Re: Improving btree performance through specializing by key shape, take 2
| От | Matthias van de Meent |
|---|---|
| Тема | Re: Improving btree performance through specializing by key shape, take 2 |
| Дата | |
| Msg-id | CAEze2WiqOONRQTUT1p_ZV19nyMA69UU2s0e2dp+jSBM=j8snuw@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Improving btree performance through specializing by key shape, take 2 (Peter Geoghegan <pg@bowt.ie>) |
| Ответы |
Re: Improving btree performance through specializing by key shape, take 2
|
| Список | pgsql-hackers |
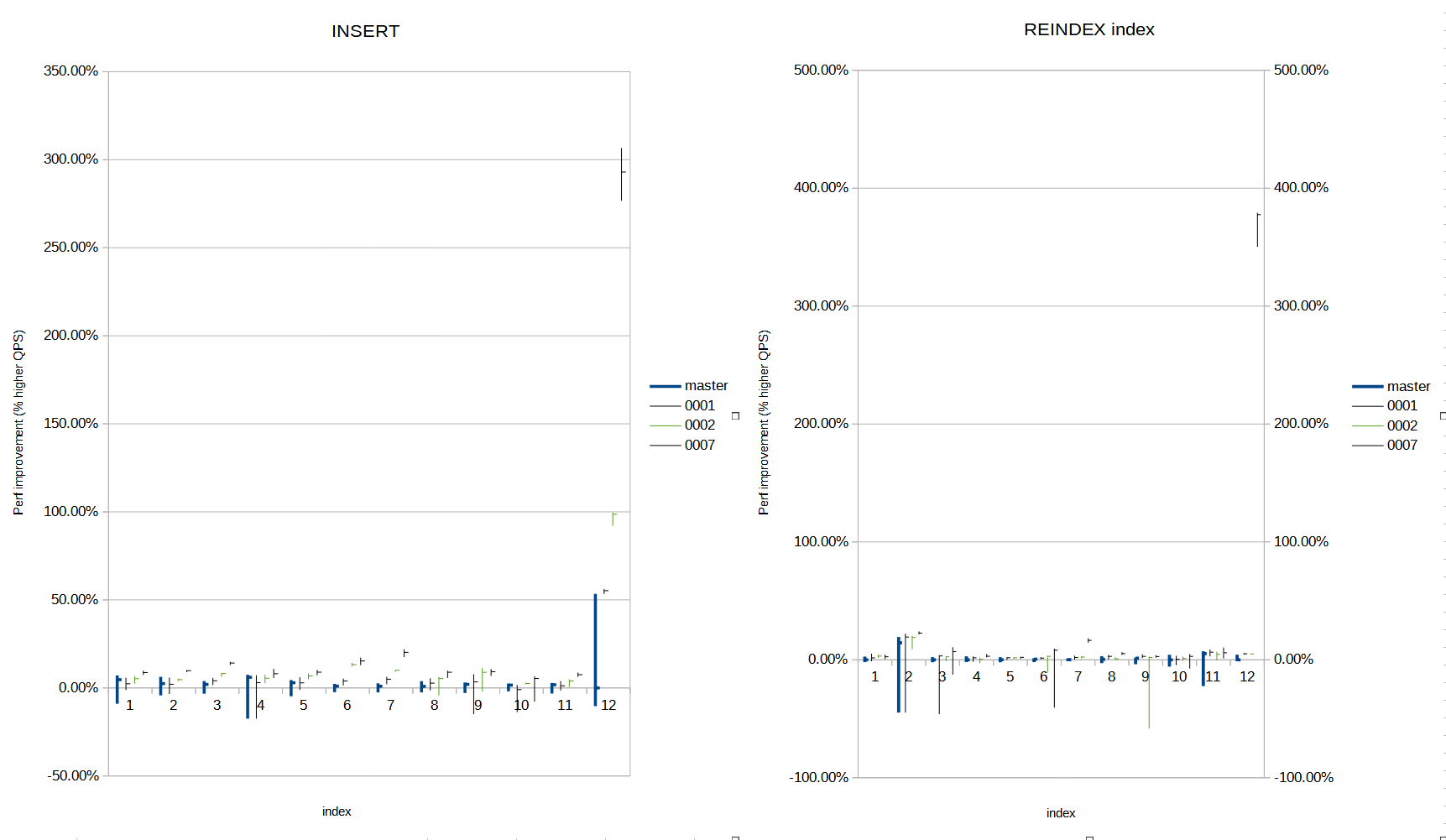
On Thu, 26 Oct 2023 at 00:36, Peter Geoghegan <pg@bowt.ie> wrote: > Most of the work with something like > this is the analysis of the trade-offs, not writing code. There are > all kinds of trade-offs that you could make with something like this, > and the prospect of doing that myself is kind of daunting. Ideally > you'd have made a significant start on that at this point. I believe I'd already made most trade-offs clear earlier in the threads, along with rationales for the changes in behaviour. But here goes again: _bt_compare currently uses index_getattr() on each attribute of the key. index_getattr() is O(n) for the n-th attribute if the index tuple has any null or non-attcacheoff attributes in front of the current one. Thus, _bt_compare costs O(n^2) work with n=the number of attributes, which can cost several % of performance, but is very very bad in extreme cases, and doesO(n) calls to opclass-supplied compare operations. To solve most of the O(n) compare operations, we can optimize _bt_compare to only compare "interesting" attributes, i.e. we can apply "dynamic prefix truncation". This is implemented by patch 0001. This is further enhanced with 0002, where we skip the compare operations if the HIKEY is the same as the right separator of the downlink we followed (due to our page split code, this case is extremely likely). However, the above only changes the attribute indexing code in _bt_compare to O(n) for at most about 76% of the index tuples on the page (1 - (2 / log2(max_tuples_per_page))), while the other on average 20+% of the compare operations still have to deal with the O(n^2) total complexity of index_getattr. To fix this O(n^2) issue (the issue this thread was originally created for) the approach I implemented originally is to not use index_getattr but an "attribute iterator" that incrementally extracts the next attribute, while keeping track of the current offset into the tuple, so each next attribute would be O(1). That is implemented in the last patches of the patchset. This attribute iterator approach has an issue: It doesn't perform very well for indexes that make full use of attcacheoff. The bookkeeping for attribute iteration proved to be much more expensive than just reading attcacheoff from memory. This is why the latter patches (patchset 14 0003+) adapt the btree code to generate different paths for different "shapes" of key index attributes, to allow the current attcacheoff code to keep its performance, but to get higher performance for indexes where the attcacheoff optimization can not be applied. In passing, it also specializes the code for single-attribute indexes, so that they don't have to manage branching code, increasing their performance, too. TLDR: The specialization in 0003+ is applied because index_getattr is good when attcacheoff applies, but very bad when it doesn't. Attribute iteration is worse than index_getattr when attcacheoff applies, but is significantly better when attcacheoff does not work. By specializing we get the best of both worlds. The 0001 and 0002 optimizations were added later to further remove unneeded calls to the btree attribute compare functions, thus further reducing the total time spent in _bt_compare. Anyway. PFA v14 of the patchset. v13's 0001 is now split in two, containing prefix truncation in 0001, and 0002 containing the downlink's right separator/HIKEY optimization. Performance numbers (data attached): 0001 has significant gains in multi-column indexes with shared prefixes, where the prefix columns are expensive to compare, but otherwise doesn't have much impact. 0002 further improves performance across the board, but again mostly for indexes with expensive compare operations. 0007 sees performance improvements almost across the board, with only the 'ul' and 'tnt' indexes getting some worse results than master (but still better average results), All patches applied, per-index average performance improvements on 15 runs range from 3% to 290% across the board for INSERT benchmarks, and -2.83 to 370% for REINDEX. Configured with autoconf: config.log: > It was created by PostgreSQL configure 17devel, which was > generated by GNU Autoconf 2.69. Invocation command line was > > $ ./configure --enable-tap-tests --enable-depend --with-lz4 --with-zstd COPT=-ggdb -O3 --prefix=/home/matthias/projects/postgresql/pg_install--no-create --no-recursion Benchmark was done on 1m random rows of the pp-complete dataset, as found on UK Gov's S3 bucket [0]: using a parallel and threaded downloader is preferred because the throughput is measured in kBps per client. I'll do a few runs on the full dataset of 29M rows soon too, but master's performance is so bad for the 'worstcase' index that I can't finish its runs fast enough; benchmarking it takes hours per iteration. Kind regards, Matthias van de Meent Neon (https://neon.tech) [0] http://prod1.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com/pp-complete.csv
Вложения
- image.png
- benchdata.zip
- v14-0005-btree-Optimize-nbts_attiter-for-indexes-with-a-s.patch
- v14-0002-btree-optimize-_bt_moveright-using-downlink-s-ri.patch
- v14-0001-btree-Implement-dynamic-prefix-compression.patch
- v14-0004-btree-Use-attribute-iterators-specialized-on-key.patch
- v14-0003-btree-Specialize-various-performance-sensitive-f.patch
- v14-0006-Add-an-attcacheoff-populating-function.patch
- v14-0007-btree-specialize-attribute-iteration-for-keys-th.patch
В списке pgsql-hackers по дате отправления: