Обсуждение: Add progressive backoff to XactLockTableWait functions
Hi hackers, This patch implements progressive backoff in XactLockTableWait() and ConditionalXactLockTableWait(). As Kevin reported in this thread [1], XactLockTableWait() can enter a tight polling loop during logical replication slot creation on standby servers, sleeping for fixed 1ms intervals that can continue for a long time. This creates significant CPU overhead. The patch implements a time-based threshold approach based on Fujii’s idea [1]: keep sleeping for 1ms until the total sleep time reaches 10 seconds, then start exponential backoff (doubling the sleep duration each cycle) up to a maximum of 10 seconds per sleep. This balances responsiveness for normal operations (which typically complete within seconds) against CPU efficiency for the long waits in some logical replication scenarios. [1] https://www.postgresql.org/message-id/flat/CAM45KeELdjhS-rGuvN%3DZLJ_asvZACucZ9LZWVzH7bGcD12DDwg%40mail.gmail.com Best regards, Xuneng
Вложения
On 2025/06/08 23:33, Xuneng Zhou wrote:
> Hi hackers,
>
> This patch implements progressive backoff in XactLockTableWait() and
> ConditionalXactLockTableWait().
>
> As Kevin reported in this thread [1], XactLockTableWait() can enter a
> tight polling loop during logical replication slot creation on standby
> servers, sleeping for fixed 1ms intervals that can continue for a long
> time. This creates significant CPU overhead.
>
> The patch implements a time-based threshold approach based on Fujii’s
> idea [1]: keep sleeping for 1ms until the total sleep time reaches 10
> seconds, then start exponential backoff (doubling the sleep duration
> each cycle) up to a maximum of 10 seconds per sleep. This balances
> responsiveness for normal operations (which typically complete within
> seconds) against CPU efficiency for the long waits in some logical
> replication scenarios.
Thanks for the patch!
When I first suggested this idea, I used 10s as an example for
the maximum sleep time. But thinking more about it now, 10s might
be too long. Even if the target transaction has already finished,
XactLockTableWait() could still wait up to 10 seconds,
which seems excessive.
What about using 1s instead? That value is already used as a max
sleep time in other places, like WaitExceedsMaxStandbyDelay().
If we agree on 1s as the max, then using exponential backoff from
1ms to 1s after the threshold might not be necessary. It might
be simpler and sufficient to just sleep for 1s once we hit
the threshold.
Based on that, I think a change like the following could work well.
Thought?
----------------------------------------
XactLockTableWaitInfo info;
ErrorContextCallback callback;
bool first = true;
+ int left_till_hibernate = 5000;
<snip>
if (!first)
{
CHECK_FOR_INTERRUPTS();
- pg_usleep(1000L);
+
+ if (left_till_hibernate > 0)
+ {
+ pg_usleep(1000L);
+ left_till_hibernate--;
+ }
+ else
+ pg_usleep(1000000L);
----------------------------------------
Regards,
--
Fujii Masao
NTT DATA Japan Corporation
Thanks for the feedback!
When I first suggested this idea, I used 10s as an example for
the maximum sleep time. But thinking more about it now, 10s might
be too long. Even if the target transaction has already finished,
XactLockTableWait() could still wait up to 10 seconds,
which seems excessive.
What about using 1s instead? That value is already used as a max
sleep time in other places, like WaitExceedsMaxStandbyDelay().
If we agree on 1s as the max, then using exponential backoff from
1ms to 1s after the threshold might not be necessary. It might
be simpler and sufficient to just sleep for 1s once we hit
the threshold.
Based on that, I think a change like the following could work well.
Thought?
Although it’s clear that replacing tight 1 ms polling loops will reduce CPU usage, I'm curious about the hard numbers. To that end, I ran a 60 s logical-replication slot–creation workload on a standby using three different XactLockTableWait() variants—on an 8-core, 16 GB AMD system—and collected both profiling traces and hardware-counter metrics.
1. Hardware‐counter results
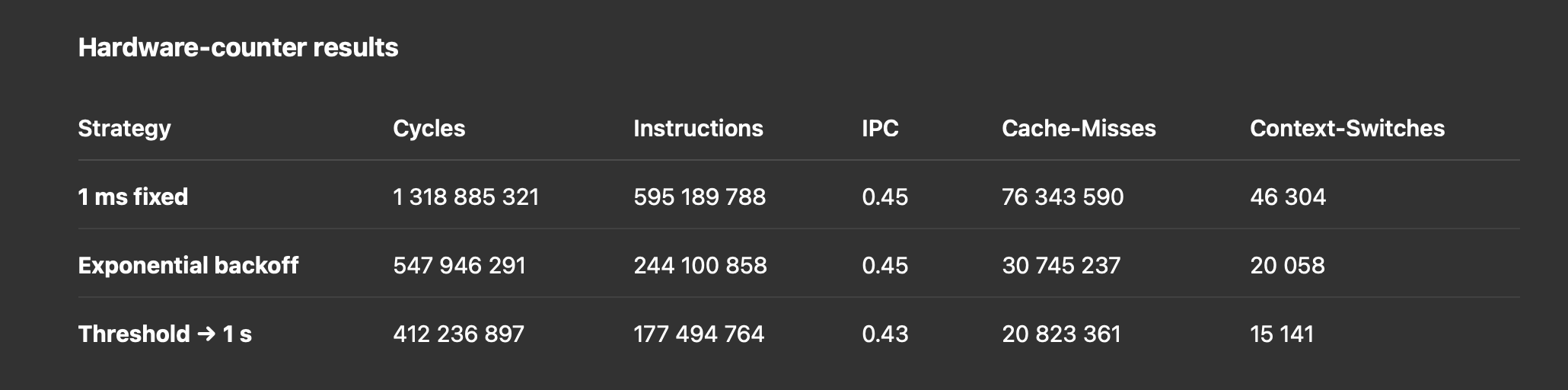
- CPU cycles drop by 58% moving from 1 ms to exp. backoff, and another 25% to the 1 s threshold variant.
- Cache‐misses and context‐switches see similarly large reductions.
- IPC remains around 0.45, dipping slightly under longer sleeps.
Вложения
{kind=link}
{kind=link}
{kind=link}
Hi, On 2025-06-08 22:33:39 +0800, Xuneng Zhou wrote: > This patch implements progressive backoff in XactLockTableWait() and > ConditionalXactLockTableWait(). > > As Kevin reported in this thread [1], XactLockTableWait() can enter a > tight polling loop during logical replication slot creation on standby > servers, sleeping for fixed 1ms intervals that can continue for a long > time. This creates significant CPU overhead. > > The patch implements a time-based threshold approach based on Fujii’s > idea [1]: keep sleeping for 1ms until the total sleep time reaches 10 > seconds, then start exponential backoff (doubling the sleep duration > each cycle) up to a maximum of 10 seconds per sleep. This balances > responsiveness for normal operations (which typically complete within > seconds) against CPU efficiency for the long waits in some logical > replication scenarios. ISTM that this is going to wrong way - the real problem is that we seem to have extended periods where XactLockTableWait() doesn't actually work, not that the sleep time is too short. The sleep in XactLockTableWait() was intended to address a very short race, not something that's essentially unbound. Greetings, Andres Freund
Thanks for looking into this!
Hi,
On 2025-06-08 22:33:39 +0800, Xuneng Zhou wrote:
> This patch implements progressive backoff in XactLockTableWait() and
> ConditionalXactLockTableWait().
>
> As Kevin reported in this thread [1], XactLockTableWait() can enter a
> tight polling loop during logical replication slot creation on standby
> servers, sleeping for fixed 1ms intervals that can continue for a long
> time. This creates significant CPU overhead.
>
> The patch implements a time-based threshold approach based on Fujii’s
> idea [1]: keep sleeping for 1ms until the total sleep time reaches 10
> seconds, then start exponential backoff (doubling the sleep duration
> each cycle) up to a maximum of 10 seconds per sleep. This balances
> responsiveness for normal operations (which typically complete within
> seconds) against CPU efficiency for the long waits in some logical
> replication scenarios.
ISTM that this is going to wrong way - the real problem is that we seem to
have extended periods where XactLockTableWait() doesn't actually work, not
that the sleep time is too short.
XactLockTableWait() works well when the targeted XID lock exists and can be waited for. However, this assumption breaks down on hot standby because transactions from the primary aren't running locally—no exclusive locks are registered in the standby's lock table, leading to potentially unbounded polling instead of proper blocking waits. XactLockTableWait() is to wait for a specified transaction to commit or abort, which remains semantically correct for SnapBuildWaitSnapshot() during logical decoding. How about adding special handling for the hot standby case within XactLockTableWait() by detecting RecoveryInProgres(). Although after studying the various calls of XactLockTableWait(), I'm uncertain whether this condition is proper and sufficient to avoid affecting other use cases.The sleep in XactLockTableWait() was
intended to address a very short race, not something that's essentially
unbound.
building snapshots for logical decoding. But in the hot standby case, the race does not exist and it becomes a polling.
Best regards,
On 2025/06/24 1:32, Xuneng Zhou wrote: > Hi, > > > Here's patch version 4. > > > 1. The problem > > I conducted further investigation on this issue. The 1ms sleep in XactLockTableWait that falls back to polling was notproblematic in certain scenarios prior to v16. It became an potential issue after the "Allow logical decoding on standbys"feature was introduced [1]. After that commit, we can now create logical replication slots on hot standby serversand perform many other logical decoding operations. [2] > > > > 2. The analysis > > Is this issue limited to calling sites related to logical decoding? I believe so. As we've discussed, the core issue isthat primary transactions are not running locally on the standby, which breaks the assumption of XactLockTableWait—thatthere is an xid lock to wait on. Other call stacks of this function, except those from logical decoding,are unlikely to encounter this problem because they are unlikely to be invoked from standby servers. > > > Analysis of XactLockTableWait calling sites: > > > Problematic Case (Hot Standby): > > - Logical decoding operations in snapbuild.c during snapshot building > > - This is thecase that can run on hot standby and experience the issue > > > Non-problematic Cases (Primary Only): > > - Heap operations (heapam.c): DML operations not possible on read-only standby > > - B-tree operations (nbtinsert.c): Index modifications impossible on standby > > - Logical apply workers (execReplication.c): Cannot start during recovery (BgWorkerStart_RecoveryFinished) > > - All other cases: Require write operations unavailable on standby > > > > 3. The proposed solution > > If the above analysis is sound, one potential fix would be to add separate branching for standby in XactLockTableWait.However, this seems inconsistent with the function's definition—there's simply no lock entry in the locktable for waiting. We could implement a new function for this logic, To be honest, I'm fine with v3, since it only increases the sleep time after 5000 loop iterations, which has negligible performance impact. But if these functions aren't intended to be used during recovery and the loop shouldn't reach that many iterations, I'm also okay with the v4 approach of introducing a separate function specifically for recovery. But this amakes me wonder if we should add something like Assert(!RecoveryInProgress()) to those two functions, to prevent them from being used during recovery in the future. > but it's hard to find a proper place for it to fit well: lmgr.c is for locks, while standby.c or procarray.c are not thatideal either. Therefore, I placed the special handling for standby in SnapBuildWaitSnapshot. Since the purpose and logic of the new function are similar to XactLockTableWait(), I think it would be better to place it nearby in lmgr.c, even though it doesn't handle a lock directly. That would help keep the related logic together and improve readability. Regards, -- Fujii Masao NTT DATA Japan Corporation
Hi, On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: > On 2025/06/24 1:32, Xuneng Zhou wrote: > > 3. The proposed solution > > > > If the above analysis is sound, one potential fix would be to add > > separate branching for standby in XactLockTableWait. However, this seems > > inconsistent with the function's definition—there's simply no lock entry > > in the lock table for waiting. We could implement a new function for > > this logic, > > To be honest, I'm fine with v3, since it only increases the sleep time > after 5000 loop iterations, which has negligible performance impact. I think this is completely the wrong direction. We should make XactLockTableWait() on standbys, not make the polling smarter. I think neither v3 nor v4 are viable patches. Greetings, Andres Freund
On 2025/07/02 23:04, Andres Freund wrote: > Hi, > > On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: >> On 2025/06/24 1:32, Xuneng Zhou wrote: >>> 3. The proposed solution >>> >>> If the above analysis is sound, one potential fix would be to add >>> separate branching for standby in XactLockTableWait. However, this seems >>> inconsistent with the function's definition—there's simply no lock entry >>> in the lock table for waiting. We could implement a new function for >>> this logic, >> >> To be honest, I'm fine with v3, since it only increases the sleep time >> after 5000 loop iterations, which has negligible performance impact. > > I think this is completely the wrong direction. We should make > XactLockTableWait() on standbys, not make the polling smarter. On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps. But are you suggesting that this doesn't need to be addressed? Or do you have another idea for how to handle it? Regards, -- Fujii Masao NTT DATA Japan Corporation
Hi, On July 2, 2025 10:15:09 AM EDT, Fujii Masao <masao.fujii@oss.nttdata.com> wrote: > > >On 2025/07/02 23:04, Andres Freund wrote: >> Hi, >> >> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: >>> On 2025/06/24 1:32, Xuneng Zhou wrote: >>>> 3. The proposed solution >>>> >>>> If the above analysis is sound, one potential fix would be to add >>>> separate branching for standby in XactLockTableWait. However, this seems >>>> inconsistent with the function's definition—there's simply no lock entry >>>> in the lock table for waiting. We could implement a new function for >>>> this logic, >>> >>> To be honest, I'm fine with v3, since it only increases the sleep time >>> after 5000 loop iterations, which has negligible performance impact. >> >> I think this is completely the wrong direction. We should make >> XactLockTableWait() on standbys, not make the polling smarter. > >On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps. Right. >But are you suggesting that this doesn't need to be addressed? No. >Or do you have another idea for how to handle it? We have all the information to make it work properly on standby. I've not find through the code to figure out not, but that'swhat needs to happen, instead on putting on another layer of hacks. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On 2025/07/02 23:19, Andres Freund wrote: > Hi, > > On July 2, 2025 10:15:09 AM EDT, Fujii Masao <masao.fujii@oss.nttdata.com> wrote: >> >> >> On 2025/07/02 23:04, Andres Freund wrote: >>> Hi, >>> >>> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: >>>> On 2025/06/24 1:32, Xuneng Zhou wrote: >>>>> 3. The proposed solution >>>>> >>>>> If the above analysis is sound, one potential fix would be to add >>>>> separate branching for standby in XactLockTableWait. However, this seems >>>>> inconsistent with the function's definition—there's simply no lock entry >>>>> in the lock table for waiting. We could implement a new function for >>>>> this logic, >>>> >>>> To be honest, I'm fine with v3, since it only increases the sleep time >>>> after 5000 loop iterations, which has negligible performance impact. >>> >>> I think this is completely the wrong direction. We should make >>> XactLockTableWait() on standbys, not make the polling smarter. >> >> On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps. > > Right. > >> But are you suggesting that this doesn't need to be addressed? > > No. > >> Or do you have another idea for how to handle it? > > We have all the information to make it work properly on standby. I've not find through the code to figure out not, butthat's what needs to happen, instead on putting on another layer of hacks. Sorry, maybe I failed to get your point... Could you explain your idea or reasoning in a bit more detail? Regards, -- Fujii Masao NTT DATA Japan Corporation
On 2025/07/02 23:19, Andres Freund wrote:
> Hi,
>
> On July 2, 2025 10:15:09 AM EDT, Fujii Masao <masao.fujii@oss.nttdata.com> wrote:
>>
>>
>> On 2025/07/02 23:04, Andres Freund wrote:
>>> Hi,
>>>
>>> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote:
>>>> On 2025/06/24 1:32, Xuneng Zhou wrote:
>>>>> 3. The proposed solution
>>>>>
>>>>> If the above analysis is sound, one potential fix would be to add
>>>>> separate branching for standby in XactLockTableWait. However, this seems
>>>>> inconsistent with the function's definition—there's simply no lock entry
>>>>> in the lock table for waiting. We could implement a new function for
>>>>> this logic,
>>>>
>>>> To be honest, I'm fine with v3, since it only increases the sleep time
>>>> after 5000 loop iterations, which has negligible performance impact.
>>>
>>> I think this is completely the wrong direction. We should make
>>> XactLockTableWait() on standbys, not make the polling smarter.
>>
>> On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps.
>
> Right.
>
>> But are you suggesting that this doesn't need to be addressed?
>
> No.
>
>> Or do you have another idea for how to handle it?
>
> We have all the information to make it work properly on standby. I've not find through the code to figure out not, but that's what needs to happen, instead on putting on another layer of hacks.
Sorry, maybe I failed to get your point...
Could you explain your idea or reasoning in a bit more detail?
My take is that XactLockTableWait() isn’t really designed to work on standby. Instead of adding another layer on top like v4 did, maybe we can tweak the function itself to support standby. One possible approach could be to add a check like RecoveryInProgress() to handle the logic when running on a standby.
To be honest, I'm fine with v3, since it only increases the sleep time
after 5000 loop iterations, which has negligible performance impact.
But if these functions aren't intended to be used during recovery and
the loop shouldn't reach that many iterations, I'm also okay with
the v4 approach of introducing a separate function specifically for recovery.
But this amakes me wonder if we should add something like
Assert(!RecoveryInProgress()) to those two functions, to prevent them
from being used during recovery in the future.
> but it's hard to find a proper place for it to fit well: lmgr.c is for locks, while standby.c or procarray.c are not that ideal either. Therefore, I placed the special handling for standby in SnapBuildWaitSnapshot.
Since the purpose and logic of the new function are similar to
XactLockTableWait(), I think it would be better to place it nearby
in lmgr.c, even though it doesn't handle a lock directly. That would
help keep the related logic together and improve readability.
Hi,
>>> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote:
>>>> On 2025/06/24 1:32, Xuneng Zhou wrote:
>>>>> 3. The proposed solution
>>>>>
>>>>> If the above analysis is sound, one potential fix would be to add
>>>>> separate branching for standby in XactLockTableWait. However, this seems
>>>>> inconsistent with the function's definition—there's simply no lock entry
>>>>> in the lock table for waiting. We could implement a new function for
>>>>> this logic,
>>>>
>>>> To be honest, I'm fine with v3, since it only increases the sleep time
>>>> after 5000 loop iterations, which has negligible performance impact.
>>>
>>> I think this is completely the wrong direction. We should make
>>> XactLockTableWait() on standbys, not make the polling smarter.
>>
>> On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps.
>
> Right.
>
>> But are you suggesting that this doesn't need to be addressed?
>
> No.
>
>> Or do you have another idea for how to handle it?
>
> We have all the information to make it work properly on standby. I've not find through the code to figure out not, but that's what needs to happen, instead on putting on another layer of hacks.
Sorry, maybe I failed to get your point...
Could you explain your idea or reasoning in a bit more detail?My take is that XactLockTableWait() isn’t really designed to work on standby. Instead of adding another layer on top like v4 did, maybe we can tweak the function itself to support standby. One possible approach could be to add a check like RecoveryInProgress() to handle the logic when running on a standby.
After thinking about this further, Andres's suggestion might be replacing polling(whether smart or not) with event-driven like waiting in XactLockTableWait. To achieve this, implementing a new notification mechanism for standby servers seems to be required. From what I can observe, the codebase appears to lack IPC infrastructure for waiting on remote transaction completion and receiving notifications when those transactions finish. I'm not familiar with this area, so additional inputs would be very helpful here.
On 2025/07/04 17:57, Xuneng Zhou wrote: > Hi, > > On Thu, Jul 3, 2025 at 9:30 AM Xuneng Zhou <xunengzhou@gmail.com <mailto:xunengzhou@gmail.com>> wrote: > > Hi, > > > >>> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: > >>>> On 2025/06/24 1:32, Xuneng Zhou wrote: > >>>>> 3. The proposed solution > >>>>> > >>>>> If the above analysis is sound, one potential fix would be to add > >>>>> separate branching for standby in XactLockTableWait. However, this seems > >>>>> inconsistent with the function's definition—there's simply no lock entry > >>>>> in the lock table for waiting. We could implement a new function for > >>>>> this logic, > >>>> > >>>> To be honest, I'm fine with v3, since it only increases the sleep time > >>>> after 5000 loop iterations, which has negligible performance impact. > >>> > >>> I think this is completely the wrong direction. We should make > >>> XactLockTableWait() on standbys, not make the polling smarter. > >> > >> On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps. > > > > Right. > > > >> But are you suggesting that this doesn't need to be addressed? > > > > No. > > > >> Or do you have another idea for how to handle it? > > > > We have all the information to make it work properly on standby. I've not find through the code to figure outnot, but that's what needs to happen, instead on putting on another layer of hacks. > > Sorry, maybe I failed to get your point... > Could you explain your idea or reasoning in a bit more detail? > > > My take is that XactLockTableWait() isn’t really designed to work on standby. Instead of adding another layer on toplike v4 did, maybe we can tweak the function itself to support standby. One possible approach could be to add a checklike RecoveryInProgress() to handle the logic when running on a standby. > > > After thinking about this further, Andres's suggestion might be replacing polling(whether smart or not) with event-drivenlike waiting in XactLockTableWait. To achieve this, implementing a new notification mechanism for standby serversseems to be required. From what I can observe, the codebase appears to lack IPC infrastructure for waiting on remotetransaction completion and receiving notifications when those transactions finish. I'm not familiar with this area,so additional inputs would be very helpful here. Your guess might be right, or maybe not. It's hard for me to say for sure. It seems better to wait for Andres to explain his idea in more detail, rather than trying to guess... Regards, -- Fujii Masao NTT DATA Japan Corporation
On 2025-07-05 01:14:45 +0900, Fujii Masao wrote: > > > On 2025/07/04 17:57, Xuneng Zhou wrote: > > Hi, > > > > On Thu, Jul 3, 2025 at 9:30 AM Xuneng Zhou <xunengzhou@gmail.com <mailto:xunengzhou@gmail.com>> wrote: > > > > Hi, > > > > > > >>> On 2025-07-02 22:55:16 +0900, Fujii Masao wrote: > > >>>> On 2025/06/24 1:32, Xuneng Zhou wrote: > > >>>>> 3. The proposed solution > > >>>>> > > >>>>> If the above analysis is sound, one potential fix would be to add > > >>>>> separate branching for standby in XactLockTableWait. However, this seems > > >>>>> inconsistent with the function's definition—there's simply no lock entry > > >>>>> in the lock table for waiting. We could implement a new function for > > >>>>> this logic, > > >>>> > > >>>> To be honest, I'm fine with v3, since it only increases the sleep time > > >>>> after 5000 loop iterations, which has negligible performance impact. > > >>> > > >>> I think this is completely the wrong direction. We should make > > >>> XactLockTableWait() on standbys, not make the polling smarter. > > >> > > >> On standby, XactLockTableWait() can enter a busy loop with 1ms sleeps. > > > > > > Right. > > > > > >> But are you suggesting that this doesn't need to be addressed? > > > > > > No. > > > > > >> Or do you have another idea for how to handle it? > > > > > > We have all the information to make it work properly on standby. I've not find through the code to figureout not, but that's what needs to happen, instead on putting on another layer of hacks. > > > > Sorry, maybe I failed to get your point... > > Could you explain your idea or reasoning in a bit more detail? > > > > > > My take is that XactLockTableWait() isn’t really designed to work on standby. Instead of adding another layer ontop like v4 did, maybe we can tweak the function itself to support standby. One possible approach could be to add a checklike RecoveryInProgress() to handle the logic when running on a standby. > > > > > > After thinking about this further, Andres's suggestion might be replacing polling(whether smart or not) with event-drivenlike waiting in XactLockTableWait. To achieve this, implementing a new notification mechanism for standby serversseems to be required. From what I can observe, the codebase appears to lack IPC infrastructure for waiting on remotetransaction completion and receiving notifications when those transactions finish. I'm not familiar with this area,so additional inputs would be very helpful here. > > Your guess might be right, or maybe not. It's hard for me to say for sure. > It seems better to wait for Andres to explain his idea in more detail, > rather than trying to guess... My position is basically: 1) We should *never* add new long-duration polling loops to postgres. We've regretted it every time. It just ends up masking bugs and biting us in scenarios we didn't predict (increased wakeups increasing power usage, increased latency because our more eager wakeup mechanisms were racy). 2) We should try rather hard to not even have any new very short lived polling code. The existing code in XactLockTableWait() isn't great, even on the primary, but the window during the polling addresses is really short, so it's *kinda* acceptable. 3) There are many ways to address the XactLockTableWait() issue here. One way would be to simply make XactLockTableWait() work on standbys, by maintaining the lock table. Another would be to teach it to add some helper to procarray.c that allows XactLockTableWait() to work based on the KnownAssignedXids machinery. I don't have a clear preference for how to make this work in a non-polling way. But it's clear to me that making it poll smarter is the completely wrong direction. Greetings, Andres Freund
Hi,
I spent some time digging deeper into the KnownAssignedXids logic in
procarray.c and made a few refinements. Below are some observations
and questions I’d like to discuss.
1) Present usage (AFAICS)
It appears that logical decoding is the only place that waits for an
XID on a standby. The single call-site is SnapBuildWaitSnapshot(),
which waits in a simple loop:
for (off = 0; off < running->xcnt; off++)
{
TransactionId xid = running->xids[off];
if (TransactionIdIsCurrentTransactionId(xid))
elog(ERROR, "waiting for ourselves");
if (TransactionIdFollows(xid, cutoff))
continue;
XactLockTableWait(xid, NULL, NULL, XLTW_None);
}
So each backend seems to block on one XID at a time.
2) Picking the waiter data structure
Given that behaviour, the total number of concurrent waits can’t exceed
MaxBackends. If logical-slot creation stays the primary consumer for
now and for future, I’m wondering
whether a simple fixed-size array (or even a single global
ConditionVariable) might be sufficient.
In the patch I currently size the hash table the same as
KnownAssignedXids (TOTAL_MAX_CACHED_SUBXIDS), but that may well be
conservative.
3) Some trims
I’ve removed WakeAllXidWaiters() and call WakeXidWaiters() at each
point where an XID is deleted from KnownAssignedXids.
Feedback would be much appreciated.
Best,
Xuneng
Вложения
Hi all, I spent some extra time walking the code to see where XactLockTableWait() actually fires. A condensed recap: 1) Current call-paths A. Logical walsender (XLogSendLogical → … → SnapBuildWaitSnapshot) in cascading standby B. SQL slot functions (pg_logical_slot_get_changes[_peek]) create_logical_replication_slot pg_sync_replication_slots pg_replication_slot_advance binary_upgrade_logical_slot_has_caught_up 2) How many backends and XIDs in practice A. Logical walsenders on a cascading standby One per replication connection, capped by max_wal_senders. default 10; hubs might run 10–40. B. Logical slot creation is infrequent and bounded by max_replication_slots, default 10; other functions are not called that often either. C. Wait pattern XIDs waited-for during a snapshot build: SnapBuildWaitSnapshot wait for one xid a time; So, under today’s workloads both the number of xids and waiters stay modest concurrently. 3) Future growth Some features could multiply the number of concurrent waiters, but I don’t have enough knowledge to predict those shapes. Feedbacks welcome. Best, Xuneng
Hi,
After studying proarray and lmgr more closely, I have found several
critical issues in the two patches and underestimated their complexity
and subtlety. Sorry for posting immature patches that may have created
noise.
I now realize that making lock acquisition— (void) LockAcquire(&tag,
ShareLock, false, false); in XactLockTableWait
work on a standby, following Andres’ first suggestion, may be simpler
and require fewer new helpers.
XactLockTableWait fails on a standby simply because we never call
XactLockTableInsert. I am considering invoking XactLockTableInsert
when an XID is added to KnownAssignedXids, and XactLockTableDelete(the
constraint for delete now is not used for main xid in primary) when it
is removed. A preliminary implementation and test shows this approach
kinda works, but still need to confirm it is safe on a standby and
does not break other things.
patched:
Performance counter stats for process id '2331196':
233,947,559 cycles
106,270,044 instructions # 0.45
insn per cycle
12,464,449 cache-misses
9,397 context-switches
60.001191369 seconds time elapsed
head:
Performance counter stats for process id '2435004':
1,258,615,994 cycles
575,248,830 instructions # 0.46
insn per cycle
72,508,027 cache-misses
43,791 context-switches
60.001040589 seconds time elapsed
Best,
Xuneng
Вложения
{kind=link}
Hi, On Thu, Jul 17, 2025 at 10:54 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > After studying proarray and lmgr more closely, I have found several > critical issues in the two patches and underestimated their complexity > and subtlety. Sorry for posting immature patches that may have created > noise. > > I now realize that making lock acquisition— (void) LockAcquire(&tag, > ShareLock, false, false); in XactLockTableWait > work on a standby, following Andres’ first suggestion, may be simpler > and require fewer new helpers. > > XactLockTableWait fails on a standby simply because we never call > XactLockTableInsert. I am considering invoking XactLockTableInsert > when an XID is added to KnownAssignedXids, and XactLockTableDelete(the > constraint for delete now is not used for main xid in primary) when it > is removed. A preliminary implementation and test shows this approach > kinda works, but still need to confirm it is safe on a standby and > does not break other things. Adding an xact lock for every tracked assigned XID on a standby—by enabling XactLockTableInsert and XactLockTableDelete in the KnownAssignedXids infrastructure— appears less attractive than I first thought. The main concern is that the actual rate of xact-lock usage may not justify the added overhead, even if that overhead is modest. 1) Usage On a primary server, a xact lock is taken for every assigned XID, and the cost is justified because xact locks are referenced in many code paths. On a standby, however—especially in versions where logical decoding is disabled—xact locks are used far less, if at all. The current call stacks for XactLockTableWait on a standby (HEAD) are listed in [1]. The only high-frequency caller is the logical walsender in a cascading standby; all other callers are infrequent. Does that single use case warrant creating a xact lock for every known assigned XID? I don't think so, given that typical configurations have few cascading standbys. In practice, most xact locks may never be touched after they are created. 2) Cost Low usage would be fine if the additional cost were negligible, but that does not appear to be the case AFAICS. * There are 5 main uses of the KnownAssignedXids data structure: * * backends taking snapshots - all valid XIDs need to be copied out * * backends seeking to determine presence of a specific XID * * startup process adding new known-assigned XIDs * * startup process removing specific XIDs as transactions end * * startup process pruning array when special WAL records arrive * * This data structure is known to be a hot spot during Hot Standby, so we * go to some lengths to make these operations as efficient and as concurrent * as possible. KnownAssignedXids is a hot spot like the comments state. The existing design replaces a hash table with a single array and minimizes exclusive locks and memory barriers to preserve concurrency. To respect that design, calls to XactLockTableInsert and XactLockTableDelete would need to occur outside any exclusive lock. Unfortunately, that re-introduces the polling we are trying to eliminate in XactLockTableWait: there is a window between registering the XIDs and adding their xact locks. During that window, a backend calling XactLockTableWait may need to poll because TransactionIdIsInProgress shows the transaction as running while the xact lock is still missing. If the window were short, this might be acceptable, but it can be lengthy because XIDs are inserted and deleted from the array in bulk. Some unlucky backends will therefore spin before they can actually wait. Placing the XactLockTableInsert/Delete calls inside the exclusive lock removes the race window but hurts concurrency—the very issue this module strives to avoid. Operations on the shared-memory hash table in lmgr are slower and hold the lock longer than simple array updates, so backends invoking GetSnapshotData could experience longer wait times. 3) Alternative Adopt the hash-table + condition-variable design from patch v6, with additional fixes and polishes. Back-ends that call XactLockTableWait() sleep on the condition variable. The startup process broadcasts a wake-up as the XID is removed from KnownAssignedXids. The broadcast happens after releasing the exclusive lock. This may be safe—sleeping back-ends remain blocked until the CV signal arrives, so no extra polling occurs even though the XID has already vanished from the array. For consistency, all removal paths (including those used during shutdown or promotion, where contention is minimal) follow the same pattern. The hash table is sized at 2 × MaxBackends, which is already conservative for today’s workload. For more potential concurrent use cases in the future, it could be switched to larger numbers like TOTAL_MAX_CACHED_SUBXIDS if necessary; even that would consume only a few megabytes. Feedbacks welcome. [1] https://www.postgresql.org/message-id/CABPTF7Wbp7MRPGsqd9NA4GbcSzUcNz1ymgWfir=Yf+N0oDRbjA@mail.gmail.com Best, Xuneng
Вложения
Hi,
During a short 100-second pg_create_logical_replication_slot benchmark
in standby, I compared HEAD with patch v7. v7 removes the
XactLockTableWait polling hot-spot (it no longer shows up in the flame
graph), yet the overall perf-counter numbers are only modestly lower,
suggesting something abnormal .
HEAD
cycles: 2,930,606,156
instructions: 1,003,179,713 (0.34 IPC)
cache-misses: 144,808,110
context-switches: 77,278
elapsed: 100 s
v7
cycles: 2,121,614,632
instructions: 802,200,231 (0.38 IPC)
cache-misses: 100,615,485
context-switches: 78,120
elapsed: 100 s
Profiling shows a second hot-spot in read_local_xlog_page_guts(),
which still relies on a check/sleep loop.
There’s also a todo suggesting further improvements:
/*
* Loop waiting for xlog to be available if necessary
*
* TODO: The walsender has its own version of this function, which uses a
* condition variable to wake up whenever WAL is flushed. We could use the
* same infrastructure here, instead of the check/sleep/repeat style of
* loop.
*/
To test the idea, I implemented an experimental patch. With both v7
and this change applied, the polling disappears from the flame graph
and the counters drop by roughly orders of magnitude:
v7 + CV in read_local_xlog_page_guts
cycles: 6,284,633
instructions: 3,990,034 (0.63 IPC)
cache-misses: 163,394
context-switches: 6
elapsed: 100 s
I plan to post a new patch to fix this as well after further
refinements and tests.
Best,
Xuneng
Вложения
{kind=link}
{kind=link}
{kind=link}
Hi, On Mon, Jul 28, 2025 at 7:14 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > On Thu, Jul 17, 2025 at 10:54 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi, > > > > After studying proarray and lmgr more closely, I have found several > > critical issues in the two patches and underestimated their complexity > > and subtlety. Sorry for posting immature patches that may have created > > noise. > > > > I now realize that making lock acquisition— (void) LockAcquire(&tag, > > ShareLock, false, false); in XactLockTableWait > > work on a standby, following Andres’ first suggestion, may be simpler > > and require fewer new helpers. > > > > XactLockTableWait fails on a standby simply because we never call > > XactLockTableInsert. I am considering invoking XactLockTableInsert > > when an XID is added to KnownAssignedXids, and XactLockTableDelete(the > > constraint for delete now is not used for main xid in primary) when it > > is removed. A preliminary implementation and test shows this approach > > kinda works, but still need to confirm it is safe on a standby and > > does not break other things. > > Adding an xact lock for every tracked assigned XID on a standby—by > enabling XactLockTableInsert and XactLockTableDelete in the > KnownAssignedXids infrastructure— appears less attractive than I first > thought. The main concern is that the actual rate of xact-lock usage > may not justify the added overhead, even if that overhead is modest. > > 1) Usage > On a primary server, a xact lock is taken for every assigned XID, and > the cost is justified because xact locks are referenced in many code > paths. On a standby, however—especially in versions where logical > decoding is disabled—xact locks are used far less, if at all. The > current call stacks for XactLockTableWait on a standby (HEAD) are > listed in [1]. The only high-frequency caller is the logical walsender > in a cascading standby; all other callers are infrequent. Does that > single use case warrant creating a xact lock for every known assigned > XID? I don't think so, given that typical configurations have few > cascading standbys. In practice, most xact locks may never be touched > after they are created. > > 2) Cost > Low usage would be fine if the additional cost were negligible, but > that does not appear to be the case AFAICS. > > * There are 5 main uses of the KnownAssignedXids data structure: > * * backends taking snapshots - all valid XIDs need to be copied out > * * backends seeking to determine presence of a specific XID > * * startup process adding new known-assigned XIDs > * * startup process removing specific XIDs as transactions end > * * startup process pruning array when special WAL records arrive > * > * This data structure is known to be a hot spot during Hot Standby, so we > * go to some lengths to make these operations as efficient and as concurrent > * as possible. > > KnownAssignedXids is a hot spot like the comments state. The existing > design replaces a hash table with a single array and minimizes > exclusive locks and memory barriers to preserve concurrency. To > respect that design, calls to XactLockTableInsert and > XactLockTableDelete would need to occur outside any exclusive lock. > Unfortunately, that re-introduces the polling we are trying to > eliminate in XactLockTableWait: there is a window between registering > the XIDs and adding their xact locks. During that window, a backend > calling XactLockTableWait may need to poll because > TransactionIdIsInProgress shows the transaction as running while the > xact lock is still missing. If the window were short, this might be > acceptable, but it can be lengthy because XIDs are inserted and > deleted from the array in bulk. Some unlucky backends will therefore > spin before they can actually wait. > > Placing the XactLockTableInsert/Delete calls inside the exclusive lock > removes the race window but hurts concurrency—the very issue this > module strives to avoid. Operations on the shared-memory hash table in > lmgr are slower and hold the lock longer than simple array updates, so > backends invoking GetSnapshotData could experience longer wait times. > > 3) Alternative > Adopt the hash-table + condition-variable design from patch v6, with > additional fixes and polishes. > Back-ends that call XactLockTableWait() sleep on the condition > variable. The startup process broadcasts a wake-up as the XID is > removed from KnownAssignedXids. The broadcast happens after releasing > the exclusive lock. This may be safe—sleeping back-ends remain blocked > until the CV signal arrives, so no extra polling occurs even though > the XID has already vanished from the array. For consistency, all > removal paths (including those used during shutdown or promotion, > where contention is minimal) follow the same pattern. The hash table > is sized at 2 × MaxBackends, which is already conservative for today’s > workload. For more potential concurrent use cases in the future, it > could be switched to larger numbers like TOTAL_MAX_CACHED_SUBXIDS if > necessary; even that would consume only a few megabytes. > > Feedbacks welcome. > > [1] https://www.postgresql.org/message-id/CABPTF7Wbp7MRPGsqd9NA4GbcSzUcNz1ymgWfir=Yf+N0oDRbjA@mail.gmail.com Because XactLocks are not maintained on a standby server, and the current waiting approach does not rely on Xact locks as well; I therefore added assertions to both functions to prevent their use on a standby and introduced an explicit primary-versus-standby branch in SnapBuildWaitSnapshot in v8. In procarray.c, two corrections are made compared with v7: Removed the seemingly redundant initialized field from XidWaitEntry. Removed the erroneous InHotStandby checks in the wait and wake helpers. With these changes applied, here's some perf stats for v8, which are about one order of magnitude smaller than those of head. Performance counter stats for process id '3273840': 351,183,876 cycles 126,586,090 instructions # 0.36 insn per cycle 16,670,633 cache-misses 10,030 context-switches 100.001419856 seconds time elapsed Best, Xuneng
Вложения
{kind=link}
Hi, On Wed, Jul 30, 2025 at 11:42 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > On Mon, Jul 28, 2025 at 7:14 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi, > > > > On Thu, Jul 17, 2025 at 10:54 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > > > Hi, > > > > > > After studying proarray and lmgr more closely, I have found several > > > critical issues in the two patches and underestimated their complexity > > > and subtlety. Sorry for posting immature patches that may have created > > > noise. > > > > > > I now realize that making lock acquisition— (void) LockAcquire(&tag, > > > ShareLock, false, false); in XactLockTableWait > > > work on a standby, following Andres’ first suggestion, may be simpler > > > and require fewer new helpers. > > > > > > XactLockTableWait fails on a standby simply because we never call > > > XactLockTableInsert. I am considering invoking XactLockTableInsert > > > when an XID is added to KnownAssignedXids, and XactLockTableDelete(the > > > constraint for delete now is not used for main xid in primary) when it > > > is removed. A preliminary implementation and test shows this approach > > > kinda works, but still need to confirm it is safe on a standby and > > > does not break other things. > > > > Adding an xact lock for every tracked assigned XID on a standby—by > > enabling XactLockTableInsert and XactLockTableDelete in the > > KnownAssignedXids infrastructure— appears less attractive than I first > > thought. The main concern is that the actual rate of xact-lock usage > > may not justify the added overhead, even if that overhead is modest. > > > > 1) Usage > > On a primary server, a xact lock is taken for every assigned XID, and > > the cost is justified because xact locks are referenced in many code > > paths. On a standby, however—especially in versions where logical > > decoding is disabled—xact locks are used far less, if at all. The > > current call stacks for XactLockTableWait on a standby (HEAD) are > > listed in [1]. The only high-frequency caller is the logical walsender > > in a cascading standby; all other callers are infrequent. Does that > > single use case warrant creating a xact lock for every known assigned > > XID? I don't think so, given that typical configurations have few > > cascading standbys. In practice, most xact locks may never be touched > > after they are created. > > > > 2) Cost > > Low usage would be fine if the additional cost were negligible, but > > that does not appear to be the case AFAICS. > > > > * There are 5 main uses of the KnownAssignedXids data structure: > > * * backends taking snapshots - all valid XIDs need to be copied out > > * * backends seeking to determine presence of a specific XID > > * * startup process adding new known-assigned XIDs > > * * startup process removing specific XIDs as transactions end > > * * startup process pruning array when special WAL records arrive > > * > > * This data structure is known to be a hot spot during Hot Standby, so we > > * go to some lengths to make these operations as efficient and as concurrent > > * as possible. > > > > KnownAssignedXids is a hot spot like the comments state. The existing > > design replaces a hash table with a single array and minimizes > > exclusive locks and memory barriers to preserve concurrency. To > > respect that design, calls to XactLockTableInsert and > > XactLockTableDelete would need to occur outside any exclusive lock. > > Unfortunately, that re-introduces the polling we are trying to > > eliminate in XactLockTableWait: there is a window between registering > > the XIDs and adding their xact locks. During that window, a backend > > calling XactLockTableWait may need to poll because > > TransactionIdIsInProgress shows the transaction as running while the > > xact lock is still missing. If the window were short, this might be > > acceptable, but it can be lengthy because XIDs are inserted and > > deleted from the array in bulk. Some unlucky backends will therefore > > spin before they can actually wait. > > > > Placing the XactLockTableInsert/Delete calls inside the exclusive lock > > removes the race window but hurts concurrency—the very issue this > > module strives to avoid. Operations on the shared-memory hash table in > > lmgr are slower and hold the lock longer than simple array updates, so > > backends invoking GetSnapshotData could experience longer wait times. > > > > 3) Alternative > > Adopt the hash-table + condition-variable design from patch v6, with > > additional fixes and polishes. > > Back-ends that call XactLockTableWait() sleep on the condition > > variable. The startup process broadcasts a wake-up as the XID is > > removed from KnownAssignedXids. The broadcast happens after releasing > > the exclusive lock. This may be safe—sleeping back-ends remain blocked > > until the CV signal arrives, so no extra polling occurs even though > > the XID has already vanished from the array. For consistency, all > > removal paths (including those used during shutdown or promotion, > > where contention is minimal) follow the same pattern. The hash table > > is sized at 2 × MaxBackends, which is already conservative for today’s > > workload. For more potential concurrent use cases in the future, it > > could be switched to larger numbers like TOTAL_MAX_CACHED_SUBXIDS if > > necessary; even that would consume only a few megabytes. > > > > Feedbacks welcome. > > > > [1] https://www.postgresql.org/message-id/CABPTF7Wbp7MRPGsqd9NA4GbcSzUcNz1ymgWfir=Yf+N0oDRbjA@mail.gmail.com > > Because XactLocks are not maintained on a standby server, and the > current waiting approach does not rely on Xact locks as well; I > therefore added assertions to both functions to prevent their use on a > standby and introduced an explicit primary-versus-standby branch in > SnapBuildWaitSnapshot in v8. > > In procarray.c, two corrections are made compared with v7: > Removed the seemingly redundant initialized field from XidWaitEntry. > Removed the erroneous InHotStandby checks in the wait and wake helpers. > > With these changes applied, here's some perf stats for v8, which are > about one order of magnitude smaller than those of head. > > Performance counter stats for process id '3273840': > > 351,183,876 cycles > 126,586,090 instructions # 0.36 > insn per cycle > 16,670,633 cache-misses > 10,030 context-switches > > 100.001419856 seconds time elapsed > V9 replaces the original partitioned xid-wait htab with a single, unified one, reflecting the modest entry count and rare contention for waiting. To prevent possible races when multiple backends wait on the same XID for the first time in XidWaitOnStandby, a dedicated lock has been added to protect the hash table. Best, Xuneng
Вложения
Xuneng Zhou <xunengzhou@gmail.com> writes:
> V9 replaces the original partitioned xid-wait htab with a single,
> unified one, reflecting the modest entry count and rare contention for
> waiting. To prevent possible races when multiple backends wait on the
> same XID for the first time in XidWaitOnStandby, a dedicated lock has
> been added to protect the hash table.
This seems like adding quite a lot of extremely subtle code in
order to solve a very small problem. I thought the v1 patch
was about the right amount of complexity.
regards, tom lane
Hi, Tom! Thanks for looking at this. On Fri, Aug 8, 2025 at 2:20 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Xuneng Zhou <xunengzhou@gmail.com> writes: > > V9 replaces the original partitioned xid-wait htab with a single, > > unified one, reflecting the modest entry count and rare contention for > > waiting. To prevent possible races when multiple backends wait on the > > same XID for the first time in XidWaitOnStandby, a dedicated lock has > > been added to protect the hash table. > > This seems like adding quite a lot of extremely subtle code in > order to solve a very small problem. I thought the v1 patch > was about the right amount of complexity. Yeah, this patch is indeed complex, and the complexity might not be well-justified—given the current use cases, it feels like we’re paying a lot for very little. TBH, getting the balance right between efficiency gains and cost, in terms of both code complexity and runtime overhead, is beyond my current ability here, since I’m touching many parts of the code for the first time. Every time I thought I’d figured it out, new subtleties surfaced—though I’ve learned a lot from the exploration and hacking. We may agree on the necessity of fixing this issue, but not yet on how to fix it. I’m open to discussion and suggestions. Best, Xuneng
Hi, On Fri, Aug 8, 2025 at 7:06 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, Tom! > > Thanks for looking at this. > > On Fri, Aug 8, 2025 at 2:20 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > Xuneng Zhou <xunengzhou@gmail.com> writes: > > > V9 replaces the original partitioned xid-wait htab with a single, > > > unified one, reflecting the modest entry count and rare contention for > > > waiting. To prevent possible races when multiple backends wait on the > > > same XID for the first time in XidWaitOnStandby, a dedicated lock has > > > been added to protect the hash table. > > > > This seems like adding quite a lot of extremely subtle code in > > order to solve a very small problem. I thought the v1 patch > > was about the right amount of complexity. > > Yeah, this patch is indeed complex, and the complexity might not be > well-justified—given the current use cases, it feels like we’re paying > a lot for very little. TBH, getting the balance right between > efficiency gains and cost, in terms of both code complexity and > runtime overhead, is beyond my current ability here, since I’m > touching many parts of the code for the first time. Every time I > thought I’d figured it out, new subtleties surfaced—though I’ve > learned a lot from the exploration and hacking. We may agree on the > necessity of fixing this issue, but not yet on how to fix it. I’m open > to discussion and suggestions. > Some changes in v10: 1) XidWaitHashLock is used for all operations on XidWaitHash though might be unnecessary for some cases. 2) Field pg_atomic_uint32 waiter_count was removed from the XidWaitEntry. The start process now takes charge of cleaning up the XidWaitHash entry after waking up processes. 3) pg_atomic_uint32 xidWaiterNum is added to avoid unnecessary lock acquire & release and htab look-up while there's no xid waiting. Hope this could eliminate some subtleties. Exponential backoff in earlier patches is simple and effective for alleviating cpu overhead in extended waiting; however it could also bring unwanted latency for more sensitive use cases like logical walsender on cascading standbys. Unfortunately, I am unable to come up with a solution that is correct, effective and simple in all cases. Best, Xuneng
Вложения
Hi, > Some changes in v10: > > 1) XidWaitHashLock is used for all operations on XidWaitHash though > might be unnecessary for some cases. > 2) Field pg_atomic_uint32 waiter_count was removed from the > XidWaitEntry. The start process now takes charge of cleaning up the > XidWaitHash entry after waking up processes. > 3) pg_atomic_uint32 xidWaiterNum is added to avoid unnecessary lock > acquire & release and htab look-up while there's no xid waiting. > > Hope this could eliminate some subtleties. > > Exponential backoff in earlier patches is simple and effective for > alleviating cpu overhead in extended waiting; however it could also > bring unwanted latency for more sensitive use cases like logical > walsender on cascading standbys. Unfortunately, I am unable to come up > with a solution that is correct, effective and simple in all cases. > v11 removed this erroneous optimization: 3) pg_atomic_uint32 xidWaiterNum is added to avoid unnecessary lock > acquire & release and htab look-up while there's no xid waiting. Best, Xuneng