Обсуждение: Re: Request for Feedback on PostgreSQL HA + Load Balancing Architecture
On 6/18/25 18:12, vijay patil wrote:
Hi Team,
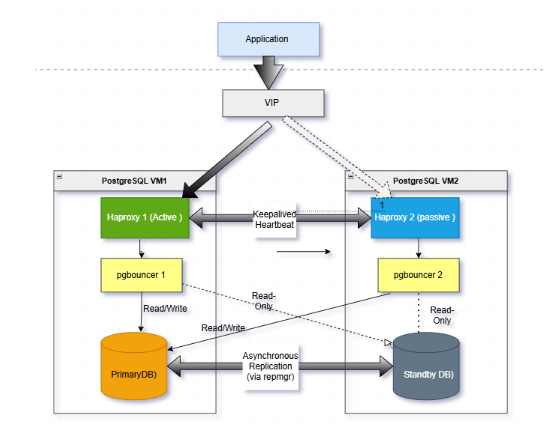
I am planning to implement a PostgreSQL High Availability (HA) and Load Balancing setup and would greatly appreciate your feedback on the architecture we've designed (see attached diagram).
Overview of the Setup:
Two PostgreSQL nodes (VM1 and VM2) configured with:
Asynchronous replication from the Primary DB (on VM1) to the Standby DB (on VM2) using
repmgrHAProxy for failover management:
HAProxy 1 (active) on VM1
HAProxy 2 (passive) on VM2 with Keepalive for heartbeat and failover detection
PgBouncer on both nodes for connection pooling
A Virtual IP (VIP) managed by HAProxy for routing traffic from the application
Read/Write operations go to the Primary DB, and Read-Only queries can be served from either node
Objectives:
Ensure high availability with automatic failover
Enable basic load balancing for read-only queries
Maintain connection pooling and routing efficiency
Request for Feedback:
Is this architecture considered a best practice within the PostgreSQL community?
Are there any potential bottlenecks or failure points I should be aware of?
Would you recommend any improvements or alternative tools for achieving better reliability and performance?
Personally I will test long run via app -> pgbouncer -> pgpool-ii in order to combine :
* Query Routing (read/write automatic split)
* Load Balancing
* High Availability
* Query caching
Have you consider pgpool-ii ? I know most support / service companies push for patroni, and manually separating read / write traffic from within the app, but I still find pgpool's query routing very nice.
Thanks
Vijay
Вложения
Re: Request for Feedback on PostgreSQL HA + Load Balancing Architecture
On Wed, 23 Jul 2025 12:13:26 +0100 Achilleas Mantzios <a.mantzios@cloud.gatewaynet.com> wrote: … > Have you consider pgpool-ii ? I know most support / service companies > push for patroni, and manually separating read / write traffic from > within the app, Indeed > but I still find pgpool's query routing very nice. Using Pgpool for HA is a no go in my opinion. Pgpool HA requires the DBA/sysadmin to deal alone with the real high availability challenges. Pgpool doesn't handle the HA complexity itself, it stays quite "naive". It requires the sysadmin/DBA to mess with the complexity to keep the cluster safe from corruption. In other word, implement the HA safety stack in bash yourself. This is partly true for repmgr as well last time I checked. Don't implement Patroni or Pacemaker yourself in a collection of "action scripts" triggered by a naive HA stack. Some people tried, some clusters has been corrupted. Pgpool for routing and/or pooling is an acceptable solution. Of course, it comes with its drawbacks and some inefficiences, that's why most support/service companies avoid it when possible. But depending on the context, it could be OK. Regards,