Обсуждение: [WiP] B-tree page merge during vacuum to reduce index bloat
Hi hackers, Together with Kirk and Nik we spent several online hacking sessions to tackle index bloat problems [0,1,2]. As a result weconcluded that B-tree index page merge should help to keep an index from pressuring shared_buffers. We are proposing a feature to automatically merge nearly-empty B-tree leaf pages during VACUUM operations to reduce indexbloat. This addresses a common issue where deleted tuples leave behind sparsely populated pages that traditional pagedeletion cannot handle because they're not completely empty. *** Implementation Overview: The patch adds a new `mergefactor` reloption (default 5%, range 0-50%) that defines when a page becomes a candidate for merging.During vacuum, when a page exceeds this threshold (e.g., 95% empty with default settings), we attempt to move theremaining tuples to the right sibling page and then delete the source page using existing page deletion mechanisms. Key changes: - New `mergefactor` reloption for configurable merge thresholds - Detection logic in `btvacuumpage()` to identify merge candidates - Tuple movement implementation in `_bt_unlink_halfdead_page()` - WAL logging enhancements to handle cross-page dependencies during replay The last part needs further improvements (it's simply REGBUF_FORCE_IMAGE for now), but I want to start a discussion and askfor known problems of the approach. *** Correctness: The implementation reuses existing locking, critical sections and WAL logging infrastructure. To handle cross-page dependenciesduring WAL replay, when tuples are merged, the right sibling buffer is registered with `REGBUF_FORCE_IMAGE`,this is a temporary workaround. *** Current Status & Questions: The patch successfully reduces index bloat and handles basic scenarios, but we've identified some areas that need communityinput: 1. Backward Scan Correctness: The primary concern is ensuring backward scans work correctly when pages are being merged concurrently.Since we maintain the same locking protocol as existing page deletion, I believe this should be safe, but wouldappreciate expert review of the approach. 2. Performance Impact: The additional checks during vacuum have minimal overhead, but broader testing would be valuable.Worst case would be the index with leaf pattern (5%,96%,5%,96%,5%,96%...). We will attempt to merge it every timespending time on acquiring locks. 3. WAL Consistency: There are still some edge cases with WAL consistency checking that need refinement. I think I can handleit, just need to spend enough time on debugging real redo instead of imaging right page. *** Usage: CREATE INDEX ON table (col) WITH (mergefactor=10); -- 10% threshold I don't know if it would be a good idea to enable mergefactor for existing indexes. The feature is particularly beneficial for workloads with high update/delete rates that create sparse index pages withouttriggering complete page deletion. I'm attaching the patch for review and would welcome feedback on the approach, especially regarding backward scan safetyand any other correctness concerns we may have missed. Thank you! Best regards, Andrey, Nik, Kirk. [0] https://www.youtube.com/watch?v=3MleDtXZUlM [1] https://www.youtube.com/watch?v=Ib3SXSFt8mE [2] https://www.youtube.com/watch?v=D1PEdDcvZTw
Вложения
On Tue, 26 Aug 2025 at 11:40, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > Hi hackers, > > Together with Kirk and Nik we spent several online hacking sessions to tackle index bloat problems [0,1,2]. As a resultwe concluded that B-tree index page merge should help to keep an index from pressuring shared_buffers. > > We are proposing a feature to automatically merge nearly-empty B-tree leaf pages during VACUUM operations to reduce indexbloat. This addresses a common issue where deleted tuples leave behind sparsely populated pages that traditional pagedeletion cannot handle because they're not completely empty. > > *** Implementation Overview: > > The patch adds a new `mergefactor` reloption (default 5%, range 0-50%) that defines when a page becomes a candidate formerging. During vacuum, when a page exceeds this threshold (e.g., 95% empty with default settings), we attempt to movethe remaining tuples to the right sibling page and then delete the source page using existing page deletion mechanisms. > > Key changes: > - New `mergefactor` reloption for configurable merge thresholds > - Detection logic in `btvacuumpage()` to identify merge candidates > - Tuple movement implementation in `_bt_unlink_halfdead_page()` > - WAL logging enhancements to handle cross-page dependencies during replay > > The last part needs further improvements (it's simply REGBUF_FORCE_IMAGE for now), but I want to start a discussion andask for known problems of the approach. > > *** Correctness: > > The implementation reuses existing locking, critical sections and WAL logging infrastructure. To handle cross-page dependenciesduring WAL replay, when tuples are merged, the right sibling buffer is registered with `REGBUF_FORCE_IMAGE`,this is a temporary workaround. > > 1. Backward Scan Correctness: The primary concern is ensuring backward scans work correctly when pages are being mergedconcurrently. Since we maintain the same locking protocol as existing page deletion, I believe this should be safe,but would appreciate expert review of the approach. I'm fairly sure there is a correctness issue here; I don't think you correctly detect the two following cases: 1.) a page (P0) is scanned by a scan, finishes processing the results, and releases its pin. It prepares to scan the next page of the scan (P1). 2.) a page (A) is split, with new right sibling page B, 3.) and the newly created page B is merged into its right sibling C, 4.) the scan continues on to the next page For backward scans, if page A is the same page as the one identified with P1, the scan won't notice that tuples from P1 (aka A) have been moved through B to P0 (C), causing the scan to skip processing for those tuples. For forward scans, if page A is the same page as the one identified with P0, the scan won't notice that tuples from P0 (A) have been moved through B to P1 (C), causing the scan to process those tuples twice in the same scan, potentially duplicating results. NB: Currently, the only way for "merge" to happen is when the index page is completely empty. This guarantees that there is no movement of scan-visible tuples to pages we've already visited/are about to visit. This invariant is used extensively to limit lock and pin coupling (and thus: improve performance) in index scans; see e.g. in 1bd4bc85. This patch will invalidate that invariant, and therefore it will require (significantly) more work in the scan code (incl. nbtsearch.c) to guarantee exactly-once results + no false negatives. Kind regards, Matthias van de Meent Databricks
On Tue, Aug 26, 2025 at 6:33 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote:
On Tue, 26 Aug 2025 at 11:40, Andrey Borodin <x4mmm@yandex-team.ru> wrote:
>
> Hi hackers,
>
> Together with Kirk and Nik we spent several online hacking sessions to tackle index bloat problems [0,1,2]. As a result we concluded that B-tree index page merge should help to keep an index from pressuring shared_buffers.
>
> We are proposing a feature to automatically merge nearly-empty B-tree leaf pages during VACUUM operations to reduce index bloat. This addresses a common issue where deleted tuples leave behind sparsely populated pages that traditional page deletion cannot handle because they're not completely empty.
>
...
I'm fairly sure there is a correctness issue here; I don't think you
correctly detect the two following cases:
1.) a page (P0) is scanned by a scan, finishes processing the results,
and releases its pin. It prepares to scan the next page of the scan
(P1).
2.) a page (A) is split, with new right sibling page B,
3.) and the newly created page B is merged into its right sibling C,
4.) the scan continues on to the next page
For backward scans, if page A is the same page as the one identified
with P1, the scan won't notice that tuples from P1 (aka A) have been
moved through B to P0 (C), causing the scan to skip processing for
those tuples.
For forward scans, if page A is the same page as the one identified
with P0, the scan won't notice that tuples from P0 (A) have been moved
through B to P1 (C), causing the scan to process those tuples twice in
the same scan, potentially duplicating results.
NB: Currently, the only way for "merge" to happen is when the index
page is completely empty. This guarantees that there is no movement of
scan-visible tuples to pages we've already visited/are about to visit.
This invariant is used extensively to limit lock and pin coupling (and
thus: improve performance) in index scans; see e.g. in 1bd4bc85. This
patch will invalidate that invariant, and therefore it will require
(significantly) more work in the scan code (incl. nbtsearch.c) to
guarantee exactly-once results + no false negatives.
Kind regards,
Matthias van de Meent
Databricks
This was one of our concerns. We will review the patch mentioned.
I do have a question, one of the IDEAS we discussed was to ADD a new page that combined the 2 pages.
Making the deletion "feel" like a page split.
This has the advantage of leaving the original 2 pages alone for anyone who is currently traversing.
And like the page split, updating the links around while marking the pages for the new path.
The downside to this approach is that we are "adding 1 page to then mark 2 pages as unused".
Could you comment on this secondary approach?
Thanks in advance!
Kirk
On Tue, Aug 26, 2025 at 5:40 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > *** Correctness: > > The implementation reuses existing locking, critical sections and WAL logging infrastructure. To handle cross-page dependenciesduring WAL replay, when tuples are merged, the right sibling buffer is registered with `REGBUF_FORCE_IMAGE`,this is a temporary workaround. I don't think that you can reuse existing locking for this. It needs to be totally reevaluated in light of the way that you've changed page deletion. In general, page deletion ends up being very complicated with the Lehman & Yao design -- even with the existing restrictions. It's a natural downside of the very permissive locking rules: there is no need for most searchers and inserters to ever hold more than a single buffer lock at a time. Searchers generally hold *no* locks when descending the index at points where they're "between levels". Almost anything can happen in the meantime -- including page deletion (it's just that the deleted page cannot be concurrently recycled right away, which is kind of a separate process). That original block number reference still has to work for these searchers, no matter what. It must at least not give them an irredeemably bad picture of what's going on; they might have to move right to deal with concurrent page deletion and page splits, but that's it. If you merge together underful pages like this, you change the key space boundaries between pages. I don't see a way to make that safe/an atomic operation, except by adding significantly more locking in the critical path of searchers. > *** Current Status & Questions: > > The patch successfully reduces index bloat and handles basic scenarios, but we've identified some areas that need communityinput: Have you benchmarked it? I wouldn't assume that free-at-empty actually is worse than merging underfull pages. It's complicated, but see this paper for some counter-arguments: https://www.sciencedirect.com/science/article/pii/002200009390020W This old Dr. Dobbs article from the same authors gives a lighter summary of the same ideas: https://web.archive.org/web/20200811014238/https://www.drdobbs.com/reexamining-b-trees/184408694?pgno=3 In any case, I believe that this optimization isn't widely implemented by other major RDBMSs, despite being a textbook technique that was known about and described early in the history of B-Trees. -- Peter Geoghegan
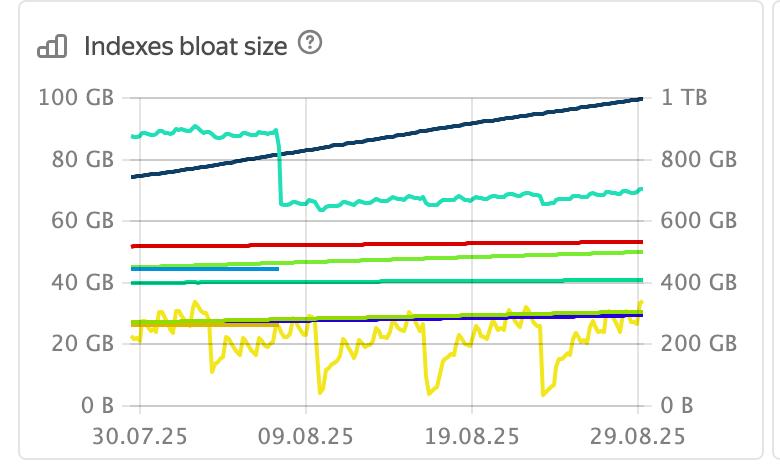
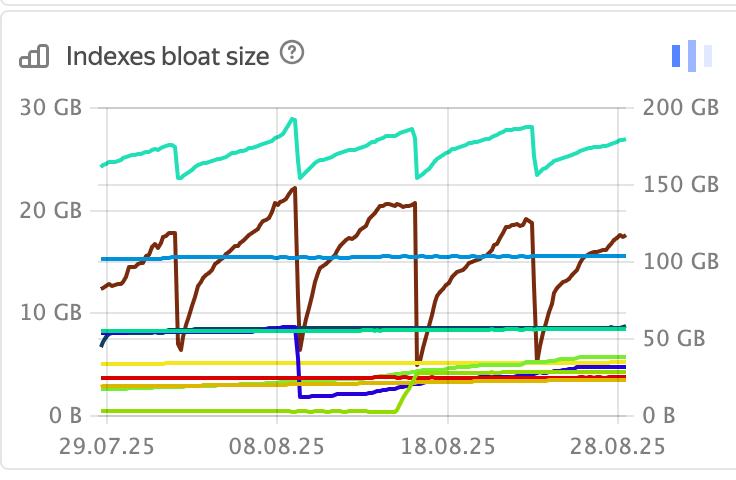
Peter, Matthias, many thanks for your input! > On 28 Aug 2025, at 01:06, Peter Geoghegan <pg@bowt.ie> wrote: > > Have you benchmarked it? Kind of. Here are bloat charts from random production clusters: Upper green line has an axis on right - it's total index bloat per cluster. Other lines are individual indexes with mostbloat, axis on the left. Notice the 7 day period on one of lines. It's our friday automatic index repack of an indexes that suffers from bloat. Mostof the week these indexes are 97%+ percents bloated. On a yellow line small period is noticeable - that's what "free at empty" vacuum can help with now. It is just one index, and even not a top bloat contributor. But 2 out of 3 random clusters had such index. (I must admitthat clusters were not truly random - I just picked browser tabs from recent incidents during my on-call duty shift) Both cases are queues with secondary index, which gets bloated quickly after reindexing. Of course, I'm not proposing to do "merge-at-half", merge-at-95%-free would be good enough for this case. 95% bloated indexcertainly has some 95% free pages. I think to establish baseline for locking correctness we are going to start from writing index scan tests, that fail withproposed merge patch and pass on current HEAD. I want to observe that forward scan is showing duplicates and backwardscan misses tuples. From that we will try to design locking that does not affect performance significantly, but allows to merge pages. Perhaps,we can design a way to switch new index scans to "safe mode" during index vacuum and waiting for existing scans tocomplete. Best regards, Andrey Borodin.
Вложения
{kind=link}
{kind=link}
> On 29 Aug 2025, at 13:39, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > I think to establish baseline for locking correctness we are going to start from writing index scan tests, that fail withproposed merge patch and pass on current HEAD. I want to observe that forward scan is showing duplicates and backwardscan misses tuples. Well, that was unexpectedly easy. See patch 0001. It brings a test where we create sparse tree, and injection point thatwill wait on a scan stepping into some middle leaf page. Then the test invokes vacuum. There are ~35 leaf pages, most of them will be merged into just a few pages. As expected, both scans produce incorrect results. t/008_btree_merge_scan_correctness.pl .. 1/? # Failed test 'Forward scan returns correct count' # at t/008_btree_merge_scan_correctness.pl line 132. # got: '364' # expected: '250' # Failed test 'Backward scan returns correct count' # at t/008_btree_merge_scan_correctness.pl line 133. # got: '142' # expected: '250' # Looks like you failed 2 tests of 2. > From that we will try to design locking that does not affect performance significantly, but allows to merge pages. Perhaps,we can design a way to switch new index scans to "safe mode" during index vacuum and waiting for existing scans tocomplete. What if we just abort a scan, that stepped on the page where tuples were moved out? I've prototype this approach, please see patch 0002. Maybe in future we will improve locking protocol if we will observehigh error rates. Unfortunately, this approach leads to default mergefactor 0 instead of 5%. What do you think? Should we add this to CF or the idea is too wild for a review? Best regards, Andrey Borodin.
Вложения
Re: [WiP] B-tree page merge during vacuum to reduce index bloat
От
Darafei "Komяpa" Praliaskouski
Дата:
Hello,
On Sun, Aug 31, 2025 at 4:16 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote:
> On 29 Aug 2025, at 13:39, Andrey Borodin <x4mmm@yandex-team.ru> wrote:
>
What if we just abort a scan, that stepped on the page where tuples were moved out?
...
What do you think?
We have a database on which we have bulk insertions and deletions of significant parts of the table.
btree- and gist-bloat becomes a significant issue there so much that we have to resort to making ad-hoc cron-like solutions[1]. REINDEX CONCURRENTLY also sometimes crashes due to memory pressure leaving half-dead indexes behind which we have to clean up and keep reindexing until success. [2]
Anything that improves the situation and makes Postgres handle this automatically would improve the experience significantly.
Regarding locks: I think that baseline to compare to here is "what would happen if I had to REINDEX instead" and that is EXCLUSIVE LOCK at some point. I'd set that as a baseline for the endeavour. I think it may dramatically simplify correctness checks for the first iterations and relieve the pain for most of the cases.
A similar mechanic for GiST will also be helpful.
1. https://github.com/konturio/insights-db/blob/main/scripts/reindex-bloated-btrees.sh
2. https://github.com/konturio/insights-db/blob/main/scripts/drop_invalid_indexes.sql
1. https://github.com/konturio/insights-db/blob/main/scripts/reindex-bloated-btrees.sh
2. https://github.com/konturio/insights-db/blob/main/scripts/drop_invalid_indexes.sql
On Sun, 31 Aug 2025 at 14:15, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > On 29 Aug 2025, at 13:39, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > > > I think to establish baseline for locking correctness we are going to start from writing index scan tests, that failwith proposed merge patch and pass on current HEAD. I want to observe that forward scan is showing duplicates and backwardscan misses tuples. > > Well, that was unexpectedly easy. See patch 0001. It brings a test where we create sparse tree, and injection point thatwill wait on a scan stepping into some middle leaf page. > Then the test invokes vacuum. There are ~35 leaf pages, most of them will be merged into just a few pages. > As expected, both scans produce incorrect results. > t/008_btree_merge_scan_correctness.pl .. 1/? > # Failed test 'Forward scan returns correct count' > # at t/008_btree_merge_scan_correctness.pl line 132. > # got: '364' > # expected: '250' > > # Failed test 'Backward scan returns correct count' > # at t/008_btree_merge_scan_correctness.pl line 133. > # got: '142' > # expected: '250' > # Looks like you failed 2 tests of 2. > > > > From that we will try to design locking that does not affect performance significantly, but allows to merge pages. Perhaps,we can design a way to switch new index scans to "safe mode" during index vacuum and waiting for existing scans tocomplete. > > What if we just abort a scan, that stepped on the page where tuples were moved out? I don't think that's viable nor valid. We can't let vacuum processes abort active scans; it'd go against the principles of vacuum being a background process; and it'd be a recipe for disaster when it triggers in catalog scans. It'd probably also fail to detect the case where a non-backward index scan's just-accessed data was merged to the right, onto the page that the scan will access next (or, a backward scan's just-accessed data merged to the left). I think the issue isn't _just_ what to do when we detect that a page was merged (it's relatively easy to keep track of what data was present on a merged-now-empty page), but rather how we detect that pages got merged, and how we then work to return to a valid scan position. Preferably, we'd have a way that guarantees that a scan can not fail to notice that a keyspace with live tuples was concurrently merged onto a page, what keyspace this was, and whether that change was relevant to the currently active index scan; all whilst still obeying the other nbtree invariants that scans currently rely on. > I've prototype this approach, please see patch 0002. Maybe in future we will improve locking protocol if we will observehigh error rates. > Unfortunately, this approach leads to default mergefactor 0 instead of 5%. > > What do you think? Should we add this to CF or the idea is too wild for a review? Aborting queries to be able to merge pages is not a viable approach; -1 on that. It would make running VACUUM concurrently with other workloads unsafe, and that's not acceptable. Kind regards, Matthias van de Meent Databricks (https://databricks.com)
On Tue, Aug 26, 2025 at 2:11 PM Kirk Wolak <wolakk@gmail.com> wrote: > I do have a question, one of the IDEAS we discussed was to ADD a new page that combined the 2 pages. Would the flow then be as follows? Please correct me if I'm wrong: Start: Parent page P, with adjacent child pages A -> B -> C -> D. Pages B and C are sparse enough and are about to be merged. 1: Acquire lock on pages B and C 2: Create a new page N, which copies the tuples in pages B and C 3: Acquire lock on parent page P, update the separator keys in P, release lock on P 4: Update pointers such that pages link like so: A -> N -> D 5: Release lock on pages B and C Regards, Madhav
On Fri, Feb 27, 2026 at 2:33 AM Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > On Tue, Aug 26, 2025 at 2:11 PM Kirk Wolak <wolakk@gmail.com> wrote: > > I do have a question, one of the IDEAS we discussed was to ADD a new page that combined the 2 pages. > > Would the flow then be as follows? Please correct me if I'm wrong: > Start: Parent page P, with adjacent child pages A -> B -> C -> D. > Pages B and C are sparse enough and are about to be merged. > 1: Acquire lock on pages B and C > 2: Create a new page N, which copies the tuples in pages B and C > 3: Acquire lock on parent page P, update the separator keys in P, > release lock on P > 4: Update pointers such that pages link like so: A -> N -> D > 5: Release lock on pages B and C > > Regards, > > Madhav On a related note, I noticed the same topic on the 2026 projects list in the Google Summer of Code page. It mentions that a prototype extension (pg_btree_compact) has been developed. How do I access the same? Thanks in advance! Madhav
> On 27 Feb 2026, at 14:54, Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > > On a related note, I noticed the same topic on the 2026 projects list > in the Google Summer of Code page. It mentions that a prototype > extension (pg_btree_compact) has been developed. How do I access the > same? Hi Madhav! It's available here [0], it's only a prototype. But the approach with AccessExclusiveLock is not practically useful. Just REINDEX INDEX CONCURRENTLY will do better in most cases. We have to develop locking and pining protocols that: 1. Allow both Forward and Backward scans 2. Have indistinguishable locking and pining effect on index Perhaps, I agree with Pavlo that it seems overly rigorous for GSoC. It's more like math research than code typing. Thanks for your interest! Best regards, Andrey Borodin. [0] https://github.com/x4m/postgres_g/commit/a5eea2d
On Thu, 26 Feb 2026 at 22:03, Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > On Tue, Aug 26, 2025 at 2:11 PM Kirk Wolak <wolakk@gmail.com> wrote: > > I do have a question, one of the IDEAS we discussed was to ADD a new page that combined the 2 pages. > > Would the flow then be as follows? Please correct me if I'm wrong: > Start: Parent page P, with adjacent child pages A -> B -> C -> D. > Pages B and C are sparse enough and are about to be merged. > 1: Acquire lock on pages B and C > 2: Create a new page N, which copies the tuples in pages B and C > 3: Acquire lock on parent page P, update the separator keys in P, > release lock on P > 4: Update pointers such that pages link like so: A -> N -> D > 5: Release lock on pages B and C That is one part of the picture (the merging part), but it's missing a lot of details: - How do concurrent workloads (index scans, backwards index scans, index insertions) detect and recover from concurrent merges when they step through pages? - Do you have a theory or proof of correctness for the above? - Can this scheme be implemented without adding significant overhead to current workloads that don't benefit significantly from the new feature? One example for a problem with the given flow: where (and how) do you update the sibling pointers in pages A (to N from B) and D (to N from C)? You haven't explicitly locked pages A and D by the time you get to step 4, even though locking pages is critical to guarantee correct and safe operations. Simply locking them in step 4 isn't sufficient, as another process may have locked page A in preparation for a split, which would then be waiting to get a lock on page B. If you've already locked page B before locking page A, you'll have a deadlock. Additionally, how does this work when you find out in step 3 that your pages B and C each are linked to from a different parent page? You'd have to update both parent pages, but that would also require locking more than just the one parent page per level that currently gets locked during page deletion. Kind regards, Matthias van de Meent Databricks (https://www.databricks.com)
On Fri, Feb 27, 2026 at 4:28 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > > Hi Madhav! > > It's available here [0], it's only a prototype. > But the approach with AccessExclusiveLock is not practically useful. > Just REINDEX INDEX CONCURRENTLY will do better in most cases. Thank you for sharing this, Andrey! > Perhaps, I agree with Pavlo that it seems overly rigorous for GSoC. > It's more like math research than code typing. That is a fair point. I do understand that this is going to be more mathematical, which is why I'd love to help make progress if mentorship is possible.
> On 28 Feb 2026, at 13:42, Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > if mentorship is possible. I will not be an official mentor this year, however I'd be happy to help if the project will happen. Especially with constructing a test against any implementation of page merge locking protocol. That proved to be most fun part... Best regards, Andrey Borodin.
On Fri, Feb 27, 2026 at 5:37 PM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > That is one part of the picture (the merging part), but it's missing a > lot of details: > - How do concurrent workloads (index scans, backwards index scans, > index insertions) detect and recover from concurrent merges when they > step through pages? > - Do you have a theory or proof of correctness for the above? > - Can this scheme be implemented without adding significant overhead > to current workloads that don't benefit significantly from the new > feature? > > One example for a problem with the given flow: where (and how) do you > update the sibling pointers in pages A (to N from B) and D (to N from > C)? > You haven't explicitly locked pages A and D by the time you get to > step 4, even though locking pages is critical to guarantee correct and > safe operations. Simply locking them in step 4 isn't sufficient, as > another process may have locked page A in preparation for a split, > which would then be waiting to get a lock on page B. If you've already > locked page B before locking page A, you'll have a deadlock. > > Additionally, how does this work when you find out in step 3 that your > pages B and C each are linked to from a different parent page? You'd > have to update both parent pages, but that would also require locking > more than just the one parent page per level that currently gets > locked during page deletion. Ohh I see, I haven't included the dynamics of such flows too. I might have to think this through. Thank you for pointing it out! Just to understand what we can control (and to help internalize the constraints so that I can think through a strategy): to handle transient merge states, are we intending to update core? Or is the bloat reduction functionality intended to be abstracted into an extension? I'm coming up with ways that might potentially update index amcheck and the like. Thanks in advance! Madhav
On Sun, Mar 1, 2026 at 4:15 PM Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > On Fri, Feb 27, 2026 at 5:37 PM Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > That is one part of the picture (the merging part), but it's missing a > > lot of details: > > - How do concurrent workloads (index scans, backwards index scans, > > index insertions) detect and recover from concurrent merges when they > > step through pages? > > - Do you have a theory or proof of correctness for the above? > > - Can this scheme be implemented without adding significant overhead > > to current workloads that don't benefit significantly from the new > > feature? > > > > One example for a problem with the given flow: where (and how) do you > > update the sibling pointers in pages A (to N from B) and D (to N from > > C)? > > You haven't explicitly locked pages A and D by the time you get to > > step 4, even though locking pages is critical to guarantee correct and > > safe operations. Simply locking them in step 4 isn't sufficient, as > > another process may have locked page A in preparation for a split, > > which would then be waiting to get a lock on page B. If you've already > > locked page B before locking page A, you'll have a deadlock. > > > > Additionally, how does this work when you find out in step 3 that your > > pages B and C each are linked to from a different parent page? You'd > > have to update both parent pages, but that would also require locking > > more than just the one parent page per level that currently gets > > locked during page deletion. > > Ohh I see, I haven't included the dynamics of such flows too. I might > have to think this through. > Thank you for pointing it out! > > Just to understand what we can control (and to help internalize the > constraints so that I can think through a strategy): to handle > transient merge states, are we intending to update core? Or is the > bloat reduction functionality intended to be abstracted into an > extension? > > I'm coming up with ways that might potentially update index amcheck > and the like. > > Thanks in advance! > > Madhav Some parts of the merge flow that I am coming up with are as follows (assuming tuples from index page B are migrated rightwards into C): 1. Leaving B's tuples as it is even after merge, to remove the possible risk of scans "skipping over" tuples. Essentially, the tuples then would be "copied" into C. 2. Marking pages B and C with flags similar to INCOMPLETE_SPLIT (say, MERGE_SRC and MERGE_DEST respectively) before the actual merge process, then marking the pages with another flag upon completion (MERGE_COMPLETE) so that other processes can handle transient merge states. 3. For example, scans that reach page B post-merge (MERGE_SRC + MERGE_COMPLETE) would be made to skip to the page to its right. 4. Updating VACUUM to handle post-merge cleanup (to remove pages such as B). Note: The underlying assumption is that B and C both are children of a single parent page P. For a start I'm picturing this flow only for sibling nodes, not for cousin nodes (B and C having different parent nodes). Would the above approach be alright? These are not exhaustive steps, I'm only raising these lines of thought so that I can fast-fail them (if there are any issues). I'd be happy to provide a doc of the exact flow I'm picturing (how to ensure TIDs are read exactly-once, how the merge process would hold up with other concurrent processes, etc), incase my thoughts seem promising. Thanks in advance! Madhav
On Fri, Mar 6, 2026 at 2:15 AM Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > Some parts of the merge flow that I am coming up with are as follows > (assuming tuples from index page B are migrated rightwards into C): > > 1. Leaving B's tuples as it is even after merge, to remove the > possible risk of scans "skipping over" tuples. Essentially, the tuples > then would be "copied" into C. > 2. Marking pages B and C with flags similar to INCOMPLETE_SPLIT (say, > MERGE_SRC and MERGE_DEST respectively) before the actual merge > process, then marking the pages with another flag upon completion > (MERGE_COMPLETE) so that other processes can handle transient merge > states. > 3. For example, scans that reach page B post-merge (MERGE_SRC + > MERGE_COMPLETE) would be made to skip to the page to its right. > 4. Updating VACUUM to handle post-merge cleanup (to remove pages such as B). > I was going through the source code to understand whether the aforementioned direction of changes would be reasonable. I was observing `BTPageOpaqueData.btpo_flags` [0] which is a uint16, but only 9 bits are used. Would using a couple bits of the same for this purpose be reasonable? Or are they being reserved for future functionality? Thanks! Madhav [0] https://github.com/postgres/postgres/blob/03facc1211b0ff1550f41bcd4da09329080c30f9/src/include/access/nbtree.h#L63
On Tue, 10 Mar 2026 at 06:09, Madhav Madhusoodanan <madhavmadhusoodanan@gmail.com> wrote: > > On Fri, Mar 6, 2026 at 2:15 AM Madhav Madhusoodanan > <madhavmadhusoodanan@gmail.com> wrote: > > > > Some parts of the merge flow that I am coming up with are as follows > > (assuming tuples from index page B are migrated rightwards into C): > > > > 1. Leaving B's tuples as it is even after merge, to remove the > > possible risk of scans "skipping over" tuples. Essentially, the tuples > > then would be "copied" into C. > > 2. Marking pages B and C with flags similar to INCOMPLETE_SPLIT (say, > > MERGE_SRC and MERGE_DEST respectively) before the actual merge > > process, then marking the pages with another flag upon completion > > (MERGE_COMPLETE) so that other processes can handle transient merge > > states. > > 3. For example, scans that reach page B post-merge (MERGE_SRC + > > MERGE_COMPLETE) would be made to skip to the page to its right. > > 4. Updating VACUUM to handle post-merge cleanup (to remove pages such as B). > > > > I was going through the source code to understand whether the > aforementioned direction of changes would be reasonable. > > I was observing `BTPageOpaqueData.btpo_flags` [0] which is a uint16, > but only 9 bits are used. > > Would using a couple bits of the same for this purpose be reasonable? > Or are they being reserved for future functionality? They're exclusively for btree code's use; extensions (*) must not add to (or change the meaning of) those bits, lest they create a forward incompatibility with core PostgreSQL btree code in newer major versions; it would cause corrupted binary upgraded databases. But patches against core btree code can use those bits, because forward compatibility is less of an issue there - we don't really support binary upgrades manually patched systems, especially if they have incompatible on-disk data. (*): I'm skeptical about whether you could make btree scans handle concurrently merged pages, when that merging is implemented as extension and the btree code doesn't know about merges. Kind regards, Matthias van de Meent Databricks (https://www.databricks.com)
On Tue, Mar 10, 2026 at 5:23 PM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > They're exclusively for btree code's use; extensions (*) must not add > to (or change the meaning of) those bits, lest they create a forward > incompatibility with core PostgreSQL btree code in newer major > versions; it would cause corrupted binary upgraded databases. > But patches against core btree code can use those bits, because > forward compatibility is less of an issue there - we don't really > support binary upgrades manually patched systems, especially if they > have incompatible on-disk data. Noted, I'm looking at it from the core btree code side of things. I'm unable to see a way where scans or VACUUM calls can recognise transient merge states if we implement merging as an extension. Madhav