Re: LWLock contention: I think I understand the problem
| От | Hannu Krosing |
|---|---|
| Тема | Re: LWLock contention: I think I understand the problem |
| Дата | |
| Msg-id | 1010358727.10359.5.camel@rh72.home.ee обсуждение исходный текст |
| Ответ на | Re: LWLock contention: I think I understand the problem (Tom Lane <tgl@sss.pgh.pa.us>) |
| Список | pgsql-hackers |
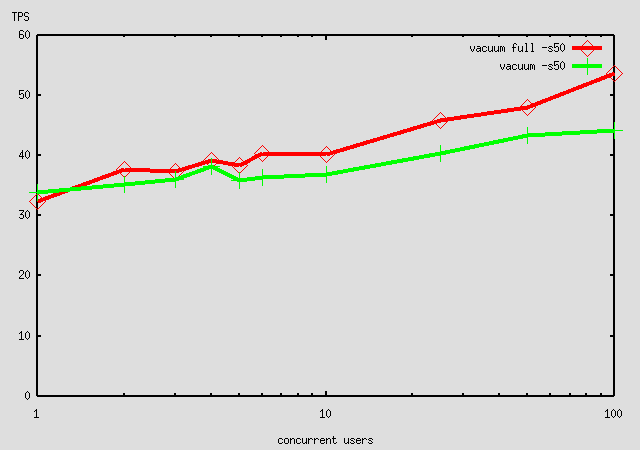
On Mon, 2002-01-07 at 06:37, Tom Lane wrote: > Hannu Krosing <hannu@krosing.net> writes: > > Should this not be 'vacuum full' ? > >> > >> Don't see why I should expend the extra time to do a vacuum full. > >> The point here is just to ensure a comparable starting state for all > >> the runs. > > > Ok. I thought that you would also want to compare performance for different > > concurrency levels where the number of dead tuples matters more as shown by > > the attached graph. It is for Dual PIII 800 on RH 7.2 with IDE hdd, scale 5, > > 1-25 concurrent backends and 10000 trx per run > > VACUUM and VACUUM FULL will provide the same starting state as far as > number of dead tuples goes: none. I misinterpreted the fact that new VACUUM will skip locked pages - here are none if run independently. > So that doesn't explain the > difference you see. My guess is that VACUUM FULL looks better because > all the new tuples will get added at the end of their tables; possibly > that improves I/O locality to some extent. After a plain VACUUM the > system will tend to allow each backend to drop new tuples into a > different page of a relation, at least until the partially-empty pages > all fill up. > > What -B setting were you using? I had the following in the postgresql.conf shared_buffers = 4096 -------------- Hannu I attach similar run, only with scale 50, from my desktop computer (uniprocessor Athlon 850MHz, RedHat 7.1) BTW, both were running unpatched postgreSQL 7.2b4. -------------- Hannu
Вложения
В списке pgsql-hackers по дате отправления: