Re: Add bump memory context type and use it for tuplesorts
| От | David Rowley |
|---|---|
| Тема | Re: Add bump memory context type and use it for tuplesorts |
| Дата | |
| Msg-id | CAApHDvrb4MUQd=CY9ZHatp_rAuLjTEQndpr=kBgGNQ6QZ3Cp0w@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Add bump memory context type and use it for tuplesorts (David Rowley <dgrowleyml@gmail.com>) |
| Ответы |
Re: Add bump memory context type and use it for tuplesorts
|
| Список | pgsql-hackers |
On Tue, 5 Mar 2024 at 15:42, David Rowley <dgrowleyml@gmail.com> wrote:
> The query I ran was:
>
> select chksz,mtype,pg_allocate_memory_test_reset(chksz,
> 1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
> sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
> cxt(mtype) order by mtype,chksz;
Andres and I were discussing this patch offlist in the context of
"should we have bump". Andres wonders if it would be better to have a
function such as palloc_nofree() (we didn't actually discuss the
name), which for aset, would forego rounding up to the next power of 2
and not bother checking the freelist and only have a chunk header for
MEMORY_CONTEXT_CHECKING builds. For non-MEMORY_CONTEXT_CHECKING
builds, the chunk header could be set to some other context type such
as one of the unused ones or perhaps a dedicated new one that does
something along the lines of BogusFree() which raises an ERROR if
anything tries to pfree or repalloc it.
An advantage of having this instead of bump would be that it could be
used for things such as the parser, where we make a possibly large
series of small allocations and never free them again.
Andres ask me to run some benchmarks to mock up AllocSetAlloc() to
have it not check the freelist to see how the performance of it
compares to BumpAlloc(). I did this in the attached 2 patches. The
0001 patch just #ifdefs that part of AllocSetAlloc out, however
properly implementing this is more complex as aset.c currently stores
the freelist index in the MemoryChunk rather than the chunk_size. I
did this because it saved having to call AllocSetFreeIndex() in
AllocSetFree() which made a meaningful performance improvement in
pfree(). The 0002 patch effectively reverses that change out so that
the chunk_size is stored. Again, these patches are only intended to
demonstrate the performance and check how it compares to bump.
I'm yet uncertain why, but I find that the first time I run the query
quoted above, the aset results are quite a bit slower than on
subsequent runs. Other context types don't seem to suffer from this.
The previous results I sent in [1] were of the initial run after
starting up the database.
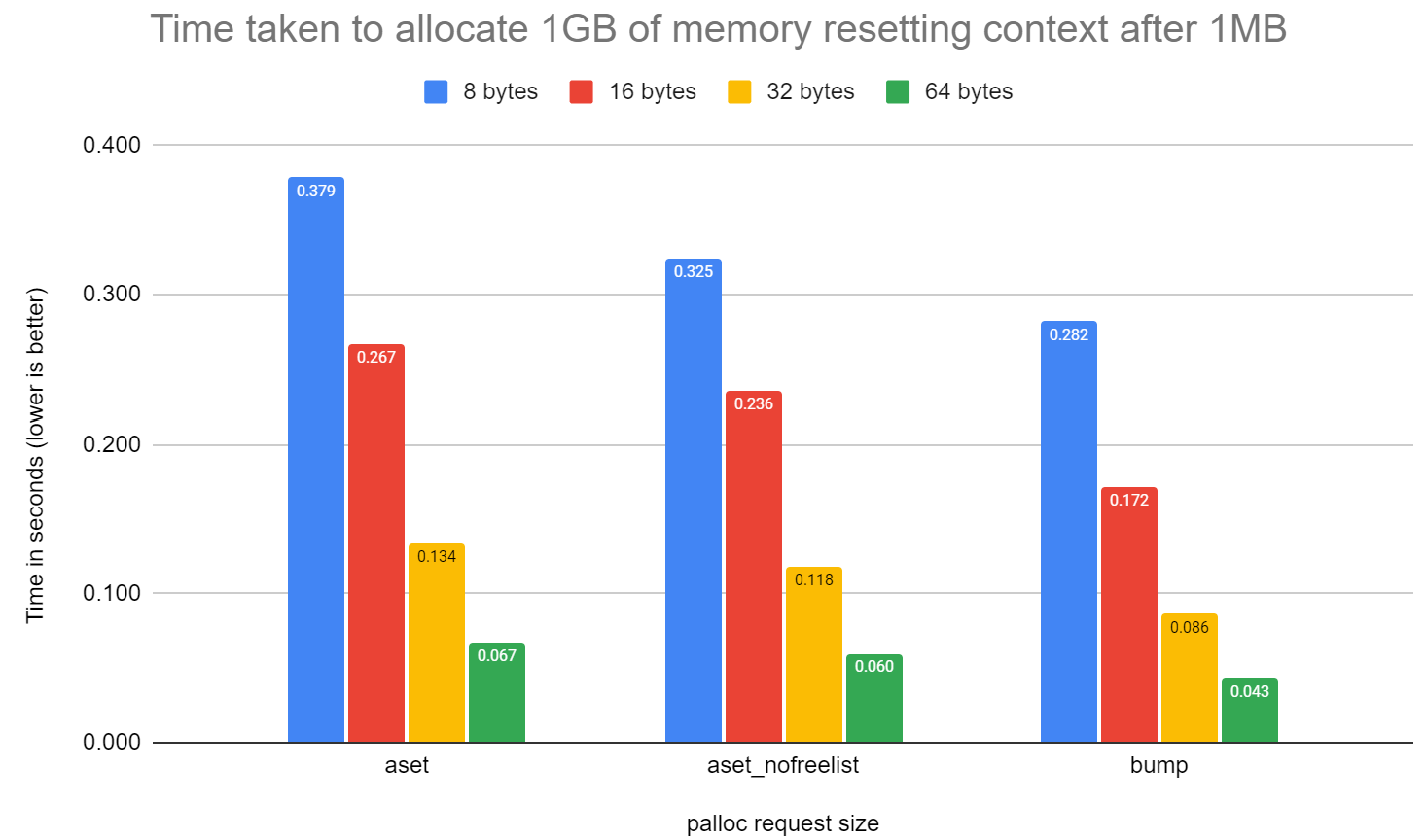
The attached graph shows the number of seconds it takes to allocate a
total of 1GBs of memory in various chunk sizes, resetting the context
after 1MBs has been allocated, so as to keep the test sized so it fits
in CPU caches.
I'm not drawing any particular conclusion from the results aside from
it's not quite as fast as bump. I also have some reservations about
how easy it would be to actually use something like palloc_nofree().
For example heap_form_minimal_tuple() does palloc0(). What if I
wanted to call ExecCopySlotMinimalTuple() and use palloc0_nofree().
Would we need new versions of various functions to give us control
over this?
David
[1] https://www.postgresql.org/message-id/CAApHDvr_hGT=kaP0YXbKSNZtbRX+6hUkieCWEn2BULwW1uTr_Q@mail.gmail.com
Вложения
В списке pgsql-hackers по дате отправления: