Обсуждение: Automatically sizing the IO worker pool
It's hard to know how to set io_workers=3. If it's too small,
io_method=worker's small submission queue overflows and it silently
falls back to synchronous IO. If it's too high, it generates a lot of
pointless wakeups and scheduling overhead, which might be considered
an independent problem or not, but having the right size pool
certainly mitigates it. Here's a patch to replace that GUC with:
io_min_workers=1
io_max_workers=8
io_worker_idle_timeout=60s
io_worker_launch_interval=500ms
It grows the pool when a backlog is detected (better ideas for this
logic welcome), and lets idle workers time out. IO jobs were already
concentrated into the lowest numbered workers, partly because that
seemed to have marginally better latency than anything else tried so
far due to latch collapsing with lucky timing, and partly in
anticipation of this.
The patch also reduces bogus wakeups a bit by being a bit more
cautious about fanout. That could probably be improved a lot more and
needs more research. It's quite tricky to figure out how to suppress
wakeups without throwing potential concurrency away.
The first couple of patches are independent of this topic, and might
be potential cleanups/fixes for master/v18. The last is a simple
latency test.
Ideas, testing, flames etc welcome.
Вложения
On 12/4/25 18:59, Thomas Munro wrote: > It's hard to know how to set io_workers=3. Hmmm.... enable the below behaviour if "io_workers=auto" (default) ? Sometimes being able to set this kind of parameters manually helps tremendously with specific workloads... :S > [snip] > Here's a patch to replace that GUC with: > > io_min_workers=1 > io_max_workers=8 > io_worker_idle_timeout=60s > io_worker_launch_interval=500ms Great as defaults / backwards compat with io_workers=auto. Sounds more user-friendly to me, at least.... > [snip] > > Ideas, testing, flames etc welcome. Logic seems sound, if a bit daunting for inexperienced users --- well, maybe just a bit more than it is now, but ISTM evolution should try and flatten novices' learning curve, right? Just .02€, though. Thanks, -- Parkinson's Law: Work expands to fill the time alloted to it.
On Mon, Apr 14, 2025 at 5:45 AM Jose Luis Tallon <jltallon@adv-solutions.net> wrote: > On 12/4/25 18:59, Thomas Munro wrote: > > It's hard to know how to set io_workers=3. > > Hmmm.... enable the below behaviour if "io_workers=auto" (default) ? Why not just delete io_workers? If you really want a fixed number, you can set io_min_workers==io_max_workers. What should io_max_workers default to? I guess it could be pretty large without much danger, but I'm not sure. If it's a small value, an overloaded storage system goes through two stages: first it fills the queue up with a backlog of requests until it overflows because the configured maximum of workers isn't keeping up, and then new submissions start falling back to synchronous IO, sort of jumping ahead of the queued backlog, but also stalling if the real reason is that the storage itself isn't keeping up. Whether it'd be better for the IO worker pool to balloon all the way up to 32 processes (an internal limit) if required to try to avoid that with default settings, I'm not entirely sure. Maybe? Why not at least try to get all the concurrency possible, before falling back to synchronous? Queued but not running IOs seem to be strictly worse than queued but not even trying to run. I'd be interested to hear people's thoughts and experiences actually trying different kinds of workloads on different kinds of storage. Whether adding more concurrency actually helps or just generates a lot of useless new processes before the backpressure kicks in depends on why it's not keeping up, eg hitting IOPS, throughput or concurrency limits in the storage. In later work I hope we can make higher levels smarter about understanding whether requesting more concurrency helps or hurts with feedback (that's quite a hard problem that some of my colleagues have been looking into), but the simpler question here seems to be: should this fairly low level system-wide setting ship with a default that includes any preconceived assumptions about that? It's superficially like max_parallel_workers, which ships with a default of 8, and that's basically where I plucked that 8 from in the current patch for lack of a serious idea to propose yet. But it's also more complex than CPU: you know how many cores you have and you know things about your workload, but even really small "on the metal" systems probably have a lot more concurrent I/O capacity -- perhaps depending on the type of operation! (and so far we only have reads) -- than CPU cores. Especially once you completely abandon the idea that anyone runs databases on spinning rust in modern times, even on low end systems, which I think we've more or less agreed to assume these days with related changes such as the recent *_io_concurrency default change (1->16). It's actually pretty hard to drive a laptop up to needing more half a dozen or a dozen or a dozen or so workers with this patch for especially without debug_io_direct=data ie with fast double-buffered I/O, but cloud environments may also be where most databases run these days, and low end cloud configurations have arbitrary made up limits that may be pretty low, so it all depends.... I really don't know, but one idea is that we could leave it open as possible, and let users worry about that with higher-level settings and the query concurrency they choose to generate... io_method=io_uring is effectively open, so why should io_method=worker be any different by default? Just some thoughts. I'm not sure.
> On Sun, Apr 13, 2025 at 04:59:54AM GMT, Thomas Munro wrote: > It's hard to know how to set io_workers=3. If it's too small, > io_method=worker's small submission queue overflows and it silently > falls back to synchronous IO. If it's too high, it generates a lot of > pointless wakeups and scheduling overhead, which might be considered > an independent problem or not, but having the right size pool > certainly mitigates it. Here's a patch to replace that GUC with: > > io_min_workers=1 > io_max_workers=8 > io_worker_idle_timeout=60s > io_worker_launch_interval=500ms > > It grows the pool when a backlog is detected (better ideas for this > logic welcome), and lets idle workers time out. I like the idea. In fact, I've been pondering about something like a "smart" configuration for quite some time, and convinced that a similar approach needs to be applied to many performance-related GUCs. Idle timeout and launch interval serving as a measure of sensitivity makes sense to me, growing the pool when a backlog (queue_depth > nworkers, so even a slightest backlog?) is detected seems to be somewhat arbitrary. From what I understand the pool growing velocity is constant and do not depend on the worker demand (i.e. queue_depth)? It may sounds fancy, but I've got an impression it should be possible to apply what's called a "low-pass filter" in the control theory (sort of a transfer function with an exponential decay) to smooth out the demand and adjust the worker pool based on that. As a side note, it might be far fetched, but there are instruments in queueing theory to figure out how much workers are needed to guarantee a certain low queueing probability, but for that one needs to have an average arrival rate (in our case, average number of IO operations dispatched to workers) and an average service rate (average number of IO operations performed by workers).
HI
> On Sun, Apr 13, 2025 at 04:59:54AM GMT, Thomas Munro wrote:
> It's hard to know how to set io_workers=3. If it's too small,
> io_method=worker's small submission queue overflows and it silently
> falls back to synchronous IO. If it's too high, it generates a lot of
> pointless wakeups and scheduling overhead, which might be considered
> an independent problem or not, but having the right size pool
> certainly mitigates it. Here's a patch to replace that GUC with:
>
> io_min_workers=1
> io_max_workers=8
> io_worker_idle_timeout=60s
> io_worker_launch_interval=500ms
>
> It grows the pool when a backlog is detected (better ideas for this
> logic welcome), and lets idle workers time out.
> It's hard to know how to set io_workers=3. If it's too small,
> io_method=worker's small submission queue overflows and it silently
> falls back to synchronous IO. If it's too high, it generates a lot of
> pointless wakeups and scheduling overhead, which might be considered
> an independent problem or not, but having the right size pool
> certainly mitigates it. Here's a patch to replace that GUC with:
>
> io_min_workers=1
> io_max_workers=8
> io_worker_idle_timeout=60s
> io_worker_launch_interval=500ms
>
> It grows the pool when a backlog is detected (better ideas for this
> logic welcome), and lets idle workers time out.
I also like idea ,can we set a
io_workers= 3
io_max_workers= cpu/4
io_workers_oversubscribe = 3 (range 1-8)
io_workers * io_workers_oversubscribe <=io_max_workers
On Sun, May 25, 2025 at 3:20 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote:
> On Sun, Apr 13, 2025 at 04:59:54AM GMT, Thomas Munro wrote:
> It's hard to know how to set io_workers=3. If it's too small,
> io_method=worker's small submission queue overflows and it silently
> falls back to synchronous IO. If it's too high, it generates a lot of
> pointless wakeups and scheduling overhead, which might be considered
> an independent problem or not, but having the right size pool
> certainly mitigates it. Here's a patch to replace that GUC with:
>
> io_min_workers=1
> io_max_workers=8
> io_worker_idle_timeout=60s
> io_worker_launch_interval=500ms
>
> It grows the pool when a backlog is detected (better ideas for this
> logic welcome), and lets idle workers time out.
I like the idea. In fact, I've been pondering about something like a
"smart" configuration for quite some time, and convinced that a similar
approach needs to be applied to many performance-related GUCs.
Idle timeout and launch interval serving as a measure of sensitivity
makes sense to me, growing the pool when a backlog (queue_depth >
nworkers, so even a slightest backlog?) is detected seems to be somewhat
arbitrary. From what I understand the pool growing velocity is constant
and do not depend on the worker demand (i.e. queue_depth)? It may sounds
fancy, but I've got an impression it should be possible to apply what's
called a "low-pass filter" in the control theory (sort of a transfer
function with an exponential decay) to smooth out the demand and adjust
the worker pool based on that.
As a side note, it might be far fetched, but there are instruments in
queueing theory to figure out how much workers are needed to guarantee a
certain low queueing probability, but for that one needs to have an
average arrival rate (in our case, average number of IO operations
dispatched to workers) and an average service rate (average number of IO
operations performed by workers).
On Sun, May 25, 2025 at 7:20 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote:
> > On Sun, Apr 13, 2025 at 04:59:54AM GMT, Thomas Munro wrote:
> > It's hard to know how to set io_workers=3. If it's too small,
> > io_method=worker's small submission queue overflows and it silently
> > falls back to synchronous IO. If it's too high, it generates a lot of
> > pointless wakeups and scheduling overhead, which might be considered
> > an independent problem or not, but having the right size pool
> > certainly mitigates it. Here's a patch to replace that GUC with:
> >
> > io_min_workers=1
> > io_max_workers=8
> > io_worker_idle_timeout=60s
> > io_worker_launch_interval=500ms
> >
> > It grows the pool when a backlog is detected (better ideas for this
> > logic welcome), and lets idle workers time out.
>
> I like the idea. In fact, I've been pondering about something like a
> "smart" configuration for quite some time, and convinced that a similar
> approach needs to be applied to many performance-related GUCs.
>
> Idle timeout and launch interval serving as a measure of sensitivity
> makes sense to me, growing the pool when a backlog (queue_depth >
> nworkers, so even a slightest backlog?) is detected seems to be somewhat
> arbitrary. From what I understand the pool growing velocity is constant
> and do not depend on the worker demand (i.e. queue_depth)? It may sounds
> fancy, but I've got an impression it should be possible to apply what's
> called a "low-pass filter" in the control theory (sort of a transfer
> function with an exponential decay) to smooth out the demand and adjust
> the worker pool based on that.
>
> As a side note, it might be far fetched, but there are instruments in
> queueing theory to figure out how much workers are needed to guarantee a
> certain low queueing probability, but for that one needs to have an
> average arrival rate (in our case, average number of IO operations
> dispatched to workers) and an average service rate (average number of IO
> operations performed by workers).
Hi Dmitry,
Thanks for looking, and yeah these are definitely the right sort of
questions. I will be both unsurprised and delighted if someone can
bring some more science to this problem. I did read up on Erlang's
formula C ("This formula is used to determine the number of agents or
customer service representatives needed to staff a call centre, for a
specified desired probability of queuing" according to Wikipedia) and
a bunch of related textbook stuff. And yeah I had a bunch of
exponential moving averages of various values using scaled fixed point
arithmetic (just a bunch of shifts and adds) to smooth inputs, in
various attempts. But ... I'm not even sure if we can say that our
I/O arrivals have a Poisson distribution, since they are not all
independent. I tried more things too, while I was still unsure what I
should even be optimising for. My current answer to that is: low
latency with low variance, as seen with io_uring.
In this version I went back to basics and built something that looks
more like the controls of a classic process/thread pool (think Apache)
or connection pool (think JDBC), with a couple of additions based on
intuition: (1) a launch interval, which acts as a bit of damping
against overshooting on brief bursts that are too far apart, and (2)
the queue length > workers * k as a simple way to determine that
latency is being introduced by not having enough workers. Perhaps
there is a good way to compute an adaptive value for k with some fancy
theories, but k=1 seems to have *some* basis: that's the lowest number
which the pool is too small and *certainly* introducing latency, but
any lower constant is harder to defend because we don't know how many
workers are already awake and about to consume tasks. Something from
queuing theory might provide an adaptive value, but in the end, I
figured we really just want to know if the queue is growing ie in
danger of overflowing (note: the queue is small! 64, and not
currently changeable, more on that later, and the overflow behaviour
is synchronous I/O as back-pressure). You seem to be suggesting that
k=1 sounds too low, not too high, but there is that separate
time-based defence against overshoot in response to rare bursts.
You could get more certainty about jobs already about to be consumed
by a worker that is about to dequeue, by doing a lot more book
keeping: assigning them to workers on submission (separate states,
separate queues, various other ideas I guess). But everything I tried
like that caused latency or latency variance to go up, because it
missed out on the chance for another worker to pick it up sooner
opportunistically. This arrangement has the most stable and
predictable pool size and lowest avg latency and stddev(latency) I
have managed to come up with so far. That said, we have plenty of
time to experiment with better ideas if you want to give it a shot or
propose concrete ideas, given that I missed v18 :-)
About control theory... yeah. That's an interesting bag of tricks.
FWIW Melanie and (more recently) I have looked into textbook control
algorithms at a higher level of the I/O stack (and Melanie gave a talk
about other applications in eg VACUUM at pgconf.dev). In
read_stream.c, where I/O demand is created, we've been trying to set
the desired I/O concurrency level and thus lookahead distance with
adaptive feedback. We've tried a lot of stuff. I hope we can share
some concept patches some time soon, well, maybe in this cycle. Some
interesting recent experiments produced graphs that look a lot like
the ones in the book "Feedback Control for Computer Systems" (an easy
software-person book I found for people without an engineering/control
theory background where the problems match our world more closely, cf
typical texts that are about controlling motors and other mechanical
stuff...). Experimental goals are: find the the smallest concurrent
I/O request level (and thus lookahead distance and thus speculative
work done and buffers pinned) that keeps the I/O stall probability
near zero (and keep adapting, since other queries and applications are
sharing system I/O queues), and if that's not even possible, find the
highest concurrent I/O request level that doesn't cause extra latency
due to queuing in lower levels (I/O workers, kernel, ..., disks).
That second part is quite hard. In other words, if higher levels own
that problem and bring the adaptivity, then perhaps io_method=worker
can get away with being quite stupid. Just a thought...
BTW I would like to push 0001 and 0002 to master/18. They are are not behaviour changes, they just fix up a bunch of inconsistent (0001) and misleading (0002) variable naming and comments to reflect reality (in AIO v1 the postmaster used to assign those I/O worker numbers, now the postmaster has its own array of slots to track them that is *not* aligned with the ID numbers/slots in shared memory ie those numbers you see in the ps status, so that's bound to confuse people maintaining this code). I just happened to notice that when working on this dynamic worker pool stuff. If there are no objections I will go ahead and do that soon.
On Mon, May 26, 2025, 8:01 AM Thomas Munro <thomas.munro@gmail.com> wrote:
But ... I'm not even sure if we can say that our
I/O arrivals have a Poisson distribution, since they are not all
independent.
Yeah, a good point, one have to be careful with assumptions about distribution -- from what I've read many processes in computer systems are better described by a Pareto. But the beauty of the queuing theory is that many results are independent from the distribution (not sure about dependencies though).
In this version I went back to basics and built something that looks
more like the controls of a classic process/thread pool (think Apache)
or connection pool (think JDBC), with a couple of additions based on
intuition: (1) a launch interval, which acts as a bit of damping
against overshooting on brief bursts that are too far apart, and (2)
the queue length > workers * k as a simple way to determine that
latency is being introduced by not having enough workers. Perhaps
there is a good way to compute an adaptive value for k with some fancy
theories, but k=1 seems to have *some* basis: that's the lowest number
which the pool is too small and *certainly* introducing latency, but
any lower constant is harder to defend because we don't know how many
workers are already awake and about to consume tasks. Something from
queuing theory might provide an adaptive value, but in the end, I
figured we really just want to know if the queue is growing ie in
danger of overflowing (note: the queue is small! 64, and not
currently changeable, more on that later, and the overflow behaviour
is synchronous I/O as back-pressure). You seem to be suggesting that
k=1 sounds too low, not too high, but there is that separate
time-based defence against overshoot in response to rare bursts.
I probably had to start with a statement that I find the current approach reasonable, and I'm only curious if there is more to get out of it. I haven't benchmarked the patch yet (plan getting to it when I'll get back), and can imagine practical considerations significantly impacting any potential solution.
About control theory... yeah. That's an interesting bag of tricks.
FWIW Melanie and (more recently) I have looked into textbook control
algorithms at a higher level of the I/O stack (and Melanie gave a talk
about other applications in eg VACUUM at pgconf.dev). In
read_stream.c, where I/O demand is created, we've been trying to set
the desired I/O concurrency level and thus lookahead distance with
adaptive feedback. We've tried a lot of stuff. I hope we can share
some concept patches some time soon, well, maybe in this cycle. Some
interesting recent experiments produced graphs that look a lot like
the ones in the book "Feedback Control for Computer Systems" (an easy
software-person book I found for people without an engineering/control
theory background where the problems match our world more closely, cf
typical texts that are about controlling motors and other mechanical
stuff...). Experimental goals are: find the the smallest concurrent
I/O request level (and thus lookahead distance and thus speculative
work done and buffers pinned) that keeps the I/O stall probability
near zero (and keep adapting, since other queries and applications are
sharing system I/O queues), and if that's not even possible, find the
highest concurrent I/O request level that doesn't cause extra latency
due to queuing in lower levels (I/O workers, kernel, ..., disks).
That second part is quite hard. In other words, if higher levels own
that problem and bring the adaptivity, then perhaps io_method=worker
can get away with being quite stupid. Just a thought...
Looking forward to it. And thanks for the reminder about the talk, wanted to watch it already long time ago, but somehow didn't managed yet.
On Wed, May 28, 2025 at 5:55 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > I probably had to start with a statement that I find the current approach reasonable, and I'm only curious if there ismore to get out of it. I haven't benchmarked the patch yet (plan getting to it when I'll get back), and can imagine practicalconsiderations significantly impacting any potential solution. Here's a rebase.
Вложения
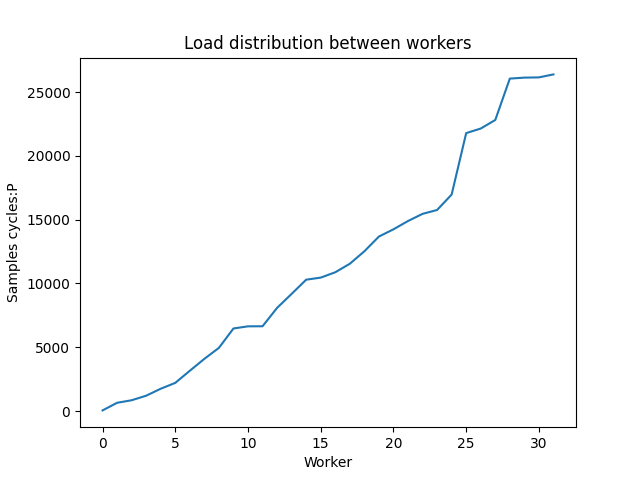
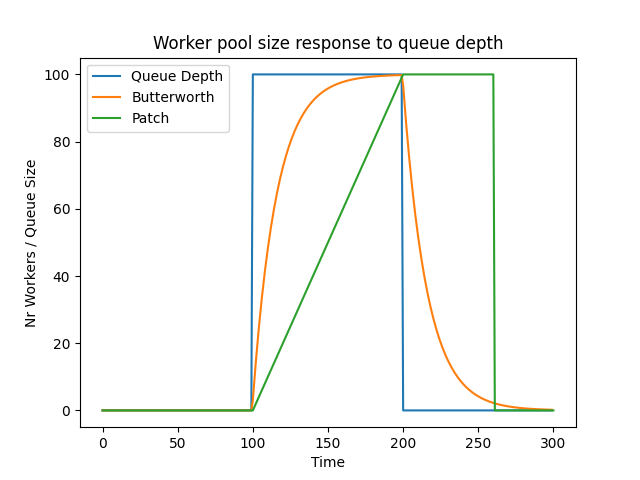
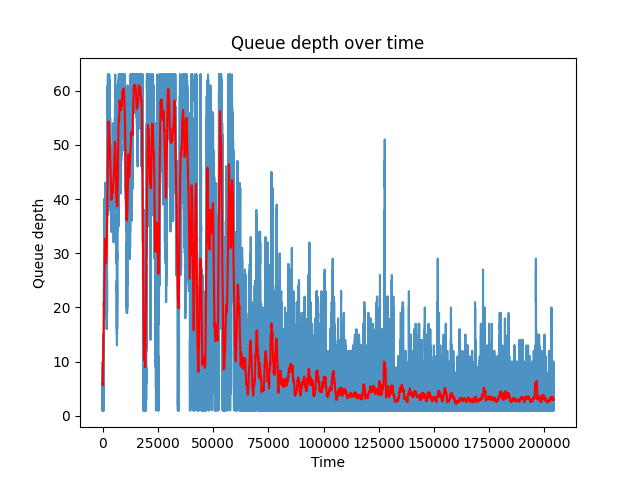
> On Sat, Jul 12, 2025 at 05:08:29PM +1200, Thomas Munro wrote: > On Wed, May 28, 2025 at 5:55 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > I probably had to start with a statement that I find the current > > approach reasonable, and I'm only curious if there is more to get > > out of it. I haven't benchmarked the patch yet (plan getting to it > > when I'll get back), and can imagine practical considerations > > significantly impacting any potential solution. > > Here's a rebase. Thanks. I was experimenting with this approach, and realized there isn't much metrics exposed about workers and the IO queue so far. Since the worker pool growth is based on the queue size and workers try to share the load uniformly, it makes to have a system view to show those numbers, let's say a system view for worker handles and a function to get the current queue size? E.g. workers load in my testing was quite varying, see "Load distribution between workers" graph, which shows a quick profiling run including currently running io workers. Regarding the worker pool growth approach, it sounds reasonable to me. With static number of workers one needs to somehow find a number suitable for all types of workload, where with this patch one needs only to fiddle with the launch interval to handle possible spikes. It would be interesting to investigate, how this approach would react to different dynamics of the queue size. I've plotted one "spike" scenario in the "Worker pool size response to queue depth", where there is a pretty artificial burst of IO, making the queue size look like a step function. If I understand the patch implementation correctly, it would respond linearly over time (green line), one could also think about applying a first order butterworth low pass filter to respond quicker but still smooth (orange line). But in reality the queue size would be of course much more volatile even on stable workloads, like in "Queue depth over time" (one can see general oscillation, as well as different modes, e.g. where data is in the page cache vs where it isn't). Event more, there is a feedback where increasing number of workers would accelerate queue size decrease -- based on [1] the system utilization for M/M/k depends on the arrival rate, processing rate and number of processors, where pretty intuitively more processors reduce utilization. But alas, as you've mentioned this result exists for Poisson distribution only. Btw, I assume something similar could be done to other methods as well? I'm not up to date on io uring, can one change the ring depth on the fly? As a side note, I was trying to experiment with this patch using dm-mapper's delay feature to introduce an arbitrary large io latency and see how the io queue is growing. But strangely enough, even though the pure io latency was high, the queue growth was smaller than e.g. on a real hardware under the same conditions without any artificial delay. Is there anything obvious I'm missing that could have explained that? [1]: Harchol-Balter, Mor. Performance modeling and design of computer systems: queueing theory in action. Cambridge University Press, 2013.
Вложения
{kind=link}
{kind=link}
{kind=link}
On Wed, Jul 30, 2025 at 10:15 PM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > Thanks. I was experimenting with this approach, and realized there isn't > much metrics exposed about workers and the IO queue so far. Since the Hmm. You can almost infer the depth from the pg_aios view. All IOs in use are visible there, and the SUBMITTED ones are all either in the queue, currently being executed by a worker, or being executed synchronously by a regular backend because the queue was full and in that case it just falls back to synchronous execution. Perhaps we just need to be able to distinguish those three cases in that view. For the synchronous-in-submitter overflow case, I think f_sync should really show 't', and I'll post a patch for that shortly. For "currently executing in a worker", I wonder if we could have an "info" column that queries a new optional callback pgaio_iomethod_ops->get_info(ioh) where worker mode could return "worker 3", or something like that. > worker pool growth is based on the queue size and workers try to share > the load uniformly, it makes to have a system view to show those Actually it's not uniform: it tries to wake up the lowest numbered worker that advertises itself as idle, in that little bitmap of idle workers. So if you look in htop you'll see that worker 0 is the most busy, then worker 1, etc. Only if they are all quite busy does it become almost uniform, which probably implies you've reached hit io_max_workers and should probably set it higher (or without this patch, you should probably just increase io_workers manually, assuming your I/O hardware can take more). Originally I made it like that to give higher numbered workers a chance to time out (anticipating this patch). Later I found another reason to do it that way: When I tried uniform distribution using atomic_fetch_add(&distributor, 1) % nworkers to select the worker to wake up, avg(latency) and stddev(latency) were both higher for simple tests like the one attached to the first message, when running several copies of it concurrently. The concentrate-into-lowest-numbers design benefits from latch collapsing and allows the busier workers to avoid going back to sleep when they could immediately pick up a new job. I didn't change that in this patch, though I did tweak the "fan out" logic a bit, after some experimentation on several machines where I realised the code in master/18 is a bit over enthusiastic about that and has a higher spurious wakeup ratio (something this patch actually measures and tries to reduce). Here is one of my less successful attempts to do a round-robin system that tries to adjust the pool size with more engineering, but it was consistently worse on those latency statistics compared to this approach, and wasn't even as good at finding a good pool size, so eventually I realised that it was a dead end and my original work contrentrating concept was better: https://github.com/macdice/postgres/tree/io-worker-pool FWIW the patch in this branch is in this public branch: https://github.com/macdice/postgres/tree/io-worker-pool-3 > Regarding the worker pool growth approach, it sounds reasonable to me. Great to hear. I wonder what other kinds of testing we should do to validate this, but I am feeling quite confident about this patch and thinking it should probably go in sooner rather than later. > With static number of workers one needs to somehow find a number > suitable for all types of workload, where with this patch one needs only > to fiddle with the launch interval to handle possible spikes. It would > be interesting to investigate, how this approach would react to > different dynamics of the queue size. I've plotted one "spike" scenario > in the "Worker pool size response to queue depth", where there is a > pretty artificial burst of IO, making the queue size look like a step > function. If I understand the patch implementation correctly, it would > respond linearly over time (green line), one could also think about > applying a first order butterworth low pass filter to respond quicker > but still smooth (orange line). Interesting. There is only one kind of smoothing in the patch currently, relating to the pool size going down. It models spurious latch wakeups in an exponentially decaying ratio of wakeups:work. That's the only way I could find to deal with the inherent sloppiness of the wakeup mechanism with a shared queue: when you wake the lowest numbered idle worker as of some moment in time, it might lose the race against an even lower numbered worker that finishes its current job and steals the new job. When workers steal jobs, latency decreases, which is good, so instead of preventing it I eventually figured out that we should measure it, smooth it, and use it to limit wakeup propagation. I wonder if that naturally produces curves a bit like your butterworth line when it's going down already, but I'm not sure. As for the curve on the way up, hmm, I'm not sure. Yes, it goes up linearly and is limited by the launch delay, but I was thinking of that only as the way it grows when the *variation* in workload changes over a long time frame. In other words, maybe it's not so important how exactly it grows, it's more important that it achieves a steady state that can handle the oscillations and spikes in your workload. The idle timeout creates that steady state by holding the current pool size for quite a while, so that it can handle your quieter and busier moments immediately without having to adjust the pool size. In that other failed attempt I tried to model that more explicitly, with "active" workers and "spare" workers, with the active set sizes for average demand with uniform wakeups and the spare set sized for some number of standard deviations that are woken up only when the queue is high, but I could never really make it work well... > But in reality the queue size would be of course much more volatile even > on stable workloads, like in "Queue depth over time" (one can see > general oscillation, as well as different modes, e.g. where data is in > the page cache vs where it isn't). Event more, there is a feedback where > increasing number of workers would accelerate queue size decrease -- > based on [1] the system utilization for M/M/k depends on the arrival > rate, processing rate and number of processors, where pretty intuitively > more processors reduce utilization. But alas, as you've mentioned this > result exists for Poisson distribution only. > Btw, I assume something similar could be done to other methods as well? > I'm not up to date on io uring, can one change the ring depth on the > fly? Each backend's io_uring submission queue is configured at startup and not changeable later, but it is sized for the maximum possible number that each backend can submit, io_max_concurrency, which corresponds to the backend's portion of the array of PgAioHandle objects that is fixed. I suppose you could say that each backend's submission queue can't overflow at that level, because it's perfectly sized and not shared with other backends, or to put it another way, the equivalent of overflow is we won't try to submit more IOs than that. Worker mode has a shared submission queue, but falls back to synchronous execution if it's full, which is a bit weird as it makes your IOs jump the queue in a sense, and that is a good reason to want this patch so that the pool can try to find the size that avoids that instead of leaving the user in the dark. As for the equivalent of pool sizing inside io_uring (and maybe other AIO systems in other kernels), hmm.... in the absolute best cases worker threads can be skipped completely, eg for direct I/O queued straight to the device, but when used, I guess they have pretty different economics. A kernel can start a thread just by allocating a bit of memory and sticking it in a queue, and can also wake them (move them to a different scheduler queue) cheaply, but we have to fork a giant process that has to open all the files and build up its caches etc. So I think they just start threads on demand immediately on need without damping, with some kind of short grace period just to avoid those smaller costs being repeated. I'm no expert on those internal details, but our worker system clearly needs all this damping and steady state discovery heuristics due to the higher overheads and sloppy wakeups. Thinking more about our comparatively heavyweight I/O workers, there must also be affinity opportunities. If you somehow tended to use the same workers for a given database in a cluster with multiple active databases, then workers might accumulate fewer open file descriptors and SMgrRelation cache objects. If you had per-NUMA node pools and queues then you might be able to reduce contention, and maybe also cache line ping-pong on buffer headers considering that the submitter dirties the header, then the worker does (in the completion callback), and then the submitter accesses it again. I haven't investigated that. > As a side note, I was trying to experiment with this patch using > dm-mapper's delay feature to introduce an arbitrary large io latency and > see how the io queue is growing. But strangely enough, even though the > pure io latency was high, the queue growth was smaller than e.g. on a > real hardware under the same conditions without any artificial delay. Is > there anything obvious I'm missing that could have explained that? Could it be alternating full and almost empty due to method_worker.c's fallback to synchronous on overflow, which slows the submission down, or something like that, and then you're plotting an average depth that is lower than you expected? With the patch I'll share shortly to make pg_aios show a useful f_sync value it might be more obvious... About dm-mapper delays, I actually found it useful to hack up worker mode itself to simulate storage behaviours, for example swamped local disks or cloud storage with deep queues and no back pressure but artificial IOPS and bandwidth caps, etc. I was thinking about developing some proper settings to help with that kind of research: debug_io_worker_queue_size (changeable at runtime), debug_io_max_worker_queue_size (allocated at startup), debug_io_worker_{latency,bandwidth,iops} to introduce calculated sleeps, and debug_io_worker_overflow_policy=synchronous|wait so that you can disable the synchronous fallback that confuses matters. That'd be more convenient, portable and flexible than dm-mapper tricks I guess. I'd been imagining that as a tool to investigate higher level work on feedback control for read_stream.c as mentioned, but come to think of it, it could also be useful to understand things about the worker pool itself. That's vapourware though, for myself I just used dirty hacks last time I was working on that stuff. In other words, patches are most welcome if you're interested in that kind of thing. I am a bit tied up with multithreading at the moment and time grows short. I will come back to that problem in a little while and that patch is on my list as part of the infrastructure needed to prove things about the I/O stream feedback work I hope to share later...