Обсуждение: Timeline switching with partial WAL records can break replica recovery
[FIX] Timeline switching with partial WAL records can break replica recovery
Hi Hackers,
I've encountered an issue where physical replicas may enter an infinite WAL
request loop under the following conditions:
1. A promotion occurs during a multi-block WAL record write.
2. The resulting timeline is very short (begin/end in the same WAL block).
== Current behavior ==
When a WAL record crosses block boundaries and gets interrupted by a promotion:
1. The partial record remains in the original timeline's WAL and is not copied
to the next timeline.
2. The new timeline begins at the end of the last valid completed record.
3. Replicas consuming the WAL stream may:
a) Encounter the partial record in timeline N,
b) Recovery fetches a non-full record from walrcv and asks for more data,
c) Fetch the timeline history, including timeline N+1,
d) Request the same record from timeline N+1,
e) Receive data up to the end of timeline N+1 (which, notably, does not contain
this record),
f) Repeat indefinitely for the incomplete record on timeline N+1.
I hope this illustration helps clarify the issue:
block block, the record is written block
| | up to that point |
v v v
--+-----------------------------+-------------------------------------------+---
: | I I | I | :
Hi Hackers,
I've encountered an issue where physical replicas may enter an infinite WAL
request loop under the following conditions:
1. A promotion occurs during a multi-block WAL record write.
2. The resulting timeline is very short (begin/end in the same WAL block).
== Current behavior ==
When a WAL record crosses block boundaries and gets interrupted by a promotion:
1. The partial record remains in the original timeline's WAL and is not copied
to the next timeline.
2. The new timeline begins at the end of the last valid completed record.
3. Replicas consuming the WAL stream may:
a) Encounter the partial record in timeline N,
b) Recovery fetches a non-full record from walrcv and asks for more data,
c) Fetch the timeline history, including timeline N+1,
d) Request the same record from timeline N+1,
e) Receive data up to the end of timeline N+1 (which, notably, does not contain
this record),
f) Repeat indefinitely for the incomplete record on timeline N+1.
I hope this illustration helps clarify the issue:
block block, the record is written block
| | up to that point |
v v v
--+-----------------------------+-------------------------------------------+---
: | I I | I | :
--+-----------------------------+-------------------------------------------+---
^ ^ ^
| └ end of TLI = N + 1, └ the point up to which the record
| start of TLI = N + 2 must be fully written,
| recovery waits data until this LSN.
|
└ end of TLI = N,
start of TLI = N + 1,
start of the record.
== Background theory ==
1. When a record crosses a page boundary, it's logically divided into parts
called "contrecords".
2. If an incomplete record is detected during crash recovery:
a) a special XLOG_OVERWRITE_CONTRECORD record is written after the incomplete
record,
b) the page header where the rest of the record would reside is flagged with
XLP_FIRST_IS_OVERWRITTEN_CONTRECORD,
c) this ensures PostgreSQL gracefully ignores the incomplete record in
subsequent recovery attempts,
3. If and incomplete record is detected during promotion recovery:
a) the new timeline starts at the end of the last valid record (before the
incomplete one),
b) the last block containing the record is copied to the new timeline, but the
record itself is zeroed out.
c) the new timeline contains neither the XLOG_OVERWRITE_CONTRECORD marker nor
the XLP_FIRST_IS_OVERWRITTEN_CONTRECORD page header flag.
== Historical context ==
1. The initial contrecord implementation [1] proposed:
a) copying the last block containing the last valid record to the new timeline,
and zeroing the partially written record,
b) writing XLOG_OVERWRITE_CONTRECORD in the new timeline.
2. Later, XLOG_OVERWRITE_CONTRECORD writing was avoided due to concerns about
zero-gaps in WAL [2].
== Proposed Solution ==
I propose preserving WAL's append-only linear nature by graceful handling of
incomplete records during timeline switches:
1. Timeline Finalization:
Before switching timelines write an XLOG_OVERWRITE_CONTRECORD record to mark
the incomplete record in the current timeline. Only then initialize the new
timeline and continue recovery. Since no concurrent WAL writes can occur
during this phase, the operation is safe.
2. Other processes may read InsertTLI from shared memory during the switch. This
can cause processes to read the current timeline instead of the new one we're
switching to.
This behaviour may occur in the walsummarizer process.
If the walsummarizer fetches InsertTLI of the current timeline (which is set
while a XLOG_OVERWRITE_CONTRECORD is being written), it can result in
latest_lsn < read_upto (which becomes walrcv->flushedUpto in this case),
triggering an assertion failure. This assertion ensures that the read-up-to
LSN is correctly updated. We can safely handle this edge case by replacing
the assertion with an if-statement.
I wrote a TAP test to reproduce the bug, but it doesn’t trigger the issue
consistently. To help investigate, I’ve also added additional logs with some
debug output.
I would appreciate review and feedback.
[1] https://postgr.es/m/202108232252.dh7uxf6oxwcy@alvherre.pgsql
[2] http://postgr.es/m/CAFiTN-t7umki=PK8dT1tcPV=mOUe2vNhHML6b3T7W7qqvvajjg@mail.gmail.com
--
Regards,
Alyona Vinter
^ ^ ^
| └ end of TLI = N + 1, └ the point up to which the record
| start of TLI = N + 2 must be fully written,
| recovery waits data until this LSN.
|
└ end of TLI = N,
start of TLI = N + 1,
start of the record.
== Background theory ==
1. When a record crosses a page boundary, it's logically divided into parts
called "contrecords".
2. If an incomplete record is detected during crash recovery:
a) a special XLOG_OVERWRITE_CONTRECORD record is written after the incomplete
record,
b) the page header where the rest of the record would reside is flagged with
XLP_FIRST_IS_OVERWRITTEN_CONTRECORD,
c) this ensures PostgreSQL gracefully ignores the incomplete record in
subsequent recovery attempts,
3. If and incomplete record is detected during promotion recovery:
a) the new timeline starts at the end of the last valid record (before the
incomplete one),
b) the last block containing the record is copied to the new timeline, but the
record itself is zeroed out.
c) the new timeline contains neither the XLOG_OVERWRITE_CONTRECORD marker nor
the XLP_FIRST_IS_OVERWRITTEN_CONTRECORD page header flag.
== Historical context ==
1. The initial contrecord implementation [1] proposed:
a) copying the last block containing the last valid record to the new timeline,
and zeroing the partially written record,
b) writing XLOG_OVERWRITE_CONTRECORD in the new timeline.
2. Later, XLOG_OVERWRITE_CONTRECORD writing was avoided due to concerns about
zero-gaps in WAL [2].
== Proposed Solution ==
I propose preserving WAL's append-only linear nature by graceful handling of
incomplete records during timeline switches:
1. Timeline Finalization:
Before switching timelines write an XLOG_OVERWRITE_CONTRECORD record to mark
the incomplete record in the current timeline. Only then initialize the new
timeline and continue recovery. Since no concurrent WAL writes can occur
during this phase, the operation is safe.
2. Other processes may read InsertTLI from shared memory during the switch. This
can cause processes to read the current timeline instead of the new one we're
switching to.
This behaviour may occur in the walsummarizer process.
If the walsummarizer fetches InsertTLI of the current timeline (which is set
while a XLOG_OVERWRITE_CONTRECORD is being written), it can result in
latest_lsn < read_upto (which becomes walrcv->flushedUpto in this case),
triggering an assertion failure. This assertion ensures that the read-up-to
LSN is correctly updated. We can safely handle this edge case by replacing
the assertion with an if-statement.
I wrote a TAP test to reproduce the bug, but it doesn’t trigger the issue
consistently. To help investigate, I’ve also added additional logs with some
debug output.
I would appreciate review and feedback.
[1] https://postgr.es/m/202108232252.dh7uxf6oxwcy@alvherre.pgsql
[2] http://postgr.es/m/CAFiTN-t7umki=PK8dT1tcPV=mOUe2vNhHML6b3T7W7qqvvajjg@mail.gmail.com
--
Regards,
Alyona Vinter
Вложения
- v1-0001-Fix-missing-XLOG_OVERWRITE_CONTRECORD-in-timeline_switches.patch
- v1-0002-Replace-assert-with-if-check-in-walsummarizer.patch
- v1-0003-TAP-test-replica-enters-infinite-data-request-loop.pl
- v1-0003-TAP-test-replica-enters-infinite-data-request-loop-master.log
- v1-0003-TAP-test-replica-enters-infinite-data-request-loop-replica.log
I've done more research and identified that replicas enter
an indefinite loop in the 'XLogReadPage' function.
The loop works as follows:
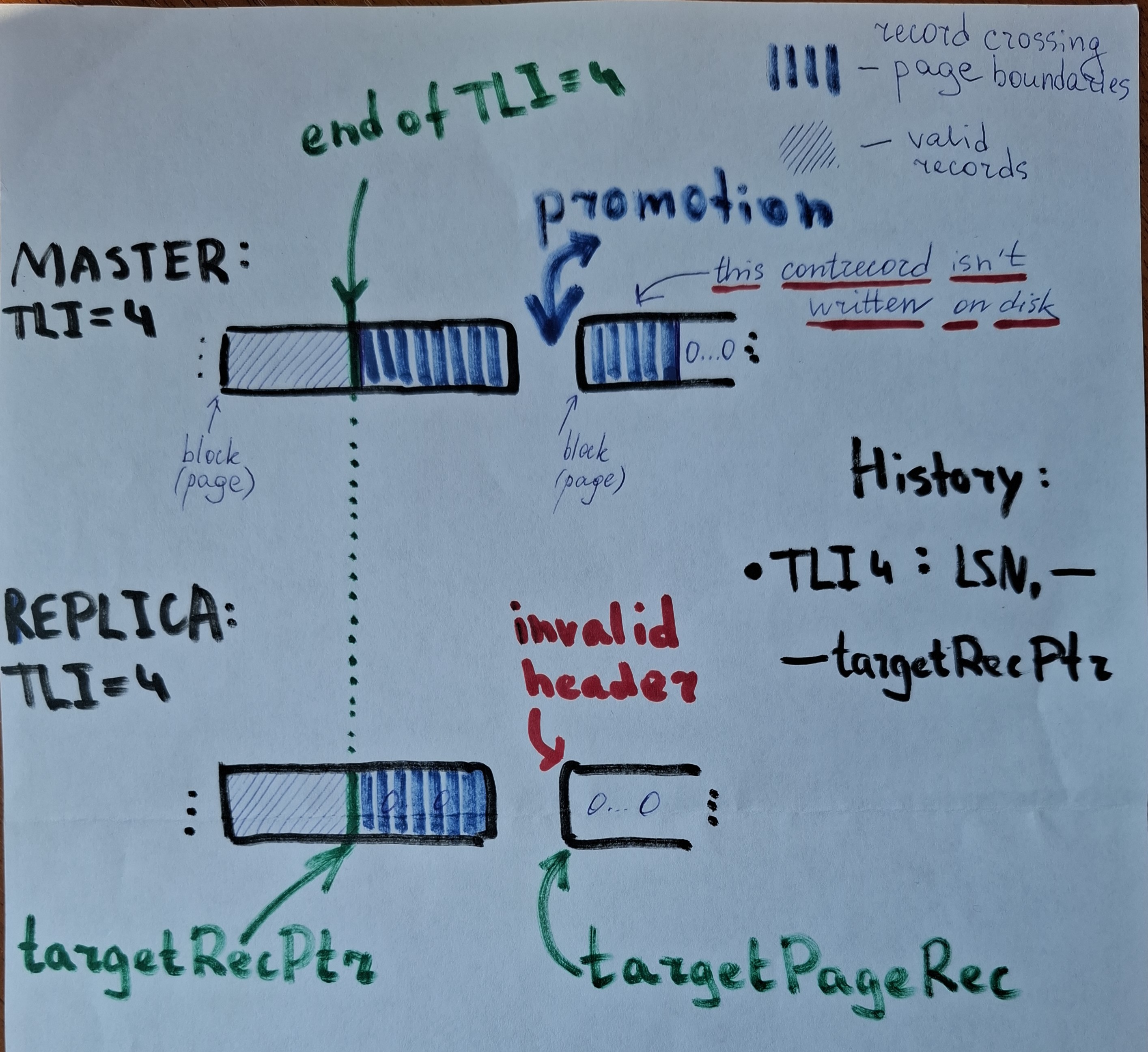
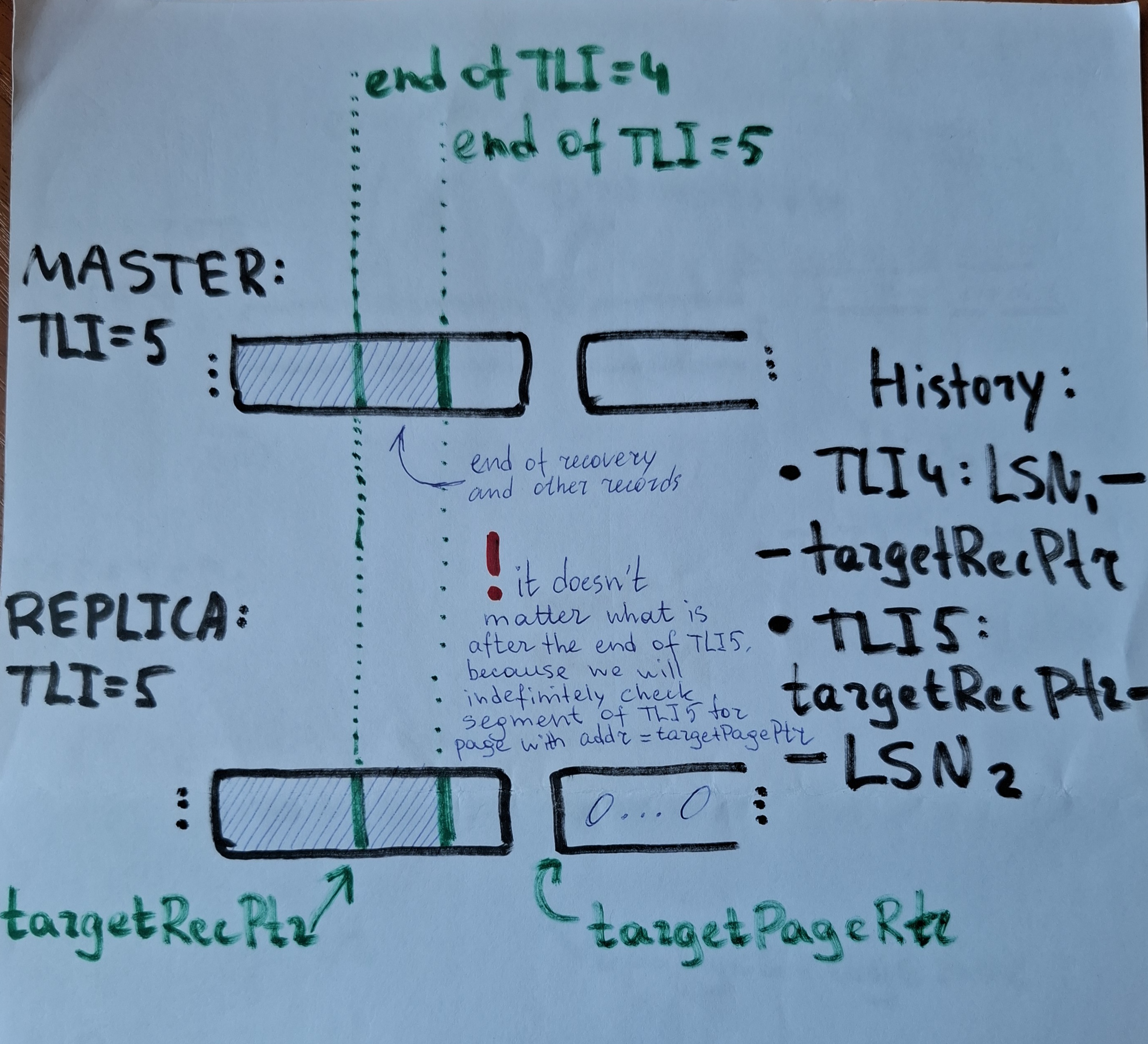
0. timeline N contains a partially written record with LSN = targetRecPtr;
1. In 'XLogReadPage' we attempt to read the next page, which has to
contain the rest of the unfinished record;
2. In 'WaitForWALToBecomeAvailable' walrcv is requested to fetch
records starting from LSN = targetRecPtr on timeline N + 1;
3. Walrcv retrieves data up to the end of page containing the end of
timeline N + 1;
4. Then, in 'WaitForWALToBecomeAvailable', replica switches to
XLOG_FROM_ARCHIVE state, and the function returns true;
5. Execution continues in 'XLogReadPage';
6. The page at addr = targetPagePtr is checked for validity, but we
get an 'invalid magic number' error because walrcv hasn't retrieved
this page;
7. Execution jumps to 'next_record_is_invalid' label;
8. Since we are in StandBy mode, the process retries from the beginning.
See the attachments for more colorful illustration this time =)
From my point of view, the first solution which I described in my
previous message still seems like a good choice.
I've also found the current solution in commit [1]. With all due
respect, but it seems to treat the symptom rather than the underlying
issue.
[1] https://github.com/postgres/postgres/commit/6cf1647d87e7cd423d71525a8759b75c4e4a47ec
an indefinite loop in the 'XLogReadPage' function.
The loop works as follows:
0. timeline N contains a partially written record with LSN = targetRecPtr;
1. In 'XLogReadPage' we attempt to read the next page, which has to
contain the rest of the unfinished record;
2. In 'WaitForWALToBecomeAvailable' walrcv is requested to fetch
records starting from LSN = targetRecPtr on timeline N + 1;
3. Walrcv retrieves data up to the end of page containing the end of
timeline N + 1;
4. Then, in 'WaitForWALToBecomeAvailable', replica switches to
XLOG_FROM_ARCHIVE state, and the function returns true;
5. Execution continues in 'XLogReadPage';
6. The page at addr = targetPagePtr is checked for validity, but we
get an 'invalid magic number' error because walrcv hasn't retrieved
this page;
7. Execution jumps to 'next_record_is_invalid' label;
8. Since we are in StandBy mode, the process retries from the beginning.
See the attachments for more colorful illustration this time =)
From my point of view, the first solution which I described in my
previous message still seems like a good choice.
I've also found the current solution in commit [1]. With all due
respect, but it seems to treat the symptom rather than the underlying
issue.
[1] https://github.com/postgres/postgres/commit/6cf1647d87e7cd423d71525a8759b75c4e4a47ec
Вложения
{kind=link}
{kind=link}
Hi hackers,
I've found an error in my previous patch and have attached a fixed version.
I'd also like to clarify the timeline switching bug scenario that this patch fixes:
The issue occurs in this cluster configuration:
[ master ] → [ cascade replica ] → [ replica ]
I've found an error in my previous patch and have attached a fixed version.
I'd also like to clarify the timeline switching bug scenario that this patch fixes:
The issue occurs in this cluster configuration:
[ master ] → [ cascade replica ] → [ replica ]
When the master is lost and the cascade replica is promoted (as described above), the downstream replica may enter an infinite loop during recovery instead of properly following the new timeline.
--
Regards,
Alyona Vinter
--
Regards,
Alyona Vinter
Вложения
On Wed, 3 Sept 2025 at 12:37, Alyona Vinter <dlaaren8@gmail.com> wrote:
I've found an error in my previous patch and have attached a fixed version.
Sorry, I've sent the wrong patches again. Here the correct ones
Вложения
On Thu, Sep 4, 2025 at 1:33 PM D Laaren <dlaaren8@gmail.com> wrote:
> [FIX] Timeline switching with partial WAL records can break replica recovery
>
> Hi Hackers,
>
> I've encountered an issue where physical replicas may enter an infinite WAL
> request loop under the following conditions:
> 1. A promotion occurs during a multi-block WAL record write.
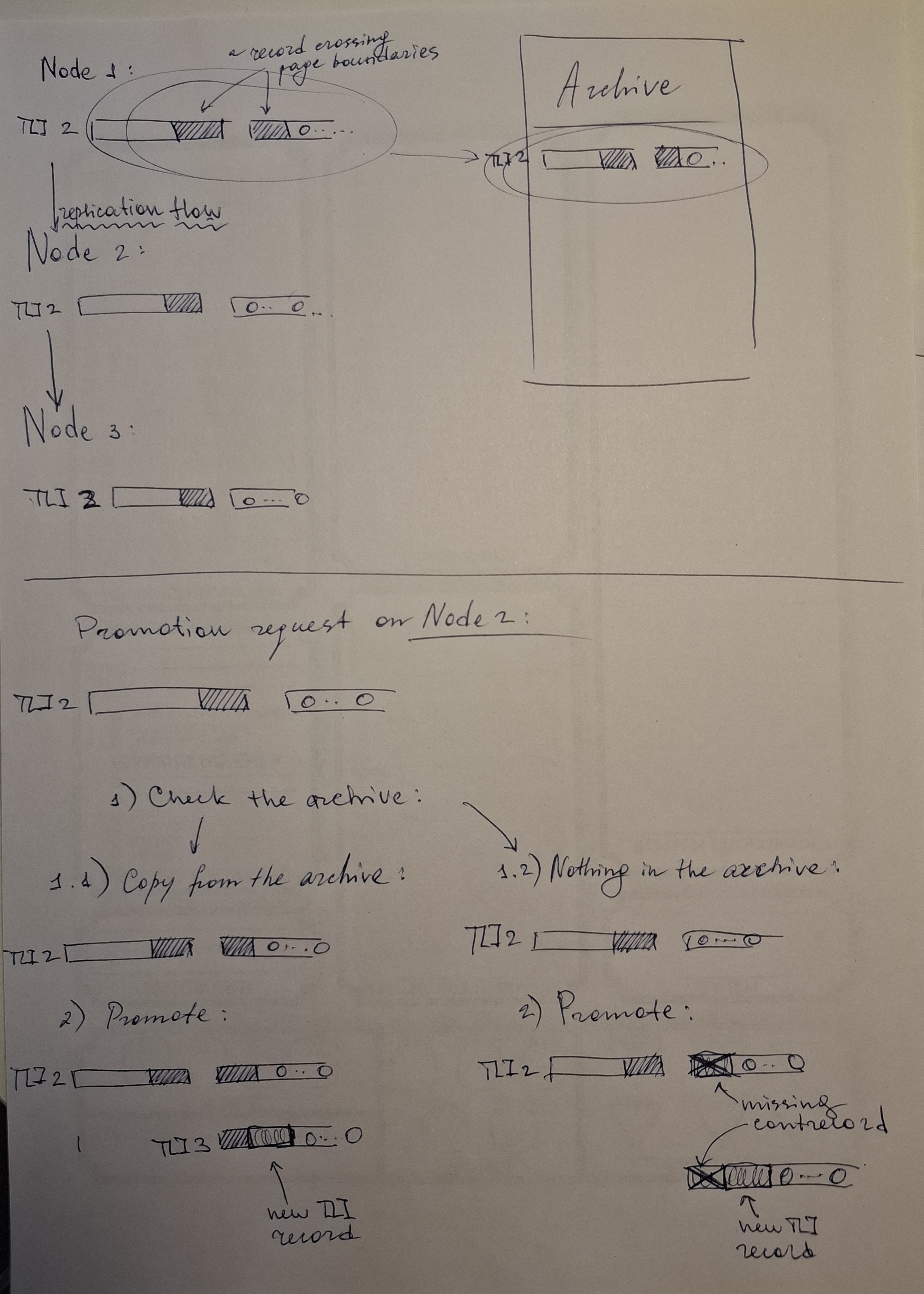
Hi everyone,
I would like to reinforce the need for this fix because I've encountered
another critical failure related to timeline switching with contrecord. In my
case in cascading replication.
Configuration: Primary -> Upstream-Replica -> Downstream-Replica
Scenario that caused a problem:
1. The primary is abruptly shut down during a multi-block WAL write.
2. Replicas received an incomplete multi-block WAL record
3. The primary zeroes the incomplete record but does not write
XLOG_OVERWRITE_CONTRECORD because it is going to switch to the new TLI
4. The primary switches timeline at the point of the incomplete
record, not after it
5. The Upstream-Replica's walreceiver processes the new timeline and rewrites
its WAL. However, its cascading walsender is unaware of this underlying
change and attempts to send data it has already sent to Downstream-Replica,
triggering an Assert.
I've attached an illustration of the WAL records on instances for better
understanding. Also I've attached a TAP test that reproduces this behaviour.
The test reproduces the issue by directly removing a WAL file to simulate
the corrupted state. In a real-world scenario, I encountered this situation
through normal replication.
Symptom: Assert in walsender.c on Upstream-Replica
-------
TRAP: failed Assert("sentPtr <= SendRqstPtr")
-------
This is an important issue to fix. While the assertion will crash a debug
build, a production build would continue, potentially causing the downstream
replica to receive corrupted or divergent WAL data.
In the scenario above, if we continue to insert data on the primary, it can
lead to a panic on replica:
-------
PANIC: could not open file "pg_wal/000000020000000000000001": No such
file or directory
-------
This panic is arguably the best outcome right now, as it stops the system
before more severe data corruption can accumulate.
> == Proposed Solution ==
> I propose preserving WAL's append-only linear nature by graceful handling of
> incomplete records during timeline switches:
> 1. Timeline Finalization:
> Before switching timelines write an XLOG_OVERWRITE_CONTRECORD record to
> mark the incomplete record in the current timeline. Only then initialize the
> new timeline and continue recovery. Since no concurrent WAL writes can occur
> during this phase, the operation is safe.
This solution repairs the situation above. On one hand, it might seem that
the walsender's code needs to change to be aware of such switches. However,
I believe the patch proposed in this thread is the better decision because
it addresses the root cause.
Best regards,
Nataliia Kokunina
Вложения
{kind=link}
Hi!
I've noticed an issue with pg_rewind caused by my patches.
Some logs for issue demonstration:
pg_rewind: Source timeline history:
pg_rewind: 1: 0/00000000 - 0/03002048
pg_rewind: 2: 0/03002048 - 0/00000000
pg_rewind: Target timeline history:
pg_rewind: 1: 0/00000000 - 0/00000000
pg_rewind: servers diverged at WAL location 0/03002048 on timeline 1
pg_rewind: error: could not find previous WAL record at 0/03002048: invalid record length at 0/03002048: expected at least 24, got 0
pg_rewind: 1: 0/00000000 - 0/03002048
pg_rewind: 2: 0/03002048 - 0/00000000
pg_rewind: Target timeline history:
pg_rewind: 1: 0/00000000 - 0/00000000
pg_rewind: servers diverged at WAL location 0/03002048 on timeline 1
pg_rewind: error: could not find previous WAL record at 0/03002048: invalid record length at 0/03002048: expected at least 24, got 0
To handle this case, I suggest looking for a checkpoint preceding the divergence point starting from the last checkpoint on the target rather than from the divergence point itself when the common timeline is unfinished on the target. This ensures we always begin from a known-valid position in WAL.
I'd appreciate any feedback!
Best Regards,
Alyona Vinter
Вложения
Hello Alyona,
Your solution, if I understood it correctly, violates the main idea of timelines, as it creates an "alternative" version for timeline N. It's possible that primary finished contrecord and whole segment was archived. Currently, replica always has subset of timeline N, so it's safe to start new timeline from any point. But with your timeline finalization logic it will create its own version timeline N that will conflict with already archived version. If replica will archive timeline N+1 you may end up with two different "tails" of timeline N in the same archive. Also I assume some third party tools that rely on WAL may be broken by such change.
--
Hi Artem!
Thank you for the clarification about archiving. I now fully understand why writing a missing contrecord into an already-archived timeline is unsafe.
Thank you for the clarification about archiving. I now fully understand why writing a missing contrecord into an already-archived timeline is unsafe.
Could this be avoided by having the standby check the WAL archive before promotion? Specifically, if the standby detects an incomplete contrecord at the end of its WAL stream, it attempts to fetch the contrecord from the archive, and only if the contrecord is not found in the archive, it proceeds with writing a missing contrecord and starting a new timeline. What do you think?
I plan to reproduce your described scenario to test both my original patch and this revised approach.
P.S. I'm attaching my notes just so I don’t lose them =)
---
Alena Vinter
Alena Vinter
Вложения
{kind=link}
Could this be avoided by having the standby check the WAL archive before promotion?
I'm afraid we can't say anything about how archiving works for the whole cluster. It's quite possible that archiving configured only on primary or primary and secondary use different archive locations or maybe you have archive_command but not restore_command configured, etc...
Maybe we can add an exception and let the new timeline start after incomplete contrecord? Most likely it will cause problems that I'm unaware of, but it seems we can handle such record in both timelines.
> let the new timeline start after incomplete contrecord
This approach seems like it could prevent issues with archiving. Upon reconsideration, I agree that we shouldn’t alter the complete timeline — instead, the missing contrecord should be detected in the next timeline.
However, there’s a problem with the ordering of the `EndOfRecovery` and `MissingContrecord` records: `EndOfRecovery` must be written to WAL at the very beginning of the new timeline. This conflicts with the current design, so we should rethink the solution.
The first easy solution that comes to my mind is to simply extend the `EndOfRecovery` record by adding an `overwritten_lsn` field. As I see it, it won’t change the code much. What do you think?
---
Alena Vinter
Alena Vinter