see the odd index tuple that has a non-consecutive TID, possibly just due to the influence of the heap FSM), "idx2" seems to have leaf pages that each have heap blocks that are somewhat "shuffled" within each page. While the average total number of heap blocks seen with "idx2" might not be very much higher than "idx", it is nevertheless true that the heap TIDs appear in a less consistent order. So AFAICT we have no principled reason to expect the "runs" seen on "idx2" to be anything like "idx" (maybe the performance gap is a real problem, since the physical attributes of each index aren't hugely different, but even then the "runs" stats don't seem all that uninformative). I'll show what I mean by "shuffled" via a comparison of 2 random leaf pages from each index. Here's what block 5555 from "idx2" looks like according to bt_page_items (it shows a certain amount of "localized shuffling"): ┌────────────┬───────────────┬───────────────┬─────────────┐ │ itemoffset │ ctid │ data │ htid │ ├────────────┼───────────────┼───────────────┼─────────────┤ │ 1 │ (379861,4097) │ (a)=(-249285) │ (379861,7) │ │ 2 │ (379880,13) │ (a)=(-249297) │ (379880,13) │ │ 3 │ (379880,14) │ (a)=(-249297) │ (379880,14) │ │ 4 │ (379880,15) │ (a)=(-249297) │ (379880,15) │ │ 5 │ (379880,16) │ (a)=(-249297) │ (379880,16) │ │ 6 │ (379880,17) │ (a)=(-249297) │ (379880,17) │ │ 7 │ (379880,18) │ (a)=(-249297) │ (379880,18) │ │ 8 │ (379880,19) │ (a)=(-249297) │ (379880,19) │ │ 9 │ (379880,20) │ (a)=(-249297) │ (379880,20) │ │ 10 │ (379880,21) │ (a)=(-249297) │ (379880,21) │ │ 11 │ (379881,2) │ (a)=(-249297) │ (379881,2) │ │ 12 │ (379881,3) │ (a)=(-249297) │ (379881,3) │ │ 13 │ (379881,4) │ (a)=(-249297) │ (379881,4) │ │ 14 │ (379878,2) │ (a)=(-249296) │ (379878,2) │ │ 15 │ (379878,3) │ (a)=(-249296) │ (379878,3) │ │ 16 │ (379878,5) │ (a)=(-249296) │ (379878,5) │ │ 17 │ (379878,6) │ (a)=(-249296) │ (379878,6) │ │ 18 │ (379878,7) │ (a)=(-249296) │ (379878,7) │ │ 19 │ (379878,8) │ (a)=(-249296) │ (379878,8) │ │ 20 │ (379878,9) │ (a)=(-249296) │ (379878,9) │ │ 21 │ (379878,10) │ (a)=(-249296) │ (379878,10) │ │ 22 │ (379878,11) │ (a)=(-249296) │ (379878,11) │ │ 23 │ (379878,12) │ (a)=(-249296) │ (379878,12) │ │ 24 │ (379878,13) │ (a)=(-249296) │ (379878,13) │ │ 25 │ (379878,14) │ (a)=(-249296) │ (379878,14) │ │ 26 │ (379878,15) │ (a)=(-249296) │ (379878,15) │ │ 27 │ (379878,16) │ (a)=(-249296) │ (379878,16) │ │ 28 │ (379878,17) │ (a)=(-249296) │ (379878,17) │ │ 29 │ (379878,18) │ (a)=(-249296) │ (379878,18) │ │ 30 │ (379878,19) │ (a)=(-249296) │ (379878,19) │ │ 31 │ (379878,20) │ (a)=(-249296) │ (379878,20) │ │ 32 │ (379878,21) │ (a)=(-249296) │ (379878,21) │ │ 33 │ (379879,1) │ (a)=(-249296) │ (379879,1) │ │ 34 │ (379879,2) │ (a)=(-249296) │ (379879,2) │ │ 35 │ (379879,3) │ (a)=(-249296) │ (379879,3) │ │ 36 │ (379879,4) │ (a)=(-249296) │ (379879,4) │ │ 37 │ (379879,5) │ (a)=(-249296) │ (379879,5) │ │ 38 │ (379879,6) │ (a)=(-249296) │ (379879,6) │ │ 39 │ (379879,7) │ (a)=(-249296) │ (379879,7) │ │ 40 │ (379879,8) │ (a)=(-249296) │ (379879,8) │ │ 41 │ (379879,9) │ (a)=(-249296) │ (379879,9) │ │ 42 │ (379879,10) │ (a)=(-249296) │ (379879,10) │ │ 43 │ (379879,12) │ (a)=(-249296) │ (379879,12) │ │ 44 │ (379879,13) │ (a)=(-249296) │ (379879,13) │ │ 45 │ (379879,14) │ (a)=(-249296) │ (379879,14) │ │ 46 │ (379876,10) │ (a)=(-249295) │ (379876,10) │ │ 47 │ (379876,12) │ (a)=(-249295) │ (379876,12) │ │ 48 │ (379876,14) │ (a)=(-249295) │ (379876,14) │ │ 49 │ (379876,16) │ (a)=(-249295) │ (379876,16) │ │ 50 │ (379876,17) │ (a)=(-249295) │ (379876,17) │ │ 51 │ (379876,18) │ (a)=(-249295) │ (379876,18) │ │ 52 │ (379876,19) │ (a)=(-249295) │ (379876,19) │ │ 53 │ (379876,20) │ (a)=(-249295) │ (379876,20) │ │ 54 │ (379876,21) │ (a)=(-249295) │ (379876,21) │ │ 55 │ (379877,1) │ (a)=(-249295) │ (379877,1) │ │ 56 │ (379877,2) │ (a)=(-249295) │ (379877,2) │ │ 57 │ (379877,3) │ (a)=(-249295) │ (379877,3) │ │ 58 │ (379877,4) │ (a)=(-249295) │ (379877,4) │ │ 59 │ (379877,5) │ (a)=(-249295) │ (379877,5) │ │ 60 │ (379877,6) │ (a)=(-249295) │ (379877,6) │ │ 61 │ (379877,7) │ (a)=(-249295) │ (379877,7) │ │ 62 │ (379877,8) │ (a)=(-249295) │ (379877,8) │ │ 63 │ (379877,9) │ (a)=(-249295) │ (379877,9) │ │ 64 │ (379877,10) │ (a)=(-249295) │ (379877,10) │ │ 65 │ (379877,11) │ (a)=(-249295) │ (379877,11) │ │ 66 │ (379877,12) │ (a)=(-249295) │ (379877,12) │ │ 67 │ (379877,13) │ (a)=(-249295) │ (379877,13) │ │ 68 │ (379877,14) │ (a)=(-249295) │ (379877,14) │ │ 69 │ (379877,15) │ (a)=(-249295) │ (379877,15) │ │ 70 │ (379877,16) │ (a)=(-249295) │ (379877,16) │ │ 71 │ (379877,17) │ (a)=(-249295) │ (379877,17) │ │ 72 │ (379877,18) │ (a)=(-249295) │ (379877,18) │ │ 73 │ (379877,19) │ (a)=(-249295) │ (379877,19) │ │ 74 │ (379877,20) │ (a)=(-249295) │ (379877,20) │ │ 75 │ (379877,21) │ (a)=(-249295) │ (379877,21) │ │ 76 │ (379878,1) │ (a)=(-249295) │ (379878,1) │ │ 77 │ (379878,4) │ (a)=(-249295) │ (379878,4) │ │ 78 │ (379874,20) │ (a)=(-249294) │ (379874,20) │ │ 79 │ (379875,2) │ (a)=(-249294) │ (379875,2) │ │ 80 │ (379875,3) │ (a)=(-249294) │ (379875,3) │ │ 81 │ (379875,5) │ (a)=(-249294) │ (379875,5) │ │ 82 │ (379875,6) │ (a)=(-249294) │ (379875,6) │ │ 83 │ (379875,7) │ (a)=(-249294) │ (379875,7) │ │ 84 │ (379875,8) │ (a)=(-249294) │ (379875,8) │ │ 85 │ (379875,9) │ (a)=(-249294) │ (379875,9) │ │ 86 │ (379875,10) │ (a)=(-249294) │ (379875,10) │ │ 87 │ (379875,11) │ (a)=(-249294) │ (379875,11) │ │ 88 │ (379875,12) │ (a)=(-249294) │ (379875,12) │ │ 89 │ (379875,13) │ (a)=(-249294) │ (379875,13) │ │ 90 │ (379875,14) │ (a)=(-249294) │ (379875,14) │ │ 91 │ (379875,15) │ (a)=(-249294) │ (379875,15) │ │ 92 │ (379875,16) │ (a)=(-249294) │ (379875,16) │ │ 93 │ (379875,17) │ (a)=(-249294) │ (379875,17) │ │ 94 │ (379875,18) │ (a)=(-249294) │ (379875,18) │ │ 95 │ (379875,19) │ (a)=(-249294) │ (379875,19) │ │ 96 │ (379875,20) │ (a)=(-249294) │ (379875,20) │ │ 97 │ (379875,21) │ (a)=(-249294) │ (379875,21) │ │ 98 │ (379876,1) │ (a)=(-249294) │ (379876,1) │ │ 99 │ (379876,2) │ (a)=(-249294) │ (379876,2) │ │ 100 │ (379876,3) │ (a)=(-249294) │ (379876,3) │ │ 101 │ (379876,4) │ (a)=(-249294) │ (379876,4) │ │ 102 │ (379876,5) │ (a)=(-249294) │ (379876,5) │ │ 103 │ (379876,6) │ (a)=(-249294) │ (379876,6) │ │ 104 │ (379876,7) │ (a)=(-249294) │ (379876,7) │ │ 105 │ (379876,8) │ (a)=(-249294) │ (379876,8) │ │ 106 │ (379876,9) │ (a)=(-249294) │ (379876,9) │ │ 107 │ (379876,11) │ (a)=(-249294) │ (379876,11) │ │ 108 │ (379876,13) │ (a)=(-249294) │ (379876,13) │ │ 109 │ (379876,15) │ (a)=(-249294) │ (379876,15) │ │ 110 │ (379873,11) │ (a)=(-249293) │ (379873,11) │ │ 111 │ (379873,13) │ (a)=(-249293) │ (379873,13) │ │ 112 │ (379873,14) │ (a)=(-249293) │ (379873,14) │ │ 113 │ (379873,15) │ (a)=(-249293) │ (379873,15) │ │ 114 │ (379873,16) │ (a)=(-249293) │ (379873,16) │ │ 115 │ (379873,17) │ (a)=(-249293) │ (379873,17) │ │ 116 │ (379873,18) │ (a)=(-249293) │ (379873,18) │ │ 117 │ (379873,19) │ (a)=(-249293) │ (379873,19) │ │ 118 │ (379873,20) │ (a)=(-249293) │ (379873,20) │ │ 119 │ (379873,21) │ (a)=(-249293) │ (379873,21) │ │ 120 │ (379874,1) │ (a)=(-249293) │ (379874,1) │ │ 121 │ (379874,2) │ (a)=(-249293) │ (379874,2) │ │ 122 │ (379874,3) │ (a)=(-249293) │ (379874,3) │ │ 123 │ (379874,4) │ (a)=(-249293) │ (379874,4) │ │ 124 │ (379874,5) │ (a)=(-249293) │ (379874,5) │ │ 125 │ (379874,6) │ (a)=(-249293) │ (379874,6) │ │ 126 │ (379874,7) │ (a)=(-249293) │ (379874,7) │ │ 127 │ (379874,8) │ (a)=(-249293) │ (379874,8) │ │ 128 │ (379874,9) │ (a)=(-249293) │ (379874,9) │ │ 129 │ (379874,10) │ (a)=(-249293) │ (379874,10) │ │ 130 │ (379874,11) │ (a)=(-249293) │ (379874,11) │ │ 131 │ (379874,12) │ (a)=(-249293) │ (379874,12) │ │ 132 │ (379874,13) │ (a)=(-249293) │ (379874,13) │ │ 133 │ (379874,14) │ (a)=(-249293) │ (379874,14) │ │ 134 │ (379874,15) │ (a)=(-249293) │ (379874,15) │ │ 135 │ (379874,16) │ (a)=(-249293) │ (379874,16) │ │ 136 │ (379874,17) │ (a)=(-249293) │ (379874,17) │ │ 137 │ (379874,18) │ (a)=(-249293) │ (379874,18) │ │ 138 │ (379874,19) │ (a)=(-249293) │ (379874,19) │ │ 139 │ (379874,21) │ (a)=(-249293) │ (379874,21) │ │ 140 │ (379875,1) │ (a)=(-249293) │ (379875,1) │ │ 141 │ (379875,4) │ (a)=(-249293) │ (379875,4) │ │ 142 │ (379871,21) │ (a)=(-249292) │ (379871,21) │ │ 143 │ (379872,2) │ (a)=(-249292) │ (379872,2) │ │ 144 │ (379872,3) │ (a)=(-249292) │ (379872,3) │ │ 145 │ (379872,4) │ (a)=(-249292) │ (379872,4) │ │ 146 │ (379872,5) │ (a)=(-249292) │ (379872,5) │ │ 147 │ (379872,6) │ (a)=(-249292) │ (379872,6) │ │ 148 │ (379872,7) │ (a)=(-249292) │ (379872,7) │ │ 149 │ (379872,8) │ (a)=(-249292) │ (379872,8) │ │ 150 │ (379872,9) │ (a)=(-249292) │ (379872,9) │ │ 151 │ (379872,10) │ (a)=(-249292) │ (379872,10) │ │ 152 │ (379872,11) │ (a)=(-249292) │ (379872,11) │ │ 153 │ (379872,12) │ (a)=(-249292) │ (379872,12) │ │ 154 │ (379872,13) │ (a)=(-249292) │ (379872,13) │ │ 155 │ (379872,14) │ (a)=(-249292) │ (379872,14) │ │ 156 │ (379872,15) │ (a)=(-249292) │ (379872,15) │ │ 157 │ (379872,16) │ (a)=(-249292) │ (379872,16) │ │ 158 │ (379872,17) │ (a)=(-249292) │ (379872,17) │ │ 159 │ (379872,18) │ (a)=(-249292) │ (379872,18) │ │ 160 │ (379872,19) │ (a)=(-249292) │ (379872,19) │ │ 161 │ (379872,20) │ (a)=(-249292) │ (379872,20) │ │ 162 │ (379872,21) │ (a)=(-249292) │ (379872,21) │ │ 163 │ (379873,1) │ (a)=(-249292) │ (379873,1) │ │ 164 │ (379873,2) │ (a)=(-249292) │ (379873,2) │ │ 165 │ (379873,3) │ (a)=(-249292) │ (379873,3) │ │ 166 │ (379873,4) │ (a)=(-249292) │ (379873,4) │ │ 167 │ (379873,5) │ (a)=(-249292) │ (379873,5) │ │ 168 │ (379873,6) │ (a)=(-249292) │ (379873,6) │ │ 169 │ (379873,7) │ (a)=(-249292) │ (379873,7) │ │ 170 │ (379873,8) │ (a)=(-249292) │ (379873,8) │ │ 171 │ (379873,9) │ (a)=(-249292) │ (379873,9) │ │ 172 │ (379873,10) │ (a)=(-249292) │ (379873,10) │ │ 173 │ (379873,12) │ (a)=(-249292) │ (379873,12) │ │ 174 │ (379870,9) │ (a)=(-249291) │ (379870,9) │ │ 175 │ (379870,11) │ (a)=(-249291) │ (379870,11) │ │ 176 │ (379870,12) │ (a)=(-249291) │ (379870,12) │ │ 177 │ (379870,14) │ (a)=(-249291) │ (379870,14) │ │ 178 │ (379870,15) │ (a)=(-249291) │ (379870,15) │ │ 179 │ (379870,16) │ (a)=(-249291) │ (379870,16) │ │ 180 │ (379870,17) │ (a)=(-249291) │ (379870,17) │ │ 181 │ (379870,18) │ (a)=(-249291) │ (379870,18) │ │ 182 │ (379870,19) │ (a)=(-249291) │ (379870,19) │ │ 183 │ (379870,20) │ (a)=(-249291) │ (379870,20) │ │ 184 │ (379870,21) │ (a)=(-249291) │ (379870,21) │ │ 185 │ (379871,1) │ (a)=(-249291) │ (379871,1) │ │ 186 │ (379871,2) │ (a)=(-249291) │ (379871,2) │ │ 187 │ (379871,3) │ (a)=(-249291) │ (379871,3) │ │ 188 │ (379871,4) │ (a)=(-249291) │ (379871,4) │ │ 189 │ (379871,5) │ (a)=(-249291) │ (379871,5) │ │ 190 │ (379871,6) │ (a)=(-249291) │ (379871,6) │ │ 191 │ (379871,7) │ (a)=(-249291) │ (379871,7) │ │ 192 │ (379871,8) │ (a)=(-249291) │ (379871,8) │ │ 193 │ (379871,9) │ (a)=(-249291) │ (379871,9) │ │ 194 │ (379871,10) │ (a)=(-249291) │ (379871,10) │ │ 195 │ (379871,11) │ (a)=(-249291) │ (379871,11) │ │ 196 │ (379871,12) │ (a)=(-249291) │ (379871,12) │ │ 197 │ (379871,13) │ (a)=(-249291) │ (379871,13) │ │ 198 │ (379871,14) │ (a)=(-249291) │ (379871,14) │ │ 199 │ (379871,15) │ (a)=(-249291) │ (379871,15) │ │ 200 │ (379871,16) │ (a)=(-249291) │ (379871,16) │ │ 201 │ (379871,17) │ (a)=(-249291) │ (379871,17) │ │ 202 │ (379871,18) │ (a)=(-249291) │ (379871,18) │ │ 203 │ (379871,19) │ (a)=(-249291) │ (379871,19) │ │ 204 │ (379871,20) │ (a)=(-249291) │ (379871,20) │ │ 205 │ (379872,1) │ (a)=(-249291) │ (379872,1) │ │ 206 │ (379868,20) │ (a)=(-249290) │ (379868,20) │ │ 207 │ (379868,21) │ (a)=(-249290) │ (379868,21) │ │ 208 │ (379869,1) │ (a)=(-249290) │ (379869,1) │ │ 209 │ (379869,3) │ (a)=(-249290) │ (379869,3) │ │ 210 │ (379869,4) │ (a)=(-249290) │ (379869,4) │ │ 211 │ (379869,5) │ (a)=(-249290) │ (379869,5) │ │ 212 │ (379869,6) │ (a)=(-249290) │ (379869,6) │ │ 213 │ (379869,7) │ (a)=(-249290) │ (379869,7) │ │ 214 │ (379869,8) │ (a)=(-249290) │ (379869,8) │ │ 215 │ (379869,9) │ (a)=(-249290) │ (379869,9) │ │ 216 │ (379869,10) │ (a)=(-249290) │ (379869,10) │ │ 217 │ (379869,11) │ (a)=(-249290) │ (379869,11) │ │ 218 │ (379869,12) │ (a)=(-249290) │ (379869,12) │ │ 219 │ (379869,13) │ (a)=(-249290) │ (379869,13) │ │ 220 │ (379869,14) │ (a)=(-249290) │ (379869,14) │ │ 221 │ (379869,15) │ (a)=(-249290) │ (379869,15) │ │ 222 │ (379869,16) │ (a)=(-249290) │ (379869,16) │ │ 223 │ (379869,17) │ (a)=(-249290) │ (379869,17) │ │ 224 │ (379869,18) │ (a)=(-249290) │ (379869,18) │ │ 225 │ (379869,19) │ (a)=(-249290) │ (379869,19) │ │ 226 │ (379869,20) │ (a)=(-249290) │ (379869,20) │ │ 227 │ (379869,21) │ (a)=(-249290) │ (379869,21) │ │ 228 │ (379870,1) │ (a)=(-249290) │ (379870,1) │ │ 229 │ (379870,2) │ (a)=(-249290) │ (379870,2) │ │ 230 │ (379870,3) │ (a)=(-249290) │ (379870,3) │ │ 231 │ (379870,4) │ (a)=(-249290) │ (379870,4) │ │ 232 │ (379870,5) │ (a)=(-249290) │ (379870,5) │ │ 233 │ (379870,6) │ (a)=(-249290) │ (379870,6) │ │ 234 │ (379870,7) │ (a)=(-249290) │ (379870,7) │ │ 235 │ (379870,8) │ (a)=(-249290) │ (379870,8) │ │ 236 │ (379870,10) │ (a)=(-249290) │ (379870,10) │ │ 237 │ (379870,13) │ (a)=(-249290) │ (379870,13) │ │ 238 │ (379867,10) │ (a)=(-249289) │ (379867,10) │ │ 239 │ (379867,11) │ (a)=(-249289) │ (379867,11) │ │ 240 │ (379867,12) │ (a)=(-249289) │ (379867,12) │ │ 241 │ (379867,13) │ (a)=(-249289) │ (379867,13) │ │ 242 │ (379867,14) │ (a)=(-249289) │ (379867,14) │ │ 243 │ (379867,15) │ (a)=(-249289) │ (379867,15) │ │ 244 │ (379867,16) │ (a)=(-249289) │ (379867,16) │ │ 245 │ (379867,17) │ (a)=(-249289) │ (379867,17) │ │ 246 │ (379867,18) │ (a)=(-249289) │ (379867,18) │ │ 247 │ (379867,19) │ (a)=(-249289) │ (379867,19) │ │ 248 │ (379867,20) │ (a)=(-249289) │ (379867,20) │ │ 249 │ (379867,21) │ (a)=(-249289) │ (379867,21) │ │ 250 │ (379868,1) │ (a)=(-249289) │ (379868,1) │ │ 251 │ (379868,2) │ (a)=(-249289) │ (379868,2) │ │ 252 │ (379868,3) │ (a)=(-249289) │ (379868,3) │ │ 253 │ (379868,4) │ (a)=(-249289) │ (379868,4) │ │ 254 │ (379868,5) │ (a)=(-249289) │ (379868,5) │ │ 255 │ (379868,6) │ (a)=(-249289) │ (379868,6) │ │ 256 │ (379868,7) │ (a)=(-249289) │ (379868,7) │ │ 257 │ (379868,8) │ (a)=(-249289) │ (379868,8) │ │ 258 │ (379868,9) │ (a)=(-249289) │ (379868,9) │ │ 259 │ (379868,10) │ (a)=(-249289) │ (379868,10) │ │ 260 │ (379868,11) │ (a)=(-249289) │ (379868,11) │ │ 261 │ (379868,12) │ (a)=(-249289) │ (379868,12) │ │ 262 │ (379868,13) │ (a)=(-249289) │ (379868,13) │ │ 263 │ (379868,14) │ (a)=(-249289) │ (379868,14) │ │ 264 │ (379868,15) │ (a)=(-249289) │ (379868,15) │ │ 265 │ (379868,16) │ (a)=(-249289) │ (379868,16) │ │ 266 │ (379868,17) │ (a)=(-249289) │ (379868,17) │ │ 267 │ (379868,18) │ (a)=(-249289) │ (379868,18) │ │ 268 │ (379868,19) │ (a)=(-249289) │ (379868,19) │ │ 269 │ (379869,2) │ (a)=(-249289) │ (379869,2) │ │ 270 │ (379865,19) │ (a)=(-249288) │ (379865,19) │ │ 271 │ (379865,20) │ (a)=(-249288) │ (379865,20) │ │ 272 │ (379865,21) │ (a)=(-249288) │ (379865,21) │ │ 273 │ (379866,2) │ (a)=(-249288) │ (379866,2) │ │ 274 │ (379866,3) │ (a)=(-249288) │ (379866,3) │ │ 275 │ (379866,4) │ (a)=(-249288) │ (379866,4) │ │ 276 │ (379866,5) │ (a)=(-249288) │ (379866,5) │ │ 277 │ (379866,6) │ (a)=(-249288) │ (379866,6) │ │ 278 │ (379866,7) │ (a)=(-249288) │ (379866,7) │ │ 279 │ (379866,8) │ (a)=(-249288) │ (379866,8) │ │ 280 │ (379866,9) │ (a)=(-249288) │ (379866,9) │ │ 281 │ (379866,10) │ (a)=(-249288) │ (379866,10) │ │ 282 │ (379866,11) │ (a)=(-249288) │ (379866,11) │ │ 283 │ (379866,12) │ (a)=(-249288) │ (379866,12) │ │ 284 │ (379866,13) │ (a)=(-249288) │ (379866,13) │ │ 285 │ (379866,14) │ (a)=(-249288) │ (379866,14) │ │ 286 │ (379866,15) │ (a)=(-249288) │ (379866,15) │ │ 287 │ (379866,16) │ (a)=(-249288) │ (379866,16) │ │ 288 │ (379866,17) │ (a)=(-249288) │ (379866,17) │ │ 289 │ (379866,18) │ (a)=(-249288) │ (379866,18) │ │ 290 │ (379866,19) │ (a)=(-249288) │ (379866,19) │ │ 291 │ (379866,20) │ (a)=(-249288) │ (379866,20) │ │ 292 │ (379866,21) │ (a)=(-249288) │ (379866,21) │ │ 293 │ (379867,1) │ (a)=(-249288) │ (379867,1) │ │ 294 │ (379867,2) │ (a)=(-249288) │ (379867,2) │ │ 295 │ (379867,3) │ (a)=(-249288) │ (379867,3) │ │ 296 │ (379867,4) │ (a)=(-249288) │ (379867,4) │ │ 297 │ (379867,5) │ (a)=(-249288) │ (379867,5) │ │ 298 │ (379867,6) │ (a)=(-249288) │ (379867,6) │ │ 299 │ (379867,7) │ (a)=(-249288) │ (379867,7) │ │ 300 │ (379867,8) │ (a)=(-249288) │ (379867,8) │ │ 301 │ (379867,9) │ (a)=(-249288) │ (379867,9) │ │ 302 │ (379864,9) │ (a)=(-249287) │ (379864,9) │ │ 303 │ (379864,10) │ (a)=(-249287) │ (379864,10) │ │ 304 │ (379864,11) │ (a)=(-249287) │ (379864,11) │ │ 305 │ (379864,12) │ (a)=(-249287) │ (379864,12) │ │ 306 │ (379864,13) │ (a)=(-249287) │ (379864,13) │ │ 307 │ (379864,14) │ (a)=(-249287) │ (379864,14) │ │ 308 │ (379864,15) │ (a)=(-249287) │ (379864,15) │ │ 309 │ (379864,16) │ (a)=(-249287) │ (379864,16) │ │ 310 │ (379864,17) │ (a)=(-249287) │ (379864,17) │ │ 311 │ (379864,18) │ (a)=(-249287) │ (379864,18) │ │ 312 │ (379864,19) │ (a)=(-249287) │ (379864,19) │ │ 313 │ (379864,20) │ (a)=(-249287) │ (379864,20) │ │ 314 │ (379864,21) │ (a)=(-249287) │ (379864,21) │ │ 315 │ (379865,1) │ (a)=(-249287) │ (379865,1) │ │ 316 │ (379865,2) │ (a)=(-249287) │ (379865,2) │ │ 317 │ (379865,3) │ (a)=(-249287) │ (379865,3) │ │ 318 │ (379865,4) │ (a)=(-249287) │ (379865,4) │ │ 319 │ (379865,5) │ (a)=(-249287) │ (379865,5) │ │ 320 │ (379865,6) │ (a)=(-249287) │ (379865,6) │ │ 321 │ (379865,7) │ (a)=(-249287) │ (379865,7) │ │ 322 │ (379865,8) │ (a)=(-249287) │ (379865,8) │ │ 323 │ (379865,9) │ (a)=(-249287) │ (379865,9) │ │ 324 │ (379865,10) │ (a)=(-249287) │ (379865,10) │ │ 325 │ (379865,11) │ (a)=(-249287) │ (379865,11) │ │ 326 │ (379865,12) │ (a)=(-249287) │ (379865,12) │ │ 327 │ (379865,13) │ (a)=(-249287) │ (379865,13) │ │ 328 │ (379865,14) │ (a)=(-249287) │ (379865,14) │ │ 329 │ (379865,15) │ (a)=(-249287) │ (379865,15) │ │ 330 │ (379865,16) │ (a)=(-249287) │ (379865,16) │ │ 331 │ (379865,17) │ (a)=(-249287) │ (379865,17) │ │ 332 │ (379865,18) │ (a)=(-249287) │ (379865,18) │ │ 333 │ (379866,1) │ (a)=(-249287) │ (379866,1) │ │ 334 │ (379862,16) │ (a)=(-249286) │ (379862,16) │ │ 335 │ (379862,17) │ (a)=(-249286) │ (379862,17) │ │ 336 │ (379862,20) │ (a)=(-249286) │ (379862,20) │ │ 337 │ (379863,1) │ (a)=(-249286) │ (379863,1) │ │ 338 │ (379863,2) │ (a)=(-249286) │ (379863,2) │ │ 339 │ (379863,3) │ (a)=(-249286) │ (379863,3) │ │ 340 │ (379863,4) │ (a)=(-249286) │ (379863,4) │ │ 341 │ (379863,5) │ (a)=(-249286) │ (379863,5) │ │ 342 │ (379863,6) │ (a)=(-249286) │ (379863,6) │ │ 343 │ (379863,7) │ (a)=(-249286) │ (379863,7) │ │ 344 │ (379863,8) │ (a)=(-249286) │ (379863,8) │ │ 345 │ (379863,9) │ (a)=(-249286) │ (379863,9) │ │ 346 │ (379863,10) │ (a)=(-249286) │ (379863,10) │ │ 347 │ (379863,11) │ (a)=(-249286) │ (379863,11) │ │ 348 │ (379863,12) │ (a)=(-249286) │ (379863,12) │ │ 349 │ (379863,13) │ (a)=(-249286) │ (379863,13) │ │ 350 │ (379863,14) │ (a)=(-249286) │ (379863,14) │ │ 351 │ (379863,15) │ (a)=(-249286) │ (379863,15) │ │ 352 │ (379863,16) │ (a)=(-249286) │ (379863,16) │ │ 353 │ (379863,17) │ (a)=(-249286) │ (379863,17) │ │ 354 │ (379863,18) │ (a)=(-249286) │ (379863,18) │ │ 355 │ (379863,19) │ (a)=(-249286) │ (379863,19) │ │ 356 │ (379863,20) │ (a)=(-249286) │ (379863,20) │ │ 357 │ (379863,21) │ (a)=(-249286) │ (379863,21) │ │ 358 │ (379864,1) │ (a)=(-249286) │ (379864,1) │ │ 359 │ (379864,2) │ (a)=(-249286) │ (379864,2) │ │ 360 │ (379864,3) │ (a)=(-249286) │ (379864,3) │ │ 361 │ (379864,4) │ (a)=(-249286) │ (379864,4) │ │ 362 │ (379864,5) │ (a)=(-249286) │ (379864,5) │ │ 363 │ (379864,6) │ (a)=(-249286) │ (379864,6) │ │ 364 │ (379864,7) │ (a)=(-249286) │ (379864,7) │ │ 365 │ (379864,8) │ (a)=(-249286) │ (379864,8) │ │ 366 │ (379861,6) │ (a)=(-249285) │ (379861,6) │ │ 367 │ (379861,7) │ (a)=(-249285) │ (379861,7) │ └────────────┴───────────────┴───────────────┴─────────────┘ (367 rows) And here's what block 5555 from "idx" looks like (note that the fact that I'm using the same index block number as before has no particular significance): ────────────┬──────────────┬─────────────┬────────────┐ │ itemoffset │ ctid │ data │ htid │ ├────────────┼──────────────┼─────────────┼────────────┤ │ 1 │ (96327,4097) │ (a)=(63216) │ (96327,15) │ │ 2 │ (96310,7) │ (a)=(63204) │ (96310,7) │ │ 3 │ (96310,8) │ (a)=(63204) │ (96310,8) │ │ 4 │ (96310,9) │ (a)=(63204) │ (96310,9) │ │ 5 │ (96310,10) │ (a)=(63204) │ (96310,10) │ │ 6 │ (96310,11) │ (a)=(63204) │ (96310,11) │ │ 7 │ (96310,12) │ (a)=(63204) │ (96310,12) │ │ 8 │ (96310,13) │ (a)=(63204) │ (96310,13) │ │ 9 │ (96310,14) │ (a)=(63204) │ (96310,14) │ │ 10 │ (96310,15) │ (a)=(63204) │ (96310,15) │ │ 11 │ (96310,16) │ (a)=(63204) │ (96310,16) │ │ 12 │ (96310,17) │ (a)=(63204) │ (96310,17) │ │ 13 │ (96310,18) │ (a)=(63204) │ (96310,18) │ │ 14 │ (96310,19) │ (a)=(63205) │ (96310,19) │ │ 15 │ (96310,20) │ (a)=(63205) │ (96310,20) │ │ 16 │ (96310,21) │ (a)=(63205) │ (96310,21) │ │ 17 │ (96311,1) │ (a)=(63205) │ (96311,1) │ │ 18 │ (96311,2) │ (a)=(63205) │ (96311,2) │ │ 19 │ (96311,3) │ (a)=(63205) │ (96311,3) │ │ 20 │ (96311,4) │ (a)=(63205) │ (96311,4) │ │ 21 │ (96311,5) │ (a)=(63205) │ (96311,5) │ │ 22 │ (96311,6) │ (a)=(63205) │ (96311,6) │ │ 23 │ (96311,7) │ (a)=(63205) │ (96311,7) │ │ 24 │ (96311,8) │ (a)=(63205) │ (96311,8) │ │ 25 │ (96311,9) │ (a)=(63205) │ (96311,9) │ │ 26 │ (96311,10) │ (a)=(63205) │ (96311,10) │ │ 27 │ (96311,11) │ (a)=(63205) │ (96311,11) │ │ 28 │ (96311,12) │ (a)=(63205) │ (96311,12) │ │ 29 │ (96311,13) │ (a)=(63205) │ (96311,13) │ │ 30 │ (96311,14) │ (a)=(63205) │ (96311,14) │ │ 31 │ (96311,15) │ (a)=(63205) │ (96311,15) │ │ 32 │ (96311,16) │ (a)=(63205) │ (96311,16) │ │ 33 │ (96311,17) │ (a)=(63205) │ (96311,17) │ │ 34 │ (96311,18) │ (a)=(63205) │ (96311,18) │ │ 35 │ (96311,19) │ (a)=(63205) │ (96311,19) │ │ 36 │ (96311,20) │ (a)=(63205) │ (96311,20) │ │ 37 │ (96311,21) │ (a)=(63205) │ (96311,21) │ │ 38 │ (96312,1) │ (a)=(63205) │ (96312,1) │ │ 39 │ (96312,2) │ (a)=(63205) │ (96312,2) │ │ 40 │ (96312,3) │ (a)=(63205) │ (96312,3) │ │ 41 │ (96312,4) │ (a)=(63205) │ (96312,4) │ │ 42 │ (96312,5) │ (a)=(63205) │ (96312,5) │ │ 43 │ (96312,6) │ (a)=(63205) │ (96312,6) │ │ 44 │ (96312,7) │ (a)=(63205) │ (96312,7) │ │ 45 │ (96312,9) │ (a)=(63205) │ (96312,9) │ │ 46 │ (96312,8) │ (a)=(63206) │ (96312,8) │ │ 47 │ (96312,10) │ (a)=(63206) │ (96312,10) │ │ 48 │ (96312,11) │ (a)=(63206) │ (96312,11) │ │ 49 │ (96312,12) │ (a)=(63206) │ (96312,12) │ │ 50 │ (96312,13) │ (a)=(63206) │ (96312,13) │ │ 51 │ (96312,14) │ (a)=(63206) │ (96312,14) │ │ 52 │ (96312,15) │ (a)=(63206) │ (96312,15) │ │ 53 │ (96312,16) │ (a)=(63206) │ (96312,16) │ │ 54 │ (96312,17) │ (a)=(63206) │ (96312,17) │ │ 55 │ (96312,18) │ (a)=(63206) │ (96312,18) │ │ 56 │ (96312,19) │ (a)=(63206) │ (96312,19) │ │ 57 │ (96312,20) │ (a)=(63206) │ (96312,20) │ │ 58 │ (96312,21) │ (a)=(63206) │ (96312,21) │ │ 59 │ (96313,1) │ (a)=(63206) │ (96313,1) │ │ 60 │ (96313,2) │ (a)=(63206) │ (96313,2) │ │ 61 │ (96313,3) │ (a)=(63206) │ (96313,3) │ │ 62 │ (96313,4) │ (a)=(63206) │ (96313,4) │ │ 63 │ (96313,5) │ (a)=(63206) │ (96313,5) │ │ 64 │ (96313,6) │ (a)=(63206) │ (96313,6) │ │ 65 │ (96313,7) │ (a)=(63206) │ (96313,7) │ │ 66 │ (96313,8) │ (a)=(63206) │ (96313,8) │ │ 67 │ (96313,9) │ (a)=(63206) │ (96313,9) │ │ 68 │ (96313,10) │ (a)=(63206) │ (96313,10) │ │ 69 │ (96313,11) │ (a)=(63206) │ (96313,11) │ │ 70 │ (96313,12) │ (a)=(63206) │ (96313,12) │ │ 71 │ (96313,13) │ (a)=(63206) │ (96313,13) │ │ 72 │ (96313,14) │ (a)=(63206) │ (96313,14) │ │ 73 │ (96313,15) │ (a)=(63206) │ (96313,15) │ │ 74 │ (96313,16) │ (a)=(63206) │ (96313,16) │ │ 75 │ (96313,17) │ (a)=(63206) │ (96313,17) │ │ 76 │ (96313,18) │ (a)=(63206) │ (96313,18) │ │ 77 │ (96313,20) │ (a)=(63206) │ (96313,20) │ │ 78 │ (96313,19) │ (a)=(63207) │ (96313,19) │ │ 79 │ (96313,21) │ (a)=(63207) │ (96313,21) │ │ 80 │ (96314,1) │ (a)=(63207) │ (96314,1) │ │ 81 │ (96314,2) │ (a)=(63207) │ (96314,2) │ │ 82 │ (96314,3) │ (a)=(63207) │ (96314,3) │ │ 83 │ (96314,4) │ (a)=(63207) │ (96314,4) │ │ 84 │ (96314,5) │ (a)=(63207) │ (96314,5) │ │ 85 │ (96314,6) │ (a)=(63207) │ (96314,6) │ │ 86 │ (96314,7) │ (a)=(63207) │ (96314,7) │ │ 87 │ (96314,8) │ (a)=(63207) │ (96314,8) │ │ 88 │ (96314,9) │ (a)=(63207) │ (96314,9) │ │ 89 │ (96314,10) │ (a)=(63207) │ (96314,10) │ │ 90 │ (96314,11) │ (a)=(63207) │ (96314,11) │ │ 91 │ (96314,12) │ (a)=(63207) │ (96314,12) │ │ 92 │ (96314,13) │ (a)=(63207) │ (96314,13) │ │ 93 │ (96314,14) │ (a)=(63207) │ (96314,14) │ │ 94 │ (96314,15) │ (a)=(63207) │ (96314,15) │ │ 95 │ (96314,16) │ (a)=(63207) │ (96314,16) │ │ 96 │ (96314,17) │ (a)=(63207) │ (96314,17) │ │ 97 │ (96314,18) │ (a)=(63207) │ (96314,18) │ │ 98 │ (96314,19) │ (a)=(63207) │ (96314,19) │ │ 99 │ (96314,20) │ (a)=(63207) │ (96314,20) │ │ 100 │ (96314,21) │ (a)=(63207) │ (96314,21) │ │ 101 │ (96315,1) │ (a)=(63207) │ (96315,1) │ │ 102 │ (96315,2) │ (a)=(63207) │ (96315,2) │ │ 103 │ (96315,3) │ (a)=(63207) │ (96315,3) │ │ 104 │ (96315,4) │ (a)=(63207) │ (96315,4) │ │ 105 │ (96315,5) │ (a)=(63207) │ (96315,5) │ │ 106 │ (96315,6) │ (a)=(63207) │ (96315,6) │ │ 107 │ (96315,7) │ (a)=(63207) │ (96315,7) │ │ 108 │ (96315,8) │ (a)=(63207) │ (96315,8) │ │ 109 │ (96315,12) │ (a)=(63207) │ (96315,12) │ │ 110 │ (96315,9) │ (a)=(63208) │ (96315,9) │ │ 111 │ (96315,10) │ (a)=(63208) │ (96315,10) │ │ 112 │ (96315,11) │ (a)=(63208) │ (96315,11) │ │ 113 │ (96315,13) │ (a)=(63208) │ (96315,13) │ │ 114 │ (96315,14) │ (a)=(63208) │ (96315,14) │ │ 115 │ (96315,15) │ (a)=(63208) │ (96315,15) │ │ 116 │ (96315,16) │ (a)=(63208) │ (96315,16) │ │ 117 │ (96315,17) │ (a)=(63208) │ (96315,17) │ │ 118 │ (96315,18) │ (a)=(63208) │ (96315,18) │ │ 119 │ (96315,19) │ (a)=(63208) │ (96315,19) │ │ 120 │ (96315,20) │ (a)=(63208) │ (96315,20) │ │ 121 │ (96315,21) │ (a)=(63208) │ (96315,21) │ │ 122 │ (96316,1) │ (a)=(63208) │ (96316,1) │ │ 123 │ (96316,2) │ (a)=(63208) │ (96316,2) │ │ 124 │ (96316,3) │ (a)=(63208) │ (96316,3) │ │ 125 │ (96316,4) │ (a)=(63208) │ (96316,4) │ │ 126 │ (96316,5) │ (a)=(63208) │ (96316,5) │ │ 127 │ (96316,6) │ (a)=(63208) │ (96316,6) │ │ 128 │ (96316,7) │ (a)=(63208) │ (96316,7) │ │ 129 │ (96316,8) │ (a)=(63208) │ (96316,8) │ │ 130 │ (96316,9) │ (a)=(63208) │ (96316,9) │ │ 131 │ (96316,10) │ (a)=(63208) │ (96316,10) │ │ 132 │ (96316,11) │ (a)=(63208) │ (96316,11) │ │ 133 │ (96316,12) │ (a)=(63208) │ (96316,12) │ │ 134 │ (96316,13) │ (a)=(63208) │ (96316,13) │ │ 135 │ (96316,14) │ (a)=(63208) │ (96316,14) │ │ 136 │ (96316,15) │ (a)=(63208) │ (96316,15) │ │ 137 │ (96316,16) │ (a)=(63208) │ (96316,16) │ │ 138 │ (96316,17) │ (a)=(63208) │ (96316,17) │ │ 139 │ (96316,18) │ (a)=(63208) │ (96316,18) │ │ 140 │ (96316,19) │ (a)=(63208) │ (96316,19) │ │ 141 │ (96316,20) │ (a)=(63208) │ (96316,20) │ │ 142 │ (96316,21) │ (a)=(63209) │ (96316,21) │ │ 143 │ (96317,1) │ (a)=(63209) │ (96317,1) │ │ 144 │ (96317,2) │ (a)=(63209) │ (96317,2) │ │ 145 │ (96317,3) │ (a)=(63209) │ (96317,3) │ │ 146 │ (96317,4) │ (a)=(63209) │ (96317,4) │ │ 147 │ (96317,5) │ (a)=(63209) │ (96317,5) │ │ 148 │ (96317,6) │ (a)=(63209) │ (96317,6) │ │ 149 │ (96317,7) │ (a)=(63209) │ (96317,7) │ │ 150 │ (96317,8) │ (a)=(63209) │ (96317,8) │ │ 151 │ (96317,9) │ (a)=(63209) │ (96317,9) │ │ 152 │ (96317,10) │ (a)=(63209) │ (96317,10) │ │ 153 │ (96317,11) │ (a)=(63209) │ (96317,11) │ │ 154 │ (96317,12) │ (a)=(63209) │ (96317,12) │ │ 155 │ (96317,13) │ (a)=(63209) │ (96317,13) │ │ 156 │ (96317,14) │ (a)=(63209) │ (96317,14) │ │ 157 │ (96317,15) │ (a)=(63209) │ (96317,15) │ │ 158 │ (96317,16) │ (a)=(63209) │ (96317,16) │ │ 159 │ (96317,17) │ (a)=(63209) │ (96317,17) │ │ 160 │ (96317,18) │ (a)=(63209) │ (96317,18) │ │ 161 │ (96317,19) │ (a)=(63209) │ (96317,19) │ │ 162 │ (96317,20) │ (a)=(63209) │ (96317,20) │ │ 163 │ (96317,21) │ (a)=(63209) │ (96317,21) │ │ 164 │ (96318,1) │ (a)=(63209) │ (96318,1) │ │ 165 │ (96318,2) │ (a)=(63209) │ (96318,2) │ │ 166 │ (96318,3) │ (a)=(63209) │ (96318,3) │ │ 167 │ (96318,4) │ (a)=(63209) │ (96318,4) │ │ 168 │ (96318,5) │ (a)=(63209) │ (96318,5) │ │ 169 │ (96318,6) │ (a)=(63209) │ (96318,6) │ │ 170 │ (96318,7) │ (a)=(63209) │ (96318,7) │ │ 171 │ (96318,8) │ (a)=(63209) │ (96318,8) │ │ 172 │ (96318,9) │ (a)=(63209) │ (96318,9) │ │ 173 │ (96318,10) │ (a)=(63209) │ (96318,10) │ │ 174 │ (96318,11) │ (a)=(63210) │ (96318,11) │ │ 175 │ (96318,12) │ (a)=(63210) │ (96318,12) │ │ 176 │ (96318,13) │ (a)=(63210) │ (96318,13) │ │ 177 │ (96318,14) │ (a)=(63210) │ (96318,14) │ │ 178 │ (96318,15) │ (a)=(63210) │ (96318,15) │ │ 179 │ (96318,16) │ (a)=(63210) │ (96318,16) │ │ 180 │ (96318,17) │ (a)=(63210) │ (96318,17) │ │ 181 │ (96318,18) │ (a)=(63210) │ (96318,18) │ │ 182 │ (96318,19) │ (a)=(63210) │ (96318,19) │ │ 183 │ (96318,20) │ (a)=(63210) │ (96318,20) │ │ 184 │ (96318,21) │ (a)=(63210) │ (96318,21) │ │ 185 │ (96319,1) │ (a)=(63210) │ (96319,1) │ │ 186 │ (96319,2) │ (a)=(63210) │ (96319,2) │ │ 187 │ (96319,3) │ (a)=(63210) │ (96319,3) │ │ 188 │ (96319,4) │ (a)=(63210) │ (96319,4) │ │ 189 │ (96319,5) │ (a)=(63210) │ (96319,5) │ │ 190 │ (96319,6) │ (a)=(63210) │ (96319,6) │ │ 191 │ (96319,7) │ (a)=(63210) │ (96319,7) │ │ 192 │ (96319,8) │ (a)=(63210) │ (96319,8) │ │ 193 │ (96319,9) │ (a)=(63210) │ (96319,9) │ │ 194 │ (96319,10) │ (a)=(63210) │ (96319,10) │ │ 195 │ (96319,11) │ (a)=(63210) │ (96319,11) │ │ 196 │ (96319,12) │ (a)=(63210) │ (96319,12) │ │ 197 │ (96319,13) │ (a)=(63210) │ (96319,13) │ │ 198 │ (96319,14) │ (a)=(63210) │ (96319,14) │ │ 199 │ (96319,15) │ (a)=(63210) │ (96319,15) │ │ 200 │ (96319,16) │ (a)=(63210) │ (96319,16) │ │ 201 │ (96319,17) │ (a)=(63210) │ (96319,17) │ │ 202 │ (96319,18) │ (a)=(63210) │ (96319,18) │ │ 203 │ (96319,19) │ (a)=(63210) │ (96319,19) │ │ 204 │ (96319,20) │ (a)=(63210) │ (96319,20) │ │ 205 │ (96320,1) │ (a)=(63210) │ (96320,1) │ │ 206 │ (96319,21) │ (a)=(63211) │ (96319,21) │ │ 207 │ (96320,2) │ (a)=(63211) │ (96320,2) │ │ 208 │ (96320,3) │ (a)=(63211) │ (96320,3) │ │ 209 │ (96320,4) │ (a)=(63211) │ (96320,4) │ │ 210 │ (96320,5) │ (a)=(63211) │ (96320,5) │ │ 211 │ (96320,6) │ (a)=(63211) │ (96320,6) │ │ 212 │ (96320,7) │ (a)=(63211) │ (96320,7) │ │ 213 │ (96320,8) │ (a)=(63211) │ (96320,8) │ │ 214 │ (96320,9) │ (a)=(63211) │ (96320,9) │ │ 215 │ (96320,10) │ (a)=(63211) │ (96320,10) │ │ 216 │ (96320,11) │ (a)=(63211) │ (96320,11) │ │ 217 │ (96320,12) │ (a)=(63211) │ (96320,12) │ │ 218 │ (96320,13) │ (a)=(63211) │ (96320,13) │ │ 219 │ (96320,14) │ (a)=(63211) │ (96320,14) │ │ 220 │ (96320,15) │ (a)=(63211) │ (96320,15) │ │ 221 │ (96320,16) │ (a)=(63211) │ (96320,16) │ │ 222 │ (96320,17) │ (a)=(63211) │ (96320,17) │ │ 223 │ (96320,18) │ (a)=(63211) │ (96320,18) │ │ 224 │ (96320,19) │ (a)=(63211) │ (96320,19) │ │ 225 │ (96320,20) │ (a)=(63211) │ (96320,20) │ │ 226 │ (96320,21) │ (a)=(63211) │ (96320,21) │ │ 227 │ (96321,1) │ (a)=(63211) │ (96321,1) │ │ 228 │ (96321,2) │ (a)=(63211) │ (96321,2) │ │ 229 │ (96321,3) │ (a)=(63211) │ (96321,3) │ │ 230 │ (96321,4) │ (a)=(63211) │ (96321,4) │ │ 231 │ (96321,5) │ (a)=(63211) │ (96321,5) │ │ 232 │ (96321,6) │ (a)=(63211) │ (96321,6) │ │ 233 │ (96321,7) │ (a)=(63211) │ (96321,7) │ │ 234 │ (96321,8) │ (a)=(63211) │ (96321,8) │ │ 235 │ (96321,9) │ (a)=(63211) │ (96321,9) │ │ 236 │ (96321,10) │ (a)=(63211) │ (96321,10) │ │ 237 │ (96321,11) │ (a)=(63211) │ (96321,11) │ │ 238 │ (96321,12) │ (a)=(63212) │ (96321,12) │ │ 239 │ (96321,13) │ (a)=(63212) │ (96321,13) │ │ 240 │ (96321,14) │ (a)=(63212) │ (96321,14) │ │ 241 │ (96321,15) │ (a)=(63212) │ (96321,15) │ │ 242 │ (96321,16) │ (a)=(63212) │ (96321,16) │ │ 243 │ (96321,17) │ (a)=(63212) │ (96321,17) │ │ 244 │ (96321,18) │ (a)=(63212) │ (96321,18) │ │ 245 │ (96321,19) │ (a)=(63212) │ (96321,19) │ │ 246 │ (96321,20) │ (a)=(63212) │ (96321,20) │ │ 247 │ (96321,21) │ (a)=(63212) │ (96321,21) │ │ 248 │ (96322,1) │ (a)=(63212) │ (96322,1) │ │ 249 │ (96322,2) │ (a)=(63212) │ (96322,2) │ │ 250 │ (96322,3) │ (a)=(63212) │ (96322,3) │ │ 251 │ (96322,4) │ (a)=(63212) │ (96322,4) │ │ 252 │ (96322,5) │ (a)=(63212) │ (96322,5) │ │ 253 │ (96322,6) │ (a)=(63212) │ (96322,6) │ │ 254 │ (96322,7) │ (a)=(63212) │ (96322,7) │ │ 255 │ (96322,8) │ (a)=(63212) │ (96322,8) │ │ 256 │ (96322,9) │ (a)=(63212) │ (96322,9) │ │ 257 │ (96322,10) │ (a)=(63212) │ (96322,10) │ │ 258 │ (96322,11) │ (a)=(63212) │ (96322,11) │ │ 259 │ (96322,12) │ (a)=(63212) │ (96322,12) │ │ 260 │ (96322,13) │ (a)=(63212) │ (96322,13) │ │ 261 │ (96322,14) │ (a)=(63212) │ (96322,14) │ │ 262 │ (96322,15) │ (a)=(63212) │ (96322,15) │ │ 263 │ (96322,16) │ (a)=(63212) │ (96322,16) │ │ 264 │ (96322,17) │ (a)=(63212) │ (96322,17) │ │ 265 │ (96322,18) │ (a)=(63212) │ (96322,18) │ │ 266 │ (96322,19) │ (a)=(63212) │ (96322,19) │ │ 267 │ (96322,20) │ (a)=(63212) │ (96322,20) │ │ 268 │ (96322,21) │ (a)=(63212) │ (96322,21) │ │ 269 │ (96323,3) │ (a)=(63212) │ (96323,3) │ │ 270 │ (96323,1) │ (a)=(63213) │ (96323,1) │ │ 271 │ (96323,2) │ (a)=(63213) │ (96323,2) │ │ 272 │ (96323,4) │ (a)=(63213) │ (96323,4) │ │ 273 │ (96323,5) │ (a)=(63213) │ (96323,5) │ │ 274 │ (96323,6) │ (a)=(63213) │ (96323,6) │ │ 275 │ (96323,7) │ (a)=(63213) │ (96323,7) │ │ 276 │ (96323,8) │ (a)=(63213) │ (96323,8) │ │ 277 │ (96323,9) │ (a)=(63213) │ (96323,9) │ │ 278 │ (96323,10) │ (a)=(63213) │ (96323,10) │ │ 279 │ (96323,11) │ (a)=(63213) │ (96323,11) │ │ 280 │ (96323,12) │ (a)=(63213) │ (96323,12) │ │ 281 │ (96323,13) │ (a)=(63213) │ (96323,13) │ │ 282 │ (96323,14) │ (a)=(63213) │ (96323,14) │ │ 283 │ (96323,15) │ (a)=(63213) │ (96323,15) │ │ 284 │ (96323,16) │ (a)=(63213) │ (96323,16) │ │ 285 │ (96323,17) │ (a)=(63213) │ (96323,17) │ │ 286 │ (96323,18) │ (a)=(63213) │ (96323,18) │ │ 287 │ (96323,19) │ (a)=(63213) │ (96323,19) │ │ 288 │ (96323,20) │ (a)=(63213) │ (96323,20) │ │ 289 │ (96323,21) │ (a)=(63213) │ (96323,21) │ │ 290 │ (96324,1) │ (a)=(63213) │ (96324,1) │ │ 291 │ (96324,2) │ (a)=(63213) │ (96324,2) │ │ 292 │ (96324,3) │ (a)=(63213) │ (96324,3) │ │ 293 │ (96324,4) │ (a)=(63213) │ (96324,4) │ │ 294 │ (96324,5) │ (a)=(63213) │ (96324,5) │ │ 295 │ (96324,6) │ (a)=(63213) │ (96324,6) │ │ 296 │ (96324,7) │ (a)=(63213) │ (96324,7) │ │ 297 │ (96324,8) │ (a)=(63213) │ (96324,8) │ │ 298 │ (96324,9) │ (a)=(63213) │ (96324,9) │ │ 299 │ (96324,11) │ (a)=(63213) │ (96324,11) │ │ 300 │ (96324,12) │ (a)=(63213) │ (96324,12) │ │ 301 │ (96324,13) │ (a)=(63213) │ (96324,13) │ │ 302 │ (96324,10) │ (a)=(63214) │ (96324,10) │ │ 303 │ (96324,14) │ (a)=(63214) │ (96324,14) │ │ 304 │ (96324,15) │ (a)=(63214) │ (96324,15) │ │ 305 │ (96324,16) │ (a)=(63214) │ (96324,16) │ │ 306 │ (96324,17) │ (a)=(63214) │ (96324,17) │ │ 307 │ (96324,18) │ (a)=(63214) │ (96324,18) │ │ 308 │ (96324,19) │ (a)=(63214) │ (96324,19) │ │ 309 │ (96324,20) │ (a)=(63214) │ (96324,20) │ │ 310 │ (96324,21) │ (a)=(63214) │ (96324,21) │ │ 311 │ (96325,1) │ (a)=(63214) │ (96325,1) │ │ 312 │ (96325,2) │ (a)=(63214) │ (96325,2) │ │ 313 │ (96325,3) │ (a)=(63214) │ (96325,3) │ │ 314 │ (96325,4) │ (a)=(63214) │ (96325,4) │ │ 315 │ (96325,5) │ (a)=(63214) │ (96325,5) │ │ 316 │ (96325,6) │ (a)=(63214) │ (96325,6) │ │ 317 │ (96325,7) │ (a)=(63214) │ (96325,7) │ │ 318 │ (96325,8) │ (a)=(63214) │ (96325,8) │ │ 319 │ (96325,9) │ (a)=(63214) │ (96325,9) │ │ 320 │ (96325,10) │ (a)=(63214) │ (96325,10) │ │ 321 │ (96325,11) │ (a)=(63214) │ (96325,11) │ │ 322 │ (96325,12) │ (a)=(63214) │ (96325,12) │ │ 323 │ (96325,13) │ (a)=(63214) │ (96325,13) │ │ 324 │ (96325,14) │ (a)=(63214) │ (96325,14) │ │ 325 │ (96325,15) │ (a)=(63214) │ (96325,15) │ │ 326 │ (96325,16) │ (a)=(63214) │ (96325,16) │ │ 327 │ (96325,17) │ (a)=(63214) │ (96325,17) │ │ 328 │ (96325,18) │ (a)=(63214) │ (96325,18) │ │ 329 │ (96325,19) │ (a)=(63214) │ (96325,19) │ │ 330 │ (96325,20) │ (a)=(63214) │ (96325,20) │ │ 331 │ (96325,21) │ (a)=(63214) │ (96325,21) │ │ 332 │ (96326,1) │ (a)=(63214) │ (96326,1) │ │ 333 │ (96326,3) │ (a)=(63214) │ (96326,3) │ │ 334 │ (96326,2) │ (a)=(63215) │ (96326,2) │ │ 335 │ (96326,4) │ (a)=(63215) │ (96326,4) │ │ 336 │ (96326,5) │ (a)=(63215) │ (96326,5) │ │ 337 │ (96326,6) │ (a)=(63215) │ (96326,6) │ │ 338 │ (96326,7) │ (a)=(63215) │ (96326,7) │ │ 339 │ (96326,8) │ (a)=(63215) │ (96326,8) │ │ 340 │ (96326,9) │ (a)=(63215) │ (96326,9) │ │ 341 │ (96326,10) │ (a)=(63215) │ (96326,10) │ │ 342 │ (96326,11) │ (a)=(63215) │ (96326,11) │ │ 343 │ (96326,12) │ (a)=(63215) │ (96326,12) │ │ 344 │ (96326,13) │ (a)=(63215) │ (96326,13) │ │ 345 │ (96326,14) │ (a)=(63215) │ (96326,14) │ │ 346 │ (96326,15) │ (a)=(63215) │ (96326,15) │ │ 347 │ (96326,16) │ (a)=(63215) │ (96326,16) │ │ 348 │ (96326,17) │ (a)=(63215) │ (96326,17) │ │ 349 │ (96326,18) │ (a)=(63215) │ (96326,18) │ │ 350 │ (96326,19) │ (a)=(63215) │ (96326,19) │ │ 351 │ (96326,20) │ (a)=(63215) │ (96326,20) │ │ 352 │ (96326,21) │ (a)=(63215) │ (96326,21) │ │ 353 │ (96327,1) │ (a)=(63215) │ (96327,1) │ │ 354 │ (96327,2) │ (a)=(63215) │ (96327,2) │ │ 355 │ (96327,3) │ (a)=(63215) │ (96327,3) │ │ 356 │ (96327,4) │ (a)=(63215) │ (96327,4) │ │ 357 │ (96327,5) │ (a)=(63215) │ (96327,5) │ │ 358 │ (96327,6) │ (a)=(63215) │ (96327,6) │ │ 359 │ (96327,7) │ (a)=(63215) │ (96327,7) │ │ 360 │ (96327,8) │ (a)=(63215) │ (96327,8) │ │ 361 │ (96327,9) │ (a)=(63215) │ (96327,9) │ │ 362 │ (96327,10) │ (a)=(63215) │ (96327,10) │ │ 363 │ (96327,11) │ (a)=(63215) │ (96327,11) │ │ 364 │ (96327,12) │ (a)=(63215) │ (96327,12) │ │ 365 │ (96327,14) │ (a)=(63215) │ (96327,14) │ │ 366 │ (96327,13) │ (a)=(63216) │ (96327,13) │ │ 367 │ (96327,15) │ (a)=(63216) │ (96327,15) │ └────────────┴──────────────┴─────────────┴────────────┘ (367 rows) I only notice one tiny discontinuity in this "unshuffled" "idx" page: the index tuple at offset 205 uses the heap TID (96320,1), whereas the index tuple right after that (at offset 206) uses the heap TID (96319,21) (before we get to a large run of heap TIDs that use heap block number 96320 once more). As I touched on already, this effect can be seen even with perfectly correlated inserts. The effect is caused by the FSM having a tiny bit of space left on one heap page -- not enough space to fit an incoming heap tuple, but still enough to fit a slightly smaller heap tuple that is inserted shortly thereafter. You end up with exactly one index tuple whose heap TID is slightly out-of-order, though only every once in a long while. -- Peter Geoghegan
On 8/13/25 18:36, Peter Geoghegan wrote: > On Wed, Aug 13, 2025 at 8:15 AM Tomas Vondra <tomas@vondra.me> wrote: >> 1) created a second table with an "inverse pattern" that's decreasing: >> >> create table t2 (like t) with (fillfactor = 20); >> insert into t2 select -a, b from t; >> create index idx2 on t2 (a); >> alter index idx2 set (deduplicate_items = false); >> reindex index idx2; >> >> The idea is that >> >> SELECT * FROM t WHERE (a BETWEEN x AND y) ORDER BY a ASC >> >> is the same "block pattern" as >> >> SELECT * FROM t2 WHERE (a BETWEEN -y AND -x) ORDER BY a DESC > > A quick look at "idx2" using pageinspect seems to show heap block numbers that > are significantly less in-order than those from the original "idx" index, > though. While the original "idx" has block numbers that are *almost* in perfect > order (I do see the odd index tuple that has a non-consecutive TID, possibly > just due to the influence of the heap FSM), "idx2" seems to have leaf pages that > each have heap blocks that are somewhat "shuffled" within each page. > > While the average total number of heap blocks seen with "idx2" might not be very > much higher than "idx", it is nevertheless true that the heap TIDs appear in a > less consistent order. So AFAICT we have no principled reason to expect the > "runs" seen on "idx2" to be anything like "idx" (maybe the performance gap is a > real problem, since the physical attributes of each index aren't hugely > different, but even then the "runs" stats don't seem all that uninformative). > > I'll show what I mean by "shuffled" via a comparison of 2 random leaf pages from > each index. Here's what block 5555 from "idx2" looks like according to > bt_page_items (it shows a certain amount of "localized shuffling"): > > ┌────────────┬───────────────┬───────────────┬─────────────┐ > │ itemoffset │ ctid │ data │ htid │ > ├────────────┼───────────────┼───────────────┼─────────────┤ > │ 1 │ (379861,4097) │ (a)=(-249285) │ (379861,7) │ > │ 2 │ (379880,13) │ (a)=(-249297) │ (379880,13) │ > │ 3 │ (379880,14) │ (a)=(-249297) │ (379880,14) │ > │ 4 │ (379880,15) │ (a)=(-249297) │ (379880,15) │ > │ 5 │ (379880,16) │ (a)=(-249297) │ (379880,16) │ > │ 6 │ (379880,17) │ (a)=(-249297) │ (379880,17) │ > │ 7 │ (379880,18) │ (a)=(-249297) │ (379880,18) │ > │ 8 │ (379880,19) │ (a)=(-249297) │ (379880,19) │ > │ 9 │ (379880,20) │ (a)=(-249297) │ (379880,20) │ > │ 10 │ (379880,21) │ (a)=(-249297) │ (379880,21) │ > │ 11 │ (379881,2) │ (a)=(-249297) │ (379881,2) │ > │ 12 │ (379881,3) │ (a)=(-249297) │ (379881,3) │ > │ 13 │ (379881,4) │ (a)=(-249297) │ (379881,4) │ > │ 14 │ (379878,2) │ (a)=(-249296) │ (379878,2) │ > │ 15 │ (379878,3) │ (a)=(-249296) │ (379878,3) │ > │ 16 │ (379878,5) │ (a)=(-249296) │ (379878,5) │ > │ 17 │ (379878,6) │ (a)=(-249296) │ (379878,6) │ > │ 18 │ (379878,7) │ (a)=(-249296) │ (379878,7) │ > │ 19 │ (379878,8) │ (a)=(-249296) │ (379878,8) │ > │ 20 │ (379878,9) │ (a)=(-249296) │ (379878,9) │ > │ 21 │ (379878,10) │ (a)=(-249296) │ (379878,10) │ > │ 22 │ (379878,11) │ (a)=(-249296) │ (379878,11) │ > │ 23 │ (379878,12) │ (a)=(-249296) │ (379878,12) │ > │ 24 │ (379878,13) │ (a)=(-249296) │ (379878,13) │ > │ 25 │ (379878,14) │ (a)=(-249296) │ (379878,14) │ > │ 26 │ (379878,15) │ (a)=(-249296) │ (379878,15) │ > │ 27 │ (379878,16) │ (a)=(-249296) │ (379878,16) │ > │ 28 │ (379878,17) │ (a)=(-249296) │ (379878,17) │ > │ 29 │ (379878,18) │ (a)=(-249296) │ (379878,18) │ > │ 30 │ (379878,19) │ (a)=(-249296) │ (379878,19) │ > │ 31 │ (379878,20) │ (a)=(-249296) │ (379878,20) │ > │ 32 │ (379878,21) │ (a)=(-249296) │ (379878,21) │ > │ 33 │ (379879,1) │ (a)=(-249296) │ (379879,1) │ > │ 34 │ (379879,2) │ (a)=(-249296) │ (379879,2) │ > │ 35 │ (379879,3) │ (a)=(-249296) │ (379879,3) │ > │ 36 │ (379879,4) │ (a)=(-249296) │ (379879,4) │ > │ 37 │ (379879,5) │ (a)=(-249296) │ (379879,5) │ > │ 38 │ (379879,6) │ (a)=(-249296) │ (379879,6) │ > │ 39 │ (379879,7) │ (a)=(-249296) │ (379879,7) │ > │ 40 │ (379879,8) │ (a)=(-249296) │ (379879,8) │ > │ 41 │ (379879,9) │ (a)=(-249296) │ (379879,9) │ > │ 42 │ (379879,10) │ (a)=(-249296) │ (379879,10) │ > │ 43 │ (379879,12) │ (a)=(-249296) │ (379879,12) │ > │ 44 │ (379879,13) │ (a)=(-249296) │ (379879,13) │ > │ 45 │ (379879,14) │ (a)=(-249296) │ (379879,14) │ > │ 46 │ (379876,10) │ (a)=(-249295) │ (379876,10) │ > │ 47 │ (379876,12) │ (a)=(-249295) │ (379876,12) │ > │ 48 │ (379876,14) │ (a)=(-249295) │ (379876,14) │ > │ 49 │ (379876,16) │ (a)=(-249295) │ (379876,16) │ > │ 50 │ (379876,17) │ (a)=(-249295) │ (379876,17) │ > │ 51 │ (379876,18) │ (a)=(-249295) │ (379876,18) │ > │ 52 │ (379876,19) │ (a)=(-249295) │ (379876,19) │ > │ 53 │ (379876,20) │ (a)=(-249295) │ (379876,20) │ > │ 54 │ (379876,21) │ (a)=(-249295) │ (379876,21) │ > │ 55 │ (379877,1) │ (a)=(-249295) │ (379877,1) │ > │ 56 │ (379877,2) │ (a)=(-249295) │ (379877,2) │ > │ 57 │ (379877,3) │ (a)=(-249295) │ (379877,3) │ > │ 58 │ (379877,4) │ (a)=(-249295) │ (379877,4) │ > │ 59 │ (379877,5) │ (a)=(-249295) │ (379877,5) │ > │ 60 │ (379877,6) │ (a)=(-249295) │ (379877,6) │ > │ 61 │ (379877,7) │ (a)=(-249295) │ (379877,7) │ > │ 62 │ (379877,8) │ (a)=(-249295) │ (379877,8) │ > │ 63 │ (379877,9) │ (a)=(-249295) │ (379877,9) │ > │ 64 │ (379877,10) │ (a)=(-249295) │ (379877,10) │ > │ 65 │ (379877,11) │ (a)=(-249295) │ (379877,11) │ > │ 66 │ (379877,12) │ (a)=(-249295) │ (379877,12) │ > │ 67 │ (379877,13) │ (a)=(-249295) │ (379877,13) │ > │ 68 │ (379877,14) │ (a)=(-249295) │ (379877,14) │ > │ 69 │ (379877,15) │ (a)=(-249295) │ (379877,15) │ > │ 70 │ (379877,16) │ (a)=(-249295) │ (379877,16) │ > │ 71 │ (379877,17) │ (a)=(-249295) │ (379877,17) │ > │ 72 │ (379877,18) │ (a)=(-249295) │ (379877,18) │ > │ 73 │ (379877,19) │ (a)=(-249295) │ (379877,19) │ > │ 74 │ (379877,20) │ (a)=(-249295) │ (379877,20) │ > │ 75 │ (379877,21) │ (a)=(-249295) │ (379877,21) │ > │ 76 │ (379878,1) │ (a)=(-249295) │ (379878,1) │ > │ 77 │ (379878,4) │ (a)=(-249295) │ (379878,4) │ > │ 78 │ (379874,20) │ (a)=(-249294) │ (379874,20) │ > │ 79 │ (379875,2) │ (a)=(-249294) │ (379875,2) │ > │ 80 │ (379875,3) │ (a)=(-249294) │ (379875,3) │ > │ 81 │ (379875,5) │ (a)=(-249294) │ (379875,5) │ > │ 82 │ (379875,6) │ (a)=(-249294) │ (379875,6) │ > │ 83 │ (379875,7) │ (a)=(-249294) │ (379875,7) │ > │ 84 │ (379875,8) │ (a)=(-249294) │ (379875,8) │ > │ 85 │ (379875,9) │ (a)=(-249294) │ (379875,9) │ > │ 86 │ (379875,10) │ (a)=(-249294) │ (379875,10) │ > │ 87 │ (379875,11) │ (a)=(-249294) │ (379875,11) │ > │ 88 │ (379875,12) │ (a)=(-249294) │ (379875,12) │ > │ 89 │ (379875,13) │ (a)=(-249294) │ (379875,13) │ > │ 90 │ (379875,14) │ (a)=(-249294) │ (379875,14) │ > │ 91 │ (379875,15) │ (a)=(-249294) │ (379875,15) │ > │ 92 │ (379875,16) │ (a)=(-249294) │ (379875,16) │ > │ 93 │ (379875,17) │ (a)=(-249294) │ (379875,17) │ > │ 94 │ (379875,18) │ (a)=(-249294) │ (379875,18) │ > │ 95 │ (379875,19) │ (a)=(-249294) │ (379875,19) │ > │ 96 │ (379875,20) │ (a)=(-249294) │ (379875,20) │ > │ 97 │ (379875,21) │ (a)=(-249294) │ (379875,21) │ > │ 98 │ (379876,1) │ (a)=(-249294) │ (379876,1) │ > │ 99 │ (379876,2) │ (a)=(-249294) │ (379876,2) │ > │ 100 │ (379876,3) │ (a)=(-249294) │ (379876,3) │ > │ 101 │ (379876,4) │ (a)=(-249294) │ (379876,4) │ > │ 102 │ (379876,5) │ (a)=(-249294) │ (379876,5) │ > │ 103 │ (379876,6) │ (a)=(-249294) │ (379876,6) │ > │ 104 │ (379876,7) │ (a)=(-249294) │ (379876,7) │ > │ 105 │ (379876,8) │ (a)=(-249294) │ (379876,8) │ > │ 106 │ (379876,9) │ (a)=(-249294) │ (379876,9) │ > │ 107 │ (379876,11) │ (a)=(-249294) │ (379876,11) │ > │ 108 │ (379876,13) │ (a)=(-249294) │ (379876,13) │ > │ 109 │ (379876,15) │ (a)=(-249294) │ (379876,15) │ > │ 110 │ (379873,11) │ (a)=(-249293) │ (379873,11) │ > │ 111 │ (379873,13) │ (a)=(-249293) │ (379873,13) │ > │ 112 │ (379873,14) │ (a)=(-249293) │ (379873,14) │ > │ 113 │ (379873,15) │ (a)=(-249293) │ (379873,15) │ > │ 114 │ (379873,16) │ (a)=(-249293) │ (379873,16) │ > │ 115 │ (379873,17) │ (a)=(-249293) │ (379873,17) │ > │ 116 │ (379873,18) │ (a)=(-249293) │ (379873,18) │ > │ 117 │ (379873,19) │ (a)=(-249293) │ (379873,19) │ > │ 118 │ (379873,20) │ (a)=(-249293) │ (379873,20) │ > │ 119 │ (379873,21) │ (a)=(-249293) │ (379873,21) │ > │ 120 │ (379874,1) │ (a)=(-249293) │ (379874,1) │ > │ 121 │ (379874,2) │ (a)=(-249293) │ (379874,2) │ > │ 122 │ (379874,3) │ (a)=(-249293) │ (379874,3) │ > │ 123 │ (379874,4) │ (a)=(-249293) │ (379874,4) │ > │ 124 │ (379874,5) │ (a)=(-249293) │ (379874,5) │ > │ 125 │ (379874,6) │ (a)=(-249293) │ (379874,6) │ > │ 126 │ (379874,7) │ (a)=(-249293) │ (379874,7) │ > │ 127 │ (379874,8) │ (a)=(-249293) │ (379874,8) │ > │ 128 │ (379874,9) │ (a)=(-249293) │ (379874,9) │ > │ 129 │ (379874,10) │ (a)=(-249293) │ (379874,10) │ > │ 130 │ (379874,11) │ (a)=(-249293) │ (379874,11) │ > │ 131 │ (379874,12) │ (a)=(-249293) │ (379874,12) │ > │ 132 │ (379874,13) │ (a)=(-249293) │ (379874,13) │ > │ 133 │ (379874,14) │ (a)=(-249293) │ (379874,14) │ > │ 134 │ (379874,15) │ (a)=(-249293) │ (379874,15) │ > │ 135 │ (379874,16) │ (a)=(-249293) │ (379874,16) │ > │ 136 │ (379874,17) │ (a)=(-249293) │ (379874,17) │ > │ 137 │ (379874,18) │ (a)=(-249293) │ (379874,18) │ > │ 138 │ (379874,19) │ (a)=(-249293) │ (379874,19) │ > │ 139 │ (379874,21) │ (a)=(-249293) │ (379874,21) │ > │ 140 │ (379875,1) │ (a)=(-249293) │ (379875,1) │ > │ 141 │ (379875,4) │ (a)=(-249293) │ (379875,4) │ > │ 142 │ (379871,21) │ (a)=(-249292) │ (379871,21) │ > │ 143 │ (379872,2) │ (a)=(-249292) │ (379872,2) │ > │ 144 │ (379872,3) │ (a)=(-249292) │ (379872,3) │ > │ 145 │ (379872,4) │ (a)=(-249292) │ (379872,4) │ > │ 146 │ (379872,5) │ (a)=(-249292) │ (379872,5) │ > │ 147 │ (379872,6) │ (a)=(-249292) │ (379872,6) │ > │ 148 │ (379872,7) │ (a)=(-249292) │ (379872,7) │ > │ 149 │ (379872,8) │ (a)=(-249292) │ (379872,8) │ > │ 150 │ (379872,9) │ (a)=(-249292) │ (379872,9) │ > │ 151 │ (379872,10) │ (a)=(-249292) │ (379872,10) │ > │ 152 │ (379872,11) │ (a)=(-249292) │ (379872,11) │ > │ 153 │ (379872,12) │ (a)=(-249292) │ (379872,12) │ > │ 154 │ (379872,13) │ (a)=(-249292) │ (379872,13) │ > │ 155 │ (379872,14) │ (a)=(-249292) │ (379872,14) │ > │ 156 │ (379872,15) │ (a)=(-249292) │ (379872,15) │ > │ 157 │ (379872,16) │ (a)=(-249292) │ (379872,16) │ > │ 158 │ (379872,17) │ (a)=(-249292) │ (379872,17) │ > │ 159 │ (379872,18) │ (a)=(-249292) │ (379872,18) │ > │ 160 │ (379872,19) │ (a)=(-249292) │ (379872,19) │ > │ 161 │ (379872,20) │ (a)=(-249292) │ (379872,20) │ > │ 162 │ (379872,21) │ (a)=(-249292) │ (379872,21) │ > │ 163 │ (379873,1) │ (a)=(-249292) │ (379873,1) │ > │ 164 │ (379873,2) │ (a)=(-249292) │ (379873,2) │ > │ 165 │ (379873,3) │ (a)=(-249292) │ (379873,3) │ > │ 166 │ (379873,4) │ (a)=(-249292) │ (379873,4) │ > │ 167 │ (379873,5) │ (a)=(-249292) │ (379873,5) │ > │ 168 │ (379873,6) │ (a)=(-249292) │ (379873,6) │ > │ 169 │ (379873,7) │ (a)=(-249292) │ (379873,7) │ > │ 170 │ (379873,8) │ (a)=(-249292) │ (379873,8) │ > │ 171 │ (379873,9) │ (a)=(-249292) │ (379873,9) │ > │ 172 │ (379873,10) │ (a)=(-249292) │ (379873,10) │ > │ 173 │ (379873,12) │ (a)=(-249292) │ (379873,12) │ > │ 174 │ (379870,9) │ (a)=(-249291) │ (379870,9) │ > │ 175 │ (379870,11) │ (a)=(-249291) │ (379870,11) │ > │ 176 │ (379870,12) │ (a)=(-249291) │ (379870,12) │ > │ 177 │ (379870,14) │ (a)=(-249291) │ (379870,14) │ > │ 178 │ (379870,15) │ (a)=(-249291) │ (379870,15) │ > │ 179 │ (379870,16) │ (a)=(-249291) │ (379870,16) │ > │ 180 │ (379870,17) │ (a)=(-249291) │ (379870,17) │ > │ 181 │ (379870,18) │ (a)=(-249291) │ (379870,18) │ > │ 182 │ (379870,19) │ (a)=(-249291) │ (379870,19) │ > │ 183 │ (379870,20) │ (a)=(-249291) │ (379870,20) │ > │ 184 │ (379870,21) │ (a)=(-249291) │ (379870,21) │ > │ 185 │ (379871,1) │ (a)=(-249291) │ (379871,1) │ > │ 186 │ (379871,2) │ (a)=(-249291) │ (379871,2) │ > │ 187 │ (379871,3) │ (a)=(-249291) │ (379871,3) │ > │ 188 │ (379871,4) │ (a)=(-249291) │ (379871,4) │ > │ 189 │ (379871,5) │ (a)=(-249291) │ (379871,5) │ > │ 190 │ (379871,6) │ (a)=(-249291) │ (379871,6) │ > │ 191 │ (379871,7) │ (a)=(-249291) │ (379871,7) │ > │ 192 │ (379871,8) │ (a)=(-249291) │ (379871,8) │ > │ 193 │ (379871,9) │ (a)=(-249291) │ (379871,9) │ > │ 194 │ (379871,10) │ (a)=(-249291) │ (379871,10) │ > │ 195 │ (379871,11) │ (a)=(-249291) │ (379871,11) │ > │ 196 │ (379871,12) │ (a)=(-249291) │ (379871,12) │ > │ 197 │ (379871,13) │ (a)=(-249291) │ (379871,13) │ > │ 198 │ (379871,14) │ (a)=(-249291) │ (379871,14) │ > │ 199 │ (379871,15) │ (a)=(-249291) │ (379871,15) │ > │ 200 │ (379871,16) │ (a)=(-249291) │ (379871,16) │ > │ 201 │ (379871,17) │ (a)=(-249291) │ (379871,17) │ > │ 202 │ (379871,18) │ (a)=(-249291) │ (379871,18) │ > │ 203 │ (379871,19) │ (a)=(-249291) │ (379871,19) │ > │ 204 │ (379871,20) │ (a)=(-249291) │ (379871,20) │ > │ 205 │ (379872,1) │ (a)=(-249291) │ (379872,1) │ > │ 206 │ (379868,20) │ (a)=(-249290) │ (379868,20) │ > │ 207 │ (379868,21) │ (a)=(-249290) │ (379868,21) │ > │ 208 │ (379869,1) │ (a)=(-249290) │ (379869,1) │ > │ 209 │ (379869,3) │ (a)=(-249290) │ (379869,3) │ > │ 210 │ (379869,4) │ (a)=(-249290) │ (379869,4) │ > │ 211 │ (379869,5) │ (a)=(-249290) │ (379869,5) │ > │ 212 │ (379869,6) │ (a)=(-249290) │ (379869,6) │ > │ 213 │ (379869,7) │ (a)=(-249290) │ (379869,7) │ > │ 214 │ (379869,8) │ (a)=(-249290) │ (379869,8) │ > │ 215 │ (379869,9) │ (a)=(-249290) │ (379869,9) │ > │ 216 │ (379869,10) │ (a)=(-249290) │ (379869,10) │ > │ 217 │ (379869,11) │ (a)=(-249290) │ (379869,11) │ > │ 218 │ (379869,12) │ (a)=(-249290) │ (379869,12) │ > │ 219 │ (379869,13) │ (a)=(-249290) │ (379869,13) │ > │ 220 │ (379869,14) │ (a)=(-249290) │ (379869,14) │ > │ 221 │ (379869,15) │ (a)=(-249290) │ (379869,15) │ > │ 222 │ (379869,16) │ (a)=(-249290) │ (379869,16) │ > │ 223 │ (379869,17) │ (a)=(-249290) │ (379869,17) │ > │ 224 │ (379869,18) │ (a)=(-249290) │ (379869,18) │ > │ 225 │ (379869,19) │ (a)=(-249290) │ (379869,19) │ > │ 226 │ (379869,20) │ (a)=(-249290) │ (379869,20) │ > │ 227 │ (379869,21) │ (a)=(-249290) │ (379869,21) │ > │ 228 │ (379870,1) │ (a)=(-249290) │ (379870,1) │ > │ 229 │ (379870,2) │ (a)=(-249290) │ (379870,2) │ > │ 230 │ (379870,3) │ (a)=(-249290) │ (379870,3) │ > │ 231 │ (379870,4) │ (a)=(-249290) │ (379870,4) │ > │ 232 │ (379870,5) │ (a)=(-249290) │ (379870,5) │ > │ 233 │ (379870,6) │ (a)=(-249290) │ (379870,6) │ > │ 234 │ (379870,7) │ (a)=(-249290) │ (379870,7) │ > │ 235 │ (379870,8) │ (a)=(-249290) │ (379870,8) │ > │ 236 │ (379870,10) │ (a)=(-249290) │ (379870,10) │ > │ 237 │ (379870,13) │ (a)=(-249290) │ (379870,13) │ > │ 238 │ (379867,10) │ (a)=(-249289) │ (379867,10) │ > │ 239 │ (379867,11) │ (a)=(-249289) │ (379867,11) │ > │ 240 │ (379867,12) │ (a)=(-249289) │ (379867,12) │ > │ 241 │ (379867,13) │ (a)=(-249289) │ (379867,13) │ > │ 242 │ (379867,14) │ (a)=(-249289) │ (379867,14) │ > │ 243 │ (379867,15) │ (a)=(-249289) │ (379867,15) │ > │ 244 │ (379867,16) │ (a)=(-249289) │ (379867,16) │ > │ 245 │ (379867,17) │ (a)=(-249289) │ (379867,17) │ > │ 246 │ (379867,18) │ (a)=(-249289) │ (379867,18) │ > │ 247 │ (379867,19) │ (a)=(-249289) │ (379867,19) │ > │ 248 │ (379867,20) │ (a)=(-249289) │ (379867,20) │ > │ 249 │ (379867,21) │ (a)=(-249289) │ (379867,21) │ > │ 250 │ (379868,1) │ (a)=(-249289) │ (379868,1) │ > │ 251 │ (379868,2) │ (a)=(-249289) │ (379868,2) │ > │ 252 │ (379868,3) │ (a)=(-249289) │ (379868,3) │ > │ 253 │ (379868,4) │ (a)=(-249289) │ (379868,4) │ > │ 254 │ (379868,5) │ (a)=(-249289) │ (379868,5) │ > │ 255 │ (379868,6) │ (a)=(-249289) │ (379868,6) │ > │ 256 │ (379868,7) │ (a)=(-249289) │ (379868,7) │ > │ 257 │ (379868,8) │ (a)=(-249289) │ (379868,8) │ > │ 258 │ (379868,9) │ (a)=(-249289) │ (379868,9) │ > │ 259 │ (379868,10) │ (a)=(-249289) │ (379868,10) │ > │ 260 │ (379868,11) │ (a)=(-249289) │ (379868,11) │ > │ 261 │ (379868,12) │ (a)=(-249289) │ (379868,12) │ > │ 262 │ (379868,13) │ (a)=(-249289) │ (379868,13) │ > │ 263 │ (379868,14) │ (a)=(-249289) │ (379868,14) │ > │ 264 │ (379868,15) │ (a)=(-249289) │ (379868,15) │ > │ 265 │ (379868,16) │ (a)=(-249289) │ (379868,16) │ > │ 266 │ (379868,17) │ (a)=(-249289) │ (379868,17) │ > │ 267 │ (379868,18) │ (a)=(-249289) │ (379868,18) │ > │ 268 │ (379868,19) │ (a)=(-249289) │ (379868,19) │ > │ 269 │ (379869,2) │ (a)=(-249289) │ (379869,2) │ > │ 270 │ (379865,19) │ (a)=(-249288) │ (379865,19) │ > │ 271 │ (379865,20) │ (a)=(-249288) │ (379865,20) │ > │ 272 │ (379865,21) │ (a)=(-249288) │ (379865,21) │ > │ 273 │ (379866,2) │ (a)=(-249288) │ (379866,2) │ > │ 274 │ (379866,3) │ (a)=(-249288) │ (379866,3) │ > │ 275 │ (379866,4) │ (a)=(-249288) │ (379866,4) │ > │ 276 │ (379866,5) │ (a)=(-249288) │ (379866,5) │ > │ 277 │ (379866,6) │ (a)=(-249288) │ (379866,6) │ > │ 278 │ (379866,7) │ (a)=(-249288) │ (379866,7) │ > │ 279 │ (379866,8) │ (a)=(-249288) │ (379866,8) │ > │ 280 │ (379866,9) │ (a)=(-249288) │ (379866,9) │ > │ 281 │ (379866,10) │ (a)=(-249288) │ (379866,10) │ > │ 282 │ (379866,11) │ (a)=(-249288) │ (379866,11) │ > │ 283 │ (379866,12) │ (a)=(-249288) │ (379866,12) │ > │ 284 │ (379866,13) │ (a)=(-249288) │ (379866,13) │ > │ 285 │ (379866,14) │ (a)=(-249288) │ (379866,14) │ > │ 286 │ (379866,15) │ (a)=(-249288) │ (379866,15) │ > │ 287 │ (379866,16) │ (a)=(-249288) │ (379866,16) │ > │ 288 │ (379866,17) │ (a)=(-249288) │ (379866,17) │ > │ 289 │ (379866,18) │ (a)=(-249288) │ (379866,18) │ > │ 290 │ (379866,19) │ (a)=(-249288) │ (379866,19) │ > │ 291 │ (379866,20) │ (a)=(-249288) │ (379866,20) │ > │ 292 │ (379866,21) │ (a)=(-249288) │ (379866,21) │ > │ 293 │ (379867,1) │ (a)=(-249288) │ (379867,1) │ > │ 294 │ (379867,2) │ (a)=(-249288) │ (379867,2) │ > │ 295 │ (379867,3) │ (a)=(-249288) │ (379867,3) │ > │ 296 │ (379867,4) │ (a)=(-249288) │ (379867,4) │ > │ 297 │ (379867,5) │ (a)=(-249288) │ (379867,5) │ > │ 298 │ (379867,6) │ (a)=(-249288) │ (379867,6) │ > │ 299 │ (379867,7) │ (a)=(-249288) │ (379867,7) │ > │ 300 │ (379867,8) │ (a)=(-249288) │ (379867,8) │ > │ 301 │ (379867,9) │ (a)=(-249288) │ (379867,9) │ > │ 302 │ (379864,9) │ (a)=(-249287) │ (379864,9) │ > │ 303 │ (379864,10) │ (a)=(-249287) │ (379864,10) │ > │ 304 │ (379864,11) │ (a)=(-249287) │ (379864,11) │ > │ 305 │ (379864,12) │ (a)=(-249287) │ (379864,12) │ > │ 306 │ (379864,13) │ (a)=(-249287) │ (379864,13) │ > │ 307 │ (379864,14) │ (a)=(-249287) │ (379864,14) │ > │ 308 │ (379864,15) │ (a)=(-249287) │ (379864,15) │ > │ 309 │ (379864,16) │ (a)=(-249287) │ (379864,16) │ > │ 310 │ (379864,17) │ (a)=(-249287) │ (379864,17) │ > │ 311 │ (379864,18) │ (a)=(-249287) │ (379864,18) │ > │ 312 │ (379864,19) │ (a)=(-249287) │ (379864,19) │ > │ 313 │ (379864,20) │ (a)=(-249287) │ (379864,20) │ > │ 314 │ (379864,21) │ (a)=(-249287) │ (379864,21) │ > │ 315 │ (379865,1) │ (a)=(-249287) │ (379865,1) │ > │ 316 │ (379865,2) │ (a)=(-249287) │ (379865,2) │ > │ 317 │ (379865,3) │ (a)=(-249287) │ (379865,3) │ > │ 318 │ (379865,4) │ (a)=(-249287) │ (379865,4) │ > │ 319 │ (379865,5) │ (a)=(-249287) │ (379865,5) │ > │ 320 │ (379865,6) │ (a)=(-249287) │ (379865,6) │ > │ 321 │ (379865,7) │ (a)=(-249287) │ (379865,7) │ > │ 322 │ (379865,8) │ (a)=(-249287) │ (379865,8) │ > │ 323 │ (379865,9) │ (a)=(-249287) │ (379865,9) │ > │ 324 │ (379865,10) │ (a)=(-249287) │ (379865,10) │ > │ 325 │ (379865,11) │ (a)=(-249287) │ (379865,11) │ > │ 326 │ (379865,12) │ (a)=(-249287) │ (379865,12) │ > │ 327 │ (379865,13) │ (a)=(-249287) │ (379865,13) │ > │ 328 │ (379865,14) │ (a)=(-249287) │ (379865,14) │ > │ 329 │ (379865,15) │ (a)=(-249287) │ (379865,15) │ > │ 330 │ (379865,16) │ (a)=(-249287) │ (379865,16) │ > │ 331 │ (379865,17) │ (a)=(-249287) │ (379865,17) │ > │ 332 │ (379865,18) │ (a)=(-249287) │ (379865,18) │ > │ 333 │ (379866,1) │ (a)=(-249287) │ (379866,1) │ > │ 334 │ (379862,16) │ (a)=(-249286) │ (379862,16) │ > │ 335 │ (379862,17) │ (a)=(-249286) │ (379862,17) │ > │ 336 │ (379862,20) │ (a)=(-249286) │ (379862,20) │ > │ 337 │ (379863,1) │ (a)=(-249286) │ (379863,1) │ > │ 338 │ (379863,2) │ (a)=(-249286) │ (379863,2) │ > │ 339 │ (379863,3) │ (a)=(-249286) │ (379863,3) │ > │ 340 │ (379863,4) │ (a)=(-249286) │ (379863,4) │ > │ 341 │ (379863,5) │ (a)=(-249286) │ (379863,5) │ > │ 342 │ (379863,6) │ (a)=(-249286) │ (379863,6) │ > │ 343 │ (379863,7) │ (a)=(-249286) │ (379863,7) │ > │ 344 │ (379863,8) │ (a)=(-249286) │ (379863,8) │ > │ 345 │ (379863,9) │ (a)=(-249286) │ (379863,9) │ > │ 346 │ (379863,10) │ (a)=(-249286) │ (379863,10) │ > │ 347 │ (379863,11) │ (a)=(-249286) │ (379863,11) │ > │ 348 │ (379863,12) │ (a)=(-249286) │ (379863,12) │ > │ 349 │ (379863,13) │ (a)=(-249286) │ (379863,13) │ > │ 350 │ (379863,14) │ (a)=(-249286) │ (379863,14) │ > │ 351 │ (379863,15) │ (a)=(-249286) │ (379863,15) │ > │ 352 │ (379863,16) │ (a)=(-249286) │ (379863,16) │ > │ 353 │ (379863,17) │ (a)=(-249286) │ (379863,17) │ > │ 354 │ (379863,18) │ (a)=(-249286) │ (379863,18) │ > │ 355 │ (379863,19) │ (a)=(-249286) │ (379863,19) │ > │ 356 │ (379863,20) │ (a)=(-249286) │ (379863,20) │ > │ 357 │ (379863,21) │ (a)=(-249286) │ (379863,21) │ > │ 358 │ (379864,1) │ (a)=(-249286) │ (379864,1) │ > │ 359 │ (379864,2) │ (a)=(-249286) │ (379864,2) │ > │ 360 │ (379864,3) │ (a)=(-249286) │ (379864,3) │ > │ 361 │ (379864,4) │ (a)=(-249286) │ (379864,4) │ > │ 362 │ (379864,5) │ (a)=(-249286) │ (379864,5) │ > │ 363 │ (379864,6) │ (a)=(-249286) │ (379864,6) │ > │ 364 │ (379864,7) │ (a)=(-249286) │ (379864,7) │ > │ 365 │ (379864,8) │ (a)=(-249286) │ (379864,8) │ > │ 366 │ (379861,6) │ (a)=(-249285) │ (379861,6) │ > │ 367 │ (379861,7) │ (a)=(-249285) │ (379861,7) │ > └────────────┴───────────────┴───────────────┴─────────────┘ > (367 rows) > > And here's what block 5555 from "idx" looks like (note that the fact that I'm > using the same index block number as before has no particular significance): > > ────────────┬──────────────┬─────────────┬────────────┐ > │ itemoffset │ ctid │ data │ htid │ > ├────────────┼──────────────┼─────────────┼────────────┤ > │ 1 │ (96327,4097) │ (a)=(63216) │ (96327,15) │ > │ 2 │ (96310,7) │ (a)=(63204) │ (96310,7) │ > │ 3 │ (96310,8) │ (a)=(63204) │ (96310,8) │ > │ 4 │ (96310,9) │ (a)=(63204) │ (96310,9) │ > │ 5 │ (96310,10) │ (a)=(63204) │ (96310,10) │ > │ 6 │ (96310,11) │ (a)=(63204) │ (96310,11) │ > │ 7 │ (96310,12) │ (a)=(63204) │ (96310,12) │ > │ 8 │ (96310,13) │ (a)=(63204) │ (96310,13) │ > │ 9 │ (96310,14) │ (a)=(63204) │ (96310,14) │ > │ 10 │ (96310,15) │ (a)=(63204) │ (96310,15) │ > │ 11 │ (96310,16) │ (a)=(63204) │ (96310,16) │ > │ 12 │ (96310,17) │ (a)=(63204) │ (96310,17) │ > │ 13 │ (96310,18) │ (a)=(63204) │ (96310,18) │ > │ 14 │ (96310,19) │ (a)=(63205) │ (96310,19) │ > │ 15 │ (96310,20) │ (a)=(63205) │ (96310,20) │ > │ 16 │ (96310,21) │ (a)=(63205) │ (96310,21) │ > │ 17 │ (96311,1) │ (a)=(63205) │ (96311,1) │ > │ 18 │ (96311,2) │ (a)=(63205) │ (96311,2) │ > │ 19 │ (96311,3) │ (a)=(63205) │ (96311,3) │ > │ 20 │ (96311,4) │ (a)=(63205) │ (96311,4) │ > │ 21 │ (96311,5) │ (a)=(63205) │ (96311,5) │ > │ 22 │ (96311,6) │ (a)=(63205) │ (96311,6) │ > │ 23 │ (96311,7) │ (a)=(63205) │ (96311,7) │ > │ 24 │ (96311,8) │ (a)=(63205) │ (96311,8) │ > │ 25 │ (96311,9) │ (a)=(63205) │ (96311,9) │ > │ 26 │ (96311,10) │ (a)=(63205) │ (96311,10) │ > │ 27 │ (96311,11) │ (a)=(63205) │ (96311,11) │ > │ 28 │ (96311,12) │ (a)=(63205) │ (96311,12) │ > │ 29 │ (96311,13) │ (a)=(63205) │ (96311,13) │ > │ 30 │ (96311,14) │ (a)=(63205) │ (96311,14) │ > │ 31 │ (96311,15) │ (a)=(63205) │ (96311,15) │ > │ 32 │ (96311,16) │ (a)=(63205) │ (96311,16) │ > │ 33 │ (96311,17) │ (a)=(63205) │ (96311,17) │ > │ 34 │ (96311,18) │ (a)=(63205) │ (96311,18) │ > │ 35 │ (96311,19) │ (a)=(63205) │ (96311,19) │ > │ 36 │ (96311,20) │ (a)=(63205) │ (96311,20) │ > │ 37 │ (96311,21) │ (a)=(63205) │ (96311,21) │ > │ 38 │ (96312,1) │ (a)=(63205) │ (96312,1) │ > │ 39 │ (96312,2) │ (a)=(63205) │ (96312,2) │ > │ 40 │ (96312,3) │ (a)=(63205) │ (96312,3) │ > │ 41 │ (96312,4) │ (a)=(63205) │ (96312,4) │ > │ 42 │ (96312,5) │ (a)=(63205) │ (96312,5) │ > │ 43 │ (96312,6) │ (a)=(63205) │ (96312,6) │ > │ 44 │ (96312,7) │ (a)=(63205) │ (96312,7) │ > │ 45 │ (96312,9) │ (a)=(63205) │ (96312,9) │ > │ 46 │ (96312,8) │ (a)=(63206) │ (96312,8) │ > │ 47 │ (96312,10) │ (a)=(63206) │ (96312,10) │ > │ 48 │ (96312,11) │ (a)=(63206) │ (96312,11) │ > │ 49 │ (96312,12) │ (a)=(63206) │ (96312,12) │ > │ 50 │ (96312,13) │ (a)=(63206) │ (96312,13) │ > │ 51 │ (96312,14) │ (a)=(63206) │ (96312,14) │ > │ 52 │ (96312,15) │ (a)=(63206) │ (96312,15) │ > │ 53 │ (96312,16) │ (a)=(63206) │ (96312,16) │ > │ 54 │ (96312,17) │ (a)=(63206) │ (96312,17) │ > │ 55 │ (96312,18) │ (a)=(63206) │ (96312,18) │ > │ 56 │ (96312,19) │ (a)=(63206) │ (96312,19) │ > │ 57 │ (96312,20) │ (a)=(63206) │ (96312,20) │ > │ 58 │ (96312,21) │ (a)=(63206) │ (96312,21) │ > │ 59 │ (96313,1) │ (a)=(63206) │ (96313,1) │ > │ 60 │ (96313,2) │ (a)=(63206) │ (96313,2) │ > │ 61 │ (96313,3) │ (a)=(63206) │ (96313,3) │ > │ 62 │ (96313,4) │ (a)=(63206) │ (96313,4) │ > │ 63 │ (96313,5) │ (a)=(63206) │ (96313,5) │ > │ 64 │ (96313,6) │ (a)=(63206) │ (96313,6) │ > │ 65 │ (96313,7) │ (a)=(63206) │ (96313,7) │ > │ 66 │ (96313,8) │ (a)=(63206) │ (96313,8) │ > │ 67 │ (96313,9) │ (a)=(63206) │ (96313,9) │ > │ 68 │ (96313,10) │ (a)=(63206) │ (96313,10) │ > │ 69 │ (96313,11) │ (a)=(63206) │ (96313,11) │ > │ 70 │ (96313,12) │ (a)=(63206) │ (96313,12) │ > │ 71 │ (96313,13) │ (a)=(63206) │ (96313,13) │ > │ 72 │ (96313,14) │ (a)=(63206) │ (96313,14) │ > │ 73 │ (96313,15) │ (a)=(63206) │ (96313,15) │ > │ 74 │ (96313,16) │ (a)=(63206) │ (96313,16) │ > │ 75 │ (96313,17) │ (a)=(63206) │ (96313,17) │ > │ 76 │ (96313,18) │ (a)=(63206) │ (96313,18) │ > │ 77 │ (96313,20) │ (a)=(63206) │ (96313,20) │ > │ 78 │ (96313,19) │ (a)=(63207) │ (96313,19) │ > │ 79 │ (96313,21) │ (a)=(63207) │ (96313,21) │ > │ 80 │ (96314,1) │ (a)=(63207) │ (96314,1) │ > │ 81 │ (96314,2) │ (a)=(63207) │ (96314,2) │ > │ 82 │ (96314,3) │ (a)=(63207) │ (96314,3) │ > │ 83 │ (96314,4) │ (a)=(63207) │ (96314,4) │ > │ 84 │ (96314,5) │ (a)=(63207) │ (96314,5) │ > │ 85 │ (96314,6) │ (a)=(63207) │ (96314,6) │ > │ 86 │ (96314,7) │ (a)=(63207) │ (96314,7) │ > │ 87 │ (96314,8) │ (a)=(63207) │ (96314,8) │ > │ 88 │ (96314,9) │ (a)=(63207) │ (96314,9) │ > │ 89 │ (96314,10) │ (a)=(63207) │ (96314,10) │ > │ 90 │ (96314,11) │ (a)=(63207) │ (96314,11) │ > │ 91 │ (96314,12) │ (a)=(63207) │ (96314,12) │ > │ 92 │ (96314,13) │ (a)=(63207) │ (96314,13) │ > │ 93 │ (96314,14) │ (a)=(63207) │ (96314,14) │ > │ 94 │ (96314,15) │ (a)=(63207) │ (96314,15) │ > │ 95 │ (96314,16) │ (a)=(63207) │ (96314,16) │ > │ 96 │ (96314,17) │ (a)=(63207) │ (96314,17) │ > │ 97 │ (96314,18) │ (a)=(63207) │ (96314,18) │ > │ 98 │ (96314,19) │ (a)=(63207) │ (96314,19) │ > │ 99 │ (96314,20) │ (a)=(63207) │ (96314,20) │ > │ 100 │ (96314,21) │ (a)=(63207) │ (96314,21) │ > │ 101 │ (96315,1) │ (a)=(63207) │ (96315,1) │ > │ 102 │ (96315,2) │ (a)=(63207) │ (96315,2) │ > │ 103 │ (96315,3) │ (a)=(63207) │ (96315,3) │ > │ 104 │ (96315,4) │ (a)=(63207) │ (96315,4) │ > │ 105 │ (96315,5) │ (a)=(63207) │ (96315,5) │ > │ 106 │ (96315,6) │ (a)=(63207) │ (96315,6) │ > │ 107 │ (96315,7) │ (a)=(63207) │ (96315,7) │ > │ 108 │ (96315,8) │ (a)=(63207) │ (96315,8) │ > │ 109 │ (96315,12) │ (a)=(63207) │ (96315,12) │ > │ 110 │ (96315,9) │ (a)=(63208) │ (96315,9) │ > │ 111 │ (96315,10) │ (a)=(63208) │ (96315,10) │ > │ 112 │ (96315,11) │ (a)=(63208) │ (96315,11) │ > │ 113 │ (96315,13) │ (a)=(63208) │ (96315,13) │ > │ 114 │ (96315,14) │ (a)=(63208) │ (96315,14) │ > │ 115 │ (96315,15) │ (a)=(63208) │ (96315,15) │ > │ 116 │ (96315,16) │ (a)=(63208) │ (96315,16) │ > │ 117 │ (96315,17) │ (a)=(63208) │ (96315,17) │ > │ 118 │ (96315,18) │ (a)=(63208) │ (96315,18) │ > │ 119 │ (96315,19) │ (a)=(63208) │ (96315,19) │ > │ 120 │ (96315,20) │ (a)=(63208) │ (96315,20) │ > │ 121 │ (96315,21) │ (a)=(63208) │ (96315,21) │ > │ 122 │ (96316,1) │ (a)=(63208) │ (96316,1) │ > │ 123 │ (96316,2) │ (a)=(63208) │ (96316,2) │ > │ 124 │ (96316,3) │ (a)=(63208) │ (96316,3) │ > │ 125 │ (96316,4) │ (a)=(63208) │ (96316,4) │ > │ 126 │ (96316,5) │ (a)=(63208) │ (96316,5) │ > │ 127 │ (96316,6) │ (a)=(63208) │ (96316,6) │ > │ 128 │ (96316,7) │ (a)=(63208) │ (96316,7) │ > │ 129 │ (96316,8) │ (a)=(63208) │ (96316,8) │ > │ 130 │ (96316,9) │ (a)=(63208) │ (96316,9) │ > │ 131 │ (96316,10) │ (a)=(63208) │ (96316,10) │ > │ 132 │ (96316,11) │ (a)=(63208) │ (96316,11) │ > │ 133 │ (96316,12) │ (a)=(63208) │ (96316,12) │ > │ 134 │ (96316,13) │ (a)=(63208) │ (96316,13) │ > │ 135 │ (96316,14) │ (a)=(63208) │ (96316,14) │ > │ 136 │ (96316,15) │ (a)=(63208) │ (96316,15) │ > │ 137 │ (96316,16) │ (a)=(63208) │ (96316,16) │ > │ 138 │ (96316,17) │ (a)=(63208) │ (96316,17) │ > │ 139 │ (96316,18) │ (a)=(63208) │ (96316,18) │ > │ 140 │ (96316,19) │ (a)=(63208) │ (96316,19) │ > │ 141 │ (96316,20) │ (a)=(63208) │ (96316,20) │ > │ 142 │ (96316,21) │ (a)=(63209) │ (96316,21) │ > │ 143 │ (96317,1) │ (a)=(63209) │ (96317,1) │ > │ 144 │ (96317,2) │ (a)=(63209) │ (96317,2) │ > │ 145 │ (96317,3) │ (a)=(63209) │ (96317,3) │ > │ 146 │ (96317,4) │ (a)=(63209) │ (96317,4) │ > │ 147 │ (96317,5) │ (a)=(63209) │ (96317,5) │ > │ 148 │ (96317,6) │ (a)=(63209) │ (96317,6) │ > │ 149 │ (96317,7) │ (a)=(63209) │ (96317,7) │ > │ 150 │ (96317,8) │ (a)=(63209) │ (96317,8) │ > │ 151 │ (96317,9) │ (a)=(63209) │ (96317,9) │ > │ 152 │ (96317,10) │ (a)=(63209) │ (96317,10) │ > │ 153 │ (96317,11) │ (a)=(63209) │ (96317,11) │ > │ 154 │ (96317,12) │ (a)=(63209) │ (96317,12) │ > │ 155 │ (96317,13) │ (a)=(63209) │ (96317,13) │ > │ 156 │ (96317,14) │ (a)=(63209) │ (96317,14) │ > │ 157 │ (96317,15) │ (a)=(63209) │ (96317,15) │ > │ 158 │ (96317,16) │ (a)=(63209) │ (96317,16) │ > │ 159 │ (96317,17) │ (a)=(63209) │ (96317,17) │ > │ 160 │ (96317,18) │ (a)=(63209) │ (96317,18) │ > │ 161 │ (96317,19) │ (a)=(63209) │ (96317,19) │ > │ 162 │ (96317,20) │ (a)=(63209) │ (96317,20) │ > │ 163 │ (96317,21) │ (a)=(63209) │ (96317,21) │ > │ 164 │ (96318,1) │ (a)=(63209) │ (96318,1) │ > │ 165 │ (96318,2) │ (a)=(63209) │ (96318,2) │ > │ 166 │ (96318,3) │ (a)=(63209) │ (96318,3) │ > │ 167 │ (96318,4) │ (a)=(63209) │ (96318,4) │ > │ 168 │ (96318,5) │ (a)=(63209) │ (96318,5) │ > │ 169 │ (96318,6) │ (a)=(63209) │ (96318,6) │ > │ 170 │ (96318,7) │ (a)=(63209) │ (96318,7) │ > │ 171 │ (96318,8) │ (a)=(63209) │ (96318,8) │ > │ 172 │ (96318,9) │ (a)=(63209) │ (96318,9) │ > │ 173 │ (96318,10) │ (a)=(63209) │ (96318,10) │ > │ 174 │ (96318,11) │ (a)=(63210) │ (96318,11) │ > │ 175 │ (96318,12) │ (a)=(63210) │ (96318,12) │ > │ 176 │ (96318,13) │ (a)=(63210) │ (96318,13) │ > │ 177 │ (96318,14) │ (a)=(63210) │ (96318,14) │ > │ 178 │ (96318,15) │ (a)=(63210) │ (96318,15) │ > │ 179 │ (96318,16) │ (a)=(63210) │ (96318,16) │ > │ 180 │ (96318,17) │ (a)=(63210) │ (96318,17) │ > │ 181 │ (96318,18) │ (a)=(63210) │ (96318,18) │ > │ 182 │ (96318,19) │ (a)=(63210) │ (96318,19) │ > │ 183 │ (96318,20) │ (a)=(63210) │ (96318,20) │ > │ 184 │ (96318,21) │ (a)=(63210) │ (96318,21) │ > │ 185 │ (96319,1) │ (a)=(63210) │ (96319,1) │ > │ 186 │ (96319,2) │ (a)=(63210) │ (96319,2) │ > │ 187 │ (96319,3) │ (a)=(63210) │ (96319,3) │ > │ 188 │ (96319,4) │ (a)=(63210) │ (96319,4) │ > │ 189 │ (96319,5) │ (a)=(63210) │ (96319,5) │ > │ 190 │ (96319,6) │ (a)=(63210) │ (96319,6) │ > │ 191 │ (96319,7) │ (a)=(63210) │ (96319,7) │ > │ 192 │ (96319,8) │ (a)=(63210) │ (96319,8) │ > │ 193 │ (96319,9) │ (a)=(63210) │ (96319,9) │ > │ 194 │ (96319,10) │ (a)=(63210) │ (96319,10) │ > │ 195 │ (96319,11) │ (a)=(63210) │ (96319,11) │ > │ 196 │ (96319,12) │ (a)=(63210) │ (96319,12) │ > │ 197 │ (96319,13) │ (a)=(63210) │ (96319,13) │ > │ 198 │ (96319,14) │ (a)=(63210) │ (96319,14) │ > │ 199 │ (96319,15) │ (a)=(63210) │ (96319,15) │ > │ 200 │ (96319,16) │ (a)=(63210) │ (96319,16) │ > │ 201 │ (96319,17) │ (a)=(63210) │ (96319,17) │ > │ 202 │ (96319,18) │ (a)=(63210) │ (96319,18) │ > │ 203 │ (96319,19) │ (a)=(63210) │ (96319,19) │ > │ 204 │ (96319,20) │ (a)=(63210) │ (96319,20) │ > │ 205 │ (96320,1) │ (a)=(63210) │ (96320,1) │ > │ 206 │ (96319,21) │ (a)=(63211) │ (96319,21) │ > │ 207 │ (96320,2) │ (a)=(63211) │ (96320,2) │ > │ 208 │ (96320,3) │ (a)=(63211) │ (96320,3) │ > │ 209 │ (96320,4) │ (a)=(63211) │ (96320,4) │ > │ 210 │ (96320,5) │ (a)=(63211) │ (96320,5) │ > │ 211 │ (96320,6) │ (a)=(63211) │ (96320,6) │ > │ 212 │ (96320,7) │ (a)=(63211) │ (96320,7) │ > │ 213 │ (96320,8) │ (a)=(63211) │ (96320,8) │ > │ 214 │ (96320,9) │ (a)=(63211) │ (96320,9) │ > │ 215 │ (96320,10) │ (a)=(63211) │ (96320,10) │ > │ 216 │ (96320,11) │ (a)=(63211) │ (96320,11) │ > │ 217 │ (96320,12) │ (a)=(63211) │ (96320,12) │ > │ 218 │ (96320,13) │ (a)=(63211) │ (96320,13) │ > │ 219 │ (96320,14) │ (a)=(63211) │ (96320,14) │ > │ 220 │ (96320,15) │ (a)=(63211) │ (96320,15) │ > │ 221 │ (96320,16) │ (a)=(63211) │ (96320,16) │ > │ 222 │ (96320,17) │ (a)=(63211) │ (96320,17) │ > │ 223 │ (96320,18) │ (a)=(63211) │ (96320,18) │ > │ 224 │ (96320,19) │ (a)=(63211) │ (96320,19) │ > │ 225 │ (96320,20) │ (a)=(63211) │ (96320,20) │ > │ 226 │ (96320,21) │ (a)=(63211) │ (96320,21) │ > │ 227 │ (96321,1) │ (a)=(63211) │ (96321,1) │ > │ 228 │ (96321,2) │ (a)=(63211) │ (96321,2) │ > │ 229 │ (96321,3) │ (a)=(63211) │ (96321,3) │ > │ 230 │ (96321,4) │ (a)=(63211) │ (96321,4) │ > │ 231 │ (96321,5) │ (a)=(63211) │ (96321,5) │ > │ 232 │ (96321,6) │ (a)=(63211) │ (96321,6) │ > │ 233 │ (96321,7) │ (a)=(63211) │ (96321,7) │ > │ 234 │ (96321,8) │ (a)=(63211) │ (96321,8) │ > │ 235 │ (96321,9) │ (a)=(63211) │ (96321,9) │ > │ 236 │ (96321,10) │ (a)=(63211) │ (96321,10) │ > │ 237 │ (96321,11) │ (a)=(63211) │ (96321,11) │ > │ 238 │ (96321,12) │ (a)=(63212) │ (96321,12) │ > │ 239 │ (96321,13) │ (a)=(63212) │ (96321,13) │ > │ 240 │ (96321,14) │ (a)=(63212) │ (96321,14) │ > │ 241 │ (96321,15) │ (a)=(63212) │ (96321,15) │ > │ 242 │ (96321,16) │ (a)=(63212) │ (96321,16) │ > │ 243 │ (96321,17) │ (a)=(63212) │ (96321,17) │ > │ 244 │ (96321,18) │ (a)=(63212) │ (96321,18) │ > │ 245 │ (96321,19) │ (a)=(63212) │ (96321,19) │ > │ 246 │ (96321,20) │ (a)=(63212) │ (96321,20) │ > │ 247 │ (96321,21) │ (a)=(63212) │ (96321,21) │ > │ 248 │ (96322,1) │ (a)=(63212) │ (96322,1) │ > │ 249 │ (96322,2) │ (a)=(63212) │ (96322,2) │ > │ 250 │ (96322,3) │ (a)=(63212) │ (96322,3) │ > │ 251 │ (96322,4) │ (a)=(63212) │ (96322,4) │ > │ 252 │ (96322,5) │ (a)=(63212) │ (96322,5) │ > │ 253 │ (96322,6) │ (a)=(63212) │ (96322,6) │ > │ 254 │ (96322,7) │ (a)=(63212) │ (96322,7) │ > │ 255 │ (96322,8) │ (a)=(63212) │ (96322,8) │ > │ 256 │ (96322,9) │ (a)=(63212) │ (96322,9) │ > │ 257 │ (96322,10) │ (a)=(63212) │ (96322,10) │ > │ 258 │ (96322,11) │ (a)=(63212) │ (96322,11) │ > │ 259 │ (96322,12) │ (a)=(63212) │ (96322,12) │ > │ 260 │ (96322,13) │ (a)=(63212) │ (96322,13) │ > │ 261 │ (96322,14) │ (a)=(63212) │ (96322,14) │ > │ 262 │ (96322,15) │ (a)=(63212) │ (96322,15) │ > │ 263 │ (96322,16) │ (a)=(63212) │ (96322,16) │ > │ 264 │ (96322,17) │ (a)=(63212) │ (96322,17) │ > │ 265 │ (96322,18) │ (a)=(63212) │ (96322,18) │ > │ 266 │ (96322,19) │ (a)=(63212) │ (96322,19) │ > │ 267 │ (96322,20) │ (a)=(63212) │ (96322,20) │ > │ 268 │ (96322,21) │ (a)=(63212) │ (96322,21) │ > │ 269 │ (96323,3) │ (a)=(63212) │ (96323,3) │ > │ 270 │ (96323,1) │ (a)=(63213) │ (96323,1) │ > │ 271 │ (96323,2) │ (a)=(63213) │ (96323,2) │ > │ 272 │ (96323,4) │ (a)=(63213) │ (96323,4) │ > │ 273 │ (96323,5) │ (a)=(63213) │ (96323,5) │ > │ 274 │ (96323,6) │ (a)=(63213) │ (96323,6) │ > │ 275 │ (96323,7) │ (a)=(63213) │ (96323,7) │ > │ 276 │ (96323,8) │ (a)=(63213) │ (96323,8) │ > │ 277 │ (96323,9) │ (a)=(63213) │ (96323,9) │ > │ 278 │ (96323,10) │ (a)=(63213) │ (96323,10) │ > │ 279 │ (96323,11) │ (a)=(63213) │ (96323,11) │ > │ 280 │ (96323,12) │ (a)=(63213) │ (96323,12) │ > │ 281 │ (96323,13) │ (a)=(63213) │ (96323,13) │ > │ 282 │ (96323,14) │ (a)=(63213) │ (96323,14) │ > │ 283 │ (96323,15) │ (a)=(63213) │ (96323,15) │ > │ 284 │ (96323,16) │ (a)=(63213) │ (96323,16) │ > │ 285 │ (96323,17) │ (a)=(63213) │ (96323,17) │ > │ 286 │ (96323,18) │ (a)=(63213) │ (96323,18) │ > │ 287 │ (96323,19) │ (a)=(63213) │ (96323,19) │ > │ 288 │ (96323,20) │ (a)=(63213) │ (96323,20) │ > │ 289 │ (96323,21) │ (a)=(63213) │ (96323,21) │ > │ 290 │ (96324,1) │ (a)=(63213) │ (96324,1) │ > │ 291 │ (96324,2) │ (a)=(63213) │ (96324,2) │ > │ 292 │ (96324,3) │ (a)=(63213) │ (96324,3) │ > │ 293 │ (96324,4) │ (a)=(63213) │ (96324,4) │ > │ 294 │ (96324,5) │ (a)=(63213) │ (96324,5) │ > │ 295 │ (96324,6) │ (a)=(63213) │ (96324,6) │ > │ 296 │ (96324,7) │ (a)=(63213) │ (96324,7) │ > │ 297 │ (96324,8) │ (a)=(63213) │ (96324,8) │ > │ 298 │ (96324,9) │ (a)=(63213) │ (96324,9) │ > │ 299 │ (96324,11) │ (a)=(63213) │ (96324,11) │ > │ 300 │ (96324,12) │ (a)=(63213) │ (96324,12) │ > │ 301 │ (96324,13) │ (a)=(63213) │ (96324,13) │ > │ 302 │ (96324,10) │ (a)=(63214) │ (96324,10) │ > │ 303 │ (96324,14) │ (a)=(63214) │ (96324,14) │ > │ 304 │ (96324,15) │ (a)=(63214) │ (96324,15) │ > │ 305 │ (96324,16) │ (a)=(63214) │ (96324,16) │ > │ 306 │ (96324,17) │ (a)=(63214) │ (96324,17) │ > │ 307 │ (96324,18) │ (a)=(63214) │ (96324,18) │ > │ 308 │ (96324,19) │ (a)=(63214) │ (96324,19) │ > │ 309 │ (96324,20) │ (a)=(63214) │ (96324,20) │ > │ 310 │ (96324,21) │ (a)=(63214) │ (96324,21) │ > │ 311 │ (96325,1) │ (a)=(63214) │ (96325,1) │ > │ 312 │ (96325,2) │ (a)=(63214) │ (96325,2) │ > │ 313 │ (96325,3) │ (a)=(63214) │ (96325,3) │ > │ 314 │ (96325,4) │ (a)=(63214) │ (96325,4) │ > │ 315 │ (96325,5) │ (a)=(63214) │ (96325,5) │ > │ 316 │ (96325,6) │ (a)=(63214) │ (96325,6) │ > │ 317 │ (96325,7) │ (a)=(63214) │ (96325,7) │ > │ 318 │ (96325,8) │ (a)=(63214) │ (96325,8) │ > │ 319 │ (96325,9) │ (a)=(63214) │ (96325,9) │ > │ 320 │ (96325,10) │ (a)=(63214) │ (96325,10) │ > │ 321 │ (96325,11) │ (a)=(63214) │ (96325,11) │ > │ 322 │ (96325,12) │ (a)=(63214) │ (96325,12) │ > │ 323 │ (96325,13) │ (a)=(63214) │ (96325,13) │ > │ 324 │ (96325,14) │ (a)=(63214) │ (96325,14) │ > │ 325 │ (96325,15) │ (a)=(63214) │ (96325,15) │ > │ 326 │ (96325,16) │ (a)=(63214) │ (96325,16) │ > │ 327 │ (96325,17) │ (a)=(63214) │ (96325,17) │ > │ 328 │ (96325,18) │ (a)=(63214) │ (96325,18) │ > │ 329 │ (96325,19) │ (a)=(63214) │ (96325,19) │ > │ 330 │ (96325,20) │ (a)=(63214) │ (96325,20) │ > │ 331 │ (96325,21) │ (a)=(63214) │ (96325,21) │ > │ 332 │ (96326,1) │ (a)=(63214) │ (96326,1) │ > │ 333 │ (96326,3) │ (a)=(63214) │ (96326,3) │ > │ 334 │ (96326,2) │ (a)=(63215) │ (96326,2) │ > │ 335 │ (96326,4) │ (a)=(63215) │ (96326,4) │ > │ 336 │ (96326,5) │ (a)=(63215) │ (96326,5) │ > │ 337 │ (96326,6) │ (a)=(63215) │ (96326,6) │ > │ 338 │ (96326,7) │ (a)=(63215) │ (96326,7) │ > │ 339 │ (96326,8) │ (a)=(63215) │ (96326,8) │ > │ 340 │ (96326,9) │ (a)=(63215) │ (96326,9) │ > │ 341 │ (96326,10) │ (a)=(63215) │ (96326,10) │ > │ 342 │ (96326,11) │ (a)=(63215) │ (96326,11) │ > │ 343 │ (96326,12) │ (a)=(63215) │ (96326,12) │ > │ 344 │ (96326,13) │ (a)=(63215) │ (96326,13) │ > │ 345 │ (96326,14) │ (a)=(63215) │ (96326,14) │ > │ 346 │ (96326,15) │ (a)=(63215) │ (96326,15) │ > │ 347 │ (96326,16) │ (a)=(63215) │ (96326,16) │ > │ 348 │ (96326,17) │ (a)=(63215) │ (96326,17) │ > │ 349 │ (96326,18) │ (a)=(63215) │ (96326,18) │ > │ 350 │ (96326,19) │ (a)=(63215) │ (96326,19) │ > │ 351 │ (96326,20) │ (a)=(63215) │ (96326,20) │ > │ 352 │ (96326,21) │ (a)=(63215) │ (96326,21) │ > │ 353 │ (96327,1) │ (a)=(63215) │ (96327,1) │ > │ 354 │ (96327,2) │ (a)=(63215) │ (96327,2) │ > │ 355 │ (96327,3) │ (a)=(63215) │ (96327,3) │ > │ 356 │ (96327,4) │ (a)=(63215) │ (96327,4) │ > │ 357 │ (96327,5) │ (a)=(63215) │ (96327,5) │ > │ 358 │ (96327,6) │ (a)=(63215) │ (96327,6) │ > │ 359 │ (96327,7) │ (a)=(63215) │ (96327,7) │ > │ 360 │ (96327,8) │ (a)=(63215) │ (96327,8) │ > │ 361 │ (96327,9) │ (a)=(63215) │ (96327,9) │ > │ 362 │ (96327,10) │ (a)=(63215) │ (96327,10) │ > │ 363 │ (96327,11) │ (a)=(63215) │ (96327,11) │ > │ 364 │ (96327,12) │ (a)=(63215) │ (96327,12) │ > │ 365 │ (96327,14) │ (a)=(63215) │ (96327,14) │ > │ 366 │ (96327,13) │ (a)=(63216) │ (96327,13) │ > │ 367 │ (96327,15) │ (a)=(63216) │ (96327,15) │ > └────────────┴──────────────┴─────────────┴────────────┘ > (367 rows) > > I only notice one tiny discontinuity in this "unshuffled" "idx" page: the index > tuple at offset 205 uses the heap TID (96320,1), whereas the index tuple right > after that (at offset 206) uses the heap TID (96319,21) (before we get to a > large run of heap TIDs that use heap block number 96320 once more). > > As I touched on already, this effect can be seen even with perfectly correlated > inserts. The effect is caused by the FSM having a tiny bit of space left on one > heap page -- not enough space to fit an incoming heap tuple, but still enough to > fit a slightly smaller heap tuple that is inserted shortly thereafter. You end > up with exactly one index tuple whose heap TID is slightly out-of-order, though > only every once in a long while. > This seems rather bizarre, considering the two tables are exactly the same, except that in t2 the first column is negative, and the rows are fixed-length. Even heap_page_items says the tables are exactly the same. So why would the index get so different like this? regards -- Tomas Vondra
On 8/13/25 16:44, Andres Freund wrote:
> Hi,
>
> On 2025-08-13 14:15:37 +0200, Tomas Vondra wrote:
>> In fact, I believe this is about io_method. I initially didn't see the
>> difference you described, and then I realized I set io_method=sync to
>> make it easier to track the block access. And if I change io_method to
>> worker, I get different stats, that also change between runs.
>>
>> With "sync" I always get this (after a restart):
>>
>> Buffers: shared hit=7435 read=52801
>>
>> while with "worker" I get this:
>>
>> Buffers: shared hit=4879 read=52801
>> Buffers: shared hit=5151 read=52801
>> Buffers: shared hit=4978 read=52801
>>
>> So not only it changes run to tun, it also does not add up to 60236.
>
> This is reproducible on master? If so, how?
>
>
>> I vaguely recall I ran into this some time ago during AIO benchmarking,
>> and IIRC it's due to how StartReadBuffersImpl() may behave differently
>> depending on I/O started earlier. It only calls PinBufferForBlock() in
>> some cases, and PinBufferForBlock() is what updates the hits.
>
> Hm, I don't immediately see an issue there. The only case we don't call
> PinBufferForBlock() is if we already have pinned the relevant buffer in a
> prior call to StartReadBuffersImpl().
>
>
> If this happens only with the prefetching patch applied, is is possible that
> what happens here is that we occasionally re-request buffers that already in
> the process of being read in? That would only happen with a read stream and
> io_method != sync (since with sync we won't read ahead). If we have to start
> reading in a buffer that's already undergoing IO we wait for the IO to
> complete and count that access as a hit:
>
> /*
> * Check if we can start IO on the first to-be-read buffer.
> *
> * If an I/O is already in progress in another backend, we want to wait
> * for the outcome: either done, or something went wrong and we will
> * retry.
> */
> if (!ReadBuffersCanStartIO(buffers[nblocks_done], false))
> {
> ...
> /*
> * Report and track this as a 'hit' for this backend, even though it
> * must have started out as a miss in PinBufferForBlock(). The other
> * backend will track this as a 'read'.
> */
> ...
> if (persistence == RELPERSISTENCE_TEMP)
> pgBufferUsage.local_blks_hit += 1;
> else
> pgBufferUsage.shared_blks_hit += 1;
> ...
>
>
I think it has to be this. It only happens with io_method != sync, and
only with effective_io_concurrency > 1. At first I was wondering why I
can't reproduce this for seqscan/bitmapscan, but then I realized those
plans never visit the same block repeatedly - indexscans do that. It's
also not surprising it's timing-sensitive, as it likely depends on how
fast the worker happens to start/complete requests.
What would be a good way to "prove" it really is this?
regards
--
Tomas Vondra
On 8/13/25 18:01, Peter Geoghegan wrote:
> On Wed, Aug 13, 2025 at 11:28 AM Andres Freund <andres@anarazel.de> wrote:
>>> With "sync" I always get this (after a restart):
>>>
>>> Buffers: shared hit=7435 read=52801
>>>
>>> while with "worker" I get this:
>>>
>>> Buffers: shared hit=4879 read=52801
>>> Buffers: shared hit=5151 read=52801
>>> Buffers: shared hit=4978 read=52801
>>>
>>> So not only it changes run to tun, it also does not add up to 60236.
>>
>> This is reproducible on master? If so, how?
>
> AFAIK it is *not* reproducible on master.
>
>> If this happens only with the prefetching patch applied, is is possible that
>> what happens here is that we occasionally re-request buffers that already in
>> the process of being read in? That would only happen with a read stream and
>> io_method != sync (since with sync we won't read ahead). If we have to start
>> reading in a buffer that's already undergoing IO we wait for the IO to
>> complete and count that access as a hit:
>
> This theory seems quite plausible to me. Though it is a bit surprising
> that I see incorrect buffer hit counts on the "good" forwards scan
> case, rather than on the "bad" backwards scan case.
>
> Here's what I mean by things being broken on the read stream side (at
> least with certain backwards scan cases):
>
> When I add instrumentation to the read stream side, by adding elog
> debug calls that show the blocknum seen by read_stream_get_block, I
> see out-of-order and repeated blocknums with the "bad" backwards scan
> case ("SELECT * FROM t WHERE a BETWEEN 16336 AND 49103 ORDER BY a
> desc"):
>
> ...
> NOTICE: index_scan_stream_read_next: index 1163 TID (25052,21)
> WARNING: prior lastBlock is 25053 for batchno 2856, new one: 25052
> WARNING: blocknum: 25052, 0x55614810efb0
> WARNING: blocknum: 25052, 0x55614810efb0
> NOTICE: index_scan_stream_read_next: index 1161 TID (25053,3)
> WARNING: prior lastBlock is 25052 for batchno 2856, new one: 25053
> WARNING: blocknum: 25053, 0x55614810efb0
> NOTICE: index_scan_stream_read_next: index 1160 TID (25052,19)
> WARNING: prior lastBlock is 25053 for batchno 2856, new one: 25052
> WARNING: blocknum: 25052, 0x55614810efb0
> WARNING: blocknum: 25052, 0x55614810efb0
> NOTICE: index_scan_stream_read_next: index 1141 TID (25051,21)
> WARNING: prior lastBlock is 25052 for batchno 2856, new one: 25051
> WARNING: blocknum: 25051, 0x55614810efb0
> ...
>
> Notice that we see the same blocknum twice in close succession. Also
> notice that we're passed 25052 and then subsequently passed 25053,
> only to be passed 25053 once more.
>
I did investigate this, and I don't think there's anything broken in
read_stream. It happens because ReadStream has a concept of "ungetting"
a block, which can happen after hitting some I/O limits.
In that case we "remember" the last block (in read_stream_look_ahead
calls read_stream_unget_block), and we return it again. It may seem as
if read_stream_get_block() produced the same block twice, but it's
really just the block from the last round.
All duplicates produced by read_stream_look_ahead were caused by this. I
suspected it's a bug in lastBlock optimization, but that's not the case,
it happens entirely within read_stream. And it's expected.
It's also not very surprising this happens with backwards scans more.
The I/O is apparently much slower (due to missing OS prefetch), so we're
much more likely to hit the I/O limits (max_ios and various other limits
in read_stream_start_pending_read).
regards
--
Tomas Vondra
On Wed, Aug 13, 2025 at 1:01 PM Tomas Vondra <tomas@vondra.me> wrote: > This seems rather bizarre, considering the two tables are exactly the > same, except that in t2 the first column is negative, and the rows are > fixed-length. Even heap_page_items says the tables are exactly the same. > > So why would the index get so different like this? In the past, when I required *perfectly* deterministic results for INSERT INTO test_table ... SELECT * FROM source_table bulk inserts (which was important during the Postgres 12 and 13 nbtree work), I found it necessary to "set synchronize_seqscans=off". If I was writing a test such as this, I'd probably do that defensively, even if it wasn't clear that it mattered. (I'm also in the habit of using unlogged tables, because VACUUM tends to set their pages all-visible more reliably than equivalent logged tables, which I notice that you're also doing here.) That said, I *think* that the "locally shuffled" heap TID pattern that we see with "t2"/"idx2" is mostly (perhaps entirely) caused by the way that you're inverting the indexed column's value when initially generating "t2". A given range of values such as "1 through to 4" becomes "-4 through to -1" as their tuples are inserted into t2. You're effectively inverting the order of the bigint indexed column "a" -- but you're *not* inverting the order of the imaginary tie-breaker heap column (it *remains* in ASC heap TID order in "t2"). In general, when doing this sort of analysis, I find it useful to manually verify that the data that I generated matches my expectations. Usually a quick check with pageinspect is enough. I'll just randomly select 2 - 3 leaf pages, and make sure that they all more or less match my expectations. -- Peter Geoghegan
Hi,
On 2025-08-13 23:07:07 +0200, Tomas Vondra wrote:
> On 8/13/25 16:44, Andres Freund wrote:
> > On 2025-08-13 14:15:37 +0200, Tomas Vondra wrote:
> >> In fact, I believe this is about io_method. I initially didn't see the
> >> difference you described, and then I realized I set io_method=sync to
> >> make it easier to track the block access. And if I change io_method to
> >> worker, I get different stats, that also change between runs.
> >>
> >> With "sync" I always get this (after a restart):
> >>
> >> Buffers: shared hit=7435 read=52801
> >>
> >> while with "worker" I get this:
> >>
> >> Buffers: shared hit=4879 read=52801
> >> Buffers: shared hit=5151 read=52801
> >> Buffers: shared hit=4978 read=52801
> >>
> >> So not only it changes run to tun, it also does not add up to 60236.
> >
> > This is reproducible on master? If so, how?
> >
> >
> >> I vaguely recall I ran into this some time ago during AIO benchmarking,
> >> and IIRC it's due to how StartReadBuffersImpl() may behave differently
> >> depending on I/O started earlier. It only calls PinBufferForBlock() in
> >> some cases, and PinBufferForBlock() is what updates the hits.
> >
> > Hm, I don't immediately see an issue there. The only case we don't call
> > PinBufferForBlock() is if we already have pinned the relevant buffer in a
> > prior call to StartReadBuffersImpl().
> >
> >
> > If this happens only with the prefetching patch applied, is is possible that
> > what happens here is that we occasionally re-request buffers that already in
> > the process of being read in? That would only happen with a read stream and
> > io_method != sync (since with sync we won't read ahead). If we have to start
> > reading in a buffer that's already undergoing IO we wait for the IO to
> > complete and count that access as a hit:
> >
> > /*
> > * Check if we can start IO on the first to-be-read buffer.
> > *
> > * If an I/O is already in progress in another backend, we want to wait
> > * for the outcome: either done, or something went wrong and we will
> > * retry.
> > */
> > if (!ReadBuffersCanStartIO(buffers[nblocks_done], false))
> > {
> > ...
> > /*
> > * Report and track this as a 'hit' for this backend, even though it
> > * must have started out as a miss in PinBufferForBlock(). The other
> > * backend will track this as a 'read'.
> > */
> > ...
> > if (persistence == RELPERSISTENCE_TEMP)
> > pgBufferUsage.local_blks_hit += 1;
> > else
> > pgBufferUsage.shared_blks_hit += 1;
> > ...
> >
> >
>
> I think it has to be this. It only happens with io_method != sync, and
> only with effective_io_concurrency > 1. At first I was wondering why I
> can't reproduce this for seqscan/bitmapscan, but then I realized those
> plans never visit the same block repeatedly - indexscans do that. It's
> also not surprising it's timing-sensitive, as it likely depends on how
> fast the worker happens to start/complete requests.
>
> What would be a good way to "prove" it really is this?
I'd just comment out those stats increments and then check if the stats are
stable afterwards.
Greetings,
Andres Freund
On Wed, Aug 13, 2025 at 5:19 PM Tomas Vondra <tomas@vondra.me> wrote: > It's also not very surprising this happens with backwards scans more. > The I/O is apparently much slower (due to missing OS prefetch), so we're > much more likely to hit the I/O limits (max_ios and various other limits > in read_stream_start_pending_read). But there's no OS prefetch with direct I/O. At most, there might be some kind of readahead implemented in the SSD's firmware. Even assuming that the SSD issue is relevant, I can't help but suspect that something is off here. To recap from yesterday, the forwards scan showed "I/O Timings: shared read=45.313" and "Execution Time: 330.379 ms" on my system, while the equivalent backwards scan showed "I/O Timings: shared read=194.774" and "Execution Time: 1236.655 ms". Does that kind of disparity *really* make sense with a modern NVME SSD such as this (I use a Samsung 980 pro), in the context of a scan that can use aggressive prefetching? Are we really, truly operating at the limits of what is possible with this hardware, for this backwards scan? What if I use a ramdisk for this? That'll be much faster, no matter the scan order. Should I expect this step to make the effect with duplicates being produced by read_stream_look_ahead to just go away, regardless of the scan direction in use? -- Peter Geoghegan
On 8/13/25 23:37, Andres Freund wrote:
> Hi,
>
> On 2025-08-13 23:07:07 +0200, Tomas Vondra wrote:
>> On 8/13/25 16:44, Andres Freund wrote:
>>> On 2025-08-13 14:15:37 +0200, Tomas Vondra wrote:
>>>> In fact, I believe this is about io_method. I initially didn't see the
>>>> difference you described, and then I realized I set io_method=sync to
>>>> make it easier to track the block access. And if I change io_method to
>>>> worker, I get different stats, that also change between runs.
>>>>
>>>> With "sync" I always get this (after a restart):
>>>>
>>>> Buffers: shared hit=7435 read=52801
>>>>
>>>> while with "worker" I get this:
>>>>
>>>> Buffers: shared hit=4879 read=52801
>>>> Buffers: shared hit=5151 read=52801
>>>> Buffers: shared hit=4978 read=52801
>>>>
>>>> So not only it changes run to tun, it also does not add up to 60236.
>>>
>>> This is reproducible on master? If so, how?
>>>
>>>
>>>> I vaguely recall I ran into this some time ago during AIO benchmarking,
>>>> and IIRC it's due to how StartReadBuffersImpl() may behave differently
>>>> depending on I/O started earlier. It only calls PinBufferForBlock() in
>>>> some cases, and PinBufferForBlock() is what updates the hits.
>>>
>>> Hm, I don't immediately see an issue there. The only case we don't call
>>> PinBufferForBlock() is if we already have pinned the relevant buffer in a
>>> prior call to StartReadBuffersImpl().
>>>
>>>
>>> If this happens only with the prefetching patch applied, is is possible that
>>> what happens here is that we occasionally re-request buffers that already in
>>> the process of being read in? That would only happen with a read stream and
>>> io_method != sync (since with sync we won't read ahead). If we have to start
>>> reading in a buffer that's already undergoing IO we wait for the IO to
>>> complete and count that access as a hit:
>>>
>>> /*
>>> * Check if we can start IO on the first to-be-read buffer.
>>> *
>>> * If an I/O is already in progress in another backend, we want to wait
>>> * for the outcome: either done, or something went wrong and we will
>>> * retry.
>>> */
>>> if (!ReadBuffersCanStartIO(buffers[nblocks_done], false))
>>> {
>>> ...
>>> /*
>>> * Report and track this as a 'hit' for this backend, even though it
>>> * must have started out as a miss in PinBufferForBlock(). The other
>>> * backend will track this as a 'read'.
>>> */
>>> ...
>>> if (persistence == RELPERSISTENCE_TEMP)
>>> pgBufferUsage.local_blks_hit += 1;
>>> else
>>> pgBufferUsage.shared_blks_hit += 1;
>>> ...
>>>
>>>
>>
>> I think it has to be this. It only happens with io_method != sync, and
>> only with effective_io_concurrency > 1. At first I was wondering why I
>> can't reproduce this for seqscan/bitmapscan, but then I realized those
>> plans never visit the same block repeatedly - indexscans do that. It's
>> also not surprising it's timing-sensitive, as it likely depends on how
>> fast the worker happens to start/complete requests.
>>
>> What would be a good way to "prove" it really is this?
>
> I'd just comment out those stats increments and then check if the stats are
> stable afterwards.
>
I tried that, but it's not enough - the buffer hits gets lower, but
remains variable. It stabilizes only if I comment out the increment in
PinBufferForBlock() too. At which point it gets to 0, of course ...
regards
--
Tomas Vondra
Hi,
On 2025-08-14 00:23:49 +0200, Tomas Vondra wrote:
> On 8/13/25 23:37, Andres Freund wrote:
> > On 2025-08-13 23:07:07 +0200, Tomas Vondra wrote:
> >> On 8/13/25 16:44, Andres Freund wrote:
> >>> On 2025-08-13 14:15:37 +0200, Tomas Vondra wrote:
> >>>> In fact, I believe this is about io_method. I initially didn't see the
> >>>> difference you described, and then I realized I set io_method=sync to
> >>>> make it easier to track the block access. And if I change io_method to
> >>>> worker, I get different stats, that also change between runs.
> >>>>
> >>>> With "sync" I always get this (after a restart):
> >>>>
> >>>> Buffers: shared hit=7435 read=52801
> >>>>
> >>>> while with "worker" I get this:
> >>>>
> >>>> Buffers: shared hit=4879 read=52801
> >>>> Buffers: shared hit=5151 read=52801
> >>>> Buffers: shared hit=4978 read=52801
> >>>>
> >>>> So not only it changes run to tun, it also does not add up to 60236.
> >>>
> >>> This is reproducible on master? If so, how?
> >>>
> >>>
> >>>> I vaguely recall I ran into this some time ago during AIO benchmarking,
> >>>> and IIRC it's due to how StartReadBuffersImpl() may behave differently
> >>>> depending on I/O started earlier. It only calls PinBufferForBlock() in
> >>>> some cases, and PinBufferForBlock() is what updates the hits.
> >>>
> >>> Hm, I don't immediately see an issue there. The only case we don't call
> >>> PinBufferForBlock() is if we already have pinned the relevant buffer in a
> >>> prior call to StartReadBuffersImpl().
> >>>
> >>>
> >>> If this happens only with the prefetching patch applied, is is possible that
> >>> what happens here is that we occasionally re-request buffers that already in
> >>> the process of being read in? That would only happen with a read stream and
> >>> io_method != sync (since with sync we won't read ahead). If we have to start
> >>> reading in a buffer that's already undergoing IO we wait for the IO to
> >>> complete and count that access as a hit:
> >>>
> >>> /*
> >>> * Check if we can start IO on the first to-be-read buffer.
> >>> *
> >>> * If an I/O is already in progress in another backend, we want to wait
> >>> * for the outcome: either done, or something went wrong and we will
> >>> * retry.
> >>> */
> >>> if (!ReadBuffersCanStartIO(buffers[nblocks_done], false))
> >>> {
> >>> ...
> >>> /*
> >>> * Report and track this as a 'hit' for this backend, even though it
> >>> * must have started out as a miss in PinBufferForBlock(). The other
> >>> * backend will track this as a 'read'.
> >>> */
> >>> ...
> >>> if (persistence == RELPERSISTENCE_TEMP)
> >>> pgBufferUsage.local_blks_hit += 1;
> >>> else
> >>> pgBufferUsage.shared_blks_hit += 1;
> >>> ...
> >>>
> >>>
> >>
> >> I think it has to be this. It only happens with io_method != sync, and
> >> only with effective_io_concurrency > 1. At first I was wondering why I
> >> can't reproduce this for seqscan/bitmapscan, but then I realized those
> >> plans never visit the same block repeatedly - indexscans do that. It's
> >> also not surprising it's timing-sensitive, as it likely depends on how
> >> fast the worker happens to start/complete requests.
> >>
> >> What would be a good way to "prove" it really is this?
> >
> > I'd just comment out those stats increments and then check if the stats are
> > stable afterwards.
> >
>
> I tried that, but it's not enough - the buffer hits gets lower, but
> remains variable. It stabilizes only if I comment out the increment in
> PinBufferForBlock() too. At which point it gets to 0, of course ...
Ah, right - that'll be the cases where IO completed before we access it a
second time. There's no good way that I can see that we can make that
deterministic - I mean, we could just search all in-progress IOs before
starting a new IO for a matching block number and wait for all IO to complete
if so. But that seems like an obviously bad idea.
I think there's just some fundamental indeterminisism here. I don't think we
gain anything by hiding it...
Greetings,
Andres Freund
On 8/13/25 23:57, Peter Geoghegan wrote: > On Wed, Aug 13, 2025 at 5:19 PM Tomas Vondra <tomas@vondra.me> wrote: >> It's also not very surprising this happens with backwards scans more. >> The I/O is apparently much slower (due to missing OS prefetch), so we're >> much more likely to hit the I/O limits (max_ios and various other limits >> in read_stream_start_pending_read). > > But there's no OS prefetch with direct I/O. At most, there might be > some kind of readahead implemented in the SSD's firmware. > Good point, I keep forgetting direct I/O means no OS read-ahead. Not sure if there's a good way to determine if the SSD can do something like that (and how well). I wonder if there's a way to do backward sequential scans in fio .. > Even assuming that the SSD issue is relevant, I can't help but suspect > that something is off here. To recap from yesterday, the forwards scan > showed "I/O Timings: shared read=45.313" and "Execution Time: 330.379 > ms" on my system, while the equivalent backwards scan showed "I/O > Timings: shared read=194.774" and "Execution Time: 1236.655 ms". Does > that kind of disparity *really* make sense with a modern NVME SSD such > as this (I use a Samsung 980 pro), in the context of a scan that can > use aggressive prefetching? Are we really, truly operating at the > limits of what is possible with this hardware, for this backwards > scan? > Hard to say. Would be interesting to get some numbers using fio. I'll try to do that for my devices. The timings I see on my ryzen (which has a RAID0 with 4 samsung 990 pro), I see these stats: 1) Q1 ASC Buffers: shared hit=4545 read=52801 I/O Timings: shared read=127.700 Execution Time: 432.266 ms 2) Q1 DESC Buffers: shared hit=7406 read=52801 I/O Timings: shared read=306.676 Execution Time: 769.246 ms 3) Q2 ASC Buffers: shared hit=32605 read=52801 I/O Timings: shared read=127.610 Execution Time: 1047.333 ms 4) Q2 DESC Buffers: shared hit=36105 read=52801 I/O Timings: shared read=157.667 Execution Time: 1140.286 ms Those timings are much better (more stable) that the numbers I shared yesterday (that was from my laptop). All of this is with direct I/O and 12 workers. > What if I use a ramdisk for this? That'll be much faster, no matter > the scan order. Should I expect this step to make the effect with > duplicates being produced by read_stream_look_ahead to just go away, > regardless of the scan direction in use? > How's that different from just running with buffered I/O and not dropping the page cache? regards -- Tomas Vondra
Hi, On 2025-08-14 01:11:07 +0200, Tomas Vondra wrote: > On 8/13/25 23:57, Peter Geoghegan wrote: > > On Wed, Aug 13, 2025 at 5:19 PM Tomas Vondra <tomas@vondra.me> wrote: > >> It's also not very surprising this happens with backwards scans more. > >> The I/O is apparently much slower (due to missing OS prefetch), so we're > >> much more likely to hit the I/O limits (max_ios and various other limits > >> in read_stream_start_pending_read). > > > > But there's no OS prefetch with direct I/O. At most, there might be > > some kind of readahead implemented in the SSD's firmware. > > > > Good point, I keep forgetting direct I/O means no OS read-ahead. Not > sure if there's a good way to determine if the SSD can do something like > that (and how well). I wonder if there's a way to do backward sequential > scans in fio .. In theory, yes, in practice, not quite: https://github.com/axboe/fio/issues/1963 So right now it only works if you skip over some blocks. For that there rather significant performance differences on my SSDs. E.g. andres@awork3:~/src/fio$ fio --directory /srv/fio --size=$((1024*1024*1024)) --name test --bs=4k --rw read:8k --buffered0 2>&1|grep READ READ: bw=179MiB/s (188MB/s), 179MiB/s-179MiB/s (188MB/s-188MB/s), io=341MiB (358MB), run=1907-1907msec andres@awork3:~/src/fio$ fio --directory /srv/fio --size=$((1024*1024*1024)) --name test --bs=4k --rw read:-8k --buffered0 2>&1|grep READ READ: bw=70.6MiB/s (74.0MB/s), 70.6MiB/s-70.6MiB/s (74.0MB/s-74.0MB/s), io=1024MiB (1074MB), run=14513-14513msec So on this WD Red SN700 there's a rather substantial performance difference. On a Samsung 970 PRO I don't see much of a difference. Nor on a ADATA SX8200PNP. Greetings, Andres Freund
On 8/13/25 23:36, Peter Geoghegan wrote: > On Wed, Aug 13, 2025 at 1:01 PM Tomas Vondra <tomas@vondra.me> wrote: >> This seems rather bizarre, considering the two tables are exactly the >> same, except that in t2 the first column is negative, and the rows are >> fixed-length. Even heap_page_items says the tables are exactly the same. >> >> So why would the index get so different like this? > > In the past, when I required *perfectly* deterministic results for > INSERT INTO test_table ... SELECT * FROM source_table bulk inserts > (which was important during the Postgres 12 and 13 nbtree work), I > found it necessary to "set synchronize_seqscans=off". If I was writing > a test such as this, I'd probably do that defensively, even if it > wasn't clear that it mattered. (I'm also in the habit of using > unlogged tables, because VACUUM tends to set their pages all-visible > more reliably than equivalent logged tables, which I notice that > you're also doing here.) > The tables are *exactly* the same, block by block. I double checked that by looking at a couple pages, and the only difference is the inverted value of the "a" column. > That said, I *think* that the "locally shuffled" heap TID pattern that > we see with "t2"/"idx2" is mostly (perhaps entirely) caused by the way > that you're inverting the indexed column's value when initially > generating "t2". A given range of values such as "1 through to 4" > becomes "-4 through to -1" as their tuples are inserted into t2. Right. > You're effectively inverting the order of the bigint indexed column > "a" -- but you're *not* inverting the order of the imaginary > tie-breaker heap column (it *remains* in ASC heap TID order in "t2"). > I have no idea what I'm supposed to do about that. As you say the tie-breaker is imaginary, selected by the system on my behalf. If it works like this, doesn't that mean it'll have this unfortunate effect on all data sets with negative correlation? > In general, when doing this sort of analysis, I find it useful to > manually verify that the data that I generated matches my > expectations. Usually a quick check with pageinspect is enough. I'll > just randomly select 2 - 3 leaf pages, and make sure that they all > more or less match my expectations. > I did that for the heap, and that's just as I expected. But the effect on the index surprised me. regards -- Tomas Vondra
On Wed Aug 13, 2025 at 5:19 PM EDT, Tomas Vondra wrote:
> I did investigate this, and I don't think there's anything broken in
> read_stream. It happens because ReadStream has a concept of "ungetting"
> a block, which can happen after hitting some I/O limits.
>
> In that case we "remember" the last block (in read_stream_look_ahead
> calls read_stream_unget_block), and we return it again. It may seem as
> if read_stream_get_block() produced the same block twice, but it's
> really just the block from the last round.
I instrumented this for myself, and I agree: backwards and forwards scan cases
are being fed the same block numbers, as expected (it's just that the order is
precisely backwards, as expected). The only real difference is that the forwards
scan case seems to be passed InvalidBlockNumber quite a bit more often. You were
right: I was confused about the read_stream_unget_block thing.
However, the magnitude of the difference that I see between the forwards and
backwards scan cases just doesn't pass the smell test -- I stand by that part.
I was able to confirm this intuition by performing a simple experiment.
I asked myself a fairly obvious question: if the backwards scan in question
takes about 2.5x as long, just because each group of TIDs for each index value
appears in descending order, then what happens if the order is made random?
Where does that leave the forwards scan case, and where does it leave the
backwards scan case?
I first made the order of the table random, except among groups of index tuples
that have exactly the same value. Those will still point to the same 1 or 2 heap
blocks in virtually all cases, so we have "heap clustering without any heap
correlation" in the newly rewritten table. To set things up this way, I first
made another index, and then clustered the table using that new index:
pg@regression:5432 [2476413]=# create index on t (hashint8(a));
CREATE INDEX
pg@regression:5432 [2476413]=# cluster t using t_hashint8_idx ;
CLUSTER
Next, I reran the queries in the obvious way (same procedure as yesterday,
though with a very different result):
pg@regression:5432 [2476413]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2476413]=# EXPLAIN (ANALYZE ,costs off, timing off) SELECT * FROM t WHERE a BETWEEN 16336 AND 49103
ORDERBY a;
┌────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────┤
│ Index Scan using idx on t (actual rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=6082 read=77813 │
│ I/O Timings: shared read=153.672 │
│ Planning Time: 0.057 ms │
│ Execution Time: 402.735 ms │
└────────────────────────────────────────────────────────────┘
(7 rows)
pg@regression:5432 [2476413]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
***SNIP***
pg@regression:5432 [2476413]=# EXPLAIN (ANALYZE ,costs off, timing off) SELECT * FROM t WHERE a BETWEEN 16336 AND 49103
ORDERBY a desc;
┌─────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├─────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using idx on t (actual rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=6082 read=77813 │
│ I/O Timings: shared read=324.305 │
│ Planning Time: 0.071 ms │
│ Execution Time: 616.268 ms │
└─────────────────────────────────────────────────────────────────────┘
(7 rows)
Apparently random I/O is twice as fast as sequential I/O in descending order! In
fact, this test case creates the appearance of random I/O being at least
slightly faster than sequential I/O for pages read in _ascending_ order!
Obviously something doesn't add up here. I'm no closer to explaining what the
underlying problem is than I was yesterday, but I find it _very_ hard to believe
that the inconsistency in performance has anything to do with SSD firmware/OS
implementation details. It just looks wonky to me.
Also possibly worth noting: I'm pretty sure that "shared hit=6082" is wrong.
Though now it's wrong in the same way with both variants.
Just for context, I'll show what the TIDs for 3 randomly chosen
adjacent-in-index values look like after CLUSTER runs (in case it was unclear
what I meant about "heap clustering without any heap correlation" earlier):
pg@regression:5432 [2476413]=# SELECT ctid, a FROM t WHERE a BETWEEN 20_000 AND 20_002 ORDER BY a;
┌─────────────┬────────┐
│ ctid │ a │
├─────────────┼────────┤
│ (142534,3) │ 20,000 │
│ (142534,4) │ 20,000 │
│ (142534,5) │ 20,000 │
│ (142534,6) │ 20,000 │
│ (142534,7) │ 20,000 │
│ (142534,8) │ 20,000 │
│ (142534,9) │ 20,000 │
│ (142534,10) │ 20,000 │
│ (142534,11) │ 20,000 │
│ (142534,12) │ 20,000 │
│ (142534,13) │ 20,000 │
│ (142534,14) │ 20,000 │
│ (142534,15) │ 20,000 │
│ (142534,16) │ 20,000 │
│ (142534,17) │ 20,000 │
│ (142534,18) │ 20,000 │
│ (142534,19) │ 20,000 │
│ (142534,20) │ 20,000 │
│ (142534,21) │ 20,000 │
│ (142535,1) │ 20,000 │
│ (142535,2) │ 20,000 │
│ (142535,3) │ 20,000 │
│ (142535,4) │ 20,000 │
│ (142535,5) │ 20,000 │
│ (142535,6) │ 20,000 │
│ (142535,7) │ 20,000 │
│ (142535,8) │ 20,000 │
│ (142535,9) │ 20,000 │
│ (142535,10) │ 20,000 │
│ (142535,11) │ 20,000 │
│ (142535,12) │ 20,000 │
│ (142535,13) │ 20,000 │
│ (216406,19) │ 20,001 │
│ (216406,20) │ 20,001 │
│ (216406,21) │ 20,001 │
│ (216407,1) │ 20,001 │
│ (216407,2) │ 20,001 │
│ (216407,3) │ 20,001 │
│ (216407,4) │ 20,001 │
│ (216407,5) │ 20,001 │
│ (216407,6) │ 20,001 │
│ (216407,7) │ 20,001 │
│ (216407,8) │ 20,001 │
│ (216407,9) │ 20,001 │
│ (216407,10) │ 20,001 │
│ (216407,11) │ 20,001 │
│ (216407,12) │ 20,001 │
│ (216407,13) │ 20,001 │
│ (216407,14) │ 20,001 │
│ (216407,15) │ 20,001 │
│ (216407,16) │ 20,001 │
│ (216407,17) │ 20,001 │
│ (216407,18) │ 20,001 │
│ (216407,19) │ 20,001 │
│ (216407,20) │ 20,001 │
│ (216407,21) │ 20,001 │
│ (216408,1) │ 20,001 │
│ (216408,2) │ 20,001 │
│ (216408,3) │ 20,001 │
│ (216408,4) │ 20,001 │
│ (216408,5) │ 20,001 │
│ (216408,6) │ 20,001 │
│ (216408,7) │ 20,001 │
│ (216408,8) │ 20,001 │
│ (260993,12) │ 20,002 │
│ (260993,13) │ 20,002 │
│ (260993,14) │ 20,002 │
│ (260993,15) │ 20,002 │
│ (260993,16) │ 20,002 │
│ (260993,17) │ 20,002 │
│ (260993,18) │ 20,002 │
│ (260993,19) │ 20,002 │
│ (260993,20) │ 20,002 │
│ (260993,21) │ 20,002 │
│ (260994,1) │ 20,002 │
│ (260994,2) │ 20,002 │
│ (260994,3) │ 20,002 │
│ (260994,4) │ 20,002 │
│ (260994,5) │ 20,002 │
│ (260994,6) │ 20,002 │
│ (260994,7) │ 20,002 │
│ (260994,8) │ 20,002 │
│ (260994,9) │ 20,002 │
│ (260994,10) │ 20,002 │
│ (260994,11) │ 20,002 │
│ (260994,12) │ 20,002 │
│ (260994,13) │ 20,002 │
│ (260994,14) │ 20,002 │
│ (260994,15) │ 20,002 │
│ (260994,16) │ 20,002 │
│ (260994,17) │ 20,002 │
│ (260994,18) │ 20,002 │
│ (260994,19) │ 20,002 │
│ (260994,20) │ 20,002 │
│ (260994,21) │ 20,002 │
│ (260995,1) │ 20,002 │
└─────────────┴────────┘
(96 rows)
--
Peter Geoghegan
On Wed, Aug 13, 2025 at 7:51 PM Peter Geoghegan <pg@bowt.ie> wrote: > Apparently random I/O is twice as fast as sequential I/O in descending order! In > fact, this test case creates the appearance of random I/O being at least > slightly faster than sequential I/O for pages read in _ascending_ order! > > Obviously something doesn't add up here. Minor clarification: If EXPLAIN ANALYZE is to be believed, "I/O Timings" is in fact higher with the randomized "t" table variant of the test case, compared to what I showed yesterday with the original sequential "t" version of the table, exactly as expected. (When I said "Apparently random I/O is twice as fast as sequential I/O in descending order!", I was just joking, of course.) It seems reasonable to suppose that the actual problem has something to do with synchronization overhead of some kind or other. Or, perhaps it's due to some kind of major inefficiency in the patch -- perhaps the patch can sometimes waste many CPU cycles on who-knows-what, at least in cases like the original/slow backwards scan case. -- Peter Geoghegan
On Thu, Aug 14, 2025 at 9:19 AM Tomas Vondra <tomas@vondra.me> wrote: > I did investigate this, and I don't think there's anything broken in > read_stream. It happens because ReadStream has a concept of "ungetting" > a block, which can happen after hitting some I/O limits. > > In that case we "remember" the last block (in read_stream_look_ahead > calls read_stream_unget_block), and we return it again. It may seem as > if read_stream_get_block() produced the same block twice, but it's > really just the block from the last round. Yeah, it's a bit of a tight corner in the algorithm, and I haven't found any better solution. It arises from this circularity: * we need a block number from the callback before we can decide if it can be combined with the pending read * if we can't combine it, we need to start the pending read to get it out of the way, so we can start a new one * we entered this path knowing that we are allowed to start one more IO, but if doing so reports a spit then we've only made the pending read smaller, ie the tail portion remains, so we still can't combine with it, so the only way to make progress is to loop and start another IO, and so on * while doing that we might hit the limits on pinned buffers (only for tiny buffer pools) or (more likely) running IOs, and then what are you going to do with that block number?
On 8/14/25 01:50, Peter Geoghegan wrote:
> On Wed Aug 13, 2025 at 5:19 PM EDT, Tomas Vondra wrote:
>> I did investigate this, and I don't think there's anything broken in
>> read_stream. It happens because ReadStream has a concept of "ungetting"
>> a block, which can happen after hitting some I/O limits.
>>
>> In that case we "remember" the last block (in read_stream_look_ahead
>> calls read_stream_unget_block), and we return it again. It may seem as
>> if read_stream_get_block() produced the same block twice, but it's
>> really just the block from the last round.
>
> I instrumented this for myself, and I agree: backwards and forwards scan cases
> are being fed the same block numbers, as expected (it's just that the order is
> precisely backwards, as expected). The only real difference is that the forwards
> scan case seems to be passed InvalidBlockNumber quite a bit more often. You were
> right: I was confused about the read_stream_unget_block thing.
>
> However, the magnitude of the difference that I see between the forwards and
> backwards scan cases just doesn't pass the smell test -- I stand by that part.
> I was able to confirm this intuition by performing a simple experiment.
>
> I asked myself a fairly obvious question: if the backwards scan in question
> takes about 2.5x as long, just because each group of TIDs for each index value
> appears in descending order, then what happens if the order is made random?
> Where does that leave the forwards scan case, and where does it leave the
> backwards scan case?
>
> I first made the order of the table random, except among groups of index tuples
> that have exactly the same value. Those will still point to the same 1 or 2 heap
> blocks in virtually all cases, so we have "heap clustering without any heap
> correlation" in the newly rewritten table. To set things up this way, I first
> made another index, and then clustered the table using that new index:
>
> pg@regression:5432 [2476413]=# create index on t (hashint8(a));
> CREATE INDEX
> pg@regression:5432 [2476413]=# cluster t using t_hashint8_idx ;
> CLUSTER
>
> Next, I reran the queries in the obvious way (same procedure as yesterday,
> though with a very different result):
>
> pg@regression:5432 [2476413]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
> ***SNIP***
> pg@regression:5432 [2476413]=# EXPLAIN (ANALYZE ,costs off, timing off) SELECT * FROM t WHERE a BETWEEN 16336 AND
49103ORDER BY a;
> ┌────────────────────────────────────────────────────────────┐
> │ QUERY PLAN │
> ├────────────────────────────────────────────────────────────┤
> │ Index Scan using idx on t (actual rows=1048576.00 loops=1) │
> │ Index Cond: ((a >= 16336) AND (a <= 49103)) │
> │ Index Searches: 1 │
> │ Buffers: shared hit=6082 read=77813 │
> │ I/O Timings: shared read=153.672 │
> │ Planning Time: 0.057 ms │
> │ Execution Time: 402.735 ms │
> └────────────────────────────────────────────────────────────┘
> (7 rows)
>
> pg@regression:5432 [2476413]=# select pg_buffercache_evict_relation('t'); select pg_prewarm('idx');
> ***SNIP***
> pg@regression:5432 [2476413]=# EXPLAIN (ANALYZE ,costs off, timing off) SELECT * FROM t WHERE a BETWEEN 16336 AND
49103ORDER BY a desc;
> ┌─────────────────────────────────────────────────────────────────────┐
> │ QUERY PLAN │
> ├─────────────────────────────────────────────────────────────────────┤
> │ Index Scan Backward using idx on t (actual rows=1048576.00 loops=1) │
> │ Index Cond: ((a >= 16336) AND (a <= 49103)) │
> │ Index Searches: 1 │
> │ Buffers: shared hit=6082 read=77813 │
> │ I/O Timings: shared read=324.305 │
> │ Planning Time: 0.071 ms │
> │ Execution Time: 616.268 ms │
> └─────────────────────────────────────────────────────────────────────┘
> (7 rows)
>
> Apparently random I/O is twice as fast as sequential I/O in descending order! In
> fact, this test case creates the appearance of random I/O being at least
> slightly faster than sequential I/O for pages read in _ascending_ order!
>
> Obviously something doesn't add up here. I'm no closer to explaining what the
> underlying problem is than I was yesterday, but I find it _very_ hard to believe
> that the inconsistency in performance has anything to do with SSD firmware/OS
> implementation details. It just looks wonky to me.
>
> Also possibly worth noting: I'm pretty sure that "shared hit=6082" is wrong.
> Though now it's wrong in the same way with both variants.
>
> Just for context, I'll show what the TIDs for 3 randomly chosen
> adjacent-in-index values look like after CLUSTER runs (in case it was unclear
> what I meant about "heap clustering without any heap correlation" earlier):
>
Interesting. It's really surprising random I/O beats the sequential.
I investigated this from a different angle, by tracing the I/O request
generated. using perf-trace. And the patterns are massively different.
What I did is roughly this:
1) restart the instance (with direct I/O)
2) perf trace record -m 128M -a -o $(date +%s).trace
3) run the query, pgrep 'io worker'
4) stop the trace
5) extract pread64 events for the I/O workers from the trace
I get these event counts:
Q1 ASC - 5395
Q1 DESC - 49969
Q2 ASC - 32804
Q2 DESC - 49958
It's interesting the DESC queries get to do almost exactly the same
number of pread calls.
Anyway, small samples of the trace look like this:
Q1 ASC
pread64(fd: 7, buf: 0x7f6011b7f000, count: 81920, pos: 475193344)
pread64(fd: 24, buf: 0x7f6011b95000, count: 131072, pos: 475275264)
pread64(fd: 7, buf: 0x7f6011bb7000, count: 131072, pos: 475406336)
pread64(fd: 24, buf: 0x7f6011bd9000, count: 131072, pos: 475537408)
pread64(fd: 7, buf: 0x7f6011bfb000, count: 81920, pos: 475668480)
pread64(fd: 24, buf: 0x7f6011c0f000, count: 24576, pos: 475750400)
pread64(fd: 24, buf: 0x7f6011c15000, count: 24576, pos: 475774976)
pread64(fd: 24, buf: 0x7f6011c1d000, count: 131072, pos: 475799552)
pread64(fd: 7, buf: 0x7f6011c3f000, count: 106496, pos: 475930624)
pread64(fd: 24, buf: 0x7f6011c59000, count: 24576, pos: 476037120)
pread64(fd: 24, buf: 0x7f6011c61000, count: 131072, pos: 476061696)
pread64(fd: 7, buf: 0x7f6011c83000, count: 131072, pos: 476192768)
pread64(fd: 24, buf: 0x7f6011ca3000, count: 24576, pos: 476323840)
pread64(fd: 24, buf: 0x7f6011ca9000, count: 24576, pos: 476348416)
pread64(fd: 24, buf: 0x7f6011cb1000, count: 131072, pos: 476372992)
pread64(fd: 7, buf: 0x7f6011cd1000, count: 57344, pos: 476504064)
Q1 DESC
pread64(fd: 24, buf: 0x7fa8c1735000, count: 8192, pos: 230883328)
pread64(fd: 7, buf: 0x7fa8c1737000, count: 8192, pos: 230875136)
pread64(fd: 6, buf: 0x7fa8c173b000, count: 8192, pos: 230866944)
pread64(fd: 24, buf: 0x7fa8c173d000, count: 8192, pos: 230858752)
pread64(fd: 7, buf: 0x7fa8c173f000, count: 8192, pos: 230850560)
pread64(fd: 6, buf: 0x7fa8c1741000, count: 8192, pos: 230842368)
pread64(fd: 24, buf: 0x7fa8c1743000, count: 8192, pos: 230834176)
pread64(fd: 7, buf: 0x7fa8c1745000, count: 8192, pos: 230825984)
pread64(fd: 24, buf: 0x7fa8c1747000, count: 8192, pos: 230817792)
pread64(fd: 6, buf: 0x7fa8c1749000, count: 8192, pos: 230809600)
pread64(fd: 7, buf: 0x7fa8c174b000, count: 8192, pos: 230801408)
pread64(fd: 24, buf: 0x7fa8c174d000, count: 8192, pos: 230793216)
pread64(fd: 6, buf: 0x7fa8c174f000, count: 8192, pos: 230785024)
pread64(fd: 7, buf: 0x7fa8c1751000, count: 8192, pos: 230776832)
pread64(fd: 24, buf: 0x7fa8c1753000, count: 8192, pos: 230768640)
pread64(fd: 7, buf: 0x7fa8c1755000, count: 8192, pos: 230760448)
pread64(fd: 6, buf: 0x7fa8c1757000, count: 8192, pos: 230752256)
Q2 ASC
pread64(fd: 7, buf: 0x7fb8bbf27000, count: 8192, pos: 258695168)
pread64(fd: 24, buf: 0x7fb8bbf29000, count: 16384, pos: 258678784)
pread64(fd: 7, buf: 0x7fb8bbf2d000, count: 8192, pos: 258670592)
pread64(fd: 24, buf: 0x7fb8bbf2f000, count: 16384, pos: 258654208)
pread64(fd: 7, buf: 0x7fb8bbf33000, count: 8192, pos: 258646016)
pread64(fd: 24, buf: 0x7fb8bbf35000, count: 16384, pos: 258629632)
pread64(fd: 7, buf: 0x7fb8bbf39000, count: 8192, pos: 258621440)
pread64(fd: 24, buf: 0x7fb8bbf3d000, count: 16384, pos: 258605056)
pread64(fd: 7, buf: 0x7fb8bbf41000, count: 8192, pos: 258596864)
pread64(fd: 24, buf: 0x7fb8bbf43000, count: 16384, pos: 258580480)
pread64(fd: 7, buf: 0x7fb8bbf47000, count: 8192, pos: 258572288)
pread64(fd: 24, buf: 0x7fb8bbf49000, count: 16384, pos: 258555904)
pread64(fd: 7, buf: 0x7fb8bbf4d000, count: 8192, pos: 258547712)
pread64(fd: 24, buf: 0x7fb8bbf4f000, count: 16384, pos: 258531328)
pread64(fd: 7, buf: 0x7fb8bbf53000, count: 16384, pos: 258514944)
pread64(fd: 24, buf: 0x7fb8bbf57000, count: 8192, pos: 258506752)
pread64(fd: 7, buf: 0x7fb8bbf59000, count: 8192, pos: 258498560)
pread64(fd: 24, buf: 0x7fb8bbf5b000, count: 16384, pos: 258482176)
Q2 DESC
pread64(fd: 24, buf: 0x7fdcf0451000, count: 8192, pos: 598974464)
pread64(fd: 7, buf: 0x7fdcf0453000, count: 8192, pos: 598999040)
pread64(fd: 6, buf: 0x7fdcf0455000, count: 8192, pos: 598990848)
pread64(fd: 24, buf: 0x7fdcf0459000, count: 8192, pos: 599007232)
pread64(fd: 7, buf: 0x7fdcf045b000, count: 8192, pos: 599023616)
pread64(fd: 6, buf: 0x7fdcf045d000, count: 8192, pos: 599015424)
pread64(fd: 24, buf: 0x7fdcf045f000, count: 8192, pos: 599031808)
pread64(fd: 7, buf: 0x7fdcf0461000, count: 8192, pos: 599048192)
pread64(fd: 6, buf: 0x7fdcf0463000, count: 8192, pos: 599040000)
pread64(fd: 24, buf: 0x7fdcf0465000, count: 8192, pos: 599056384)
pread64(fd: 7, buf: 0x7fdcf0467000, count: 8192, pos: 599072768)
pread64(fd: 6, buf: 0x7fdcf0469000, count: 8192, pos: 599064576)
pread64(fd: 24, buf: 0x7fdcf046b000, count: 8192, pos: 599080960)
pread64(fd: 7, buf: 0x7fdcf046d000, count: 8192, pos: 599097344)
pread64(fd: 6, buf: 0x7fdcf046f000, count: 8192, pos: 599089152)
pread64(fd: 24, buf: 0x7fdcf0471000, count: 8192, pos: 599105536)
pread64(fd: 7, buf: 0x7fdcf0473000, count: 8192, pos: 599121920)
pread64(fd: 6, buf: 0x7fdcf0475000, count: 8192, pos: 599113728)
So, Q1 ASC gets to combine the I/O into nice large chunks. But the DESC
queries end up doing a stream of 8K requests. The Q2 ASC gets to do 16KB
reads in about half the cases, but the rest is still 8KB.
FWIW I believe this is what Thomas Munro meant by [1]:
You'll probably see a flood of uncombined 8KB IOs in the pg_aios
view while travelling up the heap with cache misses today.
It wasn't quite this obvious in pg_aios, though. I've usually seen only
a single event there, so hard to make conclusion. The trace makes it
pretty obvious, though. We don't combine the I/O, and we also know Linux
in fact does not do any readahead for backwards scans.
regards
[1]
https://www.postgresql.org/message-id/CA%2BhUKGKMaZLmNQHaa_DZMw9MJJKGegjrqnTY3KOZB-_nvFa3wQ%40mail.gmail.com
--
Tomas Vondra
On Wed, Aug 13, 2025 at 8:59 PM Tomas Vondra <tomas@vondra.me> wrote: > I investigated this from a different angle, by tracing the I/O request > generated. using perf-trace. And the patterns are massively different. I tried a similar approach myself, using a variety of tools. That didn't get me very far. > So, Q1 ASC gets to combine the I/O into nice large chunks. But the DESC > queries end up doing a stream of 8K requests. The Q2 ASC gets to do 16KB > reads in about half the cases, but the rest is still 8KB. My randomized version of the forwards scan is about as fast (maybe even slightly faster) than your original version on my workstation, in spite of the fact that EXPLAIN ANALYZE reports that the randomized version does indeed have about a 3x higher "I/O Timings: shared read". So I tend to doubt that low-level instrumentation will be all that helpful with debugging the issue. I suppose that it *might* be helpful if you can use it to spot some kind of pattern -- a pattern that hints at the real underlying issue. To me the issue feels like a priority inversion problem. Maybe slow-ish I/O can lead to very very slow query execution time, due to some kind of second order effect (possibly an issue on the read stream side). If that's what this is then the problem still won't be that there was slow-ish I/O, or that we couldn't successfully combine I/Os in whatever way. After all, we surely won't be able to combine I/Os with the randomized version of the queries that I described to the list this evening -- and yet those are still very fast in terms of overall execution time (somehow, they are about as fast as the original variant, that will manage to combine I/Os, in spite of the obvious disadvantage of requiring random I/O for the heap accesses). -- Peter Geoghegan
On Wed Aug 13, 2025 at 7:50 PM EDT, Peter Geoghegan wrote: > pg@regression:5432 [2476413]=# EXPLAIN (ANALYZE ,costs off, timing off) SELECT * FROM t WHERE a BETWEEN 16336 AND 49103ORDER BY a desc; > ┌─────────────────────────────────────────────────────────────────────┐ > │ QUERY PLAN │ > ├─────────────────────────────────────────────────────────────────────┤ > │ Index Scan Backward using idx on t (actual rows=1048576.00 loops=1) │ > │ Index Cond: ((a >= 16336) AND (a <= 49103)) │ > │ Index Searches: 1 │ > │ Buffers: shared hit=6082 read=77813 │ > │ I/O Timings: shared read=324.305 │ > │ Planning Time: 0.071 ms │ > │ Execution Time: 616.268 ms │ > └─────────────────────────────────────────────────────────────────────┘ > (7 rows) > Also possibly worth noting: I'm pretty sure that "shared hit=6082" is wrong. > Though now it's wrong in the same way with both variants. Actually, "Buffers:" output _didn't_ have the same problem with the randomized test case variants. With master + buffered I/O, with the FS cache dropped, and with the index relation prewarmed, the same query shows the same "Buffers" details that the patch showed earlier: ┌─────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├─────────────────────────────────────────────────────────────────────┤ │ Index Scan Backward using idx on t (actual rows=1048576.00 loops=1) │ │ Index Cond: ((a >= 16336) AND (a <= 49103)) │ │ Index Searches: 1 │ │ Buffers: shared hit=6085 read=77813 │ │ I/O Timings: shared read=10572.441 │ │ Planning: │ │ Buffers: shared hit=90 read=23 │ │ I/O Timings: shared read=1.212 │ │ Planning Time: 1.505 ms │ │ Execution Time: 10711.853 ms │ └─────────────────────────────────────────────────────────────────────┘ (10 rows) Though it's not particular relevant to the problem at hand, I'll also point out that with a scan of an index such as this (an index that exhibits "heap clustering without heap correlation"), prefetching is particularly important. Here we see a ~17.3x speedup (relative to master + buffered I/O). Nice! -- Peter Geoghegan
On Wed Aug 13, 2025 at 8:59 PM EDT, Tomas Vondra wrote: > On 8/14/25 01:50, Peter Geoghegan wrote: >> I first made the order of the table random, except among groups of index tuples >> that have exactly the same value. Those will still point to the same 1 or 2 heap >> blocks in virtually all cases, so we have "heap clustering without any heap >> correlation" in the newly rewritten table. To set things up this way, I first >> made another index, and then clustered the table using that new index: > Interesting. It's really surprising random I/O beats the sequential. It should be noted that the effect seems to be limited to io_method=io_uring. I find that with io_method=worker, the execution time of the original "sequential heap access" backwards scan is very similar to the execution time of the variant with the index that exhibits "heap clustering without any heap correlation" (the variant where individual heap blocks appear in random order). Benchmark that includes both io_uring and worker ================================================ I performed the usual procedure of prewarming the index and evicting the heap relation, and then actually running the relevant query through EXPLAIN ANALYZE. Direct I/O was used throughout. io_method=worker ---------------- Original backwards scan: 1498.024 ms (shared read=48.080) "No heap correlation" backwards scan: 1483.348 ms (shared read=22.036) Original forwards scan: 656.884 ms (shared read=19.904) "No heap correlation" forwards scan: 578.076 ms (shared read=10.159) io_method=io_uring ------------------ Original backwards scan: 1052.807 ms (shared read=187.876) "No heap correlation" backwards scan: 649.473 ms (shared read=365.802) Original forwards scan: 593.126 ms (shared read=55.837) "No heap correlation" forwards scan: 429.888 ms (shared read=188.619) Summary ------- As of this morning, io_method=io_uring also shows that the forwards scan is faster with random heap accesses than without (not just the backwards scan). I double-checked, to make sure that the effect was real; it seems to be. I'm aware that some of these numbers (those for the original/sequential forward scan case) don't match what I reported on Tuesday. I believe that this is due to changes I made to my SSD's readahead using blockdev, though it's possible that there's some other explanation. (In case it matters, I'm running Debian unstable with liburing2 "2.9-1".) The important point remains: at least with io_uring, the backwards scan query is much faster with random I/O than it is with descending sequential I/O. It might make sense if they were at least at parity, but clearly they're not. -- Peter Geoghegan
On Thu, Aug 14, 2025 at 12:56 PM Peter Geoghegan <pg@bowt.ie> wrote: > I performed the usual procedure of prewarming the index and evicting the heap > relation, and then actually running the relevant query through EXPLAIN > ANALYZE. Direct I/O was used throughout. > io_method=io_uring > ------------------ > > Original backwards scan: 1052.807 ms (shared read=187.876) > "No heap correlation" backwards scan: 649.473 ms (shared read=365.802) Attached is a differential flame graph that compares the execution of these 2 queries in terms of the default perf event (which is "cycles", per the generic recipe for making one of these put out by Brendan Gregg). The actual query runtime for each query was very similar to what I report here -- the backwards scan is a little under twice as fast. The only interesting thing about the flame graph is just how little difference there seems to be (at least for this particular perf event type). The only thing that stands out even a little bit is the 8.33% extra time spent in pg_checksum_page for the "No heap correlation"/random query. But that's entirely to be expected: we're reading 49933 pages with the sequential backwards scan query, whereas the random one must read 77813 pages. -- Peter Geoghegan
Вложения
{kind=link}
On Thu Aug 14, 2025 at 1:57 PM EDT, Peter Geoghegan wrote:
> The only interesting thing about the flame graph is just how little
> difference there seems to be (at least for this particular perf event
> type).
I captured method_io_uring.c DEBUG output from running each query in the
server log, in the hope that it would shed some light on what's really going
on here. I think that it just might.
I count a total of 12,401 distinct sleeps for the sequential/slow backwards
scan test case:
$ grep -E "wait_one with [1-9][0-9]* sleeps" sequential.txt | head
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
$ grep -E "wait_one with [1-9][0-9]* sleeps" sequential.txt | awk '{ total += $11 } END { print total }'
12401
But there are only 3 such sleeps seen when the random backwards scan query is
run -- which might begin to explain the mystery of why it runs so much faster:
$ grep -E "wait_one with [1-9][0-9]* sleeps" random.txt | awk '{ total += $11 } END { print total }'
104
--
Peter Geoghegan
Hi,
On 2025-08-14 14:44:44 -0400, Peter Geoghegan wrote:
> On Thu Aug 14, 2025 at 1:57 PM EDT, Peter Geoghegan wrote:
> > The only interesting thing about the flame graph is just how little
> > difference there seems to be (at least for this particular perf event
> > type).
>
> I captured method_io_uring.c DEBUG output from running each query in the
> server log, in the hope that it would shed some light on what's really going
> on here. I think that it just might.
>
> I count a total of 12,401 distinct sleeps for the sequential/slow backwards
> scan test case:
>
> $ grep -E "wait_one with [1-9][0-9]* sleeps" sequential.txt | head
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: wait_one with 1 sleeps
> $ grep -E "wait_one with [1-9][0-9]* sleeps" sequential.txt | awk '{ total += $11 } END { print total }'
> 12401
>
> But there are only 3 such sleeps seen when the random backwards scan query is
> run -- which might begin to explain the mystery of why it runs so much faster:
>
> $ grep -E "wait_one with [1-9][0-9]* sleeps" random.txt | awk '{ total += $11 } END { print total }'
> 104
I think this is just an indicator of being IO bound. That message is output
whenever we have to wait for IO to finish. So if one workload prints that a
12k times and another 104 times, that's because the latter didn't have to wait
for IO to complete, because it already had completed by the time we needed the
IO to have finished to continue.
Factors potentially leading to slower IO:
- sometimes random IO *can* be faster for SSDs, because it allows different
flash chips to work concurrently, rather than being bound by the speed of
one one flash chip
- it's possible that with your SSD the sequential IO leads to more IO
combining. Larger IOs always have a higher latency than smaller IOs - but
obviously fewer IOs are needed. The increased latency may be bad enough for
your access pattern to trigger more waits.
It's *not* necessarily enough to just lower io_combine_limit, the OS also
can do combining.
I'd see what changes if you temporarily reduce
/sys/block/nvme6n1/queue/max_sectors_kb to a smaller size.
Could you show iostat for both cases?
Greetings,
Andres Freund
On Thu, Aug 14, 2025 at 2:53 PM Andres Freund <andres@anarazel.de> wrote: > I think this is just an indicator of being IO bound. Then why does the exact same pair of runs show "I/O Timings: shared read=194.629" for the sequential table backwards scan (with total execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" (with total execution time 697.681 ms) for the random table backwards scan? Obviously it is hard to believe that the query with shared read=194.629 is one that is naturally much more I/O bound than another similar query that shows shared read=352.88. What "I/O Timings" shows more or less makes sense to me already -- it just doesn't begin to explain why *overall query execution* is much slower when scanning backwards sequentially. > I'd see what changes if you temporarily reduce > /sys/block/nvme6n1/queue/max_sectors_kb to a smaller size. I reduced max_sectors_kb from 128 to 8. That had no significant effect. > Could you show iostat for both cases? iostat has lots of options. Can you be more specific? -- Peter Geoghegan
On Thu Aug 14, 2025 at 3:15 PM EDT, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 2:53 PM Andres Freund <andres@anarazel.de> wrote: >> I think this is just an indicator of being IO bound. > > Then why does the exact same pair of runs show "I/O Timings: shared > read=194.629" for the sequential table backwards scan (with total > execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" > (with total execution time 697.681 ms) for the random table backwards > scan? Is there any particular significance to the invalid op reports I also see in the same log files? $ cat sequential.txt | grep invalid | head 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 2, ref_gen: 1, cycle 1 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 3, ref_gen: 2, cycle 1 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 4, ref_gen: 3, cycle 1 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 5, ref_gen: 4, cycle 1 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 6, ref_gen: 5, cycle 1 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 7, ref_gen: 6, cycle 1 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 8, ref_gen: 7, cycle 1 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 9, ref_gen: 8, cycle 1 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 10, ref_gen: 9, cycle 1 2025-08-14 14:35:03.279 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 11, ref_gen: 10, cycle 1 $ cat sequential.txt | grep invalid | wc -l 5733 $ cat random.txt | grep invalid | wc -l 2206 -- Peter Geoghegan
Hi, On 2025-08-14 15:30:16 -0400, Peter Geoghegan wrote: > On Thu Aug 14, 2025 at 3:15 PM EDT, Peter Geoghegan wrote: > > On Thu, Aug 14, 2025 at 2:53 PM Andres Freund <andres@anarazel.de> wrote: > >> I think this is just an indicator of being IO bound. > > > > Then why does the exact same pair of runs show "I/O Timings: shared > > read=194.629" for the sequential table backwards scan (with total > > execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" > > (with total execution time 697.681 ms) for the random table backwards > > scan? > > Is there any particular significance to the invalid op reports I also see in > the same log files? > $ cat sequential.txt | grep invalid | head > 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 2, ref_gen: 1, cycle 1 > 2025-08-14 14:35:03.278 EDT [2516983][client backend] [[unknown]][0/1:0] DEBUG: 00000: io 0 |op invalid|targetinvalid|state IDLE : wait_one io_gen: 3, ref_gen: 2, cycle 1 No - that's likely just that the IO completed and thus the handle was made reusable (i.e. state IDLE). Note that the generation of IO we're waiting for (ref_gen) is lower than the IO handle's (io_gen). Greetings, Andres Freund
Hi, On 2025-08-14 15:15:02 -0400, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 2:53 PM Andres Freund <andres@anarazel.de> wrote: > > I think this is just an indicator of being IO bound. > > Then why does the exact same pair of runs show "I/O Timings: shared > read=194.629" for the sequential table backwards scan (with total > execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" > (with total execution time 697.681 ms) for the random table backwards > scan? > > Obviously it is hard to believe that the query with shared > read=194.629 is one that is naturally much more I/O bound than another > similar query that shows shared read=352.88. What "I/O Timings" shows > more or less makes sense to me already -- it just doesn't begin to > explain why *overall query execution* is much slower when scanning > backwards sequentially. Hm, that is somewhat curious. I wonder if there's some wait time that's not being captured by "I/O Timings". A first thing to do would be to just run strace --summary-only while running the query, and see if there are syscall wait times that seem too long. What effective_io_concurrency and io_max_concurrency setting are you using? If there are no free IO handles that's currently not nicely reported (because it's unclear how exactly to do so, see comment above pgaio_io_acquire_nb()). > > Could you show iostat for both cases? > > iostat has lots of options. Can you be more specific? iostat -xmy /path/to/block/device I'd like to see the difference in average IO size (rareq-sz), queue depth (aqu-sz) and completion time (r_await) between the fast and slow cases. Greetings, Andres Freund
On Thu, Aug 14, 2025 at 3:15 PM Peter Geoghegan <pg@bowt.ie> wrote: > Then why does the exact same pair of runs show "I/O Timings: shared > read=194.629" for the sequential table backwards scan (with total > execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" > (with total execution time 697.681 ms) for the random table backwards > scan? If you're interested in trying this out for yourself, I've pushed my working branch here: https://github.com/petergeoghegan/postgres/tree/index-prefetch-batch-v1.2 Note that the test case you'll run is added by the most recent commit: https://github.com/petergeoghegan/postgres/commit/c9ceb765f3b138f53b7f1fdf494ba7c816082aa1 Run microbenchmarks/random_backwards_weird.sql to do an initial load of both of the tables. Then run microbenchmarks/queries_random_backwards_weird.sql to actually run the relevant queries. There are 4 such queries, but only the 2 backwards scan queries really seem relevant. -- Peter Geoghegan
On Thu Aug 14, 2025 at 3:41 PM EDT, Andres Freund wrote:
> Hm, that is somewhat curious.
>
> I wonder if there's some wait time that's not being captured by "I/O
> Timings". A first thing to do would be to just run strace --summary-only while
> running the query, and see if there are syscall wait times that seem too long.
For the slow, sequential backwards scan query:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.271216 4 66808 io_uring_enter
0.00 0.000004 4 1 sendto
0.00 0.000001 0 2 1 recvfrom
0.00 0.000000 0 5 lseek
0.00 0.000000 0 1 epoll_wait
0.00 0.000000 0 4 openat
------ ----------- ----------- --------- --------- ----------------
100.00 0.271221 4 66821 1 total
For the fast, random backwards scan query:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
99.99 0.351518 4 77819 io_uring_enter
0.00 0.000007 2 3 1 epoll_wait
0.00 0.000006 6 1 sendto
0.00 0.000003 1 3 2 recvfrom
0.00 0.000002 2 1 read
0.00 0.000002 2 1 1 rt_sigreturn
0.00 0.000002 2 1 getpid
0.00 0.000002 1 2 kill
0.00 0.000000 0 3 lseek
------ ----------- ----------- --------- --------- ----------------
100.00 0.351542 4 77834 4 total
> What effective_io_concurrency and io_max_concurrency setting are you using? If
> there are no free IO handles that's currently not nicely reported (because
> it's unclear how exactly to do so, see comment above pgaio_io_acquire_nb()).
effective_io_concurrency is 100. io_max_concurrency is 64. Nothing out of
the ordinary there.
> iostat -xmy /path/to/block/device
>
> I'd like to see the difference in average IO size (rareq-sz), queue depth
> (aqu-sz) and completion time (r_await) between the fast and slow cases.
I'll show one second interval output.
Slow, sequential backwards scan query
-------------------------------------
Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz
d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
nvme0n1 24613.00 192.29 0.00 0.00 0.20 8.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 4.92 53.20
avg-cpu: %user %nice %system %iowait %steal %idle
0.22 0.00 0.44 0.85 0.00 98.50
Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz
d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
nvme0n1 25320.00 197.81 0.00 0.00 0.20 8.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 5.18 51.20
Fast, random backwards scan query
---------------------------------
Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz
d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
nvme0n1 27140.59 212.04 0.00 0.00 0.20 8.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 5.50 23.37
avg-cpu: %user %nice %system %iowait %steal %idle
0.50 0.00 0.84 0.00 0.00 98.66
Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz
d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
nvme0n1 50401.00 393.76 0.00 0.00 0.20 8.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10.06 41.60
--
Peter Geoghegan
Hi, On 2025-08-14 15:45:26 -0400, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 3:15 PM Peter Geoghegan <pg@bowt.ie> wrote: > > Then why does the exact same pair of runs show "I/O Timings: shared > > read=194.629" for the sequential table backwards scan (with total > > execution time 1132.360 ms), versus "I/O Timings: shared read=352.88" > > (with total execution time 697.681 ms) for the random table backwards > > scan? > > If you're interested in trying this out for yourself, I've pushed my > working branch here: > > https://github.com/petergeoghegan/postgres/tree/index-prefetch-batch-v1.2 > > Note that the test case you'll run is added by the most recent commit: > > https://github.com/petergeoghegan/postgres/commit/c9ceb765f3b138f53b7f1fdf494ba7c816082aa1 > > Run microbenchmarks/random_backwards_weird.sql to do an initial load > of both of the tables. Then run > microbenchmarks/queries_random_backwards_weird.sql to actually run the > relevant queries. There are 4 such queries, but only the 2 backwards > scan queries really seem relevant. Interesting. In the sequential case I see some waits that are not attributed in explain, due to the waits happening within WaitIO(), not WaitReadBuffers(). Which indicates that the read stream is trying to re-read a buffer that previously started being read. read_stream_start_pending_read() -> StartReadBuffers() -> AsyncReadBuffers() -> ReadBuffersCanStartIO() -> StartBufferIO() -> WaitIO() There are far fewer cases of this in the random case. From what I can tell the sequential case so often will re-read a buffer that it is already in the process of reading - and thus wait for that IO before continuing - that we don't actually keep enough IO in flight. In your email with iostat output you can see that the slow case has aqu-sz=5.18, while the fast case has aqu-sz=10.06, i.e. the fast case has twice as much IO in flight. While both have IOs take the same amount of time (r_await=0.20). Which certainly explains the performance difference... We can optimize that by deferring the StartBufferIO() if we're encountering a buffer that is undergoing IO, at the cost of some complexity. I'm not sure real-world queries will often encounter the pattern of the same block being read in by a read stream multiple times in close proximity sufficiently often to make that worth it. Greetings, Andres Freund
On Thu, Aug 14, 2025 at 4:44 PM Andres Freund <andres@anarazel.de> wrote: > Interesting. In the sequential case I see some waits that are not attributed > in explain, due to the waits happening within WaitIO(), not WaitReadBuffers(). > Which indicates that the read stream is trying to re-read a buffer that > previously started being read. I *knew* that something had to be up here. Thanks for your help with debugging! > read_stream_start_pending_read() > -> StartReadBuffers() > -> AsyncReadBuffers() > -> ReadBuffersCanStartIO() > -> StartBufferIO() > -> WaitIO() > > There are far fewer cases of this in the random case. Index tuples with TIDs that are slightly out of order are very normal. Even for *perfectly* sequential inserts, the FSM tends to use the last piece of free space on a heap page some time after the heap page initially becomes "almost full". I recently described this to Tomas on this thread [1]. > From what I can tell the sequential case so often will re-read a buffer that > it is already in the process of reading - and thus wait for that IO before > continuing - that we don't actually keep enough IO in flight. Oops. There is an existing stop-gap mechanism in the patch that is supposed to deal with this problem. index_scan_stream_read_next, which is the read stream callback, has logic that is supposed to suppress duplicate block requests. But that's obviously not totally effective, since it only remembers the very last heap block request. If this same mechanism remembered (say) the last 2 heap blocks it requested, that might be enough to totally fix this particular problem. This isn't a serious proposal, but it'll be simple enough to implement. Hopefully when I do that (which I plan to soon) it'll fully validate your theory. > We can optimize that by deferring the StartBufferIO() if we're encountering a > buffer that is undergoing IO, at the cost of some complexity. I'm not sure > real-world queries will often encounter the pattern of the same block being > read in by a read stream multiple times in close proximity sufficiently often > to make that worth it. We definitely need to be prepared for duplicate prefetch requests in the context of index scans. I'm far from sure how sophisticated that actually needs to be. Obviously the design choices in this area are far from settled right now. [1] DC1G2PKUO9CI.3MK1L3YBZ2V3T@bowt.ie -- Peter Geoghegan
On Thu, Aug 14, 2025 at 5:06 PM Peter Geoghegan <pg@bowt.ie> wrote: > If this same mechanism remembered (say) the last 2 heap blocks it > requested, that might be enough to totally fix this particular > problem. This isn't a serious proposal, but it'll be simple enough to > implement. Hopefully when I do that (which I plan to soon) it'll fully > validate your theory. I spoke too soon. It isn't going to be so easy, since heapam_index_fetch_tuple wants to consume buffers as a simple stream. There's no way that index_scan_stream_read_next can just suppress duplicate block number requests (in a way that's more sophisticated than the current trivial approach that stores the very last block number in IndexScanBatchState.lastBlock) without it breaking the whole concept of a stream of buffers. > > We can optimize that by deferring the StartBufferIO() if we're encountering a > > buffer that is undergoing IO, at the cost of some complexity. I'm not sure > > real-world queries will often encounter the pattern of the same block being > > read in by a read stream multiple times in close proximity sufficiently often > > to make that worth it. > > We definitely need to be prepared for duplicate prefetch requests in > the context of index scans. Can you (or anybody else) think of a quick and dirty way of working around the problem on the read stream side? I would like to prioritize getting the patch into a state where its overall performance profile "feels right". From there we can iterate on fixing the underlying issues in more principled ways. FWIW it wouldn't be that hard to require the callback (in our case index_scan_stream_read_next) to explicitly point out that it knows that the block number it's requesting has to be a duplicate. It might make sense to at least place that much of the burden on the callback/client side. -- Peter Geoghegan
On 8/14/25 01:19, Andres Freund wrote: > Hi, > > On 2025-08-14 01:11:07 +0200, Tomas Vondra wrote: >> On 8/13/25 23:57, Peter Geoghegan wrote: >>> On Wed, Aug 13, 2025 at 5:19 PM Tomas Vondra <tomas@vondra.me> wrote: >>>> It's also not very surprising this happens with backwards scans more. >>>> The I/O is apparently much slower (due to missing OS prefetch), so we're >>>> much more likely to hit the I/O limits (max_ios and various other limits >>>> in read_stream_start_pending_read). >>> >>> But there's no OS prefetch with direct I/O. At most, there might be >>> some kind of readahead implemented in the SSD's firmware. >>> >> >> Good point, I keep forgetting direct I/O means no OS read-ahead. Not >> sure if there's a good way to determine if the SSD can do something like >> that (and how well). I wonder if there's a way to do backward sequential >> scans in fio .. > > In theory, yes, in practice, not quite: > https://github.com/axboe/fio/issues/1963 > > So right now it only works if you skip over some blocks. For that there rather > significant performance differences on my SSDs. E.g. > > andres@awork3:~/src/fio$ fio --directory /srv/fio --size=$((1024*1024*1024)) --name test --bs=4k --rw read:8k --buffered0 2>&1|grep READ > READ: bw=179MiB/s (188MB/s), 179MiB/s-179MiB/s (188MB/s-188MB/s), io=341MiB (358MB), run=1907-1907msec > andres@awork3:~/src/fio$ fio --directory /srv/fio --size=$((1024*1024*1024)) --name test --bs=4k --rw read:-8k --buffered0 2>&1|grep READ > READ: bw=70.6MiB/s (74.0MB/s), 70.6MiB/s-70.6MiB/s (74.0MB/s-74.0MB/s), io=1024MiB (1074MB), run=14513-14513msec > > So on this WD Red SN700 there's a rather substantial performance difference. > > On a Samsung 970 PRO I don't see much of a difference. Nor on a ADATA > SX8200PNP. > I experimented with this a little bit today. Given the fio issues, I ended up writing a simple tool in C, doing pread() forward/backward with different block size and direct I/O. AFAICS this is roughly equivalent to fio with iodepth=1 (based on a couple tests). Too bad fio has issues with backward sequential tests ... I'll see if I can get at least some results to validate my results. On all my SSDs there's massive difference between forward and backward sequential scans. It depends on the block size, but for the smaller block sizes (1-16KB) it's roughly 4x slower. It gets better for larger blocks, but while that's interesting, we're stuck with 8K blocks. FWIW I'm not claiming this explains all odd things we're investigating in this thread, it's more a confirmation that the scan direction may matter if it translates to direction at the device level. I don't think it can explain the strange stuff with the "random" data sets constructed Peter. regards -- Tomas Vondra
Вложения
On Thu, Aug 14, 2025 at 6:24 PM Tomas Vondra <tomas@vondra.me> wrote: > FWIW I'm not claiming this explains all odd things we're investigating > in this thread, it's more a confirmation that the scan direction may > matter if it translates to direction at the device level. I don't think > it can explain the strange stuff with the "random" data sets constructed > Peter. The weird performance characteristics of that one backwards scan are now believed to be due to the WaitIO issue that Andres described about an hour ago. That issue seems unlikely to only affect backwards scans/reverse-sequential heap I/O. I accept that backwards scans are likely to be significantly slower than forwards scans on most/all SSDs. But that in itself doesn't explain why the same issue didn't cause the equivalent sequential forward scan to also be a lot slower. Actually, it probably *did* cause that forwards scan to be *somewhat* slower -- just not by enough to immediately jump out at me (not enough to make the forwards scan much slower than a scan that does wholly random I/O, which is obviously absurd). My guess is that once we fix the underlying problem, we'll see improved performance for many different types of queries. Not as big of a benefit as the one that the broken query will get, but still enough to matter. -- Peter Geoghegan
On 8/14/25 23:55, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 5:06 PM Peter Geoghegan <pg@bowt.ie> wrote: >> If this same mechanism remembered (say) the last 2 heap blocks it >> requested, that might be enough to totally fix this particular >> problem. This isn't a serious proposal, but it'll be simple enough to >> implement. Hopefully when I do that (which I plan to soon) it'll fully >> validate your theory. > > I spoke too soon. It isn't going to be so easy, since > heapam_index_fetch_tuple wants to consume buffers as a simple stream. > There's no way that index_scan_stream_read_next can just suppress > duplicate block number requests (in a way that's more sophisticated > than the current trivial approach that stores the very last block > number in IndexScanBatchState.lastBlock) without it breaking the whole > concept of a stream of buffers. > I believe this idea (checking not just the very last block, but keeping a bit longer history) was briefly discussed a couple months ago, after you pointed out the need for the "last block" optimization (which the patch didn't have). At that point we were focused on addressing a regression with correlated indexes, so the single block was enough. But as you point out, it's harder than it seems. If I recall correctly, the challenge is that heapam_index_fetch_tuple() is expected to release the block when it changes, but then how would it know there's no future read of the same buffer in the stream? >>> We can optimize that by deferring the StartBufferIO() if we're encountering a >>> buffer that is undergoing IO, at the cost of some complexity. I'm not sure >>> real-world queries will often encounter the pattern of the same block being >>> read in by a read stream multiple times in close proximity sufficiently often >>> to make that worth it. >> >> We definitely need to be prepared for duplicate prefetch requests in >> the context of index scans. > > Can you (or anybody else) think of a quick and dirty way of working > around the problem on the read stream side? I would like to prioritize > getting the patch into a state where its overall performance profile > "feels right". From there we can iterate on fixing the underlying > issues in more principled ways. > > FWIW it wouldn't be that hard to require the callback (in our case > index_scan_stream_read_next) to explicitly point out that it knows > that the block number it's requesting has to be a duplicate. It might > make sense to at least place that much of the burden on the > callback/client side. > I don't recall all the details, but IIRC my impression was it'd be best to do this "caching" entirely in the read_stream.c (so the next_block callbacks would probably not need to worry about lastBlock at all), enabled when creating the stream. And then there would be something like read_stream_release_buffer() that'd do the right to release the buffer when it's not needed. regards -- Tomas Vondra
On 8/15/25 01:05, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 6:24 PM Tomas Vondra <tomas@vondra.me> wrote: >> FWIW I'm not claiming this explains all odd things we're investigating >> in this thread, it's more a confirmation that the scan direction may >> matter if it translates to direction at the device level. I don't think >> it can explain the strange stuff with the "random" data sets constructed >> Peter. > > The weird performance characteristics of that one backwards scan are > now believed to be due to the WaitIO issue that Andres described about > an hour ago. That issue seems unlikely to only affect backwards > scans/reverse-sequential heap I/O. > Good. I admit I lost track of which the various regressions may affect existing plans, and which are specific to the prefetch patch. > I accept that backwards scans are likely to be significantly slower > than forwards scans on most/all SSDs. But that in itself doesn't > explain why the same issue didn't cause the equivalent sequential > forward scan to also be a lot slower. Actually, it probably *did* > cause that forwards scan to be *somewhat* slower -- just not by enough > to immediately jump out at me (not enough to make the forwards scan > much slower than a scan that does wholly random I/O, which is > obviously absurd). > True. That's weird. > My guess is that once we fix the underlying problem, we'll see > improved performance for many different types of queries. Not as big > of a benefit as the one that the broken query will get, but still > enough to matter. > Hopefully. Let's see. regards -- Tomas Vondra
Hi, On 2025-08-14 17:55:53 -0400, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 5:06 PM Peter Geoghegan <pg@bowt.ie> wrote: > > > We can optimize that by deferring the StartBufferIO() if we're encountering a > > > buffer that is undergoing IO, at the cost of some complexity. I'm not sure > > > real-world queries will often encounter the pattern of the same block being > > > read in by a read stream multiple times in close proximity sufficiently often > > > to make that worth it. > > > > We definitely need to be prepared for duplicate prefetch requests in > > the context of index scans. > > Can you (or anybody else) think of a quick and dirty way of working > around the problem on the read stream side? I would like to prioritize > getting the patch into a state where its overall performance profile > "feels right". From there we can iterate on fixing the underlying > issues in more principled ways. I think I can see a way to fix the issue, below read stream. Basically, whenever AsyncReadBuffers() finds a buffer that has ongoing IO, instead of waiting, as we do today, copy the wref to the ReadBuffersOperation() and set a new flag indicating that we are waiting for an IO that was not started by the wref. Then, in WaitReadBuffers(), we wait for such foreign started IOs. That has to be somewhat different code from today, because we have to deal with the fact of the "foreign" IO potentially having failed. I'll try writing a prototype for that tomorrow. I think to actually get that into a committable shape we need a test harness (probably a read stream controlled by an SQL function that gets an array of buffers). > FWIW it wouldn't be that hard to require the callback (in our case > index_scan_stream_read_next) to explicitly point out that it knows > that the block number it's requesting has to be a duplicate. It might > make sense to at least place that much of the burden on the > callback/client side. The problem actually exists outside of your case. E.g. if you have multiple backends doing a synchronized seqscan on the same relation, performance regresses, because we often end up synchronously waiting for IOs started by another backend. I don't think it has quite as large an effect for that as it has here, because the different scans basically desynchronize whenever it happens due to the synchronous waits slowing down the waiting backend a lot), limiting the impact somewhat. Greetings, Andres Freund
On Fri, Aug 15, 2025 at 11:21 AM Tomas Vondra <tomas@vondra.me> wrote: > I don't recall all the details, but IIRC my impression was it'd be best > to do this "caching" entirely in the read_stream.c (so the next_block > callbacks would probably not need to worry about lastBlock at all), > enabled when creating the stream. And then there would be something like > read_stream_release_buffer() that'd do the right to release the buffer > when it's not needed. I've thought about this problem quite a bit. xlogprefetcher.c was designed to use read_stream.c, as the comment above LsnReadQueue vaguely promises, and I have mostly working patches to finish that job (more soon). The WAL is naturally full of repetition with interleaving patterns, so there are many opportunities to avoid buffer mapping table traffic, pinning, content locking and more. I'm not sure that read_stream.c is necessarily the right place, though. I have experimented with that a bit, using a small window of recently accessed blocks, with various designs. One of my experiments did it further down. I shoved a cache line of blocknum->buffernum mappings into SMgrRelation so you can skip the buffer mapping table and find repeat accesses. I tried FIFO replacement, vectorised CLOCK (!) and some hairbrained things for this nano-buffer map. At various times I had goals including remembering where to find the internal pages in a high frequency repeated btree search (eg inserting with monotonically increasing keys or nested loop with increasing or repeated keys), and, well, lots of other stuff. That was somewhat promising (you can see a variant of that in one of the patches in the ReadRecentBuffer() thread that I will shortly be rehydrating), but I wasn't entirely satisfied because it still had to look up the local pin count, if there is one, so I had plans to investigate a tighter integration with that stuff too. Coming back to the WAL, I want something that can cheaply find the buffer and bump the local pin count (rather than introducing a secondary reference counting scheme in the WAL that I think you might be describing?), and I want it to work even if it's not in the read ahead window because the distance is very low, ie fully cached replay. Anway, that was all about microscopic stuff that I want to do to speed up CPU bound replay with little or no I/O. This stall on repeated access to a block with IO already in progress is a different beast, and I look forward to checking out the patch that Andres just described. By funny coincidence I was just studying that phenomenon and code path last week in the context of my io_method=posix_aio patch. There, completing other processes' IOs is a bit more expensive and I was thinking about ways to give the submitting backend more time to handle it if this backend is only looking ahead and doesn't strictly need the IO to be completed right now to make progress. I was studying competing synchronized_scans, ie other backends' IOs, not repeat access in this backend, but the solution he just described sounds like a way to hit both birds with one stone, and makes a pretty good trade-off: the other guy's IO almost certainly won't fail, and we almost certainly aren't deadlocked, and if that bet is wrong we can deal with it later.
On Fri, Aug 15, 2025 at 1:47 PM Thomas Munro <thomas.munro@gmail.com> wrote: > (rather than introducing a secondary reference > counting scheme in the WAL that I think you might be describing?), and s/WAL/read stream/
On Thu, Aug 14, 2025 at 7:26 PM Tomas Vondra <tomas@vondra.me> wrote: > Good. I admit I lost track of which the various regressions may affect > existing plans, and which are specific to the prefetch patch. As far as I know, we only have the following unambiguous performance regressions (that clearly need to be fixed): 1. This issue. 2. There's about a 3% loss of throughput on pgbench SELECT. This isn't surprising at all; it would be a near-miracle if this kind of prototype quality code didn't at least have a small regression here (it's not like we've even started to worry about small fixed costs for simple selective queries just yet). This will need to be fixed, but it's fairly far down the priority list right now. I feel that we're still very much at the stage where it makes sense to just fix the most prominent performance issue, and then reevaluate. Repeating that process iteratively. It's quite likely that there are more performance issues/bugs that we don't yet know about. IMV it doesn't make sense to closely track individual queries that have only been moderately regressed. -- Peter Geoghegan
Hi,
On 2025-08-14 19:36:49 -0400, Andres Freund wrote:
> On 2025-08-14 17:55:53 -0400, Peter Geoghegan wrote:
> > On Thu, Aug 14, 2025 at 5:06 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > > > We can optimize that by deferring the StartBufferIO() if we're encountering a
> > > > buffer that is undergoing IO, at the cost of some complexity. I'm not sure
> > > > real-world queries will often encounter the pattern of the same block being
> > > > read in by a read stream multiple times in close proximity sufficiently often
> > > > to make that worth it.
> > >
> > > We definitely need to be prepared for duplicate prefetch requests in
> > > the context of index scans.
> >
> > Can you (or anybody else) think of a quick and dirty way of working
> > around the problem on the read stream side? I would like to prioritize
> > getting the patch into a state where its overall performance profile
> > "feels right". From there we can iterate on fixing the underlying
> > issues in more principled ways.
>
> I think I can see a way to fix the issue, below read stream. Basically,
> whenever AsyncReadBuffers() finds a buffer that has ongoing IO, instead of
> waiting, as we do today, copy the wref to the ReadBuffersOperation() and set a
> new flag indicating that we are waiting for an IO that was not started by the
> wref. Then, in WaitReadBuffers(), we wait for such foreign started IOs. That
> has to be somewhat different code from today, because we have to deal with the
> fact of the "foreign" IO potentially having failed.
>
> I'll try writing a prototype for that tomorrow. I think to actually get that
> into a committable shape we need a test harness (probably a read stream
> controlled by an SQL function that gets an array of buffers).
Attached is a prototype of this approach. It does seem to fix this issue.
New code disabled:
#### backwards sequential table ####
┌──────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using t_pk on t (actual rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=10291 read=49933 │
│ I/O Timings: shared read=213.277 │
│ Planning: │
│ Buffers: shared hit=91 read=19 │
│ I/O Timings: shared read=2.124 │
│ Planning Time: 3.269 ms │
│ Execution Time: 1023.279 ms │
└──────────────────────────────────────────────────────────────────────┘
(10 rows)
New code enabled:
#### backwards sequential table ####
┌──────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using t_pk on t (actual rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=10291 read=49933 │
│ I/O Timings: shared read=217.225 │
│ Planning: │
│ Buffers: shared hit=91 read=19 │
│ I/O Timings: shared read=2.009 │
│ Planning Time: 2.685 ms │
│ Execution Time: 602.987 ms │
└──────────────────────────────────────────────────────────────────────┘
(10 rows)
With the change enabled, the sequential query is faster than the random query:
#### backwards random table ####
┌────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────────────────┤
│ Index Scan Backward using t_randomized_pk on t_randomized (actual rows=1048576.00 loops=1) │
│ Index Cond: ((a >= 16336) AND (a <= 49103)) │
│ Index Searches: 1 │
│ Buffers: shared hit=6085 read=77813 │
│ I/O Timings: shared read=347.285 │
│ Planning: │
│ Buffers: shared hit=127 read=5 │
│ I/O Timings: shared read=1.001 │
│ Planning Time: 1.751 ms │
│ Execution Time: 820.544 ms │
└────────────────────────────────────────────────────────────────────────────────────────────┘
(10 rows)
Greetings,
Andres Freund
Вложения
On Thu Aug 14, 2025 at 7:26 PM EDT, Tomas Vondra wrote: >> My guess is that once we fix the underlying problem, we'll see >> improved performance for many different types of queries. Not as big >> of a benefit as the one that the broken query will get, but still >> enough to matter. >> > > Hopefully. Let's see. Good news here: with Andres' bufmgr patch applied, the similar forwards scan query does indeed get more than 2x faster. And I don't mean that it gets faster on the randomized table -- it actually gets 2x faster with your original (almost but not quite entirely sequential) table, and your original query. This is especially good news because that query seems particularly likely to be representative of real world user queries. And so the "backwards scan" aspect of this investigation was always a bit of a red herring. The only reason why "backwards-ness" ever even seemed relevant was that with the backwards scan variant, performance was made so much slower by the issue that Andres' patch addresses than even my randomized version of the same query ran quite a bit faster. More concretely: Without bufmgr patch -------------------- ┌─────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├─────────────────────────────────────────────────────────────┤ │ Index Scan using t_pk on t (actual rows=1048576.00 loops=1) │ │ Index Cond: ((a >= 16336) AND (a <= 49103)) │ │ Index Searches: 1 │ │ Buffers: shared hit=6572 read=49933 │ │ I/O Timings: shared read=77.038 │ │ Planning: │ │ Buffers: shared hit=50 read=6 │ │ I/O Timings: shared read=0.570 │ │ Planning Time: 0.774 ms │ │ Execution Time: 618.585 ms │ └─────────────────────────────────────────────────────────────┘ (10 rows) With bufmgr patch ----------------- ┌─────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├─────────────────────────────────────────────────────────────┤ │ Index Scan using t_pk on t (actual rows=1048576.00 loops=1) │ │ Index Cond: ((a >= 16336) AND (a <= 49103)) │ │ Index Searches: 1 │ │ Buffers: shared hit=10257 read=49933 │ │ I/O Timings: shared read=135.825 │ │ Planning: │ │ Buffers: shared hit=50 read=6 │ │ I/O Timings: shared read=0.570 │ │ Planning Time: 0.767 ms │ │ Execution Time: 279.643 ms │ └─────────────────────────────────────────────────────────────┘ (10 rows) I _think_ that Andres' patch also fixes the EXPLAIN ANALYZE accounting, so that "I/O Timings" is actually correct. That's why EXPLAIN ANALYZE with the bufmgr patch has much higher "shared read" time, despite overall execution time being cut in half. -- Peter Geoghegan
On Fri, Aug 15, 2025 at 12:24 PM Peter Geoghegan <pg@bowt.ie> wrote: > Good news here: with Andres' bufmgr patch applied, the similar forwards scan > query does indeed get more than 2x faster. And I don't mean that it gets > faster on the randomized table -- it actually gets 2x faster with your > original (almost but not quite entirely sequential) table, and your original > query. This is especially good news because that query seems particularly > likely to be representative of real world user queries. BTW, I also think that Andres' patch makes performance a lot more stable. I'm pretty sure that I've noticed that the exact query that I just showed updated results for has at various times run faster (without Andres' patch), due to who-knows-what. FWIW, this development probably completely changes the results of many (all?) of your benchmark queries. My guess is that with Andres' patch, things will be better across the board. But in any case the numbers that you posted before now must now be considered obsolete/nonrepresentative. Since this is such a huge change. -- Peter Geoghegan
Hi, Glad to see that the prototype does fix the issue for you. On 2025-08-15 12:29:25 -0400, Peter Geoghegan wrote: > FWIW, this development probably completely changes the results of many > (all?) of your benchmark queries. My guess is that with Andres' patch, > things will be better across the board. But in any case the numbers > that you posted before now must now be considered > obsolete/nonrepresentative. Since this is such a huge change. I'd hope it doesn't improve all benchmark queries - if so the set of benchmarks would IMO be too skewed towards cases that access the same heap blocks multiple times within the readahead distance. That's definitely an important thing to measure, but it's surely not the only thing to care about. For the index workloads the patch doesn't do anything about cases where we don't up re-encountering a buffer that we already started IO for. Greetings, Andres Freund
Hi, On 2025-08-15 12:24:40 -0400, Peter Geoghegan wrote: > With bufmgr patch > ----------------- > > ┌─────────────────────────────────────────────────────────────┐ > │ QUERY PLAN │ > ├─────────────────────────────────────────────────────────────┤ > │ Index Scan using t_pk on t (actual rows=1048576.00 loops=1) │ > │ Index Cond: ((a >= 16336) AND (a <= 49103)) │ > │ Index Searches: 1 │ > │ Buffers: shared hit=10257 read=49933 │ > │ I/O Timings: shared read=135.825 │ > │ Planning: │ > │ Buffers: shared hit=50 read=6 │ > │ I/O Timings: shared read=0.570 │ > │ Planning Time: 0.767 ms │ > │ Execution Time: 279.643 ms │ > └─────────────────────────────────────────────────────────────┘ > (10 rows) > > I _think_ that Andres' patch also fixes the EXPLAIN ANALYZE accounting, so > that "I/O Timings" is actually correct. That's why EXPLAIN ANALYZE with the > bufmgr patch has much higher "shared read" time, despite overall execution > time being cut in half. Somewhat random note about I/O waits: Unfortunately the I/O wait time we measure often massively *over* estimate the actual I/O time. If I execute the above query with the patch applied, we actually barely ever wait for I/O to complete, it's all completed by the time we have to wait for the I/O. What we are measuring is the CPU cost of *initiating* the I/O. That's why we are seeing "I/O Timings" > 0 even if we do perfect readahead. Most of the cost is in the kernel, primarily looking up block locations and setting up the actual I/O. Greetings, Andres Freund
On Fri, Aug 15, 2025 at 1:09 PM Andres Freund <andres@anarazel.de> wrote: > On 2025-08-15 12:29:25 -0400, Peter Geoghegan wrote: > > FWIW, this development probably completely changes the results of many > > (all?) of your benchmark queries. My guess is that with Andres' patch, > > things will be better across the board. But in any case the numbers > > that you posted before now must now be considered > > obsolete/nonrepresentative. Since this is such a huge change. > > I'd hope it doesn't improve all benchmark queries - if so the set of > benchmarks would IMO be too skewed towards cases that access the same heap > blocks multiple times within the readahead distance. I don't think that that will be a problem. Up until recently, I had exactly the opposite complaint about the benchmark queries. > That's definitely an > important thing to measure, but it's surely not the only thing to care > about. For the index workloads the patch doesn't do anything about cases where > we don't up re-encountering a buffer that we already started IO for. IMV we need to make a conservative assumption that it might matter for any query. There have already been numerous examples where we thought we fully understood a test case, but didn't. BTW, I just rebooted my workstation, losing various procfs changes that I'd made when debugging this issue. It now looks like the forward scan query is actually made about 3x faster by the addition of your patch (not 2x faster, as reported earlier). It goes from 592.618 ms to 204.966 ms. -- Peter Geoghegan
On Fri, Aug 15, 2025 at 1:23 PM Andres Freund <andres@anarazel.de> wrote: > Somewhat random note about I/O waits: > > Unfortunately the I/O wait time we measure often massively *over* estimate the > actual I/O time. If I execute the above query with the patch applied, we > actually barely ever wait for I/O to complete, it's all completed by the time > we have to wait for the I/O. What we are measuring is the CPU cost of > *initiating* the I/O. I do get that. This was really obvious when I temporarily switched the prefetch patch over from using READ_STREAM_DEFAULT to using READ_STREAM_USE_BATCHING (this is probably buggy, but still seems likely to be representative of what's possible with some care). I noticed that that change reduced the reported "shared read" time by 10x -- which had exactly zero impact on query execution time (at least for the queries I looked at). Since, as you say, the backend didn't have to wait for I/O to complete either way. -- Peter Geoghegan
On Thu, Aug 14, 2025 at 10:12 PM Peter Geoghegan <pg@bowt.ie> wrote: > As far as I know, we only have the following unambiguous performance > regressions (that clearly need to be fixed): > > 1. This issue. > > 2. There's about a 3% loss of throughput on pgbench SELECT. I did a quick pgbench SELECT benchmark again with Andres' patch, just to see if that has been impacted. Now the regression there is much larger; it goes from a ~3% regression to a ~14% regression. I'm not worried about it. Andres' "not waiting for already-in-progress IO" patch was clearly just a prototype. Just thought it was worth noting here. -- Peter Geoghegan
Hi, On August 15, 2025 3:25:50 PM EDT, Peter Geoghegan <pg@bowt.ie> wrote: >On Thu, Aug 14, 2025 at 10:12 PM Peter Geoghegan <pg@bowt.ie> wrote: >> As far as I know, we only have the following unambiguous performance >> regressions (that clearly need to be fixed): >> >> 1. This issue. >> >> 2. There's about a 3% loss of throughput on pgbench SELECT. > >I did a quick pgbench SELECT benchmark again with Andres' patch, just >to see if that has been impacted. Now the regression there is much >larger; it goes from a ~3% regression to a ~14% regression. > >I'm not worried about it. Andres' "not waiting for already-in-progress >IO" patch was clearly just a prototype. Just thought it was worth >noting here. Are you confident in that? Because the patch should be extremely cheap in that case. What precisely were you testing? Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Fri, Aug 15, 2025 at 3:28 PM Andres Freund <andres@anarazel.de> wrote: > >I'm not worried about it. Andres' "not waiting for already-in-progress > >IO" patch was clearly just a prototype. Just thought it was worth > >noting here. > > Are you confident in that? Because the patch should be extremely cheap in that case. I'm pretty confident. > What precisely were you testing? I'm just running my usual generic pgbench SELECT script, with my usual settings (so no direct I/O, but with iouring). -- Peter Geoghegan
Hi, On 2025-08-15 15:31:47 -0400, Peter Geoghegan wrote: > On Fri, Aug 15, 2025 at 3:28 PM Andres Freund <andres@anarazel.de> wrote: > > >I'm not worried about it. Andres' "not waiting for already-in-progress > > >IO" patch was clearly just a prototype. Just thought it was worth > > >noting here. > > > > Are you confident in that? Because the patch should be extremely cheap in that case. > > I'm pretty confident. > > > What precisely were you testing? > > I'm just running my usual generic pgbench SELECT script, with my usual > settings (so no direct I/O, but with iouring). I see absolutely no effect of the patch with shared_buffers=1GB and a read-only scale 200 pgbench at 40 clients. What data sizes, shared buffers etc. were you testing? Greetings, Andres Freund
On Fri, Aug 15, 2025 at 3:38 PM Andres Freund <andres@anarazel.de> wrote: > I see absolutely no effect of the patch with shared_buffers=1GB and a > read-only scale 200 pgbench at 40 clients. What data sizes, shared buffers > etc. were you testing? Just to be clear: you are testing with both the index prefetching patch and your patch together, right? Not just your own patch? My shared_buffers is 16GB, with pgbench scale 300. -- Peter Geoghegan
Hi, On 2025-08-15 15:42:10 -0400, Peter Geoghegan wrote: > On Fri, Aug 15, 2025 at 3:38 PM Andres Freund <andres@anarazel.de> wrote: > > I see absolutely no effect of the patch with shared_buffers=1GB and a > > read-only scale 200 pgbench at 40 clients. What data sizes, shared buffers > > etc. were you testing? > > Just to be clear: you are testing with both the index prefetching > patch and your patch together, right? Not just your own patch? Correct. > My shared_buffers is 16GB, with pgbench scale 300. So there's actually no IO, given that a scale 300 is something like 4.7GB? In that case my patch could really not make a difference, neither of the changed branches would ever be reached? Or were you testing the warmup phase, rather than the steady state? Greetings, Andres Freund
On Fri, Aug 15, 2025 at 3:45 PM Andres Freund <andres@anarazel.de> wrote: > > My shared_buffers is 16GB, with pgbench scale 300. > > So there's actually no IO, given that a scale 300 is something like 4.7GB? In > that case my patch could really not make a difference, neither of the changed > branches would ever be reached? This was an error on my part -- sorry. I think that the problem was that I forgot that I temporarily increased effective_io_concurrency from 100 to 1,000 while debugging this issue. Apparently that disproportionately affected the patched server. Could also have been an issue with a recent change of mine. -- Peter Geoghegan
On Thu, Aug 14, 2025 at 10:12 PM Peter Geoghegan <pg@bowt.ie> wrote: > As far as I know, we only have the following unambiguous performance > regressions (that clearly need to be fixed): > > 1. This issue. > > 2. There's about a 3% loss of throughput on pgbench SELECT. Update: I managed to fix the performance regression with pgbench SELECT (regression 2). Since Andres' patch fixes the other regression (regression 1), we no longer have any known performance regression (though I don't doubt that they still exist somewhere). I've also added back the enable_indexscan_prefetch testing GUC (Andres asked me to do that a few weeks back). If you set enable_indexscan_prefetch=false, btgetbatch performance is virtually identical to master/btgettuple. A working copy of the patchset with these revisions is available from: https://github.com/petergeoghegan/postgres/tree/index-prefetch-batch-v1.6 The solution to the pgbench issue was surprisingly straightforward. Profiling showed that the regression was caused by the added overhead of using the read stream, for queries where prefetching cannot possibly help -- such small startup costs are relatively noticeable with pgbench's highly selective scans. It turns out that it's possible to initially avoid using a read stream, while still retaining the option of switching over to using a read stream later on. The trick to fixing the pgbench issue was delaying creating a read stream for long enough for the pgbench queries to never need to create one, without that impacting queries that at least have some chance of benefiting from prefetching. The actual heuristic I'm using to decide when to start the read stream is simple: only start a read stream right after the scan's second batch is returned by amgetbatch, but before we've fetched any heap blocks related to that second batch (start using a read stream when fetching new heap blocks from that second batch). It's possible that that heuristic isn't sophisticated enough for other types of queries. But either way the basic structure within indexam.c places no restrictions on when we start a read stream. It doesn't have to be aligned with amgetbatch-wise batch boundaries, for example (I just found that structure convenient). I haven't spent much time testing this change, but it appears to work perfectly (no pgbench regressions, but also no regressions in queries that were already seeing significant benefits from prefetching). I'd feel better about all this if we had better testing of the read stream invariants by (say) adding assertions to index_scan_stream_read_next, the read stream callback. And just having comments that explain those invariants. -- Peter Geoghegan
On 8/17/25 19:30, Peter Geoghegan wrote: > On Thu, Aug 14, 2025 at 10:12 PM Peter Geoghegan <pg@bowt.ie> wrote: >> As far as I know, we only have the following unambiguous performance >> regressions (that clearly need to be fixed): >> >> 1. This issue. >> >> 2. There's about a 3% loss of throughput on pgbench SELECT. > > Update: I managed to fix the performance regression with pgbench > SELECT (regression 2). Since Andres' patch fixes the other regression > (regression 1), we no longer have any known performance regression > (though I don't doubt that they still exist somewhere). I've also > added back the enable_indexscan_prefetch testing GUC (Andres asked me > to do that a few weeks back). If you set > enable_indexscan_prefetch=false, btgetbatch performance is virtually > identical to master/btgettuple. > > A working copy of the patchset with these revisions is available from: > https://github.com/petergeoghegan/postgres/tree/index-prefetch-batch-v1.6 > > The solution to the pgbench issue was surprisingly straightforward. > Profiling showed that the regression was caused by the added overhead > of using the read stream, for queries where prefetching cannot > possibly help -- such small startup costs are relatively noticeable > with pgbench's highly selective scans. It turns out that it's possible > to initially avoid using a read stream, while still retaining the > option of switching over to using a read stream later on. The trick to > fixing the pgbench issue was delaying creating a read stream for long > enough for the pgbench queries to never need to create one, without > that impacting queries that at least have some chance of benefiting > from prefetching. > > The actual heuristic I'm using to decide when to start the read stream > is simple: only start a read stream right after the scan's second > batch is returned by amgetbatch, but before we've fetched any heap > blocks related to that second batch (start using a read stream when > fetching new heap blocks from that second batch). It's possible that > that heuristic isn't sophisticated enough for other types of queries. > But either way the basic structure within indexam.c places no > restrictions on when we start a read stream. It doesn't have to be > aligned with amgetbatch-wise batch boundaries, for example (I just > found that structure convenient). > > I haven't spent much time testing this change, but it appears to work > perfectly (no pgbench regressions, but also no regressions in queries > that were already seeing significant benefits from prefetching). I'd > feel better about all this if we had better testing of the read stream > invariants by (say) adding assertions to index_scan_stream_read_next, > the read stream callback. And just having comments that explain those > invariants. > Thanks for investigating this. I think it's the right direction - simple OLTP queries should not be paying for building read_stream when there's little chance of benefit. Unfortunately, this seems to be causing regressions, both compared to master (or disabled prefetching), and to the earlier prefetch patches. I kept running the query generator [1] that builds data sets with randomized parameters, and then runs index scan queries on that, looking for differences between branches. Consider this data set: ------------------------------------------------------------------------ create unlogged table t (a bigint, b text) with (fillfactor = 20); insert into t select 1 * a, b from (select r, a, b, generate_series(0,1-1) AS p from (select row_number() over () AS r, a, b from (select i AS a, md5(i::text) AS b from generate_series(1, 10000000) s(i) ORDER BY (i + 256 * (random() - 0.5))) foo) bar) baz ORDER BY ((r * 1 + p) + 128 * (random() - 0.5)); create index idx on t(a ASC); vacuum freeze t; analyze t; ------------------------------------------------------------------------ Let's run this query (all runs are with cold caches): EXPLAIN (ANALYZE, COSTS OFF) SELECT * FROM t WHERE a BETWEEN 5085 AND 3053660 ORDER BY a ASC; 1) current patch ================ QUERY PLAN ----------------------------------------------------------------------- Index Scan using idx on t (actual time=0.517..6593.821 rows=3048576.00 loops=1) Index Cond: ((a >= 5085) AND (a <= 3053660)) Index Searches: 1 Prefetch Distance: 2.066 Prefetch Count: 296179 Prefetch Stalls: 2553745 Prefetch Skips: 198613 Prefetch Resets: 0 Stream Ungets: 0 Stream Forwarded: 74 Prefetch Histogram: [2,4) => 289560, [4,8) => 6604, [8,16) => 15 Buffers: shared hit=2704779 read=153516 Planning: Buffers: shared hit=78 read=27 Planning Time: 5.525 ms Execution Time: 6721.599 ms (16 rows) 2) removed priorbatch (always uses read stream) =============================================== QUERY PLAN ----------------------------------------------------------------------- Index Scan using idx on t (actual time=1.008..1932.379 rows=3048576.00 loops=1) Index Cond: ((a >= 5085) AND (a <= 3053660)) Index Searches: 1 Prefetch Distance: 87.970 Prefetch Count: 2877141 Prefetch Stalls: 1 Prefetch Skips: 198617 Prefetch Resets: 0 Stream Ungets: 27182 Stream Forwarded: 7640 Prefetch Histogram: [2,4) => 2, [4,8) => 6, [8,16) => 7, [16,32) => 10, [32,64) => 8183, [64,128) => 2868933 Buffers: shared hit=2704571 read=153516 Planning: Buffers: shared hit=78 read=27 Planning Time: 14.302 ms Execution Time: 2036.654 ms (16 rows) 3) no prefetch (same as master) =============================== set enable_indexscan_prefetch = off; QUERY PLAN ----------------------------------------------------------------------- Index Scan using idx on t (actual time=0.850..1336.723 rows=3048576.00 loops=1) Index Cond: ((a >= 5085) AND (a <= 3053660)) Index Searches: 1 Buffers: shared hit=2704779 read=153516 Planning: Buffers: shared hit=82 read=22 Planning Time: 10.696 ms Execution Time: 1433.530 ms (8 rows) The main difference in the explains is this: Prefetch Distance: 2.066 (new patch) Prefetch Distance: 87.970 (old patch, without priorbatch) The histogram just confirms this, with most prefetches either in [2,4) or [64,128) bins. The new patch has much lower prefetch distance. I believe this is the same issue with "collapsed" distance after resetting the read_stream. In that case the trouble was the reset also set distance to 1, and there were so many "hits" due to buffers read earlier it never ramped up again (we doubled it every now and then, but the decay was faster). The same thing happens here, I think. We process the first batch without using a read stream. Then after reading the second batch we create the read_stream, but it starts with distance=1 - it's just like after reset. And it never ramps up the distance, because of the hits from reading the preceding batch. For the resets, the solution (at least for now) was to remember the distance and restore it after reset. But here we don't have any distance to restore - there's no prefetch or read stream. Maybe it'd be possible to track some stats, during the initial phase, and then use that to initialize the distance for the first batch processed by read stream? Seems rather inconvenient, though. What exactly is the overhead of creating the read_stream? Is that about allocating memory, or something else? Would it be possible to reduce the overhead enough to not matter even for OLTP queries? Maybe it would be possible to initialize the read_stream only "partially", enough to do do sync I/O and track the distance, and delay only the expensive stuff? I'm also not sure it's optimal to only initialize read_stream after reading the next batch. For some indexes a batch can have hundreds of items, and that certainly could benefit from prefetching. I suppose it should be possible to initialize the read_stream half-way though a batch, right? Or is there a reason why that can't work? regards [1] https://github.com/tvondra/postgres/tree/index-prefetch-master/query-stress-test -- Tomas Vondra
On Tue, Aug 19, 2025 at 1:23 PM Tomas Vondra <tomas@vondra.me> wrote: > Thanks for investigating this. I think it's the right direction - simple > OLTP queries should not be paying for building read_stream when there's > little chance of benefit. > > Unfortunately, this seems to be causing regressions, both compared to > master (or disabled prefetching), and to the earlier prefetch patches. > The main difference in the explains is this: > > Prefetch Distance: 2.066 (new patch) > > Prefetch Distance: 87.970 (old patch, without priorbatch) > > The histogram just confirms this, with most prefetches either in [2,4) > or [64,128) bins. The new patch has much lower prefetch distance. That definitely seems like a problem. I think that you're saying that this problem happens because we have extra buffer hits earlier on, which is enough to completely change the ramp-up behavior. This seems to be all it takes to dramatically decrease the effectiveness of prefetching. Does that summary sound correct? > I believe this is the same issue with "collapsed" distance after > resetting the read_stream. In that case the trouble was the reset also > set distance to 1, and there were so many "hits" due to buffers read > earlier it never ramped up again (we doubled it every now and then, but > the decay was faster). If my summary of what you said is accurate, then to me the obvious question is: isn't this also going to be a problem *without* the new "delay starting read stream" behavior? Couldn't you break the "removed priorbatch" case in about the same way using a slightly different test case? Say a test case involving concurrent query execution? More concretely: what about similar cases where some *other* much more selective query runs around the same time as the nonselective regressed query? What if this other selective query reads the same group of heap pages into shared_buffers that our nonselective query will also need to visit (before visiting all the other heap pages not yet in shared_buffers, that we want to prefetch)? Won't this other scenario also confuse the read stream ramp-up heuristics, in a similar way? It seems bad that the initial conditions that the read stream sees can have such lasting consequences. It feels as if the read stream is chasing its own tail. I wonder if this is related to the fact that we're using the read stream in a way that it wasn't initially optimized for. After all, we're the first caller that doesn't just do sequential access all the time -- we're bound to have novel problems with the read stream for that reason alone. > The same thing happens here, I think. We process the first batch without > using a read stream. Then after reading the second batch we create the > read_stream, but it starts with distance=1 - it's just like after reset. > And it never ramps up the distance, because of the hits from reading the > preceding batch. > Maybe it'd be possible to track some stats, during the initial phase, > and then use that to initialize the distance for the first batch > processed by read stream? Seems rather inconvenient, though. But why should the stats from the first leaf page read be particularly important? It's just one page out of the thousands that are ultimately read. Unless I've misunderstood you, the real problem seems to be that the read stream effectively gets fixated on a few early buffer hits. It sounds like it is getting stuck in a local minima, or something like that. > What exactly is the overhead of creating the read_stream? Is that about > allocating memory, or something else? It's hard to be precise here, because we're only talking about a 3% regression with pgbench. A lot of that regression probably related to memory allocation overhead. I also remember get_tablespace() being visible in profiles (it is called from get_tablespace_maintenance_io_concurrency, which is itself called from read_stream_begin_impl). It's probably a lot of tiny things, that all add up to a small (though still unacceptable) regression. > Would it be possible to reduce the > overhead enough to not matter even for OLTP queries? > Maybe it would be > possible to initialize the read_stream only "partially", enough to do do > sync I/O and track the distance, and delay only the expensive stuff? Maybe, but I think that this is something to consider only after other approaches to fixing the problem fail. > I'm also not sure it's optimal to only initialize read_stream after > reading the next batch. For some indexes a batch can have hundreds of > items, and that certainly could benefit from prefetching. That does seem quite possible, and should also be investigated. But it doesn't sound like the issue you're seeing with your adversarial random query. > I suppose it > should be possible to initialize the read_stream half-way though a > batch, right? Or is there a reason why that can't work? Yes, that's right -- the general structure should be able to support switching over to a read stream when we're only mid-way through reading the TIDs associated with a given batch (likely the first batch). The only downside is that that'd require adding logic/more branches to heapam_index_fetch_tuple to detect when to do this. I think that that approach is workable, if we really need it to work -- it's definitely an option. For now I would like to focus on debugging your problematic query (which doesn't sound like the kind of query that could benefit from initializing the read_stream when we're still only half-way through a batch). Does that make sense, do you think? -- Peter Geoghegan
On Tue, Aug 19, 2025 at 2:22 PM Peter Geoghegan <pg@bowt.ie> wrote: > That definitely seems like a problem. I think that you're saying that > this problem happens because we have extra buffer hits earlier on, > which is enough to completely change the ramp-up behavior. This seems > to be all it takes to dramatically decrease the effectiveness of > prefetching. Does that summary sound correct? Update: Tomas and I discussed this over IM. We ultimately concluded that it made the most sense to treat this issue as a regression against set enable_indexscan_prefetch = off/master. It was probably made a bit worse by the recent addition of delaying creating a read stream (to avoid regressing pgbench SELECT) with io_method=worker, though for me (with io_method=io_uring) it makes things faster instead. None of this is business with io_method seems important, since either way there's a clear regression against set enable_indexscan_prefetch = off/master. And we don't want those. So ultimately we need to understand why mo prefetching wins by a not-insignificant margin with this query. Also, I just noticed that with a DESC/backwards scan version of Tomas' query, things are vastly slower. But even then, fully synchronous buffered I/O is still slightly faster. -- Peter Geoghegan
On 8/15/25 17:09, Andres Freund wrote:
> Hi,
>
> On 2025-08-14 19:36:49 -0400, Andres Freund wrote:
>> On 2025-08-14 17:55:53 -0400, Peter Geoghegan wrote:
>>> On Thu, Aug 14, 2025 at 5:06 PM Peter Geoghegan <pg@bowt.ie> wrote:
>>>>> We can optimize that by deferring the StartBufferIO() if we're encountering a
>>>>> buffer that is undergoing IO, at the cost of some complexity. I'm not sure
>>>>> real-world queries will often encounter the pattern of the same block being
>>>>> read in by a read stream multiple times in close proximity sufficiently often
>>>>> to make that worth it.
>>>>
>>>> We definitely need to be prepared for duplicate prefetch requests in
>>>> the context of index scans.
>>>
>>> Can you (or anybody else) think of a quick and dirty way of working
>>> around the problem on the read stream side? I would like to prioritize
>>> getting the patch into a state where its overall performance profile
>>> "feels right". From there we can iterate on fixing the underlying
>>> issues in more principled ways.
>>
>> I think I can see a way to fix the issue, below read stream. Basically,
>> whenever AsyncReadBuffers() finds a buffer that has ongoing IO, instead of
>> waiting, as we do today, copy the wref to the ReadBuffersOperation() and set a
>> new flag indicating that we are waiting for an IO that was not started by the
>> wref. Then, in WaitReadBuffers(), we wait for such foreign started IOs. That
>> has to be somewhat different code from today, because we have to deal with the
>> fact of the "foreign" IO potentially having failed.
>>
>> I'll try writing a prototype for that tomorrow. I think to actually get that
>> into a committable shape we need a test harness (probably a read stream
>> controlled by an SQL function that gets an array of buffers).
>
> Attached is a prototype of this approach. It does seem to fix this issue.
>
Thanks. Based on the testing so far, the patch seems to be a substantial
improvement. What's needed to make this prototype committable?
I assume this is PG19+ improvement, right? It probably affects PG18 too,
but it's harder to hit / the impact is not as bad as on PG19.
On a related note, my test that generates random datasets / queries, and
compares index prefetching with different io_method values found a
pretty massive difference between worker and io_uring. I wonder if this
might be some issue in io_method=worker.
Consider this synthetic dataset:
----------------------------------------------------------------------
create unlogged table t (a bigint, b text) with (fillfactor = 20);
insert into t
select 1 * a, b from (
select r, a, b, generate_series(0,2-1) AS p
from (select row_number() over () AS r, a, b from (
select i AS a, md5(i::text) AS b
from generate_series(1, 5000000) s(i)
order by (i + 16 * (random() - 0.5))
) foo
) bar
) baz ORDER BY ((r * 2 + p) + 8 * (random() - 0.5));
create index idx on t(a ASC) with (deduplicate_items=false);
vacuum freeze t;
analyze t;
SELECT * FROM t WHERE a BETWEEN 16150 AND 4540437 ORDER BY a ASC;
----------------------------------------------------------------------
On master (or with index prefetching disabled), this gets executed like
this (cold caches):
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Buffers: shared hit=2577599 read=455610
Planning:
Buffers: shared hit=82 read=21
Planning Time: 5.982 ms
Execution Time: 1691.708 ms
(8 rows)
while with index prefetching (with the aio prototype patch), it looks
like this:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Prefetch Distance: 2.032
Prefetch Count: 868165
Prefetch Stalls: 2140228
Prefetch Skips: 6039906
Prefetch Resets: 0
Stream Ungets: 0
Stream Forwarded: 4
Prefetch Histogram: [2,4) => 855753, [4,8) => 12412
Buffers: shared hit=2577599 read=455610
Planning:
Buffers: shared hit=78 read=26 dirtied=1
Planning Time: 1.032 ms
Execution Time: 3150.578 ms
(16 rows)
So it's about 2x slower. The prefetch distance collapses, because
there's a lot of cache hits (about 50% of requests seem to be hits of
already visited blocks). I think that's a problem with how we adjust the
distance, but I'll post about that separately.
Let's try to simply set io_method=io_uring:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Prefetch Distance: 2.032
Prefetch Count: 868165
Prefetch Stalls: 2140228
Prefetch Skips: 6039906
Prefetch Resets: 0
Stream Ungets: 0
Stream Forwarded: 4
Prefetch Histogram: [2,4) => 855753, [4,8) => 12412
Buffers: shared hit=2577599 read=455610
Planning:
Buffers: shared hit=78 read=26
Planning Time: 2.212 ms
Execution Time: 1837.615 ms
(16 rows)
That's much closer to master (and the difference could be mostly noise).
I'm not sure what's causing this, but almost all regressions my script
is finding look like this - always io_method=worker, with distance close
to 2.0. Is this some inherent io_method=worker overhead?
regards
--
Tomas Vondra
On 8/20/25 00:27, Peter Geoghegan wrote:
> On Tue, Aug 19, 2025 at 2:22 PM Peter Geoghegan <pg@bowt.ie> wrote:
>> That definitely seems like a problem. I think that you're saying that
>> this problem happens because we have extra buffer hits earlier on,
>> which is enough to completely change the ramp-up behavior. This seems
>> to be all it takes to dramatically decrease the effectiveness of
>> prefetching. Does that summary sound correct?
>
That summary is correct, yes. I kept thinking about this, while looking
at more regressions found by my script (that generates data sets with
different data distributions, etc.).
Almost all regressions (at least the top ones) now look like this, i.e.
distance collapses to ~2.0, which essentially disables prefetching.
But I no longer think it's caused by the "priorbatch" optimization,
which delays read stream creation until after the first batch. I still
think we may need to rethink that (e.g. if the first batch is huge), but
he distance can "collapse" even without it. The optimization just makes
it easier to happen.
AFAICS the distance collapse is "inherent" to how the distance gets
increased/decreased after hits/misses.
Let's start with distance=1, and let's assume 50% of buffers are hits,
in a regular pattern - hit-miss-hit-miss-hit-miss-...
In this case, the distance will never increase beyond 2, because we'll
double-decrement-double-decrement-... so it'll flip between 1 and 2, no
matter how you set effective_io_concurrency.
Of course, this can happen even with other hit ratios, there's nothing
special about 50%.
With fewer hits, it's fine - there's asymmetry, because the distance
grows by doubling and decreases by decrementing 1. So once we have a bit
more misses, it keeps growing.
But with more hits, the hit/miss ratio simply determines the "stable"
distance. Let's say there's 80% hits, so 4 hits to 1 miss. Then the
stable distance is ~4, because we get a miss, double to 8, and then 4
hits, so the distance drops back to 4. And again.
Similarly for other hit/miss ratios (it's easier to think about if you
keep the number of hits 2^n).
It's worth noticing the effective_io_concurrency has almost no impact on
what distance we end up with, it merely limits the maximum distance.
I find this distance heuristics a bit strange, for a couple reasons:
* It doesn't seem right to get stuck at distance=2 with 50% misses.
Surely that would benefit from prefetching a bit more?
* It mostly ignores effective_io_concurrency, which I think about as
"Keep this number of I/Os in the queue." But we don't try doing that.
I understand the current heuristics is trying to not prefetch for cached
data sets, but does that actually make sense? With fadvise it made
sense, because the prefetched data could get evicted if we prefetched
too far ahead. But with worker/io_uring the buffers get pinned, so this
shouldn't happen. Of course, that doesn't mean we should prefetch too
far ahead - there's LIMIT queries and limit of buffer pins, etc.
What about if the distance heuristics asks this question:
How far do we need to look to generate effective_io_concurrency IOs?
The attached patch is a PoC implementing this. The core idea is that if
we measure "miss probability" for a chunk of requests, we can use that
to estimate the distance needed to generate e_i_c IOs.
So while the current heuristics looks at individual hits/misses, the
patch looks at groups of requests.
The other idea is that the patch maintains a "distance range", with
min/max of allowed distances. The min/max values gradually grow after a
miss, the "min" value "stops" at max_ios, while "max" grows further.
This ensures gradual ramp up, helping LIMIT queries etc.
And even if there are a lot of hits, the distance is not allowed to drop
below the current "min". Because what would be the benefit of that?
- If the read is a hit, we might read it later - but the cost is about
the same, we're not really saving much by delaying the read.
- If the read is a miss, it's clearly better to issue the I/O sooner.
This may not be true if it's a LIMIT query, and it terminates early. But
if the distance_min is not too high, this should be negligible.
Attached is an example table/query, found by my script. Without the
read_stream patch (i.e. just with the current index prefetching), it
looks like this:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Prefetch Distance: 2.032
Prefetch Count: 868165
Prefetch Stalls: 2140228
Prefetch Skips: 6039906
Prefetch Resets: 0
Stream Ungets: 0
Stream Forwarded: 4
Prefetch Histogram: [2,4) => 855753, [4,8) => 12412
Buffers: shared hit=2577599 read=455610
Planning:
Buffers: shared hit=78 read=26 dirtied=1
Planning Time: 1.032 ms
Execution Time: 3150.578 ms
(16 rows)
and with the attached patch:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Prefetch Distance: 36.321
Prefetch Count: 3730750
Prefetch Stalls: 3
Prefetch Skips: 6039906
Prefetch Resets: 0
Stream Ungets: 722353
Stream Forwarded: 305265
Prefetch Histogram: [2,4) => 10, [4,8) => 11, [8,16) => 6,
[16,32) => 316890, [32,64) => 3413833
Buffers: shared hit=2574776 read=455610
Planning:
Buffers: shared hit=78 read=26
Planning Time: 2.249 ms
Execution Time: 1651.826 ms
(16 rows)
The example is not entirely perfect, because the index prefetching does
not actually beat master:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using idx on t (actual rows=9048576.00 loops=1)
Index Cond: ((a >= 16150) AND (a <= 4540437))
Index Searches: 1
Buffers: shared hit=2577599 read=455610
Planning:
Buffers: shared hit=78 read=26
Planning Time: 3.688 ms
Execution Time: 1656.790 ms
(8 rows)
So it's more a case of "mitigating a regression" (finding regressions
like this is the purpose of my script). Still, I believe the questions
about the distance heuristics are valid.
(Another interesting detail is that the regression happens only with
io_method=worker, not with io_uring. I'm not sure why.)
regards
--
Tomas Vondra
Вложения
On Tue, Aug 26, 2025 at 2:18 AM Tomas Vondra <tomas@vondra.me> wrote: > Of course, this can happen even with other hit ratios, there's nothing > special about 50%. Right, that's what this patch was attacking directly, basically only giving up when misses are so sparse we can't do anything about it for an ordered stream: https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com aio: Improve read_stream.c look-ahead heuristics C Previously we would reduce the look-ahead distance by one every time we got a cache hit, which sometimes performed poorly with mixed hit/miss patterns, especially if it was trapped at one. Instead, sustain the current distance until we've seen evidence that there is no window big enough to span the gap between rare IOs. In other words, we now use information from a much larger window to estimate the utility of looking far ahead.
On 8/25/25 16:18, Tomas Vondra wrote: > ... > > But with more hits, the hit/miss ratio simply determines the "stable" > distance. Let's say there's 80% hits, so 4 hits to 1 miss. Then the > stable distance is ~4, because we get a miss, double to 8, and then 4 > hits, so the distance drops back to 4. And again. > I forgot to mention the distance is "stable" only if you already start at it - then we keep it. But start at a higher value, and the distance keeps growing. Or start at a lower value, and it collapses to 1. Plus it's rather sensitive, a minor variation can easily push the distance in either direction. So it's more like an "unstable equilibrium" in physics. regards -- Tomas Vondra
On 8/25/25 17:43, Thomas Munro wrote: > On Tue, Aug 26, 2025 at 2:18 AM Tomas Vondra <tomas@vondra.me> wrote: >> Of course, this can happen even with other hit ratios, there's nothing >> special about 50%. > > Right, that's what this patch was attacking directly, basically only > giving up when misses are so sparse we can't do anything about it for > an ordered stream: > > https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com > > aio: Improve read_stream.c look-ahead heuristics C > > Previously we would reduce the look-ahead distance by one every time we > got a cache hit, which sometimes performed poorly with mixed hit/miss > patterns, especially if it was trapped at one. > > Instead, sustain the current distance until we've seen evidence that > there is no window big enough to span the gap between rare IOs. In > other words, we now use information from a much larger window to > estimate the utility of looking far ahead. Ah, I forgot about this patch. There's been too many PoC / experimental patches with read_stream improvements, I'm loosing track of them. I'm ready to do some evaluation, but it's not clear which ones to evaluate, etc. Could you maybe consolidate them into a patch series that I could benchmark? I did give this patch a try with the dataset/query shared in [1], and the explain looks like this: QUERY PLAN --------------------------------------------------------------------- Index Scan using idx on t (actual rows=9048576.00 loops=1) Index Cond: ((a >= 16150) AND (a <= 4540437)) Index Searches: 1 Prefetch Distance: 271.999 Prefetch Count: 4339129 Prefetch Stalls: 386 Prefetch Skips: 6039906 Prefetch Resets: 0 Stream Ungets: 1331122 Stream Forwarded: 306719 Prefetch Histogram: [2,4) => 10, [4,8) => 2, [8,16) => 2, [16,32) => 2, [32,64) => 2, [64,128) => 3, [256,512) => 4339108 Buffers: shared hit=2573920 read=455610 Planning: Buffers: shared hit=83 read=26 Planning Time: 4.142 ms Execution Time: 1694.368 ms (16 rows) which is pretty good, and pretty much on-par with master (so no regression, which is good). It's a bit strange the distance ends up being that high, though. The explain says: Prefetch Distance: 271.999 There's ~70% misses on average, so isn't 217 a bit too high? Wouldn't that cause too many concurrent IOs? Maybe I'm interpreting this wrong, or maybe the explain stats are not quite right. For comparison, the patch from [1] ends up with this: Prefetch Distance: 36.321 In any case, the patch seems to help, and maybe it's a better approach, I need to take a closer look. regards [1] https://www.postgresql.org/message-id/8f5d66cf-44e9-40e0-8349-d5590ba8efb4%40vondra.me -- Tomas Vondra
On Mon, Aug 25, 2025 at 10:18 AM Tomas Vondra <tomas@vondra.me> wrote: > Almost all regressions (at least the top ones) now look like this, i.e. > distance collapses to ~2.0, which essentially disables prefetching. Good to know. > But I no longer think it's caused by the "priorbatch" optimization, > which delays read stream creation until after the first batch. I still > think we may need to rethink that (e.g. if the first batch is huge), but > he distance can "collapse" even without it. The optimization just makes > it easier to happen. That shouldn't count against the "priorbatch" optimization. I still think that this issue should be treated as 100% unrelated to the "priorbatch" optimization. You might very well be right that the "priorbatch" optimization is too naive about index scans whose first/possibly only leaf page has TIDs that point to many distinct heap blocks (hundreds, say). But there's no reason to think that that's truly relevant to the problem at hand. If there was such a problem, then it wouldn't look like a regression against enable_indexscan_prefetch = off/master. We'd likely require a targeted approach to even notice such a problem; so far, most/all of our index scan test cases have read hundreds/thousands of index pages -- so any problem that's limited to the first leaf page read is likely to go unnoticed. I think that the "priorbatch" optimization at least takes *approximately* the right approach, which is good enough for now. It at least shouldn't ever do completely the wrong thing. It even seems possible that sufficiently testing will actually show that its naive approach to be the best one, on balance, once the cost of adding mitigations (costs for all queries, not just ones like the one you looked at recently) is taken into account. I suggest that we not even think about "priorbatch" until the problem on the read stream side is fixed. IMV we should at least have a prototype patch for the read stream that we're reasonably happy with before looking at "priorbatch" in further detail. I don't think we have that right now. > AFAICS the distance collapse is "inherent" to how the distance gets > increased/decreased after hits/misses. Right. (I think that you'll probably agree with me about addressing this problem before even thinking about limitations in the "priorbatch" optimization, but I thought it best to be clear about that.) > I find this distance heuristics a bit strange, for a couple reasons: > > * It doesn't seem right to get stuck at distance=2 with 50% misses. > Surely that would benefit from prefetching a bit more? Maybe, but at what cost? It doesn't necessarily make sense to continue to read additional leaf pages, regardless of the number of heap buffer hits in the recent past. At some point it likely makes more sense to just give up and do actual query processing/return rows to the scan. Even without a LIMIT. I have low confidence here, though. > * It mostly ignores effective_io_concurrency, which I think about as > "Keep this number of I/Os in the queue." But we don't try doing that. As I said, I might just be wrong about "just giving up at some point" making sense. I just don't necessarily think it makes sense to go from ignoring effective_io_concurrency to *only* caring about effective_io_concurrency. It's likely true that keeping effective_io_concurrency-many I/Os in flight is the single most important thing -- but I doubt it's the only thing that ever matters (again, even assuming that there's no LIMIT involved). > Attached is an example table/query, found by my script. Without the > read_stream patch (i.e. just with the current index prefetching), it > looks like this: > So it's more a case of "mitigating a regression" (finding regressions > like this is the purpose of my script). Still, I believe the questions > about the distance heuristics are valid. > > (Another interesting detail is that the regression happens only with > io_method=worker, not with io_uring. I'm not sure why.) I find that the regression happens with io_uring. I also find that your patch doesn't fix it. I have no idea why. -- Peter Geoghegan
On 8/25/25 19:57, Peter Geoghegan wrote: > On Mon, Aug 25, 2025 at 10:18 AM Tomas Vondra <tomas@vondra.me> wrote: >> Almost all regressions (at least the top ones) now look like this, i.e. >> distance collapses to ~2.0, which essentially disables prefetching. > > Good to know. > >> But I no longer think it's caused by the "priorbatch" optimization, >> which delays read stream creation until after the first batch. I still >> think we may need to rethink that (e.g. if the first batch is huge), but >> he distance can "collapse" even without it. The optimization just makes >> it easier to happen. > > That shouldn't count against the "priorbatch" optimization. I still > think that this issue should be treated as 100% unrelated to the > "priorbatch" optimization. > > You might very well be right that the "priorbatch" optimization is too > naive about index scans whose first/possibly only leaf page has TIDs > that point to many distinct heap blocks (hundreds, say). But there's > no reason to think that that's truly relevant to the problem at hand. > If there was such a problem, then it wouldn't look like a regression > against enable_indexscan_prefetch = off/master. We'd likely require a > targeted approach to even notice such a problem; so far, most/all of > our index scan test cases have read hundreds/thousands of index pages > -- so any problem that's limited to the first leaf page read is likely > to go unnoticed. > > I think that the "priorbatch" optimization at least takes > *approximately* the right approach, which is good enough for now. It > at least shouldn't ever do completely the wrong thing. It even seems > possible that sufficiently testing will actually show that its naive > approach to be the best one, on balance, once the cost of adding > mitigations (costs for all queries, not just ones like the one you > looked at recently) is taken into account. > > I suggest that we not even think about "priorbatch" until the problem > on the read stream side is fixed. IMV we should at least have a > prototype patch for the read stream that we're reasonably happy with > before looking at "priorbatch" in further detail. I don't think we > have that right now. > Right. I might have expressed it more clearly, but this is what I meant when I said priorbatch is not causing this. As for priorbatch, I'd still like to know where does the overhead come from. I mean, what's the expensive part of creating a read stream? Maybe that can be fixed, instead of delaying the creation, etc. Maybe the delay could happen within read_stream? >> AFAICS the distance collapse is "inherent" to how the distance gets >> increased/decreased after hits/misses. > > Right. (I think that you'll probably agree with me about addressing > this problem before even thinking about limitations in the > "priorbatch" optimization, but I thought it best to be clear about > that.) > Agreed. >> I find this distance heuristics a bit strange, for a couple reasons: >> >> * It doesn't seem right to get stuck at distance=2 with 50% misses. >> Surely that would benefit from prefetching a bit more? > > Maybe, but at what cost? It doesn't necessarily make sense to continue > to read additional leaf pages, regardless of the number of heap buffer > hits in the recent past. At some point it likely makes more sense to > just give up and do actual query processing/return rows to the scan. > Even without a LIMIT. I have low confidence here, though. > Yes, it doesn't make sense to continue forever. That was the point of distance_max in my patch - if we don't get enough I/Os by that distance, we give up. I'm not saying we should do whatever to meet effective_io_concurrency. It just seems a bit strange to ignore it like this, because right now it has absolutely no impact on the read stream. If the query gets into the "collapsed distance", it'll happen with any effective_io_concurrency. >> * It mostly ignores effective_io_concurrency, which I think about as >> "Keep this number of I/Os in the queue." But we don't try doing that. > > As I said, I might just be wrong about "just giving up at some point" > making sense. I just don't necessarily think it makes sense to go from > ignoring effective_io_concurrency to *only* caring about > effective_io_concurrency. It's likely true that keeping > effective_io_concurrency-many I/Os in flight is the single most > important thing -- but I doubt it's the only thing that ever matters > (again, even assuming that there's no LIMIT involved). > I'm not saying we should only care about effective_io_concurrency. But it seems like a reasonable goal to issue the I/Os early, if we're going to issue them at some point. >> Attached is an example table/query, found by my script. Without the >> read_stream patch (i.e. just with the current index prefetching), it >> looks like this: > >> So it's more a case of "mitigating a regression" (finding regressions >> like this is the purpose of my script). Still, I believe the questions >> about the distance heuristics are valid. >> >> (Another interesting detail is that the regression happens only with >> io_method=worker, not with io_uring. I'm not sure why.) > > I find that the regression happens with io_uring. I also find that > your patch doesn't fix it. I have no idea why. > That's weird. Did you see an increase of the prefetch distance? What does the EXPLAIN ANALYZE say about that? regard -- Tomas Vondra
On Mon, Aug 25, 2025 at 2:33 PM Tomas Vondra <tomas@vondra.me> wrote: > Right. I might have expressed it more clearly, but this is what I meant > when I said priorbatch is not causing this. Cool. > As for priorbatch, I'd still like to know where does the overhead come > from. I mean, what's the expensive part of creating a read stream? Maybe > that can be fixed, instead of delaying the creation, etc. Maybe the > delay could happen within read_stream? Creating a read stream is probably really cheap. It's nevertheless expensive enough to make pgbench select about 3.5% slower. I don't think that there's really an "expensive part" for us to directly target here. Separately, it's probably also true that using a read stream to prefetch 2 or 3 pages ahead when on the first leaf page read isn't going to pay for itself. There just isn't enough time to spend on useful foreground work such that we can hide the latency of an I/O wait, I imagine. But there'll still be added costs to pay from using a read stream. Anyway, whether or not this happens in the read stream itself (versus keeping the current approach of simply deferring its creation) doesn't seem all that important to me. If we do it that way then we still have the problem of (eventually) figuring out when and how to tell the read stream that it's time to really start up now. That'll be the hard part, most likely -- and it doesn't have much to do with the general design of the read stream (unlike the problem with your query). > I'm not saying we should do whatever to meet effective_io_concurrency. > It just seems a bit strange to ignore it like this, because right now it > has absolutely no impact on the read stream. If the query gets into the > "collapsed distance", it'll happen with any effective_io_concurrency. That makes sense. > That's weird. Did you see an increase of the prefetch distance? What > does the EXPLAIN ANALYZE say about that? Yes, I did. In general I find that your patch from today is very good at keeping prefetch distance at approximately effective_io_concurrency -- perhaps even a bit too good. Overall, the details that I now see seem to match with my (possibly faulty) expectations about what'll work best: the distance certainly doesn't get stuck at ~2 anymore (it gets close to effective_io_concurrency for most possible effective_io_concurrency settings, I find). The "only" problem is that the new patch doesn't actually fix the regression itself. In fact, it seems to make it worse. With enable_indexscan_prefetch = off, the query takes 2794.551 ms on my system. With enable_indexscan_prefetch = on, and with your patch from today also applied, it takes 3488.997 ms. This is the case in spite of the fact that your patch does successfully lower "shared read=" time by a small amount (in addition to making the distance look much more sane, at least to me). For context, without your patch from today (but with the base index prefetching patch still applied), the same query takes 3162.195 ms. In spite of "shared read=" time being higher than any other case, and in spite of the fact that distance gets stuck at ~2/just looks wrong. (Like I said, the patch seems to actually make the problem worse on my system.) -- Peter Geoghegan
Hi, On 2025-08-25 15:00:39 +0200, Tomas Vondra wrote: > Thanks. Based on the testing so far, the patch seems to be a substantial > improvement. What's needed to make this prototype committable? Mainly some testing infrastructure that can trigger this kind of stream. The logic is too finnicky for me to commit it without that. > I assume this is PG19+ improvement, right? It probably affects PG18 too, > but it's harder to hit / the impact is not as bad as on PG19. Yea. It does apply to 18 too, but I can't come up with realistic scenarios where it's a real issue. I can repro a slowdown when using many parallel seqscans with debug_io_direct=data - but that's even slower in 17... > On a related note, my test that generates random datasets / queries, and > compares index prefetching with different io_method values found a > pretty massive difference between worker and io_uring. I wonder if this > might be some issue in io_method=worker. > while with index prefetching (with the aio prototype patch), it looks > like this: > > QUERY PLAN > ---------------------------------------------------------------------- > Index Scan using idx on t (actual rows=9048576.00 loops=1) > Index Cond: ((a >= 16150) AND (a <= 4540437)) > Index Searches: 1 > Prefetch Distance: 2.032 > Prefetch Count: 868165 > Prefetch Stalls: 2140228 > Prefetch Skips: 6039906 > Prefetch Resets: 0 > Stream Ungets: 0 > Stream Forwarded: 4 > Prefetch Histogram: [2,4) => 855753, [4,8) => 12412 > Buffers: shared hit=2577599 read=455610 > Planning: > Buffers: shared hit=78 read=26 dirtied=1 > Planning Time: 1.032 ms > Execution Time: 3150.578 ms > (16 rows) > > So it's about 2x slower. The prefetch distance collapses, because > there's a lot of cache hits (about 50% of requests seem to be hits of > already visited blocks). I think that's a problem with how we adjust the > distance, but I'll post about that separately. > > Let's try to simply set io_method=io_uring: > > QUERY PLAN > ---------------------------------------------------------------------- > Index Scan using idx on t (actual rows=9048576.00 loops=1) > Index Cond: ((a >= 16150) AND (a <= 4540437)) > Index Searches: 1 > Prefetch Distance: 2.032 > Prefetch Count: 868165 > Prefetch Stalls: 2140228 > Prefetch Skips: 6039906 > Prefetch Resets: 0 > Stream Ungets: 0 > Stream Forwarded: 4 > Prefetch Histogram: [2,4) => 855753, [4,8) => 12412 > Buffers: shared hit=2577599 read=455610 > Planning: > Buffers: shared hit=78 read=26 > Planning Time: 2.212 ms > Execution Time: 1837.615 ms > (16 rows) > > That's much closer to master (and the difference could be mostly noise). > > I'm not sure what's causing this, but almost all regressions my script > is finding look like this - always io_method=worker, with distance close > to 2.0. Is this some inherent io_method=worker overhead? I think what you might be observing might be the inherent IPC / latency overhead of the worker based approach. This is particularly pronounced if the workers are idle (and the CPU they get scheduled on is clocked down). The latency impact of that is small, but if you never actually get to do much readahead it can be visible. Greetings, Andres Freund
On Mon Aug 25, 2025 at 10:18 AM EDT, Tomas Vondra wrote:
> The attached patch is a PoC implementing this. The core idea is that if
> we measure "miss probability" for a chunk of requests, we can use that
> to estimate the distance needed to generate e_i_c IOs.
I noticed an assertion failure when the tests run. Looks like something about
the patch breaks the read stream from the point of view of VACUUM:
TRAP: failed Assert("stream->pinned_buffers + stream->pending_read_nblocks <= stream->max_pinned_buffers"), File:
"../source/src/backend/storage/aio/read_stream.c",Line: 402, PID: 1238204
[0x55e71f653d29] read_stream_start_pending_read:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/storage/aio/read_stream.c:401
[0x55e71f6533ad] read_stream_look_ahead:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/storage/aio/read_stream.c:670
[0x55e71f652e9a] read_stream_next_buffer:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/storage/aio/read_stream.c:1173
[0x55e71f34cd2b] lazy_scan_heap:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/access/heap/vacuumlazy.c:1310
[0x55e71f34cd2b] heap_vacuum_rel:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/access/heap/vacuumlazy.c:839
[0x55e71f49a3f4] table_relation_vacuum: ../source/src/include/access/tableam.h:1670
[0x55e71f49a3f4] vacuum_rel: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/commands/vacuum.c:2296
[0x55e71f499e8f] vacuum: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/commands/vacuum.c:636
[0x55e71f49931d] ExecVacuum: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/commands/vacuum.c:468
[0x55e71f6a69f7] standard_ProcessUtility:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/utility.c:862
[0x55e71f6a67d7] ProcessUtility: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/utility.c:523
[0x55e71f6a630b] PortalRunUtility: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/pquery.c:1153
[0x55e71f6a59b3] PortalRunMulti: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/pquery.c:0
[0x55e71f6a52c5] PortalRun: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/pquery.c:788
[0x55e71f6a4119] exec_simple_query:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/postgres.c:1274
[0x55e71f6a1b84] PostgresMain: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/postgres.c:0
[0x55e71f69c078] BackendMain:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/tcop/backend_startup.c:124
[0x55e71f5e5eda] postmaster_child_launch:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/postmaster/launch_backend.c:290
[0x55e71f5ea847] BackendStartup:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/postmaster/postmaster.c:3587
[0x55e71f5ea847] ServerLoop:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/postmaster/postmaster.c:1702
[0x55e71f5e86d9] PostmasterMain:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/postmaster/postmaster.c:1400
[0x55e71f51acd9] main: /mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/main/main.c:231
[0x7ff312633ca7] __libc_start_call_main: ../sysdeps/nptl/libc_start_call_main.h:58
[0x7ff312633d64] __libc_start_main_impl: ../csu/libc-start.c:360
[0x55e71f2e09a0] [unknown]: [unknown]:0
2025-08-25 21:05:28.915 EDT postmaster[1236725] LOG: client backend (PID 1238204) was terminated by signal 6: Aborted
2025-08-25 21:05:28.915 EDT postmaster[1236725] DETAIL: Failed process was running: VACUUM (PARALLEL 0,
BUFFER_USAGE_LIMIT128) test_io_vac_strategy;
2025-08-25 21:05:28.915 EDT postmaster[1236725] LOG: terminating any other active server processes
2025-08-25 21:05:28.915 EDT postmaster[1236725] LOG: all server processes terminated; reinitializing
__
Peter Geoghegan
On 8/26/25 03:08, Peter Geoghegan wrote:
> On Mon Aug 25, 2025 at 10:18 AM EDT, Tomas Vondra wrote:
>> The attached patch is a PoC implementing this. The core idea is that if
>> we measure "miss probability" for a chunk of requests, we can use that
>> to estimate the distance needed to generate e_i_c IOs.
>
> I noticed an assertion failure when the tests run. Looks like something about
> the patch breaks the read stream from the point of view of VACUUM:
>
> TRAP: failed Assert("stream->pinned_buffers + stream->pending_read_nblocks <= stream->max_pinned_buffers"), File:
"../source/src/backend/storage/aio/read_stream.c",Line: 402, PID: 1238204
> [0x55e71f653d29] read_stream_start_pending_read:
/mnt/nvme/postgresql/patch/build_meson_dc/../source/src/backend/storage/aio/read_stream.c:401
Seems the distance adjustment was not quite right, didn't enforce the
limit on pinned buffers, and the distance could get too high. The
attached version should fix that ...
But there's still something wrong. I tried running check-world, and I
see 027_stream_regress.pl is getting stuck in join.sql, for the query on
line 417.
I haven't figured this out yet, but there's a mergejoin. It does reset
the stream a lot, so maybe there's something wrong there ... It's
strange, though. Why would a different distance make the query stuck?
Anyway, Thomas' patch from [1] doesn't seem to have this issue. And
maybe it's a better / more elegant approach in general?
[1]
https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com
--
Tomas Vondra
Вложения
On 8/26/25 01:48, Andres Freund wrote: > Hi, > > On 2025-08-25 15:00:39 +0200, Tomas Vondra wrote: >> Thanks. Based on the testing so far, the patch seems to be a substantial >> improvement. What's needed to make this prototype committable? > > Mainly some testing infrastructure that can trigger this kind of stream. The > logic is too finnicky for me to commit it without that. > So, what would that look like? The "naive" approach to testing is to simply generate a table/index, producing the right sequence of blocks. That shouldn't be too hard, it'd be enough to have an index that - has ~2-3 rows per value, on different heap pages - the values "overlap", e.g. like this (value,page) (A,1), (A,2), (A,3), (B,2), (B,3), (B,4), ... Another approach would be to test this at C level, sidestepping the query execution entirely. We'd have a "stream generator" that just generates a sequence of blocks of our own choosing (could be hard-coded, some pattern, read from a file ...), and feed it into a read stream. But how would we measure success for these tests? I don't think we want to look at query duration, that's very volatile. > >> I assume this is PG19+ improvement, right? It probably affects PG18 too, >> but it's harder to hit / the impact is not as bad as on PG19. > > Yea. It does apply to 18 too, but I can't come up with realistic scenarios > where it's a real issue. I can repro a slowdown when using many parallel > seqscans with debug_io_direct=data - but that's even slower in 17... > Makes sense. > >> On a related note, my test that generates random datasets / queries, and >> compares index prefetching with different io_method values found a >> pretty massive difference between worker and io_uring. I wonder if this >> might be some issue in io_method=worker. > >> while with index prefetching (with the aio prototype patch), it looks >> like this: >> >> QUERY PLAN >> ---------------------------------------------------------------------- >> Index Scan using idx on t (actual rows=9048576.00 loops=1) >> Index Cond: ((a >= 16150) AND (a <= 4540437)) >> Index Searches: 1 >> Prefetch Distance: 2.032 >> Prefetch Count: 868165 >> Prefetch Stalls: 2140228 >> Prefetch Skips: 6039906 >> Prefetch Resets: 0 >> Stream Ungets: 0 >> Stream Forwarded: 4 >> Prefetch Histogram: [2,4) => 855753, [4,8) => 12412 >> Buffers: shared hit=2577599 read=455610 >> Planning: >> Buffers: shared hit=78 read=26 dirtied=1 >> Planning Time: 1.032 ms >> Execution Time: 3150.578 ms >> (16 rows) >> >> So it's about 2x slower. The prefetch distance collapses, because >> there's a lot of cache hits (about 50% of requests seem to be hits of >> already visited blocks). I think that's a problem with how we adjust the >> distance, but I'll post about that separately. >> >> Let's try to simply set io_method=io_uring: >> >> QUERY PLAN >> ---------------------------------------------------------------------- >> Index Scan using idx on t (actual rows=9048576.00 loops=1) >> Index Cond: ((a >= 16150) AND (a <= 4540437)) >> Index Searches: 1 >> Prefetch Distance: 2.032 >> Prefetch Count: 868165 >> Prefetch Stalls: 2140228 >> Prefetch Skips: 6039906 >> Prefetch Resets: 0 >> Stream Ungets: 0 >> Stream Forwarded: 4 >> Prefetch Histogram: [2,4) => 855753, [4,8) => 12412 >> Buffers: shared hit=2577599 read=455610 >> Planning: >> Buffers: shared hit=78 read=26 >> Planning Time: 2.212 ms >> Execution Time: 1837.615 ms >> (16 rows) >> >> That's much closer to master (and the difference could be mostly noise). >> >> I'm not sure what's causing this, but almost all regressions my script >> is finding look like this - always io_method=worker, with distance close >> to 2.0. Is this some inherent io_method=worker overhead? > > I think what you might be observing might be the inherent IPC / latency > overhead of the worker based approach. This is particularly pronounced if the > workers are idle (and the CPU they get scheduled on is clocked down). The > latency impact of that is small, but if you never actually get to do much > readahead it can be visible. > Yeah, that's quite possible. If I understand the mechanics of this, this can behave in a rather unexpected way - lowering the load (i.e. issuing fewer I/O requests) can make the workers "more idle" and therefore more likely to get suspended ... Is there a good way to measure if this is what's happening, and the impact? For example, it'd be interesting to know how long it took for a submitted process to get picked up by a worker. And % of time a worker spent handling I/O. regards -- Tomas Vondra
On 8/26/25 17:06, Tomas Vondra wrote:
>
>
> On 8/26/25 01:48, Andres Freund wrote:
>> Hi,
>>
>> On 2025-08-25 15:00:39 +0200, Tomas Vondra wrote:
>>> Thanks. Based on the testing so far, the patch seems to be a substantial
>>> improvement. What's needed to make this prototype committable?
>>
>> Mainly some testing infrastructure that can trigger this kind of stream. The
>> logic is too finnicky for me to commit it without that.
>>
>
> So, what would that look like? The "naive" approach to testing is to
> simply generate a table/index, producing the right sequence of blocks.
> That shouldn't be too hard, it'd be enough to have an index that
>
> - has ~2-3 rows per value, on different heap pages
> - the values "overlap", e.g. like this (value,page)
>
> (A,1), (A,2), (A,3), (B,2), (B,3), (B,4), ...
>
> Another approach would be to test this at C level, sidestepping the
> query execution entirely. We'd have a "stream generator" that just
> generates a sequence of blocks of our own choosing (could be hard-coded,
> some pattern, read from a file ...), and feed it into a read stream.
>
> But how would we measure success for these tests? I don't think we want
> to look at query duration, that's very volatile.
>
>>
>>> I assume this is PG19+ improvement, right? It probably affects PG18 too,
>>> but it's harder to hit / the impact is not as bad as on PG19.
>>
>> Yea. It does apply to 18 too, but I can't come up with realistic scenarios
>> where it's a real issue. I can repro a slowdown when using many parallel
>> seqscans with debug_io_direct=data - but that's even slower in 17...
>>
>
> Makes sense.
>
>>
>>> On a related note, my test that generates random datasets / queries, and
>>> compares index prefetching with different io_method values found a
>>> pretty massive difference between worker and io_uring. I wonder if this
>>> might be some issue in io_method=worker.
>>
>>> while with index prefetching (with the aio prototype patch), it looks
>>> like this:
>>>
>>> QUERY PLAN
>>> ----------------------------------------------------------------------
>>> Index Scan using idx on t (actual rows=9048576.00 loops=1)
>>> Index Cond: ((a >= 16150) AND (a <= 4540437))
>>> Index Searches: 1
>>> Prefetch Distance: 2.032
>>> Prefetch Count: 868165
>>> Prefetch Stalls: 2140228
>>> Prefetch Skips: 6039906
>>> Prefetch Resets: 0
>>> Stream Ungets: 0
>>> Stream Forwarded: 4
>>> Prefetch Histogram: [2,4) => 855753, [4,8) => 12412
>>> Buffers: shared hit=2577599 read=455610
>>> Planning:
>>> Buffers: shared hit=78 read=26 dirtied=1
>>> Planning Time: 1.032 ms
>>> Execution Time: 3150.578 ms
>>> (16 rows)
>>>
>>> So it's about 2x slower. The prefetch distance collapses, because
>>> there's a lot of cache hits (about 50% of requests seem to be hits of
>>> already visited blocks). I think that's a problem with how we adjust the
>>> distance, but I'll post about that separately.
>>>
>>> Let's try to simply set io_method=io_uring:
>>>
>>> QUERY PLAN
>>> ----------------------------------------------------------------------
>>> Index Scan using idx on t (actual rows=9048576.00 loops=1)
>>> Index Cond: ((a >= 16150) AND (a <= 4540437))
>>> Index Searches: 1
>>> Prefetch Distance: 2.032
>>> Prefetch Count: 868165
>>> Prefetch Stalls: 2140228
>>> Prefetch Skips: 6039906
>>> Prefetch Resets: 0
>>> Stream Ungets: 0
>>> Stream Forwarded: 4
>>> Prefetch Histogram: [2,4) => 855753, [4,8) => 12412
>>> Buffers: shared hit=2577599 read=455610
>>> Planning:
>>> Buffers: shared hit=78 read=26
>>> Planning Time: 2.212 ms
>>> Execution Time: 1837.615 ms
>>> (16 rows)
>>>
>>> That's much closer to master (and the difference could be mostly noise).
>>>
>>> I'm not sure what's causing this, but almost all regressions my script
>>> is finding look like this - always io_method=worker, with distance close
>>> to 2.0. Is this some inherent io_method=worker overhead?
>>
>> I think what you might be observing might be the inherent IPC / latency
>> overhead of the worker based approach. This is particularly pronounced if the
>> workers are idle (and the CPU they get scheduled on is clocked down). The
>> latency impact of that is small, but if you never actually get to do much
>> readahead it can be visible.
>>
>
> Yeah, that's quite possible. If I understand the mechanics of this, this
> can behave in a rather unexpected way - lowering the load (i.e. issuing
> fewer I/O requests) can make the workers "more idle" and therefore more
> likely to get suspended ...
>
> Is there a good way to measure if this is what's happening, and the
> impact? For example, it'd be interesting to know how long it took for a
> submitted process to get picked up by a worker. And % of time a worker
> spent handling I/O.
>
After investigating this a bit more, I'm not sure it's due to workers
getting idle / CPU clocked down, etc. I did an experiment with booting
with idle=poll, which AFAICS should prevent cores from idling, etc.
And it made pretty much no difference - timings didn't change. It can
still be about IPC, but it does not seem to be about clocked-down cores,
or stuff like that. Maybe.
I ran a more extensive set of tests, varying additional parameters:
- iomethod: io_uring / worker (3 or 12 workers)
- shared buffers: 512MB / 16GB (table is ~3GB)
- checksums on / off
- eic: 16 / 100
- difference SSD devices
and comparing master vs. builds with different variants of the patches:
- master
- patched (index prefetching)
- no-explain (EXPLAIN ANALYZE reverted)
- munro / vondra (WIP patches preventing distance collapse)
- munro-no-explain / vondra-no-explain (should be obvious)
We've been speculating (me and Peter) maybe the extra read_stream stats
add a lot of overhead, hence the "no-explain" builds to test that. All
of this is with the recent "aio" patch eliminating I/O waits.
Attached are results from my "ryzen" machine (xeon is very similar),
sliced/colored to show patterns. It's for query:
SELECT * FROM (
SELECT * FROM t WHERE a BETWEEN 16150 AND 4540437
ORDER BY a ASC
) OFFSET 1000000000;
Which is the same query as before, except that it's not EXPLAIN ANALYZE,
and it has OFFSET so that it does not send any data back. It's a bit of
an adversarial query, it doesn't seem to benefit from prefetching.
There are some very clear patterns in the results.
In the "cold" (uncached) runs:
* io_uring does much better, with limited regressions (not negligible,
but limited compared to io_method=worker). A hint this may really be
about IPC?
* With worker, there's a massive regression with the basic prefetching
patch (when the distance collapses to 2.0). But then it mostly recovers
with the increased distance, and even does a bit better than master (or
on part with io_uring)
In the "warm" runs (with everything cached in page cache, possibly even
in shared buffers):
* With 16GB shared buffers, the regressions are about the same as for
cold runs, both for io_uring and worker. Roughly ~5%, give or take. The
extra read_stream stats seem to add ~3%.
* With 512MB it's much more complicated. io_uring regresses much more
(relative to master), for some reason. For cold runs it was ~30%, now
it's ~50%. Seems weird, but I guess there's fixed overhead and it's more
visible with data in cache.
* For worker (with buffers=512MB), the basic patch clearly causes a
massive regression, it's about 2x slower. I don't really understand why
- the assumption was this is because of idling, but is it, if it happens
with idle=poll?
In top, I see the backend takes ~60%, and the io worker ~40% (so they
clearly ping-pong the work). 40% utilization does not seem particularly
low (and with idle=poll it should not idle anyway).
I realize there's IPC with worker, and it's going to be more visible for
cases that end up doing no prefetching. But isn't 2x regression a bit
too hign? I wouldn't have expected that. Any good way to measure how
expensive the IPC is?
* With the increased prefetch distance, the regression drops to ~25%
(for worker). And in top I see the backend takes ~100%, and the single
worker uses ~60%. But the 25% is without checksums. With checksums, the
regression is roughly the 5%.
I'm not sure what to think about this.
--
Tomas Vondra
Вложения
On 8/26/25 17:06, Tomas Vondra wrote:
>
>
> On 8/26/25 01:48, Andres Freund wrote:
>> Hi,
>>
>> On 2025-08-25 15:00:39 +0200, Tomas Vondra wrote:
>>>
>>> ...
>>>
>>> I'm not sure what's causing this, but almost all regressions my script
>>> is finding look like this - always io_method=worker, with distance close
>>> to 2.0. Is this some inherent io_method=worker overhead?
>>
>> I think what you might be observing might be the inherent IPC / latency
>> overhead of the worker based approach. This is particularly pronounced if the
>> workers are idle (and the CPU they get scheduled on is clocked down). The
>> latency impact of that is small, but if you never actually get to do much
>> readahead it can be visible.
>>
>
> Yeah, that's quite possible. If I understand the mechanics of this, this
> can behave in a rather unexpected way - lowering the load (i.e. issuing
> fewer I/O requests) can make the workers "more idle" and therefore more
> likely to get suspended ...
>
> Is there a good way to measure if this is what's happening, and the
> impact? For example, it'd be interesting to know how long it took for a
> submitted process to get picked up by a worker. And % of time a worker
> spent handling I/O.
>
I kept thinking about this, and in the end I decided to try to measure
this IPC overhead. The backend/ioworker communicate by sending signals,
so I wrote a simple C program that does "signal echo" with two processes
(one fork). It works like this:
1) fork a child process
2) send a signal to the child
3) child notices the signal, sends a response signal back
4) after receiving response, go back to (2)
This happens until the requested number of signals is sent, and then it
prints stats like signals/second etc. The C file is attached, I'm sure
it's imperfect but it does the trick.
And the results mostly agree with the benchmark results from yesterday.
Which makes sense, because if the distance collapses to ~1, the AIO with
io_method=worker starts doing about the same thing for every block.
If I run the signal test on the ryzen machine, I get this:
-----------------------------------------------------------------------
root@ryzen:~# ./signal-echo 1000000
nmm_signals = 1000000
parent: sent 100000 signals in 196909 us (1.97)
...
parent: sent 1000000 signals in 1924263 us (1.92 us)
signals / sec = 519679.48
-----------------------------------------------------------------------
So it can do about 500k signals / second. This means that requesting
blocks one by one (with distance=1), a single worker can do about 4GB/s,
assuming there's no other work (no actual I/O, no checksum checks, ...).
Consider the warm runs with 512MB shared buffers, which means there's no
I/O but the data needs to be copied from page cache (by the worker). An
explain analyze for the query says this:
Buffers: shared hit=2573018 read=455610
That's 455610 blocks to read, mostly one by one. So a bit less than 1
second just for the IPC, but there's also the memcpy etc. An example
result from the benchmark looks like this:
master: 967ms
patched: 2353ms
So that's ~1400ms difference. So a bit more, but in the right ballpark,
and the extra overhead could be the due to AIO being more complex than
sync I/O, etc. Not sure.
The xeon can do ~190k signals/second, i.e. about 1/3 of ryzen, so the
index scan would spend ~3 seconds on the IPC. Timings for the same test
look like this:
master: 3049ms
patched: 9636ms
So, that's about 2x the expected difference. Not sure where the extra
overhead comes from, might be due to NUMA (which the ryzen does not have).
So I think the IPC overhead with "worker" can be quite significant,
especially for cases with distance=1. I don't think it's a major issue
for PG18, because seq/bitmap scans are unlikely to collapse the distance
like this. And with larger distances the cost amortizes. It's much
bigger issue for the index prefetching, it seems.
This is for the "warm" runs with 512MB, with the basic prefetch patch.
I'm not sure it explains the overhead with the patches that increase the
prefetch distance (be it mine or Thomas' patch), or cold runs. The
regresions seem to be smaller in those cases, though.
regards
--
Tomas Vondra
Вложения
Hi, On 2025-08-26 17:06:11 +0200, Tomas Vondra wrote: > On 8/26/25 01:48, Andres Freund wrote: > > Hi, > > > > On 2025-08-25 15:00:39 +0200, Tomas Vondra wrote: > >> Thanks. Based on the testing so far, the patch seems to be a substantial > >> improvement. What's needed to make this prototype committable? > > > > Mainly some testing infrastructure that can trigger this kind of stream. The > > logic is too finnicky for me to commit it without that. > > > > So, what would that look like? I'm thinking of something like an SQL function that accepts a relation and a series of block numbers, which creates a read stream reading the passed in block numbers. Combined with the injection points that are already used in test_aio, that should allow to test things that I don't know how to test without that. E.g. encountering an already-in-progress multi-block IO that only completes partially. > Another approach would be to test this at C level, sidestepping the > query execution entirely. We'd have a "stream generator" that just > generates a sequence of blocks of our own choosing (could be hard-coded, > some pattern, read from a file ...), and feed it into a read stream. > > But how would we measure success for these tests? I don't think we want > to look at query duration, that's very volatile. Yea, the performance effects would be harder to test, what I care more about is the error paths. Those are really hard to test interactively. Greetings, Andres Freund
Hi, On 2025-08-28 14:45:24 +0200, Tomas Vondra wrote: > On 8/26/25 17:06, Tomas Vondra wrote: > I kept thinking about this, and in the end I decided to try to measure > this IPC overhead. The backend/ioworker communicate by sending signals, > so I wrote a simple C program that does "signal echo" with two processes > (one fork). It works like this: > > 1) fork a child process > 2) send a signal to the child > 3) child notices the signal, sends a response signal back > 4) after receiving response, go back to (2) Nice! I think this might under-estimate the IPC cost a bit, because typically the parent and child process do not want to run at the same time, probably leading to them often being scheduled on the same core. Whereas a shollow IO queue will lead to some concurrent activity, just not enough to hide the IPC latency... But I don't think this matters in the grand scheme of things. > So I think the IPC overhead with "worker" can be quite significant, > especially for cases with distance=1. I don't think it's a major issue > for PG18, because seq/bitmap scans are unlikely to collapse the distance > like this. And with larger distances the cost amortizes. It's much > bigger issue for the index prefetching, it seems. I couldn't keep up with all the discussion, but is there actually valid I/O bound cases (i.e. not ones were we erroneously keep the distance short) where index scans end can't have a higher distance? Obviously you can construct cases with a low distance by having indexes point to a lot of tiny tuples pointing to perfectly correlated pages, but in that case IO can't be a significant factor. Greetings, Andres Freund
On 8/28/25 18:16, Andres Freund wrote: > Hi, > > On 2025-08-28 14:45:24 +0200, Tomas Vondra wrote: >> On 8/26/25 17:06, Tomas Vondra wrote: >> I kept thinking about this, and in the end I decided to try to measure >> this IPC overhead. The backend/ioworker communicate by sending signals, >> so I wrote a simple C program that does "signal echo" with two processes >> (one fork). It works like this: >> >> 1) fork a child process >> 2) send a signal to the child >> 3) child notices the signal, sends a response signal back >> 4) after receiving response, go back to (2) > > Nice! > > I think this might under-estimate the IPC cost a bit, because typically the > parent and child process do not want to run at the same time, probably leading > to them often being scheduled on the same core. Whereas a shollow IO queue > will lead to some concurrent activity, just not enough to hide the IPC > latency... But I don't think this matters in the grand scheme of things. > Right. I thought about measuring this stuff (different cores, different NUMA nodes, maybe adding some sleeps to simulate "idle"), but I chose to keep it simple for now. > >> So I think the IPC overhead with "worker" can be quite significant, >> especially for cases with distance=1. I don't think it's a major issue >> for PG18, because seq/bitmap scans are unlikely to collapse the distance >> like this. And with larger distances the cost amortizes. It's much >> bigger issue for the index prefetching, it seems. > > I couldn't keep up with all the discussion, but is there actually valid I/O > bound cases (i.e. not ones were we erroneously keep the distance short) where > index scans end can't have a higher distance? > I don't know, really. Is the presented example really a case of an "erroneously short distance"? From the 2x regression (compared to master) it might seem like that, but even with the increased distance it's still slower than master (by 25%). So maybe the "error" is to use AIO in these cases, instead of just switching to I/O done by the backend. It may be a bit worse for non-btree indexes, e.g. for for ordered scans on gist indexes (getting the next tuple may require reading many leaf pages, so maybe we can't look too far ahead?). Or for indexes with naturally "fat" tuples, which limits how many tuples we see ahead. > Obviously you can construct cases with a low distance by having indexes point > to a lot of tiny tuples pointing to perfectly correlated pages, but in that > case IO can't be a significant factor. > It's definitely true the examples the script finds are "adversary", but also not entirely unrealistic. I suppose there will be such cases for any heuristics we come up with. There's probably more cases like this, where we end up with many hits. Say, a merge join may visit index tuples repeatedly, and so on. But then it's likely in shared buffers, so there won't be any IPC. regards -- Tomas Vondra
Hi, On 2025-08-28 19:08:40 +0200, Tomas Vondra wrote: > On 8/28/25 18:16, Andres Freund wrote: > >> So I think the IPC overhead with "worker" can be quite significant, > >> especially for cases with distance=1. I don't think it's a major issue > >> for PG18, because seq/bitmap scans are unlikely to collapse the distance > >> like this. And with larger distances the cost amortizes. It's much > >> bigger issue for the index prefetching, it seems. > > > > I couldn't keep up with all the discussion, but is there actually valid I/O > > bound cases (i.e. not ones were we erroneously keep the distance short) where > > index scans end can't have a higher distance? > > > > I don't know, really. > > Is the presented exaple really a case of an "erroneously short > distance"? I think the query isn't actually measuring something particularly useful in the general case. You're benchmarking something were the results are never looked at - which means the time between two index fetches is unrealistically short. That means any tiny latency increase matters a lot more than with realistic queries. And this is, IIUC, on a local SSD. I'd bet that on cloud latencies AIO would still be a huge win. > From the 2x regression (compared to master) it might seem like that, but > even with the increased distance it's still slower than master (by 25%). So > maybe the "error" is to use AIO in these cases, instead of just switching to > I/O done by the backend. If it's slower at a higher distance, we're missing something. > It may be a bit worse for non-btree indexes, e.g. for for ordered scans > on gist indexes (getting the next tuple may require reading many leaf > pages, so maybe we can't look too far ahead?). Or for indexes with > naturally "fat" tuples, which limits how many tuples we see ahead. I am not worried at all about those cases. If you have to read a lot of index leaf pages to get a heap fetch, a distance of even just 2 will be fine, because the IPC overhead is a neglegible cost compared to the index processing. Similarly, if you have to do very deep index traversals due to wide index tuples, there's going to be more time between two table fetches. > > Obviously you can construct cases with a low distance by having indexes point > > to a lot of tiny tuples pointing to perfectly correlated pages, but in that > > case IO can't be a significant factor. > > > > It's definitely true the examples the script finds are "adversary", but > also not entirely unrealistic. I think doing index scans where the results are just thrown out are entirely unrealistic... > I suppose there will be such cases for any heuristics we come up with. Agreed. > There's probably more cases like this, where we end up with many hits. > Say, a merge join may visit index tuples repeatedly, and so on. But then > it's likely in shared buffers, so there won't be any IPC. Yea, I'd not expect a meaningful impact of any of this in a workload like that. Greetings, Andres Freund
On Fri, Aug 29, 2025 at 7:52 AM Andres Freund <andres@anarazel.de> wrote: > On 2025-08-28 19:08:40 +0200, Tomas Vondra wrote: > > From the 2x regression (compared to master) it might seem like that, but > > even with the increased distance it's still slower than master (by 25%). So > > maybe the "error" is to use AIO in these cases, instead of just switching to > > I/O done by the backend. > > If it's slower at a higher distance, we're missing something. Enough io_workers? What kind of I/O concurrency does it want? Does wait_event show any backends doing synchronous IO? How many does [1] want to run for that test workload and does it help? FWIW there's a very simple canned latency test in a SQL function in the first message in that thread (0005-XXX-read_buffer_loop.patch), just on the off-chance that it's useful as a starting point for other ideas. There I was interested in IPC overheads, latch collapsing and other effects, so I was deliberately stalling on/evicting a single block repeatedly without any readahead distance, so I wasn't letting the stream "hide" IPC overheads. [1] https://www.postgresql.org/message-id/flat/CA%2BhUKG%2Bm4xV0LMoH2c%3DoRAdEXuCnh%2BtGBTWa7uFeFMGgTLAw%2BQ%40mail.gmail.com
On 8/28/25 23:50, Thomas Munro wrote: > On Fri, Aug 29, 2025 at 7:52 AM Andres Freund <andres@anarazel.de> wrote: >> On 2025-08-28 19:08:40 +0200, Tomas Vondra wrote: >>> From the 2x regression (compared to master) it might seem like that, but >>> even with the increased distance it's still slower than master (by 25%). So >>> maybe the "error" is to use AIO in these cases, instead of just switching to >>> I/O done by the backend. >> >> If it's slower at a higher distance, we're missing something. > > Enough io_workers? What kind of I/O concurrency does it want? Does > wait_event show any backends doing synchronous IO? How many does [1] > want to run for that test workload and does it help? > I'm not sure how to determine what concurrency it "wants". All I know is that for "warm" runs [1], the basic index prefetch patch uses distance ~2.0 on average, and is ~2x slower than master. And with the patches the distance is ~270, and it's 30% slower than master. (IIRC there's about 30% misses, so 270 is fairly high. Can't check now, the machine is running other tests.) Not sure about wait events, but I don't think any backends are doing sychnronous I/O. There's only that one query running, and it's using AIO (except for the index, which is still read synchronously). Likewise, I don't think there's insufficient number of workers. I've tried with 3 and 12 workers, and there's virtually no difference between those. IIRC when watching "top", I've never seen more than 1 or maybe 2 workers active (using CPU). [1] https://www.postgresql.org/message-id/attachment/180630/ryzen-warm.pdf [2] https://www.postgresql.org/message-id/293a4735-79a4-499c-9a36-870ee9286281%40vondra.me > FWIW there's a very simple canned latency test in a SQL function in > the first message in that thread (0005-XXX-read_buffer_loop.patch), > just on the off-chance that it's useful as a starting point for other > ideas. There I was interested in IPC overheads, latch collapsing and > other effects, so I was deliberately stalling on/evicting a single > block repeatedly without any readahead distance, so I wasn't letting > the stream "hide" IPC overheads. > > [1] https://www.postgresql.org/message-id/flat/CA%2BhUKG%2Bm4xV0LMoH2c%3DoRAdEXuCnh%2BtGBTWa7uFeFMGgTLAw%2BQ%40mail.gmail.com Interesting, I'll give it a try tomorrow. Do you recall if the results were roughly in line with results of my signal IPC test? regards -- Tomas Vondra
On Thu, Aug 28, 2025 at 7:01 PM Tomas Vondra <tomas@vondra.me> wrote: > I'm not sure how to determine what concurrency it "wants". All I know is > that for "warm" runs [1], the basic index prefetch patch uses distance > ~2.0 on average, and is ~2x slower than master. And with the patches the > distance is ~270, and it's 30% slower than master. (IIRC there's about > 30% misses, so 270 is fairly high. Can't check now, the machine is > running other tests.) Is it possible that the increased distance only accidentally ameliorates the IPC issues that you're seeing with method=worker? I mentioned already that it makes things a bit slower with io_uring, for the same test case. I mean, if you use io_uring then things work out strictly worse with that extra patch...so something doesn't seem right. I notice that the test case in question manages to merge plenty of reads together with other pending reads, within read_stream_look_ahead (I added something to our working branch that'll show that information in EXPLAIN ANALYZE). My wild guess is that an increased distance could interact with that, somewhat masking the IPC problems with method=worker. Could that explain it? It seems possible that the distance is already roughly optimal, without your patch (or Thomas' similar read stream patch). It may be that we just aren't converging on "no prefetch" behavior when we ought to, given such a low distance. If this theory of mine was correct, it would reconcile the big differences we see between "worker vs io_uring" with your patch + test case. -- Peter Geoghegan
Hi, On 2025-08-29 01:00:58 +0200, Tomas Vondra wrote: > I'm not sure how to determine what concurrency it "wants". All I know is > that for "warm" runs [1], the basic index prefetch patch uses distance > ~2.0 on average, and is ~2x slower than master. And with the patches the > distance is ~270, and it's 30% slower than master. (IIRC there's about > 30% misses, so 270 is fairly high. Can't check now, the machine is > running other tests.) There got to be something wrong here, I don't see a reason why at any meaningful distance it'd be slower. What set of patches do I need to repro the issue? And what are the complete set of pieces to load the data? https://postgr.es/m/293a4735-79a4-499c-9a36-870ee9286281%40vondra.me has the query, but afaict not enough information to infer init.sql > Not sure about wait events, but I don't think any backends are doing > sychnronous I/O. There's only that one query running, and it's using AIO > (except for the index, which is still read synchronously). > > Likewise, I don't think there's insufficient number of workers. I've > tried with 3 and 12 workers, and there's virtually no difference between > those. IIRC when watching "top", I've never seen more than 1 or maybe 2 > workers active (using CPU). That doesn't say much - if the they are doing IO, they're not on CPU... Greetings, Andres Freund
On 8/28/25 21:52, Andres Freund wrote: > Hi, > > On 2025-08-28 19:08:40 +0200, Tomas Vondra wrote: >> On 8/28/25 18:16, Andres Freund wrote: >>>> So I think the IPC overhead with "worker" can be quite significant, >>>> especially for cases with distance=1. I don't think it's a major issue >>>> for PG18, because seq/bitmap scans are unlikely to collapse the distance >>>> like this. And with larger distances the cost amortizes. It's much >>>> bigger issue for the index prefetching, it seems. >>> >>> I couldn't keep up with all the discussion, but is there actually valid I/O >>> bound cases (i.e. not ones were we erroneously keep the distance short) where >>> index scans end can't have a higher distance? >>> >> >> I don't know, really. >> >> Is the presented exaple really a case of an "erroneously short >> distance"? > > I think the query isn't actually measuring something particularly useful in > the general case. You're benchmarking something were the results are never > looked at - which means the time between two index fetches is unrealistically > short. That means any tiny latency increase matters a lot more than with > realistic queries. > Sure, is a "microbenchmark" focusing on index scans. The point of not looking at the result is to isolate the index scan, and it's definitely true that if the query did some processing (e.g. feeding it into an aggregate or something), the relative difference would be smaller. But the absolute difference would likely remain about the same. I don't think the submitting the I/O and then not waiting long enough before actually reading the block is a significant factor here. It does affect even the "warm" runs (that do no actual I/O), and most of the difference seems to match the IPC cost. And AFAICS that cost dost not change if the delay increases, we still need to send two signals. > And this is, IIUC, on a local SSD. I'd bet that on cloud latencies AIO would > still be a huge win. > True, but only for cold runs that actually do I/O. The results for the warm runs show regressions too, although smaller ones. And that would affect any kind of storage (with buffered I/O). Also, I'm not sure "On slow storage it does not regress," is a very strong argument ;-) > >> From the 2x regression (compared to master) it might seem like that, but >> even with the increased distance it's still slower than master (by 25%). So >> maybe the "error" is to use AIO in these cases, instead of just switching to >> I/O done by the backend. > > If it's slower at a higher distance, we're missing something. > There's one weird thing I just realized - I don't think I ever saw more than a single I/O worker consuming CPU (in top), even with the higher distance. I'm not 100% sure about it, need to check tomorrow. IIRC the CPU utilization with "collapsed " distance ~2.0 was about backend: 60% ioworker: 40% and with the patches increasing the distance it was more like backend: 100% ioworker: 50% But I think it was still just one ioworker. I wonder if that's OK, intentional, or if it might be an issue ... > >> It may be a bit worse for non-btree indexes, e.g. for for ordered scans >> on gist indexes (getting the next tuple may require reading many leaf >> pages, so maybe we can't look too far ahead?). Or for indexes with >> naturally "fat" tuples, which limits how many tuples we see ahead. > > I am not worried at all about those cases. If you have to read a lot of index > leaf pages to get a heap fetch, a distance of even just 2 will be fine, > because the IPC overhead is a neglegible cost compared to the index > processing. Similarly, if you have to do very deep index traversals due to > wide index tuples, there's going to be more time between two table fetches. > Most likely, yes. > >>> Obviously you can construct cases with a low distance by having indexes point >>> to a lot of tiny tuples pointing to perfectly correlated pages, but in that >>> case IO can't be a significant factor. >>> >> >> It's definitely true the examples the script finds are "adversary", but >> also not entirely unrealistic. > > I think doing index scans where the results are just thrown out are entirely > unrealistic... > True, it's a microbenchmark focused on a specific operation. But I don't think it makes it unrealistic, even though the impact on real-world queries will be smaller. But I know what you mean. > >> I suppose there will be such cases for any heuristics we come up with. > > Agreed. > > >> There's probably more cases like this, where we end up with many hits. >> Say, a merge join may visit index tuples repeatedly, and so on. But then >> it's likely in shared buffers, so there won't be any IPC. > > Yea, I'd not expect a meaningful impact of any of this in a workload like > that. > regards -- Tomas Vondra
On 8/29/25 01:27, Andres Freund wrote: > Hi, > > On 2025-08-29 01:00:58 +0200, Tomas Vondra wrote: >> I'm not sure how to determine what concurrency it "wants". All I know is >> that for "warm" runs [1], the basic index prefetch patch uses distance >> ~2.0 on average, and is ~2x slower than master. And with the patches the >> distance is ~270, and it's 30% slower than master. (IIRC there's about >> 30% misses, so 270 is fairly high. Can't check now, the machine is >> running other tests.) > > There got to be something wrong here, I don't see a reason why at any > meaningful distance it'd be slower. > > What set of patches do I need to repro the issue? > Use this branch: https://github.com/tvondra/postgres/commits/index-prefetch-master/ and then Thomas' patch that increases the prefetch distance: https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com (IIRC there's a trivial conflict in read_stream_reset.). > And what are the complete set of pieces to load the data? > https://postgr.es/m/293a4735-79a4-499c-9a36-870ee9286281%40vondra.me > has the query, but afaict not enough information to infer init.sql > Yeah, I forgot to include that piece, sorry. Here's an init.sql, that loads the table, it also has the query. > >> Not sure about wait events, but I don't think any backends are doing >> sychnronous I/O. There's only that one query running, and it's using AIO >> (except for the index, which is still read synchronously). >> >> Likewise, I don't think there's insufficient number of workers. I've >> tried with 3 and 12 workers, and there's virtually no difference between >> those. IIRC when watching "top", I've never seen more than 1 or maybe 2 >> workers active (using CPU). > > That doesn't say much - if the they are doing IO, they're not on CPU... > True. But one worker did show up in top, using a fair amount of CPU, so why wouldn't the others (if they process the same stream)? regards -- Tomas Vondra
Вложения
On Thu, Aug 28, 2025 at 7:52 PM Tomas Vondra <tomas@vondra.me> wrote: > Use this branch: > > https://github.com/tvondra/postgres/commits/index-prefetch-master/ > > and then Thomas' patch that increases the prefetch distance: > > > https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com > > (IIRC there's a trivial conflict in read_stream_reset.). I found it quite hard to apply Thomas' patch. There's actually 3 patches, with 2 earlier patches needed for earlier in the thread. And, there were significant merge conflicts to work around. I'm not sure that Thomas'/your patch to ameliorate the problem on the read stream side is essential here. Perhaps Andres can just take a look at the test case + feature branch, without the extra patches. That way he'll be able to see whatever the immediate problem is, which might be all we need. -- Peter Geoghegan
On 8/29/25 01:57, Peter Geoghegan wrote: > On Thu, Aug 28, 2025 at 7:52 PM Tomas Vondra <tomas@vondra.me> wrote: >> Use this branch: >> >> https://github.com/tvondra/postgres/commits/index-prefetch-master/ >> >> and then Thomas' patch that increases the prefetch distance: >> >> >> https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com >> >> (IIRC there's a trivial conflict in read_stream_reset.). > > I found it quite hard to apply Thomas' patch. There's actually 3 > patches, with 2 earlier patches needed for earlier in the thread. And, > there were significant merge conflicts to work around. > I don't think the 2 earlier patches are needed, I only ever applied the one in the linked message. But you're right there were more merge conflicts, I forgot about that. Here's a patch that should apply on top of the prefetch branch. > I'm not sure that Thomas'/your patch to ameliorate the problem on the > read stream side is essential here. Perhaps Andres can just take a > look at the test case + feature branch, without the extra patches. > That way he'll be able to see whatever the immediate problem is, which > might be all we need. > AFAICS Andres was interested in reproducing the regression with an increased distance. Or maybe I got it wrong. regards -- Tomas Vondra
Вложения
Hi, On 2025-08-28 19:57:17 -0400, Peter Geoghegan wrote: > On Thu, Aug 28, 2025 at 7:52 PM Tomas Vondra <tomas@vondra.me> wrote: > > Use this branch: > > > > https://github.com/tvondra/postgres/commits/index-prefetch-master/ > > > > and then Thomas' patch that increases the prefetch distance: > > > > > > https://www.postgresql.org/message-id/CA%2BhUKGL2PhFyDoqrHefqasOnaXhSg48t1phs3VM8BAdrZqKZkw%40mail.gmail.com > > > > (IIRC there's a trivial conflict in read_stream_reset.). > > I found it quite hard to apply Thomas' patch. There's actually 3 > patches, with 2 earlier patches needed for earlier in the thread. And, > there were significant merge conflicts to work around. Same. Tomas, could you share what you applied? > I'm not sure that Thomas'/your patch to ameliorate the problem on the > read stream side is essential here. Perhaps Andres can just take a > look at the test case + feature branch, without the extra patches. > That way he'll be able to see whatever the immediate problem is, which > might be all we need. It seems caused to a significant degree by waiting at low queue depths. If I comment out the stream->distance-- in read_stream_start_pending_read() the regression is reduced greatly. As far as I can tell, after that the process is CPU bound, i.e. IO waits don't play a role. I see a variety for increased CPU usage: 1) The private ref count infrastructure in bufmgr.c gets a bit slower once more buffers are pinned 2) signalling overhead to the worker - I think we are resetting the latch too eagerly, leading to unnecessarily many signals being sent to the IO worker. 3) same issue with the resowner tracking But there's some additional difference in performance I don't yet understand... Greetings, Andres Freund
On Thu, Aug 28, 2025 at 9:10 PM Andres Freund <andres@anarazel.de> wrote: > Same. Tomas, could you share what you applied? Tomas posted a self-contained patch to the list about an hour ago? > > I'm not sure that Thomas'/your patch to ameliorate the problem on the > > read stream side is essential here. Perhaps Andres can just take a > > look at the test case + feature branch, without the extra patches. > > That way he'll be able to see whatever the immediate problem is, which > > might be all we need. > > It seems caused to a significant degree by waiting at low queue depths. If I > comment out the stream->distance-- in read_stream_start_pending_read() the > regression is reduced greatly. IIUC, that is very roughly equivalent to what the patch actually does. The fastest configuration of all, independent of io_method, is "enable_indexscan_prefetch=off". So it's hard to believe that the true underlying problem is low queue depth. Though I certainly don't doubt that higher queue depths will help *when io_method=worker*. -- Peter Geoghegan
On Fri, Aug 29, 2025 at 11:52 AM Tomas Vondra <tomas@vondra.me> wrote: > True. But one worker did show up in top, using a fair amount of CPU, so > why wouldn't the others (if they process the same stream)? It deliberately concentrates wakeups into the lowest numbered workers that are marked idle in a bitmap. * higher numbered workers snooze and eventually time out (with the patches for 19 that make the pool size dynamic) * busy workers have a better chance of staying on CPU between one job and the next * minimised duplication of various caches and descriptors Every other wakeup routing strategy I've tried so far performed worse in both avg(latency) and stddev(latency). I have wondered if we might want to consider per-NUMA-node IO worker pools with their own submission queues. Not investigated, but I suppose it might possibly help with the submission queue lock, cache line ping pong for buffer headers that the worker touches on completion, and inter-process interrupts. I don't know where to draw the line with a potential optimisations to IO worker mode that would realistically only help on Linux today, when the main performance plan for Linux is io_uring.
Hi,
I spent a fair bit more time analyzing this issue.
On 2025-08-28 21:10:48 -0400, Andres Freund wrote:
> On 2025-08-28 19:57:17 -0400, Peter Geoghegan wrote:
> > On Thu, Aug 28, 2025 at 7:52 PM Tomas Vondra <tomas@vondra.me> wrote:
> > I'm not sure that Thomas'/your patch to ameliorate the problem on the
> > read stream side is essential here. Perhaps Andres can just take a
> > look at the test case + feature branch, without the extra patches.
> > That way he'll be able to see whatever the immediate problem is, which
> > might be all we need.
>
> It seems caused to a significant degree by waiting at low queue depths. If I
> comment out the stream->distance-- in read_stream_start_pending_read() the
> regression is reduced greatly.
>
> As far as I can tell, after that the process is CPU bound, i.e. IO waits don't
> play a role.
Indeed the actual AIO subsystem is unrelated, from what I can tell:
I hacked up read_stream.c/bufmgr.c to do readahead even if the buffer is in
shared_buffers. With that, the negative performance impact of doing
enable_indexscan_prefetch=1 is of a similar magnitude even if the table is
already entirely in shared buffers. I.e. actual IO is unrelated.
I compared perf stat -ddd output for enable_indexscan_prefetch=0 with
enable_indexscan_prefetch=1. The only real difference is a substantial (~3x)
increase in branch misses.
I then took a perf profile to see where all those misses are from.
The first souce is:
> I see a variety for increased CPU usage:
>
> 1) The private ref count infrastructure in bufmgr.c gets a bit slower once
> more buffers are pinned
The problem mainly seems to be that the branches in the loop at the start of
GetPrivateRefCountEntry() are entirely unpredictable in this workload. I had
an old patch that tried to make it possible to use SIMD for the search, by
using a separate array for the Buffer ids - with that gcc generates fairly
crappy code, but does make the code branchless.
Here that substantially reduces the overhead of doing prefetching. Afterwards
it's not a meaningful source of misses anymore.
> 3) same issue with the resowner tracking
This one is much harder to address:
a) The "key" we are searching for is much wider (16 bytes), making
vectorization of the search less helpful
b) because we search up to owner->narr instead of a fixed-length, the compiler
wouldn't be able to auto-vectorize anyway
c) the branch-misses are partially caused by ResourcOwnerForget() "scrambling"
the order in the array when forgetting an element
I don't know how to fix this right now. I nevertheless wanted to see how big
the impact of this is, so I just neutered
ResourceOwner{Remember,Forget}{Buffer,BufferIO} - that's obviously not
correct, but suffices to see that the performance difference reduces
substantially.
But not completely, unfortunately.
> But there's some additional difference in performance I don't yet
> understand...
I still don't think I fully understand why the impact of this is so large. The
branch misses appear to be the only thing differentiating the two cases, but
with resowners neutralized, the remaining difference in branch misses seems
too large - it's not like the sequence of block numbers is more predictable
without prefetching...
The main increase in branch misses is in index_scan_stream_read_next...
Greetings,
Andres Freund
On Wed, Sep 3, 2025 at 2:47 PM Andres Freund <andres@anarazel.de> wrote: > I still don't think I fully understand why the impact of this is so large. The > branch misses appear to be the only thing differentiating the two cases, but > with resowners neutralized, the remaining difference in branch misses seems > too large - it's not like the sequence of block numbers is more predictable > without prefetching... > > The main increase in branch misses is in index_scan_stream_read_next... I've been working on fixing the same regressed query, but using a completely different (though likely complementary) approach: by adding a test to index_scan_stream_read_next that detects when prefetching isn't favorable. If it isn't favorable, then we stop prefetching entirely (we fall back on regular sync I/O). Although this experimental approach is still very rough, it seems promising. It ~100% fixes the problem at hand, without really creating any new problems (at least as far as our testing has been able to determine, so far). The key idea is to wait until a few batches have already been read, and then test whether the index-tuple-wise "distance" between readPos (the read position) and streamPos (the stream position used by index_scan_stream_read_next) remained excessively low within index_scan_stream_read_next. If, after processing 20 batches/leaf pages, readPos and streamPos still read from the same batch *and* have a low index-tuple-wise position within that batch (they're within 10 or 20 items of each other), we expect "thrashing", which makes prefetching unfavorable -- and so we just stop using our read stream. It's worth noting that (given the current structure of the patch) it is inherently impossible to do something like this from within the read stream. We're suppressing duplicate heap block requests iff the blocks are contiguous within the index. So read stream just doesn't see anything like what I'm calling the "index-tuple-wise distance" between readPos and streamPos. Note that the baseline behavior for the test case (the behavior with master, or with prefetching disabled) appears to be very I/O bound, due to readahead. I've confirmed this using iostat. So "synchronous" I/O isn't very synchronous here. (Prefetching actually does make sense when this query is run with direct I/O, but that's far slower with or without the use of explicit prefetching, so that likely doesn't tell us much.) -- Peter Geoghegan
Hi, On 2025-09-03 15:33:30 -0400, Peter Geoghegan wrote: > On Wed, Sep 3, 2025 at 2:47 PM Andres Freund <andres@anarazel.de> wrote: > > I still don't think I fully understand why the impact of this is so large. The > > branch misses appear to be the only thing differentiating the two cases, but > > with resowners neutralized, the remaining difference in branch misses seems > > too large - it's not like the sequence of block numbers is more predictable > > without prefetching... > > > > The main increase in branch misses is in index_scan_stream_read_next... > > I've been working on fixing the same regressed query, but using a > completely different (though likely complementary) approach: by adding > a test to index_scan_stream_read_next that detects when prefetching > isn't favorable. If it isn't favorable, then we stop prefetching > entirely (we fall back on regular sync I/O). The issue to me is that this kind of query actually *can* substantially benefit from prefetching, no? Afaict the performance without prefetching is rather atrocious as soon as a) storage has a tad higher latency or b) DIO is used. Indeed: With DIO, readahead provides a ~2.6x improvement for the query at hand. I continue to be worried that we're optimizing for queries that have no real-world relevance. The regression afaict is contingent on 1) An access pattern that is unpredictable to the CPU (due to the use of random() as part of ORDER BY during the data generation) 2) Index and heap are somewhat correlated, but fuzzily, i.e. there are backward jumps in the heap block numbers being fetched 3) There are 1 - small_number tuples on one heap tables 4) The query scans a huge number of tuples, without actually doing any meaningful analysis on the tuples. As soon as one does meaningful work for returned tuples, the small difference in per-tuple CPU costs vanishes 5) The query visits all heap pages within a range, just not quite in order. Without that the kernel readahead would not work and the query's performance without readahead would be terrible even on low-latency storage This just doesn't strike me as a particularly realistic combination of factors? I suspect we could more than eat back the loss in performance by doing batched heap_hot_search_buffer()... Greetings, Andres Freund
On Wed, Sep 3, 2025 at 4:06 PM Andres Freund <andres@anarazel.de> wrote: > The issue to me is that this kind of query actually *can* substantially > benefit from prefetching, no? As far as I can tell, not really, no. > Afaict the performance without prefetching is > rather atrocious as soon as a) storage has a tad higher latency or b) DIO is > used. I don't know that storage latency matters, when (without DIO) we're doing so well from readahead. > Indeed: With DIO, readahead provides a ~2.6x improvement for the query at hand. I don't see that level of improvement with DIO. For me it's 6054.921 ms with prefetching, 8766.287 ms without it. I can kind of accept the idea that in some sense readahead shouldn't count too much, since the future is DIO. But it's not like aggressive prefetching matches the performance of buffered I/O + readahead. Not for me, at any rate. I don't know why. > I continue to be worried that we're optimizing for queries that have no > real-world relevance. I'm not at all surprised that we're spending so much time on weird queries. For one thing, the real world queries are already much improved. For another, in order to accept a trade-off like this, we have to actually know what it is we're accepting. And how easy/hard it is to do better (we may very well be able to fix this problem at no great cost in complexity). > This just doesn't strike me as a particularly realistic combination of > factors? I agree. I just don't think that we've done enough work on this to justify accepting it as a cost of doing business. We might well do that at some point in the near future. > I suspect we could more than eat back the loss in performance by doing batched > heap_hot_search_buffer()... Maybe, but I don't think that we're all that likely to get that done for 19. -- Peter Geoghegan
Hi, On 2025-09-03 16:25:56 -0400, Peter Geoghegan wrote: > On Wed, Sep 3, 2025 at 4:06 PM Andres Freund <andres@anarazel.de> wrote: > > The issue to me is that this kind of query actually *can* substantially > > benefit from prefetching, no? > > As far as I can tell, not really, no. It seems to here - I see small wins even with kernel readahead, fwiw. > > Afaict the performance without prefetching is > > rather atrocious as soon as a) storage has a tad higher latency or b) DIO is > > used. > > I don't know that storage latency matters, when (without DIO) we're > doing so well from readahead. The readahead linux does actually is not aggressive enough once you have higher IO latency - you can tune it up, but then it often does too much IO. > > Indeed: With DIO, readahead provides a ~2.6x improvement for the query at hand. > > I don't see that level of improvement with DIO. For me it's 6054.921 > ms with prefetching, 8766.287 ms without it. I guess your SSD has lower latency than mine... > I can kind of accept the idea that in some sense readahead shouldn't > count too much, since the future is DIO. But it's not like aggressive > prefetching matches the performance of buffered I/O + readahead. Not > for me, at any rate. I don't know why. It does here, just about. The reason for not matching is fairly simple: The kernel readahead issues large reads, but with DIO we don't for this query. The adversarial pattern here rarely has two consecutive neighboring blocks, so nearly all reads are 8kB reads. This actually might be the thing to tackle to avoid this and other similar regressions: If we were able to isssue combined IOs for interspersed patterns like we have in this query, we'd easily win back the overhead. And it'd make DIO much much better. We don't want to do try to find more complicated merges for things like seqscans and bitmap heap scans, there never can be anything other than merges of consecutive blocks, and the CPU overhead of the more complicated search would likely be noticeable. But for something like index scans that's different. I don't quite know if this is best done as an optional feature for read streams, a layer atop read stream or something dedicated. For now I'll go back to working on read stream test infrastructure. That's the prerequisite for testing the "don't synchronously wait for in-progress IO" improvement. And if we want to have more complicated merging, that also seems like something much easier to develop with some testing infra. Greetings, Andres Freund
On Wed, Sep 3, 2025 at 8:16 PM Andres Freund <andres@anarazel.de> wrote: > > I don't see that level of improvement with DIO. For me it's 6054.921 > > ms with prefetching, 8766.287 ms without it. > > I guess your SSD has lower latency than mine... It's nothing special: a 4 year old Samsung 980 pro. > This actually might be the thing to tackle to avoid this and other similar > regressions: If we were able to isssue combined IOs for interspersed patterns > like we have in this query, we'd easily win back the overhead. And it'd make > DIO much much better. That sounds very plausible to me. I don't think it's at all unusual for index scans to do this (that particular aspect of the test case query wasn't unrealistic). In general this seems important to me. > I don't quite know if this is best done as an optional feature for read > streams, a layer atop read stream or something dedicated. My guess is that it would work best as an optional feature for read streams. A flag like READ_STREAM_REPEAT_READS that's passed to read_stream_begin_relation might work best. > For now I'll go back to working on read stream test infrastructure. That's the > prerequisite for testing the "don't synchronously wait for in-progress IO" > improvement. "don't synchronously wait for in-progress IO" is also very important to this project. Thanks for your help with that. > And if we want to have more complicated merging, that also seems > like something much easier to develop with some testing infra. Great. -- Peter Geoghegan
On 9/3/25 22:06, Andres Freund wrote: > ... > > I continue to be worried that we're optimizing for queries that have no > real-world relevance. The regression afaict is contingent on > > 1) An access pattern that is unpredictable to the CPU (due to the use of > random() as part of ORDER BY during the data generation) > > 2) Index and heap are somewhat correlated, but fuzzily, i.e. there are > backward jumps in the heap block numbers being fetched > Aren't those two points rather contradictory? Why would it matter that the data generator uses random() in the ORDER BY? Seems entirely irrelevant, if the generated table is "somewhat correlated". Which seems pretty normal in real-world data sets ... > 3) There are 1 - small_number tuples on one heap tables > What would you consider a reasonable number of tuples on one heap page? The current tests generate data with 20-100 tuples per page, which seems pretty reasonable to me. I mean, that's 80-400B per tuple. Sure, I could generate data with narrower tuples, but would that be more realistic? I doubt that. FWIW it's not like the regressions only happen on fillfactor=20, with 20 tuples/page. It happens on fillfactor=100 (sure, the impact is smaller). > 4) The query scans a huge number of tuples, without actually doing any > meaningful analysis on the tuples. As soon as one does meaningful work for > returned tuples, the small difference in per-tuple CPU costs vanishes > I believe I already responded to this before. Sure, the relative regression will get smaller. But I don't see why would the absolute difference get smaller. > 5) The query visits all heap pages within a range, just not quite in > order. Without that the kernel readahead would not work and the query's > performance without readahead would be terrible even on low-latency storage > I'm sorry, I don't quite understand what this says :-( Or why would that mean the issues triggered by the generated data sets are not valid even for real-world queries. > This just doesn't strike me as a particularly realistic combination of > factors? > Aren't plenty of real-world data sets correlated, but not perfectly? In any case, I'm the first one to admit these data sets are synthetic. It's meant to generate data sets that gradually shift from perfectly ordered to random, increasing number of duplicates, etc. The point was to cover a wider range of data sets, not just a couple "usual" ones. It's possible some of these data sets are not realistic, in which case we can choose to ignore them and the regressions. The approach tends to find "adversary" cases, hit corner cases (not necessarily as rare as assumed), etc. But the issues we ran into so far seem perfectly valid (or at least useful to think about). regards -- Tomas Vondra
On Thu, Sep 4, 2025 at 2:55 PM Tomas Vondra <tomas@vondra.me> wrote: > Aren't plenty of real-world data sets correlated, but not perfectly? Attached is the latest revision of the prefetching patch, taken from the shared branch that Tomas and I have been working on for some weeks. This revision is the first "official revision" that uses the complex approach, which we agreed was the best approach right before we started collaborating through this shared branch. While Tomas and I have posted versions of this "complex" approach at various times, those were "unofficial" previews of different approaches. Whereas this is the latest official patch revision of record, that should be tested by CFTester for the prefetch patch's CF entry, etc. We haven't done a good job of maintaining an unambiguous, easy to test "official" CF entry patch before now. That's why I'm being explicit about what this patch revision represents. It's the shared work of Tomas and I; it isn't some short-term experimental fork. Future revisions will be incremental improvements on what I'm posting now. Our focus has been on fixing a variety of regressions that came to light following testing by Tomas. There are a few bigger changes that are intended to fix these regressions, plus lots of small changes. There's too many small changes to list. But the bigger changes are: * We're now carrying Andres' patch [1] that deals with inefficiencies on the read stream side [2]. We need this to get decent performance with certain kinds of index scans where the same heap page buffer needs to be read multiple times in close succession. * We now delay prefetching/creating a new read stream until after we've already read one index batch, with the goal of avoiding regressions on cheap, selective queries (e.g., pgbench SELECT). This optimization has been referred to as the "priorbatch" optimization earlier in this thread. * The third patch is a new one, authored by Tomas. It aims to ameliorate nestloop join regressions by caching memory used to store batches across rescans. This is still experimental. * The regression that we were concerned about most recently [3][4] is fixed by a new mechanism that sometimes disables prefetching/the read stream some time prefetching begins, having already read a small number of batches with prefetching -- the INDEX_SCAN_MIN_TUPLE_DISTANCE optimization. This is also experimental. But it does fully fix the problem at hand, without any read stream changes. (This is part of the main prefetching patch.) This works like the "priorbatch" optimization, but in reverse. We *unset* the scan's read stream when our INDEX_SCAN_MIN_TUPLE_DISTANCE test shows that prefetching hasn't worked out (as opposed to delaying starting it up until it starts to look like prefetching might help). Like the "priorbatch" optimization, this optimization is concerned with fixed prefetching costs that cannot possibly pay for themselves. Note that we originally believed that the regression in question [3][4] necessitated more work on the read stream side, to directly account for the way that we saw prefetch distance collapse to 2.0 for the entire scan. But our current thinking is that the regression in question occurs with scans where wholly avoiding prefetching is the right goal. Which is why, tentatively, we're addressing the problem within indexam.c itself (not in the read stream), by adding this new INDEX_SCAN_MIN_TUPLE_DISTANCE test to the read stream callback. This means that various experimental read stream distance patches [3][5] that initially seemed relevant no longer appear necessary (and so aren't included in this new revision at all). Much cleanup work remains to get the changes I just described in proper shape (to say nothing about open items that we haven't made a start on yet, like moving the read stream out of indexam.c and into heapam). But it has been too long since the last revision. I'd like to establish a regular cadence for posting new revisions of the patch set. [1] https://postgr.es/m/6butbqln6ewi5kuxz3kfv2mwomnlgtate4mb4lpa7gb2l63j4t@stlwbi2dvvev [2] https://postgr.es/m/kvyser45imw3xmisfvpeoshisswazlzw35el3fq5zg73zblpql@f56enfj45nf7 [3] https://postgr.es/m/8f5d66cf-44e9-40e0-8349-d5590ba8efb4@vondra.me [4] https://github.com/tvondra/postgres/blob/index-prefetch-master/microbenchmarks/tomas-weird-issue-readstream.sql [5] https://postgr.es/m/CA+hUKG+9Qp=E5XWE+_1UPCxULLXz6JrAY=83pmnJ5ifupH-NSA@mail.gmail.com -- Peter Geoghegan
Вложения
On 9/11/25 00:24, Peter Geoghegan wrote: > On Thu, Sep 4, 2025 at 2:55 PM Tomas Vondra <tomas@vondra.me> wrote: >> Aren't plenty of real-world data sets correlated, but not perfectly? > > Attached is the latest revision of the prefetching patch, taken from > the shared branch that Tomas and I have been working on for some > weeks. > > This revision is the first "official revision" that uses the complex > approach, which we agreed was the best approach right before we > started collaborating through this shared branch. While Tomas and I > have posted versions of this "complex" approach at various times, > those were "unofficial" previews of different approaches. Whereas this > is the latest official patch revision of record, that should be tested > by CFTester for the prefetch patch's CF entry, etc. > > We haven't done a good job of maintaining an unambiguous, easy to test > "official" CF entry patch before now. That's why I'm being explicit > about what this patch revision represents. It's the shared work of > Tomas and I; it isn't some short-term experimental fork. Future > revisions will be incremental improvements on what I'm posting now. > Indeed, the thread is very confusing as it mixes up different approaches, various experimental patches etc. Thank you for cleaning this up, and doing various other fixes. > Our focus has been on fixing a variety of regressions that came to > light following testing by Tomas. There are a few bigger changes that > are intended to fix these regressions, plus lots of small changes. > > There's too many small changes to list. But the bigger changes are: > > * We're now carrying Andres' patch [1] that deals with inefficiencies > on the read stream side [2]. We need this to get decent performance > with certain kinds of index scans where the same heap page buffer > needs to be read multiple times in close succession. > > * We now delay prefetching/creating a new read stream until after > we've already read one index batch, with the goal of avoiding > regressions on cheap, selective queries (e.g., pgbench SELECT). This > optimization has been referred to as the "priorbatch" optimization > earlier in this thread. > > * The third patch is a new one, authored by Tomas. It aims to > ameliorate nestloop join regressions by caching memory used to store > batches across rescans. > > This is still experimental. > Yeah. I realize the commit message does not explain the motivation, so let me fix that - the batches are pretty much the same thing as ~BTScanPosData, which means it's ~30KB struct. That means it's not cached in memory contexts, but each palloc/pfree is malloc/free. That's already a known problem (e.g. for scans on partitioned tables), but batches make it worse - we now need more instances of the struct. So it's even more important to not do far more malloc/free calls. It's not perfect, but it was good enough to eliminate the overhead. > * The regression that we were concerned about most recently [3][4] is > fixed by a new mechanism that sometimes disables prefetching/the read > stream some time prefetching begins, having already read a small > number of batches with prefetching -- the > INDEX_SCAN_MIN_TUPLE_DISTANCE optimization. > > This is also experimental. But it does fully fix the problem at hand, > without any read stream changes. (This is part of the main prefetching > patch.) > > This works like the "priorbatch" optimization, but in reverse. We > *unset* the scan's read stream when our INDEX_SCAN_MIN_TUPLE_DISTANCE > test shows that prefetching hasn't worked out (as opposed to delaying > starting it up until it starts to look like prefetching might help). > Like the "priorbatch" optimization, this optimization is concerned > with fixed prefetching costs that cannot possibly pay for themselves. > > Note that we originally believed that the regression in question > [3][4] necessitated more work on the read stream side, to directly > account for the way that we saw prefetch distance collapse to 2.0 for > the entire scan. But our current thinking is that the regression in > question occurs with scans where wholly avoiding prefetching is the > right goal. Which is why, tentatively, we're addressing the problem > within indexam.c itself (not in the read stream), by adding this new > INDEX_SCAN_MIN_TUPLE_DISTANCE test to the read stream callback. This > means that various experimental read stream distance patches [3][5] > that initially seemed relevant no longer appear necessary (and so > aren't included in this new revision at all). > Yeah, this heuristics seems very effective in eliminating the regression (at least judging by the test results I've seen so far). Two or three question bother me about it, though: 1) I'm not sure I fully understand how the heuristics works, i.e. how tracking "tuple distance" in index AM identifies queries where prefetching can't pay for itself. It's hard to say if the tuple distance is a good predictor of that. It seems to be in case of the regressed query, I don't dispute that. AFAICS the reasoning is: We're prefetching too close ahead, so close the I/O can't possibly complete, and the overhead of submitting the I/O using AIO is higher than what what async "saves". That's great, but is the distance a good measure of that? It has no concept of what happens prefetching and reading a block, during the "distance". In the test queries it's virtually nothing, because the query doesn't do anything with the rows. For more complex queries there could be plenty of time for the I/O to complete. Of course, if the query is complex, and the I/O complete n time even for short distances, it's likely not a huge relative difference ... 2) It's a one-time decision, not adaptive. We start prefetching, and then at some point (not too long after the scan starts) we make a decision whether to continue with prefetching or not. And if we disable it, it's disabled forever. That's fine for the synthetic data sets we use for testing, because those are synthetic. I'm not sure it'll work this well for real-world data sets where different parts of the file may be very different. This is perfectly fine for a WIP patch, but I believe we should try to make this adaptive. Which probably means we need to invent a "light" version of read_stream that initially does sync I/O, and only switches to async (with all the expensive initialization) later. And then can switch back to sync, but is ready to maybe start prefetching again if the data pattern changes. 3) Now that I look at the code in index_scan_stream_read_next, it feels a bit weird we do the decision based on the "immediate" distance only. I suspect this may make it quite fragile, in the sense that even a small local irregularity in the data may result in different "step" changes. Wouldn't it be better to base this on some "average" distance? In other words, I'm afraid (2) and (3) are pretty much a "performance cliff", where a tiny difference in the input can result in wildly different behavior. > Much cleanup work remains to get the changes I just described in > proper shape (to say nothing about open items that we haven't made a > start on yet, like moving the read stream out of indexam.c and into > heapam). But it has been too long since the last revision. I'd like to > establish a regular cadence for posting new revisions of the patch > set. > Thank you! I appreciate the collaboration, it's a huge help. I kept running the stress test, trying to find cases that regress, and also to better understand the behavior. The script/charts are available here: https://github.com/tvondra/prefetch-tests So far I haven't found any massive regressions (relative to master). There are data sets where we regress by a couple percent (and it's not noise). I haven't looked into the details, but I believe most of this can be attributed to the "AIO costs" we discussed recently (with signals), and similar things. I'm attaching three charts, comparing master to "patched" build with the 20250910 patch applied. I don't think I posted these charts before, so let me explain a bit. Each chart is a simple XY chart, comparing timings from master (x-axis) to patched build (y-axis). Data points on the diagonal mean "same performance", below diagonal is "patched is faster", above diagonal is "master is faster". So the close the data point is to x-axis the better, and we want few points above the diagonal, because those are regressions. The colors identify different data sets. The script (available in git repo) generates data sets with different parameters (number of distinct values, randomness, ...), and the prefetch behavior depends on that. The charts are from three different setups, with different types of SSD storage (SATA RAID, NVMe RAID, single NVMe drive). There are some differences, but the overall behavior is quite similar. Note: The charts show different number of data sets, the data sets are not comparable. Each run generates new random parameters, so the same color does not mean the same parameters. The git has charts with the patch adjusting the prefetch distance [1]. It does improve behavior with some data sets, but it does not change the overall behavior (and it does not eliminate the small regressions). regards [1] https://www.postgresql.org/message-id/9b2106a4-4901-4b03-a0b2-db2dbaee4c1f%40vondra.me -- Tomas Vondra
Вложения
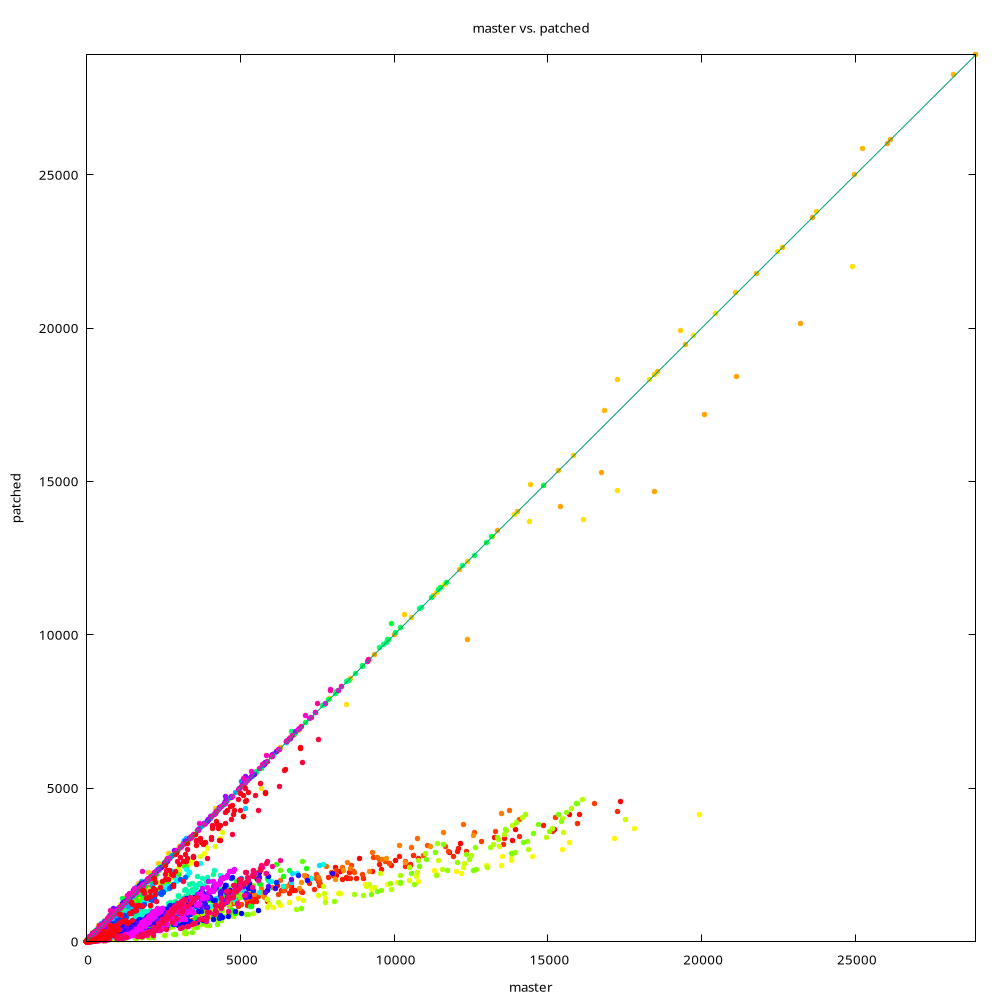{kind=link}
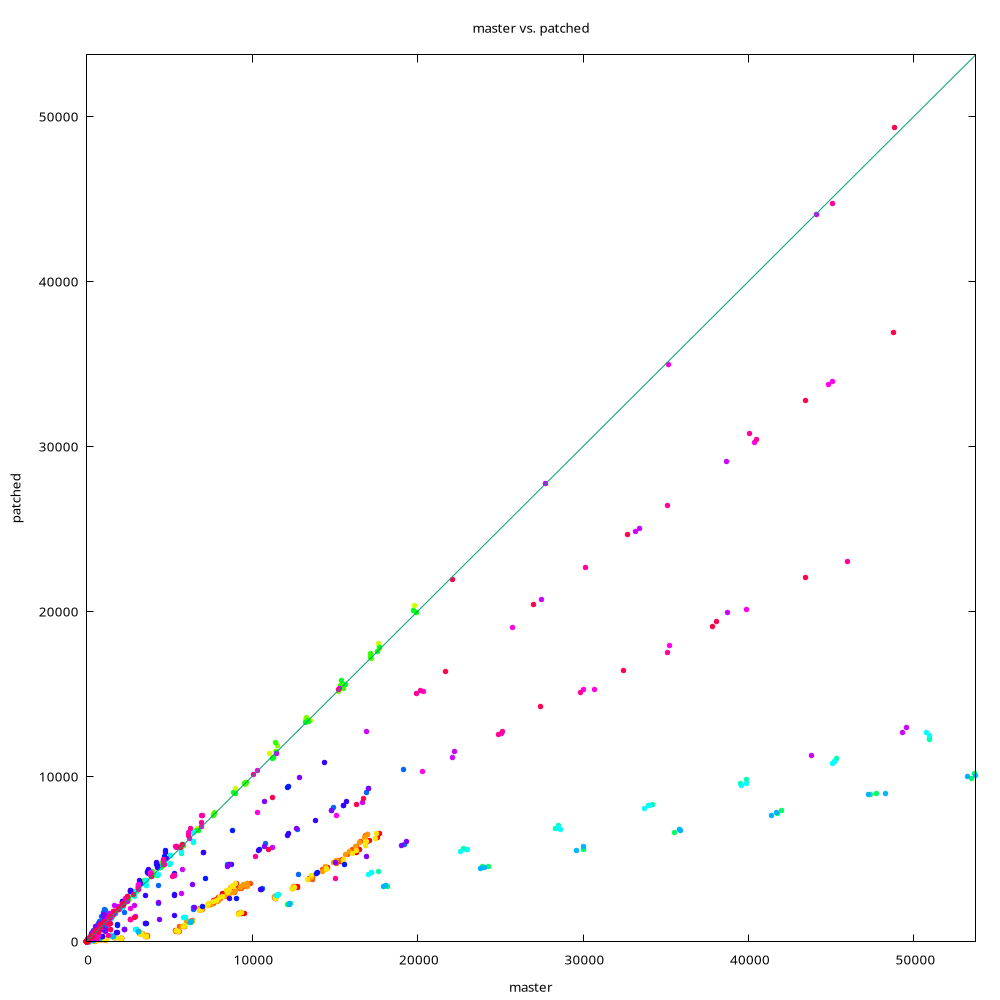{kind=link}
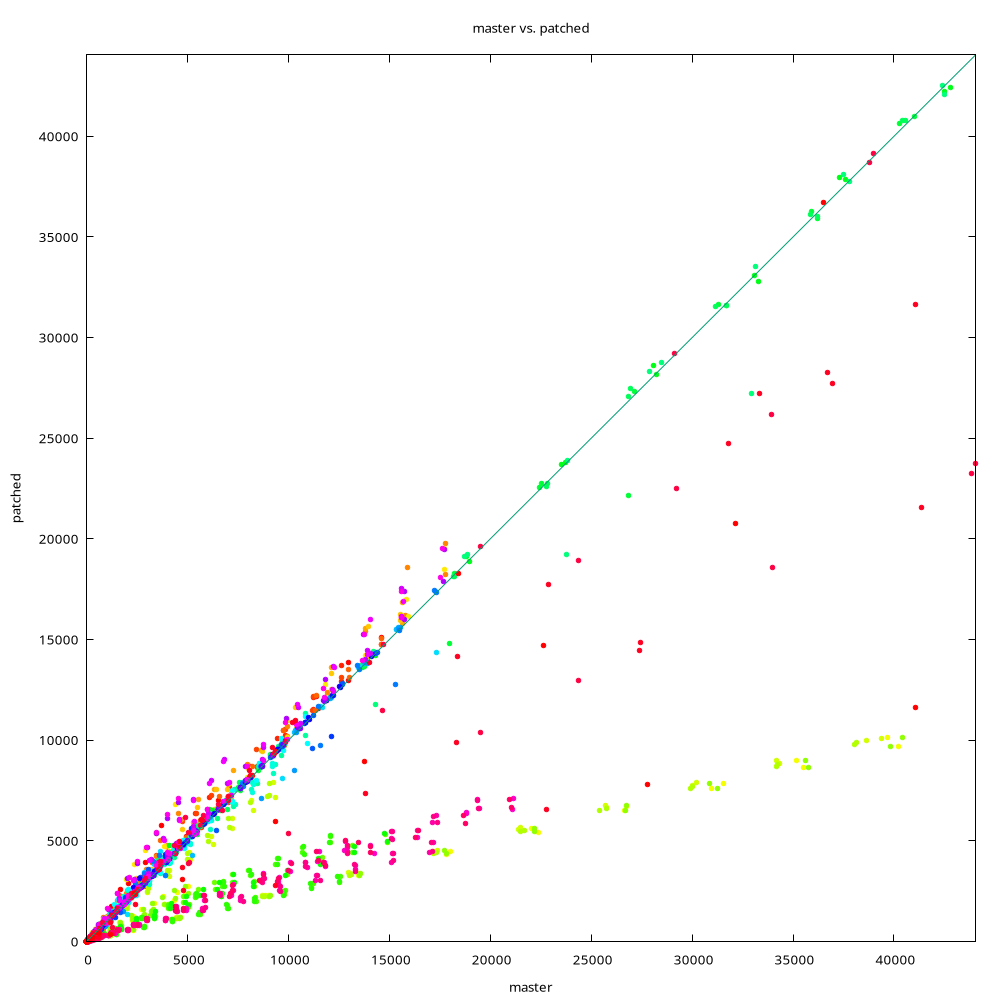{kind=link}
On Mon, Sep 15, 2025 at 9:00 AM Tomas Vondra <tomas@vondra.me> wrote: > Yeah, this heuristics seems very effective in eliminating the regression > (at least judging by the test results I've seen so far). Two or three > question bother me about it, though: I more or less agree with all of your concerns about the INDEX_SCAN_MIN_TUPLE_DISTANCE optimization. > We're prefetching too close ahead, so close the I/O can't possibly > complete, and the overhead of submitting the I/O using AIO is higher > than what what async "saves". > > That's great, but is the distance a good measure of that? The big underlying problem is that the INDEX_SCAN_MIN_TUPLE_DISTANCE heuristic was developed in a way that overrelied on brute-force testing. It probably is still flawed in some specific way that some query will actually run into, that cannot be justified. So at this point INDEX_SCAN_MIN_TUPLE_DISTANCE should still be considered nothing more than a promising experiment. It's promising because it does appear to work with a large variety of queries (we know of no query where it doesn't basically work right now). My hope is that we'll be able to come up with a simpler and more robust approach. One where we fully understand the downsides. > 2) It's a one-time decision, not adaptive. We start prefetching, and > then at some point (not too long after the scan starts) we make a > decision whether to continue with prefetching or not. And if we disable > it, it's disabled forever. That's fine for the synthetic data sets we > use for testing, because those are synthetic. I'm not sure it'll work > this well for real-world data sets where different parts of the file may > be very different. We'll probably need to accept some hard trade-off in this area. In general (not just with this patch), prefetching works through trial and error -- the errors are useful information, and useful information isn't free. The regressions that the INDEX_SCAN_MIN_TUPLE_DISTANCE heuristic addresses are cases where the errors seem unlikely to pay for themselves. Let's not forget that these are not huge regressions -- it's not as if the patch ever does completely the wrong thing without INDEX_SCAN_MIN_TUPLE_DISTANCE. It's more like it hurts us to be constantly on the verge of doing the right thing, but never quite doing the right thing. Fundamentally, we need to be willing to pay for the cost of information through which we might be able to do better. We might be able to get the cost down, through some kind of targeted optimization, but it's unlikely to ever be close to free. > This is perfectly fine for a WIP patch, but I believe we should try to > make this adaptive. Which probably means we need to invent a "light" > version of read_stream that initially does sync I/O, and only switches > to async (with all the expensive initialization) later. And then can > switch back to sync, but is ready to maybe start prefetching again if > the data pattern changes. That does seem like it'd be ideal. But how are we supposed to decide to switch back? Right now, disabling prefetching disables the only way that we have to notice that prefetching might be useful (which is to notice that we're failing to keep up with our prefetch distance). Without INDEX_SCAN_MIN_TUPLE_DISTANCE, for those queries where prefetch distance collapses to ~2.0, we really can "decide to switch back to prefetching". But maintaining the option of switching back costs us too much (that's what we need INDEX_SCAN_MIN_TUPLE_DISTANCE to manage). > 3) Now that I look at the code in index_scan_stream_read_next, it feels > a bit weird we do the decision based on the "immediate" distance only. I > suspect this may make it quite fragile, in the sense that even a small > local irregularity in the data may result in different "step" changes. > Wouldn't it be better to base this on some "average" distance? > > In other words, I'm afraid (2) and (3) are pretty much a "performance > cliff", where a tiny difference in the input can result in wildly > different behavior. You can say the same thing about hash join spilling. It might not be practical to make a strong guarantee that this will never ever happen. It might be more useful to focus on finding a way that makes it as rare as possible. If problems like this are possible, but require a "perfect storm" of buffer hits and misses that occur in precisely the same order, then maybe it can't be too much of a problem in practice. Since it shouldn't won't occur again and again. > > Much cleanup work remains to get the changes I just described in > > proper shape (to say nothing about open items that we haven't made a > > start on yet, like moving the read stream out of indexam.c and into > > heapam). But it has been too long since the last revision. I'd like to > > establish a regular cadence for posting new revisions of the patch > > set. > > > > Thank you! I appreciate the collaboration, it's a huge help. I've enjoyed our collaboration. Feels like things are definitely moving in the right direction. This is definitely a challenging project. > I kept running the stress test, trying to find cases that regress, and > also to better understand the behavior. The script/charts are available > here: https://github.com/tvondra/prefetch-tests > > So far I haven't found any massive regressions (relative to master). > There are data sets where we regress by a couple percent (and it's not > noise). I haven't looked into the details, but I believe most of this > can be attributed to the "AIO costs" we discussed recently (with > signals), and similar things. The overall picture that these tests show is a positive one. I think that this might actually be an acceptable performance profile, across the board. What's not acceptable is the code itself, and the current uncertainty about how fragile our current approach is. I hope that we can make it less fragile in the coming weeks. -- Peter Geoghegan
On 9/15/25 17:12, Peter Geoghegan wrote: > On Mon, Sep 15, 2025 at 9:00 AM Tomas Vondra <tomas@vondra.me> wrote: >> Yeah, this heuristics seems very effective in eliminating the regression >> (at least judging by the test results I've seen so far). Two or three >> question bother me about it, though: > > I more or less agree with all of your concerns about the > INDEX_SCAN_MIN_TUPLE_DISTANCE optimization. > >> We're prefetching too close ahead, so close the I/O can't possibly >> complete, and the overhead of submitting the I/O using AIO is higher >> than what what async "saves". >> >> That's great, but is the distance a good measure of that? > > The big underlying problem is that the INDEX_SCAN_MIN_TUPLE_DISTANCE > heuristic was developed in a way that overrelied on brute-force > testing. It probably is still flawed in some specific way that some > query will actually run into, that cannot be justified. > > So at this point INDEX_SCAN_MIN_TUPLE_DISTANCE should still be > considered nothing more than a promising experiment. It's promising > because it does appear to work with a large variety of queries (we > know of no query where it doesn't basically work right now). My hope > is that we'll be able to come up with a simpler and more robust > approach. One where we fully understand the downsides. > Agreed. >> 2) It's a one-time decision, not adaptive. We start prefetching, and >> then at some point (not too long after the scan starts) we make a >> decision whether to continue with prefetching or not. And if we disable >> it, it's disabled forever. That's fine for the synthetic data sets we >> use for testing, because those are synthetic. I'm not sure it'll work >> this well for real-world data sets where different parts of the file may >> be very different. > > We'll probably need to accept some hard trade-off in this area. > > In general (not just with this patch), prefetching works through trial > and error -- the errors are useful information, and useful information > isn't free. The regressions that the INDEX_SCAN_MIN_TUPLE_DISTANCE > heuristic addresses are cases where the errors seem unlikely to pay > for themselves. Let's not forget that these are not huge regressions > -- it's not as if the patch ever does completely the wrong thing > without INDEX_SCAN_MIN_TUPLE_DISTANCE. It's more like it hurts us to > be constantly on the verge of doing the right thing, but never quite > doing the right thing. > > Fundamentally, we need to be willing to pay for the cost of > information through which we might be able to do better. We might be > able to get the cost down, through some kind of targeted optimization, > but it's unlikely to ever be close to free. > True. Useful information is not free, and we can construct "adversary" cases for any heuristics. But I'd like to be sure the hard trade off really is inevitable. >> This is perfectly fine for a WIP patch, but I believe we should try to >> make this adaptive. Which probably means we need to invent a "light" >> version of read_stream that initially does sync I/O, and only switches >> to async (with all the expensive initialization) later. And then can >> switch back to sync, but is ready to maybe start prefetching again if >> the data pattern changes. > > That does seem like it'd be ideal. But how are we supposed to decide > to switch back? > > Right now, disabling prefetching disables the only way that we have to > notice that prefetching might be useful (which is to notice that we're > failing to keep up with our prefetch distance). Without > INDEX_SCAN_MIN_TUPLE_DISTANCE, for those queries where prefetch > distance collapses to ~2.0, we really can "decide to switch back to > prefetching". But maintaining the option of switching back costs us > too much (that's what we need INDEX_SCAN_MIN_TUPLE_DISTANCE to > manage). > I imagined (with no code to support it) we'd do the sync I/O through the read_stream. That way it'd know about the buffer hits and misses, and could calculate the "distance" (even if it's not used by the sync I/O). Sure, it's not perfect, because "stream distance" is not the same as "tuple distance". But we could calculate the "tuple distance", no? In the "sync" mode the stream could also switch to non-AIO reads, eliminating the signal bottleneck. >> 3) Now that I look at the code in index_scan_stream_read_next, it feels >> a bit weird we do the decision based on the "immediate" distance only. I >> suspect this may make it quite fragile, in the sense that even a small >> local irregularity in the data may result in different "step" changes. >> Wouldn't it be better to base this on some "average" distance? >> >> In other words, I'm afraid (2) and (3) are pretty much a "performance >> cliff", where a tiny difference in the input can result in wildly >> different behavior. > > You can say the same thing about hash join spilling. It might not be > practical to make a strong guarantee that this will never ever happen. > It might be more useful to focus on finding a way that makes it as > rare as possible. > Sure, it applies to various places where we "flip" to a different execution mode. All I'm saying is maybe we should try not to add more such cases. > If problems like this are possible, but require a "perfect storm" of > buffer hits and misses that occur in precisely the same order, then > maybe it can't be too much of a problem in practice. Since it > shouldn't won't occur again and again. > I'm not sure it's such a "perfect storm", really. Imagine an index where half the leafs are "nice" end get very high indexdiff values, while the other half are "not nice" and get very low indexdiff. It's a matter of random chance which leaf you get at INDEX_SCAN_MIN_DISTANCE_NBATCHES. >>> Much cleanup work remains to get the changes I just described in >>> proper shape (to say nothing about open items that we haven't made a >>> start on yet, like moving the read stream out of indexam.c and into >>> heapam). But it has been too long since the last revision. I'd like to >>> establish a regular cadence for posting new revisions of the patch >>> set. >>> >> >> Thank you! I appreciate the collaboration, it's a huge help. > > I've enjoyed our collaboration. Feels like things are definitely > moving in the right direction. This is definitely a challenging > project. > >> I kept running the stress test, trying to find cases that regress, and >> also to better understand the behavior. The script/charts are available >> here: https://github.com/tvondra/prefetch-tests >> >> So far I haven't found any massive regressions (relative to master). >> There are data sets where we regress by a couple percent (and it's not >> noise). I haven't looked into the details, but I believe most of this >> can be attributed to the "AIO costs" we discussed recently (with >> signals), and similar things. > > The overall picture that these tests show is a positive one. I think > that this might actually be an acceptable performance profile, across > the board. > Perhaps. > What's not acceptable is the code itself, and the current uncertainty > about how fragile our current approach is. I hope that we can make it > less fragile in the coming weeks. > Agreed. regards -- Tomas Vondra
On Wed, Sep 10, 2025 at 6:24 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is the latest revision of the prefetching patch, taken from > the shared branch that Tomas and I have been working on for some > weeks. Attached in a new revision, mostly just to keep CFBot happy following a recent trivial conflict introduced on master. The only other change in this revision is that it now carries the latest version of Andres' patch to prevent the scan from waiting for already-in-progress IO [1]. [1] https://postgr.es/m/zljergweqti7x67lg5ije2rzjusie37nslsnkjkkby4laqqbfw@3p3zu522yykv -- Peter Geoghegan
Вложения
On Sun, Oct 12, 2025 at 2:52 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached in a new revision, mostly just to keep CFBot happy following > a recent trivial conflict introduced on master. Attached is another revision, also just to keep CFBot happy following a conflict introduced on master. Nothing really new here (I've been working on batching on the table AM side, but nothing to show on that just yet). One minor thing to note about this revision: I added a comment to selfuncs.c's that notes that there's an unfixed bug there. That code more or less copies the approach used by nodeIndexonlyscan.c, but neglects to take the same precautions around the read stream/prefetching see different pages as all-visible that the view seen on the consumer side. ISTM that the right fix there is to totally rethink the interface such that the read stream is directly owned by the table AM. That way we won't have to work around inconsistent ideas around which heap pages are all-visible because there'll only be one view of that, in a single place. We won't have to do anything special in either selfuncs.c or in nodeIndexonlyscan.c. -- Peter Geoghegan
Вложения
On 11/3/25 00:49, Peter Geoghegan wrote: > On Sun, Oct 12, 2025 at 2:52 PM Peter Geoghegan <pg@bowt.ie> wrote: >> Attached in a new revision, mostly just to keep CFBot happy following >> a recent trivial conflict introduced on master. > > Attached is another revision, also just to keep CFBot happy following > a conflict introduced on master. Nothing really new here (I've been > working on batching on the table AM side, but nothing to show on that > just yet). > Thanks. > One minor thing to note about this revision: I added a comment to > selfuncs.c's that notes that there's an unfixed bug there. That code > more or less copies the approach used by nodeIndexonlyscan.c, but > neglects to take the same precautions around the read > stream/prefetching see different pages as all-visible that the view > seen on the consumer side. > > ISTM that the right fix there is to totally rethink the interface such > that the read stream is directly owned by the table AM. That way we > won't have to work around inconsistent ideas around which heap pages > are all-visible because there'll only be one view of that, in a single > place. We won't have to do anything special in either selfuncs.c or in > nodeIndexonlyscan.c. > I think we've already more or less agreed that the read_stream should be managed by the table AM (rather than by indexam.c), because it's up to the table AM to interpret the TID. If that also clarifies the IOS handling, that'd be a bonus. I've not been very happy with having to check visibility in the stream callback and passing it to the executor. If this gets "nicer", great. regards -- Tomas Vondra
On Sun, Nov 2, 2025 at 6:49 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is another revision, also just to keep CFBot happy following > a conflict introduced on master. Nothing really new here (I've been > working on batching on the table AM side, but nothing to show on that > just yet). Same story again today. The recent "Sort guc_parameters.dat alphabetically by name" commit made the patch no longer compile. Attached is a trivial rebased version of Sunday's revision, to keep CFBot green. Nothing new here, really. -- Peter Geoghegan
Вложения
On Wed, Nov 5, 2025 at 11:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > Same story again today. The recent "Sort guc_parameters.dat > alphabetically by name" commit made the patch no longer compile. Same again. This new revision fixes bitrot caused by Andres' recent "bufmgr: Allow some buffer state modifications while holding header lock" commit. I had to fix some of Andres' code to get this working. I think that I got this right, but haven't tested those changes very well. -- Peter Geoghegan
Вложения
On Sun, Nov 2, 2025 at 6:49 PM Peter Geoghegan <pg@bowt.ie> wrote: > Nothing really new here (I've been > working on batching on the table AM side, but nothing to show on that > just yet). Tomas and I had a meeting on Friday to discuss a way forward with this project. Progress has stalled, and we feel that now is a good time to pivot by refactoring the patch into smaller, independently useful/committable pieces. This email explains our current thinking (Tomas should correct me if I get anything wrong here). The short version/executive summary =================================== The need to get everything done in one single release seems to be hampering progress. We made quick progress for a few months, but now that we've exhausted the easy wins, the layering issues that remain are making every remaining open item near intractable. The layering issues make it very hard to keep on top of all of the regressions; we're just doing too much at once. We're trying to manage all of the regressions from the addition of prefetching/a heapam read stream, while also trying to manage the regressions from moving index AMs from the old amgettuple interface to the new amgetbatch interface. And we still need to revise the table AM to move the read stream from indexam.c over to the table AM side (this isn't in the latest version of the patch at all). Just making these AM interface changes is already a huge project on its own. This makes it hard to focus on just a few things at any one time; everything is interdependent. We seem to end up playing whack-a-mole whenever we try to zero in on any single problem; we end up going in circles. The new tentative plan is to cut scope by focussing on switching over to the new index AM + table AM interface from the patch in the short term, for Postgres 19. There is an almost immediate benefit to just doing that much, unrelated to I/O prefetching for index scans: it enables batching of heap page buffer locking/unlocking (during the point where index scans perform heap_hot_search_buffer calls) on the table AM/heapam side during ordered index scans. That can dramatically cut down on repeat buffer locking and unlocking, giving us enough of a win (more details below) to be the sole justification for switching over to the new set of AM interfaces for Postgres 19. Our long term goals won't change under this phased approach, but our timeline/short term focus certainly will. We hope to get some general feedback about this new strategy for the project now, particularly from Andres. The main practical concern is managing project risk sensibly. Difficulties with refactoring AM interfaces while introducing a read stream =========================================================================== The uncertainty about how to resolve some of the remaining individual open items for the project (specifically concerns about I/O prefetching/read stream + resource management concerns, and how they *interact* with broader layering questions) is the main blocker to further progress. I'll now give a specific example of what I mean by this, just because it's likely to be clearer than explaining the underlying problem in general terms. Currently, we can have up to 64 leaf-page-wise batches. Usually this is more than enough, but occasionally we run out of space for batches, and have to reset the read stream. This is certainly a kludge; we discard pinned buffers with useful data in order to work around what we've thought of as an implementation deficiency on the read stream side up until now. Obviously just discarding useful work like that is never okay (nobody will argue with me on this, I'm sure). At various points we talked about addressing this particular problem by teaching the read stream to "pause" such that we can consume those remaining pinned buffers as needed, without consuming even more heap pages/buffers to do so (there's no natural upper bound on those, I think). We'd then "unpause" and resume prefetching again, once we managed to free some more leaf-page-wise batches up. But I'm now starting to have serious doubts about this approach (or at least doubts about the approach that I think other people have in mind when they talk about this kind of "pausing"). Again, it's really hard to pin down *where* we should be fixing things. It occurs to me that it doesn't make much sense that the table AM/indexam.c has *no* awareness of how many heap buffers are already pinned on its behalf. The fact that that knowledge is *exclusively* confined to the read stream isn't actually good. What we really need to do is to care about all buffer pins held by the whole index scan node, whether for index pages or for heap pages (though note that holding onto buffer pins on index pages should be rare in practice). We need to directly acknowledge the tension that exists between heapam and index AM needs, I think. The read stream needs to be involved in this process, but it should be a 2-way conversation. The read stream already defensively checks externally held buffer pins, which might kinda work for what we have in mind -- but probably not. It seems bad to depend on what is supposed to be a defensive measure for all this. Separately, we'll probably eventually want the heapam side to be able to notice that a block number that it requests is already in the pending list, so that it can be marked as a duplicate (and so not unpinned until the duplicate request is also satisfied/has its heap tuples returned to the scan). That's another factor pushing things in this general direction. (Less important, but noted here for completeness.) I've been talking about problems when 64 leaf-page-wise batches isn't enough, which is rare in practice. It's far more common for 64 to be too *many* batches, which wastes memory (e.g, with largely sequential heap access we seem to need no more than 5 or 10 at a time, even when prefetching is really important). But it's hard to see how we could lazily allocate memory used for batches under anything like the current structure. It's circular: we should only allocate more leaf-page-wise batches to make it possible to do more useful heap prefetching. But right now heap prefetching will stall (or will "pause" in its own kludgey way) precisely because there aren't enough leaf-page-wise batches! Granted, adding a "pausing" capability might be useful elsewhere. But that in itself doesn't justify the general idea of pausing in the specific way that index prefetching requires. Why should it? Why should we pause when we've filled 64 leaf-page-wise batches instead of 5 or 10 or 1000? ISTM that we're tacitly assuming that the total number of usable leaf-page-wise batches remaining is a useful proxy for the costs that actually matter. But why should it be? 64 is just a number that we picked fairly arbitrarily, and one that has only a weak relationship with more concrete costs such as leaf page buffer pins held (as noted already, needing to hold onto a leaf page buffer pin until we call btfreebatch against its batch isn't actually needed during most index scans, but there will be exceptions). My gut instinct is that this stuff will actually matter, in practice, at least some of the time. And that that'll necessitate giving the implementation a clear and complete picture of costs and benefits when scheduling index scans that prefetch. Pausing can't be based on some randomly chosen magic number, like 64, since that's bound to be totally wrong in a nonzero number of cases. ISTM that we cannot subordinate the table AM to the read stream. But we also can't subordinate the read stream to the table AM. Figuring all that out is hard. This is the kind of problem that we'd like to defer for now. Minor caveat: I'm not sure that Tomas endorses everything I've said here about "pausing" the read stream. But that probably doesn't matter much. Either way, these kinds of questions still weigh on the project, and something should be done about it now, to keep things on course. Phased approach =============== As touched upon at the start of this email, under this new phased approach to the project, the short term goal is to make heapam avoid repeat buffer locks during index scans where that's clearly avoidable. Making that much work shares many of the same problems with I/O prefetching (particularly the basics of layering/AM revisions), but defers dealing with the thorniest issues with pin resource management. That's what I'll talk about here --- what we can defer, and what we cannot defer. But first, on a more positive note, I'll talk about the short term benefits. My early prototype of the "only lock heap buffer once per group of TIDs that point to the same heap page returned from an index scan" optimization has been shown to improve throughput for large-ish range scans by quite a bit. Variants of pgbench select with queries like "SELECT * FROM pg_bench_accounts WHERE aid BETWEEN 1000 AND 1500" show improvements in throughput of up to 20% (and show similar reductions in query latency). That's a nice win, all on its own. Now back to talking about risks. There's still a lot of complexity that cannot be deferred with this phased approach. We must still switch over index AMs from amgettuple to the new amgetbatch interface. And, we need to make the table AM interface used by index scans higher level: index_getnext_slot would directly call a new table-AM-wise callback, just passing it its own ScanDirection argument directly -- we wouldn't be passing TIDs to the table AM anymore. The new table AM batch interface would work in terms of "give me the next tuple in the current scan direction", not in terms of "give me this random TID, which you know nothing else about". The table AM becomes directly aware of the fact that it is participating in an ordered index scan. This design is amenable to allowing the table AM to see which accesses will be required in the near future -- that requirement is common to both I/O prefetching and this other heap buffer lock optimization. It's even more complicated than just those changes to the index AM and table AM interfaces: we'll also require that the table AM directly interfaces with another layer that manages leaf-page-wise batches on its behalf. They need to *cooperate* with each other, to a certain degree. The executor proper won't call amgetbatch directly under this scheme (it'd just provide a library of routines that help table AMs to do so on their own). That much doesn't seem deferrable. And it's hard. So this phased approach certainly doesn't eliminate project risk, by any stretch of the imagination. Offhand, I'd estimate that taking this phased approach cuts the number of blockers to making an initial commit in half. Here's a nonexhaustive list of notable pain points that *won't* need to be addressed in the short term, under this new approach/structure (I'm somewhat repeating myself here): * Most regressions are likely much easier to avoid/are automatically avoided. Particularly with selective point query scans. * No need to integrate the read stream, no need to solve most resource management problems (the prior item about regressions is very much related to this one). * No need for streamPos stuff when iterating through TIDs from a leaf-page-wise batch (only need readPos now). There's no need to keep those 2 things in sync, because there'll only be 1 thing now. Here's a nonexhaustive list of problems that we *will* still need to solve in the earliest committed patch, under this phased approach (again, I'm repeating myself somewhat): * Actually integrating the amgetbatch interface in a way that is future-proof. * Revising the table AM interface such that the table AM is directly aware of the fact that it is feeding heap/table tuples to an ordered index scan. That's a big conceptual shift for table AMs. * Making the prior 2 changes "fit together" sensibly, in a way that considers current and future needs. Also a big shift. The "only lock heap buffer once per group of TIDs that point to the same heap page returned from an index scan" optimization still requires some general awareness of index AM costs on the table AM side. It only makes sense for us to batch-up extra TIDs (from the same heap page) when determining which TIDs are about to be accessed as a group isn't too expensive/the information is readily available to the table AM, because it requested it from the index AM itself. We're setting a new precedent by saying that it's okay to share certain knowledge across what we previously thought of as strictly separate layers of abstraction. I think that that makes sense (what else could possibly work?), but I want to draw specific attention to that now. * We'll still need index-only scans to do things in a way that prevents inconsistencies/changing our mind in terms of which TIDs are all-visible. This has the advantage of allowing us to avoid accessing the visibility map from the executor proper, which is an existing modularity violation that we already agree ought to be fixed. This will also keep us honest (we won't be deferring more than we should). But that's not why I think it's essential to move VM accesses into the table AM. We should only batch together accesses to a heap page when we know for sure that those TIDs will in fact be accessed. How are we supposed to have general and robust handling for all that, in a world where the visibility map continues to be accessed from the executor proper? At best, not handling VM integration comprehensively (for index-only scans) ties our hands around reordering work, and seems like it'd be very brittle. It would likely have similar problems to our current problems with managing a read stream in indexam.c, while relying on tacit knowledge of how precisely those same heap blocks will later actually be accessed from the heapam side. The sensible solution is to put control of the scan's progress all in one place. We don't want to have to worry about what happens when the VM is concurrently set or unset. When Andres and Tomas talk about table AM modularity stuff, they tend to focus on why it's bad that the table AM interface uses heap TIDs specifically. I agree with all that. But even if I didn't, everything that I just said about the need to centralize control in the table AM would still be true. That's why I'm focussing on that here (it's really pretty subtle). That's all I have for now. My thoughts here should be considered tentative; I want to put my thinking on a more rigorous footing before really committing to this new phased approach. -- Peter Geoghegan
On 11/11/25 00:59, Peter Geoghegan wrote: > On Sun, Nov 2, 2025 at 6:49 PM Peter Geoghegan <pg@bowt.ie> wrote: >> Nothing really new here (I've been >> working on batching on the table AM side, but nothing to show on that >> just yet). > > Tomas and I had a meeting on Friday to discuss a way forward with this > project. Progress has stalled, and we feel that now is a good time to > pivot by refactoring the patch into smaller, independently > useful/committable pieces. This email explains our current thinking > (Tomas should correct me if I get anything wrong here). > > The short version/executive summary > =================================== > > The need to get everything done in one single release seems to be > hampering progress. We made quick progress for a few months, but now > that we've exhausted the easy wins, the layering issues that remain > are making every remaining open item near intractable. > > The layering issues make it very hard to keep on top of all of the > regressions; we're just doing too much at once. We're trying to manage > all of the regressions from the addition of prefetching/a heapam read > stream, while also trying to manage the regressions from moving index > AMs from the old amgettuple interface to the new amgetbatch interface. > And we still need to revise the table AM to move the read stream from > indexam.c over to the table AM side (this isn't in the latest version > of the patch at all). > > Just making these AM interface changes is already a huge project on > its own. This makes it hard to focus on just a few things at any one > time; everything is interdependent. We seem to end up playing > whack-a-mole whenever we try to zero in on any single problem; we end > up going in circles. > > The new tentative plan is to cut scope by focussing on switching over > to the new index AM + table AM interface from the patch in the short > term, for Postgres 19. There is an almost immediate benefit to just > doing that much, unrelated to I/O prefetching for index scans: it > enables batching of heap page buffer locking/unlocking (during the > point where index scans perform heap_hot_search_buffer calls) on the > table AM/heapam side during ordered index scans. That can dramatically > cut down on repeat buffer locking and unlocking, giving us enough of a > win (more details below) to be the sole justification for switching > over to the new set of AM interfaces for Postgres 19. > > Our long term goals won't change under this phased approach, but our > timeline/short term focus certainly will. We hope to get some general > feedback about this new strategy for the project now, particularly > from Andres. The main practical concern is managing project risk > sensibly. > > Difficulties with refactoring AM interfaces while introducing a read stream > =========================================================================== > > The uncertainty about how to resolve some of the remaining individual > open items for the project (specifically concerns about I/O > prefetching/read stream + resource management concerns, and how they > *interact* with broader layering questions) is the main blocker to > further progress. I'll now give a specific example of what I mean by > this, just because it's likely to be clearer than explaining the > underlying problem in general terms. > > Currently, we can have up to 64 leaf-page-wise batches. Usually this > is more than enough, but occasionally we run out of space for batches, > and have to reset the read stream. This is certainly a kludge; we > discard pinned buffers with useful data in order to work around what > we've thought of as an implementation deficiency on the read stream > side up until now. Obviously just discarding useful work like that is > never okay (nobody will argue with me on this, I'm sure). > > At various points we talked about addressing this particular problem > by teaching the read stream to "pause" such that we can consume those > remaining pinned buffers as needed, without consuming even more heap > pages/buffers to do so (there's no natural upper bound on those, I > think). We'd then "unpause" and resume prefetching again, once we > managed to free some more leaf-page-wise batches up. But I'm now > starting to have serious doubts about this approach (or at least > doubts about the approach that I think other people have in mind when > they talk about this kind of "pausing"). > > Again, it's really hard to pin down *where* we should be fixing things. > > It occurs to me that it doesn't make much sense that the table > AM/indexam.c has *no* awareness of how many heap buffers are already > pinned on its behalf. The fact that that knowledge is *exclusively* > confined to the read stream isn't actually good. What we really need > to do is to care about all buffer pins held by the whole index scan > node, whether for index pages or for heap pages (though note that > holding onto buffer pins on index pages should be rare in practice). > We need to directly acknowledge the tension that exists between heapam > and index AM needs, I think. > > The read stream needs to be involved in this process, but it should be > a 2-way conversation. The read stream already defensively checks > externally held buffer pins, which might kinda work for what we have > in mind -- but probably not. It seems bad to depend on what is > supposed to be a defensive measure for all this. > > Separately, we'll probably eventually want the heapam side to be able > to notice that a block number that it requests is already in the > pending list, so that it can be marked as a duplicate (and so not > unpinned until the duplicate request is also satisfied/has its heap > tuples returned to the scan). That's another factor pushing things in > this general direction. (Less important, but noted here for > completeness.) > > I've been talking about problems when 64 leaf-page-wise batches isn't > enough, which is rare in practice. It's far more common for 64 to be > too *many* batches, which wastes memory (e.g, with largely sequential > heap access we seem to need no more than 5 or 10 at a time, even when > prefetching is really important). But it's hard to see how we could > lazily allocate memory used for batches under anything like the > current structure. It's circular: we should only allocate more > leaf-page-wise batches to make it possible to do more useful heap > prefetching. But right now heap prefetching will stall (or will > "pause" in its own kludgey way) precisely because there aren't enough > leaf-page-wise batches! > > Granted, adding a "pausing" capability might be useful elsewhere. But > that in itself doesn't justify the general idea of pausing in the > specific way that index prefetching requires. Why should it? > > Why should we pause when we've filled 64 leaf-page-wise batches > instead of 5 or 10 or 1000? ISTM that we're tacitly assuming that the > total number of usable leaf-page-wise batches remaining is a useful > proxy for the costs that actually matter. But why should it be? 64 is > just a number that we picked fairly arbitrarily, and one that has only > a weak relationship with more concrete costs such as leaf page buffer > pins held (as noted already, needing to hold onto a leaf page buffer > pin until we call btfreebatch against its batch isn't actually needed > during most index scans, but there will be exceptions). > > My gut instinct is that this stuff will actually matter, in practice, > at least some of the time. And that that'll necessitate giving the > implementation a clear and complete picture of costs and benefits when > scheduling index scans that prefetch. Pausing can't be based on some > randomly chosen magic number, like 64, since that's bound to be > totally wrong in a nonzero number of cases. > > ISTM that we cannot subordinate the table AM to the read stream. But > we also can't subordinate the read stream to the table AM. Figuring > all that out is hard. This is the kind of problem that we'd like to > defer for now. > > Minor caveat: I'm not sure that Tomas endorses everything I've said > here about "pausing" the read stream. But that probably doesn't matter > much. Either way, these kinds of questions still weigh on the project, > and something should be done about it now, to keep things on course. > I think I generally agree with what you said here about the challenges, although it's a bit too abstract to respond to individual parts. I just don't know how to rework the design to resolve this ... For the reads stream "pausing" I think it's pretty clear it's more a workaround than a desired behavior. We only pause the stream because we need to limit the look-ahead distance (measured in index leaf pages), and the read_stream has no such concept. It only knows about heap pins, but e.g. IOS may need to read many leaf pages to find a single heap page to prefetch. And the leaf pages are invisible to the stream. The limit of 64 batches is entirely arbitrary. I needed a number that would limit the amount of memory and time wasted on useless look-ahead, and 64 seemed "reasonable" (not too high, but enough to not be hit very often). Originally there was a fixed-length queue of batches, and 64 was the capacity, but we no longer do it that way. So it's an imperfect safety measure against "runaway" streams. I don't want to get into too much detail about this particular issue, it's already discussed somewhere in this thread. But if there was a way to "tell" the read stream how much effort to spend looking ahead, we wouldn't do the pausing (not in the end+reset way). > Phased approach > =============== > > As touched upon at the start of this email, under this new phased > approach to the project, the short term goal is to make heapam avoid > repeat buffer locks during index scans where that's clearly avoidable. > Making that much work shares many of the same problems with I/O > prefetching (particularly the basics of layering/AM revisions), but > defers dealing with the thorniest issues with pin resource management. > That's what I'll talk about here --- what we can defer, and what we > cannot defer. > > But first, on a more positive note, I'll talk about the short term > benefits. My early prototype of the "only lock heap buffer once per > group of TIDs that point to the same heap page returned from an index > scan" optimization has been shown to improve throughput for large-ish > range scans by quite a bit. Variants of pgbench select with queries > like "SELECT * FROM pg_bench_accounts WHERE aid BETWEEN 1000 AND 1500" > show improvements in throughput of up to 20% (and show similar > reductions in query latency). That's a nice win, all on its own. > > Now back to talking about risks. There's still a lot of complexity > that cannot be deferred with this phased approach. We must still > switch over index AMs from amgettuple to the new amgetbatch interface. > And, we need to make the table AM interface used by index scans higher > level: index_getnext_slot would directly call a new table-AM-wise > callback, just passing it its own ScanDirection argument directly -- > we wouldn't be passing TIDs to the table AM anymore. > > The new table AM batch interface would work in terms of "give me the > next tuple in the current scan direction", not in terms of "give me > this random TID, which you know nothing else about". The table AM > becomes directly aware of the fact that it is participating in an > ordered index scan. This design is amenable to allowing the table AM > to see which accesses will be required in the near future -- that > requirement is common to both I/O prefetching and this other heap > buffer lock optimization. > > It's even more complicated than just those changes to the index AM and > table AM interfaces: we'll also require that the table AM directly > interfaces with another layer that manages leaf-page-wise batches on > its behalf. They need to *cooperate* with each other, to a certain > degree. The executor proper won't call amgetbatch directly under this > scheme (it'd just provide a library of routines that help table AMs to > do so on their own). > > That much doesn't seem deferrable. And it's hard. So this phased > approach certainly doesn't eliminate project risk, by any stretch of > the imagination. Offhand, I'd estimate that taking this phased > approach cuts the number of blockers to making an initial commit in > half. > > Here's a nonexhaustive list of notable pain points that *won't* need > to be addressed in the short term, under this new approach/structure > (I'm somewhat repeating myself here): > > * Most regressions are likely much easier to avoid/are automatically > avoided. Particularly with selective point query scans. > > * No need to integrate the read stream, no need to solve most resource > management problems (the prior item about regressions is very much > related to this one). > > * No need for streamPos stuff when iterating through TIDs from a > leaf-page-wise batch (only need readPos now). There's no need to keep > those 2 things in sync, because there'll only be 1 thing now. > > Here's a nonexhaustive list of problems that we *will* still need to > solve in the earliest committed patch, under this phased approach > (again, I'm repeating myself somewhat): > > * Actually integrating the amgetbatch interface in a way that is future-proof. > > * Revising the table AM interface such that the table AM is directly > aware of the fact that it is feeding heap/table tuples to an ordered > index scan. That's a big conceptual shift for table AMs. > > * Making the prior 2 changes "fit together" sensibly, in a way that > considers current and future needs. Also a big shift. > > The "only lock heap buffer once per group of TIDs that point to the > same heap page returned from an index scan" optimization still > requires some general awareness of index AM costs on the table AM > side. > > It only makes sense for us to batch-up extra TIDs (from the same heap > page) when determining which TIDs are about to be accessed as a group > isn't too expensive/the information is readily available to the table > AM, because it requested it from the index AM itself. We're setting a > new precedent by saying that it's okay to share certain knowledge > across what we previously thought of as strictly separate layers of > abstraction. I think that that makes sense (what else could possibly > work?), but I want to draw specific attention to that now. > > * We'll still need index-only scans to do things in a way that > prevents inconsistencies/changing our mind in terms of which TIDs are > all-visible. > > This has the advantage of allowing us to avoid accessing the > visibility map from the executor proper, which is an existing > modularity violation that we already agree ought to be fixed. This > will also keep us honest (we won't be deferring more than we should). > But that's not why I think it's essential to move VM accesses into the > table AM. > > We should only batch together accesses to a heap page when we know for > sure that those TIDs will in fact be accessed. How are we supposed to > have general and robust handling for all that, in a world where the > visibility map continues to be accessed from the executor proper? At > best, not handling VM integration comprehensively (for index-only > scans) ties our hands around reordering work, and seems like it'd be > very brittle. It would likely have similar problems to our current > problems with managing a read stream in indexam.c, while relying on > tacit knowledge of how precisely those same heap blocks will later > actually be accessed from the heapam side. > > The sensible solution is to put control of the scan's progress all in > one place. We don't want to have to worry about what happens when the > VM is concurrently set or unset. > > When Andres and Tomas talk about table AM modularity stuff, they tend > to focus on why it's bad that the table AM interface uses heap TIDs > specifically. I agree with all that. But even if I didn't, everything > that I just said about the need to centralize control in the table AM > would still be true. That's why I'm focussing on that here (it's > really pretty subtle). > > That's all I have for now. My thoughts here should be considered > tentative; I want to put my thinking on a more rigorous footing before > really committing to this new phased approach. > I don't object to the "phased approach" with doing the batching first, but without seeing the code I can't really say if/how much it helps with resolving the design/layering questions. It feels a bit too abstract to me. While working on the prefetching I moved the code between layers about three times, and I'm still not quite sure which layer should be responsible for which piece :-( regards -- Tomas Vondra
On Wed, Nov 12, 2025 at 12:39 PM Tomas Vondra <tomas@vondra.me> wrote: > I think I generally agree with what you said here about the challenges, > although it's a bit too abstract to respond to individual parts. I just > don't know how to rework the design to resolve this ... I'm trying to identify which subsets of the existing design can reasonably be committed in a single release (while acknowledging that even those subsets will need to be reworked). That is more abstract than any of us would like -- no question. What are we most confident will definitely be useful to prefetching, that also enables the "only lock heap buffer once per group of TIDs that point to the same heap page returned from an index scan" optimization? I'm trying to reach a tentative agreement that just doing the amgetbatch revisions and the table AM revisions (to do the other heap buffer lock optimization) will represent useful progress that can be committed in a single release. And on what the specifics of the table AM revisions will need to be, to get us to a patch that we can commit to Postgres 19. > For the reads stream "pausing" I think it's pretty clear it's more a > workaround than a desired behavior. We only pause the stream because we > need to limit the look-ahead distance (measured in index leaf pages), > and the read_stream has no such concept. It only knows about heap pins, > but e.g. IOS may need to read many leaf pages to find a single heap page > to prefetch. And the leaf pages are invisible to the stream. Right. But we seemed to talk about this as if the implementation of "pausing" was the problem. I was suggesting that the general idea of pausing might well be the wrong one -- at least when applied in anything like the way we currently apply it. More importantly, I feel that it'll be really hard to get a clear answer to that particular question (and a couple of others like it) without first getting clarity on what we need from the table AM at a high level, API-wise. Bearing in mind that we've made no real progress on that at all. We all agree that it's bad that indexam.c tacitly coordinates with heapam in the way it does in the current patch. And that assuming a TID representation in the API is bad. But that isn't very satisfying to me; it's too focussed on that one really obvious and glaring problem, and what we *don't* want. There's been very little (almost nothing) on this thread about what we actually *do* want. That's the thing that's still way to abstract, that I'd like to make more concrete. As you know, I think that we should add a new table AM interface that makes the table AM directly aware of the fact that it is feeding an ordered index scan, completely avoiding the use of TIDs (as well as avoiding *any* more abstract representation of a table AM tuple identifier). In other words, I think that we should just fully admit the fact that the table AM is in control of the scan, and all that comes with it. The table AM will have to directly coordinate with the index AM in a way that's quite different to what we do right now. I don't think that anybody else has really said much about that idea, at least on the list. Is it a reasonable approach to take? This is really important, especially in the short term/for Postgres 19. > The limit of 64 batches is entirely arbitrary. I needed a number that > would limit the amount of memory and time wasted on useless look-ahead, > and 64 seemed "reasonable" (not too high, but enough to not be hit very > often). Originally there was a fixed-length queue of batches, and 64 was > the capacity, but we no longer do it that way. So it's an imperfect > safety measure against "runaway" streams. Right, but we still max out at 64. And then we stay there. It just feels unprincipled to me. > I don't want to get into too much detail about this particular issue, > it's already discussed somewhere in this thread. But if there was a way > to "tell" the read stream how much effort to spend looking ahead, we > wouldn't do the pausing (not in the end+reset way). I don't want to get into that again either. It was just an example of the kinds of problems we're running into. Though a particularly good example IMV. > > That's all I have for now. My thoughts here should be considered > > tentative; I want to put my thinking on a more rigorous footing before > > really committing to this new phased approach. > > > > I don't object to the "phased approach" with doing the batching first, > but without seeing the code I can't really say if/how much it helps with > resolving the design/layering questions. It feels a bit too abstract to > me. It is in no small part based on gut feeling and intuition. I don't have anything better to go on right now. It's a really difficult project. > While working on the prefetching I moved the code between layers > about three times, and I'm still not quite sure which layer should be > responsible for which piece :-( I don't think that this is quite the same situation. The index prefetching design was completely overhauled twice now, but on both occasions that was driven by some clear goal/the need to fix some problem with the prior design. The first time it was due to the fact that the original version didn't work with kill_prior_tuple. The second time was due to the need to support reading index pages that were ahead of the current page that the scan is returning tuples from. Granted, it took a while to actually prove that the second overhaul (which created the third major redesign) was the right direction to take things in, but testing did eventually make that quite clear. I don't see this as doing the same thing a third time/creating a forth design from scratch. It's more of a refinement (albeit quite a big one) of the most recent design. And in a direction that doesn't seem too surprising to me. We knew that the table AM side of the most recent redesign still had plenty of problems. We should have been a bit more focussed on that side of things earlier on. -- Peter Geoghegan
Hi, On 2025-11-10 18:59:07 -0500, Peter Geoghegan wrote: > Tomas and I had a meeting on Friday to discuss a way forward with this > project. Progress has stalled, and we feel that now is a good time to > pivot by refactoring the patch into smaller, independently > useful/committable pieces. Makes sense. > Phased approach > =============== > > As touched upon at the start of this email, under this new phased > approach to the project, the short term goal is to make heapam avoid > repeat buffer locks during index scans where that's clearly avoidable. > Making that much work shares many of the same problems with I/O > prefetching (particularly the basics of layering/AM revisions), but > defers dealing with the thorniest issues with pin resource management. > That's what I'll talk about here --- what we can defer, and what we > cannot defer. > > But first, on a more positive note, I'll talk about the short term > benefits. My early prototype of the "only lock heap buffer once per > group of TIDs that point to the same heap page returned from an index > scan" optimization has been shown to improve throughput for large-ish > range scans by quite a bit. Variants of pgbench select with queries > like "SELECT * FROM pg_bench_accounts WHERE aid BETWEEN 1000 AND 1500" > show improvements in throughput of up to 20% (and show similar > reductions in query latency). That's a nice win, all on its own. Another benfit is that it helps even more when there multiple queries running concurrently - the high rate of lock/unlock on the buffer rather badly hurts scalability. Besides the locking overhead, it turns out that doing visibility checks one-by-one is a good bit slower than doing so in batches (or for the whole page). So that's another perf improvement this would enable. > Now back to talking about risks. There's still a lot of complexity > that cannot be deferred with this phased approach. We must still > switch over index AMs from amgettuple to the new amgetbatch interface. > And, we need to make the table AM interface used by index scans higher > level: index_getnext_slot would directly call a new table-AM-wise > callback, just passing it its own ScanDirection argument directly -- > we wouldn't be passing TIDs to the table AM anymore. > The new table AM batch interface would work in terms of "give me the > next tuple in the current scan direction", not in terms of "give me > this random TID, which you know nothing else about". The table AM > becomes directly aware of the fact that it is participating in an > ordered index scan. This design is amenable to allowing the table AM > to see which accesses will be required in the near future -- that > requirement is common to both I/O prefetching and this other heap > buffer lock optimization. Yes, I think that's clearly required. I think one nice bonus of such a change is that it'd resolve one of the biggest existing layering violations around tableam - namely that nodeIndexonlyscan.c does VM_ALL_VISIBLE() calls, which it really has no business doing. > It's even more complicated than just those changes to the index AM and > table AM interfaces: we'll also require that the table AM directly > interfaces with another layer that manages leaf-page-wise batches on > its behalf. They need to *cooperate* with each other, to a certain > degree. The executor proper won't call amgetbatch directly under this > scheme (it'd just provide a library of routines that help table AMs to > do so on their own). > That much doesn't seem deferrable. And it's hard. So this phased > approach certainly doesn't eliminate project risk, by any stretch of > the imagination. Offhand, I'd estimate that taking this phased > approach cuts the number of blockers to making an initial commit in > half. I wonder if we could actually do part of the redesign in an even more piecemeal fashion: 1) Move the responsibility for getting the next tid from the index into tableam, but do so by basically using index_getnext_tid(). 2) Have the new interface get a single batch of tuples from the index, instead of doing it on a single tid-by-tid basis. 3) Have heapam not acquire the page lock for each tuple, but do so for all the tuples on the same page. 4) Add awareness of multiple batches 5) Use read stream Greetings, Andres Freund
On Fri, Nov 21, 2025 at 5:38 PM Andres Freund <andres@anarazel.de> wrote: > Another benfit is that it helps even more when there multiple queries running > concurrently - the high rate of lock/unlock on the buffer rather badly hurts > scalability. I haven't noticed that effect myself. In fact, it seemed to be the other way around; it looked like it helped most with very low client count workloads. It's possible that that had something to do with my hacky approach to validating the general idea of optimizing heapam buffer locking/avoiding repeated locking. This was a very rough prototype. > Besides the locking overhead, it turns out that doing visibility checks > one-by-one is a good bit slower than doing so in batches (or for the whole > page). So that's another perf improvement this would enable. Isn't that just what you automatically get by only locking once per contiguous group of TIDs that all point to the same heap page? Or did you mean that we could do the visibility checks in a separate pass, or something like that? I know that we do something like that when pruning these days, but that seems quite different. > Yes, I think that's clearly required. I think one nice bonus of such a change > is that it'd resolve one of the biggest existing layering violations around > tableam - namely that nodeIndexonlyscan.c does VM_ALL_VISIBLE() calls, which > it really has no business doing. Right. One relevant artefact of that layering violation is the way that it forces index I/O prefetching (as implemented in the current draft patch) to cache visibility lookup info. But with an I/O prefetching design that puts exactly one place (namely the new table AM index scan implementation) in charge of everything, that is no longer necessary. > I wonder if we could actually do part of the redesign in an even more > piecemeal fashion: > > 1) Move the responsibility for getting the next tid from the index into > tableam, but do so by basically using index_getnext_tid(). I would prefer it if the new table AM interface was able to totally replace the existing one, for all types of index scans that currently use amgettuple. Individual table AMs would generally be expected to fully move over to the new interface in one go. That means that we'll need to have index_getnext_tid() support built into the heapam implementation of said new interface anway. We'll need it so that it is compatible with index AMs that still use amgettuple (i.e. that haven't switched over to amgetbatch). Because switching over to the amgetbatch interface isn't going to happen with every index AM in a single release -- that definitely isn't practical. Anyway, I don't see that much point in doing just step 1 in a single release. If we don't use amgetbatch in some fashion, then we risk committing something that solves the wrong problem. > 2) Have the new interface get a single batch of tuples from the index, instead > of doing it on a single tid-by-tid basis. That was already what I had in mind for this new plan/direction. There isn't any point in having more than 1 index-AM-wise batch when we just need index AM batching to implement the heapam buffer locking optimization. (Actually, we'll need up to 2 such batches to handle things like mark + restore, much like the way that nbtree uses a separate CurrPos and markPos today.) > 3) Have heapam not acquire the page lock for each tuple, but do so for all the > tuples on the same page. I think that this is very easy compared to 1 and 2. It doesn't really seem like it makes sense as a separate step/item? Unlike with I/O prefetching, there'll be nothing speculative about the way that the heap buffer lock optimization needs to schedule work done by index AMs. We'll do it only when we can readily see that there's a group of contiguous TIDs to be returned by the scan that all point to the same heap page. There's no eager work done by index AMs compared to today/compared to amgettuple -- we're just testing if the very next TID has a matching block number, and then including it when it does. > 4) Add awareness of multiple batches > > 5) Use read stream I think that it makes sense to do these 2 together. But if we were going to break them up, my guess is that it'd make the most sense to start with the read stream work, and only then add support for reading multiple index-AM-wise batches at a time. I think that it's essential that the design of amgetbatch be able to accomodate reading leaf pages that are ahead of the current leaf page, to maintain heap I/O prefetch distance with certain workloads. But I don't think it has to do it in the first committed version. -- Peter Geoghegan
Hi, On 2025-11-21 18:14:56 -0500, Peter Geoghegan wrote: > On Fri, Nov 21, 2025 at 5:38 PM Andres Freund <andres@anarazel.de> wrote: > > Another benfit is that it helps even more when there multiple queries running > > concurrently - the high rate of lock/unlock on the buffer rather badly hurts > > scalability. > > I haven't noticed that effect myself. In fact, it seemed to be the > other way around; it looked like it helped most with very low client > count workloads. It's possible that that effect is more visible on larger machines - I did test that on a 2x 24cores/48 threads machine. I do see a smaller effect on a 2x10c/20t machine. > It's possible that that had something to do with my hacky approach to > validating the general idea of optimizing heapam buffer > locking/avoiding repeated locking. This was a very rough prototype. Heh, mine also was a dirty dirty hack. So.... > > Besides the locking overhead, it turns out that doing visibility checks > > one-by-one is a good bit slower than doing so in batches (or for the whole > > page). So that's another perf improvement this would enable. > > Isn't that just what you automatically get by only locking once per > contiguous group of TIDs that all point to the same heap page? No, what I mean is to actually enter heapam_visibility.c once for a set of tuples. That allows to do some expensive-ish stuff once per page, instead of doing it repeatedly and allows for more out-of-order execution as the loop is a lot tighter. See here for my patch to do that for sequential scans: https://postgr.es/m/6rgb2nvhyvnszz4ul3wfzlf5rheb2kkwrglthnna7qhe24onwr%40vw27225tkyar Basically, instead of calling HeapTupleSatisfiesVisibility() individually for each tuple, you call HeapTupleSatisfiesMVCCBatch() once for all the tuples that you want to determine visibility for. > > Yes, I think that's clearly required. I think one nice bonus of such a change > > is that it'd resolve one of the biggest existing layering violations around > > tableam - namely that nodeIndexonlyscan.c does VM_ALL_VISIBLE() calls, which > > it really has no business doing. > > Right. One relevant artefact of that layering violation is the way > that it forces index I/O prefetching (as implemented in the current > draft patch) to cache visibility lookup info. But with an I/O > prefetching design that puts exactly one place (namely the new table > AM index scan implementation) in charge of everything, that is no > longer necessary. Yep. > > I wonder if we could actually do part of the redesign in an even more > > piecemeal fashion: > > > > 1) Move the responsibility for getting the next tid from the index into > > tableam, but do so by basically using index_getnext_tid(). > > I would prefer it if the new table AM interface was able to totally > replace the existing one, for all types of index scans that currently > use amgettuple. Individual table AMs would generally be expected to > fully move over to the new interface in one go. Right. > That means that we'll need to have index_getnext_tid() support built > into the heapam implementation of said new interface anway. We'll need > it so that it is compatible with index AMs that still use amgettuple > (i.e. that haven't switched over to amgetbatch). Because switching > over to the amgetbatch interface isn't going to happen with every > index AM in a single release -- that definitely isn't practical. > Anyway, I don't see that much point in doing just step 1 in a single > release. If we don't use amgetbatch in some fashion, then we risk > committing something that solves the wrong problem. I'm not actually suggesting that we do all these steps in separate releases or such, just that we can get them committed individually. The nice thing about my step 1) is that it would not require any indexam changes... > I think that it's essential that the design of amgetbatch be able to > accomodate reading leaf pages that are ahead of the current leaf page, > to maintain heap I/O prefetch distance with certain workloads. But I > don't think it has to do it in the first committed version. Agreed and agreed. Greetings, Andres Freund
On Fri, Nov 21, 2025 at 6:31 PM Andres Freund <andres@anarazel.de> wrote: > On 2025-11-21 18:14:56 -0500, Peter Geoghegan wrote: > > On Fri, Nov 21, 2025 at 5:38 PM Andres Freund <andres@anarazel.de> wrote: > > > Another benfit is that it helps even more when there multiple queries running > > > concurrently - the high rate of lock/unlock on the buffer rather badly hurts > > > scalability. > > > > I haven't noticed that effect myself. In fact, it seemed to be the > > other way around; it looked like it helped most with very low client > > count workloads. > > It's possible that that effect is more visible on larger machines - I did test > that on a 2x 24cores/48 threads machine. I do see a smaller effect on a > 2x10c/20t machine. Update: I find that when I build Postgres with -march=native, I see performance characteristics that are much more in line with what you saw when you ran your own experiments (experiments with minimizing the number of heap buffer locks acquired during index scans). At 1 client count, there's now only about a 10% increase in throughput for a pgbench variant that uses the type of range queries that you'd expect to benefit the most from this work (that was more like 18%-20% without -march=native). Whereas with 32 clients, it's an ~18% improvement in throughput (where before it was only around 15% - 16%). Are you in the habit of using -march=native? I'm not. I assume that most Postgres users aren't using packages that were built with the flags that -march=native implies, which is why I largely go with defaults for my release/benchmarking builds (the only exception is my use of -fno-omit-frame-pointer). In case it matters, my workstation uses a Ryzen 9 5950X CPU (which is Zen 3). -- Peter Geoghegan
Hi, On 2025-11-23 19:03:44 -0500, Peter Geoghegan wrote: > On Fri, Nov 21, 2025 at 6:31 PM Andres Freund <andres@anarazel.de> wrote: > > On 2025-11-21 18:14:56 -0500, Peter Geoghegan wrote: > > > On Fri, Nov 21, 2025 at 5:38 PM Andres Freund <andres@anarazel.de> wrote: > > > > Another benfit is that it helps even more when there multiple queries running > > > > concurrently - the high rate of lock/unlock on the buffer rather badly hurts > > > > scalability. > > > > > > I haven't noticed that effect myself. In fact, it seemed to be the > > > other way around; it looked like it helped most with very low client > > > count workloads. > > > > It's possible that that effect is more visible on larger machines - I did test > > that on a 2x 24cores/48 threads machine. I do see a smaller effect on a > > 2x10c/20t machine. > > Update: I find that when I build Postgres with -march=native, I see > performance characteristics that are much more in line with what you > saw when you ran your own experiments (experiments with minimizing the > number of heap buffer locks acquired during index scans). Huh. I wouldn't have expected -march=native to make a huge difference... > Are you in the habit of using -march=native? I'm not. I occasionally use it, but not regularly - I do however use -O3, as I found that to actually improve performance sufficiently in plenty cases. And it's something that's much more generally applicable than -march=native?. I don't think the precise gains here, particularly basedon on quick prototypes, make that much of a difference. There's so much more optimization potential other than the amortization of locking costs... Greetings, Andres Freund
On Mon, Nov 24, 2025 at 3:48 PM Andres Freund <andres@anarazel.de> wrote: > Huh. I wouldn't have expected -march=native to make a huge difference... Me neither. On the other hand I find that this area is quite sensitive to icache misses and branch misprediction penalties. This is partly due to my holding the patch to a very high standard, in terms of avoiding regressions (at least for simple point lookup queries and nestloop join queries). > I don't think the precise gains here, particularly basedon on quick > prototypes, make that much of a difference. There's so much more optimization > potential other than the amortization of locking costs... I agree that this precise issue isn't necessarily all that important. My current focus is on completely separating the I/O prefetching parts of the patch from the core AM interface changes, while avoiding regressions shown by various microbenchmarks. My experiments with -march=native were mostly about that -- not about the heap buffer locking thing specifically. That was just something I noticed in passing, and found curious. -- Peter Geoghegan
On Mon, Nov 10, 2025 at 6:59 PM Peter Geoghegan <pg@bowt.ie> wrote: > The new tentative plan is to cut scope by focussing on switching over > to the new index AM + table AM interface from the patch in the short > term, for Postgres 19. Attached patch makes the table AM revisions we talked about. This is a significant change in direction, so I'm adopting a new patch versioning scheme: this new version is v1. (I just find it easier to deal with sequential patch version numbers.) I'm sure that I'll have made numerous mistakes in this new v1. There will certainly be some bugs, and some of the exact details of how I'm doing the layering are likely suboptimal or even wrong. I am nevertheless cautiously optimistic that this will be the last major redesign that will be required for this project. > There is an almost immediate benefit to just > doing that much, unrelated to I/O prefetching for index scans: it > enables batching of heap page buffer locking/unlocking (during the > point where index scans perform heap_hot_search_buffer calls) on the > table AM/heapam side during ordered index scans. Note that this new v1 doesn't yet include the important heapam buffer locking optimization discussed here. It didn't seem worth holding up everything just for that. Plan is to get to it next. (It isn't intrinsically all that complicated to add the optimization with this new table AM orientated structure, but doing so would have made performance validation work/avoiding regressions with simple queries that much harder. So I just put it off for a bit longer.) What's new in v1 (compared to v20251109-*, the prior version): * The first patch in the series is now mostly about changing the table AM and index AM in a complementary way (not just about adding the amgetbatch interface to the index AM). To summarize this point (mostly just a recap of recent discussion on the table AM API on this thread) with its own sub points: - We're now using a slot-based table AM interface that understands scan direction. We now do all VM access for index-only scans on the heapam side, fixing that existing table AM modularity violation once and for all. - Batches returned by amgetbatch are directly managed by heapam, giving it the direct control that it requires to get the best possible performance. Whether that's for adding I/O prefetching, or for other optimizations. - The old table_index_fetch_tuple index scan interface is still needed -- though only barely. The rule going forward for core executor code is that it should always use this new slot-based interface, unless there is a specific need for such a caller to pass *their own* TID, in a way that cannot possibly be delegated to our new high level table AM interface. For example, we still need table_index_fetch_tuple for nbtree's _bt_check_unique; it must pass TIDs to heapam, and get back tuples, without starting any new index scan to do so (the only "index scan" involved in the case of the _bt_check_unique caller takes place in the btinsert that needs to perform unique index enforcement in passing). I think it makes perfect sense that a small handful of special case callers still need to use table_index_fetch_tuple, since there really is no way around the need for these callers to pass their own TID. * Major restructuring of batch management code, to allow it to work with the table AM interface (as well as related improvements and polishing). The parts of batch management that aren't under the direct control of table AMs/heapam (the batch helper functions that all table AMs will use) are no longer in indexam.c; there's a new file for those routines named indexbatch.c. indexbatch.c is also the place where a few other helper functions go. These other functions are called by indexam.c/the core executor, for things like initializing an amgetbatch scan, and informing nbtree that it is taking a mark (for mark/restore). Maybe there are certain remaining problems with the way that indexam.c and heapam_handler.c are coordinating across index scans. Hopefully the structure wasn't accidentally overfitted to heapam/isn't brittle in some other way. * Renamed and made lots of tweaks to batching related functions and structs. I've also integrated code that previously appeared in its own "batch cache" patch into the new main commit in the patch series (the first patch in the new series). The main goal of the tweaks to the data structures was to avoid indirection that previously caused small regressions in my microbenchmarks. We're very sensitive to costs from additional pointer chasing in these code paths. And from even small memory allocations. I think that I've avoided all regressions with just the first patch, at least for my own microbenchmark suite. I did not aim to avoid these regressions with the prefetching patch, since I consider it out of scope now (for Postgres 19). * v1 breaks out prefetching into its own patch, which is now the second patch in the patch series. The new I/O prefetching patch turned out to be surprisingly small. I still feel good about our choice to put that off until Postgres 20, though -- it's definitely where most of the difficulties are. Especially with things like resource management. (The problem with the second patch is that it's too small/doesn't address all the problems, not that it's too big and unwieldy.) Prefetching works at least as well as it did in earlier versions (maybe even slightly better). It's not just an afterthought here. At a minimum, we need to continue to maintain prefetching in a reasonably complete and usable form to keep us honest about the design changes in the table AM and index AM APIs. If the design itself cannot eventually accommodate Postgres 20 work on I/O prefetching (and even later work), then it's no good. Minor caveat about preserving prefetching in good working order: I disabled support for index-only scans that use I/O prefetching for heap accesses in the second patch, at least for now. To recap, IoS support requires a visibility cache so that both readBatch and streamBatch agree on exactly which heap blocks will need to be read, even when the visibility map has some relevant heap page bits concurrently set or unset. It won't be too hard to add something like that back to heapam_handler.c, but I didn't get around to doing so just yet. It might be independently useful to have some kind of visibility cache, even without prefetching; batching VM accesses (say by doing them up front, for a whole batch, right after amgetbatch returns) might work out saving cycles with cached scans. You know, somewhat like how we'll do same-heap-page heap tuple fetches eagerly as a way of minimizing buffer lock/unlock traffic. * There's a new patch that adds amgetbatch support for hash indexes. This demonstrates that the amgetbatch interface is already reasonably general. And that adding support to an index AM doesn't have to be all that invasive. I'm more focussed than ever on the generality of the API now. * Added documentation that attempts to formalize the constraints that index AMs that opt to use amgetbatch are under. I don't think that it makes sense to think of amgettuple as the legacy interface for plain index scans. There will probably always be cases like KNN GiST scans, that legitimately need the index AM to directly control the progress of index scans, a tuple at a time. After all, these scan types give an absurd amount of control over many things to the index AM -- that seems to really make it hard to put the table AM in control of the scan's progress. For example, GiST scans use their own GISTSearchHeapItem struct to manage each item returned to the scan (which has a bunch of extra fields compared to our new AM-generic BatchMatchingItem struct). This GISTSearchHeapItem struct allows GiST to indicate whether or not an index tuple's quals must be rechecked. It works at the tuple granularity (individual GiST opclasses might expect that level of flexibility), which really works against the batching concepts that we're pursuing here. It's true that hash index scans are also lossy, but that's quite different: they're inherently lossy. It's not as if hash index scans are sometimes not lossy. They certainly cannot be lossy for some tuples but not other tuples that all get returned during the same index scan. Not so with GiST scans. Likely the best solution to the problems posed by GiST and SP-GiST will be to choose one of either amgettuple and amgetbatch during planning, according to what the scan actually requires (while having support for both interfaces in both index AMs). I'm still not sure what that should look like, though -- how does the planner know which interface to use, in a world where it has to make a choice with those index AMs that offer both? Obviously the answer depends in part on what actually matters to GiST/where GiST *can* reasonably use amgetbatch, to get benefits such as prefetching. And I don't claim to have a full understanding of that right now. Here are the things that I'd like to ask from reviewers, and from Tomas: * Review of the table AM changes, with a particular emphasis on high level architectural choices. * Most importantly: will the approach in this new v1 avoid painting ourselves into a corner? It can be incomplete, as long as it doesn't block progress on things we're likely to want to do in the next couple of releases. * Help with putting the contract that amgetbatch requires of index AMs on a more rigorous footing. In other words, is amgetbatch itself sufficiently general to accomodate the needs of index AMs in the future? I've made a start on that here (by adding sgml docs about the index AM API, which mentions table AM concerns), but work remains, particularly when it comes to supporting GiST + SP-GiST. I think it makes sense to keep feedback mostly high level for now -- to make it primarily about how the individual API changes fit together, if they're coordinating too much (or not enough), and if the interface we have is able to accommodate future needs. -- Peter Geoghegan
Вложения
On 12/1/25 02:23, Peter Geoghegan wrote: > On Mon, Nov 10, 2025 at 6:59 PM Peter Geoghegan <pg@bowt.ie> wrote: >> The new tentative plan is to cut scope by focussing on switching over >> to the new index AM + table AM interface from the patch in the short >> term, for Postgres 19. > > Attached patch makes the table AM revisions we talked about. This is a > significant change in direction, so I'm adopting a new patch > versioning scheme: this new version is v1. (I just find it easier to > deal with sequential patch version numbers.) > Thanks for the new version! I like the layering in this patch, moving some of the stuff from indexam.c/executor to table AM. It makes some of the code much cleaner, I think. > I'm sure that I'll have made numerous mistakes in this new v1. There > will certainly be some bugs, and some of the exact details of how I'm > doing the layering are likely suboptimal or even wrong. I am > nevertheless cautiously optimistic that this will be the last major > redesign that will be required for this project. > Sounds good. FWIW I don't see any major issues in this version. >> There is an almost immediate benefit to just >> doing that much, unrelated to I/O prefetching for index scans: it >> enables batching of heap page buffer locking/unlocking (during the >> point where index scans perform heap_hot_search_buffer calls) on the >> table AM/heapam side during ordered index scans. > > Note that this new v1 doesn't yet include the important heapam buffer > locking optimization discussed here. It didn't seem worth holding up > everything just for that. Plan is to get to it next. > > (It isn't intrinsically all that complicated to add the optimization > with this new table AM orientated structure, but doing so would have > made performance validation work/avoiding regressions with simple > queries that much harder. So I just put it off for a bit longer.) > Understood. I presume that optimization fits mostly "seamlessly" into this patch design. > What's new in v1 (compared to v20251109-*, the prior version): > > * The first patch in the series is now mostly about changing the table > AM and index AM in a complementary way (not just about adding the > amgetbatch interface to the index AM). > > To summarize this point (mostly just a recap of recent discussion on > the table AM API on this thread) with its own sub points: > > - We're now using a slot-based table AM interface that understands > scan direction. We now do all VM access for index-only scans on the > heapam side, fixing that existing table AM modularity violation once > and for all. > I admit I was a bit skeptical about this approach, mostly because I didn't have a clear idea how would it work. But it turns out to be quite clean. Well, definitely cleaner that what I had before. > - Batches returned by amgetbatch are directly managed by heapam, > giving it the direct control that it requires to get the best possible > performance. Whether that's for adding I/O prefetching, or for other > optimizations. > > - The old table_index_fetch_tuple index scan interface is still needed > -- though only barely. > > The rule going forward for core executor code is that it should always > use this new slot-based interface, unless there is a specific need for > such a caller to pass *their own* TID, in a way that cannot possibly > be delegated to our new high level table AM interface. > > For example, we still need table_index_fetch_tuple for nbtree's > _bt_check_unique; it must pass TIDs to heapam, and get back tuples, > without starting any new index scan to do so (the only "index scan" > involved in the case of the _bt_check_unique caller takes place in the > btinsert that needs to perform unique index enforcement in passing). I > think it makes perfect sense that a small handful of special case > callers still need to use table_index_fetch_tuple, since there really > is no way around the need for these callers to pass their own TID. > Agreed. I don't think it makes sense to require eliminating all these table_index_fetch_tuple calls (even if it was possible). > * Major restructuring of batch management code, to allow it to work > with the table AM interface (as well as related improvements and > polishing). > > The parts of batch management that aren't under the direct control of > table AMs/heapam (the batch helper functions that all table AMs will > use) are no longer in indexam.c; there's a new file for those routines > named indexbatch.c. indexbatch.c is also the place where a few other > helper functions go. These other functions are called by indexam.c/the > core executor, for things like initializing an amgetbatch scan, and > informing nbtree that it is taking a mark (for mark/restore). > > Maybe there are certain remaining problems with the way that indexam.c > and heapam_handler.c are coordinating across index scans. Hopefully > the structure wasn't accidentally overfitted to heapam/isn't brittle > in some other way. > +1, seems like a clear improvement. I don't see any major issues, but I have a couple minor comments/questions. I realize this also removes mark/restore support from the old "amgettuple" interface, so only AMs implementing the new batching API will be able to do mark/restore. AFAICS in core this only affects btree, and that is switched to the batching. But won't this break external AMs that might do mark/restore, and don't want to / can't do batching? I'm not aware of any such AMs, though. Maybe it's fine. Do we want to make "per-leaf-page" batches explicit in the commit message / comments? Yes, we do create per-leaf batches, but isn't it more because it's convenient, and the AM could create larger/smaller batches if appropriate? Or is this a requirement? I'm thinking about doing batching for gist/spgist ordered scans, where the index entries are not returned leaf-at-a-time. Another question about IOS with xs_hitup - which is not supported by the patch (only IOS with xs_itup are). Is there a reason why this can't be supported? I can't think of any, maybe I'm missing something? There's also the question whether amgettuple/amgetbatch should be exclusive, or an AM could support both. In the docs the patch seems to imply it's exclusive, but then it also says "XXX uncertain" about this. I suspect it probably makes sense to allow implementing both, with the amgettuple as a "fallback" for scans where doing batching is complex and unlikely to help (I'm thinking about spgist ordered scans, which reorder the index entries). But maybe it makes sense to apply batching even to this case, not sure. If we choose to allow both, then something will have to make a decision which of the APIs to use in a given scan. This decision probably needs happen early in the planning, and can't be renegotiated. Ultimately the only part aware of all the details is the AM opclass, so there'd need to be some sort of optional AM procedure to decide this. But maybe it's not worth it? I'm concerned about painting ourselves in the corner, where some index AM can't do batching for one corner case, and therefore it can't do batching at all. > * Renamed and made lots of tweaks to batching related functions and > structs. I've also integrated code that previously appeared in its own > "batch cache" patch into the new main commit in the patch series (the > first patch in the new series). > > The main goal of the tweaks to the data structures was to avoid > indirection that previously caused small regressions in my > microbenchmarks. We're very sensitive to costs from additional pointer > chasing in these code paths. And from even small memory allocations. > > I think that I've avoided all regressions with just the first patch, > at least for my own microbenchmark suite. I did not aim to avoid these > regressions with the prefetching patch, since I consider it out of > scope now (for Postgres 19). > I think it's much more consistent now, thanks. I find the new "BatchIndexScan" name a bit confusing, it sounds more like a special type of IndexScan. Maybe IndexScanBatch would be better? Also, I find the batch_assert_pos_valid/batch_assert_batch_valid naming a bit surprising. I think the custom is to name "asserts" function something like AssertSomethingSomething(), to make it distinct from usual functions. At least that's what I saw in other patches, and I followed that practice ... But maybe it's not suitable for non-static functions. Speaking of batch_assert_batches_valid, why not to add it to relscan.h, next to the other "asserts"? > * v1 breaks out prefetching into its own patch, which is now the > second patch in the patch series. > > The new I/O prefetching patch turned out to be surprisingly small. I > still feel good about our choice to put that off until Postgres 20, > though -- it's definitely where most of the difficulties are. > Especially with things like resource management. (The problem with the > second patch is that it's too small/doesn't address all the problems, > not that it's too big and unwieldy.) > Let's see how that goes. I'm not against putting that off until Postgres 20, but maybe it's too early to make that decision. I'd like to at least give it a try for 19. If it doesn't make it, that's fine. > Prefetching works at least as well as it did in earlier versions > (maybe even slightly better). It's not just an afterthought here. At a > minimum, we need to continue to maintain prefetching in a reasonably > complete and usable form to keep us honest about the design changes in > the table AM and index AM APIs. If the design itself cannot eventually > accommodate Postgres 20 work on I/O prefetching (and even later work), > then it's no good. > > Minor caveat about preserving prefetching in good working order: I > disabled support for index-only scans that use I/O prefetching for > heap accesses in the second patch, at least for now. To recap, IoS > support requires a visibility cache so that both readBatch and > streamBatch agree on exactly which heap blocks will need to be read, > even when the visibility map has some relevant heap page bits > concurrently set or unset. It won't be too hard to add something like > that back to heapam_handler.c, but I didn't get around to doing so > just yet. > Right, I was wondering how's the patch dealing with that before I realized it's disabled. > It might be independently useful to have some kind of visibility > cache, even without prefetching; batching VM accesses (say by doing > them up front, for a whole batch, right after amgetbatch returns) > might work out saving cycles with cached scans. You know, somewhat > like how we'll do same-heap-page heap tuple fetches eagerly as a way > of minimizing buffer lock/unlock traffic. > True. > * There's a new patch that adds amgetbatch support for hash indexes. > > This demonstrates that the amgetbatch interface is already reasonably > general. And that adding support to an index AM doesn't have to be all > that invasive. I'm more focussed than ever on the generality of the > API now. > Nice, and surprisingly small. > * Added documentation that attempts to formalize the constraints that > index AMs that opt to use amgetbatch are under. > > I don't think that it makes sense to think of amgettuple as the legacy > interface for plain index scans. There will probably always be cases > like KNN GiST scans, that legitimately need the index AM to directly > control the progress of index scans, a tuple at a time. > Right. > After all, these scan types give an absurd amount of control over many > things to the index AM -- that seems to really make it hard to put the > table AM in control of the scan's progress. For example, GiST scans > use their own GISTSearchHeapItem struct to manage each item returned > to the scan (which has a bunch of extra fields compared to our new > AM-generic BatchMatchingItem struct). This GISTSearchHeapItem struct > allows GiST to indicate whether or not an index tuple's quals must be > rechecked. It works at the tuple granularity (individual GiST > opclasses might expect that level of flexibility), which really works > against the batching concepts that we're pursuing here. > > It's true that hash index scans are also lossy, but that's quite > different: they're inherently lossy. It's not as if hash index scans > are sometimes not lossy. They certainly cannot be lossy for some > tuples but not other tuples that all get returned during the same > index scan. Not so with GiST scans. > > Likely the best solution to the problems posed by GiST and SP-GiST > will be to choose one of either amgettuple and amgetbatch during > planning, according to what the scan actually requires (while having > support for both interfaces in both index AMs). I'm still not sure > what that should look like, though -- how does the planner know which > interface to use, in a world where it has to make a choice with those > index AMs that offer both? Obviously the answer depends in part on > what actually matters to GiST/where GiST *can* reasonably use > amgetbatch, to get benefits such as prefetching. And I don't claim to > have a full understanding of that right now. > Right, that's pretty much what I suggested earlier. > Here are the things that I'd like to ask from reviewers, and from Tomas: > > * Review of the table AM changes, with a particular emphasis on high > level architectural choices. > To me the proposed architecture/layering looks nice and reasonable. But I haven't really thought about table AM until Andres pointed out the issues, so maybe I may not be the right person to judge this. And I've moved the code between the various layers so many times I have vertigo. > * Most importantly: will the approach in this new v1 avoid painting > ourselves into a corner? It can be incomplete, as long as it doesn't > block progress on things we're likely to want to do in the next couple > of releases. > I don't see why we would paint ourselves in the corner with this. (I'm ignoring the question about allowing only one of amgettuple/amgetbatch.) > * Help with putting the contract that amgetbatch requires of index AMs > on a more rigorous footing. In other words, is amgetbatch itself > sufficiently general to accomodate the needs of index AMs in the > future? I've made a start on that here (by adding sgml docs about the > index AM API, which mentions table AM concerns), but work remains, > particularly when it comes to supporting GiST + SP-GiST. > So what exactly is the "contract" assumed by the current patch? Do you have any thoughts about it being too inflexible in some respect? As mentioned earlier, maybe we shouldn't tie batches to leaf pages too much, so that the AM can build batches not aligned to leaf-pages in such a simple way. I think this would allow doing batchning/prefetching for cases like the spgist ordered scans, etc. > I think it makes sense to keep feedback mostly high level for now -- > to make it primarily about how the individual API changes fit > together, if they're coordinating too much (or not enough), and if the > interface we have is able to accommodate future needs. > Makes sense. Hopefully I wasn't nitpicking about details too much. regards -- Tomas Vondra
On Mon, Dec 1, 2025 at 11:32 AM Tomas Vondra <tomas@vondra.me> wrote: > Thanks for the new version! I like the layering in this patch, moving > some of the stuff from indexam.c/executor to table AM. It makes some of > the code much cleaner, I think. Yeah, I think so too. Clearly the main way that this improves the design is by avoiding implicit coordination between code paths that are a great distance away from each other. Particularly with index prefetching, where previously we maintained a visibility info cache for use in indexOnlyscan.c, that was also used by the read stream callback. There's no need for such coordination if it all has to happen from the same few table AM routines. > > I'm sure that I'll have made numerous mistakes in this new v1. There > > will certainly be some bugs, and some of the exact details of how I'm > > doing the layering are likely suboptimal or even wrong. I am > > nevertheless cautiously optimistic that this will be the last major > > redesign that will be required for this project. > > > > Sounds good. FWIW I don't see any major issues in this version. I was thinking of stuff like how the heapam data structure still doesn't actually contain the read stream, so that indexam.c can call indexbatch.c and do things like reset the read stream if necessary. Stuff like that. Maybe we should be calling index_batch_init from heapam_handler.c, and not from indexam.c (we still do the latter). OTOH, maybe that'd be a case of adding more mechanism for no real benefit. These kinds of design choices are relatively unimportant, but did seem like the kind of thing that I'm relatively likely to have messed up in this v1. > > (It isn't intrinsically all that complicated to add the optimization > > with this new table AM orientated structure, but doing so would have > > made performance validation work/avoiding regressions with simple > > queries that much harder. So I just put it off for a bit longer.) > > > > Understood. I presume that optimization fits mostly "seamlessly" into > this patch design. Right. Obviously, that's another advantage of the new table AM interface. We could even do something much more sophisticated than what I actually have planned for 19: we could reorder table fetches, such that we only had to lock and pin each heap page exactly once *even when the TIDs returned by the index scan return TIDs slightly out of order*. For example, if an index page/batch returns TIDs "(1,1), (2,1), (1,2), (1,3), (2,2)", we could get all tuples for heap blocks 1 and 2 by locking and pinning each of those 2 pages exactly once. The only downside (other than the complexity) is that we'd sometimes hold multiple heap page pins at a time, not just one. I think of this as making index scans behave somewhat more like bitmap scans. It might even make sense to do it very aggressively. We don't have to hold on to pins if we can materialize/make our own private copies of the tuples for later. This is very speculative stuff. I won't be working on anything this complicated any time soon. But I think it's good that to have a structure that enables this kind of thing. > I admit I was a bit skeptical about this approach, mostly because I > didn't have a clear idea how would it work. But it turns out to be quite > clean. Well, definitely cleaner that what I had before. It's the least worst way of implementing a design that gives the table AM the required understanding of index AM costs. Which is just what's required to do I/O prefetching as efficiently as possible. > Agreed. I don't think it makes sense to require eliminating all these > table_index_fetch_tuple calls (even if it was possible). One could argue that the remaining use of table_index_fetch_tuple is still a modularity violation, since we're still using TIDs instead of some abstract concept that generalizes the idea of TID across all possible table AMs. But that's not a new problem, and not one that we're in any way obligated to fix within the scope of this project. > I realize this also removes mark/restore support from the old > "amgettuple" interface, so only AMs implementing the new batching API > will be able to do mark/restore. Right. > AFAICS in core this only affects btree, > and that is switched to the batching. But won't this break external AMs > that might do mark/restore, and don't want to / can't do batching? Yes. > I'm not aware of any such AMs, though. Maybe it's fine. If somebody shows up and complains about it, we can do something about it then. But I'd rather not add code to deal with a 100% theoretical problem such as this. I really doubt that there will be any complaints. > Do we want to make "per-leaf-page" batches explicit in the commit > message / comments? Yes, we do create per-leaf batches, but isn't it > more because it's convenient, and the AM could create larger/smaller > batches if appropriate? It is a structure that forces index AMs to follow the existing long documented rules about holding onto buffer locks as an interlock against unsafe concurrent TID recycling by VACUUM. There's nothing fundamentally new about it. > Or is this a requirement? I'm thinking about > doing batching for gist/spgist ordered scans, where the index entries > are not returned leaf-at-a-time. It's true that GiST and SP-GiST don't return tuples a leaf at a time, and never hold on to buffer pins. It's also true that both support index-only scans that can give wrong answers to queries, precisely because they just ignore the rules we have for index AMs. This presents us with an absurd dilemma: should we make amgetbatch work with those requirements, even though we know that they're based on a faulty understanding of the basic protocols that index scans are supposed to follow? It would be very difficult to make ordered GiST scans hold the required buffer pins sufficient to avoid races with VACUUM, fixing the index-only scan bug -- no question. But that difficulty has exactly nothing to do with this project. The easiest way to fix the bugs in GiST is likely to be by disabling KNN ordered index-only scans, while making remaining index-only scans correctly follow the index AM protocol for the first time (by holding onto leaf page pins until the table AM is done reading the heap tuples for the page's TIDs). I think that we'll probably need to disable index-only KNN scans, since I suspect that there just isn't a way to keep the number of pins held manageably low in the general case. Once all that happens (in addition to making GiST VACUUM acquire conflicting cleanup locks like nbtree does already), then it should be possible to adopt GiST to the amgetbatch paradigm with some more work. (Recall that plain index scans that use an MVCC snapshot don't actually need to hold onto buffer pins on leaf pages.) Adopting GiST to amgetbatch then becomes a matter of inventing a new layer that either treats GiST leaf pages just like nbtree leaf pages, or (in the case of KNN scans) builds virtual batches or somesuch. A virtual batch doesn't ever have a buffer pin in its batch, since the relationship between index leaf pages and the contents of the batch are fuzzy. In general the use of virtual batches is undesirable, though, because they are inherently incompatible with index-only scans. > Another question about IOS with xs_hitup - which is not supported by > the patch (only IOS with xs_itup are). Is there a reason why this can't > be supported? I can't think of any, maybe I'm missing something? We don't support them for the kinds of reasons you'd guess: they're really only useful in GiST and SP-GiST, which aren't going to be supported in the first release regardless of what we do (btw, pgvector doesn't use xs_hitup either, nor does it support any kind of index-only scan). They're also just awkward, because we can't assume that BLCKSZ space will always be enough to store all the required heap tuples (GiST uses retail palloc()s for the heap tuples). And because we have no way to test xs_hitup support. These reasons don't make it fundamentally impossible. On the other hand, not supporting xs_hitup doesn't close any doors to adding such support in a later release. > There's also the question whether amgettuple/amgetbatch should be > exclusive, or an AM could support both. In the docs the patch seems to > imply it's exclusive, but then it also says "XXX uncertain" about this. I lean towards requiring that index AMs choose one or the other in the first committed version. This is a reversible choice, after all. > But maybe it's not worth it? I'm concerned about painting ourselves in > the corner, where some index AM can't do batching for one corner case, > and therefore it can't do batching at all. Maybe not. I know that I said that I think that it might make sense to keep amgettuple to allow things like KNN GiST scans to continue to work. But now I'm not so sure. The better paradigm might still be to invent the concept of virtual batches. That allows index AMs to deal with tricky cases like KNN GiST scans as their own implementation detail (mostly). It's not particularly natural for such index AMs to use amgetbatch right now...but if they're sometimes doing so anyway, that isn't really true anymore. > I find the new "BatchIndexScan" name a bit confusing, it sounds more > like a special type of IndexScan. Maybe IndexScanBatch would be better? I did have that at one point, but was then concerned that it implied that the struct belonged in a file like indexam.c, which it does not. Do you have another suggestion? > Also, I find the batch_assert_pos_valid/batch_assert_batch_valid naming > a bit surprising. I think the custom is to name "asserts" function > something like AssertSomethingSomething(), to make it distinct from > usual functions. At least that's what I saw in other patches, and I > followed that practice ... But maybe it's not suitable for non-static > functions. I don't feel strongly either way. > Speaking of batch_assert_batches_valid, why not to add it to relscan.h, > next to the other "asserts"? No good reason. Will fix. > Let's see how that goes. I'm not against putting that off until Postgres > 20, but maybe it's too early to make that decision. I'd like to at least > give it a try for 19. If it doesn't make it, that's fine. Perhaps you're right -- I could have overreacted when I said that I/O prefetching for 19 just wasn't going to happen. I don't feel bad about putting that back in scope now, as long as the primary goal remains getting the API changes (as well as the heap buffer locking optimization) in place. > > Likely the best solution to the problems posed by GiST and SP-GiST > > will be to choose one of either amgettuple and amgetbatch during > > planning, according to what the scan actually requires (while having > > support for both interfaces in both index AMs). I'm still not sure > > what that should look like, though -- how does the planner know which > > interface to use, in a world where it has to make a choice with those > > index AMs that offer both? Obviously the answer depends in part on > > what actually matters to GiST/where GiST *can* reasonably use > > amgetbatch, to get benefits such as prefetching. And I don't claim to > > have a full understanding of that right now. > > > > Right, that's pretty much what I suggested earlier. Like I said just now, this seems pretty complicated. So complicated that not requiring the planner to figure it out at all (pushing the problem into index AMs like GiST) has a certain appeal. It's not like amgettuple and amgetbatch are all that different. The main difference is that as things stand GiST cannot just use all the amgettuple state it currently holds in GISTScanOpaqueData.GISTSearchHeapItem. > > * Review of the table AM changes, with a particular emphasis on high > > level architectural choices. > > > > To me the proposed architecture/layering looks nice and reasonable. Cool. > But I haven't really thought about table AM until Andres pointed out the > issues, so maybe I may not be the right person to judge this. And I've > moved the code between the various layers so many times I have vertigo. I can certainly sympathize with that. > I don't see why we would paint ourselves in the corner with this. (I'm > ignoring the question about allowing only one of amgettuple/amgetbatch.) We can change our mind about requiring exactly one of amgettuple or amgetbatch in the future. It's a completely reversible design decision. We could even add a caveat about it to the sgml docs that cover the index AM API. > > * Help with putting the contract that amgetbatch requires of index AMs > > on a more rigorous footing. In other words, is amgetbatch itself > > sufficiently general to accomodate the needs of index AMs in the > > future? I've made a start on that here (by adding sgml docs about the > > index AM API, which mentions table AM concerns), but work remains, > > particularly when it comes to supporting GiST + SP-GiST. > > > > So what exactly is the "contract" assumed by the current patch? Do you > have any thoughts about it being too inflexible in some respect? I was a tiny bit worried about the xs_hitup support question, but less so now. That was one. I guess that I also wondered if the use of fields like "moreLeft" and "moreRight" was sufficiently general. I think it probably is, actually, but it's a question that needs to be asked. pgvector doesn't support index-only scans at all, and only does MVCC snapshots, so AFAICT it will always be safe to assume that we can always drop a pin on a pgvector index page (especially because it doesn't do kilitems stuff). From there I think it's just a matter of building virtual/simulated batches. I'm not sure where the logic to do that belongs, but I suspect that it might belong in pgvector. After all, pgvector probably shouldn't be forced to scan most of the index to get the required number of TIDs to make up a decent sized batch. It needs to decide that the time has come to at least return the matches we have already. > As mentioned earlier, maybe we shouldn't tie batches to leaf pages too > much, so that the AM can build batches not aligned to leaf-pages in such > a simple way. I think this would allow doing batchning/prefetching for > cases like the spgist ordered scans, etc. That makes sense. But I don't think that we necessarily have to have that fully worked out to commit the first patch. After all, the problems in that area are just really hard, for reasons that have very little to do with new stuff introduced by this patch series. -- Peter Geoghegan
Hi Peter, On Mon, Dec 1, 2025 at 10:24 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Nov 10, 2025 at 6:59 PM Peter Geoghegan <pg@bowt.ie> wrote: > > The new tentative plan is to cut scope by focussing on switching over > > to the new index AM + table AM interface from the patch in the short > > term, for Postgres 19. > > Attached patch makes the table AM revisions we talked about. This is a > significant change in direction, so I'm adopting a new patch > versioning scheme: this new version is v1. (I just find it easier to > deal with sequential patch version numbers.) > > I'm sure that I'll have made numerous mistakes in this new v1. There > will certainly be some bugs, and some of the exact details of how I'm > doing the layering are likely suboptimal or even wrong. I am > nevertheless cautiously optimistic that this will be the last major > redesign that will be required for this project. > ... > > Here are the things that I'd like to ask from reviewers, and from Tomas: > > * Review of the table AM changes, with a particular emphasis on high > level architectural choices. > > * Most importantly: will the approach in this new v1 avoid painting > ourselves into a corner? It can be incomplete, as long as it doesn't > block progress on things we're likely to want to do in the next couple > of releases. I was looking at your email and the v1 patch and recalled your earlier note from my executor batching thread [1], where you mentioned: "I think that the base index prefetching patch's current notion of index-AM-wise batches can be kept quite separate from any table AM batch concept that might be invented, either as part of what I'm working on, or in Amit's patch. It probably wouldn't be terribly difficult to get the new interface I've described to return heap tuples in whatever batch format Amit comes up with. ... I doubt that adopting Amit's batch format will make life much harder for the heap_hot_search_buffer-batching mechanism (at least if it is generally understood that its new index scan interface's builds batches in Amit's format on a best-effort basis)." I want to acknowledge that figuring out the right layering to make I/O prefetching and perhaps other optimizations internal to IndexNext() work is obviously the priority right now, regardless of the output format used to populate the slots ultimately returned by table_index_getnext_slot(). However, regarding your question about "painting ourselves into a corner": In my executor batching work (which has focused on Seq Scans), the HeapBatch is essentially just a pinned buffer plus an array of pre-allocated tuple headers. I hadn't strictly considered creating a HeapBatch to return from Index Scans, largely because heap_hot_search_buffer() is designed for scalar (or non-batched) access that requires repeated buffer locking. But it seems like the eventual goal of batching calls to heap_hot_search_buffer() effectively clears that hurdle. As long as the internal logic separates the "grouping/locking" from the "materializing into a slot," it seems this design does not prevent us from eventually wiring up a table_index_getnext_batch() to populate the HeapBatch structure I am proposing for the regular non-index scan path (table_scan_getnextbatch() in my patch). Sorry to hijack the thread, but just wanted to confirm I haven't misunderstood the architectural implications for future batching. Now off to continue reading the new indexbatch.c, which kind of reminds me of the stuff I've added in my execBatch.c. :-) -- Thanks, Amit Langote [1] https://www.postgresql.org/message-id/CAH2-WznijhPtw2vtwCtfFSwamwkT2O1KXMx6tE%2BeoHi3CKwRFg%40mail.gmail.com
Hi Amit, On Thu, Dec 4, 2025 at 12:54 AM Amit Langote <amitlangote09@gmail.com> wrote: > I want to acknowledge that figuring out the right layering to make I/O > prefetching and perhaps other optimizations internal to IndexNext() > work is obviously the priority right now, regardless of the output > format used to populate the slots ultimately returned by > table_index_getnext_slot(). Right; table_index_getnext_slot simply returns a tuple into the caller's slot. That's almost the same as the existing getnext_slot interface used by those same call sites on the master branch, except that in the patch we're directly calling a table AM callback/heapam specific implementation (not code in indexam.c). The new heapam implementation heapam_index_getnext_slot applies more high-level context about ordered index scans, which enables it to reorder work quite freely, even when it is work that takes place in index AMs. > However, regarding your question about > "painting ourselves into a corner": > > In my executor batching work (which has focused on Seq Scans), the > HeapBatch is essentially just a pinned buffer plus an array of > pre-allocated tuple headers. I hadn't strictly considered creating a > HeapBatch to return from Index Scans, largely because > heap_hot_search_buffer() is designed for scalar (or non-batched) > access that requires repeated buffer locking. > > But it seems like the eventual goal of batching calls to > heap_hot_search_buffer() effectively clears that hurdle. Actually, that's not the eventual goal anymore; now we're treating it as our *immediate* goal, at least in terms of things that will have user-visible impact (as opposed to API changes needed to facilitate batching type optimizations in the future, including I/O prefetching). It's not completely clear if prefetching is off the table for Postgres 19, but it certainly seems optimistic at this point. But the heap_hot_search_buffer thing definitely is in scope for Postgres 19 (if we're going to make all these API changes then it seems best to give users an immediate benefit). > As long as > the internal logic separates the "grouping/locking" from the > "materializing into a slot," it seems this design does not prevent us > from eventually wiring up a table_index_getnext_batch() to populate > the HeapBatch structure I am proposing for the regular non-index scan > path (table_scan_getnextbatch() in my patch). That's good. Suppose we do a much more advanced version of the kind of work reordering that the heap_hot_search_buffer thing will do for Postgres 19. I described this to Tomas in my last email to this thread, when I said: """ We could even do something much more sophisticated than what I actually have planned for 19: we could reorder table fetches, such that we only had to lock and pin each heap page exactly once *even when the TIDs returned by the index scan return TIDs slightly out of order*. For example, if an index page/batch returns TIDs "(1,1), (2,1), (1,2), (1,3), (2,2)", we could get all tuples for heap blocks 1 and 2 by locking and pinning each of those 2 pages exactly once. The only downside (other than the complexity) is that we'd sometimes hold multiple heap page pins at a time, not just one. """ (To be clear this more advanced version is definitely out of scope for Postgres 19.) We'd be holding on to multiple buffer pins at a time (across calls to heapam_index_getnext_slot) were we to do this more advanced optimization. I *think* that still means that the design/internal logic will (as you put it) "separate the 'grouping/locking' from the 'materializing into a slot'". That's just the only way that could possibly work correctly, at least with heapam. It makes sense for us both to (at a minimum) have at least some general awareness of each other's goals. I really only want to avoid completely gratuitous incompatibilities/conflicts. For example, if you invent a new slot-like mechanism in the executor that can return multiple tuples in one go, then it seems like we should probably try to use that in our own work on batching. If we're already assembling the information in a way that almost works with that new interface, why wouldn't we make sure that it actually worked with and used that new interface directly? It doesn't sound like there'd be many disagreements on how that would have to work, since the requirements are largely dictated by existing constraints that we're both already naturally subject to. For example: * We need to hold on to a buffer pin on a heap page if one of its heap tuples is contained in a slot/something slot-like. For as long as there's any chance that somebody will examine that heap tuple (until the slot releases the tuple). * Buffer locks must only be acquired by lower-level access method code, for very short periods, and never in a way that requires coordination across module boundaries. It sounds like the potential for conflicts between each other's work will be absolutely minimal. It seems as if we don't even have to agree on anything new or novel. > Sorry to hijack the thread, but just wanted to confirm I haven't > misunderstood the architectural implications for future batching. I don't think that you've hijacked anything. Your input is more than welcome. -- Peter Geoghegan
On Fri, Dec 5, 2025 at 6:11 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Dec 4, 2025 at 12:54 AM Amit Langote <amitlangote09@gmail.com> wrote: > > I want to acknowledge that figuring out the right layering to make I/O > > prefetching and perhaps other optimizations internal to IndexNext() > > work is obviously the priority right now, regardless of the output > > format used to populate the slots ultimately returned by > > table_index_getnext_slot(). > > Right; table_index_getnext_slot simply returns a tuple into the > caller's slot. That's almost the same as the existing getnext_slot > interface used by those same call sites on the master branch, except > that in the patch we're directly calling a table AM callback/heapam > specific implementation (not code in indexam.c). > > The new heapam implementation heapam_index_getnext_slot applies more > high-level context about ordered index scans, which enables it to > reorder work quite freely, even when it is work that takes place in > index AMs. > > > However, regarding your question about > > "painting ourselves into a corner": > > > > In my executor batching work (which has focused on Seq Scans), the > > HeapBatch is essentially just a pinned buffer plus an array of > > pre-allocated tuple headers. I hadn't strictly considered creating a > > HeapBatch to return from Index Scans, largely because > > heap_hot_search_buffer() is designed for scalar (or non-batched) > > access that requires repeated buffer locking. > > > > But it seems like the eventual goal of batching calls to > > heap_hot_search_buffer() effectively clears that hurdle. > > Actually, that's not the eventual goal anymore; now we're treating it > as our *immediate* goal, at least in terms of things that will have > user-visible impact (as opposed to API changes needed to facilitate > batching type optimizations in the future, including I/O prefetching). That makes sense. I had thought the "vectorized HOT search" (batching heap_hot_search_buffer) was a distant goal, so pulling it into PG19 is great news. It means the internal mechanics for "group-by-page" access, which seems like the hardest part of batching an index scan, will be in place sooner rather than later, allowing us to share some bits related to batching the output. > But the > heap_hot_search_buffer thing definitely is in scope for Postgres 19 > (if we're going to make all these API changes then it seems best to > give users an immediate benefit). +1 > > As long as > > the internal logic separates the "grouping/locking" from the > > "materializing into a slot," it seems this design does not prevent us > > from eventually wiring up a table_index_getnext_batch() to populate > > the HeapBatch structure I am proposing for the regular non-index scan > > path (table_scan_getnextbatch() in my patch). > > That's good. > > Suppose we do a much more advanced version of the kind of work > reordering that the heap_hot_search_buffer thing will do for Postgres > 19. I described this to Tomas in my last email to this thread, when I > said: > > """ > We could even do something much more sophisticated than what I > actually have planned for 19: we could reorder table fetches, such > that we only had to lock and pin each heap page exactly once *even > when the TIDs returned by the index scan return TIDs slightly out of > order*. For example, if an index page/batch returns TIDs "(1,1), > (2,1), (1,2), (1,3), (2,2)", we could get all tuples for heap blocks 1 > and 2 by locking and pinning each of those 2 pages exactly once. The > only downside (other than the complexity) is that we'd sometimes hold > multiple heap page pins at a time, not just one. > """ > > (To be clear this more advanced version is definitely out of scope for > Postgres 19.) > > We'd be holding on to multiple buffer pins at a time (across calls to > heapam_index_getnext_slot) were we to do this more advanced > optimization. I *think* that still means that the design/internal > logic will (as you put it) "separate the 'grouping/locking' from the > 'materializing into a slot'". That's just the only way that could > possibly work correctly, at least with heapam. Agreed. Even if a future version holds multiple pins to handle out-of-order TIDs, the architectural separation holds. The TAM would just populate a batch that spans those multiple pinned buffers (or a more complex batch structure), but the interface between it and the executor remains the same. > It makes sense for us both to (at a minimum) have at least some > general awareness of each other's goals. I really only want to avoid > completely gratuitous incompatibilities/conflicts. For example, if you > invent a new slot-like mechanism in the executor that can return > multiple tuples in one go, then it seems like we should probably try > to use that in our own work on batching. If we're already assembling > the information in a way that almost works with that new interface, > why wouldn't we make sure that it actually worked with and used that > new interface directly? > > It doesn't sound like there'd be many disagreements on how that would > have to work, since the requirements are largely dictated by existing > constraints that we're both already naturally subject to. For example: > > * We need to hold on to a buffer pin on a heap page if one of its heap > tuples is contained in a slot/something slot-like. For as long as > there's any chance that somebody will examine that heap tuple (until > the slot releases the tuple). > > * Buffer locks must only be acquired by lower-level access method > code, for very short periods, and never in a way that requires > coordination across module boundaries. Your list of constraints matches my experience with making batches for Seq Scans. My current HeapBatch implementation for Seq Scans received in a TupleBatch executor container is designed exactly around that first point. It fills the batch from the currently pinned page, stopping either when the batch capacity (GUC in the next version of my patch) is reached or when we reach the end of the page. I deliberately avoid spanning multiple pages in a single batch (for now) to keep that pin management simple. From the executor's perspective, HeapBatch is just an opaque black box. I rely on the TAM to manage the underlying resources (pins) to keep the data valid. This aligns well with your work because it leaves the pin management strategy, whether single-page or multi-page, entirely up to the AM implementation without exposing those details to the scan node. > It sounds like the potential for conflicts between each other's work > will be absolutely minimal. It seems as if we don't even have to agree > on anything new or novel. > > > Sorry to hijack the thread, but just wanted to confirm I haven't > > misunderstood the architectural implications for future batching. > > I don't think that you've hijacked anything. Your input is more than welcome. Thanks. It would be nice to keep this channel open as your API evolves. Based on what I understand so far, the heapam internals of this work seem compatible with how I am populating "output" batches in my executor work, so I just want to ensure we don't accidentally diverge on that front. -- Thanks, Amit Langote
On Sun, Nov 30, 2025 at 8:23 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached patch makes the table AM revisions we talked about. This is a > significant change in direction, so I'm adopting a new patch > versioning scheme: this new version is v1. (I just find it easier to > deal with sequential patch version numbers.) Attached is v2, just to keep the patch set cleanly applying against HEAD following recent changes in nbtree. No real changes here. -- Peter Geoghegan
Вложения
On Mon, Dec 8, 2025 at 3:50 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v2, just to keep the patch set cleanly applying against > HEAD following recent changes in nbtree. No real changes here. Attached is v3. This is another revision whose sole purpose is to keep the patch applying cleanly. No real changes compared to v1 to report here, either. -- Peter Geoghegan
Вложения
On Wed, Dec 10, 2025 at 5:41 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v3. This is another revision whose sole purpose is to keep > the patch applying cleanly. No real changes compared to v1 to report > here, either. Attached is v4. Same story again (another bitrot-fix-only revision). -- Peter Geoghegan
Вложения
On 11/12/2025 4:21 AM, Peter Geoghegan wrote:
> On Wed, Dec 10, 2025 at 5:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
>> Attached is v3. This is another revision whose sole purpose is to keep
>> the patch applying cleanly. No real changes compared to v1 to report
>> here, either.
> Attached is v4. Same story again (another bitrot-fix-only revision).
>
I did some small benchmarking and was slightly confused by result.
I run tests at my MacBook with 64Gb RAM. Database is initialized in this
way:
create table t (pk integer primary key, payload text default repeat('x',
1000)) with (fillfactor=10);
insert into t values (generate_series(1,10000000))
So it creates table with size 80Gb (160 after vacuum) which doesn't fit
in RAM.
I used default Postgres configuration and alter the only parameter -
`effective_io_concurrency`.
File with query for pgbench:
\set pk random(1, 10000000)
select * from t where pk >= :pk order by pk limit N;
where N is 1,10,100
I run pgbench with just one client:
pgbench -T 60 -n -M prepared -f select.sql postgres
Results with current master are the following:
limit
1 7754
10 1868
100 1047
With applied index prefetching patch results are almost 2 times better
for small limit (eio=effective_io_concurrency):
limit\eio 0 10 100
1 14260 14240 13909
10 3088 3152 3174
100 1135 1020 1052
but what confuses me is that they do not depend on
`effective_io_concurrency`.
Moreover with `enable_indexscan_prefetch=off` results are the same.
Also I expected that the best effect of index prefetching should be for
larger limit (accessing more heap pages). But as you see - it is not true.
May we there is something wrong with my test scenario.
It will be nice to get some information about efficiency of prefetch,
for example add `pefetch` option to explain: `explain
(analyze,buffers,prefetch) ...`
I think that in `pgaio_io_wait` we can distinguish IO operations which
are completed without waiting and can be considered as prefetch hit.
Right now it is hard to understand without debugger whether prefetch is
perfromed at all.
On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote:
> create table t (pk integer primary key, payload text default repeat('x',
> 1000)) with (fillfactor=10);
> insert into t values (generate_series(1,10000000))
>
> So it creates table with size 80Gb (160 after vacuum) which doesn't fit
> in RAM.
160 after VACUUM? What do you mean?
> but what confuses me is that they do not depend on
> `effective_io_concurrency`.
You did change other settings, right? You didn't just use the default
shared_buffers, for example? (Sorry, I have to ask.)
> Moreover with `enable_indexscan_prefetch=off` results are the same.
It's quite unlikely that the current heuristics that trigger
prefetching would have ever allowed any prefetching, for queries such
as these.
The exact rule right now is that we don't even begin prefetching until
we've already read at least one index leaf page, and have to read
another one. So it's impossible to use prefetching with a LIMIT of 1,
with queries such as these. It's highly unlikely that you'd see any
benefits from prefetching even with LIMIT 100 (usually we wouldn't
even begin prefetching).
> Also I expected that the best effect of index prefetching should be for
> larger limit (accessing more heap pages). But as you see - it is not true.
>
> May we there is something wrong with my test scenario.
I could definitely believe that the new amgetbatch interface is
noticeably faster with range queries. Maybe 5% - 10% faster (even
without using the heap-buffer-locking optimization we've talked about
on this thread, which you can't have used here because I haven't
posted it to the list just yet). But a near 2x improvement wildly
exceeds my expectations. Honestly, I have no idea why the patch is so
much faster, and suspect an invalid result.
It might make sense for you to try it again with just the first patch
applied (the patch that adds the basic table AM and index AM interface
revisions, and makes nbtree supply its own amgetbatch/replaces
btgetbatch with btgettuple). I suppose it's possible that Andres'
patch 0004 somehow played some role here, since that is independently
useful work (I don't quite recall the details of where else that might
be useful right now). But that's just a wild guess.
> It will be nice to get some information about efficiency of prefetch,
> for example add `pefetch` option to explain: `explain
> (analyze,buffers,prefetch) ...`
> I think that in `pgaio_io_wait` we can distinguish IO operations which
> are completed without waiting and can be considered as prefetch hit.
> Right now it is hard to understand without debugger whether prefetch is
> perfromed at all.
Tomas did write a patch for that, but it isn't particularly well
optimized. I have mostly avoided using it for that reason. Basic
performance validation of the patch set is really hard in general, and
I've found it easier to just be extremely paranoid.
--
Peter Geoghegan
On 12/17/25 19:49, Peter Geoghegan wrote:
> On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote:
>> create table t (pk integer primary key, payload text default repeat('x',
>> 1000)) with (fillfactor=10);
>> insert into t values (generate_series(1,10000000))
>>
>> So it creates table with size 80Gb (160 after vacuum) which doesn't fit
>> in RAM.
>
> 160 after VACUUM? What do you mean?
>
>> but what confuses me is that they do not depend on
>> `effective_io_concurrency`.
>
> You did change other settings, right? You didn't just use the default
> shared_buffers, for example? (Sorry, I have to ask.)
>
>> Moreover with `enable_indexscan_prefetch=off` results are the same.
>
> It's quite unlikely that the current heuristics that trigger
> prefetching would have ever allowed any prefetching, for queries such
> as these.
>
> The exact rule right now is that we don't even begin prefetching until
> we've already read at least one index leaf page, and have to read
> another one. So it's impossible to use prefetching with a LIMIT of 1,
> with queries such as these. It's highly unlikely that you'd see any
> benefits from prefetching even with LIMIT 100 (usually we wouldn't
> even begin prefetching).
>
True, although I suspect some queries may benefit from prefetching if
they start close to the end of a leaf page (and so get to read the
following leaf page too).
>> Also I expected that the best effect of index prefetching should be for
>> larger limit (accessing more heap pages). But as you see - it is not true.
>>
>> May we there is something wrong with my test scenario.
>
> I could definitely believe that the new amgetbatch interface is
> noticeably faster with range queries. Maybe 5% - 10% faster (even
> without using the heap-buffer-locking optimization we've talked about
> on this thread, which you can't have used here because I haven't
> posted it to the list just yet). But a near 2x improvement wildly
> exceeds my expectations. Honestly, I have no idea why the patch is so
> much faster, and suspect an invalid result.
>
FWIW I did try to reproduce this improvement, and I don't see anything
like 2x speedup. I see this:
eic master prefetch
1 28369 28699
10 7062 8134
100 2080 2162
So on my machine there's ~5-10% speedup, just like you predicted.
There's noise, I'd need to do more runs to get more stable results. But
it's clearly far from 2x.
regards
--
Tomas Vondra
Hi, On 2025-12-17 13:49:43 -0500, Peter Geoghegan wrote: > On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote: > > Moreover with `enable_indexscan_prefetch=off` results are the same. > > It's quite unlikely that the current heuristics that trigger > prefetching would have ever allowed any prefetching, for queries such > as these. > > The exact rule right now is that we don't even begin prefetching until > we've already read at least one index leaf page, and have to read > another one. So it's impossible to use prefetching with a LIMIT of 1, > with queries such as these. It's highly unlikely that you'd see any > benefits from prefetching even with LIMIT 100 (usually we wouldn't > even begin prefetching). Note that due to the tuple size and fillfactor in Konstantin's workload, there will be one tuple per page... That should allow for some prefetching. Greetings, Andres Freund
On Wed, Dec 17, 2025 at 2:30 PM Andres Freund <andres@anarazel.de> wrote: > Note that due to the tuple size and fillfactor in Konstantin's workload, there > will be one tuple per page... That should allow for some prefetching. I don't see how, unless he also set leaf fillfactor very low (though probably not even then, with LIMIT 1, since you still get a few index tuples on each leaf page). As Tomas points out, this particularly heuristic probably has some problems. I'm not claiming that this is the ideal behavior. Just that it would seem to make it almost impossible for prefetching to ever show benefits, with a workload such as this (in particular with LIMIT 1 it seems quite impossible). -- Peter Geoghegan
On 12/17/25 20:30, Andres Freund wrote: > Hi, > > On 2025-12-17 13:49:43 -0500, Peter Geoghegan wrote: >> On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote: >>> Moreover with `enable_indexscan_prefetch=off` results are the same. >> >> It's quite unlikely that the current heuristics that trigger >> prefetching would have ever allowed any prefetching, for queries such >> as these. >> >> The exact rule right now is that we don't even begin prefetching until >> we've already read at least one index leaf page, and have to read >> another one. So it's impossible to use prefetching with a LIMIT of 1, >> with queries such as these. It's highly unlikely that you'd see any >> benefits from prefetching even with LIMIT 100 (usually we wouldn't >> even begin prefetching). > > Note that due to the tuple size and fillfactor in Konstantin's workload, there > will be one tuple per page... That should allow for some prefetching. > Yes, but that's in the heap. The mechanism Peter described is about leaf pages in the index, and the index has the usual fillfactor. So there'll be many index entries per leaf. regards -- Tomas Vondra
On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote:create table t (pk integer primary key, payload text default repeat('x', 1000)) with (fillfactor=10); insert into t values (generate_series(1,10000000)) So it creates table with size 80Gb (160 after vacuum) which doesn't fit in RAM.160 after VACUUM? What do you mean?
Sorry, it was my mistake. Now relation to vacuum.
As you can see with specified fillfactor and filler field there is exactly one record per page. So table size should be ~80Gb.
But when I did `select pg_relation_size('t') I saw 160Gb. It was because my first attempt to upload populate this relation was canceled.
For some reasons I thought that fiel will be just truncated in this case. But it is not and actually it doubles size of the relation.
But it should not affect index scan speed.
but what confuses me is that they do not depend on `effective_io_concurrency`.You did change other settings, right? You didn't just use the default shared_buffers, for example? (Sorry, I have to ask.)
No, I have not changed default value of shared buffers (128Mb).
It should be enough to provide enough free buffers for stream io to use prefetch.
Moreover with `enable_indexscan_prefetch=off` results are the same.It's quite unlikely that the current heuristics that trigger prefetching would have ever allowed any prefetching, for queries such as these. The exact rule right now is that we don't even begin prefetching until we've already read at least one index leaf page, and have to read another one. So it's impossible to use prefetching with a LIMIT of 1, with queries such as these. It's highly unlikely that you'd see any benefits from prefetching even with LIMIT 100 (usually we wouldn't even begin prefetching).
I have checked in debugger that prefetching is actually performed:
xs_heapfetch is initialized and its prefetch distance is increased (to 32).
I could definitely believe that the new amgetbatch interface is noticeably faster with range queries. Maybe 5% - 10% faster (even without using the heap-buffer-locking optimization we've talked about on this thread, which you can't have used here because I haven't posted it to the list just yet). But a near 2x improvement wildly exceeds my expectations. Honestly, I have no idea why the patch is so much faster, and suspect an invalid result. It might make sense for you to try it again with just the first patch applied (the patch that adds the basic table AM and index AM interface revisions, and makes nbtree supply its own amgetbatch/replaces btgetbatch with btgettuple). I suppose it's possible that Andres' patch 0004 somehow played some role here, since that is independently useful work (I don't quite recall the details of where else that might be useful right now). But that's just a wild guess.
I will try to find out the reason, that you for suggestion.
On 17/12/2025 9:54 PM, Tomas Vondra wrote:
> On 12/17/25 20:30, Andres Freund wrote:
>> Hi,
>>
>> On 2025-12-17 13:49:43 -0500, Peter Geoghegan wrote:
>>> On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote:
>>>> Moreover with `enable_indexscan_prefetch=off` results are the same.
>>> It's quite unlikely that the current heuristics that trigger
>>> prefetching would have ever allowed any prefetching, for queries such
>>> as these.
>>>
>>> The exact rule right now is that we don't even begin prefetching until
>>> we've already read at least one index leaf page, and have to read
>>> another one. So it's impossible to use prefetching with a LIMIT of 1,
>>> with queries such as these. It's highly unlikely that you'd see any
>>> benefits from prefetching even with LIMIT 100 (usually we wouldn't
>>> even begin prefetching).
>> Note that due to the tuple size and fillfactor in Konstantin's workload, there
>> will be one tuple per page... That should allow for some prefetching.
>>
> Yes, but that's in the heap. The mechanism Peter described is about leaf
> pages in the index, and the index has the usual fillfactor. So there'll
> be many index entries per leaf.
>
I slightly change my benchmark setup:
create table t (pk integer, sk integer, payload text default repeat('x',
1000)) with (fillfactor=10);
insert into t values (generate_series(1,10000000),random()*10000000);
create index on t(sk);
select.sql:
\set sk random(1, 10000000)
select * from t where sk >= :sk order by sk limit N;
You are right. There is almost no effect of prefetch for limit=100, but
~2x times improvement for limit=1000:
eio\limit 1 100 1000
10 11102 142 28
0 11419 137 14
master:
limit 1 100 1000
11480 130 13
One of the motivation of my experiments was to check that there is no
degrade of performance because of batching.
And it is nice that there is no performance penalty here.
Still it is not quite clear to me why there is no any positive effect
for LIMIT 100.
Reading 100 random heap pages definitely should take advantages of AIO.
We have also implemented prefetching for index only scan in Neon and
here effect for similar query is quite noticeable (~3x times).
But in Neon architecture prices of IO is much higher because requires
network communication with page server.
On 12/18/25 14:57, Konstantin Knizhnik wrote:
>
> On 17/12/2025 9:54 PM, Tomas Vondra wrote:
>> On 12/17/25 20:30, Andres Freund wrote:
>>> Hi,
>>>
>>> On 2025-12-17 13:49:43 -0500, Peter Geoghegan wrote:
>>>> On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik
>>>> <knizhnik@garret.ru> wrote:
>>>>> Moreover with `enable_indexscan_prefetch=off` results are the same.
>>>> It's quite unlikely that the current heuristics that trigger
>>>> prefetching would have ever allowed any prefetching, for queries such
>>>> as these.
>>>>
>>>> The exact rule right now is that we don't even begin prefetching until
>>>> we've already read at least one index leaf page, and have to read
>>>> another one. So it's impossible to use prefetching with a LIMIT of 1,
>>>> with queries such as these. It's highly unlikely that you'd see any
>>>> benefits from prefetching even with LIMIT 100 (usually we wouldn't
>>>> even begin prefetching).
>>> Note that due to the tuple size and fillfactor in Konstantin's
>>> workload, there
>>> will be one tuple per page... That should allow for some prefetching.
>>>
>> Yes, but that's in the heap. The mechanism Peter described is about leaf
>> pages in the index, and the index has the usual fillfactor. So there'll
>> be many index entries per leaf.
>>
> I slightly change my benchmark setup:
>
> create table t (pk integer, sk integer, payload text default repeat('x',
> 1000)) with (fillfactor=10);
> insert into t values (generate_series(1,10000000),random()*10000000);
> create index on t(sk);
>
> select.sql:
>
> \set sk random(1, 10000000)
> select * from t where sk >= :sk order by sk limit N;
>
> You are right. There is almost no effect of prefetch for limit=100, but
> ~2x times improvement for limit=1000:
>
> eio\limit 1 100 1000
> 10 11102 142 28
> 0 11419 137 14
>
> master:
> limit 1 100 1000
> 11480 130 13
>
> One of the motivation of my experiments was to check that there is no
> degrade of performance because of batching.
> And it is nice that there is no performance penalty here.
> Still it is not quite clear to me why there is no any positive effect
> for LIMIT 100.
The technical reason is that batch_getnext() does this:
/* Delay initializing stream until reading from scan's second batch */
if (priorbatch && !scan->xs_heapfetch->rs && !batchqueue->disabled &&
enable_indexscan_prefetch)
scan->xs_heapfetch->rs =
read_stream_begin_relation(READ_STREAM_DEFAULT, NULL,
....);
which means we only create the read_stream (which is what enables the
prefetching) only when creating the second batch. And with LIMIT 100 we
likely read just a single leaf page (=batch) most of the time, which
means no read_stream and thus no prefetching.
You can try disabling this "priorbatch" condition, so that the
read_stream gets created right away.
> Reading 100 random heap pages definitely should take advantages of AIO.
> We have also implemented prefetching for index only scan in Neon and
> here effect for similar query is quite noticeable (~3x times).
> But in Neon architecture prices of IO is much higher because requires
> network communication with page server.
>
True, but only if the data is not already in memory / shared buffers.
IIRC this "priorbatch" logic mitigates regressions for cached workloads,
because the read_stream initialization is expensive enough to hurt small
queries when no I/O is needed.
Maybe the tradeoff is different for Neon, which probably can't rely on
cache that much? It's also true tying this to the number of batches is a
bit coarse, because the batch size can vary a lot. It can be a couple
items or hundreds of items, easily.
I believe we're open to alternative ideas.
regards
--
Tomas Vondra
Hi, On 2025-12-18 15:40:59 +0100, Tomas Vondra wrote: > The technical reason is that batch_getnext() does this: > > /* Delay initializing stream until reading from scan's second batch */ > if (priorbatch && !scan->xs_heapfetch->rs && !batchqueue->disabled && > enable_indexscan_prefetch) > scan->xs_heapfetch->rs = > read_stream_begin_relation(READ_STREAM_DEFAULT, NULL, > ....); > > which means we only create the read_stream (which is what enables the > prefetching) only when creating the second batch. And with LIMIT 100 we > likely read just a single leaf page (=batch) most of the time, which > means no read_stream and thus no prefetching. Why is the logic tied to the number of batches, rather the number of items in batches? It's not hard to come up with scenarios where having to wait for ~100 random pages will be the majority of the queries IO wait... It makes sense to not initialize readahead if we just fetch an entry or two, but after that? Greetings, Andres Freund
On 12/18/25 14:57, Konstantin Knizhnik wrote:On 17/12/2025 9:54 PM, Tomas Vondra wrote:On 12/17/25 20:30, Andres Freund wrote:Hi, On 2025-12-17 13:49:43 -0500, Peter Geoghegan wrote:On Wed, Dec 17, 2025 at 12:19 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote:Moreover with `enable_indexscan_prefetch=off` results are the same.It's quite unlikely that the current heuristics that trigger prefetching would have ever allowed any prefetching, for queries such as these. The exact rule right now is that we don't even begin prefetching until we've already read at least one index leaf page, and have to read another one. So it's impossible to use prefetching with a LIMIT of 1, with queries such as these. It's highly unlikely that you'd see any benefits from prefetching even with LIMIT 100 (usually we wouldn't even begin prefetching).Note that due to the tuple size and fillfactor in Konstantin's workload, there will be one tuple per page... That should allow for some prefetching.Yes, but that's in the heap. The mechanism Peter described is about leaf pages in the index, and the index has the usual fillfactor. So there'll be many index entries per leaf.I slightly change my benchmark setup: create table t (pk integer, sk integer, payload text default repeat('x', 1000)) with (fillfactor=10); insert into t values (generate_series(1,10000000),random()*10000000); create index on t(sk); select.sql: \set sk random(1, 10000000) select * from t where sk >= :sk order by sk limit N; You are right. There is almost no effect of prefetch for limit=100, but ~2x times improvement for limit=1000: eio\limit 1 100 1000 10 11102 142 28 0 11419 137 14 master: limit 1 100 1000 11480 130 13 One of the motivation of my experiments was to check that there is no degrade of performance because of batching. And it is nice that there is no performance penalty here. Still it is not quite clear to me why there is no any positive effect for LIMIT 100.The technical reason is that batch_getnext() does this: /* Delay initializing stream until reading from scan's second batch */ if (priorbatch && !scan->xs_heapfetch->rs && !batchqueue->disabled && enable_indexscan_prefetch) scan->xs_heapfetch->rs = read_stream_begin_relation(READ_STREAM_DEFAULT, NULL, ....); which means we only create the read_stream (which is what enables the prefetching) only when creating the second batch. And with LIMIT 100 we likely read just a single leaf page (=batch) most of the time, which means no read_stream and thus no prefetching. You can try disabling this "priorbatch" condition, so that the read_stream gets created right away.
It makes the expected effect - performance of LIMIT 100 is increased from 142TPS to 315TPS (so also 2x times). At the same time performance of LIMIT 1 is reduced from 11419 to 3499 - ~4x times For LIMIT 10 result are 1388 with disabled prefetch and 1116 with enabled prefetch. So looks like threshold for enabling prefetch should be based not on number of batches, but on expected heap reads and it is more closer to 100 or even 10 than to 1000. And for slower disks (or remote storage), effect of prefetch should be much bigger.
True, but only if the data is not already in memory / shared buffers. IIRC this "priorbatch" logic mitigates regressions for cached workloads, because the read_stream initialization is expensive enough to hurt small queries when no I/O is needed.
I see.
But may be we should compare table size with shared buffers or effective_cache_size?
On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v4. Attached is v5. Changes from v4: * Simplified and optimized index-only scans, with a particular emphasis on avoiding regressions with nested loop joins with an inner index-only scan. There were quite a number of small problems/dead code related to index-only scans fixed by this new v5. Overall, I'm quite a bit happier with the state of index-only scans, which I'd not paid too much attention to before now. * Added Valgrind instrumentation to the hash index patch, which was required to fix some false positives. The generic indexam_util_batch_unlock routine had Valgrind instrumentation in earlier versions, just to keep nbtree's buffer locking checks from generating similar false positives. Some time later, when I added the hashgetbatch patch, there were new Valgrind false positives during hash index scans -- which I missed at first. This new v5 revisions adds similar Valgrind checks to hash itself (changes that add code that is more or less a direct port of the stuff added to nbtree by commit 4a70f829), which fixes the false positives, and is independently useful. The rule for amgetbatch-based index AMs is that they must have similar buffer locking instrumentation. That seems like a good thing. -- Peter Geoghegan
Вложения
On 18/12/2025 4:45 PM, Andres Freund wrote:
> Hi,
>
> On 2025-12-18 15:40:59 +0100, Tomas Vondra wrote:
>> The technical reason is that batch_getnext() does this:
>>
>> /* Delay initializing stream until reading from scan's second batch */
>> if (priorbatch && !scan->xs_heapfetch->rs && !batchqueue->disabled &&
>> enable_indexscan_prefetch)
>> scan->xs_heapfetch->rs =
>> read_stream_begin_relation(READ_STREAM_DEFAULT, NULL,
>> ....);
>>
>> which means we only create the read_stream (which is what enables the
>> prefetching) only when creating the second batch. And with LIMIT 100 we
>> likely read just a single leaf page (=batch) most of the time, which
>> means no read_stream and thus no prefetching.
> Why is the logic tied to the number of batches, rather the number of items in
> batches? It's not hard to come up with scenarios where having to wait for ~100
> random pages will be the majority of the queries IO wait... It makes sense to
> not initialize readahead if we just fetch an entry or two, but after that?
I did more experiments trying to understand when we can take advantage
of prefetch:
So schema is the same:
create table t (pk integer, sk integer, payload text default repeat('x',
1000)) with (fillfactor=10);
insert into t values (generate_series(1,10000000),random()*10000000);
create index on t(sk);
select.sql:
\set sk random(1, 10000000)
select * from t where sk >= :sk order by sk limit N;
And I do
pgbench -n -T 30 -M prepared -f select.sql postgres
limit\prefetch on off always incremental
1 12074 12765 3146 3282
2 5912 6198 2463 2438
4 2919 3047 1334 1964
8 1554 1496 1166 1409
16 815 775 947 940
32 424 403 687 695
64 223 208 446 453
128 115 106 258 270
256 68 53 138 149
512 43 27 72 78
1024 28 13 38 40
prefetch=always means commenting of `priorbatch` check and immediate
creation of read_stream:
/* Delay initializing stream until reading from scan's second
batch */
- if (priorbatch && !scan->xs_heapfetch->rs &&
!batchqueue->disabled &&+
+ if (/*priorbatch && */!scan->xs_heapfetch->rs &&
!batchqueue->disabled &&
prefetch=increment replaces doubling of prefetch distance with increment:
/* Look-ahead distance ramps up rapidly after we do I/O. */
- distance = stream->distance * 2;
+ distance = stream->distance ? stream->distance + 1 : 0;
So as you expected, immediate creation of read_stream cause quite
significant degrade of performance on indexscans inspecting small number
of TIDs.
Looks like the threshold where read stream provides advantages in
performance is about 10.
After it earlier initialization of read stream adds quite noticeable
performance improvement.
I tried to find out using profiler and debugger where most of the time
is spent in this case and answer was quite predictable -
in read_stream_reset->read_stream_next_buffer.
So we just consuming pefetched buffers which we do not need.
I thought that we can use some better policy for increasing prefetch
distance (right now it is just doubled).
This is why I have tried this "incremental" policy.
Unfortunately it can not help to reduce prefetch overhead for "short"
indexscans.
But what surprised me is that for longer indexscans this approach seems
to be slightly more efficient than doubling.
So look like we really should use number of items criteria for read
stream initialization rather than number of batches.
And may be think about alternative policy for increasing prefetch distance.
On 21/12/2025 7:55 PM, Peter Geoghegan wrote: > On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote: >> Attached is v4. > Attached is v5. Changes from v4: > > * Simplified and optimized index-only scans, with a particular > emphasis on avoiding regressions with nested loop joins with an inner > index-only scan. > > There were quite a number of small problems/dead code related to > index-only scans fixed by this new v5. Overall, I'm quite a bit > happier with the state of index-only scans, which I'd not paid too > much attention to before now. > > * Added Valgrind instrumentation to the hash index patch, which was > required to fix some false positives. > > The generic indexam_util_batch_unlock routine had Valgrind > instrumentation in earlier versions, just to keep nbtree's buffer > locking checks from generating similar false positives. Some time > later, when I added the hashgetbatch patch, there were new Valgrind > false positives during hash index scans -- which I missed at first. > This new v5 revisions adds similar Valgrind checks to hash itself > (changes that add code that is more or less a direct port of the stuff > added to nbtree by commit 4a70f829), which fixes the false positives, > and is independently useful. > > The rule for amgetbatch-based index AMs is that they must have similar > buffer locking instrumentation. That seems like a good thing. > > -- > Peter Geoghegan I the previous mail I shared results of my experiments with different prefetch distance. I think that we should start prefetching of heap tuples not from the second batch, but after some number of proceeded tids. Attached please find a patch which implements this approach. And below are updated results: limit\prefetch on off always inc threshold 1 12074 12765 3146 3282 12394 2 5912 6198 2463 2438 6124 4 2919 3047 1334 1964 2910 8 1554 1496 1166 1409 1588 16 815 775 947 940 600 32 424 403 687 695 478 64 223 208 446 453 358 128 115 106 258 270 232 256 68 53 138 149 131 512 43 27 72 78 71 1024 28 13 38 40 38 Last column is result of prefetch with read_stream_threshold=10.
Вложения
On 12/25/25 16:39, Konstantin Knizhnik wrote: > > On 21/12/2025 7:55 PM, Peter Geoghegan wrote: >> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote: >>> Attached is v4. >> Attached is v5. Changes from v4: >> >> * Simplified and optimized index-only scans, with a particular >> emphasis on avoiding regressions with nested loop joins with an inner >> index-only scan. >> >> There were quite a number of small problems/dead code related to >> index-only scans fixed by this new v5. Overall, I'm quite a bit >> happier with the state of index-only scans, which I'd not paid too >> much attention to before now. >> >> * Added Valgrind instrumentation to the hash index patch, which was >> required to fix some false positives. >> >> The generic indexam_util_batch_unlock routine had Valgrind >> instrumentation in earlier versions, just to keep nbtree's buffer >> locking checks from generating similar false positives. Some time >> later, when I added the hashgetbatch patch, there were new Valgrind >> false positives during hash index scans -- which I missed at first. >> This new v5 revisions adds similar Valgrind checks to hash itself >> (changes that add code that is more or less a direct port of the stuff >> added to nbtree by commit 4a70f829), which fixes the false positives, >> and is independently useful. >> >> The rule for amgetbatch-based index AMs is that they must have similar >> buffer locking instrumentation. That seems like a good thing. >> >> -- >> Peter Geoghegan > > I the previous mail I shared results of my experiments with different > prefetch distance. > I think that we should start prefetching of heap tuples not from the > second batch, but after some number of proceeded tids. > > Attached please find a patch which implements this approach. > And below are updated results: > > limit\prefetch on off always inc threshold > 1 12074 12765 3146 3282 12394 > 2 5912 6198 2463 2438 6124 > 4 2919 3047 1334 1964 2910 > 8 1554 1496 1166 1409 1588 > 16 815 775 947 940 600 > 32 424 403 687 695 478 > 64 223 208 446 453 358 > 128 115 106 258 270 232 > 256 68 53 138 149 131 > 512 43 27 72 78 71 > 1024 28 13 38 40 38 > > Last column is result of prefetch with read_stream_threshold=10. > That's great, but it only works for cases that can (and do) benefit from the prefetching. Try running the benchmark with a data set that fits into shared buffers (or RAM), which makes prefetching useless. I tried that with your test, comparing master, v5 and v5 + your read_stream_threshold patch. See the attached run.sh script, and the PDF summarizing the results. The last two column groups are comparisons to master, with green=improvement, red=regression. There are no actual improvements (1% delta is just noise). But the read_stream_threshold results have a clear pattern of pretty massive (20-30%) regressions. The difference between v5 and v5-threshold is pretty clear. IIRC cases like this are *exactly* why we ended up with the current heuristics, enabling prefetching only from the second batch. This removes the risk of expensive read_stream init for very fast queries that don't benefit anything. Of course, prefetching may be useless for later batches too (e.g. if all the data is cached), but the query will be expensive enough for the read_stream init cost to be negligible. To put this differently, the more aggressive the heuristics is (enabling prefetching in more case), the more likely it's to cause regressions. We've chosen to be more defensive, i.e. to sacrifice some possible gains in order to not regress plausible workloads. I hope we agree queries on fully cached "hot" data are pretty common / important. We can probably do better in the future. But we'll never know for sure if a given scan benefits from prefetching. It's not just about the number of items in the batch, but also about how many heap pages that translates to, what I/O pattern (random vs. sequential?), how many are already cached. For some queries we don't even know how many items we'll actually need. We can't check all that at the very beginning, because it's simply prohibitively expensive. regards -- Tomas Vondra
Вложения
On 12/18/25 15:45, Andres Freund wrote: > Hi, > > On 2025-12-18 15:40:59 +0100, Tomas Vondra wrote: >> The technical reason is that batch_getnext() does this: >> >> /* Delay initializing stream until reading from scan's second batch */ >> if (priorbatch && !scan->xs_heapfetch->rs && !batchqueue->disabled && >> enable_indexscan_prefetch) >> scan->xs_heapfetch->rs = >> read_stream_begin_relation(READ_STREAM_DEFAULT, NULL, >> ....); >> >> which means we only create the read_stream (which is what enables the >> prefetching) only when creating the second batch. And with LIMIT 100 we >> likely read just a single leaf page (=batch) most of the time, which >> means no read_stream and thus no prefetching. > > Why is the logic tied to the number of batches, rather the number of items in > batches? It's not hard to come up with scenarios where having to wait for ~100 > random pages will be the majority of the queries IO wait... It makes sense to > not initialize readahead if we just fetch an entry or two, but after that? > Because the number of items in a batch does not tell you much about prefetching either. It does not say how many TIDs (or rather the heap pages) are already in cache, it does not say what's the access pattern. It also does not say what distance will the read_stream converge to (maybe it drops to 1 or 2). Maybe it's too defensive, of course. I recall we discussed various other heuristics, but our #1 goal was to not cause regressions against master (or at least not too many). It doesn't mean we can't improve this later. regards -- Tomas Vondra
On 28/12/2025 8:08 PM, Tomas Vondra wrote: > On 12/25/25 16:39, Konstantin Knizhnik wrote: >> On 21/12/2025 7:55 PM, Peter Geoghegan wrote: >>> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote: >>>> Attached is v4. >>> Attached is v5. Changes from v4: >>> >>> * Simplified and optimized index-only scans, with a particular >>> emphasis on avoiding regressions with nested loop joins with an inner >>> index-only scan. >>> >>> There were quite a number of small problems/dead code related to >>> index-only scans fixed by this new v5. Overall, I'm quite a bit >>> happier with the state of index-only scans, which I'd not paid too >>> much attention to before now. >>> >>> * Added Valgrind instrumentation to the hash index patch, which was >>> required to fix some false positives. >>> >>> The generic indexam_util_batch_unlock routine had Valgrind >>> instrumentation in earlier versions, just to keep nbtree's buffer >>> locking checks from generating similar false positives. Some time >>> later, when I added the hashgetbatch patch, there were new Valgrind >>> false positives during hash index scans -- which I missed at first. >>> This new v5 revisions adds similar Valgrind checks to hash itself >>> (changes that add code that is more or less a direct port of the stuff >>> added to nbtree by commit 4a70f829), which fixes the false positives, >>> and is independently useful. >>> >>> The rule for amgetbatch-based index AMs is that they must have similar >>> buffer locking instrumentation. That seems like a good thing. >>> >>> -- >>> Peter Geoghegan >> I the previous mail I shared results of my experiments with different >> prefetch distance. >> I think that we should start prefetching of heap tuples not from the >> second batch, but after some number of proceeded tids. >> >> Attached please find a patch which implements this approach. >> And below are updated results: >> >> limit\prefetch on off always inc threshold >> 1 12074 12765 3146 3282 12394 >> 2 5912 6198 2463 2438 6124 >> 4 2919 3047 1334 1964 2910 >> 8 1554 1496 1166 1409 1588 >> 16 815 775 947 940 600 >> 32 424 403 687 695 478 >> 64 223 208 446 453 358 >> 128 115 106 258 270 232 >> 256 68 53 138 149 131 >> 512 43 27 72 78 71 >> 1024 28 13 38 40 38 >> >> Last column is result of prefetch with read_stream_threshold=10. >> > That's great, but it only works for cases that can (and do) benefit from > the prefetching. Try running the benchmark with a data set that fits > into shared buffers (or RAM), which makes prefetching useless. > > I tried that with your test, comparing master, v5 and v5 + your > read_stream_threshold patch. See the attached run.sh script, and the PDF > summarizing the results. The last two column groups are comparisons to > master, with green=improvement, red=regression. There are no actual > improvements (1% delta is just noise). But the read_stream_threshold > results have a clear pattern of pretty massive (20-30%) regressions. > > The difference between v5 and v5-threshold is pretty clear. > > IIRC cases like this are *exactly* why we ended up with the current > heuristics, enabling prefetching only from the second batch. This > removes the risk of expensive read_stream init for very fast queries > that don't benefit anything. Of course, prefetching may be useless for > later batches too (e.g. if all the data is cached), but the query will > be expensive enough for the read_stream init cost to be negligible. > > To put this differently, the more aggressive the heuristics is (enabling > prefetching in more case), the more likely it's to cause regressions. > We've chosen to be more defensive, i.e. to sacrifice some possible gains > in order to not regress plausible workloads. I hope we agree queries on > fully cached "hot" data are pretty common / important. > > We can probably do better in the future. But we'll never know for sure > if a given scan benefits from prefetching. It's not just about the > number of items in the batch, but also about how many heap pages that > translates to, what I/O pattern (random vs. sequential?), how many are > already cached. For some queries we don't even know how many items we'll > actually need. We can't check all that at the very beginning, because > it's simply prohibitively expensive. Thank you for looking at my patch. I agree with you that such overhead in case of presence of data in shared buffers is certainly not acceptable. But it just means that we need some better criteria than number of scanned TIDs - i.e. number of smgr heap reads. I do not think that it will be too complex or expensive to implement - I will try. But in any case - the current heuristics: prefetching only from the second batch, is IMHO not solving this problem. First of all, as far as I understand batch = TIDs from one leaf page and if there are large keys (i.e. URLs), there will be just few items in the batch. Also if all pages are present in shared buffers, then even starting prefetching from the second batch will have negative impact on performance. May be for long queries (scanning a lot of data) this overhead will be less noticeable. But as far as it is proportional to the amount of scanned data, it can be still desirable to avoid it. > > regards >
On 12/28/25 20:15, Konstantin Knizhnik wrote: > > On 28/12/2025 8:08 PM, Tomas Vondra wrote: >> On 12/25/25 16:39, Konstantin Knizhnik wrote: >>> On 21/12/2025 7:55 PM, Peter Geoghegan wrote: >>>> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote: >>>>> Attached is v4. >>>> Attached is v5. Changes from v4: >>>> >>>> * Simplified and optimized index-only scans, with a particular >>>> emphasis on avoiding regressions with nested loop joins with an inner >>>> index-only scan. >>>> >>>> There were quite a number of small problems/dead code related to >>>> index-only scans fixed by this new v5. Overall, I'm quite a bit >>>> happier with the state of index-only scans, which I'd not paid too >>>> much attention to before now. >>>> >>>> * Added Valgrind instrumentation to the hash index patch, which was >>>> required to fix some false positives. >>>> >>>> The generic indexam_util_batch_unlock routine had Valgrind >>>> instrumentation in earlier versions, just to keep nbtree's buffer >>>> locking checks from generating similar false positives. Some time >>>> later, when I added the hashgetbatch patch, there were new Valgrind >>>> false positives during hash index scans -- which I missed at first. >>>> This new v5 revisions adds similar Valgrind checks to hash itself >>>> (changes that add code that is more or less a direct port of the stuff >>>> added to nbtree by commit 4a70f829), which fixes the false positives, >>>> and is independently useful. >>>> >>>> The rule for amgetbatch-based index AMs is that they must have similar >>>> buffer locking instrumentation. That seems like a good thing. >>>> >>>> -- >>>> Peter Geoghegan >>> I the previous mail I shared results of my experiments with different >>> prefetch distance. >>> I think that we should start prefetching of heap tuples not from the >>> second batch, but after some number of proceeded tids. >>> >>> Attached please find a patch which implements this approach. >>> And below are updated results: >>> >>> limit\prefetch on off always inc threshold >>> 1 12074 12765 3146 3282 12394 >>> 2 5912 6198 2463 2438 6124 >>> 4 2919 3047 1334 1964 2910 >>> 8 1554 1496 1166 1409 1588 >>> 16 815 775 947 940 600 >>> 32 424 403 687 695 478 >>> 64 223 208 446 453 358 >>> 128 115 106 258 270 232 >>> 256 68 53 138 149 131 >>> 512 43 27 72 78 71 >>> 1024 28 13 38 40 38 >>> >>> Last column is result of prefetch with read_stream_threshold=10. >>> >> That's great, but it only works for cases that can (and do) benefit from >> the prefetching. Try running the benchmark with a data set that fits >> into shared buffers (or RAM), which makes prefetching useless. >> >> I tried that with your test, comparing master, v5 and v5 + your >> read_stream_threshold patch. See the attached run.sh script, and the PDF >> summarizing the results. The last two column groups are comparisons to >> master, with green=improvement, red=regression. There are no actual >> improvements (1% delta is just noise). But the read_stream_threshold >> results have a clear pattern of pretty massive (20-30%) regressions. >> >> The difference between v5 and v5-threshold is pretty clear. >> >> IIRC cases like this are *exactly* why we ended up with the current >> heuristics, enabling prefetching only from the second batch. This >> removes the risk of expensive read_stream init for very fast queries >> that don't benefit anything. Of course, prefetching may be useless for >> later batches too (e.g. if all the data is cached), but the query will >> be expensive enough for the read_stream init cost to be negligible. >> >> To put this differently, the more aggressive the heuristics is (enabling >> prefetching in more case), the more likely it's to cause regressions. >> We've chosen to be more defensive, i.e. to sacrifice some possible gains >> in order to not regress plausible workloads. I hope we agree queries on >> fully cached "hot" data are pretty common / important. >> >> We can probably do better in the future. But we'll never know for sure >> if a given scan benefits from prefetching. It's not just about the >> number of items in the batch, but also about how many heap pages that >> translates to, what I/O pattern (random vs. sequential?), how many are >> already cached. For some queries we don't even know how many items we'll >> actually need. We can't check all that at the very beginning, because >> it's simply prohibitively expensive. > > Thank you for looking at my patch. > I agree with you that such overhead in case of presence of data in > shared buffers is certainly not acceptable. > But it just means that we need some better criteria than number of > scanned TIDs - i.e. number of smgr heap reads. > I do not think that it will be too complex or expensive to implement - I > will try. > Feel free to try. I don't claim there is not a better heuristics. AFAIK checking if a page is already in shared buffers is not free (and what if it's only in page cache?). But I guess you'll also need to check the I/O pattern, earlier blocks in the batch, etc. > But in any case - the current heuristics: prefetching only from the > second batch, is IMHO not solving this problem. The results I shared suggest otherwise, though. It shows pretty much no regressions for the v5 patch. > First of all, as far as I understand batch = TIDs from one leaf page and > if there are large keys (i.e. URLs), there will be just few items in the > batch. > Also if all pages are present in shared buffers, then even starting > prefetching from the second batch will have negative impact on performance. > May be for long queries (scanning a lot of data) this overhead will be > less noticeable. > But as far as it is proportional to the amount of scanned data, it can > be still desirable to avoid it. > That's not what we saw in earlier testing. I'm not claiming the issue disappears entirely. Just that the regression gets much smaller (relative to the total duration) as the scan clearly processes enough entries to need the second batch. The worst regression is for queries that only need a couple items from the whole batch. Consider a query with LIMIT 10. The batch may easily have ~1000 index entries. And we don't know if we'll need just the first 10 - the read stream certainly does not know. It can easily happen it tries to prefetch all 1000 entries (e.g. because many are duplicate). I'm not saying it has to be like this forever. To some extent this happens due to the read_stream having no way to give up temporarily, based on how far ahead it got. I think the recent patches proposing a way to "yield" might help with this. But that's not how it works right now, and I don't think we should make this patch dependent on a recent WIP/PoC proposal. Anyway, feel free to test and propose alternative approaches. I certainly hope we can make this heuristics smarter. regards -- Tomas Vondra
On 28/12/2025 8:08 PM, Tomas Vondra wrote:
> On 12/25/25 16:39, Konstantin Knizhnik wrote:
>> On 21/12/2025 7:55 PM, Peter Geoghegan wrote:
>>> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote:
>>>> Attached is v4.
>>> Attached is v5. Changes from v4:
>>>
>>> * Simplified and optimized index-only scans, with a particular
>>> emphasis on avoiding regressions with nested loop joins with an inner
>>> index-only scan.
>>>
>>> There were quite a number of small problems/dead code related to
>>> index-only scans fixed by this new v5. Overall, I'm quite a bit
>>> happier with the state of index-only scans, which I'd not paid too
>>> much attention to before now.
>>>
>>> * Added Valgrind instrumentation to the hash index patch, which was
>>> required to fix some false positives.
>>>
>>> The generic indexam_util_batch_unlock routine had Valgrind
>>> instrumentation in earlier versions, just to keep nbtree's buffer
>>> locking checks from generating similar false positives. Some time
>>> later, when I added the hashgetbatch patch, there were new Valgrind
>>> false positives during hash index scans -- which I missed at first.
>>> This new v5 revisions adds similar Valgrind checks to hash itself
>>> (changes that add code that is more or less a direct port of the stuff
>>> added to nbtree by commit 4a70f829), which fixes the false positives,
>>> and is independently useful.
>>>
>>> The rule for amgetbatch-based index AMs is that they must have similar
>>> buffer locking instrumentation. That seems like a good thing.
>>>
>>> --
>>> Peter Geoghegan
>> I the previous mail I shared results of my experiments with different
>> prefetch distance.
>> I think that we should start prefetching of heap tuples not from the
>> second batch, but after some number of proceeded tids.
>>
>> Attached please find a patch which implements this approach.
>> And below are updated results:
>>
>> limit\prefetch on off always inc threshold
>> 1 12074 12765 3146 3282 12394
>> 2 5912 6198 2463 2438 6124
>> 4 2919 3047 1334 1964 2910
>> 8 1554 1496 1166 1409 1588
>> 16 815 775 947 940 600
>> 32 424 403 687 695 478
>> 64 223 208 446 453 358
>> 128 115 106 258 270 232
>> 256 68 53 138 149 131
>> 512 43 27 72 78 71
>> 1024 28 13 38 40 38
>>
>> Last column is result of prefetch with read_stream_threshold=10.
>>
> That's great, but it only works for cases that can (and do) benefit from
> the prefetching. Try running the benchmark with a data set that fits
> into shared buffers (or RAM), which makes prefetching useless.
>
> I tried that with your test, comparing master, v5 and v5 + your
> read_stream_threshold patch. See the attached run.sh script, and the PDF
> summarizing the results. The last two column groups are comparisons to
> master, with green=improvement, red=regression. There are no actual
> improvements (1% delta is just noise). But the read_stream_threshold
> results have a clear pattern of pretty massive (20-30%) regressions.
>
> The difference between v5 and v5-threshold is pretty clear.
>
> IIRC cases like this are *exactly* why we ended up with the current
> heuristics, enabling prefetching only from the second batch. This
> removes the risk of expensive read_stream init for very fast queries
> that don't benefit anything. Of course, prefetching may be useless for
> later batches too (e.g. if all the data is cached), but the query will
> be expensive enough for the read_stream init cost to be negligible.
>
> To put this differently, the more aggressive the heuristics is (enabling
> prefetching in more case), the more likely it's to cause regressions.
> We've chosen to be more defensive, i.e. to sacrifice some possible gains
> in order to not regress plausible workloads. I hope we agree queries on
> fully cached "hot" data are pretty common / important.
>
> We can probably do better in the future. But we'll never know for sure
> if a given scan benefits from prefetching. It's not just about the
> number of items in the batch, but also about how many heap pages that
> translates to, what I/O pattern (random vs. sequential?), how many are
> already cached. For some queries we don't even know how many items we'll
> actually need. We can't check all that at the very beginning, because
> it's simply prohibitively expensive.
I tried to reproduce your results, but at Mac I do not see some
noticeable difference for 250k records, fillfactor=10 and 4GB shared
buffers
between `enable_indexscan_prefetch=false` and
`enable_indexscan_prefetch=true`.
I can't believe that just adding this checks in `heap_batch_advance_pos`
can cause 75% degrade of performance (because for limit < 10, no read
stream is initialized, but still we somewhere loose 25%).
I just commented this fragment of code in heapam_handler.c:
#if 0
proceed_items = ScanDirectionIsForward(direction)
? pos->item - batch->firstItem
: batch->lastItem - pos->item;
/* Delay initializing stream until proceeding */
if (proceed_items >= read_stream_threshold
&& !scan->xs_heapfetch->rs
&& !scan->batchqueue->disabled
&& !scan->xs_want_itup /* XXX prefetching disabled for IoS,
for now */
&& enable_indexscan_prefetch)
{
scan->xs_heapfetch->rs =
read_stream_begin_relation(READ_STREAM_DEFAULT, NULL,
scan->heapRelation, MAIN_FORKNUM,
scan->heapRelation->rd_tableam->index_getnext_stream,
scan, 0);
}
#endif
and ... see no difference.
I can understand why initializing read stream earlier (not at the second
batch, but after 10 proceeded items) may have negative impact on
performance when all data is present i shared buffers for LIMIT>=10.
But how it can happen with LIMIT 1 and commented fragment above. There
is nothing else in my patch except adding GUC.
So I think that it is some "external" factor and wonder if you can
reproduce this results (just first line).
On 12/28/25 21:30, Konstantin Knizhnik wrote:
>
> On 28/12/2025 8:08 PM, Tomas Vondra wrote:
>> On 12/25/25 16:39, Konstantin Knizhnik wrote:
>>> On 21/12/2025 7:55 PM, Peter Geoghegan wrote:
>>>> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote:
>>>>> Attached is v4.
>>>> Attached is v5. Changes from v4:
>>>>
>>>> * Simplified and optimized index-only scans, with a particular
>>>> emphasis on avoiding regressions with nested loop joins with an inner
>>>> index-only scan.
>>>>
>>>> There were quite a number of small problems/dead code related to
>>>> index-only scans fixed by this new v5. Overall, I'm quite a bit
>>>> happier with the state of index-only scans, which I'd not paid too
>>>> much attention to before now.
>>>>
>>>> * Added Valgrind instrumentation to the hash index patch, which was
>>>> required to fix some false positives.
>>>>
>>>> The generic indexam_util_batch_unlock routine had Valgrind
>>>> instrumentation in earlier versions, just to keep nbtree's buffer
>>>> locking checks from generating similar false positives. Some time
>>>> later, when I added the hashgetbatch patch, there were new Valgrind
>>>> false positives during hash index scans -- which I missed at first.
>>>> This new v5 revisions adds similar Valgrind checks to hash itself
>>>> (changes that add code that is more or less a direct port of the stuff
>>>> added to nbtree by commit 4a70f829), which fixes the false positives,
>>>> and is independently useful.
>>>>
>>>> The rule for amgetbatch-based index AMs is that they must have similar
>>>> buffer locking instrumentation. That seems like a good thing.
>>>>
>>>> --
>>>> Peter Geoghegan
>>> I the previous mail I shared results of my experiments with different
>>> prefetch distance.
>>> I think that we should start prefetching of heap tuples not from the
>>> second batch, but after some number of proceeded tids.
>>>
>>> Attached please find a patch which implements this approach.
>>> And below are updated results:
>>>
>>> limit\prefetch on off always inc threshold
>>> 1 12074 12765 3146 3282 12394
>>> 2 5912 6198 2463 2438 6124
>>> 4 2919 3047 1334 1964 2910
>>> 8 1554 1496 1166 1409 1588
>>> 16 815 775 947 940 600
>>> 32 424 403 687 695 478
>>> 64 223 208 446 453 358
>>> 128 115 106 258 270 232
>>> 256 68 53 138 149 131
>>> 512 43 27 72 78 71
>>> 1024 28 13 38 40 38
>>>
>>> Last column is result of prefetch with read_stream_threshold=10.
>>>
>> That's great, but it only works for cases that can (and do) benefit from
>> the prefetching. Try running the benchmark with a data set that fits
>> into shared buffers (or RAM), which makes prefetching useless.
>>
>> I tried that with your test, comparing master, v5 and v5 + your
>> read_stream_threshold patch. See the attached run.sh script, and the PDF
>> summarizing the results. The last two column groups are comparisons to
>> master, with green=improvement, red=regression. There are no actual
>> improvements (1% delta is just noise). But the read_stream_threshold
>> results have a clear pattern of pretty massive (20-30%) regressions.
>>
>> The difference between v5 and v5-threshold is pretty clear.
>>
>> IIRC cases like this are *exactly* why we ended up with the current
>> heuristics, enabling prefetching only from the second batch. This
>> removes the risk of expensive read_stream init for very fast queries
>> that don't benefit anything. Of course, prefetching may be useless for
>> later batches too (e.g. if all the data is cached), but the query will
>> be expensive enough for the read_stream init cost to be negligible.
>>
>> To put this differently, the more aggressive the heuristics is (enabling
>> prefetching in more case), the more likely it's to cause regressions.
>> We've chosen to be more defensive, i.e. to sacrifice some possible gains
>> in order to not regress plausible workloads. I hope we agree queries on
>> fully cached "hot" data are pretty common / important.
>>
>> We can probably do better in the future. But we'll never know for sure
>> if a given scan benefits from prefetching. It's not just about the
>> number of items in the batch, but also about how many heap pages that
>> translates to, what I/O pattern (random vs. sequential?), how many are
>> already cached. For some queries we don't even know how many items we'll
>> actually need. We can't check all that at the very beginning, because
>> it's simply prohibitively expensive.
>
>
> I tried to reproduce your results, but at Mac I do not see some
> noticeable difference for 250k records, fillfactor=10 and 4GB shared
> buffers
> between `enable_indexscan_prefetch=false` and
> `enable_indexscan_prefetch=true`.
> I can't believe that just adding this checks in `heap_batch_advance_pos`
> can cause 75% degrade of performance (because for limit < 10, no read
> stream is initialized, but still we somewhere loose 25%).
>
> I just commented this fragment of code in heapam_handler.c:
>
>
> #if 0
> proceed_items = ScanDirectionIsForward(direction)
> ? pos->item - batch->firstItem
> : batch->lastItem - pos->item;
> /* Delay initializing stream until proceeding */
> if (proceed_items >= read_stream_threshold
> && !scan->xs_heapfetch->rs
> && !scan->batchqueue->disabled
> && !scan->xs_want_itup /* XXX prefetching disabled for IoS,
> for now */
> && enable_indexscan_prefetch)
> {
> scan->xs_heapfetch->rs =
> read_stream_begin_relation(READ_STREAM_DEFAULT, NULL,
> scan->heapRelation, MAIN_FORKNUM,
> scan->heapRelation->rd_tableam->index_getnext_stream,
> scan, 0);
> }
> #endif
>
> and ... see no difference.
>
> I can understand why initializing read stream earlier (not at the second
> batch, but after 10 proceeded items) may have negative impact on
> performance when all data is present i shared buffers for LIMIT>=10.
> But how it can happen with LIMIT 1 and commented fragment above. There
> is nothing else in my patch except adding GUC.
> So I think that it is some "external" factor and wonder if you can
> reproduce this results (just first line).
>
It seems this is due to sending an extra SET (for the new GUC) in the
pgbench script, which is recognized only on the v5+threshold build.
That's a thinko on my side, I should have realized the extra command
might affect this. It doesn't really affect the behavior, because 10 is
the default value for read_stream_threshold. I've fixed the script, will
check fresh results tomorrow.
Still, I think most of what I said about heuristics when to initialize
the read stream, and the risk/benefit tradeoff, still applies.
regards
--
Tomas Vondra
On 29/12/2025 1:53 AM, Tomas Vondra wrote:
> It seems this is due to sending an extra SET (for the new GUC) in the
> pgbench script, which is recognized only on the v5+threshold build.
>
> That's a thinko on my side, I should have realized the extra command
> might affect this. It doesn't really affect the behavior, because 10 is
> the default value for read_stream_threshold. I've fixed the script, will
> check fresh results tomorrow.
>
> Still, I think most of what I said about heuristics when to initialize
> the read stream, and the risk/benefit tradeoff, still applies.
I did a lot of experiments this morning but could not find any
noticeable difference at any configuration when all working set fits in
shared buffers.
And frankly speaking after more thinking I do not see good reasons which
can explain such difference.
Just initialization of read stream should not add much overhead - it
seems to be not expensive operation.
What is actually matter is async IO. Without read stream, Postgres reads
heap pages using sync operation: backend just calls pread.
With read stream, AIO is used. By default "worker" AIO mode is used, it
means that backend sends request to one of the workers and wait for it's
completion. Worker receives request, performs IO and notifies backend.
Such interprocess communication adds significant overhead and this is
why if we initialize read stream from the very beginning, then we get
about ~4x worse performance with LIMIT 1.
Please correct me if I wrong (or it is Mac specific), but it is not
caused by any overhead related with read_stream, but by AIO.
I have not made such experiment, but it seems to me that if we make read
stream to perform sync calls, then there will be almost no difference in
performance.
When all data is cached in shared buffers, then we do not perform IO at all.
It means there it doesn't matter whether and when we initialize read_stream.
We can do it after processing 10 items (current default), or immediately
- it should not affect performance.
And this is what I have tested: performance actually not depends on
`read_stream_threshold` (if data fits in shared buffers).
At least it is within few percents and may be it is just random
fluctuations.
Obviously there is no 25% degradation.
It definitely doesn't mean that it is not possible to find scenario
where this approach with enabling prefetch after processing N items will
show worse performance than master or v5. We just need to properly
choose cache hit rate. But the same is true IMHO for v5 itself: it is
possible to find workload where it will show the same degradation
comparing with master.
More precise heuristic should IMHO take in account actual number of
performed disk read.
Please notice that I do not want to predict number of disk reads - i.e.
check if candidates for prefetch are present in shared buffers.
It will really adds significant overhead. I think that it is better to
use as threshold number of performed reads.
Unfortunately looks like it is not possible to accumulate such
information without changing other Postgres code.
For example, if `ReadBuffer` can somehow inform caller that it actually
performs read, then it can be easily calculate number of reads in
`heapam_index_fetch_tuple`:
```
static pg_attribute_always_inline Buffer
ReadBuffer_common(Relation rel, SMgrRelation smgr, char smgr_persistence,
ForkNumber forkNum,
BlockNumber blockNum, ReadBufferMode mode,
BufferAccessStrategy strategy,
bool* fast_path)
{
...
if (StartReadBuffer(&operation,
&buffer,
blockNum,
flags))
{
WaitReadBuffers(&operation);
*fast_path = false;
}
else
*fast_path = true;
return buffer;
}
It can be certainly achieved without changed ReadBuffer* family, just by
directly calling StartReadBuffer
from `heapam_index_fetch_tuple` instead of `ReadBuffer`.
Not so nice because we have to duplicate some bufmgr code. Not so much -
check for local relation and
filling `ReadBuffersOperation`structure. But it is better to avoid it.
On 29/12/2025 1:53 AM, Tomas Vondra wrote:
>
> On 12/28/25 21:30, Konstantin Knizhnik wrote:
>> On 28/12/2025 8:08 PM, Tomas Vondra wrote:
>>> On 12/25/25 16:39, Konstantin Knizhnik wrote:
>>>> On 21/12/2025 7:55 PM, Peter Geoghegan wrote:
>>>>> On Wed, Dec 10, 2025 at 9:21 PM Peter Geoghegan <pg@bowt.ie> wrote:
>>>>>> Attached is v4.
>>>>> Attached is v5. Changes from v4:
>>>>>
>>>>> * Simplified and optimized index-only scans, with a particular
>>>>> emphasis on avoiding regressions with nested loop joins with an inner
>>>>> index-only scan.
>>>>>
>>>>> There were quite a number of small problems/dead code related to
>>>>> index-only scans fixed by this new v5. Overall, I'm quite a bit
>>>>> happier with the state of index-only scans, which I'd not paid too
>>>>> much attention to before now.
>>>>>
>>>>> * Added Valgrind instrumentation to the hash index patch, which was
>>>>> required to fix some false positives.
>>>>>
>>>>> The generic indexam_util_batch_unlock routine had Valgrind
>>>>> instrumentation in earlier versions, just to keep nbtree's buffer
>>>>> locking checks from generating similar false positives. Some time
>>>>> later, when I added the hashgetbatch patch, there were new Valgrind
>>>>> false positives during hash index scans -- which I missed at first.
>>>>> This new v5 revisions adds similar Valgrind checks to hash itself
>>>>> (changes that add code that is more or less a direct port of the stuff
>>>>> added to nbtree by commit 4a70f829), which fixes the false positives,
>>>>> and is independently useful.
>>>>>
>>>>> The rule for amgetbatch-based index AMs is that they must have similar
>>>>> buffer locking instrumentation. That seems like a good thing.
>>>>>
>>>>> --
>>>>> Peter Geoghegan
>>>> I the previous mail I shared results of my experiments with different
>>>> prefetch distance.
>>>> I think that we should start prefetching of heap tuples not from the
>>>> second batch, but after some number of proceeded tids.
>>>>
>>>> Attached please find a patch which implements this approach.
>>>> And below are updated results:
>>>>
>>>> limit\prefetch on off always inc threshold
>>>> 1 12074 12765 3146 3282 12394
>>>> 2 5912 6198 2463 2438 6124
>>>> 4 2919 3047 1334 1964 2910
>>>> 8 1554 1496 1166 1409 1588
>>>> 16 815 775 947 940 600
>>>> 32 424 403 687 695 478
>>>> 64 223 208 446 453 358
>>>> 128 115 106 258 270 232
>>>> 256 68 53 138 149 131
>>>> 512 43 27 72 78 71
>>>> 1024 28 13 38 40 38
>>>>
>>>> Last column is result of prefetch with read_stream_threshold=10.
>>>>
>>> That's great, but it only works for cases that can (and do) benefit from
>>> the prefetching. Try running the benchmark with a data set that fits
>>> into shared buffers (or RAM), which makes prefetching useless.
>>>
>>> I tried that with your test, comparing master, v5 and v5 + your
>>> read_stream_threshold patch. See the attached run.sh script, and the PDF
>>> summarizing the results. The last two column groups are comparisons to
>>> master, with green=improvement, red=regression. There are no actual
>>> improvements (1% delta is just noise). But the read_stream_threshold
>>> results have a clear pattern of pretty massive (20-30%) regressions.
>>>
>>> The difference between v5 and v5-threshold is pretty clear.
>>>
>>> IIRC cases like this are *exactly* why we ended up with the current
>>> heuristics, enabling prefetching only from the second batch. This
>>> removes the risk of expensive read_stream init for very fast queries
>>> that don't benefit anything. Of course, prefetching may be useless for
>>> later batches too (e.g. if all the data is cached), but the query will
>>> be expensive enough for the read_stream init cost to be negligible.
>>>
>>> To put this differently, the more aggressive the heuristics is (enabling
>>> prefetching in more case), the more likely it's to cause regressions.
>>> We've chosen to be more defensive, i.e. to sacrifice some possible gains
>>> in order to not regress plausible workloads. I hope we agree queries on
>>> fully cached "hot" data are pretty common / important.
>>>
>>> We can probably do better in the future. But we'll never know for sure
>>> if a given scan benefits from prefetching. It's not just about the
>>> number of items in the batch, but also about how many heap pages that
>>> translates to, what I/O pattern (random vs. sequential?), how many are
>>> already cached. For some queries we don't even know how many items we'll
>>> actually need. We can't check all that at the very beginning, because
>>> it's simply prohibitively expensive.
>>
>> I tried to reproduce your results, but at Mac I do not see some
>> noticeable difference for 250k records, fillfactor=10 and 4GB shared
>> buffers
>> between `enable_indexscan_prefetch=false` and
>> `enable_indexscan_prefetch=true`.
>> I can't believe that just adding this checks in `heap_batch_advance_pos`
>> can cause 75% degrade of performance (because for limit < 10, no read
>> stream is initialized, but still we somewhere loose 25%).
>>
>> I just commented this fragment of code in heapam_handler.c:
>>
>>
>> #if 0
>> proceed_items = ScanDirectionIsForward(direction)
>> ? pos->item - batch->firstItem
>> : batch->lastItem - pos->item;
>> /* Delay initializing stream until proceeding */
>> if (proceed_items >= read_stream_threshold
>> && !scan->xs_heapfetch->rs
>> && !scan->batchqueue->disabled
>> && !scan->xs_want_itup /* XXX prefetching disabled for IoS,
>> for now */
>> && enable_indexscan_prefetch)
>> {
>> scan->xs_heapfetch->rs =
>> read_stream_begin_relation(READ_STREAM_DEFAULT, NULL,
>> scan->heapRelation, MAIN_FORKNUM,
>> scan->heapRelation->rd_tableam->index_getnext_stream,
>> scan, 0);
>> }
>> #endif
>>
>> and ... see no difference.
>>
>> I can understand why initializing read stream earlier (not at the second
>> batch, but after 10 proceeded items) may have negative impact on
>> performance when all data is present i shared buffers for LIMIT>=10.
>> But how it can happen with LIMIT 1 and commented fragment above. There
>> is nothing else in my patch except adding GUC.
>> So I think that it is some "external" factor and wonder if you can
>> reproduce this results (just first line).
>>
> It seems this is due to sending an extra SET (for the new GUC) in the
> pgbench script, which is recognized only on the v5+threshold build.
>
> That's a thinko on my side, I should have realized the extra command
> might affect this. It doesn't really affect the behavior, because 10 is
> the default value for read_stream_threshold. I've fixed the script, will
> check fresh results tomorrow.
>
> Still, I think most of what I said about heuristics when to initialize
> the read stream, and the risk/benefit tradeoff, still applies.
>
>
> regards
Attached please find alternative version of the proposed patch which use
number of disk reads as criteria for using read stream.