Re: POC, WIP: OR-clause support for indexes
| От | Alena Rybakina |
|---|---|
| Тема | Re: POC, WIP: OR-clause support for indexes |
| Дата | |
| Msg-id | b301dce1-09fd-72b1-834a-527ca428db5e@yandex.ru обсуждение исходный текст |
| Ответ на | Re: POC, WIP: OR-clause support for indexes (Peter Geoghegan <pg@bowt.ie>) |
| Ответы |
Re: POC, WIP: OR-clause support for indexes
|
| Список | pgsql-hackers |
I fixed an error that caused the current optimization not to work with
prepared queries. I added a test to catch similar cases in the future.
I have attached a patch.
On 01.08.2023 22:42, Peter Geoghegan wrote:
> On Mon, Jul 31, 2023 at 9:38 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:
>> I noticed only one thing there: when we have unsorted array values in
>> SOAP, the query takes longer than
>> when it has a sorted array. I'll double-check it just in case and write
>> about the results later.
> I would expect the B-Tree preprocessing by _bt_preprocess_array_keys()
> to be very slightly faster when the query is written with presorted,
> duplicate-free constants. Sorting is faster when you don't really have
> to sort. However, I would not expect the effect to be significant
> enough to matter, except perhaps in very extreme cases.
> Although...some of the cases you care about are very extreme cases.
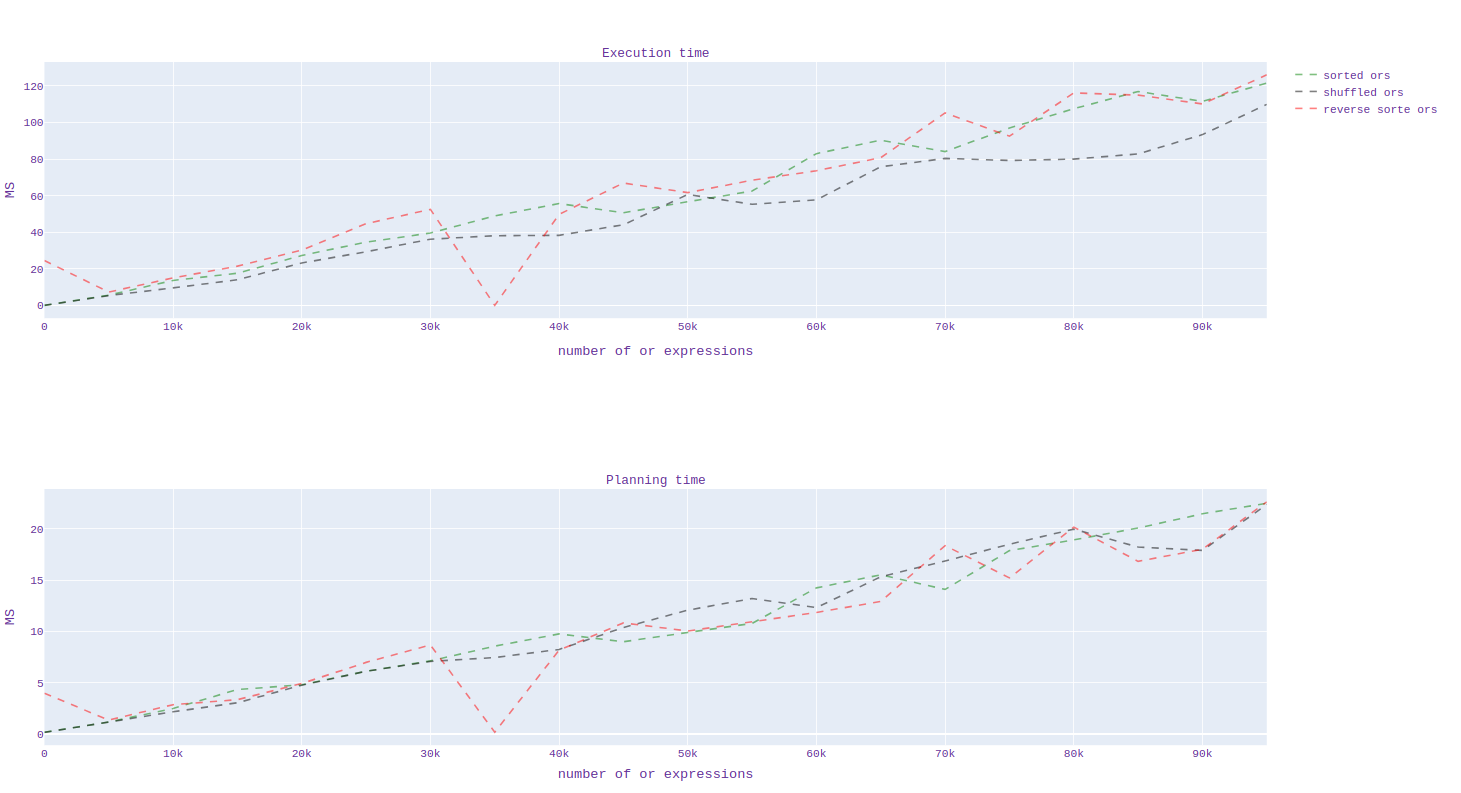
I tested an optimization to compare execution time and scheduling with
sorting, shuffling, and reverse sorting constants in the simple case and
I didn't notice any significant changes (compare_sorted.png).
(I used a database with 100 million values generated by pgbench).
>> I am also testing some experience with multi-column indexes using SAOPs.
> Have you thought about a similar transformation for when the row
> constructor syntax happens to have been used?
>
> Consider a query like the following, against a table with a composite
> index on (a, b):
>
> select * from multi_test where ( a, b ) in (( 1, 1 ), ( 2, 1 ));
>
> This query will get a BitmapOr based plan that's similar to the plans
> that OR-based queries affected by your transformation patch get today,
> on HEAD. However, this equivalent spelling has the potential to be
> significantly faster:
>
> select * from multi_test where a = any('{1,2}') and b = 1;
>
> (Of course, this is more likely to be true with my nbtree SAOP patch in place.)
No, I haven't thought about it yet. I studied the example and it would
really be nice to add optimization here. I didn't notice any problems
with its implementation. I also have an obvious example with the "or"
operator, for example
, select * from multi_test, where (a, b ) = ( 1, 1 ) or (a, b ) = ( 2, 1
) ...;
Although I think such a case will be used less often.
Thank you for the example, I think I understand better why our patches
help each other, but I will review your patch again.
I tried another example to see the lack of optimization in the pgbench
database, but I also created an additional index:
create index ind1 on pgbench_accounts(aid,bid);
test_db=# explain analyze select * from pgbench_accounts where (aid,
bid) in ((2,1), (2,2), (2,3), (3,3));
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on pgbench_accounts (cost=17.73..33.66 rows=1
width=97) (actual time=0.125..0.133 rows=1 loops=1)
Recheck Cond: ((aid = 2) OR (aid = 2) OR (aid = 2) OR (aid = 3))
Filter: (((aid = 2) AND (bid = 1)) OR ((aid = 2) AND (bid = 2)) OR
((aid = 2) AND (bid = 3)) OR ((aid = 3) AND (bid = 3)))
Rows Removed by Filter: 1
Heap Blocks: exact=1
-> BitmapOr (cost=17.73..17.73 rows=4 width=0) (actual
time=0.100..0.102 rows=0 loops=1)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.036..0.037 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.021..0.022 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.021..0.021 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.019..0.020 rows=1 loops=1)
Index Cond: (aid = 3)
Planning Time: 0.625 ms
Execution Time: 0.227 ms
(16 rows)
I think such optimization would be useful here: aid =2 and bid in (1,2)
or (aid,bid)=((3,3))
> Note that we currently won't use RowCompareExpr in many simple cases
> where the row constructor syntax has been used. For example, a query
> like this:
>
> select * from multi_test where ( a, b ) = (( 2, 1 ));
>
> This case already involves a transformation that is roughly comparable
> to the one you're working on now. We'll remove the RowCompareExpr
> during parsing. It'll be as if my example row constructor equality
> query was written this way instead:
>
> select * from multi_test where a = 2 and b = 1;
>
> This can be surprisingly important, when combined with other things,
> in more realistic examples.
>
> The nbtree code has special knowledge of RowCompareExpr that makes the
> rules for comparing index tuples different to those from other kinds
> of index scans. However, due to the RowCompareExpr transformation
> process I just described, we don't need to rely on that specialized
> nbtree code when the row constructor syntax is used with a simple
> equality clause -- which is what makes the normalization process have
> real value. If the nbtree code cannot see RowCompareExpr index quals
> then it cannot have this problem in the first place. In general it is
> useful to "normalize to conjunctive normal form" when it might allow
> scan key preprocessing in the nbtree code to come up with a much
> faster approach to executing the scan.
>
> It's easier to understand what I mean by showing a simple example. The
> nbtree preprocessing code is smart enough to recognize that the
> following query doesn't really need to do any work, due to having
> quals that it recognizes as contradictory (it can set so->qual_okay to
> false for unsatisfiable quals):
>
> select * from multi_test where ( a, b ) = (( 2, 1 )) and a = -1;
>
> However, it is not smart enough to perform the same trick if we change
> one small detail with the query:
>
> select * from multi_test where ( a, b ) >= (( 2, 1 )) and a = -1;
Yes, I have run the examples and I see it.
((ROW(aid, bid) >= ROW(2, 1)) AND (aid = '-1'::integer))
As I see it, we can implement such a transformation:
'( a, b ) >= (( 2, 1 )) and a = -1' -> 'aid >= 2 and bid >= 1 and
aid =-1'
It seems to me the most difficult thing is to notice problematic cases
where the transformations are incorrect, but I think it can be implemented.
> Ideally, the optimizer would canonicalize/normalize everything in a
> way that made all of the nbtree preprocessing optimizations work just
> as well, without introducing any new special cases. Obviously, there
> is no reason why we can't perform the same trick with the second
> variant. (Note also that the nbtree preprocessing code can be smart
> about redundant quals, not just contradictory quals, so it matters
> more than it may appear from this simple, unrealistic example of
> mine.)
I agree with your position, but I still don't understand how to consider
transformations to generalized cases without relying on special cases.
As I understand it, you assume that it is possible to apply
transformations at the index creation stage, but there I came across the
selectivity overestimation problem.
I still haven't found a solution for this problem.
> While these similar RowCompareExpr transformations are at least
> somewhat important, that's not really why I bring them up now. I am
> pointing them out now because I think that it might help you to
> develop a more complete mental model of these transformations.
> Ideally, your initial approach will generalize to other situations
> later on. So it's worth considering the relationship between this
> existing RowCompareExpr transformation, and the one that you're
> working on currently. Plus other, future transformations.
I will consider my case more broadly, but for this I will need some
research work.
> This example might also give you some appreciation of why my SAOP
> patch is confused about when we need to do normalization/safety
> checks. Some things seem necessary when generating index paths in the
> optimizer. Other things seem necessary during preprocessing, in the
> nbtree code, at the start of the index scan. Unfortunately, it's not
> obvious to me where the right place is to deal with each aspect of
> setting up multi-column SAOP index quals. My mental model is very
> incomplete.
To be honest, I think that in your examples I understand better what you
mean by normalization to the conjunctive norm, because I only had a
theoretical idea from the logic course.
Hence, yes, normalization/security checks - now I understand why they
are necessary.
--
Regards,
Alena Rybakina
Postgres Professional
Вложения
В списке pgsql-hackers по дате отправления: