Обсуждение: [WIP PATCH] Index scan offset optimisation using visibility map
Hello.
WIP-Patch for optimisation of OFFSET + IndexScan using visibility map.
Patch based on idea of Maxim Boguk [1] with some inspiration from Douglas Doole [2].
---------
Everyone knows - using OFFSET (especially big) is not an good practice.
But in reality they widely used mostly for paging (because it is simple).
Typical situation is some table (for example tickets) with indexes used for paging\sorting:
VACUUM FULL;
VACUUM ANALYZE ticket;
SET work_mem = '512MB';
SET random_page_cost = 1.0;
CREATE TABLE ticket AS
SELECT
id,
TRUNC(RANDOM() * 100 + 1) AS project_id,
NOW() + (RANDOM() * (NOW()+'365 days' - NOW())) AS created_date,
repeat((TRUNC(RANDOM() * 100 + 1)::text), 1000) as payload
FROM GENERATE_SERIES(1, 1000000) AS g(id);
CREATE INDEX simple_index ON ticket using btree(project_id, created_date);
And some typical query to do offset on tickets of some project with paging, some filtration (based on index) and sorting:
SELECT * FROM ticket
WHERE project_id = ?
AND created_date > '20.06.2017'
ORDER BY created_date offset 500 limit 100;
At the current moment IndexScan node will be required to do 600 heap fetches to execute the query.
But first 500 of them are just dropped by the NodeLimit.
The idea of the patch is to push down offset information in ExecSetTupleBound (like it done for Top-sort) to IndexScan in case
of simple scan (without projection, reordering and qual). In such situation we could use some kind of index only scan
(even better because we dont need index data) to avoid fetching tuples while they are just thrown away by nodeLimit.
Patch is also availble on Github:
https://github.com/michail-nikolaev/postgres/commit/a368c3483250e4c02046d418a27091678cb963f4?diff=split
And some test here:
https://gist.github.com/michail-nikolaev/b7cbe1d6f463788407ebcaec8917d1e0
So, at the moment everything seems to work (check-world is ok too) and I got next result for test ticket table:
| offset | master | patch
| 100 | ~1.3ms | ~0.7ms
| 1000 | ~5.6ms | ~1.1ms
| 10000 | ~46.7ms | ~3.6ms
To continue development I have following questions:
0) Maybe I missed something huge...
1) Is it required to support non-mvvc (dirty) snapshots? They are not supported for IndexOnlyScan - not sure about IndexScan.
2) Should I try to pass informaiton about such optimisation to planner/optimizer? It is not too easy with current desigh but seems possible.
3) If so, should I add something to EXPLAIN?
4) If so, should I add some counters to EXPLAIN ANALYZE? (for example number of heap fetch avoided).
5) Should I add description of optimisation to https://www.postgresql.org/docs/10/static/queries-limit.html ?
6) Maybe you have some ideas for additional tests I need to add.
Thanks a lot.
[1] https://www.postgresql.org/message-id/CAK-MWwQpZobHfuTtHj9%2B9G%2B5%3Dck%2BaX-ANWHtBK_0_D_qHYxWuw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CADE5jYLuugnEEUsyW6Q_4mZFYTxHxaVCQmGAsF0yiY8ZDggi-w%40mail.gmail.com
WIP-Patch for optimisation of OFFSET + IndexScan using visibility map.
Patch based on idea of Maxim Boguk [1] with some inspiration from Douglas Doole [2].
---------
Everyone knows - using OFFSET (especially big) is not an good practice.
But in reality they widely used mostly for paging (because it is simple).
Typical situation is some table (for example tickets) with indexes used for paging\sorting:
VACUUM FULL;
VACUUM ANALYZE ticket;
SET work_mem = '512MB';
SET random_page_cost = 1.0;
CREATE TABLE ticket AS
SELECT
id,
TRUNC(RANDOM() * 100 + 1) AS project_id,
NOW() + (RANDOM() * (NOW()+'365 days' - NOW())) AS created_date,
repeat((TRUNC(RANDOM() * 100 + 1)::text), 1000) as payload
FROM GENERATE_SERIES(1, 1000000) AS g(id);
CREATE INDEX simple_index ON ticket using btree(project_id, created_date);
And some typical query to do offset on tickets of some project with paging, some filtration (based on index) and sorting:
SELECT * FROM ticket
WHERE project_id = ?
AND created_date > '20.06.2017'
ORDER BY created_date offset 500 limit 100;
At the current moment IndexScan node will be required to do 600 heap fetches to execute the query.
But first 500 of them are just dropped by the NodeLimit.
The idea of the patch is to push down offset information in ExecSetTupleBound (like it done for Top-sort) to IndexScan in case
of simple scan (without projection, reordering and qual). In such situation we could use some kind of index only scan
(even better because we dont need index data) to avoid fetching tuples while they are just thrown away by nodeLimit.
Patch is also availble on Github:
https://github.com/michail-nikolaev/postgres/commit/a368c3483250e4c02046d418a27091678cb963f4?diff=split
And some test here:
https://gist.github.com/michail-nikolaev/b7cbe1d6f463788407ebcaec8917d1e0
So, at the moment everything seems to work (check-world is ok too) and I got next result for test ticket table:
| offset | master | patch
| 100 | ~1.3ms | ~0.7ms
| 1000 | ~5.6ms | ~1.1ms
| 10000 | ~46.7ms | ~3.6ms
To continue development I have following questions:
0) Maybe I missed something huge...
1) Is it required to support non-mvvc (dirty) snapshots? They are not supported for IndexOnlyScan - not sure about IndexScan.
2) Should I try to pass informaiton about such optimisation to planner/optimizer? It is not too easy with current desigh but seems possible.
3) If so, should I add something to EXPLAIN?
4) If so, should I add some counters to EXPLAIN ANALYZE? (for example number of heap fetch avoided).
5) Should I add description of optimisation to https://www.postgresql.org/docs/10/static/queries-limit.html ?
6) Maybe you have some ideas for additional tests I need to add.
Thanks a lot.
[1] https://www.postgresql.org/message-id/CAK-MWwQpZobHfuTtHj9%2B9G%2B5%3Dck%2BaX-ANWHtBK_0_D_qHYxWuw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CADE5jYLuugnEEUsyW6Q_4mZFYTxHxaVCQmGAsF0yiY8ZDggi-w%40mail.gmail.com
Вложения
Hi, Michail! Thanks for the patch! > 1 февр. 2018 г., в 1:17, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > > Hello. > > WIP-Patch for optimisation of OFFSET + IndexScan using visibility map. While the patch seems to me useful improvement, I see few problems with code: 1. Both branches of "if (node->iss_tuples_skipped_remaning != 0)" seem too similar. There is a lot of duplicate commentset c. I think that this branch should be refactored to avoid code duplication. 2. Most of comments are formatted not per project style. Besides this, patch looks good. Please, add it to the following commitfest so that work on the patch could be tracked. Best regards, Andrey Borodin.
Hello.
Thanks a lot for review.
Patch updated + rebased on master. check-world is passing.
Still not sure about comment formatting. Have you seen any style guid about it except "strict ANSI C comment formatting"? Anyway still need to work on comments.
Also, non-MVCC snaphots are now supported.
Github is updated too. https://github.com/postgres/postgres/compare/master...michail-nikolaev:offset_index_only
Still not sure about questions 0, 2, 3, 4, 5, and 6 from initial mail (about explain, explain analyze, documentation and optimiser).
Thanks.
пн, 5 февр. 2018 г. в 23:36, Andrey Borodin <x4mmm@yandex-team.ru>:
Hi, Michail!
Thanks for the patch!
> 1 февр. 2018 г., в 1:17, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а):
>
> Hello.
>
> WIP-Patch for optimisation of OFFSET + IndexScan using visibility map.
While the patch seems to me useful improvement, I see few problems with code:
1. Both branches of "if (node->iss_tuples_skipped_remaning != 0)" seem too similar. There is a lot of duplicate comments et c. I think that this branch should be refactored to avoid code duplication.
2. Most of comments are formatted not per project style.
Besides this, patch looks good. Please, add it to the following commitfest so that work on the patch could be tracked.
Best regards, Andrey Borodin.
Вложения
Michail Nikolaev <michail.nikolaev@gmail.com> writes: > Still not sure about comment formatting. Have you seen any style guid about > it except "strict ANSI C comment formatting"? Anyway still need to work on > comments. The short answer is "make the new code look like the code around it". But there is actually documentation on the point: https://www.postgresql.org/docs/current/static/source-format.html The rest of that chapter is recommendable reading as well. regards, tom lane
Hi! I've played with patch. I observe that in some expected scenarios it reduces read buffers significantly. > 14 февр. 2018 г., в 0:04, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > Patch updated + rebased on master. check-world is passing. Minor spots: There are some trailing whitespaces at line ends > Offset cannot be optimized because parallel execution I'd replace with > Offset cannot be optimized [in spite of | due to] parallel execution More important thing: now nodeindexonlyscan.c and nodeindexscan.c share more similar code and comments. I do not think itis strictly necessary to avoid, but we certainly have to answer the question: Is it possible to refactor code to avoid duplication? Currently, patch is not invasive, touches only some relevant code. If refactoring will make it shotgun-suregery, I thinkit is better to avoid it. > Still not sure about questions 0, 2, 3, 4, 5, and 6 from initial mail (about explain, explain analyze, documentation andoptimiser). I think that I'd be cool if EXPLAIN ANALYZE printed heap fetch information if "Index-Only" way was used. But we already havethis debug information in form of reduced count in "Buffers". There is nothing to add to plain EXPLAIN, in my opinion. From my point of view, you should add to patch some words here https://www.postgresql.org/docs/current/static/indexes-index-only-scans.html and, if patch will be accepted, here https://wiki.postgresql.org/wiki/Index-only_scans I do not know if it is possible to take into account this optimization in cost estimation. Does Limit node take cost of scanning into startup cost? Thanks! Best regards, Andrey Borodin.
Hi, Michail! Here are points that we need to address before advancing the patch. > 20 февр. 2018 г., в 11:45, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): > > Minor spots: > There are some trailing whitespaces at line ends >> Offset cannot be optimized because parallel execution > I'd replace with >> Offset cannot be optimized [in spite of | due to] parallel execution > > From my point of view, you should add to patch some words here > https://www.postgresql.org/docs/current/static/indexes-index-only-scans.html And few thoughts about plan cost estimation. Plz check create_limit_path() logic on cost estimation. I don't think you haveenough information there to guess about possibility of IoS offset computation. > I do not know if it is possible to take into account this optimization in cost estimation. > Does Limit node take cost of scanning into startup cost? I'm marking patch as WoA, plz ping it to Need Review when done. Thanks! Best regards, Andrey Borodin.
Hello, Andrey.
Thanks for review.
I have updated comments according your review also renamed some fields for consistency.
Additional some notes added to documentation.
Thanks for review.
I have updated comments according your review also renamed some fields for consistency.
Additional some notes added to documentation.
Updated patch in attach, github updated too.
Вложения
Hello Michail, On Tue, March 6, 2018 4:03 pm, Michail Nikolaev wrote: > Hello, Andrey. > > Thanks for review. > > I have updated comments according your review also renamed some fields for > consistency. > Additional some notes added to documentation. > > Updated patch in attach, github updated too. That is a cool idea, and can come in very handy if you regulary need large offsets. Cannot comment on the code, but there is at least one regular typo: + * Decrement counter for remaning skipped tuples. + * If last tuple skipped - release the buffer. + */ + if (node->iss_TuplesSkippedRemaning > 0) + node->iss_TuplesSkippedRemaning--; The English word is "remaining", with "ai" instead of "a" :) Also the variable name "iss_TuplesSkipped" has its grammar at odds with the purpose the code seems to be. It could be named "SkipTuples" (e.g. this is the number of tuples we need to skip, not the number we have skipped), and the other one then "iss_SkipTuplesRemaining" so they are consistent with each other. Others might have a better name for these two, of course. Best wishes, Tels
> 7 марта 2018 г., в 3:25, Tels <nospam-pg-abuse@bloodgate.com> написал(а): > > It could be named "SkipTuples" (e.g. this is the number of tuples we need > to skip, not the number we have skipped), and the other one then > "iss_SkipTuplesRemaining" so they are consistent with each other. I agree that name sounds strange (even for my globish ear). I'm not sure, but may be this ! Assert(!(scandesc->numberOfOrderBys > 0 && scandesc->xs_recheckorderby)); should be if() elog(ERROR,...); ? Also, I think that this check could be removed from loop. We do not expect that it's state will change during execution,do we? Besides this, I think the patch is ready for committer. Best regards, Andrey Borodin.
Hello.
Andrey, Tels - thanks for review.
> It could be named "SkipTuples" (e.g. this is the number of tuples we need
> to skip, not the number we have skipped), and the other one then
> "iss_SkipTuplesRemaining" so they are consistent with each other.
> to skip, not the number we have skipped), and the other one then
> "iss_SkipTuplesRemaining" so they are consistent with each other.
Agreed, done.
> Also, I think that this check could be removed from loop. We do not expect that it's state will change during execution, do we?
Removed.
Patch is attached, github is updated too.
Michail.
Вложения
> 10 марта 2018 г., в 19:20, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > > > Also, I think that this check could be removed from loop. We do not expect that it's state will change during execution,do we? > > Removed. Sorry, seems like I've incorrectly expressed what I wanted to say. I mean this Assert() can be checked before loop, not on every loop cycle. Best regards, Andrey Borodin.
Hello.
> Sorry, seems like I've incorrectly expressed what I wanted to say.
> I mean this Assert() can be checked before loop, not on every loop cycle.
Yes, I understood it. Condition should be checked every cycle - at least it is done this way for index only scan: https://github.com/postgres/postgres/blob/master/src/backend/executor/nodeIndexonlyscan.c#L234
But since original index scan do not contains such check (probably due ot https://github.com/postgres/postgres/blob/master/src/backend/executor/nodeIndexscan.c#L552) - I think it could be removed.
Michail.
> Sorry, seems like I've incorrectly expressed what I wanted to say.
> I mean this Assert() can be checked before loop, not on every loop cycle.
Yes, I understood it. Condition should be checked every cycle - at least it is done this way for index only scan: https://github.com/postgres/postgres/blob/master/src/backend/executor/nodeIndexonlyscan.c#L234
But since original index scan do not contains such check (probably due ot https://github.com/postgres/postgres/blob/master/src/backend/executor/nodeIndexscan.c#L552) - I think it could be removed.
Michail.
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: tested, passed Documentation: tested, passed I've tested this patch with different types of order by, including needing recheck, but everything seems to work as expected. There are some missing spaces before some comment lines and I'm a bit unsure on some lines of code duplicated between nodeIndexonlyscan.cand nodeIndexscan.c But besides this, I have no more notes on the code. I think the patch is ready for committer. Best regards, Andrey Borodin. The new status of this patch is: Ready for Committer
Michail Nikolaev <michail.nikolaev@gmail.com> writes:
> [ offset_index_only_v4.patch ]
I started to go through this patch with the intention of committing it,
but the more I looked at it the less happy I got. What you've done to
IndexNext() is a complete disaster from a modularity standpoint: it now
knows all about the interactions between index_getnext, index_getnext_tid,
and index_fetch_heap. Or that is, it knows too much and still not enough,
because it's flat out wrong for the case that xs_continue_hot is set.
You can't call index_getnext_tid when that's still true from last time.
I'm not sure about a nicer way to refactor that, but I'd suggest that
maybe you need an additional function in indexam.c that hides all this
knowledge about the internal behavior of an IndexScanDesc.
The PredicateLockPage call also troubles me quite a bit, not only from
a modularity standpoint but because that implies a somewhat-user-visible
behavioral change when this optimization activates. People who are using
serializable mode are not going to find it to be an improvement if their
queries fail and need retries a lot more often than they did before.
I don't know if that problem is bad enough that we should disable skipping
when serializable mode is active, but it's something to think about.
You haven't documented the behavior required for tuple-skipping in any
meaningful fashion, particularly not the expectation that the child plan
node will still return tuples that just need not contain any valid
content. Also, this particular implementation of that:
+ ExecClearTuple(slot);
+ slot->tts_isempty = false;
+ slot->tts_nvalid = 0;
is a gross hack and probably wrong. You could use ExecStoreAllNullTuple,
perhaps.
I'm disturbed by the fact that you've not taught the planner about the
potential cost saving from this, so that it won't have any particular
reason to pick a regular indexscan over some other plan type when this
optimization applies. Maybe there's no practical way to do that, or maybe
it wouldn't really matter in practice; I've not looked into it. But not
doing anything feels like a hack.
Setting this back to Waiting on Author.
regards, tom lane
Tom, thanks for inspecting the patch. There's so many problems that slipped from my attention... But one thing that bothers me most is the problem with predicatelocking > 13 марта 2018 г., в 0:55, Tom Lane <tgl@sss.pgh.pa.us> написал(а): > > The PredicateLockPage call also troubles me quite a bit, not only from > a modularity standpoint but because that implies a somewhat-user-visible > behavioral change when this optimization activates. People who are using > serializable mode are not going to find it to be an improvement if their > queries fail and need retries a lot more often than they did before. > I don't know if that problem is bad enough that we should disable skipping > when serializable mode is active, but it's something to think about. Users already have to expect this if the scan turns into IoS somewhat accidentally. There will be page predicate locks withpossible false positive conflicts. I'm not sure that keeping existing tuple-level lock granularity is necessary. I think we can do it if we introduce PredicateLockTuple that do not require tuple's xmin, that takes only tid and does notlook into heap. But this tweak seems outside of the patch scope and I believe it's better avoid messing with SSI internalswithout strong reason. Best regards, Andrey Borodin.
Hello.
Tom, thanks a lot for your thorough review.
> What you've done to
> IndexNext() is a complete disaster from a modularity standpoint: it now
> knows all about the interactions between index_getnext, index_getnext_tid,
> and index_fetch_heap.
I was looking into the current IndexOnlyNext implementation as a starting point - and it knows about index_getnext_tid and index_fetch_heap already.
At the same time I was trying to keep patch non-invasive.
Patched IndexNext now only knowns about index_getnext_tid and index_fetch_heap - the same as IndexOnlyNext.
But yes, it probably could be done better.
> I'm not sure about a nicer way to refactor that, but I'd suggest that
> maybe you need an additional function in indexam.c that hides all this
> knowledge about the internal behavior of an IndexScanDesc.
I'll try to split index_getnext into two functions. A new one will do everything index_getnext does except index_fetch_heap.
> Or that is, it knows too much and still not enough,
> because it's flat out wrong for the case that xs_continue_hot is set.
> You can't call index_getnext_tid when that's still true from last time.
Oh.. Yes, clear error here.
< The PredicateLockPage call also troubles me quite a bit, not only from
< a modularity standpoint but because that implies a somewhat-user-visible
< behavioral change when this optimization activates. People who are using
< serializable mode are not going to find it to be an improvement if their
< queries fail and need retries a lot more often than they did before.
< I don't know if that problem is bad enough that we should disable skipping
< when serializable mode is active, but it's something to think about.
Current IndexOnlyScan already does that. And I think a user should expect such a change in serializable mode.
> You haven't documented the behavior required for tuple-skipping in any
> meaningful fashion, particularly not the expectation that the child plan
> node will still return tuples that just need not contain any valid
> content.
Only nodeLimit could receive such tuples and they are immediately discarded. I'll add some comment to it.
> is a gross hack and probably wrong. You could use ExecStoreAllNullTuple,
> perhaps.
Oh, nice, missed it.
> I'm disturbed by the fact that you've not taught the planner about the
> potential cost saving from this, so that it won't have any particular
> reason to pick a regular indexscan over some other plan type when this
> optimization applies. Maybe there's no practical way to do that, or maybe
> it wouldn't really matter in practice; I've not looked into it. But not
> doing anything feels like a hack.
I was trying to do it. But current planner architecture does not provide a nice way to achive it due to the way it handles limit and offset.
So, I think it is better to to be avoided for now.
> Setting this back to Waiting on Author.
I'll try to make the required changes in a few days.
Tom, thanks a lot for your thorough review.
> What you've done to
> IndexNext() is a complete disaster from a modularity standpoint: it now
> knows all about the interactions between index_getnext, index_getnext_tid,
> and index_fetch_heap.
I was looking into the current IndexOnlyNext implementation as a starting point - and it knows about index_getnext_tid and index_fetch_heap already.
At the same time I was trying to keep patch non-invasive.
Patched IndexNext now only knowns about index_getnext_tid and index_fetch_heap - the same as IndexOnlyNext.
But yes, it probably could be done better.
> I'm not sure about a nicer way to refactor that, but I'd suggest that
> maybe you need an additional function in indexam.c that hides all this
> knowledge about the internal behavior of an IndexScanDesc.
I'll try to split index_getnext into two functions. A new one will do everything index_getnext does except index_fetch_heap.
> Or that is, it knows too much and still not enough,
> because it's flat out wrong for the case that xs_continue_hot is set.
> You can't call index_getnext_tid when that's still true from last time.
Oh.. Yes, clear error here.
< The PredicateLockPage call also troubles me quite a bit, not only from
< a modularity standpoint but because that implies a somewhat-user-visible
< behavioral change when this optimization activates. People who are using
< serializable mode are not going to find it to be an improvement if their
< queries fail and need retries a lot more often than they did before.
< I don't know if that problem is bad enough that we should disable skipping
< when serializable mode is active, but it's something to think about.
Current IndexOnlyScan already does that. And I think a user should expect such a change in serializable mode.
> You haven't documented the behavior required for tuple-skipping in any
> meaningful fashion, particularly not the expectation that the child plan
> node will still return tuples that just need not contain any valid
> content.
Only nodeLimit could receive such tuples and they are immediately discarded. I'll add some comment to it.
> is a gross hack and probably wrong. You could use ExecStoreAllNullTuple,
> perhaps.
Oh, nice, missed it.
> I'm disturbed by the fact that you've not taught the planner about the
> potential cost saving from this, so that it won't have any particular
> reason to pick a regular indexscan over some other plan type when this
> optimization applies. Maybe there's no practical way to do that, or maybe
> it wouldn't really matter in practice; I've not looked into it. But not
> doing anything feels like a hack.
I was trying to do it. But current planner architecture does not provide a nice way to achive it due to the way it handles limit and offset.
So, I think it is better to to be avoided for now.
> Setting this back to Waiting on Author.
I'll try to make the required changes in a few days.
Thanks.
Hello everyone.
I need an advice.
I was reworking the patch: added support for the planner, added support for queries with projection, addded support for predicates which could be executed over index data.
And.. I realized that my IndexScan is even more index-only than the original IndexOnlyScan. So, it seems to be a wrong way.
I think the task could be splitted into two:
1. Extended support for index-only-scan
Currently IndexOnlyScan is used only in case when target data is fully located in
index. If we need some additional columns - regular index scan is used anyway.
For example, let's consider such table and index:
CREATE TABLE test_events (
time timestamp ,
event varchar(255),
data jsonb
);
CREATE INDEX on test_events USING btree(time, event);
It is some kind of big table with log events. And let's consinder such query:
SELECT data->>'event_id'
FROM test_events
WHERE
time > (now() - interval '2 year') AND -- indexqual
event = 'tax' AND -- indexqual
extract(ISODOW from time) = 1 --qpquals
ORDER BY time DESC
At the moment IndexScan plan will be used for such query due to result data. But 1/7 of all heap access will be lost. At the same time "extract(ISODOW from time) = 1" (qpqualsl) could be easily calculated over index data.
The idea is simple: extend IndexOnly scan to be used if all query predicates (both indexqual and qpquals) could be calculated over index data. And if all checks are passed - just load tuple from heap to return.
It seems like index-data access is really cheap now and such plan will be faster even for qpquals without high selectivity. At least for READCOMMITED.
I think I will able to create prototype within a few days (most of work is done in current patch rework).
Probably it is not an ne idea - so, is it worth implementation? Maybe I've missed something huge.
2. For extented IndexOnlyScan - add support to avoid heap fetch in case of OFFSET applied to tuple.
If first part is implemented - OFFSET optimisation is much easier to achieve.
Thanks,
Michail.
Hi! The work on the patch goes on, where was some discussion of this patch off-list with author. Advise-request is still actual. I think that we should move this patch to next CF. So I'm marking patch as needs review. Best regards, Andrey Borodin.
Hello everyone.
This letter related to “Extended support for index-only-scan” from my previous message in the thread.
WIP version of the patch is ready for a while now and I think it is time to resume the work on the feature. BTW, I found a small article about Oracle vs Postgres focusing this issue - https://blog.dbi-services.com/postgres-vs-oracle-access-paths-viii/
Current WIP version of the patch is located here - https://github.com/postgres/postgres/compare/88ba0ae2aa4aaba8ea0d85c0ff81cc46912d9308...michail-nikolaev:index_only_fetch, passing all checks. In addition, patch includes small optimization for caching of amcostestimate results.
For now, I decide to name the plan as “Index Only Fetch Scan”. Therefore:
* In case of “Index Scan” – we touch the index and heap for EVERY tuple we need to test
* For “Index Only Scan” – we touch the index for every tuple and NEVER touch the heap
* For “Index Only Fetch Scan” – we touch the index for every tuple and touch the heap for those tuples we need to RETURN ONLY.
I still have no idea – maybe it should be just “Index Only Scan”, or just “Index Scan” or whatever. Technically, it is implemented inside nodeIndexonlyscan.c for now.
I made simple test framework based on pg_bench to compare performance under different conditions. It seems like performance boost mostly depends on two parameters – index correlation and predicate selectivity (and percentage of completely visible pages, of course). Testing script is located here - https://gist.github.com/michail-nikolaev/23e1520a1db1a09ff2b48d78f0cde91d
WIP version of the patch is ready for a while now and I think it is time to resume the work on the feature. BTW, I found a small article about Oracle vs Postgres focusing this issue - https://blog.dbi-services.com/postgres-vs-oracle-access-paths-viii/
Current WIP version of the patch is located here - https://github.com/postgres/postgres/compare/88ba0ae2aa4aaba8ea0d85c0ff81cc46912d9308...michail-nikolaev:index_only_fetch, passing all checks. In addition, patch includes small optimization for caching of amcostestimate results.
For now, I decide to name the plan as “Index Only Fetch Scan”. Therefore:
* In case of “Index Scan” – we touch the index and heap for EVERY tuple we need to test
* For “Index Only Scan” – we touch the index for every tuple and NEVER touch the heap
* For “Index Only Fetch Scan” – we touch the index for every tuple and touch the heap for those tuples we need to RETURN ONLY.
I still have no idea – maybe it should be just “Index Only Scan”, or just “Index Scan” or whatever. Technically, it is implemented inside nodeIndexonlyscan.c for now.
I made simple test framework based on pg_bench to compare performance under different conditions. It seems like performance boost mostly depends on two parameters – index correlation and predicate selectivity (and percentage of completely visible pages, of course). Testing script is located here - https://gist.github.com/michail-nikolaev/23e1520a1db1a09ff2b48d78f0cde91d
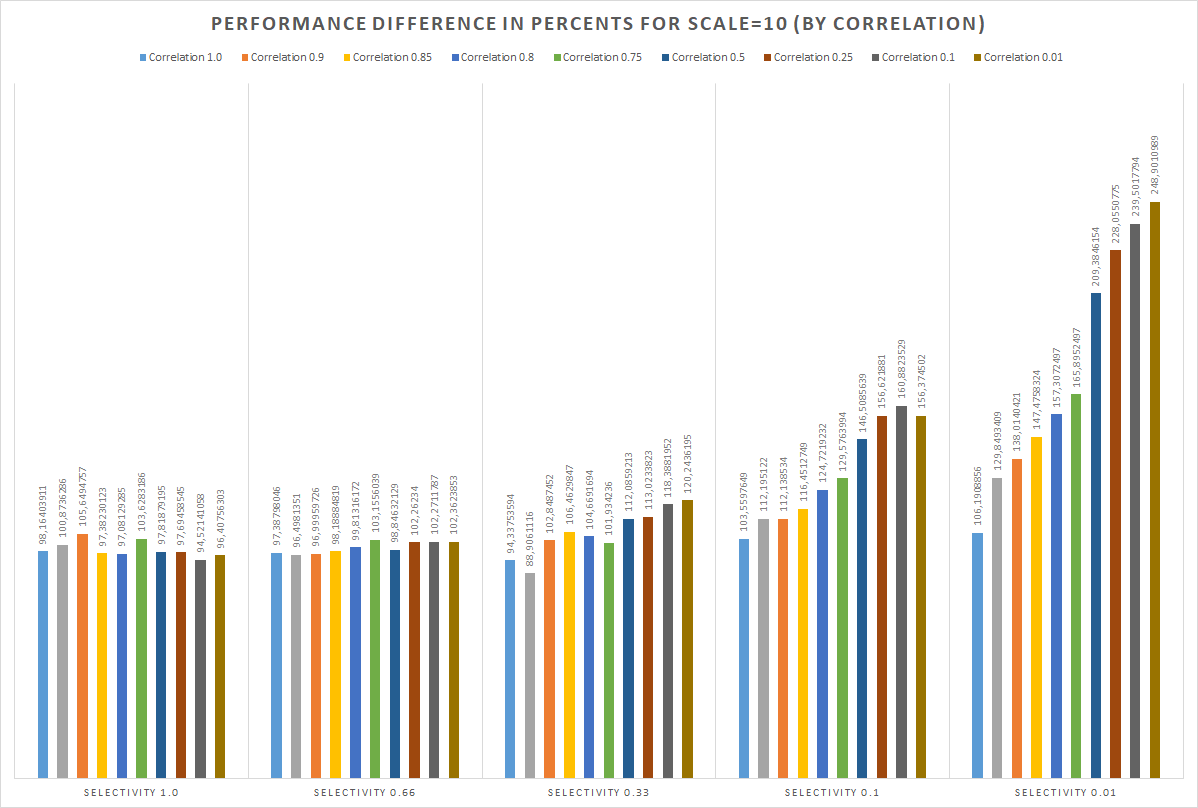
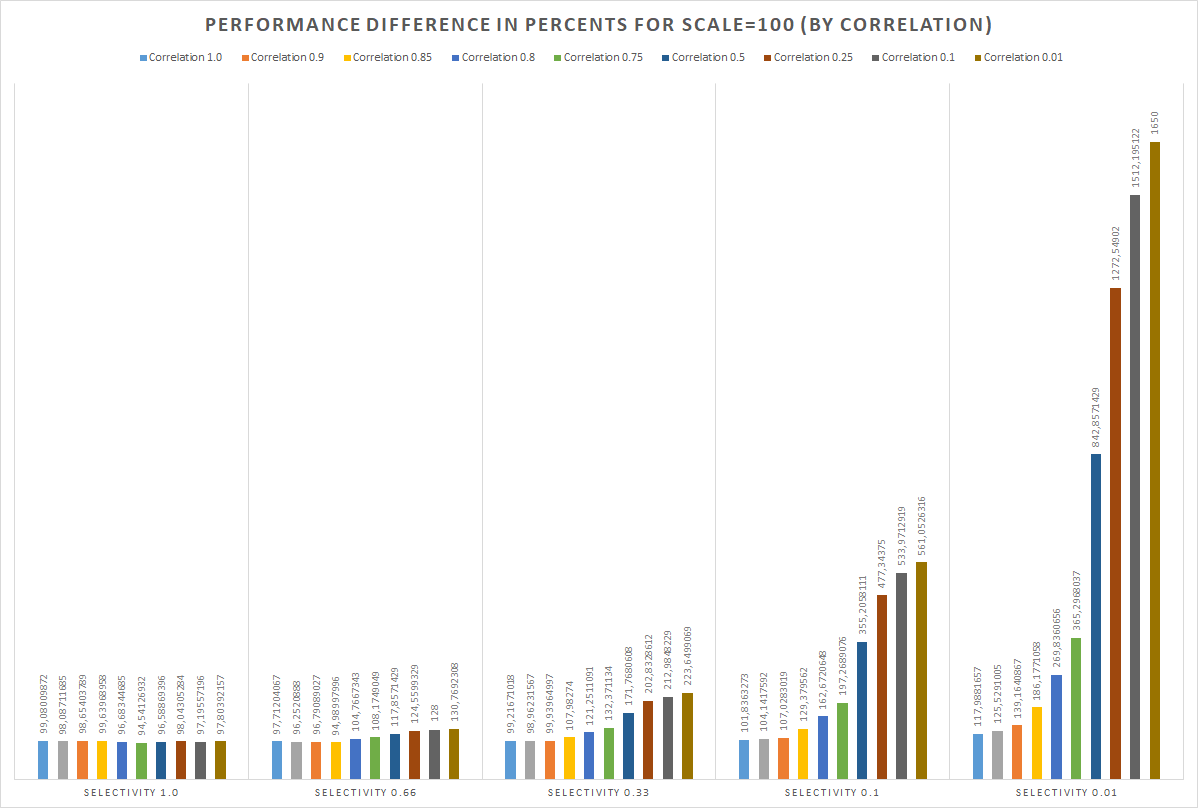
There are raw testing results for SSD - https://gist.github.com/michail-nikolaev/9cfbeee1555c6f051822bf1a2b2fe76d . In addition, some graphics are attached. Basically speaking - optimization provides great performance impact, especially for indexes with low correlation and queries with low predicate selectivity. However, to avoid 3-4% performance degradation in opposite cases – it is required to design and implement accurate costing solution.
I think it could be a great feature, especially together with covering indexes. However, am I still not sure how to name it, what is a better way to implement it (custom plan or part of index-only), is any chance to merge it once it is ready?
It seems to be kind of big deal – new type of scan (ignoring the fact is it not so new technically). Of course, it applies only to queries with predicates that are not used for index traverse but could be resolved using index data (qpquals).
Additionally, OFFSET optimization could be easily achieved once “Index Only Fetch” is implemented.
Still need some advice here…
I think it could be a great feature, especially together with covering indexes. However, am I still not sure how to name it, what is a better way to implement it (custom plan or part of index-only), is any chance to merge it once it is ready?
It seems to be kind of big deal – new type of scan (ignoring the fact is it not so new technically). Of course, it applies only to queries with predicates that are not used for index traverse but could be resolved using index data (qpquals).
Additionally, OFFSET optimization could be easily achieved once “Index Only Fetch” is implemented.
Still need some advice here…
Вложения
{kind=link}
{kind=link}
Hi, Michail! > 21 мая 2018 г., в 20:43, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > This letter related to “Extended support for index-only-scan” from my previous message in the thread. This is great that you continue your work in this direction! The concept of scan that you propose looks interesting. I have few questions: 1. Charts are measured in percents of pgbench TPS, right? 2. For example, is 97% actually 3% degrade? 3. The results are obtained on actual "sort of TPC-B" script? Best regards, Andrey Borodin.
Hello.
> 1. Charts are measured in percents of pgbench TPS, right?
Yes, correct. Actual values are calculated as TPS_of_patched / TPS_of_vanilla. TPS was measured using single postgres process (one core) (I was also did tests with multiple processes, but they shows pretty same results).
> 2. For example, is 97% actually 3% degrade?
Yes, such degrade happens for indexes with high correlation and predicates with low selectivity. In such cases 2-4% overhead is caused by index data read and page visibility check. But it is possible to detect such cases in planner and use regular IndexScan instead.
> 3. The results are obtained on actual "sort of TPC-B" script?
You could check testing script (https://gist.github.com/michail-nikolaev/23e1520a1db1a09ff2b48d78f0cde91d) for SQL queries.
But briefly:
* Vanilla pg_bench initialization
* ALTER TABLE pgbench_accounts drop constraint pgbench_accounts_pkey; -- drop non-required constraint
* UPDATE pgbench_accounts SET bid = TRUNC(RANDOM() * {ROWS_N} + 1 -- randomize BID (used for selectivy predicate)
* UPDATE pgbench_accounts SET aid = TRUNC(RANDOM() * {ROWS_N} + 1) WHERE random() <= (1.0 - {CORRELATION}) -- emulate index correlation by changing some part of AID values
* CREATE index test_index ON pgbench_accounts USING btree(aid, bid) -- create index used for test
* VACUUM FULL;
* VACUUM ANALYZE pgbench_accounts;
* SELECT * FROM pgbench_accounts WHERE aid > {RANDOM} and bid % 100 <= {SELECTIVITY} order by aid limit 50
Thanks,
Michail.
> 1. Charts are measured in percents of pgbench TPS, right?
Yes, correct. Actual values are calculated as TPS_of_patched / TPS_of_vanilla. TPS was measured using single postgres process (one core) (I was also did tests with multiple processes, but they shows pretty same results).
> 2. For example, is 97% actually 3% degrade?
Yes, such degrade happens for indexes with high correlation and predicates with low selectivity. In such cases 2-4% overhead is caused by index data read and page visibility check. But it is possible to detect such cases in planner and use regular IndexScan instead.
> 3. The results are obtained on actual "sort of TPC-B" script?
You could check testing script (https://gist.github.com/michail-nikolaev/23e1520a1db1a09ff2b48d78f0cde91d) for SQL queries.
But briefly:
* Vanilla pg_bench initialization
* ALTER TABLE pgbench_accounts drop constraint pgbench_accounts_pkey; -- drop non-required constraint
* UPDATE pgbench_accounts SET bid = TRUNC(RANDOM() * {ROWS_N} + 1 -- randomize BID (used for selectivy predicate)
* UPDATE pgbench_accounts SET aid = TRUNC(RANDOM() * {ROWS_N} + 1) WHERE random() <= (1.0 - {CORRELATION}) -- emulate index correlation by changing some part of AID values
* CREATE index test_index ON pgbench_accounts USING btree(aid, bid) -- create index used for test
* VACUUM FULL;
* VACUUM ANALYZE pgbench_accounts;
* SELECT * FROM pgbench_accounts WHERE aid > {RANDOM} and bid % 100 <= {SELECTIVITY} order by aid limit 50
Thanks,
Michail.
On 21/05/18 18:43, Michail Nikolaev wrote: > Hello everyone. > This letter related to “Extended support for index-only-scan” from my > previous message in the thread. > > WIP version of the patch is ready for a while now and I think it is time to > resume the work on the feature. BTW, I found a small article about Oracle > vs Postgres focusing this issue - > https://blog.dbi-services.com/postgres-vs-oracle-access-paths-viii/ > > Current WIP version of the patch is located here - > https://github.com/postgres/postgres/compare/88ba0ae2aa4aaba8ea0d85c0ff81cc46912d9308...michail-nikolaev:index_only_fetch, > passing all checks. In addition, patch includes small optimization for > caching of amcostestimate results. Please submit an actual path, extracted e.g. with "git format-patch -n1", rather than a link to an external site. That is a requirement for archival purposes, so that people reading the email archives later on can see what was being discussed. (And that link doesn't return a proper diff, anyway.) > For now, I decide to name the plan as “Index Only Fetch Scan”. Therefore: > * In case of “Index Scan” – we touch the index and heap for EVERY tuple we > need to test > * For “Index Only Scan” – we touch the index for every tuple and NEVER > touch the heap > * For “Index Only Fetch Scan” – we touch the index for every tuple and > touch the heap for those tuples we need to RETURN ONLY. Hmm. IIRC there was some discussion on doing that, when index-only scans were implemented. It's not generally OK to evaluate expressions based on data that has already been deleted from the table. As an example of the kind of problems you might get: Imagine that a user does "DELETE * FROM table WHERE div = 0; SELECT * FROM table WHERE 100 / div < 10". Would you expect the query to throw a "division by zero error"? If there was an index on 'div', you might evaluate the "100 / div" expression based on values from the index, which still includes entries for the just-deleted tuples with div = 0. They would be filtered out later, after performing the visibility checks, but it's too late if you already threw an error. Now, maybe there's some way around that, but I don't know what. Without some kind of a solution, this won't work. - Heikki
Hello.
Thanks a lot for your feedback. I'll try to update patch in few days (currently stuck at small performance regression in unknown place).
Regarding issue with delete: yes, it is valid point, but record removing should clear visibility buffer - and tuple will be fetched from heap to test its existance. In such case expression are not evaluated at all. Not sure for delete and query in same transaction - I'll check.
Also, need to recheck possible issues with EvalPlanQual.
PS.
Updated link in case someone want to briefly see code until git patch is ready: https://github.com/michail-nikolaev/postgres/compare/e3eb8be77ef82ccc8f87c515f96d01bf7c726ca8...michail-nikolaev:index_only_fetch?ts=4
сб, 14 июл. 2018 г. в 0:17, Heikki Linnakangas <hlinnaka@iki.fi>:
On 21/05/18 18:43, Michail Nikolaev wrote:
> Hello everyone.
> This letter related to “Extended support for index-only-scan” from my
> previous message in the thread.
>
> WIP version of the patch is ready for a while now and I think it is time to
> resume the work on the feature. BTW, I found a small article about Oracle
> vs Postgres focusing this issue -
> https://blog.dbi-services.com/postgres-vs-oracle-access-paths-viii/
>
> Current WIP version of the patch is located here -
> https://github.com/postgres/postgres/compare/88ba0ae2aa4aaba8ea0d85c0ff81cc46912d9308...michail-nikolaev:index_only_fetch,
> passing all checks. In addition, patch includes small optimization for
> caching of amcostestimate results.
Please submit an actual path, extracted e.g. with "git format-patch
-n1", rather than a link to an external site. That is a requirement for
archival purposes, so that people reading the email archives later on
can see what was being discussed. (And that link doesn't return a proper
diff, anyway.)
> For now, I decide to name the plan as “Index Only Fetch Scan”. Therefore:
> * In case of “Index Scan” – we touch the index and heap for EVERY tuple we
> need to test
> * For “Index Only Scan” – we touch the index for every tuple and NEVER
> touch the heap
> * For “Index Only Fetch Scan” – we touch the index for every tuple and
> touch the heap for those tuples we need to RETURN ONLY.
Hmm. IIRC there was some discussion on doing that, when index-only scans
were implemented. It's not generally OK to evaluate expressions based on
data that has already been deleted from the table. As an example of the
kind of problems you might get:
Imagine that a user does "DELETE * FROM table WHERE div = 0; SELECT *
FROM table WHERE 100 / div < 10". Would you expect the query to throw a
"division by zero error"? If there was an index on 'div', you might
evaluate the "100 / div" expression based on values from the index,
which still includes entries for the just-deleted tuples with div = 0.
They would be filtered out later, after performing the visibility
checks, but it's too late if you already threw an error.
Now, maybe there's some way around that, but I don't know what. Without
some kind of a solution, this won't work.
- Heikki
On Mon, Jul 16, 2018 at 02:11:57PM +0300, Michail Nikolaev wrote: > Thanks a lot for your feedback. I'll try to update patch in few days > (currently stuck at small performance regression in unknown place). Okay, it has been more than a couple of days and the patch has not been updated, so I am marking as returned with feedback. -- Michael
Вложения
Hello.
> Okay, it has been more than a couple of days and the patch has not been
> updated, so I am marking as returned with feedback.
Yes, it is more than couple of days passed, but also there is almost no feedback since 20 Mar after patch design was changed :)
But seriously - I still working on it and was digging into just last night ( https://github.com/michail-nikolaev/postgres/commits/index_only_fetch )
The main issue currently is a cost estimation. In right case (10m relation, 0.5 index correlation, 0.1 selectivity for filter) - it works like a charm with 200%-400% performance boost.
But the same case with 1.0 selectivity gives 96% comparing to baseline. So, to do correct cost estimation I need correct selectivity of filter predicate.
Currently I am thinking to calculate it on fly - and switch to the new method if selectivity is small. But it feels a little akward.
Thanks,
Michail.
Hi! > 2 окт. 2018 г., в 11:55, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > > > Okay, it has been more than a couple of days and the patch has not been > > updated, so I am marking as returned with feedback. > > Yes, it is more than couple of days passed, but also there is almost no feedback since 20 Mar after patch design was changed:) > But seriously - I still working on it Let's move this to CF 2018-11? Obviously, it is WiP, but it seems that patch is being discussed, author cares about it. Best regards, Andrey Borodin.
On Wed, Oct 03, 2018 at 10:54:14AM +0500, Andrey Borodin wrote: > Let's move this to CF 2018-11? Obviously, it is WiP, but it seems that > patch is being discussed, author cares about it. If you are still working on it, which is not something obvious based on the thread activity, then moving it to next commit fest could make sense. However please post a new patch first and then address the comments your patch has received before doing so. -- Michael