Обсуждение: [TIPS] Tuning PostgreSQL 9.2
Hi all,
Trying to improve the performance, it would be great hear from you some tips to it...
My current scenario is:
128 GB Ram - Raid 10 - PostgreSQL 9.2 in a Centos 6.6 64 Bits
How could I measure a nice parameter to it?
Can you guys tell your experience and how did you get nice results with your changes?
But biggest problem nowadays are slow queries and I/O (In some spikes I get 100% I/O usage)
Thank you!
Current confs:
1 - Newrelic
2 - pg_stat_statements = on
3 - log_min_duration_statement = 1000
4 - log_statement = 'ddl'
5 - Munin
6 - Vaccum:
vacuum_cost_delay = 20ms
vacuum_cost_page_hit = 1
vacuum_cost_page_miss = 10
vacuum_cost_page_dirty = 20
vacuum_cost_limit = 100
autovacuum = on
log_autovacuum_min_duration = 30000
autovacuum_max_workers = 2
autovacuum_naptime = 1min
autovacuum_vacuum_threshold = 500
autovacuum_analyze_threshold = 500
autovacuum_vacuum_scale_factor = 0.1
autovacuum_analyze_scale_factor = 0.1
autovacuum_freeze_max_age = 200000000
autovacuum_vacuum_cost_delay = -1
autovacuum_vacuum_cost_limit = -1
vacuum_freeze_min_age = 50000000
vacuum_freeze_table_age = 150000000
shared_buffers = 51605MB
work_mem = 32MB
maintenance_work_mem = 128 MB
effective_cache_size = 96760MB
On Wed, Feb 17, 2016 at 6:03 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > Hi all, > > Trying to improve the performance, it would be great hear from you some tips > to it... > > My current scenario is: > 128 GB Ram - Raid 10 - PostgreSQL 9.2 in a Centos 6.6 64 Bits > > How could I measure a nice parameter to it? > Can you guys tell your experience and how did you get nice results with your > changes? > > But biggest problem nowadays are slow queries and I/O (In some spikes I get > 100% I/O usage) > > Thank you! > > Current confs: > 1 - Newrelic > 2 - pg_stat_statements = on > 3 - log_min_duration_statement = 1000 > 4 - log_statement = 'ddl' > 5 - Munin > 6 - Vaccum: >> >> vacuum_cost_delay = 20ms >> vacuum_cost_page_hit = 1 >> vacuum_cost_page_miss = 10 >> vacuum_cost_page_dirty = 20 >> vacuum_cost_limit = 100 >> autovacuum = on >> log_autovacuum_min_duration = 30000 >> autovacuum_max_workers = 2 >> autovacuum_naptime = 1min >> autovacuum_vacuum_threshold = 500 >> autovacuum_analyze_threshold = 500 >> autovacuum_vacuum_scale_factor = 0.1 >> autovacuum_analyze_scale_factor = 0.1 >> autovacuum_freeze_max_age = 200000000 >> autovacuum_vacuum_cost_delay = -1 >> autovacuum_vacuum_cost_limit = -1 >> vacuum_freeze_min_age = 50000000 >> vacuum_freeze_table_age = 150000000 > > > shared_buffers = 51605MB > work_mem = 32MB > maintenance_work_mem = 128 MB > effective_cache_size = 96760MB There are a lot of things you can do to improve performance, but we don't know your usage patterns or underlying IO subsystem. What does your IO sybsystem look like? How fast can you get something like pgbench to go on this machine? Might I ask where the idea for shared_buffers being 51GB came from? Generally speaking shared_buffers don't work well that big, except in some very specific circumstances maybe. So when you say IO is 100% utilized, is that being used by sorts, the background writer, reads? How many active and idle connections do you typically have on this machine? If you have a lot of connections have you considered pooling? What are max_connections, effective_io_concurrency, ramdom_page_cost, wal_writer_delay, commit_delay, commit_siblings, checkpoint_segments, temp_buffers, set to? Turn on things like log_temp_files, log_checkpoints. Also got a slow query and an explain analyze output?
Echoing (other) Scott's comments, specifically, when he says "what does your IO subsystem looks like," what's the hardware?RAID 10 is all well and good, but how many drives, what type are they, and how is your RAID-10 configured? Specificmodel numbers would be useful. ________________________________________ From: pgsql-admin-owner@postgresql.org <pgsql-admin-owner@postgresql.org> on behalf of Scott Marlowe <scott.marlowe@gmail.com> Sent: Thursday, February 18, 2016 11:52 AM To: drum.lucas@gmail.com Cc: pgsql-admin@postgresql.org Subject: Re: [ADMIN] [TIPS] Tuning PostgreSQL 9.2 On Wed, Feb 17, 2016 at 6:03 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > Hi all, > > Trying to improve the performance, it would be great hear from you some tips > to it... > > My current scenario is: > 128 GB Ram - Raid 10 - PostgreSQL 9.2 in a Centos 6.6 64 Bits > > How could I measure a nice parameter to it? > Can you guys tell your experience and how did you get nice results with your > changes? > > But biggest problem nowadays are slow queries and I/O (In some spikes I get > 100% I/O usage) > > Thank you! > > Current confs: > 1 - Newrelic > 2 - pg_stat_statements = on > 3 - log_min_duration_statement = 1000 > 4 - log_statement = 'ddl' > 5 - Munin > 6 - Vaccum: >> >> vacuum_cost_delay = 20ms >> vacuum_cost_page_hit = 1 >> vacuum_cost_page_miss = 10 >> vacuum_cost_page_dirty = 20 >> vacuum_cost_limit = 100 >> autovacuum = on >> log_autovacuum_min_duration = 30000 >> autovacuum_max_workers = 2 >> autovacuum_naptime = 1min >> autovacuum_vacuum_threshold = 500 >> autovacuum_analyze_threshold = 500 >> autovacuum_vacuum_scale_factor = 0.1 >> autovacuum_analyze_scale_factor = 0.1 >> autovacuum_freeze_max_age = 200000000 >> autovacuum_vacuum_cost_delay = -1 >> autovacuum_vacuum_cost_limit = -1 >> vacuum_freeze_min_age = 50000000 >> vacuum_freeze_table_age = 150000000 > > > shared_buffers = 51605MB > work_mem = 32MB > maintenance_work_mem = 128 MB > effective_cache_size = 96760MB There are a lot of things you can do to improve performance, but we don't know your usage patterns or underlying IO subsystem. What does your IO sybsystem look like? How fast can you get something like pgbench to go on this machine? Might I ask where the idea for shared_buffers being 51GB came from? Generally speaking shared_buffers don't work well that big, except in some very specific circumstances maybe. So when you say IO is 100% utilized, is that being used by sorts, the background writer, reads? How many active and idle connections do you typically have on this machine? If you have a lot of connections have you considered pooling? What are max_connections, effective_io_concurrency, ramdom_page_cost, wal_writer_delay, commit_delay, commit_siblings, checkpoint_segments, temp_buffers, set to? Turn on things like log_temp_files, log_checkpoints. Also got a slow query and an explain analyze output? -- Sent via pgsql-admin mailing list (pgsql-admin@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-admin Journyx, Inc. 7600 Burnet Road #300 Austin, TX 78757 www.journyx.com p 512.834.8888 f 512-834-8858 Do you receive our promotional emails? You can subscribe or unsubscribe to those emails at http://go.journyx.com/emailPreference/e/4932/714/
Hello Use pgtuning in you server. > On Wed, Feb 17, 2016 at 6:03 PM, drum.lucas@gmail.com > <drum.lucas@gmail.com> wrote: >> Hi all, >> >> Trying to improve the performance, it would be great hear from you some >> tips >> to it... >> >> My current scenario is: >> 128 GB Ram - Raid 10 - PostgreSQL 9.2 in a Centos 6.6 64 Bits >> >> How could I measure a nice parameter to it? >> Can you guys tell your experience and how did you get nice results with >> your >> changes? >> >> But biggest problem nowadays are slow queries and I/O (In some spikes I >> get >> 100% I/O usage) >> >> Thank you! >> >> Current confs: >> 1 - Newrelic >> 2 - pg_stat_statements = on >> 3 - log_min_duration_statement = 1000 >> 4 - log_statement = 'ddl' >> 5 - Munin >> 6 - Vaccum: >>> >>> vacuum_cost_delay = 20ms >>> vacuum_cost_page_hit = 1 >>> vacuum_cost_page_miss = 10 >>> vacuum_cost_page_dirty = 20 >>> vacuum_cost_limit = 100 >>> autovacuum = on >>> log_autovacuum_min_duration = 30000 >>> autovacuum_max_workers = 2 >>> autovacuum_naptime = 1min >>> autovacuum_vacuum_threshold = 500 >>> autovacuum_analyze_threshold = 500 >>> autovacuum_vacuum_scale_factor = 0.1 >>> autovacuum_analyze_scale_factor = 0.1 >>> autovacuum_freeze_max_age = 200000000 >>> autovacuum_vacuum_cost_delay = -1 >>> autovacuum_vacuum_cost_limit = -1 >>> vacuum_freeze_min_age = 50000000 >>> vacuum_freeze_table_age = 150000000 >> >> >> shared_buffers = 51605MB >> work_mem = 32MB >> maintenance_work_mem = 128 MB >> effective_cache_size = 96760MB > > There are a lot of things you can do to improve performance, but we > don't know your usage patterns or underlying IO subsystem. What does > your IO sybsystem look like? How fast can you get something like > pgbench to go on this machine? > > Might I ask where the idea for shared_buffers being 51GB came from? > Generally speaking shared_buffers don't work well that big, except in > some very specific circumstances maybe. > > So when you say IO is 100% utilized, is that being used by sorts, the > background writer, reads? > > How many active and idle connections do you typically have on this > machine? If you have a lot of connections have you considered pooling? > > What are max_connections, effective_io_concurrency, ramdom_page_cost, > wal_writer_delay, commit_delay, commit_siblings, checkpoint_segments, > temp_buffers, set to? > > Turn on things like log_temp_files, log_checkpoints. > > Also got a slow query and an explain analyze output? > > > -- > Sent via pgsql-admin mailing list (pgsql-admin@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-admin > -- Saludos, Gilberto Castillo ETECSA, La Habana, Cuba
On 19 February 2016 at 06:56, Scott Whitney <scott@journyx.com> wrote:
Echoing (other) Scott's comments, specifically, when he says "what does your IO subsystem looks like," what's the hardware? RAID 10 is all well and good, but how many drives, what type are they, and how is your RAID-10 configured? Specific model numbers would be useful.
HI there!
So...
The disks are:
HP 3TB 6G SAS 7.2K 3.5inch HDD,, HDD RPM: 7200, GB Hard Drive: 3072
HP Smart Array P840/4GB FBWC 12Gb/s SAS Raid Controller
raid 10
LVM with ext4 filesystem
Following are some helpful links to help you tune your system better:
Plenty of other resources online.
On Thu, Feb 18, 2016 at 5:15 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote:
On 19 February 2016 at 06:56, Scott Whitney <scott@journyx.com> wrote:Echoing (other) Scott's comments, specifically, when he says "what does your IO subsystem looks like," what's the hardware? RAID 10 is all well and good, but how many drives, what type are they, and how is your RAID-10 configured? Specific model numbers would be useful.HI there!So...The disks are:HP 3TB 6G SAS 7.2K 3.5inch HDD,, HDD RPM: 7200, GB Hard Drive: 3072
HP Smart Array P840/4GB FBWC 12Gb/s SAS Raid Controller
raid 10
LVM with ext4 filesystem
On 19 February 2016 at 11:20, Payal Singh <payal@omniti.com> wrote:
Following are some helpful links to help you tune your system better:Plenty of other resources online.
Thanks! BUT I'd love to hear from all of you.. sometimes talking each other is better than put some random confs in prod. I want to know what u guys have been through and, maybe, do some changes here as well.
I've sent an email to the list, showing the graphs (i think it is waiting for approval)
In the meantime...
I'm able to change to any of this below, if it will improve my performance:
Replace existing 4x3TB Disk with 1.5TB Silver SAN
Replace existing 4x3TB Disk with 4x800GB SSD Drives (Raid 5)
Replace existing 4x3TB Disk with 8x600GB 15K SAS (Raid 10)
Add 4x3TB to existing Raid 10
On 19 February 2016 at 11:24, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote:
On 19 February 2016 at 11:20, Payal Singh <payal@omniti.com> wrote:Following are some helpful links to help you tune your system better:Plenty of other resources online.Thanks! BUT I'd love to hear from all of you.. sometimes talking each other is better than put some random confs in prod. I want to know what u guys have been through and, maybe, do some changes here as well.
Hi there!
So the server is: HP DL380 G9 Dual Socket Octo Core Intel Xeon E5-2630v3 2.4GHz 128 GB RAM
So the server is: HP DL380 G9 Dual Socket Octo Core Intel Xeon E5-2630v3 2.4GHz 128 GB RAM
It's a production server, so I can't "play" with it.
I'll post here some graphs about the SPIKE I had yesterday (2016-02-18) - Note that the spike isn't so big, but usually they are.
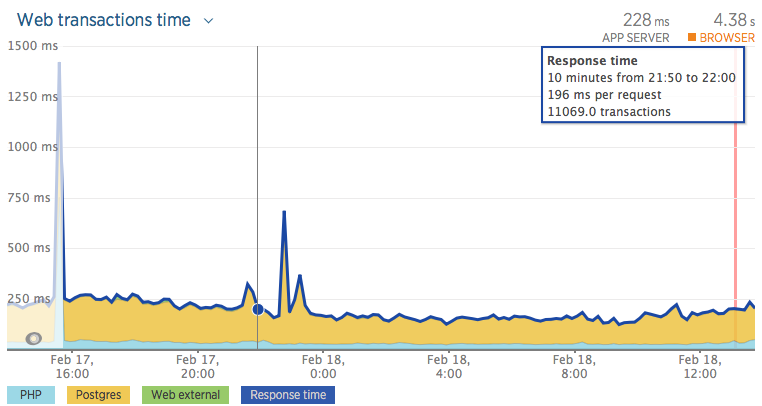
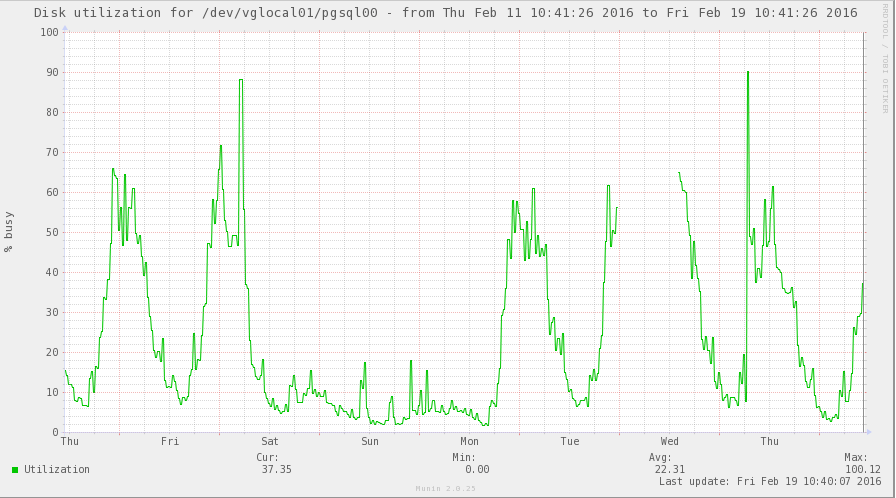
Disk utilization during that period
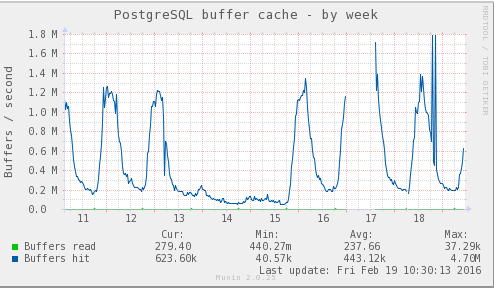
PostgreSQL buffer cache during that period:
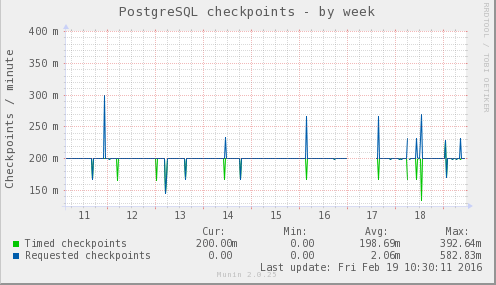
Postgres checkpoints:
There are a lot of things you can do to improve performance, but we
don't know your usage patterns or underlying IO subsystem. What does
your IO sybsystem look like? How fast can you get something like
pgbench to go on this machine?
Might I ask where the idea for shared_buffers being 51GB came from?
Generally speaking shared_buffers don't work well that big, except in
some very specific circumstances maybe.
The shared_buffers idea, was made by the previous DBA.
So when you say IO is 100% utilized, is that being used by sorts, the
background writer, reads?
How many active and idle connections do you typically have on this
machine? If you have a lot of connections have you considered pooling?
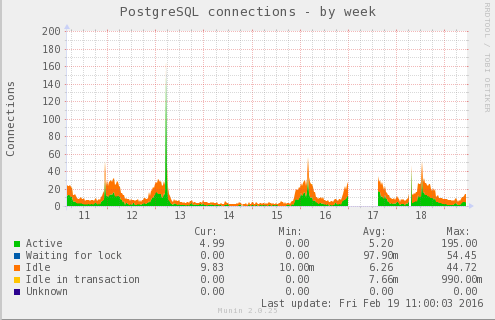
What are max_connections, effective_io_concurrency, ramdom_page_cost,
wal_writer_delay, commit_delay, commit_siblings, checkpoint_segments,
temp_buffers, set to?
max_connections = 200
effective_io_concurrency = 0
wal_writer_delay = 200ms
commit_delay = 0
#####commit_siblings = 5
checkpoint_segments = 64
#####ramdom_page_cost (Couldn't find that parameter in postgresql.conf)
temp_buffers = 16MB
Turn on things like log_temp_files, log_checkpoints.
They are already on:
log_temp_files = 4096
log_checkpoints = on
Also got a slow query and an explain analyze output?
Sometimes slow queries are INSERT/UPDATEs ... so no explain analyze for them
Вложения
So how big is your data set? Is it much bigger, about the same, or much smaller than your shared_buffers? The problem with a giant shared_buffers is that postgresql has a VERY big set of data to keep track of when it comes time to write it out, evict stuff, etc etc. generally speaking the kernel is better optimized to cache huge data sets. For instance, I can get very good performance on a machine with a multi-terabyte data set, running with 512GB RAM and only using 10GB as shared_buffers, and letting the kernel use the rest as cache. Making share_buffers bigger doesn't make it faster after a few gigabytes, even with 24 cores and 10 SSDs in RAID-5 (we can go faster with RAID 10 but we need the space). 51GB is a huge shared_buffer setting. I'd want to see some benchmarks showing it was faster than 1 or 2GB. I'm betting it won't be. Also are you using a pooler? I would take it as no. Note that your connections go from 30 or so to over 140 during a spike. A computer, based on number of concurrent iops it can handle etc, will have a performance graph that climbs as you hit a certain peak number of active connections. On a machine like yours I'd expect that peak to be between 4 and 20. Restricting active connections to a number in that range makes the machine faster in terms of throughput, and keeps it from slowly tipping over as you go further and further past it's peak number. pgbouncer is super easy to setup and it can handle huge numbers of idle connections (10,000 etc) while keeping the db running at its fastest. My advice? Get a pooler in there.
Thanks for the reply, Scott.
On 19 February 2016 at 13:47, Scott Marlowe <scott.marlowe@gmail.com> wrote:
So how big is your data set? Is it much bigger, about the same, or
much smaller than your shared_buffers? The problem with a giant
The total DB size is 1,9 TB
shared_buffers is that postgresql has a VERY big set of data to keep
track of when it comes time to write it out, evict stuff, etc etc.
generally speaking the kernel is better optimized to cache huge data
sets. For instance, I can get very good performance on a machine with
a multi-terabyte data set, running with 512GB RAM and only using 10GB
as shared_buffers, and letting the kernel use the rest as cache.
Making share_buffers bigger doesn't make it faster after a few
gigabytes, even with 24 cores and 10 SSDs in RAID-5 (we can go faster
with RAID 10 but we need the space). 51GB is a huge shared_buffer
setting. I'd want to see some benchmarks showing it was faster than 1
or 2GB. I'm betting it won't be.
Also are you using a pooler? I would take it as no. Note that your
connections go from 30 or so to over 140 during a spike. A computer,
based on number of concurrent iops it can handle etc, will have a
performance graph that climbs as you hit a certain peak number of
active connections. On a machine like yours I'd expect that peak to be
between 4 and 20. Restricting active connections to a number in that
range makes the machine faster in terms of throughput, and keeps it
from slowly tipping over as you go further and further past it's peak
number.
pgbouncer is super easy to setup and it can handle huge numbers of
idle connections (10,000 etc) while keeping the db running at its
fastest. My advice? Get a pooler in there.
I'm not using a pooler.. But I'll have a look on it
Should I decrease my max_connections as well?
On Thu, Feb 18, 2016 at 6:48 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > Thanks for the reply, Scott. > > > On 19 February 2016 at 13:47, Scott Marlowe <scott.marlowe@gmail.com> wrote: >> >> So how big is your data set? Is it much bigger, about the same, or >> much smaller than your shared_buffers? The problem with a giant > > > The total DB size is 1,9 TB Yeah 50GB isn't gonna hold the whole thing so being that big is probably counterproductive. I'd drop it to anywhere from 1 to 10GB, and test work load on each size etc. >> Also are you using a pooler? I would take it as no. Note that your >> connections go from 30 or so to over 140 during a spike. A computer, >> based on number of concurrent iops it can handle etc, will have a >> performance graph that climbs as you hit a certain peak number of >> active connections. On a machine like yours I'd expect that peak to be >> between 4 and 20. Restricting active connections to a number in that >> range makes the machine faster in terms of throughput, and keeps it >> from slowly tipping over as you go further and further past it's peak >> number. >> >> pgbouncer is super easy to setup and it can handle huge numbers of >> idle connections (10,000 etc) while keeping the db running at its >> fastest. My advice? Get a pooler in there. > > > I'm not using a pooler.. But I'll have a look on it Cool. pic a pool size (4 to 20 etc) that corresponds to the best throughput (transactions per second etc). > Should I decrease my max_connections as well? Not before you put a connection pooler in place. Right now lowering it will likely create as many problems as it solves, with failed to connect error messages etc. After a pooler's in place it's nice to set the max conns to something about 2x what you think you should see with the connection pooler in place. -- To understand recursion, one must first understand recursion.
I also noticed you're running RHEL 6.x which runs on the truly ancient (but pretty reliable) 2.6.32 kernel. The newer 3.11 and 3.13 kernels are MUCH faster at IO and a lot smarter about caching and when to swap etc. I've seen several big machines go from a few thousand tps to 15 to 20k tps just from going from 3.2 to 3.13. Keep us updated on whether or not a pooler works for you.
On 22 February 2016 at 07:34, Scott Marlowe <scott.marlowe@gmail.com> wrote:
I also noticed you're running RHEL 6.x which runs on the truly ancient
(but pretty reliable) 2.6.32 kernel. The newer 3.11 and 3.13 kernels
are MUCH faster at IO and a lot smarter about caching and when to swap
etc. I've seen several big machines go from a few thousand tps to 15
to 20k tps just from going from 3.2 to 3.13. Keep us updated on
whether or not a pooler works for you.
I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6
Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think only in Centos 7)
Is so, can you please provide me any link that shows a IO improvement between two kernels? something that I can study
On Mon, Feb 22, 2016 at 6:23 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote:
On 22 February 2016 at 07:34, Scott Marlowe <scott.marlowe@gmail.com> wrote:I also noticed you're running RHEL 6.x which runs on the truly ancient
(but pretty reliable) 2.6.32 kernel. The newer 3.11 and 3.13 kernels
are MUCH faster at IO and a lot smarter about caching and when to swap
etc. I've seen several big machines go from a few thousand tps to 15
to 20k tps just from going from 3.2 to 3.13. Keep us updated on
whether or not a pooler works for you.I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think only in Centos 7)Is so, can you please provide me any link that shows a IO improvement between two kernels? something that I can study
Dorian Machado
On Mon, Feb 22, 2016 at 2:23 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > > > On 22 February 2016 at 07:34, Scott Marlowe <scott.marlowe@gmail.com> wrote: >> >> I also noticed you're running RHEL 6.x which runs on the truly ancient >> (but pretty reliable) 2.6.32 kernel. The newer 3.11 and 3.13 kernels >> are MUCH faster at IO and a lot smarter about caching and when to swap >> etc. I've seen several big machines go from a few thousand tps to 15 >> to 20k tps just from going from 3.2 to 3.13. Keep us updated on >> whether or not a pooler works for you. > > > > I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6 > > Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think > only in Centos 7) > Is so, can you please provide me any link that shows a IO improvement > between two kernels? something that I can study It has been many years since I took care of a Centos box, but in this article by Josh Berkus about avoiding kernel 3.2 it is mentioned that centos 7 can in fact run 3.10 kernel. http://www.databasesoup.com/2014/09/why-you-need-to-avoid-linux-kernel-32.html
On 02/22/2016 07:41 PM, Scott Marlowe wrote: >> I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6 >> >> Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think >> only in Centos 7) >> Is so, can you please provide me any link that shows a IO improvement >> between two kernels? something that I can study > > It has been many years since I took care of a Centos box, but in this > article by Josh Berkus about avoiding kernel 3.2 it is mentioned that > centos 7 can in fact run 3.10 kernel. > > http://www.databasesoup.com/2014/09/why-you-need-to-avoid-linux-kernel-32.html It isn't just 3.2. You should avoid 3.2-3.8. 2.6 is fine. JD > > -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them.
On Mon, Feb 22, 2016 at 9:05 PM, Joshua D. Drake <jd@commandprompt.com> wrote: > On 02/22/2016 07:41 PM, Scott Marlowe wrote: > >>> I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6 >>> >>> Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think >>> only in Centos 7) >>> Is so, can you please provide me any link that shows a IO improvement >>> between two kernels? something that I can study >> >> >> It has been many years since I took care of a Centos box, but in this >> article by Josh Berkus about avoiding kernel 3.2 it is mentioned that >> centos 7 can in fact run 3.10 kernel. >> >> >> http://www.databasesoup.com/2014/09/why-you-need-to-avoid-linux-kernel-32.html > > > It isn't just 3.2. You should avoid 3.2-3.8. 2.6 is fine. I wouldn't say 2.6 is fine, but it is better than 3.2 through 3.8. But it still has plenty of performance issues under load that 3.11 and up addressed for me. -- To understand recursion, one must first understand recursion.
On 23 February 2016 at 17:32, Scott Marlowe <scott.marlowe@gmail.com> wrote:
On Mon, Feb 22, 2016 at 9:05 PM, Joshua D. Drake <jd@commandprompt.com> wrote:
> On 02/22/2016 07:41 PM, Scott Marlowe wrote:
>
>>> I'm running a CentOS 6.6 with Kernel 2.6.32-504.el6
>>>
>>> Is it possible to upgrade to the 3.13 version using Centos 6.6? (I think
>>> only in Centos 7)
>>> Is so, can you please provide me any link that shows a IO improvement
>>> between two kernels? something that I can study
>>
>>
>> It has been many years since I took care of a Centos box, but in this
>> article by Josh Berkus about avoiding kernel 3.2 it is mentioned that
>> centos 7 can in fact run 3.10 kernel.
>>
>>
>> http://www.databasesoup.com/2014/09/why-you-need-to-avoid-linux-kernel-32.html
>
>
> It isn't just 3.2. You should avoid 3.2-3.8. 2.6 is fine.
I wouldn't say 2.6 is fine, but it is better than 3.2 through 3.8. But
it still has plenty of performance issues under load that 3.11 and up
addressed for me.
Hi guys... how are you all doing?
Scott Marlowe, you sent an email about the pooler...
I've done some tests on my VM, but can't do tests on the servers, as they are already in production...
However... I'm willing to set-up the pgbouncer pool on my postgresql 9.2 server...
Just got some questions first.. can you please give me your opinion?
my scenario:
1 Load Balancer (nginx) --->
2 web servers (www01 and www02) --->
4 DB servers (master01, slave01 (read-only), slave02 (hot_standby), slave03 (hot_standby), slave04 (hot_standby)
I'd install the pgbouncer on the www01 server... What do you guys think about it? Having in mind my scenario?
Cheers
Lucas
Hi guys... how are you all doing?Scott Marlowe, you sent an email about the pooler...I've done some tests on my VM, but can't do tests on the servers, as they are already in production...However... I'm willing to set-up the pgbouncer pool on my postgresql 9.2 server...Just got some questions first.. can you please give me your opinion?my scenario:1 Load Balancer (nginx) --->
2 web servers (www01 and www02) --->
4 DB servers (master01, slave01 (read-only), slave02 (hot_standby), slave03 (hot_standby), slave04 (hot_standby)I'd install the pgbouncer on the www01 server... What do you guys think about it? Having in mind my scenario?CheersLucas
I mean... can pgbouncer handle with my master and slave01? As I'm using slave01 as read-only server? Also.. I've got 2 www servers... Do I have to have pgbouncer in both of them?
On Mon, Apr 11, 2016 at 4:45 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > >>> >> >> Hi guys... how are you all doing? >> >> >> Scott Marlowe, you sent an email about the pooler... >> >> I've done some tests on my VM, but can't do tests on the servers, as they >> are already in production... >> However... I'm willing to set-up the pgbouncer pool on my postgresql 9.2 >> server... >> >> Just got some questions first.. can you please give me your opinion? >> >> my scenario: >>> >>> 1 Load Balancer (nginx) ---> >>> 2 web servers (www01 and www02) ---> >>> 4 DB servers (master01, slave01 (read-only), slave02 (hot_standby), >>> slave03 (hot_standby), slave04 (hot_standby) >> >> >> I'd install the pgbouncer on the www01 server... What do you guys think >> about it? Having in mind my scenario? >> >> Cheers >> Lucas >> > > I mean... can pgbouncer handle with my master and slave01? As I'm using > slave01 as read-only server? Also.. I've got 2 www servers... Do I have to > have pgbouncer in both of them? pgbouncer is kinda happy living almost anywhere. Putting it on separate vms means you can reconfigure when needed for say another db or web server without having to edit anything but the pgbouncer vms. Putting it on the db servers means that if a db server goes down then you need to reconfigure the app side to not look for them Putting them on the app side means you have to configured according to how many app servers you have etc. It all really depends on your use cases. but putting it on the www servers works fine and is how I've done it many times in the past.
pgbouncer is kinda happy living almost anywhere.
Putting it on separate vms means you can reconfigure when needed for
say another db or web server without having to edit anything but the
pgbouncer vms.
Putting it on the db servers means that if a db server goes down then
you need to reconfigure the app side to not look for them
Putting them on the app side means you have to configured according to
how many app servers you have etc.
It all really depends on your use cases. but putting it on the www
servers works fine and is how I've done it many times in the past.
Thanks for the reply...
But as I'm using two web servers, do I have to put pgbouncer on both of them?
Not sure how is going to work as I have two web servers
On Mon, Apr 11, 2016 at 6:20 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: >> >> >> pgbouncer is kinda happy living almost anywhere. >> >> Putting it on separate vms means you can reconfigure when needed for >> say another db or web server without having to edit anything but the >> pgbouncer vms. >> >> Putting it on the db servers means that if a db server goes down then >> you need to reconfigure the app side to not look for them >> >> Putting them on the app side means you have to configured according to >> how many app servers you have etc. >> >> It all really depends on your use cases. but putting it on the www >> servers works fine and is how I've done it many times in the past. > > > Thanks for the reply... > > But as I'm using two web servers, do I have to put pgbouncer on both of > them? > > Not sure how is going to work as I have two web servers Either way will work. The advantage to having one on each is that connections are simpler to configure and if one goes fown you still have pgbouncer running
On 12 April 2016 at 13:55, Scott Marlowe <scott.marlowe@gmail.com> wrote:
Either way will work. The advantage to having one on each is thatOn Mon, Apr 11, 2016 at 6:20 PM, drum.lucas@gmail.com
<drum.lucas@gmail.com> wrote:
>>
>>
>> pgbouncer is kinda happy living almost anywhere.
>>
>> Putting it on separate vms means you can reconfigure when needed for
>> say another db or web server without having to edit anything but the
>> pgbouncer vms.
>>
>> Putting it on the db servers means that if a db server goes down then
>> you need to reconfigure the app side to not look for them
>>
>> Putting them on the app side means you have to configured according to
>> how many app servers you have etc.
>>
>> It all really depends on your use cases. but putting it on the www
>> servers works fine and is how I've done it many times in the past.
>
>
> Thanks for the reply...
>
> But as I'm using two web servers, do I have to put pgbouncer on both of
> them?
>
> Not sure how is going to work as I have two web servers
connections are simpler to configure and if one goes fown you still
have pgbouncer running
hmm ok..
So basically would be:
1 - Install the pgbouncer into the www server
2 - Do the tests to see if it works
3 - Change the APP connection parameters to start using pgbouncer (probably just the port)
Basically would be that, right?
Would my slave01 still be able to work as read-only?
On Mon, Apr 11, 2016 at 9:17 PM, drum.lucas@gmail.com <drum.lucas@gmail.com> wrote: > > > On 12 April 2016 at 13:55, Scott Marlowe <scott.marlowe@gmail.com> wrote: >> >> On Mon, Apr 11, 2016 at 6:20 PM, drum.lucas@gmail.com >> <drum.lucas@gmail.com> wrote: >> >> >> >> >> >> pgbouncer is kinda happy living almost anywhere. >> >> >> >> Putting it on separate vms means you can reconfigure when needed for >> >> say another db or web server without having to edit anything but the >> >> pgbouncer vms. >> >> >> >> Putting it on the db servers means that if a db server goes down then >> >> you need to reconfigure the app side to not look for them >> >> >> >> Putting them on the app side means you have to configured according to >> >> how many app servers you have etc. >> >> >> >> It all really depends on your use cases. but putting it on the www >> >> servers works fine and is how I've done it many times in the past. >> > >> > >> > Thanks for the reply... >> > >> > But as I'm using two web servers, do I have to put pgbouncer on both of >> > them? >> > >> > Not sure how is going to work as I have two web servers >> >> Either way will work. The advantage to having one on each is that >> connections are simpler to configure and if one goes fown you still >> have pgbouncer running > > > hmm ok.. > > So basically would be: > > 1 - Install the pgbouncer into the www server > 2 - Do the tests to see if it works > 3 - Change the APP connection parameters to start using pgbouncer (probably > just the port) > > Basically would be that, right? > > Would my slave01 still be able to work as read-only? Yes.