Re: Todo: Teach planner to evaluate multiple windows in the optimal order
| От | David Rowley |
|---|---|
| Тема | Re: Todo: Teach planner to evaluate multiple windows in the optimal order |
| Дата | |
| Msg-id | CAApHDvqh+qOHk4sbvvy=Qr2NjPqAAVYf82oXY0g=Z2hRpC2Vmg@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Todo: Teach planner to evaluate multiple windows in the optimal order (Ankit Kumar Pandey <itsankitkp@gmail.com>) |
| Ответы |
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Re: Todo: Teach planner to evaluate multiple windows in the optimal order Re: Todo: Teach planner to evaluate multiple windows in the optimal order |
| Список | pgsql-hackers |
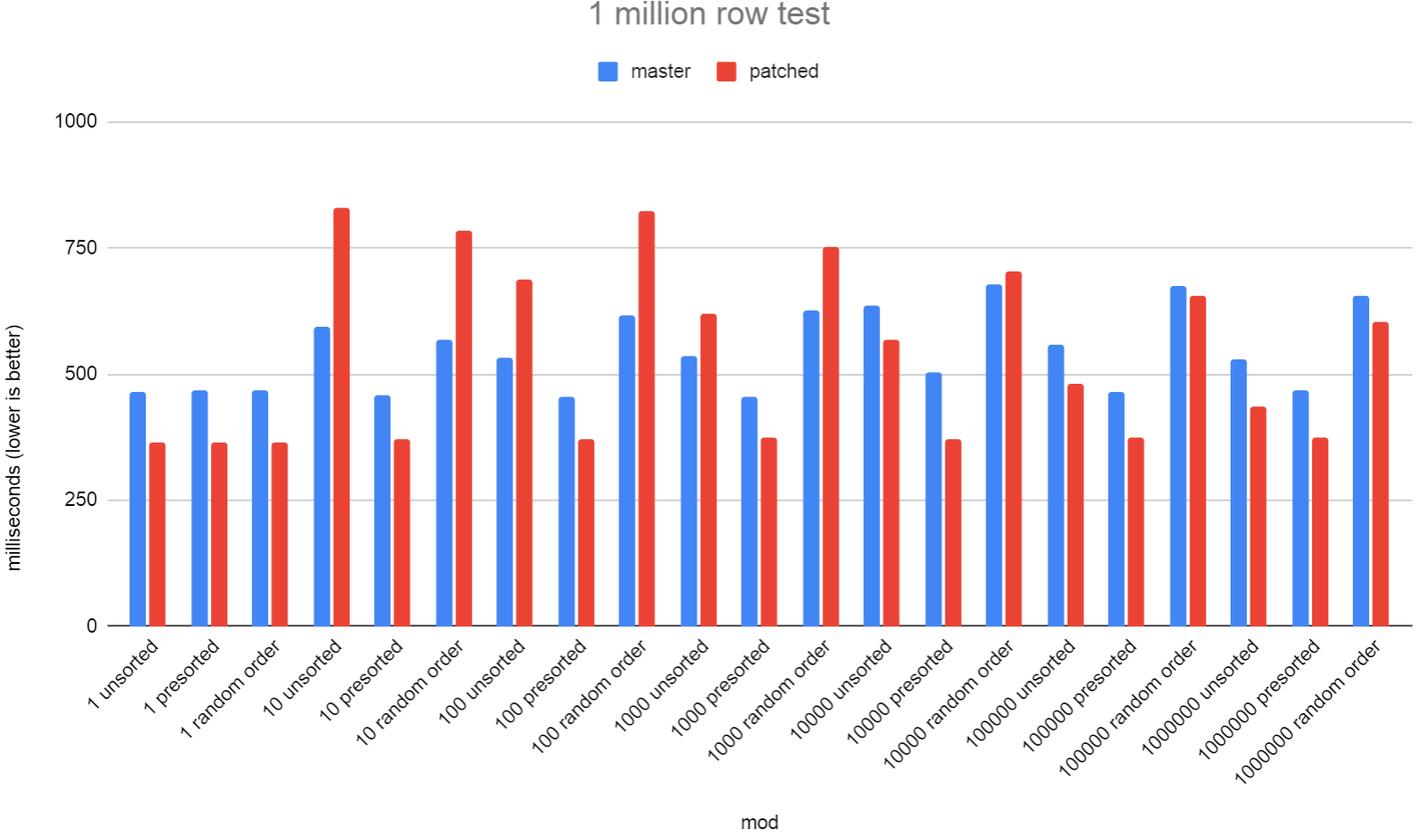
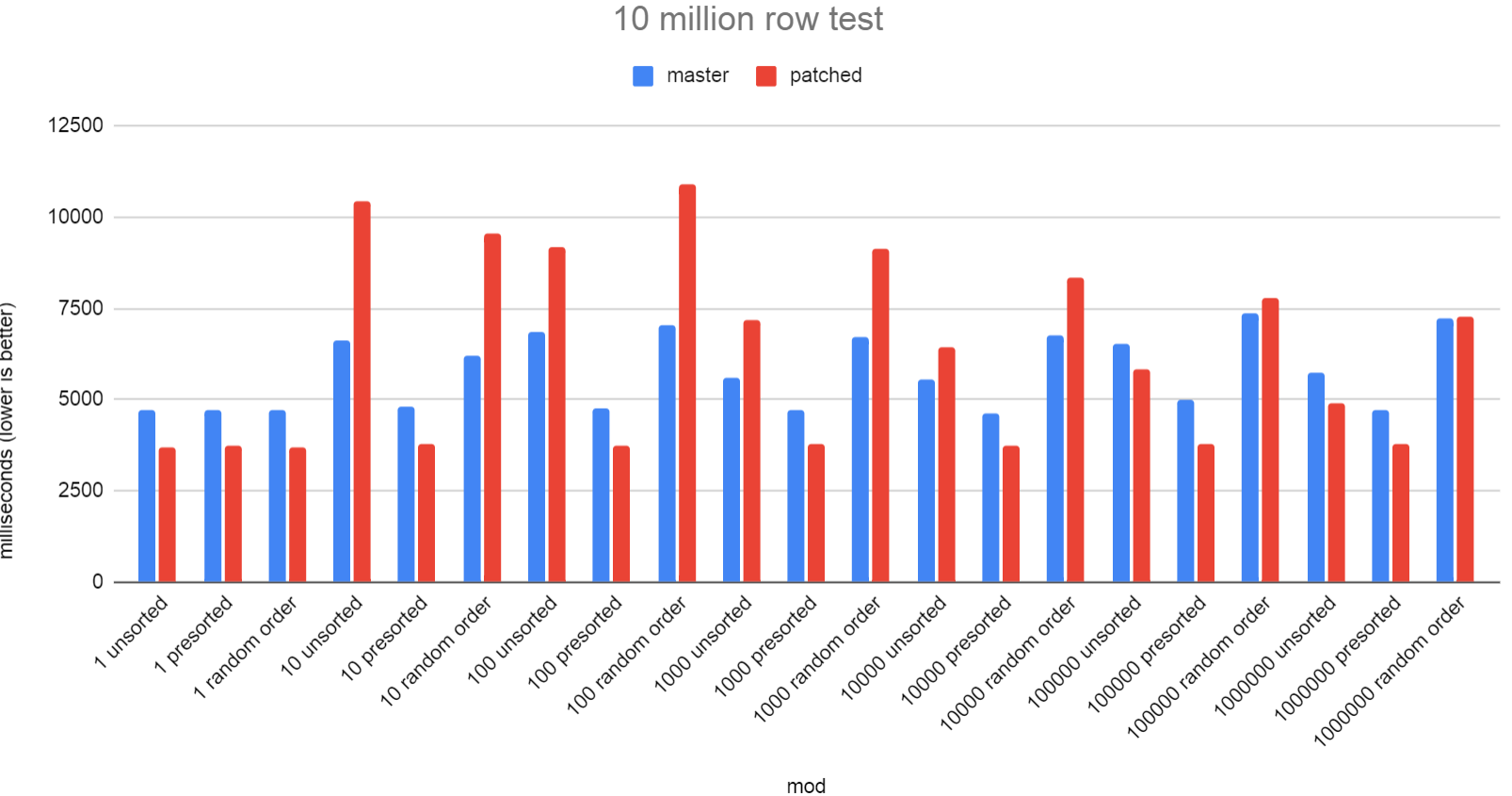
On Wed, 25 Jan 2023 at 06:32, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > I am not seeing other cases where patch version is consistently slower. I just put together a benchmark script to try to help paint a picture of under what circumstances reducing the number of sorts slows down performance. The benchmark I used creates a table with 2 int4 columns, "a" and "b". I have a single WindowClause that sorts on "a" and then ORDER BY a,b. In each test, I change the number of distinct values in "a" starting with 1 distinct value then in each subsequent test I multiply that number by 10 each time all the way up to 1 million. The idea here is to control how often the sort that's performing a sort by both columns must call the tiebreak function. I did 3 subtests for each number of distinct rows in "a". 1) Unsorted case where the rows are put into the tuples store in an order that's not presorted, 2) tuplestore rows are already sorted leading to hitting our qsort fast path. 3) random order. You can see from the results that the patched version is not looking particularly great. I did a 1 million row test and a 10 million row test. work_mem was 4GB for each, so the sorts never went to disk. Overall, the 1 million row test on master took 11.411 seconds and the patched version took 11.282 seconds, so there was a *small* gain overall there. With the 10 million row test, overall, master took 121.063 seconds, whereas patched took 130.727 seconds. So quite a large performance regression there. I'm unsure if 69749243 might be partially to blame here as it favours single-key sorts. If you look at qsort_tuple_signed_compare(), you'll see that the tiebreak function will be called only when it's needed and there are > 1 sort keys. The comparetup function will re-compare the first key all over again. If I get some more time I'll run the tests again with the sort specialisation code disabled to see if the situation is the same or not. Another way to test that would be to have a table with 3 columns and always sort by at least 2. I've attached the benchmark script that I used and also a copy of the patch with a GUC added solely to allow easier benchmarking of patched vs unpatched. I think we need to park this patch until we can figure out what can be done to stop these regressions. We might want to look at 1) Expanding on what 69749243 did and considering if we want sort specialisations that are specifically for 1 column and another set for multi-columns. The multi-column ones don't need to re-compare key[0] again. 2) Sorting in smaller batches that better fit into CPU cache. Both of these ideas would require a large amount of testing and discussion. For #1 we're considering other specialisations, for example NOT NULL, and we don't want to explode the number of specialisations we have to compile into the binary. David
Вложения
В списке pgsql-hackers по дате отправления: