Отказоустойчивый кластер СУБД на основе Postgres Pro Enterprise BiHA
Сокращения
БД – база данных
ВМ – виртуальная машина
СУБД – система управления базами данных
BiHA (англ. Built-in High Availability) – встроенная высокая доступность
SQL (англ. Structured Query Language) – язык структурированных запросов
BCP (англ. BiHA Control Protocol) – протокол управления кластером BiHA
WAL (англ. Write-Ahead Log) – журнал упреждающей записи
SLA (англ. Service Level Agreement) – соглашение об уровне сервиса
RPO (англ. Recovery Point Objective) – целевая точка восстановления
RTO (англ. Recovery Time Objective) – целевое время восстановления
DNS (англ. Domain Name System) – система доменных имен
Терминология и определения
BiHA – технология, которая интегрирована в ядро СУБД Postgres Pro для обеспечения отказоустойчивости кластера.
Узел кластера – физический сервер или виртуальная машина с установленным сервером СУБД Postgres Pro и кластерным программным обеспечением.
Raft – алгоритм определения консенсуса для распределенных вычислительных систем.
Отказоустойчивый кластер – группа экземпляров Postgres Pro, объединенных в логическую группу и образующих единый ресурс.
Потоковая репликация – репликация, при которой от ведущего сервера Postgres Pro на ведомые передается WAL. Каждый ведомый узел по журналу применяет изменения с ведущего узла.
WAL – метод обеспечения целостности данных посредством ведения отдельного от базы данных журнала предзаписи, в котором информация об изменениях в базе данных вносится и фиксируется перед записью в базу данных.
split-brain – появление в кластере одновременно двух узлов, выполняющих роль ведущего узла СУБД
failover – аварийная передача нагрузки на ведомый узел с повышением его функциональной роли до ведущего узла в кластере в случае сбоя или нарушения в работе ведущего узла.
switchover – штатная или запланированная передача нагрузки на ведомый узел с повышением его функциональной роли до ведущего узла в кластере.
Raft – алгоритм определения консенсуса для распределенных вычислительных систем.
RPO – допустимый объем потерянных данных, измеряется интервалом времени. Любая информационная система должна обеспечивать защиту своих данных от потери не хуже требуемого уровня.
RTO – допустимый простой системы или допустимое время восстановления данных, измеряется интервалом времени. Любая информационная система должна обеспечивать возможность восстановления своей работы не хуже требуемого времени.
DNS – интернет-сервис, распределенная база данных иерархической системы имен узлов сети Интернет (маршрутизаторов, серверов, пользовательских устройств и т.п.), а также способ (протокол прикладного уровня) преобразования символьных адресов (доменных имен) узлов сети Интернет в числовые IP-адреса и обратно.
Возможности BiHA
Автоматическое аварийное переключение роли узлов кластера
Узлы кластера на постоянной основе мониторят друг-друга. В случае выявления недоступности ведущего узла запускается процесс выборов нового ведущего узла среди доступных ведомых узлов, если их количество не меньше, чем значение кворума. После избрания нового ведущего узла репликация данных на всех ведомых узлах перенастраивается на этот узел. Старый ведущий узел при сетевой изоляции или при восстановлении после сбоя становится доступным только на чтение. Его можно вернуть в кластер, выполнив ряд ручных действий.
Автоматизированная настройка потоковой репликации.
Настройки, которые необходимы для создания потоковой репликации на ведомом узле выполняются одной командой. Можно настроить репликацию данных в синхронном или асинхронном режиме.
SQL-интерфейс для управления и мониторинга кластера.
Доступны представления, в которых можно посмотреть информацию о состоянии кластера и каждого узла. Также поддерживается автоматизированное изменение некоторых параметров кластера и переключение роли ведущего узла с помощью методов.
Утилита командной строки bihactl для настройки кластера.
Утилита позволяет инициализировать кластер и создавать ведущий узел, добавлять ведомые узлы, преобразовывать существующий узел в ведущий или ведомый узел в кластере BiHA, а также проверять статус узлов кластера.
Достоинства BiHA
- Встроенное решение отказоустойчивости в СУБД Postgres Pro. Не требуется стороннее кластерное ПО. Обновление версии BiHA выходит одновременно с выходом новой версии Postgres Pro.
- Не требует дополнительного администрирования и мониторинга, в отличии от внешнего кластерного ПО.
- Полностью автоматическое или автоматизированное переключение роли узлов кластера. BiHA следит за состоянием узлов кластера и в случае сбоя производит автоматическое переключение роли на другой узел. Так же позволяет производить плановое переключение.
- Входит в состав Postgres Pro Enterprise, не требуется дополнительных лицензий.
- Изоляция узлов оказавшихся вне кластера. При сетевой изоляции узел переходит в режим только чтение.
SLA, RTO и RPO
Прежде всего важно определить, требуют ли сервисы архитектуры высокой доступности. Если да, то в какой степени должна быть обеспечена высокая доступность. Доступность сервисов обычно определяется метрикой SLA. В SLA ключевыми метриками являются RPO и RTO. Требования должны подбираться в соответствии с потребностями бизнеса. Например, в некоторых случаях не требуется высокая доступность.
RPO зависит от объема потери данных, приемлемого с точки зрения бизнеса. Любая информационная система должна обеспечивать защиту своих данных от потери выше приемлемого уровня.
RTO зависит от количества времени, приемлемого с точки зрения бизнеса. Любая информационная система должна обеспечивать возможность восстановления своей работы в приемлемый срок.
Формула расчета SLA: ([количество ms в сутках] - [количество ms недоступности кластера в сутках])/([количество ms в сутках])
Доступность сервиса | Продолжительность простоев в неделю | Продолжительность простоев в месяц | Продолжительность простоев в год |
99% | 1.68 ч | 7.2 ч | 3,65 дня |
99.90% | 10.1 мин | 43.2 мин | 8.76 ч |
99.95% | 5 мин | 21.6 мин | 4.38 ч |
99.99% | 1.01 мин | 4.32 мин | 52.56 мин |
99.999% | 6 с | 25.9 с | 5.26 мин |
Таблица 1. Уровни доступности.
Кластеризация базы данных
Основная цель кластеризации базы данных – обеспечить высокую доступность к данным.
Доступность характеризуется свойствами:
- Надежность – восстановление без потери данных после сбоя узла кластера СУБД.
- Отказоустойчивость – бесперебойная запись и чтение данных в случае сбоя узла кластера СУБД.
- Производительность и горизонтальная масштабируемость (по чтению) – возможность добавления новых узлов в кластер СУБД и распределение нагрузки одного узла на остальные узлы кластера СУБД.
Общая архитектура
Общая архитектура кластерного решения на примере схемы 1 представляет собой единую точку входа для запросов к базам данных от приложений или пользователей и минимум два узла СУБД, между которыми настроена потоковая репликация. Основной узел называется ведущим узлом, который доступен на запись и чтение. Копию ведущего узла называют ведомым узлом. Доступность и согласованность данных на узлах достигается механизмом потоковой репликации.
Надежность кластера достигается путем дублирования всех критически важных для работы компонентов на различные физические сервера или виртуальные машины. Поэтому в кластер добавляется минимум еще один узел, который является точной копией ведущего узла.
Отказоустойчивость достигается автоматическим переключением роли узла в случае какого-либо сбоя на ведущем узле. Если ведущий узел становится недоступен, то ведомый узел берет роль ведущего на себя, что обеспечивает непрерывность работы приложений.
Горизонтальная масштабируемость (по чтению) обеспечивается распределением запросов на чтение между всеми узлами кластера.
Производительность увеличивается за счет распределения нагрузки по чтению с ведущего узла на ведомые.
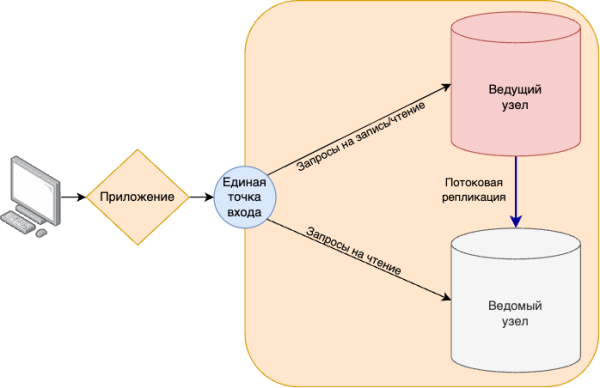
Схема 1. Общая архитектура отказоустойчивого кластера СУБД.
Отказоустойчивость
Для обеспечения отказоустойчивости в Postgres Pro потребуются компоненты, которые обеспечат:
- Избыточность
- Аварийное автоматическое переключение
- Отсутствие единой точки отказа
Чтобы обеспечить избыточность данных, размещаются копии экземпляров Postgres Pro на других узлах с запущенной потоковой репликацией. В случае сбоя ведущего узла потребуется механизм аварийного переключения ведомого узла на роль ведущего. Также потребуется перенастройка маршрутизации и балансировки запросов к базам данных, чтобы приложение или пользователь продолжили дальше осуществлять запись и чтение.
Потоковая репликация
В отказоустойчивом кластере СУБД с использованием потоковой репликации ведущий узел Postgres Pro реплицирует изменения данных БД целиком на ведомые узлы. Ведущий узел непрерывно передает WAL на ведомые узлы, которые проигрывают полученные WAL модифицируя каталог БД Postgres Pro и приводя его в идентичное состояние с каталогом БД на ведущем узле.
Потоковая репликация работает в двух режимах:
- Синхронная потоковая репликация. В этом режиме ведущий узел ожидает подтверждения хотя бы от одного ведомого узла перед завершением транзакции. Подтверждение фиксации транзакции на ведомом узле гарантирует, что данные реплицируются до заданного уровня избыточности без потери.
- Асинхронная потоковая репликация. В этом режиме ведущий узел не ждет подтверждения фиксации транзакции на ведомом узле. Плюсом асинхронной репликации является повышение производительности СУБД, однако, в случае сбоя может произойти потеря данных.
Переключение роли узла
Ведомый узел может стать новым ведущим узлом по разным причинам, как запланированным, так и неожиданным. Неожиданные причины принято называть сбоями. Сбои могут иметь различную природу. В кластере Postgres Pro переключение роли узла можно выполнять вручную или же переключение автоматизировать. Автоматизация переключения ролей называется обходом отказа узла.
Для автоматизации аварийного переключения дополнительно потребуются механизм определения сбоя, который запретит запись на аварийном узле для исключения ситуации split-brain и отправит предупреждение о том, что ведущий узел недоступен. Должен сработать алгоритм выбора нового ведущего узла из оставшихся доступных узлов в кластере. После успешного повышения роли одного из ведомых узлов на новый ведущий узел перенастраивается маршрутизация запросов и балансировка нагрузки к новому ведущему узлу кластера СУБД. Вышеупомянутые функции выполняет кластерное ПО для СУБД Postgres Pro такое, как Patroni от Zalando. Так же есть и другие реализации кластерного ПО такие, как Corosync/Pacemaker от ClusterLabs, Stolon от компании SorintLab и иные.
Средства доступа к узлам кластера
В СУБД Postgres Pro отсутствуют инструменты балансировки нагрузки, такие как пул соединений и маршрутизация, для распределения входящих запросов и транзакций между несколькими серверами баз данных. Данная функциональность реализуется внешними компонентами.
Пул соединений мультиплексирует множество входящих клиентских соединений к СУБД в заранее настроенное фиксированное количество соединений. Пулеры соединений, например Pgbouncer или pgpool-II – менеджеры соединений, которые принимают клиентские подключения и перенаправляют подключения к соответствующим базам данных. Пул соединений выделяет свободное соединение из заранее преднастроенного количества соединений к СУБД для совершения клиентом транзакции, и возвращает соединение обратно в пул, после завершения работы клиента.
TCP-прокси или балансировщики нагрузки, например, HAProxy или nginx могут маршрутизировать соединения к серверам СУБД в отказоустойчивом кластере. Они перенаправляют запросы от приложений или клиентов на соответствующий внутренний сервер, в зависимости от его роли в отказоустойчивом кластере.
Доступ к узлам кластера с использованием DNS делает возможным распределение соединений приложений между узлами кластера Postgres Pro в зависимости от их роли. Для доступа к узлам кластера с использованием на сервере разрешения имен настраиваются записи, указывающие как на ведущий, так и на совокупность ведомых узлов в кластере. Для подключения к узлам кластера СУБД приложения или клиенты используют DNS-записи согласно их роли в отказоустойчивом кластере.
Архитектура BiHA
Технология BiHA интегрирована в ядро СУБД Postgres Pro Enterprise, начиная с 16-й версии.
BiHA это расширение, которое объединяет несколько узлов СУБД Postgres Pro в отказоустойчивый высокодоступный кластер.
Первичная настройка кластера BiHA и добавление новых ведомых узлов выполняется с помощью консольного менеджера bihactl.
Для запуска кластера, состоящего из одного ведущего и одного ведомого узлов, достаточно двух серверов или ВМ с установленными пакетами СУБД Postgres Pro (см. схему 2). При необходимости в дальнейшем можно добавлять ведомые узлы в состав кластера.
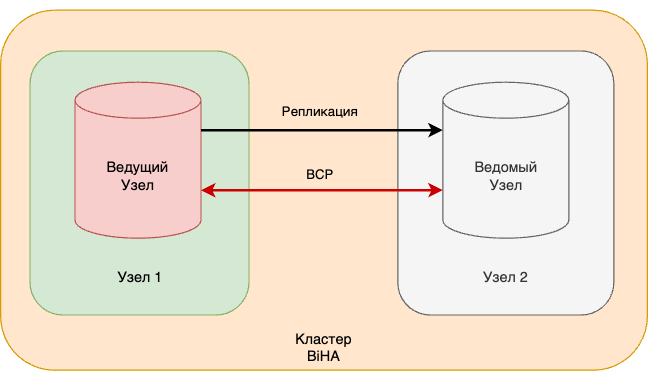
Схема 2. Общая архитектура кластера с использованием BiHA.
На всех запущенных узлах СУБД Postgres Pro работает дочерний процесс BiHA, который решает задачу надежного переключения роли ведущего узла на ведомый узел. Процессы BiHA обмениваются сообщениями между узлами через специальный протокол BCP. Сообщение содержит информацию о состоянии узла, которое обрабатывается соответствующим обработчиком. Для максимальной доступности обработчики обновляют информацию о конфигурации кластера и состоянии узла в специальной структуре и сохраняют в конфигурационных файлах директории СУБД Postgres Pro.
Автоматическое голосование по выбору нового ведущего узла осуществляется с использованием модифицированного алгоритма Raft. При голосовании учитывается отставание ведомых узлов от ведущего и выбирается тот, что с минимальным отставанием.
Типовые конфигурации
Существует два базовых варианта развертывания отказоустойчивых кластеров – двухузловые и трехузловые кластеры.
Двухузловой кластер это решение, в котором один ведущий узел и один синхронный ведомый узел (см. схему 2). В зависимости от настроек конфигурации при отказе лидера или сбое соединения возможны следующие сценарии:
- Ведомый узел становится ведущим узлом. При сетевой изоляции это приведет к появлению двух ведущих узлов.
- При сбое соединения ничего не происходит. В этом случае ведомый не станет новым ведущим узлом.
Достоинством такого кластера является его экономичность.
Трехузловой кластер это решение, в котором один ведущий узел и два ведомых узла, один из которых синхронный (см. схему 3). Так же, как и двухузловой, трехузловой кластер позволяет пережить недоступность одного из узлов.
В результате аварийного переключения узлов новый лидер выбирается простым большинством голосов. При сбоях соединения кластер может разделиться на несколько групп узлов. В этом случае новый лидер выбирается в группе с наибольшим числом узлов.
Достоинством такого кластера является исключение потерь данных при повторном сбое в кластере или потери двух узлов подряд.
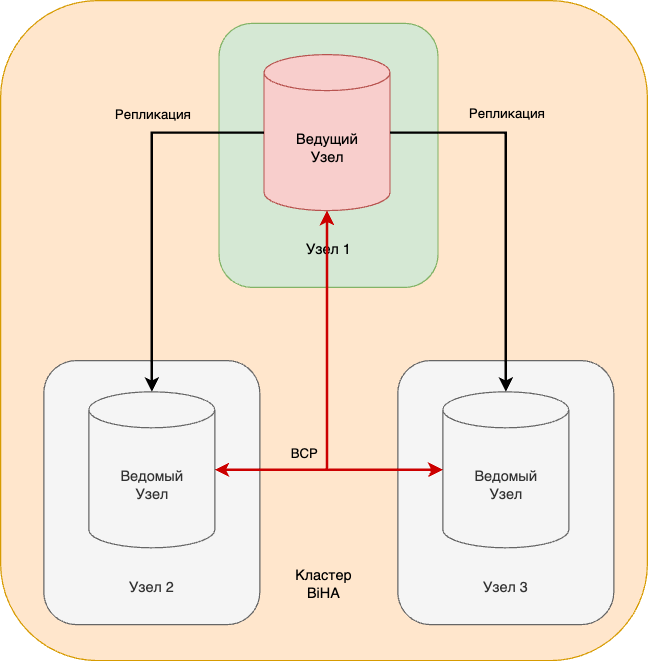
Схема 3. Трехузловой кластер BiHA.
Единая точка входа
Единую точку входа можно организовать разными способами, например, с помощью DNS или на стороне приложения, но рекомендуется организовывать на стороне приложения.
Отказоустойчивость на стороне приложения
Библиотека libpq поддерживает строки подключения к более чем одному серверу базы данных. Это полезно в сочетании с решениями высокой доступности, поскольку позволяет клиенту переключаться на резервный сервер без необходимости использования дополнительного программного обеспечения для балансировки нагрузки.
Однако есть один недостаток: если не известно, какой из узлов СУБД является ведущим, то можно случайно подключиться к ведомому, который не позволит выполнить изменение данных.
Есть возможность использовать дополнительный параметр target_session_attrs, который определяет возможность подключения к серверу в режиме “только чтение” и/или “чтение-запись”. Если в строке подключения задать значение параметра “read-write”, то клиент Postgres Pro не примет соединение с сервером, на котором он не может выполнять изменение данных.
Поскольку эта функциональность является частью клиентской библиотеки libpq, написанной на языке C, все клиенты, использующие эту библиотеку, автоматически поддерживают этот параметр подключения. Сюда входит библиотека Python psycopg2, драйверы для Go, Rust и большинства других языков программирования.
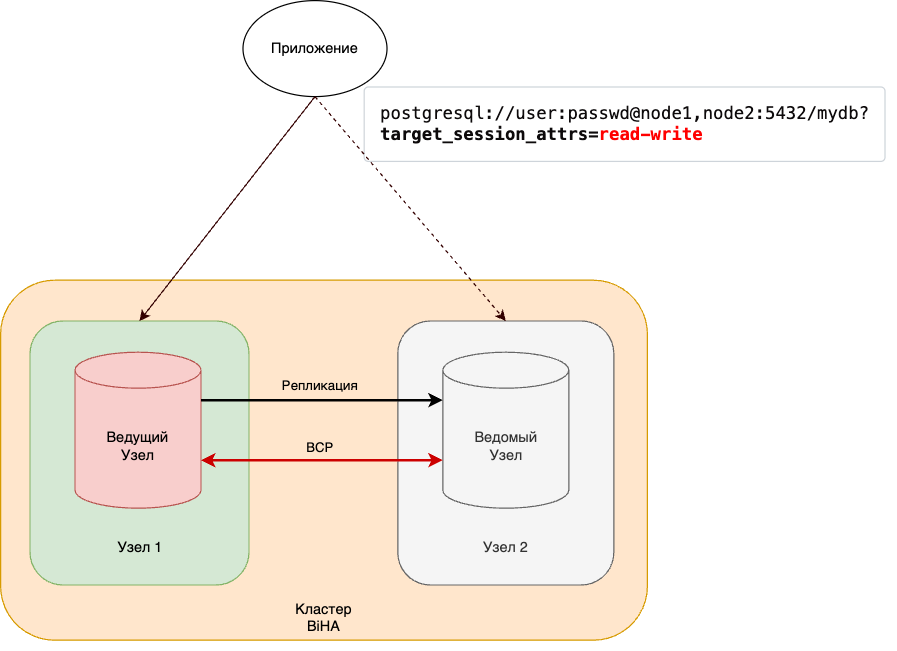
Схема 4. Автоматическое переключение соединения с БД на стороне приложения.
Пулинг соединений
В Postgres Pro для каждого подключения клиента к серверу баз данных порождается собственный обслуживающий процесс.
Если подключений не очень много и они происходят не слишком часто, при этом на всех хватает оперативной памяти, то проблемы нет.
Если подключений слишком много, или соединения устанавливаются и разрываются слишком часто, стоит подумать о применении пула соединений. Такую функцию обычно предоставляет сервер приложений или можно воспользоваться сторонними менеджерами пула. Наиболее известен PgBouncer, но так же есть pgpool-II, odyssey, pgcat и другие.
Клиенты подключаются не к серверу Postgres Pro, а к менеджеру пула. Менеджер удерживает открытыми несколько соединений с сервером баз данных и использует одно из свободных для того, чтобы выполнять запросы клиента. Таким образом, с точки зрения сервера число клиентов остается постоянным вне зависимости от того, сколько клиентов обращаются к менеджеру пула.
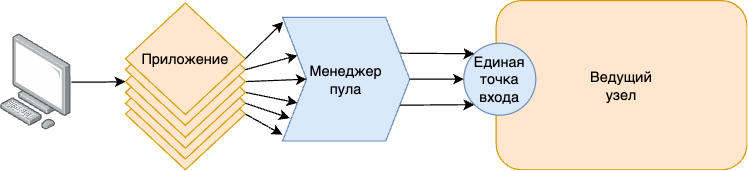
Схема 5. Подключение к серверу баз данных через менеджер пула соединений.
Резервное копирование
Несмотря на надёжность современных компьютеров и серверов, время от времени случаются поломки. А значит есть риск частично или полностью потерять данные. Для решение проблемы потери данных рекомендуется делать резервное копирование.
Существует два вида резервирования: логическое и физическое.
Логическое резервирование – это набор команд SQL, восстанавливающих кластер (или базу данных, или отдельный объект) с нуля. Для данного решения предназначены команда copy, утилиты pg_dump и pg_dumpall.
Физическая резервная копия – копия файлов кластера и набор файлов WAL. Физическое резервирование использует механизм восстановления после сбоев. Для этого требуются копия файлов кластера (базовая резервная копия) и набор журналов предзаписи, необходимых для восстановления согласованности. Для данного решения существуют утилиты pg_probackup и другие.
К физическому резервированию также относится архивирование журналов WAL и интеграции с СРК такими, как КИБЕР Бэкап и NetBackup.
pg_probackup
Pg_probackup – это утилита для управления резервным копированием и восстановлением баз данных Postgres Pro. Она предназначена для регулярного создания резервных копий экземпляра Postgres Pro, позволяющих восстанавливать СУБД в случае необходимости.
Резервная копия базы данных
Для управления резервными копиями pg_probackup создает каталог резервных копий. В этом каталоге хранятся все файлы резервных копий с дополнительной метаинформацией, а также архивы WAL, необходимые для восстановления на момент времени. Можно хранить резервные копии разных экземпляров в отдельных подкаталогах одного каталога копий. Также можно выполнять полное или инкрементальное резервное копирование. В инкрементальном резервном копировании поддерживаются режимы страничного копирования, разностного копирования и копирования изменений.
Основная отличительная черта данного инструмента заключается в том, что pg_probackup работает с репозиторием резервных копий, который должен быть проинициализирован перед началом работы. В репозиторий добавляются инстансы, в данном случае инстанс репозитария резервных копий эквивалентен всему кластеру СУБД.
В один момент времени резервное копирование осуществляется с любого узла в кластере на разделяемую сетевую файловую систему. Архивные журналы также копируются в репозиторий резервных копий.
Восстановления из резервной копии
Процедура восстановления БД на одном из узлов кластера подразумевает, что в момент восстановления данный узел кластера будет недоступен для использования. Для восстановления БД необходимо, чтобы экземпляр БД был остановлен для этой операции.
Случаи в которых потребуется восстановление из бекапа:
- Сбои на ведущем узле:
- Повреждение данных (аппаратные ошибки)
- Искажение данных (программные ошибки, человеческий фактор)
- Сбои на ведомом узле:
- Повреждение данных (аппаратные ошибки)
- Добавление (создание) ведомого узла
Часто встречающиеся варианты восстановления:
- Восстановление БД одного узла
- Восстановление БД нескольких узлов
- Восстановление виртуальных машин из снапшотов с последующим восстановлением БД
Организация архива WAL
Архив WAL позволяет восстановить систему на произвольный момент времени. При этом должна быть базовая копия узла на заданный момент времени, начиная с которого будет производиться применение архивных WAL.
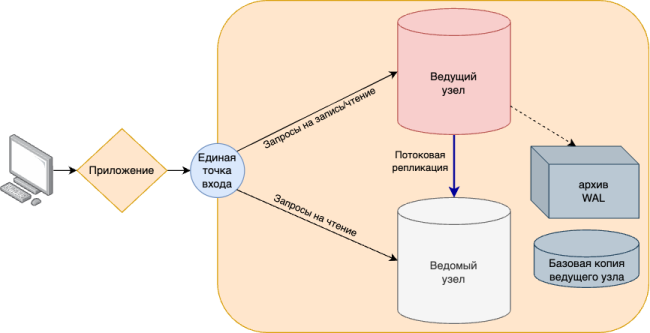
Схема 6. Схема архивации журналов предзаписи (WAL).
Ведение архива WAL можно осуществлять одним из способов:
- Файловый архив – сегменты WAL копируются в архив по мере заполнения. Особенностью данного способа является наличие неизбежных задержек попадания данных в архив.
- Потоковый архив – в архив постоянно записывается поток журнальных записей, не дожидаясь заполнения сегмента WAL, с минимальными задержками.
Мониторинг
Для сбора и хранения данных используются инструменты такие, как Prometheus и Zabbix.
Для наилучшего восприятия и визуализации метрик используется Grafana. Основная единица визуализации метрик в Grafana – дашборд, или график. На один дашборд могут быть выведено несколько метрик, которые в совокупности отражают какую-либо смысловую величину работы компонентов кластера.