Обсуждение: Making empty Bitmapsets always be NULL
When I designed the Bitmapset module, I set things up so that an empty
Bitmapset could be represented either by a NULL pointer, or by an
allocated object all of whose bits are zero. I've recently come to
the conclusion that that was a bad idea and we should instead have
a convention like the longstanding invariant for Lists: an empty
list is represented by NIL and nothing else.
To do this, we need to fix bms_intersect, bms_difference, and a couple
of other functions to check for having produced an empty result; but
then we can replace bms_is_empty() by a simple NULL test. I originally
guessed that that would be a bad tradeoff, but now I think it likely
is a win performance-wise, because we call bms_is_empty() many more
times than those other functions put together.
However, any performance gain would likely be marginal; the real
reason why I'm pushing this is that we have various places that have
hand-implemented a rule about "this Bitmapset variable must be exactly
NULL if empty", so that they can use checks-for-null in place of
bms_is_empty() calls in particularly hot code paths. That is a really
fragile, mistake-prone way to do things, and I'm surprised that we've
seldom been bitten by it. It's not well documented at all which
variables have this property, so you can't readily tell which code
might be violating those conventions.
So basically I'd like to establish that convention everywhere and
get rid of these ad-hoc reduce-to-NULL checks. I put together the
attached draft patch to do so. I've not done any hard performance
testing on it --- I did do one benchmark that showed maybe 0.8%
speedup, but I'd regard that as below the noise.
I found just a few places that have issues with this idea. One thing
that is problematic is bms_first_member(): assuming you allow it to
loop to completion, it ends with the passed Bitmapset being empty,
which is now an invariant violation. I made it pfree the argument
at that point, and fixed a couple of callers that would be broken
thereby; but I wonder if it wouldn't be better to get rid of that
function entirely and convert all its callers to use bms_next_member.
There are only about half a dozen.
I also discovered that nodeAppend.c is relying on bms_del_members
not reducing a non-empty set to NULL, because it uses the nullness
of appendstate->as_valid_subplans as a state boolean. That was
probably acceptable when it was written, but whoever added
classify_matching_subplans made a hash of the state invariants here,
because that can set as_valid_subplans to empty. I added a separate
boolean as an easy way out, but maybe that code could do with a more
thorough revisit.
I'll add this to the about-to-start CF.
regards, tom lane
diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
index 7eb79cee58..a5d74cc462 100644
--- a/src/backend/access/heap/heapam.c
+++ b/src/backend/access/heap/heapam.c
@@ -3046,6 +3046,7 @@ heap_update(Relation relation, ItemPointer otid, HeapTuple newtup,
modified_attrs = HeapDetermineColumnsInfo(relation, interesting_attrs,
id_attrs, &oldtup,
newtup, &id_has_external);
+ interesting_attrs = NULL; /* don't try to free it again */
/*
* If we're not updating any "key" column, we can grab a weaker lock type.
@@ -3860,8 +3861,9 @@ heap_attr_equals(TupleDesc tupdesc, int attrnum, Datum value1, Datum value2,
* listed as interesting) of the old tuple is a member of external_cols and is
* stored externally.
*
- * The input interesting_cols bitmapset is destructively modified; that is OK
- * since this is invoked at most once in heap_update.
+ * The input interesting_cols bitmapset is destructively modified, and freed
+ * before we return; that is OK since this is invoked at most once in
+ * heap_update.
*/
static Bitmapset *
HeapDetermineColumnsInfo(Relation relation,
diff --git a/src/backend/executor/execUtils.c b/src/backend/executor/execUtils.c
index c33a3c0bec..cfa95a07e4 100644
--- a/src/backend/executor/execUtils.c
+++ b/src/backend/executor/execUtils.c
@@ -877,15 +877,7 @@ UpdateChangedParamSet(PlanState *node, Bitmapset *newchg)
* include anything else into its chgParam set.
*/
parmset = bms_intersect(node->plan->allParam, newchg);
-
- /*
- * Keep node->chgParam == NULL if there's not actually any members; this
- * allows the simplest possible tests in executor node files.
- */
- if (!bms_is_empty(parmset))
- node->chgParam = bms_join(node->chgParam, parmset);
- else
- bms_free(parmset);
+ node->chgParam = bms_join(node->chgParam, parmset);
}
/*
diff --git a/src/backend/executor/nodeAgg.c b/src/backend/executor/nodeAgg.c
index 20d23696a5..51a30ddf65 100644
--- a/src/backend/executor/nodeAgg.c
+++ b/src/backend/executor/nodeAgg.c
@@ -1642,7 +1642,7 @@ find_hash_columns(AggState *aggstate)
perhash->hashGrpColIdxHash[i] = i + 1;
perhash->numhashGrpCols++;
/* delete already mapped columns */
- bms_del_member(colnos, grpColIdx[i]);
+ colnos = bms_del_member(colnos, grpColIdx[i]);
}
/* and add the remaining columns */
@@ -1673,7 +1673,6 @@ find_hash_columns(AggState *aggstate)
&TTSOpsMinimalTuple);
list_free(hashTlist);
- bms_free(colnos);
}
bms_free(base_colnos);
diff --git a/src/backend/executor/nodeAppend.c b/src/backend/executor/nodeAppend.c
index cb25499b3f..c185b11c67 100644
--- a/src/backend/executor/nodeAppend.c
+++ b/src/backend/executor/nodeAppend.c
@@ -157,7 +157,10 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
* later calls to ExecFindMatchingSubPlans.
*/
if (!prunestate->do_exec_prune && nplans > 0)
+ {
appendstate->as_valid_subplans = bms_add_range(NULL, 0, nplans - 1);
+ appendstate->as_valid_subplans_identified = true;
+ }
}
else
{
@@ -170,6 +173,7 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
Assert(nplans > 0);
appendstate->as_valid_subplans = validsubplans =
bms_add_range(NULL, 0, nplans - 1);
+ appendstate->as_valid_subplans_identified = true;
appendstate->as_prune_state = NULL;
}
@@ -259,7 +263,7 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
appendstate->as_asyncresults = (TupleTableSlot **)
palloc0(nasyncplans * sizeof(TupleTableSlot *));
- if (appendstate->as_valid_subplans != NULL)
+ if (appendstate->as_valid_subplans_identified)
classify_matching_subplans(appendstate);
}
@@ -414,13 +418,11 @@ ExecReScanAppend(AppendState *node)
bms_overlap(node->ps.chgParam,
node->as_prune_state->execparamids))
{
+ node->as_valid_subplans_identified = false;
bms_free(node->as_valid_subplans);
node->as_valid_subplans = NULL;
- if (nasyncplans > 0)
- {
- bms_free(node->as_valid_asyncplans);
- node->as_valid_asyncplans = NULL;
- }
+ bms_free(node->as_valid_asyncplans);
+ node->as_valid_asyncplans = NULL;
}
for (i = 0; i < node->as_nplans; i++)
@@ -574,11 +576,14 @@ choose_next_subplan_locally(AppendState *node)
if (node->as_nasyncplans > 0)
{
/* We'd have filled as_valid_subplans already */
- Assert(node->as_valid_subplans);
+ Assert(node->as_valid_subplans_identified);
}
- else if (node->as_valid_subplans == NULL)
+ else if (!node->as_valid_subplans_identified)
+ {
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
+ }
whichplan = -1;
}
@@ -640,10 +645,11 @@ choose_next_subplan_for_leader(AppendState *node)
* run-time pruning is disabled then the valid subplans will always be
* set to all subplans.
*/
- if (node->as_valid_subplans == NULL)
+ if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
/*
* Mark each invalid plan as finished to allow the loop below to
@@ -715,10 +721,12 @@ choose_next_subplan_for_worker(AppendState *node)
* run-time pruning is disabled then the valid subplans will always be set
* to all subplans.
*/
- else if (node->as_valid_subplans == NULL)
+ else if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
+
mark_invalid_subplans_as_finished(node);
}
@@ -866,10 +874,11 @@ ExecAppendAsyncBegin(AppendState *node)
Assert(node->as_nasyncplans > 0);
/* If we've yet to determine the valid subplans then do so now. */
- if (node->as_valid_subplans == NULL)
+ if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
classify_matching_subplans(node);
}
@@ -1143,6 +1152,7 @@ classify_matching_subplans(AppendState *node)
{
Bitmapset *valid_asyncplans;
+ Assert(node->as_valid_subplans_identified);
Assert(node->as_valid_asyncplans == NULL);
/* Nothing to do if there are no valid subplans. */
@@ -1161,9 +1171,8 @@ classify_matching_subplans(AppendState *node)
}
/* Get valid async subplans. */
- valid_asyncplans = bms_copy(node->as_asyncplans);
- valid_asyncplans = bms_int_members(valid_asyncplans,
- node->as_valid_subplans);
+ valid_asyncplans = bms_intersect(node->as_asyncplans,
+ node->as_valid_subplans);
/* Adjust the valid subplans to contain sync subplans only. */
node->as_valid_subplans = bms_del_members(node->as_valid_subplans,
diff --git a/src/backend/nodes/bitmapset.c b/src/backend/nodes/bitmapset.c
index 98660524ad..af62a85980 100644
--- a/src/backend/nodes/bitmapset.c
+++ b/src/backend/nodes/bitmapset.c
@@ -5,10 +5,8 @@
*
* A bitmap set can represent any set of nonnegative integers, although
* it is mainly intended for sets where the maximum value is not large,
- * say at most a few hundred. By convention, a NULL pointer is always
- * accepted by all operations to represent the empty set. (But beware
- * that this is not the only representation of the empty set. Use
- * bms_is_empty() in preference to testing for NULL.)
+ * say at most a few hundred. By convention, we always represent the
+ * empty set by a NULL pointer.
*
*
* Copyright (c) 2003-2023, PostgreSQL Global Development Group
@@ -66,6 +64,8 @@
#error "invalid BITS_PER_BITMAPWORD"
#endif
+static bool bms_is_empty_internal(const Bitmapset *a);
+
/*
* bms_copy - make a palloc'd copy of a bitmapset
@@ -104,10 +104,10 @@ bms_equal(const Bitmapset *a, const Bitmapset *b)
{
if (b == NULL)
return true;
- return bms_is_empty(b);
+ return false;
}
else if (b == NULL)
- return bms_is_empty(a);
+ return false;
/* Identify shorter and longer input */
if (a->nwords <= b->nwords)
{
@@ -151,9 +151,9 @@ bms_compare(const Bitmapset *a, const Bitmapset *b)
/* Handle cases where either input is NULL */
if (a == NULL)
- return bms_is_empty(b) ? 0 : -1;
+ return (b == NULL) ? 0 : -1;
else if (b == NULL)
- return bms_is_empty(a) ? 0 : +1;
+ return +1;
/* Handle cases where one input is longer than the other */
shortlen = Min(a->nwords, b->nwords);
for (i = shortlen; i < a->nwords; i++)
@@ -282,6 +282,12 @@ bms_intersect(const Bitmapset *a, const Bitmapset *b)
resultlen = result->nwords;
for (i = 0; i < resultlen; i++)
result->words[i] &= other->words[i];
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(result))
+ {
+ pfree(result);
+ return NULL;
+ }
return result;
}
@@ -300,12 +306,22 @@ bms_difference(const Bitmapset *a, const Bitmapset *b)
return NULL;
if (b == NULL)
return bms_copy(a);
+
+ /*
+ * In Postgres' usage, an empty result is a very common case, so it's
+ * worth optimizing for that by testing bms_nonempty_difference(). This
+ * saves us a palloc/pfree cycle compared to checking after-the-fact.
+ */
+ if (!bms_nonempty_difference(a, b))
+ return NULL;
+
/* Copy the left input */
result = bms_copy(a);
/* And remove b's bits from result */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
result->words[i] &= ~b->words[i];
+ /* Need not check for empty result, since we handled that case above */
return result;
}
@@ -323,7 +339,7 @@ bms_is_subset(const Bitmapset *a, const Bitmapset *b)
if (a == NULL)
return true; /* empty set is a subset of anything */
if (b == NULL)
- return bms_is_empty(a);
+ return false;
/* Check common words */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
@@ -362,10 +378,10 @@ bms_subset_compare(const Bitmapset *a, const Bitmapset *b)
{
if (b == NULL)
return BMS_EQUAL;
- return bms_is_empty(b) ? BMS_EQUAL : BMS_SUBSET1;
+ return BMS_SUBSET1;
}
if (b == NULL)
- return bms_is_empty(a) ? BMS_EQUAL : BMS_SUBSET2;
+ return BMS_SUBSET2;
/* Check common words */
result = BMS_EQUAL; /* status so far */
shortlen = Min(a->nwords, b->nwords);
@@ -554,7 +570,7 @@ bms_nonempty_difference(const Bitmapset *a, const Bitmapset *b)
if (a == NULL)
return false;
if (b == NULL)
- return !bms_is_empty(a);
+ return true;
/* Check words in common */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
@@ -696,12 +712,13 @@ bms_membership(const Bitmapset *a)
}
/*
- * bms_is_empty - is a set empty?
+ * bms_is_empty_internal - is a set empty?
*
- * This is even faster than bms_membership().
+ * This is now used only locally, to detect cases where a function has
+ * computed an empty set that we must now get rid of.
*/
-bool
-bms_is_empty(const Bitmapset *a)
+static bool
+bms_is_empty_internal(const Bitmapset *a)
{
int nwords;
int wordnum;
@@ -786,6 +803,12 @@ bms_del_member(Bitmapset *a, int x)
bitnum = BITNUM(x);
if (wordnum < a->nwords)
a->words[wordnum] &= ~((bitmapword) 1 << bitnum);
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
@@ -922,6 +945,12 @@ bms_int_members(Bitmapset *a, const Bitmapset *b)
a->words[i] &= b->words[i];
for (; i < a->nwords; i++)
a->words[i] = 0;
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
@@ -943,6 +972,12 @@ bms_del_members(Bitmapset *a, const Bitmapset *b)
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
a->words[i] &= ~b->words[i];
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
@@ -985,7 +1020,8 @@ bms_join(Bitmapset *a, Bitmapset *b)
/*
* bms_first_member - find and remove first member of a set
*
- * Returns -1 if set is empty. NB: set is destructively modified!
+ * Returns -1 if set is empty.
+ * NB: set is destructively modified, and will be freed once empty!
*
* This is intended as support for iterating through the members of a set.
* The typical pattern is
@@ -1021,6 +1057,8 @@ bms_first_member(Bitmapset *a)
return result;
}
}
+ /* Set is now empty, so it violates the empty-set invariant */
+ pfree(a);
return -1;
}
diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c
index 011a0337da..9f4698f2a2 100644
--- a/src/backend/optimizer/path/indxpath.c
+++ b/src/backend/optimizer/path/indxpath.c
@@ -949,9 +949,6 @@ build_index_paths(PlannerInfo *root, RelOptInfo *rel,
/* We do not want the index's rel itself listed in outer_relids */
outer_relids = bms_del_member(outer_relids, rel->relid);
- /* Enforce convention that outer_relids is exactly NULL if empty */
- if (bms_is_empty(outer_relids))
- outer_relids = NULL;
/* Compute loop_count for cost estimation purposes */
loop_count = get_loop_count(root, rel->relid, outer_relids);
diff --git a/src/backend/optimizer/plan/subselect.c b/src/backend/optimizer/plan/subselect.c
index 04eda4798e..0956a33952 100644
--- a/src/backend/optimizer/plan/subselect.c
+++ b/src/backend/optimizer/plan/subselect.c
@@ -1486,7 +1486,6 @@ convert_EXISTS_sublink_to_join(PlannerInfo *root, SubLink *sublink,
if (varno <= rtoffset)
upper_varnos = bms_add_member(upper_varnos, varno);
}
- bms_free(clause_varnos);
Assert(!bms_is_empty(upper_varnos));
/*
@@ -2824,15 +2823,6 @@ finalize_plan(PlannerInfo *root, Plan *plan,
/* but not any initplan setParams */
plan->extParam = bms_del_members(plan->extParam, initSetParam);
- /*
- * For speed at execution time, make sure extParam/allParam are actually
- * NULL if they are empty sets.
- */
- if (bms_is_empty(plan->extParam))
- plan->extParam = NULL;
- if (bms_is_empty(plan->allParam))
- plan->allParam = NULL;
-
return plan->allParam;
}
diff --git a/src/backend/optimizer/util/pathnode.c b/src/backend/optimizer/util/pathnode.c
index d749b50578..e8e06397a9 100644
--- a/src/backend/optimizer/util/pathnode.c
+++ b/src/backend/optimizer/util/pathnode.c
@@ -2372,12 +2372,6 @@ calc_nestloop_required_outer(Relids outerrelids,
/* ... and remove any mention of now-satisfied outer rels */
required_outer = bms_del_members(required_outer,
outerrelids);
- /* maintain invariant that required_outer is exactly NULL if empty */
- if (bms_is_empty(required_outer))
- {
- bms_free(required_outer);
- required_outer = NULL;
- }
return required_outer;
}
diff --git a/src/backend/optimizer/util/placeholder.c b/src/backend/optimizer/util/placeholder.c
index 9c6cb5eba7..b1723578e6 100644
--- a/src/backend/optimizer/util/placeholder.c
+++ b/src/backend/optimizer/util/placeholder.c
@@ -125,8 +125,6 @@ find_placeholder_info(PlannerInfo *root, PlaceHolderVar *phv)
*/
rels_used = pull_varnos(root, (Node *) phv->phexpr);
phinfo->ph_lateral = bms_difference(rels_used, phv->phrels);
- if (bms_is_empty(phinfo->ph_lateral))
- phinfo->ph_lateral = NULL; /* make it exactly NULL if empty */
phinfo->ph_eval_at = bms_int_members(rels_used, phv->phrels);
/* If no contained vars, force evaluation at syntactic location */
if (bms_is_empty(phinfo->ph_eval_at))
diff --git a/src/backend/optimizer/util/relnode.c b/src/backend/optimizer/util/relnode.c
index 9ad44a0508..68fd033595 100644
--- a/src/backend/optimizer/util/relnode.c
+++ b/src/backend/optimizer/util/relnode.c
@@ -772,8 +772,6 @@ build_join_rel(PlannerInfo *root,
*/
joinrel->direct_lateral_relids =
bms_del_members(joinrel->direct_lateral_relids, joinrel->relids);
- if (bms_is_empty(joinrel->direct_lateral_relids))
- joinrel->direct_lateral_relids = NULL;
/*
* Construct restrict and join clause lists for the new joinrel. (The
@@ -1024,11 +1022,6 @@ min_join_parameterization(PlannerInfo *root,
*/
result = bms_union(outer_rel->lateral_relids, inner_rel->lateral_relids);
result = bms_del_members(result, joinrelids);
-
- /* Maintain invariant that result is exactly NULL if empty */
- if (bms_is_empty(result))
- result = NULL;
-
return result;
}
diff --git a/src/backend/replication/logical/relation.c b/src/backend/replication/logical/relation.c
index 9f139c64db..7e32eee77e 100644
--- a/src/backend/replication/logical/relation.c
+++ b/src/backend/replication/logical/relation.c
@@ -214,6 +214,8 @@ logicalrep_rel_att_by_name(LogicalRepRelation *remoterel, const char *attname)
/*
* Report error with names of the missing local relation column(s), if any.
+ *
+ * Note that missingatts will be freed before we return.
*/
static void
logicalrep_report_missing_attrs(LogicalRepRelation *remoterel,
@@ -429,9 +431,6 @@ logicalrep_rel_open(LogicalRepRelId remoteid, LOCKMODE lockmode)
logicalrep_report_missing_attrs(remoterel, missingatts);
- /* be tidy */
- bms_free(missingatts);
-
/*
* Set if the table's replica identity is enough to apply
* update/delete.
diff --git a/src/backend/rewrite/rewriteManip.c b/src/backend/rewrite/rewriteManip.c
index 04718f66c0..d28d0da621 100644
--- a/src/backend/rewrite/rewriteManip.c
+++ b/src/backend/rewrite/rewriteManip.c
@@ -1247,16 +1247,11 @@ remove_nulling_relids_mutator(Node *node,
!bms_is_member(var->varno, context->except_relids) &&
bms_overlap(var->varnullingrels, context->removable_relids))
{
- Relids newnullingrels = bms_difference(var->varnullingrels,
- context->removable_relids);
-
- /* Micro-optimization: ensure nullingrels is NULL if empty */
- if (bms_is_empty(newnullingrels))
- newnullingrels = NULL;
/* Copy the Var ... */
var = copyObject(var);
/* ... and replace the copy's varnullingrels field */
- var->varnullingrels = newnullingrels;
+ var->varnullingrels = bms_difference(var->varnullingrels,
+ context->removable_relids);
return (Node *) var;
}
/* Otherwise fall through to copy the Var normally */
@@ -1268,26 +1263,20 @@ remove_nulling_relids_mutator(Node *node,
if (phv->phlevelsup == context->sublevels_up &&
!bms_overlap(phv->phrels, context->except_relids))
{
- Relids newnullingrels = bms_difference(phv->phnullingrels,
- context->removable_relids);
-
/*
- * Micro-optimization: ensure nullingrels is NULL if empty.
- *
* Note: it might seem desirable to remove the PHV altogether if
* phnullingrels goes to empty. Currently we dare not do that
* because we use PHVs in some cases to enforce separate identity
* of subexpressions; see wrap_non_vars usages in prepjointree.c.
*/
- if (bms_is_empty(newnullingrels))
- newnullingrels = NULL;
/* Copy the PlaceHolderVar and mutate what's below ... */
phv = (PlaceHolderVar *)
expression_tree_mutator(node,
remove_nulling_relids_mutator,
(void *) context);
/* ... and replace the copy's phnullingrels field */
- phv->phnullingrels = newnullingrels;
+ phv->phnullingrels = bms_difference(phv->phnullingrels,
+ context->removable_relids);
/* We must also update phrels, if it contains a removable RTI */
phv->phrels = bms_difference(phv->phrels,
context->removable_relids);
diff --git a/src/include/nodes/bitmapset.h b/src/include/nodes/bitmapset.h
index 3d2225e1ae..e1d6cabeba 100644
--- a/src/include/nodes/bitmapset.h
+++ b/src/include/nodes/bitmapset.h
@@ -5,10 +5,8 @@
*
* A bitmap set can represent any set of nonnegative integers, although
* it is mainly intended for sets where the maximum value is not large,
- * say at most a few hundred. By convention, a NULL pointer is always
- * accepted by all operations to represent the empty set. (But beware
- * that this is not the only representation of the empty set. Use
- * bms_is_empty() in preference to testing for NULL.)
+ * say at most a few hundred. By convention, we always represent the
+ * empty set by a NULL pointer.
*
*
* Copyright (c) 2003-2023, PostgreSQL Global Development Group
@@ -102,7 +100,9 @@ extern int bms_num_members(const Bitmapset *a);
/* optimized tests when we don't need to know exact membership count: */
extern BMS_Membership bms_membership(const Bitmapset *a);
-extern bool bms_is_empty(const Bitmapset *a);
+
+/* NULL is now the only allowed representation of an empty bitmapset */
+#define bms_is_empty(a) ((a) == NULL)
/* these routines recycle (modify or free) their non-const inputs: */
diff --git a/src/include/nodes/execnodes.h b/src/include/nodes/execnodes.h
index 20f4c8b35f..e7eb1e666f 100644
--- a/src/include/nodes/execnodes.h
+++ b/src/include/nodes/execnodes.h
@@ -1350,6 +1350,7 @@ struct AppendState
ParallelAppendState *as_pstate; /* parallel coordination info */
Size pstate_len; /* size of parallel coordination info */
struct PartitionPruneState *as_prune_state;
+ bool as_valid_subplans_identified; /* is as_valid_subplans valid? */
Bitmapset *as_valid_subplans;
Bitmapset *as_valid_asyncplans; /* valid asynchronous plans indexes */
bool (*choose_next_subplan) (AppendState *);
diff --git a/src/pl/plpgsql/src/pl_exec.c b/src/pl/plpgsql/src/pl_exec.c
index ffd6d2e3bc..b0a2cac227 100644
--- a/src/pl/plpgsql/src/pl_exec.c
+++ b/src/pl/plpgsql/src/pl_exec.c
@@ -6240,12 +6240,9 @@ setup_param_list(PLpgSQL_execstate *estate, PLpgSQL_expr *expr)
Assert(expr->plan != NULL);
/*
- * We only need a ParamListInfo if the expression has parameters. In
- * principle we should test with bms_is_empty(), but we use a not-null
- * test because it's faster. In current usage bits are never removed from
- * expr->paramnos, only added, so this test is correct anyway.
+ * We only need a ParamListInfo if the expression has parameters.
*/
- if (expr->paramnos)
+ if (!bms_is_empty(expr->paramnos))
{
/* Use the common ParamListInfo */
paramLI = estate->paramLI;
On Tue, Feb 28, 2023 at 04:59:48PM -0500, Tom Lane wrote: > When I designed the Bitmapset module, I set things up so that an empty > Bitmapset could be represented either by a NULL pointer, or by an > allocated object all of whose bits are zero. I've recently come to > the conclusion that that was a bad idea and we should instead have > a convention like the longstanding invariant for Lists: an empty > list is represented by NIL and nothing else. +1 > I found just a few places that have issues with this idea. One thing > that is problematic is bms_first_member(): assuming you allow it to > loop to completion, it ends with the passed Bitmapset being empty, > which is now an invariant violation. I made it pfree the argument > at that point, and fixed a couple of callers that would be broken > thereby; but I wonder if it wouldn't be better to get rid of that > function entirely and convert all its callers to use bms_next_member. > There are only about half a dozen. Unless there is a way to avoid the invariant violation that doesn't involve scanning the rest of the words before bms_first_member returns, +1 to removing it. Perhaps we could add a num_members variable to the struct so that we know right away when the set becomes empty. But maintaining that might be more trouble than it's worth. > I also discovered that nodeAppend.c is relying on bms_del_members > not reducing a non-empty set to NULL, because it uses the nullness > of appendstate->as_valid_subplans as a state boolean. That was > probably acceptable when it was written, but whoever added > classify_matching_subplans made a hash of the state invariants here, > because that can set as_valid_subplans to empty. I added a separate > boolean as an easy way out, but maybe that code could do with a more > thorough revisit. The separate boolean certainly seems less fragile. That might even be worthwhile independent of the rest of the patch. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Tue, Feb 28, 2023 at 1:59 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I also discovered that nodeAppend.c is relying on bms_del_members > not reducing a non-empty set to NULL, because it uses the nullness > of appendstate->as_valid_subplans as a state boolean. I seem to recall that Deep and I tripped into this during the zedstore column projection work. I think we started out using NULL as a sentinel value for our bitmaps, too, and it looked like it worked, until it didn't... so +1 to the simplification. --Jacob
Nathan Bossart <nathandbossart@gmail.com> writes:
> On Tue, Feb 28, 2023 at 04:59:48PM -0500, Tom Lane wrote:
>> When I designed the Bitmapset module, I set things up so that an empty
>> Bitmapset could be represented either by a NULL pointer, or by an
>> allocated object all of whose bits are zero. I've recently come to
>> the conclusion that that was a bad idea and we should instead have
>> a convention like the longstanding invariant for Lists: an empty
>> list is represented by NIL and nothing else.
> +1
Thanks for looking at this.
> Unless there is a way to avoid the invariant violation that doesn't involve
> scanning the rest of the words before bms_first_member returns, +1 to
> removing it. Perhaps we could add a num_members variable to the struct so
> that we know right away when the set becomes empty. But maintaining that
> might be more trouble than it's worth.
bms_first_member is definitely legacy code, so let's just get
rid of it. Done like that in 0001 below. (This was slightly more
complex than I foresaw, because some of the callers were modifying
the result variables. But they're probably cleaner this way anyway.)
>> I also discovered that nodeAppend.c is relying on bms_del_members
>> not reducing a non-empty set to NULL, because it uses the nullness
>> of appendstate->as_valid_subplans as a state boolean.
> The separate boolean certainly seems less fragile. That might even be
> worthwhile independent of the rest of the patch.
Yeah. I split out those executor fixes as 0002; 0003 is the changes
to bitmapsets proper, and then 0004 removes now-dead code.
regards, tom lane
From b60df906e9894d061f3f37025b92c6b258e9c8fc Mon Sep 17 00:00:00 2001
From: Tom Lane <tgl@sss.pgh.pa.us>
Date: Wed, 1 Mar 2023 17:02:30 -0500
Subject: [PATCH v2 1/4] Remove bms_first_member().
This function has been semi-deprecated ever since we invented
bms_next_member(). Its habit of scribbling on the input bitmapset
isn't great, plus for sufficiently large bitmapsets it would take
O(N^2) time to complete a loop. Now we have the additional problem
that reducing the input to empty while leaving it still accessible
would violate a proposed invariant. So let's just get rid of it,
after updating the few extant callers to use bms_next_member().
Discussion: https://postgr.es/m/1159933.1677621588@sss.pgh.pa.us
---
contrib/file_fdw/file_fdw.c | 9 ++---
contrib/sepgsql/dml.c | 3 +-
src/backend/access/heap/heapam.c | 27 +++++---------
src/backend/executor/nodeAgg.c | 3 +-
src/backend/nodes/bitmapset.c | 42 ----------------------
src/backend/optimizer/plan/subselect.c | 3 +-
src/backend/parser/parse_expr.c | 2 +-
src/backend/replication/logical/relation.c | 3 +-
src/include/nodes/bitmapset.h | 1 -
9 files changed, 23 insertions(+), 70 deletions(-)
diff --git a/contrib/file_fdw/file_fdw.c b/contrib/file_fdw/file_fdw.c
index 8ccc167548..2d2b0b6a6b 100644
--- a/contrib/file_fdw/file_fdw.c
+++ b/contrib/file_fdw/file_fdw.c
@@ -858,7 +858,7 @@ check_selective_binary_conversion(RelOptInfo *baserel,
ListCell *lc;
Relation rel;
TupleDesc tupleDesc;
- AttrNumber attnum;
+ int attidx;
Bitmapset *attrs_used = NULL;
bool has_wholerow = false;
int numattrs;
@@ -901,10 +901,11 @@ check_selective_binary_conversion(RelOptInfo *baserel,
rel = table_open(foreigntableid, AccessShareLock);
tupleDesc = RelationGetDescr(rel);
- while ((attnum = bms_first_member(attrs_used)) >= 0)
+ attidx = -1;
+ while ((attidx = bms_next_member(attrs_used, attidx)) >= 0)
{
- /* Adjust for system attributes. */
- attnum += FirstLowInvalidHeapAttributeNumber;
+ /* attidx is zero-based, attnum is the normal attribute number */
+ AttrNumber attnum = attidx + FirstLowInvalidHeapAttributeNumber;
if (attnum == 0)
{
diff --git a/contrib/sepgsql/dml.c b/contrib/sepgsql/dml.c
index 3cc927c79e..8c8f6f1e3a 100644
--- a/contrib/sepgsql/dml.c
+++ b/contrib/sepgsql/dml.c
@@ -231,7 +231,8 @@ check_relation_privileges(Oid relOid,
updated = fixup_whole_row_references(relOid, updated);
columns = bms_union(selected, bms_union(inserted, updated));
- while ((index = bms_first_member(columns)) >= 0)
+ index = -1;
+ while ((index = bms_next_member(columns, index)) >= 0)
{
AttrNumber attnum;
uint32 column_perms = 0;
diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
index 7eb79cee58..a84290c434 100644
--- a/src/backend/access/heap/heapam.c
+++ b/src/backend/access/heap/heapam.c
@@ -3859,9 +3859,6 @@ heap_attr_equals(TupleDesc tupdesc, int attrnum, Datum value1, Datum value2,
* has_external indicates if any of the unmodified attributes (from those
* listed as interesting) of the old tuple is a member of external_cols and is
* stored externally.
- *
- * The input interesting_cols bitmapset is destructively modified; that is OK
- * since this is invoked at most once in heap_update.
*/
static Bitmapset *
HeapDetermineColumnsInfo(Relation relation,
@@ -3870,19 +3867,20 @@ HeapDetermineColumnsInfo(Relation relation,
HeapTuple oldtup, HeapTuple newtup,
bool *has_external)
{
- int attrnum;
+ int attidx;
Bitmapset *modified = NULL;
TupleDesc tupdesc = RelationGetDescr(relation);
- while ((attrnum = bms_first_member(interesting_cols)) >= 0)
+ attidx = -1;
+ while ((attidx = bms_next_member(interesting_cols, attidx)) >= 0)
{
+ /* attidx is zero-based, attrnum is the normal attribute number */
+ int attrnum = attidx + FirstLowInvalidHeapAttributeNumber;
Datum value1,
value2;
bool isnull1,
isnull2;
- attrnum += FirstLowInvalidHeapAttributeNumber;
-
/*
* If it's a whole-tuple reference, say "not equal". It's not really
* worth supporting this case, since it could only succeed after a
@@ -3890,9 +3888,7 @@ HeapDetermineColumnsInfo(Relation relation,
*/
if (attrnum == 0)
{
- modified = bms_add_member(modified,
- attrnum -
- FirstLowInvalidHeapAttributeNumber);
+ modified = bms_add_member(modified, attidx);
continue;
}
@@ -3905,9 +3901,7 @@ HeapDetermineColumnsInfo(Relation relation,
{
if (attrnum != TableOidAttributeNumber)
{
- modified = bms_add_member(modified,
- attrnum -
- FirstLowInvalidHeapAttributeNumber);
+ modified = bms_add_member(modified, attidx);
continue;
}
}
@@ -3924,9 +3918,7 @@ HeapDetermineColumnsInfo(Relation relation,
if (!heap_attr_equals(tupdesc, attrnum, value1,
value2, isnull1, isnull2))
{
- modified = bms_add_member(modified,
- attrnum -
- FirstLowInvalidHeapAttributeNumber);
+ modified = bms_add_member(modified, attidx);
continue;
}
@@ -3943,8 +3935,7 @@ HeapDetermineColumnsInfo(Relation relation,
* member of external_cols.
*/
if (VARATT_IS_EXTERNAL((struct varlena *) DatumGetPointer(value1)) &&
- bms_is_member(attrnum - FirstLowInvalidHeapAttributeNumber,
- external_cols))
+ bms_is_member(attidx, external_cols))
*has_external = true;
}
diff --git a/src/backend/executor/nodeAgg.c b/src/backend/executor/nodeAgg.c
index 20d23696a5..5960e4a6c1 100644
--- a/src/backend/executor/nodeAgg.c
+++ b/src/backend/executor/nodeAgg.c
@@ -1646,7 +1646,8 @@ find_hash_columns(AggState *aggstate)
}
/* and add the remaining columns */
- while ((i = bms_first_member(colnos)) >= 0)
+ i = -1;
+ while ((i = bms_next_member(colnos, i)) >= 0)
{
perhash->hashGrpColIdxInput[perhash->numhashGrpCols] = i;
perhash->numhashGrpCols++;
diff --git a/src/backend/nodes/bitmapset.c b/src/backend/nodes/bitmapset.c
index 98660524ad..10dbbdddf5 100644
--- a/src/backend/nodes/bitmapset.c
+++ b/src/backend/nodes/bitmapset.c
@@ -982,48 +982,6 @@ bms_join(Bitmapset *a, Bitmapset *b)
return result;
}
-/*
- * bms_first_member - find and remove first member of a set
- *
- * Returns -1 if set is empty. NB: set is destructively modified!
- *
- * This is intended as support for iterating through the members of a set.
- * The typical pattern is
- *
- * while ((x = bms_first_member(inputset)) >= 0)
- * process member x;
- *
- * CAUTION: this destroys the content of "inputset". If the set must
- * not be modified, use bms_next_member instead.
- */
-int
-bms_first_member(Bitmapset *a)
-{
- int nwords;
- int wordnum;
-
- if (a == NULL)
- return -1;
- nwords = a->nwords;
- for (wordnum = 0; wordnum < nwords; wordnum++)
- {
- bitmapword w = a->words[wordnum];
-
- if (w != 0)
- {
- int result;
-
- w = RIGHTMOST_ONE(w);
- a->words[wordnum] &= ~w;
-
- result = wordnum * BITS_PER_BITMAPWORD;
- result += bmw_rightmost_one_pos(w);
- return result;
- }
- }
- return -1;
-}
-
/*
* bms_next_member - find next member of a set
*
diff --git a/src/backend/optimizer/plan/subselect.c b/src/backend/optimizer/plan/subselect.c
index 04eda4798e..22ffe4ca42 100644
--- a/src/backend/optimizer/plan/subselect.c
+++ b/src/backend/optimizer/plan/subselect.c
@@ -1481,7 +1481,8 @@ convert_EXISTS_sublink_to_join(PlannerInfo *root, SubLink *sublink,
*/
clause_varnos = pull_varnos(root, whereClause);
upper_varnos = NULL;
- while ((varno = bms_first_member(clause_varnos)) >= 0)
+ varno = -1;
+ while ((varno = bms_next_member(clause_varnos, varno)) >= 0)
{
if (varno <= rtoffset)
upper_varnos = bms_add_member(upper_varnos, varno);
diff --git a/src/backend/parser/parse_expr.c b/src/backend/parser/parse_expr.c
index 7ff41acb84..78221d2e0f 100644
--- a/src/backend/parser/parse_expr.c
+++ b/src/backend/parser/parse_expr.c
@@ -2759,7 +2759,7 @@ make_row_comparison_op(ParseState *pstate, List *opname,
* them ... this coding arbitrarily picks the lowest btree strategy
* number.
*/
- i = bms_first_member(strats);
+ i = bms_next_member(strats, -1);
if (i < 0)
{
/* No common interpretation, so fail */
diff --git a/src/backend/replication/logical/relation.c b/src/backend/replication/logical/relation.c
index 9f139c64db..55bfa07871 100644
--- a/src/backend/replication/logical/relation.c
+++ b/src/backend/replication/logical/relation.c
@@ -227,7 +227,8 @@ logicalrep_report_missing_attrs(LogicalRepRelation *remoterel,
initStringInfo(&missingattsbuf);
- while ((i = bms_first_member(missingatts)) >= 0)
+ i = -1;
+ while ((i = bms_next_member(missingatts, i)) >= 0)
{
missingattcnt++;
if (missingattcnt == 1)
diff --git a/src/include/nodes/bitmapset.h b/src/include/nodes/bitmapset.h
index 3d2225e1ae..c344ac04be 100644
--- a/src/include/nodes/bitmapset.h
+++ b/src/include/nodes/bitmapset.h
@@ -115,7 +115,6 @@ extern Bitmapset *bms_del_members(Bitmapset *a, const Bitmapset *b);
extern Bitmapset *bms_join(Bitmapset *a, Bitmapset *b);
/* support for iterating through the integer elements of a set: */
-extern int bms_first_member(Bitmapset *a);
extern int bms_next_member(const Bitmapset *a, int prevbit);
extern int bms_prev_member(const Bitmapset *a, int prevbit);
--
2.31.1
From 8a5e732157f5faaac234ea037998ac278721edef Mon Sep 17 00:00:00 2001
From: Tom Lane <tgl@sss.pgh.pa.us>
Date: Wed, 1 Mar 2023 17:27:34 -0500
Subject: [PATCH v2 2/4] Mop up some undue familiarity with the innards of
Bitmapsets.
nodeAppend.c used non-nullness of appendstate->as_valid_subplans as
a state flag to indicate whether it'd done ExecFindMatchingSubPlans
(or some sufficient approximation to that). This was pretty
questionable even in the beginning, since it wouldn't really work
right if there are no valid subplans. It got more questionable
after commit 27e1f1456 added logic that could reduce as_valid_subplans
to an empty set: at that point we were depending on unspecified
behavior of bms_del_members, namely that it'd not return an empty
set as NULL. It's about to start doing that, which breaks this
logic entirely. Hence, add a separate boolean flag to signal
whether as_valid_subplans has been computed.
Also fix a previously-cosmetic bug in nodeAgg.c, wherein it ignored
the return value of bms_del_member instead of updating its pointer.
Discussion: https://postgr.es/m/1159933.1677621588@sss.pgh.pa.us
---
src/backend/executor/nodeAgg.c | 2 +-
src/backend/executor/nodeAppend.c | 37 +++++++++++++++++++------------
src/include/nodes/execnodes.h | 1 +
3 files changed, 25 insertions(+), 15 deletions(-)
diff --git a/src/backend/executor/nodeAgg.c b/src/backend/executor/nodeAgg.c
index 5960e4a6c1..19342a420c 100644
--- a/src/backend/executor/nodeAgg.c
+++ b/src/backend/executor/nodeAgg.c
@@ -1642,7 +1642,7 @@ find_hash_columns(AggState *aggstate)
perhash->hashGrpColIdxHash[i] = i + 1;
perhash->numhashGrpCols++;
/* delete already mapped columns */
- bms_del_member(colnos, grpColIdx[i]);
+ colnos = bms_del_member(colnos, grpColIdx[i]);
}
/* and add the remaining columns */
diff --git a/src/backend/executor/nodeAppend.c b/src/backend/executor/nodeAppend.c
index cb25499b3f..c185b11c67 100644
--- a/src/backend/executor/nodeAppend.c
+++ b/src/backend/executor/nodeAppend.c
@@ -157,7 +157,10 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
* later calls to ExecFindMatchingSubPlans.
*/
if (!prunestate->do_exec_prune && nplans > 0)
+ {
appendstate->as_valid_subplans = bms_add_range(NULL, 0, nplans - 1);
+ appendstate->as_valid_subplans_identified = true;
+ }
}
else
{
@@ -170,6 +173,7 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
Assert(nplans > 0);
appendstate->as_valid_subplans = validsubplans =
bms_add_range(NULL, 0, nplans - 1);
+ appendstate->as_valid_subplans_identified = true;
appendstate->as_prune_state = NULL;
}
@@ -259,7 +263,7 @@ ExecInitAppend(Append *node, EState *estate, int eflags)
appendstate->as_asyncresults = (TupleTableSlot **)
palloc0(nasyncplans * sizeof(TupleTableSlot *));
- if (appendstate->as_valid_subplans != NULL)
+ if (appendstate->as_valid_subplans_identified)
classify_matching_subplans(appendstate);
}
@@ -414,13 +418,11 @@ ExecReScanAppend(AppendState *node)
bms_overlap(node->ps.chgParam,
node->as_prune_state->execparamids))
{
+ node->as_valid_subplans_identified = false;
bms_free(node->as_valid_subplans);
node->as_valid_subplans = NULL;
- if (nasyncplans > 0)
- {
- bms_free(node->as_valid_asyncplans);
- node->as_valid_asyncplans = NULL;
- }
+ bms_free(node->as_valid_asyncplans);
+ node->as_valid_asyncplans = NULL;
}
for (i = 0; i < node->as_nplans; i++)
@@ -574,11 +576,14 @@ choose_next_subplan_locally(AppendState *node)
if (node->as_nasyncplans > 0)
{
/* We'd have filled as_valid_subplans already */
- Assert(node->as_valid_subplans);
+ Assert(node->as_valid_subplans_identified);
}
- else if (node->as_valid_subplans == NULL)
+ else if (!node->as_valid_subplans_identified)
+ {
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
+ }
whichplan = -1;
}
@@ -640,10 +645,11 @@ choose_next_subplan_for_leader(AppendState *node)
* run-time pruning is disabled then the valid subplans will always be
* set to all subplans.
*/
- if (node->as_valid_subplans == NULL)
+ if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
/*
* Mark each invalid plan as finished to allow the loop below to
@@ -715,10 +721,12 @@ choose_next_subplan_for_worker(AppendState *node)
* run-time pruning is disabled then the valid subplans will always be set
* to all subplans.
*/
- else if (node->as_valid_subplans == NULL)
+ else if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
+
mark_invalid_subplans_as_finished(node);
}
@@ -866,10 +874,11 @@ ExecAppendAsyncBegin(AppendState *node)
Assert(node->as_nasyncplans > 0);
/* If we've yet to determine the valid subplans then do so now. */
- if (node->as_valid_subplans == NULL)
+ if (!node->as_valid_subplans_identified)
{
node->as_valid_subplans =
ExecFindMatchingSubPlans(node->as_prune_state, false);
+ node->as_valid_subplans_identified = true;
classify_matching_subplans(node);
}
@@ -1143,6 +1152,7 @@ classify_matching_subplans(AppendState *node)
{
Bitmapset *valid_asyncplans;
+ Assert(node->as_valid_subplans_identified);
Assert(node->as_valid_asyncplans == NULL);
/* Nothing to do if there are no valid subplans. */
@@ -1161,9 +1171,8 @@ classify_matching_subplans(AppendState *node)
}
/* Get valid async subplans. */
- valid_asyncplans = bms_copy(node->as_asyncplans);
- valid_asyncplans = bms_int_members(valid_asyncplans,
- node->as_valid_subplans);
+ valid_asyncplans = bms_intersect(node->as_asyncplans,
+ node->as_valid_subplans);
/* Adjust the valid subplans to contain sync subplans only. */
node->as_valid_subplans = bms_del_members(node->as_valid_subplans,
diff --git a/src/include/nodes/execnodes.h b/src/include/nodes/execnodes.h
index 20f4c8b35f..e7eb1e666f 100644
--- a/src/include/nodes/execnodes.h
+++ b/src/include/nodes/execnodes.h
@@ -1350,6 +1350,7 @@ struct AppendState
ParallelAppendState *as_pstate; /* parallel coordination info */
Size pstate_len; /* size of parallel coordination info */
struct PartitionPruneState *as_prune_state;
+ bool as_valid_subplans_identified; /* is as_valid_subplans valid? */
Bitmapset *as_valid_subplans;
Bitmapset *as_valid_asyncplans; /* valid asynchronous plans indexes */
bool (*choose_next_subplan) (AppendState *);
--
2.31.1
From 54644de166623238b2411c8710cd4bab9f97bfdc Mon Sep 17 00:00:00 2001
From: Tom Lane <tgl@sss.pgh.pa.us>
Date: Wed, 1 Mar 2023 17:44:06 -0500
Subject: [PATCH v2 3/4] Require empty Bitmapsets to be represented as NULL.
When I designed the Bitmapset module, I set things up so that an empty
Bitmapset could be represented either by a NULL pointer, or by an
allocated object all of whose bits are zero. I've recently come to
the conclusion that that was a bad idea and we should instead have a
convention like the longstanding invariant for Lists, whereby an empty
list is represented by NIL and nothing else.
To do this, we need to fix bms_intersect, bms_difference, and a couple
of other functions to check for having produced an empty result; but
then we can replace bms_is_empty(a) by a simple "a == NULL" test.
This is very likely a (marginal) win performance-wise, because we
call bms_is_empty many more times than those other functions put
together. However, the real reason to do it is that we have various
places that have hand-implemented a rule about "this Bitmapset
variable must be exactly NULL if empty", so that they can use
checks-for-null in place of bms_is_empty calls in particularly hot
code paths. That is a really fragile, mistake-prone way to do things,
and I'm surprised that we've seldom been bitten by it. It's not well
documented at all which variables have this property, so you can't
readily tell which code might be violating those conventions. By
making the convention universal, we can eliminate a subtle source of
bugs.
Discussion: https://postgr.es/m/1159933.1677621588@sss.pgh.pa.us
---
src/backend/nodes/bitmapset.c | 67 ++++++++++++++++++++++++++---------
src/include/nodes/bitmapset.h | 10 +++---
2 files changed, 56 insertions(+), 21 deletions(-)
diff --git a/src/backend/nodes/bitmapset.c b/src/backend/nodes/bitmapset.c
index 10dbbdddf5..c43de74cdf 100644
--- a/src/backend/nodes/bitmapset.c
+++ b/src/backend/nodes/bitmapset.c
@@ -5,10 +5,8 @@
*
* A bitmap set can represent any set of nonnegative integers, although
* it is mainly intended for sets where the maximum value is not large,
- * say at most a few hundred. By convention, a NULL pointer is always
- * accepted by all operations to represent the empty set. (But beware
- * that this is not the only representation of the empty set. Use
- * bms_is_empty() in preference to testing for NULL.)
+ * say at most a few hundred. By convention, we always represent the
+ * empty set by a NULL pointer.
*
*
* Copyright (c) 2003-2023, PostgreSQL Global Development Group
@@ -66,6 +64,8 @@
#error "invalid BITS_PER_BITMAPWORD"
#endif
+static bool bms_is_empty_internal(const Bitmapset *a);
+
/*
* bms_copy - make a palloc'd copy of a bitmapset
@@ -104,10 +104,10 @@ bms_equal(const Bitmapset *a, const Bitmapset *b)
{
if (b == NULL)
return true;
- return bms_is_empty(b);
+ return false;
}
else if (b == NULL)
- return bms_is_empty(a);
+ return false;
/* Identify shorter and longer input */
if (a->nwords <= b->nwords)
{
@@ -151,9 +151,9 @@ bms_compare(const Bitmapset *a, const Bitmapset *b)
/* Handle cases where either input is NULL */
if (a == NULL)
- return bms_is_empty(b) ? 0 : -1;
+ return (b == NULL) ? 0 : -1;
else if (b == NULL)
- return bms_is_empty(a) ? 0 : +1;
+ return +1;
/* Handle cases where one input is longer than the other */
shortlen = Min(a->nwords, b->nwords);
for (i = shortlen; i < a->nwords; i++)
@@ -282,6 +282,12 @@ bms_intersect(const Bitmapset *a, const Bitmapset *b)
resultlen = result->nwords;
for (i = 0; i < resultlen; i++)
result->words[i] &= other->words[i];
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(result))
+ {
+ pfree(result);
+ return NULL;
+ }
return result;
}
@@ -300,12 +306,22 @@ bms_difference(const Bitmapset *a, const Bitmapset *b)
return NULL;
if (b == NULL)
return bms_copy(a);
+
+ /*
+ * In Postgres' usage, an empty result is a very common case, so it's
+ * worth optimizing for that by testing bms_nonempty_difference(). This
+ * saves us a palloc/pfree cycle compared to checking after-the-fact.
+ */
+ if (!bms_nonempty_difference(a, b))
+ return NULL;
+
/* Copy the left input */
result = bms_copy(a);
/* And remove b's bits from result */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
result->words[i] &= ~b->words[i];
+ /* Need not check for empty result, since we handled that case above */
return result;
}
@@ -323,7 +339,7 @@ bms_is_subset(const Bitmapset *a, const Bitmapset *b)
if (a == NULL)
return true; /* empty set is a subset of anything */
if (b == NULL)
- return bms_is_empty(a);
+ return false;
/* Check common words */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
@@ -362,10 +378,10 @@ bms_subset_compare(const Bitmapset *a, const Bitmapset *b)
{
if (b == NULL)
return BMS_EQUAL;
- return bms_is_empty(b) ? BMS_EQUAL : BMS_SUBSET1;
+ return BMS_SUBSET1;
}
if (b == NULL)
- return bms_is_empty(a) ? BMS_EQUAL : BMS_SUBSET2;
+ return BMS_SUBSET2;
/* Check common words */
result = BMS_EQUAL; /* status so far */
shortlen = Min(a->nwords, b->nwords);
@@ -554,7 +570,7 @@ bms_nonempty_difference(const Bitmapset *a, const Bitmapset *b)
if (a == NULL)
return false;
if (b == NULL)
- return !bms_is_empty(a);
+ return true;
/* Check words in common */
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
@@ -696,12 +712,13 @@ bms_membership(const Bitmapset *a)
}
/*
- * bms_is_empty - is a set empty?
+ * bms_is_empty_internal - is a set empty?
*
- * This is even faster than bms_membership().
+ * This is now used only locally, to detect cases where a function has
+ * computed an empty set that we must now get rid of.
*/
-bool
-bms_is_empty(const Bitmapset *a)
+static bool
+bms_is_empty_internal(const Bitmapset *a)
{
int nwords;
int wordnum;
@@ -786,6 +803,12 @@ bms_del_member(Bitmapset *a, int x)
bitnum = BITNUM(x);
if (wordnum < a->nwords)
a->words[wordnum] &= ~((bitmapword) 1 << bitnum);
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
@@ -922,6 +945,12 @@ bms_int_members(Bitmapset *a, const Bitmapset *b)
a->words[i] &= b->words[i];
for (; i < a->nwords; i++)
a->words[i] = 0;
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
@@ -943,6 +972,12 @@ bms_del_members(Bitmapset *a, const Bitmapset *b)
shortlen = Min(a->nwords, b->nwords);
for (i = 0; i < shortlen; i++)
a->words[i] &= ~b->words[i];
+ /* If we computed an empty result, we must return NULL */
+ if (bms_is_empty_internal(a))
+ {
+ pfree(a);
+ return NULL;
+ }
return a;
}
diff --git a/src/include/nodes/bitmapset.h b/src/include/nodes/bitmapset.h
index c344ac04be..14de6a9ff1 100644
--- a/src/include/nodes/bitmapset.h
+++ b/src/include/nodes/bitmapset.h
@@ -5,10 +5,8 @@
*
* A bitmap set can represent any set of nonnegative integers, although
* it is mainly intended for sets where the maximum value is not large,
- * say at most a few hundred. By convention, a NULL pointer is always
- * accepted by all operations to represent the empty set. (But beware
- * that this is not the only representation of the empty set. Use
- * bms_is_empty() in preference to testing for NULL.)
+ * say at most a few hundred. By convention, we always represent the
+ * empty set by a NULL pointer.
*
*
* Copyright (c) 2003-2023, PostgreSQL Global Development Group
@@ -102,7 +100,9 @@ extern int bms_num_members(const Bitmapset *a);
/* optimized tests when we don't need to know exact membership count: */
extern BMS_Membership bms_membership(const Bitmapset *a);
-extern bool bms_is_empty(const Bitmapset *a);
+
+/* NULL is now the only allowed representation of an empty bitmapset */
+#define bms_is_empty(a) ((a) == NULL)
/* these routines recycle (modify or free) their non-const inputs: */
--
2.31.1
From ae52bce53b203fdee7427963613bf00e42dcddea Mon Sep 17 00:00:00 2001
From: Tom Lane <tgl@sss.pgh.pa.us>
Date: Wed, 1 Mar 2023 17:52:25 -0500
Subject: [PATCH v2 4/4] Remove local optimizations of empty Bitmapsets into
null pointers.
These are all dead code now that it's done centrally.
Discussion: https://postgr.es/m/1159933.1677621588@sss.pgh.pa.us
---
src/backend/executor/execUtils.c | 10 +---------
src/backend/optimizer/path/indxpath.c | 3 ---
src/backend/optimizer/plan/subselect.c | 9 ---------
src/backend/optimizer/util/pathnode.c | 6 ------
src/backend/optimizer/util/placeholder.c | 2 --
src/backend/optimizer/util/relnode.c | 7 -------
src/backend/rewrite/rewriteManip.c | 19 ++++---------------
src/pl/plpgsql/src/pl_exec.c | 7 ++-----
8 files changed, 7 insertions(+), 56 deletions(-)
diff --git a/src/backend/executor/execUtils.c b/src/backend/executor/execUtils.c
index c33a3c0bec..cfa95a07e4 100644
--- a/src/backend/executor/execUtils.c
+++ b/src/backend/executor/execUtils.c
@@ -877,15 +877,7 @@ UpdateChangedParamSet(PlanState *node, Bitmapset *newchg)
* include anything else into its chgParam set.
*/
parmset = bms_intersect(node->plan->allParam, newchg);
-
- /*
- * Keep node->chgParam == NULL if there's not actually any members; this
- * allows the simplest possible tests in executor node files.
- */
- if (!bms_is_empty(parmset))
- node->chgParam = bms_join(node->chgParam, parmset);
- else
- bms_free(parmset);
+ node->chgParam = bms_join(node->chgParam, parmset);
}
/*
diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c
index 011a0337da..9f4698f2a2 100644
--- a/src/backend/optimizer/path/indxpath.c
+++ b/src/backend/optimizer/path/indxpath.c
@@ -949,9 +949,6 @@ build_index_paths(PlannerInfo *root, RelOptInfo *rel,
/* We do not want the index's rel itself listed in outer_relids */
outer_relids = bms_del_member(outer_relids, rel->relid);
- /* Enforce convention that outer_relids is exactly NULL if empty */
- if (bms_is_empty(outer_relids))
- outer_relids = NULL;
/* Compute loop_count for cost estimation purposes */
loop_count = get_loop_count(root, rel->relid, outer_relids);
diff --git a/src/backend/optimizer/plan/subselect.c b/src/backend/optimizer/plan/subselect.c
index 22ffe4ca42..052263aea6 100644
--- a/src/backend/optimizer/plan/subselect.c
+++ b/src/backend/optimizer/plan/subselect.c
@@ -2825,15 +2825,6 @@ finalize_plan(PlannerInfo *root, Plan *plan,
/* but not any initplan setParams */
plan->extParam = bms_del_members(plan->extParam, initSetParam);
- /*
- * For speed at execution time, make sure extParam/allParam are actually
- * NULL if they are empty sets.
- */
- if (bms_is_empty(plan->extParam))
- plan->extParam = NULL;
- if (bms_is_empty(plan->allParam))
- plan->allParam = NULL;
-
return plan->allParam;
}
diff --git a/src/backend/optimizer/util/pathnode.c b/src/backend/optimizer/util/pathnode.c
index d749b50578..e8e06397a9 100644
--- a/src/backend/optimizer/util/pathnode.c
+++ b/src/backend/optimizer/util/pathnode.c
@@ -2372,12 +2372,6 @@ calc_nestloop_required_outer(Relids outerrelids,
/* ... and remove any mention of now-satisfied outer rels */
required_outer = bms_del_members(required_outer,
outerrelids);
- /* maintain invariant that required_outer is exactly NULL if empty */
- if (bms_is_empty(required_outer))
- {
- bms_free(required_outer);
- required_outer = NULL;
- }
return required_outer;
}
diff --git a/src/backend/optimizer/util/placeholder.c b/src/backend/optimizer/util/placeholder.c
index 9c6cb5eba7..b1723578e6 100644
--- a/src/backend/optimizer/util/placeholder.c
+++ b/src/backend/optimizer/util/placeholder.c
@@ -125,8 +125,6 @@ find_placeholder_info(PlannerInfo *root, PlaceHolderVar *phv)
*/
rels_used = pull_varnos(root, (Node *) phv->phexpr);
phinfo->ph_lateral = bms_difference(rels_used, phv->phrels);
- if (bms_is_empty(phinfo->ph_lateral))
- phinfo->ph_lateral = NULL; /* make it exactly NULL if empty */
phinfo->ph_eval_at = bms_int_members(rels_used, phv->phrels);
/* If no contained vars, force evaluation at syntactic location */
if (bms_is_empty(phinfo->ph_eval_at))
diff --git a/src/backend/optimizer/util/relnode.c b/src/backend/optimizer/util/relnode.c
index 9ad44a0508..68fd033595 100644
--- a/src/backend/optimizer/util/relnode.c
+++ b/src/backend/optimizer/util/relnode.c
@@ -772,8 +772,6 @@ build_join_rel(PlannerInfo *root,
*/
joinrel->direct_lateral_relids =
bms_del_members(joinrel->direct_lateral_relids, joinrel->relids);
- if (bms_is_empty(joinrel->direct_lateral_relids))
- joinrel->direct_lateral_relids = NULL;
/*
* Construct restrict and join clause lists for the new joinrel. (The
@@ -1024,11 +1022,6 @@ min_join_parameterization(PlannerInfo *root,
*/
result = bms_union(outer_rel->lateral_relids, inner_rel->lateral_relids);
result = bms_del_members(result, joinrelids);
-
- /* Maintain invariant that result is exactly NULL if empty */
- if (bms_is_empty(result))
- result = NULL;
-
return result;
}
diff --git a/src/backend/rewrite/rewriteManip.c b/src/backend/rewrite/rewriteManip.c
index 04718f66c0..d28d0da621 100644
--- a/src/backend/rewrite/rewriteManip.c
+++ b/src/backend/rewrite/rewriteManip.c
@@ -1247,16 +1247,11 @@ remove_nulling_relids_mutator(Node *node,
!bms_is_member(var->varno, context->except_relids) &&
bms_overlap(var->varnullingrels, context->removable_relids))
{
- Relids newnullingrels = bms_difference(var->varnullingrels,
- context->removable_relids);
-
- /* Micro-optimization: ensure nullingrels is NULL if empty */
- if (bms_is_empty(newnullingrels))
- newnullingrels = NULL;
/* Copy the Var ... */
var = copyObject(var);
/* ... and replace the copy's varnullingrels field */
- var->varnullingrels = newnullingrels;
+ var->varnullingrels = bms_difference(var->varnullingrels,
+ context->removable_relids);
return (Node *) var;
}
/* Otherwise fall through to copy the Var normally */
@@ -1268,26 +1263,20 @@ remove_nulling_relids_mutator(Node *node,
if (phv->phlevelsup == context->sublevels_up &&
!bms_overlap(phv->phrels, context->except_relids))
{
- Relids newnullingrels = bms_difference(phv->phnullingrels,
- context->removable_relids);
-
/*
- * Micro-optimization: ensure nullingrels is NULL if empty.
- *
* Note: it might seem desirable to remove the PHV altogether if
* phnullingrels goes to empty. Currently we dare not do that
* because we use PHVs in some cases to enforce separate identity
* of subexpressions; see wrap_non_vars usages in prepjointree.c.
*/
- if (bms_is_empty(newnullingrels))
- newnullingrels = NULL;
/* Copy the PlaceHolderVar and mutate what's below ... */
phv = (PlaceHolderVar *)
expression_tree_mutator(node,
remove_nulling_relids_mutator,
(void *) context);
/* ... and replace the copy's phnullingrels field */
- phv->phnullingrels = newnullingrels;
+ phv->phnullingrels = bms_difference(phv->phnullingrels,
+ context->removable_relids);
/* We must also update phrels, if it contains a removable RTI */
phv->phrels = bms_difference(phv->phrels,
context->removable_relids);
diff --git a/src/pl/plpgsql/src/pl_exec.c b/src/pl/plpgsql/src/pl_exec.c
index ffd6d2e3bc..b0a2cac227 100644
--- a/src/pl/plpgsql/src/pl_exec.c
+++ b/src/pl/plpgsql/src/pl_exec.c
@@ -6240,12 +6240,9 @@ setup_param_list(PLpgSQL_execstate *estate, PLpgSQL_expr *expr)
Assert(expr->plan != NULL);
/*
- * We only need a ParamListInfo if the expression has parameters. In
- * principle we should test with bms_is_empty(), but we use a not-null
- * test because it's faster. In current usage bits are never removed from
- * expr->paramnos, only added, so this test is correct anyway.
+ * We only need a ParamListInfo if the expression has parameters.
*/
- if (expr->paramnos)
+ if (!bms_is_empty(expr->paramnos))
{
/* Use the common ParamListInfo */
paramLI = estate->paramLI;
--
2.31.1
On Wed, Mar 01, 2023 at 05:59:45PM -0500, Tom Lane wrote: > bms_first_member is definitely legacy code, so let's just get > rid of it. Done like that in 0001 below. (This was slightly more > complex than I foresaw, because some of the callers were modifying > the result variables. But they're probably cleaner this way anyway.) Yeah, it's nice that you don't have to subtract FirstLowInvalidHeapAttributeNumber in so many places. I think future changes might end up using attidx when they ought to use attrnum (and vice versa), but you could just as easily forget to subtract FirstLowInvalidHeapAttributeNumber today, so it's probably fine. > + /* attidx is zero-based, attrnum is the normal attribute number */ > + int attrnum = attidx + FirstLowInvalidHeapAttributeNumber; nitpick: Shouldn't this be an AttrNumber? > Yeah. I split out those executor fixes as 0002; 0003 is the changes > to bitmapsets proper, and then 0004 removes now-dead code. These all looked reasonable to me. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Nathan Bossart <nathandbossart@gmail.com> writes:
> On Wed, Mar 01, 2023 at 05:59:45PM -0500, Tom Lane wrote:
>> + /* attidx is zero-based, attrnum is the normal attribute number */
>> + int attrnum = attidx + FirstLowInvalidHeapAttributeNumber;
> nitpick: Shouldn't this be an AttrNumber?
I stuck with the existing type choices for those variables,
but I don't mind changing to AttrNumber here.
regards, tom lane
On Thu, Mar 2, 2023 at 6:59 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Yeah. I split out those executor fixes as 0002; 0003 is the changes
to bitmapsets proper, and then 0004 removes now-dead code.
+1 to all these patches. Some minor comments from me.
*0003
It seems that the Bitmapset checked by bms_is_empty_internal cannot be
NULL from how it is computed by a function. So I wonder if we can
remove the check of 'a' being NULL in that function, or reduce it to an
Assert.
- if (a == NULL)
- return true;
+ Assert(a != NULL);
*0004
It seems that in create_lateral_join_info around line 689, the
bms_is_empty check of lateral_relids is not necessary, since we've
checked that lateral_relids cannot be NULL several lines earlier.
@@ -682,12 +682,6 @@ create_lateral_join_info(PlannerInfo *root)
if (lateral_relids == NULL)
continue;
- /*
- * We should not have broken the invariant that lateral_relids is
- * exactly NULL if empty.
- */
- Assert(!bms_is_empty(lateral_relids));
-
Thanks
Richard
*0003
It seems that the Bitmapset checked by bms_is_empty_internal cannot be
NULL from how it is computed by a function. So I wonder if we can
remove the check of 'a' being NULL in that function, or reduce it to an
Assert.
- if (a == NULL)
- return true;
+ Assert(a != NULL);
*0004
It seems that in create_lateral_join_info around line 689, the
bms_is_empty check of lateral_relids is not necessary, since we've
checked that lateral_relids cannot be NULL several lines earlier.
@@ -682,12 +682,6 @@ create_lateral_join_info(PlannerInfo *root)
if (lateral_relids == NULL)
continue;
- /*
- * We should not have broken the invariant that lateral_relids is
- * exactly NULL if empty.
- */
- Assert(!bms_is_empty(lateral_relids));
-
Thanks
Richard
Richard Guo <guofenglinux@gmail.com> writes:
> It seems that the Bitmapset checked by bms_is_empty_internal cannot be
> NULL from how it is computed by a function. So I wonder if we can
> remove the check of 'a' being NULL in that function, or reduce it to an
> Assert.
Yeah, I think just removing it is sufficient. The subsequent attempts
to dereference the pointer will crash just fine if it's NULL; we don't
need an Assert to help things along.
> It seems that in create_lateral_join_info around line 689, the
> bms_is_empty check of lateral_relids is not necessary, since we've
> checked that lateral_relids cannot be NULL several lines earlier.
Good catch, I missed that one.
Pushed, thanks for reviewing.
regards, tom lane
On Wed, 1 Mar 2023 at 10:59, Tom Lane <tgl@sss.pgh.pa.us> wrote: > When I designed the Bitmapset module, I set things up so that an empty > Bitmapset could be represented either by a NULL pointer, or by an > allocated object all of whose bits are zero. I've recently come to > the conclusion that that was a bad idea and we should instead have > a convention like the longstanding invariant for Lists: an empty > list is represented by NIL and nothing else. I know I'm late to the party here, but I just wanted to add that I agree with this and also that I've never been a fan of having to decide if it was safe to check for NULL when I needed performance or if I needed to use bms_is_empty() because the set might have all its words set to 0. I suggest tightening the rule even further so instead of just empty sets having to be represented as NULL, the rule should be that sets should never contain any trailing zero words, which is effectively a superset of the "empty is NULL" rule that you've just changed. If we did this, then various functions can shake loose some crufty code and various other functions become more optimal due to not having to loop over trailing zero words needlessly. For example. * bms_equal() and bms_compare() can precheck nwords match before troubling themselves with looping over each member, and; * bms_is_subset() can return false early if 'a' has more words than 'b', and; * bms_subset_compare() becomes more simple as it does not have to look for trailing 0 words, and; * bms_nonempty_difference() can return true early if 'a' has more words than 'b', plus no need to check for trailing zero words at the end. We can also chop the set down to size in; bms_intersect(), bms_difference(), bms_int_members(), bms_del_members() and bms_intersect() which saves looping needlessly over empty words when various other BMS operations are performed later on the set, for example, bms_next_member(), bms_prev_member, bms_copy(), etc. The only reason I can think of that this would be a bad idea is that if we want to add members again then we need to do repalloc(). If we're only increasing the nwords back to what it had been on some previous occasion then repalloc() is effectively a no-op, so I doubt this will really be a net negative. I think the effort we'll waste by carrying around needless trailing zero words in most cases is likely to outweigh the overhead of any no-op repallocs. Take bms_int_members(), for example, we'll purposefully 0 out all the trailing words possibly having to read in new cachelines from RAM to do so. It would be better to leave having to read those in again until we actually need to do something more useful with them, like adding some new members to the set again. We'll have to dirty those cachelines then anyway and we may have flushed those cachelines out of the CPU cache by the time we get around to adding the new members again. I've coded this up in the attached and followed the lead in list.c and added a function named check_bitmapset_invariants() which ensures the above rule is followed. I think the code as it stands today should really have something like that anyway. The patch also optimizes sub-optimal newly added code which calls bms_is_empty_internal() when we have other more optimal means to determine if the set is empty or not. David
Вложения
David Rowley <dgrowleyml@gmail.com> writes:
> I suggest tightening the rule even further so instead of just empty
> sets having to be represented as NULL, the rule should be that sets
> should never contain any trailing zero words, which is effectively a
> superset of the "empty is NULL" rule that you've just changed.
Hmm, I'm not immediately a fan of that, because it'd mean more
interaction with aset.c to change the allocated size of results.
(Is it worth carrying both "allocated words" and "nonzero words"
fields to avoid useless memory-management effort? Dunno.)
Another point here is that I'm pretty sure that just about all
bitmapsets we deal with are only one or two words, so I'm not
convinced you're going to get any performance win to justify
the added management overhead.
regards, tom lane
On Fri, 3 Mar 2023 at 15:17, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> (Is it worth carrying both "allocated words" and "nonzero words"
> fields to avoid useless memory-management effort? Dunno.)
It would have been a more appealing thing to do before Bitmapset
became a node type as we'd have had empty space in the struct to have
another 32-bit word on 64-bit builds.
> Another point here is that I'm pretty sure that just about all
> bitmapsets we deal with are only one or two words, so I'm not
> convinced you're going to get any performance win to justify
> the added management overhead.
It's true that the majority of Bitmapsets are going to be just 1 word,
but it's important to acknowledge that we do suffer in some more
extreme cases when Bitmapsets become large. Partition with large
numbers of partitions is one such case.
create table lp(a int) partition by list(a);
select 'create table lp'||x||' partition of lp for values
in('||x||');' from generate_series(0,9999)x;
\gexec
# cat bench.sql
select * from lp where a > 1 and a < 3;
$ pgbench -n -T 15 -f bench.sql postgres | grep tps
master:
tps = 28055.619289 (without initial connection time)
tps = 27819.235083 (without initial connection time)
tps = 28486.099808 (without initial connection time)
master + bms_no_trailing_zero_words.patch:
tps = 30840.840266 (without initial connection time)
tps = 29491.519705 (without initial connection time)
tps = 29471.083938 (without initial connection time)
(~6.45% faster)
Of course, it's an extreme case, I'm merely trying to show that
trimming the Bitmapsets down can have an impact in some cases.
David
David Rowley <dgrowleyml@gmail.com> writes:
> On Fri, 3 Mar 2023 at 15:17, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Another point here is that I'm pretty sure that just about all
>> bitmapsets we deal with are only one or two words, so I'm not
>> convinced you're going to get any performance win to justify
>> the added management overhead.
> It's true that the majority of Bitmapsets are going to be just 1 word,
> but it's important to acknowledge that we do suffer in some more
> extreme cases when Bitmapsets become large. Partition with large
> numbers of partitions is one such case.
Maybe, but optimizing for that while pessimizing every other case
doesn't sound very attractive from here. I think we need some
benchmarks on normal-size bitmapsets before considering doing much
in this area.
Also, if we're going to make any sort of changes here it'd probably
behoove us to make struct Bitmapset private in bitmapset.c, so that
we can have confidence that nobody is playing games with them.
I had a go at that and was pleasantly surprised to find that
actually nobody has; the attached passes check-world. It'd probably
be smart to commit this as a follow-on to 00b41463c, whether or not
we go any further.
Also, given that we do this, I don't think that check_bitmapset_invariants
as you propose it is worth the trouble. The reason we've gone to such
lengths with checking List invariants is that initially we had a large
number of places doing creative and not-too-structured things with Lists,
plus we've made several absolutely fundamental changes to that data
structure. Despite the far larger bug surface, I don't recall that those
invariant checks ever found anything after the initial rounds of changes.
So I don't buy that there's an argument for a similarly expensive set
of checks here. bitmapset.c is small enough that we should be able to
pretty much prove it correct by eyeball.
regards, tom lane
diff --git a/src/backend/nodes/Makefile b/src/backend/nodes/Makefile
index af12c64878..a6eb2a87bb 100644
--- a/src/backend/nodes/Makefile
+++ b/src/backend/nodes/Makefile
@@ -54,7 +54,6 @@ node_headers = \
commands/trigger.h \
executor/tuptable.h \
foreign/fdwapi.h \
- nodes/bitmapset.h \
nodes/extensible.h \
nodes/lockoptions.h \
nodes/miscnodes.h \
diff --git a/src/backend/nodes/bitmapset.c b/src/backend/nodes/bitmapset.c
index 7ba3cf635b..c11daeb303 100644
--- a/src/backend/nodes/bitmapset.c
+++ b/src/backend/nodes/bitmapset.c
@@ -24,6 +24,34 @@
#include "port/pg_bitutils.h"
+/*
+ * Data representation
+ *
+ * Larger bitmap word sizes generally give better performance, so long as
+ * they're not wider than the processor can handle efficiently. We use
+ * 64-bit words if pointers are that large, else 32-bit words.
+ */
+#if SIZEOF_VOID_P >= 8
+
+#define BITS_PER_BITMAPWORD 64
+typedef uint64 bitmapword; /* must be an unsigned type */
+typedef int64 signedbitmapword; /* must be the matching signed type */
+
+#else
+
+#define BITS_PER_BITMAPWORD 32
+typedef uint32 bitmapword; /* must be an unsigned type */
+typedef int32 signedbitmapword; /* must be the matching signed type */
+
+#endif
+
+struct Bitmapset
+{
+ NodeTag type; /* it's a Node */
+ int nwords; /* number of words in array */
+ bitmapword words[FLEXIBLE_ARRAY_MEMBER]; /* really [nwords] */
+};
+
#define WORDNUM(x) ((x) / BITS_PER_BITMAPWORD)
#define BITNUM(x) ((x) % BITS_PER_BITMAPWORD)
diff --git a/src/backend/nodes/gen_node_support.pl b/src/backend/nodes/gen_node_support.pl
index ecbcadb8bf..fd5d61bfd4 100644
--- a/src/backend/nodes/gen_node_support.pl
+++ b/src/backend/nodes/gen_node_support.pl
@@ -65,7 +65,6 @@ my @all_input_files = qw(
commands/trigger.h
executor/tuptable.h
foreign/fdwapi.h
- nodes/bitmapset.h
nodes/extensible.h
nodes/lockoptions.h
nodes/miscnodes.h
@@ -132,6 +131,19 @@ my @special_read_write;
# node types we don't want any support functions for, just node tags
my @nodetag_only;
+# Nodes with custom copy/equal implementations are skipped from
+# .funcs.c but need case statements in .switch.c.
+my @custom_copy_equal;
+
+# Similarly for custom read/write implementations.
+my @custom_read_write;
+
+# Similarly for custom query jumble implementation.
+my @custom_query_jumble;
+
+# Track node types with manually assigned NodeTag numbers.
+my %manual_nodetag_number;
+
# types that are copied by straight assignment
my @scalar_types = qw(
bits32 bool char double int int8 int16 int32 int64 long uint8 uint16 uint32 uint64
@@ -166,18 +178,12 @@ push @no_equal, qw(List);
push @no_query_jumble, qw(List);
push @special_read_write, qw(List);
-# Nodes with custom copy/equal implementations are skipped from
-# .funcs.c but need case statements in .switch.c.
-my @custom_copy_equal;
-
-# Similarly for custom read/write implementations.
-my @custom_read_write;
-
-# Similarly for custom query jumble implementation.
-my @custom_query_jumble;
-
-# Track node types with manually assigned NodeTag numbers.
-my %manual_nodetag_number;
+# Likewise, Bitmapset is specially handled rather than being parsed
+# out of a header file. This supports making it an opaque struct.
+push @node_types, qw(Bitmapset);
+push @custom_copy_equal, qw(Bitmapset);
+push @no_query_jumble, qw(Bitmapset);
+push @special_read_write, qw(Bitmapset);
# This is a struct, so we can copy it by assignment. Equal support is
# currently not required.
diff --git a/src/backend/nodes/tidbitmap.c b/src/backend/nodes/tidbitmap.c
index 29a1858441..541626e697 100644
--- a/src/backend/nodes/tidbitmap.c
+++ b/src/backend/nodes/tidbitmap.c
@@ -42,7 +42,6 @@
#include "access/htup_details.h"
#include "common/hashfn.h"
-#include "nodes/bitmapset.h"
#include "nodes/tidbitmap.h"
#include "storage/lwlock.h"
#include "utils/dsa.h"
@@ -72,7 +71,14 @@
*/
#define PAGES_PER_CHUNK (BLCKSZ / 32)
-/* We use BITS_PER_BITMAPWORD and typedef bitmapword from nodes/bitmapset.h */
+/* We use the same BITS_PER_BITMAPWORD and typedef bitmapword as bitmapset.c */
+#if SIZEOF_VOID_P >= 8
+#define BITS_PER_BITMAPWORD 64
+typedef uint64 bitmapword; /* must be an unsigned type */
+#else
+#define BITS_PER_BITMAPWORD 32
+typedef uint32 bitmapword; /* must be an unsigned type */
+#endif
#define WORDNUM(x) ((x) / BITS_PER_BITMAPWORD)
#define BITNUM(x) ((x) % BITS_PER_BITMAPWORD)
diff --git a/src/include/nodes/bitmapset.h b/src/include/nodes/bitmapset.h
index 14de6a9ff1..3f5be0b9a3 100644
--- a/src/include/nodes/bitmapset.h
+++ b/src/include/nodes/bitmapset.h
@@ -18,43 +18,14 @@
#ifndef BITMAPSET_H
#define BITMAPSET_H
-#include "nodes/nodes.h"
-
/*
* Forward decl to save including pg_list.h
*/
struct List;
-/*
- * Data representation
- *
- * Larger bitmap word sizes generally give better performance, so long as
- * they're not wider than the processor can handle efficiently. We use
- * 64-bit words if pointers are that large, else 32-bit words.
- */
-#if SIZEOF_VOID_P >= 8
-
-#define BITS_PER_BITMAPWORD 64
-typedef uint64 bitmapword; /* must be an unsigned type */
-typedef int64 signedbitmapword; /* must be the matching signed type */
-
-#else
-
-#define BITS_PER_BITMAPWORD 32
-typedef uint32 bitmapword; /* must be an unsigned type */
-typedef int32 signedbitmapword; /* must be the matching signed type */
-
-#endif
-
-typedef struct Bitmapset
-{
- pg_node_attr(custom_copy_equal, special_read_write, no_query_jumble)
-
- NodeTag type;
- int nwords; /* number of words in array */
- bitmapword words[FLEXIBLE_ARRAY_MEMBER]; /* really [nwords] */
-} Bitmapset;
+/* struct Bitmapset is private in bitmapset.c */
+typedef struct Bitmapset Bitmapset;
/* result of bms_subset_compare */
typedef enum
diff --git a/src/include/nodes/meson.build b/src/include/nodes/meson.build
index efe0834afb..81f1e7a890 100644
--- a/src/include/nodes/meson.build
+++ b/src/include/nodes/meson.build
@@ -15,7 +15,6 @@ node_support_input_i = [
'commands/trigger.h',
'executor/tuptable.h',
'foreign/fdwapi.h',
- 'nodes/bitmapset.h',
'nodes/extensible.h',
'nodes/lockoptions.h',
'nodes/miscnodes.h',
On Sat, 4 Mar 2023 at 11:08, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> David Rowley <dgrowleyml@gmail.com> writes:
> > On Fri, 3 Mar 2023 at 15:17, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > It's true that the majority of Bitmapsets are going to be just 1 word,
> > but it's important to acknowledge that we do suffer in some more
> > extreme cases when Bitmapsets become large. Partition with large
> > numbers of partitions is one such case.
>
> Maybe, but optimizing for that while pessimizing every other case
> doesn't sound very attractive from here. I think we need some
> benchmarks on normal-size bitmapsets before considering doing much
> in this area.
After thinking about this again and looking at the code, I'm not
really sure where the pessimism has been added. For the changes made
to say bms_equal(), there was already a branch that checked the nwords
column so that we could find the shorter and longer sets out of the
two input sets. That's been replaced with a comparison of both input
set's nwords, which does not really seem any more expensive. For
bms_compare() we needed to do Min(a->nwords, b->nwords) to find the
shortest set, likewise for bms_nonempty_difference() and
bms_is_subset(). That does not seem less expensive than the
replacement code.
I think the times where we have sets that we do manage to trim down
the nword count with that we actually end up having to expand again
are likely fairly rare.
I also wondered if we could shave off a few instructions by utilising
the knowledge that nwords is never 0. That would mean that some of
the loops could be written as:
i = 0; do { <stuff>; } while (++i < set->nwords);
instead of:
for (i = 0; i < set->nwords; i++) { <stuff>; }
if we do assume that the vast majority of sets are nwords==1 sets,
then this reduces the loop condition checks by half for all those.
I see that gcc manages to optimize: for (i = 0; i < set->nwords || i
== 0; i++) { <stuff>; } into the same code as the do while loop. clang
does not seem to manage that.
> Also, if we're going to make any sort of changes here it'd probably
> behoove us to make struct Bitmapset private in bitmapset.c, so that
> we can have confidence that nobody is playing games with them.
> I had a go at that and was pleasantly surprised to find that
> actually nobody has; the attached passes check-world. It'd probably
> be smart to commit this as a follow-on to 00b41463c, whether or not
> we go any further.
That seems like a good idea. This will give us extra reassurance that
nobody is making up their own Bitmapsets through some custom function
that don't follow the rules.
> Also, given that we do this, I don't think that check_bitmapset_invariants
> as you propose it is worth the trouble.
I wondered if maybe just Assert(a == NULL || a->words[a->nwords - 1]
!= 0); would be worthwhile anywhere. However, I don't see any
particular function that is more likely to catch those errors, so it's
maybe not worth doing anywhere if we're not doing it everywhere.
I adjusted the patch to remove the invariant checks and fixed up a
couple of things I'd missed. The 0002 patch changes the for loops
into do while loops. I wanted to see if we could see any performance
gains from doing this.
The performance numbers are nowhere near as stable as I'd like them to
have been, but testing the patch shows:
Test 1:
setup:
create table t1 (a int) partition by list(a);
select 'create table t1_'||x||' partition of t1 for values
in('||x||');' from generate_series(0,9)x;
\gexec
Test 1's sql:
select * from t1 where a > 1 and a < 3;
for i in {1..3}; do pgbench -n -f test1.sql -T 15 postgres | grep tps; done
master (cf96907aad):
tps = 29534.189309
tps = 30465.722545
tps = 30328.290553
master + 0001:
tps = 28915.174536
tps = 29817.950994
tps = 29387.084581
master + 0001 + 0002:
tps = 29438.216512
tps = 29951.905408
tps = 31445.191414
Test 2:
setup:
create table t2 (a int) partition by list(a);
select 'create table t2_'||x||' partition of t2 for values
in('||x||');' from generate_series(0,9999)x;
\gexec
Test 2's sql:
select * from t2 where a > 1 and a < 3;
for i in {1..3}; do pgbench -n -f test2.sql -T 15 postgres | grep tps; done
master (cf96907aad):
tps = 28470.504990
tps = 29175.450905
tps = 28123.699176
master + 0001:
tps = 28056.256805
tps = 28380.401746
tps = 28384.395217
master + 0001 + 0002:
tps = 29365.992219
tps = 28418.374923
tps = 28303.924129
Test 3:
setup:
create table t3a (a int primary key);
create table t3b (a int primary key);
Test 3's sql:
select * from t3a inner join t3b on t3a.a = t3b.a;
for i in {1..3}; do pgbench -n -f test3.sql -T 15 postgres | grep tps; done
master (cf96907aad):
tps = 20458.710550
tps = 20527.898929
tps = 20284.165277
master + 0001:
tps = 20700.340713
tps = 20571.913956
tps = 20541.771589
master + 0001 + 0002:
tps = 20046.674601
tps = 20016.649536
tps = 19487.999853
I've attached a graph of this too. It shows that there might be a
small increase in performance with tests 1 and 2. It seems like test 3
regresses a bit. I suspect this might just be a code arrangement issue
as master + 0001 is faster than 0001 + 0002 for that test.
David
Вложения
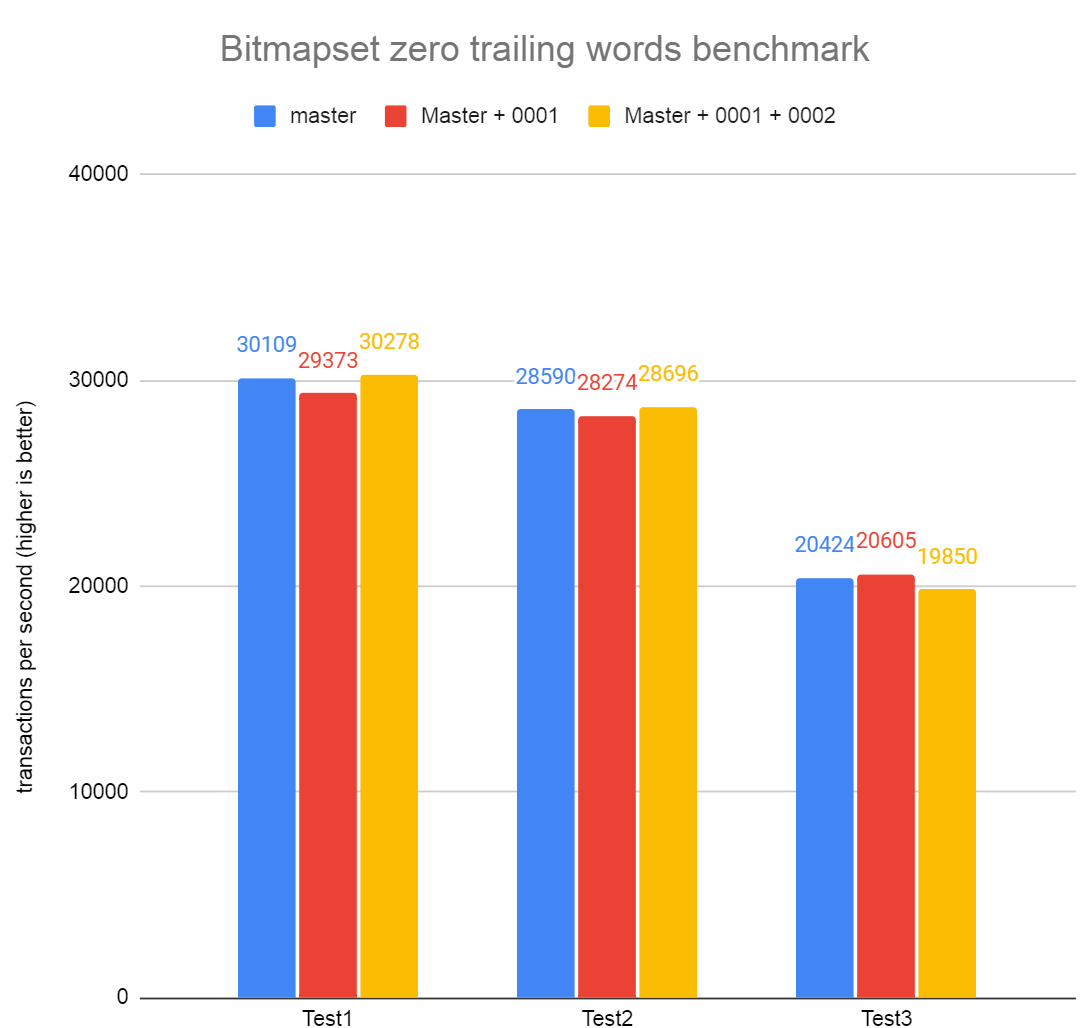{kind=link}
Hello,
On Tue, Mar 7, 2023 at 1:07 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I adjusted the patch to remove the invariant checks and fixed up a
> couple of things I'd missed. The 0002 patch changes the for loops
> into do while loops. I wanted to see if we could see any performance
> gains from doing this.
I noticed that these patches caused significant degradation while
working on improving planning performance in another thread [1].
In the experiment, I used the query attached to this email. This
workload consists of eight tables, each of which is split into n
partitions. The "query.sql" measures the planning time of a query that
joins these tables. You can quickly reproduce my experiment using the
following commands.
=====
psql -f create-tables.sql
psql -f query.sql
=====
I show the result in the following tables. I refer to David's patches
in [2] as the "trailing-zero" patch. When n was large, the
trailing-zero patch showed significant degradation. This is due to too
many calls of repalloc(). With this patch, we cannot reuse spaces
after the last non-zero bitmapword, so we need to call repalloc() more
frequently than before. When n is 256, repalloc() was called only 670
times without the patch, while it was called 5694 times with the
patch.
Table 1: Planning time (ms)
-----------------------------------------------------------------
n | Master | Patched (trailing-zero) | Patched (bitwise-OR)
-----------------------------------------------------------------
1 | 37.639 | 37.330 | 36.979
2 | 36.066 | 35.646 | 36.044
4 | 37.958 | 37.349 | 37.842
8 | 42.397 | 42.994 | 39.779
16 | 54.565 | 67.713 | 44.186
32 | 89.220 | 100.828 | 65.542
64 | 227.854 | 269.059 | 150.398
128 | 896.513 | 1279.965 | 577.671
256 | 4241.994 | 8220.508 | 2538.681
-----------------------------------------------------------------
Table 2: Planning time speedup (higher is better)
------------------------------------------------------
n | Patched (trailing-zero) | Patched (bitwise-OR)
------------------------------------------------------
1 | 100.8% | 101.8%
2 | 101.2% | 100.1%
4 | 101.6% | 100.3%
8 | 98.6% | 106.6%
16 | 80.6% | 123.5%
32 | 88.5% | 136.1%
64 | 84.7% | 151.5%
128 | 70.0% | 155.2%
256 | 51.6% | 167.1%
------------------------------------------------------
On Fri, Mar 3, 2023 at 10:52 AM David Rowley <dgrowleyml@gmail.com> wrote:
> The patch also optimizes sub-optimal newly added code which calls
> bms_is_empty_internal() when we have other more optimal means to
> determine if the set is empty or not.
However, I agree with David's opinion regarding the
bms_is_empty_internal() calls, which is quoted above. I have
implemented this optimization in a slightly different way than David.
My patch is attached to this email. The difference between my patch
and David's is in the determination method of whether the result is
empty: David's patch records the last index of non-zero bitmapword to
minimize the Bitmapset. If the index is -1, we can conclude that the
result is empty. In contrast, my patch uses a more lightweight
operation. I show my changes as follows.
=====
@@ -263,6 +261,7 @@ bms_intersect(const Bitmapset *a, const Bitmapset *b)
const Bitmapset *other;
int resultlen;
int i;
+ bitmapword bitwise_or = 0;
/* Handle cases where either input is NULL */
if (a == NULL || b == NULL)
@@ -281,9 +280,17 @@ bms_intersect(const Bitmapset *a, const Bitmapset *b)
/* And intersect the longer input with the result */
resultlen = result->nwords;
for (i = 0; i < resultlen; i++)
- result->words[i] &= other->words[i];
+ {
+ bitmapword w = (result->words[i] &= other->words[i]);
+
+ /*
+ * Compute bitwise OR of all bitmapwords to determine if the result
+ * is empty
+ */
+ bitwise_or |= w;
+ }
/* If we computed an empty result, we must return NULL */
- if (bms_is_empty_internal(result))
+ if (bitwise_or == 0)
{
pfree(result);
return NULL;
@@ -711,30 +718,6 @@ bms_membership(const Bitmapset *a)
return result;
}
=====
My idea is to compute the bitwise OR of all bitmapwords of the result
Bitmapset. The bitwise OR can be represented as a single operation in
the machine code and does not require any conditional branches. If the
bitwise ORed value is zero, we can conclude the result Bitmapset is
empty. The costs related to this operation can be almost negligible;
it is significantly cheaper than calling bms_is_empty_internal() and
less expensive than using a conditional branch such as 'if.'
In the tables above, I called my patch the "bitwise-OR" patch. The
patch is much faster than the master when n is large. Its speed up
reached 167.1%. I think just adopting this optimization is worth
considering.
[1] https://www.postgresql.org/message-id/CAJ2pMkY10J_PA2jpH5M-VoOo6BvJnTOO_-t_znu_pOaP0q10pA@mail.gmail.com
[2] https://www.postgresql.org/message-id/CAApHDvq9eq0W_aFUGrb6ba28ieuQN4zM5Uwqxy7+LMZjJc+VGg@mail.gmail.com
--
Best regards,
Yuya Watari
Вложения
Hello, On Thu, Mar 16, 2023 at 10:30 AM Yuya Watari <watari.yuya@gmail.com> wrote: > My idea is to compute the bitwise OR of all bitmapwords of the result > Bitmapset. The bitwise OR can be represented as a single operation in > the machine code and does not require any conditional branches. If the > bitwise ORed value is zero, we can conclude the result Bitmapset is > empty. The costs related to this operation can be almost negligible; > it is significantly cheaper than calling bms_is_empty_internal() and > less expensive than using a conditional branch such as 'if.' After posting the patch, I noticed that my patch had some bugs. My idea above is not applicable to bms_del_member(), and I missed some additional operations required in bms_del_members(). I have attached the fixed version to this email. I really apologize for making the mistakes. Should we add new regression tests to prevent this kind of bug? The following tables illustrate the result of a re-run experiment. The significant improvement was a mistake, but a speedup of about 2% was still obtained when the number of partitions, namely n, was large. This result indicates that the optimization regarding bms_is_empty_internal() is effective on some workloads. Table 1: Planning time (ms) (n: the number of partitions of each table) ----------------------------------------------------------------- n | Master | Patched (trailing-zero) | Patched (bitwise-OR) ----------------------------------------------------------------- 1 | 36.903 | 36.621 | 36.731 2 | 35.842 | 35.031 | 35.704 4 | 37.756 | 37.457 | 37.409 8 | 42.069 | 42.578 | 42.322 16 | 53.670 | 67.792 | 53.618 32 | 88.412 | 100.605 | 89.147 64 | 229.734 | 271.259 | 225.971 128 | 889.367 | 1272.270 | 870.472 256 | 4209.312 | 8223.623 | 4129.594 ----------------------------------------------------------------- Table 2: Planning time speedup (higher is better) ------------------------------------------------------ n | Patched (trailing-zero) | Patched (bitwise-OR) ------------------------------------------------------ 1 | 100.8% | 100.5% 2 | 102.3% | 100.4% 4 | 100.8% | 100.9% 8 | 98.8% | 99.4% 16 | 79.2% | 100.1% 32 | 87.9% | 99.2% 64 | 84.7% | 101.7% 128 | 69.9% | 102.2% 256 | 51.2% | 101.9% ------------------------------------------------------ -- Best regards, Yuya Watari
Вложения
Hello,
On Tue, Mar 7, 2023 at 1:07 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I adjusted the patch to remove the invariant checks and fixed up a
> couple of things I'd missed. The 0002 patch changes the for loops
> into do while loops. I wanted to see if we could see any performance
> gains from doing this.
In March, I reported that David's patch caused a degradation in
planning performance. I have investigated this issue further and found
some bugs in the patch. Due to these bugs, Bitmapset operations in the
original patch computed incorrect results. This incorrect computation
resulted in unexpected behavior, which I observed as performance
degradation. After fixing the bugs, David's patch showed significant
performance improvements. In particular, it is worth noting that the
patch obtained a good speedup even when most Bitmapsets have only one
word.
1.1. Wrong truncation that we should not do (fixed in v2-0003)
The first bug is in bms_difference() and bms_del_members(). At the end
of these functions, the original patch truncated the result Bitmapset
when lastnonzero was -1. However, we must not do this when the result
Bitmapset is longer than the other. In such a case, the last word of
the result was still non-zero, so we cannot shorten nwords. I fixed
this bug in v2-0003.
1.2. Missing truncation that we should do (fixed in v2-0004)
The other bug is in bms_del_member(). As seen from v2-0004-*.patch,
the original patch missed the necessary truncation. I also fixed this
bug.
2. Experiments
I conducted experiments to evaluate the performance of David's patch
with bug fixes. In the experiments, I used two queries attached to
this email. The first query, Query A (query-a.sql), joins three tables
and performs an aggregation. This is quite a simple query. The second
query, Query B (query-b.sql), is more complicated because it joins
eight tables. In both queries, every table is split into n partitions.
I issued these queries with varying n and measured their planning
times. The following tables and attached figure show the results.
Table 1: Planning time and its speedup of Query A
(n: the number of partitions of each table)
(Speedup: higher is better)
---------------------------------------------
n | Master (ms) | Patched (ms) | Speedup
---------------------------------------------
1 | 0.722 | 0.682 | 105.8%
2 | 0.779 | 0.774 | 100.6%
4 | 0.977 | 0.958 | 101.9%
8 | 1.286 | 1.287 | 99.9%
16 | 1.993 | 1.986 | 100.4%
32 | 3.967 | 3.900 | 101.7%
64 | 7.783 | 7.310 | 106.5%
128 | 23.369 | 19.722 | 118.5%
256 | 108.723 | 75.149 | 144.7%
384 | 265.576 | 167.354 | 158.7%
512 | 516.468 | 301.100 | 171.5%
640 | 883.167 | 494.960 | 178.4%
768 | 1423.839 | 755.201 | 188.5%
896 | 2195.935 | 1127.786 | 194.7%
1024 | 3041.131 | 1444.145 | 210.6%
---------------------------------------------
Table 2: Planning time and its speedup of Query B
--------------------------------------------
n | Master (ms) | Patched (ms) | Speedup
--------------------------------------------
1 | 36.038 | 35.455 | 101.6%
2 | 34.831 | 34.178 | 101.9%
4 | 36.537 | 35.998 | 101.5%
8 | 41.234 | 40.333 | 102.2%
16 | 52.427 | 50.596 | 103.6%
32 | 87.064 | 80.013 | 108.8%
64 | 228.050 | 187.762 | 121.5%
128 | 886.140 | 645.731 | 137.2%
256 | 4212.709 | 2853.072 | 147.7%
--------------------------------------------
You can quickly reproduce my experiments by the following commands.
== Query A ==
psql -f create-tables-a.sql
psql -f query-a.sql
=============
== Query B ==
psql -f create-tables-b.sql
psql -f query-b.sql
=============
The above results indicate that David's patch demonstrated outstanding
performance. The speedup reached 210.6% for Query A and 147.7% for
Query B. Even when n is small, the patch reduced planning time. The
main concern about this patch was overheads for Bitmapsets with only
one or two words. My experiments imply that such overheads are
non-existent or negligible because some performance improvements were
obtained even for small sizes.
The results of my experiments strongly support the effectiveness of
David's patch. I think this optimization is worth considering.
I am looking forward to your comments.
--
Best regards,
Yuya Watari
Вложения
- v2-0001-Remove-trailing-zero-words-from-Bitmapsets.patch
- v2-0002-Use-do-while-loops-instead-of-for-loops.patch
- v2-0003-Fixed-a-bug-where-the-result-Bitmapset-was-incorr.patch
- v2-0004-Fix-a-bug-where-the-necessary-truncation-was-miss.patch
- figure.png
- create-tables-a.sql
- query-a.sql
- create-tables-b.sql
- query-b.sql
{kind=link}
On Tue, 13 Jun 2023 at 00:32, Yuya Watari <watari.yuya@gmail.com> wrote: > In March, I reported that David's patch caused a degradation in > planning performance. I have investigated this issue further and found > some bugs in the patch. Due to these bugs, Bitmapset operations in the > original patch computed incorrect results. This incorrect computation > resulted in unexpected behavior, which I observed as performance > degradation. After fixing the bugs, David's patch showed significant > performance improvements. In particular, it is worth noting that the > patch obtained a good speedup even when most Bitmapsets have only one > word. Thank you for looking at this again and finding and fixing the two bugs and running some benchmarks. I've incorporated fixes for the bugs in the attached patch. I didn't quite use the same approach as you did. I did the fix for 0003 slightly differently and added two separate paths. We've no need to track the last non-zero word when 'a' has more words than 'b' since we can't truncate any zero-words off for that case. Not having to do that makes the do/while loop pretty tight. For the fix in the 0004 patch, I think we can do what you did more simply. I don't think there's any need to perform the loop to find the last non-zero word. We're only deleting a member from a single word here, so we only need to check if that word is the last word and remove it if it's become zero. If it's not the last word then we can't remove it as there must be some other non-zero word after it. I also made a small adjustment to bms_get_singleton_member() and bms_singleton_member() to have them Assert fail if result is < 0 after looping over the set. This should no longer happen so I thought it would make more compact code if that check was just removed. We'd likely do better if we got reports of Assert failures here than, in the case of bms_get_singleton_member, some code accidentally doing the wrong thing based on a corrupt Bitmapset. David
Вложения
Hello, On Tue, Jun 13, 2023 at 8:07 PM David Rowley <dgrowleyml@gmail.com> wrote: > I've incorporated fixes for the bugs in the attached patch. I didn't > quite use the same approach as you did. I did the fix for 0003 > slightly differently and added two separate paths. We've no need to > track the last non-zero word when 'a' has more words than 'b' since we > can't truncate any zero-words off for that case. Not having to do > that makes the do/while loop pretty tight. I really appreciate your quick response and incorporating those fixes into your patch. The fix for 0003 looks good to me. I believe your change improves performance more. > For the fix in the 0004 patch, I think we can do what you did more > simply. I don't think there's any need to perform the loop to find > the last non-zero word. We're only deleting a member from a single > word here, so we only need to check if that word is the last word and > remove it if it's become zero. If it's not the last word then we > can't remove it as there must be some other non-zero word after it. If my thinking is correct, the do-while loop I added is still necessary. Consider the following code. The Assertion in this code passes in the master but fails in the new patch. ===== Bitmapset *x = bms_make_singleton(1000); x = bms_del_member(x, 1000); Assert(x == NULL); ===== In the code above, we get a new Bitmapset by bms_make_singleton(1000). This Bitmapset has many words. Only the last word is non-zero, and all the rest are zero. If we call bms_del_member(x, 1000) for the Bitmapset, all words of the result will be zero, including the last word, so we must return NULL. However, the new patch truncates only the last word, leading to an incorrect result. Therefore, we need to perform the loop to find the actual non-zero word after the deletion. Of course, I agree that if we are not modifying the last word, we don't have to truncate anything, so we can omit the loop. > I also made a small adjustment to bms_get_singleton_member() and > bms_singleton_member() to have them Assert fail if result is < 0 after > looping over the set. This should no longer happen so I thought it > would make more compact code if that check was just removed. We'd > likely do better if we got reports of Assert failures here than, in > the case of bms_get_singleton_member, some code accidentally doing the > wrong thing based on a corrupt Bitmapset. I agree with your change. I think failing by Assertion is better than a runtime error or unexpected behavior. -- Best regards, Yuya Watari
On Thu, 15 Jun 2023 at 20:57, Yuya Watari <watari.yuya@gmail.com> wrote: > > On Tue, Jun 13, 2023 at 8:07 PM David Rowley <dgrowleyml@gmail.com> wrote: > > For the fix in the 0004 patch, I think we can do what you did more > > simply. I don't think there's any need to perform the loop to find > > the last non-zero word. We're only deleting a member from a single > > word here, so we only need to check if that word is the last word and > > remove it if it's become zero. If it's not the last word then we > > can't remove it as there must be some other non-zero word after it. > > If my thinking is correct, the do-while loop I added is still > necessary. Consider the following code. The Assertion in this code > passes in the master but fails in the new patch. > > ===== > Bitmapset *x = bms_make_singleton(1000); > > x = bms_del_member(x, 1000); > Assert(x == NULL); > ===== I'm not sure what I was thinking there. Yeah, you're right, we do need to do the backwards loop over the set to trim off the trailing zero words. I've adjusted the attached patch to do that. David
Вложения
Hi,
David Rowley wrote:
>I've adjusted the attached patch to do that.
I think that was room for more improvements.
1. bms_member_index Bitmapset can be const.
2. Only compute BITNUM when necessary.
3. Avoid enlargement when nwords is equal wordnum.
Can save cycles when in corner cases?
Just for convenience I made a new version of the patch,
If want to use it.
regards,
Ranier Vilela
Вложения
On Thu, 22 Jun 2023 at 00:16, Ranier Vilela <ranier.vf@gmail.com> wrote: > 2. Only compute BITNUM when necessary. I doubt this will help. The % 64 done by BITNUM will be transformed to an AND operation by the compiler which is likely going to be single instruction latency on most CPUs which probably amounts to it being "free". There's maybe a bit of reading for you in [1] and [2] if you're wondering how any operation could be free. (The compiler is able to transform the % into what is effectively & because 64 is a power of 2. uintvar % 64 is the same as uintvar & 63. Play around with [3] to see what I mean) > 3. Avoid enlargement when nwords is equal wordnum. > Can save cycles when in corner cases? No, you're just introducing a bug here. Arrays in C are zero-based, so "wordnum >= a->nwords" is exactly the correct way to check if wordnum falls outside the bounds of the existing allocated memory. By changing that to "wordnum > a->nwords" we'll fail to enlarge the words array when it needs to be enlarged by 1 element. It looks like you've introduced a bunch of random white space and changed around a load of other random things in the patch too. I'm not sure why you think that's a good idea. FWIW, we normally only write "if (somevar)" as a shortcut when somevar is boolean and we want to know that it's true. The word value is not a boolean type, so although "if (someint)" and "if (someint != 0)" will compile to the same machine code, we don't normally write our C code that way in PostgreSQL. We also tend to write "if (someptr != NULL)" rather than "if (someptr)". The compiler will produce the same code for each, but we write the former to assist people reading the code so they know we're checking for NULL rather than checking if some boolean variable is true. Overall, I'm not really interested in sneaking any additional changes that are unrelated to adjusting Bitmapsets so that don't carry trailing zero words. If have other optimisations you think are worthwhile, please include them in another thread along with benchmarks to show the performance increase. For learning, I'd encourage you to do some micro benchmarks outside of PostgreSQL and mock up some Bitmapset code in a single .c file and try out with any without your changes after calling the function in a tight loop to see if you can measure any performance gains. Just remember you'll never see any gains in performance when your change compiles into the exact same code as without your change. Between [1] and [2], you still might not see performance changes even when the compiled code is changed (I'm thinking of your #2 change here). David [1] https://en.wikipedia.org/wiki/Speculative_execution [2] https://en.wikipedia.org/wiki/Out-of-order_execution [3] https://godbolt.org/z/9vbbnMKEE
Hello, On Thu, Jun 22, 2023 at 1:43 PM David Rowley <dgrowleyml@gmail.com> wrote: > > 3. Avoid enlargement when nwords is equal wordnum. > > Can save cycles when in corner cases? > > No, you're just introducing a bug here. Arrays in C are zero-based, > so "wordnum >= a->nwords" is exactly the correct way to check if > wordnum falls outside the bounds of the existing allocated memory. By > changing that to "wordnum > a->nwords" we'll fail to enlarge the words > array when it needs to be enlarged by 1 element. I agree with David. Unfortunately, some of the regression tests failed with the v5 patch. These failures are due to the bug introduced by the #3 change. -- Best regards, Yuya Watari
Hello, On Tue, Jun 20, 2023 at 1:17 PM David Rowley <dgrowleyml@gmail.com> wrote: > I've adjusted the attached patch to do that. Thank you for updating the patch. The v4 patch looks good to me. I ran another experiment. In the experiment, I issued queries of the Join Order Benchmark [1] and measured its planning times. The following table shows the result. The v4 patch obtained outstanding performance improvements in planning time. This result supports the effectiveness of the patch in real workloads. Table 1: Planning time and its speedup of Join Order Benchmark (n: the number of partitions of each table) (Speedup: higher is better) -------------------- n | Speedup (v4) -------------------- 2 | 102.4% 4 | 101.0% 8 | 101.6% 16 | 103.1% 32 | 107.5% 64 | 115.7% 128 | 142.9% 256 | 187.7% -------------------- [1] https://github.com/winkyao/join-order-benchmark -- Best regards, Yuya Watari
Em qui., 22 de jun. de 2023 às 01:43, David Rowley <dgrowleyml@gmail.com> escreveu:
On Thu, 22 Jun 2023 at 00:16, Ranier Vilela <ranier.vf@gmail.com> wrote:
> 2. Only compute BITNUM when necessary.
I doubt this will help. The % 64 done by BITNUM will be transformed
to an AND operation by the compiler which is likely going to be single
instruction latency on most CPUs which probably amounts to it being
"free". There's maybe a bit of reading for you in [1] and [2] if
you're wondering how any operation could be free.
I think the word free is not the right one.
The end result of the code is the same, so whatever you write it one way or the other,
The end result of the code is the same, so whatever you write it one way or the other,
the compiler will transform it as if it were written without calculating BITNUM in advance.
See at:
https://godbolt.org/z/39MdcP7M3
See at:
https://godbolt.org/z/39MdcP7M3
The issue is the code becomes clearer and more readable with the calculation in advance.
In that case, I think so.
But this is on a case-by-case basis, in other contexts it can be more expensive.
(The compiler is able to transform the % into what is effectively &
because 64 is a power of 2. uintvar % 64 is the same as uintvar & 63.
Play around with [3] to see what I mean)
> 3. Avoid enlargement when nwords is equal wordnum.
> Can save cycles when in corner cases?
No, you're just introducing a bug here. Arrays in C are zero-based,
so "wordnum >= a->nwords" is exactly the correct way to check if
wordnum falls outside the bounds of the existing allocated memory. By
changing that to "wordnum > a->nwords" we'll fail to enlarge the words
array when it needs to be enlarged by 1 element.
Yeah, this is my fault.
Unfortunately, I missed the failure of the regression tests.
It looks like you've introduced a bunch of random white space and
changed around a load of other random things in the patch too. I'm not
sure why you think that's a good idea.
Weel, It is much easier to read and follows the general style of the other fonts.
FWIW, we normally only write "if (somevar)" as a shortcut when somevar
is boolean and we want to know that it's true. The word value is not
a boolean type, so although "if (someint)" and "if (someint != 0)"
will compile to the same machine code, we don't normally write our C
code that way in PostgreSQL. We also tend to write "if (someptr !=
NULL)" rather than "if (someptr)". The compiler will produce the same
code for each, but we write the former to assist people reading the
code so they know we're checking for NULL rather than checking if some
boolean variable is true.
No, this is not the case.
With unsigned words, it can be a more appropriate test without == 0.
See:
In some contexts, it can be faster when it has CMP instruction before.
Overall, I'm not really interested in sneaking any additional changes
that are unrelated to adjusting Bitmapsets so that don't carry
trailing zero words. If have other optimisations you think are
worthwhile, please include them in another thread along with
benchmarks to show the performance increase. For learning, I'd
encourage you to do some micro benchmarks outside of PostgreSQL and
mock up some Bitmapset code in a single .c file and try out with any
without your changes after calling the function in a tight loop to see
if you can measure any performance gains. Just remember you'll never
see any gains in performance when your change compiles into the exact
same code as without your change. Between [1] and [2], you still
might not see performance changes even when the compiled code is
changed (I'm thinking of your #2 change here).
Well, *const* always is a good style and can prevent mistakes and
allows the compiler to do optimizations.
regards,
Ranier Vilela
Em qui., 22 de jun. de 2023 às 05:50, Yuya Watari <watari.yuya@gmail.com> escreveu:
Hello,
On Thu, Jun 22, 2023 at 1:43 PM David Rowley <dgrowleyml@gmail.com> wrote:
> > 3. Avoid enlargement when nwords is equal wordnum.
> > Can save cycles when in corner cases?
>
> No, you're just introducing a bug here. Arrays in C are zero-based,
> so "wordnum >= a->nwords" is exactly the correct way to check if
> wordnum falls outside the bounds of the existing allocated memory. By
> changing that to "wordnum > a->nwords" we'll fail to enlarge the words
> array when it needs to be enlarged by 1 element.
I agree with David. Unfortunately, some of the regression tests failed
with the v5 patch. These failures are due to the bug introduced by the
#3 change.
Yeah, this is my fault.
Anyway thanks for the brilliant ideas about optimize bitmapset.
I worked a bit more on the v4 version and made a new v6 version, with some changes.
Windows 64 bits
msvc 2019 64 bits
== Query A ==
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\create-tables-a.sql
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\query-a.sql
=============
head:
Time: 3489,097 ms (00:03,489)
Time: 3501,780 ms (00:03,502)
patched v4:
Time: 2434,873 ms (00:02,435)
Time: 2310,832 ms (00:02,311)
Time: 2305,445 ms (00:02,305)
Time: 2185,972 ms (00:02,186)
Time: 2177,434 ms (00:02,177)
Time: 2169,883 ms (00:02,170)
patched v6:
Time: 2162,633 ms (00:02,163)
Time: 2159,805 ms (00:02,160)
Time: 2002,771 ms (00:02,003)
Time: 1944,436 ms (00:01,944)
Time: 1906,364 ms (00:01,906)
Time: 1903,897 ms (00:01,904)
== Query B ==
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\create-tables-b.sql
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\query-b.sql
patched v4:
Time: 2684,360 ms (00:02,684)
Time: 2482,571 ms (00:02,483)
Time: 2452,699 ms (00:02,453)
Time: 2465,223 ms (00:02,465)
patched v6:
Time: 1837,775 ms (00:01,838)
Time: 1801,274 ms (00:01,801)
Time: 1800,802 ms (00:01,801)
Time: 1798,786 ms (00:01,799)
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\create-tables-a.sql
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\query-a.sql
=============
head:
Time: 3489,097 ms (00:03,489)
Time: 3501,780 ms (00:03,502)
patched v4:
Time: 2434,873 ms (00:02,435)
Time: 2310,832 ms (00:02,311)
Time: 2305,445 ms (00:02,305)
Time: 2185,972 ms (00:02,186)
Time: 2177,434 ms (00:02,177)
Time: 2169,883 ms (00:02,170)
patched v6:
Time: 2162,633 ms (00:02,163)
Time: 2159,805 ms (00:02,160)
Time: 2002,771 ms (00:02,003)
Time: 1944,436 ms (00:01,944)
Time: 1906,364 ms (00:01,906)
Time: 1903,897 ms (00:01,904)
== Query B ==
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\create-tables-b.sql
psql -U postgres -f c:\postgres_bench\tmp\bitmapset\query-b.sql
patched v4:
Time: 2684,360 ms (00:02,684)
Time: 2482,571 ms (00:02,483)
Time: 2452,699 ms (00:02,453)
Time: 2465,223 ms (00:02,465)
patched v6:
Time: 1837,775 ms (00:01,838)
Time: 1801,274 ms (00:01,801)
Time: 1800,802 ms (00:01,801)
Time: 1798,786 ms (00:01,799)
I can see some improvement, would you mind testing v6 and reporting back?
regards,
Ranier Vilela
Вложения
On Sat, 24 Jun 2023 at 07:43, Ranier Vilela <ranier.vf@gmail.com> wrote: > I worked a bit more on the v4 version and made a new v6 version, with some changes. > I can see some improvement, would you mind testing v6 and reporting back? Please don't bother. I've already mentioned that I'm not going to consider any changes here which are unrelated to changing the rule that Bitmapsets no longer can have trailing zero words. I've already said in [1] that if you have unrelated changes that you wish to pursue in regards to Bitmapset, then please do so on another thread. Also, FWIW, from glancing over it, your v6 patch introduces a bunch of out-of-bounds memory access bugs and a few things are less efficient than I'd made them. The number of bytes you're zeroing using memset in bms_add_member() and bms_add_range() is wrong. bms_del_member() now needlessly rechecks if a->words[wordnum] is 0. We already know it is 0 from the above check. You may have misunderstood the point of swapping for loops for do/while loops? They're meant to save the needless loop bounds check on the initial loop due to the knowledge that the Bitmapset contains at least 1 word. Additionally, it looks like you've made various places that loop over the set and check for the "lastnonzero" less efficiently by adding an additional surplus check. Depending on the CPU architecture, looping backwards over arrays can be less efficient due to lack of hardware prefetching when accessing memory in reverse order. It's not clear to me why you think looping backwards is faster. I've no desire to introduce code that needlessly performs more slowly depending on the ability of the hardware prefetcher on the CPU architecture PostgreSQL is running on. Also, if you going to post benchmark results, they're not very meaningful unless you can demonstrate what you actually tested. You've mentioned nothing here to say what query-b.sql contains. David [1] https://postgr.es/m/CAApHDvo65DXFZcGJZ7pvXS75vUT+1-wSaP_kvefWGsns2y2vsg@mail.gmail.com
On Thu, 22 Jun 2023 at 20:59, Yuya Watari <watari.yuya@gmail.com> wrote: > Table 1: Planning time and its speedup of Join Order Benchmark > (n: the number of partitions of each table) > (Speedup: higher is better) > 64 | 115.7% > 128 | 142.9% > 256 | 187.7% Thanks for benchmarking. It certainly looks like a win for larger sets. Would you be able to profile the 256 partition case to see where exactly master is so slow? (I'm surprised this patch improves performance that much.) I think it's also important to check we don't slow anything down for more normal-sized sets. The vast majority of sets will contain just a single word, so we should probably focus on making sure we're not slowing anything down for those. To get the ball rolling on that I used the attached plan_times.patch so that the planner writes the number of elapsed nanosecond from calling standard_planner(). Patching with this then running make installcheck kicks out about 35k log lines with times on it. I ran this on a Linux AMD 3990x machine and also an Apple M2 pro machine. Taking the sum of the nanoseconds and converting into seconds, I see: AMD 3990x master: 1.384267931 seconds patched 1.339178764 seconds (3.37% faster) M2 pro: master: 0.58293 seconds patched: 0.581483 seconds (0.25% faster) So it certainly does not look any slower. Perhaps a little faster with the zen2 machine. (The m2 only seems to have microsecond resolution on the timer code whereas the zen2 has nanosecond. I don't think this matters much as the planner takes enough microseconds to plan even for simple queries) I've also attached the v4 patch again as I'll add this patch to the commitfest and if I don't do that then the CFbot will pick up Ranier's patch instead of mine. David
Вложения
Hello,
Thank you for your reply and for creating the patch to measure planning times.
On Sat, Jun 24, 2023 at 1:15 PM David Rowley <dgrowleyml@gmail.com> wrote:
> Thanks for benchmarking. It certainly looks like a win for larger
> sets. Would you be able to profile the 256 partition case to see
> where exactly master is so slow? (I'm surprised this patch improves
> performance that much.)
I have profiled the 256 partition case of the Join Order Benchmark
using the perf command. The attached figures are its frame graphs.
From these figures, we can see that bms_equal() function calls in blue
circles were heavy, and their performance improved after applying the
patch.
To investigate this further, I have created a patch
(profile-patch-for-*.txt) that profiles the bms_equal() function in
more detail. This patch
(1) prints what we are comparing by bms_equal, and
(2) measures the number of loops executed within bms_equal.
(1) is for debugging. (2) intends to see the effect of the
optimization to remove trailing zero words. The guarantee that the
last word is always non-zero enables us to immediately determine two
Bitmapsets having different nwords are not the same. When the patch
works effectively, the (2) will be much smaller than the total number
of the function calls. I will show the results as follows.
=== Master ===
[bms_equal] Comparing (b 335) and (b 35)
[bms_equal] Comparing (b 1085) and (b 61)
[bms_equal] Comparing (b 1208) and (b 86)
[bms_equal] Comparing (b 781) and (b 111)
[bms_equal] Comparing (b 361) and (b 135)
...
[bms_equal] Comparing (b 668) and (b 1773)
[bms_equal] Comparing (b 651) and (b 1781)
[bms_equal] Comparing (b 1191) and (b 1789)
[bms_equal] Comparing (b 771) and (b 1797)
[bms_equal] Total 3950748839 calls, 3944762037 loops executed
==============
=== Patched ===
[bms_equal] Comparing (b 335) and (b 35)
[bms_equal] Comparing (b 1085) and (b 61)
[bms_equal] Comparing (b 1208) and (b 86)
[bms_equal] Comparing (b 781) and (b 111)
[bms_equal] Comparing (b 361) and (b 135)
...
[bms_equal] Comparing (b 668) and (b 1773)
[bms_equal] Comparing (b 651) and (b 1781)
[bms_equal] Comparing (b 1191) and (b 1789)
[bms_equal] Comparing (b 771) and (b 1797)
[bms_equal] Total 3950748839 calls, 200215204 loops executed
===============
The above results reveal that the bms_equal() in this workload
compared two singleton Bitmapsets in most cases, and their members
were more than 64 apart. Therefore, we could have omitted 94.9% of
3,950,748,839 loops with the patch, whereas the percentage was only
0.2% in the master. This is why we obtained a significant performance
improvement and is evidence that the optimization of this patch worked
very well.
The attached figures show these bms_equal() function calls exist in
make_pathkey_from_sortinfo(). The actual location is
get_eclass_for_sort_expr(). I quote the code below.
=====
EquivalenceClass *
get_eclass_for_sort_expr(PlannerInfo *root,
Expr *expr,
List *opfamilies,
Oid opcintype,
Oid collation,
Index sortref,
Relids rel,
bool create_it)
{
...
foreach(lc1, root->eq_classes)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) lfirst(lc1);
...
foreach(lc2, cur_ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
/*
* Ignore child members unless they match the request.
*/
if (cur_em->em_is_child &&
!bms_equal(cur_em->em_relids, rel)) // <--- Here
continue;
...
}
}
...
}
=====
The bms_equal() is used to find an EquivalenceMember satisfying some
conditions. The above heavy loop was the bottleneck in the master.
This bottleneck is what I am trying to optimize in another thread [1]
with you. I hope the optimization in this thread will help [1]'s speed
up. (Looking at CFbot, I noticed that [1]'s patch does not compile due
to some compilation errors. I will send a fixed version soon.)
> I think it's also important to check we don't slow anything down for
> more normal-sized sets. The vast majority of sets will contain just a
> single word, so we should probably focus on making sure we're not
> slowing anything down for those.
I agree with you and thank you for sharing the results. I ran
installcheck with your patch. The result is as follows. The speedup
was 0.33%. At least in my environment, I did not observe any
regression with this test. So, the patch looks very good.
Master: 2.559648 seconds
Patched: 2.551116 seconds (0.33% faster)
[1] https://www.postgresql.org/message-id/CAJ2pMkY10J_PA2jpH5M-VoOo6BvJnTOO_-t_znu_pOaP0q10pA@mail.gmail.com
--
Best regards,
Yuya Watari
Вложения
{kind=link}
{kind=link}
Thank you for running the profiles.
On Tue, 27 Jun 2023 at 21:11, Yuya Watari <watari.yuya@gmail.com> wrote:
> On Sat, Jun 24, 2023 at 1:15 PM David Rowley <dgrowleyml@gmail.com> wrote:
> > I think it's also important to check we don't slow anything down for
> > more normal-sized sets. The vast majority of sets will contain just a
> > single word, so we should probably focus on making sure we're not
> > slowing anything down for those.
>
> I agree with you and thank you for sharing the results. I ran
> installcheck with your patch. The result is as follows. The speedup
> was 0.33%. At least in my environment, I did not observe any
> regression with this test. So, the patch looks very good.
>
> Master: 2.559648 seconds
> Patched: 2.551116 seconds (0.33% faster)
I wondered if the common case could be made slightly faster by
checking the 0th word before checking the word count before going onto
check the remaining words. For bms_equal(), that's something like:
if (a->words[0] != b->words[0] || a->nwords != b->nwords)
return false;
/* check all the remaining words match */
for (int i = 1; i < a->nwords; i++) ...
I wrote the patch and tried it out, but it seems slightly slower than
the v4 patch.
Linux with AMD 3990x, again using the patch from [1] with make installcheck
master: 1.41720145 seconds
v4: 1.392969606 seconds (1.74% faster than master)
v4 with 0th word check: 1.404199748 seconds (0.93% faster than master)
I've attached a delta patch of what I used to test. Since it's not
any faster, I don't think it's worth doing. It'll also produce
slightly more compiled code.
David
[1] https://postgr.es/m/CAApHDvo68m_0JuTHnEHFNsdSJEb2uPphK6BWXStj93u_QEi2rg@mail.gmail.com
Вложения
Hello,
Thank you for your reply and for creating a new patch.
On Wed, Jun 28, 2023 at 7:58 PM David Rowley <dgrowleyml@gmail.com> wrote:
> Linux with AMD 3990x, again using the patch from [1] with make installcheck
>
> master: 1.41720145 seconds
> v4: 1.392969606 seconds (1.74% faster than master)
> v4 with 0th word check: 1.404199748 seconds (0.93% faster than master)
I have tested these versions with installcheck. Since the planning
times obtained by installcheck vary each time, it is important to run
it repeatedly and examine its distribution. I ran installcheck 100
times for each version. The following tables and the attached figure
show the results. From these results, we can conclude that the v4
patch has no regression in the installcheck test. It seems to be
slightly (0.31-0.38%) faster than the master. The difference between
v4 and v4 with 0th word check is not so clear, but v4 may be faster.
Table 1: Total Planning Time During installcheck (seconds)
---------------------------------------------------------
| Mean | Median | Stddev
---------------------------------------------------------
Master | 2.520865 | 2.521189 | 0.017651
v4 | 2.511447 | 2.513369 | 0.018299
v4 with 0th word check | 2.513393 | 2.515652 | 0.018391
---------------------------------------------------------
Table 2: Speedup (higher is better)
------------------------------------------------------------
| Speedup (Mean) | Speedup (Median)
------------------------------------------------------------
v4 | 0.38% | 0.31%
v4 with 0th word check | 0.30% | 0.22%
------------------------------------------------------------
--
Best regards,
Yuya Watari
Вложения
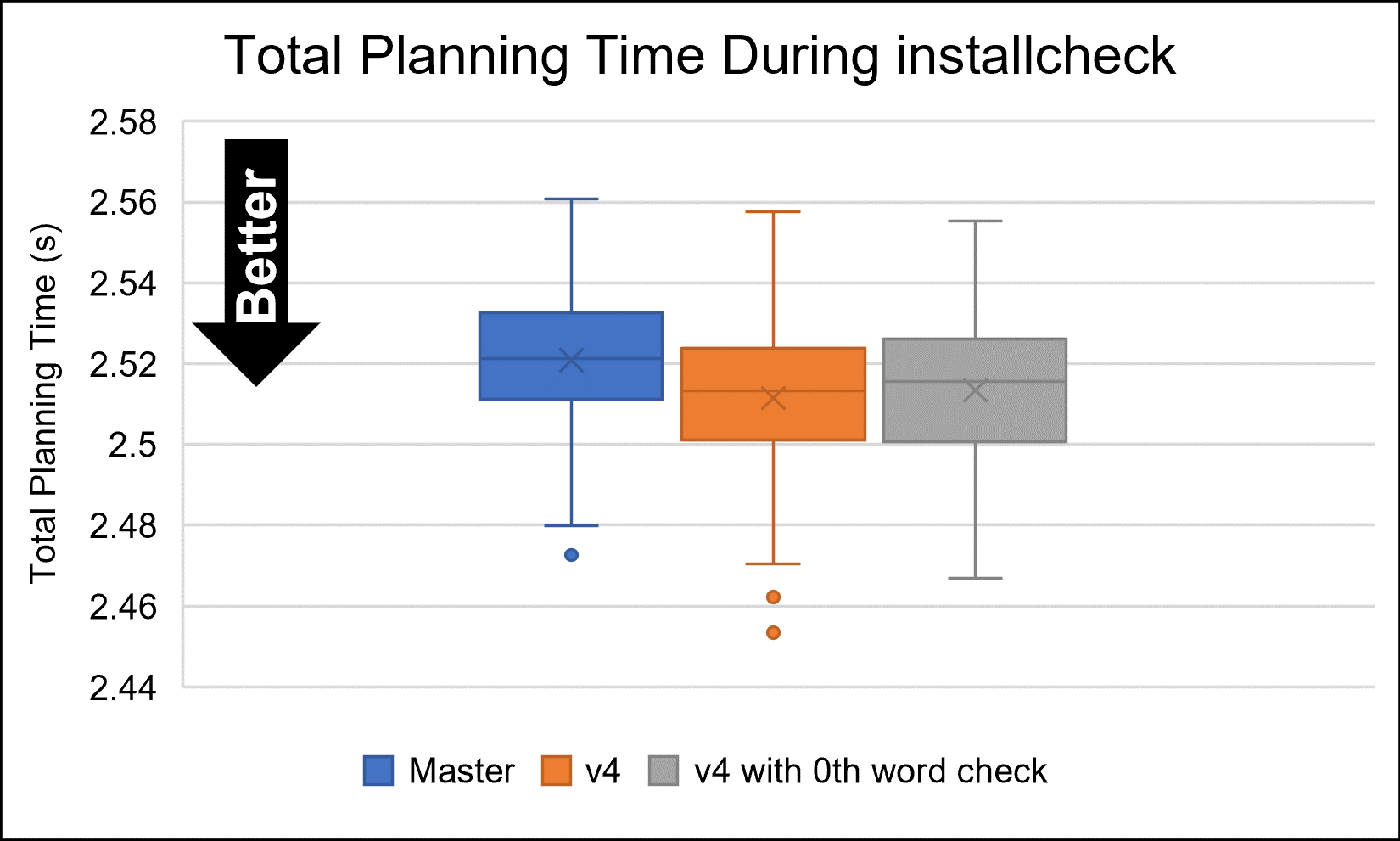{kind=link}
On Fri, 30 Jun 2023 at 14:11, Yuya Watari <watari.yuya@gmail.com> wrote: > I have tested these versions with installcheck. Since the planning > times obtained by installcheck vary each time, it is important to run > it repeatedly and examine its distribution. I ran installcheck 100 > times for each version. The following tables and the attached figure > show the results. From these results, we can conclude that the v4 > patch has no regression in the installcheck test. It seems to be > slightly (0.31-0.38%) faster than the master. The difference between > v4 and v4 with 0th word check is not so clear, but v4 may be faster. I did the same on the AMD 3990x machine and an Apple M2 Pro machine. On the M2 over the 100 runs v4 came out 1.18% faster and the 3990x was 1.25% faster than master. I've plotted the results in the attached graphs. Looking over the patch again, the only thing I'm tempted into changing is to add Asserts like: Assert(a == NULL || a->words[a->nword - 1] != 0) to each function just as extra reassurance that nothing accidentally leaves trailing empty words. If nobody else wants to take a look, then I plan to push the v4 + the asserts in the next day or so. David
Вложения
{kind=link}
{kind=link}
On Mon, 3 Jul 2023 at 09:27, David Rowley <dgrowleyml@gmail.com> wrote: > If nobody else wants to take a look, then I plan to push the v4 + the > asserts in the next day or so. Here's the patch which includes those Asserts. I also made some small tweaks to a comment. I understand that Tom thought that the Asserts were a step too far in [1], but per the bugs found in [2], I think having them is worthwhile. In the attached, I only added Asserts to the locations where the code relies on there being no trailing zero words. I didn't include them in places like bms_copy() since nothing there would do the wrong thing if there were trailing zero words. David [1] https://postgr.es/m/2686153.1677881312@sss.pgh.pa.us [2] https://postgr.es/m/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q@mail.gmail.com
Вложения
Hello, On Mon, Jul 3, 2023 at 9:10 AM David Rowley <dgrowleyml@gmail.com> wrote: > Here's the patch which includes those Asserts. I also made some small > tweaks to a comment. Thank you for your reply. I am +1 to your change. I think these assertions will help someone who changes the Bitmapset implementations in the future. -- Best regards, Yuya Watari
On Mon, 3 Jul 2023 at 18:10, Yuya Watari <watari.yuya@gmail.com> wrote: > Thank you for your reply. I am +1 to your change. I think these > assertions will help someone who changes the Bitmapset implementations > in the future. I've now pushed the patch. Thanks for all your reviews and detailed benchmarks. David
Hello, On Tue, Jul 4, 2023 at 9:36 AM David Rowley <dgrowleyml@gmail.com> wrote: > I've now pushed the patch. Thanks for the commit! -- Best regards, Yuya Watari