[PATCH] TODO “Allow LISTEN on patterns”
| От | Alexander Cheshev |
|---|---|
| Тема | [PATCH] TODO “Allow LISTEN on patterns” |
| Дата | |
| Msg-id | CAN_hQmuysJpMzWcyhQwYtHpao8XXMpc48A8F=n-0e6x_z2P_Fw@mail.gmail.com обсуждение исходный текст |
| Ответы |
Re: [PATCH] TODO “Allow LISTEN on patterns”
|
| Список | pgsql-hackers |
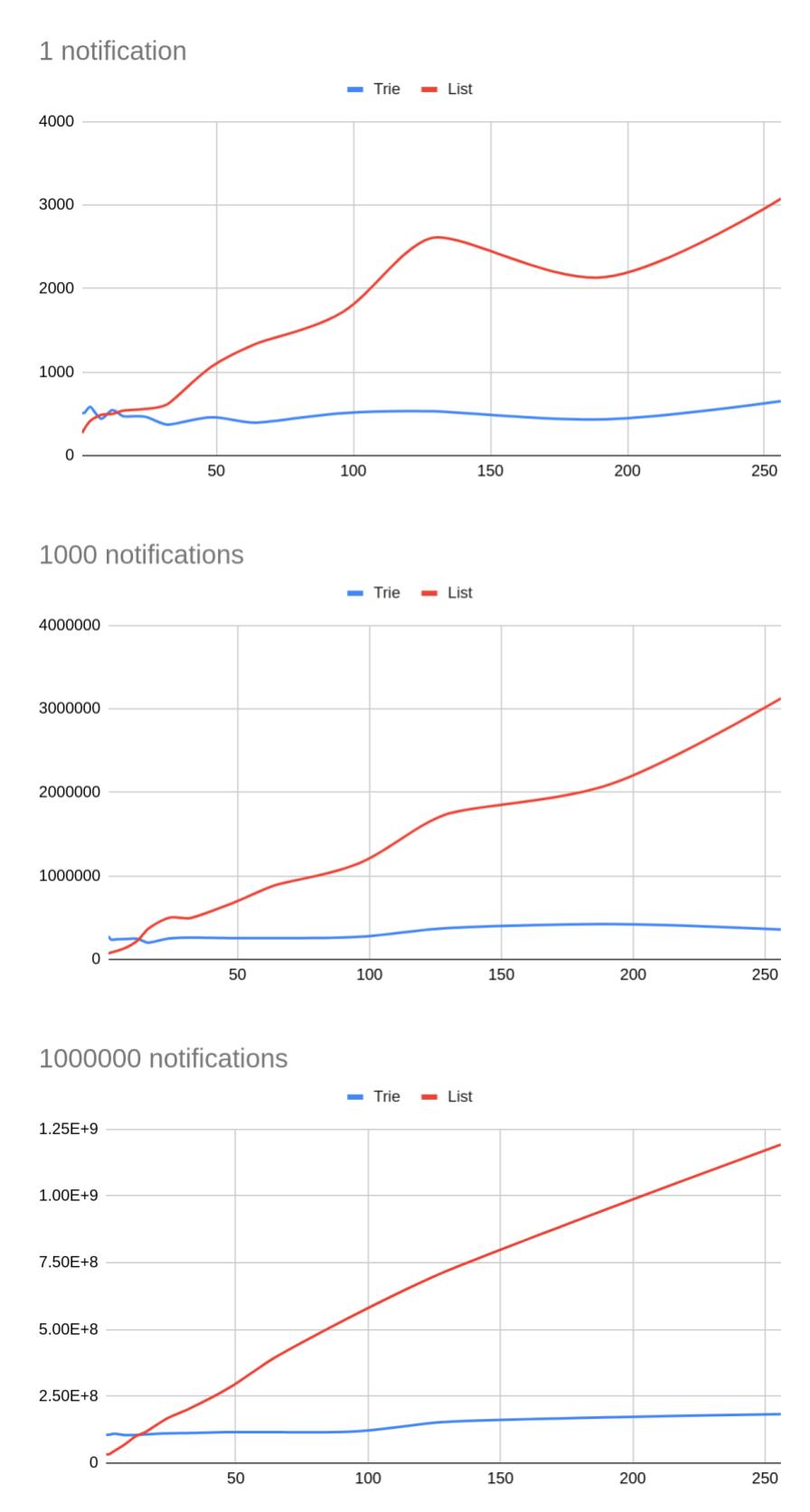
Hello Hackers, I have implemented TODO “Allow LISTEN on patterns” [1] and attached the patch to the email. The patch basically consists of the following two parts. 1. Support wildcards in LISTEN command Notification channels can be composed of multiple levels in the form ‘a.b.c’ where ‘a’, ‘b’ and ‘c’ are identifiers. Listen channels can be composed of multiple levels in the form ‘a.b.c’ where ‘a’, ‘b’ and ‘c’ are identifiers which can contain the following wildcards: * ‘%’ matches everything until the end of a level. Can only appear at the end of a level. For example, the notification channels ‘a.b.c’, ‘a.bc.c’ match against the listen channel ‘a.b%.c’. * ‘>’ matches everything to the right. Can only appear at the end of the last level. For example, the notification channels ‘a.b’, ‘a.bc.d’ match against the listen channel ‘a.b>’. In [1] Sev Zaslavsky proposed to add a GUC so that we don't break existing code. The patch adds three additional characters ‘.’, ‘%’ and ‘>’ which are forbidden in existing code. Without these characters the patch works in the same way as existing code. So there is no need to add a GUC. 2. Performance improvement of matching To match a notification channel against listen channels Postgres uses the function IsListeningOn which iterates over all listen channels and compares them with the notification channel. The time complexity can be estimated as O(nm) where n is the number of the listen channels and m is the size of the notification channel. To match a notification channel against listen channels the patch searches in binary trie. The time complexity can be estimated as O(m) where m is the size of the notification channel. So there is no dependence on the number of the listen channels. The patch builds binary trie in O(nm) where n is the number of the listen channels and m is the maximum length among the listen channels. The space complexity required to build a binary trie is dominated by the leaf nodes and can be estimated as O(n) where n is the number of the listen channels. I gathered data to compare Postgres with the patch. In the file benchmark.jpg you can find three graphics for three different amounts of notifications. Horizontal line represents number of listen channels and vertical line represents time in nanoseconds. The time measures pure calls to IsListeningOn and IsMatchingOn. From the graphics you can deduce the following observations: * The time of the trie match doesn’t depend on the number of listen channels and remains the same. The time of the list search depends linerary on the number of listen channels. So the practical results coincide with the theoretical observations. * When the number of listen channels is higher than 250 the trie match outperforms list search around 6 times. * When the number of listen channels is lower than 16 the list search outperforms the trie match around 2 times. I tried to use list match on a small number of listen channels but it didn’t perform any better than the trie match. The reason for that is that the list search uses strcmp under the hood which I couldn’t purely use because I also had to deal with wildcards. [1] https://www.postgresql.org/message-id/flat/52693FC5.7070507%40gmail.com Regards, Alexander Cheshev
Вложения
В списке pgsql-hackers по дате отправления: