Обсуждение: Aggregate Push Down - Performing aggregation on foreign server
Hi all,
Attached is the patch which adds support to push down aggregation and grouping
to the foreign server for postgres_fdw. Performing aggregation on foreign
server results into fetching fewer rows from foreign side as compared to
fetching all the rows and aggregating/grouping locally. Performing grouping on
foreign server may use indexes if available. So pushing down aggregates/
grouping on foreign server performs better than doing that locally. (Attached
EXPLAIN output for few simple grouping queries, with and without push down).
Here are the few details of the implementation
Creating Paths:
Implements the FDW hook GetForeignUpperPaths, which adds foreign scan path to
the output relation when upper relation kind is UPPERREL_GROUP_AGG. This path
represents the aggregation/grouping operations to be performed on the foreign
server. We are able to push down aggregation/grouping if (implemented in
foreign_grouping_ok()),
a. Underlying input relation is safe to push down and has no local conditions,
as local conditions need to be applied before aggregation.
b. All the aggregates, GROUP BY expressions are safe to push down.
foreign_grouping_ok() functions assesses it.
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relation
d. Var and Aggref nodes from non-shippable HAVING conditions.
The shippable having conditions are sent to the foreign server as part of the
HAVING clause of the remote SQL.
is_foreign_expr() function, now handles T_Aggref node. Aggregate is safe to
push down if,
a. Aggregate is a built-in aggregate
b. All its arguments are safe to push-down
c. Other expressions involved like aggorder, aggdistinct, aggfilter etc. are
safe to be pushed down.
Costing:
If use_foreign_estimate is true for input relation, like JOIN case, we use
EXPLAIN output to get the cost of query with aggregation/grouping on the
foreign server. If not we calculate the costs locally. Similar to core, we use
get_agg_clause_costs() to get costs for aggregation and then using logic
similar to cost_agg() we calculate startup and total cost. Since we have no
idea which aggregation strategy will be used at foreign side, we add all
startup cost (startup cost of input relation, aggregates etc.) into startup
cost for the grouping path and similarly for total cost.
Deparsing the query:
Target list created while checking for shippability is deparsed using
deparseExplicitTargetList(). sortgroupref are adjusted according to this
target list. Most of the logic to deparse an Aggref is inspired from
get_agg_expr(). For an upper relation, FROM and WHERE clauses come from the
underlying scan relation and thus for simplicity, FROM clause deparsing logic
is moved from deparseSelectSql() to a new function deparseFromClause(). The
same function adds WHERE clause to the remote SQL.
Area of future work:
1. Adding path with path-keys to push ORDER BY clause along with aggregation/
grouping. Should be supported as a separate patch.
2. Grouping Sets/Rollup/Cube is not supported in current version. I have left
this aside to keep patch smaller. If required I can add that support in the
next version of the patch.
Most of the code in this patch is inspired from the JOIN push down code.
Ashutosh Bapat provided a high-level design and a skeleton patch to start-with
offlist. Thanks to Tom Lane for his upper-planner pathification work and adding
GetForeignUpperPaths callback function.
ThanksAttached is the patch which adds support to push down aggregation and grouping
to the foreign server for postgres_fdw. Performing aggregation on foreign
server results into fetching fewer rows from foreign side as compared to
fetching all the rows and aggregating/grouping locally. Performing grouping on
foreign server may use indexes if available. So pushing down aggregates/
grouping on foreign server performs better than doing that locally. (Attached
EXPLAIN output for few simple grouping queries, with and without push down).
Here are the few details of the implementation
Creating Paths:
Implements the FDW hook GetForeignUpperPaths, which adds foreign scan path to
the output relation when upper relation kind is UPPERREL_GROUP_AGG. This path
represents the aggregation/grouping operations to be performed on the foreign
server. We are able to push down aggregation/grouping if (implemented in
foreign_grouping_ok()),
a. Underlying input relation is safe to push down and has no local conditions,
as local conditions need to be applied before aggregation.
b. All the aggregates, GROUP BY expressions are safe to push down.
foreign_grouping_ok() functions assesses it.
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relation
d. Var and Aggref nodes from non-shippable HAVING conditions.
The shippable having conditions are sent to the foreign server as part of the
HAVING clause of the remote SQL.
is_foreign_expr() function, now handles T_Aggref node. Aggregate is safe to
push down if,
a. Aggregate is a built-in aggregate
b. All its arguments are safe to push-down
c. Other expressions involved like aggorder, aggdistinct, aggfilter etc. are
safe to be pushed down.
Costing:
If use_foreign_estimate is true for input relation, like JOIN case, we use
EXPLAIN output to get the cost of query with aggregation/grouping on the
foreign server. If not we calculate the costs locally. Similar to core, we use
get_agg_clause_costs() to get costs for aggregation and then using logic
similar to cost_agg() we calculate startup and total cost. Since we have no
idea which aggregation strategy will be used at foreign side, we add all
startup cost (startup cost of input relation, aggregates etc.) into startup
cost for the grouping path and similarly for total cost.
Deparsing the query:
Target list created while checking for shippability is deparsed using
deparseExplicitTargetList(). sortgroupref are adjusted according to this
target list. Most of the logic to deparse an Aggref is inspired from
get_agg_expr(). For an upper relation, FROM and WHERE clauses come from the
underlying scan relation and thus for simplicity, FROM clause deparsing logic
is moved from deparseSelectSql() to a new function deparseFromClause(). The
same function adds WHERE clause to the remote SQL.
Area of future work:
1. Adding path with path-keys to push ORDER BY clause along with aggregation/
grouping. Should be supported as a separate patch.
2. Grouping Sets/Rollup/Cube is not supported in current version. I have left
this aside to keep patch smaller. If required I can add that support in the
next version of the patch.
Most of the code in this patch is inspired from the JOIN push down code.
Ashutosh Bapat provided a high-level design and a skeleton patch to start-with
offlist. Thanks to Tom Lane for his upper-planner pathification work and adding
GetForeignUpperPaths callback function.
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Phone: +91 20 30589500
Website: www.enterprisedb.com
EnterpriseDB Blog: http://blogs.enterprisedb.com/
Follow us on Twitter: http://www.twitter.com/enterprisedb
This e-mail message (and any attachment) is intended for the use of the individual or entity to whom it is addressed. This message contains information from EnterpriseDB Corporation that may be privileged, confidential, or exempt from disclosure under applicable law. If you are not the intended recipient or authorized to receive this for the intended recipient, any use, dissemination, distribution, retention, archiving, or copying of this communication is strictly prohibited. If you have received this e-mail in error, please notify the sender immediately by reply e-mail and delete this message.
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Phone: +91 20 30589500
Website: www.enterprisedb.com
EnterpriseDB Blog: http://blogs.enterprisedb.com/
Follow us on Twitter: http://www.twitter.com/enterprisedb
This e-mail message (and any attachment) is intended for the use of the individual or entity to whom it is addressed. This message contains information from EnterpriseDB Corporation that may be privileged, confidential, or exempt from disclosure under applicable law. If you are not the intended recipient or authorized to receive this for the intended recipient, any use, dissemination, distribution, retention, archiving, or copying of this communication is strictly prohibited. If you have received this e-mail in error, please notify the sender immediately by reply e-mail and delete this message.
Вложения
Hi
2016-08-30 15:02 GMT+02:00 Jeevan Chalke <jeevan.chalke@enterprisedb.com>:
Hi all,
Attached is the patch which adds support to push down aggregation and grouping
to the foreign server for postgres_fdw. Performing aggregation on foreign
server results into fetching fewer rows from foreign side as compared to
fetching all the rows and aggregating/grouping locally. Performing grouping on
foreign server may use indexes if available. So pushing down aggregates/
grouping on foreign server performs better than doing that locally. (Attached
EXPLAIN output for few simple grouping queries, with and without push down).
is it work without FDW too?. It can be pretty interesting too.
Regards
Pavel
Thanks
Here are the few details of the implementation
Creating Paths:
Implements the FDW hook GetForeignUpperPaths, which adds foreign scan path to
the output relation when upper relation kind is UPPERREL_GROUP_AGG. This path
represents the aggregation/grouping operations to be performed on the foreign
server. We are able to push down aggregation/grouping if (implemented in
foreign_grouping_ok()),
a. Underlying input relation is safe to push down and has no local conditions,
as local conditions need to be applied before aggregation.
b. All the aggregates, GROUP BY expressions are safe to push down.
foreign_grouping_ok() functions assesses it.
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relation
d. Var and Aggref nodes from non-shippable HAVING conditions.
The shippable having conditions are sent to the foreign server as part of the
HAVING clause of the remote SQL.
is_foreign_expr() function, now handles T_Aggref node. Aggregate is safe to
push down if,
a. Aggregate is a built-in aggregate
b. All its arguments are safe to push-down
c. Other expressions involved like aggorder, aggdistinct, aggfilter etc. are
safe to be pushed down.
Costing:
If use_foreign_estimate is true for input relation, like JOIN case, we use
EXPLAIN output to get the cost of query with aggregation/grouping on the
foreign server. If not we calculate the costs locally. Similar to core, we use
get_agg_clause_costs() to get costs for aggregation and then using logic
similar to cost_agg() we calculate startup and total cost. Since we have no
idea which aggregation strategy will be used at foreign side, we add all
startup cost (startup cost of input relation, aggregates etc.) into startup
cost for the grouping path and similarly for total cost.
Deparsing the query:
Target list created while checking for shippability is deparsed using
deparseExplicitTargetList(). sortgroupref are adjusted according to this
target list. Most of the logic to deparse an Aggref is inspired from
get_agg_expr(). For an upper relation, FROM and WHERE clauses come from the
underlying scan relation and thus for simplicity, FROM clause deparsing logic
is moved from deparseSelectSql() to a new function deparseFromClause(). The
same function adds WHERE clause to the remote SQL.
Area of future work:
1. Adding path with path-keys to push ORDER BY clause along with aggregation/
grouping. Should be supported as a separate patch.
2. Grouping Sets/Rollup/Cube is not supported in current version. I have left
this aside to keep patch smaller. If required I can add that support in the
next version of the patch.
Most of the code in this patch is inspired from the JOIN push down code.
Ashutosh Bapat provided a high-level design and a skeleton patch to start-with
offlist. Thanks to Tom Lane for his upper-planner pathification work and adding
GetForeignUpperPaths callback function.--Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Phone: +91 20 30589500
Website: www.enterprisedb.com
EnterpriseDB Blog: http://blogs.enterprisedb.com/
Follow us on Twitter: http://www.twitter.com/enterprisedb
This e-mail message (and any attachment) is intended for the use of the individual or entity to whom it is addressed. This message contains information from EnterpriseDB Corporation that may be privileged, confidential, or exempt from disclosure under applicable law. If you are not the intended recipient or authorized to receive this for the intended recipient, any use, dissemination, distribution, retention, archiving, or copying of this communication is strictly prohibited. If you have received this e-mail in error, please notify the sender immediately by reply e-mail and delete this message.
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Aug 30, 2016 at 6:51 PM, Pavel Stehule <pavel.stehule@gmail.com> wrote:
No. Aggrgate push down is supported through the GetForeignUpperPaths() hook
added for postgres_fdw. Thus it works only with postgres_fdw.
Do you mean whether this works with any extensions via implementing
create_upper_paths_hook() function?
The answer is No. This patch does not touch this hook.
Hi2016-08-30 15:02 GMT+02:00 Jeevan Chalke <jeevan.chalke@enterprisedb.com>: Hi all,
Attached is the patch which adds support to push down aggregation and grouping
to the foreign server for postgres_fdw. Performing aggregation on foreign
server results into fetching fewer rows from foreign side as compared to
fetching all the rows and aggregating/grouping locally. Performing grouping on
foreign server may use indexes if available. So pushing down aggregates/
grouping on foreign server performs better than doing that locally. (Attached
EXPLAIN output for few simple grouping queries, with and without push down).is it work without FDW too?. It can be pretty interesting too.
No. Aggrgate push down is supported through the GetForeignUpperPaths() hook
added for postgres_fdw. Thus it works only with postgres_fdw.
Do you mean whether this works with any extensions via implementing
create_upper_paths_hook() function?
The answer is No. This patch does not touch this hook.
RegardsPavel
Thanks
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
2016-08-31 8:17 GMT+02:00 Jeevan Chalke <jeevan.chalke@enterprisedb.com>:
On Tue, Aug 30, 2016 at 6:51 PM, Pavel Stehule <pavel.stehule@gmail.com> wrote:Hi2016-08-30 15:02 GMT+02:00 Jeevan Chalke <jeevan.chalke@enterprisedb.com>: Hi all,
Attached is the patch which adds support to push down aggregation and grouping
to the foreign server for postgres_fdw. Performing aggregation on foreign
server results into fetching fewer rows from foreign side as compared to
fetching all the rows and aggregating/grouping locally. Performing grouping on
foreign server may use indexes if available. So pushing down aggregates/
grouping on foreign server performs better than doing that locally. (Attached
EXPLAIN output for few simple grouping queries, with and without push down).is it work without FDW too?. It can be pretty interesting too.
No. Aggrgate push down is supported through the GetForeignUpperPaths() hook
added for postgres_fdw. Thus it works only with postgres_fdw.
Do you mean whether this works with any extensions via implementing
create_upper_paths_hook() function?
The answer is No. This patch does not touch this hook.
It is pity - lot of performance issues are related to this missing feature.
Regards
Pavel
RegardsPavelThanks--Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
On Wed, Aug 31, 2016 at 11:56 AM, Pavel Stehule <pavel.stehule@gmail.com> wrote: > It is pity - lot of performance issues are related to this missing feature. I don't think you are being very clear about what feature you are talking about. The feature that Jeevan has implemented is pushing aggregates to the remote side when postgres_fdw is in use. The feature you are talking about is evidently something else, but you haven't really said what it is. Or not in a way that I can understand. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
2016-08-31 9:00 GMT+02:00 Robert Haas <robertmhaas@gmail.com>:
On Wed, Aug 31, 2016 at 11:56 AM, Pavel Stehule <pavel.stehule@gmail.com> wrote:
> It is pity - lot of performance issues are related to this missing feature.
I don't think you are being very clear about what feature you are
talking about. The feature that Jeevan has implemented is pushing
aggregates to the remote side when postgres_fdw is in use. The
feature you are talking about is evidently something else, but you
haven't really said what it is. Or not in a way that I can
understand.
yes, It is not clear if FDW aggregate push down can be implemented together with internal aggregate push down. Aggregate push down ~ try to aggregate first when it is possible
Regards
Pavel
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2016/08/31 16:42, Pavel Stehule wrote: > 2016-08-31 9:00 GMT+02:00 Robert Haas <robertmhaas@gmail.com>: > >> On Wed, Aug 31, 2016 at 11:56 AM, Pavel Stehule <pavel.stehule@gmail.com> >> wrote: >>> It is pity - lot of performance issues are related to this missing >> feature. >> >> I don't think you are being very clear about what feature you are >> talking about. The feature that Jeevan has implemented is pushing >> aggregates to the remote side when postgres_fdw is in use. The >> feature you are talking about is evidently something else, but you >> haven't really said what it is. Or not in a way that I can >> understand. >> > > yes, It is not clear if FDW aggregate push down can be implemented together > with internal aggregate push down. Aggregate push down ~ try to aggregate > first when it is possible What do you mean by "internal aggregate push down"? Partition-wise aggregation? Aggregate/group by before join (something like [1])? IIUC, what Jeevan proposes in this thread is to implement the aggregate push down API that is specific to FDWs in postgres_fdw. Any other push down work would need to use different APIs and would need to separately proposed/discussed. Thanks, Amit [1] https://www.postgresql.org/message-id/CAKJS1f9kw95K2pnCKAoPmNw==7fgjSjC-82cy1RB+-x-Jz0QHA@mail.gmail.com
2016-08-31 10:03 GMT+02:00 Amit Langote <Langote_Amit_f8@lab.ntt.co.jp>:
On 2016/08/31 16:42, Pavel Stehule wrote:
> 2016-08-31 9:00 GMT+02:00 Robert Haas <robertmhaas@gmail.com>:
>
>> On Wed, Aug 31, 2016 at 11:56 AM, Pavel Stehule <pavel.stehule@gmail.com>
>> wrote:
>>> It is pity - lot of performance issues are related to this missing
>> feature.
>>
>> I don't think you are being very clear about what feature you are
>> talking about. The feature that Jeevan has implemented is pushing
>> aggregates to the remote side when postgres_fdw is in use. The
>> feature you are talking about is evidently something else, but you
>> haven't really said what it is. Or not in a way that I can
>> understand.
>>
>
> yes, It is not clear if FDW aggregate push down can be implemented together
> with internal aggregate push down. Aggregate push down ~ try to aggregate
> first when it is possible
What do you mean by "internal aggregate push down"? Partition-wise
aggregation? Aggregate/group by before join (something like [1])? IIUC,
what Jeevan proposes in this thread is to implement the aggregate push
down API that is specific to FDWs in postgres_fdw. Any other push down
work would need to use different APIs and would need to separately
proposed/discussed.
ok I understand now.
Regards
Pavel
Thanks,
Amit
[1]
https://www.postgresql.org/message-id/ CAKJS1f9kw95K2pnCKAoPmNw== 7fgjSjC-82cy1RB+-x-Jz0QHA@ mail.gmail.com
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relation
The code in the patch doesn't seem to add Var nodes explicitly. It assumes that
the Var nodes will be part of GROUP BY clause. The code is correct, I think.
the Var nodes will be part of GROUP BY clause. The code is correct, I think.
d. Var and Aggref nodes from non-shippable HAVING conditions.
This needs to be changed as per the comments below.
Costing:
If use_foreign_estimate is true for input relation, like JOIN case, we use
EXPLAIN output to get the cost of query with aggregation/grouping on the
foreign server. If not we calculate the costs locally. Similar to core, we use
get_agg_clause_costs() to get costs for aggregation and then using logic
similar to cost_agg() we calculate startup and total cost. Since we have no
idea which aggregation strategy will be used at foreign side, we add all
startup cost (startup cost of input relation, aggregates etc.) into startup
cost for the grouping path and similarly for total cost.
This looks OK to me.
Deparsing the query:
Target list created while checking for shippability is deparsed using
deparseExplicitTargetList(). sortgroupref are adjusted according to this
target list. Most of the logic to deparse an Aggref is inspired from
get_agg_expr(). For an upper relation, FROM and WHERE clauses come from the
underlying scan relation and thus for simplicity, FROM clause deparsing logic
is moved from deparseSelectSql() to a new function deparseFromClause(). The
same function adds WHERE clause to the remote SQL.
Ok.
Area of future work:
1. Adding path with path-keys to push ORDER BY clause along with aggregation/
grouping. Should be supported as a separate patch.
2. Grouping Sets/Rollup/Cube is not supported in current version. I have left
this aside to keep patch smaller. If required I can add that support in the
next version of the patch.
I am fine with these limitations for first cut of this feature.
I think we should try to measure performance gain because of aggregate pushdown. The EXPLAIN
doesn't show actual improvement in the execution times.
Here are the comments on the patch.
Patch compiles without errors/warnings - Yes
make check passes - Yes.
make check in contrib/postgres_fdw passes - Yes
Attached patch (based on your patch) has some typos corrected, some comments
rephrased. It also has some code changes, as explained in various comments
below. Please see if those look good.
1. Usually for any deparseSomething function, Something is the type of node
produced by the parser when the string output by that function is parsed.
deparseColumnRef, for example, produces a string, which when parsed produces a
columnRef node. There is are nodes of type FromClause and AggOrderBy. I guess,
you meant FromExpr instead of FromClause. deparseAggOrderBy() may be renamed as
appendOrderByFromList() or something similar. It may be utilized for window
functions if required.
2. Can we infer the value of foragg flag from the RelOptInfo passed to
is_foreign_expr()? For any upper relation, it is ok to have aggregate in
there. For any other relation aggregate is not expected.
3. In function foreign_grouping_ok(), should we use classifyConditions()? The
function is written and used for base relations. There's nothing in that
function, which prohibits it being used for other relations. I feel that
foreign_join_ok() should have used the same function to classify the other
clauses.
4. May be the individual criteria in the comment block
+ /*
+ * Aggregate is safe to pushdown if
+ * 1. It is a built-in aggregate
+ * 2. All its arguments are safe to push-down
+ * 3. The functions involved are immutable.
+ * 4. Other expressions involved like aggorder, aggdistinct are
+ * safe to be pushed down.
+ */
should be associated with the code blocks which implement those. As the
criteria change it's difficult to maintain the numbered list in sync with the
code.
5. The comment
+ /* Aggregates other than simple one are non-pushable. */
should read /* Only non-split aggregates are pushable. */ as AGGSPLIT_SIMPLE
means a complete, non-split aggregation step.
6. An aggregate function has transition, combination and finalization function
associated with it. Should we check whether all of the functions are shippable?
But probably it suffices to check whether aggregate function as whole is
shippable or not using is_shippable() since it's the whole aggregate we are
interested in and not the intermediate results. Probably, we should add a
comment explaining why it's sufficient to check the aggregate function as a
whole. I wondered whether we should check shippability of aggregate return
type, but we don't do that for functions as well. So it's fine.
7. It looks like aggdirectargs, aggdistinct, aggorder expressions are all
present in args list. If all the expressions in args are shippable, it means
those lists are also shippable and hence corresponding aggregate subclauses are
shippable. Are we unnecessarily checking shippability of those other lists?
8. The prologue of build_tlist_to_deparse() mentions that the output targetlist
contains columns, which is not true with your patch. The targetlist returned by
this function can have expressions for upper relations. Please update the
prologue to reflect this change.
9. In build_tlist_to_deparse(), we are including aggregates from unshippable
conditions without checking whether they are shippable or not. This can cause
an unshippable expression to be pushed to the foreign server as seen below
explain verbose select avg(c1) from ft1 having avg(c1 * random()) > 100;
QUERY PLAN
--------------------------------------------------------------------------------------
Foreign Scan (cost=112.50..133.53 rows=1 width=32)
Output: (avg(c1))
Filter: ((avg(((ft1.c1)::double precision * random()))) > '100'::double precision)
Relations: Aggregate on (public.ft1)
Remote SQL: SELECT avg(r1."C 1"), avg((r1."C 1" * random())) FROM "S 1"."T 1" r1
(5 rows)
We should check shippability of aggregates in unshippable conditions in
foreign_grouping_ok(). If any of those are not shippable, aggregation can not
be pushed down. Otherwise, include those in the grouped_tlist.
10. Comment /* Construct FROM clause */ should read "Construct FROM and WHERE
clauses." to be in sync with the next function call. deparseFromClause() should
be renamed as deparseFromExpr() inline with the naming convention of
deparse<something> functions. From the function signature of
deparseFromClause(), it doesn't become clear as to what contributes to the FROM
clause. Should we add a comment in the prologue of that function explaining the
same. Also it strikes odd that for an upper relation, we pass remote_conds to
this function, but it doesn't deparse those but deparses the remote conditions
from the scan relation and later deparses the same remote_conds as HAVING
clause. Although this is correct, the code looks odd. May be the codeblock in
deparseFuncClause()
1008 /*
1009 * For aggregates the FROM clause will be build from underneath scan rel.
1010 * WHERE clause conditions too taken from there.
1011 */
1012 if (foreignrel->reloptkind == RELOPT_UPPER_REL)
1013 {
1014 PgFdwRelationInfo *ofpinfo;
1015
1016 ofpinfo = (PgFdwRelationInfo *) fpinfo->outerrel->fdw_private;
1017 scan_rel = fpinfo->outerrel;
1018 context->foreignrel = scan_rel;
1019 remote_conds = ofpinfo->remote_conds;
1020 }
should be moved into deparseSelectStmtForRel() to make the things clear.
11. Whether to qualify a column name by an alias should be based on whether the
underlying scan relation is a join or base relation scan. That can be achieved
by setting scanrel in the deparse_context. Attached patch has this implemented.
Instead of scanrel, we may also have use_alias value as part of the context,
which is used everywhere.
12. The code to print the function name in deparseAggref() seems similar to
that in deparseFuncExpr(). Should we extract it out into a separate function
and call that function in deparseAggref() and deparseFuncExpr() both?
13. While deparsing the direct aggregates, the code is not adding "," between
two arguments, resulting in error like below.
select rank(c1, c2) within group (order by c1, c2) from ft1 group by c1, c2;
ERROR: syntax error at or near "c2"
CONTEXT: Remote SQL command: SELECT rank("C 1"c2) WITHIN GROUP (ORDER BY "C
1", c2), "C 1", c2 FROM "S 1"."T 1" GROUP BY "C 1", c2
May be we should add support to deparse List expressions by separating list
items by "," similar to get_rule_expr() and use that here.
14. In deparseAggOrderBy() we do not output anything for default cases like ASC
or NULLS FIRST (for DESC). But like appendOrderByClause() it's better to be
explicit and output even the default specifications. That way, we do not leave
anything to the interpretation of the foreign server.
15. deparseAggOrderBy supports deparsing USING subclause for ORDER BY for an
aggregate, but there is no corresponding shippability check for ordering
operator. Also, we should try to produce a testcase for the same.
16. The code to deparse a sort/group reference in deparseAggOrderBy() and
appendGroupByClause() looks similar. Should we extract it out into a function
by itself and call that function in those two places similar to
get_rule_sortgroupclause()?
17. In postgresGetForeignPlan() the code to extract conditions and targetlist
is duplicated for join and upper relation. Attached patch removes this
duplication. Since DML, FOR SHARE/UPDATE is not allowed with aggregation and
grouping, we should get an outer plan in that code.
18. estimate_path_cost_size() has grown quite long (~400 lines). Half of that
function deals with estimating costs locally. Should we split this function
into smaller functions, one for estimating size and costs of each kind of
relations locally?
19. Condition below
+ if (sgref && query->groupClause && query->groupingSets == NIL &&
+ get_sortgroupref_clause_noerr(sgref, query->groupClause) != NULL)
can be rewritten as
if (sgref && get_sortgroupref_clause_noerr(sgref, query->groupClause))
since we won't come here with non-NULL query->groupingSets and
get_sortgroupref_clause_noerr() will return NULL, if there aren't any
groupClause.
20. Please use word "foreign" instead of "remote" in comments.
21. This code looks dubious
+ /* If not GROUP BY ref, reset it as we are not pushing those */
+ if (sgref)
+ grouping_target->sortgrouprefs[i] = 0;
grouping_target comes from RelOptInfo, which is being modified here. We
shouldn't be modifying anything in the RelOptInfo while checking whether the
aggregate/grouping is shippable. You may want to copy the pathtaget and modify
the copy.
22. Following comment needs more elaboration.
+ /*
+ * Add aggregates, if any, into tlist. Plain Var nodes pulled
+ * are already part of GROUP BY and thus no need to add them
+ * explicitly.
+ */
Plain Var nodes will either be same as some GROUP BY expression or should be
part of some GROUP BY expression. In the later case, the query can not refer
those without the surrounding expression. which will be part of the targetlist
list. Hence we don't need to add plain Var nodes in the targetlist. In fact
adding those in SELECT clause will cause error on the foreign server if they
are not part of GROUP BY clause.
23. Probably you don't need to save this in fpinfo. You may want to calculate
it whenever it's needed.
+ fpinfo->grouped_exprs = get_sortgrouplist_exprs(query->groupClause, tlist);
24. Can this ever happen for postgres_fdw? The core sets fdwroutine and calls
this function when the underlying scan relation has fdwroutine set, which
implies that it called corresponding GetForeignPath hooks, which should have
set fdw_private. Nonetheless, I think, still the condition is useful to avoid
crashing the server in case the fdw_private is not set. But we need better
comments.
+ /* If input rel is not aware of fdw, simply return */
+ if (!input_rel->fdw_private)
+ return;
25. Although it's desirable to get a switch case in
postgresGetForeignUpperPaths() eventually, for this patch I guess we should
have an if condition there.
26. Attached patch has restructured code in appendGroupByClause() to reduce
indentation and make the code readable. Let me know if this looks good to you.
27. Prologue of create_foreign_grouping_paths() does not have formatting
similar to the surrounding functions. Please fix it. Since the function
"create"s and "add"s paths, it might be better to rename it as
add_foreign_grouping_paths().
28. Isn't the following true for any upper relation and shouldn't it be part of
postgresGetForeignUpperPaths(), rather than create_foreign_grouping_paths()?
+ /*
+ * If input rel is not safe to pushdown, we cannot do grouping and/or
+ * aggregation on it.
+ */
+ if (!ifpinfo || !ifpinfo->pushdown_safe)
+ return;
29. We require RelOptInfo::relids since create_foreignscan_plan() copies them
into ForeignPlan::fs_relids and executor uses them. So, I guess, we have to set
those in the core somewhere. May be while calling fetch_upper_rel() in
grouping_planner(), we should call it with relids of the underlying scan
relation. I don't see any function calling fetch_upper_rel() with non-NULL
relids. In fact, if we are to create an upper relation with relids in future,
this code is going to wipe that out, which will be undesirable. Also,
generally, when copying relids, it's better to use bms_copy() to make a copy
of Bitmapset, instead of just assigning the pointer.
30. By the time postgresGetForeignUpperPaths() gets called, the core has
already added its own paths, so it doesn't make much sense to set rows and
width grouped_rel in create_foreign_grouping_paths().
31. fpinfo->server and user fields are being set twice, once in
create_foreign_grouping_paths() then in foreign_grouping_ok(). Do we need that?
32.
+ /*
+ * Do we want to create paths with pathkeys corresponding for
+ * root->query_pathkeys.
+ */
Yes, it would be desirable to do that. If we are not going to do that in this
patch, may be remove that line or add a TODO kind of comment.
33. The patch marks build_path_tlist() as non-static but does not use it
anywhere outside creatplan.c. Is this change intentional?
--
Best Wishes,
Ashutosh Bapat
EnterpriseDB Corporation
The Postgres Database Company
Ashutosh Bapat
EnterpriseDB Corporation
The Postgres Database Company
Вложения
Hi,
While testing "Aggregate pushdown", i found the below error:
-- GROUP BY alias showing different behavior after adding patch.
-- Create table "t1", insert few records.
create table t1(c1 int);
insert into t1 values(10), (20);
-- Create foreign table:
create foreign table f_t1 (c1 int) server db1_server options (table_name 't1');
-- with local table:
postgres=# select 2 a, avg(c1) from t1 group by a;
a | avg
---+---------------------
2 | 15.0000000000000000
(1 row)
-- with foreign table:
postgres=# select 2 a, avg(c1) from f_t1 group by a;
ERROR: aggregate functions are not allowed in GROUP BY
CONTEXT: Remote SQL command: EXPLAIN SELECT 2, avg(c1) FROM public.t1 GROUP BY 2
While testing "Aggregate pushdown", i found the below error:
-- GROUP BY alias showing different behavior after adding patch.
-- Create table "t1", insert few records.
create table t1(c1 int);
insert into t1 values(10), (20);
-- Create foreign table:
create foreign table f_t1 (c1 int) server db1_server options (table_name 't1');
-- with local table:
postgres=# select 2 a, avg(c1) from t1 group by a;
a | avg
---+---------------------
2 | 15.0000000000000000
(1 row)
-- with foreign table:
postgres=# select 2 a, avg(c1) from f_t1 group by a;
ERROR: aggregate functions are not allowed in GROUP BY
CONTEXT: Remote SQL command: EXPLAIN SELECT 2, avg(c1) FROM public.t1 GROUP BY 2
On Thu, Sep 8, 2016 at 10:41 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relationThe code in the patch doesn't seem to add Var nodes explicitly. It assumes that
the Var nodes will be part of GROUP BY clause. The code is correct, I think.
d. Var and Aggref nodes from non-shippable HAVING conditions.This needs to be changed as per the comments below.
Costing:
If use_foreign_estimate is true for input relation, like JOIN case, we use
EXPLAIN output to get the cost of query with aggregation/grouping on the
foreign server. If not we calculate the costs locally. Similar to core, we use
get_agg_clause_costs() to get costs for aggregation and then using logic
similar to cost_agg() we calculate startup and total cost. Since we have no
idea which aggregation strategy will be used at foreign side, we add all
startup cost (startup cost of input relation, aggregates etc.) into startup
cost for the grouping path and similarly for total cost.This looks OK to me.
Deparsing the query:
Target list created while checking for shippability is deparsed using
deparseExplicitTargetList(). sortgroupref are adjusted according to this
target list. Most of the logic to deparse an Aggref is inspired from
get_agg_expr(). For an upper relation, FROM and WHERE clauses come from the
underlying scan relation and thus for simplicity, FROM clause deparsing logic
is moved from deparseSelectSql() to a new function deparseFromClause(). The
same function adds WHERE clause to the remote SQL.Ok.
Area of future work:
1. Adding path with path-keys to push ORDER BY clause along with aggregation/
grouping. Should be supported as a separate patch.
2. Grouping Sets/Rollup/Cube is not supported in current version. I have left
this aside to keep patch smaller. If required I can add that support in the
next version of the patch.I am fine with these limitations for first cut of this feature.I think we should try to measure performance gain because of aggregate pushdown. The EXPLAINdoesn't show actual improvement in the execution times.Here are the comments on the patch.
Patch compiles without errors/warnings - Yes
make check passes - Yes.
make check in contrib/postgres_fdw passes - Yes
Attached patch (based on your patch) has some typos corrected, some comments
rephrased. It also has some code changes, as explained in various comments
below. Please see if those look good.
1. Usually for any deparseSomething function, Something is the type of node
produced by the parser when the string output by that function is parsed.
deparseColumnRef, for example, produces a string, which when parsed produces a
columnRef node. There is are nodes of type FromClause and AggOrderBy. I guess,
you meant FromExpr instead of FromClause. deparseAggOrderBy() may be renamed as
appendOrderByFromList() or something similar. It may be utilized for window
functions if required.
2. Can we infer the value of foragg flag from the RelOptInfo passed to
is_foreign_expr()? For any upper relation, it is ok to have aggregate in
there. For any other relation aggregate is not expected.
3. In function foreign_grouping_ok(), should we use classifyConditions()? The
function is written and used for base relations. There's nothing in that
function, which prohibits it being used for other relations. I feel that
foreign_join_ok() should have used the same function to classify the other
clauses.
4. May be the individual criteria in the comment block
+ /*
+ * Aggregate is safe to pushdown if
+ * 1. It is a built-in aggregate
+ * 2. All its arguments are safe to push-down
+ * 3. The functions involved are immutable.
+ * 4. Other expressions involved like aggorder, aggdistinct are
+ * safe to be pushed down.
+ */
should be associated with the code blocks which implement those. As the
criteria change it's difficult to maintain the numbered list in sync with the
code.
5. The comment
+ /* Aggregates other than simple one are non-pushable. */
should read /* Only non-split aggregates are pushable. */ as AGGSPLIT_SIMPLE
means a complete, non-split aggregation step.
6. An aggregate function has transition, combination and finalization function
associated with it. Should we check whether all of the functions are shippable?
But probably it suffices to check whether aggregate function as whole is
shippable or not using is_shippable() since it's the whole aggregate we are
interested in and not the intermediate results. Probably, we should add a
comment explaining why it's sufficient to check the aggregate function as a
whole. I wondered whether we should check shippability of aggregate return
type, but we don't do that for functions as well. So it's fine.
7. It looks like aggdirectargs, aggdistinct, aggorder expressions are all
present in args list. If all the expressions in args are shippable, it means
those lists are also shippable and hence corresponding aggregate subclauses are
shippable. Are we unnecessarily checking shippability of those other lists?
8. The prologue of build_tlist_to_deparse() mentions that the output targetlist
contains columns, which is not true with your patch. The targetlist returned by
this function can have expressions for upper relations. Please update the
prologue to reflect this change.
9. In build_tlist_to_deparse(), we are including aggregates from unshippable
conditions without checking whether they are shippable or not. This can cause
an unshippable expression to be pushed to the foreign server as seen below
explain verbose select avg(c1) from ft1 having avg(c1 * random()) > 100;
QUERY PLAN
------------------------------------------------------------ --------------------------
Foreign Scan (cost=112.50..133.53 rows=1 width=32)
Output: (avg(c1))
Filter: ((avg(((ft1.c1)::double precision * random()))) > '100'::double precision)
Relations: Aggregate on (public.ft1)
Remote SQL: SELECT avg(r1."C 1"), avg((r1."C 1" * random())) FROM "S 1"."T 1" r1
(5 rows)
We should check shippability of aggregates in unshippable conditions in
foreign_grouping_ok(). If any of those are not shippable, aggregation can not
be pushed down. Otherwise, include those in the grouped_tlist.
10. Comment /* Construct FROM clause */ should read "Construct FROM and WHERE
clauses." to be in sync with the next function call. deparseFromClause() should
be renamed as deparseFromExpr() inline with the naming convention of
deparse<something> functions. From the function signature of
deparseFromClause(), it doesn't become clear as to what contributes to the FROM
clause. Should we add a comment in the prologue of that function explaining the
same. Also it strikes odd that for an upper relation, we pass remote_conds to
this function, but it doesn't deparse those but deparses the remote conditions
from the scan relation and later deparses the same remote_conds as HAVING
clause. Although this is correct, the code looks odd. May be the codeblock in
deparseFuncClause()
1008 /*
1009 * For aggregates the FROM clause will be build from underneath scan rel.
1010 * WHERE clause conditions too taken from there.
1011 */
1012 if (foreignrel->reloptkind == RELOPT_UPPER_REL)
1013 {
1014 PgFdwRelationInfo *ofpinfo;
1015
1016 ofpinfo = (PgFdwRelationInfo *) fpinfo->outerrel->fdw_private;
1017 scan_rel = fpinfo->outerrel;
1018 context->foreignrel = scan_rel;
1019 remote_conds = ofpinfo->remote_conds;
1020 }
should be moved into deparseSelectStmtForRel() to make the things clear.
11. Whether to qualify a column name by an alias should be based on whether the
underlying scan relation is a join or base relation scan. That can be achieved
by setting scanrel in the deparse_context. Attached patch has this implemented.
Instead of scanrel, we may also have use_alias value as part of the context,
which is used everywhere.
12. The code to print the function name in deparseAggref() seems similar to
that in deparseFuncExpr(). Should we extract it out into a separate function
and call that function in deparseAggref() and deparseFuncExpr() both?
13. While deparsing the direct aggregates, the code is not adding "," between
two arguments, resulting in error like below.
select rank(c1, c2) within group (order by c1, c2) from ft1 group by c1, c2;
ERROR: syntax error at or near "c2"
CONTEXT: Remote SQL command: SELECT rank("C 1"c2) WITHIN GROUP (ORDER BY "C
1", c2), "C 1", c2 FROM "S 1"."T 1" GROUP BY "C 1", c2
May be we should add support to deparse List expressions by separating list
items by "," similar to get_rule_expr() and use that here.
14. In deparseAggOrderBy() we do not output anything for default cases like ASC
or NULLS FIRST (for DESC). But like appendOrderByClause() it's better to be
explicit and output even the default specifications. That way, we do not leave
anything to the interpretation of the foreign server.
15. deparseAggOrderBy supports deparsing USING subclause for ORDER BY for an
aggregate, but there is no corresponding shippability check for ordering
operator. Also, we should try to produce a testcase for the same.
16. The code to deparse a sort/group reference in deparseAggOrderBy() and
appendGroupByClause() looks similar. Should we extract it out into a function
by itself and call that function in those two places similar to
get_rule_sortgroupclause()?
17. In postgresGetForeignPlan() the code to extract conditions and targetlist
is duplicated for join and upper relation. Attached patch removes this
duplication. Since DML, FOR SHARE/UPDATE is not allowed with aggregation and
grouping, we should get an outer plan in that code.
18. estimate_path_cost_size() has grown quite long (~400 lines). Half of that
function deals with estimating costs locally. Should we split this function
into smaller functions, one for estimating size and costs of each kind of
relations locally?
19. Condition below
+ if (sgref && query->groupClause && query->groupingSets == NIL &&
+ get_sortgroupref_clause_noerr(sgref, query->groupClause) != NULL)
can be rewritten as
if (sgref && get_sortgroupref_clause_noerr(sgref, query->groupClause))
since we won't come here with non-NULL query->groupingSets and
get_sortgroupref_clause_noerr() will return NULL, if there aren't any
groupClause.
20. Please use word "foreign" instead of "remote" in comments.
21. This code looks dubious
+ /* If not GROUP BY ref, reset it as we are not pushing those */
+ if (sgref)
+ grouping_target->sortgrouprefs[i] = 0;
grouping_target comes from RelOptInfo, which is being modified here. We
shouldn't be modifying anything in the RelOptInfo while checking whether the
aggregate/grouping is shippable. You may want to copy the pathtaget and modify
the copy.
22. Following comment needs more elaboration.
+ /*
+ * Add aggregates, if any, into tlist. Plain Var nodes pulled
+ * are already part of GROUP BY and thus no need to add them
+ * explicitly.
+ */
Plain Var nodes will either be same as some GROUP BY expression or should be
part of some GROUP BY expression. In the later case, the query can not refer
those without the surrounding expression. which will be part of the targetlist
list. Hence we don't need to add plain Var nodes in the targetlist. In fact
adding those in SELECT clause will cause error on the foreign server if they
are not part of GROUP BY clause.
23. Probably you don't need to save this in fpinfo. You may want to calculate
it whenever it's needed.
+ fpinfo->grouped_exprs = get_sortgrouplist_exprs(query->groupClause, tlist);
24. Can this ever happen for postgres_fdw? The core sets fdwroutine and calls
this function when the underlying scan relation has fdwroutine set, which
implies that it called corresponding GetForeignPath hooks, which should have
set fdw_private. Nonetheless, I think, still the condition is useful to avoid
crashing the server in case the fdw_private is not set. But we need better
comments.
+ /* If input rel is not aware of fdw, simply return */
+ if (!input_rel->fdw_private)
+ return;
25. Although it's desirable to get a switch case in
postgresGetForeignUpperPaths() eventually, for this patch I guess we should
have an if condition there.
26. Attached patch has restructured code in appendGroupByClause() to reduce
indentation and make the code readable. Let me know if this looks good to you.
27. Prologue of create_foreign_grouping_paths() does not have formatting
similar to the surrounding functions. Please fix it. Since the function
"create"s and "add"s paths, it might be better to rename it as
add_foreign_grouping_paths().
28. Isn't the following true for any upper relation and shouldn't it be part of
postgresGetForeignUpperPaths(), rather than create_foreign_grouping_paths( )?
+ /*
+ * If input rel is not safe to pushdown, we cannot do grouping and/or
+ * aggregation on it.
+ */
+ if (!ifpinfo || !ifpinfo->pushdown_safe)
+ return;
29. We require RelOptInfo::relids since create_foreignscan_plan() copies them
into ForeignPlan::fs_relids and executor uses them. So, I guess, we have to set
those in the core somewhere. May be while calling fetch_upper_rel() in
grouping_planner(), we should call it with relids of the underlying scan
relation. I don't see any function calling fetch_upper_rel() with non-NULL
relids. In fact, if we are to create an upper relation with relids in future,
this code is going to wipe that out, which will be undesirable. Also,
generally, when copying relids, it's better to use bms_copy() to make a copy
of Bitmapset, instead of just assigning the pointer.
30. By the time postgresGetForeignUpperPaths() gets called, the core has
already added its own paths, so it doesn't make much sense to set rows and
width grouped_rel in create_foreign_grouping_paths().
31. fpinfo->server and user fields are being set twice, once in
create_foreign_grouping_paths() then in foreign_grouping_ok(). Do we need that?
32.
+ /*
+ * Do we want to create paths with pathkeys corresponding for
+ * root->query_pathkeys.
+ */
Yes, it would be desirable to do that. If we are not going to do that in this
patch, may be remove that line or add a TODO kind of comment.
33. The patch marks build_path_tlist() as non-static but does not use it
anywhere outside creatplan.c. Is this change intentional?
--Best Wishes,
Ashutosh Bapat
EnterpriseDB Corporation
The Postgres Database Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
--
On Thu, Sep 8, 2016 at 10:41 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
While checking for shippability, we build the target list which is passed to
the foreign server as fdw_scan_tlist. The target list contains
a. All the GROUP BY expressions
b. Shippable entries from the target list of upper relation
c. Var and Aggref nodes from non-shippable entries from the target list of
upper relationThe code in the patch doesn't seem to add Var nodes explicitly. It assumes that
the Var nodes will be part of GROUP BY clause. The code is correct, I think.
Yes. Code is correct. Var nodes are already part of GROUP BY else we hit error well before this point.
Thanks Ashutosh for the detailed review comments.
I am working on it and will post updated patch once I fix all your concerns.
Thanks
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
On Mon, Sep 12, 2016 at 12:20 PM, Prabhat Sahu <prabhat.sahu@enterprisedb.com
-- Hi,
While testing "Aggregate pushdown", i found the below error:
-- GROUP BY alias showing different behavior after adding patch.
-- Create table "t1", insert few records.
create table t1(c1 int);
insert into t1 values(10), (20);
-- Create foreign table:
create foreign table f_t1 (c1 int) server db1_server options (table_name 't1');
-- with local table:
postgres=# select 2 a, avg(c1) from t1 group by a;
a | avg
---+---------------------
2 | 15.0000000000000000
(1 row)
-- with foreign table:
postgres=# select 2 a, avg(c1) from f_t1 group by a;
ERROR: aggregate functions are not allowed in GROUP BY
CONTEXT: Remote SQL command: EXPLAIN SELECT 2, avg(c1) FROM public.t1 GROUP BY 2
Thanks for reporting this bug in *v1.patch Prabhat.
I will have a look over this issue and will post a fix in next version.
Thanks
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Hi,
On Mon, Sep 12, 2016 at 5:17 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote:
Thanks Ashutosh for the detailed review comments.I am working on it and will post updated patch once I fix all your concerns.
Attached new patch fixing the review comments.
Here are few comments on the review points:
1. Renamed deparseFromClause() to deparseFromExpr() and
deparseAggOrderBy() to appendAggOrderBy()
2. Done
3. classifyConditions() assumes list expressions of type RestrictInfo. But
HAVING clause expressions (and JOIN conditions) are plain expressions. Do
you mean we should modify the classifyConditions()? If yes, then I think it
should be done as a separate (cleanup) patch.
4, 5. Both done.
6. Per my understanding, I think checking for just aggregate function is
enough as we are interested in whole aggregate result. Meanwhile I will
check whether we need to find and check shippability of transition,
combination and finalization functions or not.
7, 8, 9, 10, 11, 12. All done.
13. Fixed. However instead of adding new function made those changes inline.
Adding support for deparsing List expressions separating list by comma can be
considered as cleanup patch as it will touch other code area not specific to
aggregate push down.
14, 15, 16, 17. All done.
18. I think re-factoring estimate_path_cost_size() should be done separately
as a cleanup patch too.
19, 20, 21, 22, 23, 24, 25, 26, 27, 28. All done.
29. I have tried passing input rel's relids to fetch_upper_rel() call in
create_grouping_paths(). It solved this patch's issue, but ended up with
few regression failures which is mostly plan changes. I am not sure whether
we get good plan now or not as I have not analyzed them.
So for this patch, I am setting relids in add_foreign_grouping_path() itself.
However as suggested, used bms_copy(). I still kept the FIXME over there as
I think it should have done by the core itself.
30, 31, 32, 33. All done.
Let me know your views.
Here are few comments on the review points:
1. Renamed deparseFromClause() to deparseFromExpr() and
deparseAggOrderBy() to appendAggOrderBy()
2. Done
3. classifyConditions() assumes list expressions of type RestrictInfo. But
HAVING clause expressions (and JOIN conditions) are plain expressions. Do
you mean we should modify the classifyConditions()? If yes, then I think it
should be done as a separate (cleanup) patch.
4, 5. Both done.
6. Per my understanding, I think checking for just aggregate function is
enough as we are interested in whole aggregate result. Meanwhile I will
check whether we need to find and check shippability of transition,
combination and finalization functions or not.
7, 8, 9, 10, 11, 12. All done.
13. Fixed. However instead of adding new function made those changes inline.
Adding support for deparsing List expressions separating list by comma can be
considered as cleanup patch as it will touch other code area not specific to
aggregate push down.
14, 15, 16, 17. All done.
18. I think re-factoring estimate_path_cost_size() should be done separately
as a cleanup patch too.
19, 20, 21, 22, 23, 24, 25, 26, 27, 28. All done.
29. I have tried passing input rel's relids to fetch_upper_rel() call in
create_grouping_paths(). It solved this patch's issue, but ended up with
few regression failures which is mostly plan changes. I am not sure whether
we get good plan now or not as I have not analyzed them.
So for this patch, I am setting relids in add_foreign_grouping_path() itself.
However as suggested, used bms_copy(). I still kept the FIXME over there as
I think it should have done by the core itself.
30, 31, 32, 33. All done.
Let me know your views.
Thanks
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Вложения
On Mon, Sep 12, 2016 at 5:19 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote:
To fix this issue, we need to make deparseConst() function aware of showtype
flag exactly as that of get_const_expr(). While deparsing Const in GROUP BY
clause, we need to show "::typename" so that it won't treat the constant value
as a column position in the target list and rather treat it as constant value.
Fixed this in earlier attached patch and added test-case too.
On Mon, Sep 12, 2016 at 12:20 PM, Prabhat Sahu <prabhat.sahu@enterprisedb.com> wrote: Hi,
While testing "Aggregate pushdown", i found the below error:
-- GROUP BY alias showing different behavior after adding patch.
-- Create table "t1", insert few records.
create table t1(c1 int);
insert into t1 values(10), (20);
-- Create foreign table:
create foreign table f_t1 (c1 int) server db1_server options (table_name 't1');
-- with local table:
postgres=# select 2 a, avg(c1) from t1 group by a;
a | avg
---+---------------------
2 | 15.0000000000000000
(1 row)
-- with foreign table:
postgres=# select 2 a, avg(c1) from f_t1 group by a;
ERROR: aggregate functions are not allowed in GROUP BY
CONTEXT: Remote SQL command: EXPLAIN SELECT 2, avg(c1) FROM public.t1 GROUP BY 2Thanks for reporting this bug in *v1.patch Prabhat.I will have a look over this issue and will post a fix in next version.
To fix this issue, we need to make deparseConst() function aware of showtype
flag exactly as that of get_const_expr(). While deparsing Const in GROUP BY
clause, we need to show "::typename" so that it won't treat the constant value
as a column position in the target list and rather treat it as constant value.
Fixed this in earlier attached patch and added test-case too.
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
On Fri, Sep 16, 2016 at 9:45 AM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > 6. Per my understanding, I think checking for just aggregate function is > enough as we are interested in whole aggregate result. +1. > Meanwhile I will > check whether we need to find and check shippability of transition, > combination and finalization functions or not. I don't think that'd be appropriate. The user is calling the aggregate, not its constituent functions. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Thanks Jeevan for working on the comments.
>
> 3. classifyConditions() assumes list expressions of type RestrictInfo. But
> HAVING clause expressions (and JOIN conditions) are plain expressions. Do
> you mean we should modify the classifyConditions()? If yes, then I think it
> should be done as a separate (cleanup) patch.
Ok. Yes, we should also handle bare conditions in
classifyConditions(). I am fine doing it as a separate patch.
>
> 6. Per my understanding, I think checking for just aggregate function is
> enough as we are interested in whole aggregate result. Meanwhile I will
> check whether we need to find and check shippability of transition,
> combination and finalization functions or not.
Ok. I agree with this analysis.
> 13. Fixed. However instead of adding new function made those changes inline.
> Adding support for deparsing List expressions separating list by comma can
> be
> considered as cleanup patch as it will touch other code area not specific to
> aggregate push down.
Ok.
>
> 18. I think re-factoring estimate_path_cost_size() should be done separately
> as a cleanup patch too.
Ok.
>
> 29. I have tried passing input rel's relids to fetch_upper_rel() call in
> create_grouping_paths(). It solved this patch's issue, but ended up with
> few regression failures which is mostly plan changes. I am not sure whether
> we get good plan now or not as I have not analyzed them.
> So for this patch, I am setting relids in add_foreign_grouping_path()
> itself.
> However as suggested, used bms_copy(). I still kept the FIXME over there as
> I think it should have done by the core itself.
I don't think add_foreign_grouping_path() is the right place to change
a structure managed by the core and esp when we are half-way adding
paths. An FDW should not meddle with an upper RelOptInfo. Since
create_foreignscan_plan() picks those up from RelOptInfo and both of
those are part of core, we need a place in core to set the
RelOptInfo::relids for an upper relation OR we have stop using
fs_relids for upper relation foreign scans.
Here are some more comments on the patch, mostly focused on the tests.
1. If we dig down each usage of deparse_expr_cxt::scanrel, it boils down
checking whether a given Var comes from given scan relation (deparseVar()) or
checking whether a given Var needs relation qualification while deparsing
(again deparseVar()). I think both of those purposes can be served by looking
at scanrel::relids, multiple relids implying relation qualification. So,
instead of having a separate member scan_rel, we should instead fetch the
relids from deparse_expr_cxt::foreignrel. I am assuming that the proposed
change to set relids in upper relations is acceptable. If it's not, we should
pass scanrel->relids through the context instead of scanrel itself.
2. SortGroupClause is a parser node, so we can name appendSortGroupClause() as
deparseSortGroupClause(), to be consistent with the naming convention. If we do
that change, may be it's better to pass SortGroupClause as is and handle other
members of that structure as well.
3. Following block may be reworded
+ /*
+ * aggorder too present into args so no need to check its
+ * shippability explicitly. However, if any expression has
+ * USING clause with sort operator, we need to make sure the
+ * shippability of that operator.
+ */
as "For aggorder elements, check whether the sort operator, if specified, is
shippable or not." and mention aggorder expression along with aggdirectargs in
the comment before this one.
4. Following line is correct as long as there is only one upper relation.
+ context.scanrel = (rel->reloptkind == RELOPT_UPPER_REL) ?
fpinfo->outerrel : rel;
But as we push down more and more of upper operation, there will be a chain of
upper relations on top of scan relation. So, it's better to assert that the
scanrel is a join or a base relation to be future proof.
5. In deparseConst(), showtype is compared with hardcoded values. The
callers of this function pass hardcoded values. Instead, we should
define an enum and use it. I understand that this logic has been borrowed from
get_const_expr(), which also uses hardcoded values. Any reason why not to adopt
a better style here? In fact, it only uses two states for showtype, 0 and ">
0". Why don't we use a boolean then OR why isn't the third state in
get_const_expr() applicable here?
6. "will" or "should" is missing from the following sentence.
"Plain var nodes either be same as some GROUP BY expression or part of some
GROUP BY expression.
7. The changes in block else { /* * If we have sortgroupref set, then
itmeans that we have an * ORDER BY entry pointing to this expression. Since we are * not
pushingORDER BY with GROUP BY, clear it. */ if (sgref)
grouping_target->sortgrouprefs[i]= 0;
/* Not matched exactly, pull the var with aggregates then */ aggvars =
pull_var_clause((Node*) expr, PVC_INCLUDE_AGGREGATES);
if (!is_foreign_expr(root, grouped_rel, (Expr *) aggvars)) return false;
/* * Add aggregates, if any, into the targetlist. Plain var * nodes
eitherbe same as some GROUP BY expression or part of * some GROUP BY expression. In later case, the
querycannot * refer plain var nodes without the surrounding expression. * In both the
cases,they are already part of the targetlist * and thus no need to add them again. In fact adding
pulled * plain var nodes in SELECT clause will cause an error on the * foreign server if
theyare not same as some GROUP BY * expression. */ foreach(l, aggvars)
{ Expr *expr = (Expr *) lfirst(l);
if (IsA(expr, Aggref)) tlist = add_to_flat_tlist(tlist, list_make1(expr));
} }
and those in the block if (fpinfo->local_conds) { ListCell *lc; List *aggvars =
pull_var_clause((Node*) fpinfo->local_conds, PVC_INCLUDE_AGGREGATES);
foreach(lc, aggvars) { Expr *expr = (Expr *) lfirst(lc);
/* * If aggregates within local conditions are not safe to push down, * then we cannot
pushdown the query. Vars are already part of * GROUP BY clause which are checked above, so no need to
access * them again here. */ if (IsA(expr, Aggref) && !is_foreign_expr(root,
grouped_rel,expr)) return false; }
/* Add Vars and aggregates into the target list. */ tlist = add_to_flat_tlist(tlist, aggvars); }
should be in sync. The later block adds both aggregates and Vars but the first
one doesn't. Why is this difference?
8. In the comment, "If input rel is not safe to pushdown, then simply return
as we cannot perform any post-join operations remotely on it.", "remotely on
it" may be rephrased as "on the foreign server." to be consistent with the
terminology at in the file.
9. EXPLAIN of foreign scan is adding paranthesis around output expressions,
which is not needed. EXPLAIN output of other plan nodes like Aggregate doesn't
do that. If it's easy to avoid paranthesis, we should do it in this patch. With
this patch, we have started pushing down expressions in the target list, so
makes sense to fix it in this patch.
10. While deparsing the GROUP BY clauses, the code fetches the expressions and
deparses the expressions. We might save some CPU cycles if we deparse the
clauses by their positional indexes in SELECT clause instead of the actual
expressions. This might make the query slightly unreadable. What do you think?
Comments about tests:
1. I don't think the comment below is required. Someone wants to know the
status of that flag might read the corresponding CREATE TABLE command.
+-- Both ft1 and ft2 are used to exercise cost estimates when
+-- use_remote_estimate is false and true respectively.
2. I am assuming that you will remove the SQL statements involving local
tables. They are being used only to test the outputs.
3. The test select count(c6) from ft1; may be clubbed with a previous
testcase? Why is it separate? Some tests like this do not have comments
explaining the purpose behind them. Can you please add comments there.
4. May be bulk of these testcases need to be moved next to Join testcases.
That way their outputs do not change in case the DMLs change in future. In case
you do that, adjust capitalization accordingly.
5. Can we merge following testcase
+select count(*) from ft1 t1 inner join ft2 t2 on (t1.c2 = t2.c2)
where t2.c2 = 6;
with a testcase just before that? I don't see much point in having them
separate.
6. From the comments below, it seems that you want to test the case when the
underlying scan (as a whole) has some local conditions. But the way case has
been written, the underlying join is itself not pushable. Is this intended?
+-- Not pushed down due to local conditions present in underneath input relk
+explain (verbose, costs off)
+select count(*) from ft1 t1 inner join ft1 t2 on (t1.c2 = t2.c2 * random());
7. Instead of separating tests with and without GROUP BY clause into separate
sections, you may want to add them one after the other. Better even if you can
combine them to reduce the number of SQL statements in the file. Do you see any
advantage in having them separate?
8. These two testcases are commented
+--select c1 * random(), sum(c1) * c1 from ft1 group by c1;
+--select "C 1" * random(), sum("C 1") * "C 1" from "S 1"."T 1" group by "C 1";
Either uncomment them and add expected output or remove them altogether. I do
not see any purpose in having them commented.
9. The comment below is too specific.
+-- Aggregate is not pushed down as random() is part of group by expression
It should probably be "Aggregates with unshippable GROUP BY clause are not
shippable" or something general like that.
10. Need some comment about the intention of this and following 3 tests.
+explain (verbose, costs off)
+select count(c2), 5 from ft1 group by 2;
11. About section C, I have a comment similar to comment 7 above. I see that
you have built testcases by gradually adding each clause to a simple SQL
statement. It will become more evident if the improvizations next to the simple
test. Again better if we can merge them into one. Maintaining expected output
of many testcases becomes a pain, if the plans change in future.
12. Following comments
+-- Having clause with random() will be evaluated locally
+-- Having clause with random() will be evaluated locally, and other
having qual is pushed
may be better worded as "Unshippable having clause will be evaluated locally."
to clarify the intention behind the testcase.
13. Wouldn't having random() in the testcase, make them produce different
output in different runs? Also, please see if we can reduce the output rows to
a handful few. Following query produces 21 rows. Is it really important to have
all those rows in the output?
+select c2, sum(c1) from ft2 group by c2 having sum(c1) * random() <
500000 order by c2;
14. For many testcases in section D, one needs to read the testcases carefully
in order to understand the difference between successive testcases. A comment
line clarifying the intention will help.
15. If you have GROUP BY expression in the SELECT clause and apply DISTINCT on
it, DISTINCT is not going to have any effect, will it?
+select distinct sum(c1), c2 from ft2 where c2 < 6 group by c2 order by c2;
16. In the following query, the subquery returns only a single row, so DISTINCT
doesn't have any effects. Please change the subquery to return multiple rows
with some duplicates so that DISTINCT will be propertly tested.
+select distinct (select count(*) filter (where t2.c2 = 6 and t2.c1 <
10) from ft1 t1 where t1.c1 = 6) from ft1 t2 order by 1;
What's the difference between this query and the next one. The comment mentions
INNER and OUTER queries, but I don't see that difference. Am I missing
something?
17. Please mention Why.
+-- Aggregate not pushed down
18. Please club percentile and rank testcases into one to reduce number of SQL
statements.
19. This comment is misleading. VARIADIC is not the reason why the aggregate
was not being pushed down.
+-- Now aggregate with VARIADIC will be pushed
20. Why do we need the last statement ALTERing server extensions? Is it not
already done when the function was added to the extension?
+alter extension postgres_fdw drop function least_accum(anyelement,
variadic anyarray);
+alter extension postgres_fdw drop aggregate least_agg(variadic items anyarray);
+alter server loopback options (set extensions 'postgres_fdw');
21. Following comment is misleading. It will not be pushed down because a user
defined operator is considered unshippable (unless it's part of an extension
known to be shippable.)
+-- This will not be pushed as sort operator is not known to extension.
22. Is following scenario already covered in testcases in section for HAVING?
+-- Clauses with random() will be evaluated locally, and other clauses
are pushed
23. This comment talks about deeper code level internal details. Should have a
better user-visible explanations.
+-- ORDER BY expression is not present as is in target list of remote
query. This needed clearing out sortgrouprefs flag.
24. In the following query, which tests PlaceHolderVars, shouldn't there be an
aggregate on the placeholder column i.e. q.a? Else, I don't see much use of
this case in the context of aggregates. Also, for some reason, the planner
thinks that only avg(ft1.c1) is useful and other two can be nullified. Is that
intentional?
+select count(ft4.c1), sum(q.b) from ft4 left join (select 13,
avg(ft1.c1), sum(ft2.c1) from ft1 right join ft2 on (ft1.c1 = ft2.c1)
where ft1.c1 = 12) q(a, b, c) on (ft4.c1 = q.b) where ft4.c1 between
10 and 15 group by q.b order by 1;
25. Following test looks more appropriate as a join pushdown test, rather than
aggregate pushdown. Nothing in this test gets pushed down.
+select q.a, count(q.a), avg(ft2.c1) from (select 13 from ft1 where c1
= 13) q(a) right join ft2 on (q.a = ft2.c1) where ft2.c1 between 10
and 15 group by q.a order by 1 nulls last;
26. Instead of the testcase below a test which has window aggregates over a
pushed down aggregate makes sense in the context of aggregate pushdown.
+-- WindowAgg
+explain (verbose, costs off)
+select c2, count(c2) over (partition by c2%2) from ft2 where c2 < 10
order by 1 limit 5 offset 95;
postgres_fdw.out has grown by 2000 lines because of testcases in this
patch. We need to compact the testcases so that easier to maintain in
the future.
--
Best Wishes,
Ashutosh Bapat
EnterpriseDB Corporation
The Postgres Database Company
This patch will need some changes to conversion_error_callback(). That function reports an error in case there was an error converting the result obtained from the foreign server into an internal datum e.g. when the string returned by the foreign server is not acceptable by local input function for the expected datatype. In such cases, the input function will throw error and conversion_error_callback() will provide appropriate context for that error. postgres_fdw.sql has tests to test proper context -- =================================================================== -- conversion error -- =================================================================== ALTER FOREIGN TABLE ft1 ALTER COLUMN c8 TYPE int; SELECT * FROM ft1 WHERE c1 = 1; -- ERROR SELECT ft1.c1, ft2.c2, ft1.c8 FROM ft1, ft2 WHERE ft1.c1 = ft2.c1 AND ft1.c1 = 1; -- ERROR SELECT ft1.c1, ft2.c2, ft1 FROM ft1, ft2 WHERE ft1.c1 = ft2.c1 AND ft1.c1 = 1; -- ERROR ALTER FOREIGN TABLE ft1 ALTER COLUMN c8 TYPE user_enum; Right now we report the column name in the error context. This needs to change for aggregate pushdown, which is pushing down expressions. Right now, in case the aggregate on foreign server produces a string unacceptable locally, it would crash at 4982 Assert(IsA(var, Var)); 4983 4984 rte = rt_fetch(var->varno, estate->es_range_table); since it's not a Var node as expected. We need to fix the error context to provide meaningful information or at least not crash. This has been discussed briefly in [1]. [1] https://www.postgresql.org/message-id/flat/CAFjFpRdcC7Ykb1SkARBYikx9ubKniBiAgHqMD9e47TxzY2EYFw%40mail.gmail.com#CAFjFpRdcC7Ykb1SkARBYikx9ubKniBiAgHqMD9e47TxzY2EYFw@mail.gmail.com On Fri, Sep 16, 2016 at 7:15 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > Hi, > > On Mon, Sep 12, 2016 at 5:17 PM, Jeevan Chalke > <jeevan.chalke@enterprisedb.com> wrote: >> >> Thanks Ashutosh for the detailed review comments. >> >> I am working on it and will post updated patch once I fix all your >> concerns. >> >> > > Attached new patch fixing the review comments. > > Here are few comments on the review points: > > 1. Renamed deparseFromClause() to deparseFromExpr() and > deparseAggOrderBy() to appendAggOrderBy() > > 2. Done > > 3. classifyConditions() assumes list expressions of type RestrictInfo. But > HAVING clause expressions (and JOIN conditions) are plain expressions. Do > you mean we should modify the classifyConditions()? If yes, then I think it > should be done as a separate (cleanup) patch. > > 4, 5. Both done. > > 6. Per my understanding, I think checking for just aggregate function is > enough as we are interested in whole aggregate result. Meanwhile I will > check whether we need to find and check shippability of transition, > combination and finalization functions or not. > > 7, 8, 9, 10, 11, 12. All done. > > 13. Fixed. However instead of adding new function made those changes inline. > Adding support for deparsing List expressions separating list by comma can > be > considered as cleanup patch as it will touch other code area not specific to > aggregate push down. > > 14, 15, 16, 17. All done. > > 18. I think re-factoring estimate_path_cost_size() should be done separately > as a cleanup patch too. > > 19, 20, 21, 22, 23, 24, 25, 26, 27, 28. All done. > > 29. I have tried passing input rel's relids to fetch_upper_rel() call in > create_grouping_paths(). It solved this patch's issue, but ended up with > few regression failures which is mostly plan changes. I am not sure whether > we get good plan now or not as I have not analyzed them. > So for this patch, I am setting relids in add_foreign_grouping_path() > itself. > However as suggested, used bms_copy(). I still kept the FIXME over there as > I think it should have done by the core itself. > > 30, 31, 32, 33. All done. > > Let me know your views. > > Thanks > -- > Jeevan B Chalke > Principal Software Engineer, Product Development > EnterpriseDB Corporation > The Enterprise PostgreSQL Company > -- Best Wishes, Ashutosh Bapat EnterpriseDB Corporation The Postgres Database Company
Hi Ashutosh,
--
On Mon, Sep 26, 2016 at 2:28 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
Yes, agree that relids must be set by the core rather than a fdw.
However I don't want to touch the core for this patch and also not
exactly sure where we can do that. I think, for this patch, we can
copy relids into grouped_rel in create_grouping_paths() at place
where we assign fdwroutine, userid etc. from the input relation.
Yep. Removed scanrel altogether and used relids whenever required.
Renamed appendSortGroupClause() to deparseSortGroupClause().
I have kept this function in sync with get_rule_sortgroupclause() which
takes the Index ref from SortGroupClause(). This function require just
an index and thus passing SortGroupClause as whole is unnecessary. However
we cannot pass entire order by list or group by list, because in case of
order by list we need some extra processing on list elements. So passing
just Index is sufficient and in sync with get_rule_sortgroupclause() too.
After making changes reported in (1), this line has removed.
For future proof, as discussed offline, added Assert() in deparseFromExpr().
We certainly can add an enum here, but for consistency with other related
code I think using hard-coded value is good for now. Also I see this
comment in prologue of deparseConst()
* This function has to be kept in sync with ruleutils.c's get_const_expr.
So better to have handling like it.
Also, currently we use only two values for showtype. But for consistency
let use int instead of bool. In future if we add support for coercion
expr, then we need this third value. At that time we will not need changes
here.
However if required, we can submit a separate patch for adding enum
instead of int for showtype in ruleutils.c.
add_to_flat_tlist() is taking care of duplicate entries and thus in second
block, I was calling it after the loop to avoid calling it for every list
element. Well, moved that inside loop like first block.
ExecInitForeignScan() while determining scan tuple type from passed
fdw_scan_tlist, has target list containing Vars with varno set to
INDEX_VAR. Due to which while deparsing we go through
resolve_special_varno() and get_special_variable() function which
forces parenthesis around the expression.
I can't think of any easy and quick solution here. So keeping this
as is. Input will be welcome or this can be done separately later.
To me it is better to have expression in the GROUP BY clause as it is
more readable and easy to understand. Also it is in sync with deparsing
logic in ruleutils.c.
Moved testcases after Join testcases.
However I have not made any capitalization changes. I see many tests
like those elsewhere in the file too. Let me know if that's the policy
to have appropriate capitalization in test-case. I don't want violate
the policy if any and will prefer to do the changes as per the policy.
The condition is written in such a way that we will get all rows,
nullifying the random() effect, so I don't think there will be any
issue with the multiple runs.
In case of INNER aggregate query, we get multiple rows and thus used
DISTINCT to have small number of output. However in case of OUTER
aggregate query, we get single row. But to keep that query much
identical with INNER query, I have used DISTINCT. It becomes easy to
compare and follow too.
Please see the EXPLAIN output for observing difference between INNER
and OUTER aggregate query. When inner query is aggregate query you
should see that aggregation is performing on t1 and when outer query
is aggregate query, you will see t2.
Whenever we alter extension, we must refresh the server and thus required
last statement ALTERing server. Without that elements added into extension
does not reflect in the server.
Not sure how can I put those comments without referring some code level
internal details. I have tried altering those comments but it will be
good if you too try rephrasing it.
I have removed many duplicate tests and also combined many of them.
Also removed tests involving local tables. Testcase changes now
become 1/3 of earlier one.
In the attached patch I have fixed all other review comments you have
posted. All the comments were excellent and helped me a lot to improve
in various areas.
Thanks
Thanks Jeevan for working on the comments.
Ok. Yes, we should also handle bare conditions in
classifyConditions(). I am fine doing it as a separate patch.
Doing that with separate patch would be good.
I don't think add_foreign_grouping_path() is the right place to change
a structure managed by the core and esp when we are half-way adding
paths. An FDW should not meddle with an upper RelOptInfo. Since
create_foreignscan_plan() picks those up from RelOptInfo and both of
those are part of core, we need a place in core to set the
RelOptInfo::relids for an upper relation OR we have stop using
fs_relids for upper relation foreign scans.
Yes, agree that relids must be set by the core rather than a fdw.
However I don't want to touch the core for this patch and also not
exactly sure where we can do that. I think, for this patch, we can
copy relids into grouped_rel in create_grouping_paths() at place
where we assign fdwroutine, userid etc. from the input relation.
Here are some more comments on the patch, mostly focused on the tests.
1. If we dig down each usage of deparse_expr_cxt::scanrel, it boils down
checking whether a given Var comes from given scan relation (deparseVar()) or
checking whether a given Var needs relation qualification while deparsing
(again deparseVar()). I think both of those purposes can be served by looking
at scanrel::relids, multiple relids implying relation qualification. So,
instead of having a separate member scan_rel, we should instead fetch the
relids from deparse_expr_cxt::foreignrel. I am assuming that the proposed
change to set relids in upper relations is acceptable. If it's not, we should
pass scanrel->relids through the context instead of scanrel itself.
Yep. Removed scanrel altogether and used relids whenever required.
2. SortGroupClause is a parser node, so we can name appendSortGroupClause() as
deparseSortGroupClause(), to be consistent with the naming convention. If we do
that change, may be it's better to pass SortGroupClause as is and handle other
members of that structure as well.
Renamed appendSortGroupClause() to deparseSortGroupClause().
I have kept this function in sync with get_rule_sortgroupclause() which
takes the Index ref from SortGroupClause(). This function require just
an index and thus passing SortGroupClause as whole is unnecessary. However
we cannot pass entire order by list or group by list, because in case of
order by list we need some extra processing on list elements. So passing
just Index is sufficient and in sync with get_rule_sortgroupclause() too.
4. Following line is correct as long as there is only one upper relation.
+ context.scanrel = (rel->reloptkind == RELOPT_UPPER_REL) ?
fpinfo->outerrel : rel;
But as we push down more and more of upper operation, there will be a chain of
upper relations on top of scan relation. So, it's better to assert that the
scanrel is a join or a base relation to be future proof.
After making changes reported in (1), this line has removed.
For future proof, as discussed offline, added Assert() in deparseFromExpr().
5. In deparseConst(), showtype is compared with hardcoded values. The
callers of this function pass hardcoded values. Instead, we should
define an enum and use it. I understand that this logic has been borrowed from
get_const_expr(), which also uses hardcoded values. Any reason why not to adopt
a better style here? In fact, it only uses two states for showtype, 0 and ">
0". Why don't we use a boolean then OR why isn't the third state in
get_const_expr() applicable here?
We certainly can add an enum here, but for consistency with other related
code I think using hard-coded value is good for now. Also I see this
comment in prologue of deparseConst()
* This function has to be kept in sync with ruleutils.c's get_const_expr.
So better to have handling like it.
Also, currently we use only two values for showtype. But for consistency
let use int instead of bool. In future if we add support for coercion
expr, then we need this third value. At that time we will not need changes
here.
However if required, we can submit a separate patch for adding enum
instead of int for showtype in ruleutils.c.
7. The changes in block ...
should be in sync. The later block adds both aggregates and Vars but the first
one doesn't. Why is this difference?
add_to_flat_tlist() is taking care of duplicate entries and thus in second
block, I was calling it after the loop to avoid calling it for every list
element. Well, moved that inside loop like first block.
9. EXPLAIN of foreign scan is adding paranthesis around output expressions,
which is not needed. EXPLAIN output of other plan nodes like Aggregate doesn't
do that. If it's easy to avoid paranthesis, we should do it in this patch. With
this patch, we have started pushing down expressions in the target list, so
makes sense to fix it in this patch.
ExecInitForeignScan() while determining scan tuple type from passed
fdw_scan_tlist, has target list containing Vars with varno set to
INDEX_VAR. Due to which while deparsing we go through
resolve_special_varno() and get_special_variable() function which
forces parenthesis around the expression.
I can't think of any easy and quick solution here. So keeping this
as is. Input will be welcome or this can be done separately later.
10. While deparsing the GROUP BY clauses, the code fetches the expressions and
deparses the expressions. We might save some CPU cycles if we deparse the
clauses by their positional indexes in SELECT clause instead of the actual
expressions. This might make the query slightly unreadable. What do you think?
To me it is better to have expression in the GROUP BY clause as it is
more readable and easy to understand. Also it is in sync with deparsing
logic in ruleutils.c.
Comments about tests:
4. May be bulk of these testcases need to be moved next to Join testcases.
That way their outputs do not change in case the DMLs change in future. In case
you do that, adjust capitalization accordingly.
Moved testcases after Join testcases.
However I have not made any capitalization changes. I see many tests
like those elsewhere in the file too. Let me know if that's the policy
to have appropriate capitalization in test-case. I don't want violate
the policy if any and will prefer to do the changes as per the policy.
13. Wouldn't having random() in the testcase, make them produce different
output in different runs? Also, please see if we can reduce the output rows to
a handful few. Following query produces 21 rows. Is it really important to have
all those rows in the output?
+select c2, sum(c1) from ft2 group by c2 having sum(c1) * random() <
500000 order by c2;
The condition is written in such a way that we will get all rows,
nullifying the random() effect, so I don't think there will be any
issue with the multiple runs.
16. In the following query, the subquery returns only a single row, so DISTINCT
doesn't have any effects. Please change the subquery to return multiple rows
with some duplicates so that DISTINCT will be propertly tested.
+select distinct (select count(*) filter (where t2.c2 = 6 and t2.c1 <
10) from ft1 t1 where t1.c1 = 6) from ft1 t2 order by 1;
What's the difference between this query and the next one. The comment mentions
INNER and OUTER queries, but I don't see that difference. Am I missing
something?
In case of INNER aggregate query, we get multiple rows and thus used
DISTINCT to have small number of output. However in case of OUTER
aggregate query, we get single row. But to keep that query much
identical with INNER query, I have used DISTINCT. It becomes easy to
compare and follow too.
Please see the EXPLAIN output for observing difference between INNER
and OUTER aggregate query. When inner query is aggregate query you
should see that aggregation is performing on t1 and when outer query
is aggregate query, you will see t2.
20. Why do we need the last statement ALTERing server extensions? Is it not
already done when the function was added to the extension?
+alter extension postgres_fdw drop function least_accum(anyelement,
variadic anyarray);
+alter extension postgres_fdw drop aggregate least_agg(variadic items anyarray);
+alter server loopback options (set extensions 'postgres_fdw');
Whenever we alter extension, we must refresh the server and thus required
last statement ALTERing server. Without that elements added into extension
does not reflect in the server.
23. This comment talks about deeper code level internal details. Should have a
better user-visible explanations.
+-- ORDER BY expression is not present as is in target list of remote
query. This needed clearing out sortgrouprefs flag.
Not sure how can I put those comments without referring some code level
internal details. I have tried altering those comments but it will be
good if you too try rephrasing it.
postgres_fdw.out has grown by 2000 lines because of testcases in this
patch. We need to compact the testcases so that easier to maintain in
the future.
I have removed many duplicate tests and also combined many of them.
Also removed tests involving local tables. Testcase changes now
become 1/3 of earlier one.
In the attached patch I have fixed all other review comments you have
posted. All the comments were excellent and helped me a lot to improve
in various areas.
Thanks
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Вложения
On Mon, Sep 26, 2016 at 6:15 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
Oops. I had that in mind when working on this. Somehow skipped checking
for conversion error context. I have fixed that in v3 patch.
Removed assert and for non Var expressions, printing generic context.
This context is almost in-line with the discussion you referred here.
ThanksThis patch will need some changes to conversion_error_callback(). That
function reports an error in case there was an error converting the
result obtained from the foreign server into an internal datum e.g.
when the string returned by the foreign server is not acceptable by
local input function for the expected datatype. In such cases, the
input function will throw error and conversion_error_callback() will
provide appropriate context for that error. postgres_fdw.sql has tests
to test proper context
We need to fix the error context to provide meaningful information or
at least not crash. This has been discussed briefly in [1].
Oops. I had that in mind when working on this. Somehow skipped checking
for conversion error context. I have fixed that in v3 patch.
Removed assert and for non Var expressions, printing generic context.
This context is almost in-line with the discussion you referred here.
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
On Fri, Sep 30, 2016 at 8:58 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > On Mon, Sep 26, 2016 at 6:15 PM, Ashutosh Bapat > <ashutosh.bapat@enterprisedb.com> wrote: >> >> This patch will need some changes to conversion_error_callback(). That >> function reports an error in case there was an error converting the >> result obtained from the foreign server into an internal datum e.g. >> when the string returned by the foreign server is not acceptable by >> local input function for the expected datatype. In such cases, the >> input function will throw error and conversion_error_callback() will >> provide appropriate context for that error. postgres_fdw.sql has tests >> to test proper context >> We need to fix the error context to provide meaningful information or >> at least not crash. This has been discussed briefly in [1]. > > Oops. I had that in mind when working on this. Somehow skipped checking > for conversion error context. I have fixed that in v3 patch. > Removed assert and for non Var expressions, printing generic context. > This context is almost in-line with the discussion you referred here. Moved to next CF. -- Michael
Thanks Jeevan for taking care of the comments. On Fri, Sep 30, 2016 at 5:23 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > Hi Ashutosh, > > On Mon, Sep 26, 2016 at 2:28 PM, Ashutosh Bapat > <ashutosh.bapat@enterprisedb.com> wrote: >> >> Thanks Jeevan for working on the comments. >> >> Ok. Yes, we should also handle bare conditions in >> classifyConditions(). I am fine doing it as a separate patch. > > > Doing that with separate patch would be good. Ok. > >> >> >> I don't think add_foreign_grouping_path() is the right place to change >> a structure managed by the core and esp when we are half-way adding >> paths. An FDW should not meddle with an upper RelOptInfo. Since >> create_foreignscan_plan() picks those up from RelOptInfo and both of >> those are part of core, we need a place in core to set the >> RelOptInfo::relids for an upper relation OR we have stop using >> fs_relids for upper relation foreign scans. > > > Yes, agree that relids must be set by the core rather than a fdw. > However I don't want to touch the core for this patch and also not > exactly sure where we can do that. I think, for this patch, we can > copy relids into grouped_rel in create_grouping_paths() at place > where we assign fdwroutine, userid etc. from the input relation. I don't think this is acceptable since it changes the search key for an upper without going through fetch_upper_rel(). Rest of the code, which tries to find this upper rel with relids = NULL, will not be able to find it anymore. I have started a discussion on this topic [1]. One possible solution discussed there is to use all_baserels for an upper rel. But that solution looks temporary. The discussion has not yet concluded. In case we decide not to have any relids in the upper relation, we will have to obtain those from the scanrel in the context, which is not being used right now. Also there are places in code where we check reloptkind and assume it to be either JOINREL or BASEREL e.g. deparseLockingClause. Those need to be examined again since now we handle an upper relation. As discussed before, we might user bms_num_members() on relids to decide whether the underlying scan is join or base relation. > >> >> >> 2. SortGroupClause is a parser node, so we can name >> appendSortGroupClause() as >> deparseSortGroupClause(), to be consistent with the naming convention. If >> we do >> that change, may be it's better to pass SortGroupClause as is and handle >> other >> members of that structure as well. > > > Renamed appendSortGroupClause() to deparseSortGroupClause(). > I have kept this function in sync with get_rule_sortgroupclause() which > takes the Index ref from SortGroupClause(). This function require just > an index and thus passing SortGroupClause as whole is unnecessary. However > we cannot pass entire order by list or group by list, because in case of > order by list we need some extra processing on list elements. So passing > just Index is sufficient and in sync with get_rule_sortgroupclause() too. Ok. In this function+ /* Must force parens for other expressions */ Please explain why we need parenthesis. > >> >> 5. In deparseConst(), showtype is compared with hardcoded values. The >> callers of this function pass hardcoded values. Instead, we should >> define an enum and use it. I understand that this logic has been borrowed >> from >> get_const_expr(), which also uses hardcoded values. Any reason why not to >> adopt >> a better style here? In fact, it only uses two states for showtype, 0 and >> "> >> 0". Why don't we use a boolean then OR why isn't the third state in >> get_const_expr() applicable here? > > > We certainly can add an enum here, but for consistency with other related > code I think using hard-coded value is good for now. Also I see this > comment in prologue of deparseConst() > * This function has to be kept in sync with ruleutils.c's get_const_expr. > > So better to have handling like it. > Also, currently we use only two values for showtype. But for consistency > let use int instead of bool. In future if we add support for coercion > expr, then we need this third value. At that time we will not need changes > here. > However if required, we can submit a separate patch for adding enum > instead of int for showtype in ruleutils.c. > Since this patch adds showtype argument which is present in get_const_expr(), it's clear that we haven't really kept those two functions in sync, even though the comment says so. It's kind of ugly to see those hardcoded values. But you have a point. Let's see what committer says. >> >> >> 7. The changes in block ... >> should be in sync. The later block adds both aggregates and Vars but the >> first >> one doesn't. Why is this difference? > > > add_to_flat_tlist() is taking care of duplicate entries and thus in second > block, I was calling it after the loop to avoid calling it for every list > element. Well, moved that inside loop like first block. > + /* + * We may need to modify the sortgrouprefs from path target, thus copy it + * so that we will not have any undesired effect. We need to modify the + * sortgrouprefs when it points to one of the ORDER BY expression but not + * to any GROUP BY expression and that expression is not pushed as is. If + * we do not clear such entries, then we will end up into an error. + */ What kind of error? Explain it better. >> >> >> 9. EXPLAIN of foreign scan is adding paranthesis around output >> expressions, >> which is not needed. EXPLAIN output of other plan nodes like Aggregate >> doesn't >> do that. If it's easy to avoid paranthesis, we should do it in this patch. >> With >> this patch, we have started pushing down expressions in the target list, >> so >> makes sense to fix it in this patch. > > > ExecInitForeignScan() while determining scan tuple type from passed > fdw_scan_tlist, has target list containing Vars with varno set to > INDEX_VAR. Due to which while deparsing we go through > resolve_special_varno() and get_special_variable() function which > forces parenthesis around the expression. > I can't think of any easy and quick solution here. So keeping this > as is. Input will be welcome or this can be done separately later. > I guess, you can decide whether or not to add paranthesis by looking at the corresponding namespace in the deparse_context. If the planstate there is ForeignScanState, you may skip the paranthesis if istoplevel is true. Can you please check if this works? >> >> >> 10. While deparsing the GROUP BY clauses, the code fetches the expressions >> and >> deparses the expressions. We might save some CPU cycles if we deparse the >> clauses by their positional indexes in SELECT clause instead of the actual >> expressions. This might make the query slightly unreadable. What do you >> think? > > > To me it is better to have expression in the GROUP BY clause as it is > more readable and easy to understand. Also it is in sync with deparsing > logic in ruleutils.c. Not exactly. get_rule_sortgroupclause() prints only the target list positions instead of actual expression in GROUP BY or ORDER BY clause if requested so. We could opt to do the same in all cases. But I think it's better to add the whole expression in the remote query for readability. > >> >> >> Comments about tests: >> >> 4. May be bulk of these testcases need to be moved next to Join testcases. >> That way their outputs do not change in case the DMLs change in future. In >> case >> you do that, adjust capitalization accordingly. > > > Moved testcases after Join testcases. > However I have not made any capitalization changes. I see many tests > like those elsewhere in the file too. Let me know if that's the policy > to have appropriate capitalization in test-case. I don't want violate > the policy if any and will prefer to do the changes as per the policy. This file has used different styles for different sets. But we usually adopt the style from surrounding testcases. The testcases surrounding aggregate testcase block are capitalized. It will look odd to have just the aggregate tests using different style. > >> >> >> 13. Wouldn't having random() in the testcase, make them produce different >> output in different runs? Also, please see if we can reduce the output >> rows to >> a handful few. Following query produces 21 rows. Is it really important to >> have >> all those rows in the output? >> +select c2, sum(c1) from ft2 group by c2 having sum(c1) * random() < >> 500000 order by c2; > > > The condition is written in such a way that we will get all rows, > nullifying the random() effect, so I don't think there will be any > issue with the multiple runs. > While I agree with that, we can't deny a future change where the test returns random results. Usually the other tests have used t1.c8 to induce an unshippable condition. Or use a condition like (random() <= 1) which is always true for any value returned by random(). The expression will be deemed as volatile. See if you can do something like that. >> >> >> 20. Why do we need the last statement ALTERing server extensions? Is it >> not >> already done when the function was added to the extension? >> +alter extension postgres_fdw drop function least_accum(anyelement, >> variadic anyarray); >> +alter extension postgres_fdw drop aggregate least_agg(variadic items >> anyarray); >> +alter server loopback options (set extensions 'postgres_fdw'); > > > Whenever we alter extension, we must refresh the server and thus required > last statement ALTERing server. Without that elements added into extension > does not reflect in the server. > Ok. >> >> 23. This comment talks about deeper code level internal details. Should >> have a >> better user-visible explanations. >> +-- ORDER BY expression is not present as is in target list of remote >> query. This needed clearing out sortgrouprefs flag. > > > Not sure how can I put those comments without referring some code level > internal details. I have tried altering those comments but it will be > good if you too try rephrasing it. I think that testcase can be simplified if we use a non-shippable expression where an aggregate if shippable e.g. random() * sum(c2) and order the result by this expression. Because of the unshippable expression, ORDER BY won't be pushed down and we test the case when ORDER BY expression is part of the targetlist but can not be pushed down. If we do that, this need not be a separate testcase and can be merged with one of the tests earlier. I guess, it will suffice if the comment just says that it's testing a case where ORDER BY expression is part of the targetlist but not pushed down. You don't need to explain what kind of problem that showed and how it was fixed. If the code changes later, the comment in the test will be out of sync. > >> >> postgres_fdw.out has grown by 2000 lines because of testcases in this >> patch. We need to compact the testcases so that easier to maintain in >> the future. > > > I have removed many duplicate tests and also combined many of them. > Also removed tests involving local tables. Testcase changes now > become 1/3 of earlier one. I guess, there are still avenues for compressing the testcases e.g. following three testcases and some test cases with HAVING clauses, can be merged together, since they are testing orthogonal functionality. +-- Simple aggregates +explain (verbose, costs off) +select count(c6), sum(c1), avg(c1), min(c2), max(c1), stddev(c2) from ft1 group by c2 order by 1, 2; +select count(c6), sum(c1), avg(c1), min(c2), max(c1), stddev(c2) from ft1 group by c2 order by 1, 2; + +-- Only sum() is pushed. Expression will be executed locally. +explain (verbose, costs off) +select sum(c1) * random() from ft1; + +-- Simple aggregate with WHERE clause +explain (verbose, costs off) +select sum(c1) from ft2 where c2 < 5; +select sum(c1) from ft2 where c2 < 5; Here are some more (mostly minor comments) Why do we need this deparse.c? Even without this include, the code compiles fine for me. +#include "utils/ruleutils.h" +#include "nodes/print.h" May be you want to explain when foreignrel and scanrel will be different and their purpose in the comment just above this structure definition. Please use "foreign server" instead of "remote". + /* + * If aggregate's input collation is not derived from a foreign + * Var, it can't be sent to remote. + */ I guess, aggregate's input collation should consider aggfilter collation, since that doesn't affect aggregates collation. But we should make sure that aggfilter is safe to pushdown from collation's perspective. + /* Check aggregate filter */ + if (!foreign_expr_walker((Node *) agg->aggfilter, + glob_cxt, &inner_cxt)) + return false; We need an "a" before upper, I guess. + * For upper relation, we have already built the target list while checking If we add a new kind of RELOPT, this assertion will unintentionally accept it. May be it's good idea to explicitly list all the RELOPTs even if we support all of them except one. It was probably I who suggested this change, but thinking about it again, it doesn't seems to be a good idea. What do you think? - /* We handle relations for foreign tables and joins between those */ - Assert(rel->reloptkind == RELOPT_JOINREL || - rel->reloptkind == RELOPT_BASEREL || - rel->reloptkind == RELOPT_OTHER_MEMBER_REL); + /* We handle all relations other than dead one. */ + Assert(rel->reloptkind != RELOPT_DEADREL); missing "expect" after ... so we don't + /* + * Queries with grouping sets are not pushed down, so we don't grouping + * sets here. + */ Do we need following #include in postgres_fdw.c? I am able to compile the code fine with those. +#include "nodes/print.h" [1] http://www.mail-archive.com/pgsql-hackers@postgresql.org/msg295435.html -- Best Wishes, Ashutosh Bapat EnterpriseDB Corporation The Postgres Database Company
On Thu, Sep 8, 2016 at 10:41 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
I did performance testing for aggregate push down and see good performance
with the patch.
Attached is the script I have used to get the performance numbers along with
the results I got with and without patch (pg_agg_push_down_v3.patch). Also
attached few GNU plots from the readings I got. These were run on my local
VM having following details:
Linux centos7 3.10.0-327.28.3.el7.x86_64 #1 SMP Thu Aug 18 19:05:49 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
RAM alloted: 8 GB
CPUs alloted: 8
postgresql.conf is default.
With aggregate push down I see around 12x performance for count(*) operation.
In another test, I have observed that if number of groups returned from
remote server is same as that of input rows, then aggregate push down performs
slightly poor which I think is expected. However in all other cases where
number of groups are less than input rows, pushing down aggregate gives better
performance than performing grouping on the local server.
I did this performance testing on my local setup. I would expected even better
numbers on a specialized high-end performance machine. I would be more than
happy if someone does this testing on such high-end machine.
Let me know if you need any help.
Thanks
-- I think we should try to measure performance gain because of aggregate pushdown. The EXPLAINdoesn't show actual improvement in the execution times.
I did performance testing for aggregate push down and see good performance
with the patch.
Attached is the script I have used to get the performance numbers along with
the results I got with and without patch (pg_agg_push_down_v3.patch). Also
attached few GNU plots from the readings I got. These were run on my local
VM having following details:
Linux centos7 3.10.0-327.28.3.el7.x86_64 #1 SMP Thu Aug 18 19:05:49 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
RAM alloted: 8 GB
CPUs alloted: 8
postgresql.conf is default.
With aggregate push down I see around 12x performance for count(*) operation.
In another test, I have observed that if number of groups returned from
remote server is same as that of input rows, then aggregate push down performs
slightly poor which I think is expected. However in all other cases where
number of groups are less than input rows, pushing down aggregate gives better
performance than performing grouping on the local server.
I did this performance testing on my local setup. I would expected even better
numbers on a specialized high-end performance machine. I would be more than
happy if someone does this testing on such high-end machine.
Let me know if you need any help.
Thanks
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Вложения
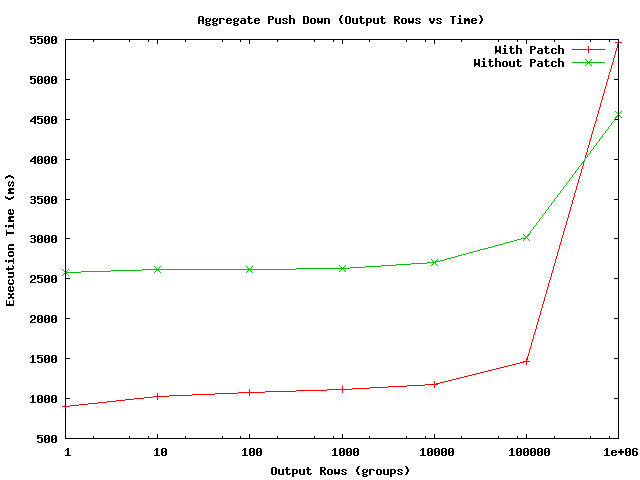{kind=link}
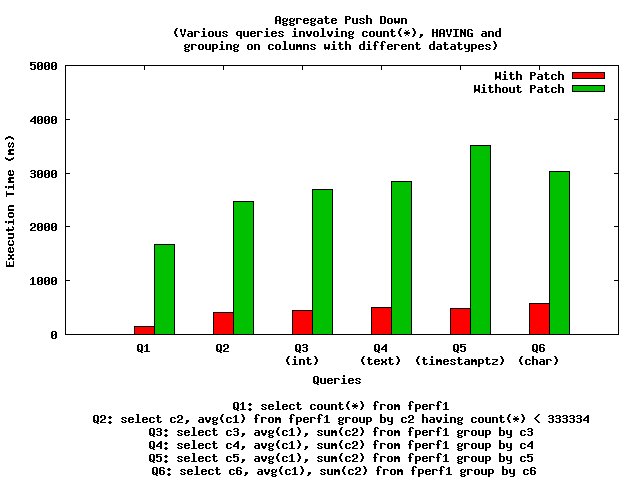{kind=link}
On Fri, Sep 30, 2016 at 5:23 PM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote:
Hi,
I have tested and created few extra testcases which we can consider to add in "postgres_fdw.sql".
Note: This patch is an addition on top of Jeevan Chalke's patch Dt: 30th, Sept 2016.
In the attached patch I have fixed all other review comments you haveposted. All the comments were excellent and helped me a lot to improve
in various areas.
Hi,
I have tested and created few extra testcases which we can consider to add in "postgres_fdw.sql".
Please find attached patch.
Note: This patch is an addition on top of Jeevan Chalke's patch Dt: 30th, Sept 2016.
Вложения
On Wed, Oct 12, 2016 at 9:18 AM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > I did performance testing for aggregate push down and see good performance > with the patch. Are you planning another update to this patch based on Ashutosh's comments? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Oct 12, 2016 at 3:38 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
Done.
Using scan rel's relids in the context and checking for any foreign var
reference. Added Relids member in foreign_glob_cxt and scanrel in
deparse_expr_cxt to accomplish this. Removed logic of copying relids
from scanrel to grouped_rel. In create_foreignscan_plan(), assigned
all_baserels to fs_relids for upper relations per one of the suggestion
mentioned in the said email discussion.
I have observed that in deparse.c we do add parenthesis around
expressions, unlike to PRETTY_PAREN handling in ruleutils.c.
Thus we need parenthesis here too. However changed this comments
per other comment in the file.
I have tried it. Attached separate patch for it.
However I have noticed that istoplevel is always false (at-least for the
testcase we have, I get it false always). And I also think that taking
this decision only on PlanState is enough. Does that in attached patch.
To fix this, I have passed deparse_namespace to the private argument and
accessed it in get_special_variable(). Changes looks very simple. Please
have a look and let me know your views.
This issue is not introduced by the changes done for the aggregate push
down, it only got exposed as we now ship expressions in the target list.
Thus I think it will be good if we make these changes separately as new
patch, if required.
I see mixed use of capitalization in the file and use of it is adhoc too.
So not convinced with your argument yet. I don't think there is any policy
for that; otherwise use of capitalization in this file would have been
consistent already. Can we defer this to the committer's opinion.
This is consistent with other nodetyps usage. see FuncExpr for example.
inner_cxt is a merger of all the args/expressions context which is then
checked with aggregate's input collation. So I believe aggfilter collation
is also verified as expected.
Am I missing anything here?
>> I don't think add_foreign_grouping_path() is the right place to change
>> a structure managed by the core and esp when we are half-way adding
>> paths. An FDW should not meddle with an upper RelOptInfo. Since
>> create_foreignscan_plan() picks those up from RelOptInfo and both of
>> those are part of core, we need a place in core to set the
>> RelOptInfo::relids for an upper relation OR we have stop using
>> fs_relids for upper relation foreign scans.
>
>
> Yes, agree that relids must be set by the core rather than a fdw.
> However I don't want to touch the core for this patch and also not
> exactly sure where we can do that. I think, for this patch, we can
> copy relids into grouped_rel in create_grouping_paths() at place
> where we assign fdwroutine, userid etc. from the input relation.
I don't think this is acceptable since it changes the search key for
an upper without going through fetch_upper_rel(). Rest of the code,
which tries to find this upper rel with relids = NULL, will not be
able to find it anymore. I have started a discussion on this topic
[1]. One possible solution discussed there is to use all_baserels for
an upper rel. But that solution looks temporary. The discussion has
not yet concluded.
In case we decide not to have any relids in the upper relation, we
will have to obtain those from the scanrel in the context, which is
not being used right now.
Also there are places in code where we check reloptkind and assume it
to be either JOINREL or BASEREL e.g. deparseLockingClause. Those need
to be examined again since now we handle an upper relation. As
discussed before, we might user bms_num_members() on relids to decide
whether the underlying scan is join or base relation.
Done.
Using scan rel's relids in the context and checking for any foreign var
reference. Added Relids member in foreign_glob_cxt and scanrel in
deparse_expr_cxt to accomplish this. Removed logic of copying relids
from scanrel to grouped_rel. In create_foreignscan_plan(), assigned
all_baserels to fs_relids for upper relations per one of the suggestion
mentioned in the said email discussion.
Ok.
In this function
+ /* Must force parens for other expressions */
Please explain why we need parenthesis.
I have observed that in deparse.c we do add parenthesis around
expressions, unlike to PRETTY_PAREN handling in ruleutils.c.
Thus we need parenthesis here too. However changed this comments
per other comment in the file.
Since this patch adds showtype argument which is present in
get_const_expr(), it's clear that we haven't really kept those two
functions in sync, even though the comment says so. It's kind of ugly
to see those hardcoded values. But you have a point. Let's see what
committer says.
Sure, no issues.
>
> ExecInitForeignScan() while determining scan tuple type from passed
> fdw_scan_tlist, has target list containing Vars with varno set to
> INDEX_VAR. Due to which while deparsing we go through
> resolve_special_varno() and get_special_variable() function which
> forces parenthesis around the expression.
> I can't think of any easy and quick solution here. So keeping this
> as is. Input will be welcome or this can be done separately later.
>
I guess, you can decide whether or not to add paranthesis by looking
at the corresponding namespace in the deparse_context. If the
planstate there is ForeignScanState, you may skip the paranthesis if
istoplevel is true. Can you please check if this works?
I have tried it. Attached separate patch for it.
However I have noticed that istoplevel is always false (at-least for the
testcase we have, I get it false always). And I also think that taking
this decision only on PlanState is enough. Does that in attached patch.
To fix this, I have passed deparse_namespace to the private argument and
accessed it in get_special_variable(). Changes looks very simple. Please
have a look and let me know your views.
This issue is not introduced by the changes done for the aggregate push
down, it only got exposed as we now ship expressions in the target list.
Thus I think it will be good if we make these changes separately as new
patch, if required.
> To me it is better to have expression in the GROUP BY clause as it is
> more readable and easy to understand. Also it is in sync with deparsing
> logic in ruleutils.c.
Not exactly. get_rule_sortgroupclause() prints only the target list
positions instead of actual expression in GROUP BY or ORDER BY clause
if requested so. We could opt to do the same in all cases. But I think
it's better to add the whole expression in the remote query for
readability.
Right.
>> case
>> you do that, adjust capitalization accordingly.
>
>
> Moved testcases after Join testcases.
> However I have not made any capitalization changes. I see many tests
> like those elsewhere in the file too. Let me know if that's the policy
> to have appropriate capitalization in test-case. I don't want violate
> the policy if any and will prefer to do the changes as per the policy.
This file has used different styles for different sets. But we usually
adopt the style from surrounding testcases. The testcases surrounding
aggregate testcase block are capitalized. It will look odd to have
just the aggregate tests using different style.
I see mixed use of capitalization in the file and use of it is adhoc too.
So not convinced with your argument yet. I don't think there is any policy
for that; otherwise use of capitalization in this file would have been
consistent already. Can we defer this to the committer's opinion.
Please use "foreign server" instead of "remote".
+ /*
+ * If aggregate's input collation is not derived from a foreign
+ * Var, it can't be sent to remote.
+ */
This is consistent with other nodetyps usage. see FuncExpr for example.
I guess, aggregate's input collation should consider aggfilter collation, since
that doesn't affect aggregates collation. But we should make sure that
aggfilter is safe to pushdown from collation's perspective.
+ /* Check aggregate filter */
+ if (!foreign_expr_walker((Node *) agg->aggfilter,
+ glob_cxt, &inner_cxt))
+ return false;
inner_cxt is a merger of all the args/expressions context which is then
checked with aggregate's input collation. So I believe aggfilter collation
is also verified as expected.
Am I missing anything here?
Fixed all other comments including test-cases changes as suggested.
[1] http://www.mail-archive.com/pgsql-hackers@postgresql.org/ msg295435.html --
Best Wishes,
Ashutosh Bapat
EnterpriseDB Corporation
The Postgres Database Company
Thanks
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Вложения
The patch compiles and make check-world doesn't show any failures. >> >> > >> > ExecInitForeignScan() while determining scan tuple type from passed >> > fdw_scan_tlist, has target list containing Vars with varno set to >> > INDEX_VAR. Due to which while deparsing we go through >> > resolve_special_varno() and get_special_variable() function which >> > forces parenthesis around the expression. >> > I can't think of any easy and quick solution here. So keeping this >> > as is. Input will be welcome or this can be done separately later. >> > >> >> I guess, you can decide whether or not to add paranthesis by looking >> at the corresponding namespace in the deparse_context. If the >> planstate there is ForeignScanState, you may skip the paranthesis if >> istoplevel is true. Can you please check if this works? > > > I have tried it. Attached separate patch for it. > However I have noticed that istoplevel is always false (at-least for the > testcase we have, I get it false always). And I also think that taking > this decision only on PlanState is enough. Does that in attached patch. > To fix this, I have passed deparse_namespace to the private argument and > accessed it in get_special_variable(). Changes looks very simple. Please > have a look and let me know your views. > This issue is not introduced by the changes done for the aggregate push > down, it only got exposed as we now ship expressions in the target list. > Thus I think it will be good if we make these changes separately as new > patch, if required. > The patch looks good and pretty simple. + * expression. However if underneath PlanState is ForeignScanState, then + * don't force parentheses. We need to explain why it's safe not to add paranthesis. The reason this function adds paranthesis so as to preserve any operator precedences imposed by the expression tree of which this IndexVar is part. For ForeignScanState, the Var may represent the root of the expression tree, and thus not need paranthesis. But we need to verify this and explain it in the comments. As you have explained this is an issue exposed by this patch; something not must have in this patch. If committers feel that aggregate pushdown needs this fix as well, please provide a patch addressing the above comment. >> > >> > >> > Moved testcases after Join testcases. >> > However I have not made any capitalization changes. I see many tests >> > like those elsewhere in the file too. Let me know if that's the policy >> > to have appropriate capitalization in test-case. I don't want violate >> > the policy if any and will prefer to do the changes as per the policy. >> >> This file has used different styles for different sets. But we usually >> adopt the style from surrounding testcases. The testcases surrounding >> aggregate testcase block are capitalized. It will look odd to have >> just the aggregate tests using different style. > > > I see mixed use of capitalization in the file and use of it is adhoc too. > So not convinced with your argument yet. I don't think there is any policy > for that; otherwise use of capitalization in this file would have been > consistent already. Can we defer this to the committer's opinion. > Ok. PFA patch with cosmetic changes (mostly rewording comments). Let me know if those look good. I am marking this patch is ready for committer. -- Best Wishes, Ashutosh Bapat EnterpriseDB Corporation The Postgres Database Company
Вложения
On Thu, Oct 20, 2016 at 12:49 PM, Ashutosh Bapat <ashutosh.bapat@enterprisedb.com> wrote:
The patch compiles and make check-world doesn't show any failures.
>>
>
>
> I have tried it. Attached separate patch for it.
> However I have noticed that istoplevel is always false (at-least for the
> testcase we have, I get it false always). And I also think that taking
> this decision only on PlanState is enough. Does that in attached patch.
> To fix this, I have passed deparse_namespace to the private argument and
> accessed it in get_special_variable(). Changes looks very simple. Please
> have a look and let me know your views.
> This issue is not introduced by the changes done for the aggregate push
> down, it only got exposed as we now ship expressions in the target list.
> Thus I think it will be good if we make these changes separately as new
> patch, if required.
>
The patch looks good and pretty simple.
+ * expression. However if underneath PlanState is ForeignScanState, then
+ * don't force parentheses.
We need to explain why it's safe not to add paranthesis. The reason
this function adds paranthesis so as to preserve any operator
precedences imposed by the expression tree of which this IndexVar is
part. For ForeignScanState, the Var may represent the root of the
expression tree, and thus not need paranthesis. But we need to verify
this and explain it in the comments.
As you have explained this is an issue exposed by this patch;
something not must have in this patch. If committers feel that
aggregate pushdown needs this fix as well, please provide a patch
addressing the above comment.
Sure.
Ok. PFA patch with cosmetic changes (mostly rewording comments). Let
me know if those look good. I am marking this patch is ready for
committer.
Changes look good to me.
Thanks for the detailed review.
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
On Thu, Oct 20, 2016 at 5:38 AM, Jeevan Chalke <jeevan.chalke@enterprisedb.com> wrote: > Changes look good to me. > Thanks for the detailed review. I didn't find anything structurally wrong with this patch, so I've committed it with many cosmetic changes. Judging by what happened with join pushdown, there are probably some residual bugs, but hopefully not too many. Anyhow, I don't think waiting longer to commit this is necessarily going to help, so let's see what happens... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> I didn't find anything structurally wrong with this patch, so I've
> committed it with many cosmetic changes. Judging by what happened
> with join pushdown, there are probably some residual bugs, but
> hopefully not too many.
dromedary seems to have found one, or at least an unstable test result.
regards, tom lane
On Fri, Oct 21, 2016 at 10:47 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> I didn't find anything structurally wrong with this patch, so I've >> committed it with many cosmetic changes. Judging by what happened >> with join pushdown, there are probably some residual bugs, but >> hopefully not too many. > > dromedary seems to have found one, or at least an unstable test result. OK, looking at that now. Thanks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Fri, Oct 21, 2016 at 10:47 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> dromedary seems to have found one, or at least an unstable test result.
> OK, looking at that now. Thanks.
Looking at further failures, it looks like 32-bit machines in general
get that result. Might be just a cost estimation difference.
Also, some of the windows machines are folding "sqrt(2)" to a different
constant than is hard-wired into the expected-result file. That's
slightly annoying because it calls into question whether we can ship
floating-point computations to the far end at all :-(.
regards, tom lane
On Fri, Oct 21, 2016 at 11:20 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Fri, Oct 21, 2016 at 10:47 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> dromedary seems to have found one, or at least an unstable test result. > >> OK, looking at that now. Thanks. > > Looking at further failures, it looks like 32-bit machines in general > get that result. Might be just a cost estimation difference. > > Also, some of the windows machines are folding "sqrt(2)" to a different > constant than is hard-wired into the expected-result file. That's > slightly annoying because it calls into question whether we can ship > floating-point computations to the far end at all :-(. IMHO, not shipping floating-point computations for that reason would be more annoying than helpful. To really guarantee that the remote and identical results are identical, you'd need far more infrastructure than we have - you'd have to make sure the operating system collations matched, for example. And we're already assuming (without any proof) that the default collations match and, for that matter, that the datatypes match. If you're pushing down to PostgreSQL on the other end, you at least have a hope that the other side might be sufficiently identical to the local side that the results will be the same, but if somebody implements these pushdowns for Oracle or SQL server, you almost might as well give up and go home. Even for PostgreSQL, getting the same results in every possible corner case requires a certain degree of optimism. For my money, the way to handle that is to add more control over pushdown rather than automatically disabling it in certain cases. For example, we could have GUCs that disable all pushdown or certain types of pushdown - e.g. you could specify that you don't trust the remote side to sort data properly, or that you don't like it's floating-point implementation. I'm not sure what controls are most useful here, but I'd be willing to bet you a nice glass of white wine that many people will be happier with a system that they can control than they will be with one that just disables the optimization in every case where it might hypothetically not work out. It's not clear that we can even reasonably foresee all such cases. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Oct 21, 2016 at 8:50 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Fri, Oct 21, 2016 at 10:47 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> dromedary seems to have found one, or at least an unstable test result. > >> OK, looking at that now. Thanks. > > Looking at further failures, it looks like 32-bit machines in general > get that result. Might be just a cost estimation difference. How do I or Jeevan get to look at those results? > > Also, some of the windows machines are folding "sqrt(2)" to a different > constant than is hard-wired into the expected-result file. That's > slightly annoying because it calls into question whether we can ship > floating-point computations to the far end at all :-(. > There are two things where the floating point push-down can go wrong: a. the floating point calculation on the foreign server itself is different from the local server, b. while converting the binary floating point representation into text, the actual number gets truncated because of limit on the number of digits in the text representation. The later can be avoided by using binary data transfer mode for floating point number. Is that something worth considering? -- Best Wishes, Ashutosh Bapat EnterpriseDB Corporation The Postgres Database Company
On Fri, Oct 21, 2016 at 9:09 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Oct 21, 2016 at 11:20 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> Robert Haas <robertmhaas@gmail.com> writes: >>> On Fri, Oct 21, 2016 at 10:47 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>>> dromedary seems to have found one, or at least an unstable test result. >> >>> OK, looking at that now. Thanks. >> >> Looking at further failures, it looks like 32-bit machines in general >> get that result. Might be just a cost estimation difference. >> >> Also, some of the windows machines are folding "sqrt(2)" to a different >> constant than is hard-wired into the expected-result file. That's >> slightly annoying because it calls into question whether we can ship >> floating-point computations to the far end at all :-(. > > IMHO, not shipping floating-point computations for that reason would > be more annoying than helpful. +1 > To really guarantee that the remote > and identical results are identical, you'd need far more > infrastructure than we have - you'd have to make sure the operating > system collations matched, for example. And we're already assuming > (without any proof) that the default collations match and, for that > matter, that the datatypes match. If you're pushing down to > PostgreSQL on the other end, you at least have a hope that the other > side might be sufficiently identical to the local side that the > results will be the same, but if somebody implements these pushdowns > for Oracle or SQL server, you almost might as well give up and go > home. Even for PostgreSQL, getting the same results in every possible > corner case requires a certain degree of optimism. > > For my money, the way to handle that is to add more control over > pushdown rather than automatically disabling it in certain cases. For > example, we could have GUCs that disable all pushdown or certain types > of pushdown - e.g. you could specify that you don't trust the remote > side to sort data properly, or that you don't like it's floating-point > implementation. I'm not sure what controls are most useful here, but > I'd be willing to bet you a nice glass of white wine that many people > will be happier with a system that they can control than they will be > with one that just disables the optimization in every case where it > might hypothetically not work out. It's not clear that we can even > reasonably foresee all such cases. +1. But having too many of them will make the customer go crazy. Everytime s/he stumbles upon such a problem (or bug from her/his point of view), we will add a GUC/option OR tell, "oh! you have to turn on/off that GUC/option". That will just make the users loose faith in FDW (or at least postgres_fdw), if we end up with too many of them. Instead, we may want to add the intelligence to detect when floating point calculations on the foreign server are different from local one OR that the default locale or collation on the foreign server are different from the local one and accordingly set the foreign server options automatically. This may be part of the postgres_fdw or a separate utility. I guess, this will be similar to what configure does to detect compatible libraries. The information gathered will certainly become obsolete if the user re-configures the server or changes settings, but at least we can advice them to run the utility to detect any inconsistencies caused by changes and report or correct them. I think this is a bigger project, separate from any FDW pushdown. -- Best Wishes, Ashutosh Bapat EnterpriseDB Corporation The Postgres Database Company
brolga is still not terribly happy with this patch: it's choosing not to
push down the aggregates in one of the queries. While I failed to
duplicate that result locally, investigation suggests that brolga's result
is perfectly sane; in fact it's not very clear why we're not getting that
from multiple critters, because the plan brolga is choosing is not
inferior to the expected one.
The core of the problem is this subquery:
contrib_regression=# explain verbose select min(13), avg(ft1.c1), sum(ft2.c1) from ft1 right join ft2 on (ft1.c1 =
ft2.c1)where ft1.c1 = 12; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------Foreign
Scan (cost=108.61..108.64 rows=1 width=44) Output: (min(13)), (avg(ft1.c1)), (sum(ft2.c1)) Relations: Aggregate on
((public.ft1)INNER JOIN (public.ft2)) Remote SQL: SELECT min(13), avg(r1."C 1"), sum(r2."C 1") FROM ("S 1"."T 1" r1
INNERJOIN "S 1"."T 1" r2 ON (((r2."C 1" = 12)) AND ((r1."C 1" = 12))))
(4 rows)
If you look at the estimate to just fetch the data, it's:
contrib_regression=# explain verbose select ft1.c1, ft2.c1 from ft1 right join ft2 on (ft1.c1 = ft2.c1) where ft1.c1 =
12; QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------Foreign
Scan (cost=100.55..108.62 rows=1 width=8) Output: ft1.c1, ft2.c1 Relations: (public.ft1) INNER JOIN (public.ft2)
RemoteSQL: SELECT r1."C 1", r2."C 1" FROM ("S 1"."T 1" r1 INNER JOIN "S 1"."T 1" r2 ON (((r2."C 1" = 12)) AND ((r1."C
1"= 12))))
(4 rows)
Note we're expecting only one row out of the join. Now the cost of doing
three aggregates on a single row of input is not a lot. Comparing these
local queries:
regression=# explain select min(13),avg(q1),sum(q2) from int8_tbl where q2=456; QUERY PLAN
---------------------------------------------------------------Aggregate (cost=1.07..1.08 rows=1 width=68) -> Seq
Scanon int8_tbl (cost=0.00..1.06 rows=1 width=16) Filter: (q2 = 456)
(3 rows)
regression=# explain select (q1),(q2) from int8_tbl where q2=456; QUERY PLAN
---------------------------------------------------------Seq Scan on int8_tbl (cost=0.00..1.06 rows=1 width=16)
Filter:(q2 = 456)
(2 rows)
we seem to have startup = input cost + .01 and then another .01
for total. So the estimate to do the above remote scan and then
aggregate locally should have been 108.63 startup and 108.64 total,
give or take. The estimate for aggregating remotely is a hair better,
but it's not nearly better enough to guarantee that the planner won't
see it as fuzzily the same cost.
In short: the problem with this test case is that it's considering
aggregation over only a single row, which is a situation in which
pushing down the aggregate actually doesn't save us anything, because
we're retrieving one row from the remote either way. So it's not at all
surprising that we don't get a stable plan choice. The test query needs
to be adjusted so that the aggregation is done over multiple rows,
allowing fdw_tuple_cost to kick in and provide some daylight between
the cost estimates.
regards, tom lane
On Sat, Oct 22, 2016 at 9:09 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Attached patch which performs aggrgation over 1000 rows as suggested by Tom.
I believe it will have a stable output/plan now.
Thanks
brolga is still not terribly happy with this patch: it's choosing not to
push down the aggregates in one of the queries. While I failed to
duplicate that result locally, investigation suggests that brolga's result
is perfectly sane; in fact it's not very clear why we're not getting that
from multiple critters, because the plan brolga is choosing is not
inferior to the expected one.
The core of the problem is this subquery:
contrib_regression=# explain verbose select min(13), avg(ft1.c1), sum(ft2.c1) from ft1 right join ft2 on (ft1.c1 = ft2.c1) where ft1.c1 = 12;
QUERY PLAN
------------------------------------------------------------ ------------------------------ ------------------------------ ------------------------------ ---
Foreign Scan (cost=108.61..108.64 rows=1 width=44)
Output: (min(13)), (avg(ft1.c1)), (sum(ft2.c1))
Relations: Aggregate on ((public.ft1) INNER JOIN (public.ft2))
Remote SQL: SELECT min(13), avg(r1."C 1"), sum(r2."C 1") FROM ("S 1"."T 1" r1 INNER JOIN "S 1"."T 1" r2 ON (((r2."C 1" = 12)) AND ((r1."C 1" = 12))))
(4 rows)
If you look at the estimate to just fetch the data, it's:
contrib_regression=# explain verbose select ft1.c1, ft2.c1 from ft1 right join ft2 on (ft1.c1 = ft2.c1) where ft1.c1 = 12;
QUERY PLAN
------------------------------------------------------------ ------------------------------ ------------------------------ --------------
Foreign Scan (cost=100.55..108.62 rows=1 width=8)
Output: ft1.c1, ft2.c1
Relations: (public.ft1) INNER JOIN (public.ft2)
Remote SQL: SELECT r1."C 1", r2."C 1" FROM ("S 1"."T 1" r1 INNER JOIN "S 1"."T 1" r2 ON (((r2."C 1" = 12)) AND ((r1."C 1" = 12))))
(4 rows)
Note we're expecting only one row out of the join. Now the cost of doing
three aggregates on a single row of input is not a lot. Comparing these
local queries:
regression=# explain select min(13),avg(q1),sum(q2) from int8_tbl where q2=456;
QUERY PLAN
------------------------------------------------------------ ---
Aggregate (cost=1.07..1.08 rows=1 width=68)
-> Seq Scan on int8_tbl (cost=0.00..1.06 rows=1 width=16)
Filter: (q2 = 456)
(3 rows)
regression=# explain select (q1),(q2) from int8_tbl where q2=456;
QUERY PLAN
---------------------------------------------------------
Seq Scan on int8_tbl (cost=0.00..1.06 rows=1 width=16)
Filter: (q2 = 456)
(2 rows)
we seem to have startup = input cost + .01 and then another .01
for total. So the estimate to do the above remote scan and then
aggregate locally should have been 108.63 startup and 108.64 total,
give or take. The estimate for aggregating remotely is a hair better,
but it's not nearly better enough to guarantee that the planner won't
see it as fuzzily the same cost.
In short: the problem with this test case is that it's considering
aggregation over only a single row, which is a situation in which
pushing down the aggregate actually doesn't save us anything, because
we're retrieving one row from the remote either way. So it's not at all
surprising that we don't get a stable plan choice. The test query needs
to be adjusted so that the aggregation is done over multiple rows,
allowing fdw_tuple_cost to kick in and provide some daylight between
the cost estimates.
Attached patch which performs aggrgation over 1000 rows as suggested by Tom.
I believe it will have a stable output/plan now.
Thanks
regards, tom lane
--
Jeevan B Chalke
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company
Principal Software Engineer, Product Development
EnterpriseDB Corporation
The Enterprise PostgreSQL Company