Обсуждение: pgstattuple: Use streaming read API in pgstatindex functions
Hi hackers,
While reading the code related to streaming reads and their current
use cases, I noticed that pgstatindex could potentially benefit from
adopting the streaming read API. The required change is relatively
simple—similar to what has already been implemented in the pg_warm and
pg_visibility extensions. I also ran some performance tests on an
experimental patch to validate the improvement.
Summary
Cold cache performance (the typical use case for diagnostic tools):
- Medium indexes (~21MB): 1.21x - 1.79x faster (20-44% speedup)
- Large indexes (~214MB): 1.50x - 1.90x faster (30-47% speedup)
- Xlarge indexes (~1351MB):1.4x–1.9x gains. (29–47% speedup)
Hardware: AX162-R from hetzner
Test matrix:
- Index types: Primary key, timestamp, float, composite (3 columns)
- Sizes: Medium (1M rows, ~21MB), Large (10M rows, ~214MB), XLarge
(50M rows, ~ 1351MB))
- Layouts: Unfragmented (sequential) and Fragmented (random insert order)
- Cache states: Cold (dropped OS cache) and Warm (pg_prewarm)
Xlarge fragmented example:
==> Creating secondary indexes on test_xlarge
Created 3 secondary indexes: created_at, score, composite
Created test_xlarge_pkey: 1351 MB
Fragmentation stats (random insert order):
leaf_frag_pct | avg_density_pct | leaf_pages | size
---------------+-----------------+------------+---------
49.9 | 71.5 | 172272 | 1351 MB
(1 row)
configuration:
- shared_buffers = 16GB
- effective_io_concurrency = 500
- io_combine_limit = 16
- autovacuum = off
- checkpoint_timeout = 1h
- bgwriter_delay = 10000ms (minimize background writes)
- jit = off
- max_parallel_workers_per_gather = 0
Unfragmented Indexes (Cold Cache)
Index Type Size Baseline Patched Speedup
Primary Key Medium 31.5 ms 19.6 ms 1.58×
Primary Key Large 184.0 ms 119.0 ms 1.54×
Timestamp Medium 13.4 ms 10.5 ms 1.28×
Timestamp Large 85.0 ms 45.6 ms 1.86×
Float (score) Medium 13.7 ms 11.4 ms 1.21×
Float (score) Large 84.0 ms 45.0 ms 1.86×
Composite (3 col) Medium 26.7 ms 17.2 ms 1.56×
Composite (3 col) Large 89.8 ms 51.2 ms 1.75×
⸻
Fragmented Indexes (Cold Cache)
To address concerns about filesystem fragmentation, I tested indexes built
with random inserts (ORDER BY random()) to trigger page splits and create
fragmented indexes:
Index Type Size Baseline Patched Speedup
Primary Key Medium 41.9 ms 23.5 ms 1.79×
Primary Key Large 236.0 ms 148.0 ms 1.58×
Primary Key XLarge 953.4 ms 663.1 ms 1.43×
Timestamp Medium 32.1 ms 18.8 ms 1.70×
Timestamp Large 188.0 ms 117.0 ms 1.59×
Timestamp XLarge 493.0 ms 518.6 ms 0.95×
Float (score) Medium 14.0 ms 10.9 ms 1.28×
Float (score) Large 85.8 ms 45.2 ms 1.89×
Float (score) XLarge 263.2 ms 176.5 ms 1.49×
Composite (3 col) Medium 42.3 ms 24.1 ms 1.75×
Composite (3 col) Large 245.0 ms 162.0 ms 1.51×
Composite (3 col) XLarge 1052.5 ms 716.5 ms 1.46×
Summary: Fragmentation generally does not hurt streaming reads; most
fragmented cases still see 1.4×–1.9× gains. One outlier (XLarge
Timestamp) shows a slight regression (0.95×).
⸻
Warm Cache Results
When indexes are fully cached in shared_buffers:
Unfragmented: infrequent little regression for small to medium size
index(single digit ms variance, barely noticeable); small gains for
large size index
Fragmented: infrequent little regression for small to medium size
index(single digit ms variance, barely noticeable); small gains for
large size index
Best,
Xuneng
Вложения
Hi, On Mon, Oct 13, 2025 at 10:07 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi hackers, > > While reading the code related to streaming reads and their current > use cases, I noticed that pgstatindex could potentially benefit from > adopting the streaming read API. The required change is relatively > simple—similar to what has already been implemented in the pg_warm and > pg_visibility extensions. I also ran some performance tests on an > experimental patch to validate the improvement. > > Summary > Cold cache performance (the typical use case for diagnostic tools): > - Medium indexes (~21MB): 1.21x - 1.79x faster (20-44% speedup) > - Large indexes (~214MB): 1.50x - 1.90x faster (30-47% speedup) > - Xlarge indexes (~1351MB):1.4x–1.9x gains. (29–47% speedup) > > Hardware: AX162-R from hetzner > > Test matrix: > - Index types: Primary key, timestamp, float, composite (3 columns) > - Sizes: Medium (1M rows, ~21MB), Large (10M rows, ~214MB), XLarge > (50M rows, ~ 1351MB)) > - Layouts: Unfragmented (sequential) and Fragmented (random insert order) > - Cache states: Cold (dropped OS cache) and Warm (pg_prewarm) > > Xlarge fragmented example: > ==> Creating secondary indexes on test_xlarge > Created 3 secondary indexes: created_at, score, composite > Created test_xlarge_pkey: 1351 MB > Fragmentation stats (random insert order): > leaf_frag_pct | avg_density_pct | leaf_pages | size > ---------------+-----------------+------------+--------- > 49.9 | 71.5 | 172272 | 1351 MB > (1 row) > > configuration: > - shared_buffers = 16GB > - effective_io_concurrency = 500 > - io_combine_limit = 16 > - autovacuum = off > - checkpoint_timeout = 1h > - bgwriter_delay = 10000ms (minimize background writes) > - jit = off > - max_parallel_workers_per_gather = 0 > > Unfragmented Indexes (Cold Cache) > > Index Type Size Baseline Patched Speedup > Primary Key Medium 31.5 ms 19.6 ms 1.58× > Primary Key Large 184.0 ms 119.0 ms 1.54× > Timestamp Medium 13.4 ms 10.5 ms 1.28× > Timestamp Large 85.0 ms 45.6 ms 1.86× > Float (score) Medium 13.7 ms 11.4 ms 1.21× > Float (score) Large 84.0 ms 45.0 ms 1.86× > Composite (3 col) Medium 26.7 ms 17.2 ms 1.56× > Composite (3 col) Large 89.8 ms 51.2 ms 1.75× > > ⸻ > > Fragmented Indexes (Cold Cache) > > To address concerns about filesystem fragmentation, I tested indexes built > with random inserts (ORDER BY random()) to trigger page splits and create > fragmented indexes: > > Index Type Size Baseline Patched Speedup > Primary Key Medium 41.9 ms 23.5 ms 1.79× > Primary Key Large 236.0 ms 148.0 ms 1.58× > Primary Key XLarge 953.4 ms 663.1 ms 1.43× > Timestamp Medium 32.1 ms 18.8 ms 1.70× > Timestamp Large 188.0 ms 117.0 ms 1.59× > Timestamp XLarge 493.0 ms 518.6 ms 0.95× > Float (score) Medium 14.0 ms 10.9 ms 1.28× > Float (score) Large 85.8 ms 45.2 ms 1.89× > Float (score) XLarge 263.2 ms 176.5 ms 1.49× > Composite (3 col) Medium 42.3 ms 24.1 ms 1.75× > Composite (3 col) Large 245.0 ms 162.0 ms 1.51× > Composite (3 col) XLarge 1052.5 ms 716.5 ms 1.46× > > Summary: Fragmentation generally does not hurt streaming reads; most > fragmented cases still see 1.4×–1.9× gains. One outlier (XLarge > Timestamp) shows a slight regression (0.95×). > > ⸻ > > Warm Cache Results > When indexes are fully cached in shared_buffers: > Unfragmented: infrequent little regression for small to medium size > index(single digit ms variance, barely noticeable); small gains for > large size index > Fragmented: infrequent little regression for small to medium size > index(single digit ms variance, barely noticeable); small gains for > large size index > Fix indentation issue in v1. Best, Xuneng
Вложения
Hi,
Thank you for working on this!
On Mon, 13 Oct 2025 at 06:20, Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Fix indentation issue in v1.
I did not look at the benchmarks, so here are my code comments.
- I would avoid creating a new scope for the streaming read. While it
makes the streaming code easier to interpret, it introduces a large
diff due to indentation changes.
- I suggest adding the following comment about streaming batching, as
it is used in other places:
/*
* It is safe to use batchmode as block_range_read_stream_cb takes no
* locks.
*/
- For the '/* Scan all blocks except the metapage using streaming
reads */' comments, it might be helpful to clarify that the 0th page
is the metapage. Something like: '/* Scan all blocks except the
metapage (0th page) using streaming reads */'.
Other than these comments, the code looks good to me.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Hi Bilal,
Thanks for looking into this.
On Mon, Oct 13, 2025 at 3:00 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> Thank you for working on this!
>
> On Mon, 13 Oct 2025 at 06:20, Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Fix indentation issue in v1.
>
> I did not look at the benchmarks, so here are my code comments.
>
> - I would avoid creating a new scope for the streaming read. While it
> makes the streaming code easier to interpret, it introduces a large
> diff due to indentation changes.
>
> - I suggest adding the following comment about streaming batching, as
> it is used in other places:
>
> /*
> * It is safe to use batchmode as block_range_read_stream_cb takes no
> * locks.
> */
>
> - For the '/* Scan all blocks except the metapage using streaming
> reads */' comments, it might be helpful to clarify that the 0th page
> is the metapage. Something like: '/* Scan all blocks except the
> metapage (0th page) using streaming reads */'.
>
> Other than these comments, the code looks good to me.
>
Here is patch v3. The comments have been added, and the extra scope
({}) has been removed as suggested.
Best,
Xuneng
Вложения
Hi Xuneng Zhou
> - /* Unlock and release buffer */
> - LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
> - ReleaseBuffer(buffer);
> + UnlockReleaseBuffer(buffer);
> }
> - /* Unlock and release buffer */
> - LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
> - ReleaseBuffer(buffer);
> + UnlockReleaseBuffer(buffer);
> }
Thanks for your patch! Just to nitpick a bit — I think this comment is worth keeping, even though the function name already conveys its meaning.
On Mon, Oct 13, 2025 at 4:42 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
Hi Bilal,
Thanks for looking into this.
On Mon, Oct 13, 2025 at 3:00 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> Thank you for working on this!
>
> On Mon, 13 Oct 2025 at 06:20, Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Fix indentation issue in v1.
>
> I did not look at the benchmarks, so here are my code comments.
>
> - I would avoid creating a new scope for the streaming read. While it
> makes the streaming code easier to interpret, it introduces a large
> diff due to indentation changes.
>
> - I suggest adding the following comment about streaming batching, as
> it is used in other places:
>
> /*
> * It is safe to use batchmode as block_range_read_stream_cb takes no
> * locks.
> */
>
> - For the '/* Scan all blocks except the metapage using streaming
> reads */' comments, it might be helpful to clarify that the 0th page
> is the metapage. Something like: '/* Scan all blocks except the
> metapage (0th page) using streaming reads */'.
>
> Other than these comments, the code looks good to me.
>
Here is patch v3. The comments have been added, and the extra scope
({}) has been removed as suggested.
Best,
Xuneng
Hi,
On Mon, 13 Oct 2025 at 11:42, Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Here is patch v3. The comments have been added, and the extra scope
> ({}) has been removed as suggested.
Thanks, the code looks good to me!
The benchmark results are nice. I have a quick question about the
setup, if you are benchmarking with the default io_method (worker),
then the results might show the combined benefit of async I/O and
streaming I/O, rather than just streaming I/O alone. If that is the
case, I would suggest also running a benchmark with io_method=sync to
isolate the performance impact of streaming I/O. You might get
interesting results.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Hi Wenhui, Thanks for looking into this. On Mon, Oct 13, 2025 at 5:41 PM wenhui qiu <qiuwenhuifx@gmail.com> wrote: > > Hi Xuneng Zhou > > > > - /* Unlock and release buffer */ > > - LockBuffer(buffer, BUFFER_LOCK_UNLOCK); > > - ReleaseBuffer(buffer); > > + UnlockReleaseBuffer(buffer); > > } > Thanks for your patch! Just to nitpick a bit — I think this comment is worth keeping, even though the function name alreadyconveys its meaning. > It makes sense. I'll keep it. Best, Xuneng
Hi,
On Mon, Oct 13, 2025 at 5:42 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> On Mon, 13 Oct 2025 at 11:42, Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Here is patch v3. The comments have been added, and the extra scope
> > ({}) has been removed as suggested.
>
> Thanks, the code looks good to me!
>
> The benchmark results are nice. I have a quick question about the
> setup, if you are benchmarking with the default io_method (worker),
> then the results might show the combined benefit of async I/O and
> streaming I/O, rather than just streaming I/O alone. If that is the
> case, I would suggest also running a benchmark with io_method=sync to
> isolate the performance impact of streaming I/O. You might get
> interesting results.
The previous benchmark was conducted using the default
io_method=worker. The following results are from a new benchmark run
with io_method=sync. The performance gains from streaming reads are
still present, though smaller than those observed when asynchronous
I/O and streaming I/O are combined — which is expected. Thanks for the
suggestion!
Fragmented Indexes (Cold Cache)
Index Type Size Baseline Patched Speedup
Primary Key Medium 43.80 ms 38.61 ms 1.13×
Primary Key Large 238.24 ms 202.47 ms 1.17×
Primary Key XLarge 962.90 ms 793.57 ms 1.21×
Timestamp Medium 33.34 ms 29.98 ms 1.11×
Timestamp Large 190.41 ms 161.34 ms 1.18×
Timestamp XLarge 794.52 ms 647.82 ms 1.22×
Float (score) Medium 14.46 ms 13.51 ms 1.06×
Float (score) Large 87.38 ms 77.22 ms 1.13×
Float (score) XLarge 278.47 ms 233.22 ms 1.19×
Composite (3 col) Medium 44.49 ms 40.10 ms 1.10×
Composite (3 col) Large 244.86 ms 211.01 ms 1.16×
Composite (3 col) XLarge 1073.32 ms 872.42 ms 1.23×
________________________________
Fragmented Indexes (Warm Cache)
Index Type Size Baseline Patched Speedup
Primary Key Medium 7.91 ms 7.88 ms 1.00×
Primary Key Large 35.58 ms 36.41 ms 0.97×
Primary Key XLarge 126.29 ms 126.95 ms 0.99×
Timestamp Medium 5.14 ms 6.82 ms 0.75×
Timestamp Large 22.96 ms 29.55 ms 0.77×
Timestamp XLarge 104.26 ms 106.01 ms 0.98×
Float (score) Medium 3.76 ms 4.18 ms 0.90×
Float (score) Large 13.65 ms 13.01 ms 1.04×
Float (score) XLarge 40.58 ms 41.28 ms 0.98×
Composite (3 col) Medium 8.23 ms 8.25 ms 0.99×
Composite (3 col) Large 37.10 ms 37.59 ms 0.98×
Composite (3 col) XLarge 139.89 ms 138.21 ms 1.01×
Best,
Xuneng
Вложения
Hi,
Here’s the updated summary report(cold cache, fragmented index), now including results for the streaming I/O + io_uring configuration.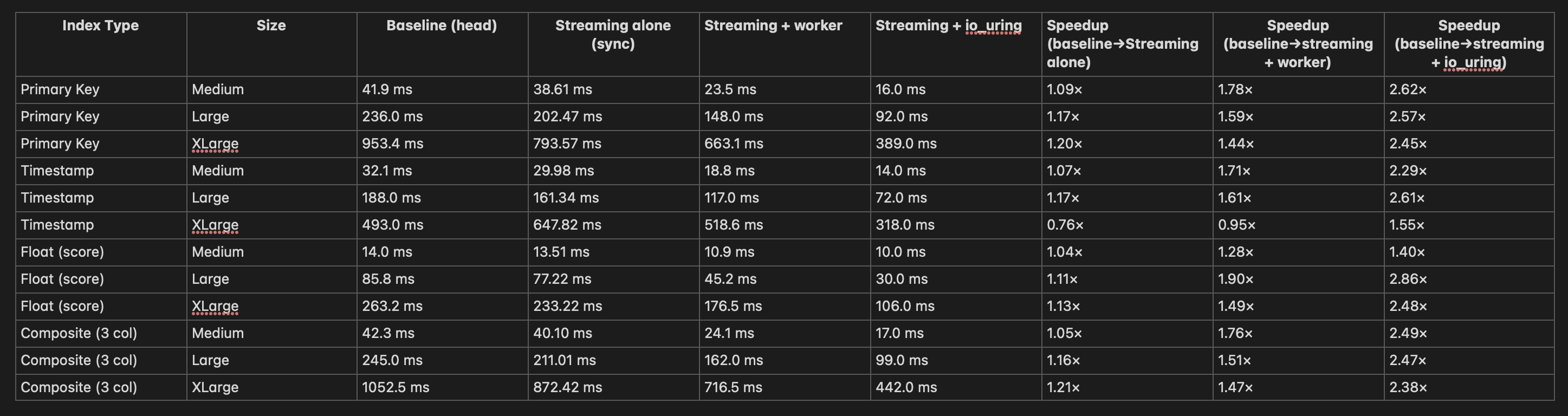
Best,
Xuneng
Вложения
Hi,
On Wed, Oct 15, 2025 at 10:25 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
Hi,Here’s the updated summary report(cold cache, fragmented index), now including results for the streaming I/O + io_uring configuration.
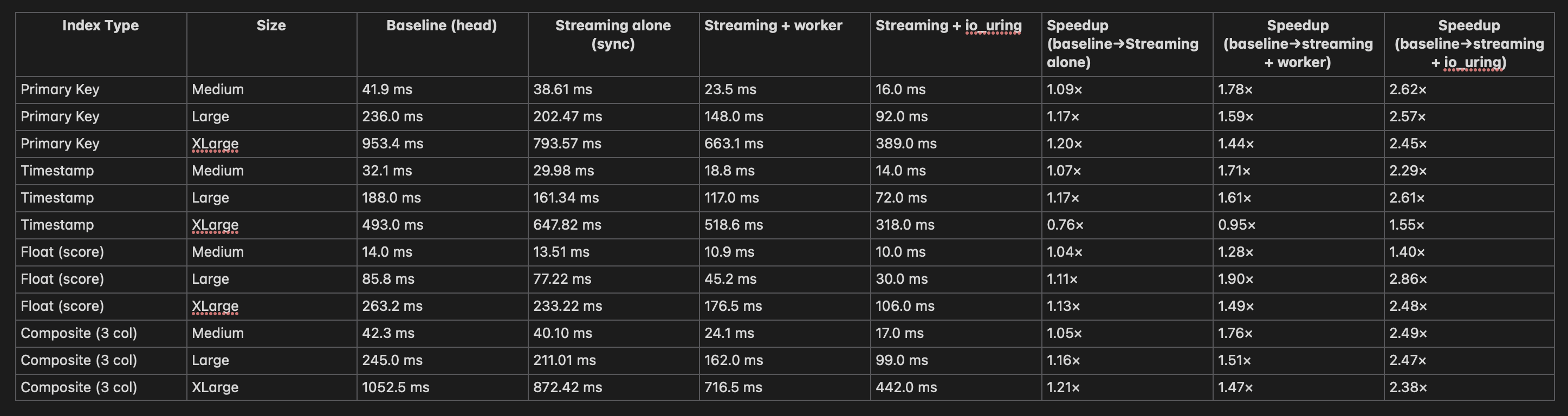
Thank you for the additional tests. I can see the image on Gmail, but I cannot on pgsql-hackers archive [0], so it might be a good idea to attach it and not to paste it on the body.
I saw the patch and have a few minor comments.
+ p.current_blocknum = 1;
To improve readability, how about using the following, which is consistent with nbtree.c [1]?
p.current_blocknum = BTREE_METAPAGE + 1;
Similarly, for hash index:
p.current_blocknum = HASH_METAPAGE + 1;
+ /* Unlock and release buffer */
UnlockReleaseBuffer(buf);
UnlockReleaseBuffer(buf);
I think this comment is redundant since the function name UnlockReleaseBuffer is self-explanatory. I suggest omitting it from pgstathashindex and removing the existing one from pgstatindex_impl.
Best regards,
Shinya Kato
NTT OSS Center
Вложения
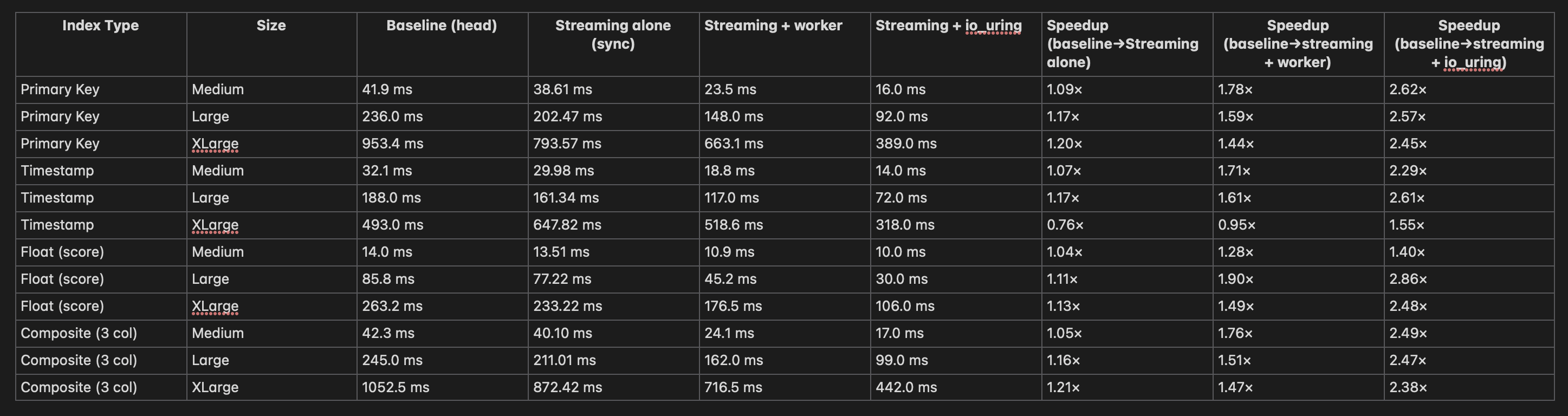
Hi Kato-san, Thanks for looking into this. On Thu, Oct 16, 2025 at 4:21 PM Shinya Kato <shinya11.kato@gmail.com> wrote: > > Hi, > > On Wed, Oct 15, 2025 at 10:25 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: >> >> Hi, >> >> Here’s the updated summary report(cold cache, fragmented index), now including results for the streaming I/O + io_uringconfiguration. >> > > Thank you for the additional tests. I can see the image on Gmail, but I cannot on pgsql-hackers archive [0], so it mightbe a good idea to attach it and not to paste it on the body. Please see the attachment. > > > I saw the patch and have a few minor comments. > > + p.current_blocknum = 1; > > To improve readability, how about using the following, which is consistent with nbtree.c [1]? > p.current_blocknum = BTREE_METAPAGE + 1; > > Similarly, for hash index: > p.current_blocknum = HASH_METAPAGE + 1; This is more readable. I made the replacements. > > + /* Unlock and release buffer */ > UnlockReleaseBuffer(buf); > > I think this comment is redundant since the function name UnlockReleaseBuffer is self-explanatory. I suggest omitting itfrom pgstathashindex and removing the existing one from pgstatindex_impl. UnlockReleaseBuffer seems clearer and simpler than the original > LockBuffer(buffer, BUFFER_LOCK_UNLOCK); > ReleaseBuffer(buffer); So the comment might be less meaningful for UnlockReleaseBuffer. I removed it as you suggested. Best, Xuneng
Вложения
{kind=link}
HI Xuneng Zhou
> - /* Unlock and release buffer */
> - LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
> - ReleaseBuffer(buffer);
> + UnlockReleaseBuffer(buffer);
> }
> - LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
> - ReleaseBuffer(buffer);
> + UnlockReleaseBuffer(buffer);
> }
The previous suggestion to keep it was based on the fact that the original code already had a similar comment.
In fact, the code itself is quite easy to understand. My earlier email was simply following the style of the existing code when making the suggestion.
If anyone thinks the comment is unnecessary, it can certainly be removed.
In fact, the code itself is quite easy to understand. My earlier email was simply following the style of the existing code when making the suggestion.
If anyone thinks the comment is unnecessary, it can certainly be removed.
On Thu, Oct 16, 2025 at 5:39 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
Hi Kato-san,
Thanks for looking into this.
On Thu, Oct 16, 2025 at 4:21 PM Shinya Kato <shinya11.kato@gmail.com> wrote:
>
> Hi,
>
> On Wed, Oct 15, 2025 at 10:25 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
>>
>> Hi,
>>
>> Here’s the updated summary report(cold cache, fragmented index), now including results for the streaming I/O + io_uring configuration.
>>
>
> Thank you for the additional tests. I can see the image on Gmail, but I cannot on pgsql-hackers archive [0], so it might be a good idea to attach it and not to paste it on the body.
Please see the attachment.
>
>
> I saw the patch and have a few minor comments.
>
> + p.current_blocknum = 1;
>
> To improve readability, how about using the following, which is consistent with nbtree.c [1]?
> p.current_blocknum = BTREE_METAPAGE + 1;
>
> Similarly, for hash index:
> p.current_blocknum = HASH_METAPAGE + 1;
This is more readable. I made the replacements.
>
> + /* Unlock and release buffer */
> UnlockReleaseBuffer(buf);
>
> I think this comment is redundant since the function name UnlockReleaseBuffer is self-explanatory. I suggest omitting it from pgstathashindex and removing the existing one from pgstatindex_impl.
UnlockReleaseBuffer seems clearer and simpler than the original
> LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
> ReleaseBuffer(buffer);
So the comment might be less meaningful for UnlockReleaseBuffer. I
removed it as you suggested.
Best,
Xuneng
Hi, On Thu, Oct 16, 2025 at 6:32 PM wenhui qiu <qiuwenhuifx@gmail.com> wrote: > > HI Xuneng Zhou > > > - /* Unlock and release buffer */ > > - LockBuffer(buffer, BUFFER_LOCK_UNLOCK); > > - ReleaseBuffer(buffer); > > + UnlockReleaseBuffer(buffer); > > } > The previous suggestion to keep it was based on the fact that the original code already had a similar comment. > In fact, the code itself is quite easy to understand. My earlier email was simply following the style of the existing codewhen making the suggestion. > If anyone thinks the comment is unnecessary, it can certainly be removed. > > On Thu, Oct 16, 2025 at 5:39 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: >> >> Hi Kato-san, >> >> Thanks for looking into this. >> >> On Thu, Oct 16, 2025 at 4:21 PM Shinya Kato <shinya11.kato@gmail.com> wrote: >> > >> > Hi, >> > >> > On Wed, Oct 15, 2025 at 10:25 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: >> >> >> >> Hi, >> >> >> >> Here’s the updated summary report(cold cache, fragmented index), now including results for the streaming I/O + io_uringconfiguration. >> >> >> > >> > Thank you for the additional tests. I can see the image on Gmail, but I cannot on pgsql-hackers archive [0], so it mightbe a good idea to attach it and not to paste it on the body. >> >> Please see the attachment. >> >> > >> > >> > I saw the patch and have a few minor comments. >> > >> > + p.current_blocknum = 1; >> > >> > To improve readability, how about using the following, which is consistent with nbtree.c [1]? >> > p.current_blocknum = BTREE_METAPAGE + 1; >> > >> > Similarly, for hash index: >> > p.current_blocknum = HASH_METAPAGE + 1; >> >> This is more readable. I made the replacements. >> >> > >> > + /* Unlock and release buffer */ >> > UnlockReleaseBuffer(buf); >> > >> > I think this comment is redundant since the function name UnlockReleaseBuffer is self-explanatory. I suggest omittingit from pgstathashindex and removing the existing one from pgstatindex_impl. >> >> UnlockReleaseBuffer seems clearer and simpler than the original >> >> > LockBuffer(buffer, BUFFER_LOCK_UNLOCK); >> > ReleaseBuffer(buffer); >> >> So the comment might be less meaningful for UnlockReleaseBuffer. I >> removed it as you suggested. It might be worthwhile to benchmark this patch on a machine with non-SSD storage. However, I don’t currently have access to one, and still, I plan to mark patch v5 as Ready for Committer. Best, Xuneng