Re: Skip partition tuple routing with constant partition key
| От | David Rowley |
|---|---|
| Тема | Re: Skip partition tuple routing with constant partition key |
| Дата | |
| Msg-id | CAApHDvqFeW5hvQqprXOLuGMMJSf+1C+Wk4w_L-M03sVduF3oYg@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Skip partition tuple routing with constant partition key (Amit Langote <amitlangote09@gmail.com>) |
| Ответы |
Re: Skip partition tuple routing with constant partition key
|
| Список | pgsql-hackers |
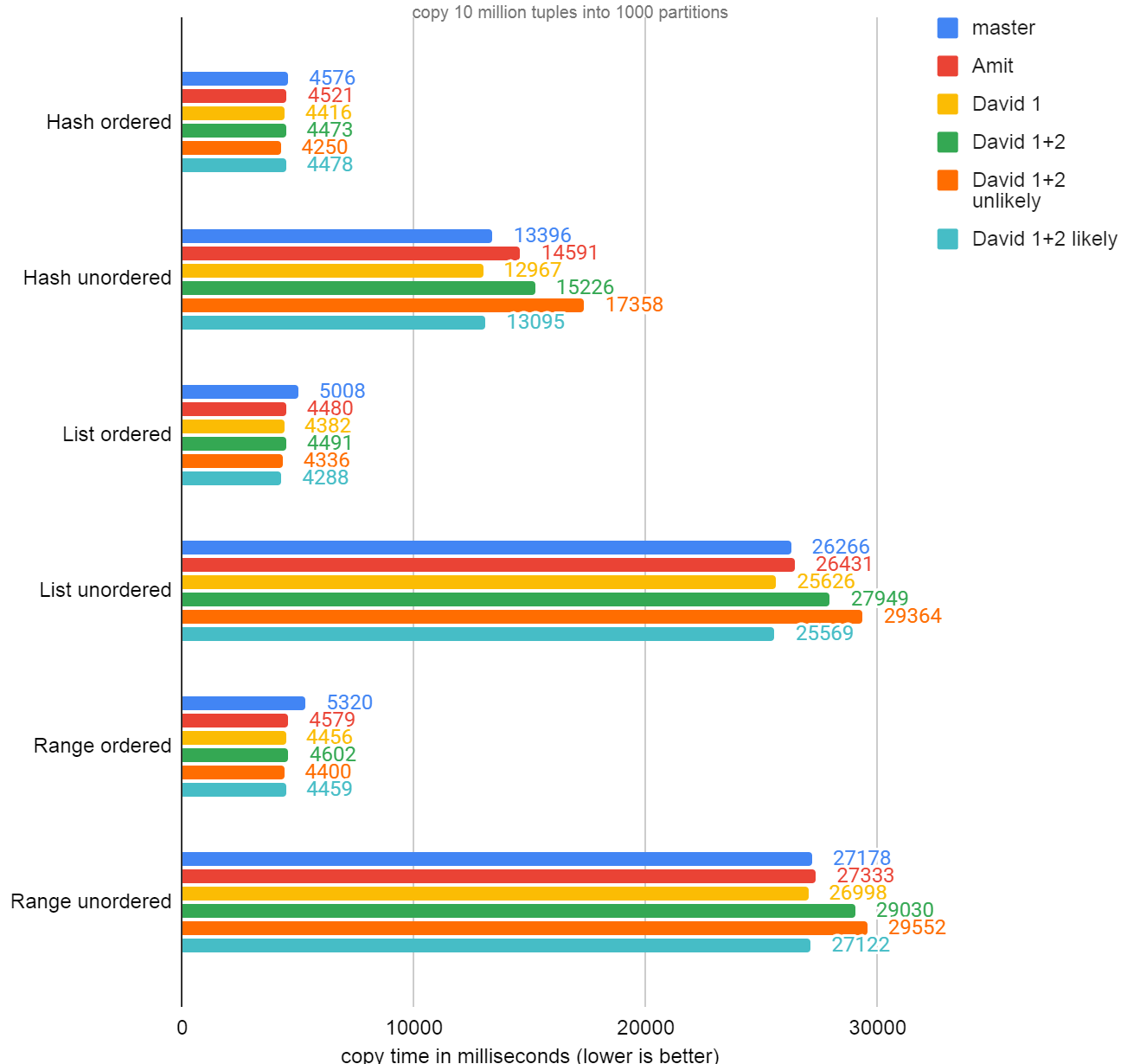
I've spent some time looking at the v10 patch, and to be honest, I don't really like the look of it :( 1. I think we should be putting the cache fields in PartitionDescData rather than PartitionDispatch. Having them in PartitionDescData allows caching between statements. 2. The function name maybe_cache_partition_bound_offset() fills me with dread. It's very unconcise. I don't think anyone should ever use that word in a function or variable name. 3. I'm not really sure why there's a field named n_tups_inserted. That would lead me to believe that ExecFindPartition is only executed for INSERTs. UPDATEs need to know the partition too. 4. The fields you're adding to PartitionDispatch are very poorly documented. I'm not really sure what n_offset_changed means. Why can't you just keep track by recording the last used partition, the last index into the datum array, and then just a count of the number of times we've found the last used partition in a row? When the found partition does not match the last partition, just reset the counter and when the counter reaches the cache threshold, use the cache path. I've taken a go at rewriting this, from scratch, into what I think it should look like. I then looked at what I came up with and decided the logic for finding partitions should all be kept in a single function. That way there's much less chance of someone forgetting to update the double-checking logic during cache hits when they update the logic for finding partitions without the cache. The 0001 patch is my original attempt. I then rewrote it and came up with 0002 (applies on top of 0001). After writing a benchmark script, I noticed that the performance of 0002 was quite a bit worse than 0001. I noticed that the benchmark where the partition changes each time got much worse with 0002. I can only assume that's due to the increased code size, so I played around with likely() and unlikely() to see if I could use those to shift the code layout around in such a way to make 0002 faster. Surprisingly using likely() for the cache hit path make it faster. I'd have assumed it would be unlikely() that would work. cache_partition_bench.png shows the results. I tested with master @ a5f9f1b88. The "Amit" column is your v10 patch. copybench.sh is the script I used to run the benchmarks. This tries all 3 partitioning strategies and performs 2 COPY FROMs, one with the rows arriving in partition order and another where the next row always goes into a different partition. I'm expecting to see the "ordered" case get better for LIST and RANGE partitions and the "unordered" case not to get any slower. With all of the attached patches applied, it does seem like I've managed to slightly speed up all of the unordered cases slightly. This might be noise, but I did manage to remove some redundant code that needlessly checked if the HASH partitioned table had a DEFAULT partition, which it cannot. This may account for some of the increase in performance. I do need to stare at the patch a bit more before I'm confident that it's correct. I just wanted to share it before I go and do that. David
Вложения
В списке pgsql-hackers по дате отправления: