Обсуждение: SLRUs in the main buffer pool, redux
Hi,
I was re-reviewing the proposed batch of GUCs for controlling the SLRU
cache sizes[1], and I couldn't resist sketching out $SUBJECT as an
obvious alternative. This patch is highly experimental and full of
unresolved bits and pieces (see below for some), but it passes basic
tests and is enough to start trying the idea out and figuring out
where the real problems lie. The hypothesis here is that CLOG,
multixact, etc data should compete for space with relation data in one
unified buffer pool so you don't have to tune them, and they can
benefit from the better common implementation (mapping, locking,
replacement, bgwriter, checksums, etc and eventually new things like
AIO, TDE, ...).
I know that many people have talked about doing this and maybe they
already have patches along these lines too; I'd love to know what
others imagined differently/better.
In the attached sketch, the SLRU caches are psuedo-relations in
pseudo-database 9. Yeah. That's a straw-man idea stolen from the
Zheap/undo project[2] (I also stole DiscardBuffer() from there);
better ideas for identifying these buffers without making BufferTag
bigger are very welcome. You can list SLRU buffers with:
WITH slru(relfilenode, path) AS (VALUES (0, 'pg_xact'),
(1, 'pg_multixact/offsets'),
(2, 'pg_multixact/members'),
(3, 'pg_subtrans'),
(4, 'pg_serial'),
(5, 'pg_commit_ts'),
(6, 'pg_notify'))
SELECT bufferid, path, relblocknumber, isdirty, usagecount, pinning_backends
FROM pg_buffercache NATURAL JOIN slru
WHERE reldatabase = 9
ORDER BY path, relblocknumber;
Here are some per-cache starter hypotheses about locking that might be
completely wrong and obviously need real analysis and testing.
pg_xact:
I couldn't easily get rid of XactSLRULock, because it didn't just
protect buffers, it's also used to negotiate "group CLOG updates". (I
think it'd be nice to replace that system with an atomic page update
scheme so that concurrent committers stay on CPU, something like [3],
but that's another topic.) I decided to try a model where readers
only have to pin the page (the reads are sub-byte values that we can
read atomically, and you'll see a value as least as fresh as the time
you took the pin, right?), but writers have to take an exclusive
content lock because otherwise they'd clobber each other at byte
level, and because they need to maintain the page LSN consistently.
Writing back is done with a share lock as usual and log flushing can
be done consistently. I also wanted to try avoiding the extra cost of
locking and accessing the buffer mapping table in common cases, so I
use ReadRecentBuffer() for repeat access to the same page (this
applies to the other SLRUs too).
pg_subtrans:
I got rid of SubtransSLRULock because it only protected page contents.
Can be read with only a pin. Exclusive page content lock to write.
pg_multixact:
I got rid of the MultiXact{Offset,Members}SLRULock locks. Can be read
with only a pin. Writers take exclusive page content lock. The
multixact.c module still has its own MultiXactGenLock.
pg_commit_ts:
I got rid of CommitTsSLRULock since it only protected buffers, but
here I had to take shared content locks to read pages, since the
values can't be read atomically. Exclusive content lock to write.
pg_serial:
I could not easily get rid of SerialSLRULock, because it protects the
SLRU + also some variables in serialControl. Shared and exclusive
page content locks.
pg_notify:
I got rid of NotifySLRULock. Shared and exclusive page content locks
are used for reading and writing. The module still has a separate
lock NotifyQueueLock to coordinate queue positions.
Some problems tackled incompletely:
* I needed to disable checksums and in-page LSNs, since SLRU pages
hold raw data with no header. We'd probably eventually want regular
(standard? formatted?) pages (the real work here may be implementing
FPI for SLRUs so that checksums don't break your database on torn
writes). In the meantime, suppressing those things is done by the
kludge of recognising database 9 as raw data, but there should be
something better than this. A separate array of size NBuffer holds
"external" page LSNs, to drive WAL flushing.
* The CLOG SLRU also tracks groups of async commit LSNs in a fixed
sized array. The obvious translation would be very wasteful (an array
big enough for NBuffers * groups per page), but I hope that there is a
better way to do this... in the sketch patch I changed it to use the
single per-page LSN for simplicity (basically group size is 32k
instead of 32...), which is certainly not good enough.
Some stupid problems not tackled yet:
* It holds onto the virtual file descriptor for the last segment
accessed, but there is no invalidation for when segment files are
recycled; that could be fixed with a cycle counter or something like
that.
* It needs to pin buffers during the critical section in commit
processing, but that crashes into the ban on allocating memory while
dealing with resowner.c book-keeping. It's also hard to know how many
buffers you'll need to pin in advance. For now, I just commented out
the assertions...
* While hacking on the pg_stat_slru view I realised that there is
support for "other" SLRUs, presumably for extensions to define their
own. Does anyone actually do that? I, erm, didn't support that in
this sketch (not too hard though, I guess).
* For some reason this is failing on Windows CI, but I haven't looked
into that yet.
Thoughts on the general concept, technical details? Existing patches
for this that are further ahead/better?
[1] https://commitfest.postgresql.org/36/2627/
[2] https://commitfest.postgresql.org/36/3228/
[3] http://www.vldb.org/pvldb/vol13/p3195-kodandaramaih.pdf
Вложения
On Thu, Jan 13, 2022 at 9:00 AM Thomas Munro <thomas.munro@gmail.com> wrote: > I was re-reviewing the proposed batch of GUCs for controlling the SLRU > cache sizes[1], and I couldn't resist sketching out $SUBJECT as an > obvious alternative. This patch is highly experimental and full of > unresolved bits and pieces (see below for some), but it passes basic > tests and is enough to start trying the idea out and figuring out > where the real problems lie. The hypothesis here is that CLOG, > multixact, etc data should compete for space with relation data in one > unified buffer pool so you don't have to tune them, and they can > benefit from the better common implementation (mapping, locking, > replacement, bgwriter, checksums, etc and eventually new things like > AIO, TDE, ...). I endorse this hypothesis. The performance cliff when the XID range you're regularly querying exceeds the hardcoded constant is quite steep, and yet we can't just keep pushing that constant up. Linear search does not scale well to infinitely large arrays.[citation needed] > [ long list of dumpster-fire level problems with the patch ] Honestly, none of this sounds that bad. I mean, it sounds bad in the sense that you're going to have to fix all of this somehow and I'm going to unhelpfully give you no advice whatsoever about how to do that, but my guess is that a moderate amount of persistence will be sufficient for you to get the job done. None of it sounds hopeless. Before fixing all of that, one thing you might want to consider is whether it uh, works. And by "work" I don't mean "get the right answer" even though I agree with my esteemed fellow hacker that this is an important thing to do.[1] What I mean is that it would be good to see some evidence that the number of buffers that end up being used to cache any particular SLRU is somewhat sensible, and varies by workload. For example, consider a pgbench workload. As you increase the scale factor, the age of the oldest XIDs that you regularly encounter will also increase, because on the average, the row you're now updating will not have been updated for a larger number of transactions. So it would be interesting to know whether all of the CLOG buffers that are regularly being accessed do in fact remain in cache - and maybe even whether buffers that stop being regularly accessed get evicted in the face of cache pressure. Also, the existing clog code contains a guard that absolutely prevents the latest CLOG buffer from being evicted. Because - at least in a pgbench test like the one postulated above, and probably in general - the frequency of access to older CLOG buffers decays exponentially, evicting the newest or even the second or third newest CLOG buffer is really bad. At present, there's a hard-coded guard to prevent the newest buffer from being evicted, which is a band-aid, but an effective one. Even with that band-aid, evicting any of the most recent few can produce a system-wide stall, where every backend ends up waiting for the evicted buffer to be retrieved. It would be interesting to know whether the same problem can be recreated with your patch, because the buffer eviction algorithm for shared buffers is only a little bit less dumb than the one for SLRUs, and can pretty commonly devolve into little more than evict-at-random. Evict-at-random is very bad here, because evicting a hot CLOG page is probably even worse than evicting, say, a btree root page. Another interesting test might be one that puts pressure on some other SLRU, like pg_multixact or pg_subtrans. In general SLRU pages that are actually being used are hot enough that we should keep them in cache almost no matter what else is competing for cache space ... but the number of such pages can be different from one SLRU to another, and can change over time. -- Robert Haas EDB: http://www.enterprisedb.com [1] http://postgr.es/m/3151122.1642086632@sss.pgh.pa.us
On 13/01/2022 15:59, Thomas Munro wrote: > Hi, > > I was re-reviewing the proposed batch of GUCs for controlling the SLRU > cache sizes[1], and I couldn't resist sketching out $SUBJECT as an > obvious alternative. This patch is highly experimental and full of > unresolved bits and pieces (see below for some), but it passes basic > tests and is enough to start trying the idea out and figuring out > where the real problems lie. The hypothesis here is that CLOG, > multixact, etc data should compete for space with relation data in one > unified buffer pool so you don't have to tune them, and they can > benefit from the better common implementation (mapping, locking, > replacement, bgwriter, checksums, etc and eventually new things like > AIO, TDE, ...). +1 > I know that many people have talked about doing this and maybe they > already have patches along these lines too; I'd love to know what > others imagined differently/better. IIRC one issue with this has been performance. When an SLRU is working well, a cache hit in the SLRU is very cheap. Linearly scanning the SLRU array is cheap, compared to computing the hash and looking up a buffer in the buffer cache. Would be good to do some benchmarking of that. I wanted to do this with the CSN (Commit Sequence Number) work a long time ago. That would benefit from something like an SLRU with very fast access, to look up CSNs. Even without CSNs, if the CLOG was very fast to access we might not need hint bits anymore. I guess trying to make SLRUs faster than they already are is moving the goalposts, but at a minimum let's make sure they don't get any slower. - Heikki
On Mon, Jan 17, 2022 at 11:23 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > IIRC one issue with this has been performance. When an SLRU is working > well, a cache hit in the SLRU is very cheap. Linearly scanning the SLRU > array is cheap, compared to computing the hash and looking up a buffer > in the buffer cache. Would be good to do some benchmarking of that. One trick I want to experiment with is trying to avoid the mapping table lookup by using ReadRecentBuffer(). In the prototype patch I do that for one buffer per SLRU cache (so that'll often point to the head CLOG page), but it could be extended to a small array of recently accessed buffers to scan linearly, much like the current SLRU happy case except that it's not shared and doesn't need a lock so it's even happier. I'm half joking here, but that would let us keep calling this subsystem SLRU :-) > I wanted to do this with the CSN (Commit Sequence Number) work a long > time ago. That would benefit from something like an SLRU with very fast > access, to look up CSNs. Even without CSNs, if the CLOG was very fast to > access we might not need hint bits anymore. I guess trying to make SLRUs > faster than they already are is moving the goalposts, but at a minimum > let's make sure they don't get any slower. One idea I've toyed with is putting a bitmap into shared memory where each bit corresponds to a range of (say) 256 xids, accessed purely with atomics. If a bit is set we know they're all committed, and otherwise you have to do more pushups. I've attached a quick and dirty experimental patch along those lines, but I don't think it's quite right, especially with people waving 64 bit xid patches around. Perhaps it'd need to be a smaller sliding window, somehow, and perhaps people will balk at the wild and unsubstantiated assumption that transactions generally commit.
Вложения
Rebased, debugged and fleshed out a tiny bit more, but still with plenty of TODO notes and questions. I will talk about this idea at PGCon, so I figured it'd help to have a patch that actually applies, even if it doesn't work quite right yet. It's quite a large patch but that's partly because it removes a lot of lines...
Вложения
On Fri, May 27, 2022 at 11:24 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Rebased, debugged and fleshed out a tiny bit more, but still with > plenty of TODO notes and questions. I will talk about this idea at > PGCon, so I figured it'd help to have a patch that actually applies, > even if it doesn't work quite right yet. It's quite a large patch but > that's partly because it removes a lot of lines... FWIW, here are my PGCon slides about this: https://speakerdeck.com/macdice/improving-the-slru-subsystem There was a little bit of discussion on #pgcon-stream2 which I could summarise as: can we figure out a way to keep parts of the CLOG pinned so that backends don't have to do that for each lookup? Then CLOG checks become simple reads. There may be some relation to the idea of 'nailing' btree root pages that I've heard of from a couple of people now (with ProcSignalBarrier or something more fine grained along those lines if you need to unnail anything). Something to think about. I'm also wondering if it would be possible to do "optimistic" pinning instead for reads that normally need only a pin, using some kind of counter scheme with read barriers to tell you if the page might have been evicted after you read the data...
Hi, On 2022-05-28 13:13:20 +1200, Thomas Munro wrote: > There was a little bit of discussion on #pgcon-stream2 which I could > summarise as: can we figure out a way to keep parts of the CLOG pinned > so that backends don't have to do that for each lookup? Then CLOG > checks become simple reads. Included in that is not needing to re-check that the identity of the buffer changed since the last use and to not need a PrivateRefCountEntry. Neither is cheap... I'd structure it so that there's a small list of slru buffers that's pinned in a "shared" mode. Entering the buffer into that increases the BufferDesc's refcount, but is *not* memorialized in the backend's refcount structures, because it's "owned by the SLRU". > There may be some relation to the idea of > 'nailing' btree root pages that I've heard of from a couple of people > now (with ProcSignalBarrier or something more fine grained along those > lines if you need to unnail anything). Something to think about. I'm very doubtful it's a good idea to combine those things - I think it's quite different to come up with a design for SLRUs, of which there's a constant number and shared memory ownership datastructures, and btree root pages etc, of which there are arbitrary many. For the nbtree (and similar) cases, I think it'd make sense to give backends a size-limited number of pages they can keep pinned, but in a backend local way. With, as you suggest, a procsignal barrier or such to force release. > I'm also wondering if it would be possible to do "optimistic" pinning > instead for reads that normally need only a pin, using some kind of > counter scheme with read barriers to tell you if the page might have > been evicted after you read the data... -many That seems fragile and complicated, without, at least to me, a clear need. Greetings, Andres Freund
On 28.05.2022 04:13, Thomas Munro wrote:
On Fri, May 27, 2022 at 11:24 PM Thomas Munro <thomas.munro@gmail.com> wrote:Rebased, debugged and fleshed out a tiny bit more, but still with plenty of TODO notes and questions. I will talk about this idea at PGCon, so I figured it'd help to have a patch that actually applies, even if it doesn't work quite right yet. It's quite a large patch but that's partly because it removes a lot of lines...FWIW, here are my PGCon slides about this: https://speakerdeck.com/macdice/improving-the-slru-subsystem There was a little bit of discussion on #pgcon-stream2 which I could summarise as: can we figure out a way to keep parts of the CLOG pinned so that backends don't have to do that for each lookup? Then CLOG checks become simple reads. There may be some relation to the idea of 'nailing' btree root pages that I've heard of from a couple of people now (with ProcSignalBarrier or something more fine grained along those lines if you need to unnail anything). Something to think about. I'm also wondering if it would be possible to do "optimistic" pinning instead for reads that normally need only a pin, using some kind of counter scheme with read barriers to tell you if the page might have been evicted after you read the data...
I wonder if there are some tests which can illustrate advantages of storing SLRU pages in shared buffers?
In PgPro we had a customer which run PL-PgSql code with recursively called function containing exception handling code. Each exception block creates subtransaction
and subxids SLRU becomes bottleneck.
I have simulated this workload with large number subxids using the following function:
create or replace function do_update(id integer, level integer) returns void as $$
begin
begin
if level > 0 then
perform do_update(id, level-1);
else
update pgbench_accounts SET abalance = abalance + 1 WHERE aid = id;
end if;
exception WHEN OTHERS THEN
raise notice '% %', SQLERRM, SQLSTATE;
end;
end; $$ language plpgsql;
With the following test script:
\set aid random(1, 1000)
select do_update(:aid,100)
\set aid random(1, 1000)
select do_update(:aid,100)
I got the following results:
pgbench (15beta1)
starting vacuum...end.
progress: 1.0 s, 3030.8 tps, lat 3.238 ms stddev 1.110, 0 failed
progress: 2.0 s, 3018.0 tps, lat 3.303 ms stddev 1.088, 0 failed
progress: 3.0 s, 3000.4 tps, lat 3.329 ms stddev 1.063, 0 failed
progress: 4.0 s, 2855.6 tps, lat 3.494 ms stddev 1.152, 0 failed
progress: 5.0 s, 2747.0 tps, lat 3.631 ms stddev 1.306, 0 failed
progress: 6.0 s, 2664.0 tps, lat 3.743 ms stddev 1.410, 0 failed
progress: 7.0 s, 2498.0 tps, lat 3.992 ms stddev 1.659, 0 failed
...
progress: 93.0 s, 670.0 tps, lat 14.964 ms stddev 10.555, 0 failed
progress: 94.0 s, 615.0 tps, lat 16.222 ms stddev 11.419, 0 failed
progress: 95.0 s, 580.0 tps, lat 17.251 ms stddev 11.622, 0 failed
progress: 96.0 s, 568.0 tps, lat 17.582 ms stddev 11.679, 0 failed
progress: 97.0 s, 573.0 tps, lat 17.389 ms stddev 11.771, 0 failed
progress: 98.0 s, 611.0 tps, lat 16.428 ms stddev 11.768, 0 failed
progress: 99.0 s, 568.0 tps, lat 17.622 ms stddev 11.912, 0 failed
progress: 100.0 s, 568.0 tps, lat 17.631 ms stddev 11.672, 0 failed
tps = 1035.566054 (without initial connection time)
With Thomas patch results are the following:
progress: 1.0 s, 2949.8 tps, lat 3.332 ms stddev 1.285, 0 failed
progress: 2.0 s, 3009.1 tps, lat 3.317 ms stddev 1.077, 0 failed
progress: 3.0 s, 2993.6 tps, lat 3.338 ms stddev 1.099, 0 failed
progress: 4.0 s, 3034.4 tps, lat 3.291 ms stddev 1.056, 0 failed
...
progress: 97.0 s, 1113.0 tps, lat 8.972 ms stddev 3.885, 0 failed
progress: 98.0 s, 1138.0 tps, lat 8.803 ms stddev 3.496, 0 failed
progress: 99.0 s, 1174.8 tps, lat 8.471 ms stddev 3.875, 0 failed
progress: 100.0 s, 1094.1 tps, lat 9.123 ms stddev 3.842, 0 failed
tps = 2133.240094 (without initial connection time)
So there is still degrade of performance but smaller than in case of vanilla and total TPS are almost two times higher.
And this is another example demonstrating degrade of performance from presentation by Alexander Korotkov:
pgbench script:
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime)
VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
SAVEPOINT s1;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime)
VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
....
SAVEPOINT sN;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime)
VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
SELECT pg_sleep(1.0);
END;
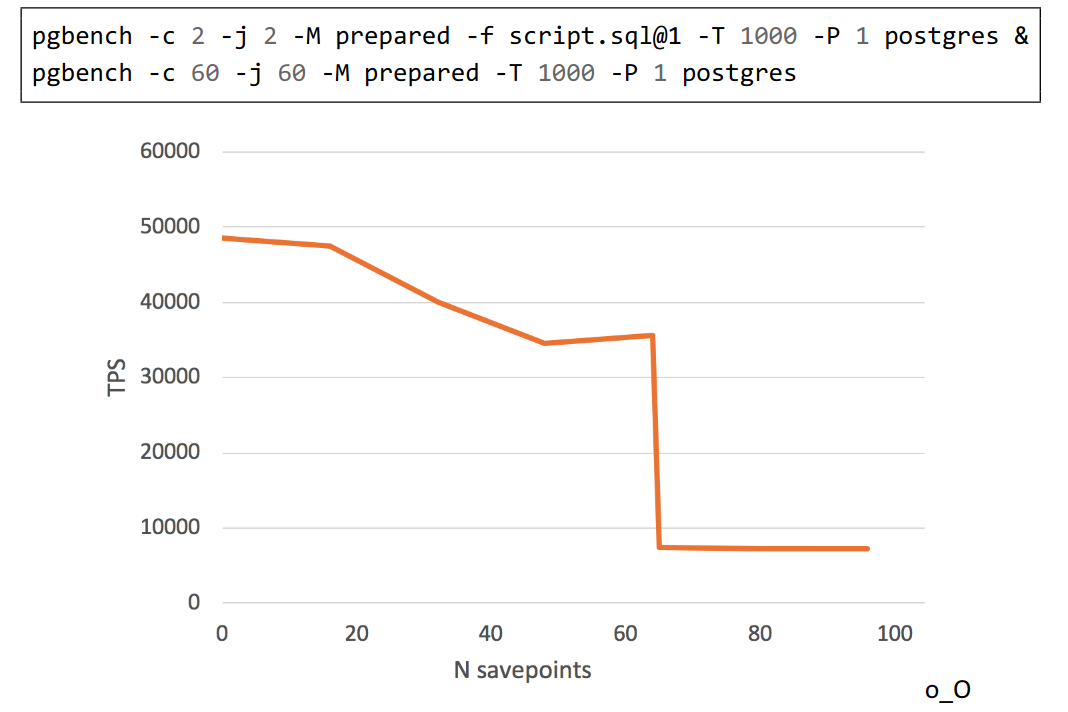
I wonder which workload can cause CLOG to become a bottleneck?
Usually Postgres uses hint bits to avoid clog access. So standard pgbench doesn't demonstrate any degrade of performance even in case of presence of long living transactions,
which keeps XMIN horizon.
Вложения
On Thu, Jun 16, 2022 at 1:13 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote: > I wonder which workload can cause CLOG to become a bottleneck? > Usually Postgres uses hint bits to avoid clog access. So standard pgbench doesn't demonstrate any degrade of performanceeven in case of presence of long living transactions, > which keeps XMIN horizon. I haven't done research on this in a number of years and a bunch of other improvements have been made since then, but I remember discovering that CLOG could become a bottleneck on standard pgbench tests especially when using unlogged tables. The higher you raised the scale factor, the more of a bottleneck CLOG became. That makes sense: no matter what the scale factor is, you're constantly updating rows that have not previously been hinted, but as the scale factor gets bigger, those rows are likely to be older (in terms of XID age) on average, and so you need to cache more CLOG buffers to maintain performance. But the SLRU system provides no such flexibility: it doesn't scale to large numbers of buffers the way the code is written, and it certainly can't vary the number of buffers devoted to this purpose at runtime. So I think that the approach we're talking about here has potential in that sense. However, another problem with the SLRU code is that it's old and crufty and hard to work with. It's hard to imagine anyone being able to improve things very much as long as that's the basis. I don't know that whatever code Thomas has written or will write is better, but if it is, that would be good, because I don't see a lot of improvement in this area being possible otherwise. -- Robert Haas EDB: http://www.enterprisedb.com
Good day, Thomas В Пт, 27/05/2022 в 23:24 +1200, Thomas Munro пишет: > Rebased, debugged and fleshed out a tiny bit more, but still with > plenty of TODO notes and questions. I will talk about this idea at > PGCon, so I figured it'd help to have a patch that actually applies, > even if it doesn't work quite right yet. It's quite a large patch but > that's partly because it removes a lot of lines... Looks like it have to be rebased again.
On 21/07/2022 16:23, Yura Sokolov wrote:
> Good day, Thomas
>
> В Пт, 27/05/2022 в 23:24 +1200, Thomas Munro пишет:
>> Rebased, debugged and fleshed out a tiny bit more, but still with
>> plenty of TODO notes and questions. I will talk about this idea at
>> PGCon, so I figured it'd help to have a patch that actually applies,
>> even if it doesn't work quite right yet. It's quite a large patch but
>> that's partly because it removes a lot of lines...
>
> Looks like it have to be rebased again.
Here's a rebase.
I'll write a separate post with my thoughts on the high-level design of
this, but first a couple of more detailed issues:
In RecordTransactionCommit(), we enter a critical section, and then call
TransactionIdCommitTree() to update the CLOG pages. That now involves a
call to ReadBuffer_common(), which in turn calls
ResourceOwnerEnlargeBuffers(). That can fail, because it might require
allocating memory, which is forbidden in a critical section. I ran into
an assertion about that with "make check" when I was playing around with
a heavily modified version of this patch. Haven't seen it with your
original one, but I believe that's just luck.
Calling ResourceOwnerEnlargeBuffers() before entering the critical
section would probably fix that, although I'm a bit worried about having
the Enlarge call so far away from the point where it's needed.
> +void
> +CheckPointSLRU(void)
> +{
> + /* Ensure that directory entries for new files are on disk. */
> + for (int i = 0; i < lengthof(defs); ++i)
> + {
> + if (defs[i].synchronize)
> + fsync_fname(defs[i].path, true);
> + }
> +}
> +
Is it really necessary to fsync() the directories? We don't do that
today for the SLRUs, and we don't do it for the tablespace/db
directories holding relations.
- Heikki
Вложения
On 25/07/2022 09:54, Heikki Linnakangas wrote: > In RecordTransactionCommit(), we enter a critical section, and then call > TransactionIdCommitTree() to update the CLOG pages. That now involves a > call to ReadBuffer_common(), which in turn calls > ResourceOwnerEnlargeBuffers(). That can fail, because it might require > allocating memory, which is forbidden in a critical section. I ran into > an assertion about that with "make check" when I was playing around with > a heavily modified version of this patch. Haven't seen it with your > original one, but I believe that's just luck. > > Calling ResourceOwnerEnlargeBuffers() before entering the critical > section would probably fix that, although I'm a bit worried about having > the Enlarge call so far away from the point where it's needed. Oh I just saw that you had a comment about that in the patch and had hacked around it. Anyway, calling ResourceOwnerEnlargeBuffers() might be a solution. Or switch to a separate "CriticalResourceOwner" that's guaranteed to have enough pre-allocated space, before entering the critical section. - Heikki
On 25/07/2022 09:54, Heikki Linnakangas wrote: > I'll write a separate post with my thoughts on the high-level design of > this, ... This patch represents each SLRU as a relation. The CLOG is one relation, pg_subtrans is another relations, and so forth. The SLRU relations use a different SMGR implementation, which is implemented in slru.c. As you know, I'd like to make the SMGR implementation replaceable by extensions. We need that for Neon, and I'd imagine it to be useful for many other things, too, like compression, encryption, or restoring data from a backup on-demand. I'd like all file operations to go through the smgr API as much as possible, so that an extension can intercept SLRU file operations too. If we introduce another internal SMGR implementation, then an extension would need to replace both implementations separately. I'd prefer to use the current md.c implementation for SLRUs too, instead. Thus I propose: Let's represent each SLRU *segment* as a separate relation, giving each SLRU segment a separate relNumber. Then we can use md.c for SLRUs, too. Dropping an SLRU segment can be done by calling smgrunlink(). You won't need to deal with missing segments in md.c, because each individual SLRU file is a complete file, with no holes. Dropping buffers for one SLRU segment can be done with DropRelationBuffers(), instead of introducing the new DiscardBuffer() function. You can let md.c handle the caching of the file descriptors, you won't need to reimplement that with 'slru_file_segment'. SLRUs won't need the segmentation into 1 GB segments that md.c does, because each SLRU file is just 256 kB in size. That's OK. (BTW, I propose that we bump the SLRU segment size up to a whopping 1 MB or even more, while we're at it. But one step at a time.) SLRUs also won't need the concept of relation forks. That's fine, we can just use MAIN_FORKNUM. elated to that, I'm somewhat bothered by the way that SMgrRelation currently bundles all the relation forks together. A comment in smgr.h says: > smgr.c maintains a table of SMgrRelation objects, which are essentially > cached file handles. But when we introduced relation forks, that got a bit muddled. Each SMgrRelation object is now a file handle for a bunch of related relation forks, and each fork is a separate file that can be created and truncated separately. That means that an SMGR implementation, like md.c, needs to track the file handles for each fork. I think things would be more clear if we unbundled the forks at the SMGR level, so that we would have a separate SMgrRelation struct for each fork. And let's rename it to SMgrFile to make the role more clear. I think that would reduce the confusion when we start using it for SLRUs; an SLRU is not a relation, after all. md.c would still segment each logical file into 1 GB segments, but it would not need to deal with forks. Attached is a draft patch to refactor it that way, and a refactored version of your SLRU patch over that. The relation cache now needs to hold a separate reference to the SMgrFile of each fork of a relation. And smgr cache invalidation still works at relation granularity. Doing it per SmgrFile would be more clean in smgr.c, but in practice all the forks of a relation are unlinked and truncated together, so sending a separate invalidation event for each SMgrFile would increase the cache invalidation traffic. In the passing, I moved the DropRelationBuffers() calls from smgr.c to the callers. smgr.c doesn't otherwise make any effort to keep the buffer manager in sync with the state on-disk, that responsibility is normally with the code that *uses* the smgr functions, so I think that's more logical. The first patch currently causes the '018_wal_optimize.pl' test to fail. I guess I messed up something in the relation truncation code, but I haven't investigated it yet. I wanted to post this to get comments on the design, before spending more time on that. What do you think? - Heikki
Вложения
Hi Thomas,
While I was working on adding the page headers to SLRU pages on your patch, I came across this code where it seems like
"MultiXactIdToMemberPage"is mistakenly being used instead of MultiXactIdToOffsetPage in the TrimMultiXact function.
Below is the area of concern in the patch:
@@ -2045,14 +1977,7 @@ TrimMultiXact(void)
oldestMXactDB = MultiXactState->oldestMultiXactDB;
LWLockRelease(MultiXactGenLock);
- /* Clean up offsets state */
- LWLockAcquire(MultiXactOffsetSLRULock, LW_EXCLUSIVE);
-
- /*
- * (Re-)Initialize our idea of the latest page number for offsets.
- */
- pageno = MultiXactIdToOffsetPage(nextMXact);
- MultiXactOffsetCtl->shared->latest_page_number = pag0eno;
+ pageno = MXOffsetToMemberPage(offset);
Let us know if I am missing something here or if it is an error.
Sincerely,
Rishu Bagga (Amazon Web Services)
On 9/16/22, 5:37 PM, "Thomas Munro" <thomas.munro@gmail.com> wrote:
CAUTION: This email originated from outside of the organization. Do not click links or open attachments unless you
canconfirm the sender and know the content is safe.
Rebased, debugged and fleshed out a tiny bit more, but still with
plenty of TODO notes and questions. I will talk about this idea at
PGCon, so I figured it'd help to have a patch that actually applies,
even if it doesn't work quite right yet. It's quite a large patch but
that's partly because it removes a lot of lines...
On Sat, Sep 17, 2022 at 12:41 PM Bagga, Rishu <bagrishu@amazon.com> wrote: > While I was working on adding the page headers to SLRU pages on your patch, I came across this code where it seems like"MultiXactIdToMemberPage" is mistakenly being used instead of MultiXactIdToOffsetPage in the TrimMultiXact function. Thanks Rishu. Right. Will fix soon in the next version, along with my long overdue replies to Heikki and Konstantin.
On Mon, Jul 25, 2022 at 11:54:36AM +0300, Heikki Linnakangas wrote: > Oh I just saw that you had a comment about that in the patch and had hacked > around it. Anyway, calling ResourceOwnerEnlargeBuffers() might be a > solution. Or switch to a separate "CriticalResourceOwner" that's guaranteed > to have enough pre-allocated space, before entering the critical section. Wanted to bump up this thread. Rishu in my team posted a patch in the other SLRU thread [1] with the latest updates and fixes and looks like performance numbers do not show any regression. This change is currently in the January commitfest [2] as well. Any feedback would be appreciated! [1] https://www.postgresql.org/message-id/A09EAE0D-0D3F-4A34-ADE9-8AC1DCBE7D57%40amazon.com [2] https://commitfest.postgresql.org/41/3514/ Shawn Amazon Web Services (AWS)
On 20/01/2023 19:00, Shawn Debnath wrote: > On Mon, Jul 25, 2022 at 11:54:36AM +0300, Heikki Linnakangas wrote: > >> Oh I just saw that you had a comment about that in the patch and had hacked >> around it. Anyway, calling ResourceOwnerEnlargeBuffers() might be a >> solution. Or switch to a separate "CriticalResourceOwner" that's guaranteed >> to have enough pre-allocated space, before entering the critical section. > > Wanted to bump up this thread. Rishu in my team posted a patch in the other > SLRU thread [1] with the latest updates and fixes and looks like performance > numbers do not show any regression. This change is currently in the > January commitfest [2] as well. Any feedback would be appreciated! Here's a rebased set of patches. The second patch is failing the pg_upgrade tests. Before I dig into that, I'd love to get some feedback on this general approach. - Heikki
Вложения
On 27/02/2023 15:31, Heikki Linnakangas wrote: > On 20/01/2023 19:00, Shawn Debnath wrote: >> On Mon, Jul 25, 2022 at 11:54:36AM +0300, Heikki Linnakangas wrote: >> >>> Oh I just saw that you had a comment about that in the patch and had hacked >>> around it. Anyway, calling ResourceOwnerEnlargeBuffers() might be a >>> solution. Or switch to a separate "CriticalResourceOwner" that's guaranteed >>> to have enough pre-allocated space, before entering the critical section. >> >> Wanted to bump up this thread. Rishu in my team posted a patch in the other >> SLRU thread [1] with the latest updates and fixes and looks like performance >> numbers do not show any regression. This change is currently in the >> January commitfest [2] as well. Any feedback would be appreciated! > > Here's a rebased set of patches. > > The second patch is failing the pg_upgrade tests. Before I dig into > that, I'd love to get some feedback on this general approach. Forgot to include the new "slrulist.h" file in the previous patch, fixed here. - Heikki
Вложения
Hi, > > Here's a rebased set of patches. > > > > The second patch is failing the pg_upgrade tests. Before I dig into > > that, I'd love to get some feedback on this general approach. > > Forgot to include the new "slrulist.h" file in the previous patch, fixed > here. Unfortunately the patchset rotted quite a bit since February and needs a rebase. -- Best regards, Aleksander Alekseev
Hi, > Unfortunately the patchset rotted quite a bit since February and needs a rebase. A consensus was reached [1] to mark this patch as RwF for now. There are many patches to be reviewed and this one doesn't seem to be in the best shape, so we have to prioritise. Please feel free re-submitting the patch for the next commitfest. [1]: https://postgr.es/m/0737f444-59bb-ac1d-2753-873c40da0840%40eisentraut.org -- Best regards, Aleksander Alekseev
Hi, > > Unfortunately the patchset rotted quite a bit since February and needs a rebase. > > A consensus was reached to mark this patch as RwF for now. There > are many patches to be reviewed and this one doesn't seem to be in the > best shape, so we have to prioritise. Please feel free re-submitting > the patch for the next commitfest. See also [1] """ [...] Also, please consider joining the efforts and having one thread with a single patchset rather than different threads with different competing patches. This will simplify the work of the reviewers a lot. Personally I would suggest taking one step back and agree on a particular RFC first and then continue working on a single patchset according to this RFC. We did it in the past in similar cases and this approach proved to be productive. [...] """ [1]: https://postgr.es/m/CAJ7c6TME5Z8k4undYUmKavD_dQFL0ujA%2BzFCK1eTH0_pzM%3DXrA%40mail.gmail.com -- Best regards, Aleksander Alekseev