Re: Lockless queue of waiters in LWLock
| От | Pavel Borisov |
|---|---|
| Тема | Re: Lockless queue of waiters in LWLock |
| Дата | |
| Msg-id | CALT9ZEF7q+Sarz1MjrX-fM7OsoU7CK16=ONoGCOkY3Efj+Grnw@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Lockless queue of waiters in LWLock (Alexander Korotkov <aekorotkov@gmail.com>) |
| Ответы |
Re: Lockless queue of waiters in LWLock
|
| Список | pgsql-hackers |
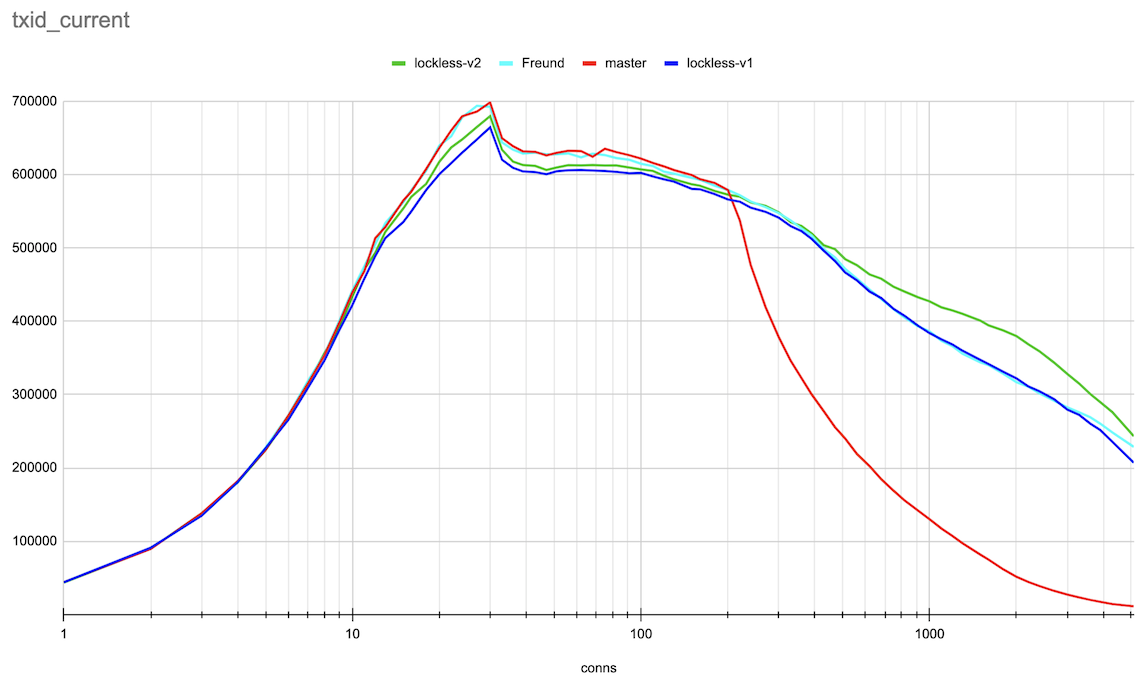
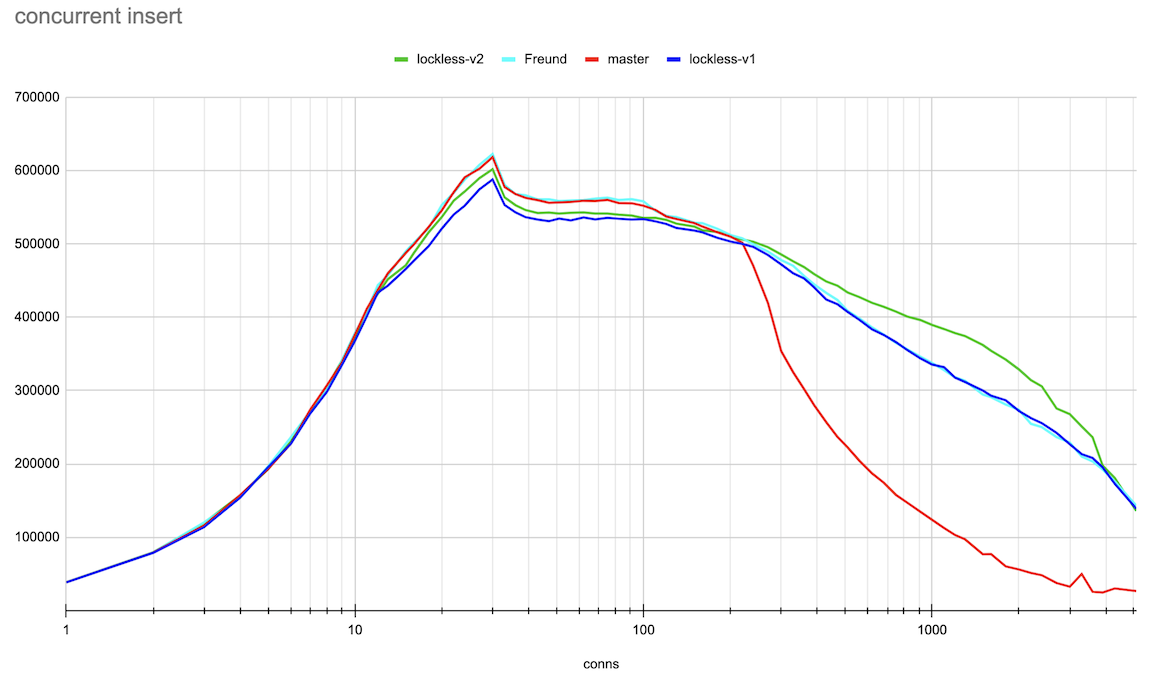
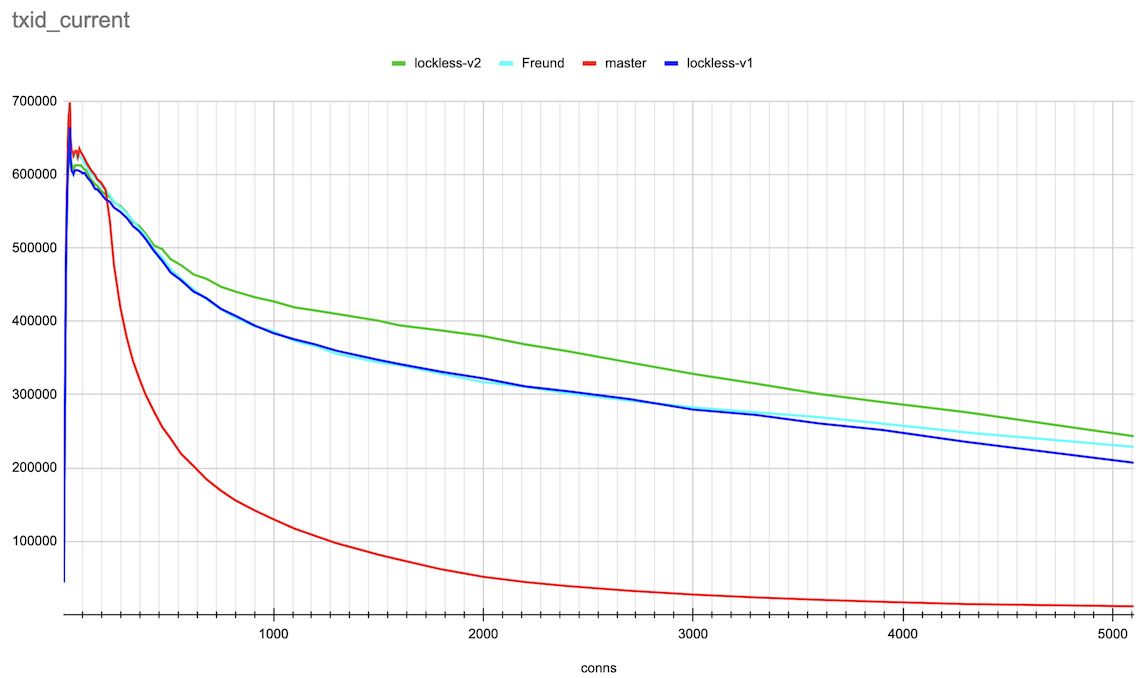
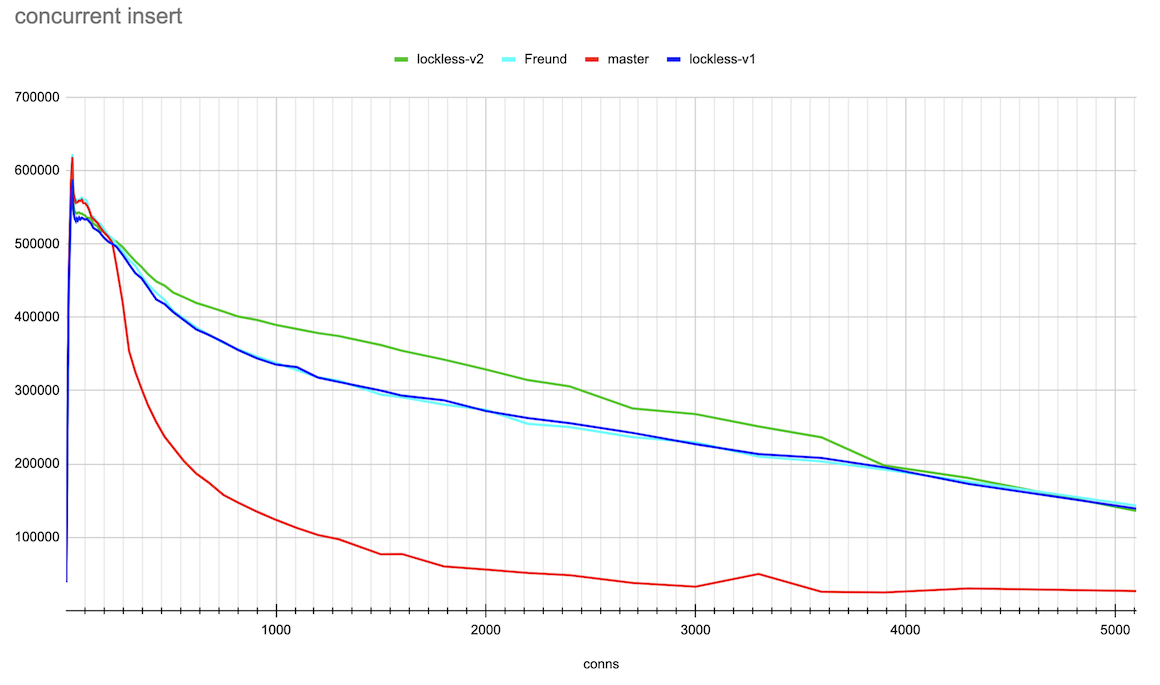
Hi, Andres, Thank you very much for the ideas on this topic! > > > If the lock state contains references to the queue head and tail, we can > > > implement a lockless queue of waiters for the LWLock. Adding new items to > > > the queue head or tail can be done with a single CAS operation (adding to > > > the tail will also require further setting the reference from the previous > > > tail). Given that there could be only one lock releaser, which wakes up > > > waiters in the queue, we can handle all the concurrency issues with > > > reasonable complexity. > > > > Right now lock releases happen *after* the lock is released. > > That makes sense. The patch makes the locker hold the lock, which it's > processing the queue. So, the lock is held for a longer time. > > > I suspect that is > > at least part of the reason for the regression you're seeing. It also looks > > like you're going to need a substantially higher number of atomic operations - > > right now the queue processing needs O(1) atomic ops, but your approach ends > > up with O(waiters) atomic ops. > > Hmm... In the patch, queue processing calls CAS once after processing > the queue. There could be retries to process the queue parts, which > were added concurrently. But I doubt it ends up with O(waiters) atomic > ops. Pavel, I think we could gather some statistics to check how many > retries we have on average. > I've made some measurements on the number of repeated CAS operations on lock acquire and release. (For this I applied Print-lwlock-stats-on-CAS-repeats.patch onto the previous patch v1 in this thread) The results when running the same insert test, that produced the results in the original post on 20 connections are as follows: lwlock ProcArray: -------------| locks acquired | CAS repeats to acquire | CAS repeats to release shared | 493187 | 57310 | 12049 exclusive | 46816 | 42329 | 8816 wait-until-free | - | 0 | 76124 blk 79473 > > I suspect it might be worth going halfway, i.e. put the list head/tail in the > > atomic variable, but process the list with a lock held, after the lock is > > released. > > Good idea. We, anyway, only allow one locker at a time to process the queue. Alexander added these changes in v2 of a patch. The results of the same benchmarking master vs Andres' patch vs lockless queue patch v1 and v2 are attached. They are done in the same way as in the original post. The small difference is that I've gone further until 5000 connections and also produced both log and linear scale connections axis plots for the more clear demonstration. Around 20 connections TPS increased though not yet to the same value the master and Andres' patches has. And in a range 300-3000 connections the v2 patch demonstrated clear gain. I'm planning to gather more detailed statistics on different LWLockAcquire calls soon to understand prospects for further optimizations. Best regards, Pavel Borisov
Вложения
В списке pgsql-hackers по дате отправления: