Обсуждение: BUG #19006: Assert(BufferIsPinned) in BufferGetBlockNumber() is triggered for forwarded buffer
BUG #19006: Assert(BufferIsPinned) in BufferGetBlockNumber() is triggered for forwarded buffer
От
PG Bug reporting form
Дата:
The following bug has been logged on the website:
Bug reference: 19006
Logged by: Alexander Lakhin
Email address: exclusion@gmail.com
PostgreSQL version: 18beta2
Operating system: Ubuntu 24.04
Description:
The following script (based on the regress scripts):
CREATE TABLE public.tenk1 (
unique1 integer,
unique2 integer,
two integer,
four integer,
ten integer,
twenty integer,
hundred integer,
thousand integer,
twothousand integer,
fivethous integer,
tenthous integer,
odd integer,
even integer,
stringu1 name,
stringu2 name,
string4 name
);
COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
DELETE FROM tenk1;
COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
SELECT COUNT(*) FROM tenk1 t1 LEFT JOIN
LATERAL (SELECT t1.twenty, t2.two FROM tenk1 t2) s
ON t1.two = s.two
WHERE s.twenty < 0;
with
shared_buffers = 16MB
triggers:
TRAP: failed Assert("BufferIsPinned(buffer)"), File: "bufmgr.c", Line: 4233,
PID: 2785555
Core was generated by `postgres: law regression [local] SELECT
'.
Program terminated with signal SIGABRT, Aborted.
...
#0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=<optimized
out>) at ./nptl/pthread_kill.c:44
#1 __pthread_kill_internal (signo=6, threadid=<optimized out>) at
./nptl/pthread_kill.c:78
#2 __GI___pthread_kill (threadid=<optimized out>, signo=signo@entry=6) at
./nptl/pthread_kill.c:89
#3 0x000075efce04527e in __GI_raise (sig=sig@entry=6) at
../sysdeps/posix/raise.c:26
#4 0x000075efce0288ff in __GI_abort () at ./stdlib/abort.c:79
#5 0x00006419a43d5e3f in ExceptionalCondition
(conditionName=conditionName@entry=0x6419a445bb56 "BufferIsPinned(buffer)",
fileName=fileName@entry=0x6419a445b9b7 "bufmgr.c",
lineNumber=lineNumber@entry=4233) at assert.c:66
#6 0x00006419a423f028 in BufferGetBlockNumber (buffer=<optimized out>) at
bufmgr.c:4233
#7 0x00006419a42445c5 in StartReadBuffersImpl (allow_forwarding=true,
flags=0, nblocks=0x7fff9765ee74, blockNum=710, buffers=0x6419bc3d127c,
operation=0x6419bc3d1428) at bufmgr.c:1292
#8 StartReadBuffers (operation=0x6419bc3d1428,
buffers=buffers@entry=0x6419bc3d127c, blockNum=710,
nblocks=nblocks@entry=0x7fff9765ee74, flags=flags@entry=0) at bufmgr.c:1500
#9 0x00006419a423afc4 in read_stream_start_pending_read
(stream=stream@entry=0x6419bc3d1218) at read_stream.c:335
#10 0x00006419a423b3df in read_stream_look_ahead
(stream=stream@entry=0x6419bc3d1218) at read_stream.c:493
#11 0x00006419a423b7b3 in read_stream_next_buffer (stream=0x6419bc3d1218,
per_buffer_data=per_buffer_data@entry=0x0) at read_stream.c:971
#12 0x00006419a3efaede in heap_fetch_next_buffer (dir=<optimized out>,
scan=0x6419bc3d0cf8) at heapam.c:675
#13 heapgettup_pagemode (scan=scan@entry=0x6419bc3d0cf8, dir=<optimized
out>, nkeys=<optimized out>, key=<optimized out>) at heapam.c:1037
#14 0x00006419a3efb5d2 in heap_getnextslot (sscan=0x6419bc3d0cf8,
direction=<optimized out>, slot=0x6419bc3c11a8) at heapam.c:1391
#15 0x00006419a40d1503 in table_scan_getnextslot (slot=0x6419bc3c11a8,
direction=ForwardScanDirection, sscan=<optimized out>) at
../../../src/include/access/tableam.h:1031
#16 SeqNext (node=node@entry=0x6419bc3c0f88) at nodeSeqscan.c:81
#17 0x00006419a40d197f in ExecScanFetch (recheckMtd=0x6419a40d1490
<SeqRecheck>, accessMtd=0x6419a40d14a0 <SeqNext>, epqstate=0x0,
node=<optimized out>) at ../../../src/include/executor/execScan.h:126
#18 ExecScanExtended (projInfo=0x0, qual=0x6419bc38a650, epqstate=0x0,
recheckMtd=0x6419a40d1490 <SeqRecheck>, accessMtd=0x6419a40d14a0 <SeqNext>,
node=0x6419bc3c0f88) at ../../../src/include/executor/execScan.h:187
#19 ExecSeqScanWithQual (pstate=0x6419bc3c0f88) at nodeSeqscan.c:138
#20 0x00006419a40cf97b in ExecProcNode (node=0x6419bc3c0f88) at
../../../src/include/executor/executor.h:313
#21 ExecNestLoop (pstate=<optimized out>) at nodeNestloop.c:159
...
Reproduced starting from 12ce89fd0.
Re: BUG #19006: Assert(BufferIsPinned) in BufferGetBlockNumber() is triggered for forwarded buffer
От
Michael Paquier
Дата:
On Sun, Aug 03, 2025 at 12:00:02PM +0000, PG Bug reporting form wrote: > Reproduced starting from 12ce89fd0. Added an open item to track this one. Thanks for the report. -- Michael
Вложения
Hi,
On Sun, Aug 3, 2025 at 8:58 PM PG Bug reporting form
<noreply@postgresql.org> wrote:
>
> The following bug has been logged on the website:
>
> Bug reference: 19006
> Logged by: Alexander Lakhin
> Email address: exclusion@gmail.com
> PostgreSQL version: 18beta2
> Operating system: Ubuntu 24.04
> Description:
>
> The following script (based on the regress scripts):
> CREATE TABLE public.tenk1 (
> unique1 integer,
> unique2 integer,
> two integer,
> four integer,
> ten integer,
> twenty integer,
> hundred integer,
> thousand integer,
> twothousand integer,
> fivethous integer,
> tenthous integer,
> odd integer,
> even integer,
> stringu1 name,
> stringu2 name,
> string4 name
> );
>
> COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
> COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
> DELETE FROM tenk1;
> COPY tenk1 FROM '.../src/test/regress/data/tenk.data';
>
> SELECT COUNT(*) FROM tenk1 t1 LEFT JOIN
> LATERAL (SELECT t1.twenty, t2.two FROM tenk1 t2) s
> ON t1.two = s.two
> WHERE s.twenty < 0;
>
> with
> shared_buffers = 16MB
> triggers:
> TRAP: failed Assert("BufferIsPinned(buffer)"), File: "bufmgr.c", Line: 4233,
> PID: 2785555
>
> Core was generated by `postgres: law regression [local] SELECT
> '.
> Program terminated with signal SIGABRT, Aborted.
> ...
> #0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=<optimized
> out>) at ./nptl/pthread_kill.c:44
> #1 __pthread_kill_internal (signo=6, threadid=<optimized out>) at
> ./nptl/pthread_kill.c:78
> #2 __GI___pthread_kill (threadid=<optimized out>, signo=signo@entry=6) at
> ./nptl/pthread_kill.c:89
> #3 0x000075efce04527e in __GI_raise (sig=sig@entry=6) at
> ../sysdeps/posix/raise.c:26
> #4 0x000075efce0288ff in __GI_abort () at ./stdlib/abort.c:79
> #5 0x00006419a43d5e3f in ExceptionalCondition
> (conditionName=conditionName@entry=0x6419a445bb56 "BufferIsPinned(buffer)",
> fileName=fileName@entry=0x6419a445b9b7 "bufmgr.c",
> lineNumber=lineNumber@entry=4233) at assert.c:66
> #6 0x00006419a423f028 in BufferGetBlockNumber (buffer=<optimized out>) at
> bufmgr.c:4233
> #7 0x00006419a42445c5 in StartReadBuffersImpl (allow_forwarding=true,
> flags=0, nblocks=0x7fff9765ee74, blockNum=710, buffers=0x6419bc3d127c,
> operation=0x6419bc3d1428) at bufmgr.c:1292
> #8 StartReadBuffers (operation=0x6419bc3d1428,
> buffers=buffers@entry=0x6419bc3d127c, blockNum=710,
> nblocks=nblocks@entry=0x7fff9765ee74, flags=flags@entry=0) at bufmgr.c:1500
> #9 0x00006419a423afc4 in read_stream_start_pending_read
> (stream=stream@entry=0x6419bc3d1218) at read_stream.c:335
> #10 0x00006419a423b3df in read_stream_look_ahead
> (stream=stream@entry=0x6419bc3d1218) at read_stream.c:493
> #11 0x00006419a423b7b3 in read_stream_next_buffer (stream=0x6419bc3d1218,
> per_buffer_data=per_buffer_data@entry=0x0) at read_stream.c:971
> #12 0x00006419a3efaede in heap_fetch_next_buffer (dir=<optimized out>,
> scan=0x6419bc3d0cf8) at heapam.c:675
> #13 heapgettup_pagemode (scan=scan@entry=0x6419bc3d0cf8, dir=<optimized
> out>, nkeys=<optimized out>, key=<optimized out>) at heapam.c:1037
> #14 0x00006419a3efb5d2 in heap_getnextslot (sscan=0x6419bc3d0cf8,
> direction=<optimized out>, slot=0x6419bc3c11a8) at heapam.c:1391
> #15 0x00006419a40d1503 in table_scan_getnextslot (slot=0x6419bc3c11a8,
> direction=ForwardScanDirection, sscan=<optimized out>) at
> ../../../src/include/access/tableam.h:1031
> #16 SeqNext (node=node@entry=0x6419bc3c0f88) at nodeSeqscan.c:81
> #17 0x00006419a40d197f in ExecScanFetch (recheckMtd=0x6419a40d1490
> <SeqRecheck>, accessMtd=0x6419a40d14a0 <SeqNext>, epqstate=0x0,
> node=<optimized out>) at ../../../src/include/executor/execScan.h:126
> #18 ExecScanExtended (projInfo=0x0, qual=0x6419bc38a650, epqstate=0x0,
> recheckMtd=0x6419a40d1490 <SeqRecheck>, accessMtd=0x6419a40d14a0 <SeqNext>,
> node=0x6419bc3c0f88) at ../../../src/include/executor/execScan.h:187
> #19 ExecSeqScanWithQual (pstate=0x6419bc3c0f88) at nodeSeqscan.c:138
> #20 0x00006419a40cf97b in ExecProcNode (node=0x6419bc3c0f88) at
> ../../../src/include/executor/executor.h:313
> #21 ExecNestLoop (pstate=<optimized out>) at nodeNestloop.c:159
> ...
>
> Reproduced starting from 12ce89fd0.
>
Thanks for reporting this. I can reproduce this issue reliably when
shared_buffers is set to 16 MB; raising the value allows the query to
complete normally. However, I don't have the expertise to investigate
and fix it. Perhaps we could CC Thomas on this thread to see whether
he might have time to look into it.
Best,
Xuneng
Thanks. Repro'd here. Looking...
Here's my proposed fix. Great reproducer, Alexander, thanks!
Вложения
Thomas Munro <thomas.munro@gmail.com> writes:
> Here's my proposed fix. Great reproducer, Alexander, thanks!
I've not looked at the issue actually being fixed, but a drive-by
comment: these loops
+ for (int i = 0; i < stream->forwarded_buffers; ++i)
+ Assert(BufferGetBlockNumber(stream->buffers[stream->next_buffer_index + i]) ==
+ stream->pending_read_blocknum + i);
should be wrapped in "#ifdef USE_ASSERT_CHECKING". Maybe the
compiler is smart enough to throw away the useless looping logic
in a production build, or maybe it isn't.
regards, tom lane
Re: BUG #19006: Assert(BufferIsPinned) in BufferGetBlockNumber() is triggered for forwarded buffer
От
Michael Paquier
Дата:
On Tue, Aug 05, 2025 at 12:43:06AM -0400, Tom Lane wrote: > I've not looked at the issue actually being fixed, but a drive-by > comment: these loops > > + for (int i = 0; i < stream->forwarded_buffers; ++i) > + Assert(BufferGetBlockNumber(stream->buffers[stream->next_buffer_index + i]) == > + stream->pending_read_blocknum + i); > > should be wrapped in "#ifdef USE_ASSERT_CHECKING". Maybe the > compiler is smart enough to throw away the useless looping logic > in a production build, or maybe it isn't. I'd bet it is usually not that smart.. Embedding these in an extra #ifdef is a sound defense IMO. -- Michael
Вложения
Hi, On Wed, Aug 6, 2025 at 4:40 PM Michael Paquier <michael@paquier.xyz> wrote: > > On Tue, Aug 05, 2025 at 12:43:06AM -0400, Tom Lane wrote: > > I've not looked at the issue actually being fixed, but a drive-by > > comment: these loops > > > > + for (int i = 0; i < stream->forwarded_buffers; ++i) > > + Assert(BufferGetBlockNumber(stream->buffers[stream->next_buffer_index + i]) == > > + stream->pending_read_blocknum + i); > > > > should be wrapped in "#ifdef USE_ASSERT_CHECKING". Maybe the > > compiler is smart enough to throw away the useless looping logic > > in a production build, or maybe it isn't. > > I'd bet it is usually not that smart.. Embedding these in an extra > #ifdef is a sound defense IMO. > -- > Michael +1 Best, Xuneng
Hi,
On Tue, Aug 5, 2025 at 12:29 PM Thomas Munro <thomas.munro@gmail.com> wrote:
>
> Here's my proposed fix. Great reproducer, Alexander, thanks!
I tested the fix, it works well now. I tried to review the code logic
but found it hard to figure out this line on my own due to the
unfamiliarity with this module currently:
stream->buffers[stream->queue_size + stream->oldest_buffer_index] =
InvalidBuffer;
Could you please elaborate on it a little bit more? Thanks.
Best,
Xuneng
On Fri, Aug 8, 2025 at 3:09 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> Could you please elaborate on it a little bit more? Thanks.
Sure. It's a bit complicated and involves many moving parts, so let
me try to summarise the read_stream.c fast path, forwarded buffers and
the motivation and complexities, and then finally the bug. This email
turned out longer than I feared so sorry for the wall of text, but it
seemed useful to work through it with illustrations to help more
people understand this stuff and contribute improvements, and also
recheck my assumptions at the same time.
New version with #ifdefs. I believe that qualified for trivial dead
code elimination in optimized builds but yeah it's still better this
way, thanks all. This is the version I plan to push if there are no
further comments.
Before digging further, a brief recap of read_stream.c and its fast path:
The goal is to be able to perform the equivalent of a stream of
ReadBuffer() while minimising system calls, IOPS and I/O stalls by
looking a variable distance ahead in the block number stream,
combining consecutive blocks into a wider read operation according to
your io_combine_limit setting, and running some number of I/Os
asynchronously up to your {effective,maintenance}_io_concurrency
setting. It starts off looking just one block into the future, but
adjusts it up and down according to the history of demand and cache
misses, as a prediction of future I/O needs.
If the blocks are all cached, the lookahead distance is minimised and
it becomes very similar to a plain loop of ReadBuffer() calls, since
I/O and thus I/O combining and concurrency aren't predicted to be
useful. It has a special fast path mode to squeeze a bit more
performance out of the extreme case of all-cached blocks that don't
use the facility for streaming optional data along with each block.
It uses specialised code in read_stream.c and bufmgr.c to minimise
bookkeeping, branching and data cache misses through queue maintenance
and movement.
The bug involves multiple fast path transitions and short reads, so
next let me describe the bufmgr.c's interface for combined and
asynchronous I/O and the need for short reads:
read_stream.c works by issuing overlapping pairs of calls to
StartReadBuffers() and WaitReadBuffers(), with stream->ios holding the
queue of IOs with a pending call to WaitReadBuffers(). The interface
of StartReadBuffers() is more complex than ReadBuffer() because it has
to cope with a lot of edge cases. It takes a relation and fork, a
block number, an input/output nblocks count, and an input/output array
of buffers. It returns true if you need to call WaitReadBuffers(),
meaning the operation wasn't completed immediately from cache. The
reason nblocks is input/output is that the operation must sometimes be
"split", also known as a short read.
It splits IOs partly because we want StartReadBuffers() to start
exactly zero or one IOs, and the caller would lose control of the I/O
depth if StartReadBuffers() were capable of starting multiple IOs. We
also want to avoid some avoidable waits. Here are some reasons for
splits:
1. The leading block is BM_VALID, so we choose to give it to you
immediately and not look further (we could look further and return
more than one consecutive BM_VALID block at a time, but this isn't
implemented)
2. An internal block is BM_VALID, so any non-BM_VALID blocks either
side of it can't be combined into one operation
3. An internal block is BM_IO_IN_PROGRESS, meaning that another
backend is reading or writing it
4. An internal or final block is in a different 1GB segment file
(Reason 3 will usually turn in to reason 2 eventually, or the other
backend's IO attempt might in theory fail and then it'll be this
backend's turn to try, and there are some slightly complicated rules
about whether we have to wait for that or split the IO here, for
deadlock avoidance and progress guarantees.)
Forwarded buffers are an artefact of the short reads. Let me
summarize what changed in v18:
In v17, we didn't have real AIO yet, just I/O combining and pseudo-AIO
with POSIX_FADV_WILLNEED, so StartReadBuffers() pinned buffers and
possibly shortened the read for reasons #1 and #2. This meant that it
pinned at most one extra buffer that terminated the operation, and it
used a bit of a kludge do deal with that: for reason #1 you get the
buffer, and for reason #2, it pretended that block was part of the IO,
it just didn't include it in the actual read operation. This was
simple, but not scalable to later work. Then WaitReadBuffers() tried
to acquire the BM_IO_IN_PROGRESS flags for all the blocks, and "hid"
all four split reasons by looping: it skipped buffers that had become
BM_VALID in the meantime (someone else read them) and waited for
BM_IO_IN_PROGRESS to become BM_VALID (or not if another backend's read
failed and this backend could now try), and then md.c internally
looped to handle reason #4. WaitReadBuffers() *had* to acquire
BM_IO_IN_PROGRESS in this second phase when I/O was really synchronous
and StartReadBuffers() was just feeding advice to the kernel: if we
acquired it sooner then other backends might wait for this backend to
reach WaitReadBuffers(), which could deadlock, and we had no
infrastructure to deal with that. In other words, I/Os were already
split for all the same reasons, but #3 and #4 were handled at the
later WaitReadBuffers() stage and in secret.
In v18, the handling of reasons #3 and #4 moved into
StartReadBuffers(). By definition we have to try to acquire
BM_IO_IN_PROGRESS at that earlier stage now, because the IO really is
in progress, and the deadlock risk is gone, because any backend can
drive an IO started by any other backend to completion using the
associated PgAioHandle.
This increased the pin management problem: StartReadBuffers() can
acquire a lot of pins, up to 128 (io_combine_limit=1MB) and then
discover a reason to split the IO. So what do do with all those pins?
A simple answer would be: unpin all the buffers after the split
point.
We didn't want to do that, because read_stream.c is almost certainly
going to call StartReadBuffers() for the rest of the blocks (and
possibly more that it now wants after those ones). So we wanted a way
to transfer them from one StartReadBuffer() call to the following one,
avoiding an unpin-and-repin dance. This was quite a difficult API
design question, and this isn't the only design we considered, but we
settled on making the buffer array that you give to StartReadBuffers()
an input/output array for transporting these extra pinned buffers
between calls, while in v17 it was a output-only array. In v18, you
have to fill it up with InvalidBuffer initially. If it wants to
report that it has pinned buffers but then excluded them from a read
that is now a short read, it writes them into that array, but it
doesn't count them in the *nblocks value that it gives you. The term
I dreamed up for that is "forwarded" buffers. It is the caller's job
to pass them in as input to the next StartReadBuffers() call, or if
for whatever reason it doesn't want to continue, it has to unpin them.
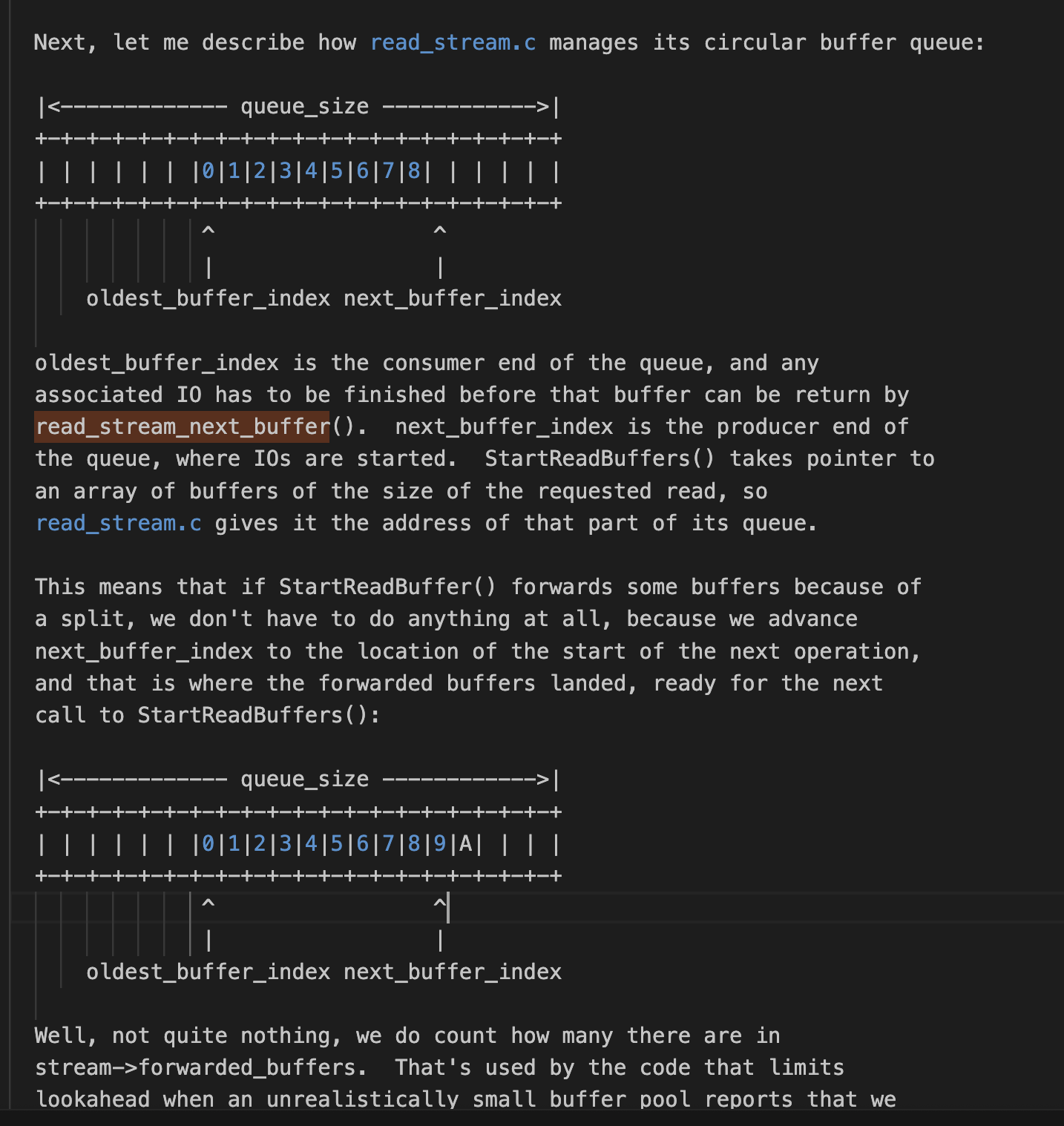
Next, let me describe how read_stream.c manages its circular buffer queue:
|<------------- queue_size ------------>|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| | | | | | |0|1|2|3|4|5|6|7|8| | | | | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^ ^
| |
oldest_buffer_index next_buffer_index
oldest_buffer_index is the consumer end of the queue, and any
associated IO has to be finished before that buffer can be return by
read_stream_next_buffer(). next_buffer_index is the producer end of
the queue, where IOs are started. StartReadBuffers() takes pointer to
an array of buffers of the size of the requested read, so
read_stream.c gives it the address of that part of its queue.
This means that if StartReadBuffer() forwards some buffers because of
a split, we don't have to do anything at all, because we advance
next_buffer_index to the location of the start of the next operation,
and that is where the forwarded buffers landed, ready for the next
call to StartReadBuffers():
|<------------- queue_size ------------>|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| | | | | | |0|1|2|3|4|5|6|7|8|9|A| | | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^ ^
| |
oldest_buffer_index next_buffer_index
Well, not quite nothing, we do count how many there are in
stream->forwarded_buffers. That's used by the code that limits
lookahead when an unrealistically small buffer pool reports that we
hold too many pins already. Those are pins that this backend holds,
so they are not counted as extra pins that StartReadBuffer() would
acquire.
That's a nice way for successive StartReadBuffers() calls to
communicate, without having to copy them to and from some other
storage between calls. In exchange for that convenience, we also need
to fill the entries with InvalidBuffer initially so they don't look
like forwarded buffers. We don't want to do that up front: the queue
might be up to {effective,maintenance}_io_concurrency *
io_combine_limit in size (highest possible value: 128,000), and if
this is a small or perfectly cached scan then we will never use most
of the queue. So, we:
* initialize them on the first go around the queue only, tracked in
stream->initialized_buffers
* invalidate entries consumed by read_stream_next_buffer() in
preparation for reuse
The fast path repeatedly uses the same queue entry instead of
advancing oldest_buffer_index and next_buffer_index, so it doesn't
need to invalidate queue entries, saving an instruction and reducing
cache line pollution. Now I am getting pretty close to explaining the
bug, but there is one final complication...
Sometimes a StartReadBuffers() call spans past the physical end of the
queue. It needs to wrap around. We could have chosen to give
StartReadBuffers() an iov, iov_cnt style interface like preadv() so
that we could use iov_cnt = 2 and locate some buffers at the physical
end of the queue and the rest at the physical start of the queue, but
StartReadBuffers()'s interface was complicated enough already. The
solution I went with was to allocate extra array entries after the
queue to allow for the maximum possible overflow if beginning a read
into a buffer located in the final queue entry. The overflowing
buffers are immediately copied to the physical start of the queue,
ready for consumption in regular circular queue position. Note the
twin positions for buffer 2 in this example:
|<------------- queue_size ------------>|<--- overflow_size --->|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|2|3|4|5|6|7| | | | | | | | | | | | |0|1|2|3|4|5|6|7| | | | | | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^ ^
| |
next_buffer_index oldest_buffer_index
(Perhaps it would be clearer if overflow_size were a member variable
in ReadStream instead of being open coded as io_combine_limit - 1 in a
few places.)
The non-fast-path invalidates the queue entry holding the buffer it is
returning to the caller of read_stream_next_buffer(), as required to
mark it as "not a forwarded buffer" when reused next time we go around
the circular queue. If it's in the low physical entries that also
might have a twin in the overflow zone, it must also be invalidated.
The reason we keep both copies for a bit longer is that we don't know
whether the following StartReadBuffers() will also be split, so we
don't know whether it will also overflow, so we allow for any number
of following StartReadBuffers() calls to overflow too OR move to the
physical start of the queue.
Now I can finally explain the bug :-)
The fast-path doesn't have to invalidate queue entries, because it
spins on the same queue entry repeatedly as an optimisation.
Unfortunately I forgot to consider that there might be a copy of it in
the overflow zone. If there is a multi-block StartReadBuffers() that
spans into the overflow zone but is split, a continuing
StartReadBuffers(), and then all the requirements for entering fast
path mode are met, the fast path begins to spin on one buffer entry
repeatedly near the physical start of the queue, and it initially
holds a buffer that was copied from the overflow zone. Nothing goes
wrong yet, but then we leave fast path mode because we need to do I/O,
and begin to cycle around the queue again in the regular non-fast path
code. Eventually we have another StartReadBuffers() call that spans
into the overflow zone, and bufmgr.c sees a stale buffer number that
we failed to clear out earlier. It thinks it's a forwarded buffer.
Forwarded buffers must be pinned and map to blocknum + i, and it
asserts that to avoid corrupting the buffer pool by overwriting a
random buffer, which failed due to the bug.
I don't want the fast path to do extra steps. The solution I found
was to clear the overflow entry *before* entering the fast path. We
already know which buffer entry the fast path is going to use, and we
also know that there is no I/O split needing to be continued as part
of the conditions of entry to the fast path, so the solution is simply
to clear any corresponding overflow entry, very slightly ahead of the
usual time.
Вложения
On Fri, Aug 8, 2025 at 2:43 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> We don't want to do that up front: the queue
> might be up to {effective,maintenance}_io_concurrency *
> io_combine_limit in size (highest possible value: 128,000), and if
> this is a small or perfectly cached scan then we will never use most
> of the queue.
Correction: it's actually clamped to fit into int16_t arithmetic so it
can't really be 128,000 entries with maximum GUCs, and there are also
a few more entries allocated for overflow and other technical reasons,
but that doesn't change the material point about delaying
initialisation to keep stream initialisation cheap with high GUC
values. I'll probably propose to flip it all to regular int
arithmetic soon anyway as int16_t was only wide enough for v17s GUC
limits that have since been increased, and int16_t turned out to be
all pain and no gain anyway :-)
Hi, Thomas!
Thanks a lot for the exceptionally detailed and insightful
explanation—it’s far more comprehensive than I anticipated. It is
excellent for unpacking the intricate interplay and state transitions
between submodules, which is what makes this topic challenging to
grasp. I’ll need some time to fully digest it, so I’m bookmarking this
email for future reference. I’m also considering turning it into a
blog post after studying—it’s the kind of deep, clear writing that
could benefit more interested audiences.
On Fri, Aug 8, 2025 at 10:44 AM Thomas Munro <thomas.munro@gmail.com> wrote:
>
> On Fri, Aug 8, 2025 at 3:09 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > Could you please elaborate on it a little bit more? Thanks.
>
> Sure. It's a bit complicated and involves many moving parts, so let
> me try to summarise the read_stream.c fast path, forwarded buffers and
> the motivation and complexities, and then finally the bug. This email
> turned out longer than I feared so sorry for the wall of text, but it
> seemed useful to work through it with illustrations to help more
> people understand this stuff and contribute improvements, and also
> recheck my assumptions at the same time.
>
> New version with #ifdefs. I believe that qualified for trivial dead
> code elimination in optimized builds but yeah it's still better this
> way, thanks all. This is the version I plan to push if there are no
> further comments.
>
> Before digging further, a brief recap of read_stream.c and its fast path:
>
> The goal is to be able to perform the equivalent of a stream of
> ReadBuffer() while minimising system calls, IOPS and I/O stalls by
> looking a variable distance ahead in the block number stream,
> combining consecutive blocks into a wider read operation according to
> your io_combine_limit setting, and running some number of I/Os
> asynchronously up to your {effective,maintenance}_io_concurrency
> setting. It starts off looking just one block into the future, but
> adjusts it up and down according to the history of demand and cache
> misses, as a prediction of future I/O needs.
>
> If the blocks are all cached, the lookahead distance is minimised and
> it becomes very similar to a plain loop of ReadBuffer() calls, since
> I/O and thus I/O combining and concurrency aren't predicted to be
> useful. It has a special fast path mode to squeeze a bit more
> performance out of the extreme case of all-cached blocks that don't
> use the facility for streaming optional data along with each block.
> It uses specialised code in read_stream.c and bufmgr.c to minimise
> bookkeeping, branching and data cache misses through queue maintenance
> and movement.
>
> The bug involves multiple fast path transitions and short reads, so
> next let me describe the bufmgr.c's interface for combined and
> asynchronous I/O and the need for short reads:
>
> read_stream.c works by issuing overlapping pairs of calls to
> StartReadBuffers() and WaitReadBuffers(), with stream->ios holding the
> queue of IOs with a pending call to WaitReadBuffers(). The interface
> of StartReadBuffers() is more complex than ReadBuffer() because it has
> to cope with a lot of edge cases. It takes a relation and fork, a
> block number, an input/output nblocks count, and an input/output array
> of buffers. It returns true if you need to call WaitReadBuffers(),
> meaning the operation wasn't completed immediately from cache. The
> reason nblocks is input/output is that the operation must sometimes be
> "split", also known as a short read.
>
> It splits IOs partly because we want StartReadBuffers() to start
> exactly zero or one IOs, and the caller would lose control of the I/O
> depth if StartReadBuffers() were capable of starting multiple IOs. We
> also want to avoid some avoidable waits. Here are some reasons for
> splits:
>
> 1. The leading block is BM_VALID, so we choose to give it to you
> immediately and not look further (we could look further and return
> more than one consecutive BM_VALID block at a time, but this isn't
> implemented)
> 2. An internal block is BM_VALID, so any non-BM_VALID blocks either
> side of it can't be combined into one operation
> 3. An internal block is BM_IO_IN_PROGRESS, meaning that another
> backend is reading or writing it
> 4. An internal or final block is in a different 1GB segment file
>
> (Reason 3 will usually turn in to reason 2 eventually, or the other
> backend's IO attempt might in theory fail and then it'll be this
> backend's turn to try, and there are some slightly complicated rules
> about whether we have to wait for that or split the IO here, for
> deadlock avoidance and progress guarantees.)
>
> Forwarded buffers are an artefact of the short reads. Let me
> summarize what changed in v18:
>
> In v17, we didn't have real AIO yet, just I/O combining and pseudo-AIO
> with POSIX_FADV_WILLNEED, so StartReadBuffers() pinned buffers and
> possibly shortened the read for reasons #1 and #2. This meant that it
> pinned at most one extra buffer that terminated the operation, and it
> used a bit of a kludge do deal with that: for reason #1 you get the
> buffer, and for reason #2, it pretended that block was part of the IO,
> it just didn't include it in the actual read operation. This was
> simple, but not scalable to later work. Then WaitReadBuffers() tried
> to acquire the BM_IO_IN_PROGRESS flags for all the blocks, and "hid"
> all four split reasons by looping: it skipped buffers that had become
> BM_VALID in the meantime (someone else read them) and waited for
> BM_IO_IN_PROGRESS to become BM_VALID (or not if another backend's read
> failed and this backend could now try), and then md.c internally
> looped to handle reason #4. WaitReadBuffers() *had* to acquire
> BM_IO_IN_PROGRESS in this second phase when I/O was really synchronous
> and StartReadBuffers() was just feeding advice to the kernel: if we
> acquired it sooner then other backends might wait for this backend to
> reach WaitReadBuffers(), which could deadlock, and we had no
> infrastructure to deal with that. In other words, I/Os were already
> split for all the same reasons, but #3 and #4 were handled at the
> later WaitReadBuffers() stage and in secret.
>
> In v18, the handling of reasons #3 and #4 moved into
> StartReadBuffers(). By definition we have to try to acquire
> BM_IO_IN_PROGRESS at that earlier stage now, because the IO really is
> in progress, and the deadlock risk is gone, because any backend can
> drive an IO started by any other backend to completion using the
> associated PgAioHandle.
>
> This increased the pin management problem: StartReadBuffers() can
> acquire a lot of pins, up to 128 (io_combine_limit=1MB) and then
> discover a reason to split the IO. So what do do with all those pins?
> A simple answer would be: unpin all the buffers after the split
> point.
>
> We didn't want to do that, because read_stream.c is almost certainly
> going to call StartReadBuffers() for the rest of the blocks (and
> possibly more that it now wants after those ones). So we wanted a way
> to transfer them from one StartReadBuffer() call to the following one,
> avoiding an unpin-and-repin dance. This was quite a difficult API
> design question, and this isn't the only design we considered, but we
> settled on making the buffer array that you give to StartReadBuffers()
> an input/output array for transporting these extra pinned buffers
> between calls, while in v17 it was a output-only array. In v18, you
> have to fill it up with InvalidBuffer initially. If it wants to
> report that it has pinned buffers but then excluded them from a read
> that is now a short read, it writes them into that array, but it
> doesn't count them in the *nblocks value that it gives you. The term
> I dreamed up for that is "forwarded" buffers. It is the caller's job
> to pass them in as input to the next StartReadBuffers() call, or if
> for whatever reason it doesn't want to continue, it has to unpin them.
>
> Next, let me describe how read_stream.c manages its circular buffer queue:
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8| | | | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
> oldest_buffer_index is the consumer end of the queue, and any
> associated IO has to be finished before that buffer can be return by
> read_stream_next_buffer(). next_buffer_index is the producer end of
> the queue, where IOs are started. StartReadBuffers() takes pointer to
> an array of buffers of the size of the requested read, so
> read_stream.c gives it the address of that part of its queue.
>
> This means that if StartReadBuffer() forwards some buffers because of
> a split, we don't have to do anything at all, because we advance
> next_buffer_index to the location of the start of the next operation,
> and that is where the forwarded buffers landed, ready for the next
> call to StartReadBuffers():
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8|9|A| | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
> Well, not quite nothing, we do count how many there are in
> stream->forwarded_buffers. That's used by the code that limits
> lookahead when an unrealistically small buffer pool reports that we
> hold too many pins already. Those are pins that this backend holds,
> so they are not counted as extra pins that StartReadBuffer() would
> acquire.
>
> That's a nice way for successive StartReadBuffers() calls to
> communicate, without having to copy them to and from some other
> storage between calls. In exchange for that convenience, we also need
> to fill the entries with InvalidBuffer initially so they don't look
> like forwarded buffers. We don't want to do that up front: the queue
> might be up to {effective,maintenance}_io_concurrency *
> io_combine_limit in size (highest possible value: 128,000), and if
> this is a small or perfectly cached scan then we will never use most
> of the queue. So, we:
>
> * initialize them on the first go around the queue only, tracked in
> stream->initialized_buffers
> * invalidate entries consumed by read_stream_next_buffer() in
> preparation for reuse
>
> The fast path repeatedly uses the same queue entry instead of
> advancing oldest_buffer_index and next_buffer_index, so it doesn't
> need to invalidate queue entries, saving an instruction and reducing
> cache line pollution. Now I am getting pretty close to explaining the
> bug, but there is one final complication...
>
> Sometimes a StartReadBuffers() call spans past the physical end of the
> queue. It needs to wrap around. We could have chosen to give
> StartReadBuffers() an iov, iov_cnt style interface like preadv() so
> that we could use iov_cnt = 2 and locate some buffers at the physical
> end of the queue and the rest at the physical start of the queue, but
> StartReadBuffers()'s interface was complicated enough already. The
> solution I went with was to allocate extra array entries after the
> queue to allow for the maximum possible overflow if beginning a read
> into a buffer located in the final queue entry. The overflowing
> buffers are immediately copied to the physical start of the queue,
> ready for consumption in regular circular queue position. Note the
> twin positions for buffer 2 in this example:
>
> |<------------- queue_size ------------>|<--- overflow_size --->|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> |2|3|4|5|6|7| | | | | | | | | | | | |0|1|2|3|4|5|6|7| | | | | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> next_buffer_index oldest_buffer_index
>
> (Perhaps it would be clearer if overflow_size were a member variable
> in ReadStream instead of being open coded as io_combine_limit - 1 in a
> few places.)
>
> The non-fast-path invalidates the queue entry holding the buffer it is
> returning to the caller of read_stream_next_buffer(), as required to
> mark it as "not a forwarded buffer" when reused next time we go around
> the circular queue. If it's in the low physical entries that also
> might have a twin in the overflow zone, it must also be invalidated.
> The reason we keep both copies for a bit longer is that we don't know
> whether the following StartReadBuffers() will also be split, so we
> don't know whether it will also overflow, so we allow for any number
> of following StartReadBuffers() calls to overflow too OR move to the
> physical start of the queue.
>
> Now I can finally explain the bug :-)
>
> The fast-path doesn't have to invalidate queue entries, because it
> spins on the same queue entry repeatedly as an optimisation.
> Unfortunately I forgot to consider that there might be a copy of it in
> the overflow zone. If there is a multi-block StartReadBuffers() that
> spans into the overflow zone but is split, a continuing
> StartReadBuffers(), and then all the requirements for entering fast
> path mode are met, the fast path begins to spin on one buffer entry
> repeatedly near the physical start of the queue, and it initially
> holds a buffer that was copied from the overflow zone. Nothing goes
> wrong yet, but then we leave fast path mode because we need to do I/O,
> and begin to cycle around the queue again in the regular non-fast path
> code. Eventually we have another StartReadBuffers() call that spans
> into the overflow zone, and bufmgr.c sees a stale buffer number that
> we failed to clear out earlier. It thinks it's a forwarded buffer.
> Forwarded buffers must be pinned and map to blocknum + i, and it
> asserts that to avoid corrupting the buffer pool by overwriting a
> random buffer, which failed due to the bug.
>
> I don't want the fast path to do extra steps. The solution I found
> was to clear the overflow entry *before* entering the fast path. We
> already know which buffer entry the fast path is going to use, and we
> also know that there is no I/O split needing to be continued as part
> of the conditions of entry to the fast path, so the solution is simply
> to clear any corresponding overflow entry, very slightly ahead of the
> usual time.
Best,
Xuneng
On Fri, Aug 8, 2025 at 4:39 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > Thanks a lot for the exceptionally detailed and insightful > explanation—it’s far more comprehensive than I anticipated. It is > excellent for unpacking the intricate interplay and state transitions > between submodules, which is what makes this topic challenging to > grasp. I’ll need some time to fully digest it, so I’m bookmarking this > email for future reference. I’m also considering turning it into a > blog post after studying—it’s the kind of deep, clear writing that > could benefit more interested audiences. Well, one benefit of trying to describe a complex system from the top is that higher level stupidity can sometimes become clear... I realised that the queue wouldn't even need to be initialised or cleared if StartReadBuffers() had an explicit in/out npinned argument to transmit the count between calls along with the buffers, or examined after each call. This is a draft alternative fix that I am studying that removes quite a lot of lines and fragility, though time is not on my side so I might push the one-liner fix ahead of the upcoming freeze and then see what to do about this.
Вложения
On Sat, Aug 9, 2025 at 3:06 AM Thomas Munro <thomas.munro@gmail.com> wrote: > Well, one benefit of trying to describe a complex system from the top > is that higher level stupidity can sometimes become clear... I > realised that the queue wouldn't even need to be initialised or > cleared if StartReadBuffers() had an explicit in/out npinned argument > to transmit the count between calls along with the buffers, or > examined after each call. This is a draft alternative fix that I am > studying that removes quite a lot of lines and fragility, though time > is not on my side so I might push the one-liner fix ahead of the > upcoming freeze and then see what to do about this. One-liner fix pushed. Here is a new version of the slightly more ambitious fix, for discussion. I need to figure out if there is any measurable performance impact, but from an interface sanity and fragility POV it seems infinitely better like this. I recall being paranoid about function call width, but it still fits in 6 registers. I think perhaps the InvalidBuffer-based API might have seemed a shade more reasonable before I reworked the pin limiting logic, but once I had to start scanning for forwarded buffers after every StartReadBuffers() call, I really should have reconsidered that interface. In other words, maybe a bit of myopic path dependency here...
Вложения
Re: BUG #19006: Assert(BufferIsPinned) in BufferGetBlockNumber() is triggered for forwarded buffer
От
Michael Paquier
Дата:
On Sat, Aug 09, 2025 at 04:03:41PM +1200, Thomas Munro wrote: > Here is a new version of the slightly more ambitious fix, for > discussion. I need to figure out if there is any measurable > performance impact, but from an interface sanity and fragility POV it > seems infinitely better like this. I recall being paranoid about > function call width, but it still fits in 6 registers. I think > perhaps the InvalidBuffer-based API might have seemed a shade more > reasonable before I reworked the pin limiting logic, but once I had to > start scanning for forwarded buffers after every StartReadBuffers() > call, I really should have reconsidered that interface. In other > words, maybe a bit of myopic path dependency here... > > XXX does the change have any measurable performance impact? > XXX is the single-buffer specialization unaffected due to dead > code elimination, as expected? > xxx unused queue entries could potentially be electrified with > wipe_mem/VALGRIND_MAKE_MEM_NOACCESS, though existing bufmgr.c assertions > are very likely to reveal any fencepost bugs already > XXX perhaps we don't need quite so many _npinned <= _nblocks assertions With all these comments and b421223172a2 already applied, are you sure that it is a good idea to play with the v18 branch more than necessary? We are in a baked beta2 state, and it looks like all these could qualify as HEAD-only improvements. Perhaps the open item can be closed then? -- Michael
Вложения
On Sun, Aug 10, 2025 at 12:22 PM Michael Paquier <michael@paquier.xyz> wrote: > With all these comments and b421223172a2 already applied, are you sure > that it is a good idea to play with the v18 branch more than > necessary? We are in a baked beta2 state, and it looks like all these > could qualify as HEAD-only improvements. Yeah, b421223172a2 closes the known bug and thus the critical path item for 18. I am happy to propose this patch as an improvement for master, and I am not aware of remaining bugs in this area in v18. I just wanted to publish the patch with analysis ASAP once the existing read_stream.c/bufmgr.c interaction began to seem egregiously suboptimal to me and I saw what to do about, having addressed the bug with a low risk patch as a first priority. That keeps the options open, even if not very wide given the date: on the off-chance that others think the status quo isn't good enough and perhaps the fragility of the existing API is actually riskier than the bigger change, at least there's a patch on the table to discuss. I have no plans to take any action without such a consensus. > Perhaps the open item can be closed then? Done.
On Sun, Aug 10, 2025 at 02:01:22PM +1200, Thomas Munro wrote: > On Sun, Aug 10, 2025 at 12:22 PM Michael Paquier <michael@paquier.xyz> wrote: >> Perhaps the open item can be closed then? > > Done. This was marked as closed before 18rc1, but it appears to have been committed in time for 18beta3, so I moved it to the "resolved before 18beta3" section. -- nathan
Hi, On Sun, Aug 10, 2025 at 10:01 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Sun, Aug 10, 2025 at 12:22 PM Michael Paquier <michael@paquier.xyz> wrote: > > With all these comments and b421223172a2 already applied, are you sure > > that it is a good idea to play with the v18 branch more than > > necessary? We are in a baked beta2 state, and it looks like all these > > could qualify as HEAD-only improvements. > > Yeah, b421223172a2 closes the known bug and thus the critical path item for 18. > > I am happy to propose this patch as an improvement for master, and I > am not aware of remaining bugs in this area in v18. I just wanted to > publish the patch with analysis ASAP once the existing > read_stream.c/bufmgr.c interaction began to seem egregiously > suboptimal to me and I saw what to do about, having addressed the bug > with a low risk patch as a first priority. That keeps the options > open, even if not very wide given the date: on the off-chance that > others think the status quo isn't good enough and perhaps the > fragility of the existing API is actually riskier than the bigger > change, at least there's a patch on the table to discuss. I have no > plans to take any action without such a consensus. > > > Perhaps the open item can be closed then? > > Done. I read the high level explanation in the prior email; it's a pretty dense reading. I wouldn't claim to have a very good understanding of it, but the one line clean-up seems to fix the bug well. This overall idea of the follow-up patch looks sound; however it feels more like performance improvement enabled by enhanced design. I also did a rough read on the patch itself and found two minor typos. "the output value can be used directly (as input as input) to the following call along with the buffers it counts." "On entry, *nblocks is the (desire) number of block to read." Best, Xuneng
Hi,
> 1. The leading block is BM_VALID, so we choose to give it to you
> immediately and not look further (we could look further and return
> more than one consecutive BM_VALID block at a time, but this isn't
> implemented)
I am curious about why this isn't implemented. It looks helpful.
Is there any blocking issue or trade-off for not doing so?
> Next, let me describe how read_stream.c manages its circular buffer queue:
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8| | | | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
> oldest_buffer_index is the consumer end of the queue, and any
> associated IO has to be finished before that buffer can be return by
> read_stream_next_buffer(). next_buffer_index is the producer end of
> the queue, where IOs are started. StartReadBuffers() takes pointer to
> an array of buffers of the size of the requested read, so
> read_stream.c gives it the address of that part of its queue.
>
> This means that if StartReadBuffer() forwards some buffers because of
> a split, we don't have to do anything at all, because we advance
> next_buffer_index to the location of the start of the next operation,
> and that is where the forwarded buffers landed, ready for the next
> call to StartReadBuffers():
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8|9|A| | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
The format of this part is not aligned well in gmail, so I copy it into vs code.
Is this layout right? I found second illustration somewhat hard to follow, especially
the "do nothing" trick and the movement of next_buffef_index in the second queue.
Maybe I need to read the corresponding code.
> 1. The leading block is BM_VALID, so we choose to give it to you
> immediately and not look further (we could look further and return
> more than one consecutive BM_VALID block at a time, but this isn't
> implemented)
I am curious about why this isn't implemented. It looks helpful.
Is there any blocking issue or trade-off for not doing so?
> Next, let me describe how read_stream.c manages its circular buffer queue:
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8| | | | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
> oldest_buffer_index is the consumer end of the queue, and any
> associated IO has to be finished before that buffer can be return by
> read_stream_next_buffer(). next_buffer_index is the producer end of
> the queue, where IOs are started. StartReadBuffers() takes pointer to
> an array of buffers of the size of the requested read, so
> read_stream.c gives it the address of that part of its queue.
>
> This means that if StartReadBuffer() forwards some buffers because of
> a split, we don't have to do anything at all, because we advance
> next_buffer_index to the location of the start of the next operation,
> and that is where the forwarded buffers landed, ready for the next
> call to StartReadBuffers():
>
> |<------------- queue_size ------------>|
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> | | | | | | |0|1|2|3|4|5|6|7|8|9|A| | | |
> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
> ^ ^
> | |
> oldest_buffer_index next_buffer_index
>
The format of this part is not aligned well in gmail, so I copy it into vs code.
Is this layout right? I found second illustration somewhat hard to follow, especially
the "do nothing" trick and the movement of next_buffef_index in the second queue.
Maybe I need to read the corresponding code.
Best,
Xuneng
Xuneng
Вложения
On Wed, Aug 13, 2025 at 5:29 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > 1. The leading block is BM_VALID, so we choose to give it to you > > immediately and not look further (we could look further and return > > more than one consecutive BM_VALID block at a time, but this isn't > > implemented) > > I am curious about why this isn't implemented. It looks helpful. > Is there any blocking issue or trade-off for not doing so? stream->distance tends to be 1 for well cached data (it grows when IO is needed and it is worth looking far ahead, and shrinks when data is found in cache). So we won't currently have a distance > 1 for well cached data, so we wouldn't benefit much. That may not always be true: if the buffer mapping table is changed to a tree data structure (like the way kernels manage virtual memory pages associated with a file or other VM object), then we might have an incentive to look up lots of cached blocks at the same time, and then we might want to change the distance tuning algorithm, and then we might want StartReadBuffers() to be able to return more than one cached block at a time. We've focused mainly on I/O so far, and just tried not to make the well cached cases worse. > The format of this part is not aligned well in gmail, so I copy it into vs code. > Is this layout right? Yes. > I found second illustration somewhat hard to follow, especially > the "do nothing" trick and the movement of next_buffef_index in the second queue. > Maybe I need to read the corresponding code. Suppose you have pending_read_blocknum = 100, pending_read_nblock = 5, next_buffer_index = 200. Now you decide to start that read, because the next block the caller wants can't be combined, so you call StartReadBuffers(blocknum = 100, *nblocks = 4, buffers = &buffers[200]). StartReadBuffers() pins 5 buffers and starts an IO, but finds a reason to split it at size 2. It sets *nblocks to 2, and returns. Now read_stream.c adds 2 to pending_read_blocknum, subtracts 2 from pending_read_nblocks, so that it represents the continuation of the previous read. It also adds 2 to next_buffer_index with modulo arithmetic (so it wraps around the queue), because that is the location of the buffers for the next read, and sets forwarded_buffers to 3, because there are 3 buffers already pinned (in that patch ^ it is renamed to pending_read_npinned). The three buffers themselves are already in the queue at the right position for StartReadBuffers() to receive them and know that it doesn't have to pin them again. What I was referring to with "doing nothing" is the way that if you keep sliding StartReadBuffers() call along the queue, the extra buffers it spits out become its input next time, without having to be copied anywhere. In that picture there are two forwarded buffers, labeled 9 and A.
Hi, On Wed, Aug 13, 2025 at 2:02 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Wed, Aug 13, 2025 at 5:29 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > 1. The leading block is BM_VALID, so we choose to give it to you > > > immediately and not look further (we could look further and return > > > more than one consecutive BM_VALID block at a time, but this isn't > > > implemented) > > > > I am curious about why this isn't implemented. It looks helpful. > > Is there any blocking issue or trade-off for not doing so? > > stream->distance tends to be 1 for well cached data (it grows when IO > is needed and it is worth looking far ahead, and shrinks when data is > found in cache). So we won't currently have a distance > 1 for well > cached data, so we wouldn't benefit much. That may not always be > true: if the buffer mapping table is changed to a tree data structure > (like the way kernels manage virtual memory pages associated with a > file or other VM object), then we might have an incentive to look up > lots of cached blocks at the same time, and then we might want to > change the distance tuning algorithm, and then we might want > StartReadBuffers() to be able to return more than one cached block at > a time. We've focused mainly on I/O so far, and just tried not to > make the well cached cases worse. Understood. I came across Alexander’s article on the topic. It appears to require a major re-architecture, which could be challenging to land HEAD. https://www.orioledb.com/blog/buffer-management > > > The format of this part is not aligned well in gmail, so I copy it into vs code. > > Is this layout right? > > Yes. > > > I found second illustration somewhat hard to follow, especially > > the "do nothing" trick and the movement of next_buffef_index in the second queue. > > Maybe I need to read the corresponding code. > > Suppose you have pending_read_blocknum = 100, pending_read_nblock = 5, > next_buffer_index = 200. Now you decide to start that read, because > the next block the caller wants can't be combined, so you call > StartReadBuffers(blocknum = 100, *nblocks = 4, buffers = > &buffers[200]). StartReadBuffers() pins 5 buffers and starts an IO, > but finds a reason to split it at size 2. It sets *nblocks to 2, and > returns. Now read_stream.c adds 2 to pending_read_blocknum, subtracts > 2 from pending_read_nblocks, so that it represents the continuation of > the previous read. It also adds 2 to next_buffer_index with modulo > arithmetic (so it wraps around the queue), because that is the > location of the buffers for the next read, and sets forwarded_buffers > to 3, because there are 3 buffers already pinned (in that patch ^ it > is renamed to pending_read_npinned). The three buffers themselves are > already in the queue at the right position for StartReadBuffers() to > receive them and know that it doesn't have to pin them again. What I > was referring to with "doing nothing" is the way that if you keep > sliding StartReadBuffers() call along the queue, the extra buffers it > spits out become its input next time, without having to be copied > anywhere. In that picture there are two forwarded buffers, labeled 9 > and A. Got it. Elegant technique. Patch 2 also reads as a robustness improvement now. :-) I'll try to map the high-level design to code and review patch 2. Thanks for the great guidance! Best, Xuneng
Hi, The mailing list seems to prefer compressed attachments over many scattered ones. On Fri, Aug 22, 2025 at 11:08 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > XXX does the change have any measurable performance impact? > I did some preliminary performance tests on this patch and Head. Not > sure whether the methodology of tests is right, still post some > findings in here: > > 1) Query runtimes (EXPLAIN (ANALYZE, BUFFERS), ms) > > Bitmap heap scan > • HEAD (5 reps): [94.121, 89.600, 92.732, 78.383, 78.068] > mean 86.58 ms, median 89.60, min 78.07, max 94.12. Buffers: shared hit only. > • PATCHED (5 reps): [89.130, 80.375, 88.227, 98.661, 88.113] > mean 88.90 ms, median 88.227, min 80.38, max 98.66. Buffers: shared hit only. > > Delta (PATCHED vs HEAD): mean +2.68% (slower), median −1.53% (faster). > > Sequential scan > • HEAD (5 reps): [2718.212, 2691.739, 3253.613, 3060.852, 2963.142] > mean 2937.51 ms, median 2963.14. > • PATCHED (5 reps): [2719.971, 2770.082, 2697.245, 2610.932, 2662.142] > mean 2692.07 ms, median 2697.25. Plans + buffer counts shown in the > attached file (example snippets include Buffers: shared hit ~600–900, > read ~343–344k; I/O Timings ~10–16 ms). > > Delta (PATCHED vs HEAD): mean −8.36%, median −8.97%. > > > 2) CPU micro-latencies (bpftrace) — hot read-stream functions > > Functions: StartReadBuffers, read_stream_start_pending_read, > read_stream_next_buffer. Averages are µs; totals are over the ~60 s > run. > > Bitmap > • HEAD — calls: SRB 2,697,243, start_pending 2,696,591, next_buffer 2,697,105; > avg_us: SRB ≈4, start_pending ≈5, next_buffer ≈10. > • PATCHED — calls: SRB 2,677,563, start_pending 2,676,940, next_buffer > 2,677,477; > avg_us: SRB ≈4, start_pending ≈5, next_buffer ≈10. > > Seq (control) > • HEAD — calls: SRB 712,927, start_pending 2,042,992, next_buffer 5,528,071; > avg_us: SRB ≈8, start_pending ≈3, next_buffer ≈6. > • PATCHED — calls: SRB 727,083, start_pending 2,083,866, next_buffer 5,636,554; > avg_us: SRB ≈8, start_pending ≈3, next_buffer ≈6. > > Read: Per-call costs are indistinguishable. Small call-count drift is > noise-level and doesn’t suggest a behavioral change. > > > 3) perf stat (-d) — counters over ~60 s (single backend) > > Key: task-clock (ms), CPU util (=task-clock/elapsed), cycles, > instructions, IPC, branch-miss rate, L1D miss rate. > > Bitmap > • HEAD → PATCHED (Δ) > • task-clock: 8528.28 → 8542.37 ms (+0.17%) > • CPU util: 0.1421 → 0.1424 (+0.16%) > • cycles: 16.844 G → 16.796 G (−0.28%) > • instructions: 51.161 G → 51.435 G (+0.54%) > • IPC: 3.037 → 3.062 (+0.82%) > • branch-miss rate: 0.125% → 0.115% (−7.6%) > • L1D miss rate: 0.379% → 0.383% (+1.1%) > > Read: CPU-side efficiency is neutral-to-slightly better with the patch > (↑IPC, ↓cycles, ↓branch-miss), matching the bpftrace picture. > > Seq (control) > > • HEAD → PATCHED (Δ) > • task-clock: 10,862.53 → 8,896.26 ms (−18.1%) > • CPU util: 0.181 → 0.148 (−18.1%) > • cycles: 16.275 G → 13.049 G (−19.8%) > • instructions: 39.782 G → 33.343 G (−16.2%) > • IPC: 2.444 → 2.555 (+4.5%) > • branch-miss rate: 0.380% → 0.350% (−8.0%) > • L1D miss rate: 1.009% → 0.997% (−1.2%) > > Read: Control path remains healthy: IPC improves; miss rates improve slightly. > > > Takeaways > • The new *npinned interface and removal of “forwarded buffer” > bookkeeping appears neutral-to-positive under warm-cache conditions. > • Bitmap workload: unchanged micro-latencies, modest CPU-efficiency > uplift (↑IPC ~0.8%, ↓cycles), and runtimes that straddle zero with > identical plans/buffer behavior. > • Seq control: unchanged micro-latencies; perf shows higher IPC and > slightly better miss rates; EXPLAIN shows a modest runtime improvement > (~9% median). > > Best, > Xuneng
Вложения
Hi,
These are the results of a cold-cache(not strictly) bench:
Cold-cache readstream microbench (20M rows, shared_buffers=128MB). Use
a somewhat unrealistic setting to amplify the potential impact.
Patch: Make StartReadBuffers() carry npinned in/out
Workload: single-session COUNT(*) on large_table
• Seq scan: SET enable_{indexscan,indexonlyscan,bitmapscan}=off;
SELECT count(*) FROM large_table;
• Bitmap scan: 16 wide tiles over id (contiguous ranges)
Machine: AMD, 16G mem, 8 cores
Config (per run):
shared_buffers=128MB, io_combine_limit=8, track_io_timing=on, jit=off,
effective_io_concurrency=32. Table is clustered by id. N≈20M rows
(int, text(100)).
1) Query runtimes (EXPLAIN ANALYZE)
Sequential scan — 5 reps each
• BASE: mean 2937 ms, median 2963 ms, p95 3254 ms
(per-run: 2719, 2692, 3254, 3061, 2963 ms)
• PATCHED: mean 2692 ms, median 2697 ms, p95 2770 ms
(per-run: 2720, 2770, 2697, 2611, 2662 ms)
PATCHED faster: mean –8.4%, p95 –14.8% vs BASE.
Bitmap scan — 5 reps each
• BASE: mean 86.6 ms, median 89.6 ms, p95 94.1 ms
• PATCHED: mean 88.9 ms, median 88.2 ms, p95 98.7 ms
2) perf stat (60s pgbench drive of the same SQL)
Sequential scan
metric BASE PATCHED
task-clock (ms) 10,862.53 8,896.26 –18.1%
cycles 16.27e9 13.05e9 –19.8%
instructions 39.78e9 33.34e9 –16.2%
IPC 2.44 2.56 +4.5%
branches 8.62e9 7.33e9 –14.9%
branch-misses 32.74e6 24.47e6 –25.2%
Bitmap scan
metric BASE PATCHED
task-clock (ms) 8,528.28 8,542.37 +0.2%
cycles 16.84e9 16.80e9 –0.3%
instructions 51.16e9 51.43e9 +0.5%
IPC 3.04 3.06 +0.8%
branch-misses 11.86e6 11.05e6 –6.9%
3) bpftrace micro-latency on the readstream path
(averages in µs; also showing call counts and total time seen in probes)
Sequential scan (60s)
function BASE avg (µs) PATCHED avg (µs) BASE calls PATCHED calls BASE
sum (s) PATCHED sum (s)
StartReadBuffers 8 8 712,927 727,083 6.14 6.23
read_stream_start_pending_read 3 3 2,042,992 2,083,866 7.52 7.61
read_stream_next_buffer 6 6 5,528,071 5,636,554 35.40 35.36
Bitmap scan (60s)
function BASE avg (µs) PATCHED avg (µs) BASE calls PATCHED calls BASE
sum (s) PATCHED sum (s)
StartReadBuffers 4 4 2,697,243 2,677,563 11.28 11.26
read_stream_start_pending_read 5 5 2,696,591 2,676,940 14.72 14.60
read_stream_next_buffer 10 10 2,697,105 2,677,477 28.74 28.67
Indistinguishable between BASE and PATCHED
Best,
Xuneng
Вложения
Hi,
shared_buffers = '128MB'
track_io_timing = on
jit = off
effective_io_concurrency = 500
log_min_messages = warning
max_parallel_workers_per_gather = 0
io_combine_limit = ${IO_COMBINE_LIMIT:-36}
NROWS="${NROWS:-20000000}"
shared_buffers = '64GB'
track_io_timing = on
jit = off
effective_io_concurrency = 500
log_min_messages = warning
max_parallel_workers_per_gather = 0
io_combine_limit = ${IO_COMBINE_LIMIT:-36}
NROWS="${NROWS:-200000000}"
With these settings, running the benchmark script on a larger machine
(AX162-R from hetzner) installed with NVMe SSDs did not reveal
consistent or obvious performance gains or regressions in the patched
version, although it did show slightly better results for bitmap scans
in some runs.
Best,
Xuneng
Hi,
I've reviewed patch v2 carefully and found no correctness problems.
Although the performance benefit it brings might be intangible, the
new interface is more robust and simpler than the current one. It does
save a lot of bookkeeping:
1) Initialize slots to InvalidBuffer: Before calling StartReadBuffers,
it had to zero out buffer slots:
while (stream->initialized_buffers < buffer_index + nblocks)
stream->buffers[stream->initialized_buffers++] = InvalidBuffer;
2) Scan for forwarded buffers: After the call, it had to scan the
array to count how many buffers were forwarded:
forwarded = 0;
while (nblocks + forwarded < requested_nblocks &&
stream->buffers[buffer_index + nblocks + forwarded] != InvalidBuffer)
forwarded++;
stream->forwarded_buffers = forwarded;
3) Clear consumed slots: When returning a buffer to the consumer, it
had to clear the slot:
stream->buffers[oldest_buffer_index] = InvalidBuffer;
This could be fragile because:
- read_stream.c must maintain the invariant that unused slots are InvalidBuffer.
- The scanning loop is O(n) and "layer-violating" (it's re-discovering
information that StartReadBuffers already knew).
- Missing a = InvalidBuffer assignment anywhere would cause silent corruption.
With the new interface -- Make npinned an explicit in/out parameter.
1) No initialization needed: StartReadBuffers doesn't look at
uninitialized slots. It only reads buffers[0..npinned-1].
2) No scanning needed: The count is returned directly: *npinned =
actual_npinned - *nblocks; // Buffer manager tells you the count
3) No clearing needed: The "is it forwarded?" check is now i <
actual_npinned, not buffers[i] != InvalidBuffer.
As for the xxx questions, here're some thoughts:
XXX is the single-buffer specialization unaffected due to dead code
elimination, as expected?
- The single-buffer specialization stays unchanged: StartReadBuffer()
still passes npinned=0 with allow_forwarding=false, so the extra
parameter is dead code there and the compiler will inline/strip it
just as before.
XXX unused queue entries could potentially be electrified with
wipe_mem/VALGRIND_MAKE_MEM_NOACCESS, though existing bufmgr.c
assertions are very likely to reveal any fencepost bugs already
- The queue-entry sanitization step removed should not affect
behavior, since StartReadBuffers() now relies on npinned rather than
InvalidBuffer sentinels. Leaving stale values in the array is likely
harmless. If desired, using wipe_mem or VALGRIND_MAKE_MEM_NOACCESS
would simply provide additional debugging hardening.
XXX perhaps we don't need quite so many _npinned <= _nblocks assertions
- I think this makes sense. In my experience, reading through the
read_stream module already requires a fair amount of effort and focus.
There are many edge cases to watch, and the complexity is amplified by
managing two arrays, pointer arithmetic across function calls, and
numerous assertions to validate those operations. Removing assertions
that are not strictly necessary can make the code more readable and
easier to follow, without weakening its defensive properties.
// In read_stream_start_pending_read():
// REMOVE this pre-call assertion:
- Assert(stream->pending_read_npinned <= stream->pending_read_nblocks);
// Entry in StartReadBuffersImpl (bufmgr.c):
- Assert(*npinned <= *nblocks);
// KEEP this post-call assertion:
Assert(stream->pending_read_nblocks >= stream->pending_read_npinned);
The pre-call assertion in read_stream_start_pending_read looks less
needed since the entry assertion in StartReadBuffersImpl catches
exactly a subset of bugs that the entry assertion catches, with no
intervening code that could obscure the failure or change program
state.
--
Best,
Xuneng